
A Real-Time Green and Lightweight Model for Detection of Liquefied Petroleum Gas Cylinder Surface Defects Based on YOLOv5


Abstract
1. Introduction
- A new dataset of 2360 LPG cylinder images with defective surfaces is proposed.
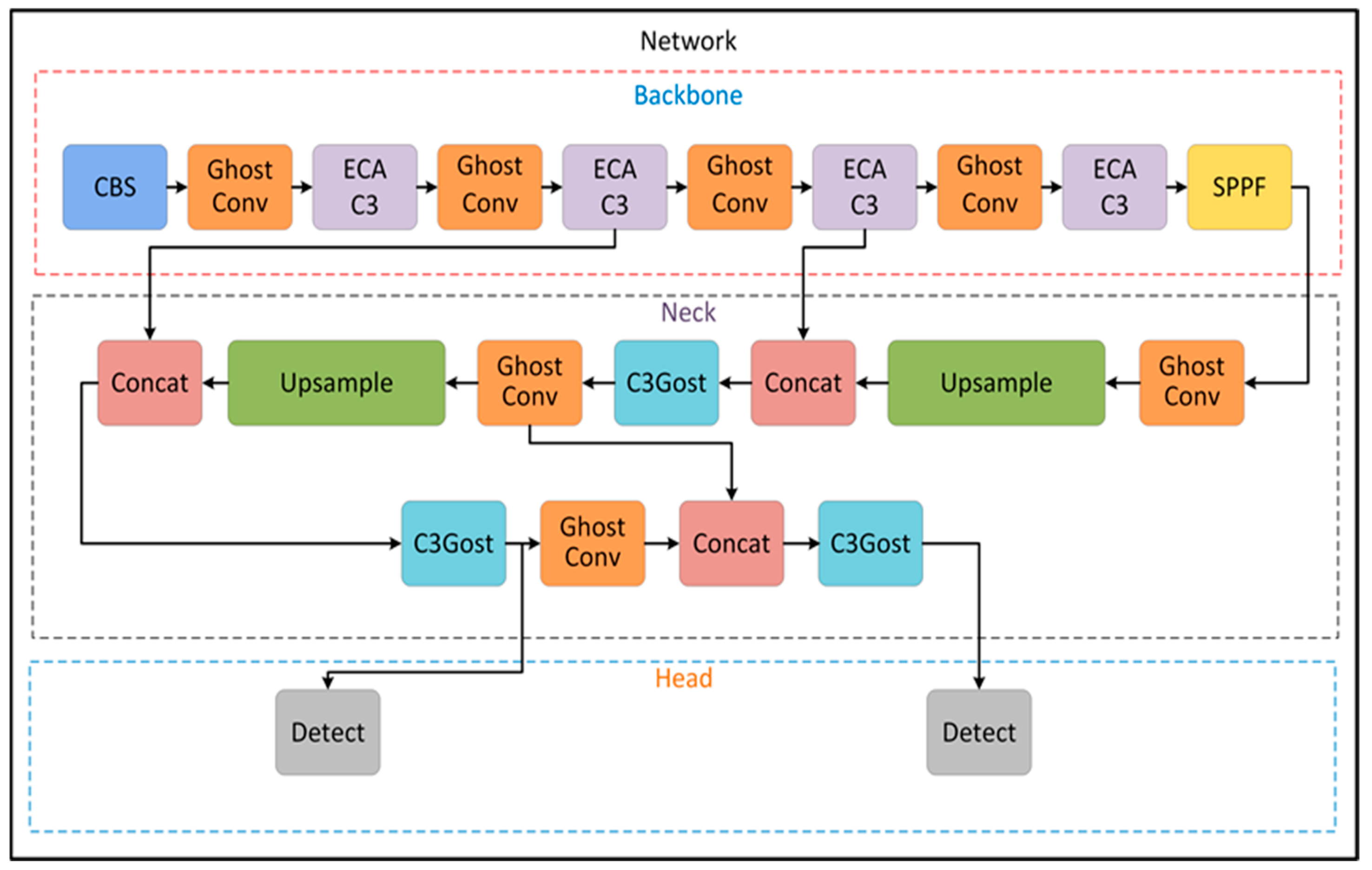
- To lighten the network, the Ghost module was used both in the backbone and neck sections of YOLOv5. In addition, the C3Ghost module has been added to the neck section, and the P5 head, responsible for detecting large objects, has been removed from the head. In this way, low memory consumption with small model size, reduced computing costs, and fast inference are achieved.
- In this network, ECA is a channel-based attention mechanism that further optimises this network by enhancing the feature extraction capability to recognise accurate surface defects.
- The efficacy of the proposed model is validated through comprehensive experimentation on a custom dataset.
2. Related Work
2.1. Deep Learning-Based Defect Detection Methods
2.2. Research on Model Lightweight and Improvement
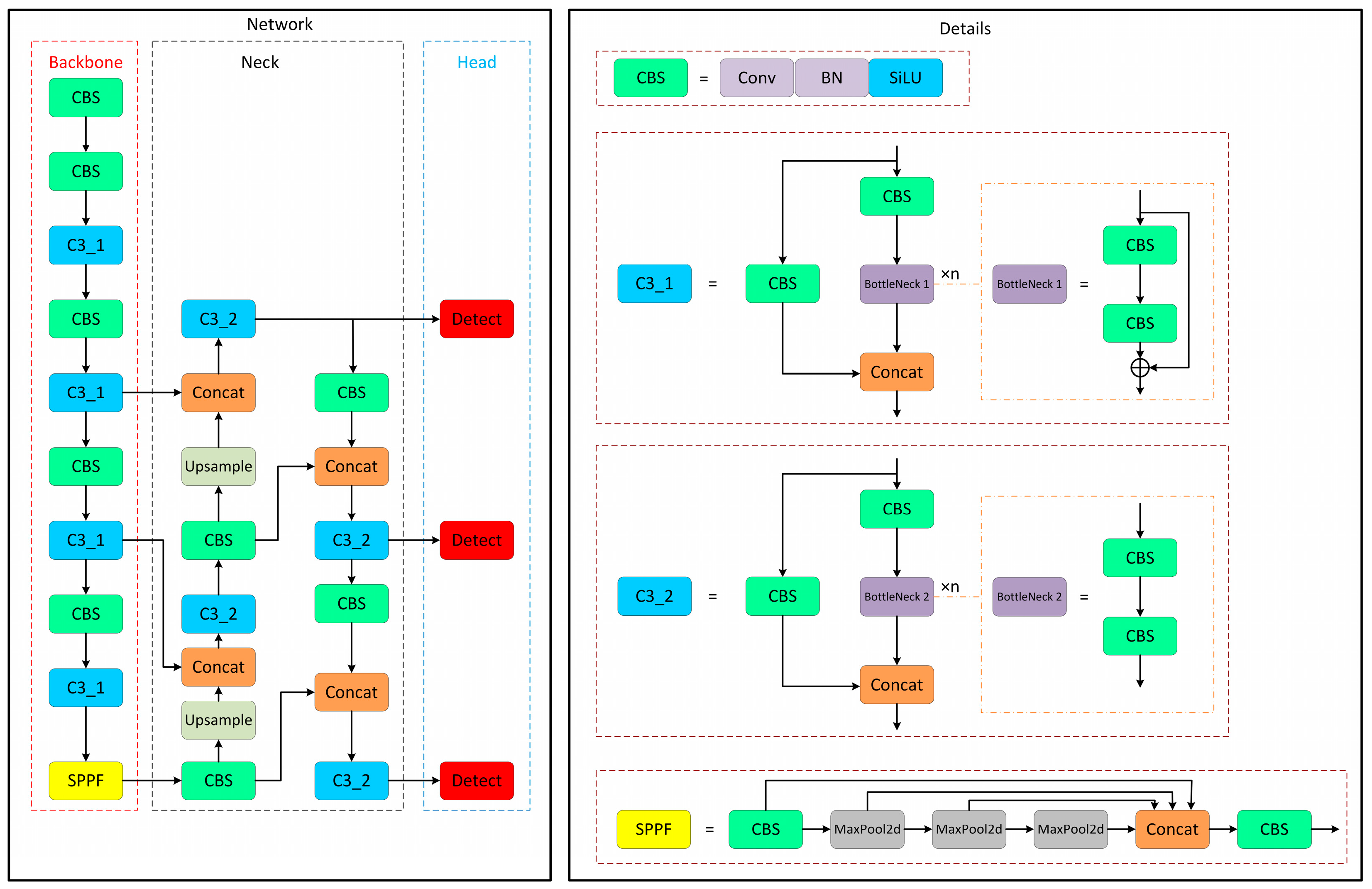
2.3. YOLO Networks
YOLOv5s Architecture
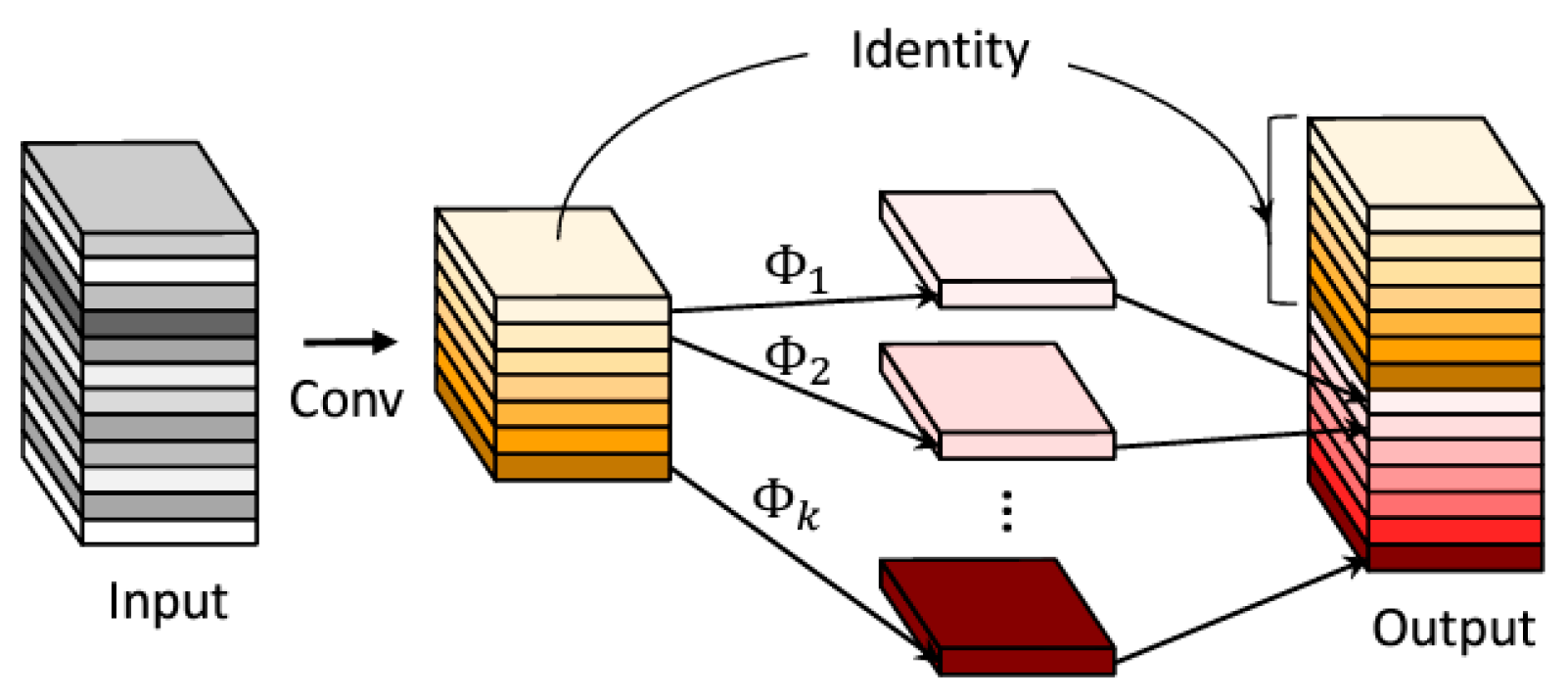
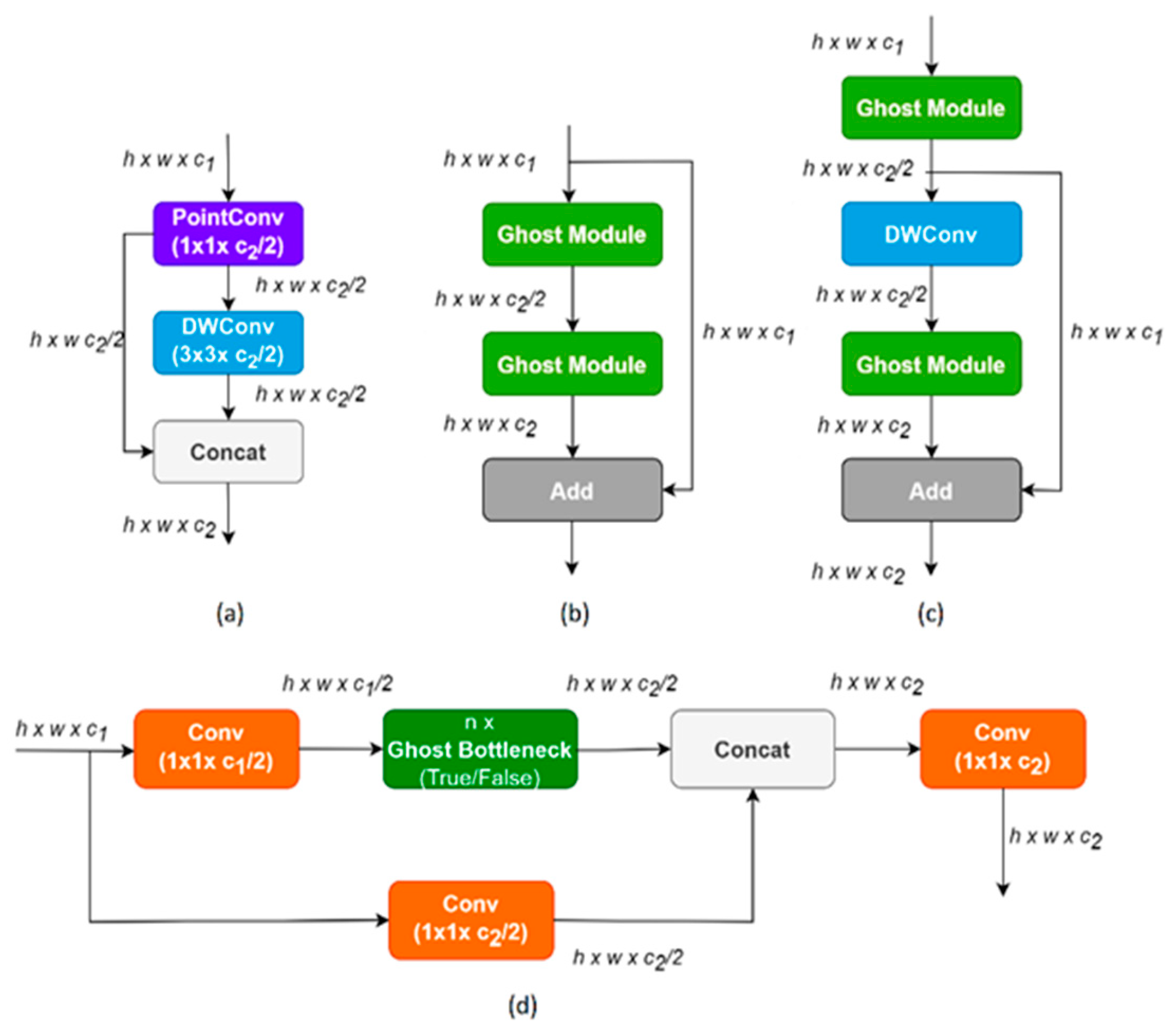
2.4. Ghost Module
2.5. Attention Mechanism
3. Proposed Method
3.1. Backbone
3.2. Neck
3.3. Head
4. Results
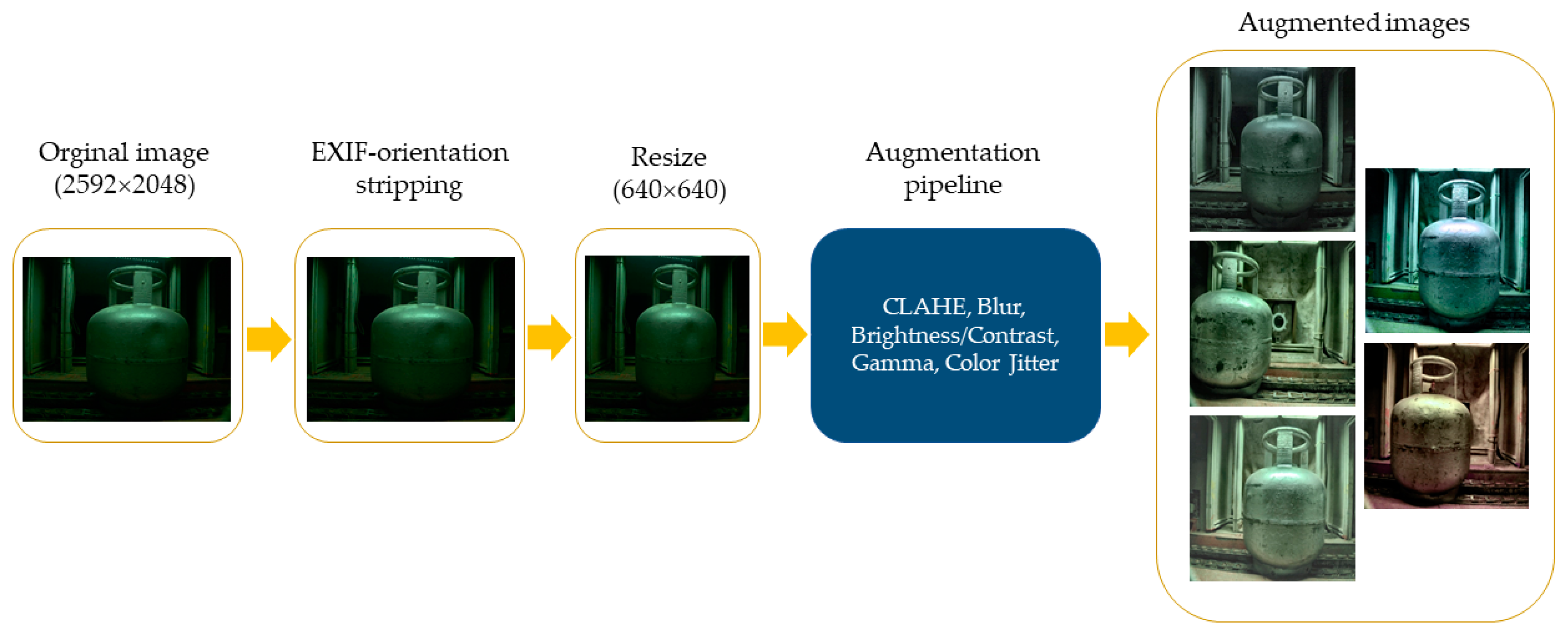
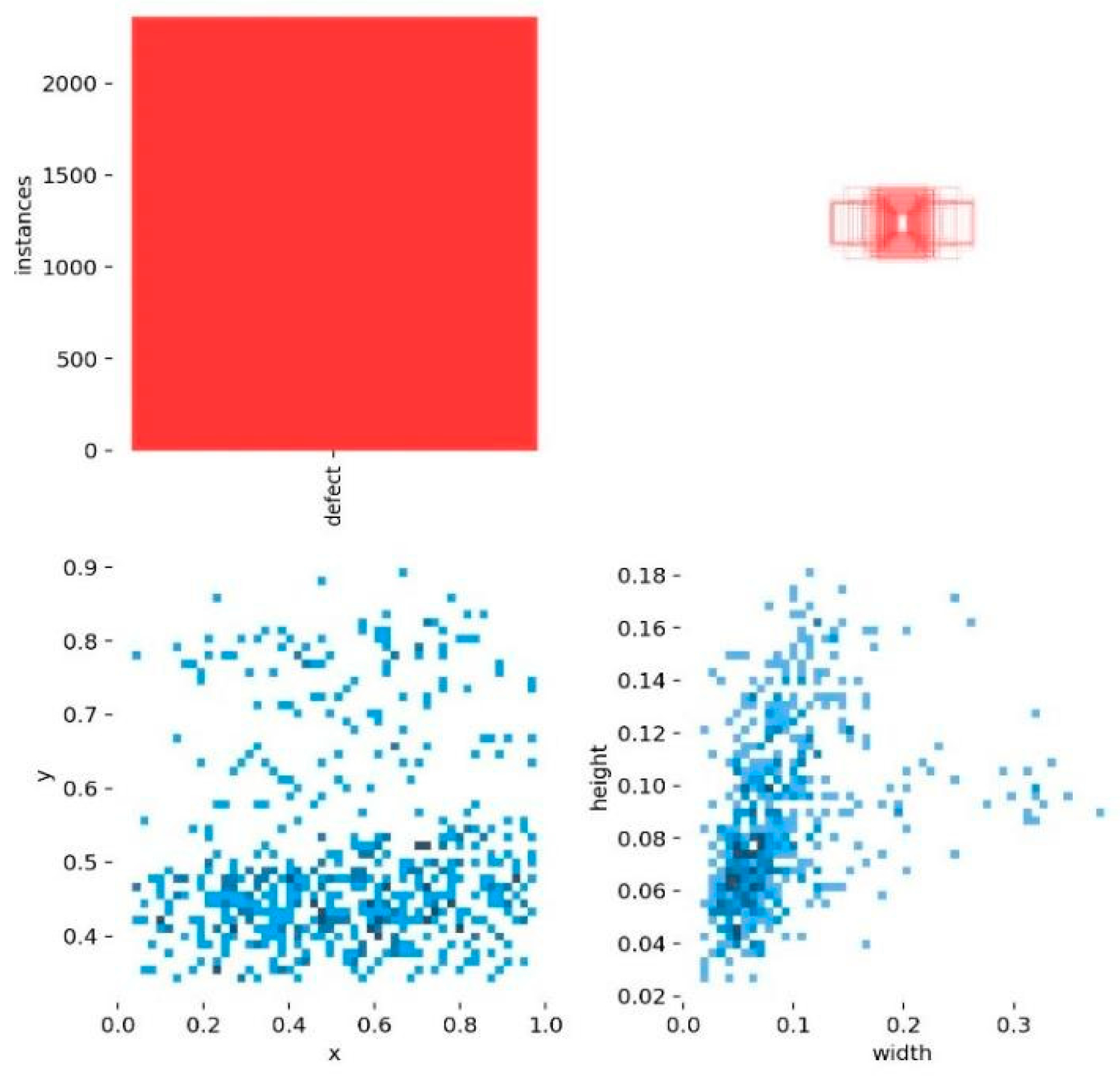
4.1. Experimental Dataset
4.2. Evaluation Metrics
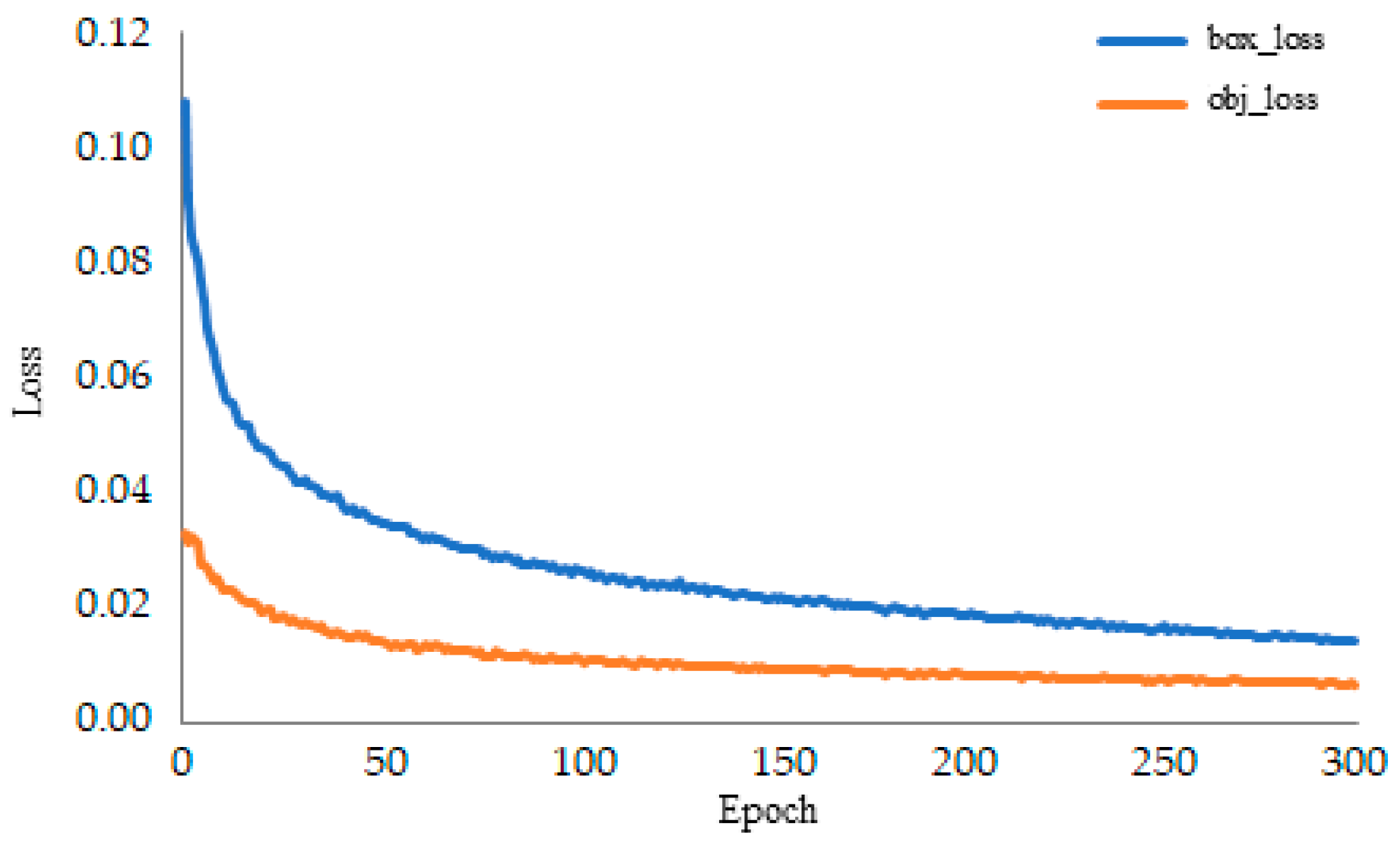
4.3. Implementation Details
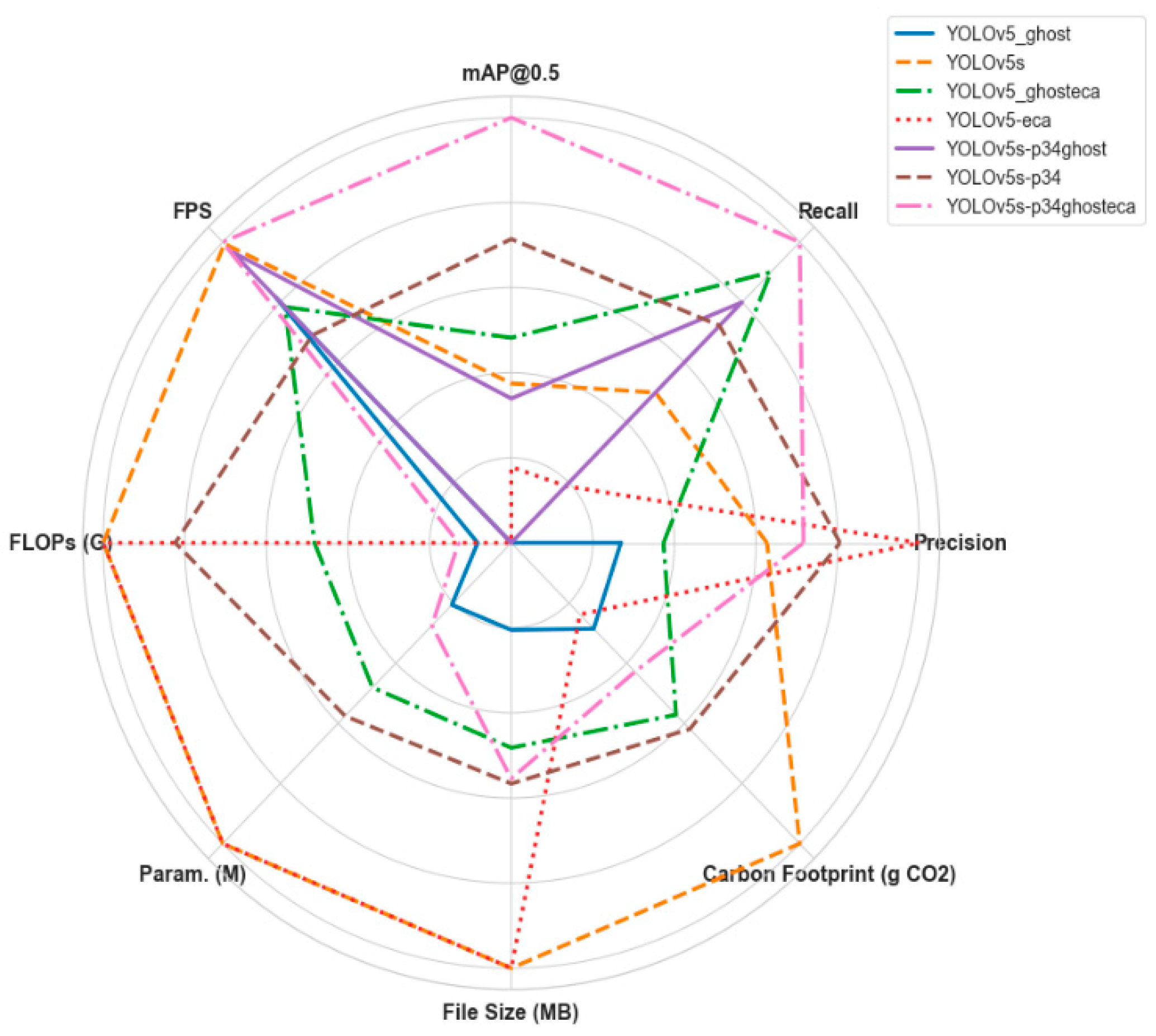
4.4. Comparison of YOLO Networks on a Custom Dataset
4.5. Ablation Experiments
4.6. Comparison with Large-Scale Object Detection Network
4.7. Qualitative Visualisation of the Detection Results
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Venegas-Vásconez, D.; Ayabaca-Sarria, C.; Reina-Guzmán, S.; Tipanluisa-Sarchi, L.; Farías-Fuentes, Ó. Liquefied Petroleum Gas Systems: A Review on Design and Sizing Guidelines. Ingenius Rev. Cienc. Tecnol. 2024, 31, 81–93. [Google Scholar]
- Turkish Standards Institute (TSE). TS EN 1439: LPG Equipment and Accessories—Periodic Inspection and Testing of LPG Cylinders. Available online: https://intweb.tse.org.tr/Standard/Standard/StandardAra.aspx (accessed on 27 December 2024).
- Singh, S.A.; Desai, K.A. Automated surface defect detection framework using machine vision and convolutional neural networks. J. Intell. Manuf. 2023, 34, 1995–2011. [Google Scholar] [CrossRef]
- Bai, J.; Wu, D.; Shelley, T.; Schubel, P.; Twine, D.; Russell, J.; Zeng, X.; Zhang, J. A comprehensive survey on machine learning-driven material defect detection: Challenges, solutions, and future prospects. arXiv 2024, arXiv:2406.07880. [Google Scholar] [CrossRef]
- Jung, H.; Lee, C.; Park, G. Fast and non-invasive surface crack detection of press panels using image processing. Proced. Eng. 2017, 188, 72–79. [Google Scholar] [CrossRef]
- Shi, T.; Kong, J.-Y.; Wang, X.-D.; Liu, Z.; Zheng, G. Improved Sobel algorithm for defect detection of rail surfaces with enhanced efficiency and accuracy. J. Cent. S. Univ. 2016, 23, 2867–2875. [Google Scholar] [CrossRef]
- Liu, W.; Yan, Y. Automated surface defect detection for cold-rolled steel strip based on wavelet anisotropic diffusion method. Int. J. Ind. Syst. Eng. 2014, 17, 224. [Google Scholar] [CrossRef]
- Neogi, N.; Mohanta, D.K.; Dutta, P.K. Defect detection of steel surfaces with global adaptive percentile thresholding of gradient image. J. Inst. Eng. India Ser. B 2017, 98, 557–565. [Google Scholar] [CrossRef]
- Hassanin, A.-A.I.M.; El-Samie, F.E.A.; El Banby, G.M. A real-time approach for automatic defect detection from PCBs based on SURF features and morphological operations. Multimed. Tools Appl. 2019, 78, 34437–34457. [Google Scholar] [CrossRef]
- Saberironaghi, A.; Ren, J.; El-Gindy, M. Defect detection methods for industrial products using deep learning techniques: A review. Algorithms 2023, 16, 95. [Google Scholar] [CrossRef]
- Li, J.; Pan, H.; Li, J. ESD-YOLOv5: A Full-Surface Defect Detection Network for Bearing Collars. Electronics 2023, 12, 16. [Google Scholar] [CrossRef]
- Su, P.; Han, H.; Liu, M.; Yang, T.; Liu, S. MOD-YOLO: Rethinking the YOLO Architecture at the Level of Feature Information and Applying It to Crack Detection. Expert Syst. Appl. 2024, 237, 121346. [Google Scholar] [CrossRef]
- Chen, X.; Wu, Y.; He, X.; Ming, W. A comprehensive review of deep learning-based PCB defect detection. IEEE Access 2023, 11, 139017–139038. [Google Scholar] [CrossRef]
- Liu, J.; Hu, M.; Dong, J.; Lu, X. Summary of insulator defect detection based on deep learning. Electr. Power Syst. Res. 2023, 224, 109688. [Google Scholar] [CrossRef]
- Demir, K.; Ay, M.; Cavas, M.; Demir, F. Automated steel surface defect detection and classification using a new deep learning-based approach. Neural Comput. Appl. 2023, 35, 8389–8406. [Google Scholar] [CrossRef]
- Li, Z.; Wei, X.; Hassaballah, M.; Li, Y.; Jiang, X. A deep learning model for steel surface defect detection. Complex Intell. Syst. 2024, 10, 885–897. [Google Scholar] [CrossRef]
- Singh, S.A.; Kumar, A.S.; Desai, K.A. Comparative assessment of common pre-trained CNNs for vision-based surface defect detection of machined components. Expert Syst. Appl. 2023, 218, 119623. [Google Scholar] [CrossRef]
- Li, C.; Li, J.; Li, Y.; He, L.; Fu, X.; Chen, J. Fabric defect detection in textile manufacturing: A survey of the state of the art. Secur. Commun. Netw. 2021, 2021, 9948808. [Google Scholar] [CrossRef]
- Yi, L.P.; Akbar, M.F.; Wahab, M.N.A.; Rosdi, B.A.; Fauthan, M.A.; Shrifan, N.H.M.M. The prospect of artificial intelligence-based wood surface inspection: A review. IEEE Access 2024, 12, 84706–84725. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xu, J.; Zhou, W.; Fu, Z.; Zhou, H.; Li, L. A survey on green deep learning. arXiv 2021, arXiv:2111.05193. [Google Scholar]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J.; Stoken, N. YOLOv5 v6.0. GitHub Repository. 2021. Available online: https://github.com/ultralytics/yolov5/releases/tag/v6.0 (accessed on 2 October 2024).
- Ren, F.; Fei, J.; Li, H.; Doma, B.T. Steel surface defect detection using improved deep learning algorithm: ECA-SimSPPF-SIoU-YOLOv5. IEEE Access 2024, 12, 32545–32553. [Google Scholar] [CrossRef]
- Zhang, D.-Y.; Zhang, W.; Cheng, T.; Zhou, X.-G.; Yan, Z.; Wu, Y.; Zhang, G.; Yang, X. Detection of wheat scab fungus spores utilizing the YOLOv5-ECA-ASFF network structure. Comput. Electron. Agric. 2023, 210, 107953. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Lu, L.; Chen, Z.; Wang, R.; Liu, L.; Chi, H. YOLO-Inspection: Defect detection method for power transmission lines based on enhanced YOLOv5s. J. Real Time Image Process. 2023, 20, 104. [Google Scholar] [CrossRef]
- Huang, J.; Chen, J.; Wang, H. A lightweight and efficient one-stage detection framework. Comput. Electr. Eng. 2023, 105, 108520. [Google Scholar] [CrossRef]
- Liu, M.; Chen, Y.; Xie, J.; He, L.; Zhang, Y. LF-YOLO: A lighter and faster YOLO for weld defect detection of X-ray image. IEEE Sens. J. 2023, 23, 7430–7439. [Google Scholar] [CrossRef]
- Hou, W.; Wen, S.; Li, P.; Feng, S. Surface defect detection of fabric based on improved Faster R-CNN. In Proceedings of the 2023 IEEE International Conference on Sensors, Electronics and Computer Engineering (ICSECE), Jinzhou, China, 18–20 August 2023; pp. 600–604. [Google Scholar]
- Wang, J.; Xu, G.; Yan, F.; Wang, J.; Wang, Z. Defect transformer: An efficient hybrid transformer architecture for surface defect detection. Measurement 2023, 211, 112614. [Google Scholar] [CrossRef]
- Liu, X.; Gao, J. Surface defect detection method of hot rolling strip based on improved SSD model. In Database Systems for Advanced Applications, Proceedings of the DASFAA 2021 International Workshops: GDMA, MLDLDSA, MobiSocial, and MUST, Taipei, Taiwan, 11–14 April 2021; Springer International Publishing: Berlin/Heidelberg, Germany; pp. 209–222. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Gao, J. Swin Transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Zhu, W.; Zhang, H.; Zhang, C.; Zhu, X.; Guan, Z.; Jia, J. Surface defect detection and classification of steel using an efficient Swin Transformer. Adv. Eng. Inform. 2023, 57, 102061. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, R.; Hu, R.; Shu, C.; Tang, X.; Li, X. ETDNet: Efficient transformer-based detection network for surface defect detection. IEEE Trans. Instrum. Meas. 2023, 72, 2525014. [Google Scholar] [CrossRef]
- Shang, H.; Sun, C.; Liu, J.; Chen, X.; Yan, R. Defect-aware transformer network for intelligent visual surface defect detection. Adv. Eng. Inform. 2023, 55, 101882. [Google Scholar] [CrossRef]
- Khan, A.; Rauf, Z.; Sohail, A.; Rehman, A.; Asif, H.; Asif, A.; Farooq, U. A survey of the Vision Transformers and their CNN-Transformer based variants. arXiv 2023, arXiv:2305.09880. [Google Scholar] [CrossRef]
- Lee, S.I.; Koo, K.; Lee, J.H.; Lee, G.; Jeong, S.; Kim, H.O.S. Vis. Transform. Models Mob. /Edge Devices: A Survey. Multimed. Syst. 2024, 30, 109. [Google Scholar] [CrossRef]
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing vision transformers and convolutional neural networks for image classification: A literature review. Appl. Sci. 2023, 13, 9. [Google Scholar] [CrossRef]
- Tao, Y.; Zongyang, Z.; Jun, Z.; Xinghua, C.; Fuqiang, Z. Low-altitude small-sized object detection using lightweight feature-enhanced convolutional neural network. J. Syst. Eng. Electron. 2021, 32, 841–853. [Google Scholar] [CrossRef]
- Kamath, V.; Renuka, A. Deep learning based object detection for resource-constrained devices: Systematic review, future trends and challenges ahead. Neurocomputing 2023, 531, 34–60. [Google Scholar] [CrossRef]
- Xiang, C.; Guo, J.; Cao, R.; Deng, L. A crack-segmentation algorithm fusing transformers and convolutional neural networks for complex detection scenarios. Autom. Constr. 2023, 152, 104894. [Google Scholar] [CrossRef]
- Taye, M.M. Theoretical understanding of convolutional neural network: Concepts, architectures, applications, future directions. Computation 2023, 11, 52. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, G.; Sandler, M.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Keutzer, K. SqueezeNext: Hardware-aware neural network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1638–1647. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical guidelines for efficient CNN architecture design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Zhang, G.; Liu, S.; Nie, S.; Yun, L. YOLO-RDP: Lightweight Steel Defect Detection through Improved YOLOv7-Tiny and Model Pruning. Symmetry 2024, 16, 458. [Google Scholar] [CrossRef]
- Zhou, S.; Ao, S.; Yang, Z.; Liu, H. Surface defect detection of steel plate based on SKS-YOLO. IEEE Access 2024, 12, 91499–91510. [Google Scholar] [CrossRef]
- Huang, H. TLI-YOLOv5: A lightweight object detection framework for transmission line inspection by unmanned aerial vehicle. Electronics 2023, 12, 3340. [Google Scholar] [CrossRef]
- Sapkota, R.; Meng, Z.; Churuvija, M.; Du, X.; Ma, Z.; Karkee, M. Comprehensive performance evaluation of YOLOv10, YOLOv9 and YOLOv8 on detecting and counting fruitlet in complex orchard environments. arXiv 2024, arXiv:2407.12040. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Ma, Z.; Li, M.; Wang, Y. PAN: Path integral based convolution for deep graph neural networks. arXiv 2019, arXiv:1904.10996. [Google Scholar] [CrossRef]
- Hussain, M.; Khanam, R. In-depth review of YOLOv1 to YOLOv10 variants for enhanced photovoltaic defect detection. Solar 2024, 4, 351–386. [Google Scholar] [CrossRef]
- Sohan, M.; Ram, T.S.; Reddy, C.V.R. A review on YOLOv8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics 2024, Tirunelveli, India, 18–20 November 2024; Springer: Singapore, 2024; pp. 529–545. [Google Scholar]
- Alif, M.A.R.; Hussain, M. YOLOv1 to YOLOv10: A comprehensive review of YOLO variants and their application in the agricultural domain. arXiv 2024, arXiv:2406.10139. [Google Scholar] [CrossRef]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-YOLO: A report on real-time object detection design. arXiv 2022, arXiv:2406.10139. [Google Scholar] [CrossRef]
- Ultralytics. Home. 2023. Available online: https://docs.ultralytics.com/ (accessed on 5 November 2024).
- Solawetz, J. What Is YOLOv8? A Complete Guide. Roboflow Blog. 2024. Available online: https://blog.roboflow.com/whats-new-in-yolov8/ (accessed on 5 November 2024).
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.2105. [Google Scholar]
- Wang, A.; Liu, F.; Gao, S.; Zhang, S.; Li, C.; Zhang, X.; Zhang, W.; Sun, W.; Ding, X. YOLOv10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M. YOLOv1 to YOLOv10: The fastest and most accurate real-time object detection systems. arXiv 2024, arXiv:2408.1738. [Google Scholar] [CrossRef]
- Jin, Y.; Lu, Z.; Wang, R.; Liang, C. Research on lightweight pedestrian detection based on improved YOLOv5. Math. Model. Eng. 2023, 9, 178–187. [Google Scholar] [CrossRef]
- Arifando, R.; Eto, S.; Wada, C. Improved YOLOv5-based lightweight object detection algorithm for people with visual impairment to detect buses. Appl. Sci. 2023, 13, 5802. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-Based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Wang, S.; Wang, Y.; Chang, Y.; Zhao, R.; She, Y. EBSE-YOLO: High Precision Recognition Algorithm for Small Target Foreign Object Detection. IEEE Access 2023, 11, 57951–57964. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Liu, X.; Wang, T.; Yang, J.; Tang, C.; Lv, J. MPQ-YOLO: Ultra Low Mixed-Precision Quantization of YOLO for Edge Devices Deployment. Neurocomputing 2024, 574, 127210. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, C. A Light-Weight Object Detection Method Based on Knowledge Distillation and Model Pruning for Seam Tracking System. Measurement 2023, 220, 113438. [Google Scholar] [CrossRef]
- Guan, B.; Li, J. Lightweight Detection Network for Bridge Defects Based on Model Pruning and Knowledge Distillation. Structures 2024, 62, 106276. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Input Size (pixel) | Inference Time (ms) * | mAP@0.5 | FLOPs (G) | Param. (M) | File Size (MB) |
|---|---|---|---|---|---|---|
| YOLOv5s | 640 × 640 | 4.0 | 0.79 | 15.9 | 7.02 | 14.4 |
| YOLOv6s | 640 × 640 | 4.6 | 0.78 | 45.17 | 18.50 | 40.7 |
| YOLOv7 | 640 × 640 | 8.3 | 0.59 | 105.1 | 37.19 | 74.8 |
| YOLOv8s | 640 × 640 | 5.4 | 0.76 | 28.4 | 11.1 | 22.5 |
| YOLOv9s | 640 × 640 | 13.2 | 0.78 | 38.7 | 9.74 | 20.3 |
| YOLO10s | 640 × 640 | 11.9 | 0.74 | 24.8 | 8.06 | 16.6 |
| YOLO Networks | |||||||
|---|---|---|---|---|---|---|---|
| YOLOv5-Ghost | YOLOv5-ECA | YOLOv5-P34-Ghost | YOLOv5s | YOLOv5-Ghost-ECA | YOLOv5-P34 | YOLOv5-P34-Ghost-ECA | |
| Ghost | √ | - | √ | - | √ | - | √ |
| ECA | - | √ | - | - | √ | - | √ |
| P34 | - | - | √ | - | - | √ | √ |
| Precision | 0.792 | 0.841 | 0.774 | 0.816 | 0.799 | 0.828 | 0.822 |
| Recall | 0.695 | 0.712 | 0.767 | 0.74 | 0.776 | 0.76 | 0.785 |
| mAP@0.5 | 0.75 | 0.76 | 0.769 | 0.771 | 0.777 | 0.79 | 0.806 |
| FPS | 135 | 163 | 158.7 | 169 | 138.8 | 175 | 163.9 |
| FLOPs (G) | 8 | 15.8 | 7.3 | 15.8 | 11.4 | 14.3 | 8.4 |
| Param. (M) | 3.67 | 7.02 | 2.80 | 7.02 | 4.83 | 5.23 | 3.96 |
| File Size (MB) | 7.8 | 14.4 | 6.1 | 14.4 | 10.1 | 10.8 | 10.7 |
| Carbon Footprint (gCO2e) | 0.147 | 0.150 | 0.144 | 0.151 | 0.150 | 0.143 | 0.145 |
| Model | Input Size (pixel) | FPS | mAP@0.5 | mAP@0.5_0.95 | FLOPs (G) | File Size (MB) |
|---|---|---|---|---|---|---|
| RT-DETR | 640 × 640 | 31.23 | 0.72 | 0.30 | 68.81 | 171.5 |
| GLDD-YOLOv5 | 640 × 640 | 163.9 | 0.806 | 0.34 | 8.4 | 10.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duman, B. A Real-Time Green and Lightweight Model for Detection of Liquefied Petroleum Gas Cylinder Surface Defects Based on YOLOv5. Appl. Sci. 2025, 15, 458. https://doi.org/10.3390/app15010458
Duman B. A Real-Time Green and Lightweight Model for Detection of Liquefied Petroleum Gas Cylinder Surface Defects Based on YOLOv5. Applied Sciences. 2025; 15(1):458. https://doi.org/10.3390/app15010458
Chicago/Turabian StyleDuman, Burhan. 2025. "A Real-Time Green and Lightweight Model for Detection of Liquefied Petroleum Gas Cylinder Surface Defects Based on YOLOv5" Applied Sciences 15, no. 1: 458. https://doi.org/10.3390/app15010458
APA StyleDuman, B. (2025). A Real-Time Green and Lightweight Model for Detection of Liquefied Petroleum Gas Cylinder Surface Defects Based on YOLOv5. Applied Sciences, 15(1), 458. https://doi.org/10.3390/app15010458