A Formula-Structure-Embedding-Based GNN for Formula Equivalence Determination


Abstract
1. Introduction
2. Related Work
3. Method
3.1. Encoder
3.1.1. Formula Standardization Module
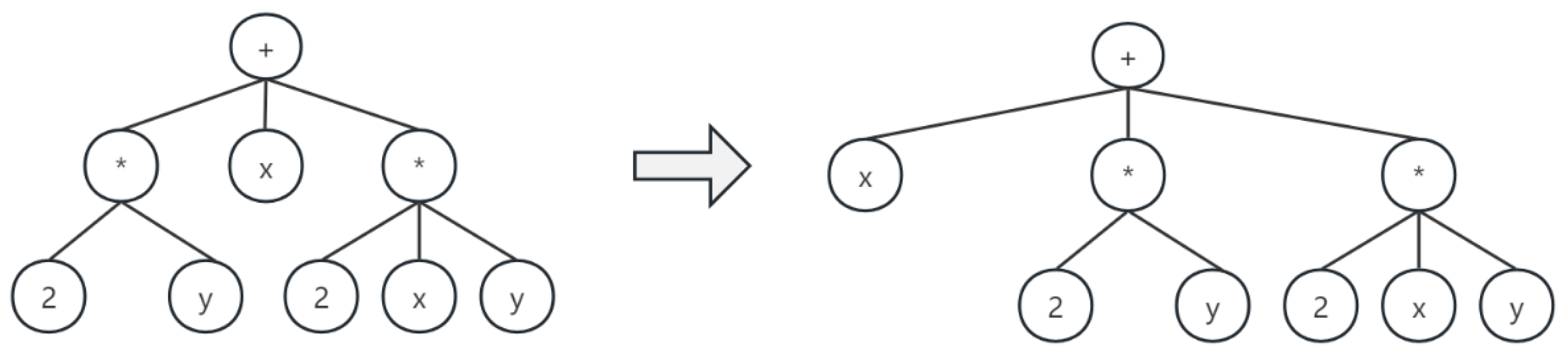
- When processing operators with associative property (such as addition or multiplication), this method examines whether the operators of the current node and its child nodes are the same: if yes, the associative law can be used on these two nodes, and other sub-trees of the current node and the two sub-trees of the child node will be set as the next children of the current node. This operation will be performed recursively operations until all operator nodes have been examined. After this step, the AST will become an N-ary tree (see in Figure 3).
- To process an operator with commutative property (such as addition or multiplication), we first provide a unique value for each type of operators or operands, then recursively calculate the dictionary order of each sub-tree, and rearrange the order of all sub-trees of the operator in ascending order of the sub-tree dictionary orders. The dictionary order is defined as a unique sequence obtained by recursively performing a breadth-first traversal, where the value of corresponding operator, the number of its sub-trees and the orders of all its sub-trees are sequentially recorded during the traversal process (see Figure 4).
3.1.2. Multi-Level Node Feature Embedding Module
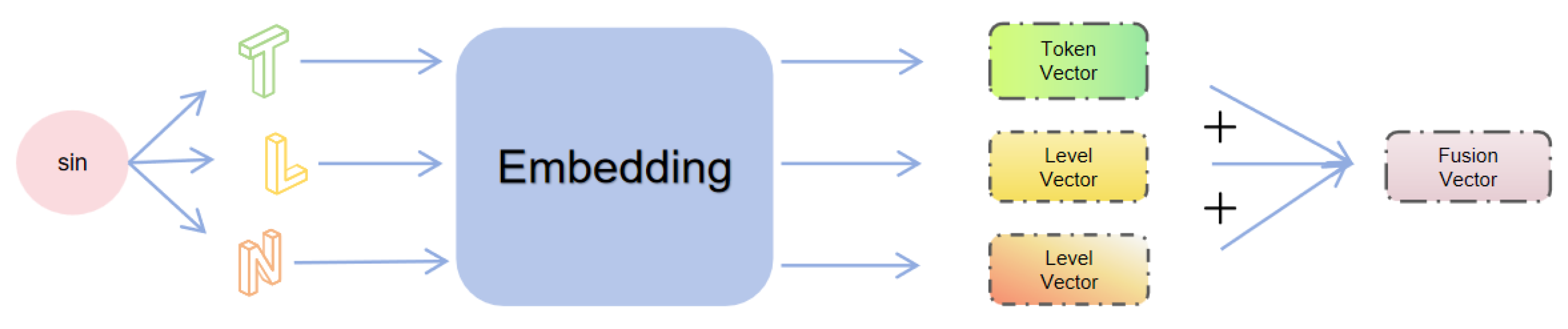
- Each node’s ‘Token T’, ‘Level L’, and ‘Number N’ are converted into corresponding vectors by embedding, such that each embedding vector contains all structure information of corresponding node.
- The three embedding vectors of a node are fused to form a node feature vector that contains all structure information of corresponding node (see Figure 5).
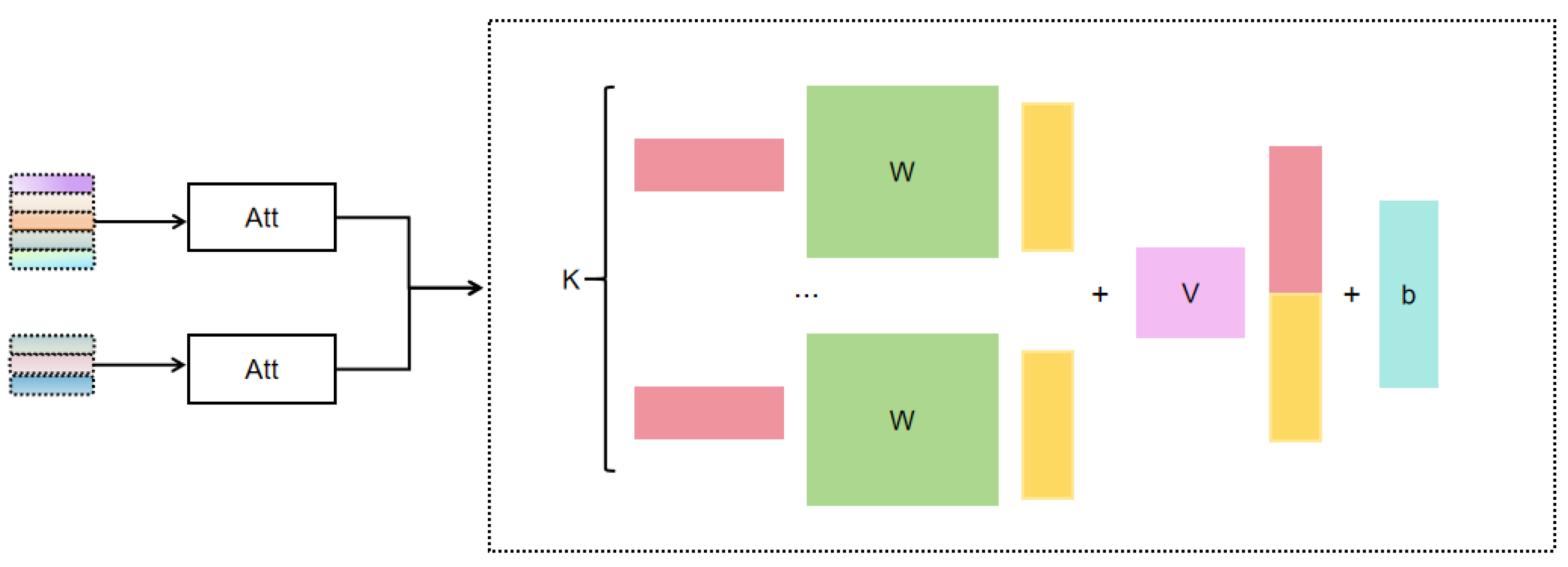
- A breadth-first traversal is performed on the formula tree to aggregate all node vectors, generating a vector that represents the structure information of the formula tree (see Figure 6).
3.1.3. Node Embedding Module
3.1.4. Graph Embedding Module
3.2. Processor
3.2.1. Graph–Graph Interaction Module
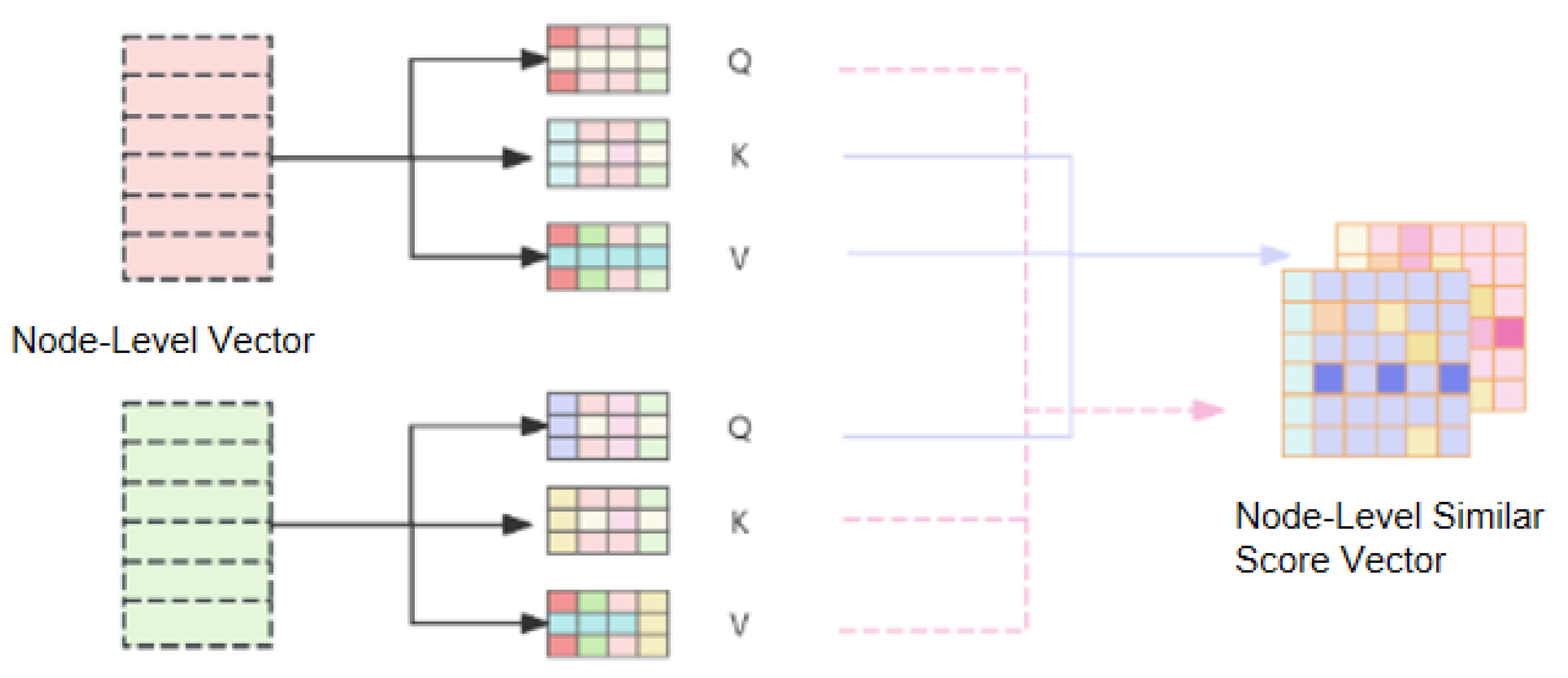
3.2.2. Node–Node Interaction Module
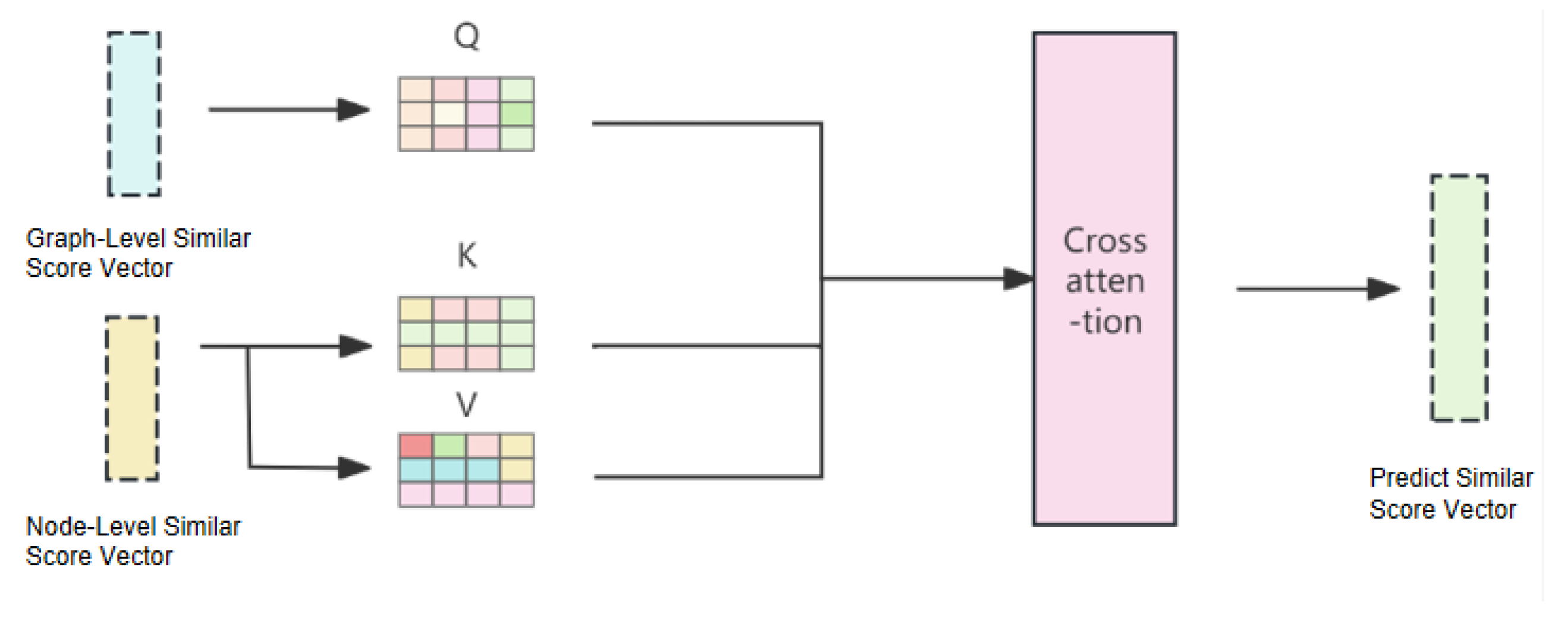
3.3. Decoder
4. Experiments and Analysis
4.1. Dataset
4.2. Evaluation Indicators
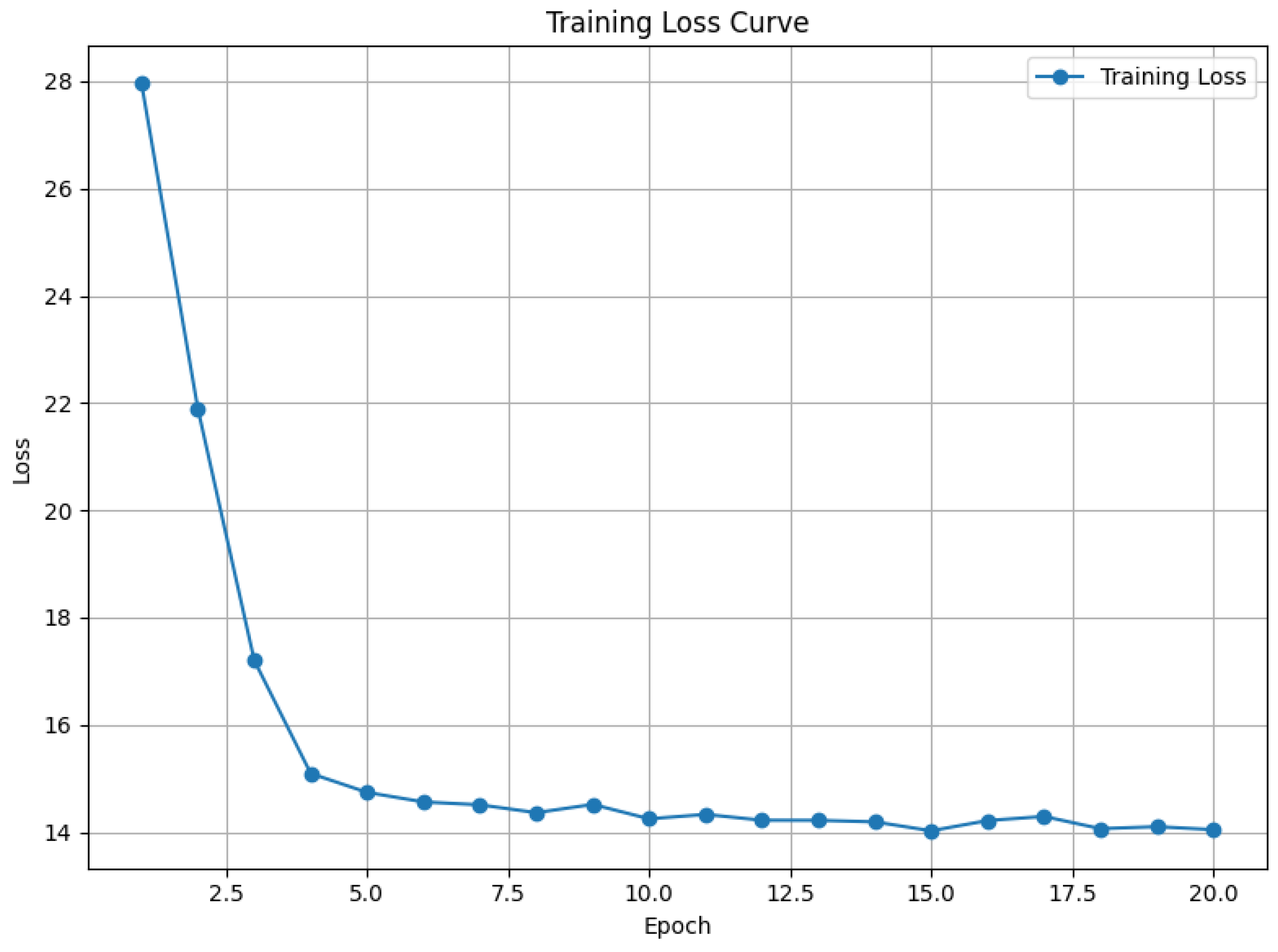
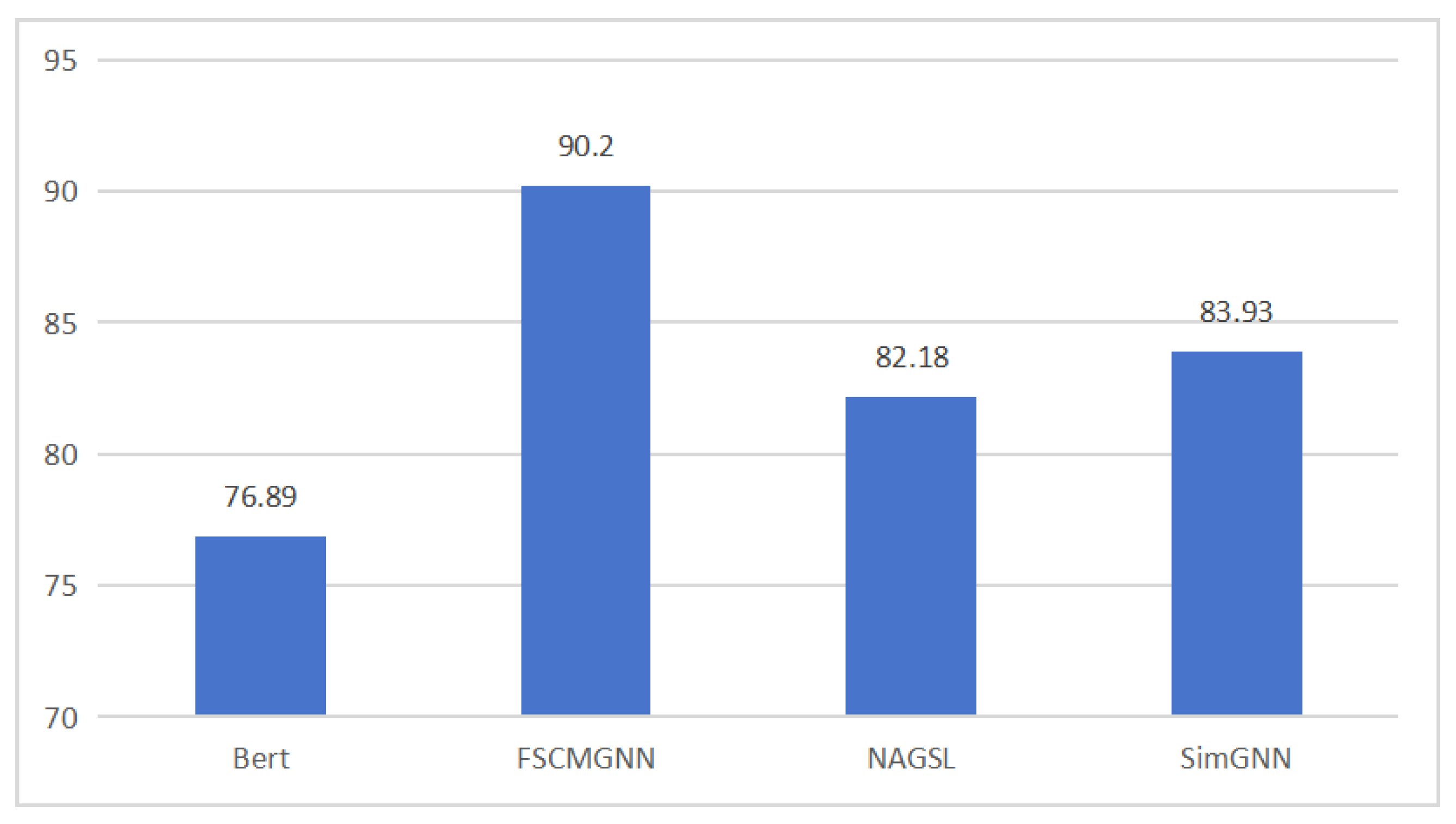
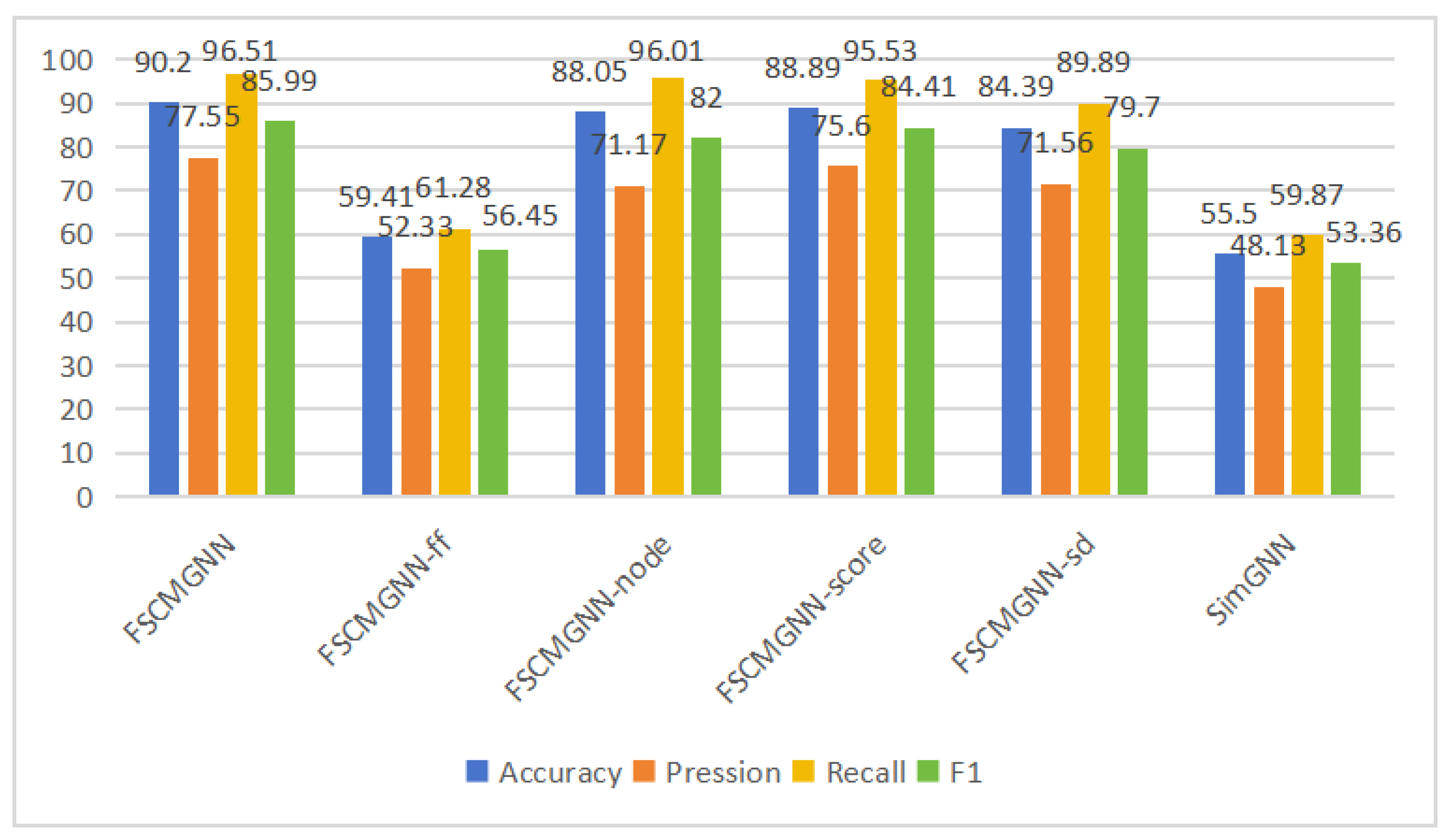
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garcez, A.d.; Gori, M.; Lamb, L.C.; Serafini, L.; Spranger, M.; Tran, S.N. Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning. arXiv 2019, arXiv:1905.06088. [Google Scholar]
- Besold, T.R.; Bader, S.; Bowman, H.; Domingos, P.; Hitzler, P.; Kühnberger, K.U.; Lamb, L.C.; Lima, P.M.V.; de Penning, L.; Pinkas, G.; et al. Neural-symbolic learning and reasoning: A survey and interpretation 1. In Neuro-Symbolic Artificial Intelligence: The State of the Art; IOS Press: Amsterdam, The Netherlands, 2021; pp. 1–51. [Google Scholar]
- Yokoi, K.; Aizawa, A. An approach to similarity search for mathematical expressions using MathML. In Towards a Digital Mathematics Library. Grand Bend, Ontario, Canada, July 8–9th, 2009; Masaryk University Press: Brno, Czech Republic, 2009; pp. 27–35. [Google Scholar]
- Kamali, S.; Tompa, F.W. Structural similarity search for mathematics retrieval. In Proceedings of the International Conference on Intelligent Computer Mathematics, Bath, UK, 8–12 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 246–262. [Google Scholar]
- Zanibbi, R.; Yuan, B. Keyword and image-based retrieval of mathematical expressions. In Proceedings of the Document Recognition and Retrieval XVIII, San Francisco, CA, USA, 23–27 January 2011; Volume 7874, pp. 141–149. [Google Scholar]
- Miner, R.; Munavalli, R. An approach to mathematical search through query formulation and data normalization. In Proceedings of the International Conference on Mathematical Knowledge Management, Hagenberg, Austria, 27–30 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 342–355. [Google Scholar]
- Zanibbi, R.; Blostein, D. Recognition and retrieval of mathematical expressions. Int. J. Doc. Anal. Recognit. (IJDAR) 2012, 15, 331–357. [Google Scholar] [CrossRef]
- Zaremba, W.; Kurach, K.; Fergus, R. Learning to discover efficient mathematical identities. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Irving, G.; Szegedy, C.; Alemi, A.A.; Eén, N.; Chollet, F.; Urban, J. Deepmath-deep sequence models for premise selection. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Allamanis, M.; Chanthirasegaran, P.; Kohli, P.; Sutton, C. Learning continuous semantic representations of symbolic expressions. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 80–88. [Google Scholar]
- Davila, K.; Zanibbi, R. Layout and semantics: Combining representations for mathematical formula search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1165–1168. [Google Scholar]
- Gao, L.; Jiang, Z.; Yin, Y.; Yuan, K.; Yan, Z.; Tang, Z. Preliminary Exploration of Formula Embedding for Mathematical Information Retrieval: Can mathematical formulae be embedded like a natural language? arXiv 2017, arXiv:1707.05154. [Google Scholar]
- Arabshahi, F.; Singh, S.; Anandkumar, A. Towards solving differential equations through neural programming. In Proceedings of the ICML Workshop on Neural Abstract Machines and Program Induction (NAMPI), Stockholm, Sweden, 14 July 2018. [Google Scholar]
- Lample, G.; Charton, F. Deep learning for symbolic mathematics. arXiv 2019, arXiv:1912.01412. [Google Scholar]
- Zhong, W.; Rohatgi, S.; Wu, J.; Giles, C.L.; Zanibbi, R. Accelerating substructure similarity search for formula retrieval. In Proceedings of the Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Proceedings, Part I 42. Springer: Berlin/Heidelberg, Germany, 2020; pp. 714–727. [Google Scholar]
- Peng, S.; Yuan, K.; Gao, L.; Tang, Z. Mathbert: A pre-trained model for mathematical formula understanding. arXiv 2021, arXiv:2105.00377. [Google Scholar]
- Li, Z.; Wu, Y.; Li, Z.; Wei, X.; Zhang, X.; Yang, F.; Ma, X. Autoformalize mathematical statements by symbolic equivalence and semantic consistency. Adv. Neural Inf. Process. Syst. 2025, 37, 53598–53625. [Google Scholar]
- Raz, T.; Shalyt, M.; Leibtag, E.; Kalisch, R.; Hadad, Y.; Kaminer, I. From Euler to AI: Unifying Formulas for Mathematical Constants. arXiv 2025, arXiv:2502.17533. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Bai, Y.; Ding, H.; Bian, S.; Chen, T.; Sun, Y.; Wang, W. Simgnn: A neural network approach to fast graph similarity computation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 384–392. [Google Scholar]
- Bittinger, M.L.; Ellenbogen, D.; Surgent, S.A. Calculus and Its Applications; Pearson: London, UK, 2016. [Google Scholar]
- Stewart, J.; Clegg, D.; Watson, S. Single Variable Calculus: Early Transcendentals, 2nd ed.; Brooks/Cole Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]
- Zill, D.G.; Wright, W.S. Calculus: Early Transcendentals; Jones & Bartlett Publishers: Burlington, MA, USA, 2009. [Google Scholar]
- Jimidovich, B.P. Mathematical Analysis Exercise Set; MIR Publishers: Moscow, Russia, 2002. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Symbol | Edges | Tokens | Levels | Numbers |
|---|---|---|---|---|---|
| 0 | + | (0, 1) (0, 2) (0, 3) | 21 | 0 | 0 |
| 1 | x | (1, 0) | 50 | 1 | 0 |
| 2 | × | (2, 0) (2, 4) (2, 5) | 23 | 1 | 1 |
| 3 | × | (3, 0) (3, 6) (3, 7) (3, 8) | 23 | 1 | 2 |
| 4 | 2 | (4, 2) | 54 | 2 | 0 |
| 5 | y | (5, 2) | 51 | 2 | 1 |
| 6 | 2 | (6, 3) | 54 | 2 | 2 |
| 7 | x | (7, 3) | 50 | 2 | 3 |
| 8 | y | (8, 3) | 51 | 2 | 4 |
| Books | Equivalent Pairs | Unequivalent Pairs |
|---|---|---|
| Single Variable Calculus: Early Transcendentals [22] | 301 | 700 |
| Calculus and its applications [21] | 303 | 980 |
| CALCULUS EARLY TRANSCENDENTALS [23] | 459 | 1020 |
| Jimidovich Mathematical Analysis Exercise Set [24] | 590 | 1270 |
| Model | Acc% | Pre% | Re% | F1% |
|---|---|---|---|---|
| Bert | 50.75 | 46.02 | 56.53 | 50.74 |
| Bert+FSE | 69.5 | 60.11 | 76.72 | 67.41 |
| Bert+FSE+SD | 76.89 | 67.85 | 84.12 | 72.26 |
| SimGNN | 55.5 | 48.13 | 59.87 | 53.36 |
| SimGNN+FSE | 75.14 | 67.91 | 86.47 | 76.08 |
| SimGNN+FSE+SD | 83.93 | 71.02 | 90.41 | 79.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Jiang, D. A Formula-Structure-Embedding-Based GNN for Formula Equivalence Determination. Appl. Sci. 2025, 15, 5448. https://doi.org/10.3390/app15105448
Liu S, Jiang D. A Formula-Structure-Embedding-Based GNN for Formula Equivalence Determination. Applied Sciences. 2025; 15(10):5448. https://doi.org/10.3390/app15105448
Chicago/Turabian StyleLiu, Shan, and Dongchen Jiang. 2025. "A Formula-Structure-Embedding-Based GNN for Formula Equivalence Determination" Applied Sciences 15, no. 10: 5448. https://doi.org/10.3390/app15105448
APA StyleLiu, S., & Jiang, D. (2025). A Formula-Structure-Embedding-Based GNN for Formula Equivalence Determination. Applied Sciences, 15(10), 5448. https://doi.org/10.3390/app15105448