
Applications of Linear and Ensemble-Based Machine Learning for Predicting Winning Teams in League of Legends



Abstract
:1. Introduction
- The findings from this research have the potential to enhance matchmaking algorithms, which could positively affect players’ perceptions of match fairness [26], thereby increasing both player retention and revenue.
- Furthermore, the broader infrastructure that contributes to the game’s success, including esports, benefits from the incorporation of machine learning (ML) techniques. These techniques could facilitate player development, enable talent scouts to identify emerging players more effectively, and aid coaches in formulating strategic plans, similar to their applications in traditional sports [5]. In particular, the influence of winning/losing streaks on match prediction is statistically significant (p < 0.05), but its impact on prediction is relatively small.
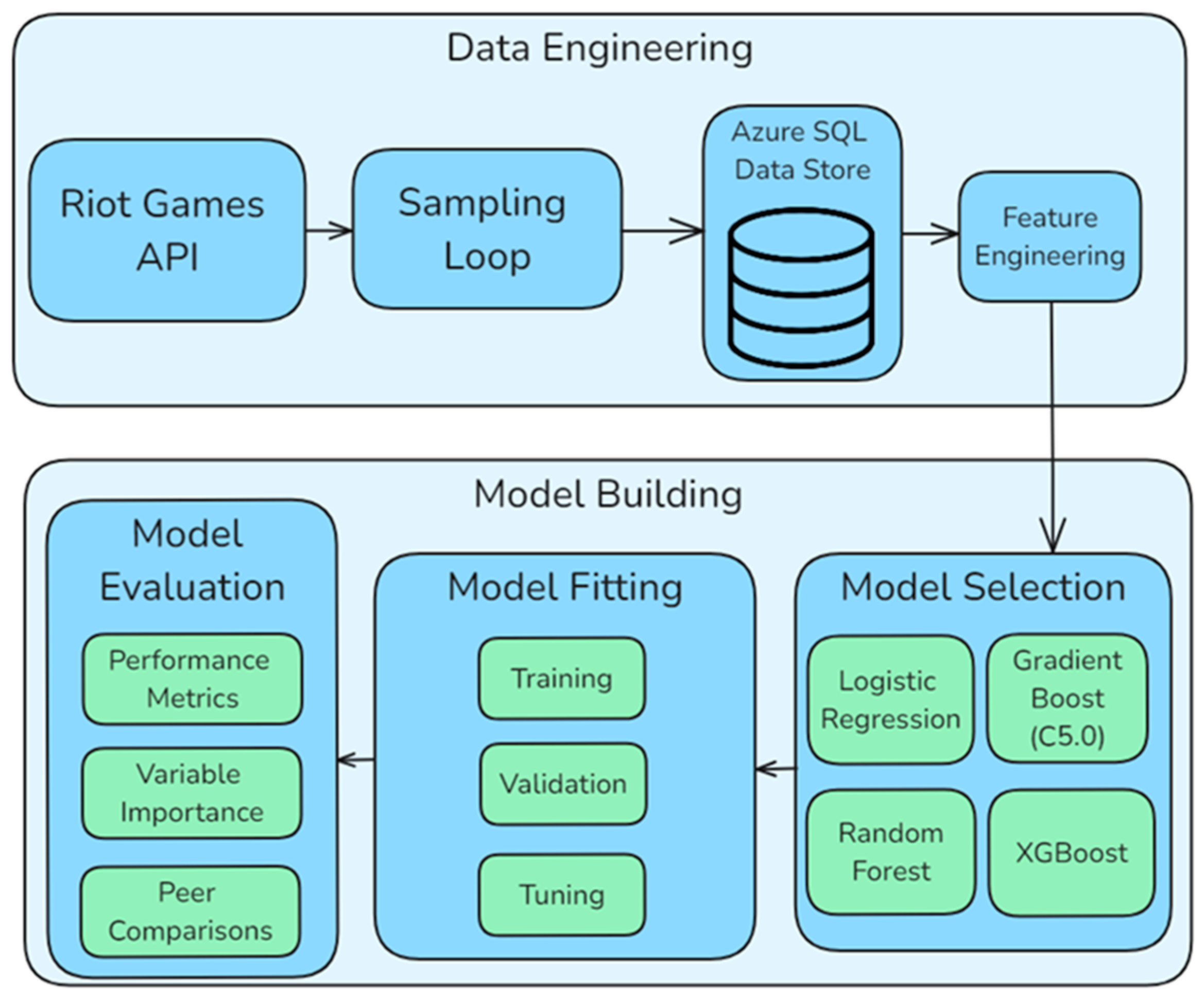
- This study provides a data engineering framework to allow easy representative sampling from the Riot API, which can be extended to incorporate further features easily.
- It explores the relative importance of pre-game vs. in-game in the context of predicting match outcomes while also ensuring that the results are generalizable across all different skill levels in the player base, as opposed to professional matches, which are the focus of much of the literature. The models built on representative training data still have high accuracy (76.8%) when combining pre-game and in-game features.
- Finally, it bridges the findings of offline, player-centric studies looking at the effects of factors such as mindset, tilt, and ‘streakiness’ with online game-centric studies built around model training high-volume API data. It does this by engineering a novel ‘streak’ feature from the API and providing a set of functions to enable replication of this feature engineering in the future. It explored the impact of this streak feature on the prediction accuracy. By doing so, it will assess whether the findings of smaller, focused qualitative studies are equally applicable at macro scales.
2. Review of the Existing Literature
2.1. Overview of League of Legends
2.2. Current Research on Machine Learning for Match Prediction
2.3. Research Gap
- Data from nonprofessional matches (important for the generalization of predictions)
- A representative split of player skill in their dataset was ensured via the player’s in-game ranking.
- Pre-game and in-game features are combined in one model.
- Researchers have attempted to engineer features that could be linked to factors explored in experimental studies, such as the effects of tilt and streakiness.
3. Proposed Research Methodology
3.1. Sampling
3.2. Feature Engineering
3.3. Models
3.3.1. Logistic Regression
3.3.2. Random Forest
3.3.3. Gradient Boost and XGBoost
- Initializing a model with a weak learner (a decision tree with limited depth)
- Quantifying the model error is quantified via a chosen loss function (usually Cross Entropy for classification).
- Gradient Descent is used to compute the direction and magnitude of the steepest decrease in error.
- Subsequent weak learners attempt to minimize loss based on the derivative of the loss function with respect to the previous tree’s prediction.
- The outputs of subsequent learners are scaled down by a learning rate hyperparameter before being added to the ensemble. This limits the rate of improvement per iteration step, reduces overfitting, and aids convergence.
- A regularization parameter is added to determine the optimal split, further reducing overfitting.
- An approximate greedy algorithm that utilizes a Weighted Quantile Sketch algorithm for selecting the optimal split is introduced. This vastly improves performance on large, highly dimensional datasets, as it also allows parallelization.
- A novel sparsity-aware splitting algorithm that optimizes for missing data by creating default directions to follow when building the tree ensures that only nonmissing branches are visited. This also reduces the need for preprocessing to remove missing observations.
- Cache-aware access is implemented by allocating a buffer in the cache for computed gradients, which rapidly increases the speed at which subsequent trees can compute their loss.
- This method optimizes for hard-disk access in large datasets by compressing data, reducing the need for repeated reads on the hard drive. In instances where data are split across multiple drives, XGBoost can also make use of sharding to parallelize access to data, further improving training speed.
3.4. Training and Evaluation
- Tree depth;
- Minimum number of data points at a node for further splitting;
- Minimum loss reduction for a split;
- Fraction of training data used for each tree;
- Number of predictors sampled at each split;
- Learning rate.
- Minimum number of data points at a node for further splitting;
- Fraction of training data used for each tree.
- Number of predictors sampled at each split;
- Minimum data points at node for further splitting.
4. Results and Discussion
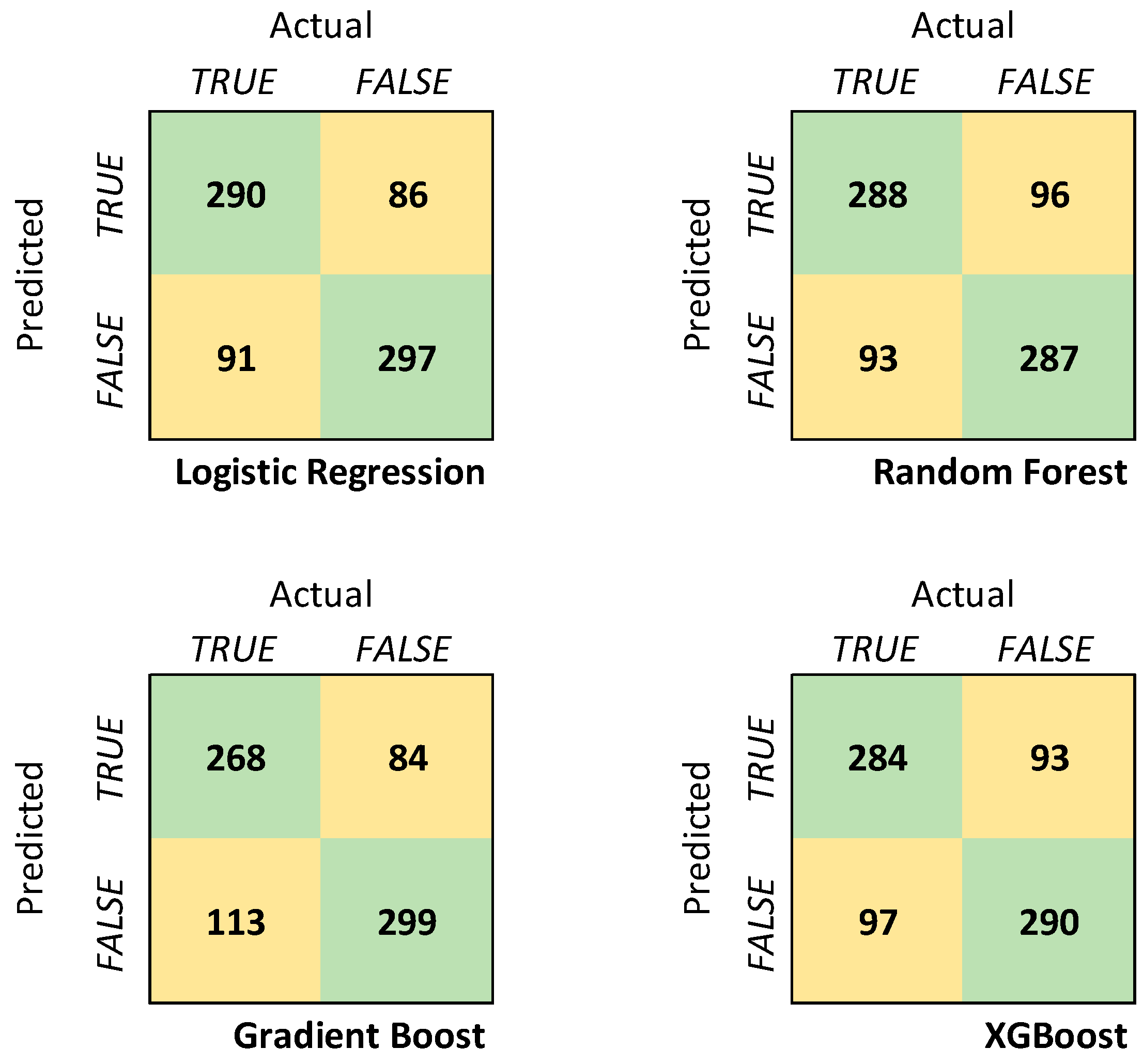
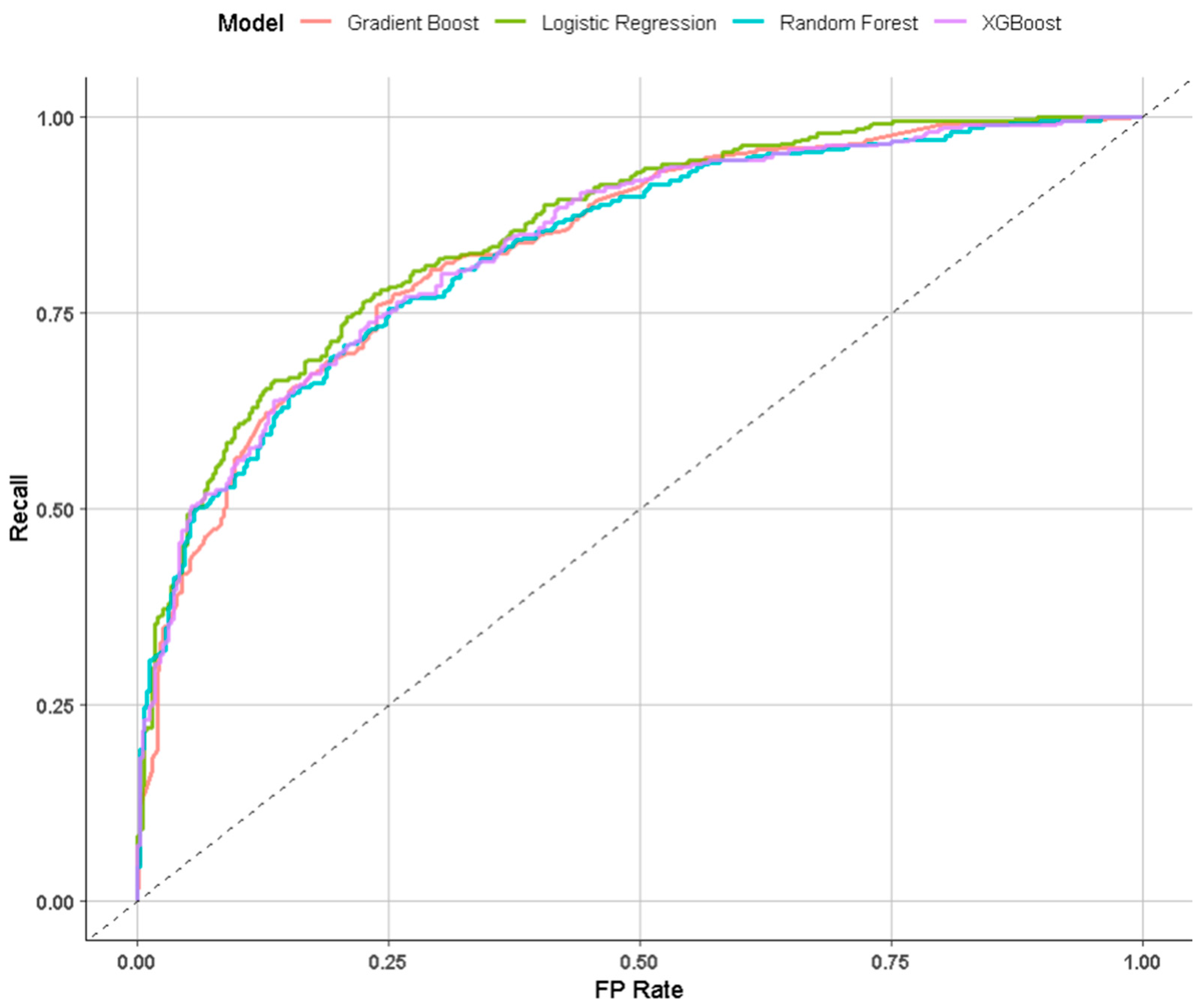
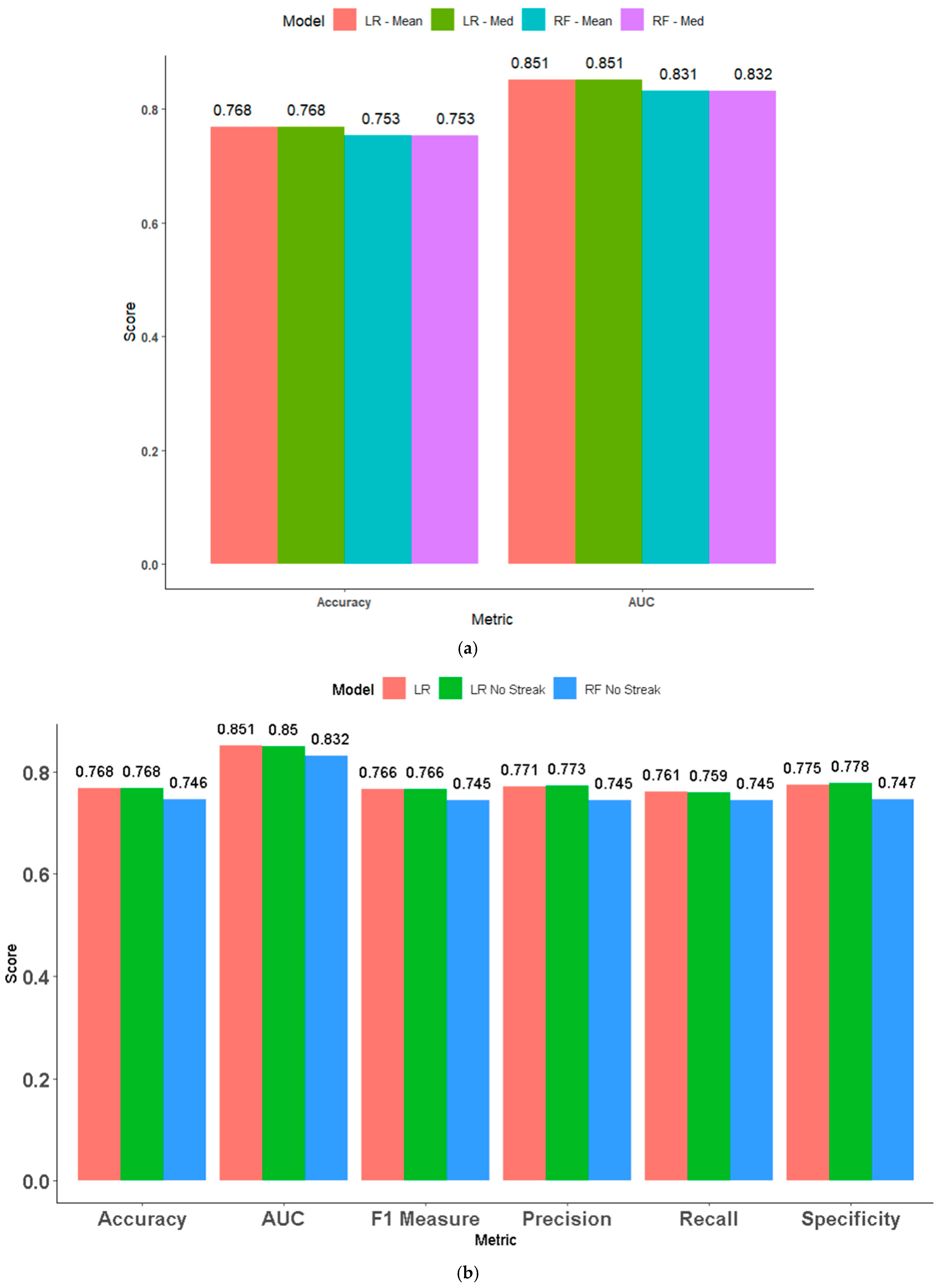
4.1. Combined Pre-Game/In-Game Model Performance
- -
- The external train/test split mechanism that was used (75%/25%) meant only 75% of data were available for training at all (n = 2290).
- -
- Cross-validation during the training phase meant only 90% of data were available during any given iteration (2290 × 0.9 = 2061).
- -
- The internal bootstrapping mechanisms of tree models further reduce the information space. The ranger engine, for instance, internally reserves 36.8% of samples for out-of-bag error estimation during its training phase, meaning each tree would be trained on 2061 × 0.632 = 1302 samples. C5.0 and XGBoost also use the sample size hyperparameter to train on a subset of data only.
- -
- This could have meant increased variance in performance across both folds and trees within the models; however, it does mean comprehensive validation of models against unseen data at multiple layers.
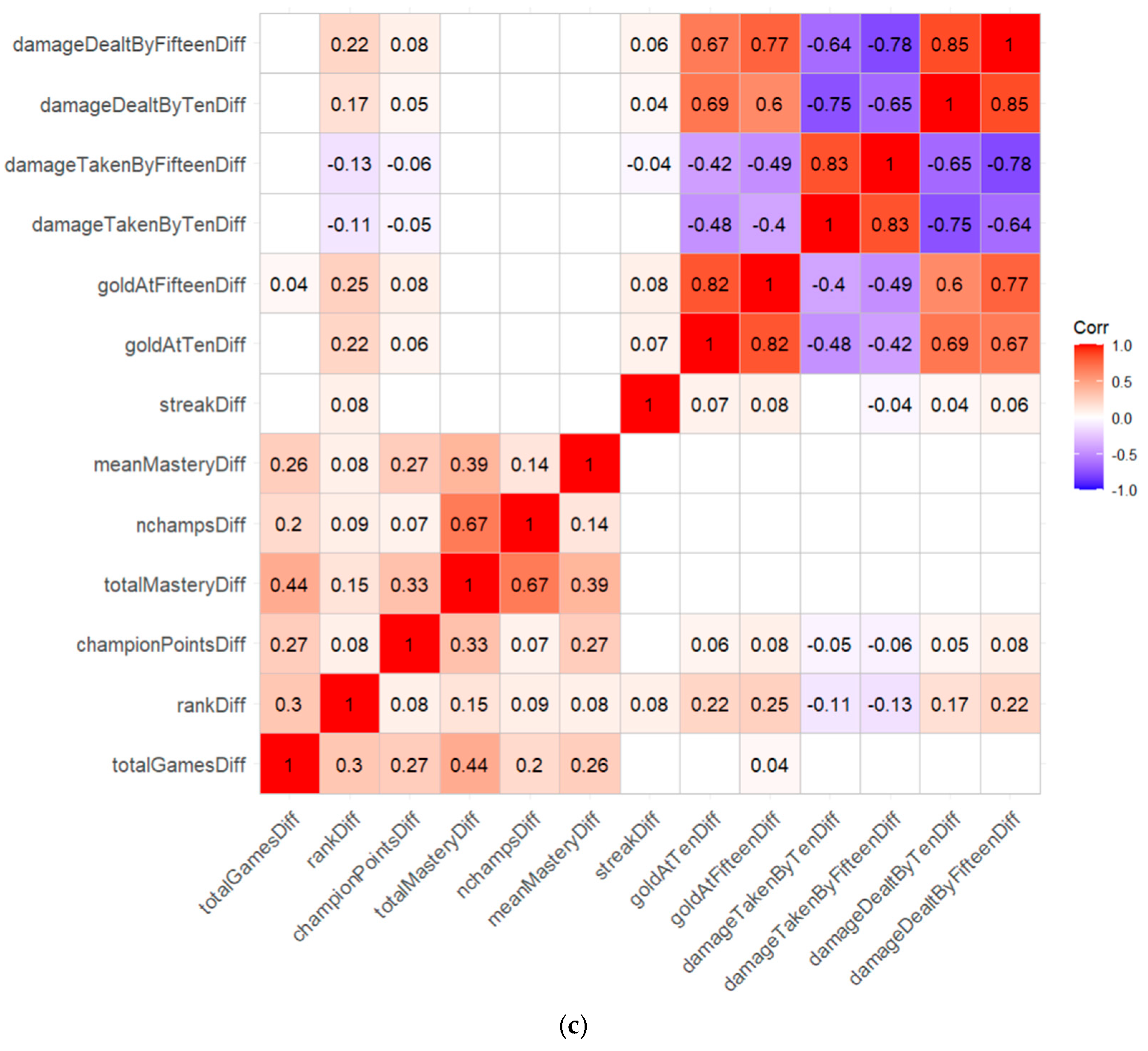
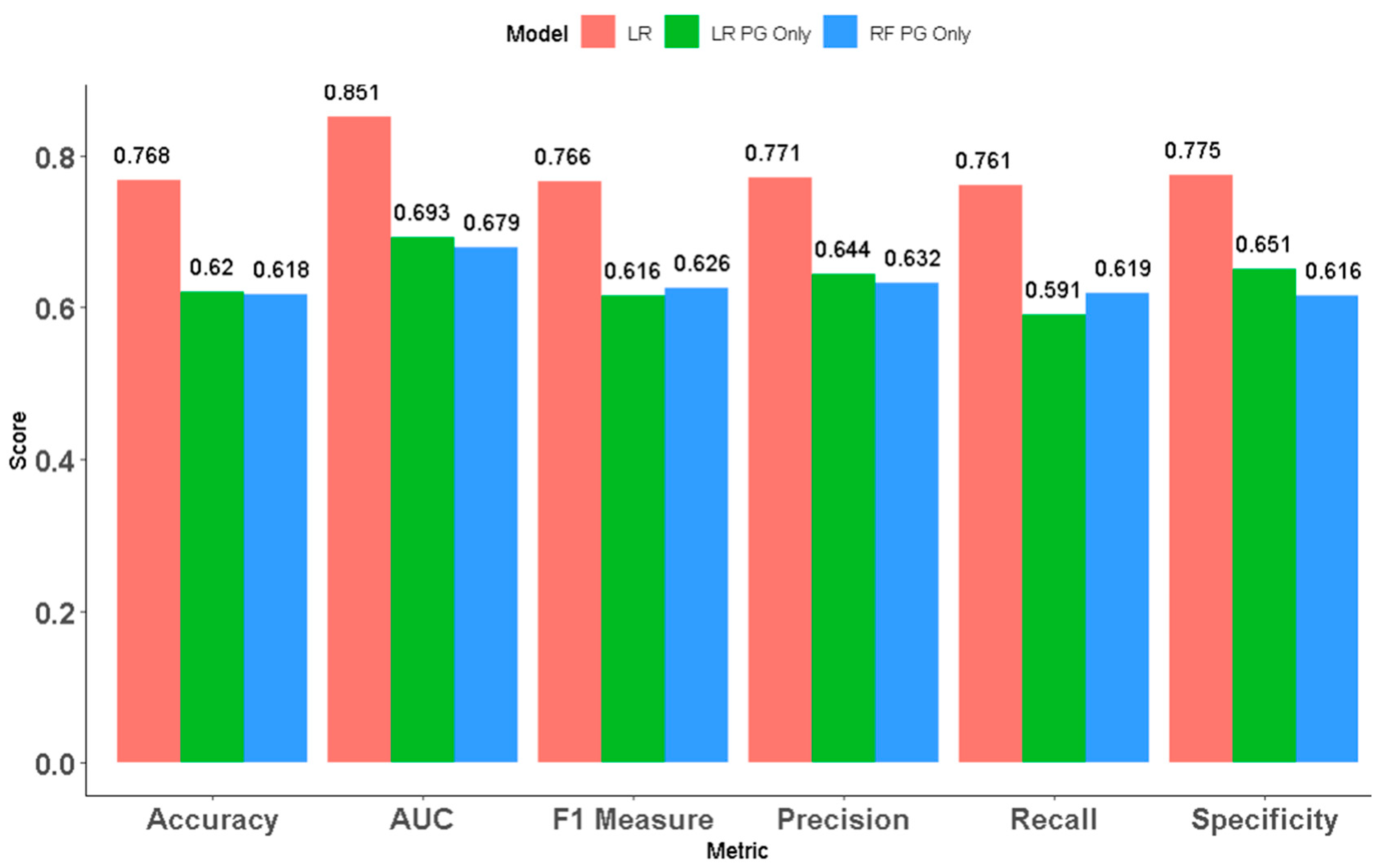
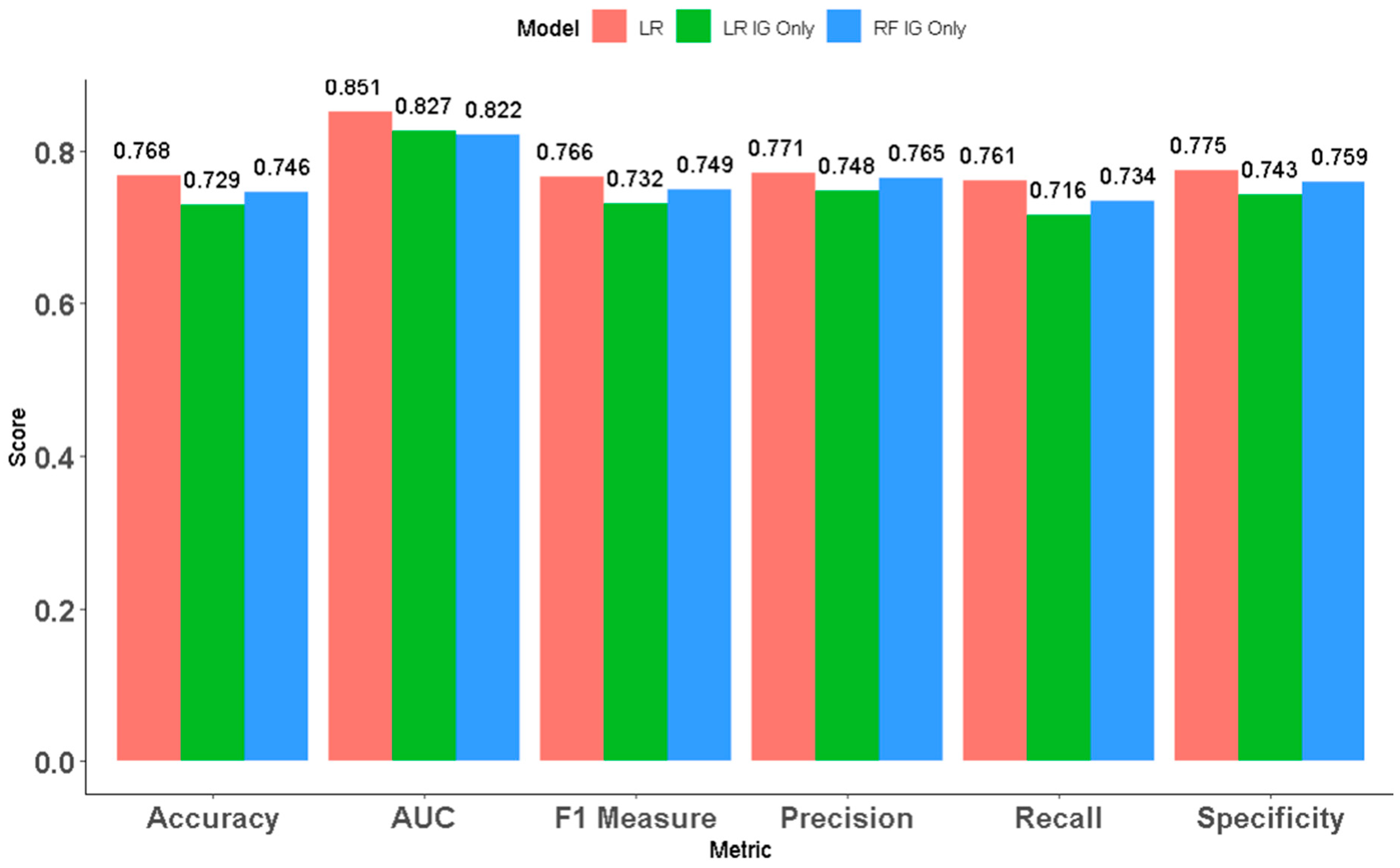
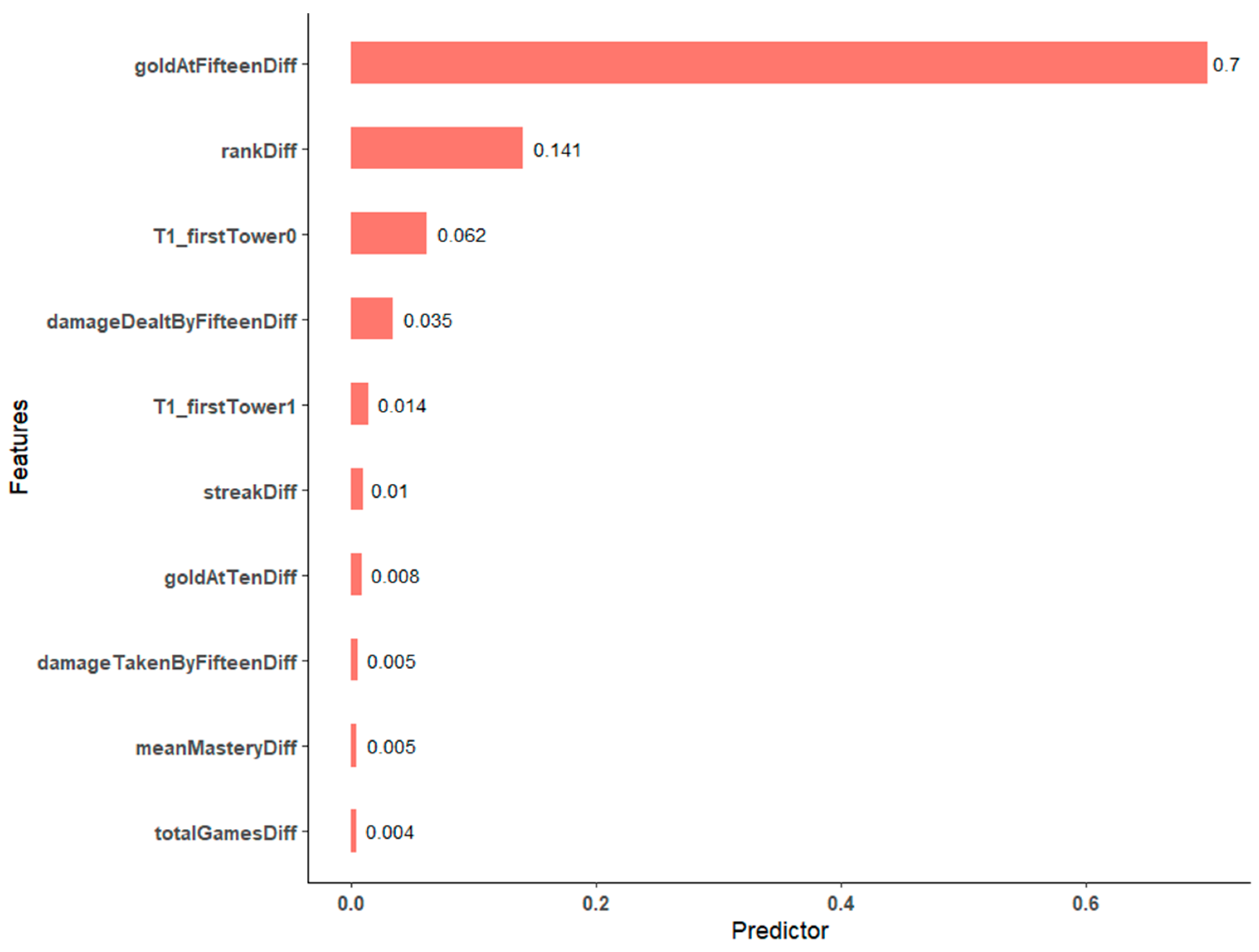
4.2. Variable Importance Groups
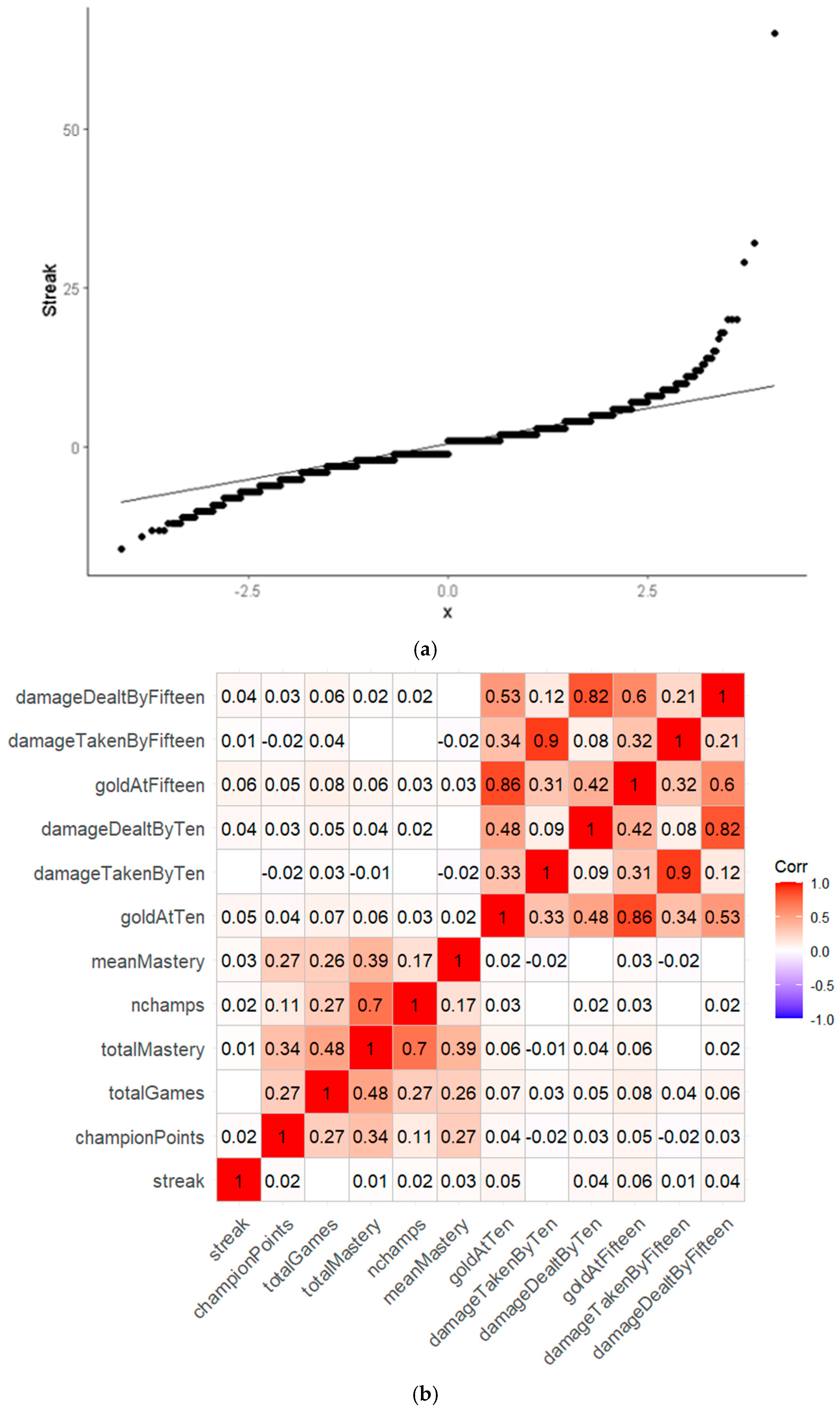
4.3. Effect of Streak
4.4. Critical Analysis and Discussion
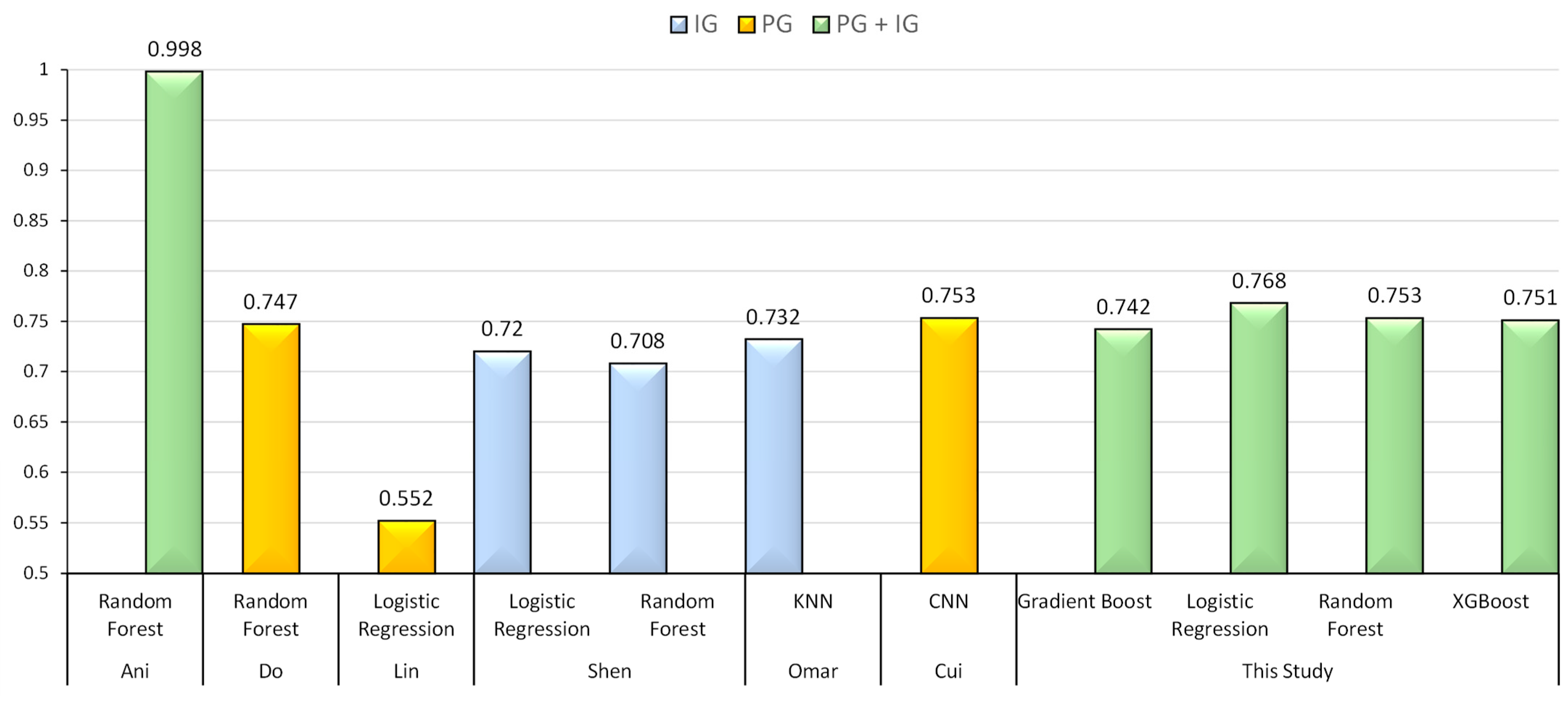
4.4.1. Combined Model Performance Against Existing Literature
4.4.2. The Effect of Streak
4.4.3. Strengths of This Work
4.4.4. Limitations and Future Research
5. Conclusions
- Models trained on a representative dataset (by rank split of players) of matches show reasonable accuracy (76.8% for the best-performing model) compared with models trained on datasets from professional matches only.
- Streak is a relatively important pre-game predictor but has low predictive power in a combined pre-game/in-game model. In-game predictors contribute more to feature importance than pre-game predictors do.
- Compared with the models trained on only pre-game (62% for the best performing) or in-game (74.6% for the best performing) features, the models trained on the combined pre-game and early in-game feature sets have improved accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bhattacharyya, S.; Jha, S.; Tharakunnel, K.; Westland, J.C. Data mining for credit card fraud: A comparative study. Decis. Support Syst. 2011, 50, 602–613. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Balkanli, E.; Zincir-Heywood, A.N. On the analysis of backscatter traffic. In Proceedings of the 2014 IEEE 39th Conference on Local Computer Networks (LCN), Edmonton, AB, Canada, 8–11 September 2014; pp. 671–678. [Google Scholar] [CrossRef]
- Hina, M.; Ali, M.; Javed, A.R.; Srivastava, G.; Gadekallu, T.R.; Jalil, Z. Email Classification and Forensics Analysis using Machine Learning. In Proceedings of the 2021 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/IOP/SCI), Virtual, 18–21 October 2021; pp. 630–635. [Google Scholar] [CrossRef]
- Herold, M.; Goes, F.; Nopp, S.; Bauer, P.; Thompson, C.; Meyer, T. Machine learning in men’s professional football: Current applications and future directions for improving attacking play. Int. J. Sports Sci. Coach. 2019, 14, 798–817. [Google Scholar] [CrossRef]
- Cornman, A.; Spellman, G.; Wright, D. Machine Learning for Professional Tennis Match Prediction and Betting; Working Paper; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Miljković, D.; Gajić, L.; Kovačević, A.; Konjović, Z. The use of data mining for basketball matches outcomes prediction. In Proceedings of the IEEE 8th International Symposium on Intelligent and Informatics, Subotica, Serbia, 10–11 September 2010; pp. 309–312. [Google Scholar] [CrossRef]
- Bunker, R.P.; Thabtah, F. A machine learning framework for sport result prediction. Appl. Comput. Inform. 2019, 15, 27–33. [Google Scholar] [CrossRef]
- Gaming Market Size, Share & Growth|Research Report [2028]. Available online: https://www.fortunebusinessinsights.com/gaming-market-105730 (accessed on 23 May 2022).
- Sibley, A. Predicting Win Rates in Competitive OverwatchTM; Louisiana State University: Baton Rouge, LA, USA, 2019. [Google Scholar]
- League of Legends Live Player Count and Statistics. Available online: https://activeplayer.io/league-of-legends/ (accessed on 27 October 2022).
- League of Legends—Statistics & Facts|Statista. Available online: https://www.statista.com/topics/4266/league-of-legends/#dossierKeyfigures (accessed on 23 May 2022).
- Riot Developer Portal. Available online: https://developer.riotgames.com/terms#definitions (accessed on 20 May 2022).
- Caino, P.C.G.; Resett, S. Toxic Behavior and Tilt as Predictors of Mental Toughness in League of Legends Players of Argentina. In Communications in Computer and Information Science; CCIS: Cham, Switzerland, 2024; Volume 1958, pp. 464–468. [Google Scholar] [CrossRef]
- Jeong, I.; Kudo, K.; Kaneko, N.; Nakazawa, K. Esports experts have a wide gaze distribution and short gaze fixation duration: A focus on League of Legends players. PLoS ONE 2024, 19, e0288770. [Google Scholar] [CrossRef] [PubMed]
- Fuentes, R. A Qualitative Examination of Tilt in League of Legends Esports Players. Master’s Thesis, Högskolan i Halmstad, Halmstad, Sweden, 2021. [Google Scholar]
- Do, T.D.; Wang, S.I.; Yu, D.S.; Mcmillian, M.G.; Mcmahan, R.P.; Wang, I. Using Machine Learning to Predict Game Outcomes Based on Player-Champion Experience in League of Legends. In Proceedings of the 16th International Conference on the Foundations of Digital Games (FDG) 2021, Montreal, QC, Canada, 3–6 August 2021. [Google Scholar] [CrossRef]
- Eaton, J.A.; Mendonça, D.J.; Sangster, M.-D.D. Attack, Damage and Carry: Role Familiarity and Team Performance in League of Legends. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Philadelphia, PA, USA, 1–5 October 2018; Volume 1, pp. 130–134. [Google Scholar] [CrossRef]
- Maymin, P.Z. Smart kills and worthless deaths: eSports analytics for League of Legends. J. Quant. Anal. Sports 2020, 17, 11–27. [Google Scholar] [CrossRef]
- Birant, K.U. Multi-view rank-based random forest: A new algorithm for prediction in eSports. Expert Syst. 2021, 39, e12857. [Google Scholar] [CrossRef]
- Liang, M. Research on Prediction of the Game Winner Based on Artificial Intelligence Methods. In Proceedings of the 5th International Conference on Advances in Image Processing, Chengdu, China, 12–14 November 2021; pp. 97–102. [Google Scholar] [CrossRef]
- League of Legends—1.000.000+ Master+ 1v1 Matchup|Kaggle. Available online: https://www.kaggle.com/datasets/jasperan/league-of-legends-1v1-matchups-results (accessed on 20 May 2022).
- Laurel, K.E.Y.; Gutierrez, A.N.R.; Tan, K.A.S.; Baldovino, R.G. Using Multiple AI Classification Models to Predict the Winner of a League of Legends (LoL) Game Based on its First 10-Minutes of Gameplay. In Proceedings of the 2023 International Conference on Consumer Electronics—Taiwan (ICCE-Taiwan), Pingtung, Taiwan, 17–19 July 2023; pp. 693–694. [Google Scholar] [CrossRef]
- Lin, L. League of Legends Match Outcome Prediction; Computer Science Department, Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Junior, J.; Campelo, C.E. League of Legends: Real-Time Result Prediction. arXiv 2023, arXiv:2309.02449. [Google Scholar]
- Kou, Y.; Li, Y.; Gui, X.; Suzuki-Gill, E. Playing with streakiness in online games: How players perceive and react to winning and losing streaks in league of legends. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–14. [Google Scholar] [CrossRef]
- Dubois, L.-E.; Weststar, J. Games-as-a-service: Conflicted identities on the new front-line of video game development. New Media Soc. 2021, 24, 2332–2353. [Google Scholar] [CrossRef]
- Demediuk, S.; Murrin, A.; Bulger, D.; Hitchens, M.; Drachen, A.; Raffe, W.L.; Tamassia, M. Player retention in league of legends: A study using survival analysis. In Proceedings of the Australasian Computer Science Week Multiconference, Brisbane, QLD, Australia, 29 January–2 February 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Figueroa, R.L.; Zeng-Treitler, Q.; Kandula, S.; Ngo, L.H. Predicting sample size required for classification performance. BMC Med. Inform. Decis. Mak. 2012, 12, 8. [Google Scholar] [CrossRef]
- Kica, A.; La Manna, A.; O’Donnell, L.; Paolillo, T.; Claypool, M. Nerfs, Buffs and Bugs—Analysis of the Impact of Patching on League of Legends. In Proceedings of the 2016 International Conference on Collaboration Technologies and Systems (CTS), Orlando, FL, USA, 31 October–4 November 2016; pp. 128–135. [Google Scholar]
- Do, T.D.; Yu, D.S.; Anwer, S.; Wang, S.I. Using Collaborative Filtering to Recommend Champions in League of Legends. In Proceedings of the 2020 IEEE Conference on Games (CoG), Osaka, Japan, 24–27 August 2020; pp. 650–653. [Google Scholar] [CrossRef]
- Mora-Cantallops, M.; Sicilia, M. Team efficiency and network structure: The case of professional League of Legends. Soc. Netw. 2019, 58, 105–115. [Google Scholar] [CrossRef]
- Jonquière, É. Investigating the Role of Esport on the Free to Play Business Model: An Analysis of League of Legends Economic Success. Master’s Thesis, ISCTE-Instituto Universitario de Lisboa, Lisboa, Portugal, 2020. [Google Scholar]
- Sabtan, B.; Cao, S.; Paul, N. Current practice and challenges in coaching Esports players: An interview study with league of legends professional team coaches. Entertain. Comput. 2022, 42, 100481. [Google Scholar] [CrossRef]
- Kou, Y.; Gui, X.; Kow, Y.M. Ranking Practices and Distinction in League of Legends. In Proceedings of the 2016 Annual Symposium on Computer-Human Interaction in Play (CHI PLAY 2016), Austin, TX, USA, 16–19 October 2016; pp. 4–9. [Google Scholar]
- Monge, C.K.; O’brien, T.C. Effects of individual toxic behavior on team performance in League of Legends. Media Psychol. 2021, 25, 82–105. [Google Scholar] [CrossRef]
- Kho, L.C.; Kasihmuddin, M.S.M.; Mansor, M.A.; Sathasivam, S. Science & Technology Logic Mining in League of Legends. Pertanika J. Sci. Technol. 2020, 28, 211–225. [Google Scholar]
- Hitar-García, J.A.; Morán-Fernández, L.; Bolón-Canedo, V. Machine Learning Methods for Predicting League of Legends Game Outcome. IEEE Trans. Games 2022, 15, 171–181. [Google Scholar] [CrossRef]
- Costa, L.M.; Mantovani, R.G.; Souza, F.C.M.; Xexeo, G. Feature Analysis to League of Legends Victory Prediction on the Picks and Bans Phase. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Luis, A.; Silva, C.; Pappa, G.L.; Chaimowicz, L. Continuous Outcome Prediction of League of Legends Competitive Matches Using Recurrent Neural Networks. In Proceedings of the SBC—Proceedings of SBGames 2018, Foz do Iguaçu, Brazil, 29 October–1 November 2018. [Google Scholar]
- Ani, R.; Harikumar, V.; Devan, A.K.; Deepa, O. Victory prediction in League of Legends using Feature Selection and Ensemble methods. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 74–77. [Google Scholar] [CrossRef]
- Li, Q.; Xu, P.; Chan, Y.Y.; Wang, Y.; Wang, Z.; Qu, H.; Ma, X. A Visual Analytics Approach for Understanding Reasons behind Snowballing and Comeback in MOBA Games. IEEE Trans. Vis. Comput. Graph. 2016, 23, 211–220. [Google Scholar] [CrossRef]
- Peabody, D. Detecting Metagame Shifts in League of Legends Using Unsupervised Learning; University of New Orleans: New Orleans, LA, USA, 2018. [Google Scholar]
- Jadowski, R.; Cunningham, S. Statistical Models for Predicting Results in Professional League of Legends. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering (LNICST); Springer International Publishing: Cham, Switzerland, 2022; Volume 422, pp. 138–152. [Google Scholar] [CrossRef]
- Donaldson, S. Mechanics and Metagame. Games Cult. 2015, 12, 426–444. [Google Scholar] [CrossRef]
- Kim, Y.J.; Engel, D.; Woolley, A.W.; Lin, J.Y.T.; McArthur, N.; Malone, T.W. What Makes a Strong Team? Using Collective Intelligence to Predict Team Performance in League of Legends. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017. [Google Scholar] [CrossRef]
- Leavitt, A.; Keegan, B.C.; Clark, J. Ping to win? Nonverbal communication and team performance in competitive online multiplayer games. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 4337–4350. [Google Scholar] [CrossRef]
- Ong, H.Y.; Deolalikar, S.; Peng, M.V. Player Behavior and Optimal Team Composition for Online Multiplayer Games. arXiv 2015, arXiv:1503.02230. [Google Scholar]
- Zhang, X.; Gu, X.; Niu, B.; Feng, Y.Y. Investigating the Impact of Champion Features and Player Information on Champion Usage in League of Legends. In Proceedings of the 2017 International Conference on Information Technology—ICIT 2017, Singapore, 27–29 December 2017. [Google Scholar] [CrossRef]
- Cruz, A.C.S.; De, T.; Filho, M.; Malheiros, Y. League of Legends: An Application of Classification Algorithms to Verify the Prediction Importance of Main In-Game Variables. In Proceedings of the SB Games 2021, Gramado, Brazil, 18–21 October 2021. [Google Scholar]
- Chu, X.; Ilyas, I.F.; Krishnan, S.; Wang, J. Data cleaning: Overview and emerging challenges. In Proceedings of the ACM SIGMOD International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 2201–2206. [Google Scholar] [CrossRef]
- Somasundaram, R.; Nedunchezhian, R. Evaluation of Three Simple Imputation Methods for Enhancing Preprocessing of Data with Missing Values. Int. J. Comput. Appl. 2011, 21, 14–19. [Google Scholar] [CrossRef]
- League of Legends Rank Distribution in Solo Queue—November 2022|Esports Tales. Available online: https://www.esportstales.com/league-of-legends/rank-distribution-percentage-of-players-by-tier (accessed on 13 December 2022).
- Zhang, S.; Sadaoui, S.; Mouhoub, M. An Empirical Analysis of Imbalanced Data Classification. Comput. Inf. Sci. 2014, 8, 151. [Google Scholar] [CrossRef]
- Gaina, R.; Nordmoen, C. League of Legends: A Study of Early Game Impact; School of Electronic Engineering and Computer Science, Queen Mary University of London: London, UK, 2018. [Google Scholar]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Albert, A.; Anderson, J.A. On the existence of maximum likelihood estimates in logistic regression models. Biometrika 1984, 71, 1–10. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Hssina, B.; Merbouha, A.; Ezzikouri, H.; Erritali, M. A comparative study of decision tree ID3 and C4.5. Int. J. Adv. Comput. Sci. Appl. 2014, 4, 13–19. [Google Scholar] [CrossRef]
- Cohen, P.R.; Jensen, D. Overfitting explained. In Sixth International Workshop on Artificial Intelligence and Statistics. Mach. Learn. Res. 1997, 115–122. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rokach, L. Decision forest: Twenty years of research. Inf. Fusion 2016, 27, 111–125. [Google Scholar] [CrossRef]
- Armano, G.; Tamponi, E. Building forests of local trees. Pattern Recognit. 2018, 76, 380–390. [Google Scholar] [CrossRef]
- Lindgren, T. Random Rule Sets—Combining Random Covering with the Random Subspace Method. Int. J. Mach. Learn. Comput. 2018, 8, 8–13. [Google Scholar] [CrossRef]
- Loh, W.-Y.; Chen, C.-W.; Zheng, W. Extrapolation errors in linear model trees. ACM Trans. Knowl. Discov. Data 2007, 1, 6-es. [Google Scholar] [CrossRef]
- Fox, E.W.; Hill, R.A.; Leibowitz, S.G.; Olsen, A.R.; Thornbrugh, D.J.; Weber, M.H. Assessing the accuracy and stability of variable selection methods for random forest modeling in ecology. Environ. Monit. Assess. 2017, 189, 316. [Google Scholar] [CrossRef]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection; Morgan Kaufman Publishing: Burlington, MA, USA, 1995. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Tidymodels. Available online: https://www.tidymodels.org/ (accessed on 13 December 2022).
- Wang, S.; Peng, J.; Liu, W. An ℓ2/ℓ1 regularization framework for diverse learning tasks. Signal Process. 2015, 109, 206–211. [Google Scholar] [CrossRef]
- Eggensperger, K.; Feurer, M.; Hutter, F.; Berstra, J.; Snoek, J.; Hoos, H.; Leyton-Brown, K. Towards an Empirical Foundation for Assessing Bayesian Optimization of Hyperparameters. NIPS Workshop Bayesian Optim. Theory Pract. 2013, 10, 1–5. [Google Scholar]
- Neunhoeffer, M.; Sternberg, S. How Cross-Validation Can Go Wrong and What to Do About It. Political Anal. 2018, 27, 101–106. [Google Scholar] [CrossRef]
- Mentch, L.; Hooker, G. Quantifying Uncertainty in Random Forests via Confidence Intervals and Hypothesis Tests. J. Mach. Learn. Res. 2014, 17, 1–41. [Google Scholar]
- Archer, K.J.; Kimes, R.V. Empirical characterization of random forest variable importance measures. Comput. Stat. Data Anal. 2008, 52, 2249–2260. [Google Scholar] [CrossRef]
- Thiese, M.S.; Ronna, B.; Ott, U. P value interpretations and considerations. J. Thorac. Dis. 2016, 8, E928–E931. [Google Scholar] [CrossRef]
- Wu, M.; Lee, J.S.; Steinkuehler, C. Understanding Tilt in Esports: A Study on Young League of Legends Players. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Virtual, 8–13 May 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Shen, Q. A machine learning approach to predict the result of League of Legends. In Proceedings of the 2022 International Conference on Machine Learning and Knowledge Engineering (MLKE), Guilin, China, 25–27 February 2022; pp. 38–45. [Google Scholar] [CrossRef]
- Omar, H.I.; Prayogo, M.; Muliawan, V.; Gunawan, A.A.S.; Setiawan, K.E. Finding Feature Importance in Optimized Classification Model: League of Legends Ranked Matches. In Proceedings of the 2024 IEEE International Conference on Artificial Intelligence and Mechatronics Systems (AIMS), Bandung, Indonesia, 22–23 February 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Cui, H. Research on winning rate prediction of e-sport League of Legends based on machine learning. In Proceedings of the International Conference on Optics, Electronics, and Communication Engineering (OECE 2024), Wuhan, China, 12 November 2024; Volume 133953E. [Google Scholar] [CrossRef]
- Cordova, C.J.A.; Villaceran, C.V.A.; Peña, C.F. Predicting League of Legends Match Outcomes Through Machine Learning Models Using Past Match Player Performance. In Proceedings of the 2024 IEEE International Conference on Computing (ICOCO), Kuala Lumpur, Malaysia, 12–14 December 2024; pp. 522–527. [Google Scholar] [CrossRef]
- Eaton, J.A.; Sangster, M.-D.D.; Renaud, M.; Mendonca, D.J.; Gray, W.D. Carrying the Team: The Importance of One Player’s Survival for Team Success in League of Legends. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; SAGE Publications: Los Angeles, CA, USA, 2017; pp. 272–276. [Google Scholar] [CrossRef]
- Bahrololloomi, F.; Klonowski, F.; Sauer, S.; Horst, R.; Dörner, R. E-Sports Player Performance Metrics for Predicting the Outcome of League of Legends Matches Considering Player Roles. SN Comput. Sci. 2023, 4, 238. [Google Scholar] [CrossRef]
- Asgarkhani, N.; Kazemi, F.; Jankowski, R. Machine learning-based prediction of residual drift and seismic risk assessment of steel moment-resisting frames considering soil-structure interaction. Comput. Struct. 2023, 289, 107181. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Records | % |
|---|---|---|
| Iron | 2118 | 7% |
| Bronze | 5505 | 18% |
| Silver | 5797 | 19% |
| Gold | 5569 | 18% |
| Platinum | 5643 | 18% |
| Diamond | 4905 | 16% |
| Master | 980 | 3% |
| Grandmaster | 17 | 0% |
| Team 1 Won | Records | % |
|---|---|---|
| False | 15,300 | 50.1% |
| True | 15,240 | 49.9% |
| Pre-Game Predictors | In-Game Predictors |
|---|---|
| Average difference between teams in: | Whether Team 1 eliminated an opponent first |
| Total games played | Whether Team 1 secured the first objective of the game |
| Rank | Average difference between teams in: |
| Experience on selected character | Difference in average gold acquired at 10 min |
| Total experience across all characters | Difference in average gold acquired at 15 min |
| Number of characters played across all games | Difference in average damage taken by 10 min |
| Mean experience across all characters | Difference in average damage taken by 15 min |
| Current win/loss streak | Difference in average damage dealt by 10 min |
| Difference in average damage dealt by 15 min |
| Predictor | Odds Ratio | p Value |
|---|---|---|
| rankDiff | 0.513 | 2.76 × 10−25 |
| streakDiff | 0.880 | 1.95 × 10−2 |
| goldAtFifteenDiff | 0.176 | 2.79 × 10−28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chowdhury, S.; Ahsan, M.; Barraclough, P. Applications of Linear and Ensemble-Based Machine Learning for Predicting Winning Teams in League of Legends. Appl. Sci. 2025, 15, 5241. https://doi.org/10.3390/app15105241
Chowdhury S, Ahsan M, Barraclough P. Applications of Linear and Ensemble-Based Machine Learning for Predicting Winning Teams in League of Legends. Applied Sciences. 2025; 15(10):5241. https://doi.org/10.3390/app15105241
Chicago/Turabian StyleChowdhury, Supratik, Mominul Ahsan, and Phoebe Barraclough. 2025. "Applications of Linear and Ensemble-Based Machine Learning for Predicting Winning Teams in League of Legends" Applied Sciences 15, no. 10: 5241. https://doi.org/10.3390/app15105241
APA StyleChowdhury, S., Ahsan, M., & Barraclough, P. (2025). Applications of Linear and Ensemble-Based Machine Learning for Predicting Winning Teams in League of Legends. Applied Sciences, 15(10), 5241. https://doi.org/10.3390/app15105241