
Refining Zero-Shot Text-to-SQL Benchmarks via Prompt Strategies with Large Language Models


Abstract
1. Introduction
2. Related Works
3. Challenges
4. Methods
4.1. Dataset Creation
- Avoid Mismatch Between Questions and SQL Outputs:
- Avoid Ambiguities in Questions Leading to Misaligned SQL:
- Avoid Overly Complex SQL for Simple Queries:
- Avoid Redundancies or Missing Logic:
- Avoid Inconsistent Use of Data Representations:
- Avoid over-testing the same issue:
- Adding Information about Data into Table Schema:
- Assigning Difficulty Level Properly:
4.2. Testing Method
4.3. Prompt Generation
4.3.1. General Guidelines and Table Schema in Prompt
4.3.2. Extra Guidelines in Prompt
5. Results
5.1. Experimental Setup
5.2. Average Accuracy
5.3. Ablation Studies
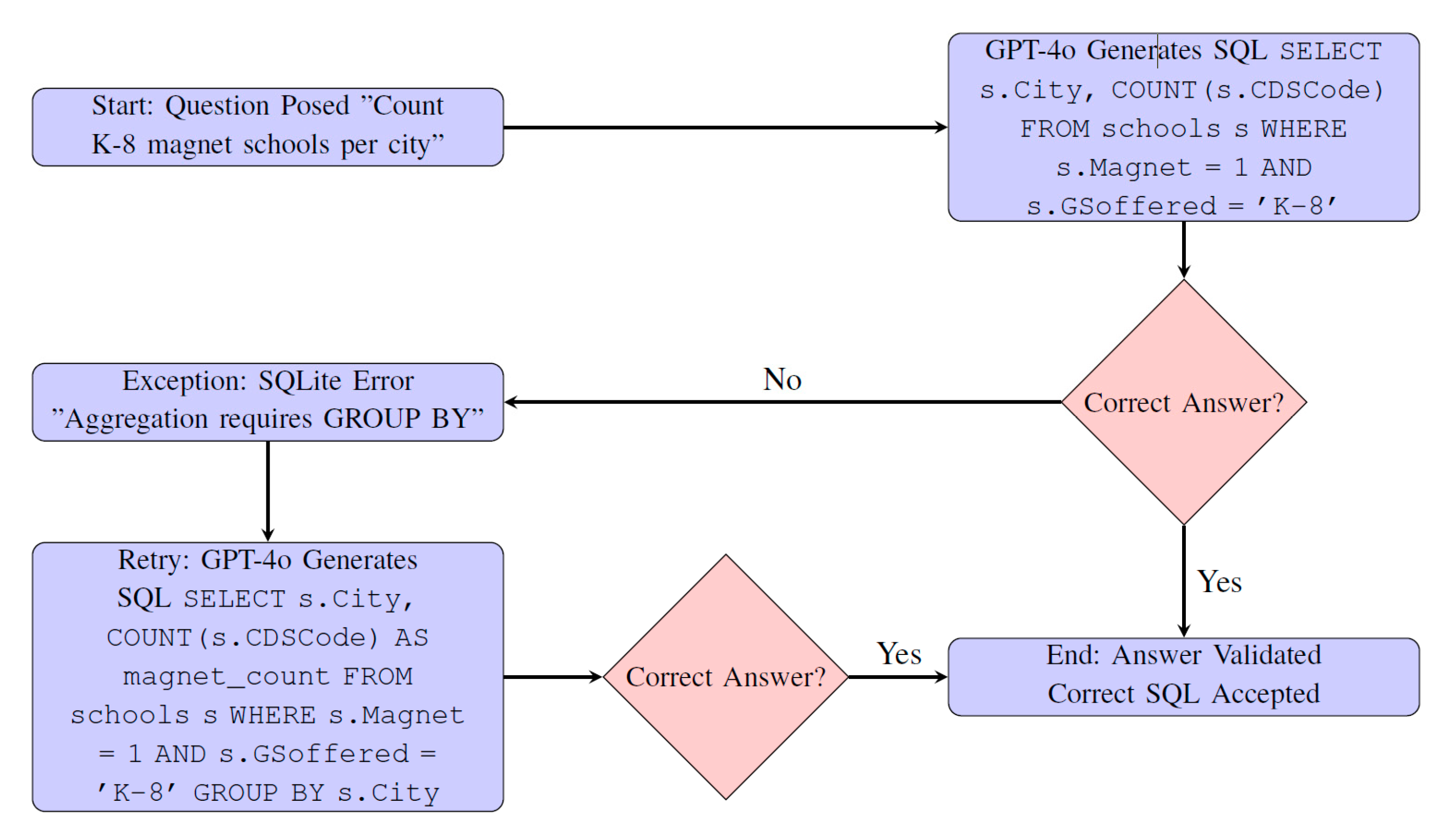
- Impact of Logical Alignment: Removing logical alignment caused the largest accuracy drop across all models (−6.17% to −7.19%). For GPT-4o (new), Table 2 shows Type 5 errors (query logic) rising significantly, contributing ~82% of the total gain over BIRD. Errors increased substantially in domains like formula_1 and california_schools. This underscores how resolving logical misalignments [12] is pivotal for improving baseline reasoning accuracy, thus enhancing the model’s reliability and generalization potential on logically complex tasks.
- Impact of Schema Enhancement: Excluding schema enhancement reduced accuracy (−2.75% to −3.56%). For GPT-4o (new), Type 2 (forgetting requirements) and Type 4 (data handling) errors rose, reflecting reduced guesswork. Domain errors also increased. This supports the role of schema enhancement in reducing guesswork and improving cross-domain generalization by providing clearer data context, leading to more reliable outputs.
- Impact of Prompt Guidelines: Dropping prompt guidelines lowered accuracy moderately (−1.23% to −1.78%). For GPT-4o (new), Type 3 (syntax) and Type 6 (edge cases) errors increased slightly. Domain impacts were smaller. This indicates that while data quality is primary, prompt guidelines play a significant secondary role in fine-tuning reasoning and improving precision, contributing to overall model reliability across different models.
5.4. Cross-Round Accuracy
- Domain Analysis: Figure 12 shows O1-Preview’s edge, particularly in complex domains.
- Difficulty Analysis: Figure 13 highlights O1-Preview’s robustness on challenging tasks compared to others.
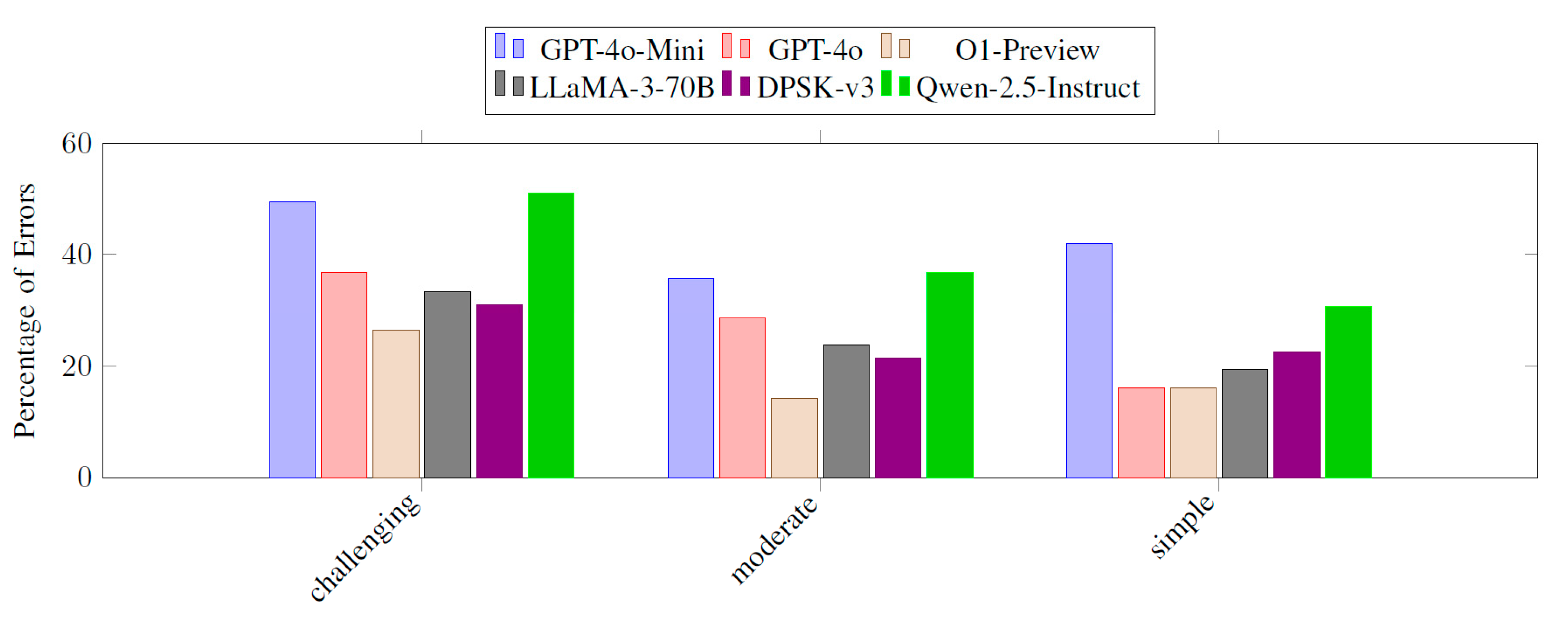
- Error Analysis: Figure 14 details seven error types (T1–T7). On BIRD, errors rose significantly. Type 5 (query logic) dominated but was cut by 33% with logical alignment. O1-Preview’s performance confirms refinement enhances reasoning. While this error typing provides more insight than a simple pass/fail metric, future work could explore even more granular partial correctness evaluations.
5.5. Case Studies
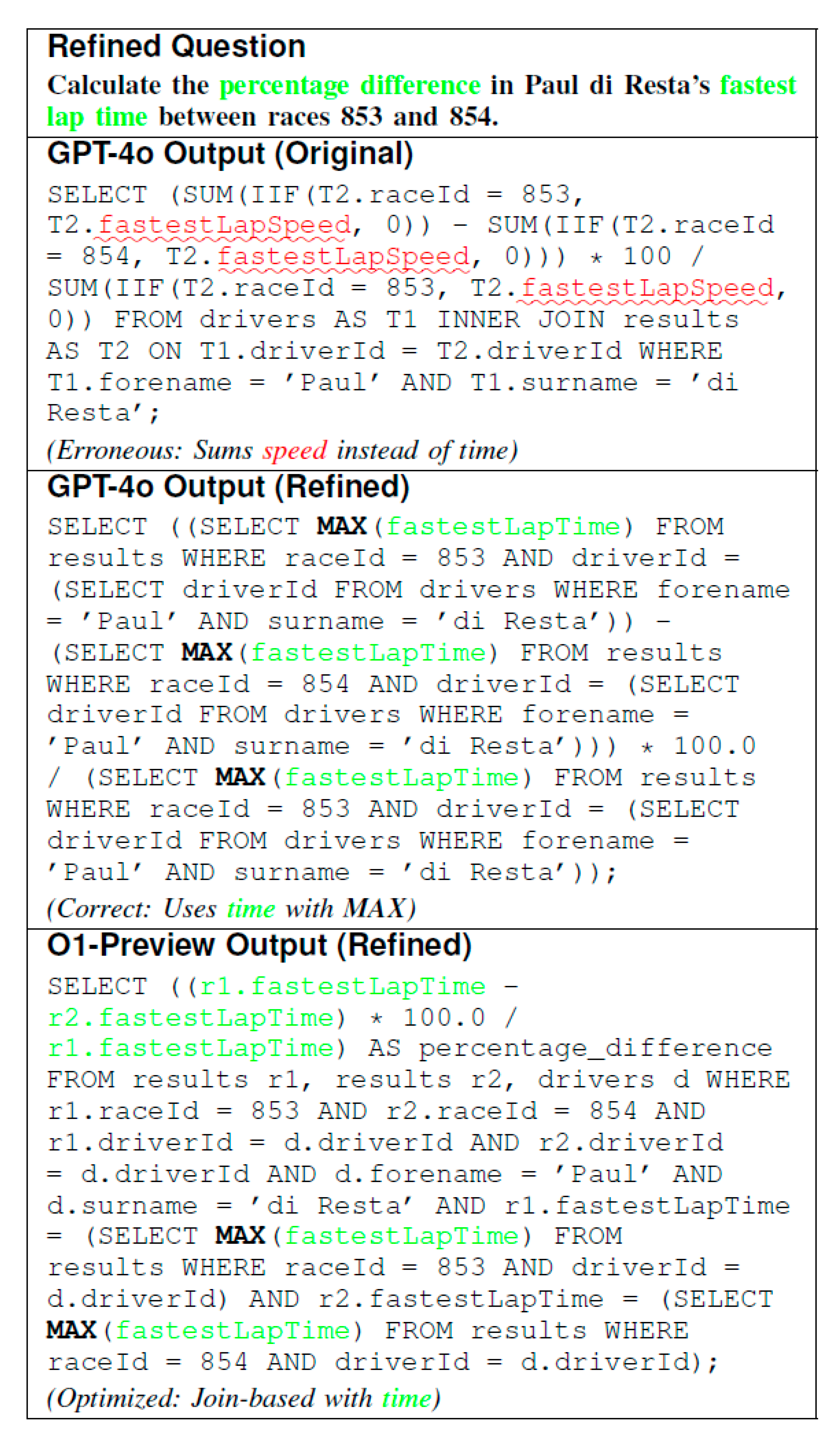
- These case studies confirm that our method resolves BIRD’s issues, enhancing LLM reasoning and supporting accuracy uplift.
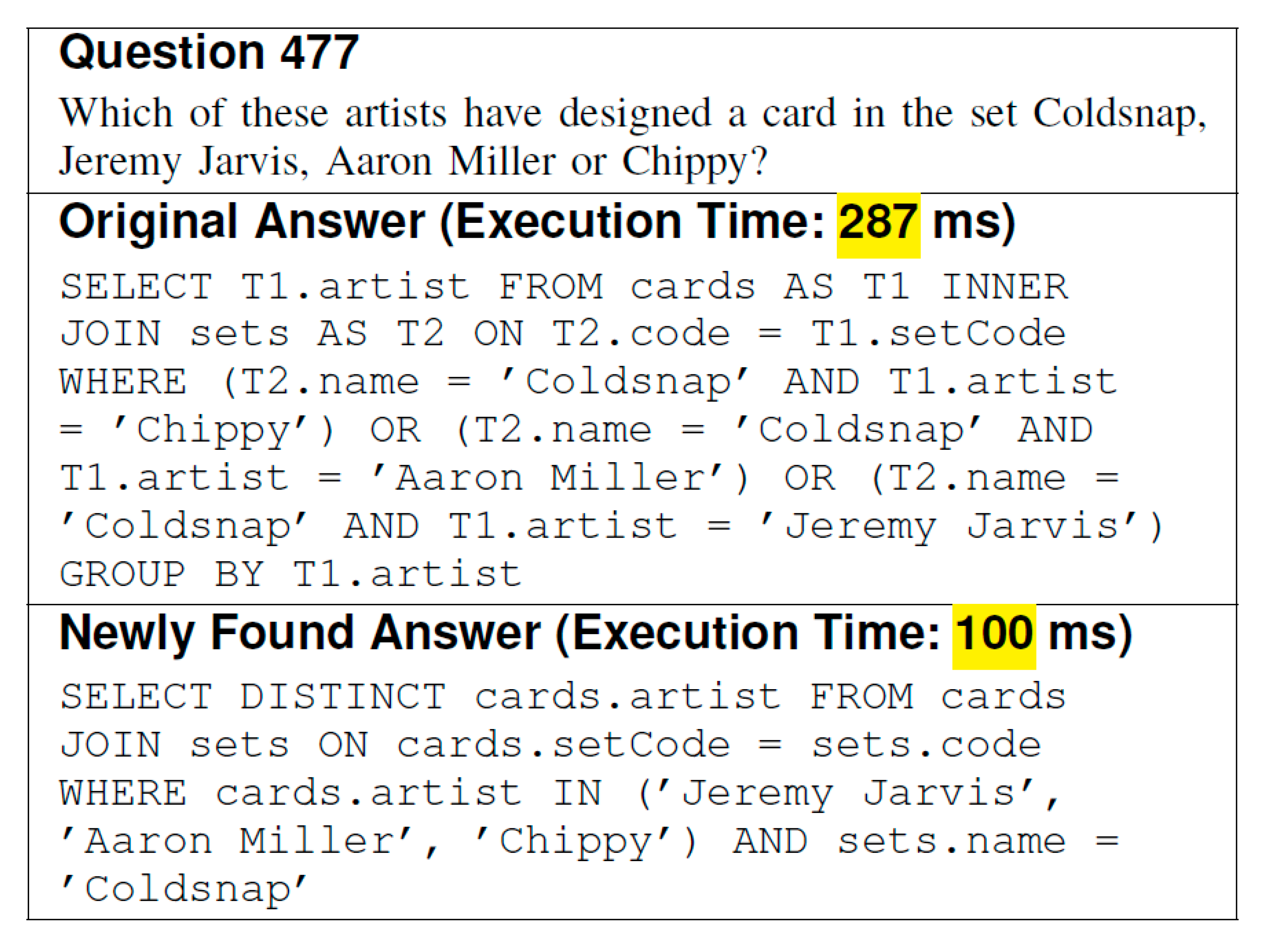
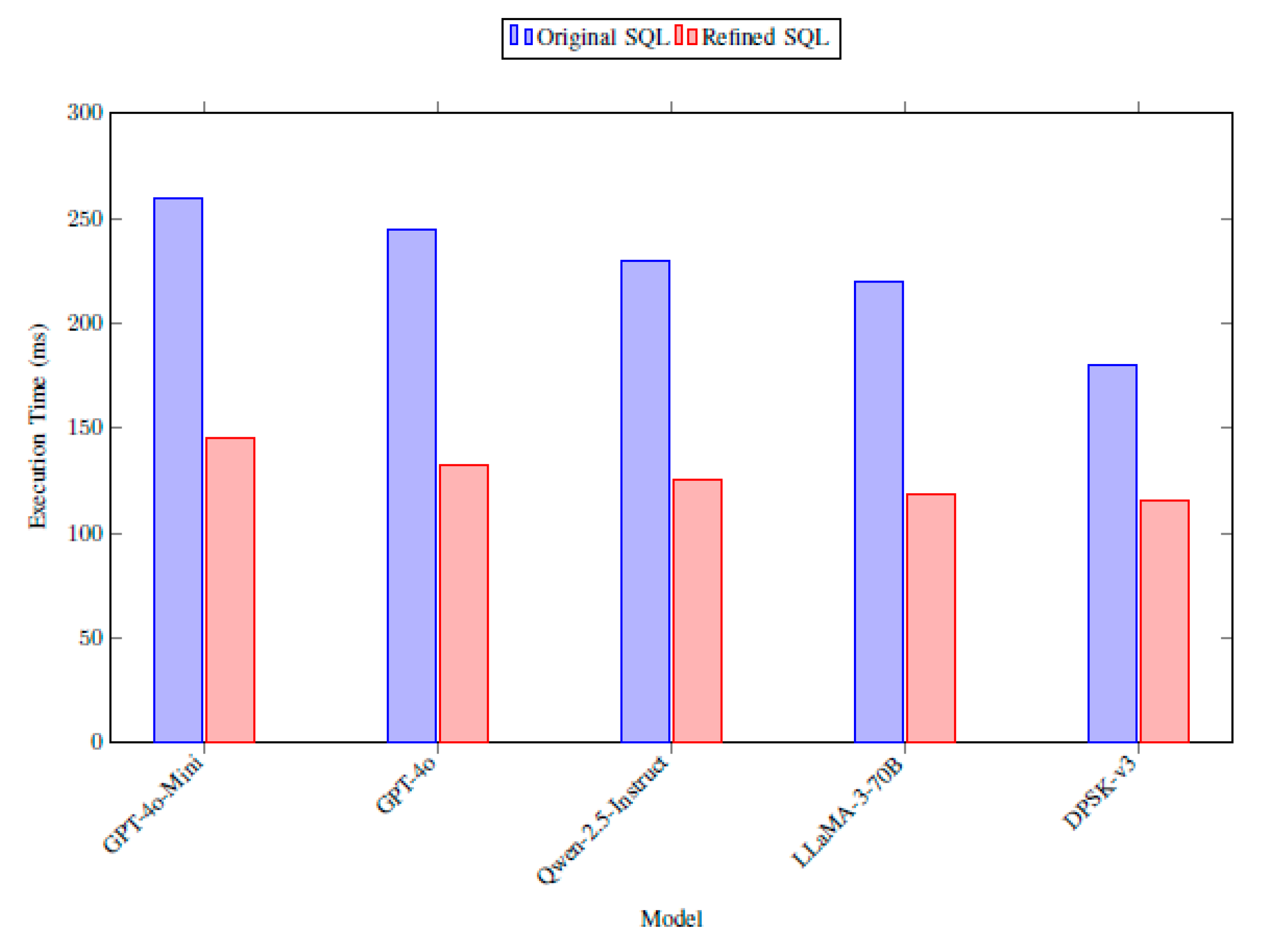
- Improvements in Runtime Performance: Refinements also enhance SQL execution efficiency (1). For instance, simplifying Question 477 (Figure A1) reduced execution time by 65.16% (2). We measured the times for 20 representative pairs across models (3). Figure 18 shows that refined SQL consistently reduces execution time (e.g., GPT-4o’s average drop of 46.12%) (4), particularly in complex domains (5). Improvements stem from logical alignment and prompt guidelines reducing computational overhead (6). Schema enhancements have a minimal direct runtime impact (7). This demonstrates practical runtime gains critical for real-world applications (8).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Examples of Errors and Inconsistencies in the Original BIRD Dataset
Appendix A.1. Logical and Structural Errors in SQL
Appendix A.2. Inconsistent Data Representation
Appendix A.3. Ambiguities and Poorly Defined Questions
Appendix A.4. Redundancy and Unreasonable Difficulty Tags
Appendix A.5. Incorrect Domain-Specific Knowledge Assumptions
Appendix A.6. Evaluation Challenges
Appendix A.7. Summary of Identified Error Types in Original BIRD Dataset
| Error Category | Description | Example Figure(s) |
| Logical/Structural SQL Errors | The SQL query does not accurately reflect the question’s logic, or the SQL structure is inefficient/suboptimal. | Figure A1 and Figure A2 |
| Data Representation Issues | Inconsistencies between schema descriptions and actual data values, or misleading naming conventions. | Figure A3 |
| Question Ambiguity | Vague phrasing, undefined terms, or unclear intent in the natural language question leads to ambiguity. | Figure A4 and Figure A5 |
| Dataset Bias Issues | Excessive repetition of specific query types/concepts or inaccurate difficulty labeling. | Figure A6 and Figure A7 |
| Domain Knowledge Issues | Reliance on incorrect or unstated domain-specific assumptions embedded within the question or SQL. | Figure A8 |
| Evaluation Ambiguity | Lack of clear criteria for evaluating the correctness of the output, allowing multiple plausible answers. | Figure A9 |








References
- Zhong, V.; Xiong, C.; Socher, R. Seq2SQL: Generating structured queries from natural language using reinforcement learning. arXiv 2017, arXiv:1709.00103. [Google Scholar]
- Xu, X.; Liu, C.; Yu, D. SQLNet: Generating structured queries from natural language without reinforcement learning. arXiv 2017, arXiv:1711.04436. [Google Scholar]
- Yu, T.; Yasunaga, M.; Yang, K.; Zhang, R.; Wang, D.; Li, Z.; Radev, D. SyntaxSQLNet: Syntax tree networks for complex and cross-domaintext-to-SQL task. arXiv 2018, arXiv:1810.05237. [Google Scholar]
- Gao, D.; Wang, H.; Li, Y.; Sun, X.; Qian, Y.; Ding, B.; Zhou, J. Text-to-SQL empowered by large language models: A benchmark evaluation. arXiv 2023, arXiv:2308.15363. [Google Scholar] [CrossRef]
- Sun, R.; Arik, S.Ö.; Muzio, A.; Miculicich, L.; Gundabathula, S.; Yin, P.; Dai, H.; Nakhost, H.; Sinha, R.; Wang, Z.; et al. SQL-PaLM: Improved large language model adaptation for text-to-SQL. arXiv 2023, arXiv:2306.00739. [Google Scholar]
- Hong, Z.; Yuan, Z.; Zhang, Q.; Chen, H.; Dong, J.; Huang, F.; Huang, X. Next-generation database interfaces: A survey of llm-based text-to-SQL. arXiv 2024, arXiv:2406.08426. [Google Scholar]
- Shi, L.; Tang, Z.; Zhang, N.; Zhang, X.; Yang, Z. A survey on employing large language models for text-to-SQL tasks. arXiv 2023, arXiv:2407.15109. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Liu, A.; Hu, X.; Wen, L.; Yu, P.S. A comprehensive evaluation of chatgpt’s zero-shot text-to-SQL capability. arXiv 2023, arXiv:2303.13547. [Google Scholar]
- Li, J.; Hui, B.; Qu, G.; Yang, J.; Li, B.; Li, B.; Wang, B.; Qin, B.; Geng, R.; Huo, N.; et al. Can llm already serve as a database interface? a big bench for large-scale database grounded textto-SQLs. arXiv 2023, arXiv:2305.03111. [Google Scholar]
- Dong, X.; Zhang, C.; Ge, Y.; Mao, Y.; Gao, Y.; Lin, J.; Lou, D. C3: Zero-shot text-to-SQL with chatgpt. arXiv 2023, arXiv:2307.07306. [Google Scholar]
- Yu, T.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Ma, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task. arXiv 2018, arXiv:1809.08887. [Google Scholar]
- Lei, F.; Chen, J.; Ye, Y.; Cao, R.; Shin, D.; Su, H.; Suo, Z.; Gao, H.; Hu, W.; Yin, P.; et al. Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows. arXiv 2024, arXiv:2411.07763. [Google Scholar]
- Yu, T.; Zhang, R.; Yasunaga, M.; Tan, Y.C.; Lin, X.V.; Li, S.; Er, H.; Li, I.; Pang, B.; Chen, T.; et al. Sparc: Crossdomain semantic parsing in context. arXiv 2019, arXiv:1906.02285. [Google Scholar]
- Yu, T.; Zhang, R.; Er, H.Y.; Li, S.; Xue, E.; Pang, B.; Lin, X.V.; Tan, Y.C.; Shi, T.; Li, Z.; et al. CoSQL: A conversational text-to-SQL challenge towards cross-domain natural language interfaces to databases. arXiv 2019, arXiv:1909.05378. [Google Scholar]
- Dahl, D.A.; Bates, M.; Brown, M.; Fisher, W.; Hunicke-Smith, K.; Pallett, D.; Pao, C.; Rudnicky, A.; Shriberg, E. Expanding the scope of the ATIS task: The ATIS-3 corpus. In Proceedings of the Human Language Technology: Proceedings of a Workshop, Plainsboro, NJ, USA, 8–11 March 1994. [Google Scholar]
- Kelkar, A.; Relan, R.; Bhardwaj, V.; Vaichal, S.; Khatri, C.; Relan, P. Bertrand-dr: Improving text-to-SQL using a discriminative re-ranker. arXiv 2020, arXiv:2002.00557. [Google Scholar]
- Scholak, T.; Schucher, N.; Bahdanau, D. PICARD: Parsing incrementally for constrained auto-regressive decoding from language models. arXiv 2021, arXiv:2109.05093. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. PaLM 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Rajkumar, N.; Li, R.; Bahdanau, D. Evaluating the text-to-SQL capabilities of large language models. arXiv 2022, arXiv:2204.00498. [Google Scholar]
- Wang, B.; Ren, C.; Yang, J.; Liang, X.; Bai, J.; Chai, L.; Yan, Z.; Zhang, Q.W.; Yin, D.; Sun, X.; et al. Mac-SQL: A multi-agent collaborative framework for text-to-SQL. arXiv 2024, arXiv:2312.11242. [Google Scholar]
- Cen, J.; Liu, J.; Li, Z.; Wang, J. SQLfixagent: Towards semantic-accurate text-to-SQL parsing via consistency-enhanced multi-agent collaboration. arXiv 2024, arXiv:2406.13408. [Google Scholar] [CrossRef]
- Tai, C.Y.; Chen, Z.; Zhang, T.; Deng, X.; Sun, H. Exploring chain of thought style prompting for text-to-SQL. Empirical Methods in Natural Language Processing (EMNLP). arXiv 2023, arXiv:2305.14215. [Google Scholar]
- Li, H.; Zhang, J.; Liu, H.; Fan, J.; Zhang, X.; Zhu, J.; Wei, R.; Pan, H.; Li, C.; Chen, H. Codes: Towards building opensource language models for text-to-SQL. Conf. Manag. Data (SIGMOD) 2024, 2, 1–28. [Google Scholar]
- Li, C.; Shao, Y.; Li, Y.; Liu, Z. Sea-SQL: Semantic-enhanced text-to-SQL with adaptive refinement. arXiv 2024, arXiv:2408.04919. [Google Scholar]
- Sun, Y.; Guo, Z.; Yu, H.; Liu, C.; Li, X.; Wang, B.; Yu, X.; Zhao, T. Qda-SQL: Questions enhanced dialogue augmentation for multi-turn text-to-SQL. arXiv 2024, arXiv:2406.10593. [Google Scholar]
- Xie, X.; Xu, G.; Zhao, L.; Guo, R. Opensearch-SQL: Enhancing text-to-SQL with dynamic few-shot and consistency alignment. arXiv 2025, arXiv:2502.14913. [Google Scholar]
- Lee, D.; Park, C.; Kim, J.; Park, H. Mcs-SQL: Leveraging multiple prompts and multiple-choice selection for text-to-SQL generation. arXiv 2024, arXiv:2405.07467. [Google Scholar]
- Xie, W.; Wu, G.; Zhou, B. Mag-SQL: Multi-agent generative approach with soft schema linking and iterative sub-SQL refinement for text-to-SQL. arXiv 2024, arXiv:2408.07930. [Google Scholar]
- Gu, Z.; Fan, J.; Tang, N.; Cao, L.; Jia, B.; Madden, S.; Du, X. Few-shot text-to-SQL translation using structure and content prompt learning. Proc. ACM Manag. Data 2023, 1, 1–28. [Google Scholar] [CrossRef]
- Zhu, X.; Li, Q.; Cui, L.; Liu, Y. Large language model enhanced textto-SQL generation: A survey. arXiv 2024, arXiv:2410.05678. [Google Scholar]
- Xia, H.; Jiang, F.; Deng, N.; Wang, C.; Zhao, G.; Mihalcea, R.; Zhang, Y. SQL-craft: Text-to-SQL through interactive refinement and enhanced reasoning. arXiv 2024, arXiv:2402.14851. [Google Scholar]
- Nan, L.; Zhao, Y.; Zou, W.; Ri, N.; Tae, J.; Zhang, E.; Cohan, A.; Radev, D. Enhancing text-toSQL capabilities of large language models: A study on prompt design strategies. In Findings of Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Singapore, 2023. [Google Scholar]
- Wu, Z.; Zhu, F.; Shang, X.; Zhang, Y.; Zhou, P. Cooperative SQL generation for segmented databases by using multi-functional llm agents. arXiv 2024, arXiv:2412.05850. [Google Scholar]
- Chang, S.; Fosler-Lussier, E. Selective demonstrations for crossdomain text-to-SQL. arXiv 2023, arXiv:2310.06302. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Refined Dataset (New Prompt) | Avg (New) | Refined Dataset (Old Prompt) | Avg (Old) | Original BIRD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test 1 | Test 2 | Test 3 | Test 4 | Test 5 | Test 1 | Test 2 | Test 3 | Test 4 | Test 5 | Avg (New) | Avg (Old) | |||
| GPT-4o-Mini | 42.47% | 46.58% | 39.73% | 41.78% | 37.67% | 41.65% | 40.41% | 32.88% | 39.73% | 34.93% | 36.30% | 36.85% | 34.12% | 31.25% |
| GPT-4o | 47.94% | 53.42% | 51.36% | 53.42% | 50.00% | 51.23% | 50.00% | 50.00% | 52.05% | 42.46% | 52.74% | 49.45% | 43.68% | 41.10% |
| Qwen-2.5-Instruct | 46.58% | 42.47% | 45.21% | 41.10% | 45.89% | 44.25% | 43.84% | 43.84% | 44.52% | 46.57% | 36.30% | 43.01% | 38.90% | 37.12% |
| LLaMA-3-70B | 47.26% | 50.00% | 46.58% | 45.21% | 47.95% | 47.80% | 46.58% | 47.95% | 45.21% | 44.52% | 43.84% | 45.62% | 41.23% | 39.80% |
| DPSK-v3 | 48.63% | 50.00% | 51.37% | 47.26% | 48.63% | 49.10% | 47.26% | 48.63% | 50.00% | 46.58% | 46.58% | 47.80% | 42.80% | 41.50% |
| O1-Preview | 77.40% | 79.45% | 76.03% | 80.14% | 78.08% | 78.22% | 75.34% | 77.40% | 74.66% | 76.71% | 75.34% | 75.89% | 69.50% | 67.80% |
| Configuration | Accuracy (%) | Errors by Type (GPT-4o, New Prompt) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o (New) | GPT-4o (Old) | GPT-4o-Mini (New) | O1-Preview (New) | T1 | T2 | T3 | T4 | T5 | T6 | T7 | |
| Full Refinement | 51.23 | 49.45 | 41.65 | 78.08 | 12 | 5 | 5 | 10 | 24 | 8 | 3 |
| w/o Prompt Guidelines | 49.80 | 47.67 | 40.00 | 76.85 | 12 | 6 | 6 | 10 | 25 | 9 | 3 |
| w/o Schema Enhancement | 48.12 | 46.30 | 38.90 | 74.52 | 14 | 8 | 5 | 13 | 26 | 8 | 3 |
| w/o Logical Alignment | 45.06 | 43.15 | 36.25 | 70.89 | 15 | 10 | 6 | 12 | 32 | 9 | 4 |
| Original BIRD Subset | 43.68 | 41.10 | 34.12 | 68.49 | 16 | 12 | 7 | 14 | 35 | 10 | 4 |
| ∆ from Full (GPT-4o, New) | - | −1.78 | −9.58 | +26.85 | +4 | +7 | +2 | +4 | +11 | +2 | +1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, R.; Zhang, F. Refining Zero-Shot Text-to-SQL Benchmarks via Prompt Strategies with Large Language Models. Appl. Sci. 2025, 15, 5306. https://doi.org/10.3390/app15105306
Zhou R, Zhang F. Refining Zero-Shot Text-to-SQL Benchmarks via Prompt Strategies with Large Language Models. Applied Sciences. 2025; 15(10):5306. https://doi.org/10.3390/app15105306
Chicago/Turabian StyleZhou, Ruikang, and Fan Zhang. 2025. "Refining Zero-Shot Text-to-SQL Benchmarks via Prompt Strategies with Large Language Models" Applied Sciences 15, no. 10: 5306. https://doi.org/10.3390/app15105306
APA StyleZhou, R., & Zhang, F. (2025). Refining Zero-Shot Text-to-SQL Benchmarks via Prompt Strategies with Large Language Models. Applied Sciences, 15(10), 5306. https://doi.org/10.3390/app15105306