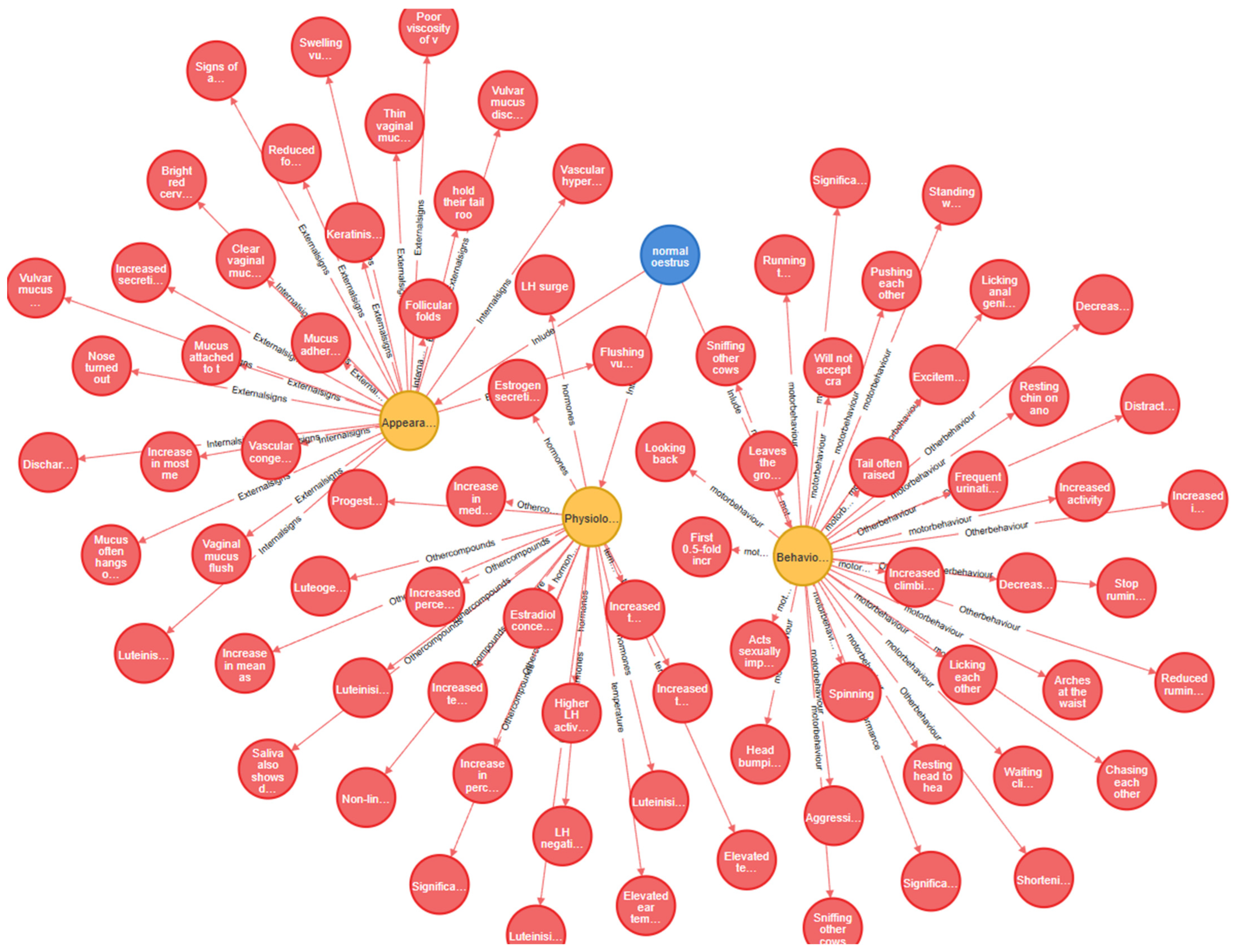
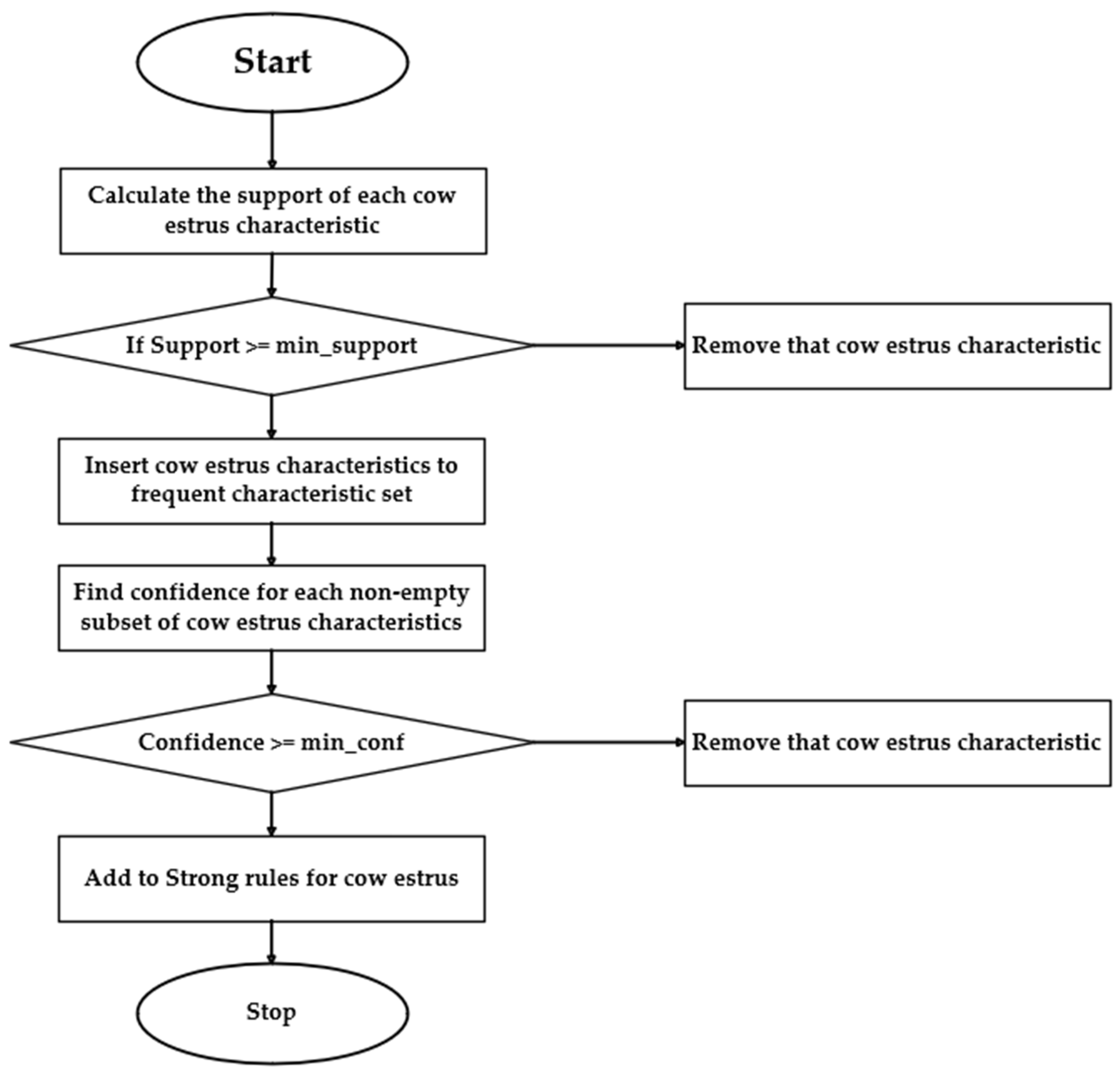
Although a knowledge graph was constructed and 22 strong association rules were identified, and while the introduction of lift led to the deletion of 10 rules and the addition of 7 new ones, the accuracy of these rules in predicting estrus cannot be assessed solely based on these metrics. Therefore, we developed rule-based Boolean functions to judge estrus, and compared the association rules mined by the knowledge graph-based approach and the FP-Growth-based approach to assess whether the association rules positively impacted the completeness of the knowledge graph.
5.1. Data Preparation and Quantification of the Characteristics of Association Rules
To ensure the reliability and generalizability of the results, we utilized an independent dataset that was not involved in the rule mining process. The data were gathered through web crawling techniques to extract information on cow estrus and non-estrus cases from various online resources, excluding the China National Knowledge Infrastructure (CNKI). This approach allowed us to gather a wide range of data from different sources, ensuring diversity and comprehensiveness. Specifically, we sourced data from websites such as the Journal of Dairy Science, which provided data on estrus and non-estrus behaviors. Additionally, we utilized data from agricultural databases and research institutions to supplement our dataset.
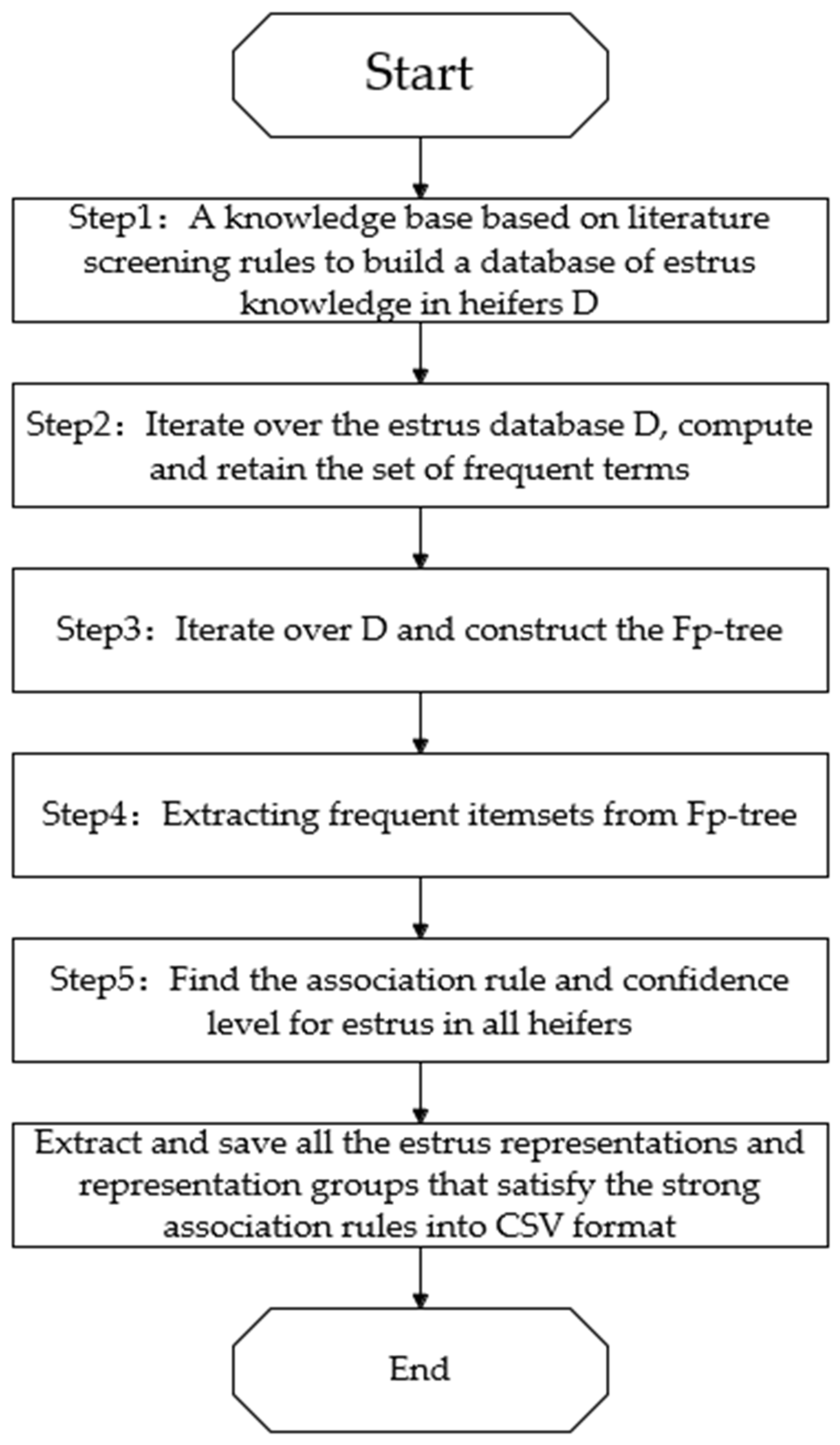
The data underwent a series of preprocessing steps, similar to the workflow depicted in
Figure 1 for processing the CNKI data. This included the removal of duplicates and the correction of inconsistencies to ensure data quality. The dataset was then randomly divided into training and testing sets, maintaining the randomness and representativeness of the data. Specifically, 70% of the data were used for training and 30% were used for testing. This split ratio was chosen to provide a sufficient amount of data for both training and validation, ensuring that the model could be effectively evaluated.
To assess the impact of dataset size on the performance of the estrus prediction model, we prepared three different datasets, with 200, 500, and 1000 data entries, respectively. These datasets were randomly selected to ensure representativeness and unbiased results. The data were carefully cleaned and preprocessed to remove duplicates and inconsistencies, ensuring the quality and reliability of the dataset.
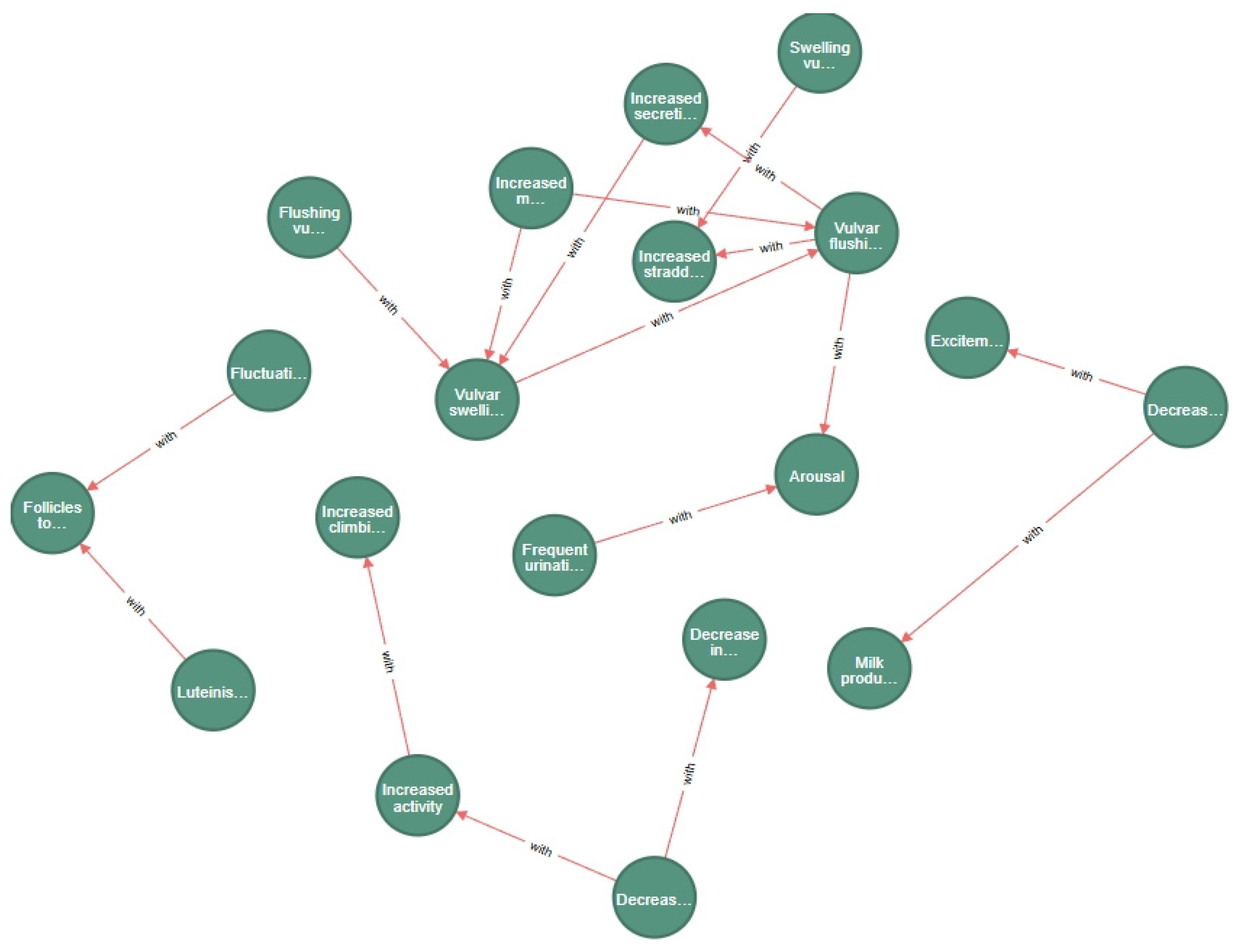
The data source of this study was based on the quantitative indicators related to estrus in heifers extracted from the literature knowledge base, and the CiteSpace literature indexing tool was used to systematically sort and screen six types of quantifiable core features in the strong association rules: increase in the multiplicity of the amount of exercise, increase in body temperature, decrease in the amount of ruminating, decrease in the amount of rumination, shortening of ruminating time, change in the amount of milk production, and change in the amount of laying down time. These indexes were summarized through empirical studies in several literature studies, covering multi-dimensional patterns of change in the physiology, behavior, and production performance of heifers during estrus.
In constructing an abnormal estrus discrimination model, the core challenge of feature quantification lay in the individual differences and environmental heterogeneity of heifers. Baseline values of exercise during estrus may vary significantly among heifers of different breeds, ages, and rearing conditions. If absolute values are used directly, such as ‘1000 step increase in exercise’ as the discriminant threshold, this will lead to limited generalization, feature range expansion, and reduced interpretability. Individual baseline differences make it difficult to adapt absolute thresholds to different farms or herds, and the model would be prone to overfitting to a specific dataset, while due to the significant differences in the milk production of high-yielding and low-yielding cows, the range of absolute values fluctuates. Due to the significant difference between high-yielding cows and low-yielding cows, the range of fluctuation of the absolute value may be greatly expanded, leading to a decrease in model differentiation. Moreover, absolute values lack a uniform scale of biological significance, which is not conducive to cross-study comparison and application.
In order to effectively eliminate the influence of individual cow differences and heterogeneity of the breeding environment on the characterization of features, this study used literature data for constructing a knowledge map of estrus in cows, and organized all quantitative data indexes and adopted relative rate of change or multiples as the core quantitative indexes, as shown in the
Table 7.
5.3. Iforest-OCSVM in Abnormal Estrus Prediction
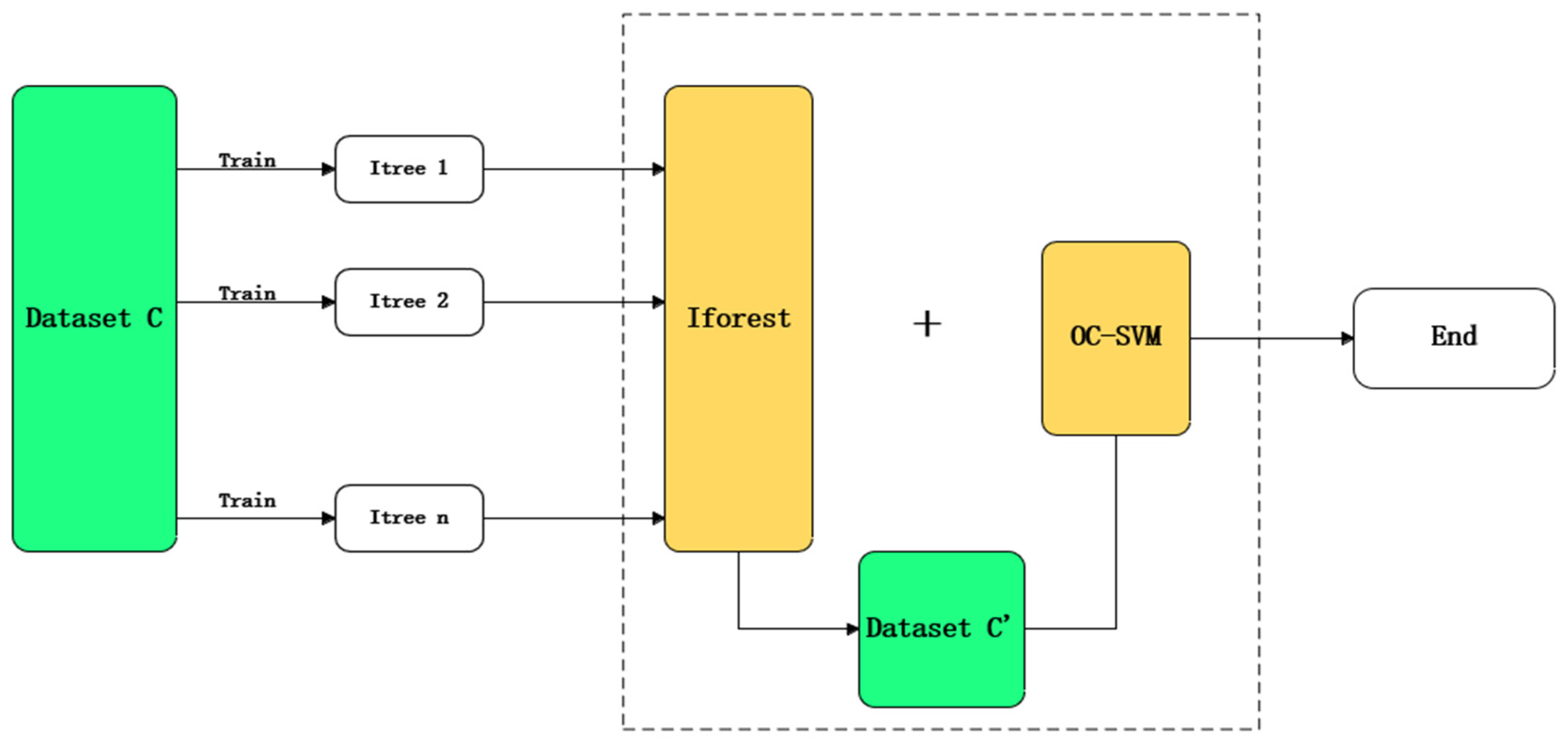
In order to test association rules for abnormal estrus determination in cow estrus, we adopted a progressive strategy based on Iforest with strong association rule weighting combined with weighted one-class support vector machine OC-SVM, to achieve efficient and robust abnormal discrimination. The framework is mainly divided into two key phases: the coarse screening phase, and the fine judgment phase.
In the coarse screening stage, we utilized Iforest to perform rapid preliminary screening of the estrus data. Isolated forest can efficiently isolate anomalous samples by constructing a randomized tree structure. This method is particularly suitable for preliminary screening of large-scale data because it can narrow down the scope of anomaly detection by eliminating high-confidence normal samples in a shorter period of time. With this stage, we were able to significantly reduce the amount of data for subsequent processing and improve the overall detection efficiency.
In the fine-tuning stage, we analyzed the suspected abnormal samples output from the isolated forest in depth. Here, weighted OC-SVM was used. OC-SVM is able to finely distinguish anomalous samples with fuzzy boundaries by constructing a maximally spaced hyperplane. This progressive strategy not only improved the efficiency of anomaly detection, but also enhanced the robustness and adaptability of the model.
Different characteristics are often not equally important for the detection of abnormalities in estrus studies in heifers. Some features may be decisive for the description of normal data, while others may be more prominent in the performance of abnormal data. Therefore, weighting features and constructing a weighted feature matrix can more accurately reflect the essential characteristics of the data. This study proposed an association-rule-driven feature weighting fusion method, i.e., defining feature weights based on a strong association rule of FP-Growth mining. This method could capture the synergistic effect between features more accurately, thus improving the model’s sensitivity to anomalous data and its detection accuracy. Second, strong association rules can quantify the importance of features in anomaly detection. In the mining process, metrics such as the support and confidence of each rule can be used as a basis for measuring the importance of features. Rules with higher support indicate that the combination of features appears more frequently in the data and may be important for anomaly detection; rules with higher confidence indicate that the association between the combination of features and anomalies is stronger. By transforming these indicators into weights, the actual contribution of features in anomaly detection can be reflected more scientifically. The formula for defining feature weights is as follows:
In this formula, indicates the weight of the first feature, the value range is between [0, 1], the larger the weight, the more important the feature is in cow estrus. represents the support degree of the first feature in the dataset, that is, the frequency of the feature, and a higher support degree means that the feature is more common in the data. The degree of enhancement of the first feature is the strength of the association rule between the feature and other features. When the degree of enhancement is greater than 1, this means that there is a positive correlation between the features, and the larger the value, the stronger the correlation. In the denominator, the sum of the product of support and lift of all features is used to normalize the weights to ensure that the sum of all weights is 1. If a feature participates in more than one rule, its weight will be determined by all the related rules, which enhances the global importance of the feature. The sum of the product of support and lift of all features is used for normalization. And the resultant weight [0, 1] reflects the combined importance of the features for estrus discrimination. The rule weight calculation provides a data-driven feature importance scale for the model by quantifying the universality and uniqueness of features in association rules. The method retains the structured information of the knowledge graph and enhances the robustness of the model through normalization and multi-rule fusion, which is a key point of innovation for detecting association rules in the realization of abnormal estrus detection.
5.4. Evaluation Metrics and Experimental Comparison
We used four model evaluation metrics in our experiments, namely Precision, Recall, the reconciled mean of Precision and Recall (F1-Score), and Intersection over Union (IoU).
Before analyzing, it is necessary to understand the definitions of the two types of samples: positive samples are samples that belong to a specific category, which is usually the focus of the study, while negative samples are samples that do not belong to that category. The specific meanings are shown in
Table 8.
True Positives (TP) are samples that were correctly predicted as positive. False Positives (FP) are samples that were incorrectly predicted as positive when they were actually negative. False Negatives (FN) are samples that were incorrectly predicted as negative when they were actually positive. True Negatives (TN) are samples that were correctly predicted as negative.
Accuracy is the proportion of all predicted samples that are correctly categorized.
Precision is defined as the proportion of true positive cases among all predicted positive cases, as shown in the formula below.
Recall is the ratio of the number of positive classes predicted to be positive to the number of classes that are actually positive, as shown in the formula below.
Fl-score is the reconciled mean of Precision and Recall, as shown in the formula below.
Through the comprehensive analysis of these metrics, this study comprehensively evaluated and compared the performance of the two Boolean function validation models, graph-based and rule-based, so as to select the most suitable method for practical application.
To validate the effectiveness of these rules, we developed rule-based Boolean functions to assess the estrus status of cows. The results showed that the precision of estrus identification improved significantly with the introduction of lift, demonstrating the effectiveness of the optimized rules in various environments, as shown in
Table 9.
To further validate the effectiveness of the strong association rules, we conducted an experiment comparing the performance of the knowledge-graph-based approach with the association-rule-based approach. The experiment involved using Boolean functions derived from both the initial knowledge graph and the enhanced knowledge graph with strong association rules. As demonstrated in
Table 9, we conducted an experiment to further validate the effectiveness of the strong association rules. The experiment compared the performance of two approaches: the knowledge-graph-based method and the association-rule-based method. The data used for the experiment were varied in size, including 200, 500, and 1000 data entries, which allowed us to assess the scalability and robustness of each approach.
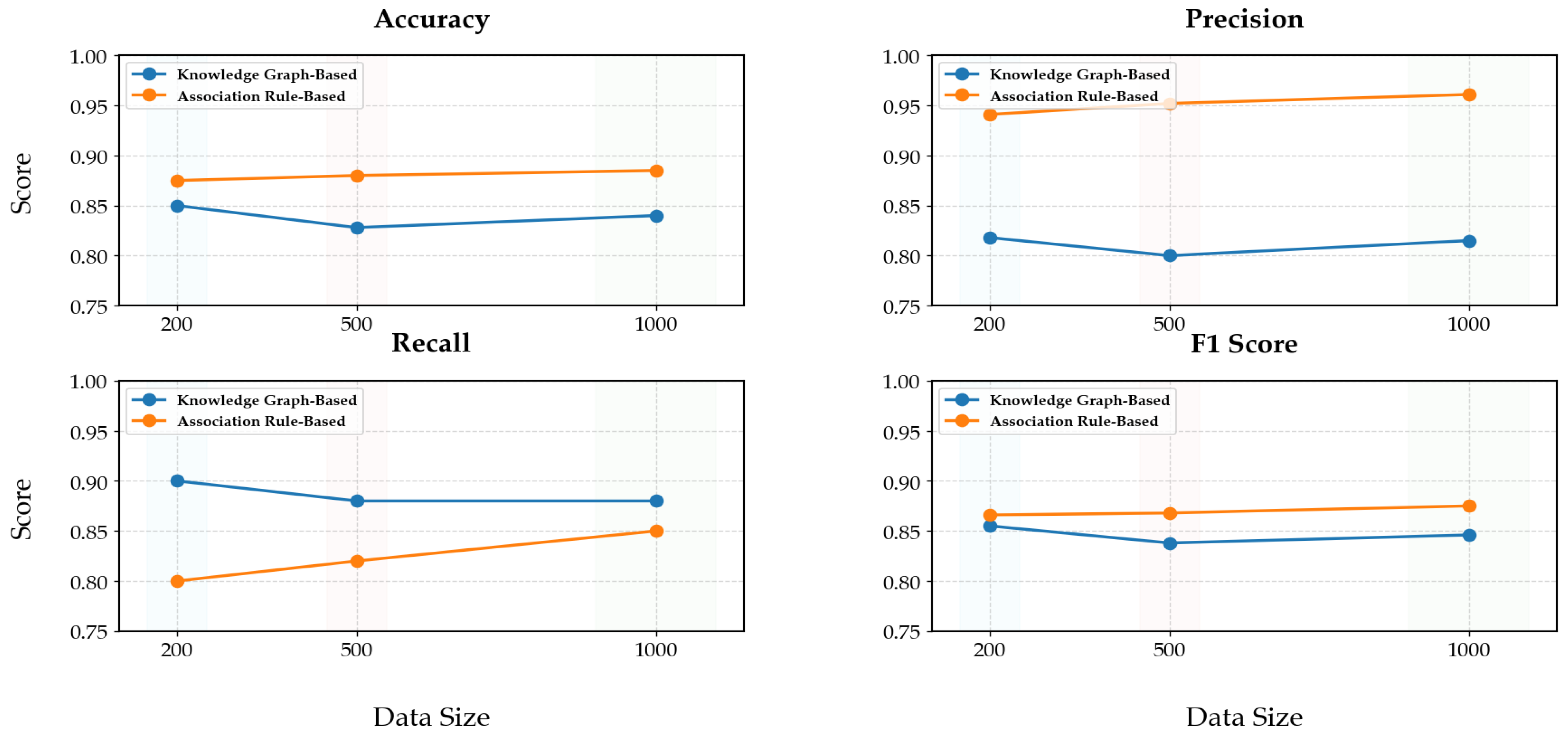
The results of this comparative analysis are depicted in
Figure 11. This figure presents a visual representation of the performance metrics—accuracy, precision, recall, and F1 score—across both methods and different dataset sizes. It provides a clear and concise comparison that underscores the advantages of integrating strong association rules into the knowledge-graph-based approach, as evidenced by the improved performance metrics.
The key findings are as follows: In terms of accuracy, the knowledge-graph-based approach with strong association rules consistently outperformed the initial knowledge-graph-based approach. For precision, the precision of estrus identification was significantly higher when using the strong association rules, indicating a reduction in false positives. Regarding recall, the recall improved with the introduction of strong association rules, indicating a reduction in false negatives. The F1 score, which balances precision and recall, was also higher for the knowledge-graph-based approach with strong association rules. These results clearly demonstrate that the knowledge-graph-based approach, enhanced with strong association rules, outperformed the initial approach in terms of accuracy, precision, recall, and F1 score. The improvement in performance was consistent across different dataset sizes, indicating the robustness and effectiveness of the enhanced approach in accurately identifying estrus in cows.
To assess the effectiveness of the association rules in detecting abnormal estrus, we conducted a comparative experiment involving four distinct approaches: the Iforest-OCSVM model with association rule-based feature weighting, the standard Iforest-OCSVM without feature weighting, the Iforest-OCSVM model with association rule-based feature weighting excluding the Lift metric, and the Iforest-OCSVM model with CNN-based feature extraction. This experiment was conducted on a dataset comprising 1000 samples. The outcomes, as detailed in
Table 8, revealed that the Iforest-OCSVM model augmented with association-rule-based feature weighting achieved superior performance over the other models across accuracy, precision, recall, and F1-score metrics. These findings underscore the significant contribution of integrating association rules with feature weighting to enhance the detection of abnormal estrus, and also demonstrate the potential of CNN-based feature extraction for improving model performance.
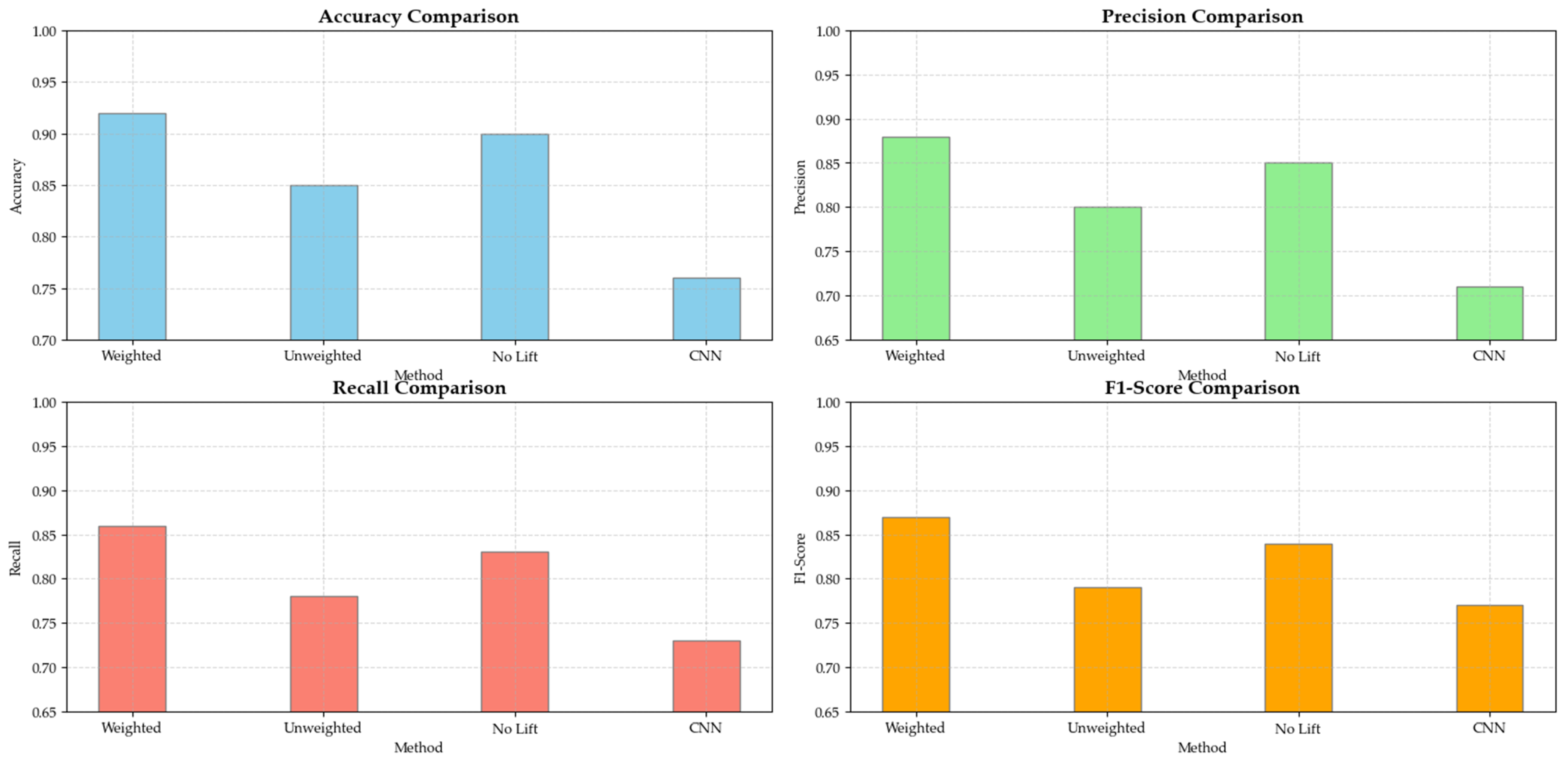
The results presented in
Table 10 demonstrate that the Iforest-OCSVM model enhanced with association-rule-based feature weighting outperformed the standard model across all evaluation metrics. Specifically, the weighted model exhibited improvements of 5% in accuracy, 6% in precision, 7% in recall, and 6% in F1-score over the unweighted counterpart. These enhancements underscore the substantial benefit of integrating association-rule-based feature weighting, which refined the model’s ability to effectively detect abnormal estrus, as shown in
Figure 12.
Additionally, the model excluding the Lift metric from the association-rule-based feature weighting also showed competitive performance, achieving 0.90 in accuracy and 0.84 in F1-score. This suggests that while the Lift metric contributed to the model’s performance, its exclusion did not significantly diminish the model’s effectiveness.
The CNN model’s lower accuracy in detecting cow estrus was mainly due to its limited feature extraction capability for non-image data, its model complexity leading to overfitting, and inadequate data preprocessing. In contrast, association rules exceled by effectively capturing relationships between features, providing interpretable and actionable insights, and enhancing the robustness and completeness of the knowledge graph. These advantages make association rules a more suitable approach for this specific application.
These findings highlight the effectiveness of association-rule-based feature weighting, including the Lift metric, in enhancing estrus detection and also point to the potential of CNN-based approaches, warranting further investigation.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}