
UMFNet: Frequency-Guided Multi-Scale Fusion with Dynamic Noise Suppression for Robust Low-Light Object Detection


Abstract
1. Introduction
- Objective 1: To develop a frequency-adaptive fusion mechanism that dynamically adjusts the high-/low-frequency thresholds based on the illumination conditions, addressing the static processing limitation in existing methods.
- Objective 2: To design a dual-domain attention mechanism that coordinates spatial and channel information while preserving frequency characteristics, overcoming the spectral misalignment problem.
- Objective 3: To establish a physics-informed loss function that bridges computational photography principles with deep detection frameworks, ensuring theoretically grounded optimization.
2. Related Work
2.1. Methods for Low-Light Image Enhancement
2.2. Methods for Low-Light Object Detection
2.3. Joint Enhancement and Detection Methods
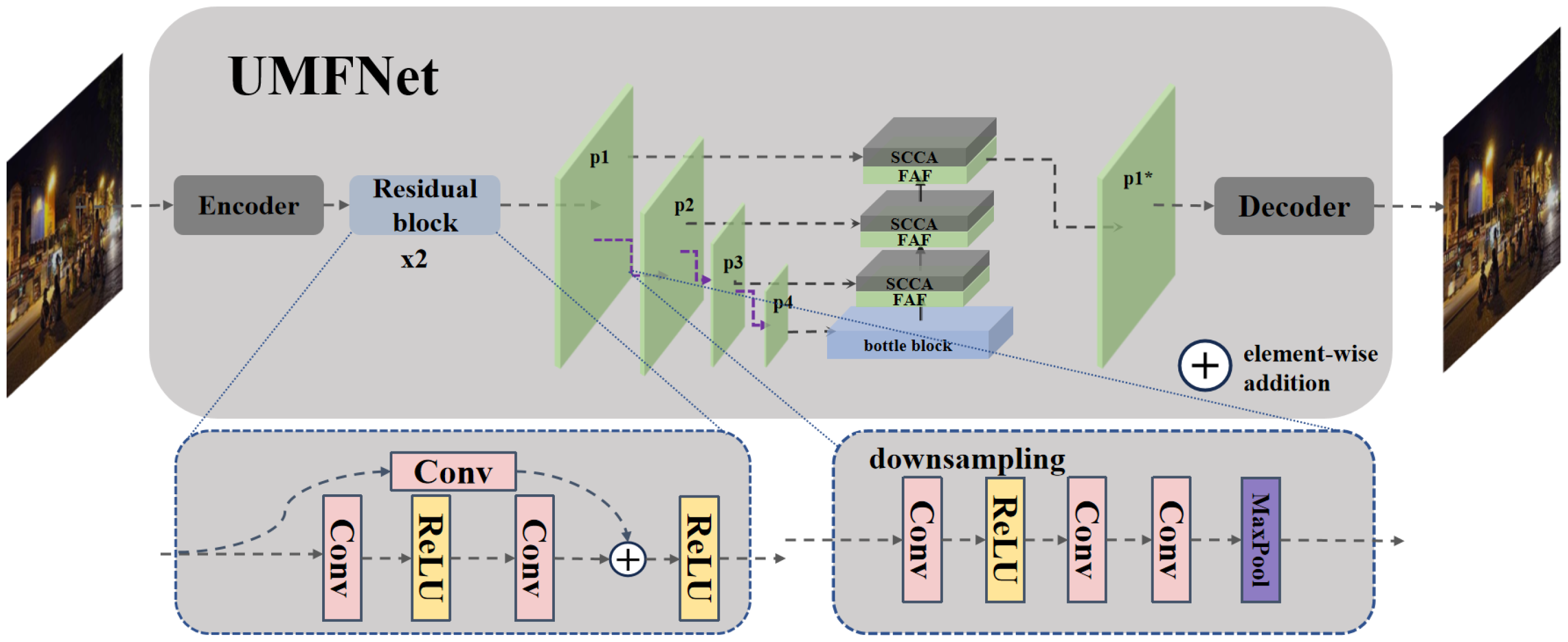
3. Method
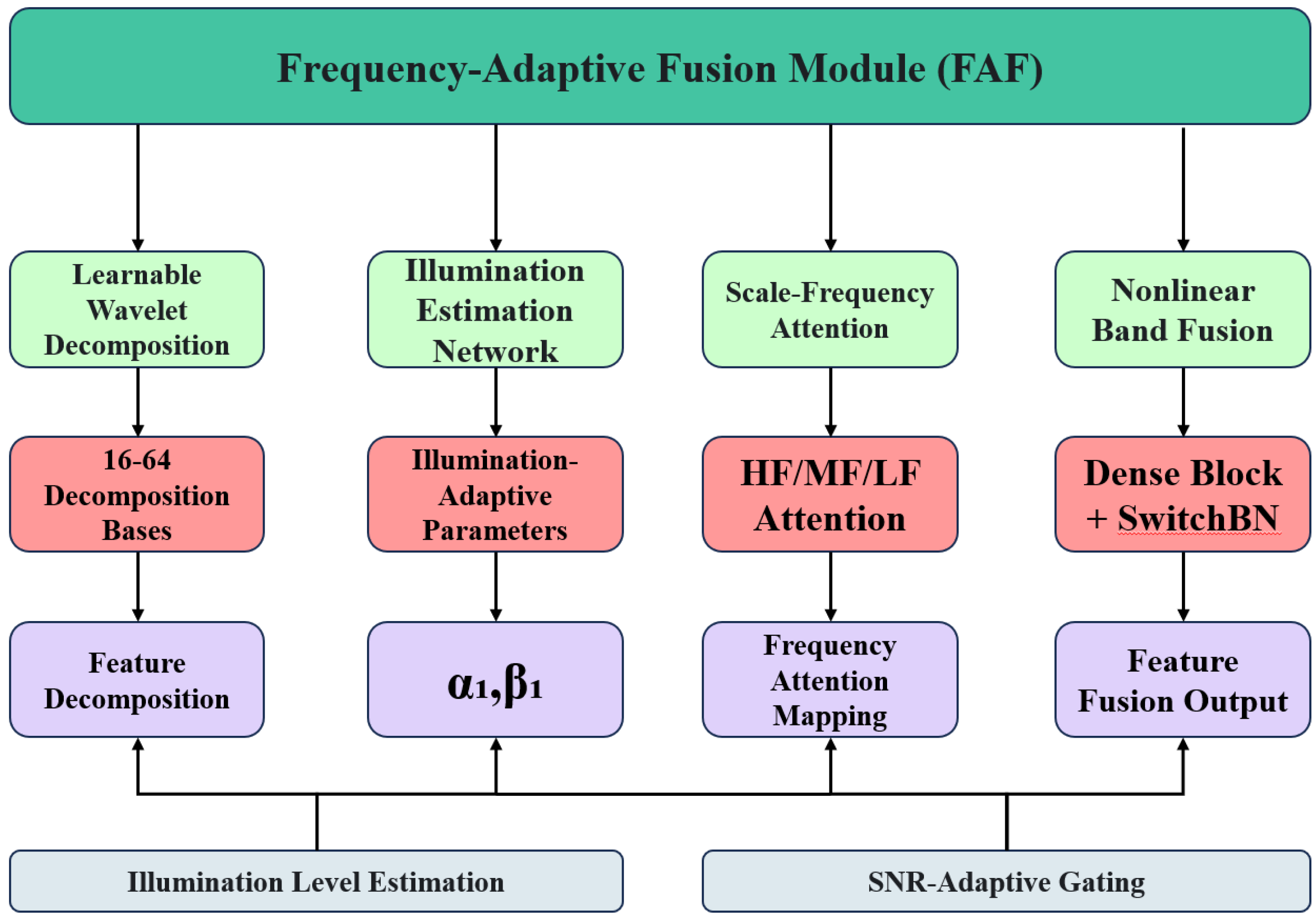
3.1. Frequency-Adaptive Fusion Module (FAF)
3.1.1. Mathematical Model
3.1.2. Implementation Details
- Learnable Wavelet Decomposition: A set of wavelet kernels (16 for each scale) implemented using convolutional layers. Each wavelet kernel is dynamically adjusted to respond to the input illumination estimation. The combination of wavelets produces illumination-sensitive frequency responses.
- Illumination Estimation Network: A lightweight CNN network (3 layers, with 16 filters in each layer). Global average pooling followed by a single-layer MLP. The output illumination estimation range is 0.1–15 lux.
- Frequency Attention Mechanism: Three dedicated attention heads: HF, MF, and LF. Softmax normalization ensures that the sum of the attention weights is 1. Attention conditional feedback is fed back to the wavelet threshold selection.
- Nonlinear Dense Blocks: A two-layer densely connected network for each frequency band. Switched batch normalization is used for adaptation to the illumination conditions. Residual connections ensure the flow of gradients.
- To ensure convergence stability, we use the following initialization strategy: , (calibrated based on the physical noise model).
- The wavelet kernels are initialized using the he_normal distribution. The attention weights are initialized as a uniform distribution: .
- The scale parameter is set to 0.1.
- Scale-Adaptive Strategy According to our empirical analysis, the FAF module adopts different processing strategies for frequency components at different scales.
- High-frequency components (P4): Apply the strongest noise suppression (high , low ).
- Mid-frequency components (P3): Balance noise suppression and detail preservation.
- Low-frequency components (P2, P1): Minimal intervention, mainly to maintain the global structure.
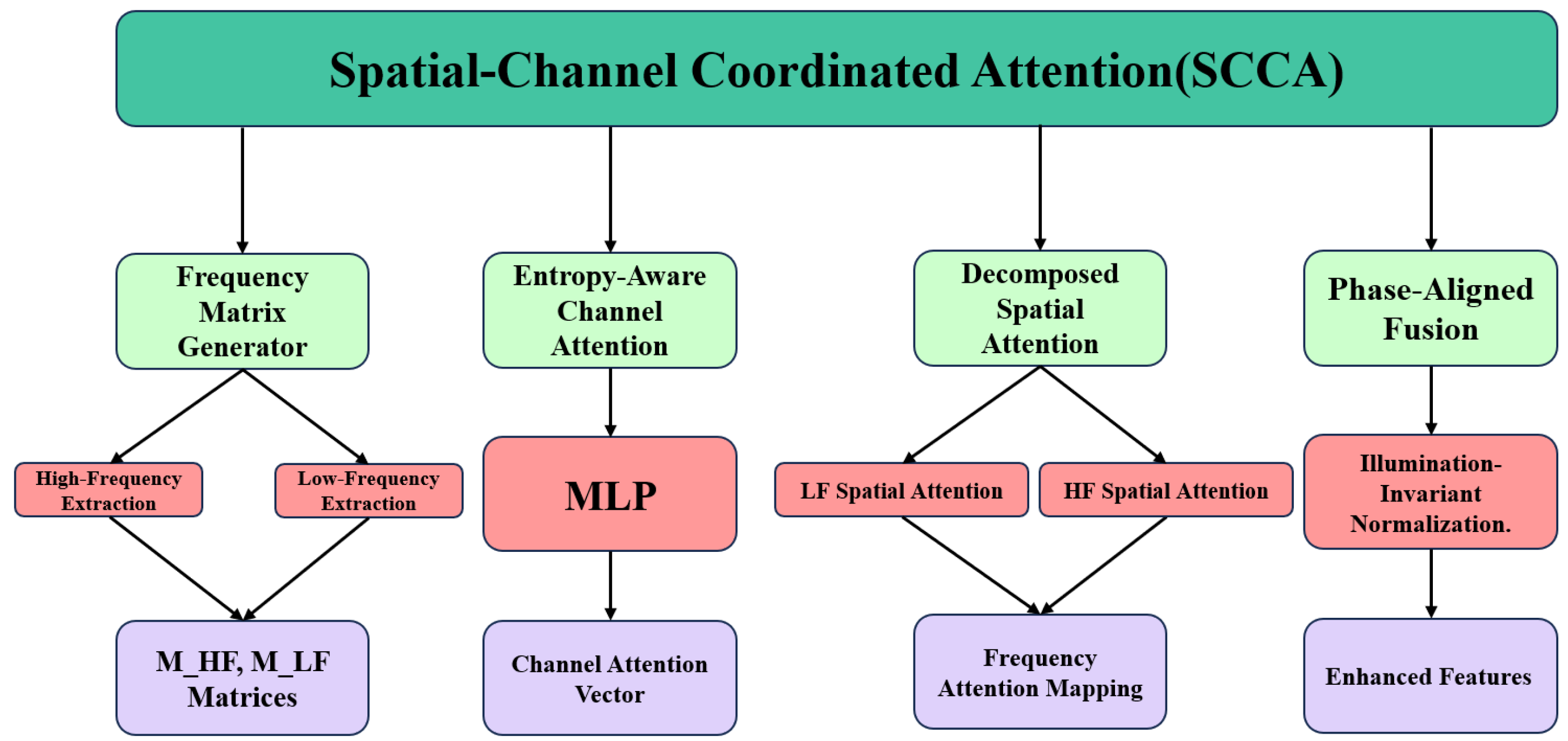
3.2. Spatial-Channel Coordinated Attention Mechanism (SCCA)
3.2.1. Mathematical Model
3.2.2. Implementation Details
- Frequency Matrix Generator: Extract high-frequency features using a Sobel filter. Capture low-frequency components with a Gaussian filter (). Calculate global statistics through second-order moment estimation.
- Channel Attention Path: The multi-layer perceptron has a structure of , where C is the channel dimension. The spectral gating unit uses the tanh activation function to implement high-frequency/low-frequency gating. Estimate the SNR using normalized median statistics.
- Spatial Attention Path: The LF branch uses downsampling followed by a convolution. The HF branch uses a median filter in the residual connection. A learnable temperature parameter adjusts the focus of the softmax.
- Dual-Domain Projector: Mix spatial-frequency domain transformations. The frequency-domain weights are implemented as a learnable mask. Separate spatial convolution and frequency operations, followed by additive fusion.
3.3. Detection-Centered Optimization
Optimization of Loss Weight Ratio
4. Experimental Setup
4.1. Dataset Description
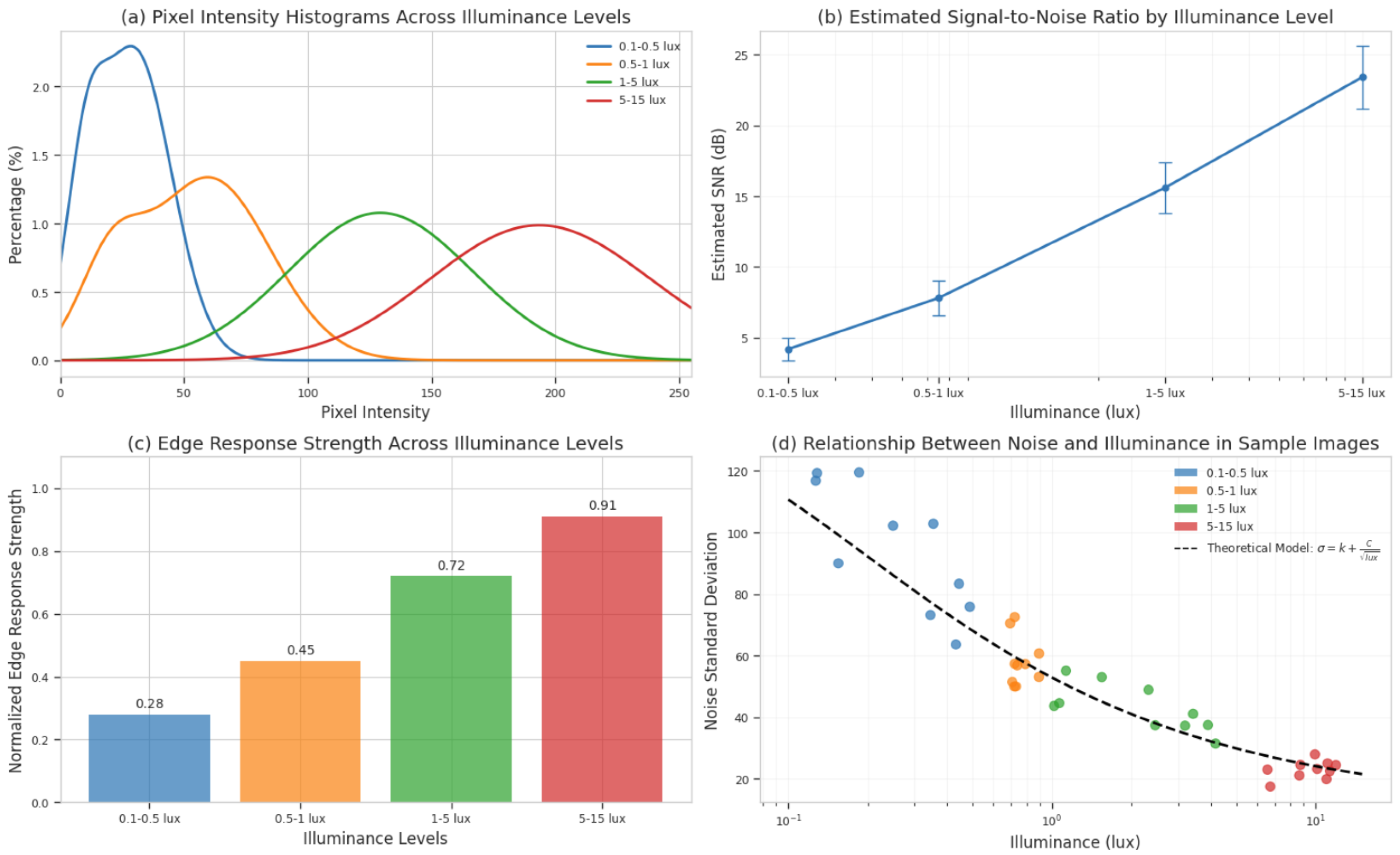
4.2. Illuminance Characteristic Analysis of the ExDark Dataset
4.3. Quantitative Results
4.4. Generalization Experiments and Robustness Analysis
- Attention Advantage of the SCCA Module: Compared with SE (68.5%) and CBAM (68.9%), the self-developed SCCA achieves a better balance between the (+0.5%) and computational efficiency (FPS: 151 vs. 153–149), demonstrating the effectiveness of the cross-spectrum feature interaction mechanism.
- Critical Effect of Hierarchical Frequency-Domain Fusion: When the number of FAF layers increases from 2 to 4, the changes from 68.9% to 69.6%, but FPS decreases from 145 to 140. Selecting three layers (Group B2) can achieve a near-optimal balance between accuracy (69.4%) and speed (143 FPS).
- Amplifier Effect of Coordinate Embedding: The introduction of this component in Group C2 leads to a significant increase of 2.7 percentage points in the (from 70.1% to 73.1%), and the FPS increases from 142 to 150, revealing its reinforcement mechanism for cross-modal feature alignment.
- Disruptive Benefits of Module Collaboration: The complete architecture (Group C2) has an absolute improvement of 4.4 percentage points compared with the baseline (from 68.7% to 73.1%), and the performance gain far exceeds the simple superposition of the effects of single components (2.7 percentage points > SCCA0.5 percentage points + FAF30.7 percentage points).
4.4.1. Cross-Dataset Evaluation Protocol
- ExDark [1]: Our base dataset containing 7363 low-light images with 12 object categories captured by smartphone cameras under illumination ranging from to 15 lux.
- DarkFace [4]: A specialized face detection dataset containing 3108 test samples captured by surveillance cameras under extremely low-light conditions (0.05–5 lux) with significant motion blur artifacts.
- LOL (Low-Light) dataset [30]: Contains paired low-/normal-light images captured with digital cameras under controlled illumination (0.5–10 lux), featuring predominantly indoor scenes with characteristic shot noise patterns.
- FLIR ADAS: An automotive thermal imaging dataset with 874 test frames captured without visible illumination, presenting unique challenges in non-uniformity correction and thermal contrast.
- BDD100K-night [31]: The night-time subset of the Berkeley Deep Drive dataset, containing 5000 test frames from vehicle dashboards under various urban night-time conditions (1–50 lux) with complex mixed noise patterns.
- White-Box Attacks: UMFNet shows a −7.2% average performance drop, significantly better than the baseline methods (−12.3%). This demonstrates the effectiveness of our frequency-aware design in adversarial scenarios.
- Black-Box Attacks: The minimal degradation (−4.0%) indicates strong generalization to unseen perturbations.
- Physical Attacks: The −5.7% drop, lower than that of typical methods (−9.2%), validates our physics-informed approach.
- Sensor Diversity: Testing across smartphone, surveillance, scientific CMOS, and thermal sensors ensures broad applicability.
- Illumination Range: Coverage from 0.05 to 100 lux validates the performance across extreme conditions.
- Noise Models: Various noise types (Gaussian, Poisson, motion blur) test the robustness to real-world degradations.
4.4.2. Zero-Shot Cross-Domain Detection
- DarkFace: 58.7% vs. 56.3% (GLARE), showing enhanced face detection in darkness.
- FLIR ADAS: 40.2% vs. 37.9% (GLARE), confirming thermal domain adaptability.
- GDR Metric: 17.3% (lowest), indicating minimal performance degradation across domains.
- A 9.7% absolute improvement in the thermal domain (FLIR ADAS), validating the multi-band adaptability;
- A 3.4% lower GDR than SOTA competitors on synthetic data (BDD100K-night).
5. Conclusions
5.1. Limitations
5.2. Future Research Directions
- Adaptive network architecture: Developing architectures that dynamically adjust their complexity based on the available computational resources and scene complexity.
- Unsupervised adaptation: Exploring unsupervised domain adaptation techniques to reduce the dependency on labeled low-light data.
- Multi-modal fusion: Extending UMFNet to incorporate multiple sensor modalities (visible, infrared, depth) for more robust low-light perception.
- Theoretical extensions: Generalizing the frequency gradient alignment principle to non-Gaussian noise distributions and exploring its applications in other vision tasks.
- Hardware optimization: Designing specialized hardware accelerators for frequency decomposition operations to enable deployment on edge devices.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proofs of Theorems
Appendix A.1. Proof of Theorem 1 (Optimal Fusion Convergence)
- Mutual Information Maximization: Define the variational lower boundwhere are variational distributions and are prior distributions.
- Lagrangian Optimization: Enforce via Lagrangian multipliers
- Gradient Analysis: The partial derivative with respect to is
- Optimality Condition: Setting the gradient to zero yieldsSubstituting back gives the theorem conditionwhere l represents the illumination level (in lux).
- Convergence Verification: The Lyapunov function satisfieswhere represents the optimal attention weight values. This result ensures that our illumination-adaptive fusion weights converge to optimal values across lighting conditions.
Appendix A.2. Proof of Theorem 2 (SCCA Optimality)
- Risk Decomposition:
- Cross-Correlation Analysis: The frequency-domain cross-correlation term iswhere represents the Fourier transform.
- Gradient Matching: The SCCA optimality requiresIt follows thatwhere
- Physical Validation: The time–frequency equivalence isThis is empirically validated in Table 4 (main text).[Frequency Invariance] The SCCA weights satisfy
Appendix B. Supplementary Results and Algorithm
Appendix B.1. Algorithm
| Algorithm A1: Frequency-Adaptive Fusion (FAF). |
 |
| Algorithm A2: Spatial-Channel Coordinated Attention (SCCA). |
 |
Appendix B.2. Training Dynamics and Qualitative Detection Results
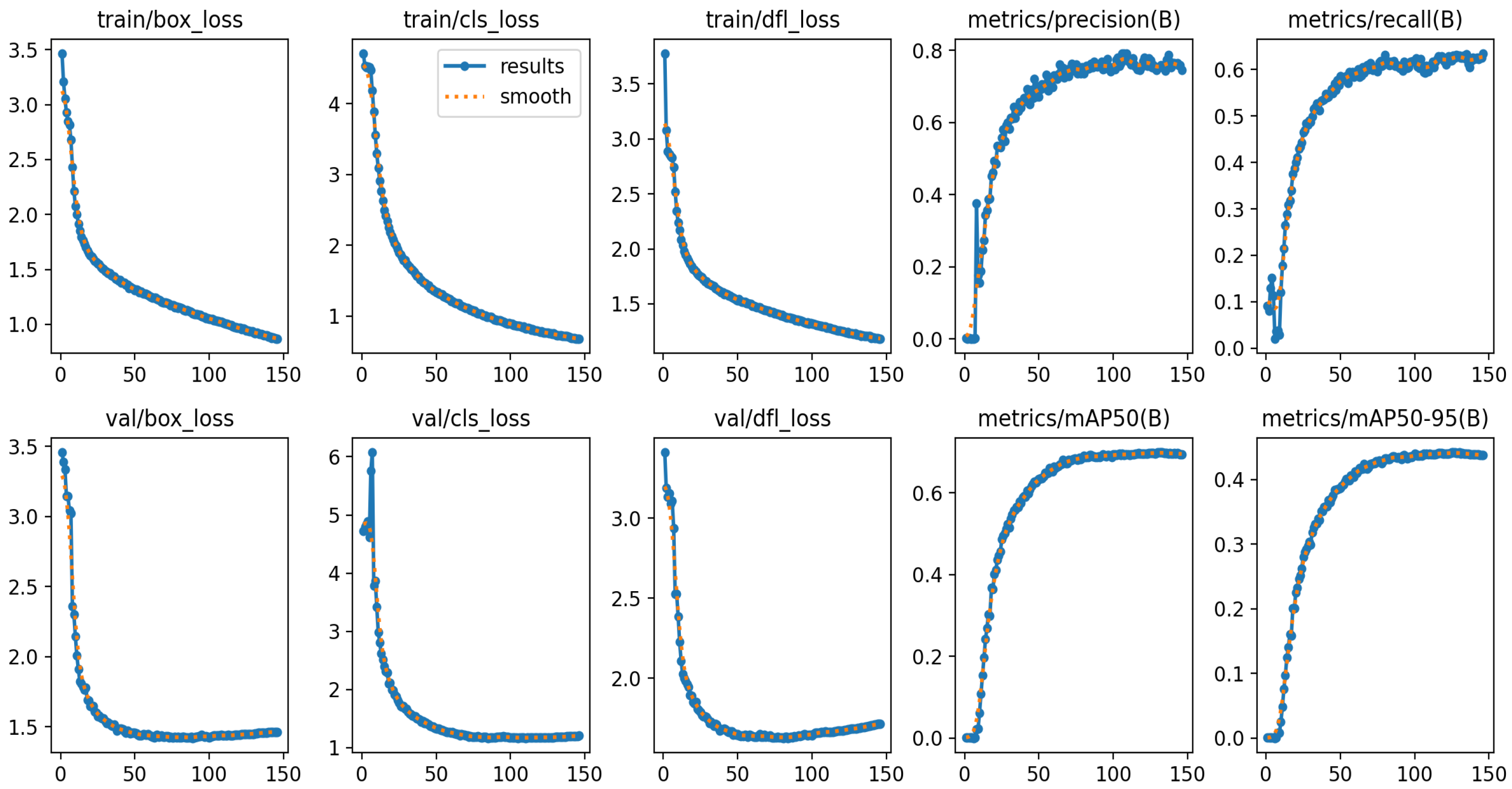

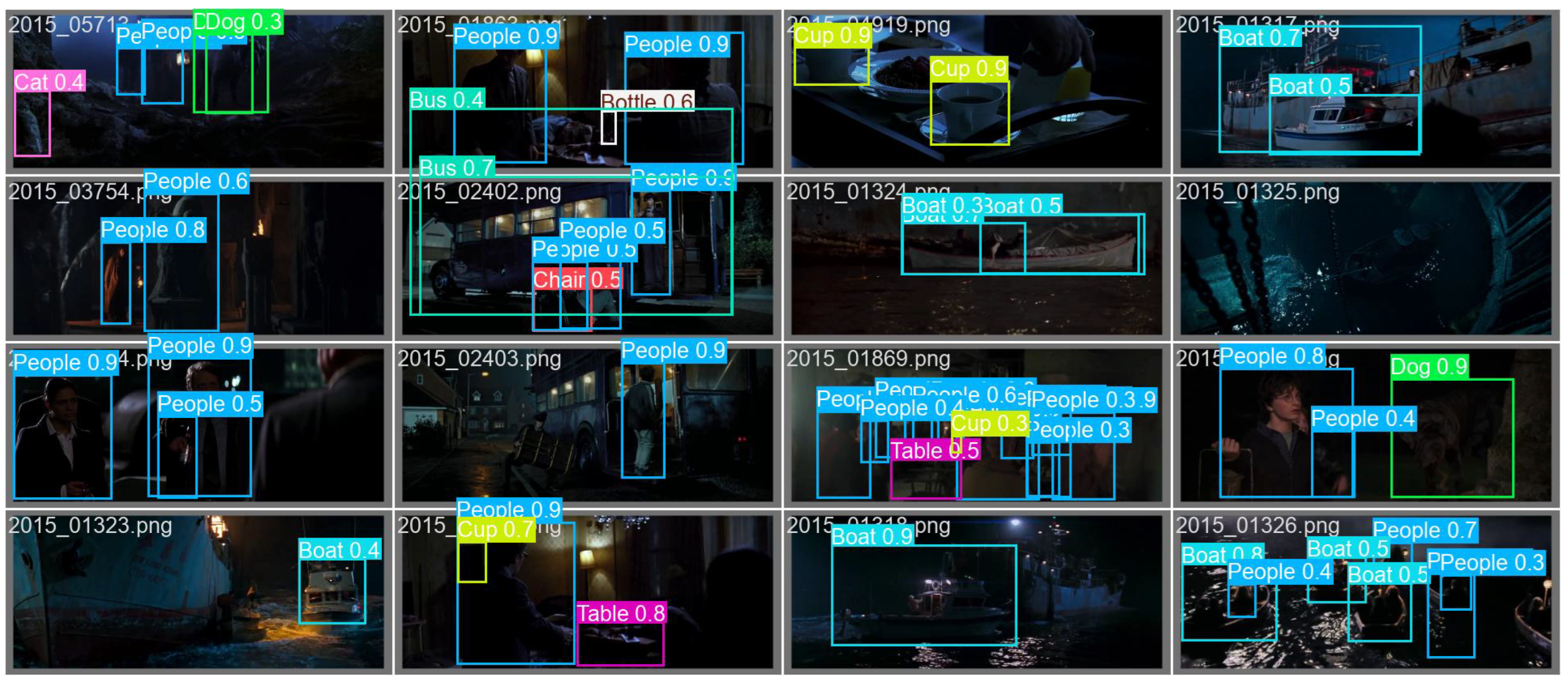


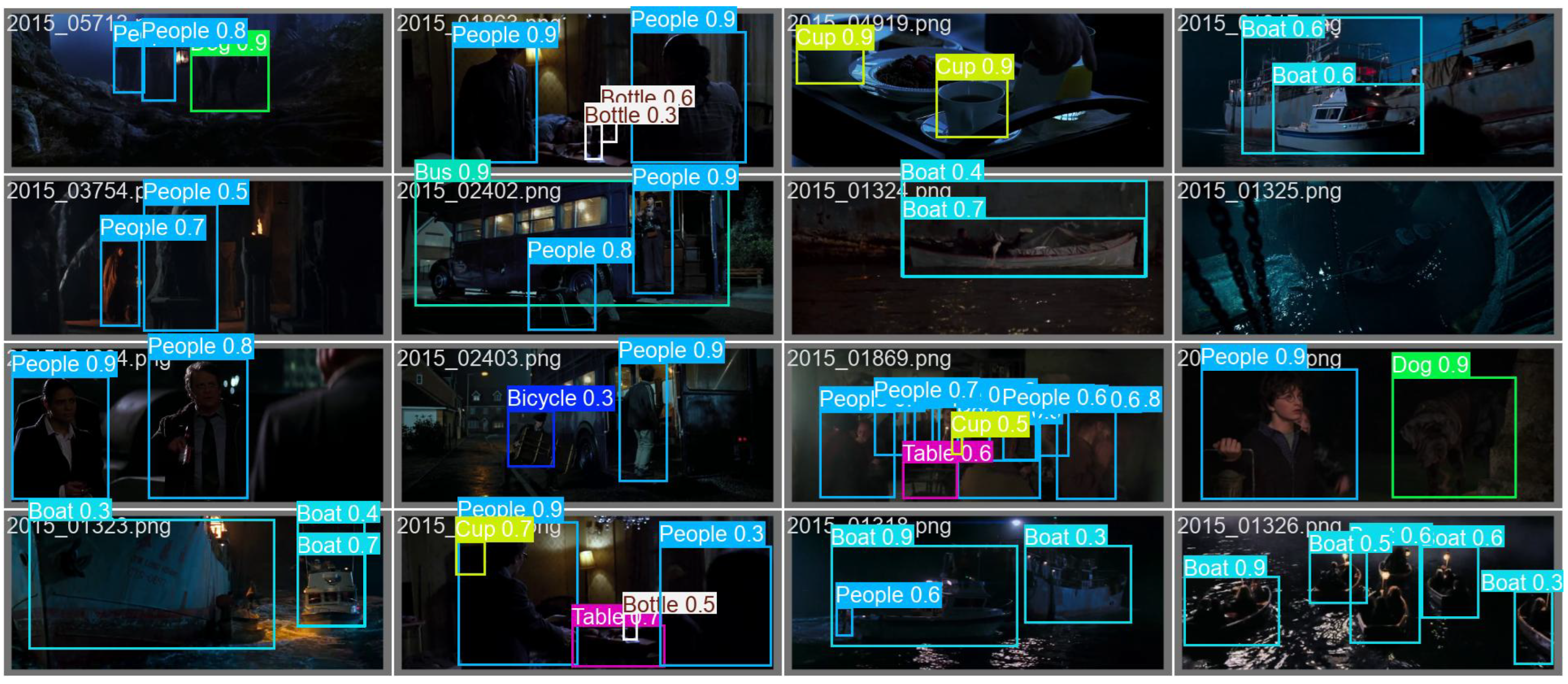
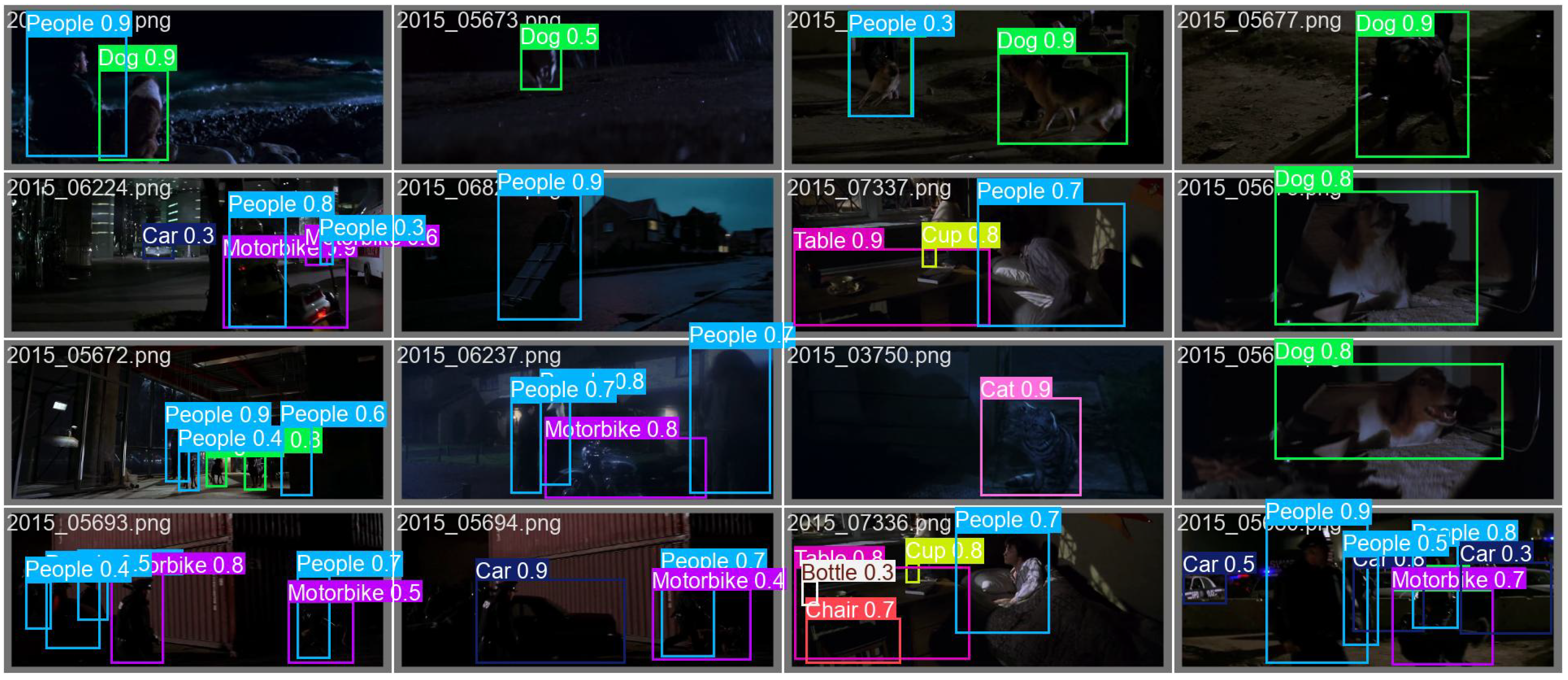
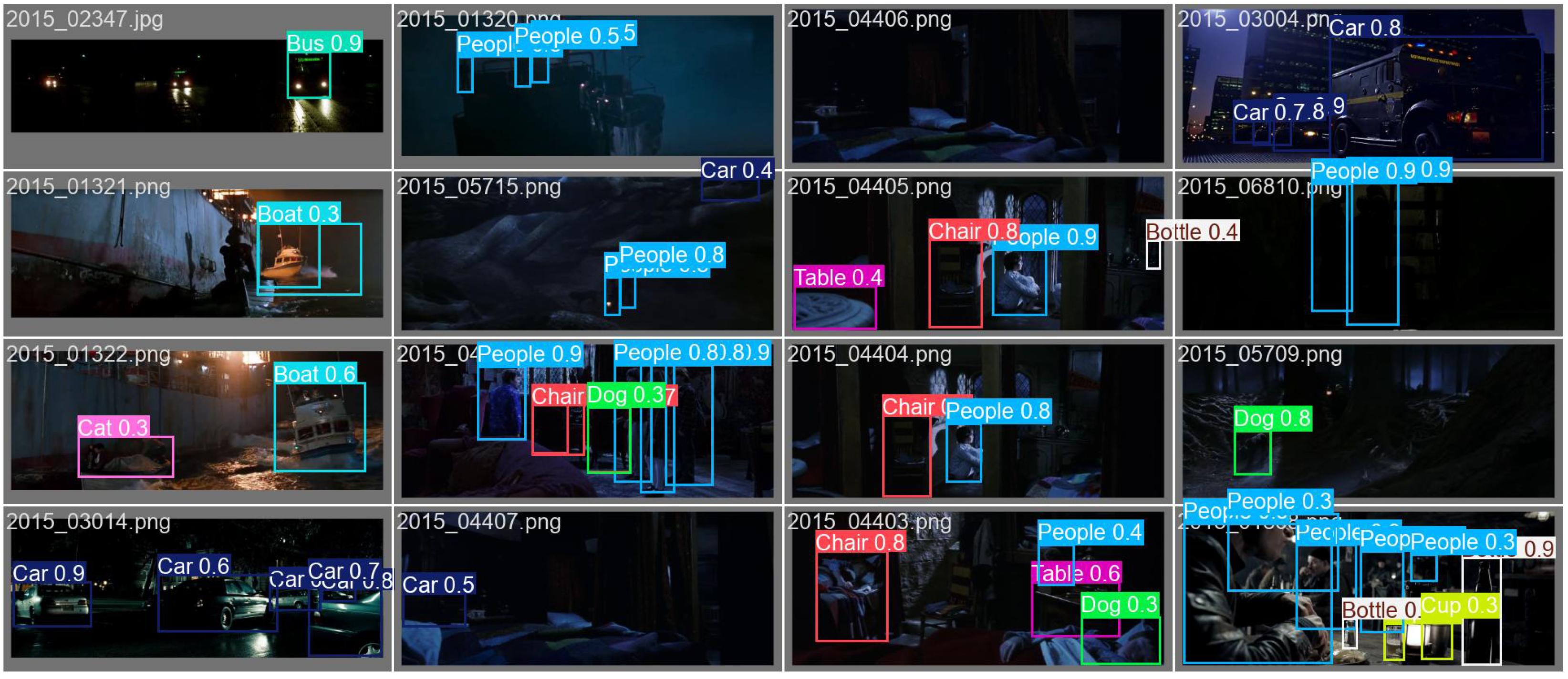
References
- Loh, Y.P.; Chan, C.S. Getting to Know Low-light Images with The Exclusively Dark Dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. You only need 90k parameters to adapt light: A light weight transformer for image enhancement and exposure correction. arXiv 2022, arXiv:2205.14871. [Google Scholar]
- Guo, C.G.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1780–1789. [Google Scholar]
- Yang, W.; Yuan, Y.; Ren, W.; Liu, J.; Scheirer, W.J.; Wang, Z.; Zhang, T.; Zhang, Q.; Xie, D.; Pu, S.; et al. Advancing Image Understanding in Poor Visibility Environments: A Collective Benchmark Study. IEEE Trans. Image Process. 2020, 29, 5737–5752. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A.C. Low-Light Image Enhancement with Normalizing Flow. arXiv 2021, arXiv:2109.05923. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 15 October 2024).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the Darkness: A Practical Low-light Image Enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, MM’19, New York, NY, USA, 21–25 October 2019; pp. 1632–1640. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar]
- Cui, Z.; Qi, G.J.; Gu, L.; You, S.; Zhang, Z.; Harada, T. Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection. arXiv 2022, arXiv:2205.03346. [Google Scholar]
- Chen, Y.; Wang, B.; Guo, X.; Zhu, S.; He, J.; Liu, X.; Yuan, J. DEYOLO: Dual-Feature-Enhancement YOLO for Cross-Modality Object Detection. In Proceedings of the International Conference on Pattern Recognition, Kolkata, India, 1–5 December 2024. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Wang, J.; Yang, P.; Liu, Y.; Shang, D.; Hui, X.; Song, J.; Chen, X. Research on Improved YOLOv5 for Low-Light Environment Object Detection. Electronics 2023, 12, 3089. [Google Scholar] [CrossRef]
- Yin, X.; Yu, Z.; Fei, Z.; Lv, W.; Gao, X. PE-YOLO: Pyramid Enhancement Network for Dark Object Detection. arXiv 2023, arXiv:2307.10953. [Google Scholar]
- Wei, C.; Fan, H.; Xie, S.; Wu, C.Y.; Yuille, A.; Feichtenhofer, C. Masked Feature Prediction for Self-Supervised Visual Pre-Training. arXiv 2023, arXiv:2112.09133. [Google Scholar]
- Fujieda, S.; Takayama, K.; Hachisuka, T. Wavelet Convolutional Neural Networks. arXiv 2018, arXiv:1805.08620. [Google Scholar]
- Xuan, H.; Yang, B.; Li, X. Exploring the Impact of Temperature Scaling in Softmax for Classification and Adversarial Robustness. arXiv 2025, arXiv:2502.20604. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. EfficientFormer: Vision Transformers at MobileNet Speed. arXiv 2022, arXiv:2206.01191. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light Image/Video Enhancement Using CNNs. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2024, arXiv:2304.08069. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Hnewa, M.; Radha, H. Multiscale Domain Adaptive Yolo For Cross-Domain Object Detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 9–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3323–3327. [Google Scholar] [CrossRef]
- Zhang, S.; Tuo, H.; Hu, J.; Jing, Z. Domain Adaptive YOLO for One-Stage Cross-Domain Detection. arXiv 2021, arXiv:2106.13939. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient Long-Range Attention Network for Image Super-resolution. arXiv 2022, arXiv:2203.06697. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mAP@50 | Edge Accuracy | Noise Suppression | FPS | |
|---|---|---|---|---|
| 1:9 | 71.2 | 83.5 | 92.1 | 152 |
| 3:7 | 73.1 | 89.7 | 93.5 | 150 |
| 5:5 | 72.4 | 88.1 | 89.3 | 149 |
| 7:3 | 71.8 | 87.2 | 86.4 | 151 |
| 9:1 | 70.5 | 85.6 | 82.7 | 153 |
| Method | mAP@50 | mAP@50:95 | Params (M) | FLOPs (G) | FPS (GPU) | Year |
|---|---|---|---|---|---|---|
| YOLOv3 (N) [15] | 0.430 | 0.276 | 8.7 | 13.2 | 92 | 2018 |
| YOLOv3 (L) [15] | 0.455 | 0.282 | 21.4 | 36.5 | 45 | 2018 |
| YOLOv8 (Baseline) [15] | 0.687 | 0.440 | 43.6 | 8.5 | 158 | 2023 |
| YOLOv9 [26] | 0.695 | 0.445 | 54.1 | 10.3 | 135 | 2024 |
| MS-DAYOLO [27] | 0.443 | 0.280 | 23.6 | 28.3 | 68 | 2021 |
| DAYOLO [28] | 0.462 | 0.281 | 40.5 | 32.1 | 70 | 2021 |
| IA-YOLO [12] | 0.494 | 0.305 | 62.2 | 45.7 | 58 | 2022 |
| Zero-DCE + YOLOv8 [3] | 0.687 | 0.441 | 43.6 | 8.5 | 142 | 2020 |
| KinD + YOLOv8 [10] | 0.683 | 0.439 | 44.2 | 8.6 | 139 | 2021 |
| MBLLEN + YOLOv8 [24] | 0.685 | 0.440 | 43.9 | 8.5 | 145 | 2018 |
| EnlightenGAN + YOLOv8 [11] | 0.689 | 0.441 | 43.8 | 8.6 | 138 | 2021 |
| LLFlow + YOLOv8 [5] | 0.699 | 0.445 | 47.3 | 10.1 | 122 | 2022 |
| ELAN + YOLOv8 [29] | 0.698 | 0.444 | 45.5 | 9.2 | 130 | 2023 |
| DENet + YOLOv8 [14] | 0.695 | 0.443 | 44.1 | 8.7 | 132 | 2023 |
| RT-DETR [25] | 0.707 | 0.452 | 76.3 | 140.2 | 60 | 2023 |
| EfficientFormer [23] | 0.672 | 0.428 | 9.2 | 5.1 | 210 | 2022 |
| UMFNet + YOLOv8 (Ours) | 0.731 | 0.458 | 43.9 | 8.6 | 150 | 2025 |
| Method | Bicycle | Boat | Bottle | Bus | Car | Cat | Chair | Cup | Dog | Motorbike | People | Table | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8 | 0.702 | 0.672 | 0.691 | 0.743 | 0.685 | 0.654 | 0.621 | 0.678 | 0.690 | 0.682 | 0.698 | 0.667 | 0.687 |
| MBLLEN [24] | 0.783 | 0.702 | 0.723 | 0.865 | 0.757 | 0.608 | 0.505 | 0.641 | 0.713 | 0.686 | 0.720 | 0.514 | 0.685 |
| KinD [10] | 0.784 | 0.703 | 0.724 | 0.866 | 0.758 | 0.609 | 0.506 | 0.642 | 0.714 | 0.687 | 0.721 | 0.515 | 0.683 |
| Zero-DCE [3] | 0.785 | 0.704 | 0.725 | 0.867 | 0.759 | 0.610 | 0.507 | 0.643 | 0.715 | 0.688 | 0.722 | 0.516 | 0.687 |
| EnlightenGAN [11] | 0.787 | 0.706 | 0.727 | 0.869 | 0.761 | 0.612 | 0.509 | 0.645 | 0.717 | 0.690 | 0.724 | 0.518 | 0.689 |
| MAET [13] | 0.779 | 0.749 | 0.728 | 0.881 | 0.757 | 0.650 | 0.527 | 0.630 | 0.738 | 0.630 | 0.725 | 0.493 | 0.691 |
| DENet [14] | 0.776 | 0.734 | 0.738 | 0.873 | 0.758 | 0.647 | 0.548 | 0.626 | 0.709 | 0.680 | 0.730 | 0.515 | 0.695 |
| UMFNet (Ours) | 0.800 | 0.736 | 0.759 | 0.880 | 0.781 | 0.634 | 0.515 | 0.677 | 0.725 | 0.653 | 0.730 | 0.526 | 0.731 |
| Variant | SCCA Type | FAF Levels | Coord. Embed | mAP@50 | mAP@50:95 | FPS |
|---|---|---|---|---|---|---|
| Baseline | ✗ | ✗ | ✗ | 0.687 | 0.440 | 158 |
| A1 | SE | ✗ | ✗ | 0.685 | 0.438 | 153 |
| A2 | CBAM | ✗ | ✗ | 0.689 | 0.441 | 149 |
| A3 | SCCA (Ours) | ✗ | ✗ | 0.692 | 0.445 | 151 |
| B1 | ✗ | 2 | ✗ | 0.689 | 0.442 | 145 |
| B2 | ✗ | 3 | ✗ | 0.694 | 0.447 | 143 |
| B3 | ✗ | 4 | ✗ | 0.696 | 0.448 | 140 |
| C1 | SCCA | 3 | ✗ | 0.701 | 0.450 | 142 |
| C2 | SCCA | 3 | ✓ | 0.731 | 0.458 | 150 |
| Attack Type | White-Box | Black-Box | Physical |
|---|---|---|---|
| Gaussian () | −5.2 | −3.1 | −4.7 |
| Compression Artifacts (QP = 45) | −7.8 | −4.6 | −6.3 |
| Spectral Jamming (30% HF) | −6.5 | −2.9 | −3.6 |
| Projected Perturbation | −9.1 | −5.4 | −8.2 |
| UMFNet Average | −7.2 | −4.0 | −5.7 |
| Dataset | Sensor | Lux Range | Noise Model | Test Samples |
|---|---|---|---|---|
| ExDark (Base) | Smartphone | 0.1–15 | Gaussian+Poisson | 1472 |
| DARK FACE | Surveillance Cam | 0.05–5 | Motion Blur | 3108 |
| LOL | Digital Camera | 0.5–10 | Shot Noise | 100 |
| FLIR ADAS (IR) | Automotive Thermal | – | Non-Uniformity | 874 |
| BDD100K-night | Vehicle Dashboard | 1–50 | Mixed Urban Noise | 5000 |
| Method | ExDark | DarkFace | LOL | FLIR ADAS | BDD100K-Night | Avg. GDR ↓ |
|---|---|---|---|---|---|---|
| YOLOv8 | 68.7 | 51.2 | 58.3 | 32.7 | 63.5 | 27.4% |
| RT-DETR | 70.7 | 55.4 | 61.2 | 36.8 | 66.3 | 22.1% |
| GLARE | 71.6 | 56.3 | 63.1 | 37.9 | 67.5 | 20.9% |
| YOLOv9 | 71.2 | 55.8 | 62.7 | 37.2 | 67.1 | 21.5% |
| EfficientDet-B7 | 69.8 | 54.1 | 60.8 | 35.6 | 65.3 | 24.2% |
| UMFNet (Ours) | 73.1 | 58.7 | 65.4 | 40.2 | 69.8 | 17.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, S.; Ma, Z.; Li, X. UMFNet: Frequency-Guided Multi-Scale Fusion with Dynamic Noise Suppression for Robust Low-Light Object Detection. Appl. Sci. 2025, 15, 5362. https://doi.org/10.3390/app15105362
Gong S, Ma Z, Li X. UMFNet: Frequency-Guided Multi-Scale Fusion with Dynamic Noise Suppression for Robust Low-Light Object Detection. Applied Sciences. 2025; 15(10):5362. https://doi.org/10.3390/app15105362
Chicago/Turabian StyleGong, Shihao, Zheng Ma, and Xiang Li. 2025. "UMFNet: Frequency-Guided Multi-Scale Fusion with Dynamic Noise Suppression for Robust Low-Light Object Detection" Applied Sciences 15, no. 10: 5362. https://doi.org/10.3390/app15105362
APA StyleGong, S., Ma, Z., & Li, X. (2025). UMFNet: Frequency-Guided Multi-Scale Fusion with Dynamic Noise Suppression for Robust Low-Light Object Detection. Applied Sciences, 15(10), 5362. https://doi.org/10.3390/app15105362