1. Introduction
Rolling bearings are widely used in industrial production and life, such as aerospace, engines, mining machinery, agricultural machinery, and other fields, and they are known as ‘industrial joints‘. The primary failure modes of rolling bearings include rolling contact fatigue, wear, corrosion, electrical erosion, plastic deformation, cracking, and fracture. These failures are mainly attributed to material fatigue and inadequate lubrication [
1]. Operating rolling bearings under rated conditions and applying appropriate types and amounts of lubricant at regular intervals can significantly reduce the likelihood of failures caused by factors other than fatigue [
2]. As one of the key components of mechanical equipment, a good running state is very important for the normal operation of mechanical equipment [
3]. Bearing failures can lead to outcomes ranging from unplanned downtime to complete system breakdowns, resulting in substantial economic losses and even potential safety hazards [
4]. Therefore, research on accurate prediction methods for the remaining useful life (RUL) of rolling bearings holds significant practical importance.
The RUL of a rolling bearing is defined as the time interval from the current moment to the point of failure [
5]. Currently, RUL prediction methods for rolling bearings can be broadly classified into two categories [
6]: physics-based methods and data-driven methods. Physics-based approaches aim to build accurate mathematical models by deeply analyzing the operating mechanisms, degradation processes, and failure modes of equipment. Common models include the Paris model [
7], the Forman crack growth model [
8], and the Palmgren–Miner linear damage accumulation model [
9]. These methods offer strong interpretability and reliable prediction accuracy without requiring large datasets. However, with the increasing complexity and integration of modern industrial systems, accurate physical modeling has become extremely challenging, which significantly limits the practical applicability of physics-based approaches. With advances in signal processing and artificial intelligence, data-driven methods have emerged as a research hotspot for the RUL prediction of rolling bearings [
10]. These methods can be further divided into statistical learning, shallow machine learning, and deep learning approaches. Statistical learning methods often depend heavily on prior knowledge and high-quality data; shallow machine learning models tend to struggle with complex tasks and high-dimensional data. In contrast, deep learning methods can autonomously learn degradation patterns from large volumes of historical data without requiring expert knowledge, making them a focal point in the data-driven domain. For the accurate RUL prediction of rolling bearings, two key challenges must be addressed [
11]: (1) how to select an optimal feature set that effectively characterizes bearing degradation trends, and (2) how to choose an appropriate model to map degradation features to the remaining useful life.
In terms of feature selection, several studies [
12,
13,
14] have proposed constructing composite indicators based on specific criteria to identify features that are beneficial for bearing RUL prediction. While such indicators can effectively filter features related to the degradation process, they often overlook the interrelationships among features. Zhu et al. [
15] applied kernel principal component analysis to reduce multi-domain features, which helped to mitigate redundancy but lacked interpretability. Li et al. [
16] proposed a dual-selection method combining mutual information with hierarchical clustering. Their experimental results demonstrated that this approach reduced feature redundancy and improved model classification performance. Feng et al. [
17] introduced an adaptive feature selection algorithm that integrates the ideal point method with K-medoids clustering, enabling effective optimization of the feature set.
In terms of prediction models, commonly used deep learning architectures include Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and their various improvements and variants. Yang et al. [
18] proposed a dual-CNN architecture for bearing RUL prediction, and their experimental results demonstrated good prediction accuracy and robustness. While CNNs can be effective for RUL estimation, their inherent structural limitations hinder their ability to capture long-term dependencies in sequential data. To address this issue, researchers have adopted RNNs with recurrent structures for RUL prediction. Among these, Long Short-Term Memory (LSTM) networks and Gated Recurrent Unit (GRU) are the most widely used RNN variants. Wang et al. [
19] enhanced feature signals using maximum correlation kurtosis deconvolution and applied multiscale permutation entropy as a degradation indicator, which was then fed into an LSTM model optimized by the sparrow search algorithm for RUL prediction. Cao et al. [
20] improved prediction accuracy by integrating multi-sensor information with a GRU network. Additionally, based on CNNs, researchers have proposed Temporal Convolutional Networks (TCNs), which incorporate residual connections and dilated causal convolutions to effectively capture long-range dependencies. Qiu et al. [
21] extracted and selected multi-domain features, which were highly correlated with the degradation process, segmented the bearing lifecycle, and utilized TCN for prediction, thereby overcoming the limitations of traditional models in handling time series. Moreover, Transformer networks have been widely adopted across various domains due to their exceptional modeling efficiency and strong performance on long-sequence data. In the context of bearing RUL prediction, Transformer-based models have also shown promising results. Zhou et al. [
22] used cumulative-transformed traditional features as inputs and employed a Transformer network to predict the RUL of rolling bearings.
Although the aforementioned studies have achieved promising results in the RUL prediction of rolling bearings, several challenges remain: (1) insufficient feature selection during feature set construction often leads to redundancy; and (2) the limited predictive capability of single models constrains overall prediction performance. To address these issues and improve the accuracy of bearing RUL prediction by eliminating redundant features, this paper proposes a novel method that combines hierarchical-clustering-based feature selection with a hybrid Transformer–GRU model. The main contributions of this paper are as follows:
- (1)
An adaptive feature selection method combining hierarchical clustering and the elbow method is proposed, which can effectively eliminate redundant information in the feature set, thereby reducing data volume and model complexity. Compared with other studies, this approach does not require manual specification of clustering parameters.
- (2)
A hybrid Transformer–GRU model is developed for predicting the RUL of rolling bearings, leveraging the Transformer encoder’s ability to capture relationships across different time steps and GRU’s strength in modeling temporal dependencies (trends), thus improving prediction accuracy.
- (3)
The proposed approach provides a novel and effective method for RUL prediction of rolling bearings.
The structure of this paper is organized as follows:
Section 2 presents the relevant theories, and
Section 3 introduces the proposed methods and models, as well as the entire prediction process.
Section 4 provides experimental verification of the proposed methods, and
Section 5 concludes the paper.
3. RUL Prediction Method Based on Hierarchical Clustering and Transformer–GRU
3.1. Feature Extraction
The vibration signal of rolling bearings contains abundant degradation information and can be used to assess the health condition of the bearing. According to previous studies [
32], the vibration acceleration signals of rolling bearings exhibit distinct variation patterns across the three stages of their full life cycle. In the time domain, during the normal operation stage, the vibration signal remains stable with low amplitude. In the early degradation stage, the amplitude begins to fluctuate more significantly, and the signal becomes less stable overall. As the bearing approaches failure, the amplitude fluctuations become increasingly severe. In the frequency domain, during the healthy stage, the amplitude of the vibration signal is low and mainly concentrated in the low-frequency range. As degradation progresses, higher-frequency components emerge, and their amplitudes increase. Near failure, the frequency components become concentrated in the high-frequency range and show peak amplitude values. Therefore, vibration signals can be used to extract features that reflect the degradation state of the bearing and enable further analysis and prediction of its remaining useful life.
However, the signal is often contaminated by noise during the acquisition process, making denoising a necessary preprocessing step. In this study, wavelet decomposition and reconstruction are employed to eliminate meaningless noise from the original signal. Additionally, as vibration signals are high-dimensional time series, feature extraction is performed to significantly reduce the data volume and to effectively capture the degradation information embedded in the signals.
Time-domain features are data characteristics directly calculated from the time series of bearing vibration signals. They can effectively reflect signal variations at different stages of the bearing’s full life cycle and are computationally simple. Common time-domain features are typically categorized into two types [
28]: dimensional parameters and dimensionless parameters. Dimensional features are sensitive to operating conditions, showing significant numerical variation under different conditions, and they generally exhibit an increasing trend as bearing faults evolve and worsen. In contrast, dimensionless features are less sensitive to operating conditions but are more responsive to early-stage faults; however, their sensitivity tends to decrease as the faults progress. Based on the references [
28,
33,
34], this study selects 10 commonly used dimensional indicators and 6 dimensionless indicators.
Dimensional indicators: The mean value characterizes the stable component of the vibration signal. The standard deviation reflects the degree of fluctuation in the signal. The mean square value and root mean square (RMS) are commonly used to represent the energy level of the signal and are widely applied in the field of RUL prediction, as they effectively indicate the progression of faults. The maximum and minimum values provide an indication of the equipment’s health condition to a certain extent. The peak value, representing the highest amplitude at a given moment, can signal transient impact faults in the bearing. The peak-to-peak value, defined as the difference between the maximum and minimum amplitudes within a single sampling interval, captures the range of signal variation. The mean absolute value is the average of the absolute values of the signal data, while the square root amplitude is also a useful indicator of fault development. Dimensionless indicators: Skewness describes the direction and degree of asymmetry in the signal data. Kurtosis indicates the distribution characteristics of the signal and is particularly sensitive to early-stage faults in the field of fault diagnosis. The waveform factor, defined as the ratio of the RMS to the mean absolute value, characterizes changes in the signal waveform. The crest factor, calculated as the ratio of the peak value to the RMS, reflects the extremity of peaks within the waveform. The impulse factor, the ratio of the peak value to the mean absolute value, is commonly used to assess the presence of impact components in the signal and is generally smaller than the crest factor. The margin factor, defined as the ratio of the peak value to the square root amplitude, can be used to reflect the wear condition of the bearing.
For a given signal segment
= {
,
,
… }, the specific calculation formulas for the selected time-domain features are presented in
Table 1.
As the bearing begins to degrade, the frequency components, energy magnitude, and dominant frequency band position of the spectral signal will change [
35]. Therefore, it is essential to extract frequency-domain features from the vibration signal. Twelve frequency-domain features referenced from [
36] are selected and denoted as P17–P28.
In addition, to more comprehensively extract the degradation information contained in the vibration signal, features are extracted from the time-frequency domain. The time-domain signals are decomposed using a three-level wavelet packet decomposition with the db5 wavelet, dividing the frequency axis into eight sub-bands. The energy ratio of each sub-band is calculated as the time-frequency domain features, denoted as P29–P36. The detailed calculation [
28] is shown in Equation (13).
where
represents the decomposition level of the wavelet packet,
is the number of sub-bands obtained from the decomposition, and
denotes the length of the sub-band signal.
denotes the
-th decomposition coefficient of the
-th coefficient vector at the
-th level of decomposition, and
represents the proportion of energy contained in the
-th frequency band when the signal is decomposed to the
-th level.
3.2. Comprehensive Index Screening
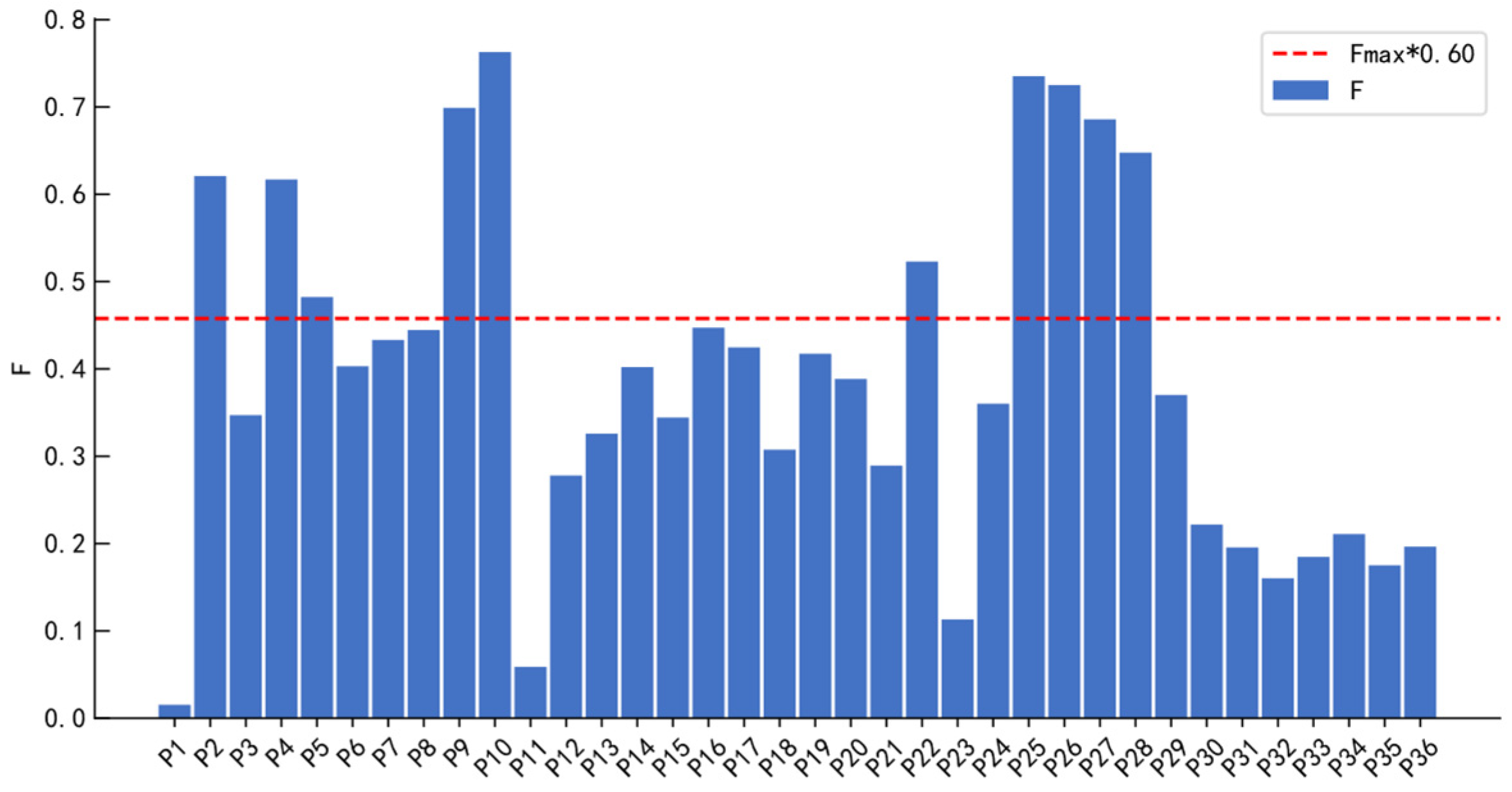
Not all extracted features are sensitive to the degradation process of rolling bearings. Therefore, feature selection is required. Since the degradation process of a bearing evolves over time and is irreversible, an effective degradation feature should exhibit strong temporal correlation and monotonicity. Monotonicity and correlation [
10] are used to construct a comprehensive index (F) for feature selection, eliminating those features that are insensitive to the degradation process and creating a sensitive feature set. A higher F value indicates that the corresponding feature is more sensitive to bearing degradation. The calculations of monotonicity, correlation, and the composite index are as follows:
Monotonicity:
where
represents the differential between adjacent values in the feature curve,
denotes the length of the feature data series, and
denotes the count function, which calculates the number of elements satisfying a given condition.
Correlation:
where
and
represent the i-th elements of the feature vector and the RUL label, respectively,
and
represent the mean values of the feature vector and the RUL labels, respectively, and
denotes the sequence length.
Aggregative indicator:
where
denotes the feature vector, and
represents the weight corresponding to each evaluation metric. According to reference [
10],
is set to 0.3 and
to 0.7. F denotes the comprehensive score of the feature.
3.3. Hierarchical Clustering Adaptively Removes Redundant Features
If the similarity between features is excessively high, the information they contain is largely redundant. This not only increases computational complexity but may also negatively affect the prediction performance of subsequent models. Therefore, it is essential to perform classification and reduction on the initially selected feature set. In this study, a redundancy elimination method based on the combination of hierarchical clustering and the elbow method is proposed. Given a feature set with a total of n features and a target number of clusters
, the procedure is illustrated in
Figure 5, with the specific steps outlined as follows:
Step 1: Compute the distance matrix as defined in
Section 2.1.
Step 2: Use the distance matrix as the input to the hierarchical clustering algorithm to perform agglomerative clustering. Obtain clustering results for different values of (where = 2, 3, 4, …, n) from the resulting dendrogram.
Step 3: Based on the clustering results from Step 2 and Formula (2), calculate the sum of squared errors for clusters and plot the elbow graph (where = 2, 3, 4, …, n).
Step 4: Determine the optimal number of clusters by identifying the “elbow point” on the curve using a combination of visual inspection and slope change analysis.
Step 5: Trim the dendrogram to obtain clusters according to the determined number of clusters.
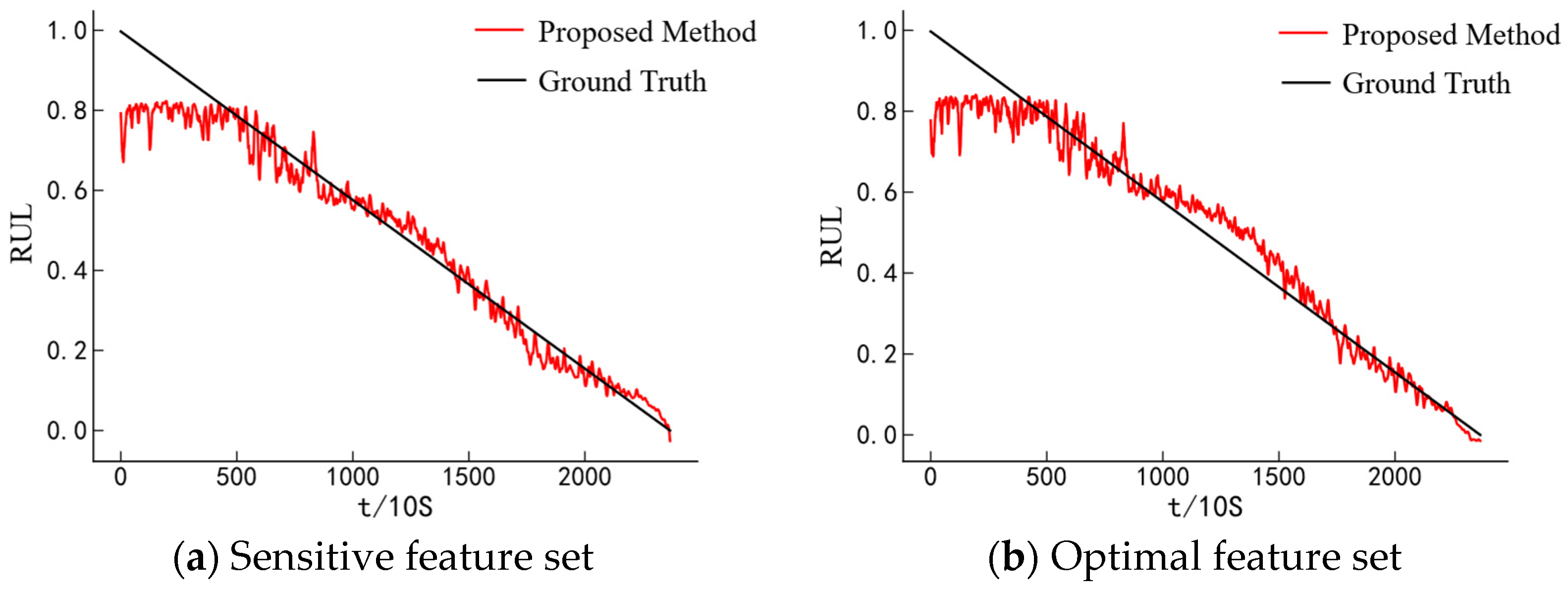
Step 6: Select the optimal feature within each cluster as the cluster representative and construct the optimal feature set from these representatives.
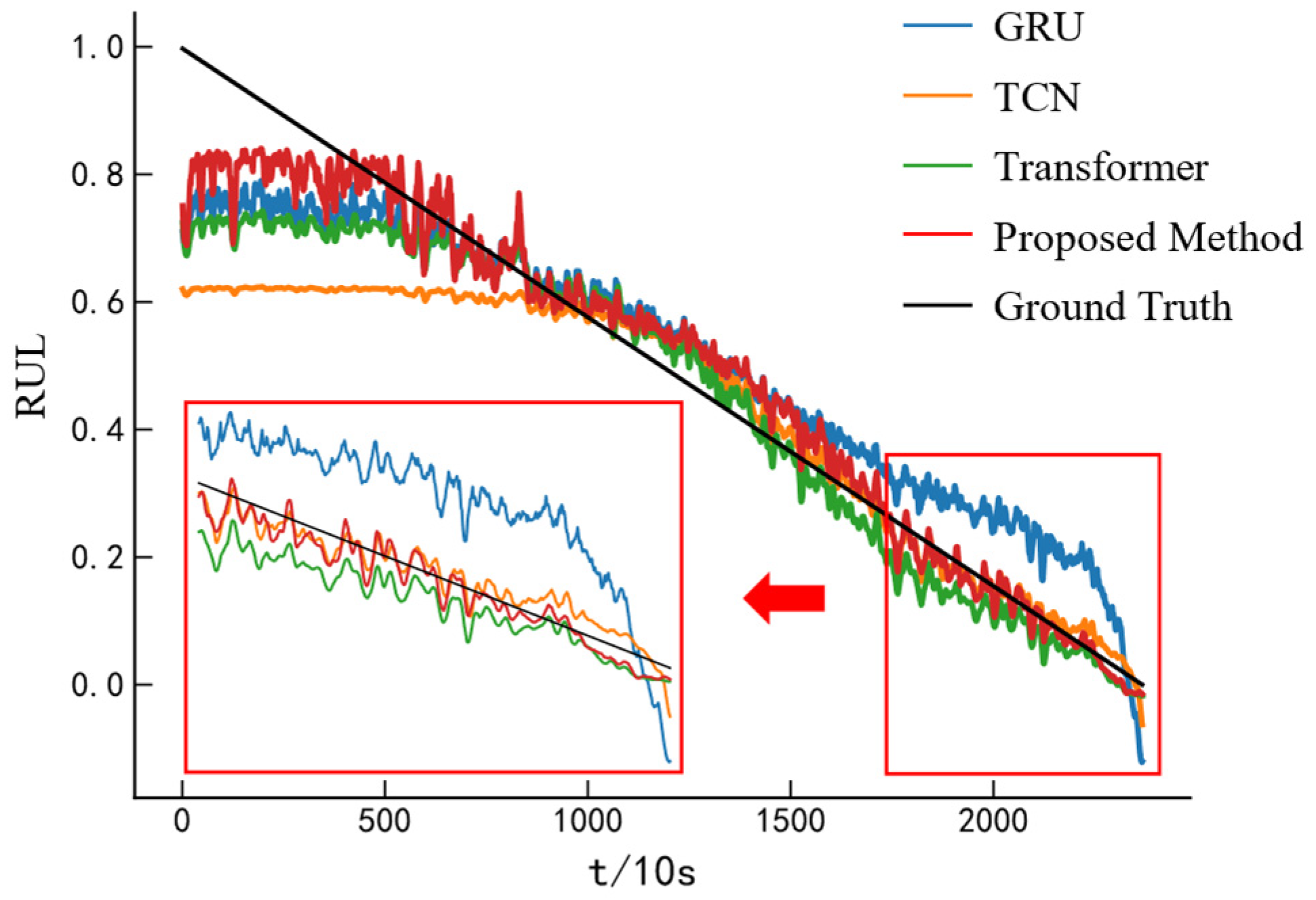
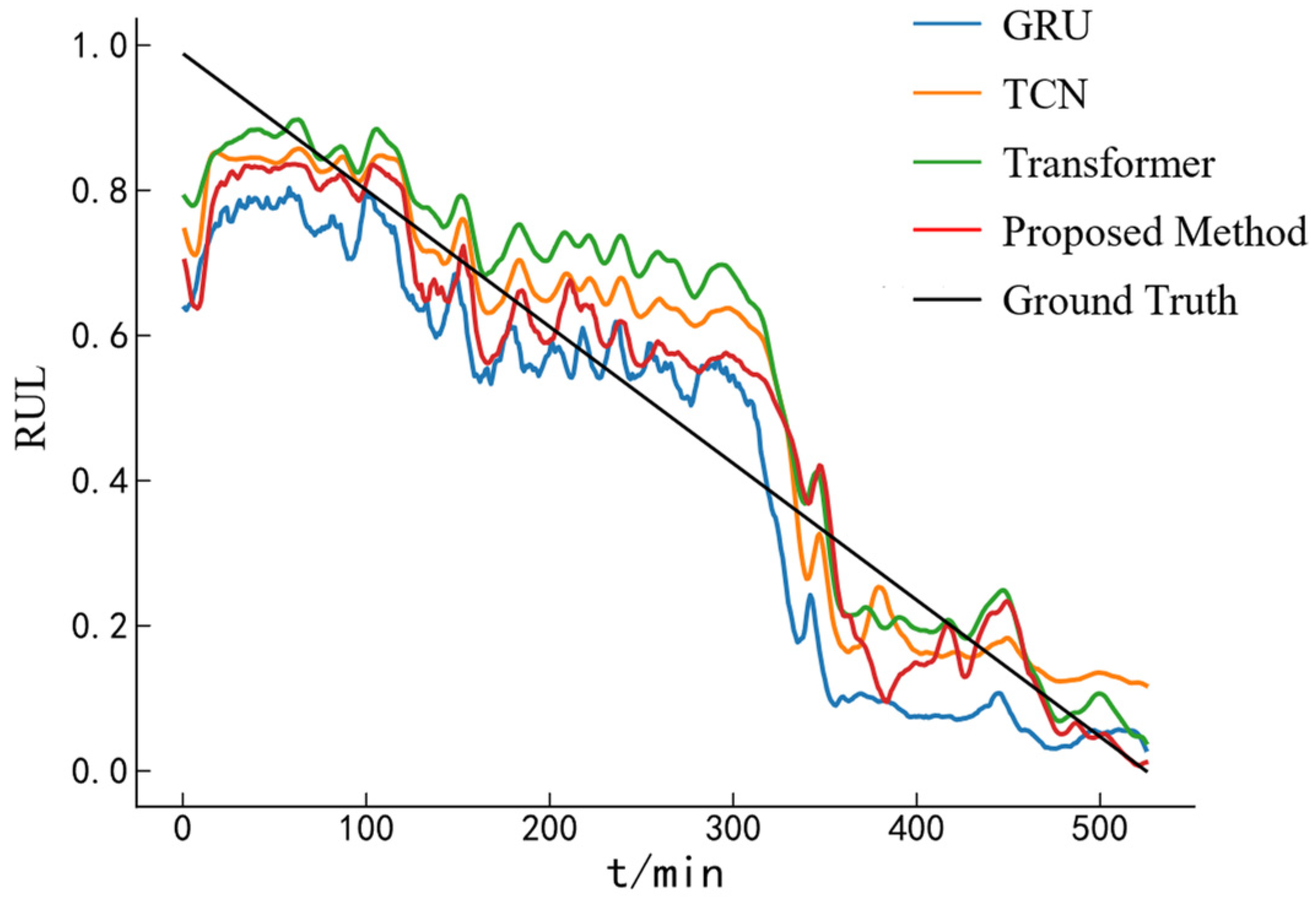
3.4. Transformer–GRU Combination Model
To fully explore the relationship between the bearing degradation process and the RUL, a Transformer–GRU hybrid model is constructed, as illustrated in
Figure 6. After inputting the data into the model, the multi-head attention mechanism in the Transformer encoder is first employed to capture various dependencies across different time steps in parallel subspaces [
27]. This allows the original input feature sequences to be transformed into high-level feature representations rich in contextual information. Subsequently, the GRU, with its strong ability to capture temporal dependencies and trend patterns in sequential data [
37], is used to extract the degradation trends from these high-level features. Finally, a fully connected layer maps the extracted features to the bearing’s RUL.
The mean absolute error (MAE) and root mean square error (RMSE) [
6] are employed as evaluation metrics to assess the prediction performance of the proposed model. Their definitions are given in Equations (18) and (19), respectively:
where
denotes the number of samples,
represents the predicted value, and
denotes the true value.
3.5. Process of the Proposed Method
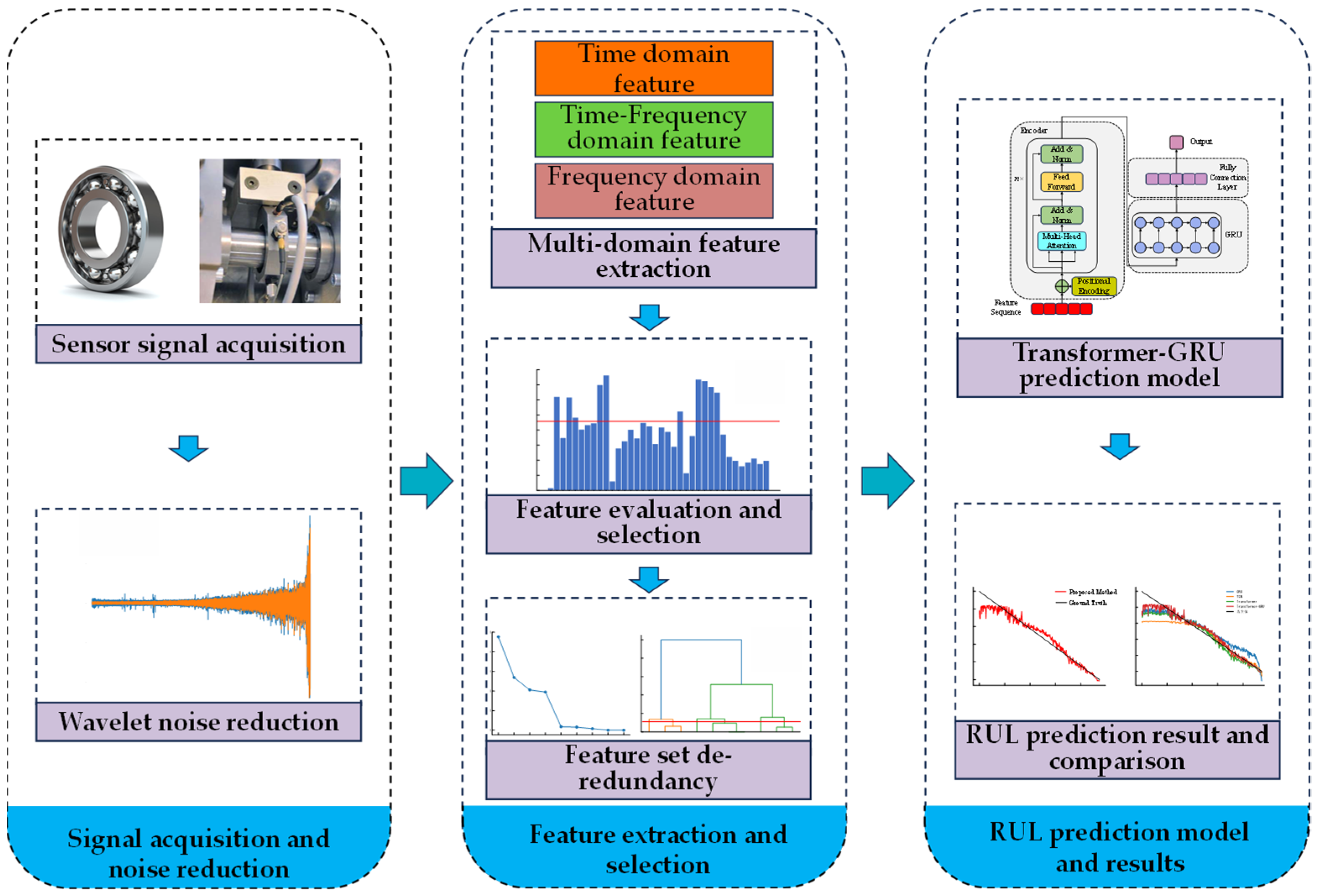
The flowchart of the proposed method for rolling bearing RUL prediction is illustrated in
Figure 7, and the specific steps are as follows:
Step 1: Signal acquisition and denoising: Vibration signals of the full life cycle of the bearing are collected using an acceleration sensor. Wavelet denoising is applied to reduce noise in the original signals.
Step 2: Feature extraction: Time-domain, frequency-domain, and time–frequency-domain features are extracted from the denoised signals to form the original feature set, which is then smoothed and normalized.
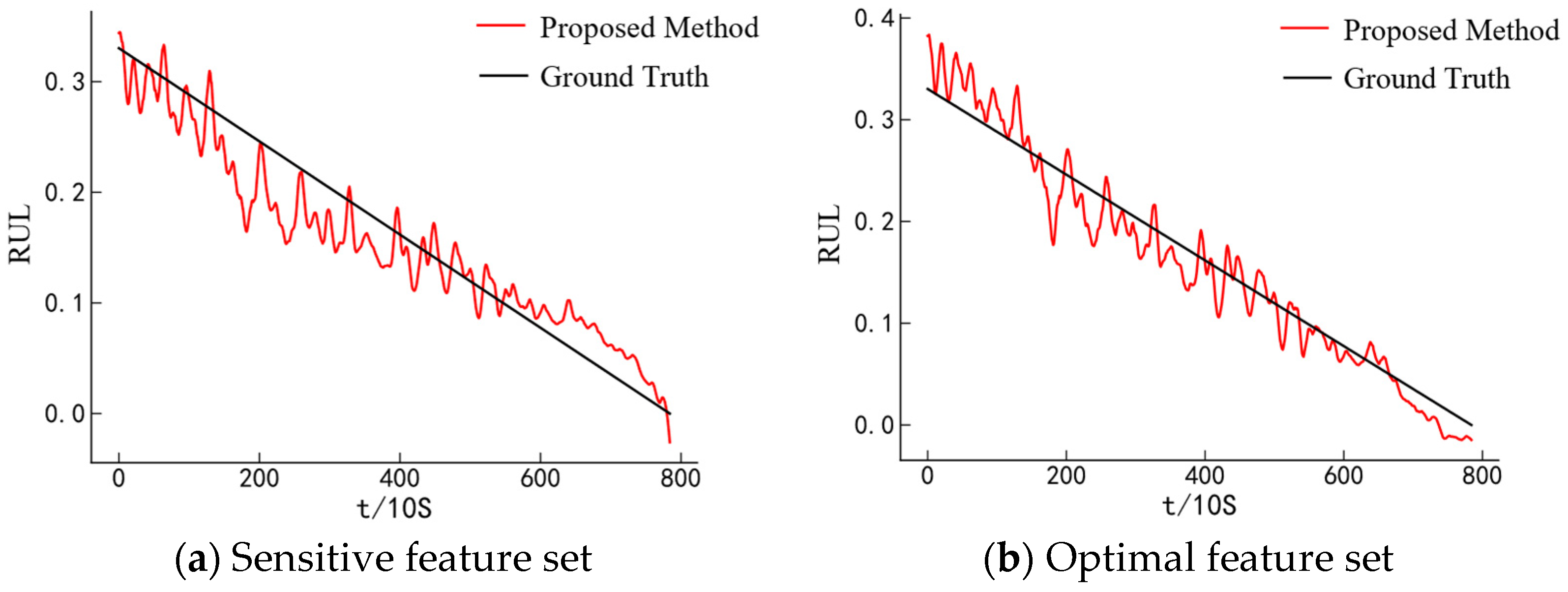
Step 3: Feature selection: Based on a composite index constructed from monotonicity and correlation, features insensitive to bearing degradation are filtered out to form a sensitive feature set.
Step 4: Feature redundancy reduction: A hierarchical clustering method combined with the elbow method is employed to adaptively reduce redundancy in the sensitive feature set, resulting in the optimal feature set.
Step 5: Model training: The optimal feature set is used as input data for model training. The ratio of RUL to the total life cycle is used as the label.
Step 6: Model testing: The test set is fed into the trained model to predict the corresponding RUL labels, and the model performance is evaluated accordingly.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}