

Analyzing Data Reduction Techniques: An Experimental Perspective




Abstract
1. Introduction
- New data reduction techniques’ taxonomies.
- Comparison of different data reduction techniques.
- Experimental evaluation of data reduction techniques.
2. Background
- Data size reduction is a percentage-based size comparison of the original and reduced data after applying the reduction techniques.
- Data accuracy quantifies the fidelity of the reduced data to the original dataset, typically expressed as a percentage. This metric measures the integrity and reliability of the reduced dataset, providing insight into the accuracy and fidelity of the information retained by the reduction process.
3. Related Work
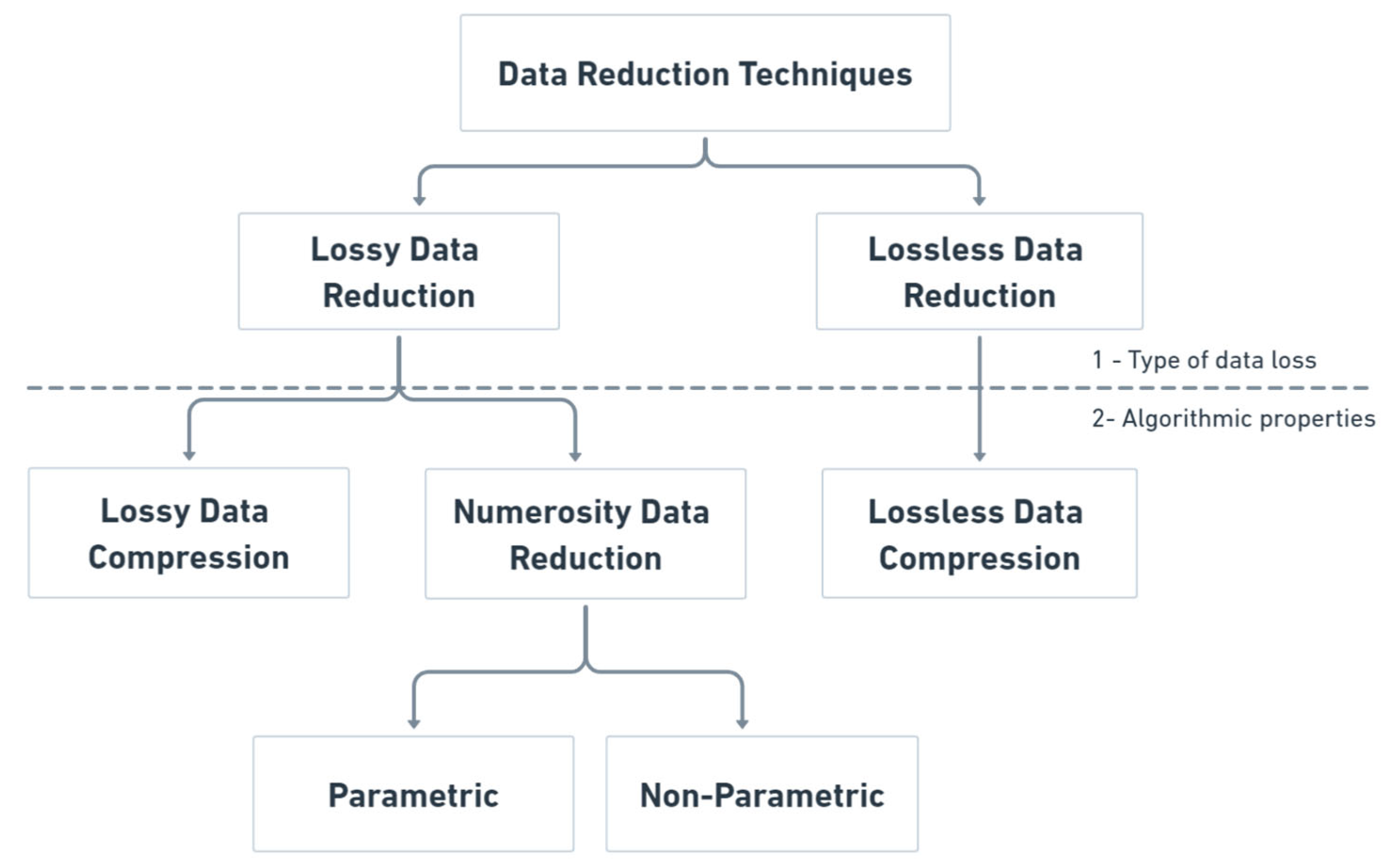
4. Proposed Taxonomy
- Lossless data reduction techniques [14,21,22]: these focus on identifying redundancies, patterns, and other inherent characteristics within the data to eliminate or minimize unnecessary and repetitive information. Reducing the data size without any loss is remarkable. However, these algorithms often depend on the type of data they are analyzing. These perform better on repetitive single-sensor data, such as temperature readings. For large-scale datasets, these techniques tend to require a significant processing time to complete the compression, which can be challenging in real-time environments. When time is a primary feature and the workload is enormous and complex, using lossy data reduction algorithms is a viable option. These algorithms include various methods for reducing the data size by selectively discarding or approximating information from the original dataset. Their main advantages include faster processing speeds and the ability to handle a variety of data formats. All these lossless algorithms compress data and can decode the reduced algorithm back to its original size. Some examples of lossless algorithms include Delta Encoding, LZ77, LZ78, Huffman coding, and Run Length Encoding [23,24].
- Lossy data reduction techniques [10,25,26,27]: these focus on reducing data by discarding some details considered less relevant to the analysis or less noticeable to human perception, and thus achieve higher compression ratios than other methods. Some examples of these techniques are transform encoding, Discrete Cosine Transform, Random Projection, Bzip2, or Fractal Compression [28,29,30]. Numerosity data reduction techniques [10,25,26] reduce the amount of data by capturing the overall trend or patterns of the data. These techniques aim to represent concise and summarized data while preserving its essential characteristics and patterns. Unlike lossy compression, numerosity data reduction techniques do not intentionally discard data details but summarize them to make them more manageable and efficient. There are two main types of numerosity data reduction techniques: parametric and non-parametric.
- ○
- Parametric techniques [31] rely on pre-existing data models, such as Linear Regression and Log–Linear, to estimate the data and reduce its quantity.
- ○
5. Datasets
6. Experimental Evaluation Metrics
7. Data Reduction Techniques
7.1. Lossy Data Reduction Algorithms
7.2. Lossless Data Reduction Algorithms
8. Experimental Evaluation
8.1. Lossy Data Reduction Algorithms
8.1.1. Random Projection
8.1.2. Quantization
8.1.3. Linear Regression
8.1.4. Principal Component Analysis
8.1.5. K-Means
8.1.6. Simple Random Sampling
8.2. Lossless Data Reduction Algorithms
8.2.1. Delta Encoding
8.2.2. BZip2
9. Discussion
9.1. Lossy Data Reduction Algorithms
9.2. Lossless Data Reduction Algorithms
10. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siddiqui, S.T.; Khan, M.R.; Khan, Z.; Rana, N.; Khan, H.; Alam, M.I. Significance of Internet-of-Things Edge and Fog Computing in Education Sector. In Proceedings of the 2023 International Conference on Smart Computing and Application (ICSCA), Hail, Saudi Arabia, 5–6 February 2023; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Sagiroglu, S.; Sinanc, D. Big data: A review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems, CTS, San Diego, CA, USA, 20–24 May 2013; pp. 42–47. [Google Scholar]
- Mostajabi, F.; Safaei, A.A.; Sahafi, A. A Systematic Review of Data Models for the Big Data Problem. IEEE Access 2021, 9, 128889–128904. [Google Scholar] [CrossRef]
- Rani, R.; Khurana, M.; Kumar, A.; Kumar, N. Big data dimensionality reduction techniques in IoT: Review, applications and open research challenges. Clust. Comput. 2022, 25, 4027–4049. [Google Scholar] [CrossRef]
- Ougiaroglou, S.; Filippakis, P.; Fotiadou, G.; Evangelidis, G. Data reduction via multi-label prototype generation. Neurocomputing 2023, 526, 1–8. [Google Scholar] [CrossRef]
- Obaise, R.M.; Salman, M.A.; Lafta, H.A. Data reduction approach based on fog computing in iot environment. In Proceedings of the International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Yogyakarta, Indonesia, 1–2 October 2020; pp. 65–70. [Google Scholar]
- Mahmoud, D.F.; Moussa, S.M.; Badr, N.L. The Spatiotemporal Data Reduction (STDR): An Adaptive IoT-based Data Reduction Approach. In Proceedings of the 2021 IEEE 10th International Conference on Intelligent Computing and Information Systems, ICICIS, Cairo, Egypt, 5–7 December 2021; pp. 355–360. [Google Scholar]
- Fathy, Y.; Barnaghi, P.; Tafazolli, R. An adaptive method for data reduction in the Internet of Things. In Proceedings of the IEEE World Forum on Internet of Things, WF-IoT, Singapore, 5–8 February 2018; pp. 729–735. [Google Scholar]
- Muhammad Habib Liew, C.S.; Abbas, A.; Jayaraman, P.P.; Wah, T.Y.; Khan, S.U. Big Data Reduction Methods: A Survey. Data Sci. Eng. 2016, 1, 265–284. [Google Scholar]
- Dias, G.M.; Bellalta, B.; Oechsner, S. A Survey About Prediction-Based Data Reduction in Wireless Sensor Networks. ACM Comput. Surv. 2016, 49, 1–35. [Google Scholar] [CrossRef]
- Chhikara, P.; Jain, N.; Tekchandani, R.; Kumar, N. Data dimensionality reduction techniques for Industry 4.0: Research results, challenges, and future research directions. Softw. Pract. Exp. 2022, 52, 658–688. [Google Scholar] [CrossRef]
- Azar, J.; Makhoul, A.; Barhamgi, M.; Couturier, R. An energy efficient IoT data compression approach for edge machine learning. Future Gener. Comput. Syst. 2019, 96, 168–175. [Google Scholar] [CrossRef]
- Papageorgiou, A.; Cheng, B.; Kovacs, E. Real-time data reduction at the network edge of Internet-of-Things systems. In Proceedings of the 11th International Conference on Network and Service Management, CNSM, Barcelona, Spain, 9–13 November 2015; pp. 284–291. [Google Scholar]
- Hanumanthaiah, A.; Gopinath, A.; Arun, C.; Hariharan, B.; Murugan, R. Comparison of Lossless Data Compression Techniques in Low-Cost Low-Power (LCLP) IoT Systems. In Proceedings of the 2019 International Symposium on Embedded Computing and System Design, ISED, Kollam, India, 13–14 December 2019; pp. 63–67. [Google Scholar]
- Chen, A.; Liu, F.H.; Wang, S.D.e. Data reduction for real-time bridge vibration data on edge. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics, DSAA, Washington, DC, USA, 5–8 October 2019; pp. 602–603. [Google Scholar]
- Radha, V.; Maheswari, D. Secured Compound Image Compression Using Encryption Techniques. In Proceedings of the International Conference on Computational Intelligence and Computing Research, San Francisco, CA, USA, 19–21 October 2011. [Google Scholar]
- Li, M.; Yi, X.; Ma, H. A scalable encryption scheme for CCSDS image data compression standard. In Proceedings of the 2010 IEEE International Conference on Information Theory and Information Security, ICITIS, Beijing, China, 17–19 December 2010; pp. 646–649. [Google Scholar]
- Shunmugan, S.; Rani, P.A.J. Encryption-then-compression techniques: A survey. In Proceedings of the 2016 International Conference on Control Instrumentation Communication and Computational Technologies, ICCICCT, Kumaracoil, India, 16–17 December 2016; pp. 675–679. [Google Scholar]
- Abdulwahab, H.M.; Ajitha, S.; Saif, M.A.N. Feature selection techniques in the context of big data: Taxonomy and analysis. Appl. Intell. 2022, 52, 13568–13613. [Google Scholar] [CrossRef]
- Papia Ray, S. Surender Reddy, Tuhina Banerjee. Various dimension reduction techniques for high dimensional data analysis: A review. Artif. Intell. Rev. 2021, 54, 3473–3515. [Google Scholar]
- Singh, S.; Devgon, R. Analysis of encryption and lossless compression techniques for secure data transmission. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems, ICCCS, Singapore, 23–25 February 2019; pp. 120–124. [Google Scholar]
- Gia, T.N.; Qingqing, L.; Pena Queralta, J.; Tenhunen, H.; Zou, Z.; Westerlund, T. Lossless Compression Techniques in Edge Computing for Mission-Critical Applications in the IoT. In Proceedings of the 2019 12th International Conference on Mobile Computing and Ubiquitous Network, ICMU, Kathmandu, Nepal, 4–6 November 2019. [Google Scholar]
- Nasif, A.; Othman, Z.A.; Sani, N.S. The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities. Sensors 2021, 21, 4223. [Google Scholar] [CrossRef] [PubMed]
- Jindal, R.; Kumar, N.; Patidar, S. IoT streamed data handling model using delta encoding. Int. J. Commun. Syst. 2022, 35, e5243. [Google Scholar] [CrossRef]
- Dias, G.M.; Bellalta, B.; Oechsner, S. The impact of dual prediction schemes on the reduction of the number of transmissions in sensor networks. Comput. Commun. 2017, 112, 58–72. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of Dimensionality Reduction Techniques on Big Data. IEEE Access 2020, 8, 54776–54788. [Google Scholar] [CrossRef]
- Abdulzahra, S.A.; Al-Qurabat, A.K.M.; Idrees, A.K. Data Reduction Based on Compression Technique for Big Data in IoT. In Proceedings of the 2020 International Conference on Emerging Smart Computing and Informatics, ESCI, Pune, India, 12–14 March 2020; pp. 103–108. [Google Scholar]
- Agarwal, M.; Gupta, V.; Goel, A.; Dhiman, N. Near Lossless Image Compression Using Discrete Cosine Transformation and Principal Component Analysis. AIP Conf. Proc. 2022, 2481, 020002. [Google Scholar]
- Ince, I.F.; Bulut, F.; Kilic, I.; Yildirim, M.E.; Ince, O.F. Low dynamic range discrete cosine transform (LDR-DCT) for high-performance JPEG image compression. Vis. Comput. 2022, 38, 1845–1870. [Google Scholar] [CrossRef]
- Pinto, A.C.; Maciel, M.D.; Pinho, M.S.; Medeiros, R.R.; Motta, S.F.; Moraes, A.O. Evaluation of lossy compression algorithms using discrete cosine transform for sounding rocket vibration data. Meas. Sci. Technol. 2022, 34, 015117. [Google Scholar] [CrossRef]
- Sharanyaa, S.; Renjith, P.N.; Ramesh, K. Classification of parkinson’s disease using speech attributes with parametric and nonparametric machine learning techniques. In Proceedings of the 3rd International Conference on Intelligent Sustainable Systems, ICISS, Thoothukudi, India, 3–5 December 2020; pp. 437–442. [Google Scholar]
- Harb, H.; Jaoude, C.A. Combining compression and clustering techniques to handle big data collected in sensor networks. In Proceedings of the 2018 IEEE Middle East and North Africa Communications Conference, MENACOMM, Jounieh, Lebanon, 18–20 April 2018; pp. 1–6. [Google Scholar]
- Cui, Z.; Jing, X.; Zhao, P.; Zhang, W.; Chen, J. A New Subspace Clustering Strategy for AI-Based Data Analysis in IoT System. IEEE Internet Things J. 2021, 8, 12540–12549. [Google Scholar] [CrossRef]
- Yang, F.; Liu, S.; Dobriban, E.; Woodruff, D.P. How to Reduce Dimension with PCA and Random Projections? IEEE Trans. Inf. Theory 2021, 67, 8154–8189. [Google Scholar] [CrossRef]
- Bingham, E.; Mannila, H. Random projection in dimensionality reduction: Applications to image and text data. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001. [Google Scholar]
- Al-Qurabat, A.K.M.; Abdulzahra, S.A.; Idrees, A.K. Two-level energy-efficient data reduction strategies based on SAX-LZW and hierarchical clustering for minimizing the huge data conveyed on the internet of things networks. J. Supercomput. 2022, 78, 17844–17890. [Google Scholar] [CrossRef]
- MacKay, D.J. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Rao, A.R.; Wang, H.; Gupta, C. Functional approach for Two Way Dimension Reduction in Time Series. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022. [Google Scholar]
- Smola, A.; Vishwanathan, S.V.N.; Clara, S. Introduction to Machine Learning; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Biswas, A.; Dutta, S.; Turton, T.L.; Ahrens, J. Sampling for Scientific Data Analysis and Reduction; Mathematics and Visualization; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Suel, T. Delta Compression Techniques. In Encyclopedia of Big Data Technologies; Sakr, S., Zomaya, A., Eds.; Springer International Publishing: New York, NY, USA, 2018. [Google Scholar]
- Qiao, W.; Fang, Z.; Chang, M.C.F.; Cong, J. An FPGA-based bwt accelerator for bzip2 data compression. In Proceedings of the 27th IEEE International Symposium on Field-Programmable Custom Computing Machines, FCCM, San Diego, CA, USA, 28 April–1 May 2019. [Google Scholar]
- Random Projection—Scikit-Learn 1.4.1 Documentation. Available online: https://scikit-learn.org/stable/modules/random_projection.html (accessed on 5 March 2024).
- LinearRegression—Scikit-Learn 1.4.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html (accessed on 5 March 2024).
- PCA—Scikit-Learn 1.4.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html (accessed on 5 March 2024).
- KMeans—Scikit-Learn 1.4.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html (accessed on 5 March 2024).
- bz2—Support for bzip2 Compression—Python 3.12.2 Documentation. Available online: https://docs.python.org/3/library/bz2.html (accessed on 5 March 2024).

{kind=link}
| Algorithm | Accuracy | Dataset Size | Reduction Percentage | Reference |
|---|---|---|---|---|
| Subtractive Clustering Algorithm | NA 1 | NA 1 | ~97% | [6] |
| Spatiotemporal Data Reduction | 95% | 843 KB, 960 KB | ~54% | [7] |
| Perceptually Important Points, Sampling, Piecewise Approximation | 76.3% to 93.8% | NA 1 | ~66% | [13] |
| Run Length Encoding and Delta lossless compression | NA 1 | NA 1 | ~52% | [14] |
| Pattern System | NA 1 | 2880 lines | NA 1 | [15] |
| DCT and mixing operation of scrambled image | 100% | NA 1 | 44.16% | [16] |
| CCSDS and Scalable encryption scheme | 100% | NA 1 | 12.19% | [17] |
| JPEG XR compression and Block Scrambling | 100% | NA 1 | 60.77% | [18] |
| Data Reduction Techniques Categories | Examples of Data Reduction Algorithms |
|---|---|
| Lossless Data Compression Algorithms | Delta Encoding 1, BZip2 1, Huffman Encoding, Run-Length Encoding, Lempel-Ziv Compression (LZ77, LZ78, LZW) |
| Lossy Data Compression Algorithms | Random Projection 1, Quantization 1, Discrete Cosine Transform, Wavelet Compression, Cartesian Perceptual Compression, Fractal Compression |
| Parametric Numerosity Data Reduction Algorithms | Linear Regression 1, Principal Component Analysis 1, Random Forest, Support Vector Machines, Gaussian Regression, Log–Linear Models |
| Non-Parametric Numerosity Data Reduction Algorithms | K-Means 1, Simple Random Sampling 1, DBSCAN, Mean-Shift, OPTICS |
| Data Type | Name | Size (MB) | Number of Lines | Number of Columns |
|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 3650 | 2 |
| Electric Production | 0.0730 | 397 | 2 | |
| Monthly Beer Production in Austria | 0.0690 | 476 | 2 | |
| Numeric | Accelerometer | 3.7000 | 153,000 | 5 |
| Smoke Detection | 5.8000 | 62,631 | 15 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 97,606 | 5 |
| Algorithm | Use Case | Application |
|---|---|---|
| Random Projection | High-dimensional data reduction | Random Projection can be used in scenarios where the dataset has a high dimensionality, such as text data, image data, or genomic data. It efficiently reduces the dimensionality of the data while preserving as much of the structure as possible. Applications include dimensionality reduction for machine learning tasks, data visualization, and speeding up computation in high-dimensional spaces. |
| Quantization | Image and audio compression, signal processing | Quantization is commonly used in image and audio compression algorithms such as JPEG and MP3. It involves reducing the precision of the data representation by mapping continuous values to a finite set of discrete values. This results in lossy compression, where some information is lost, but for many applications it allows a significant reduction in file size with no noticeable loss in quality. |
| Linear Regression | Predictive modeling, trend analysis | Linear Regression is widely used in various fields to predict continuous outcomes based on one or more predictor variables. Applications include forecasting sales, predicting housing prices, analyzing relationships between variables in scientific research, and assessing the impact of marketing campaigns. |
| Principal Component Analysis | Dimensionality reduction, feature extraction | PCA is commonly used to reduce the dimensionality of high-dimensional data while preserving the most important information. It finds a set of orthogonal axes (principal components) that maximize the variance of the data. Applications include image and face recognition, data compression, noise reduction in data, and visualization of high-dimensional data. |
| Clustering | Data segmentation, pattern recognition | Clustering algorithms, such as K-means, hierarchical clustering, and DBSCAN, are used to group similar data points together based on their characteristics. Applications include customer segmentation for targeted marketing, anomaly detection in network traffic, grouping genes with similar expression patterns in bioinformatics, and organizing documents in information retrieval. |
| Sampling | Large-scale data analysis, data summarization | Sampling is the process of selecting a subset of data points from a larger population for analysis. It is often used in situations where processing the entire dataset is impractical or costly. Applications include opinion polling, manufacturing quality control, real-time data stream analysis, and estimating population parameters from sample statistics. |
| Algorithm | Use Case | Application |
|---|---|---|
| Delta Encoding | Data storage optimization, version control systems | Delta Encoding is commonly used in scenarios where data changes over time, such as in version control systems like Git. Instead of storing entire files, only the differences (delta) between versions are stored. It is also used in data compression techniques to reduce redundancy. Applications include minimizing storage requirements for historical versions of files, efficient data transfer over network protocols, and optimizing database storage for incremental backups. |
| BZip2 | File compression, data transmission over networks | BZip2 is used to compress files and data streams. It provides a high compression ratio and is particularly effective for compressing text files, XML, and large datasets. Applications include compressing software distributions for faster downloads, reducing storage requirements for archival data, and optimizing data transmission over limited bandwidth networks. It is often used in conjunction with formats such as TAR to create compressed archives (tar.bz2 files). |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0600 | +7.53% | 0.002 | 0.0358 |
| Electric Production | 0.0730 | 0.0732 | +0.27% | 0.001 | 0.0137 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0800 | +15.94% | 0.001 | 0.0145 | |
| Numeric | Accelerometer | 3.7000 | 2.9501 | −20.27% 1 | 0.007 | 0.0019 |
| Smoke Detection | 5.8000 | 4.8203 | −16.89% | 0.007 | 0.0012 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 6.7202 | +0.30% | 0.002 | 0.0003 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Electric Production | 0.0730 | 0.0600 | −17.81% 1 | 0.0006 | 0.0082 |
| Numeric | Accelerometer | 3.7000 | 3.2100 | −13.24% | 0.2240 | 0.0605 |
| Smoke Detection | 5.8000 | 5.6780 | −2.10% | 0.0680 | 0.0117 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0118 | −78.78% | 0.003 | 0.0538 |
| Electric Production | 0.0730 | 0.0144 | −80.27% | 0.006 | 0.0822 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0170 | −75.36% | 0.004 | 0.0580 | |
| Numeric | Accelerometer | 3.7000 | 0.7670 | −79.27% | 0.040 | 0.0108 |
| Smoke Detection | 5.8000 | 1.3140 | −77.34% | 0.050 | 0.0086 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 1.2977 | −80.63% 1 | 0.008 | 0.0012 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variation | Execution Time (ms) | Processing time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0680 | +21.86% | 0.002 | 0.0358 |
| Electric Production | 0.0730 | 0.0750 | +2.74% | 0.001 | 0.0137 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0890 | +28.99% | 0.001 | 0.0145 | |
| Numeric | Accelerometer | 3.7000 | 2.9300 | −20.81% 1 | 0.160 | 0.0432 |
| Smoke Detection | 5.8000 | 4.7500 | −18.10% | 0.160 | 0.0276 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 6.7600 | +0.90% | 0.050 | 0.0075 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 | MSE |
|---|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0401 | −28.14% | 0.370 | 6.6308 | 0.623 |
| Electric Production | 0.0730 | 0.0430 | −41.10% 1 | 0.160 | 2.1918 | 0.315 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0502 | −27.24% | 0.170 | 2.4638 | 0.328 | |
| Numeric | Accelerometer | 3.7000 | 3.7700 | +1.90% | 24.404 | 6.5957 | 0.849 |
| Smoke Detection | 5.8000 | 5.5090 | −5.02% | 16.107 | 2.7771 | 0.674 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 5.9060 | −11.85% | 13.918 | 2.0773 | 0.574 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0530 | −5.02% | 0.003 | 0.0538 |
| Electric Production | 0.0730 | 0.0692 | −5.21% | 0.001 | 0.0137 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0600 | −13.04% 1 | 0.002 | 0.0290 | |
| Numeric | Accelerometer | 3.7000 | 3.6740 | −0.70% | 0.160 | 0.0432 |
| Smoke Detection | 5.8000 | 5.7710 | −0.5% | 0.054 | 0.0093 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 6.6000 | −1.49% | 0.068 | 0.0101 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0301 | −46.06% 1 | 2.030 | 36.3799 |
| Electric Production | 0.0730 | 0.0401 | −45.07% | 0.302 | 4.1370 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0620 | −10.14% | 0.330 | 4.7826 | |
| Numeric | Accelerometer | 3.7000 | 3.6885 | −0.31% | 285.220 | 77.0865 |
| Smoke Detection | 5.8000 | 4.7600 | −17.93% | 422.130 | 72.7810 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 5.4600 | −18.51% | 693.040 | 103.4388 |
| Data Type | Name | Original Size (MB) | Final Size (MB) | Percentage Variance | Execution Time (ms) | Processing Time per MB (ms/MB) 2 |
|---|---|---|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | 0.0558 | 0.0093 | −83.33% | 0.010 | 0.1792 |
| Electric Production | 0.0730 | 0.0010 | −98.63% 1 | 0.001 | 0.0137 | |
| Monthly Beer Production in Austria | 0.0690 | 0.0010 | −98.55% | 0.010 | 0.1449 | |
| Numeric | Accelerometer | 3.7000 | 0.5682 | −84.64% | 0.340 | 0.0919 |
| Smoke Detection | 5.8000 | 1.1703 | −79.82% | 0.399 | 0.0688 | |
| Temporal, Text | IoT Temperatures | 6.7000 | 0.8702 | −87.01% | 0.640 | 0.0955 |
| Data Type | Dataset Name | Algorithm with the Best Percentage Variance | Algorithm with the Best Processing Time per MB |
|---|---|---|---|
| Temporal, Numeric | Daily Minimum Temperatures in Melbourne | Linear Regression | Linear Regression/Simple Random Sampling |
| Electric Production | Linear Regression | Quantization | |
| Monthly Beer Production in Austria | Linear Regression | Simple Random Sampling | |
| Numeric | Accelerometer | Linear Regression | Random Projection |
| Smoke Detection | Linear Regression | Random Projection | |
| Temporal, Text | IoT Temperatures | Linear Regression | Linear Regression |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernandes, V.; Carvalho, G.; Pereira, V.; Bernardino, J. Analyzing Data Reduction Techniques: An Experimental Perspective. Appl. Sci. 2024, 14, 3436. https://doi.org/10.3390/app14083436
Fernandes V, Carvalho G, Pereira V, Bernardino J. Analyzing Data Reduction Techniques: An Experimental Perspective. Applied Sciences. 2024; 14(8):3436. https://doi.org/10.3390/app14083436
Chicago/Turabian StyleFernandes, Vítor, Gonçalo Carvalho, Vasco Pereira, and Jorge Bernardino. 2024. "Analyzing Data Reduction Techniques: An Experimental Perspective" Applied Sciences 14, no. 8: 3436. https://doi.org/10.3390/app14083436
APA StyleFernandes, V., Carvalho, G., Pereira, V., & Bernardino, J. (2024). Analyzing Data Reduction Techniques: An Experimental Perspective. Applied Sciences, 14(8), 3436. https://doi.org/10.3390/app14083436