In this section, we present the results from the experiments conducted to evaluate the performance of models trained on EduDCM-generated datasets. We analyze various metrics such as accuracy, F1 score, and recall, and compare the performance of models on EduTalk and TalkMoves datasets. The results also include expert evaluations that validate the quality of the EduDCM-generated data.
4.1. Expert Evaluation
To evaluate the quality of the EduTalk dataset generated by the EduDCM framework, a rigorous expert review was conducted. This process involved three domain experts with extensive experience in educational dialogue analysis. The first expert is a professor in educational technology with over 15 years of experience in classroom interaction research, focusing on pedagogical strategies and dialogue analysis. The second expert is a senior researcher specializing in natural language processing for education, with a background in developing automated annotation tools for educational datasets. The third expert is a curriculum designer with a Ph.D. in education, who has contributed to the development of taxonomy-based frameworks for evaluating classroom interactions. A random sample comprising 30% of the dataset, totaling 1560 instances, was selected to ensure a comprehensive assessment. Each dialogue utterance was annotated according to the pedagogical categories outlined in the TalkMoves taxonomy, including categories such as Learning Community, Content Knowledge, and Rigorous Thinking, with subcategories such as Relating to another student, Pressing for accuracy, and Providing evidence or reasoning.
The results presented in
Table 1 demonstrate that the EduTalk dataset achieves high semantic accuracy across most categories, with an average positive annotation rate of 85%. Categories such as
Learning Community: Keeping everyone together and
Learning Community: Getting students to relate to another’s ideas exhibit the highest accuracy rates (94% and 91%, respectively), highlighting the EduDCM framework’s ability to capture well-structured teacher talk moves. Similarly, categories like
Learning Community: Restating and
Content Knowledge: Pressing for accuracy show strong performance, with positive annotation rates exceeding 85%. These findings suggest that the EduDCM framework is particularly adept at identifying and annotating dialogue types with clear pedagogical functions. However, the categories
Content Knowledge: Making a claim and
Rigorous Thinking: Providing evidence or reasoning demonstrated relatively lower accuracy rates, with positive annotation rates of 77% and 74%, respectively. This indicates challenges in accurately capturing student talk moves involving abstract reasoning or detailed evidence. These discrepancies could be attributed to the variability in how students articulate reasoning and evidence, often requiring contextual interpretation that may not always align with predefined annotation rules.
Consistency in annotations was generally high for categories with well-defined boundaries, such as Learning Community: Keeping everyone together and Learning Community: Restating. In contrast, categories like Rigorous Thinking: Pressing for reasoning and Rigorous Thinking: Providing evidence or reasoning exhibited more variability in expert agreement, highlighting the need for further refinement in the framework’s handling of nuanced or context-dependent utterances. The representational coverage of categories across the dataset appears balanced, with no single category disproportionately dominating the annotations. This ensures that the EduTalk dataset provides a diverse and equitable foundation for training and evaluating dialogue classification models. Overall, the expert evaluation underscores the strength of the EduDCM framework in generating high-quality educational datasets while identifying opportunities for improvement in handling complex dialogue types involving reasoning and evidence.
4.2. Three-Phase Evaluation
In this section, we present a comprehensive evaluation of the EduDCM framework through three distinct experimental phases. These phases are designed to assess the effectiveness of EduDCM-generated datasets in various contexts, including individual dataset performance, the combination of EduTalk and TalkMoves datasets, and a comparison with other data generation methods. Each phase aims to provide valuable insights into the scalability and generalizability of the EduDCM framework.
4.2.1. Phase 1: Individual Dataset Performance Evaluation
The performance of various models was evaluated on the TalkMoves and EduTalk datasets to establish baseline metrics and assess the quality of annotations. The models used for evaluation include BERT, mREBEL, GPT-2, OneRel, and CasRel. The evaluation metrics include F1 score, precision (P), and recall (R), providing a comprehensive view of each model’s effectiveness in handling the different datasets.
The results in
Table 2 demonstrate that models perform better on the EduTalk dataset compared to TalkMoves. This is largely attributed to the controlled and consistent nature of EduTalk’s annotations, which align closely with the structured output generated by the EduDCM framework. The CasRel and OneRel models exhibit superior performance on both datasets, with F1 scores of 0.914 and 0.917 on EduTalk, and 0.778 and 0.742 on TalkMoves, respectively. These results highlight the effectiveness of models specifically designed for joint entity and relation extraction when applied to datasets with high annotation quality.
For the TalkMoves dataset, which contains manually annotated data, performance metrics are generally lower. This can be attributed to the inherent complexity and variability of the dataset, as well as the potential for ambiguous or overlapping pedagogical categories. The CasRel model outperforms other models with an F1 score of 0.778, reflecting its robustness in handling diverse and nuanced annotations. OneRel also performs well, achieving an F1 score of 0.742, indicating its adaptability to tasks requiring precise annotation quality. In contrast, the EduTalk dataset, generated via EduDCM, demonstrates competitive results, with models achieving performance metrics comparable to those on manually annotated datasets like TalkMoves. The structured nature of the annotations, combined with the semantic alignment mechanisms employed by the EduDCM framework, likely contributes to the high performance. CasRel and OneRel maintain their leading positions, achieving precision and recall scores above 0.91, which underscores their ability to capitalize on the dataset’s quality.
Models like BERT and mREBEL exhibit comparatively lower performance on both datasets. This discrepancy is particularly pronounced on TalkMoves, where the variability and complexity of the data pose significant challenges. However, their results on EduTalk suggest that the EduDCM framework mitigates some of the limitations associated with simpler modeling approaches, providing structured annotations that enhance model learning.
To evaluate annotation quality, three domain experts reviewed a random sample of 300 instances from each dataset.
Table 3 summarizes the results. Both datasets received high scores for annotation accuracy, category coverage, and consistency, with EduTalk achieving mean scores of 4.4, 4.3, and 4.4, respectively, and TalkMoves scoring slightly higher with 4.5, 4.4, and 4.5. Annotation accuracy was measured by how well the generated labels matched the intended pedagogical categories as defined in the taxonomy. Category coverage was evaluated by determining whether all relevant categories were adequately represented in the dataset. Consistency was assessed by verifying the uniformity of annotations across similar dialogue instances. The inter-rater reliability, measured by Cohen’s Kappa, was 0.85 or higher for both datasets, reflecting strong agreement among the experts. Experts noted that EduTalk’s structured and context-aware annotations, generated by the EduDCM framework, aligned well with pedagogical categories, enabling consistent interpretation. However, the manually annotated TalkMoves dataset exhibited slightly higher annotation accuracy due to the direct involvement of human annotators with domain expertise.
In summary, the evaluation results demonstrate the reliability of the EduTalk dataset generated by EduDCM, as evidenced by the comparable performance of models trained on EduTalk to those trained on manually annotated datasets like TalkMoves. These findings validate the framework’s potential to bridge the gap between distant supervision and manual annotation in educational NLP tasks.
4.2.2. Phase 2: Combined Dataset Evaluation
In this phase, we aim to evaluate the generalization capability of models trained on the EduTalk dataset. To achieve this, we created mixed test sets by combining EduTalk and TalkMoves datasets in different ratios (3:7 and 1:1) and assessed the models’ performance on these test sets. This approach allows us to determine the extent to which the EduTalk data generated by the EduDCM framework can match the quality of the manually annotated TalkMoves dataset.
The results, as shown in
Table 4, reveal several important trends. In the 3:7 dataset ratio, where TalkMoves dominates the test set, all models exhibit lower performance compared to the 1:1 ratio. This decline can be attributed to the smaller size of the TalkMoves dataset, which limits the diversity of the data and reduces the models’ ability to generalize effectively. Among the models, CasRel and OneRel demonstrate the highest F1 scores of 0.779 and 0.747, respectively, reflecting their superior ability to adapt to mixed datasets, even with a significant proportion of manually annotated TalkMoves data.
In the 1:1 dataset ratio, where EduTalk and TalkMoves are equally represented, all models show improved performance. This improvement underscores the role of the high-quality EduTalk data in enriching the diversity of the smaller TalkMoves dataset, addressing the challenges arising from its limited size. CasRel achieves the highest F1 score of 0.838, followed closely by OneRel with an F1 score of 0.818. Both models demonstrate balanced precision and recall, indicating their robust generalization capability in handling diverse test sets.
Lower-performing models, such as BERT and mREBEL, show similar trends, with better performance in the 1:1 ratio compared to the 3:7 ratio. However, their F1 scores of 0.739 and 0.722 in the 1:1 ratio suggest limitations in handling the variability of manually annotated TalkMoves data. These models rely more heavily on dataset size and quality, which may restrict their adaptability in low-resource scenarios. The performance of GPT-2, with an F1 score of 0.760 in the 1:1 ratio, indicates its competitive ability to generalize when presented with a balanced dataset. However, its slightly lower precision compared to CasRel and OneRel suggests that it struggles with maintaining high accuracy in more diverse data conditions.
Overall, these results highlight the capability of the EduTalk dataset to enhance model performance when combined with manually annotated TalkMoves data. High-performing models like CasRel and OneRel exhibit robust adaptability to mixed datasets, validating the EduDCM framework’s potential to generate high-quality data that effectively support dialogue classification tasks in low-resource educational contexts.
4.2.3. Phase 3: Data Generation Method Comparison
In this phase, EduDCM is compared against two prominent data generation approaches. The first is Template-Based Generation, which creates synthetic dialogues using predefined templates and expert-defined rules. While structured, this method is labor-intensive and commonly used in early natural language generation tasks. The second approach is Few-Shot GPT Data Generation, which leverages GPT-3.5 in a few-shot setup to generate datasets based on limited annotated examples, relying on the model’s capability to extrapolate patterns from minimal inputs. The datasets generated by these methods are evaluated through identical models and examined by domain experts across three dimensions.
The results presented in
Table 5 reveal significant differences in dataset quality across the three methods. EduDCM consistently outperforms the other methods, achieving the highest scores in all three dimensions. Specifically, its score of 4.7 in accuracy of annotations highlights its ability to correctly label utterances, thanks to the framework’s integration of context-aware label generation and heuristic alignment techniques. Similarly, EduDCM achieves a coverage score of 4.6, demonstrating its capacity to ensure balanced representation across all pedagogical categories. Its consistency score of 4.8 reflects its effectiveness in maintaining a coherent and uniform annotation style, reducing variability that could negatively impact downstream tasks.
In contrast, the Template-Based Generation method performs the worst across all dimensions. Its accuracy score of 3.2 indicates limited flexibility in capturing the nuanced and context-dependent nature of educational dialogues. The coverage score of 2.8 reveals significant biases in category representation, as predefined templates tend to favor certain dialogue structures while underrepresenting others. Additionally, the consistency score of 3.0, while reflecting a uniform style within the constraints of the templates, highlights its inability to adapt to real-world variations in dialogue.
The Few-Shot GPT method demonstrates substantial improvements over Template-Based Generation. Its accuracy score of 4.1 indicates that GPT-3.5 can leverage contextual understanding to generate meaningful and accurate annotations. However, its coverage score of 4.0 suggests that certain pedagogical categories, especially those less represented in the prompt examples, may not be adequately annotated. The consistency score of 4.2 shows that Few-Shot GPT maintains a relatively uniform annotation style, though occasional variability due to inherent model randomness is observed.
In summary, these results highlight the superiority of EduDCM in generating high-quality datasets for educational dialogue classification. While Few-Shot GPT offers a viable alternative with reasonable performance, its reliance on limited prompts restricts its effectiveness in achieving comprehensive category coverage. Template-Based Generation, though structured, lacks the flexibility and adaptability required for the nuanced nature of educational dialogues.
4.3. Ablation Study
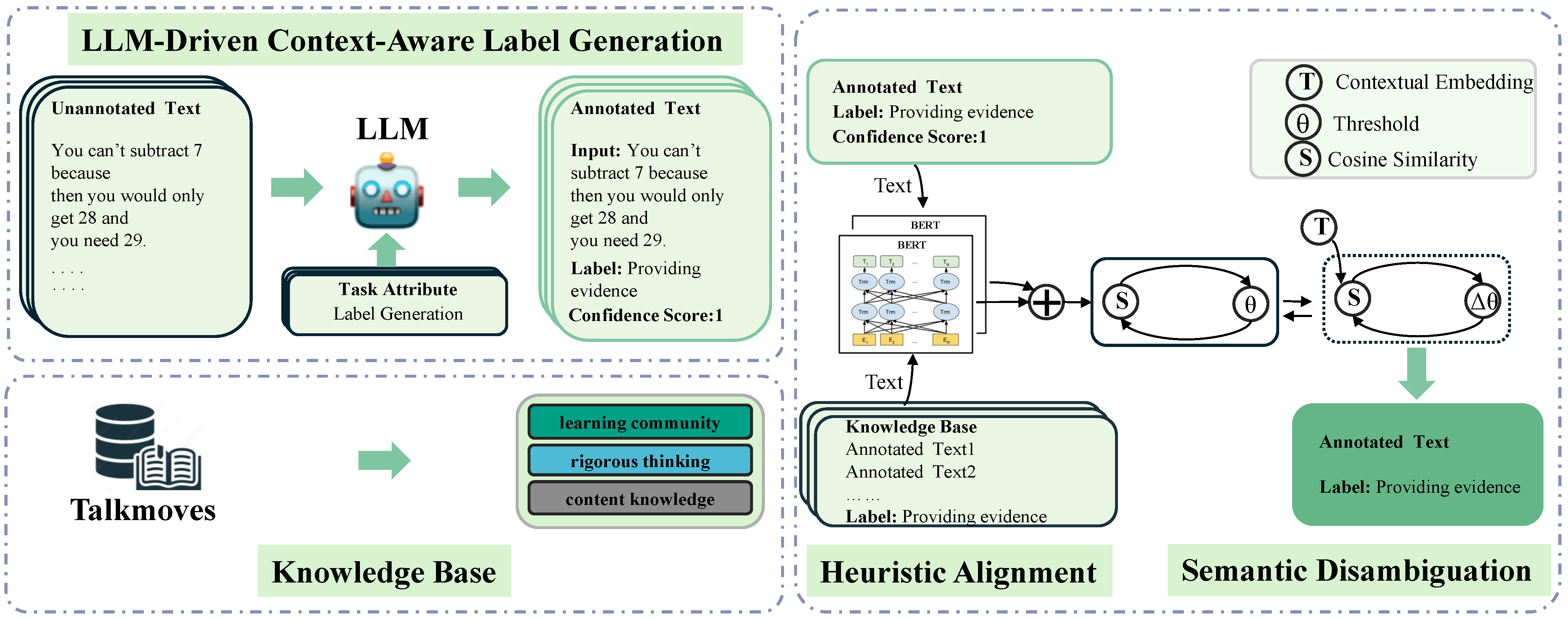
To comprehensively evaluate the contributions of each component in the EduDCM framework to dataset generation quality, we conducted a series of ablation experiments. The configurations included (1) the complete framework, (2) removal of the LLM-Driven Context-Aware Label Generation (replaced with traditional distant supervision, where an utterance is labeled based on semantic similarity to knowledge base examples), (3) exclusion of heuristic alignment, and (4) exclusion of optimized semantic disambiguation. The knowledge base component was retained in all configurations, as it is integral to the framework. Each configuration generated 100 annotated samples spanning the pedagogical categories in the EduTalk dataset. Evaluation metrics included the proportion of positive instances and a data richness score, developed by domain experts, to measure the depth and complexity of annotations on a 1-to-5 scale.
The results in
Table 6 highlight the critical role of each component in the EduDCM framework. Removing the LLM-Driven Context-Aware Label Generation component caused the most significant drop in both metrics, with the proportion of positive instances decreasing from 87% to 72% and the data richness score falling from 4.6 to 3.2. This decline underscores the importance of context-aware label generation, as traditional distant supervision relies solely on semantic similarity, often missing nuanced context in dialogues.
Excluding heuristic alignment led to a moderate performance decline, reducing the positive instance proportion to 83% and the data richness score to 4.3. This indicates that heuristic alignment effectively refines the initial labels, improving both accuracy and semantic depth by aligning utterances with relevant knowledge base examples.
The removal of optimized semantic disambiguation resulted in a smaller impact, with the positive instance proportion dropping to 82% and the data richness score to 4.1. While this component aids in handling ambiguous cases and improving multilingual adaptability, its influence is supplementary compared to the other components.
Overall, the ablation study demonstrates that LLM-Driven Context-Aware Label Generation is the cornerstone of the EduDCM framework. Heuristic alignment and semantic disambiguation further enhance annotation quality, suggesting that the integration of these components is essential for generating high-quality datasets for educational dialogue classification.
Evaluation of Different LLMs in the LLM-Driven Labeling Component
This section evaluates the impact of integrating different LLMs into the LLM-Driven Labeling component of the EduDCM framework. The assessment focuses on how the replacement of the baseline GPT-3.5 with other LLMs such as Gemini-pro [
31], Claude2 [
32], and GPT-4o [
33] affects the framework’s performance, measured by the positive instance proportion and data richness score. These metrics reflect the accuracy and depth of annotations generated by each LLM. The baseline GPT-3.5 has demonstrated robust performance in prior evaluations and serves as the standard for comparison. All models were tested under identical conditions to ensure consistency in results.
Table 7 summarizes the performance of different LLMs within the LLM-Driven Labeling component. The baseline GPT-3.5 achieved strong results, with a positive instance proportion of 87% and a data richness score of 4.6. This reinforces its capability to generate accurate and contextually rich annotations, setting a high standard for comparison.
Replacing GPT-3.5 with Gemini-pro resulted in a notable decline in both metrics, with the positive instance proportion dropping to 81% and the data richness score decreasing to 4.1. This suggests that while Gemini-pro can provide basic annotation functionality, its capacity for capturing nuanced pedagogical interactions and generating semantically rich annotations is limited compared to GPT-3.5.
Claude2 demonstrated competitive performance, achieving a positive instance proportion of 85% and a data richness score of 4.4. Although slightly below the baseline, its consistent results indicate that Claude2 is a viable alternative in scenarios where cost or computational constraints favor its adoption.
GPT-4o outperformed all other LLMs, achieving the highest positive instance proportion (89%) and data richness score (4.8). This superior performance highlights its advanced ability to understand conversational context and generate precise, detailed annotations. The results suggest that GPT-4o’s enhanced contextual understanding and semantic capabilities make it particularly suitable for tasks requiring deep processing and high-quality annotation generation.
These findings underscore the importance of selecting an appropriate LLM for the LLM-Driven Labeling component. While GPT-4o offers the best overall performance, Claude2 provides a cost-effective alternative with near-baseline results. Gemini-pro, while functional, may require additional optimization to meet the demands of complex educational dialogue classification tasks. This evaluation further highlights how advancements in LLM technology can significantly enhance the effectiveness of frameworks like EduDCM, enabling more scalable and accurate dataset generation in low-resource settings.






{kind=link}
{kind=link}