

A Review Toward Deep Learning for High Dynamic Range Reconstruction

 ,
,  , , ,
, , ,  , , ,
, , ,  and
and 
Abstract
1. Introduction
2. Main Concepts
2.1. Single-Frame Reconstruction
2.2. Multi-Frame Reconstruction
2.2.1. Burst
2.2.2. Bracketing
2.2.3. Multi-Exposure
2.3. Tone Mapping
2.4. Artifacts
2.4.1. Motion-Related Artifacts: Blur, Ghosting, and Misalignment
2.4.2. Photometric Artifacts: Noise, Saturation, and Texture Loss
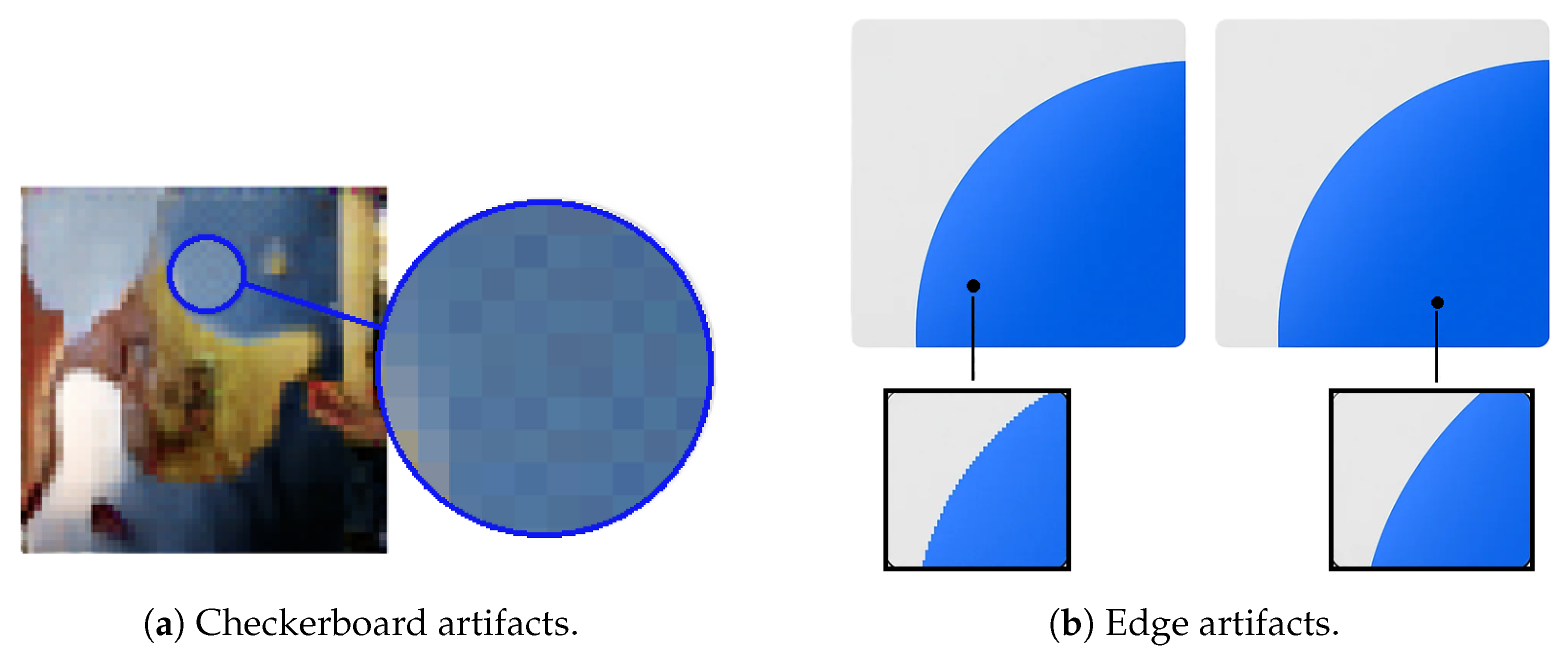
2.4.3. Model-Induced Structural Artifacts: Checkerboard and Edge
3. Datasets and Evaluation Metrics
3.1. Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Quantity | Resolution | Type | Key Features | Applications |
|---|---|---|---|---|---|
| Kalantari et al. [15] | 89 sequences | 1500 × 1000 | Real | Dynamic Scenes, Multi-Exposure, Deghosting | HDR Reconstruction, Machine Learning |
| Sen et al. [65] | 8 sequences | 1350 × 900 | Real | Extracted from HDR Videos, Continuous Motion, Deghosting | HDR Video Reconstruction |
| IISc VAL [48] | 582 sequences | 1000 × 1500 | Real | Variety of Scenarios, Moving Objects, Deghosting | Multi-Frame Fusion, Deghosting |
| IISc VAL 7-1 [76] | 84 sequences | 1000 × 1500 | Real | Dynamic Scenes, Reconstruction Method Evaluation | Deghosting, Multi-Frame Fusion |
| Funt et al. [77] | 105 scenes | 2142 × 1422 | Real | Multiple Exposures, Broad Range of Scenarios, Deghosting | HDR Reconstruction, Deghosting Studies |
| Tursun et al. [78] | 16 sequences | 1024 × 682 | Real | Indoor and Outdoor Scenes, Motion Focus | HDR Fusion, Deghosting |
| HDR-Eye [79] | 46 images | 1920 × 1080 | Real | Multi-Frame Images of Natural Scenes, Humans, Stained Glass, Sculptures | Assessment of HDR Algorithms in Complex Scenarios |
| Laval Indoor [80] | 2100 images | 2048 × 1024 | Real | High-Resolution Indoor Panoramas, Multi-Exposure | HDR Reconstruction in Indoor Environments |
| Laval Outdoor [80] | 205 images | 2048 × 1024 | Real | High-Resolution Outdoor Panoramas, Multi-Exposure | HDR Reconstruction in Outdoor Environments |
| Liu et al. [40] | 502 sequences | 512 × 512 | Real/ Synthetic | Indoor and Outdoor Scenes, Reconstruction from a Single LDR Image | Single-Frame HDR Reconstruction |
| Chen et al. [81] | 1352 sequences | 4K | Synthetic | LDR to HDR Conversion in Videos, Dynamic and Static Scenarios | HDR Video Compression and Quality Optimization |
| SI-HDR [82] | 181 images | 1920 × 1280 | Synthetic | Simulation of Different Exposures Using CRF, Multiple Frames | Multi-Frame Fusion, Full Dynamic Range Capture |
| NTIRE2021 [83] | 1761 images | 1900 × 1060 | Real HDR/ Synthetic LDR | Multi- and Single-Frame, 29 Scenes | HDR Reconstruction from LDR, NTIRE 2021 Challenge |
| DeepHDRVideo [31] | Real Videos | 1080p | Real | Complex Scenes, HDR Algorithm Evaluation in Videos | HDR Video Reconstruction |
| GTA-HDR [84] | 40,000 images | 512 × 512 | Synthetic | Scenes from GTA V Game, Variety of Lighting and Dynamic Environments | HDR Reconstruction Techniques in Synthetic Environments |
| Zhang et al. [85] | 880 scenes | 2304 × 1728 | Real | Medical Images, Significant Lighting Variations | Advanced Image Processing, HDR Reconstruction |
| Google HDR+ [52] | 3640 sequences | Various | Real | Burst Mode Images, Multiple Exposures, Less Noise | Mobile HDR Processing |
| MobileHDR [86] | 251 sequences | 4K | Real | Captured by Smartphones, Wide Range of Lighting Conditions | Mobile HDR Reconstruction |
| UPIQ [87] | 3779 LDR/380 HDR images | Various | Real | Absolute Photometric and Colorimetric Units, Derived from Known IQA Datasets | HDR and LDR Image Quality Evaluation |
3.1.1. Real Multi-Frame HDR Datasets
3.1.2. Synthetic or Simulated HDR Datasets Based on CRF
3.1.3. Datasets of HDR Captured with Mobile Devices
3.1.4. Datasets Aimed at Image Quality Assessment
3.1.5. Data Enhancement for HDR
Neural Augmentation for Saturation Restoration
Local-Area-Based Mixed Data Augmentation
Traditional Data Augmentation Techniques
3.2. HDR Image Quality Assessment
3.2.1. HDR Metrics
FovVideoVDP
VDP
ColorVideoVDP
HDR-VQM
HDR-VDP
HDR-VDP2
HDR-VDP3
3.2.2. Application of LDR Metrics to HDR Images
BRISQUE
NIQE
PIQUE
NIMA
LPIPS
MUSIQ
SSIM (Structural Similarity Index)
MS-SSIM (Multi-Scale SSIM)
FSIM (Feature Similarity Index)
VSI (Visual Saliency-Induced Index)
MSE (Mean Squared Error)
PSNR (Peak Signal-to-Noise Ratio)
4. Deep Learning Methods for HDR Reconstruction
4.1. CNN for HDR Reconstruction
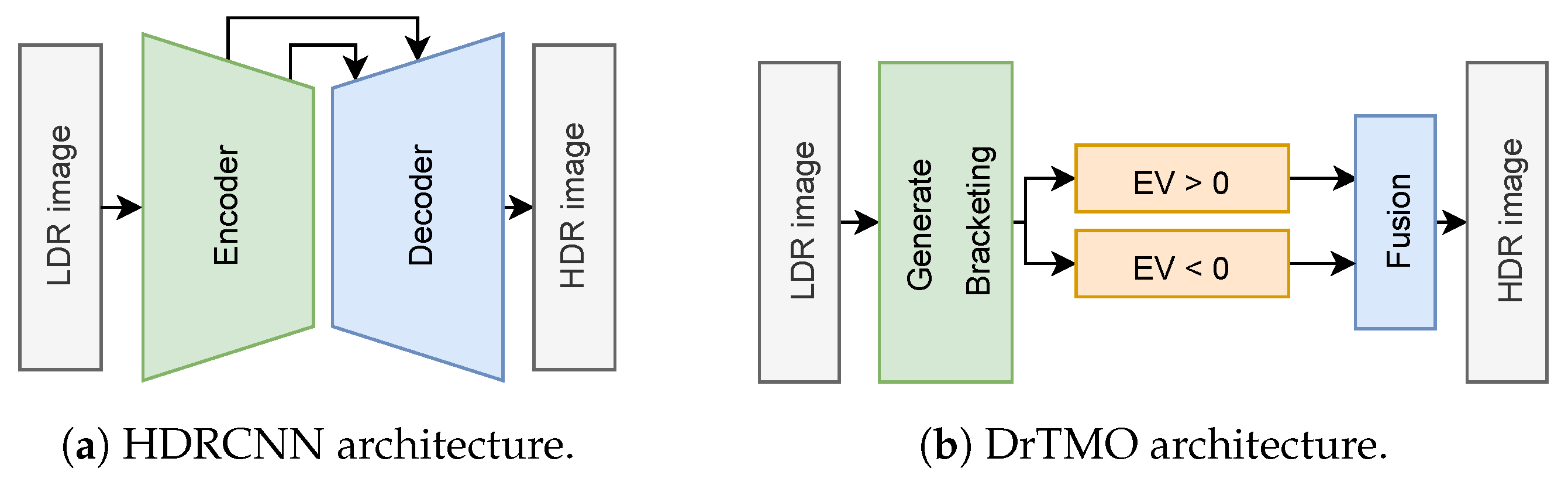
4.1.1. Single LDR to HDR Reconstruction with CNN
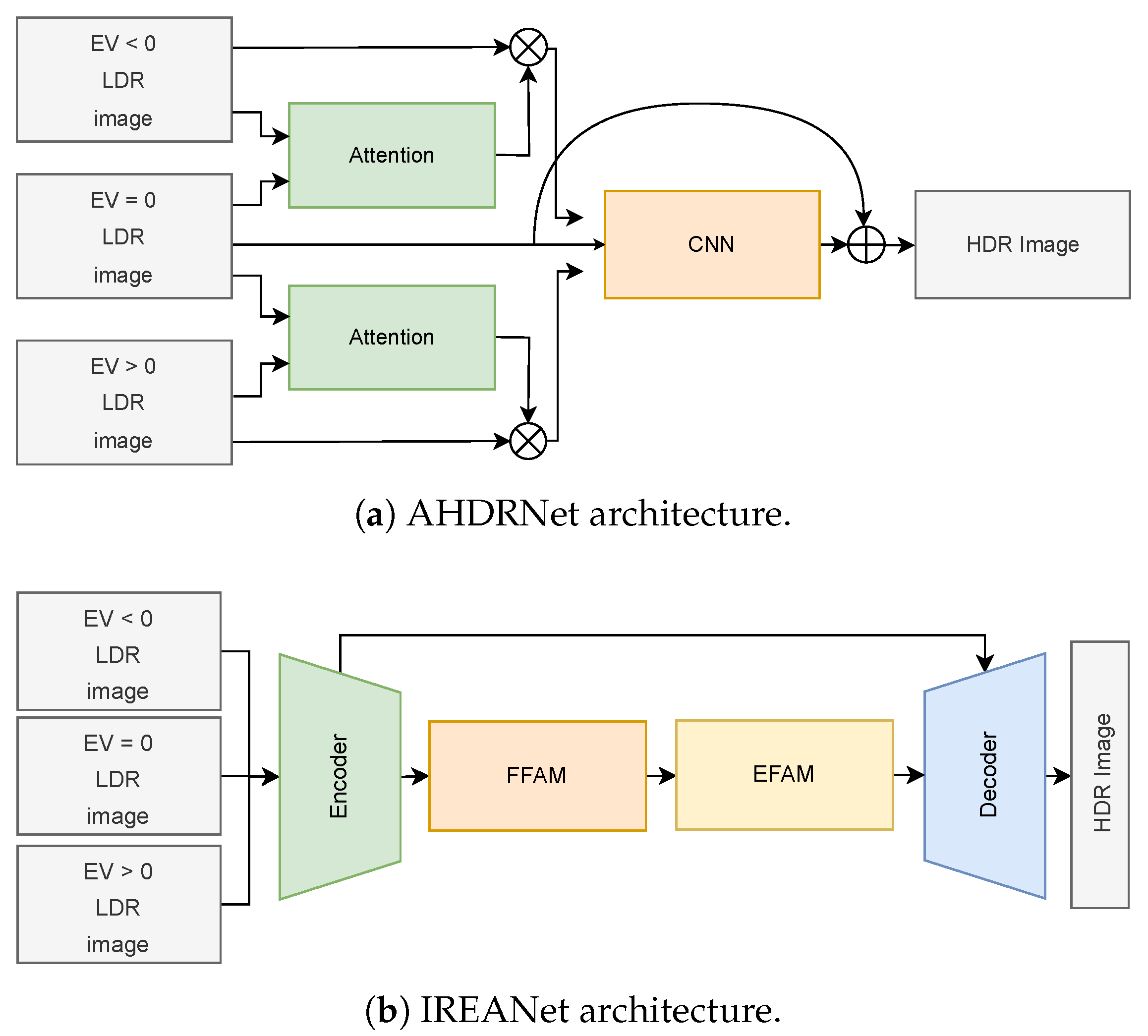
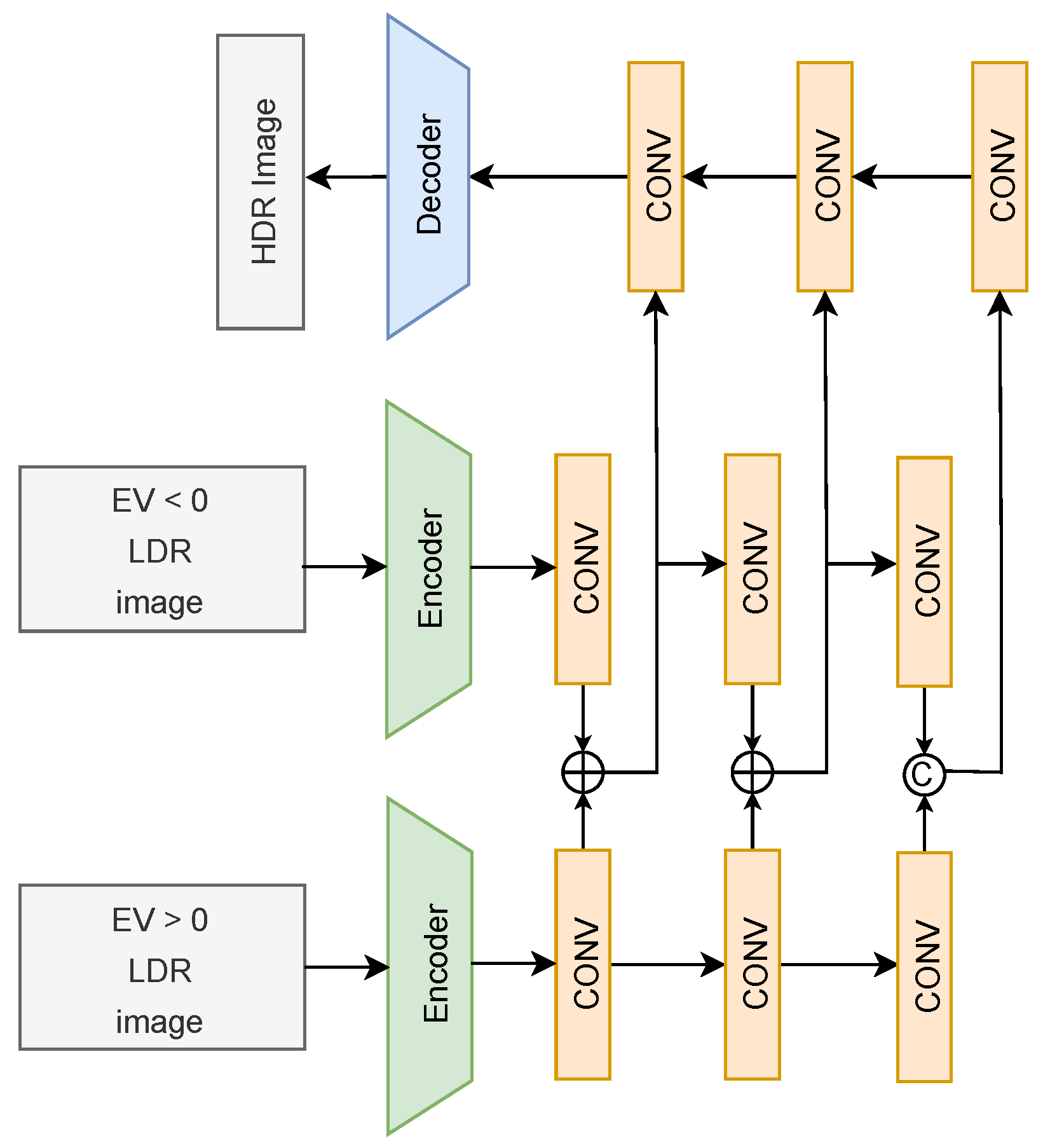
4.1.2. Multi LDR to HDR Reconstruction with CNN
4.1.3. Single and Multi LDR to HDR Reconstruction with CNN
4.2. GAN for HDR Reconstruction
4.2.1. Single LDR to HDR Reconstruction with GAN
4.2.2. Multi LDR to HDR Reconstruction with GAN
4.3. Transformers for HDR Reconstruction
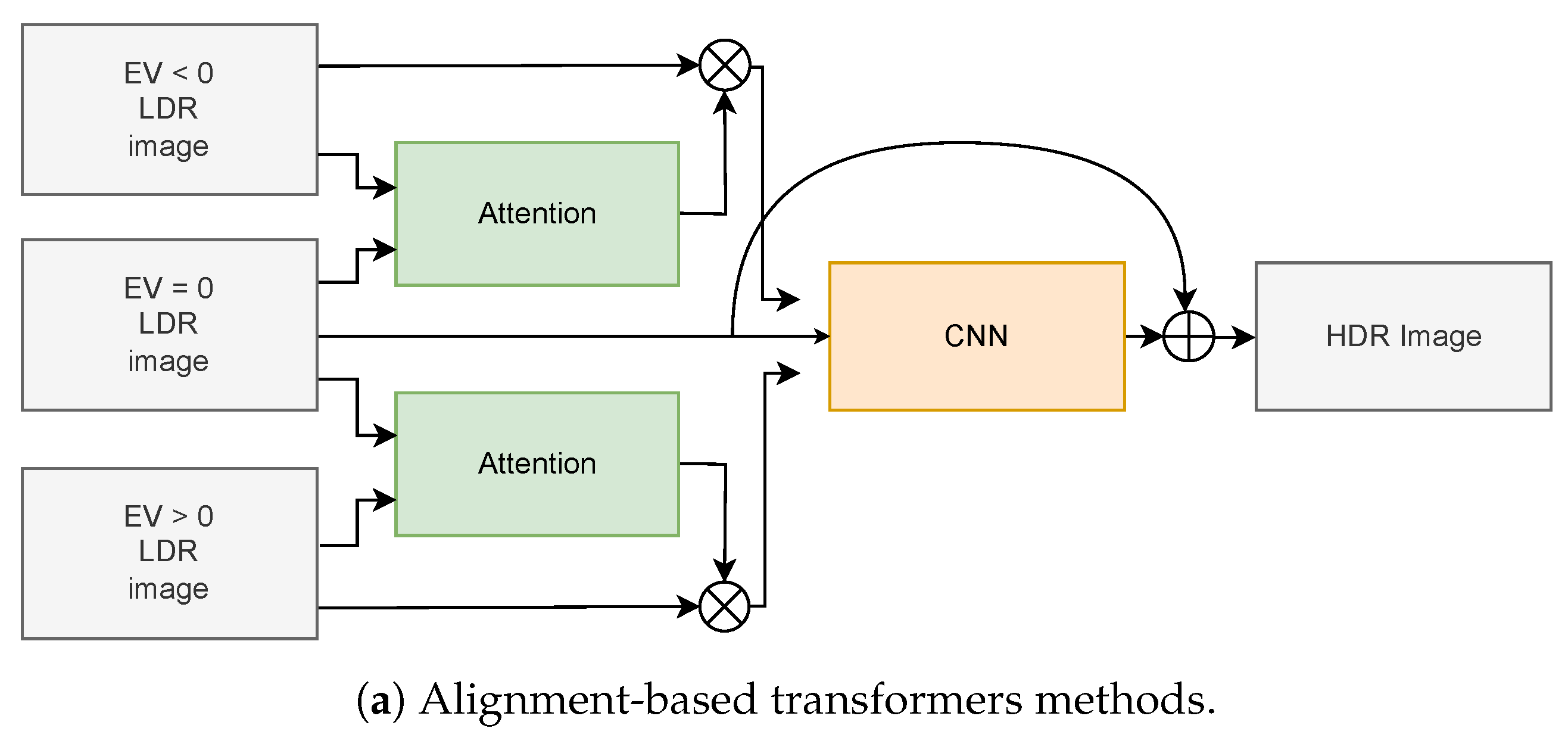
4.3.1. Alignment-Based Methods
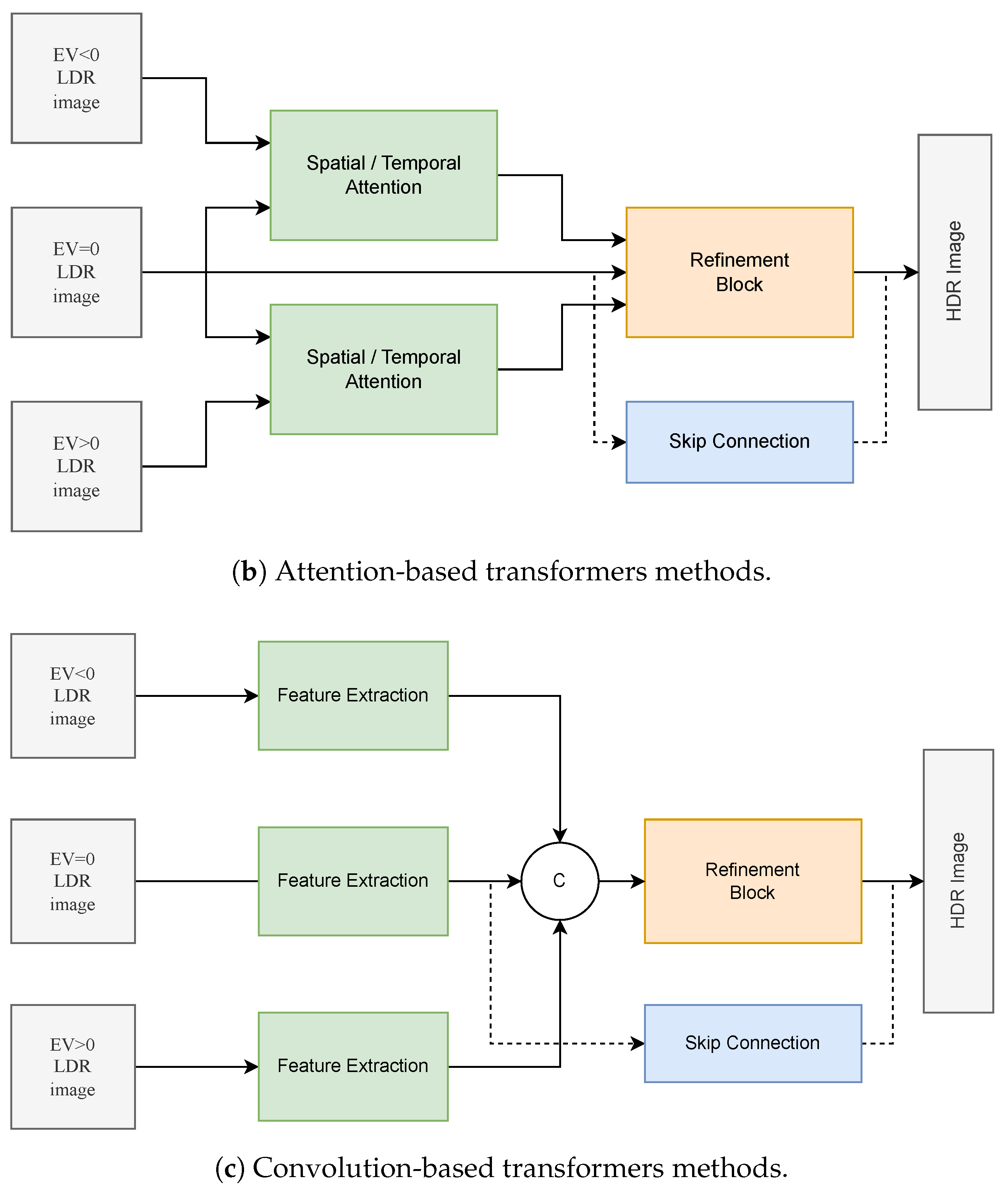
4.3.2. Attention-Based Methods
4.3.3. Convolution-Based Methods
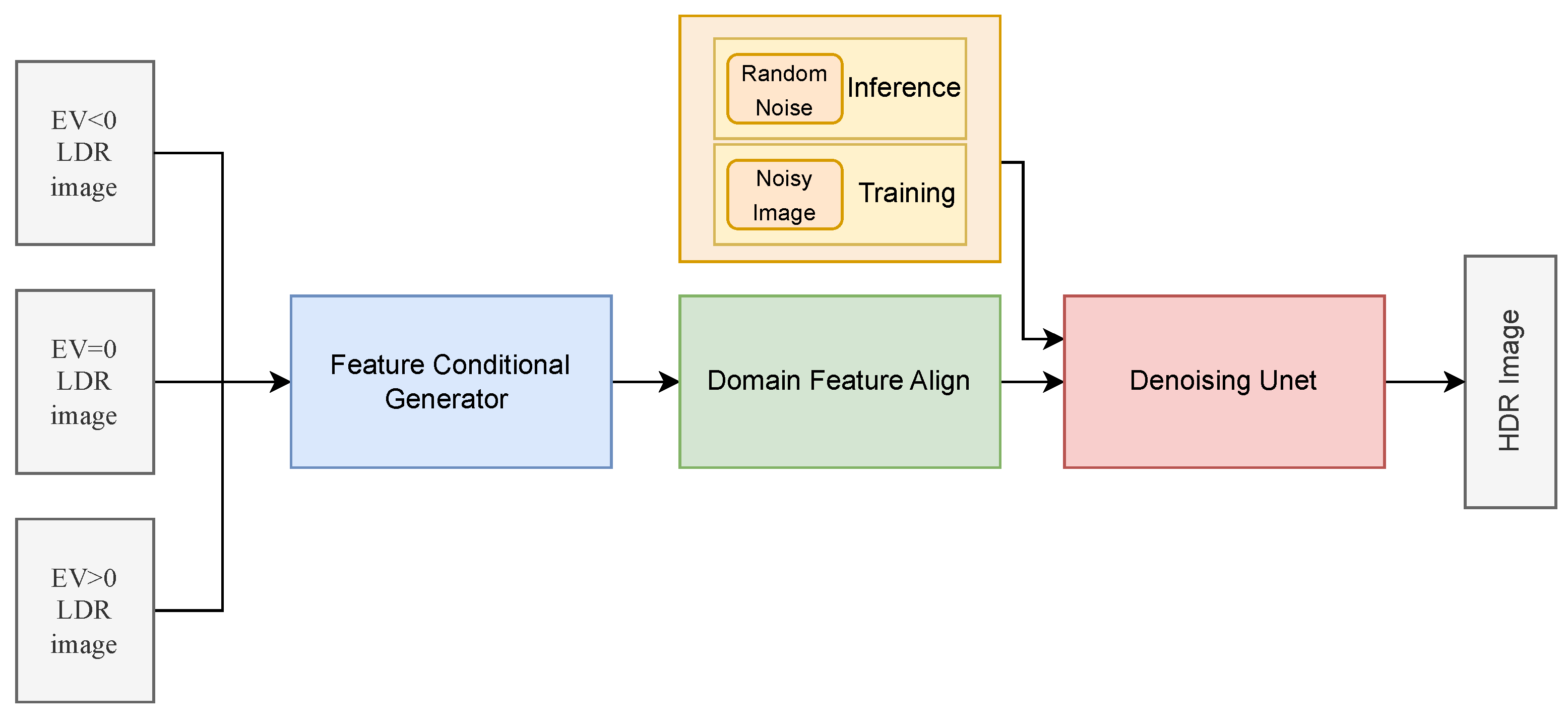
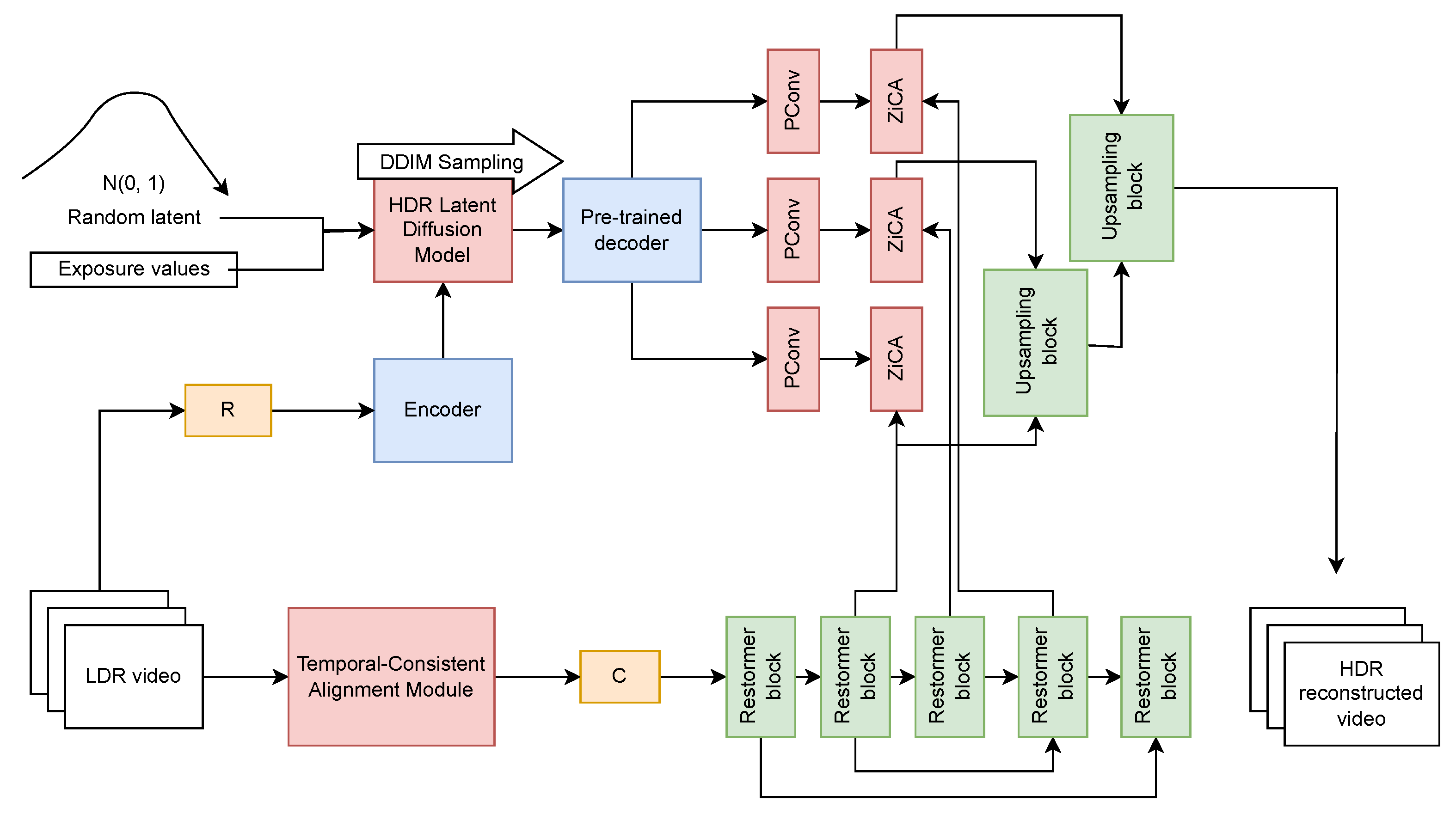
4.4. Diffusion Models for HDR Reconstruction
4.4.1. Diffusion Models for Single-Frame
4.4.2. Diffusion Models for Multi-Frame
4.4.3. Diffusion Models for Image Enhancement
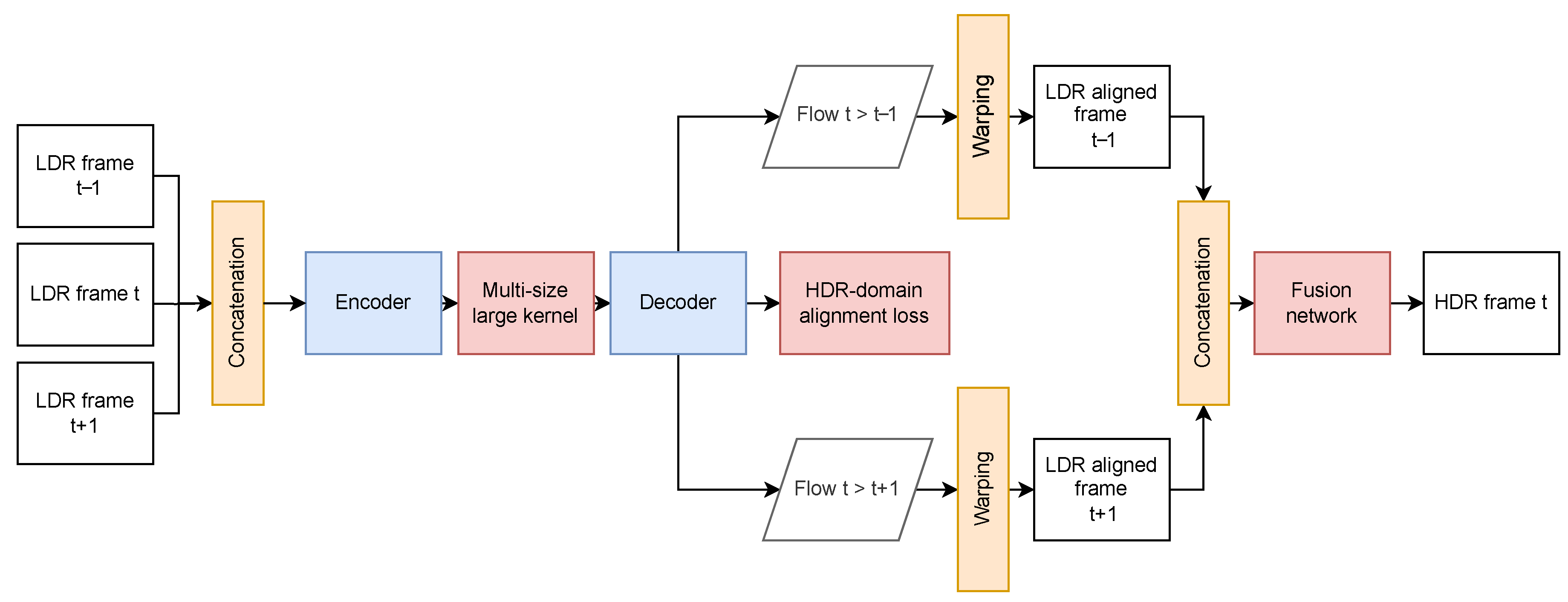
4.5. HDR Video Reconstruction
4.5.1. Optical Flow-Based Approaches
4.5.2. Attention-Based Approaches
5. Discussions and Future Perspectives
5.1. State of the Art
- CNN-Based Models: CNN-based approaches have long dominated the field and remain highly relevant. Works like HDRCNN [8] and variants such as HDRUnet, HDRTV, and DCDR-UNet highlight the use of convolutional architectures, often complemented by skip connections and deformable modules, to recover lost details in overexposed and underexposed areas [41,45].
- GAN-Based Models: The application of GANs, as seen in HDR-cGAN [138] and GlowGAN [10], shows potential for producing photorealistic images thanks to the adversarial generator’s ability to simulate nuances of exposure and contrast.Typically, GAN models for HDR reconstruction analyzed in this review use a combination of loss functions. The classic adversarial loss (based on the minimax formulation or variations like LSGAN or WGAN) encourages the generator to produce visually plausible results that deceive the discriminator. However, to ensure fidelity to the input image content (LDR) and the reference (HDR ground truth, when available), this adversarial loss is often combined with pixelwise reconstruction losses (like L1, which is preferred over L2 to avoid excessive smoothing) and/or perceptual losses (like LPIPS), which measure similarity in the feature spaces of pretrained networks, better capturing the structural and textural similarity perceived by the human eye [26,138]. The relative weighting between these losses is a crucial hyperparameter for balancing realism and fidelity.
- Transformer-Based Models: Initially prominent in NLP, Transformers have been adapted for HDR image reconstruction in computer vision. Models like CA-ViT [17] and HDT-HDR [161] employ self-attention mechanisms to enhance alignment and fuse multiple exposures, achieving more accurate and detailed reconstructions. Typically, the loss functions used in Transformer-based models for HDR image reconstruction combine the classic loss function in the logarithmic domain with perceptual loss, resulting in the form [17,27,157,159,162], aiming to optimize both objective fidelity and the perceived visual quality of the reconstruction. However, although there are proposals that employ loss functions based on Sobel filters aiming to maintain structural details, the results obtained so far have not proven promising [156].
- Diffusion Models (DMs): Recently, new diffusion-based architectures have emerged to address stability and training issues found in other generative methods. By iteratively adjusting pixel estimates, these models allow for the progressive refinement of reconstructed images. In general, Diffusion Models applied to HDR reconstruction use a loss function based on the L2 loss. The standard diffusion loss, different from the traditional approach that uses information from the input image and the neural network output, compares the noise added to the input data with the noise predicted by the network [3,25].
5.2. Current Challenges and Limitations
- Computational Complexity and Real-Time HDR: Advanced architectures, particularly Transformer- and DM-based models, demand significant computational power and memory, potentially hindering their use in real-time scenarios or on resource-constrained devices like smartphones, drones, and AR/VR [10]. Achieving real-time or near real-time performance is a critical requirement for many practical applications, demanding efficient model designs and evaluation strategies that consider not only quality metrics but also inference speed, computational cost (e.g., FLOPS), and memory consumption. In this regard, some works have advanced toward low-cost efficient reconstruction like [32,178].
- Real-World Generalization: Models trained on synthetic or rigidly controlled datasets may fail to generalize to real-world scenarios where lighting and motion conditions are highly variable [84].
- Metric Adaptation and Correlation: Metrics originally designed for LDR must be revised or redesigned for HDR images, complicating the interpretation of results and the standardization of evaluations. Furthermore, ensuring that objective metrics accurately correlate with subjective human perception of HDR quality remains an ongoing challenge.
5.3. Ongoing Solutions and Advancements
- Hybrid Architectures: Combining CNNs, Transformers, and DMs leverages the strengths of each. Hybrid models like PASTA [50] integrate temporal and spatial attention mechanisms, enhancing alignment and multi-exposure fusion while reducing artifacts and improving visual quality.
- Self-Supervised and Unsupervised Models: Methods that reduce reliance on large annotated datasets are gaining attention. Self-supervised models can learn representations from unlabeled data, simplifying training in data-scarce environments [50]. Approaches based on Large Language Models (LLMs), such as LLM-HDR, explore self-supervised learning for unpaired LDR-to-HDR translation [179].
- Computational Optimization: Efforts to develop lighter and more efficient models, such as RepUNet [122], aim to reduce computational costs without substantially compromising HDR image quality. Techniques like pruning, quantization, and knowledge distillation also yield more compact models suitable for real-time applications. Hardware-based solutions, such as those using FPGAs and optimized lookup tables, also represent viable paths to achieve real-time HDR video processing [178].
- Integration of Multi-modal Data: Incorporating depth, polarization, event cameras, or other modalities can enhance HDR reconstruction by providing deeper scene perception and facilitating exposure alignment and fusion.
- Better Loss Functions: New hybrid loss functions considering perceptual and structural aspects of HDR images are being introduced to guide model training more effectively. Combining adversarial, perceptual, and reconstruction losses helps reduce artifacts [41]. Losses guided by semantic information or human knowledge (e.g., LLM-based loss) are also being explored [179].
5.4. Applications and Interdisciplinary Connections
- Medicine: Images with higher exposure fidelity can reveal critical details for earlier and more accurate diagnoses, aiding medical imaging.
- VR/AR: HDR reconstruction algorithms can enhance immersion and realism in virtual environments, benefiting applications in entertainment, training, and simulation.
- Entertainment and Media: Televisions, monitors, and cameras using HDR technology provide richer visual experiences, increasing the impact of cinematic and advertising content.
- Autonomous Vehicles: Handling extreme lighting variations is crucial for vehicle vision systems, improving environmental interpretation under adverse conditions.
5.5. Trends and Future Ideas
- Multi-modal Models: Integrating information from different sensor modalities, such as depth (from LiDAR/Stereo), polarization, or event cameras, can result in more robust and accurate HDR reconstructions. Models leveraging multiple input modalities could capture extra scene nuances, boosting HDR image quality, especially in complex dynamic scenarios.
- Self-Supervised and Unsupervised Learning: Techniques that do not require massive annotated datasets are attracting greater interest. Self-supervised methods can enable HDR reconstruction from unlabeled data, facilitating training in data-scarce settings [50]. Unsupervised approaches, including those using cycle consistency or domain adaptation, are particularly valuable for unpaired LDR–HDR datasets [179].
- Computational Optimization and Energy Efficiency: Developing lighter and more efficient models that maintain high HDR reconstruction quality while reducing resource usage is a growing research area. Pruning, quantization, and knowledge distillation will play a key role in creating models suitable for mobile and real-time applications [122]. The exploration of new and efficient architectures, such as SSMs, notably Mamba, which offer linear scaling and effective modeling of long-range dependencies, could provide significant efficiency gains for high-resolution images and video compared to traditional Transformers.
- Large Language/Vision Models (LLMs/LVMs): Integrating the perception and semantic understanding capabilities of LLMs and LVMs presents an innovative direction. These models can provide high-level guidance for reconstruction (e.g., identifying objects/regions, suggesting enhancement styles), enable zero-shot or few-shot adaptation to new scenarios, or serve as powerful priors or feature extractors within HDR pipelines, especially for human-knowledge-guided unpaired data reconstruction [179].
- Standardization and Evaluation Protocols: Establishing consistent standards for HDR data collection, labeling, and evaluation—both in terms of metrics (including their correlation with human perception and real-time suitability) and benchmark datasets covering diverse real-world scenarios—would facilitate fair comparisons and promote collaboration within the scientific community [94].
- Advanced Transformers and Attention Mechanisms: The ongoing adaptation and refinement of Transformers in vision tasks are poised to further enhance HDR reconstruction. More sophisticated attention mechanisms, considering relationships between multiple exposures and overall scene structure, may lead to more detailed reconstructions with fewer artifacts [17].
- Adaptive and Controllable Reconstruction: Future models may offer more user control, allowing for adjustments to tone mapping style, artifact tolerance, or region-specific enhancement interactively, which could be possibly guided by semantic scene understanding.
- Vision Mamba: This is an approach that maintains the high performance characteristic of Transformers but with lower computational cost. Originally presented as Mamba, the technique was extended to computer vision tasks, resulting in the variant called Vision Mamba. This approach has demonstrated superior performance compared to Transformers in various tasks, such as detection, segmentation [180], and image restoration [181]. Future work may investigate the impact of Vision Mamba on the task of HDR image reconstruction, especially in the feature enhancement stage, positioning it as a promising candidate to replace Transformer-based architectures, which are more complex and costly.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ferreti, G.d.S.; Paixão, T.; Alvarez, A.B. Generative Adversarial Network-Based Lightweight High-Dynamic-Range Image Reconstruction Model. Appl. Sci. 2025, 15, 4801. [Google Scholar] [CrossRef]
- Lopez-Cabrejos, J.; Paixão, T.; Alvarez, A.B.; Luque, D.B. An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction. Sensors 2025, 25, 1497. [Google Scholar] [CrossRef] [PubMed]
- Fuest, M.; Ma, P.; Gui, M.; Fischer, J.S.; Hu, V.T.; Ommer, B. Diffusion Models and Representation Learning: A Survey. arXiv 2024, arXiv:2407.00783. [Google Scholar]
- Zhu, R.; Xu, S.; Liu, P.; Li, S.; Lu, Y.; Niu, D.; Liu, Z.; Meng, Z.; Li, Z.; Chen, X.; et al. Zero-Shot Structure-Preserving Diffusion Model for High Dynamic Range Tone Mapping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26130–26139. [Google Scholar]
- Beckmann, M.; Krahmer, F.; Bhandari, A. HDR tomography via modulo Radon transform. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: New York, NY, USA, 2020; pp. 3025–3029. [Google Scholar]
- Abebe, M. High Dynamic Range Imaging. In Fundamentals and Applications of Colour Engineering; Springer: Cham, Switzerland, 2023; pp. 293–310. [Google Scholar]
- Takayanagi, I.; Kuroda, R. HDR CMOS image sensors for automotive applications. IEEE Trans. Electron Devices 2022, 69, 2815–2823. [Google Scholar] [CrossRef]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR image reconstruction from a single exposure using deep CNNs. ACM Trans. Graph. 2017, 36, 178. [Google Scholar] [CrossRef]
- Le, P.; Le, Q.; Nguyen, R.; Hua, B. Single-Image HDR Reconstruction by Multi-Exposure Generation. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Los Alamitos, CA, USA, 2–7 January 2023; pp. 4052–4061. [Google Scholar] [CrossRef]
- Wang, C.; Serrano, A.; Pan, X.; Chen, B.; Myszkowski, K.; Seidel, H.P.; Theobalt, C.; Leimkühler, T. Glowgan: Unsupervised learning of hdr images from ldr images in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 10509–10519. [Google Scholar]
- Dalal, D.; Vashishtha, G.; Singh, P.; Raman, S. Single Image LDR to HDR Conversion using Conditional Diffusion. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023. [Google Scholar]
- Prabhakar, K.R.; Agrawal, S.; Singh, D.K.; Ashwath, B.; Babu, R.V. Towards practical and efficient high-resolution HDR deghosting with CNN. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Cham, Switzerland, 2020; pp. 497–513. [Google Scholar]
- Yan, Q.; Gong, D.; Shi, Q.; Hengel, A.v.d.; Shen, C.; Reid, I.; Zhang, Y. Attention-guided network for ghost-free high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1751–1760. [Google Scholar]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. The state of the art in HDR deghosting: A survey and evaluation. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015; Volume 34, pp. 683–707. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, W.; Li, X.; Rao, Q.; Jiang, T.; Han, M.; Fan, H.; Sun, J.; Liu, S. ADNet: Attention-guided Deformable Convolutional Network for High Dynamic Range Imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liu, Z.; Wang, Y.; Zeng, B.; Liu, S. Ghost-free high dynamic range imaging with context-aware transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 344–360. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yan, Q.; Hu, T.; Sun, Y.; Tang, H.; Zhu, Y.; Dong, W.; Van Gool, L.; Zhang, Y. Towards high-quality hdr deghosting with conditional diffusion models. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 4011–4026. [Google Scholar] [CrossRef]
- Kinoshita, Y.; Kiya, H. Checkerboard-Artifact-Free Image-Enhancement Network Considering Local and Global Features. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020. [Google Scholar]
- Santos, M.S.; Tsang, I.R.; Kalantari, N. Single image HDR reconstruction using a CNN with masked features and perceptual loss. ACM Trans. Graph. (TOG) 2020, 39, 80:1–80:10. [Google Scholar] [CrossRef]
- Khan, Z.; Khanna, M.; Raman, S. FHDR: HDR Image Reconstruction from a Single LDR Image using Feedback Network. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Endo, Y.; Kanamori, Y.; Mitani, J. Deep Reverse Tone Mapping. ACM Trans. Graph. 2017, 36, 1–10. [Google Scholar] [CrossRef]
- Chakraborty, T.; S, U.R.K.; Naik, S.M.; Panja, M.; Manvitha, B. Ten years of generative adversarial nets (GANs): A survey of the state-of-the-art. Mach. Learn. Sci. Technol. 2024, 5, 011001. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Niu, Y.; Wu, J.; Liu, W.; Guo, W.; Lau, R.W. Hdr-gan: Hdr image reconstruction from multi-exposed ldr images with large motions. IEEE Trans. Image Process. 2021, 30, 3885–3896. [Google Scholar] [CrossRef] [PubMed]
- Tel, S.; Wu, Z.; Zhang, Y.; Heyrman, B.; Demonceaux, C.; Timofte, R.; Ginhac, D. Alignment-free HDR Deghosting with Semantics Consistent Transformer. arXiv 2023, arXiv:2305.18135. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.H. Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.J. Deep learning for hdr imaging: State-of-the-art and future trends. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8874–8895. [Google Scholar] [CrossRef]
- Kalantari, N.K.; Ramamoorthi, R. Deep HDR video from sequences with alternating exposures. In Computer Graphics Forum; Wiley: Hoboken, NJ, USA, 2019; pp. 193–205. [Google Scholar]
- Chen, G.; Chen, C.; Guo, S.; Liang, Z.; Wong, K.Y.K.; Zhang, L. HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Xu, G.; Wang, Y.; Gu, J.; Xue, T.; Yang, X. HDRFlow: Real-Time HDR Video Reconstruction with Large Motions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 24851–24860. [Google Scholar]
- Chung, H.; Cho, N.I. LAN-HDR: Luminance-based Alignment Network for High Dynamic Range Video Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Guan, Y.; Xu, R.; Yao, M.; Gao, R.; Wang, L.; Xiong, Z. Diffusion-Promoted HDR Video Reconstruction. arXiv 2024, arXiv:2406.08204. [Google Scholar]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Trans. Graph. (TOG) 2011, 30, 1–14. [Google Scholar] [CrossRef]
- Mantiuk, R.K.; Hammou, D.; Hanji, P. HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content. arXiv 2023, arXiv:2304.13625. [Google Scholar]
- Azimi, M.; Mantiuk, R.K. PU21: A novel perceptually uniform encoding for adapting existing quality metrics for HDR. In Proceedings of the 2021 Picture Coding Symposium (PCS), Bristol, UK, 29 June–2 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar]
- Liu, Y.; Tian, Y.; Wang, S.; Zhang, X.; Kwong, S. Overview of High-Dynamic-Range Image Quality Assessment. J. Imaging 2024, 10, 243. [Google Scholar] [CrossRef]
- Marnerides, D.; Bashford-Rogers, T.; Hatchett, J.; Debattista, K. ExpandNet: A Deep Convolutional Neural Network for High Dynamic Range Expansion from Low Dynamic Range Content. Comput. Graph. Forum 2018, 37, 37–49. [Google Scholar] [CrossRef]
- Liu, Y.L.; Lai, W.S.; Chen, Y.S.; Kao, Y.L.; Yang, M.H.; Chuang, Y.Y.; Huang, J.B. Single-Image HDR Reconstruction by Learning to Reverse the Camera Pipeline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, X.; Liu, Y.; Zhang, Z.; Qiao, Y.; Dong, C. HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–18 June 2021; pp. 354–363. [Google Scholar]
- Yao, Z.; Bi, J.; Deng, W.; He, W.; Wang, Z.; Kuang, X.; Zhou, M.; Gao, Q.; Tong, T. DEUNet: Dual-encoder UNet for simultaneous denoising and reconstruction of single HDR image. Comput. Graph. 2024, 119, 103882. [Google Scholar] [CrossRef]
- Banterle, F.; Ledda, P.; Debattista, K.; Chalmers, A. Inverse tone mapping. In Proceedings of the GRAPHITE ’06: Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia, Kuala Lumpur, Malaysia, 29 November–2 December 2005; pp. 349–356. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Kim, J.; Zhu, Z.; Bau, T.; Liu, C. DCDR-UNet: Deformable Convolution Based Detail Restoration via U-shape Network for Single Image HDR Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–18 June 2024; pp. 5909–5918. [Google Scholar]
- Li, Y.; Peng, X.; Zhang, J.; Li, Z.; Wen, M. DCT-GAN: Dilated convolutional transformer-based GAN for time series anomaly detection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3632–3644. [Google Scholar] [CrossRef]
- Kronander, J.; Gustavson, S.; Bonnet, G.; Ynnerman, A.; Unger, J. A unified framework for multi-sensor HDR video reconstruction. Signal Process. Image Commun. 2014, 29, 203–215. [Google Scholar] [CrossRef]
- Prabhakar, K.R.; Arora, R.; Swaminathan, A.; Singh, K.P.; Babu, R.V. A fast, scalable, and reliable deghosting method for extreme exposure fusion. In Proceedings of the 2019 IEEE International Conference on Computational Photography (ICCP), Tokyo, Japan, 15–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]
- Liu, X.; Li, A.; Wu, Z.; Du, Y.; Zhang, L.; Zhang, Y.; Timofte, R.; Zhu, C. PASTA: Towards Flexible and Efficient HDR Imaging Via Progressively Aggregated Spatio-Temporal Aligment. arXiv 2024, arXiv:2403.10376. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Hasinoff, S.W.; Sharlet, D.; Geiss, R.; Adams, A.; Barron, J.T.; Kainz, F.; Chen, J.; Levoy, M. Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Trans. Graph. (TOG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Wronski, B.; Garcia-Dorado, I.; Ernst, M.; Kelly, D.; Krainin, M.; Liang, C.K.; Levoy, M.; Milanfar, P. Handheld multi-frame super-resolution. ACM Trans. Graph. (TOG) 2019, 38, 1–18. [Google Scholar] [CrossRef]
- Karadeniz, A.S.; Erdem, E.; Erdem, A. Burst Photography for Learning to Enhance Extremely Dark Images. IEEE Trans. Image Process. 2020, 30, 9372–9385. [Google Scholar] [CrossRef]
- Debevec, P.E.; Malik, J. Recovering High Dynamic Range Radiance Maps from Photographs. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, 1st ed.; Association for Computing Machinery: New York, NY, USA, 2023. [Google Scholar]
- Xu, F.; Liu, J.; Song, Y.; Sun, H.; Wang, X. Multi-exposure image fusion techniques: A comprehensive review. Remote Sens. 2022, 14, 771. [Google Scholar] [CrossRef]
- Ou, Y.; Ambalathankandy, P.; Ikebe, M.; Takamaeda, S.; Motomura, M.; Asai, T. Real-time tone mapping: A state of the art report. arXiv 2020, arXiv:2003.03074. [Google Scholar]
- Han, X.; Khan, I.R.; Rahardja, S. High dynamic range image tone mapping: Literature review and performance benchmark. Digit. Signal Process. 2023, 137, 104015. [Google Scholar] [CrossRef]
- Ward, G. A contrast-based scalefactor for luminance display. In Graphics Gems IV; Academic Press Professional Inc: New York, NY, USA, 1994; pp. 415–421. [Google Scholar]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Pattanaik, S.N.; Ferwerda, J.A.; Fairchild, M.D.; Greenberg, D.P. A multiscale model of adaptation and spatial vision for realistic image display. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 19–24 July 1998; pp. 287–298. [Google Scholar]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; Association for Computing Machinery: New York, NY, USA, 2023; pp. 661–670. [Google Scholar]
- Hu, J.; Gallo, O.; Pulli, K.; Sun, X. HDR deghosting: How to deal with saturation? In Proceedings of the IEEE conference on computer vision and pattern recognition, Portland, OR, USA, 23–28 June 2013; pp. 1163–1170. [Google Scholar]
- Yoon, H.; Uddin, S.M.N.; Jung, Y.J. Multi-Scale Attention-Guided Non-Local Network for HDR Image Reconstruction. Sensors 2022, 22, 7044. [Google Scholar] [CrossRef]
- Sen, P.; Kalantari, N.K.; Yaesoubi, M.; Darabi, S.; Goldman, D.B.; Shechtman, E. Robust patch-based hdr reconstruction of dynamic scenes. ACM Trans. Graph. 2012, 31, 203-1. [Google Scholar] [CrossRef]
- Zheng, M.; Zhi, K.; Zeng, J.; Tian, C.; You, L. A hybrid CNN for image denoising. J. Artif. Intell. Technol. 2022, 2, 93–99. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Fei, L.; Wang, J.; Wen, J.; Luo, N. Enhanced CNN for image denoising. CAAI Trans. Intell. Technol. 2019, 4, 17–23. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the NIPS’16: Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- He, J.; Dong, C.; Qiao, Y. Modulating image restoration with continual levels via adaptive feature modification layers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11056–11064. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Cao, G.; Zhou, F.; Liu, K.; Wang, A.; Fan, L. A Decoupled Kernel Prediction Network Guided by Soft Mask for Single Image HDR Reconstruction. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 19, 1–23. [Google Scholar] [CrossRef]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially Learned Inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.I.; Albahri, A.S.; Al-dabbagh, B.S.N.; Fadhel, M.A.; Manoufali, M.; Zhang, J.; Al-timemy, A.H.; et al. A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. J. Big Data 2023, 10, 1–82. [Google Scholar] [CrossRef]
- Prabhakar, K.R.; Babu, R.V. High Dynamic Range Deghosting Dataset. 2020. Available online: https://val.cds.iisc.ac.in/HDR/HDRD/ (accessed on 12 December 2024).
- Funt, B.V.; Shi, L. The Rehabilitation of MaxRGB. In Proceedings of the International Conference on Communications in Computing, Cape Town, South Africa, 23–27 May 2010. [Google Scholar]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. An Objective Deghosting Quality Metric for HDR Images. Comput. Graph. Forum 2016, 35, 139–152. [Google Scholar] [CrossRef]
- Nemoto, H.; Korshunov, P.; Hanhart, P.; Ebrahimi, T. Visual attention in LDR and HDR images. In Proceedings of the 9th International Workshop on Video Processing and Quality Metrics for Consumer Electronics (VPQM), Chandler, AZ, USA, 5–6 February 2015. [Google Scholar]
- Gardner, M.A.; Sunkavalli, K.; Yumer, E.; Shen, X.; Gambaretto, E.; Gagné, C.; Lalonde, J.F. Learning to Predict Indoor Illumination from a Single Image. arXiv 2017, arXiv:1704.00090. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Zhang, Z.; Ren, J.S.; Liu, Y.; He, J.; Qiao, Y.; Zhou, J.; Dong, C. Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation. arXiv 2023, arXiv:2309.04084. [Google Scholar]
- Hanji, P.; Mantiuk, R.; Eilertsen, G.; Hajisharif, S.; Unger, J. Comparison of single image HDR reconstruction methods—The caveats of quality assessment. In Proceedings of the SIGGRAPH ’22: ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022. [Google Scholar] [CrossRef]
- Perez-Pellitero, E.; Catley-Chandar, S.; Leonardis, A.; Timofte, R.; Wang, X.; Li, Y.; Wang, T.; Song, F.; Liu, Z.; Lin, W.; et al. NTIRE 2021 Challenge on High Dynamic Range Imaging: Dataset, Methods and Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 410–425. [Google Scholar]
- Barua, H.B.; Stefanov, K.; Wong, K.; Dhall, A.; Krishnasamy, G. GTA-HDR: A Large-Scale Synthetic Dataset for HDR Image Reconstruction. arXiv 2024, arXiv:2403.17837. [Google Scholar]
- Zhang, Q.; Li, Q.; Yu, G.; Sun, L.; Zhou, M.; Chu, J. A Multidimensional Choledoch Database and Benchmarks for Cholangiocarcinoma Diagnosis. IEEE Access 2019, 7, 149414–149421. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, X.; Sun, L.; Liang, Z.; Zeng, H.; Zhang, L. Joint hdr denoising and fusion: A real-world mobile hdr image dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13966–13975. [Google Scholar]
- Mikhailiuk, A.; Perez-Ortiz, M.; Yue, D.; Suen, W.; Mantiuk, R.K. Consolidated dataset and metrics for high-dynamic-range image quality. IEEE Trans. Multimed. 2021, 24, 2125–2138. [Google Scholar] [CrossRef]
- Zheng, C.; Ying, W.; Wu, S.; Li, Z. Neural Augmentation-Based Saturation Restoration for LDR Images of HDR Scenes. IEEE Trans. Instrum. Meas. 2023, 72, 4506011. [Google Scholar] [CrossRef]
- Zhao, F.; Liu, Q.; Ikenaga, T. HDR-LMDA: A Local Area-Based Mixed Data Augmentation Method for Hdr Video Reconstruction. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 2020–2024. [Google Scholar]
- Richter, T. On the standardization of the JPEG XT image compression. In Proceedings of the 2013 Picture Coding Symposium (PCS), San Jose, CA, USA, 8–11 December 2013; IEEE: New York, NY, USA, 2013; pp. 37–40. [Google Scholar]
- Mai, Z.; Mansour, H.; Mantiuk, R.; Nasiopoulos, P.; Ward, R.; Heidrich, W. Optimizing a tone curve for backward-compatible high dynamic range image and video compression. IEEE Trans. Image Process. 2010, 20, 1558–1571. [Google Scholar] [PubMed]
- Valenzise, G.; De Simone, F.; Lauga, P.; Dufaux, F. Performance evaluation of objective quality metrics for HDR image compression. In Proceedings of the Applications of Digital Image Processing XXXVII, San Diego, CA, USA, 18–21 August 2014; SPIE: Bellingham, WA, USA, 2014; Volume 9217, pp. 78–87. [Google Scholar]
- Zerman, E.; Valenzise, G.; Dufaux, F. An extensive performance evaluation of full-reference HDR image quality metrics. Qual. User Exp. 2017, 2, 1–16. [Google Scholar] [CrossRef]
- Hanhart, P.; Bernardo, M.V.; Pereira, M.G.; Pinheiro, A.M.; Ebrahimi, T. Benchmarking of objective quality metrics for HDR image quality assessment. EURASIP J. Image Video Process. 2015, 2015, 1–18. [Google Scholar] [CrossRef]
- Mantiuk, R.K.; Denes, G.; Chapiro, A.; Kaplanyan, A.; Rufo, G.; Bachy, R.; Lian, T.; Patney, A. FovVideoVDP: A visible difference predictor for wide field-of-view video. ACM Trans. Graph. 2021, 40, 1–19. [Google Scholar] [CrossRef]
- Narwaria, M.; Da Silva, M.P.; Le Callet, P. HDR-VQM: An objective quality measure for high dynamic range video. Signal Process. Image Commun. 2015, 35, 46–60. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Mantiuk, R.; Daly, S.; Kerofsky, L. Display adaptive tone mapping. In ACM SIGGRAPH 2008 Papers; ACM: New York, NY, USA, 2008; pp. 1–10. [Google Scholar]
- Talebi, H.; Milanfar, P. NIMA: Neural image assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: New York, NY, USA, 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, Y.; Li, H. VSI: A visual saliency-induced index for perceptual image quality assessment. IEEE Trans. Image Process. 2014, 23, 4270–4281. [Google Scholar] [CrossRef] [PubMed]
- Mantiuk, R.K.; Hanji, P.; Ashraf, M.; Asano, Y.; Chapiro, A. ColorVideoVDP: A visual difference predictor for image, video and display distortions. arXiv 2024, arXiv:2401.11485. [Google Scholar] [CrossRef]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. MUSIQ: Multi-Scale Image Quality Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5148–5157. [Google Scholar]
- Mantiuk, R.; Myszkowski, K.; Seidel, H.P. Visible difference predicator for high dynamic range images. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics (IEEE Cat. No. 04CH37583), The Hague, The Netherlands, 10–13 October 2004; IEEE: New York, NY, USA, 2004; Volume 3, pp. 2763–2769. [Google Scholar]
- Daly, S.J. Visible differences predictor: An algorithm for the assessment of image fidelity. In Human Vision, Visual Processing, and Digital Display III; SPIE: Bellingham, WA, USA, 1992. [Google Scholar]
- Mantiuk, R.; Daly, S.J.; Myszkowski, K.; Seidel, H.P. Predicting visible differences in high dynamic range images: Model and its calibration. In Proceedings of the Human Vision and Electronic Imaging X, San Jose, CA, USA, 17 January 2005; SPIE: Bellingham, WA, USA, 2005; Volume 5666, pp. 204–214. [Google Scholar]
- Korshunov, P.; Hanhart, P.; Richter, T.; Artusi, A.; Mantiuk, R.; Ebrahimi, T. Subjective quality assessment database of HDR images compressed with JPEG XT. In Proceedings of the 2015 Seventh International Workshop on Quality of Multimedia Experience (QoMEX), Costa Navarino, Greece, 26–29 May 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- O’Shea, K. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Chen, X.; Zhang, Z.; Ren, J.S.; Tian, L.; Qiao, Y.; Dong, C. A new journey from SDRTV to HDRTV. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4500–4509. [Google Scholar]
- Lee, S.; Hwan An, G.; Kang, S.J. Deep recursive hdri: Inverse tone mapping using generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 596–611. [Google Scholar]
- Chen, S.K.; Yen, H.L.; Liu, Y.L.; Chen, M.H.; Hu, H.N.; Peng, W.H.; Lin, Y.Y. CEVR: Learning Continuous Exposure Value Representations for Single-Image HDR Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]
- Kim, J.H.; Lee, S.; Kang, S.J. End-to-End Differentiable Learning to HDR Image Synthesis for Multi-exposure Images. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Chen, J.; Yang, Z.; Chan, T.N.; Li, H.; Hou, J.; Chau, L.P. Attention-guided progressive neural texture fusion for high dynamic range image restoration. IEEE Trans. Image Process. 2022, 31, 2661–2672. [Google Scholar] [CrossRef]
- Yan, Q.; Zhang, S.; Chen, W.; Tang, H.; Zhu, Y.; Sun, J.; Van Gool, L.; Zhang, Y. Smae: Few-shot learning for hdr deghosting with saturation-aware masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5775–5784. [Google Scholar]
- Liu, C. Beyond Pixels: Exploring New Representations and Applications for Motion Analysis. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2009. [Google Scholar]
- Wu, S.; Xu, J.; Tai, Y.W.; Tang, C.K. Deep High Dynamic Range Imaging with Large Foreground Motions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, W.; Liu, Z.; Jiang, C.; Han, M.; Jiang, T.; Liu, S. Improving Bracket Image Restoration and Enhancement with Flow-guided Alignment and Enhanced Feature Aggregation. arXiv 2024, arXiv:2404.10358. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, Q.; Yue, H.; Li, K.; Yang, J. Efficient HDR Reconstruction from Real-World Raw Images. arXiv 2024, arXiv:2306.10311. [Google Scholar]
- Li, H.; Yang, Z.; Zhang, Y.; Tao, D.; Yu, Z. Single-Image HDR Reconstruction Assisted Ghost Suppression and Detail Preservation Network for Multi-Exposure HDR Imaging. IEEE Trans. Comput. Imaging 2024, 10, 429–445. [Google Scholar] [CrossRef]
- Barua, H.B.; Krishnasamy, G.; Wong, K.; Stefanov, K.; Dhall, A. ArtHDR-Net: Perceptually Realistic and Accurate HDR Content Creation. In Proceedings of the 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Taipei, China, 31 October–3 November 2023; pp. 806–812. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. IEEE Trans. Knowl. Data Eng. 2023, 35, 3313–3332. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, Y.; Bilinski, P.; Bremond, F.; Dantcheva, A. Imaginator: Conditional spatio-temporal gan for video generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1160–1169. [Google Scholar]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: New York, NY, USA, 2018; pp. 289–293. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, Y.; Gan, Z.; Carin, L. Generating text via adversarial training. NIPS Workshop Advers. Train. 2016, 21, 21–32. [Google Scholar]
- Guibas, J.T.; Virdi, T.S.; Li, P.S. Synthetic medical images from dual generative adversarial networks. arXiv 2017, arXiv:1709.01872. [Google Scholar]
- Wang, T.; Trugman, D.; Lin, Y. SeismoGen: Seismic waveform synthesis using GAN with application to seismic data augmentation. J. Geophys. Res. Solid Earth 2021, 126, e2020JB020077. [Google Scholar] [CrossRef]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to real reinforcement learning for autonomous driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Dam, T.; Ferdaus, M.M.; Pratama, M.; Anavatti, S.G.; Jayavelu, S.; Abbass, H. Latent preserving generative adversarial network for imbalance classification. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: New York, NY, USA, 2022; pp. 3712–3716. [Google Scholar]
- Gonog, L.; Zhou, Y. A Review: Generative Adversarial Networks. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 505–510. [Google Scholar] [CrossRef]
- Wang, L.; Cho, W.; Yoon, K.J. Deceiving image-to-image translation networks for autonomous driving with adversarial perturbations. IEEE Robot. Autom. Lett. 2020, 5, 1421–1428. [Google Scholar] [CrossRef]
- Raipurkar, P.; Pal, R.; Raman, S. HDR-cGAN: Single LDR to HDR Image Translation using Conditional GAN. arXiv 2021, arXiv:2110.01660. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Jain, D.; Raman, S. Deep over and under exposed region detection. In Proceedings of the Computer Vision and Image Processing: 5th International Conference, CVIP 2020, Prayagraj, India, 4–6 December 2020; Revised Selected Papers, Part III 5. Springer: Cham, Switzerland, 2021; pp. 34–45. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sauer, A.; Schwarz, K.; Geiger, A. Stylegan-xl: Scaling stylegan to large diverse datasets. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Li, R.; Wang, C.; Wang, J.; Liu, G.; Zhang, H.Y.; Zeng, B.; Liu, S. UPHDR-GAN: Generative Adversarial Network for High Dynamic Range Imaging with Unpaired Data. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7532–7546. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Zhang, X.P. MEF-GAN: Multi-Exposure Image Fusion via Generative Adversarial Networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cai, Y.; Bian, H.; Lin, J.; Wang, H.; Timofte, R.; Zhang, Y. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 12504–12513. [Google Scholar]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2654–2662. [Google Scholar]
- Chang, H.; Zhang, H.; Jiang, L.; Liu, C.; Freeman, W.T. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11315–11325. [Google Scholar]
- Hudson, D.A.; Zitnick, L. Generative adversarial transformers. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021; pp. 4487–4499. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Baktash, J.A.; Dawodi, M. Gpt-4: A review on advancements and opportunities in natural language processing. arXiv 2023, arXiv:2305.03195. [Google Scholar]
- Chen, R.; Zheng, B.; Zhang, H.; Chen, Q.; Yan, C.; Slabaugh, G.; Yuan, S. Improving dynamic hdr imaging with fusion transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 340–349. [Google Scholar]
- Kim, J.; Kim, M.H. Joint demosaicing and deghosting of time-varying exposures for single-shot hdr imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 12292–12301. [Google Scholar]
- Suda, T.; Tanaka, M.; Monno, Y.; Okutomi, M. Deep snapshot hdr imaging using multi-exposure color filter array. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Yan, Q.; Chen, W.; Zhang, S.; Zhu, Y.; Sun, J.; Zhang, Y. A unified HDR imaging method with pixel and patch level. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22211–22220. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Zhou, F.; Fu, Z.; Zhang, D. High dynamic range imaging with context-aware transformer. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Chi, Y.; Zhang, X.; Chan, S.H. Hdr imaging with spatially varying signal-to-noise ratios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5724–5734. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Prince, S.J. Understanding Deep Learning; MIT Press: Cambridge, MA, USA, 2023. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021; pp. 8162–8171. [Google Scholar]
- Song, Y.; Dhariwal, P.; Chen, M.; Sutskever, I. Consistency models. arXiv 2023, arXiv:2303.01469. [Google Scholar]
- Bemana, M.; Leimkühler, T.; Myszkowski, K.; Seidel, H.P.; Ritschel, T. Exposure Diffusion: HDR Image Generation by Consistent LDR denoising. arXiv 2024, arXiv:2405.14304. [Google Scholar]
- Goswami, A.; Singh, A.R.; Banterle, F.; Debattista, K.; Bashford-Rogers, T. Semantic Aware Diffusion Inverse Tone Mapping. arXiv 2024, arXiv:2405.15468. [Google Scholar]
- Hu, T.; Yan, Q.; Qi, Y.; Zhang, Y. Generating content for hdr deghosting from frequency view. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 25732–25741. [Google Scholar]
- Li, B.; Ma, S.; Zeng, Y.; Xu, X.; Fang, Y.; Zhang, Z.; Wang, J.; Chen, K. Sagiri: Low Dynamic Range Image Enhancement with Generative Diffusion Prior. arXiv 2024, arXiv:2406.09389. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3836–3847. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11461–11471. [Google Scholar]
- Wang, Y.; Yu, Y.; Yang, W.; Guo, L.; Chau, L.P.; Kot, A.C.; Wen, B. Exposurediffusion: Learning to expose for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 12438–12448. [Google Scholar]
- Heide, F.; Steinberger, M.; Tsai, Y.T.; Rouf, M.; Pajak, D.; Reddy, D.; Gallo, O.; Liu, J.; Heidrich, W.; Egiazarian, K.; et al. FlexISP: A flexible camera image processing framework. ACM Trans. Graph. (TOG) 2014, 33, 1–13. [Google Scholar] [CrossRef]
- Kang, S.B.; Uyttendaele, M.; Winder, S.; Szeliski, R. High dynamic range video. ACM Trans. Graph. (TOG) 2003, 22, 319–325. [Google Scholar] [CrossRef]
- Mangiat, S.; Gibson, J. High dynamic range video with ghost removal. In Proceedings of the Applications of Digital Image Processing XXXIII, San Diego, CA, USA, 7–10 August 2010. [Google Scholar] [CrossRef]
- Kalantari, N.K.; Shechtman, E.; Barnes, C.; Darabi, S.; Goldman, D.B.; Sen, P. Patch-based high dynamic range video. ACM Trans. Graph. (TOG) 2013, 32, 202:1–202:8. [Google Scholar] [CrossRef]
- Mann, S.; Lo, R.C.H.; Ovtcharov, K.; Gu, S.; Dai, D.; Ngan, C.; Ai, T. Realtime HDR (High Dynamic Range) video for eyetap wearable computers, FPGA-based seeing aids, and glasseyes (EyeTaps). In Proceedings of the 2012 25th IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Montreal, QC, Canada, 29 April–2 May 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Barua, H.; Stefanov, K.; Che, L.; Dhall, A.; Wong, K.; Krishnasamy, G. LLM-HDR: Bridging LLM-based Perception and Self-Supervision for Unpaired LDR-to-HDR Image Reconstruction. arXiv 2025, arXiv:2410.15068. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Guo, H.; Guo, Y.; Zha, Y.; Zhang, Y.; Li, W.; Dai, T.; Xia, S.T.; Li, Y. MambaIRv2: Attentive State Space Restoration. arXiv 2024, arXiv:2411.15269. [Google Scholar]




| Metric | Applicability | Reference Type | Evaluation Type | Domain | Computational Cost |
|---|---|---|---|---|---|
| FovVideoVDP [95] | Both | FR | Global | Spatial and Temporal | High |
| HDR-VQM [96] | HDR | FR | Global | Spatial | Medium |
| HDR-VDP2 [35] | Both | FR | Global | Spatial | High |
| HDR-VDP3 [36] | Both | FR | Global | Spatial | High |
| BRISQUE [97] | LDR | NR | Local | Spatial | Low |
| NIQE [98] | LDR | NR | Global | Spatial | Low |
| PIQUE [99] | LDR | NR | Local | Spatial | Medium |
| NIMA [100] | LDR | NR | Global | Spatial | Medium |
| LPIPS [101] | LDR | FR | Global | Spatial | Medium |
| SSIM [102] | LDR | FR | Global | Spatial | Low |
| MS-SSIM [103] | LDR | FR | Global | Spatial | Low |
| FSSIM [104] | LDR | FR | Global | Spatial | Low |
| VSI [105] | LDR | FR | Global | Spatial | Medium |
| PSNR [29] | LDR | FR | Global | Spatial | Low |
| MSE [29] | LDR | FR | Global | Spatial | Low |
| ColorVideoVDP [106] | Both | FR | Global | Spatial and Temporal | High |
| MUSIQ [107] | LDR | NR | Global and Local | Spatial | Medium |
| Model | PSNR-L (dB) | PSNR-µ (dB) | SSIM | SSIM-µ | HDR-VDP2 | LPIPS |
|---|---|---|---|---|---|---|
| Single-frame | ||||||
| HDRUNet [41] | 41.61 | 34.02 | — | — | — | — |
| ArtHDR-Net [124] | 35 | — | 0.93 | — | 69 | — |
| DCDR-UNet [45] | 52.47 | 54.71 | 0.9985 | — | 68.68 | 0.0026 |
| Multi-frame | ||||||
| APNT-Fusion [117] | — | 43.96 | — | 0.9957 | — | — |
| IREANet [121] | 39.78 | — | 0.9556 | — | — | 0.102 |
| RepUNet [122] | 44.8081 | — | — | — | — | — |
| Single-frame and Multi-frame | ||||||
| SAMHDR [123] | 52.49 | 46.98 | 0.9991 | 0.9961 | 69.76 | — |
| Method | PSNR-l | PSNR-µ | PSNR-PU | SSIM-l | SSIM-µ | SSIM-PU | MSSIM | HDR-VDP2 | HDR-VDP3 |
|---|---|---|---|---|---|---|---|---|---|
| Single-Frame | |||||||||
| GlowGAN [10] | — | — | 31.8 | — | — | — | — | — | 7.44 |
| HDR-cGAN [138] | 17.57 | — | — | 0.78 | — | — | — | 51.94 | — |
| Multi-Frame | |||||||||
| HDR-GAN [26] | 41.76 | 43.64 | 43.2004 | 0.9869 | 0.9891 | 0.9913 | — | 65.45 | — |
| UPHDR-GAN [143] | 43.005 | — | 42.115 | 0.988 | — | 0.986 | — | 63.542 | — |
| MEF-GAN [144] | 68.42 | — | — | — | — | — | 0.982 | — | — |
| Category | Architecture | Strengths | Limitations |
|---|---|---|---|
| Alignment-based | HFT-HDR [156], KIM et al. [157], HyHDRNet [159] |
|
|
| Attention-based | CA-ViT [17], HDT-HDR [161], PASTA [50] |
|
|
| Convolution-based | SCTNet [27], SV-HDR [162], SSHDR [118] |
|
|
| Architecture | PSNR-µ | SSIM-µ | HDR-VDP2 |
|---|---|---|---|
| CA-ViT [17] | 44.32 | 0.9916 | 66.03 |
| SCTNet [27] | 44.49 | 0.9924 | 66.65 |
| KIM et al. [157] 1 | 40.10 | 0.9619 | 75.57 |
| HDT-HDR [161] | 44.36 | 66.08 | — |
| HFT-HDR [156] | 44.45 | 0.988 | — |
| PASTA [50] | 44.53 | 0.9918 | 65.92 |
| HyHDRNet [159] | 44.64 | 0.9915 | 66.05 |
| SV-HDR [162] 1 | 37.30 | 0.9826 | — |
| SSHDR [118] | 41.97 | 0.9895 | 67.77 |
| Metric | LF-Diff | DiffHDR | LS-Sagiri | Zero-Shot | Exp. Diff. | Cond. Diff. | DITMO |
|---|---|---|---|---|---|---|---|
| PSNR-l | 44.76 | 44.11 | — | — | — | 16.97 | — |
| SSIM-l | 0.9919 | 0.9911 | — | — | — | — | — |
| PSNR-µ | 42.59 | 41.73 | — | — | — | 81 | — |
| SSIM-µ | 0.9906 | 0.9885 | — | — | — | — | — |
| HDR VDP-2 | 66.54 | 65.52 | — | — | — | — | — |
| HDR VDP-2.2 | — | — | — | — | — | 52.29 | — |
| BRISQUE | — | — | 19.72 | — | — | — | — |
| NIQE | — | — | 20.31 | 2.34 | — | — | — |
| TMQI | — | — | — | 0.8915 | — | — | — |
| MANIQA | — | — | 0.57 | — | — | — | — |
| CLIP-IQA | — | — | 0.67 | — | — | — | — |
| NoR-VDP++ | — | — | — | — | — | — | 54.337 |
| PU21-Pique | — | — | — | — | — | — | 8.789 |
| Methods | 2-Exposure | 3-Exposure | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNRT | SSIMT | HDR-VDP-2 | Time (ms) | PSNRT | SSIMT | HDR-VDP-2 | Time (ms) | |
| Kalantari19 [30] | 39.91 | 0.9329 | 71.11 | 200 | 38.78 | 0.9331 | 65.73 | 220 |
| Chen [31] | 42.48 | 0.9620 | 74.80 | 522 | 39.44 | 0.9569 | 67.76 | 540 |
| LAN-HDR [33] | 41.59 | 0.9472 | 71.34 | 415 | 40.48 | 0.9504 | 68.61 | 525 |
| HDRFlow [32] | 43.25 | 0.9520 | 77.29 | 35 | 40.56 | 0.9535 | 72.42 | 50 |
| HDR-V-Diff [34] | 42.07 | 0.9604 | 70.88 | – | 40.82 | 0.9581 | 68.16 | – |
| Category | Model | Strengths | Limitations |
|---|---|---|---|
| Optical Flow-Based | HFT-HDR [31], KIM et al. [157], HDRFlow [32] |
|
|
| Attention-Based | LAN-HDR [33], HDR-V-Diff [34] |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martins, G.d.L.; Lopez-Cabrejos, J.; Martins, J.; Leher, Q.; Ferreti, G.d.S.; Carvalho, L.H.C.; Lima, F.B.; Paixão, T.; Alvarez, A.B. A Review Toward Deep Learning for High Dynamic Range Reconstruction. Appl. Sci. 2025, 15, 5339. https://doi.org/10.3390/app15105339
Martins GdL, Lopez-Cabrejos J, Martins J, Leher Q, Ferreti GdS, Carvalho LHC, Lima FB, Paixão T, Alvarez AB. A Review Toward Deep Learning for High Dynamic Range Reconstruction. Applied Sciences. 2025; 15(10):5339. https://doi.org/10.3390/app15105339
Chicago/Turabian StyleMartins, Gabriel de Lima, Josue Lopez-Cabrejos, Julio Martins, Quefren Leher, Gustavo de Souza Ferreti, Lucas Hildelbrano Costa Carvalho, Felipe Bezerra Lima, Thuanne Paixão, and Ana Beatriz Alvarez. 2025. "A Review Toward Deep Learning for High Dynamic Range Reconstruction" Applied Sciences 15, no. 10: 5339. https://doi.org/10.3390/app15105339
APA StyleMartins, G. d. L., Lopez-Cabrejos, J., Martins, J., Leher, Q., Ferreti, G. d. S., Carvalho, L. H. C., Lima, F. B., Paixão, T., & Alvarez, A. B. (2025). A Review Toward Deep Learning for High Dynamic Range Reconstruction. Applied Sciences, 15(10), 5339. https://doi.org/10.3390/app15105339