
Improving Classification Performance by Addressing Dataset Imbalance: A Case Study for Pest Management




Abstract
1. Introduction
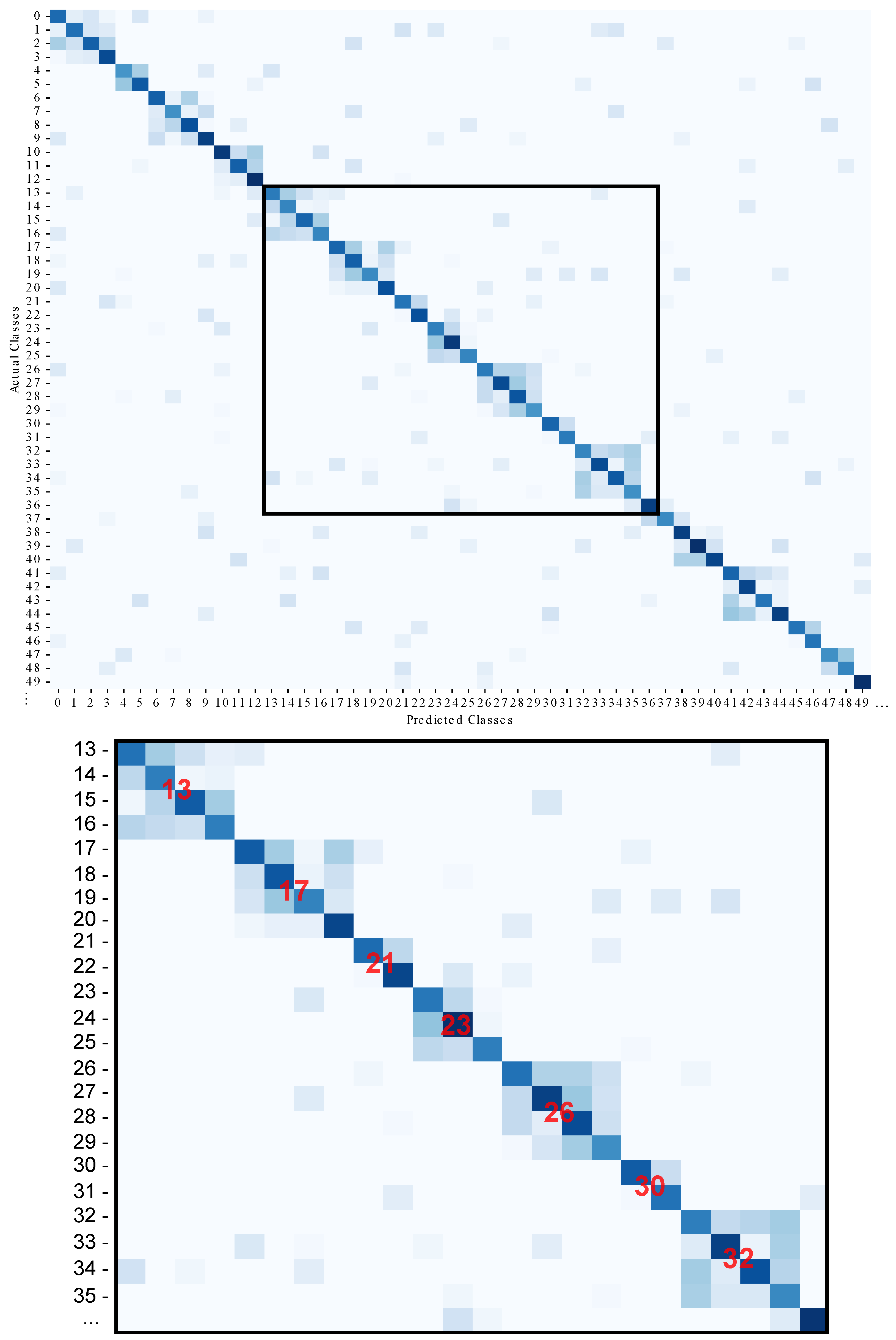
- A novel, general-purpose balancing technique to reduce biasing and variability in the presence of high-unbalanced multi-class datasets is proposed, thus improving classification performance. The designed method is a multi-stage pipeline comprising initial feature analysis, data cleaning, and data filtering steps. The actual balancing process tackles the problem of overnumbered classes by partitioning in multiple subclasses rather than deleting samples, so that the model can still learn from the original feature space. During inference, most of the misclassifications are related to the high correlation between subclasses originated from the same category. The generated confusion matrix will therefore have a block-diagonal trend in which all the errors in a specific sub-block must not be counted as classification errors.
- The construction of a balanced and enhanced version of the IP102 dataset to improve the classification accuracy and robustness of the methods is developed.
- The development of two multi-class insect pest detection and classification models trained on the proposed balanced IP102 dataset is proposed. which reached good performance with challenging images too and outperformed state-of-the-art models trained on the same dataset.
2. Related Studies
2.1. Pest Detection and Classification Frameworks
2.2. Techniques for Handling Data Imbalance
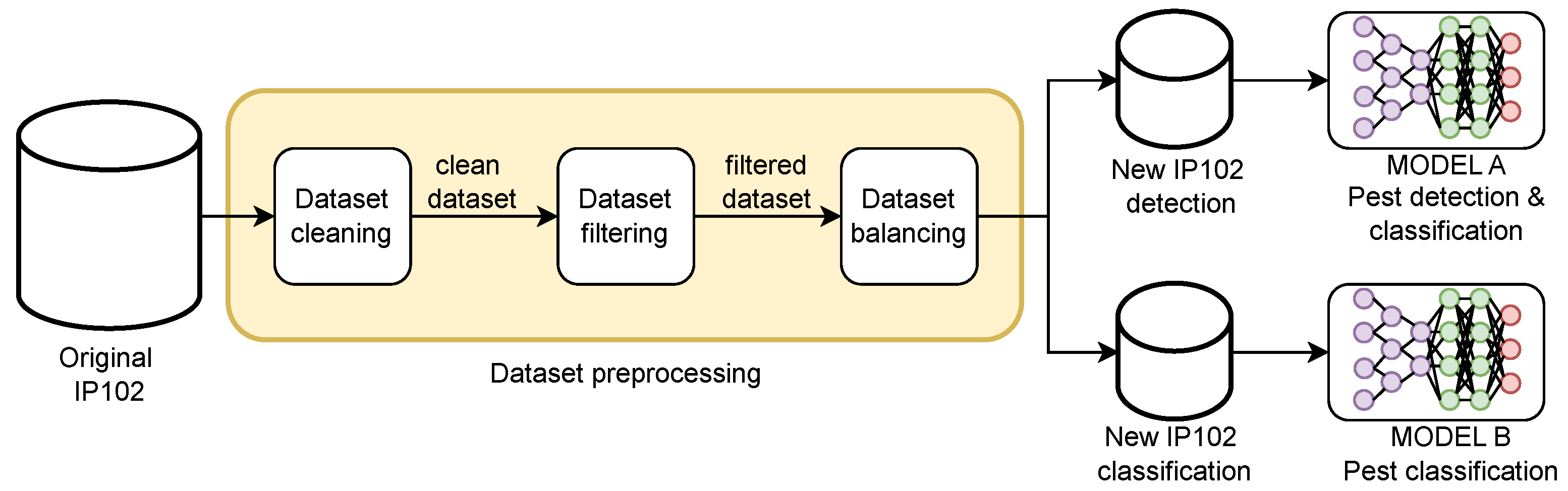
3. Materials and Methods
3.1. Pest Image Dataset
3.2. An Overview of YOLOv8
3.3. Proposed Method
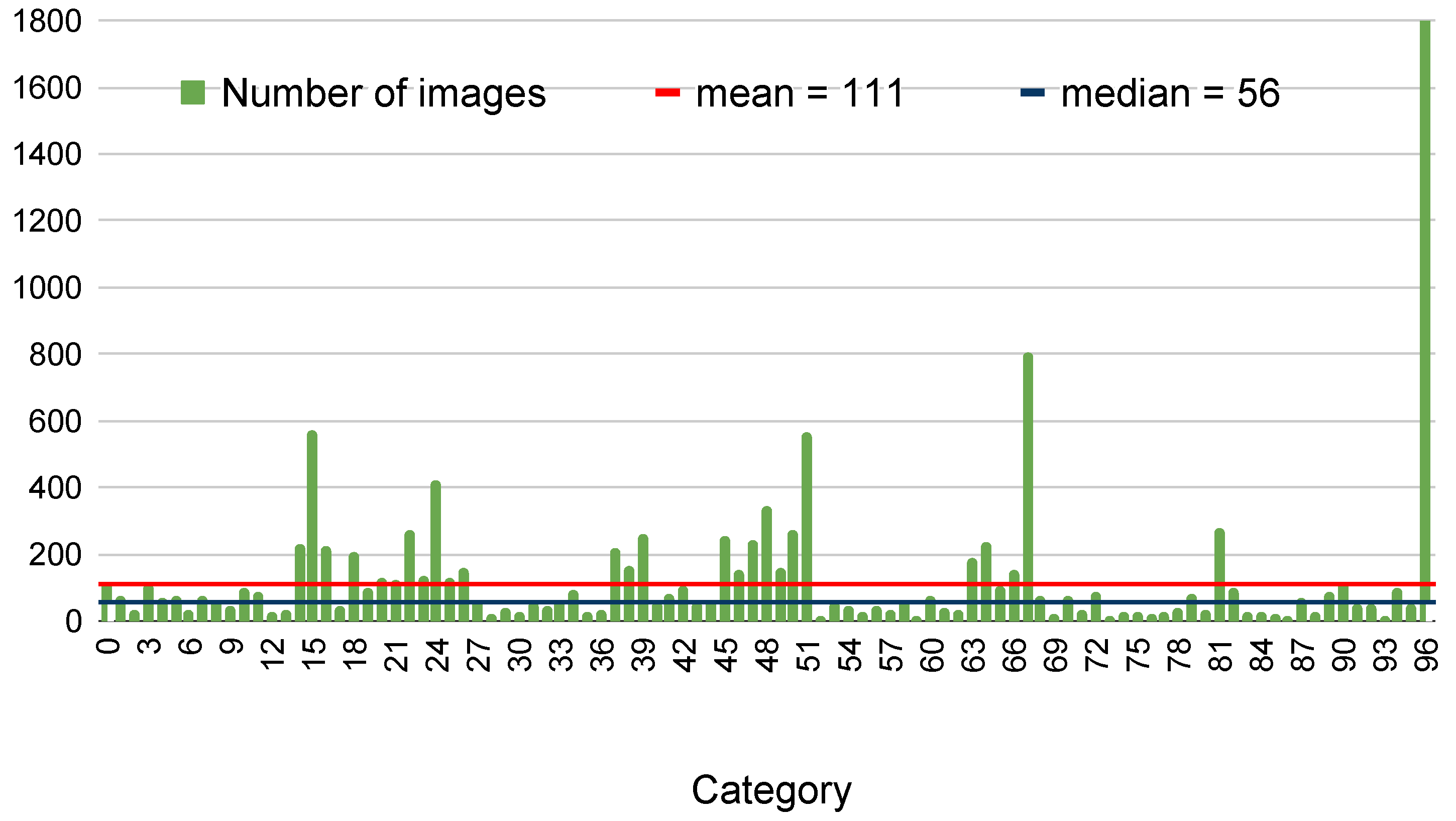
3.3.1. Data Exploration and Data Cleaning
- Pest category distribution is highly unbalanced, ranging from classes with less than 10 samples to classes with more than 1000 samples.
- About of images composing the dataset have a single instance.
- Different life stages of a specific insect are grouped into the same class.
- Models trained on the dataset as is are likely to become biased towards the majority class and may have trouble generalizing with respect to the less represented classes.
- The detection model will tend to look for a single bounding box on each image under test rather than hunting for a greater number of insect instances as a consequence of the dataset composition.
- There is low similarity between insects belonging to the same class because the same insect can assume very different aspect throughout its lifecycle, thus increasing the in-class variability.
- There is high correlation among dataset categories due to the similar characteristics shared by different insects at the same stage that decrease intra-class diversity.
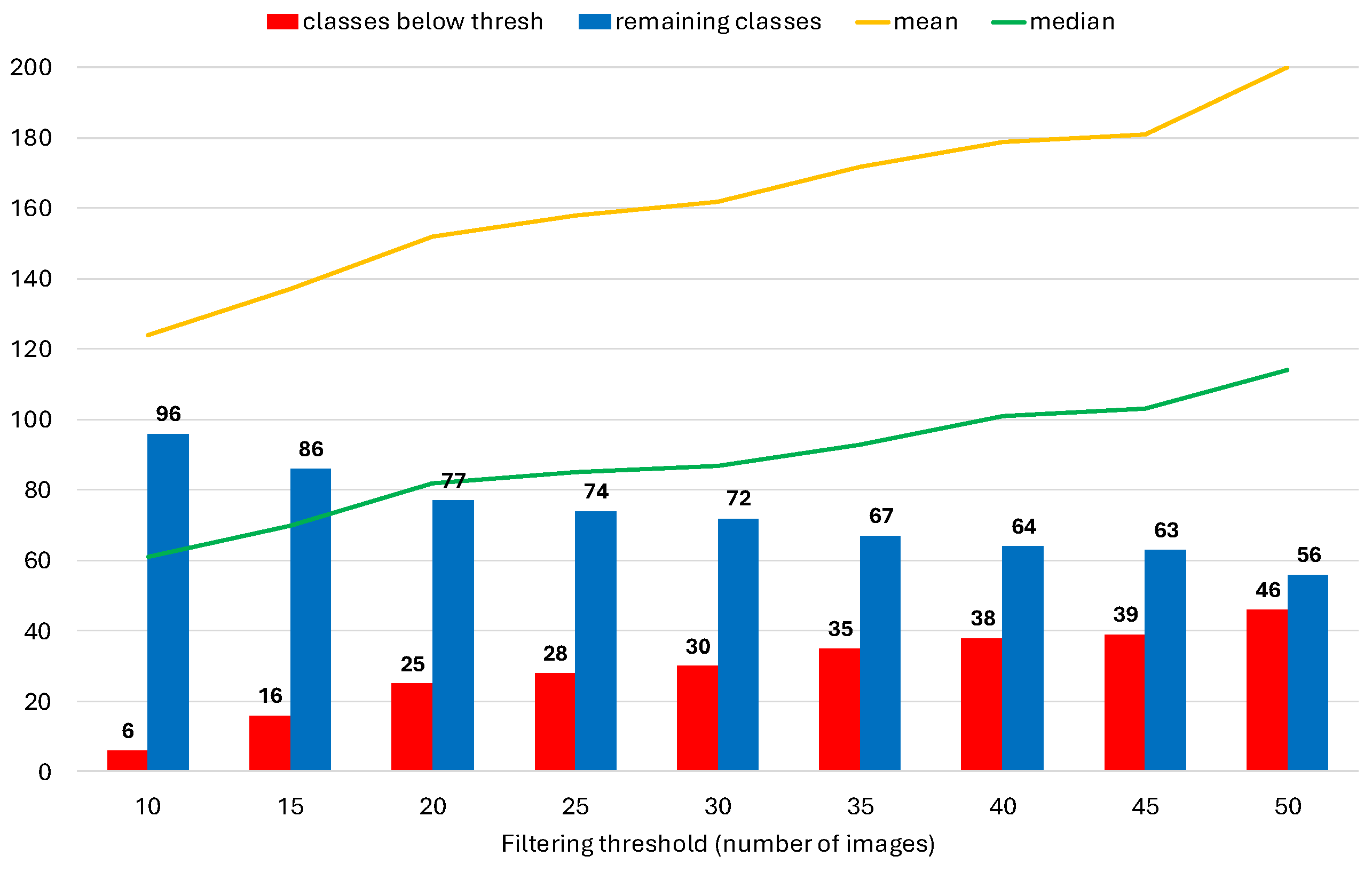
3.3.2. Class-Based Data Filtering
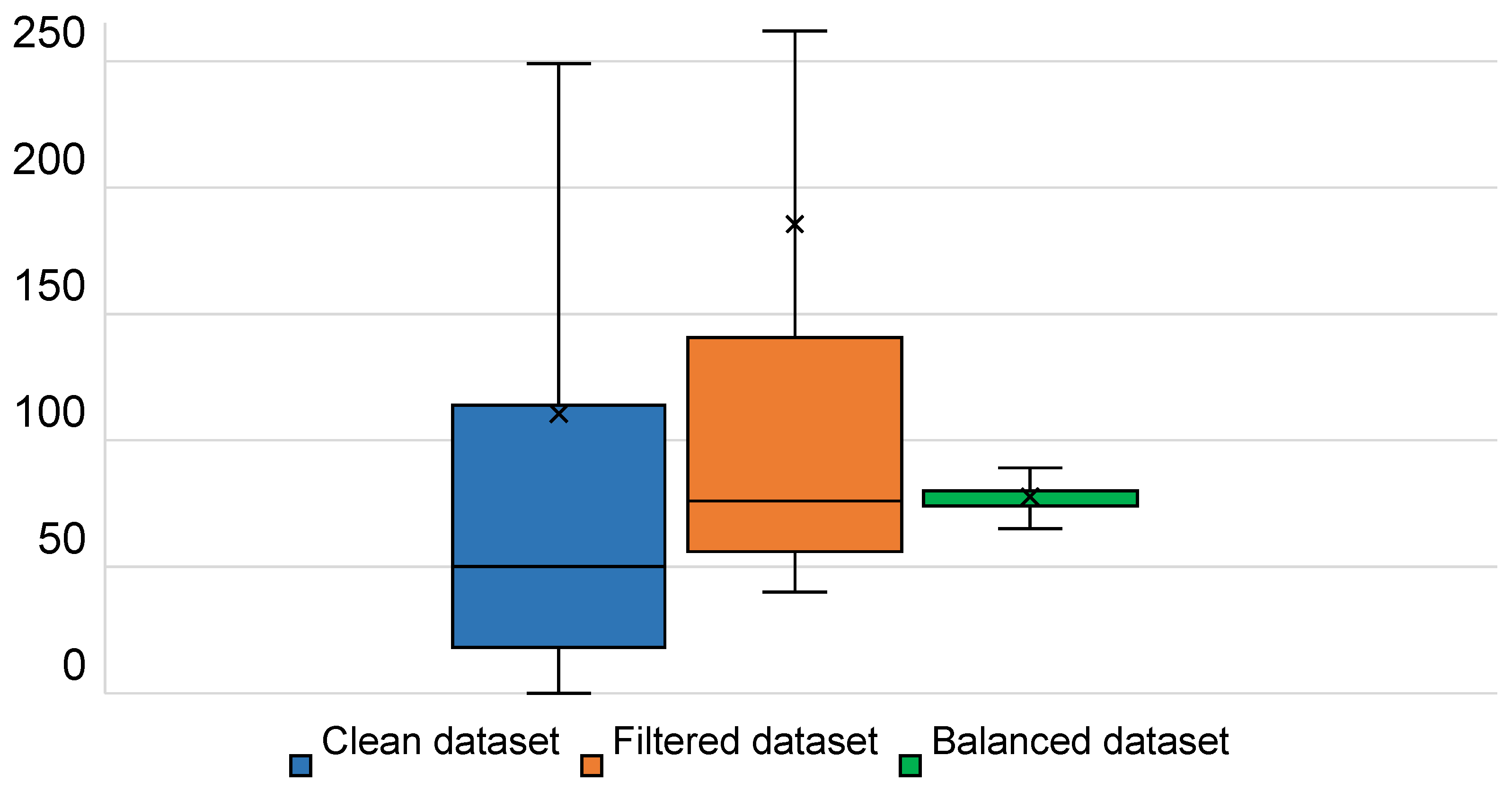
3.3.3. Dataset Balancing
- Classes with a number of images within the above defined range are left unchanged.
- Classes with a cardinality below the lower bound of the range are upsampled.
- Classes with a cardinality exceeding the upper bound undergo a downsampling process generating new subclasses.
| Algorithm 1: Dataset balancing |
 |

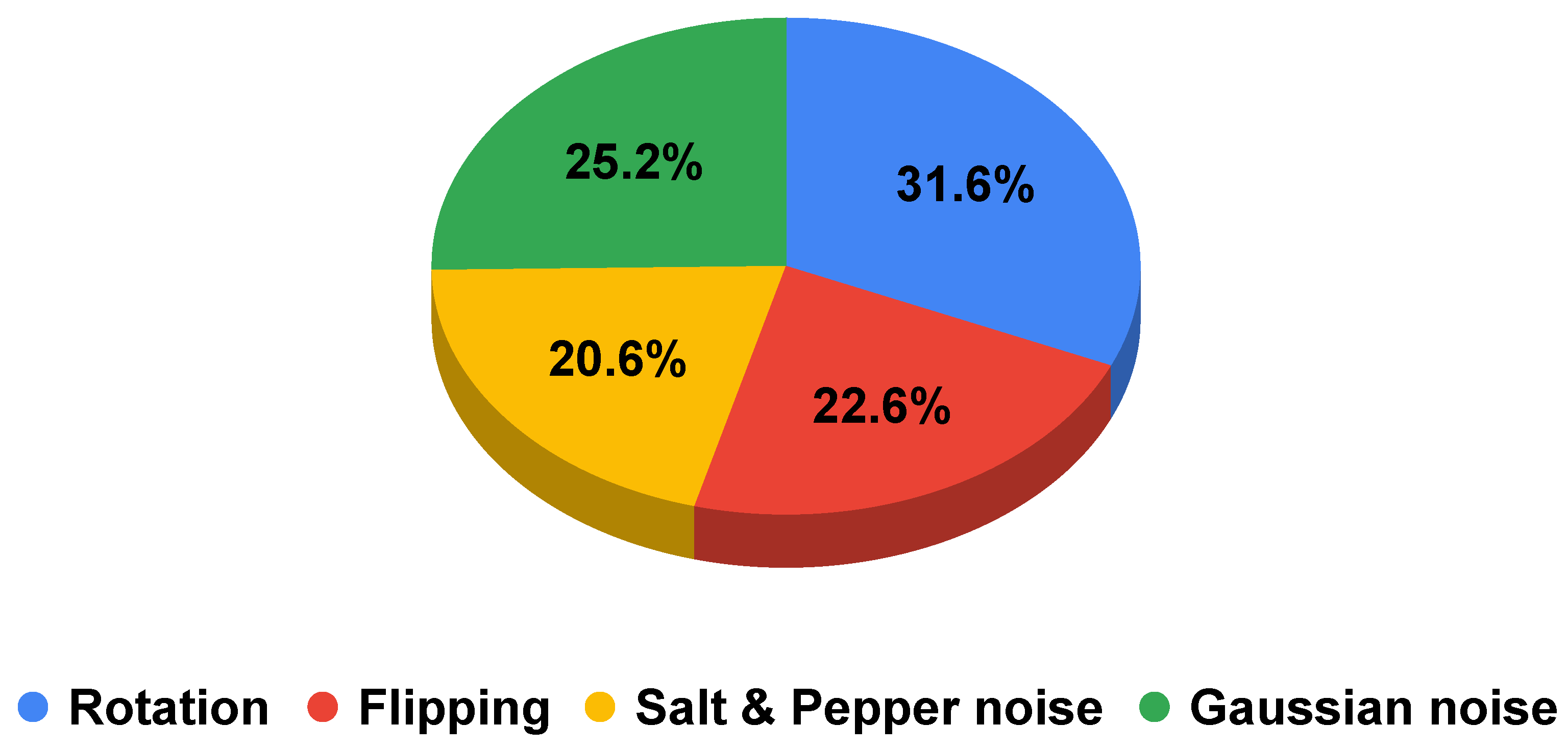
Upsampling Processing Technique
- Rotation with a random angle between 90, 180, and 270. The values of the angles are fixed to avoid the creation of blank spaces in the corners of the image.
- Flipping along the randomly selected axis.
- Gaussian noise addition, with a mean of 0 and std of 10.
- Salt and pepper noise addition, with a random number of pixels between and of the total number of pixels, equally distributed between black and white noise.
Downsampling Processing Technique
3.3.4. Model Design
3.4. Setup and Strategy
3.5. Evaluation Metrics
4. Experimental Results and Analysis
4.1. Performance Analysis and Comparison
4.1.1. Pest Detection and Classification Results
4.1.2. Pest Classification Results
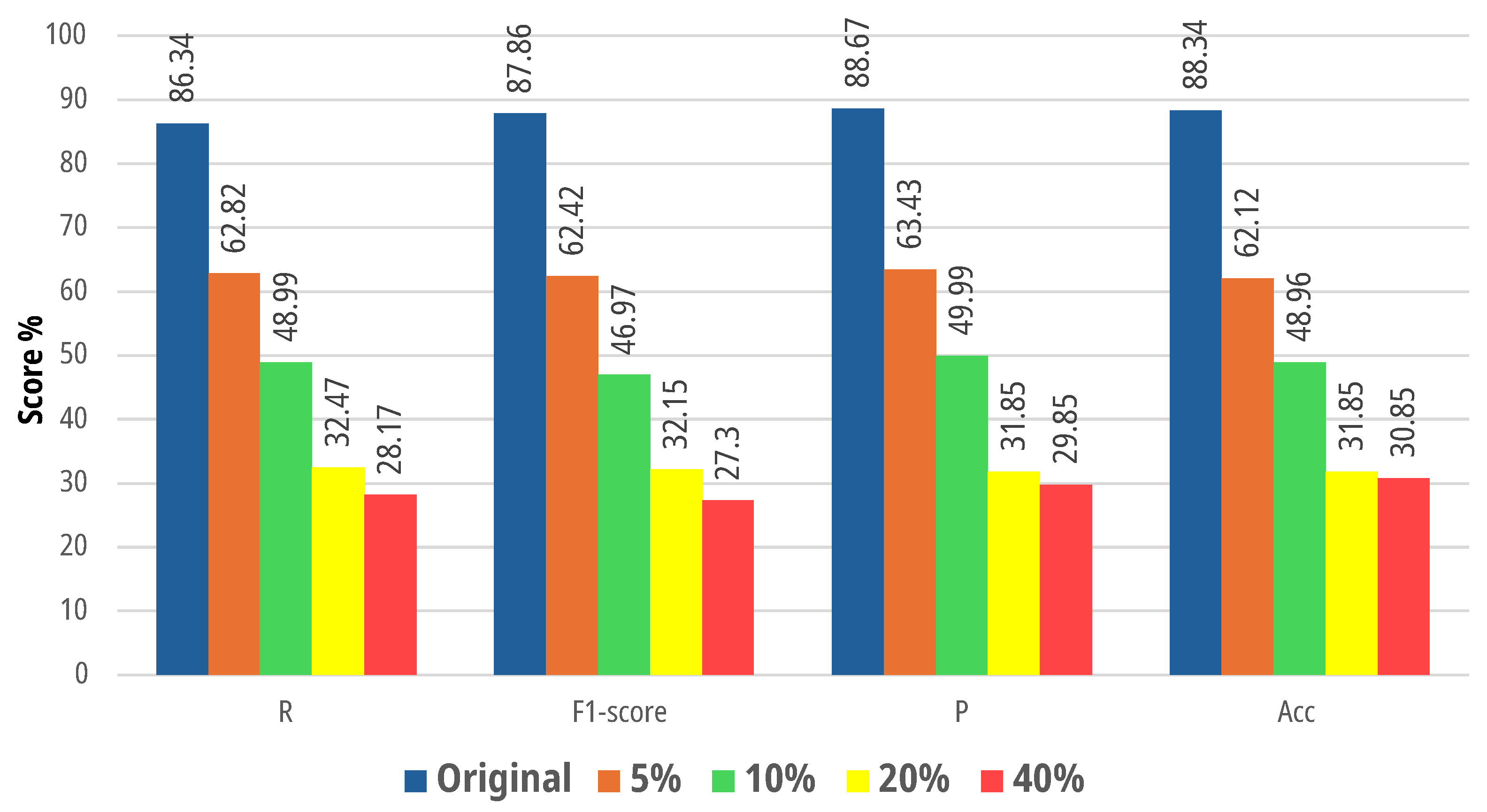
4.2. Model Robustness
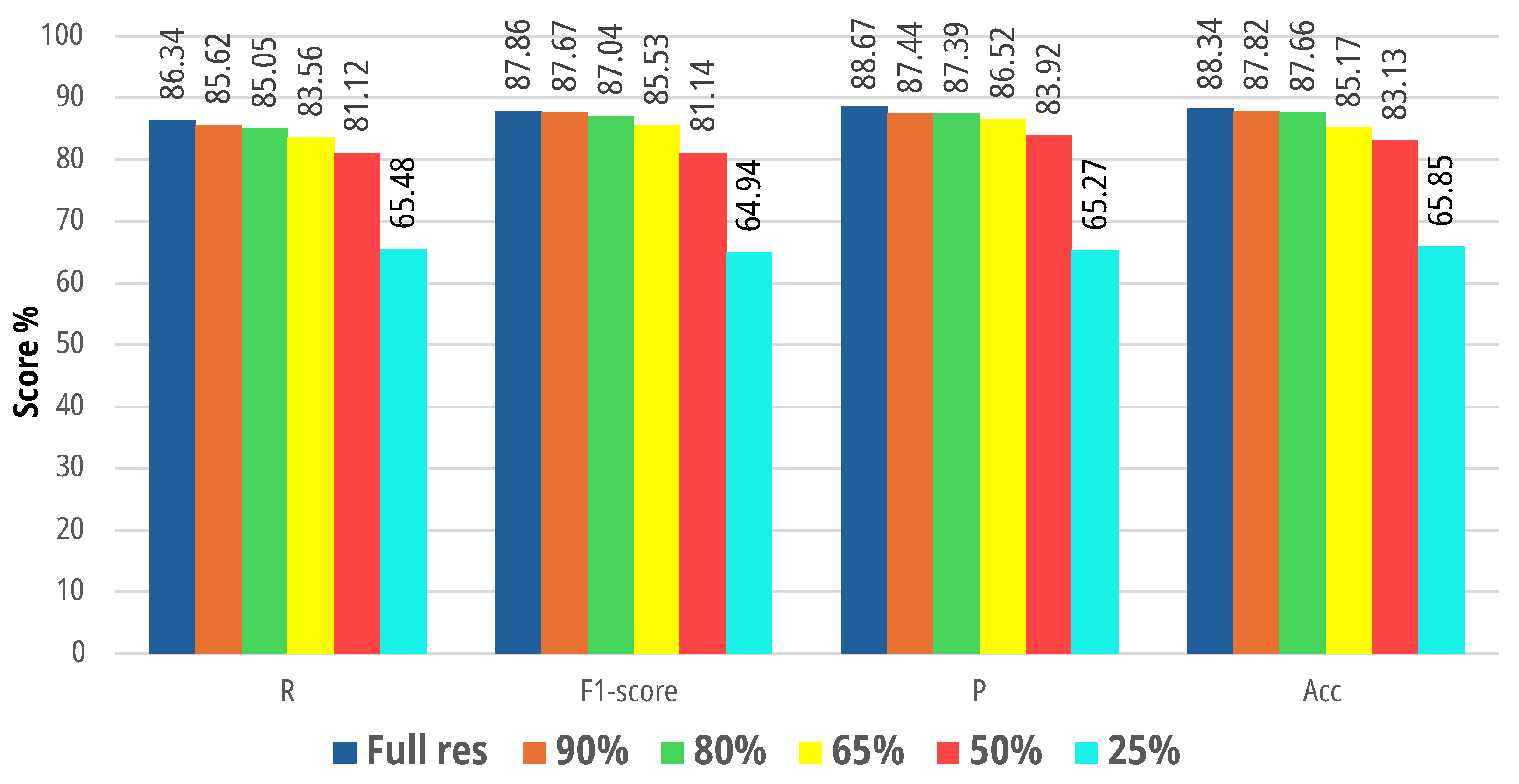
4.2.1. Robustness of the Designed System to Image Resolution
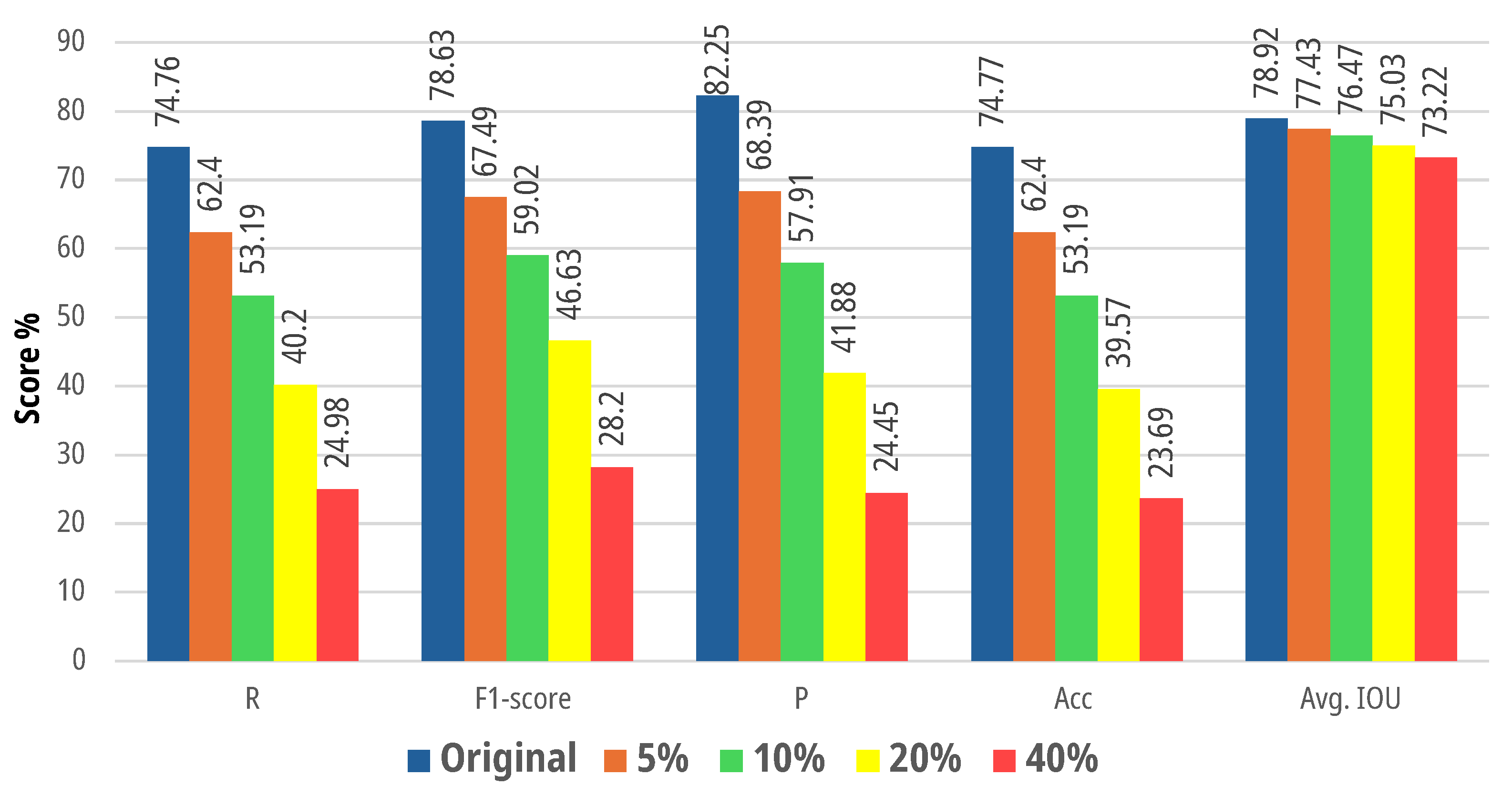
4.2.2. Robustness of the Designed Systems to Noise
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Puliga, G.A.; Sprangers, T.; Huiting, H.; Dauber, J. Management practices influence biocontrol potential of generalist predators in maize cropping systems. Entomol. Exp. Appl. 2024, 172, 132–144. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep learning for precision agriculture: A bibliometric analysis. Intell. Syst. Appl. 2022, 16, 200102. [Google Scholar] [CrossRef]
- Mamdouh, N.; Wael, M.; Khattab, A. Artificial intelligence-based detection and counting of olive fruit flies: A comprehensive survey. In Cognitive Data Science in Sustainable Computing; Deep Learning for Sustainable Agriculture; Academic Press: Cambridge, MA, USA, 2022; pp. 357–380. [Google Scholar] [CrossRef]
- Karlsson Green, K.; Stenberg, J.A.; Lankinen, Å. Making sense of Integrated Pest Management (IPM) in the light of evolution. Evol. Appl. 2020, 13, 1791–1805. [Google Scholar] [CrossRef] [PubMed]
- Lello, F.; Dida, M.; Mkiramweni, M.; Matiko, J.; Akol, R.; Nsabagwa, M.; Katumba, A. Fruit fly automatic detection and monitoring techniques: A review. Smart Agric. Technol. 2023, 5, 100294. [Google Scholar] [CrossRef]
- Preti, M.; Verheggen, F.; Angeli, S. Insect pest monitoring with camera-equipped traps: Strengths and limitations. J. Pest Sci. 2021, 94, 203–217. [Google Scholar] [CrossRef]
- Teixeira, A.C.; Ribeiro, J.; Morais, R.; Sousa, J.J.; Cunha, A. A systematic review on automatic insect detection using deep learning. Agriculture 2023, 13, 713. [Google Scholar] [CrossRef]
- Spelmen, V.S.; Porkodi, R. A review on handling imbalanced data. In Proceedings of the 2018 International Conference on Current Trends Towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Zheng, T.; Yang, X.; Lv, J.; Li, M.; Wang, S.; Li, W. An efficient mobile model for insect image classification in the field pest management. Eng. Sci. Technol. Int. J. 2023, 39, 101335. [Google Scholar] [CrossRef]
- Setiawan, A.; Yudistira, N.; Wihandika, R.C. Large scale pest classification using efficient Convolutional Neural Network with augmentation and regularizers. Comput. Electron. Agric. 2022, 200, 107204. [Google Scholar] [CrossRef]
- Ali, F.; Qayyum, H.; Iqbal, M.J. Faster-PestNet: A Lightweight deep learning framework for crop pest detection and classification. IEEE Access 2023, 11, 104016–104027. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Pancino, F. Insect pest image detection and recognition based on bio-inspired methods. Ecol. Inform. 2020, 57, 101089. [Google Scholar] [CrossRef]
- Li, C.; Zhen, T.; Li, Z. Image classification of pests with residual neural network based on transfer learning. Appl. Sci. 2022, 12, 4356. [Google Scholar] [CrossRef]
- Liu, W.; Wu, G.; Ren, F.; Kang, X. DFF-ResNet: An insect pest recognition model based on residual networks. Big Data Min. Anal. 2020, 3, 300–310. [Google Scholar] [CrossRef]
- Ren, F.; Liu, W.; Wu, G. Feature reuse residual networks for insect pest recognition. IEEE Access 2019, 7, 122758–122768. [Google Scholar] [CrossRef]
- Zhou, S.Y.; Su, C.Y. Efficient convolutional neural network for pest recognition-ExquisiteNet. In Proceedings of the 2020 IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 23–25 October 2020; pp. 216–219. [Google Scholar] [CrossRef]
- Ayan, E. Genetic algorithm-based hyperparameter optimization for convolutional neural networks in the classification of crop pests. Arab. J. Sci. Eng. 2024, 49, 3079–3093. [Google Scholar] [CrossRef]
- Albattah, W.; Masood, M.; Javed, A.; Nawaz, M.; Albahli, S. Custom CornerNet: A drone-based improved deep learning technique for large-scale multiclass pest localization and classification. Complex Intell. Syst. 2023, 9, 1299–1316. [Google Scholar] [CrossRef]
- Anwar, Z.; Masood, S. Exploring deep ensemble model for insect and pest detection from images. Procedia Comput. Sci. 2023, 218, 2328–2337. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, M.; Guo, M.; Wang, J.; Zheng, N. Pest recognition based on multi-image feature localization and adaptive filtering fusion. Front. Plant Sci. 2023, 14, 1282212. [Google Scholar] [CrossRef]
- Yang, X.; Luo, Y.; Li, M.; Yang, Z.; Sun, C.; Li, W. Recognizing pests in field-based images by combining spatial and channel attention mechanism. IEEE Access 2021, 9, 162448–162458. [Google Scholar] [CrossRef]
- Liu, H.; Zhan, Y.; Xia, H.; Mao, Q.; Tan, Y. Self-supervised transformer-based pre-training method using latent semantic masking auto-encoder for pest and disease classification. Comput. Electron. Agric. 2022, 203, 107448. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, J.; Deng, H.; Wu, X.; Wang, Y.; Hao, G. Aa-trans: Core attention aggregating transformer with information entropy selector for fine-grained visual classification. Pattern Recognit. 2023, 140, 109547. [Google Scholar] [CrossRef]
- Xia, W.; Han, D.; Li, D.; Wu, Z.; Han, B.; Wang, J. An ensemble learning integration of multiple CNN with improved vision transformer models for pest classification. Ann. Appl. Biol. 2023, 182, 144–158. [Google Scholar] [CrossRef]
- Suzauddola, M.; Zhang, D.; Zeb, A.; Chen, J.; Wei, L.; Rayhan, A.S. Advanced deep learning model for crop-specific and cross-crop pest identification. Expert Syst. Appl. 2025, 274, 126896. [Google Scholar] [CrossRef]
- Song, L.; Liu, M.; Liu, S.; Wang, H.; Luo, J. Pest species identification algorithm based on improved YOLOv4 network. Signal Image Video Process. 2023, 17, 3127–3134. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, C.; Feng, Y.; Li, D. Pests identification of ip102 by yolov5 embedded with the novel lightweight module. Agronomy 2023, 13, 1583. [Google Scholar] [CrossRef]
- Ali, F.; Qayyum, H.; Saleem, K.; Ahmad, I.; Iqbal, M.J. YOLOCSP-PEST for Crops Pest Localization and Classification. Comput. Mater. Contin. 2025, 82, 2373–2388. [Google Scholar] [CrossRef]
- Doan, T.N. An efficient system for real-time mobile smart device-based insect detection. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 6. [Google Scholar] [CrossRef]
- An, J.; Du, Y.; Hong, P.; Zhang, L.; Weng, X. Insect recognition based on complementary features from multiple views. Sci. Rep. 2023, 13, 2966. [Google Scholar] [CrossRef]
- Qian, Y.; Xiao, Z.; Deng, Z. Fine-grained Crop Pest Classification based on Multi-scale Feature Fusion and Mixed Attention Mechanisms. Front. Plant Sci. 2025, 16, 1500571. [Google Scholar] [CrossRef]
- Doan, T.N. Large-scale insect pest image classification. J. Adv. Inf. Technol. 2023, 14, 328–341. [Google Scholar] [CrossRef]
- Nandhini, C.; Brindha, M. Visual regenerative fusion network for pest recognition. Neural Comput. Appl. 2024, 36, 2867–2882. [Google Scholar] [CrossRef]
- Bollis, E.; Pedrini, H.; Avila, S. Weakly supervised learning guided by activation mapping applied to a novel citrus pest benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 70–71. [Google Scholar] [CrossRef]
- Khan, M.K.; Ullah, M.O. Deep transfer learning inspired automatic insect pest recognition. In Proceedings of the 3rd International Conference on Computational Sciences and Technologies. Mehran University of Engineering and Technology, Jamshoro, Pakistan, 17–19 February 2022; pp. 17–19. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ramentol, E.; Verbiest, N.; Bello, R.; Caballero, Y.; Cornelis, C.; Herrera, F. SMOTE-FRST: A new resampling method using fuzzy rough set theory. Uncertain. Model. Knowl. Eng. Decis. Mak. 2012, 7, 800–805. [Google Scholar] [CrossRef]
- Gao, M.; Hong, X.; Chen, S.; Harris, C.J. A combined SMOTE and PSO based RBF classifier for two-class imbalanced problems. Neurocomputing 2011, 74, 3456–3466. [Google Scholar] [CrossRef]
- Gurcan, F.; Soylu, A. Synthetic Boosted Resampling Using Deep Generative Adversarial Networks: A Novel Approach to Improve Cancer Prediction from Imbalanced Datasets. Cancers 2024, 16, 4046. [Google Scholar] [CrossRef]
- Majeed, A.; Hwang, S.O. CTGAN-MOS: Conditional generative adversarial network based minority-class-augmented oversampling scheme for imbalanced problems. IEEE Access 2023, 11, 85878–85899. [Google Scholar] [CrossRef]
- Ai, Q.; Wang, P.; He, L.; Wen, L.; Pan, L.; Xu, Z. Generative oversampling for imbalanced data via majority-guided VAE. In Proceedings of the International Conference on Artificial Intelligence and Statistics. PMLR, Valencia, Spain, 25–27 April 2023; pp. 3315–3330. [Google Scholar]
- Dablain, D.; Krawczyk, B.; Chawla, N. Towards a holistic view of bias in machine learning: Bridging algorithmic fairness and imbalanced learning. Discov. Data 2024, 2, 4. [Google Scholar] [CrossRef]
- Adiputra, I.N.M.; Lin, P.C.; Wanchai, P. The Effectiveness of Generative Adversarial Network-Based Oversampling Methods for Imbalanced Multi-Class Credit Score Classification. Electronics 2025, 14, 697. [Google Scholar] [CrossRef]
- Wu, X.; Zhan, C.; Lai, Y.K.; Cheng, M.M.; Yang, J. Ip102: A large-scale benchmark dataset for insect pest recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8787–8796. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 83. [Google Scholar] [CrossRef]
- Sohan, M.; Sai Ram, T.; Rami Reddy, C.V. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics; Springer: Singapore, 2024; pp. 529–545. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; proceedings, part v 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Ciaglia, F.; Zuppichini, F.S.; Guerrie, P.; McQuade, M.; Solawetz, J. Roboflow 100: A rich, multi-domain object detection benchmark. arXiv 2022, arXiv:2211.13523. [Google Scholar]
- Sharma, A.; Kumar, V.; Longchamps, L. Comparative performance of YOLOv8, YOLOv9, YOLOv10, YOLOv11 and Faster R-CNN models for detection of multiple weed species. Smart Agric. Technol. 2024, 9, 100648. [Google Scholar] [CrossRef]
- Shobaki, W.A.; Milanova, M. A comparative study ofYOLO, SSD, Faster R-CNN, and more for optimized eye-gaze writing. Sci 2025, 7, 47. [Google Scholar] [CrossRef]
- Orchi, H.; Sadik, M.; Khaldoun, M.; Sabir, E. Real-time detection of crop leaf diseases using enhanced YOLOv8 algorithm. In Proceedings of the 2023 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2023; pp. 1690–1696. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An improved road defect detection model based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef] [PubMed]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar] [CrossRef]
- Liang, H.; Li, N.; Zhao, S. Salt and pepper noise removal method based on a detail-aware filter. Symmetry 2021, 13, 515. [Google Scholar] [CrossRef]
- Gao, J.; Li, L.; Ren, X.; Chen, Q.; Abdul-Abbass, Y.M. An effective method for salt and pepper noise removal based on algebra and fuzzy logic function. Multimed. Tools Appl. 2024, 83, 9547–9576. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv8 Parameters | Classification Model | Detection and Classification Model |
|---|---|---|
| Image size | 640 | 640 |
| Batch size | 32 | 24 |
| Epochs | 1000 | 1000 |
| Pre-trained | True | True |
| Optimizer | SGD | SGD |
| Early stopping | Disabled | Disabled |
| Learning rate | 0.01 | 0.01 |
| Momentum | 0.937 | 0.937 |
| Weight decay | 0.0005 | 0.0005 |
| Augment | False | False |
| Mosaic | False | False |
| Translate | 0.0 | 0.0 |
| Flipud | 0.0 | 0.0 |
| Fliplr | 0.0 | 0.0 |
| Hsv_h | 0.0 | 0.015 |
| Hsv_s | 0.0 | 0.7 |
| Hsv_v | 0.0 | 0.4 |
| Degrees | 0.0 | - |
| Scale | 0.0 | - |
| Shear | 0.0 | - |
| Perspective | 0.0 | - |
| Mixup | False | - |
| Erasing | 0.0 | - |
| Acc | F1 | IoU | P | R | |
|---|---|---|---|---|---|
| [18] | 68.74 | 59.39 | 0.621 | 61.72 | 57.46 |
| [27] | - | 57.50 | - | 57.40 | - |
| Our method | 74.77 | 78.63 | 0.79 | 82.25 | 74.76 |
| Acc % | F1 | P | R | Y | T | |
|---|---|---|---|---|---|---|
| [9] | 73.7 | - | - | - | 2023 | Lightweight CNNs + embedded attention |
| [10] | 71.32 | - | - | - | 2021 | Lightweight CNNs + embedded attention |
| [11] | 82.43 | 82 | 83 | 81 | 2023 | Faster-RCNN + MobileNet |
| [12] | 61.93 | 59.2 | - | - | 2020 | Saliency + CNNs |
| [13] | 86.95 | - | - | - | 2023 | ResNeXt-50 |
| [14] | 55.43 | 54.18 | - | - | 2022 | Residual Network (DFF-ResNet) |
| [15] | 55.24 | 54.18 | - | - | 2019 | Residual network (FR-ResNet) |
| [16] | 52.32 | - | - | - | 2020 | ExquisiteNet |
| [17] | 71.48 | 64.06 | 65.85 | 63.22 | 2024 | Pre-trained CNN + genetic algorithm |
| [19] | 82.5 | - | - | - | 2023 | 3 pre-trained CNNs |
| [20] | 73.9 | 73.6 | - | - | 2023 | CNN + EFLM + AFFM |
| [21] | 73.29 | - | - | - | 2021 | CNN+ spatial attention |
| [22] | 74.69 | 74.36 | - | - | 2022 | Self-supervised transformer |
| [23] | 75 | - | - | - | 2023 | Attention aggregating transformer |
| [24] | 74.20 | - | - | - | 2023 | CNN + improved Vision Transformer |
| [25] | 78.15 | - | - | 69.24 | 2025 | Channel-Enhanced and Multi-Scale |
| [27] | - | 57.5 | 57.4 | - | 2023 | Improved yolov5 architecture |
| [28] | - | - | 85.55 | 84.25 | 2025 | Modified yolov7 |
| [30] | 65.6 | 60.3 | 60.9 | 59.7 | 2023 | CNN ResNet + attention Vision Transformer |
| [31] | 75.74 | - | - | - | 2024 | CNN + Transformers |
| [32] | 72.31 | - | - | - | 2023 | Fine-tuning EfficientNets + SVM |
| [33] | 68.34 | 68.34 | 68.37 | 68.33 | 2024 | Visual regenerative fusion network |
| [34] | 60.7 | 59.6 | - | - | 2020 | Multiple-Instance LCNN |
| [35] | 81.7 | - | - | - | 2022 | InceptionV3 |
| Our method | 88.34 | 87.86 | 88.67 | 86.34 | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Longo, A.; Rizzi, M.; Guaragnella, C. Improving Classification Performance by Addressing Dataset Imbalance: A Case Study for Pest Management. Appl. Sci. 2025, 15, 5385. https://doi.org/10.3390/app15105385
Longo A, Rizzi M, Guaragnella C. Improving Classification Performance by Addressing Dataset Imbalance: A Case Study for Pest Management. Applied Sciences. 2025; 15(10):5385. https://doi.org/10.3390/app15105385
Chicago/Turabian StyleLongo, Antonello, Maria Rizzi, and Cataldo Guaragnella. 2025. "Improving Classification Performance by Addressing Dataset Imbalance: A Case Study for Pest Management" Applied Sciences 15, no. 10: 5385. https://doi.org/10.3390/app15105385
APA StyleLongo, A., Rizzi, M., & Guaragnella, C. (2025). Improving Classification Performance by Addressing Dataset Imbalance: A Case Study for Pest Management. Applied Sciences, 15(10), 5385. https://doi.org/10.3390/app15105385