1. Introduction
With the rapid development of science and technology, autonomous driving, remote monitoring, and other technologies are widely used. However, the instability of weather factors can lead to the frequent occurrence of fog. Suspended particles, such as water vapor, smoke, and dust in fog, can absorb and scatter reflected light from the surfaces of target objects. Due to the scattering of natural light, the light received by monitoring and acquisition equipment attenuates along the line of sight, resulting in visual blurring, decreased contrast, color distortion, and other problems in the collected images. This further decreases the reliability of visual application systems and even poses a threat, especially for visible light vision systems such as object detection. Removing haze through dehazing methods to improve image quality can be suitable for various computer vision tasks, such as image segmentation [
1] and object detection in hazy weather [
2]. Therefore, research on image dehazing technology has important practical significance and application value.
Due to the powerful learning ability of neural networks [
3], researchers have proposed a large number of methods for image dehazing. Most current approaches achieve dehazing in a supervised manner [
4,
5], relying on a large number of mapping pairs of haze-free images for model training. While these methods achieve promising results on specific benchmark datasets, they face several critical challenges in real-world applications. First, obtaining large-scale paired datasets is extremely difficult and costly. As a result, most methods rely on synthetic datasets generated using physical models. However, the domain gap between synthetic and real-world hazy images often leads to overfitting issues. Second, existing methods are often limited to specific types of scenes (e.g., land scenes) or haze concentrations, making them less effective under diverse real-world conditions involving complex terrain, variable lighting, and a range of haze densities. Third, many methods overlook the inherent depth variation and atmospheric light in the scene, which are crucial for realistic dehazing. These shortcomings often result in degraded visual quality, including color distortion and the loss of fine details.
To address the abovementioned issues within a unified framework, we propose FA-CycleGAN, an improved cycle-consistent generative adversarial network integrated with a feature fusion attention mechanism. Our approach is designed with three core motivations: (1) to eliminate the need for paired training data by employing an unpaired training strategy via CycleGAN, (2) to enhance physical interpretability by incorporating an atmospheric scattering model that guides the generator in simulating realistic haze removal, and (3) to preserve more discriminative features by introducing a feature fusion block with coordinate attention (FBCA) that adaptively fuses multi-scale features and enhances important spatial and channel-wise information. This unified framework allows our model to simultaneously address dataset limitations, multi-scene application issues, and feature loss problems, resulting in improved performance across diverse dehazing scenarios.
2. Related Work
Since the introduction of image dehazing, various algorithms have been proposed. According to their processing methods, these algorithms can be roughly divided into image enhancement-based methods, physical model-based methods, and deep learning-based methods.
Image enhancement-based methods can improve the visual quality of images by enhancing their contrast. Xu et al. [
6] proposed a foggy image enhancement algorithm based on bilinear interpolation dynamic histogram equalization, which divides the image histogram into several sub-histograms and assigns specific gray level ranges to these sub-histograms, thus ensuring that no serious edge effects are generated while enhancing the image. Liu [
7] proposed a ship video surveillance image dehazing algorithm based on adaptive histogram equalization. The algorithm converts the hazy image into a histogram and equalizes the gray levels of the histogram. Chen et al. [
8] proposed using the modified Butterworth filter as the transfer function for homomorphic filtering. Considering the different propagation characteristics of signal and noise on different wavelet transform scales, Chen et al. [
9] proposed an adaptive threshold estimation method that alters the change of decomposition scale. Wang et al. [
10] proposed using the improved wavelet function combined with the dark channel algorithm for multiple fusion to dehaze the source image. Su et al. [
11] proposed transforming the image to HSI color space and using the improved Retinex algorithm to enhance the I component to achieve haze removal. Pazhani et al. [
12] proposed using the multiscale retinex technique to eliminate the uneven information of ambient atmospheric light values and only retain the reflection of the object’s surface. The grayscale range of images is stretched in these methods, significantly improving their contrast. They are simple and easy to use, with obvious visual effects. However, the fundamental reasons for image quality degradation were not considered in this type of method, leading to the loss of image detail information or over-enhancement during dehazing, resulting in poor robustness.
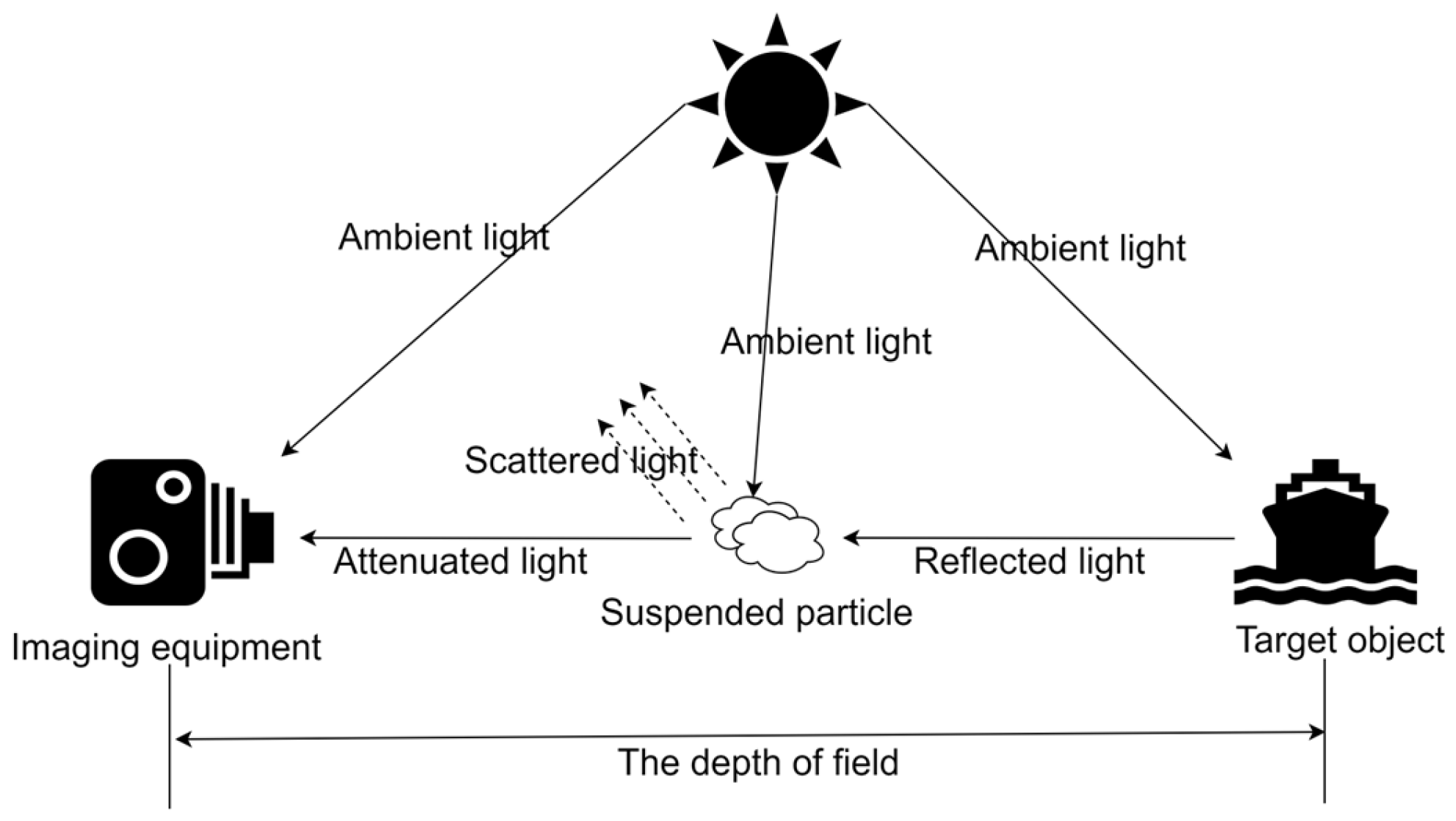
Physical model-based methods can analyze image information according to the mathematical model of foggy imaging [
13], and they can use prior knowledge to obtain the dehazed image. As shown in
Figure 1, the model is mainly based on the scattering and absorption of light in atmospheric media and simulates the image degradation phenomenon that occurs under complex atmospheric conditions. Therefore, researchers have proposed several methods to estimate the correlation coefficient for calculating the defogged image. Among these, the dark channel prior method proposed by He et al. [
14] is one of the most common algorithms. Due to the large sky areas and high white light components, it is easy to obtain higher values in all three channels using this method. Therefore, researchers have proposed a series of improved algorithms based on the dark channel prior method. Zhao et al. [
15] proposed segmenting the image using the four-division method to select the best area for the estimation of atmospheric light value, aiming to address the problem of color spots in the sky area during the processing of the original dark channel prior theory. Zhou et al. [
16] proposed segmenting the sky region based on the gray feature value to better calculate the atmospheric light value. In the bright channel prior theory, it is assumed that at least one color channel pixel in certain target areas has a reflectance of 100%, allowing for better differentiation of images in large sky backgrounds using this theory. Liu et al. [
17] proposed using the L channel of the Lab color space as a guide map, predicting the atmospheric light value through guided filtering, and then estimating the transmittance by using the bright channel prior theory. Zhang et al. [
18] proposed using the Al-Alaoui operator to enhance the image through convolution filtering, and based on this, to carry out dehazing. Combining the two theories to process different image regions separately is also common. Yu et al. [
19] proposed a pixel-wise alpha blending method for estimating the transmission map, where the transmissions estimated from the dark channel prior and the proposed bright channel prior are effectively blended into one transmission map, guided by a brightness-aware weights map. Tang et al. [
20] combined and corrected the two estimation methods of transmittance by assigning different weights. These methods, which study the imaging principle of the object, have a significantly better dehazing effect than image enhancement-based methods. However, a priori assumptions need to be utilized for the evaluation of transmittance and global atmospheric light. These assumptions will fail in certain situations, such as image distortion when processing large sky areas.
Deep learning-based methods can use a large amount of data to learn the mapping relationships between haze-free images. Cai et al. proposed the DehazeNet network [
21] to estimate transmittance and atmospheric light values and perform dehazing of images based on the atmospheric scattering model. Li et al. first proposed the end-to-end dehazing network, AOD-Net [
22]. To address the problem of grid artifacts easily caused by dilated convolution, Chen et al. proposed an end-to-end gated context aggregation network, GCA-Net [
23]. Li et al. proposed an image dehazing network with an encoding and decoding structure based on a conditional generative adversarial network (GAN) [
24]. Engin et al. proposed Cycle-Dehaze [
25], combining cyclic consistency loss and perceptual loss to train the network. Zhao et al. proposed an encoder–decoder based on GAN [
26] to further improve the network dehazing capability by learning different high- and low-frequency information of the image. Hyun Kwon proposed a novel method for generating untargeted adversarial examples using GAN in an unrestricted black box environment [
27]. Song et al. proposed DehazeFormer for image dehazing, based on the Transformer model [
28]. These methods have achieved significant results by leveraging the learning capability of neural networks. However, they heavily depend on extensive natural scene datasets, and it is easy to overfit during the learning process, resulting in a general effect in real scene dehazing.
In conclusion, although image enhancement-based methods are simple, they can easily lose image detail information and exhibit poor robustness. Physical model-based methods can analyze the reasons for image degradation, but in practical applications, they can suffer from parameter estimation biases, which lead to incomplete image dehazing. Deep learning-based methods can learn from a large amount of image data, understand image information more accurately, and exhibit strong adaptability. Therefore, we choose deep learning-based methods for multi-scene image dehazing. However, this type of method requires a large amount of data for training. It is difficult to obtain paired datasets, and using synthetic datasets can easily lead to overfitting. Additionally, problems such as insufficient use of feature information can result in blurred edges and loss of fine details in dehazed images. To address these issues, we propose an improved model of cyclic generative adversarial networks. The network is based on CycleGAN for image dehazing, using unpaired datasets for model training, which can alleviate the overfitting problem to some extent. A weight allocation mechanism is introduced into feature fusion to make full use of feature information and retain image details after dehazing.
3. Methods
Since paired haze-free datasets are difficult to obtain in many scenarios, the extensive use of synthetic datasets may lead to overfitting issues in deep learning models, resulting in insignificant dehazing effects in real-world images. Using the CycleGAN unpaired image-to-image translation framework, the image dehazing problem is treated as an image transformation between two distinct style domains. Hazy images are considered the source domain, while haze-free images are regarded as the target domain. The core of the CycleGAN-based image dehazing method lies in mapping the source domain images to the target domain, transforming haze images into haze-free images. However, the physical properties of hazy environments in the real world are often ignored in end-to-end dehazing methods, resulting in generated haze that usually lacks realism and diversity, further impacting the learning of the subsequent dehazing network. To address the abovementioned issues, we propose the FA-CycleGAN model. Using the CycleGAN model can effectively solve the problem of difficult pairwise image acquisition. In the training process, convolutional operations are used to extract the parameters of the atmospheric scattering model and reconstruct the clear image. At the same time, a deep learning model is used to refine the process to make up for the parameter estimation error of the atmospheric scattering model. A feature fusion attention module is introduced into the generator structure for multi-scale feature fusion and different weight assignments, which can retain more feature information and focus on different regions’ features to varying degrees. While ensuring the authenticity of dehazed images, more image details are retained, and the dehazing performance of the model is improved.
3.1. Overall Framework of the Model
In this paper, the atmospheric scattering model is used as a physical constraint in combination with CycleGAN. On the theoretical basis of the mathematical model, the hazy imaging atmospheric scattering model can be described as follows:
where
H(
x) is the X-th pixel value of the hazy image,
C(
x) is the dehazed image,
A is the global atmospheric light value, and
t(
x) is the transmittance. The relationship between the transmittance and the depth information of the image is shown in Equation (2), where
β is the scattering coefficient and
d(
x) is the depth information of the image.
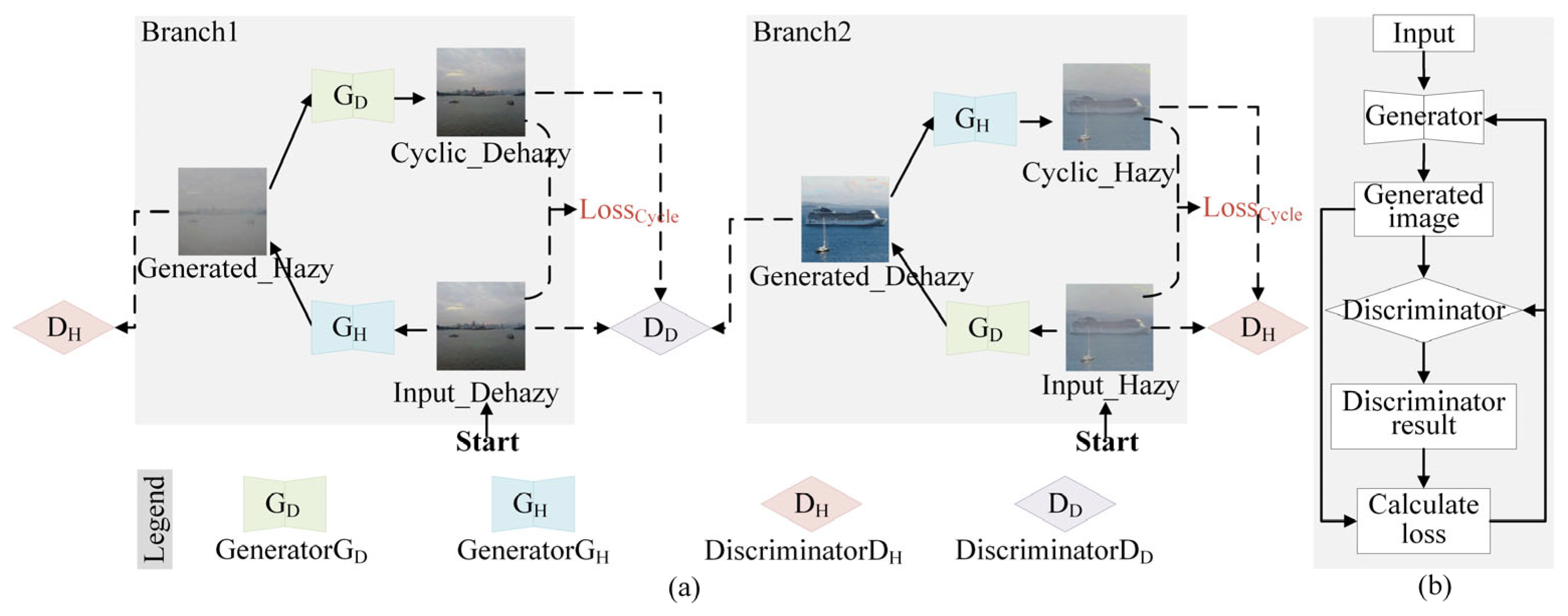
Based on the improvements to the CycleGAN network, FA-CycleGAN is proposed. Its structure is shown in
Figure 2a. FA-CycleGAN consists of two generators and two discriminators. Haze-free images are generated from haze images by the generator, G
D, aligning their distribution with that of the target domain images, thereby deceiving the discriminator D
D. Haze images are generated from haze-free images by the generator, G
H, to deceive the discriminator, D
H. The discriminator, D
H, is responsible for determining whether the input image is a haze image, while the discriminator, D
D, assesses whether the input image is a haze-free image.
The workflow of generator G
D and generator G
H is shown in
Figure 2b. The image is fed into the generator to produce the generated image. This generated image is then fed into the discriminator to determine whether it is a real image. Then, the loss is calculated based on the generated image and the discriminator’s results, followed by updating the generator and discriminator parameters based on this loss. During the training process, increasingly realistic images are produced by the generator in an attempt to deceive the discriminator, which is used to distinguish between real and generated images. Through the adversarial interaction between the generator and discriminator, the conversion of haze images to haze-free images is achieved. Finally, an optimal paired image generator model with haze and haze-free images is obtained. The pseudocode is as shown in Algorithm 1.
| Algorithm 1 FA-CycleGAN Network Training Process |
| Input: Input_Dehazy, Input_Hazy.//clear images and hazy images. |
| Output: Training log information. |
- 1:
#===== Branch1: Clean → Hazy → Cyclic Clean ===== - 2:
Generated_Hazy, gt_beta = GH(Input_Dehazy) - 3:
Cyclic_Dehazy, pred_beta = GD(Generated_Hazy) - 4:
# ===== Branch2: Hazy → Dehazy → Cyclic Hazy ===== - 5:
Generated_Dehazy, gt_d = GD(Input_Hazy) - 6:
Cyclic_Hazy, pred_d = GH(Generated_Dehazy) - 7:
# ===== Discriminators training ===== - 8:
dis_real_clean = DD(Input_Dehazy) - 9:
dis_fake_clean = DD(Generated_Dehazy) - 10:
loss_dis_clean = adversarial_loss(dis_real_clean, True) + adversarial_loss(dis_fake_clean, False) - 11:
dis_real_hazy = DH(Input_Hazy) - 12:
dis_fake_hazy = DH(Generated_Hazy) - 13:
loss_dis_hazy = adversarial_loss(dis_real_hazy, True) + adversarial_loss(dis_fake_hazy, False) - 14:
total_dis_loss = (loss_dis_clean + loss_dis_hazy)/4 - 15:
total_dis_loss.backward() - 16:
# ===== Generators training ===== - 17:
fake_clean_logits = DH(Generated_Dehazy) - 18:
fake_hazy_logits = DD(Generated_Hazy) - 19:
loss_gan = (adversarial_loss(fake_clean_logits, True) + adversarial_loss(fake_hazy_logits, True))/2 - 20:
loss_cycle = L1(Input_Hazy, Cyclic_Hazy) + L1(Input_Dehazy, Cyclic_Dehazy) - 21:
loss_β = L2(pred_beta, gt_beta) - 22:
loss_d = L1(gt_d, pred_d) - 23:
total_gen_loss = λ_gen*loss_gan + λ_cycle*loss_cycle + λ_β*loss_β + λ_d*loss_d - 24:
total_gen_loss.backward()
|
3.2. Structure of the Specific Network
3.2.1. Structure of the Generators
Unlike traditional CycleGAN, a heterogeneous generator structure, in which the two generators utilize different network structures, is employed in FA-CycleGAN.
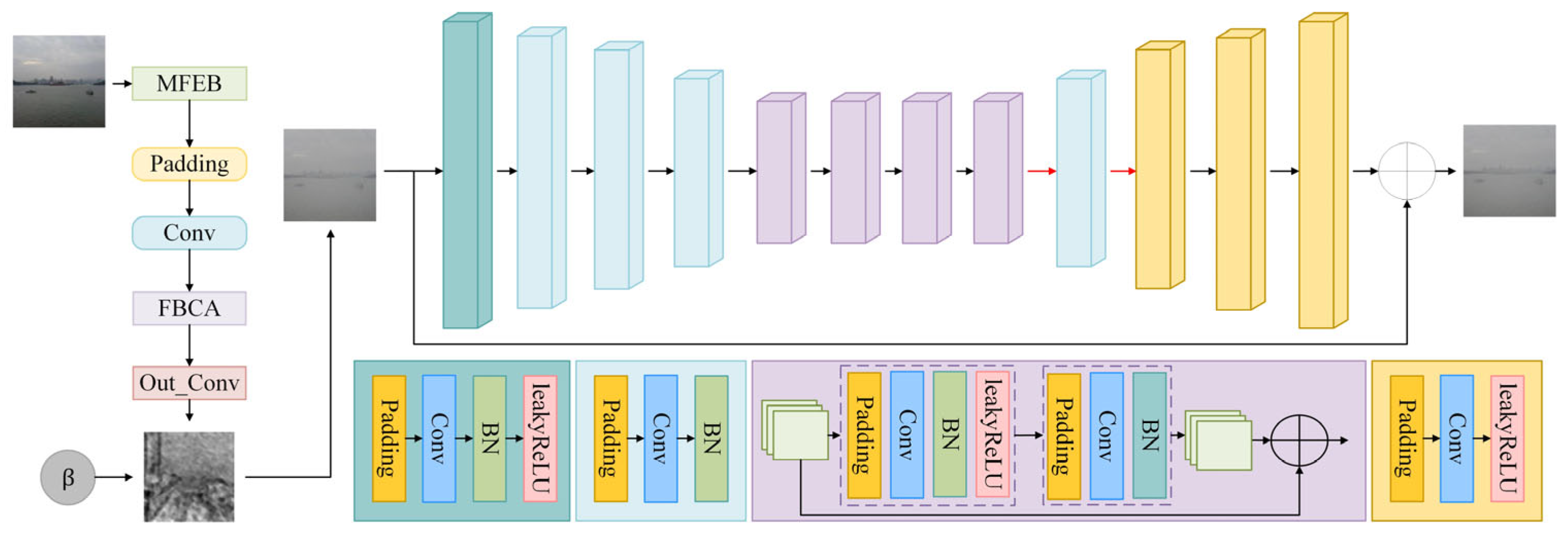
Image dehazing is performed on the input hazy image by the G
D. The model structure is shown in
Figure 3. The pseudocode is shown in Algorithm 2. The depth information of the image is estimated through feature extraction and residual fusion by the transmittance estimation module. The scattering coefficient of the image is estimated through feature extraction and average pooling operations by the scattering coefficient estimation module. G
D is first used to extract features from the input image,
H. The extracted features at different levels are processed to obtain the image’s transmittance,
, and scattering coefficient,
, as follows:
The generated haze-free image,
, can be calculated based on the atmospheric scattering model as follows:
where
is the atmospheric light value estimated from the dark channel prior,
H is the hazy images, and
is the image’s transmittance.
| Algorithm 2 Process flow of the generator, GD |
| Input: Input_Hazy.//hazy images. |
| Output: Generated_Dehazy. |
- 1:
Initialize: - 2:
Bulid the multi-layer feature extraction block(MFEB) - 3:
Build the feature fusion attention block(FBCA) - 4:
Build the output layers(output_Conv) - 5:
Method forward_get_A(input_image) - 6:
If use_dc_A - 7:
then Estimate atmospheric light A via dark channel method - 8:
else Set A as the maximum RGB value over spatial dimensions - 9:
return A - 10:
Method forward(Input_Hazy) - 11:
features = MFEB(Input_Hazy) - 12:
t = output_Conv(FBCA(features)) - 13:
β = AvgPooling(features) - 14:
Normalize t and β into valid ranges - 15:
A = forward_get_A(Input_Hazy) - 16:
Compute Generated_Dehazy according to Equation (4)
|
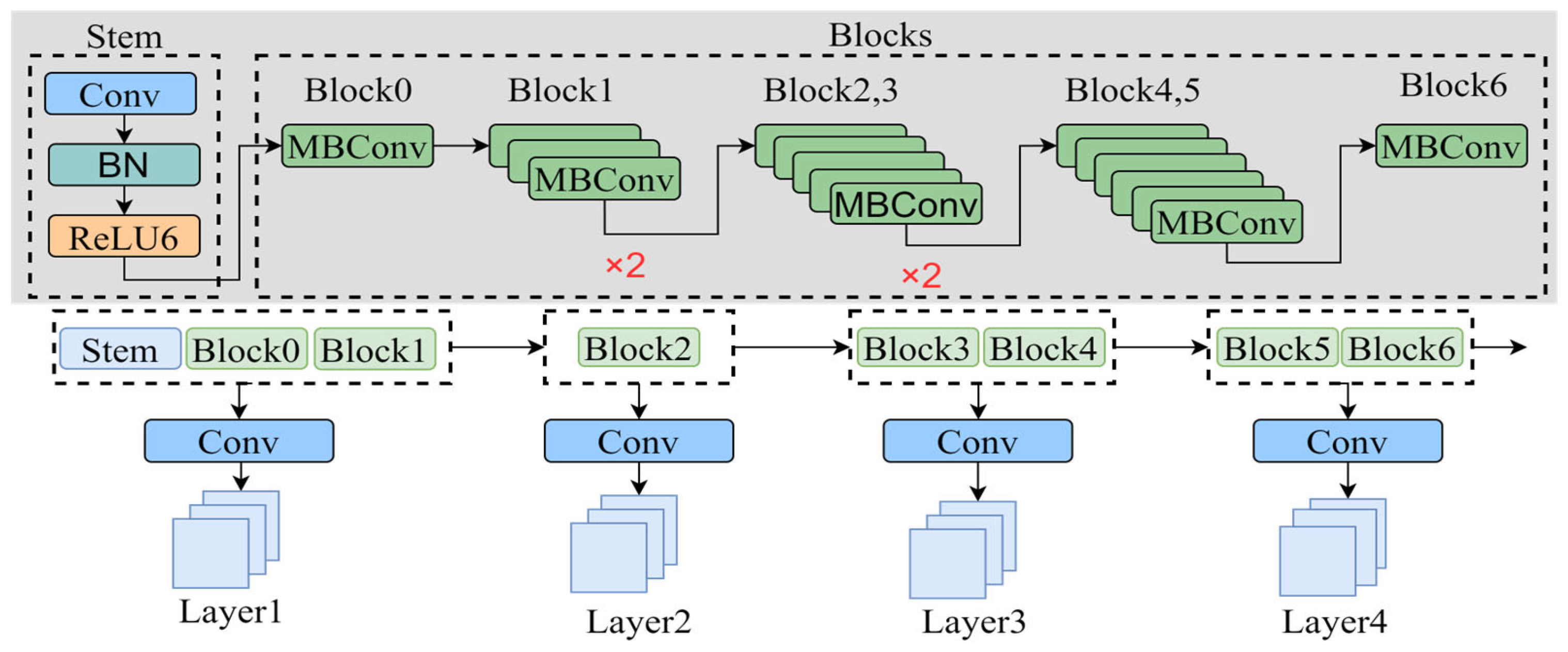
As shown in
Figure 4, the multi-layer feature extraction block (MFEB) is built based on the EfficientNet-lite3 network. The backbone network is divided into four layers to gradually extract advanced features from the image. Through layered feature extraction, the network can gradually learn low-level details and high-level semantic information, which aids in learning complex structures and patterns in the image, enabling the network to better understand the input data.
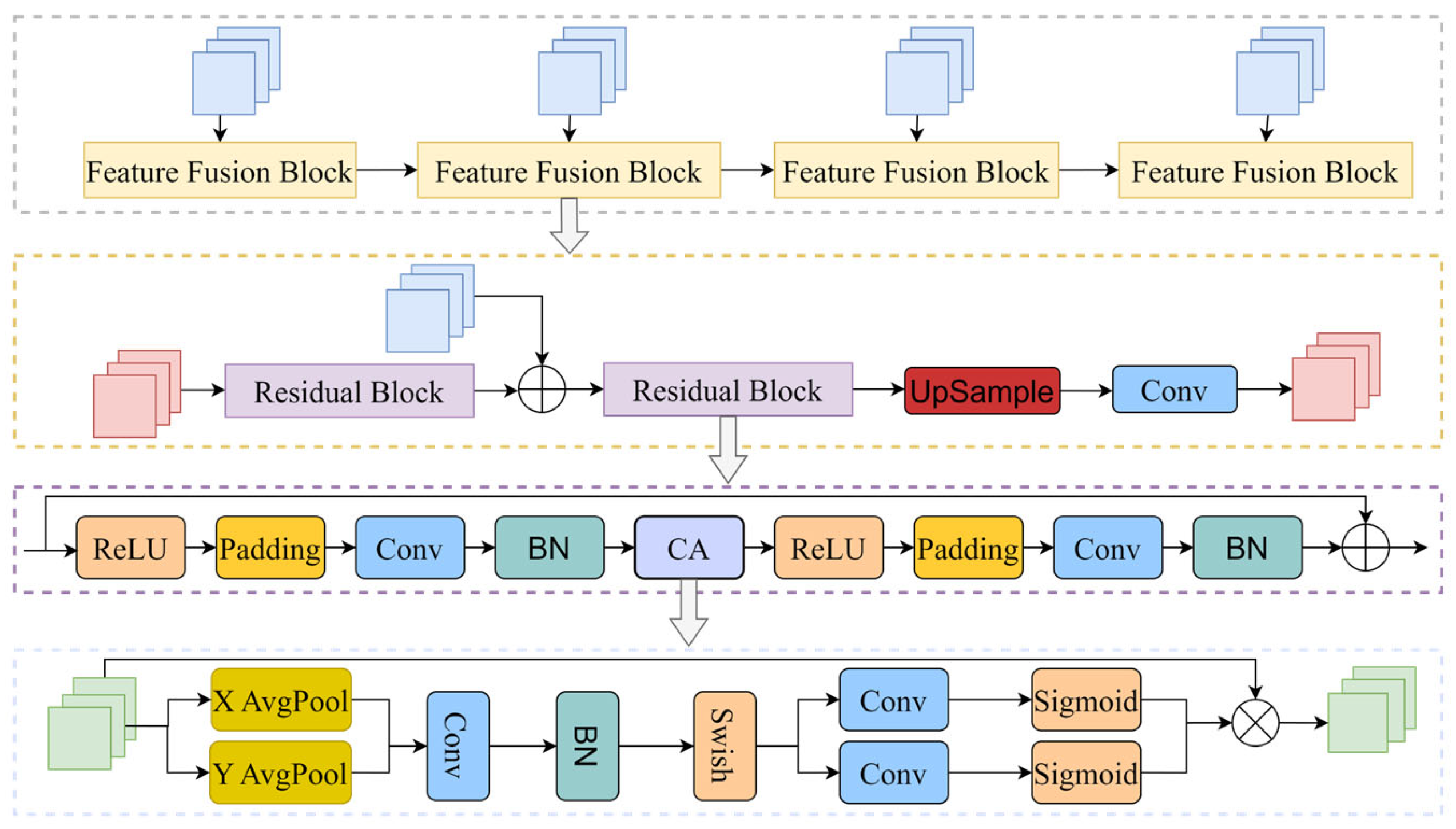
The feature fusion attention module (FBCA) performs multi-scale feature fusion on extracted features of different levels. Its structure is shown in
Figure 5. The idea of residual connection is adopted in FBCA, where different levels of features are separately fed into different feature fusion blocks for fusion. The output of the previous layer’s feature fusion block is processed by a residual unit and added to the input features of the current layer. The result of this addition is then processed by the residual unit to obtain the output of the current layer. This approach allows for improved retention of low-level features while promoting the learning of high-level features, thus improving the dehazing effect. To enhance the model’s attention to input data, the CA attention module is introduced to improve the model’s performance in handling complex tasks. In this module, the model can focus on complex areas to recover details more efficiently. Most current attention mechanisms (e.g., SE attention mechanism) significantly enhance model performance. Unlike traditional channel attention, which aggregates spatial information globally and may overlook location-specific features, attention is decomposed by CA into two complementary 1D encodings along the horizontal and vertical directions. This approach captures long-range dependencies while preserving precise positional information. By embedding location awareness into channel attention, CA allows the network to adaptively emphasize features that are not only important across channels but also relevant to specific spatial coordinates. This enables the generator to identify and enhance important regions, such as object boundaries, edges, and textured areas, which are often degraded or obscured in hazy images. This results in better structural preservation, reduced artifacts, and improved clarity in localized areas in practice. Thus, the integration of CA within the FBCA module helps the network focus on both channel importance and spatial position, leading to a more refined feature representation that contributes to more effective and visually coherent dehazing outcomes.
Image hazing is performed by the G
H based on the input clear image. The model structure is shown in
Figure 6. The pseudocode is shown in Algorithm 3. Firstly, the transmittance estimation module is used to estimate the depth information,
, of the input clear image, and a scattering coefficient,
β, is randomly sampled within the range of [0.6, 1.8]. Then, the atmospheric scattering model is used to calculate a rough pseudo-hazy image. Finally, the rough pseudo-hazy image is refined using the U-Net network to avoid the visual unreality of the image caused by parameter estimation errors, as follows:
| Algorithm 3 Process flow of the generator, GH |
| Input: Input_Dehazy.//clear images. |
| Output: Generated_Hazy. |
- 17:
Initialize: - 18:
Bulid the multi-layer feature extraction block(MFEB) - 19:
Build the feature fusion attention block(FBCA) - 20:
Build the output layers(output_Conv) - 21:
Build the U-Net network(UNet) - 22:
Method forward(Input_Dehazy) - 23:
features = MFEB(Input_Dehazy) - 24:
d = output_Conv(FBCA(Conv(features))) - 25:
β = Ramdom [0.8, 1.6] - 26:
Compute Generated_Hazy according to Eqs.(5) - 27:
Generated_Hazy = UNet(Generated_Hazy)//Refined by U-Net
|
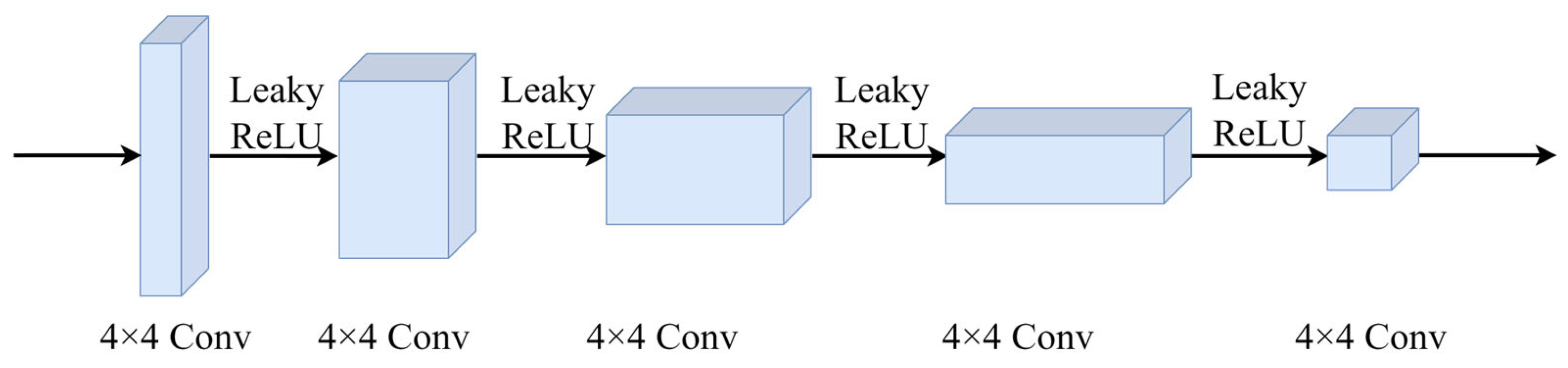
3.2.2. Structure of the Discriminator
A basic convolutional discriminator was used to distinguish between real and generated images. Its network structure is shown in
Figure 7. The discriminator receives the input image and performs feature extraction through a series of convolutional operations. Spectral normalization is applied to stabilize the training process. Using LeakyReLU as the activation function helps preserve more information and prevent gradient vanishing issues. The last layer maps the output to the range [0, 1], providing the probability that the input image is a real image.
3.3. Loss Function
Similar to CycleGAN, cyclic consistency loss and adversarial training loss are used to penalize content consistency and data distribution, respectively. According to the atmospheric scattering model, the degree of fog in the real world is related to the scene depth, d, and the scattering coefficient, β. Therefore, pseudo scattering coefficient-supervised loss and pseudo depth-supervised loss are employed to learn physical properties (depth and density) from unpaired hazy-free images.
Adversarial training loss is used to evaluate whether the generated images belong to a specific domain, penalizing the visual fidelity of the hazy and free images while ensuring that they follow the same distribution as the images in the training set. To address the issue of slow convergence of the discriminator caused by the min–max loss, non-saturating GAN (NSGAN) [
29] loss is used. NSGAN loss has good stability and visual quality. For the generator, G, and the corresponding discriminator, D, the adversarial loss can be expressed as follows, where
rh is real_hazy sample of the hazy image set, and
rc is real_clean sample of the clean image set:
Training CycleGAN using only adversarial training loss does not guarantee the cyclic consistency of the network [
30], which refers to the consistency between the input and output. Therefore, cyclic consistency loss is used to penalize the consistency of the inputs and outputs. This loss is defined as the difference between the input value, x, and the forward prediction, F(G(
x)), as well as the input value, y, and the forward prediction, G(F(
y)). The larger the difference, the further the prediction is from the original input. The cyclic consistency loss is implemented using L1 loss, as shown in Equation (8) as follows:
The pseudo-scattering coefficient supervised loss is used to penalize the difference between the randomly sampled scattering coefficients generated and the scattering coefficients estimated from the generated hazy images. It is calculated as follows:
Pseudo-depth supervised loss is used to penalize the difference between the depth information,
d, estimated from the hazy image,
H, and the depth information,
, estimated from the dehazed image. The L1 loss is used, which is defined as follows:
In summary, joint optimization is performed using a weighted combination of the abovementioned losses as follows:
where
λGAN,
λcycle,
λβ, and
λd are the weights used to balance different items. Based on previous experience and experiments conducted, setting these weights to 0.2, 1, 1, and 1, respectively, works well in our experiments.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}