
Posture Detection of Passengers’ Movement When Boarding and Alighting an Urban Bus: A Pilot Study in Valparaíso, Chile

 ,
,  , , ,
, , , 
Abstract
1. Introduction
2. Literature Review
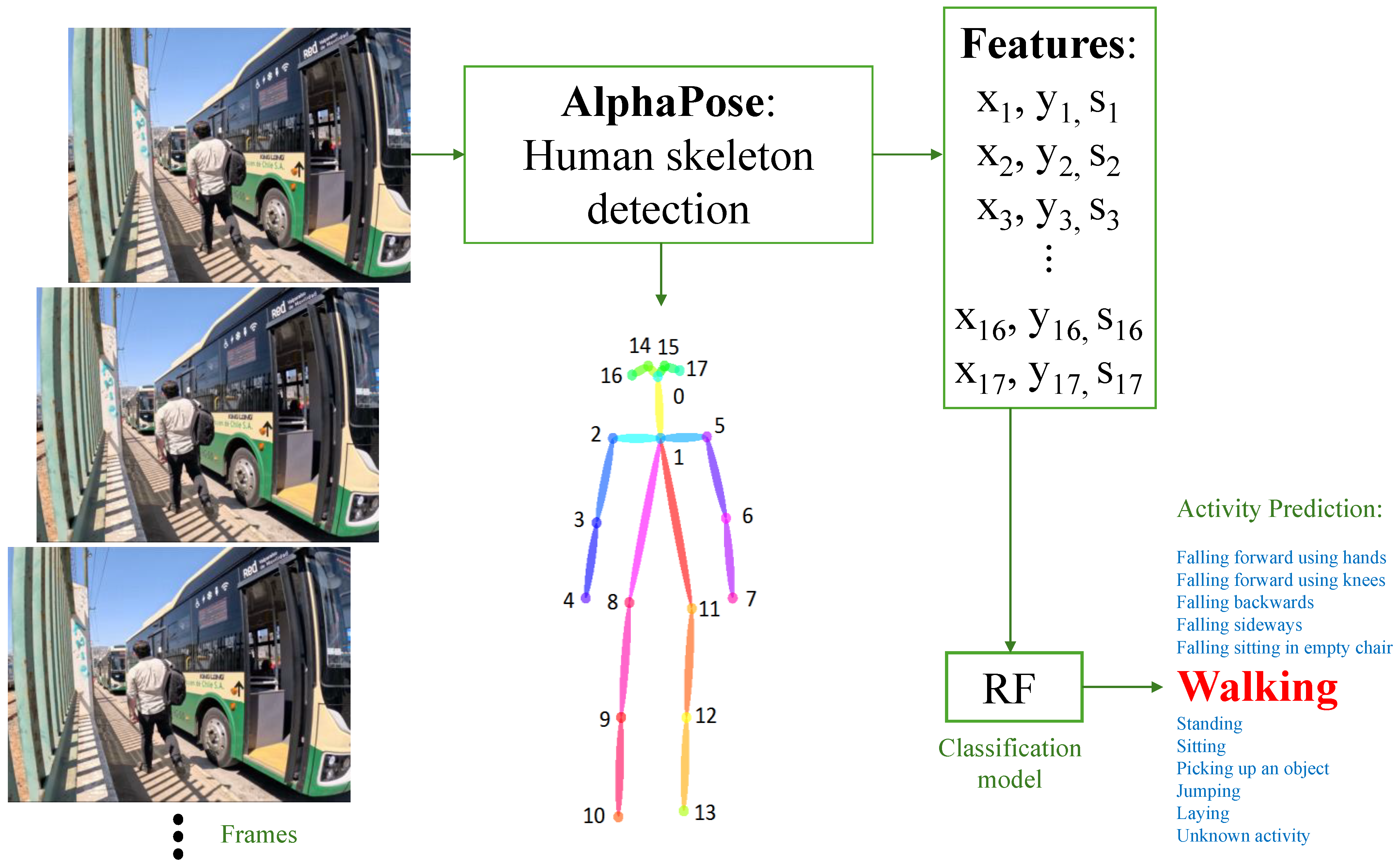
3. Methodology
- Data Capture: RGB video recordings are collected at urban bus stops using a fixed camera. These videos capture real-world passenger behaviors, including standing, walking, boarding, and alighting.
- Pose Estimation: Each video frame is processed with a pose estimation algorithm, which detects and maps 17 key body joints per person. The output is a structured JSON file containing the coordinates (X, Y) and confidence scores for each joint.
- Feature Extraction: The raw JSON data are parsed and transformed into CSV format. For each detected individual, 51 features are computed (17 joints × 3 values per joint: X, Y, Score), forming the feature vector used in the prediction stage.
- Activity Prediction: The feature vector is input into a pre-trained machine learning model, which classifies the activity for each person in every frame. The model distinguishes between activities such as standing, sitting, walking, and falling.
3.1. Method
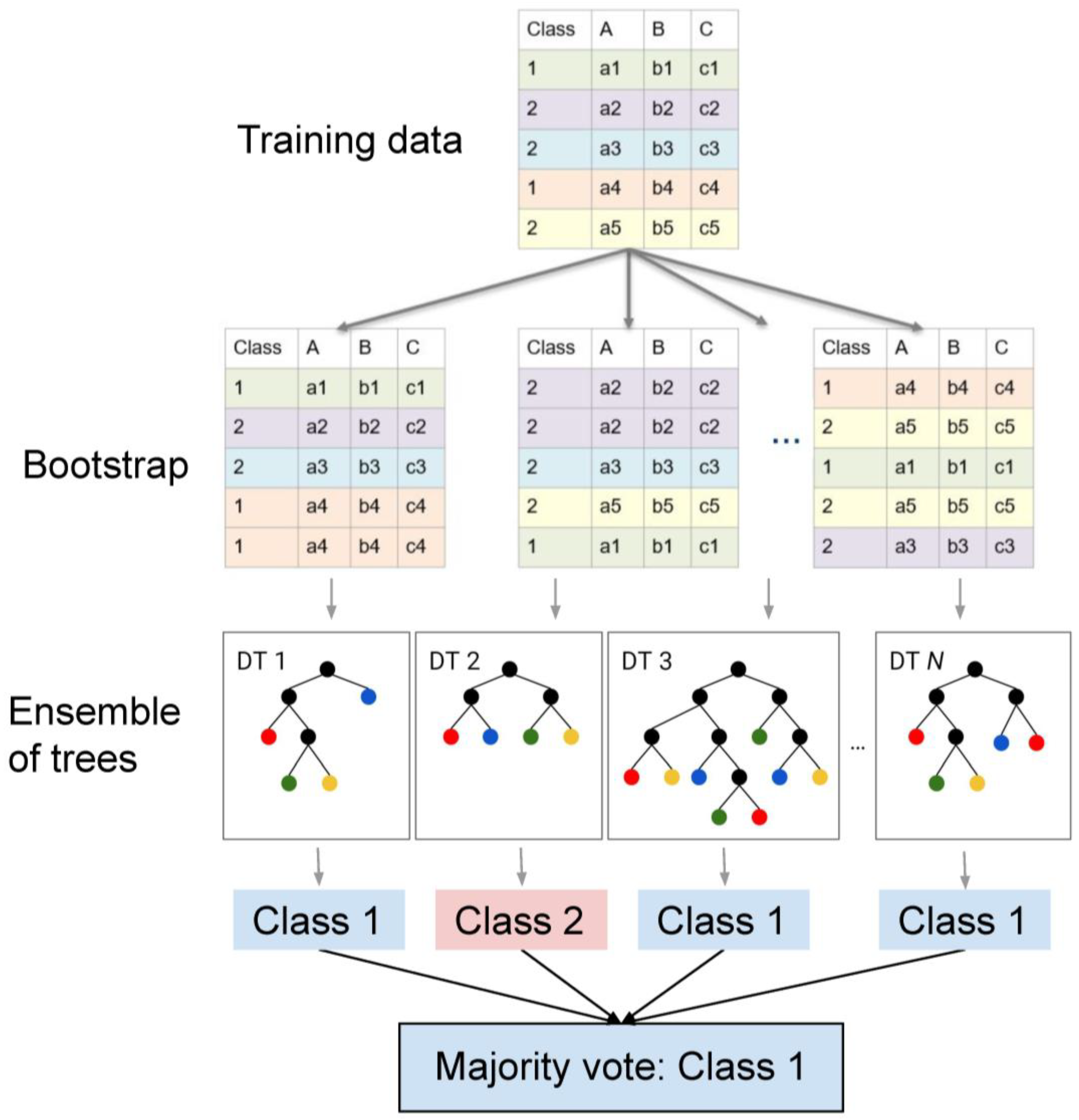
3.2. AI Selected Model
- Forward falls using the hands
- Forward falls using the knees
- Backward falls
- Using an object
- Sitting falls on an empty chair
- Walking
- Lying down
- Sitting
- Walking forward
- Jumping
- Standing
- Unknown activity
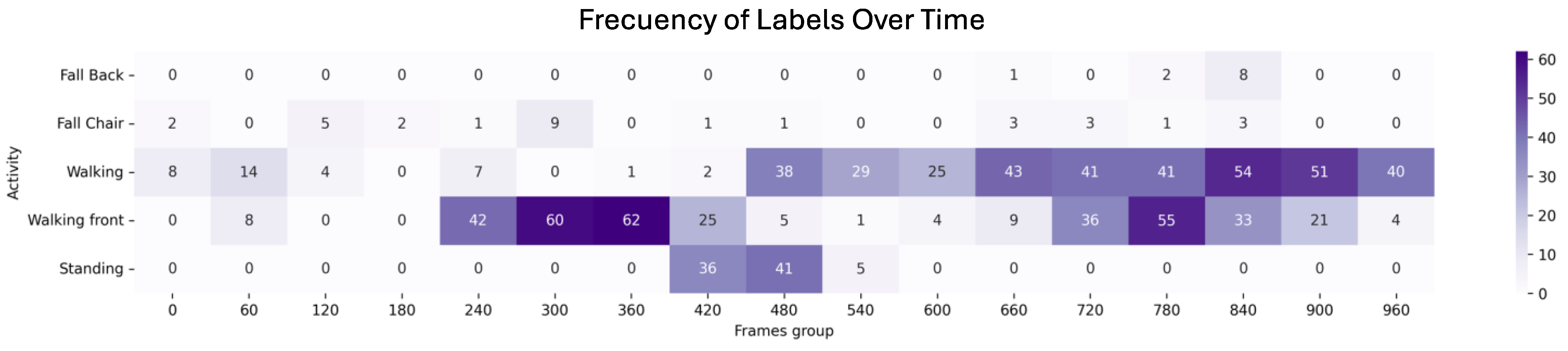
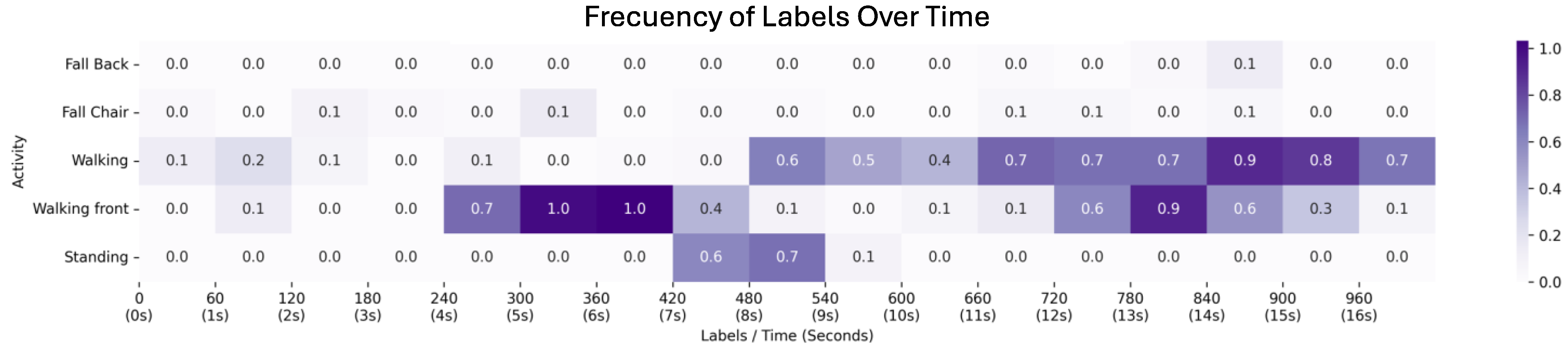
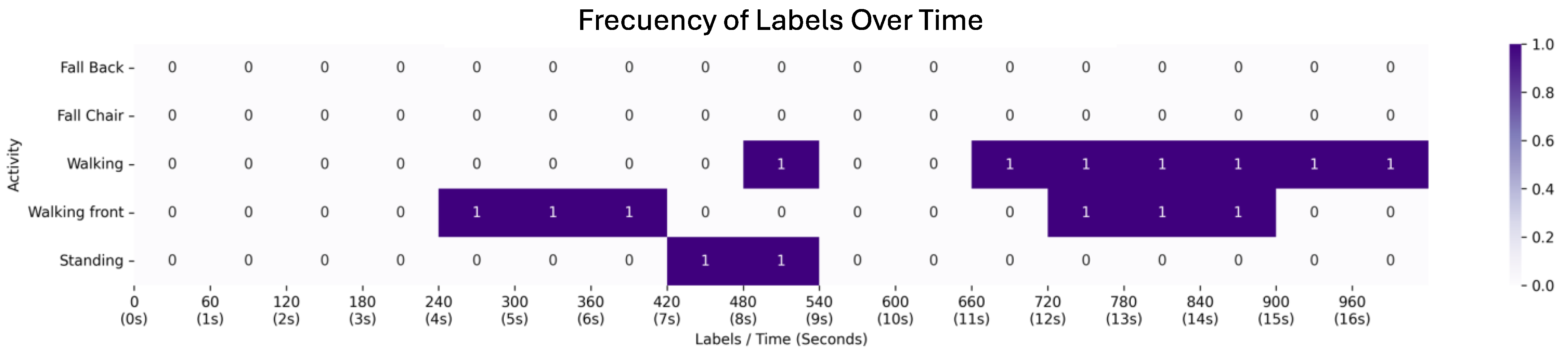
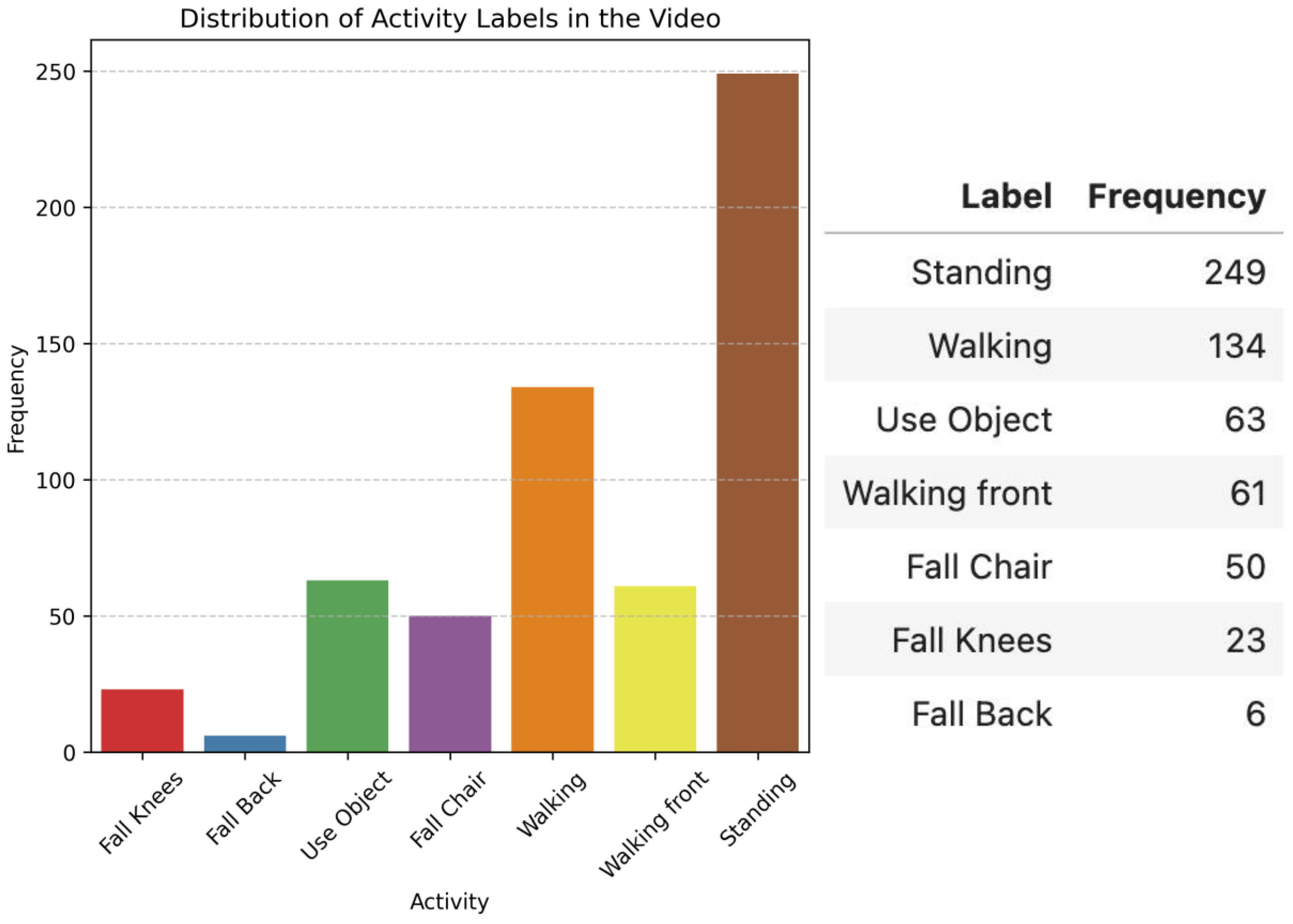
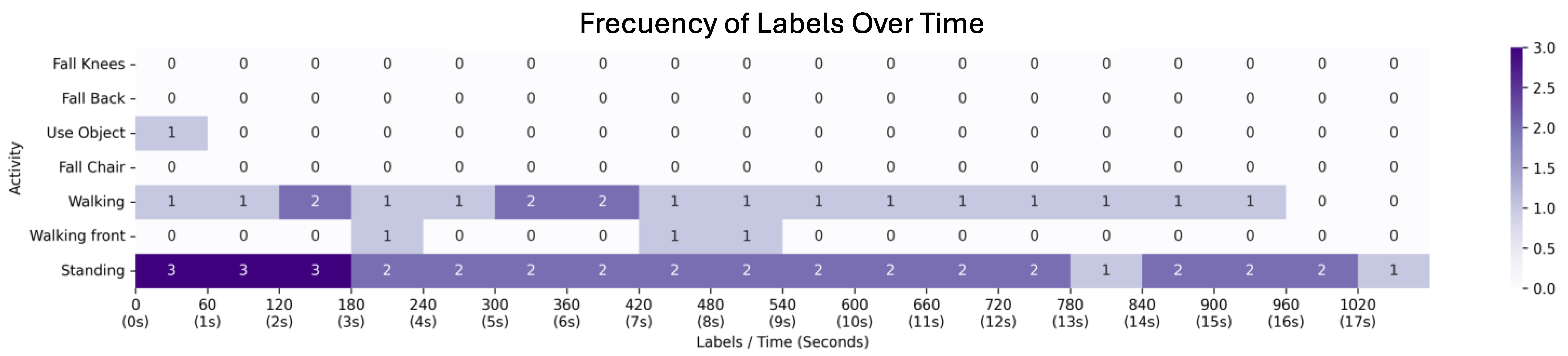
4. Results
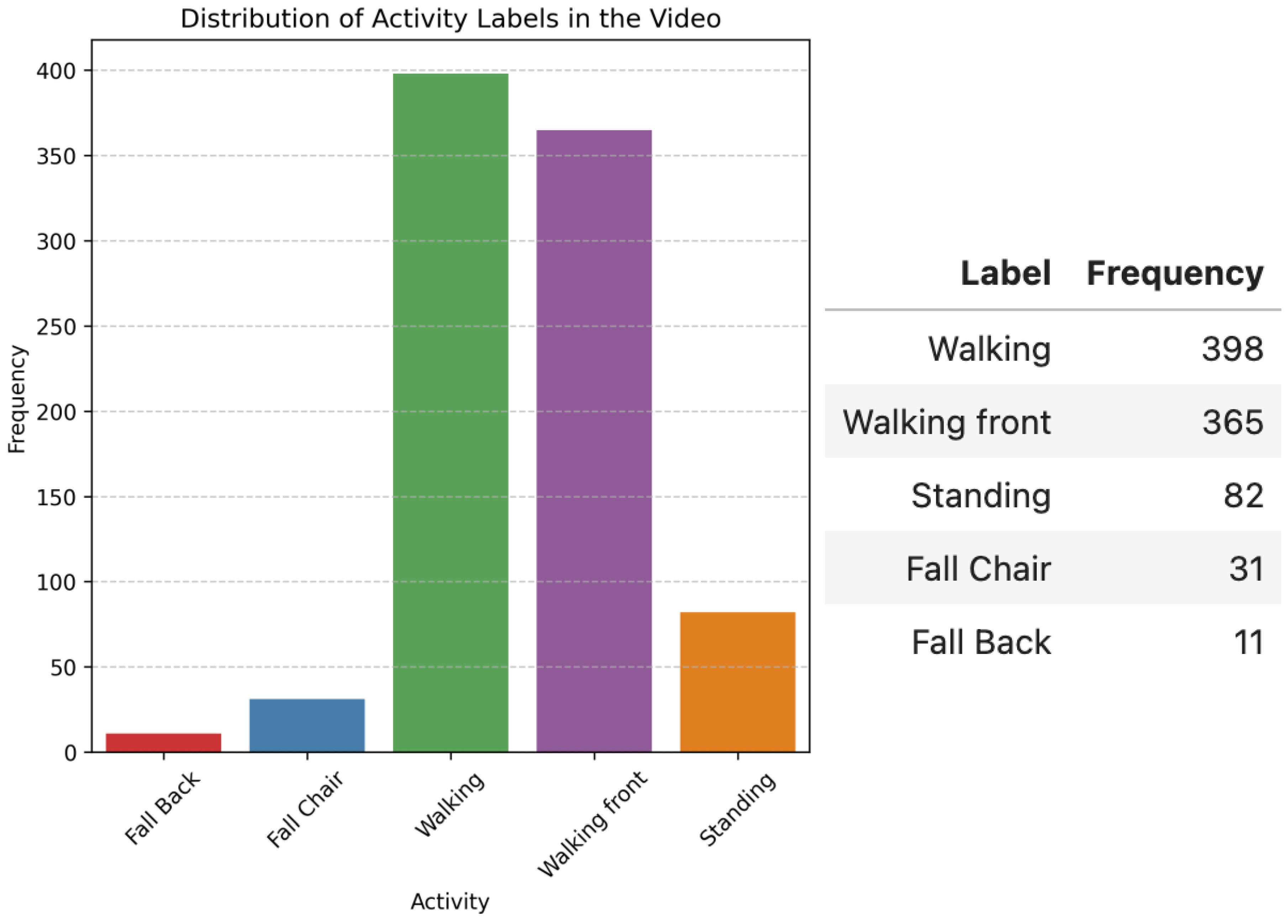
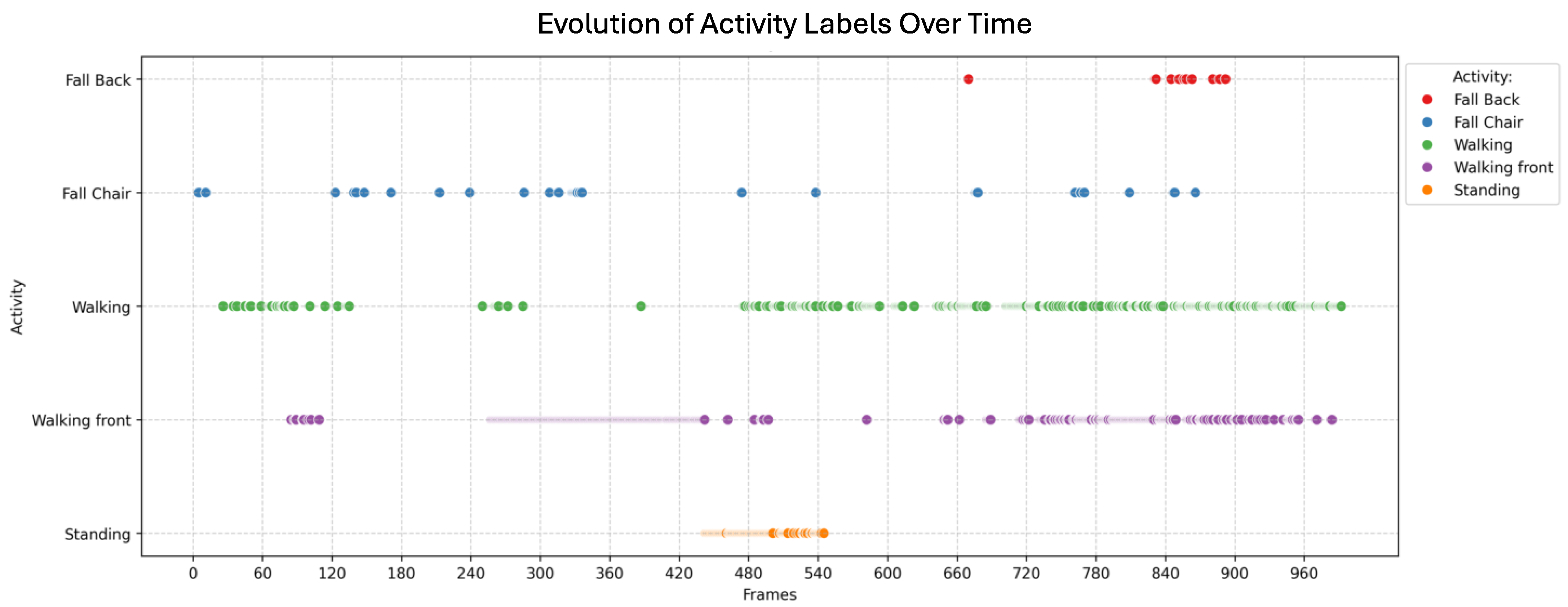
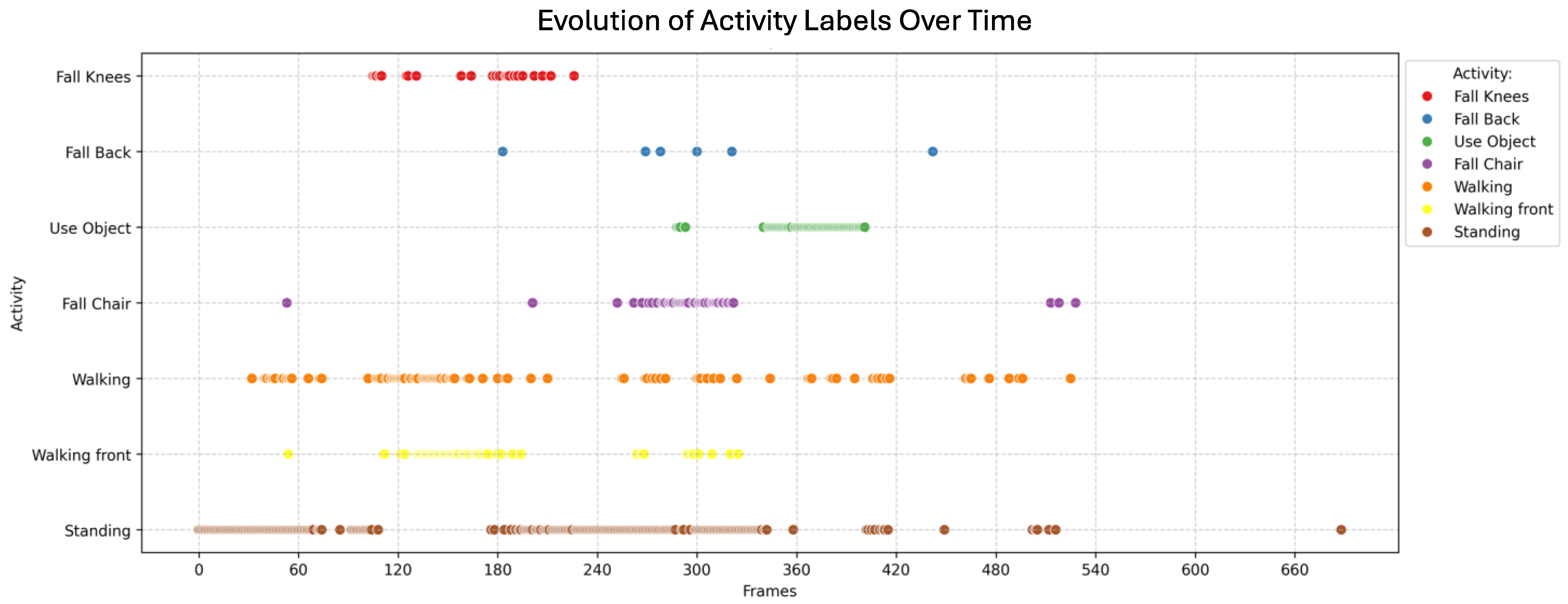
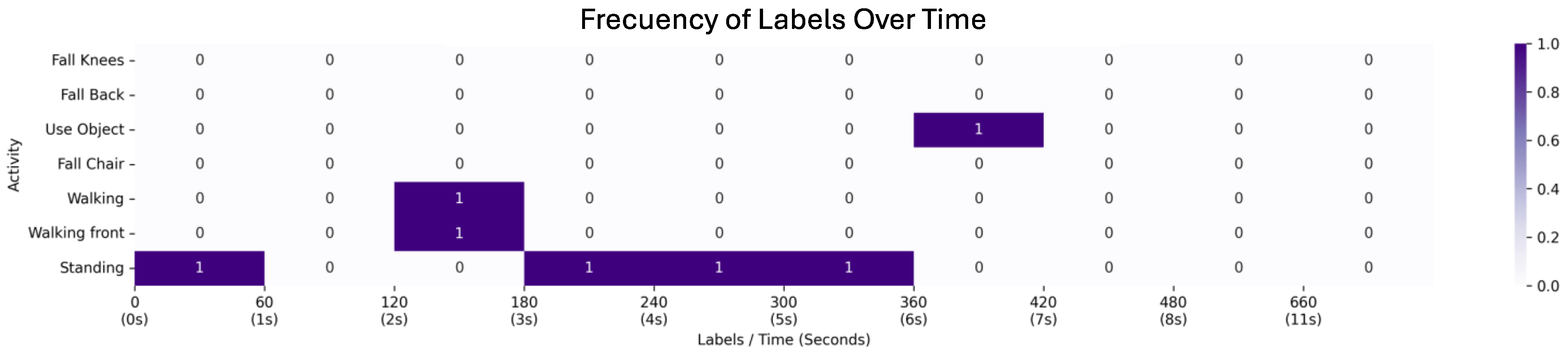
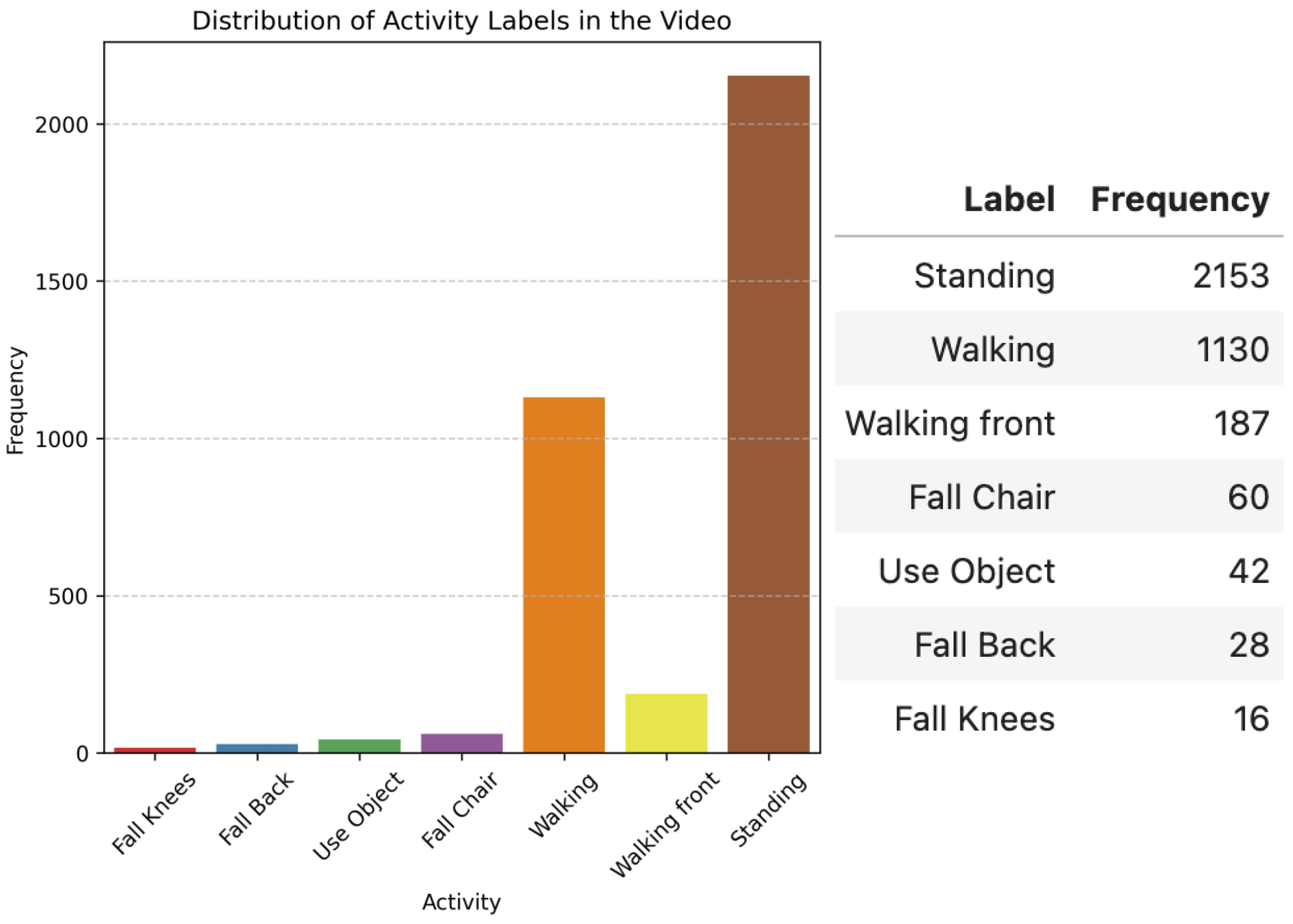
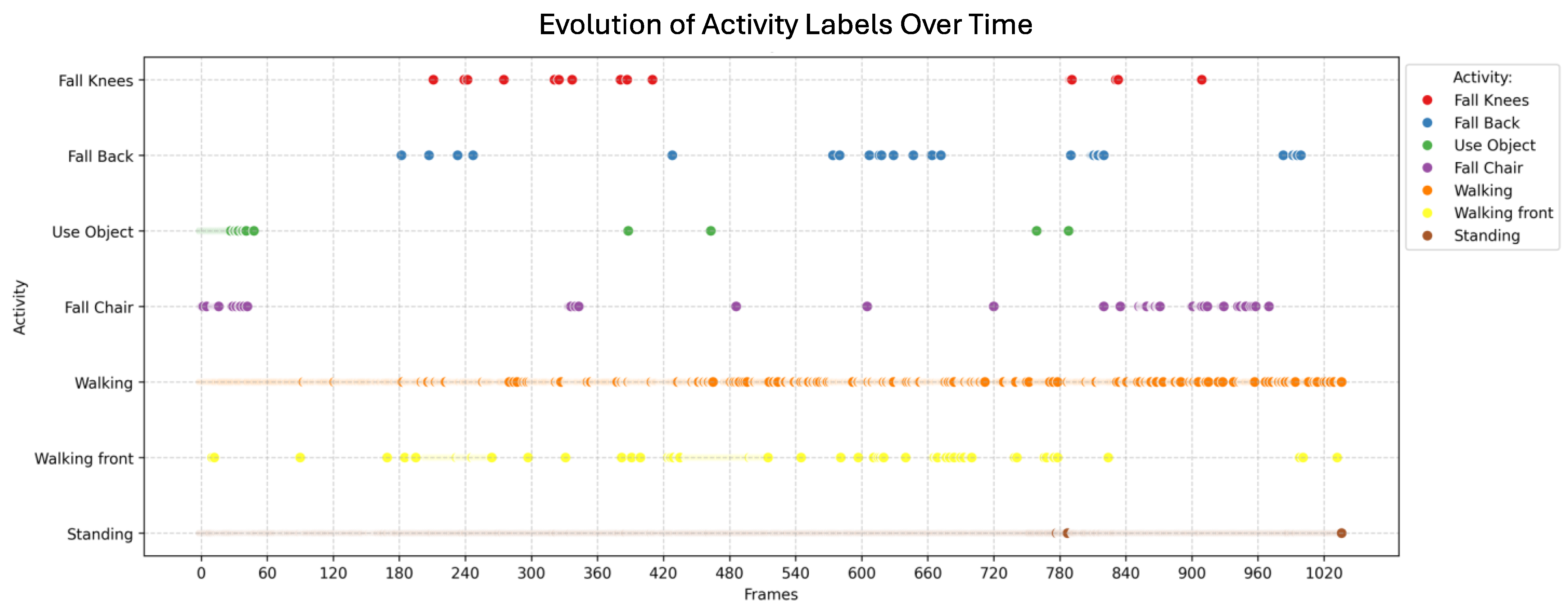
4.1. First Scenario: Video with a Passenger Getting off the Bus
4.2. Second Scenario: Video with a Passenger Running to the Bus
4.3. Third Scenario: Video with Pedestrians Waiting for the Bus
- Knee fall
- Falling backward
- Using an object
- Sitting down on a chair
- Walking
- Walking towards the camera
- Standing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Patni, S.; Srinivasan, S. Modeling boardings and alightings by route at transit stops. Public Transp. 2025, 1–29. [Google Scholar] [CrossRef]
- Warchoł-Jakubowska, A.; Szwoch, I.; Szczeciński, P.; Krejtz, I.; Krejtz, K. Accessible Public Transport: A Case Study of Warsaw. In Transforming Media Accessibility in Europe; Springer: Cham, Switzerland, 2024; pp. 21–38. [Google Scholar] [CrossRef]
- Yendra, D.; Haworth, N.; Watson-Brown, N. A comparison of factors influencing the safety of pedestrians accessing bus stops in countries of differing income levels. Accid. Anal. Prev. 2024, 207, 107725. [Google Scholar] [CrossRef]
- Gumasing, M.J.J.; Prasetyo, Y.T.; Ong, A.K.S.; Carcellar, M.R.I.M.; Aliado, J.B.J.; Nadlifatin, R.; Persada, S.F. Ergonomic design of apron bus with consideration for passengers with mobility constraints. Safety 2022, 8, 33. [Google Scholar] [CrossRef]
- Kaitaro, K.K.; Budiman, I.A.; Sahroni, T.R. Analysis and Assessment of Passenger Comfort Level in Sustainable Public Bus Transportation System. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Banjarbaru, Indonesia, 5–6 October 2024; IOP Publishing: Bristol, UK, 2024; Volume 1324, p. 012067. [Google Scholar]
- Drabicki, A.; Cats, O.; Kucharski, R.; Fonzone, A.; Szarata, A. Should I stay or should I board? Willingness to wait with real-time crowding information in urban public transport. Res. Transp. Bus. Manag. 2023, 47, 100963. [Google Scholar] [CrossRef]
- Ramirez, H.; Velastin, S.A.; Meza, I.; Fabregas, E.; Makris, D.; Farias, G. Fall detection and activity recognition using human skeleton features. IEEE Access 2021, 9, 33532–33542. [Google Scholar] [CrossRef]
- Garcia, G.; Velastin, S.A.; Lastra, N.; Ramirez, H.; Seriani, S.; Farias, G. Train station pedestrian monitoring pilot study using an artificial intelligence approach. Sensors 2024, 24, 3377. [Google Scholar] [CrossRef]
- Hörcher, D.; Tirachini, A. A review of public transport economics. Econ. Transp. 2021, 25, 100196. [Google Scholar] [CrossRef]
- Andrade, A.; Escudero, M.; Parker, J.; Bartolucci, C.; Seriani, S.; Aprigliano, V. Perceptions of people with reduced mobility regarding universal accessibility at bus stops: A pilot study in Santiago, Chile. Case Stud. Transp. Policy 2024, 16, 101190. [Google Scholar] [CrossRef]
- Tirachini, A. Bus dwell time: The effect of different fare collection systems, bus floor level and age of passengers. Transp. A Transp. Sci. 2013, 9, 28–49. [Google Scholar] [CrossRef]
- Fernández, R.; Zegers, P.; Weber, G.; Tyler, N. Influence of platform height, door width, and fare collection on bus dwell time: Laboratory evidence for Santiago de Chile. Transp. Res. Rec. 2010, 2143, 59–66. [Google Scholar] [CrossRef]
- Ittamalla, R.; Kumar, D.V.S. Determinants of holistic passenger experience in public transportation: Scale development and validation. J. Retail. Consum. Serv. 2021, 61, 102564. [Google Scholar] [CrossRef]
- Vitale Brovarone, E. Design as if bus stops mattered: Exploring the potential role of public transport stops in the urban environment. Urban Des. Int. 2021, 26, 82–96. [Google Scholar] [CrossRef]
- Liu, K.; Lin, X.; Xu, J.; Ma, F.; Yang, W.; Cao, R.; Hu, X.; Wei, Y.; Jiang, L.; Wang, Z. Investigating the influence of platform design on the distribution of traffic particulate matter at the bus stop. Build. Environ. 2024, 255, 111395. [Google Scholar] [CrossRef]
- Hosseini, S.H.; Pourkhosro, S.; Gentile, G.; Miristice, L.M.B. GPS-based trip phase and waiting time detection to and from public transport stops via machine learning models. Transp. Res. Procedia 2024, 78, 530–537. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, C.; Zhang, L.; Yang, X. Optimal bus service frequency setting and limited-stop operation with varying vehicle capacity limit. Comput. Electr. Eng. 2024, 118, 109356. [Google Scholar] [CrossRef]
- Xu, J.; Yu, S.S. Assessing the time-varying spatial influence of bus stops on crime by context: A street network analysis. Secur. J. 2025, 38, 19. [Google Scholar] [CrossRef]
- Jevinger, Å.; Zhao, C.; Persson, J.A.; Davidsson, P. Artificial intelligence for improving public transport: A mapping study. Public Transp. 2024, 16, 99–158. [Google Scholar] [CrossRef]
- Lian, T.; Loo, B.P.; Fan, Z. Advances in estimating pedestrian measures through artificial intelligence: From data sources, computer vision, video analytics to the prediction of crash frequency. Comput. Environ. Urban Syst. 2024, 107, 102057. [Google Scholar] [CrossRef]
- Singh, N.; Kumar, K. A review of bus arrival time prediction using artificial intelligence. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1457. [Google Scholar] [CrossRef]
- Mahor, V.; Rawat, R.; Kumar, A.; Garg, B.; Pachlasiya, K. IoT and artificial intelligence techniques for public safety and security. In Smart Urban Computing Applications; River Publishers: Aalborg, Denmark, 2023; pp. 111–126. [Google Scholar]
- Nguyen, T.; Nguyen-Phuoc, D.Q.; Wong, Y.D. Developing artificial neural networks to estimate real-time onboard bus ride comfort. Neural Comput. Appl. 2021, 33, 5287–5299. [Google Scholar] [CrossRef]
- Liyanage, S.; Abduljabbar, R.; Dia, H.; Tsai, P.W. AI-based neural network models for bus passenger demand forecasting using smart card data. J. Urban Manag. 2022, 11, 365–380. [Google Scholar] [CrossRef]
- Kong, X.; Shen, Z.; Wang, K.; Shen, G.; Fu, Y. Exploring bus stop mobility pattern: A multi-pattern deep learning prediction framework. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6604–6616. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Espinosa-Zúñiga, J.J. Aplicación de algoritmos Random Forest y XGBoost en una base de solicitudes de tarjetas de crédito. Ing. Investig. Y Tecnología 2020, 21, 2000. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-fall detection dataset: A multimodal approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef]
- Sase, P.S.; Bhandari, S.H. Human fall detection using depth videos. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; IEEE: New York, NY, USA, 2018; pp. 546–549. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ML Model | Parameters |
|---|---|
| estimators = 10 | |
| Random Forest (RF) | min. samples splits = 2 |
| min. samples leaf = 1 | |
| bootstrap = true |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramirez, H.; Seriani, S.; Aprigliano, V.; Peña, A.; Arredondo, B.; Bastias, I.; Farias, G. Posture Detection of Passengers’ Movement When Boarding and Alighting an Urban Bus: A Pilot Study in Valparaíso, Chile. Appl. Sci. 2025, 15, 5367. https://doi.org/10.3390/app15105367
Ramirez H, Seriani S, Aprigliano V, Peña A, Arredondo B, Bastias I, Farias G. Posture Detection of Passengers’ Movement When Boarding and Alighting an Urban Bus: A Pilot Study in Valparaíso, Chile. Applied Sciences. 2025; 15(10):5367. https://doi.org/10.3390/app15105367
Chicago/Turabian StyleRamirez, Heilym, Sebastian Seriani, Vicente Aprigliano, Alvaro Peña, Bernardo Arredondo, Iván Bastias, and Gonzalo Farias. 2025. "Posture Detection of Passengers’ Movement When Boarding and Alighting an Urban Bus: A Pilot Study in Valparaíso, Chile" Applied Sciences 15, no. 10: 5367. https://doi.org/10.3390/app15105367
APA StyleRamirez, H., Seriani, S., Aprigliano, V., Peña, A., Arredondo, B., Bastias, I., & Farias, G. (2025). Posture Detection of Passengers’ Movement When Boarding and Alighting an Urban Bus: A Pilot Study in Valparaíso, Chile. Applied Sciences, 15(10), 5367. https://doi.org/10.3390/app15105367