
SnowMamba: Achieving More Precise Snow Removal with Mamba


Abstract
1. Introduction
- This paper presents a novel multi-scale residual snow removal architecture based on Mamba, marking the first attempt to apply Mamba in the field of snow removal;
- This paper designs the SCM module to combine local and contextual image features, to accurately identify snowflakes and background information, and to assist the network in removing snowflakes and restoring clear images;
- Extensive experiments show that the method proposed in this paper outperforms existing approaches on three major synthetic datasets and real-world datasets, achieving higher-quality snow removal in images.
2. Methods
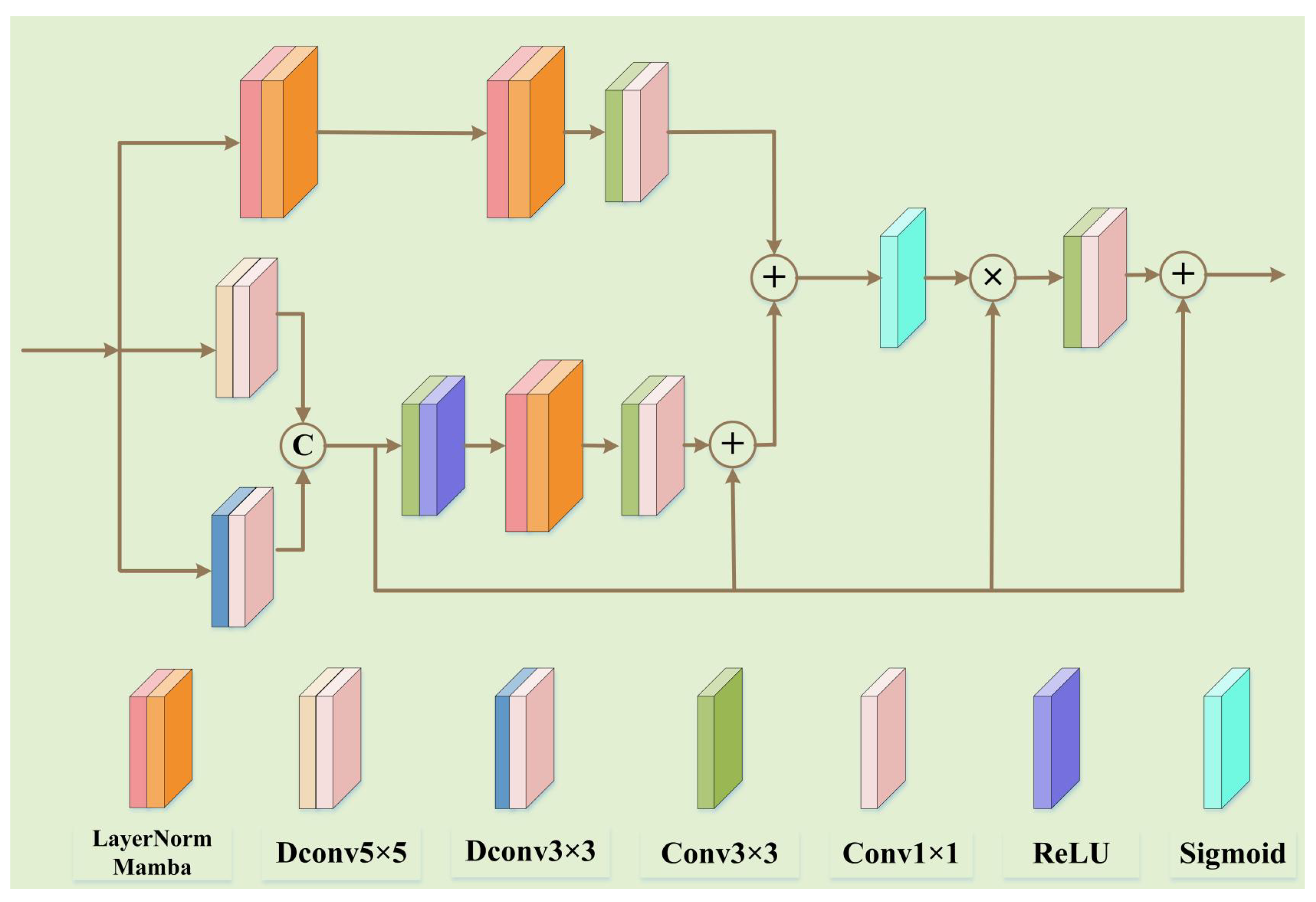
2.1. Design of the SnowMamba Framework
2.2. SEBlock
2.3. Snow Caption Mamba (SCM)
2.4. LOSS
3. Experiments
3.1. Experimental Configuration and Evaluation
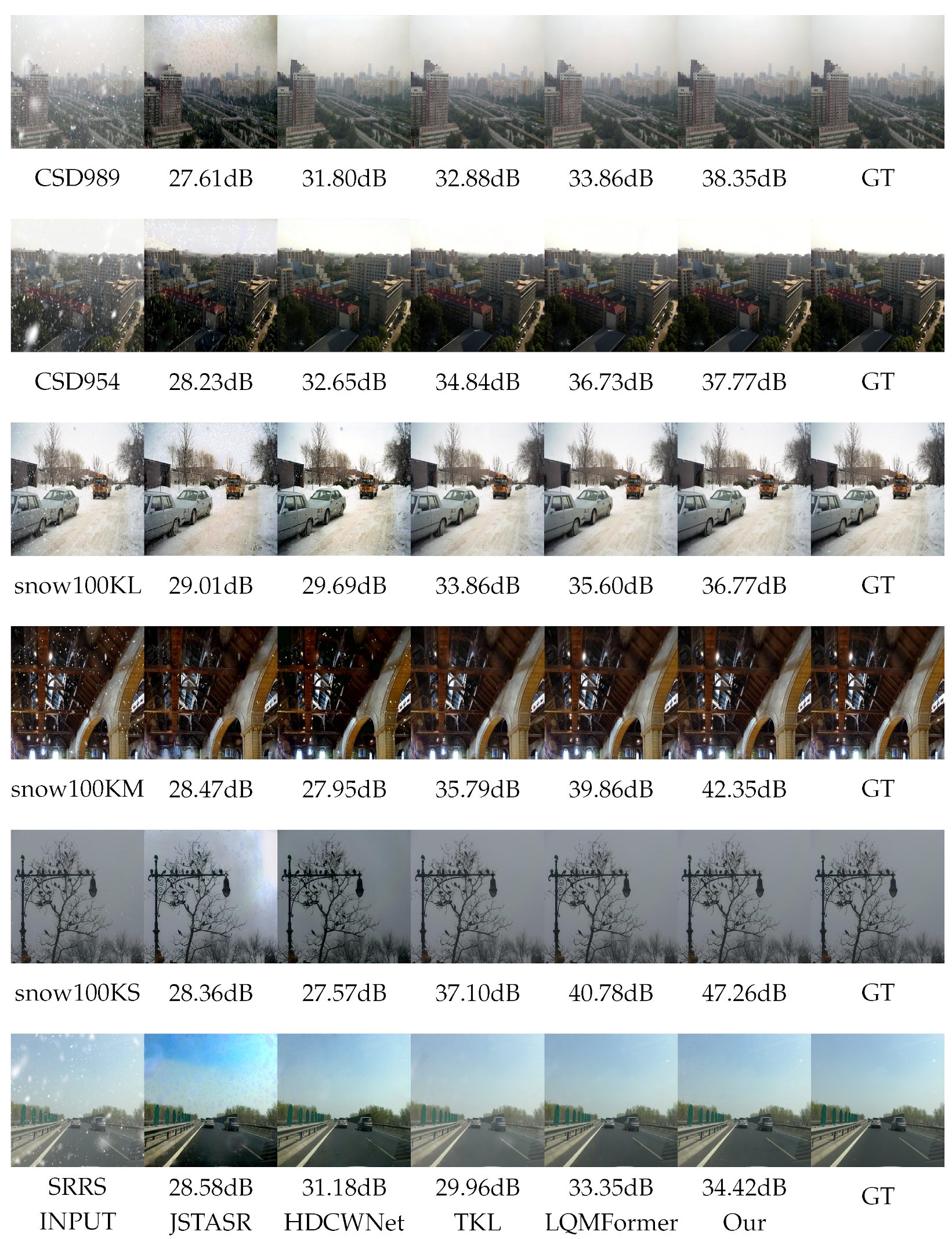
3.2. Qualitative Evaluation
3.3. Quantitative Evaluation
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Liu, Q.; Xu, Z.; Bertasius, G.; Niethammer, M. Simpleclick: Interactive image segmentation with simple vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 22290–22300. [Google Scholar]
- Rezaee, K.; Rezakhani, S.M.; Khosravi, M.R.; Moghimi, M.K. A survey on deep learning-based real-time crowd anomaly detection for secure distributed video surveillance. Pers. Ubiquitous Comput. 2024, 28, 135–151. [Google Scholar] [CrossRef]
- Zheng, X.; Liao, Y.; Guo, W.; Fu, X.; Ding, X. Single-image-based rain and snow removal using multi-guided filter. In Proceedings of the Neural Information Processing: 20th International Conference, ICONIP 2013, Daegu, Republic of Korea, 3–7 November 2013; Proceedings, Part III 20. Springer: Berlin/Heidelberg, Germany, 2013; pp. 258–265. [Google Scholar]
- Ding, X.; Chen, L.; Zheng, X.; Huang, Y.; Zeng, D. Single image rain and snow removal via guided L0 smoothing filter. Multimed. Tools Appl. 2016, 75, 2697–2712. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, S.; Chen, C.; Zeng, B. A hierarchical approach for rain or snow removing in a single color image. IEEE Trans. Image Process. 2017, 26, 3936–3950. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.F.; Jaw, D.W.; Huang, S.C.; Hwang, J.N. DesnowNet: Context-aware deep network for snow removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Yun, M.; Tian, J.; Tang, Y.; Wang, G.; Wu, C. Stacked dense networks for single-image snow removal. Neurocomputing 2019, 367, 152–163. [Google Scholar] [CrossRef]
- Chen, W.T.; Fang, H.Y.; Ding, J.J.; Tsai, C.C.; Kuo, S.Y. JSTASR: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 754–770. [Google Scholar]
- Chen, W.T.; Fang, H.Y.; Hsieh, C.L.; Tsai, C.C.; Chen, I.; Ding, J.J.; Kuo, S.Y. All snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and contradict channel loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4196–4205. [Google Scholar]
- Chen, Z.; Sun, Y.; Bi, X.; Yue, J. Lightweight image de-snowing: A better trade-off between network capacity and performance. Neural Netw. 2023, 165, 896–908. [Google Scholar] [CrossRef] [PubMed]
- Cheng, B.; Li, J.; Chen, Y.; Zeng, T. Snow mask guided adaptive residual network for image snow removal. Comput. Vis. Image Underst. 2023, 236, 103819. [Google Scholar] [CrossRef]
- Quan, Y.; Tan, X.; Huang, Y.; Xu, Y.; Ji, H. Image desnowing via deep invertible separation. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3133–3144. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.J. Image de-raining transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12978–12995. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.T.; Huang, Z.K.; Tsai, C.C.; Yang, H.H.; Ding, J.J.; Kuo, S.Y. Learning multiple adverse weather removal via two-stage knowledge learning and multi-contrastive regularization: Toward a unified model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17653–17662. [Google Scholar]
- Lin, J.; Jiang, N.; Zhang, Z.; Chen, W.; Zhao, T. LMQFormer: A laplace-prior-guided mask query transformer for lightweight snow removal. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6225–6235. [Google Scholar] [CrossRef]
- Zhang, T.; Jiang, N.; Wu, H.; Zhang, K.; Niu, Y.; Zhao, T. HCSD-Net: Single Image Desnowing with Color Space Transformation. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 8125–8133. [Google Scholar]
- Chen, S.; Ye, T.; Liu, Y.; Liao, T.; Jiang, J.; Chen, E.; Chen, P. Msp-former: Multi-scale projection transformer for single image desnowing. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Ma, J.; Li, F.; Wang, B. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv 2024, arXiv:2401.04722. [Google Scholar]
- Wang, Z.; Zheng, J.Q.; Zhang, Y.; Cui, G.; Li, L. Mamba-unet: Unet-like pure visual mamba for medical image segmentation. arXiv 2024, arXiv:2402.05079. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image quality assessment: Unifying structure and texture similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Tan, R.T.; Cheong, L.F. All in one bad weather removal using architectural search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3175–3185. [Google Scholar]
- Valanarasu, J.M.J.; Yasarla, R.; Patel, V.M. Transweather: Transformer-based restoration of images degraded by adverse weather conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2353–2363. [Google Scholar]
- Chen, E.; Chen, S.; Ye, T.; Liu, Y. Degradation-adaptive neural network for jointly single image dehazing and desnowing. Front. Comput. Sci. 2024, 18, 182707. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patches | 128 × 128 | 192 × 192 | 224 × 224 | 256 × 256 | 384 × 384 | 464 × 464 |
| Iterations (K) | 128 | 128 | 92 | 92 | 64 | 64 |
| Type | Method/Dataset | Snow100K(2000) | SRRS(2000) | CSD(2000) | |||
|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| Desnowing Task | DesnowNet(TIP’2018) | 30.80 | 0.92 | 20.38 | 0.84 | 20.13 | 0.81 |
| JSTASR(ECCV’2020) | 23.12 | 0.86 | 25.82 | 0.89 | 28.42 | 0.69 | |
| HDCWNet(ICCV’2021) | 21.23 | 0.73 | 27.78 | 0.92 | 31.80 | 0.90 | |
| SMGARN(CVIU’2023) | 31.92 | 0.93 | 29.14 | 0.94 | 31.93 | 0.95 | |
| LMQFormer(TCSVT’2023) | 35.14 | 0.93 | 31.05 | 0.95 | 34.53 | 0.96 | |
| Adverse Weather | All in One(CVPR’2020) | 26.07 | 0.88 | 24.98 | 0.88 | 26.31 | 0.87 |
| TransWeather(CVPR’2022) | 31.82 | 0.93 | 28.29 | 0.92 | 31.76 | 0.93 | |
| DAN-Net(Front.Comput’2024) | 32.48 | 0.96 | 29.34 | 0.95 | 30.82 | 0.95 | |
| TKL(CVPR’2022) | 31.27 | 0.90 | 29.37 | 0.93 | 33.01 | 0.93 | |
| OUR(SnowMamba) | 36.26 | 0.958 | 32.99 | 0.968 | 36.56 | 0.977 | |
| Method/Dataset | Snow 100KS | Snow 100KM | Snow 100KL | |||
|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | |
| LPIPS↓ | DISTS↓ | LPIPS↓ | DISTS↓ | LPIPS↓ | DISTS↓ | |
| JSTASR | 28.94 | 0.61 | 28.92 | 0.59 | 28.07 | 0.51 |
| 0.3650 | 0.1787 | 0.3854 | 0.1881 | 0.4415 | 0.2225 | |
| HDWCNet | 28.54 | 0.61 | 21.66 | 0.72 | 28.74 | 0.53 |
| 0.3278 | 0.1692 | 0.3468 | 0.1779 | 0.4006 | 0.2116 | |
| DesnowNet | 32.23 | 0.95 | 30.86 | 0.94 | 27.16 | 0.89 |
| - | - | - | - | - | - | |
| TKL | 34.71 | 0.92 | 33.95 | 0.91 | 31.63 | 0.85 |
| 0.1188 | 0.0566 | 0.1367 | 0.0665 | 0.1964 | 0.1018 | |
| LMQFormer | 36.74 | 0.95 | 35.74 | 0.94 | 32.95 | 0.90 |
| 0.0751 | 0.0381 | 0.0898 | 0.0460 | 0.1399 | 0.0748 | |
| SnowMamba (ours) | 38.40 | 0.972 | 36.89 | 0.964 | 33.49 | 0.938 |
| 0.0667 | 0.0377 | 0.0832 | 0.0459 | 0.1376 | 0.0746 | |
| Setting | Model | Metric | |||
|---|---|---|---|---|---|
| SCM Blockbase | SCM Block | SEBlock | PSNR | SSIM | |
| S1 | ✓ | ✘ | ✘ | 33.44 | 0.95 |
| S2 | ✘ | ✓ | ✘ | 35.61 | 0.96 |
| S3 | ✘ | ✓ | ✓ | 36.56 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Zhou, Y.; Shi, F.; Jia, Z. SnowMamba: Achieving More Precise Snow Removal with Mamba. Appl. Sci. 2025, 15, 5404. https://doi.org/10.3390/app15105404
Wang G, Zhou Y, Shi F, Jia Z. SnowMamba: Achieving More Precise Snow Removal with Mamba. Applied Sciences. 2025; 15(10):5404. https://doi.org/10.3390/app15105404
Chicago/Turabian StyleWang, Guoqiang, Yanyun Zhou, Fei Shi, and Zhenhong Jia. 2025. "SnowMamba: Achieving More Precise Snow Removal with Mamba" Applied Sciences 15, no. 10: 5404. https://doi.org/10.3390/app15105404
APA StyleWang, G., Zhou, Y., Shi, F., & Jia, Z. (2025). SnowMamba: Achieving More Precise Snow Removal with Mamba. Applied Sciences, 15(10), 5404. https://doi.org/10.3390/app15105404