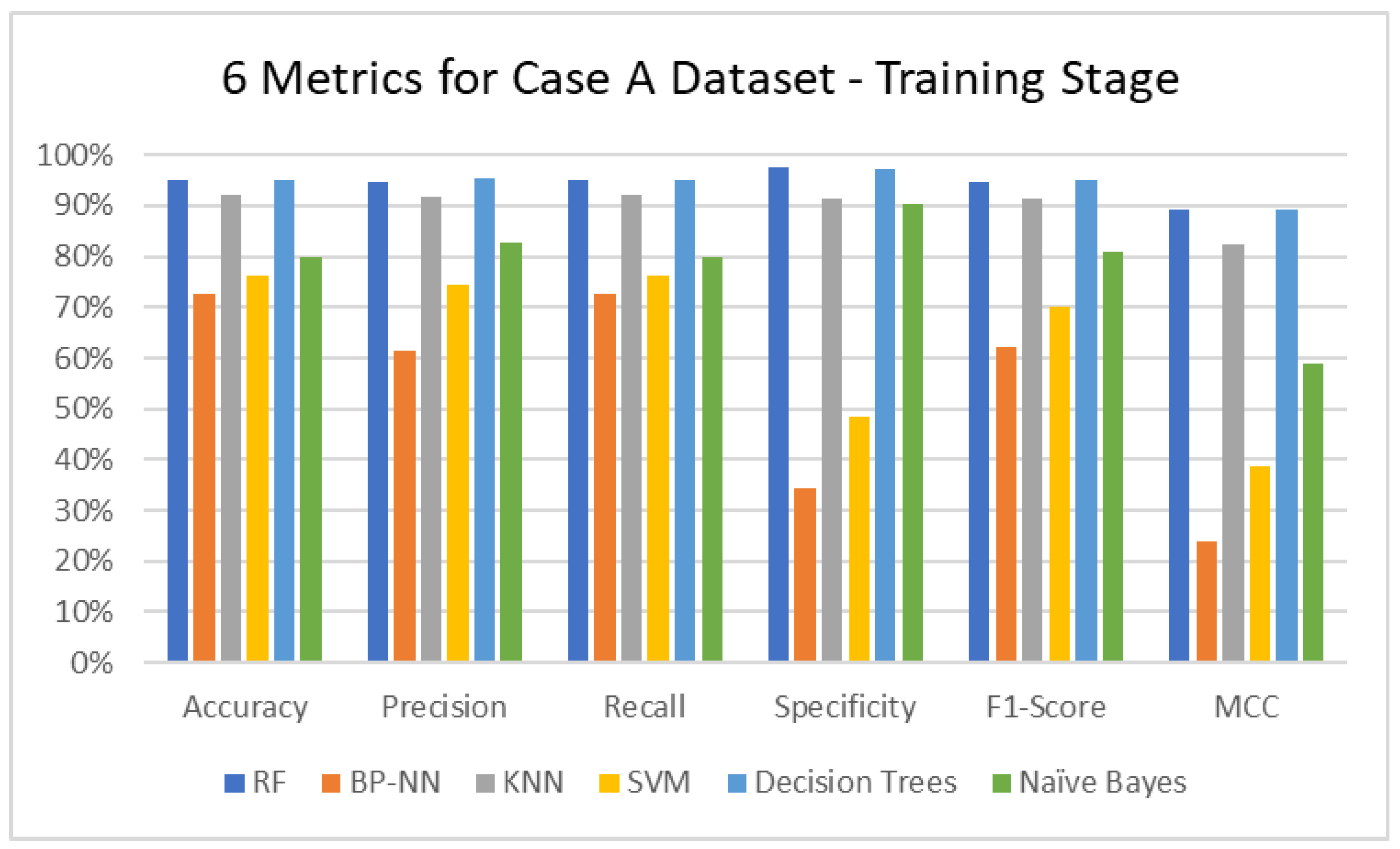
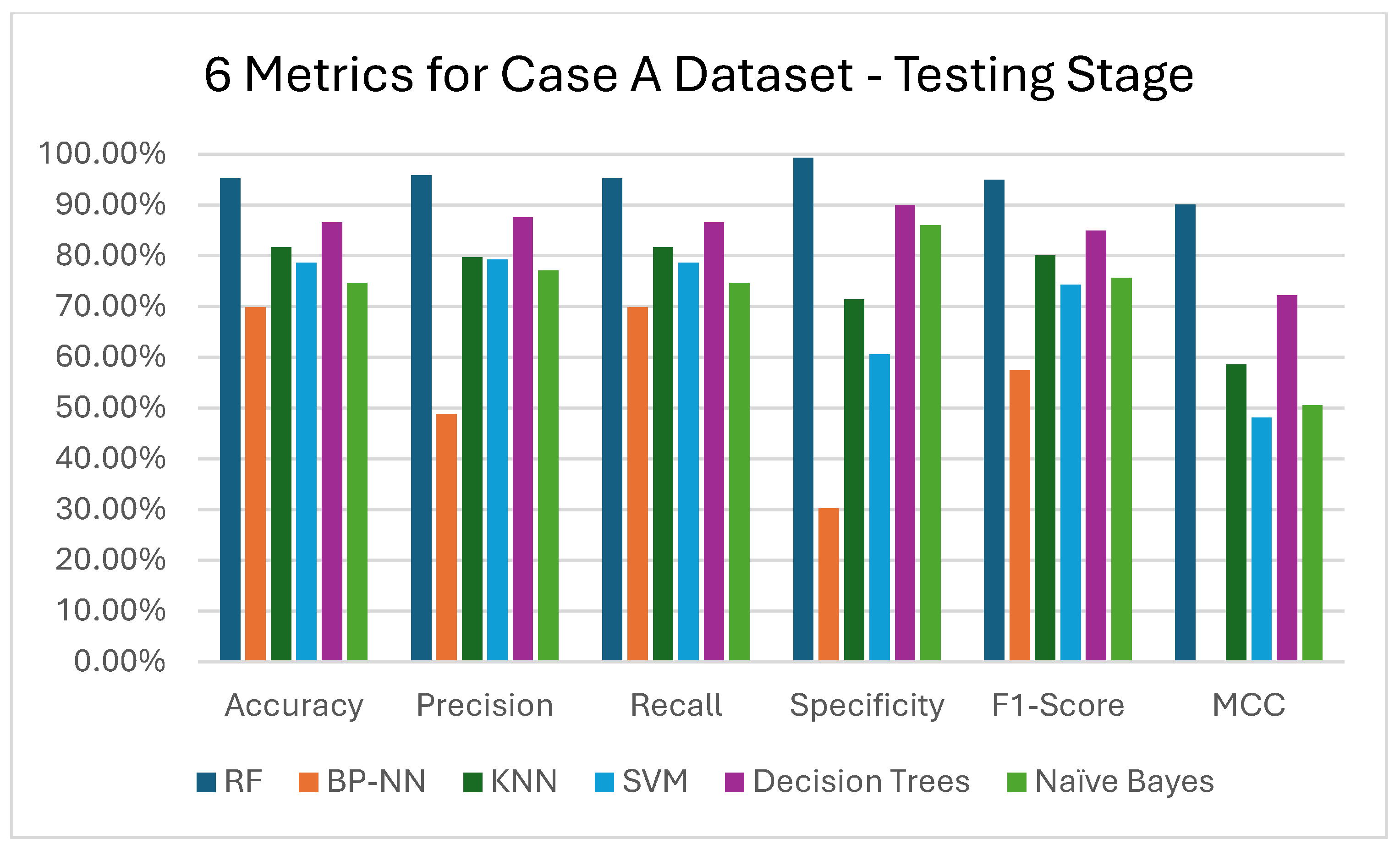
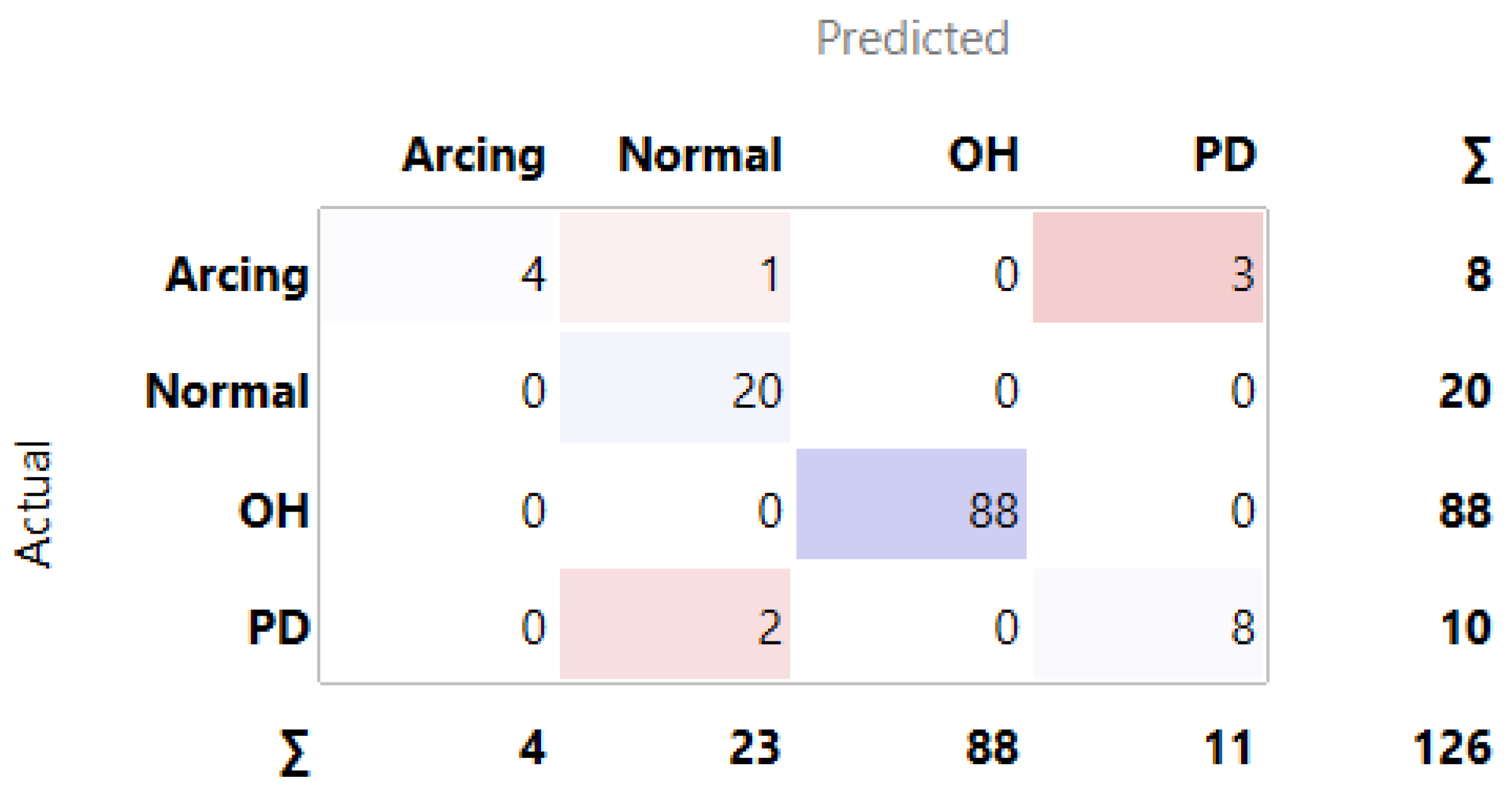
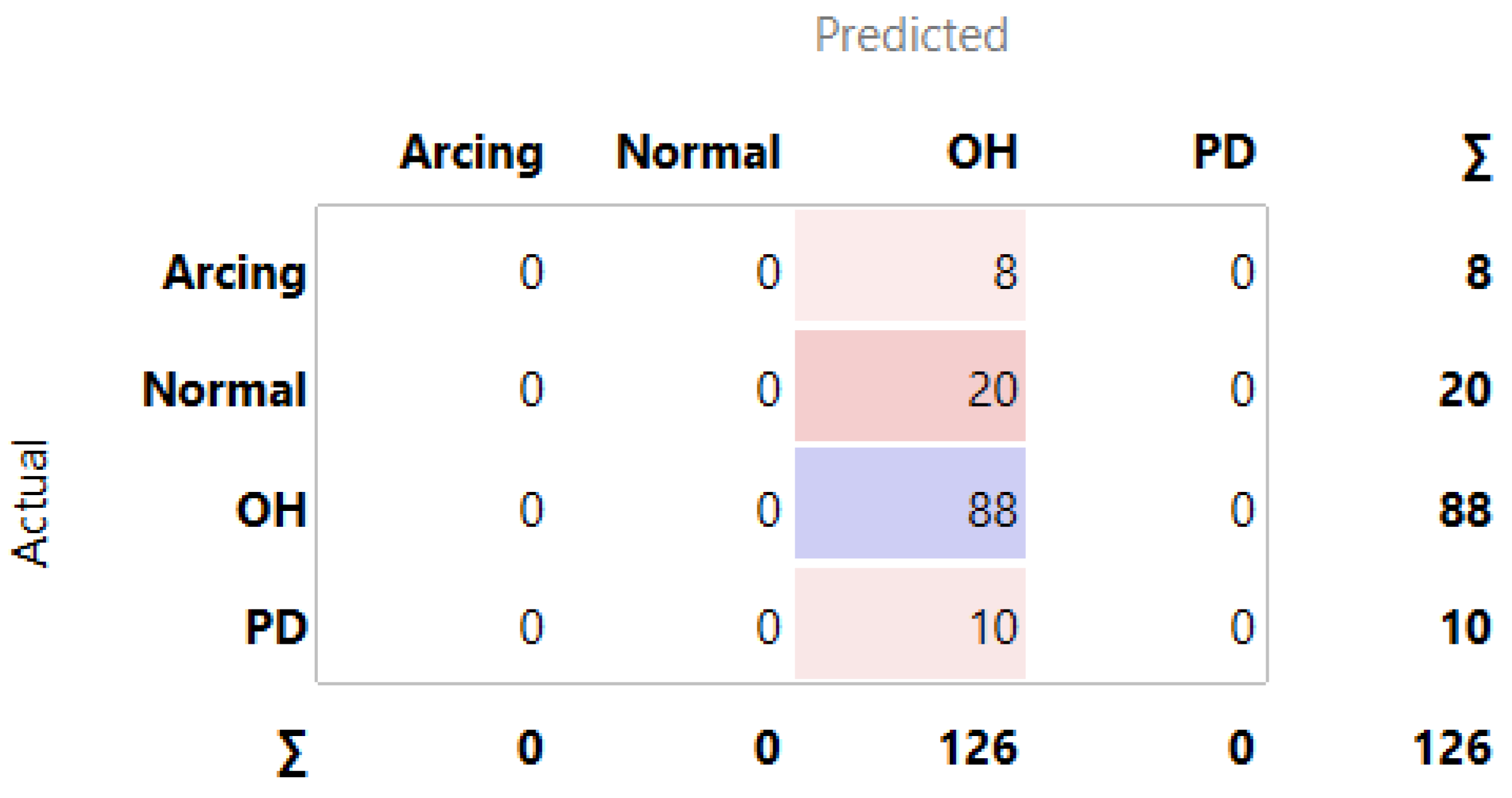
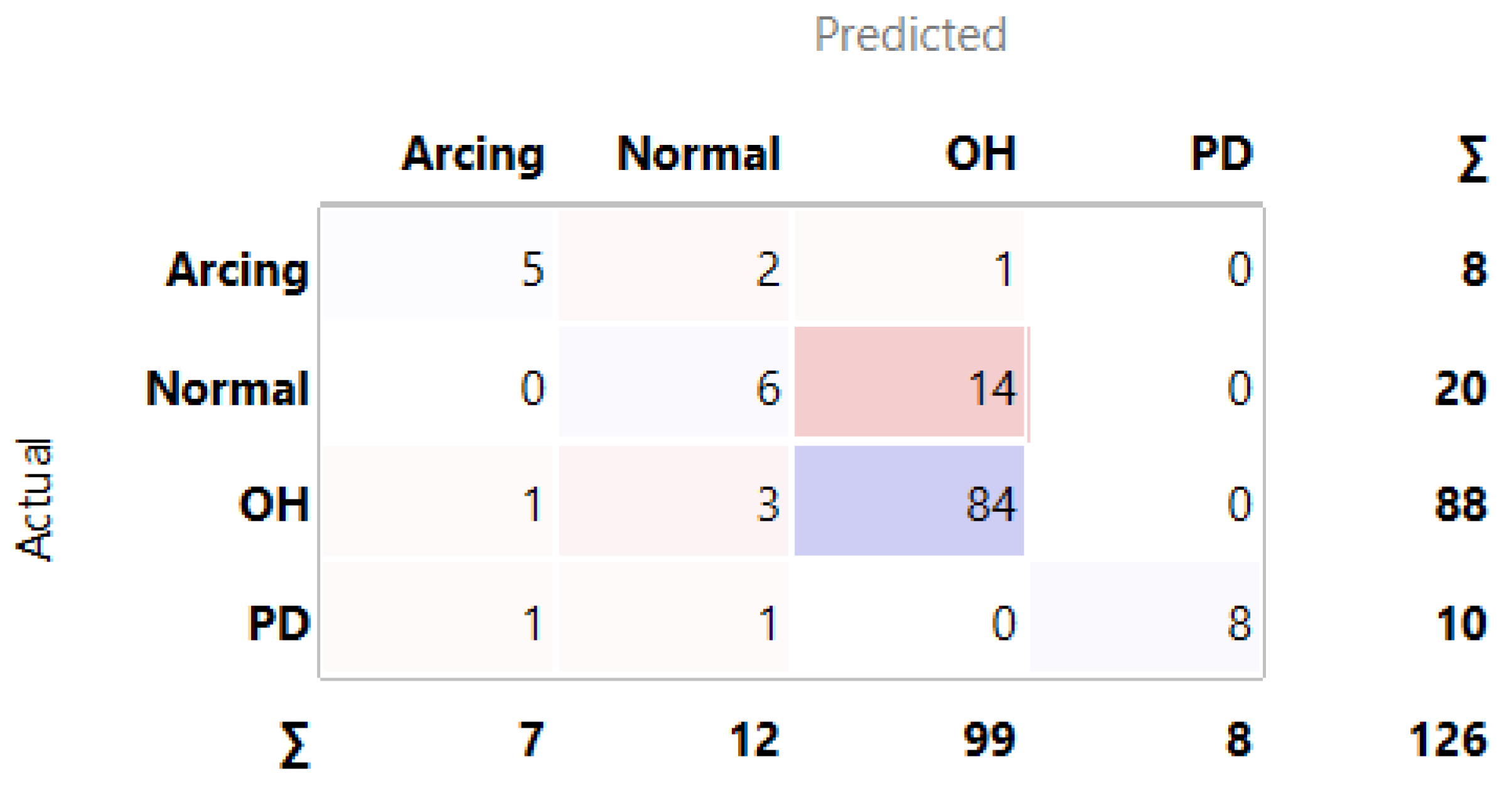
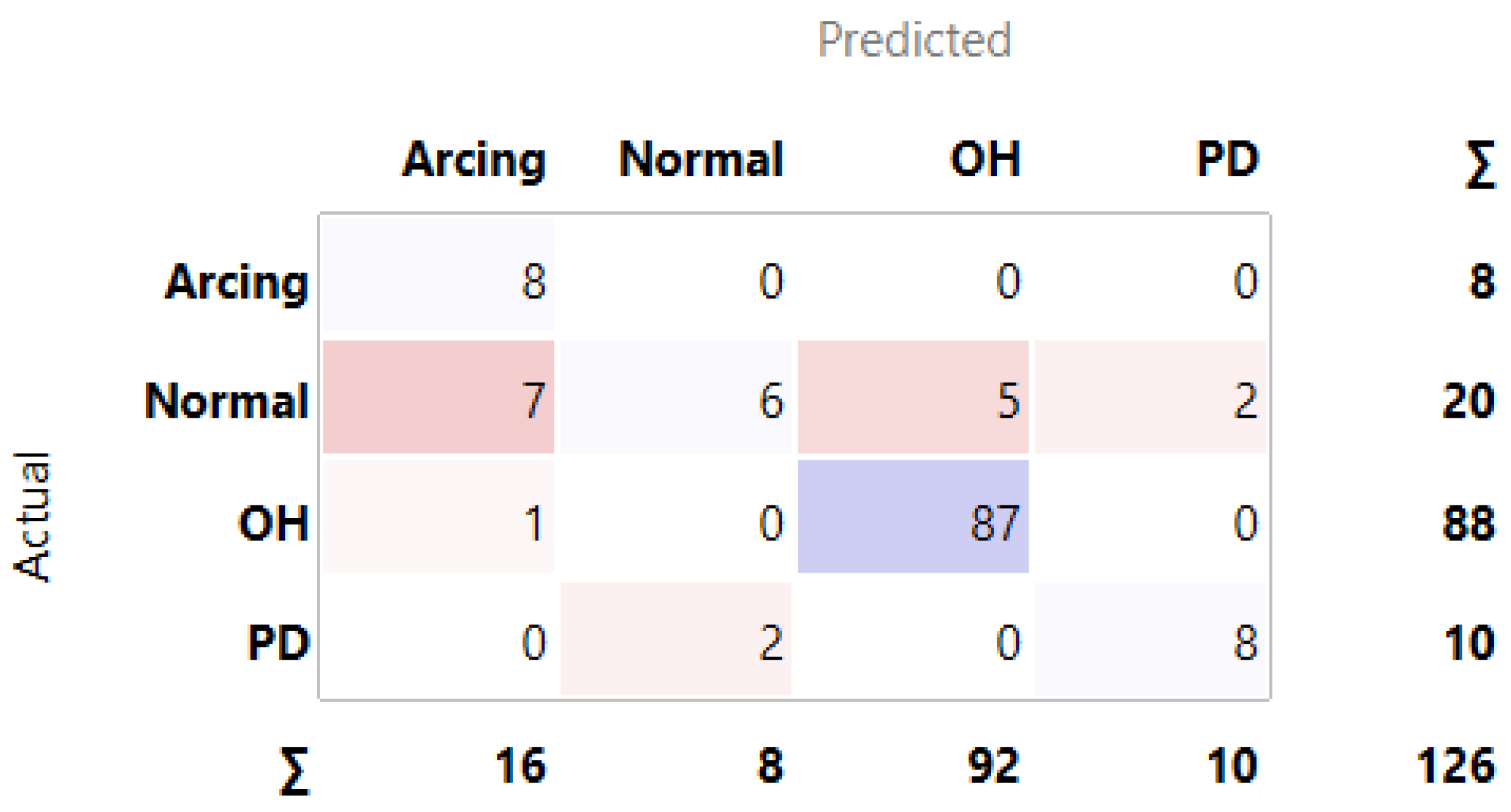
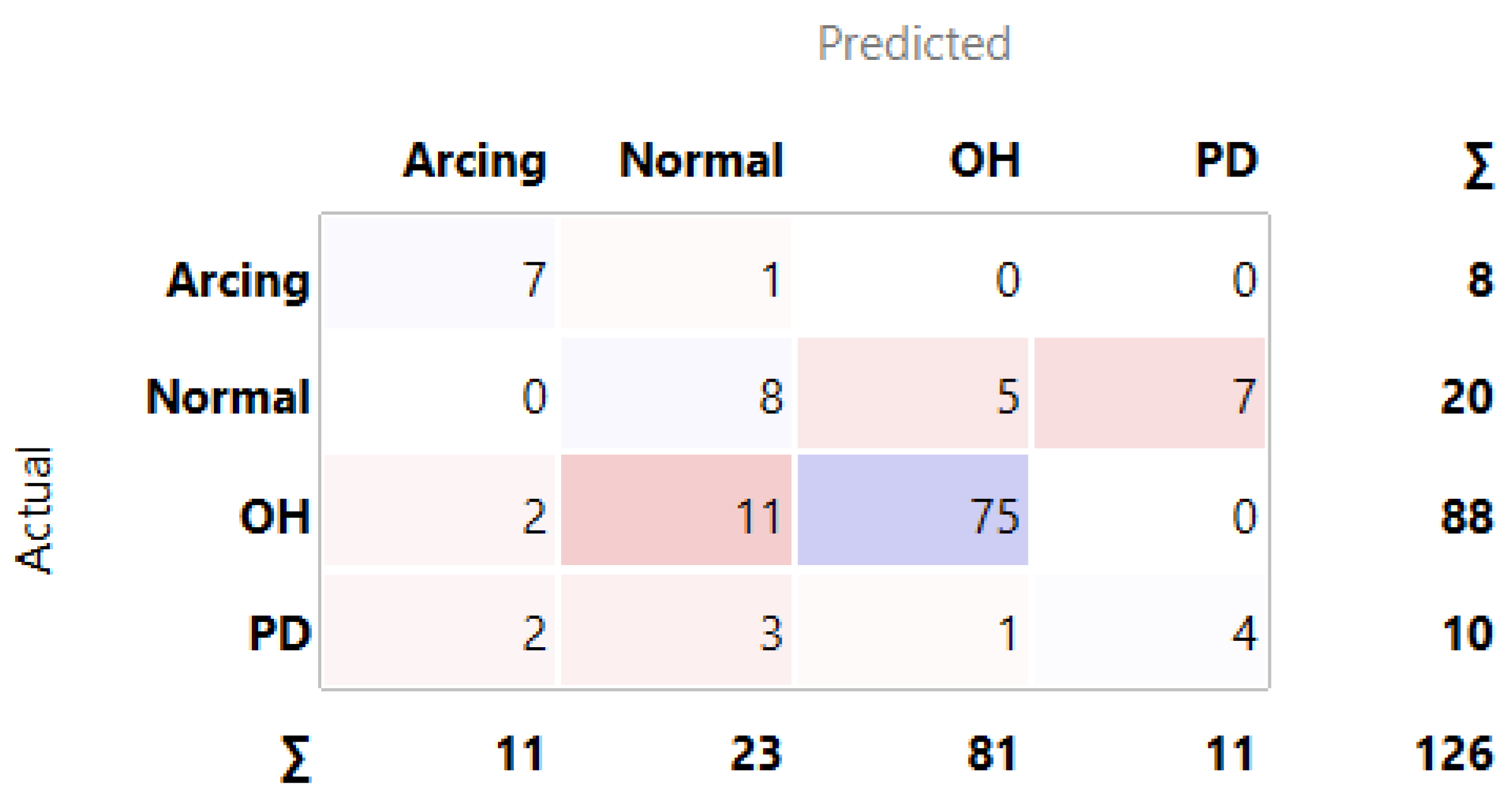
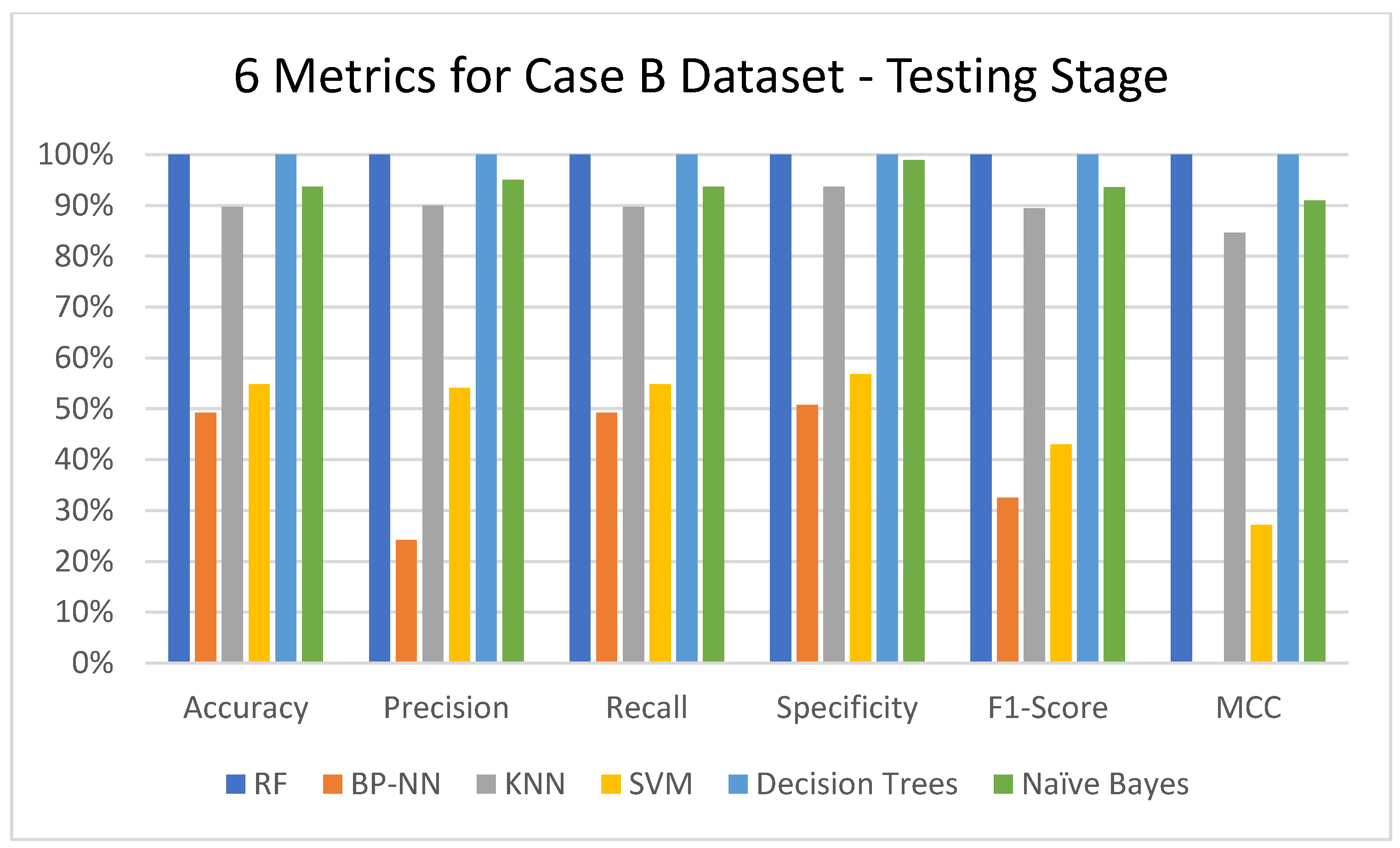
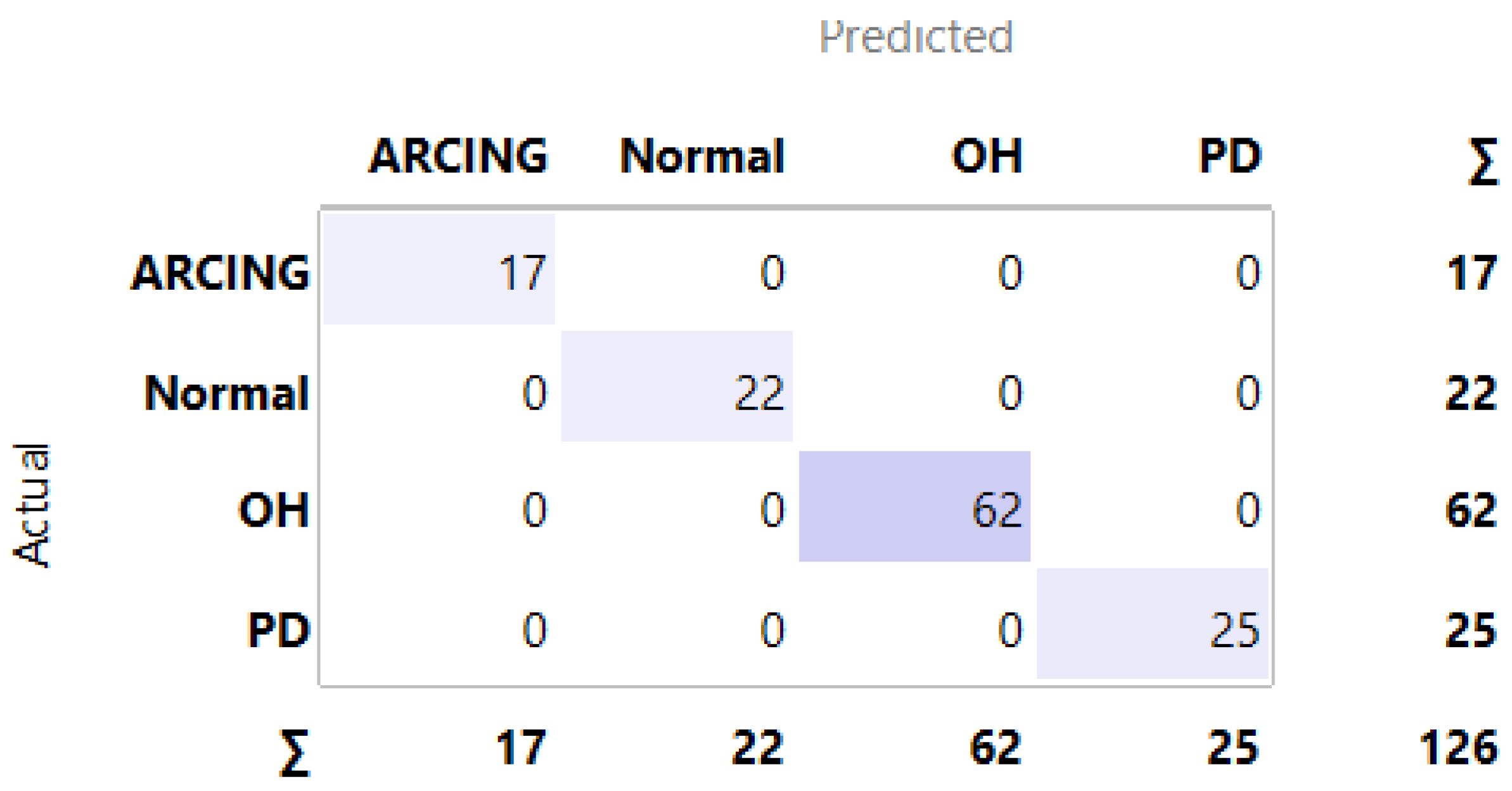
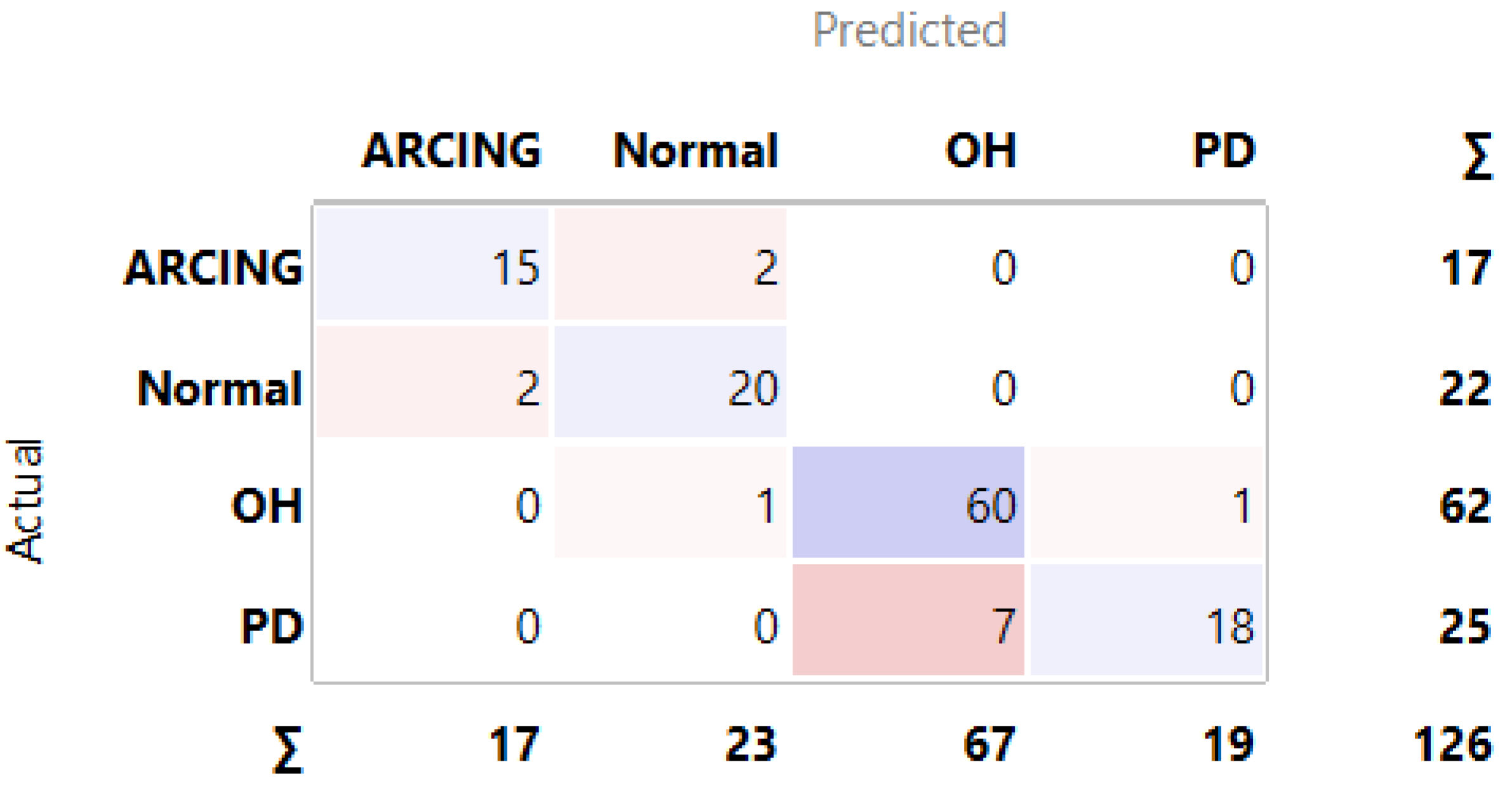
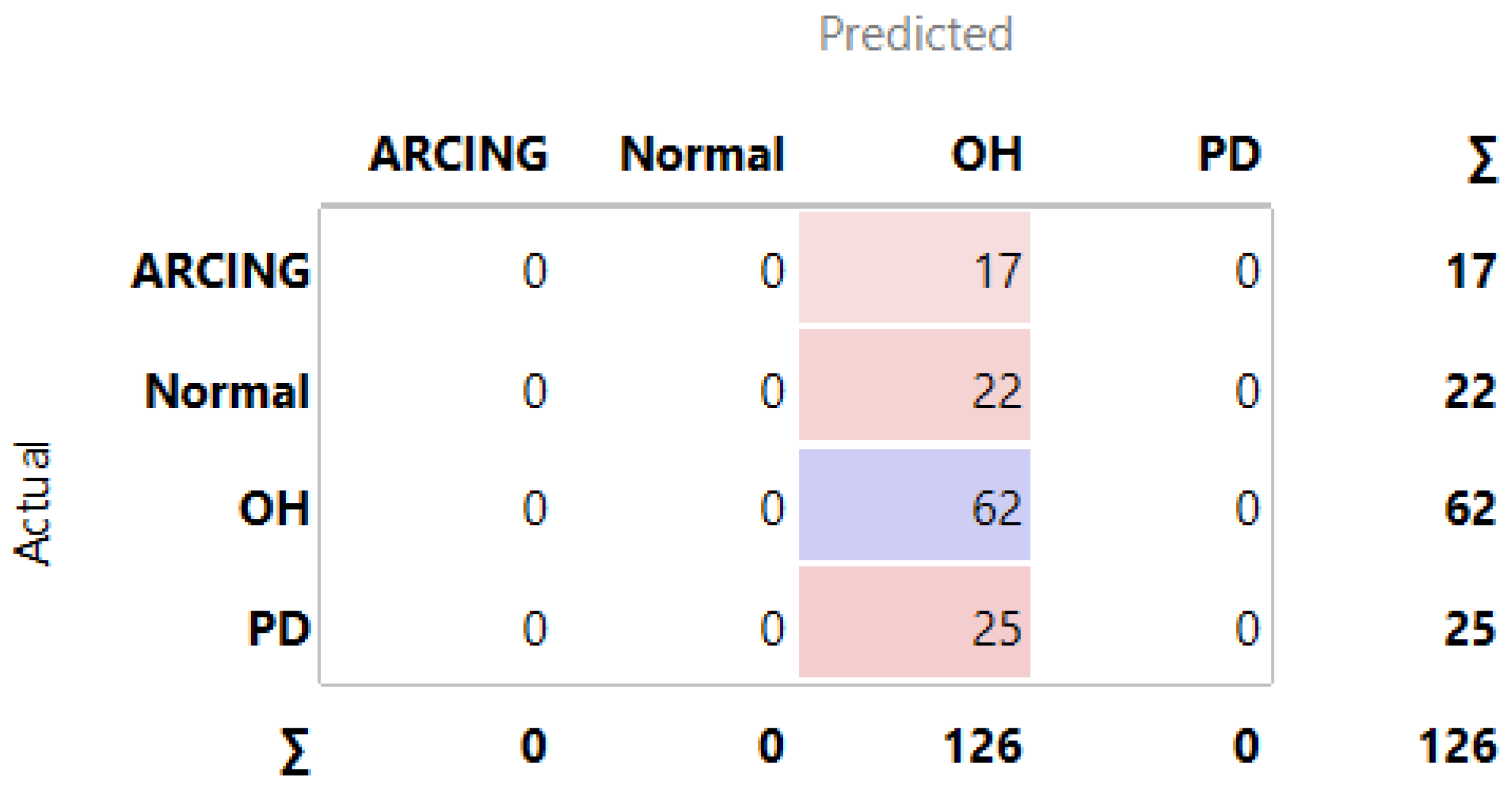
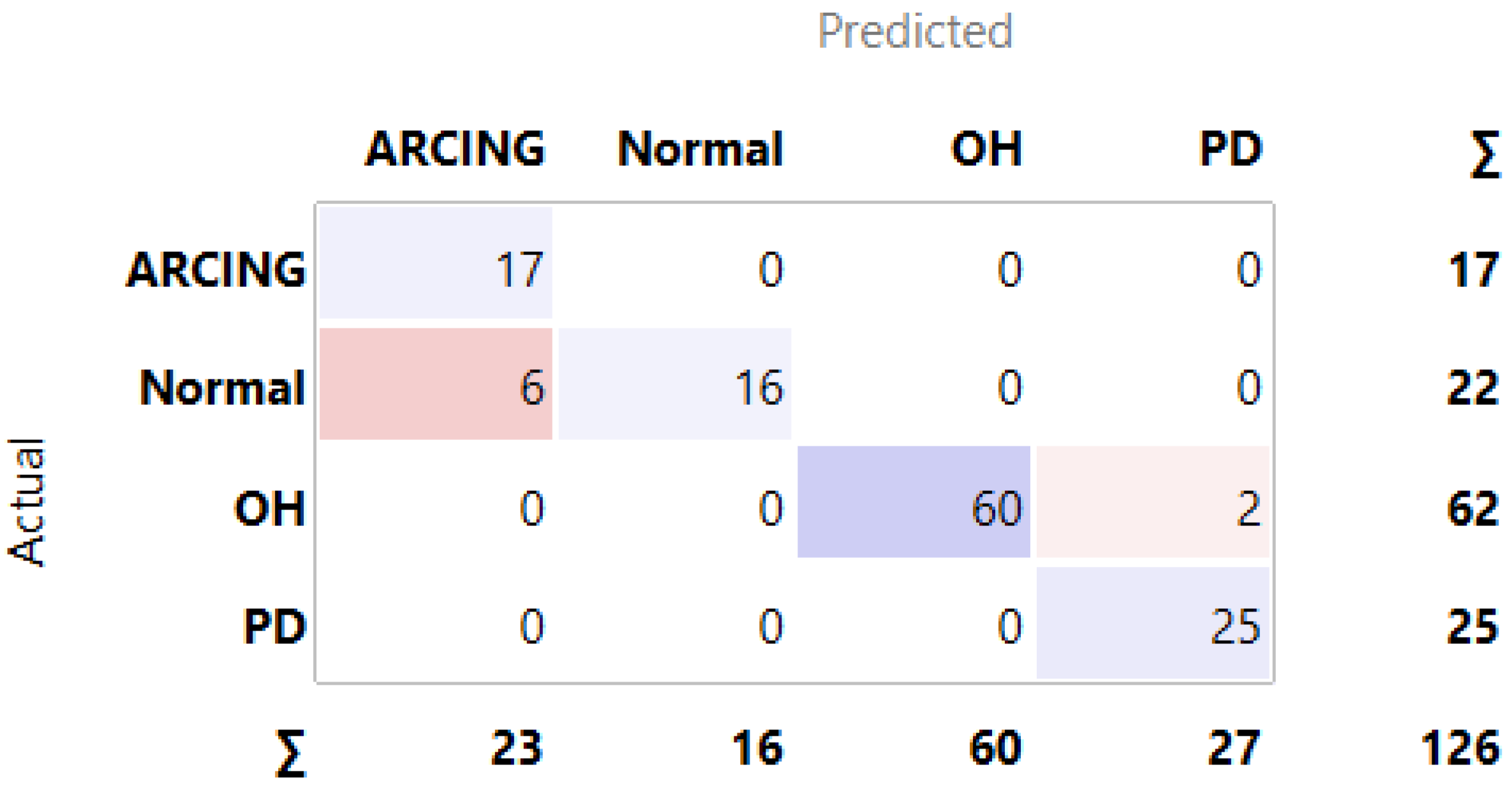
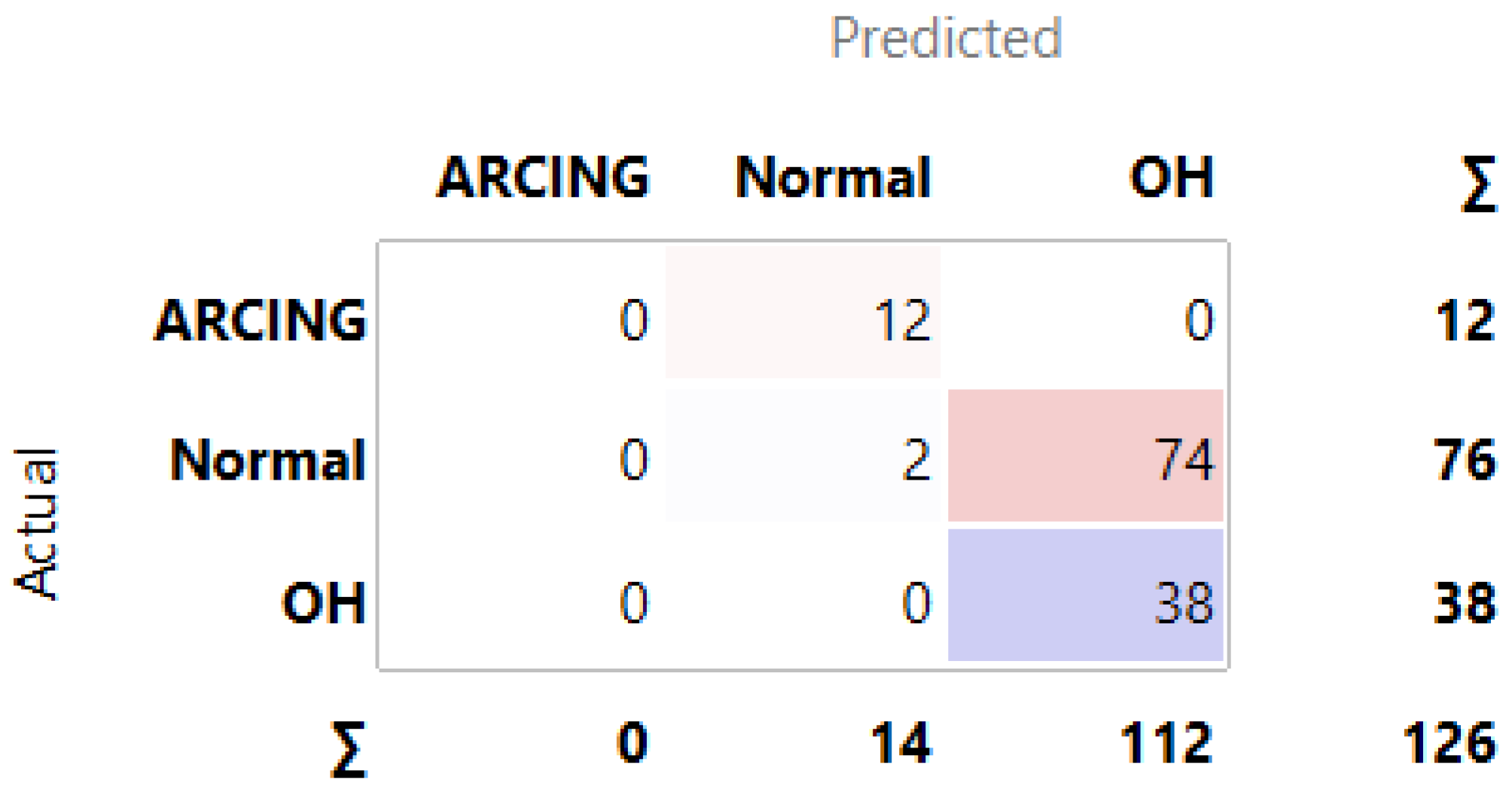
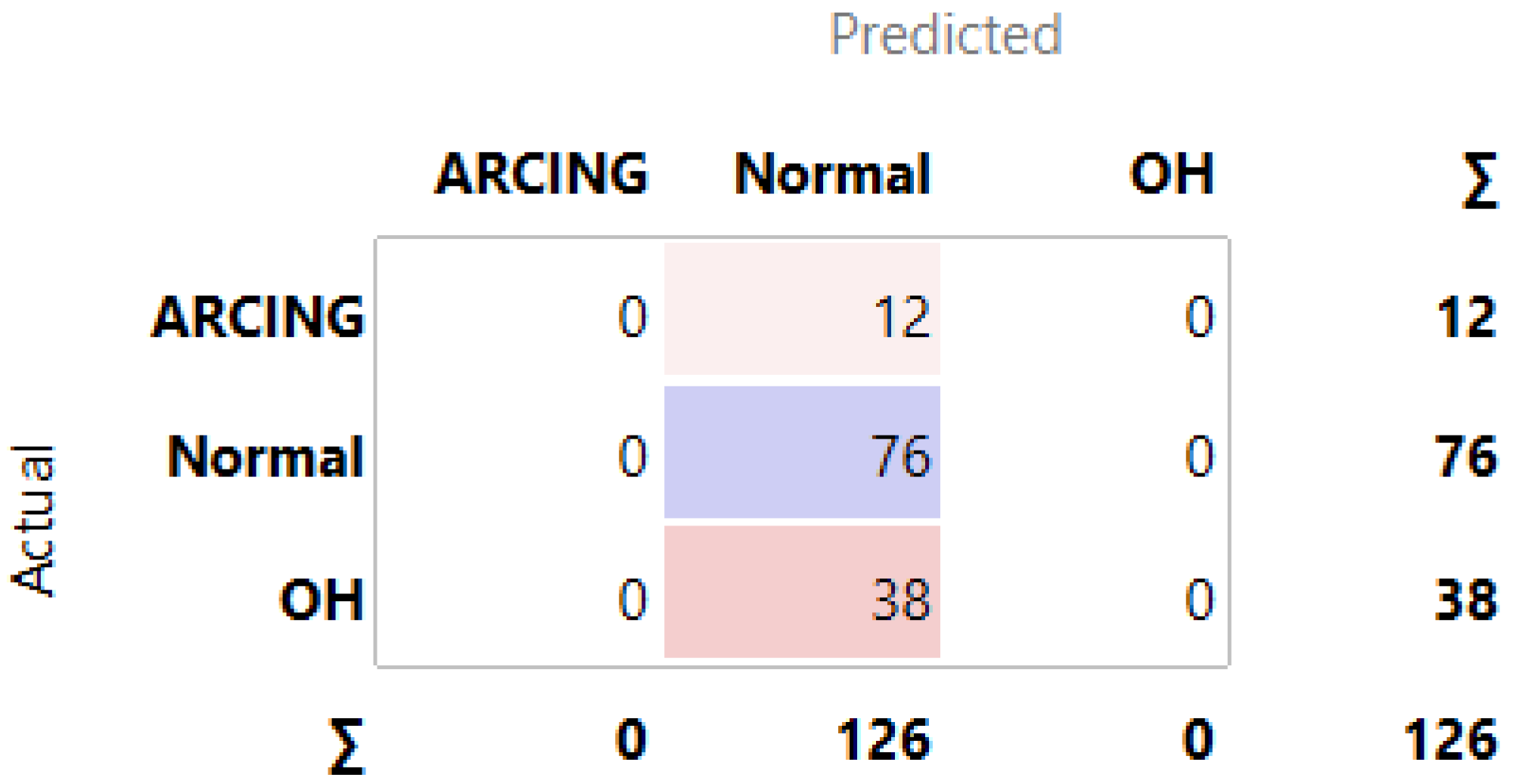
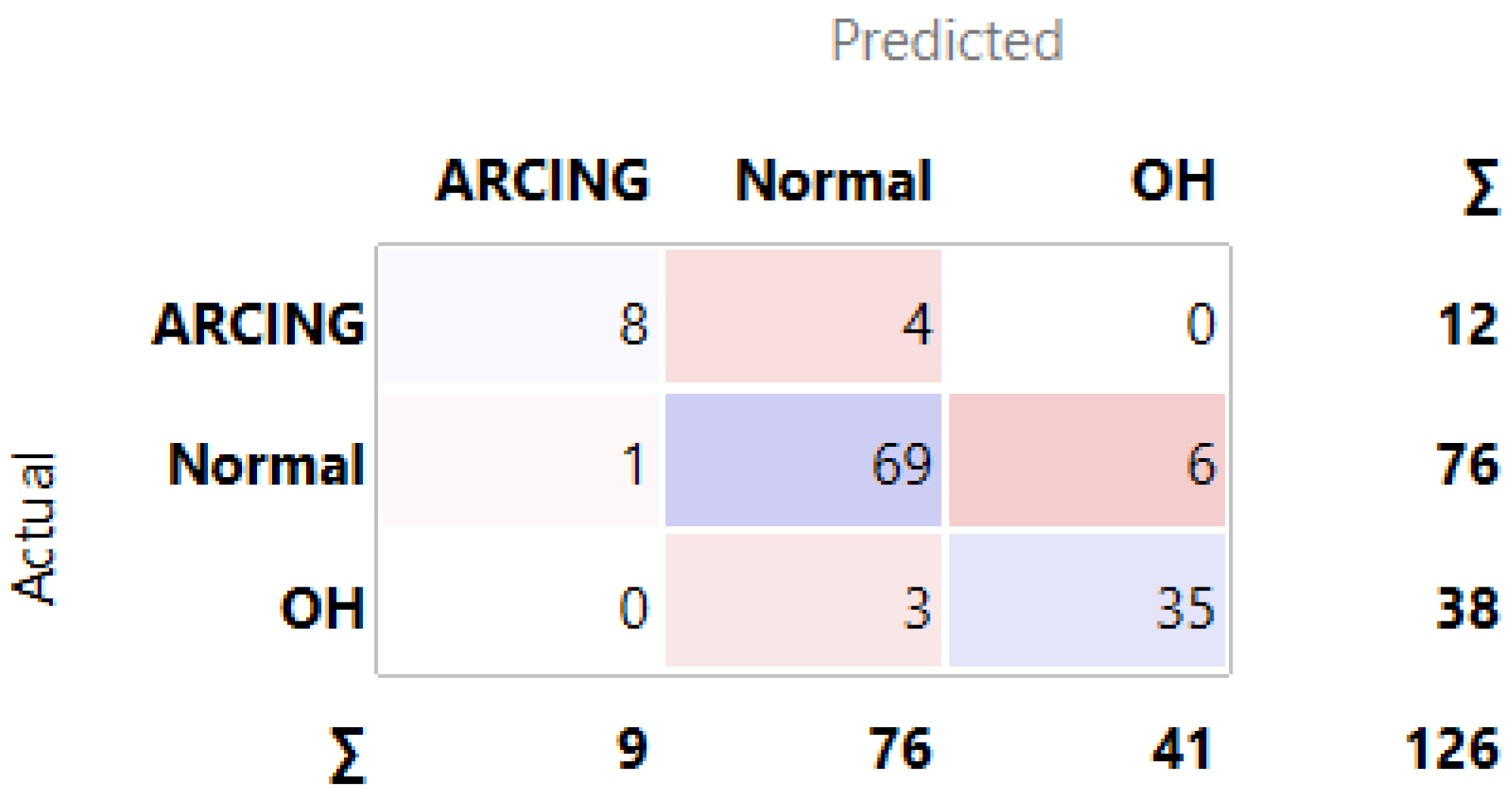
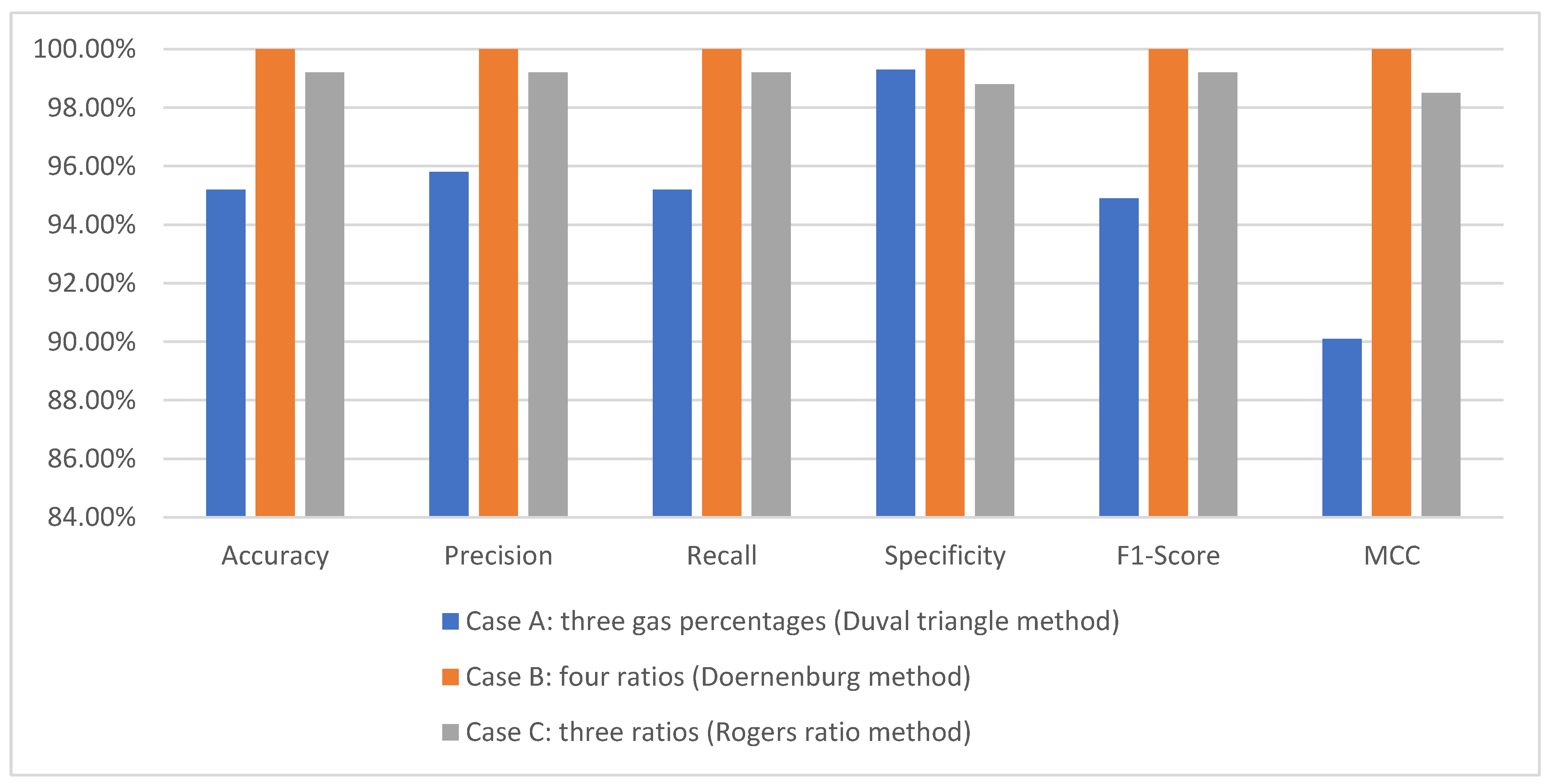
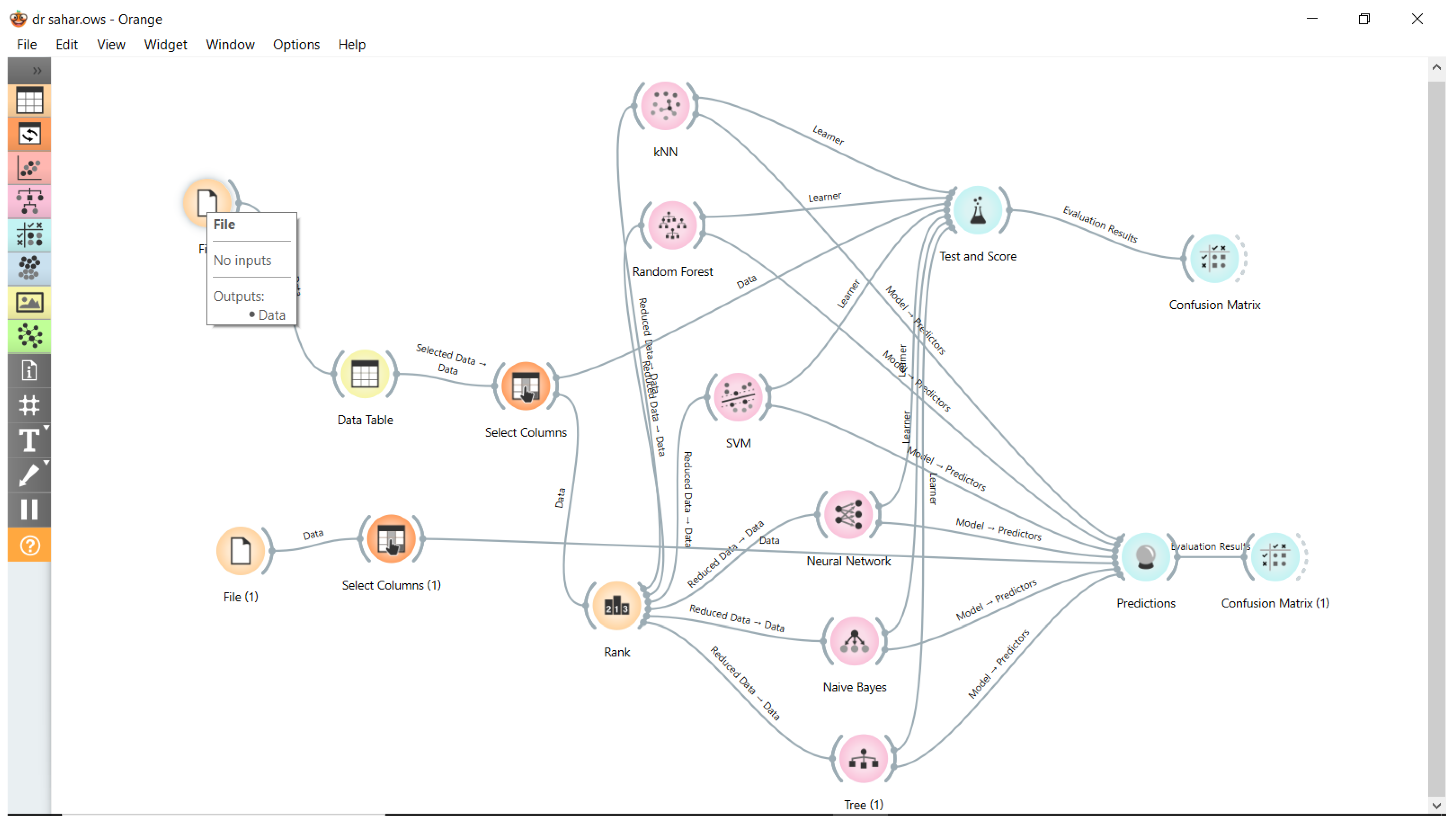
3.1. MLMs
This section gives a concise overview of the six ML approaches included in the classification toolbox.
3.1.1. Random Forest (RF)
Random forest algorithms can be used in both classification and regression problems, like decision trees. The logic of the approach is to create more than one decision tree and produce average results with the help of these trees. The reason why this algorithm is called random is that it offers extra randomness during the creation of the tree structure. When splitting a node, instead of looking for the best attribute directly, it looks for the best attribute in a subset of random attributes. This situation creates more diverse trees [
23,
24,
25].
The brief main stages of RF are as below:
if stopping_condition_met(data) then:
return CreateLeafNode(data)
selected_features = RandomSubset(features)
best_feature = FindBestSplit(data, selected_features)
subsets = SplitData(data, best_feature)
node = CreateNode(best_feature)
for each subset in subsets do:
child_tree = BuildRandomTree(subset, features)
node.add_child(child_tree)
return node
votes = {}//Initialize a dictionary to count votes for each class
for each tree in forest do:
prediction = tree.Predict(test_instance)//Get prediction from each tree
if prediction not in votes then:
votes[prediction] = 0
votes[prediction] += 1//Count the vote for this prediction
final_prediction = ArgMax(votes)//Get the class with the highest vote count
3.1.2. Backpropagation Neural Network (BPNN)
A neural network (NN) consists of interconnected ‘units’ organized in a sequence of layers, with each layer being connected to adjacent layers. Neural networks draw inspiration from biological systems, such as the brain, and their information-processing capabilities. NNs, or neural networks, consist of several interconnected processing components that collaborate to address particular issues [
26]. The brief main steps of a BPNN are as below:
Set learning rate (α)
Set number of epochs (E)
Define network architecture (number of layers, number of neurons per layer)
For each layer in the network:
Initialize weights randomly
Initialize biases to zero
For each epoch in range(E):
For each training sample (x, y):
For each hidden layer:
Compute weighted sum: z = W1 ∗ x + b
Apply activation function: H = activation(z)
For each node in Output layer:
Compute weighted sum: s = W2 ∗ H + b
Apply activation function: Out = activation(s)
Calculate loss using Cross-Entropy loss function
Compute gradients of loss with respect to output
For each layer from output to input:
Compute gradients for weights and biases
Update weights and biases using gradient descent:
W = W − α ∗ gradient_W
b = b − α ∗ gradient_b
3.1.3. The K-Nearest Neighbors (KNN) Algorithm
The K-nearest neighbors method is indeed one of the most efficient OML strategies for classification tasks in many different application scenarios [
27]. The key idea behind this approach is to search, for every class, for the samples in the training dataset that are closest to any given query position [
28]. Bayesian optimization (BO) is used to find the optimal hyperparameters of the KNN algorithm so that the highest achievable classification accuracy is reached. The hyperparameters of the optimization of KNN include the number of neighbors, the metric of distance, the weight of distance, and normalization of the dataset. The main steps of the KNN method are as follows:
For each Test_Point in Test Data
distances = []
For each Train_Point in Train Data
distance = calculate_distance(test_point, train_point)
distances.append((distance, train_point.class_label))
Sort distances by the first element (distance)
nearest_neighbors = distances[0:K]
class_votes = {}
For each neighbor in nearest_neighbors:
class_label = neighbor.class_label
if class_label in class_votes:
class_votes[class_label] += 1
else
class_votes[class_label] = 1
predicted_class = argmax(class_votes)
Assign predicted_class to test_point
3.1.4. Support Vector Machine (SVM)
The support vector machine classifies the dataset by constructing several hyperplanes that enable clear discrimination between the multiple classes present in the training dataset [
29]. The SVM falls under the category of a kernel-based approach. A hyperplane is selected to maximize the margin between the different classes. The kernel function is used to ascertain the path of the hyperplane. The advantages of the SVM include its high accuracy in prediction for classification problems, but the training process is very time-consuming. In this regard, the BO technique has been applied to identify the most optimal parameters during the training of the support vector machine algorithm. The most critical decisions to be considered that may be dealt with for improvement in the SVM technique include the selection of the kernel function, the scale of the kernel, the box constraint level, the cautious approach, and the normalization of the dataset. The stages of the SVM algorithm are as follows:
Set regularization parameter (C)
Set RBF (exp(-gamma ∗ ||x1 − x2||^2)) as a kernel
Set tolerance for stopping criterion (tol)
Set maximum number of iterations (max_iter)
Set weights (w) to zero
Set bias (b) to zero
For each iteration in range(max_iter):
For each training sample (xi, yi):
Compute margin: margin = yi ∗ (dot(w, xi) + b)
If margin < 1 then
w = w + C ∗ yi ∗ xi
b = b + C ∗ yi
Normalize weights by w = w/||w||
3.1.5. Decision Tree (DT)
A decision tree is composed of four general parts: a root node, branches, internal nodes, and a leaf node [
30]. Within the classification processes of the DT method, the information of each attribute is assessed and utilized to separate datasets.
A BO technique is used to obtain the best values of the DT’s hyperparameters, including the maximum number of splits and the split criterion. The technique is not only superfluous but also cumbersome as it entails removing the branches that are not effective in the classification process to arrive at the last decision tree model. The stages of the DT algorithm are as below:
if all Dataset are in the same class:
return the class label of dataset
else if Features is empty:
return the majority class label of dataset
else if Dataset is empty:
return the majority class label of parent node
else:
best_feature = choose_best_feature(features, dataset)
tree = new TreeNode(best_feature)
for each value v in best_feature:
subset = dataset where best_feature = v
subtree = DecisionTree(subset, features − {best_feature})
tree.add_child(v, subtree)
return tree
3.1.6. Naive Bayes (NB)
The Naive Bayes (NB) classifier relies on the use of Bayes’ theorem throughout the classification process [
31]. This approach presupposes that the input characteristics are independent of each other when determining the output classes in the classification process. The Naive Bayes (NB) algorithm outperforms the support vector machine (SVM) and elastic net (EN) methods in terms of training speed. Additionally, NB is particularly well suited for training huge datasets. The ideal parameters of the Naive Bayes classifier are calculated via Bayesian optimization during the training step. The ideal parameters for the NB technique consist of the names of the distributions and the kind of kernel. The algorithm of NB is as follows:
class_priors = {}
for each class c in training_data:
class_priors[c] = count(class == c)/total_count(training_data)
likelihoods = {}
for each feature f in training_data:
for each class c in training_data:
likelihoods[f][c] = calculate_likelihood(training_data, f, c)
predictions = []
for each instance in test_data:
max_prob = −1
best_class = None
for each class for each class c in class_priors:
posterior_prob = class_priors[c]
for each feature f in instance:
posterior_prob * = likelihoods[f][c]
if posterior_prob > max_prob:
max_prob = posterior_prob
best_class = c
predictions.append(best_class)
return predictions
Function calculate_likelihood(training_data, feature, class):
feature_values = unique_values(training_data, feature)
likelihoods = {}
for value in feature_values:
count_feature_value_and_class = count(training_data where feature == value and class == c)
count_class = count(training_data where class == c)
likelihoods[value][class] = (count_feature_value_and_class + 1)/(count_class + number_of_unique_values(training_data, feature))
return likelihoods




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}