1. Introduction
Agricultural production is a crucial means for humans to meet the demand for food and agricultural products. It also serves as the foundation for the development of human society. Some automated equipment and technologies have been implemented in agricultural production [
1]; for example, harvesters and automatic watering systems. However, due to the diversity and specificity of agricultural tasks, despite the advancements in modern technology driving agricultural automation, the level of automation varies depending on crops and regions. Manual labor still remains a crucial component of production in certain regions and for certain crops. However, with a shortage of human resources and low labor efficiency, traditional manual labor methods no longer suffice to meet the demands of modern agricultural production [
2]. Hence, the imperative to integrate intelligent technologies and innovations to enhance the efficacy and quality of agricultural production has grown more pronounced. The incorporation of intelligent technologies, including artificial intelligence and the Internet of Things, into agricultural practices has significantly contributed to the optimization of production efficiency, reduction of operational costs, and augmentation of both yield and quality of agricultural products [
3]. In the realm of agricultural production, areas of paramount concern encompass crop growth and yield, soil and environmental conditions, the quality of agricultural products, and the pursuit of sustainable development [
4]. The physical labor behaviors carried out in the field, including activities such as sowing, fertilizing, spraying, plowing, weeding, etc., play a pivotal role in fostering optimal crop growth and achieving high-quality agricultural output. Consequently, the establishment of relevant datasets contributes to the development and improvement of automation technologies that are gradually replacing labor-intensive operations. These datasets will support research in both academia and practical applications, promote the development of agricultural robots and intelligent systems for automatically identifying agricultural workers’ labor behaviors, and provide effective information for traceability systems, allowing consumers to understand the entire process of agricultural product growth. The intelligent analysis of these physical labor behaviors holds substantial significance in enhancing and streamlining physical labor processes. Such analyses contribute to heightened production efficiency, the optimization of resource utilization [
5], the implementation of sophisticated business management practices [
6], and the assurance of both crop growth and product quality. This is of significant importance for driving agricultural enterprises toward digitized and standardized management of farm workers, further promoting the transformation of traditional agriculture toward automation and smart farming.
Currently, the monitoring of manual labor behavior in agricultural production predominantly depends on surveillance videos and intelligent analysis technology for the observation and analysis of labor activities conducted by farmers throughout the production process. Meanwhile, the processing of surveillance videos primarily hinges on manual operations [
7]. Nevertheless, when confronted with substantial video data, this processing approach proves sluggish and inefficient, and incapable of facilitating all-weather monitoring. Consequently, enhancing the recognition capabilities of physical labor behaviors in the field and fortifying the guidance and supervision of farmers’ labor [
8] stand as pivotal facets in the advancement of smart agriculture aiming to attain the objective of refined management.
The evolution of deep learning within the domain of human behavior recognition can be traced back to approximately 2010. Preceding the ascent of deep learning, human behavior recognition predominantly depended on conventional computer vision techniques. Nonetheless, traditional methods exhibit constrained accuracy in intricate scenarios as they necessitate meticulous feature design, which proves challenging in capturing intricate human behavior patterns. Deep learning has progressively emerged at the forefront of research in recent years [
9], establishing itself as a predominant research tool in areas such as image recognition, image classification, and target detection [
10]. It also presents novel opportunities for advancing human behavior recognition. Moreover, given the prevalent use of industrial communication devices, such as cameras, in agricultural settings, there exists an opportunity to integrate deep learning algorithms into these communication devices for the purpose of recognizing agricultural behaviors across diverse geographical regions.
Scholars both at home and abroad have undertaken numerous endeavors to apply existing convolutional neural network algorithms to tasks related to video behavior recognition. Diverging from the scope of image classification, video behavior recognition necessitates the extraction of both spatial and temporal features, amalgamating them into spatio-temporal features. Some researchers [
11,
12,
13] have suggested employing 2D convolution to extract spatial features frame by frame and store them in a buffer. Subsequently, new input frames are processed and their spatial features are combined with those in the buffer to construct spatio-temporal features for behavior recognition. Conversely, other researchers [
14,
15,
16,
17] have advocated for the use of 3D convolution to extract spatio-temporal features directly from video clips for behavior recognition. The classical behavior recognition method based on 2D convolution is the spatio-temporal dual-stream CNN [
18]. This approach utilizes optical flow to capture temporal information between video frames, and it has several variants, including the dual-stream network, TSN network [
19], and I3D network [
20], among others. Despite the enhancements in accuracy achieved by optical flow methods in behavior recognition, the substantial memory consumption and computational cost associated with extracting optical flow features preclude the attainment of end-to-end recognition. Instead of relying on optical flow for learning intricate temporal features, 3D convolution-based behavior recognition introduces an additional temporal dimension compared to 2D convolution, facilitating end-to-end feature extraction and classification. The seminal approach in this domain is the C3D network [
21], which extends the convolution kernel of VGGNet from a 3 × 3 2D convolution to a 3 × 3 × 3 3D convolution. Despite its simplicity, the 3D convolutional kernel results in an exponential increase in the number of parameters and computational cost for the network. The algorithmic design of C3D marked a significant milestone in behavior recognition, and subsequent 3D networks have been developed, including the R3D [
22] and P3D [
23] algorithms.
In the domain of agricultural behavior recognition, Xu Jinbo et al. introduced an enhanced ConvLSTM model [
24] and an improved (2 + 1)D model [
25] for the recognition of four types of agricultural behaviors in 2021 and 2022. Additionally, Yang Xinting et al. devised a methodology for recognizing two types of agricultural behaviors using the YOLOv7-tiny model in 2023 [
26]. However, the datasets used to train these models suffer from small-scale and missing behavior categories, which limits their practical applicability. Moreover, these models exhibit certain deficiencies in computational efficiency and feature extraction. These are: insufficient global feature extraction capability and inadequate spatio-temporal feature extraction when extracting agricultural labor images. This paper proposes an enhanced SlowFast network. The network incorporates a CoordAttention (CA) attention module to compensate for the shortcomings in CNN’s global feature extraction ability. Additionally, it augments the model’s capacity to extract temporal information about the action through an action (ACTION) attention module, resulting in superior feature extraction results. The main work of this paper can be summarized in the following three points:
Implementing the CA attention module and presenting the enhanced SlowFast network with improved slow branching to enhance the accuracy of video recognition for human labor actions.
Introducing the ACTION attention module, devising the enhanced SlowFast network with improved fast branching, and integrating the two attention modules to further enhance the accuracy of video recognition for human labor actions.
Collecting agricultural labor data from diverse perspectives in the field and producing the Field Work Behavior Dataset (FWBD).
Through the aforementioned efforts, the enhanced SlowFast network, as proposed in this study, attains superior outcomes in agricultural behavior recognition, demonstrating enhanced precision in the video recognition of agricultural labor actions. The primary tasks of this paper are delineated as follows.
Section 1 provides an overview of the current research landscape in the domain of human behavior recognition, encompassing existing methodologies and techniques, along with an elucidation of the research approaches and contributions of this paper.
Section 2 reviews pertinent works related to the methodology employed in this paper, encompassing existing research and associated techniques.
Section 3 meticulously provides a detailed exposition of the research methodology and data sources employed in this study, encompassing the creation of the dataset, model architecture, feature extraction methods, and other pertinent details.
Section 4 undertakes experimental endeavors, encompassing trials with varied parameter configurations, alongside a comprehensive analysis and discussion of the experimental outcomes.
Section 5 synthesizes the research findings of this paper and outlines prospects for future research.
3. Dataset and Methods
In this section, we will intricately delineate the content and fabrication process of the Field Work Behavior Dataset. Additionally, we will elucidate the principal enhancements made to the SlowFast model in comparison to its original iteration, focusing on the key modules that underwent improvement.
3.1. Dateset
In the past decade, despite the proliferation of numerous large-scale video datasets for action recognition, there has been a notable absence of dedicated datasets specifically designed for agricultural behavior recognition. This deficiency in datasets is apparent. In this study, we addressed this gap by constructing a dataset named FWBD (If data is needed, interested parties may contact the corresponding author) (Field Work Behavior Dataset). While certain portions of this dataset were sourced from public databases such as Tencent Video and Youku, the quality of the videos was suboptimal, and they were limited in both quantity and coverage of labor types. To address these limitations, we adopted a multi-angle shooting approach in the field to augment the dataset with a greater number of videos and increased diversity in labor types. During the data preprocessing stage, we employed editing techniques to eliminate dirty data. Dirty data refers to video data capturing field labor activities that are challenging for human eyes to recognize. Dirty data were generated for two main reasons: 1. people were backlit or obscured by crop weeds, making it difficult to clearly visualize human labor practices and labor tools; and 2. most videos were edited during the web video collection process, resulting in a prolonged lack of people appearing in the frame. For videos in which it was challenging to discern agricultural labor due to the above-mentioned circumstances and other reasons, we opted for their removal. The subsequent stage involved data augmentation. The prior steps of data cleaning and video editing led to a decrease in both the quantity and duration of videos within each behavioral category, and this consequently impacted the overall dataset’s size. Notably, certain behavioral categories experienced more pronounced reductions, particularly those derived from public web databases. To establish equilibrium in data distribution among behavioral categories within the database, our objective was to ensure a comparable number of actions within each behavioral segment. This strategy aimed to enhance the model’s stability and accuracy in real-world applications by mitigating overfitting to the constructed dataset. To achieve this objective, we conducted data augmentation procedures on the videos for each behavioral category. The employed data augmentation methods encompass horizontal flipping, clipping, and color adjustment. Horizontal flipping is employed to generate visually distinct data points by flipping the video data horizontally. The clipping operation is applied to subtly modify the background content of the image. Additionally, adjustments to brightness and saturation were made during the model training process. We incorporated various strategies to address changes in illumination, including data in which lighting naturally dims over time, data with altered brightness achieved through changes in shooting angles, and data augmented to simulate variations in lighting conditions. These measures were implemented to ensure that the trained model can effectively handle images under different lighting and color conditions. Ultimately, we successfully compiled a dataset comprising 200 original videos depicting manual labor behaviors in the field. These encompass hoeing, fertilizing, seeding, transplanting, spraying pesticides, watering, and weeding—seven of the most prevalent and conventional categories. The videos maintain a frame rate of approximately 30 frames per second (fps).
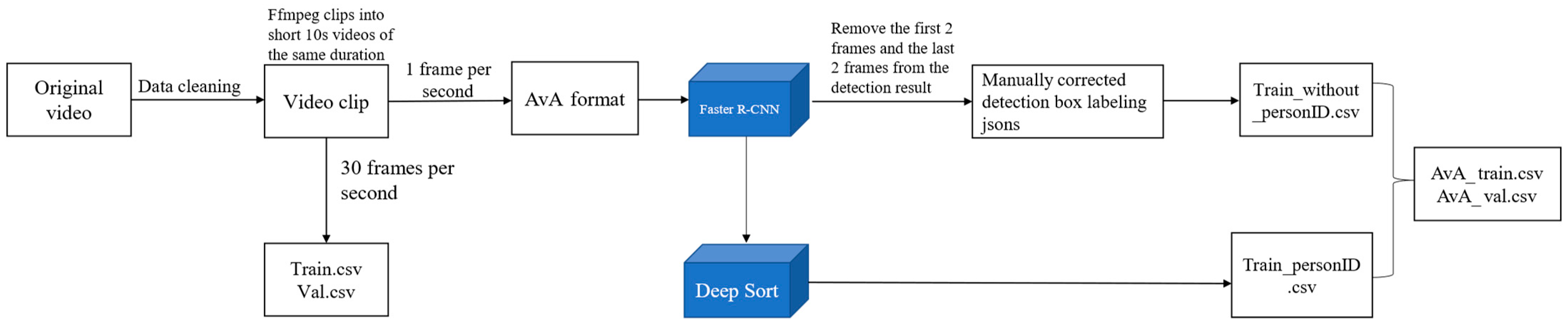
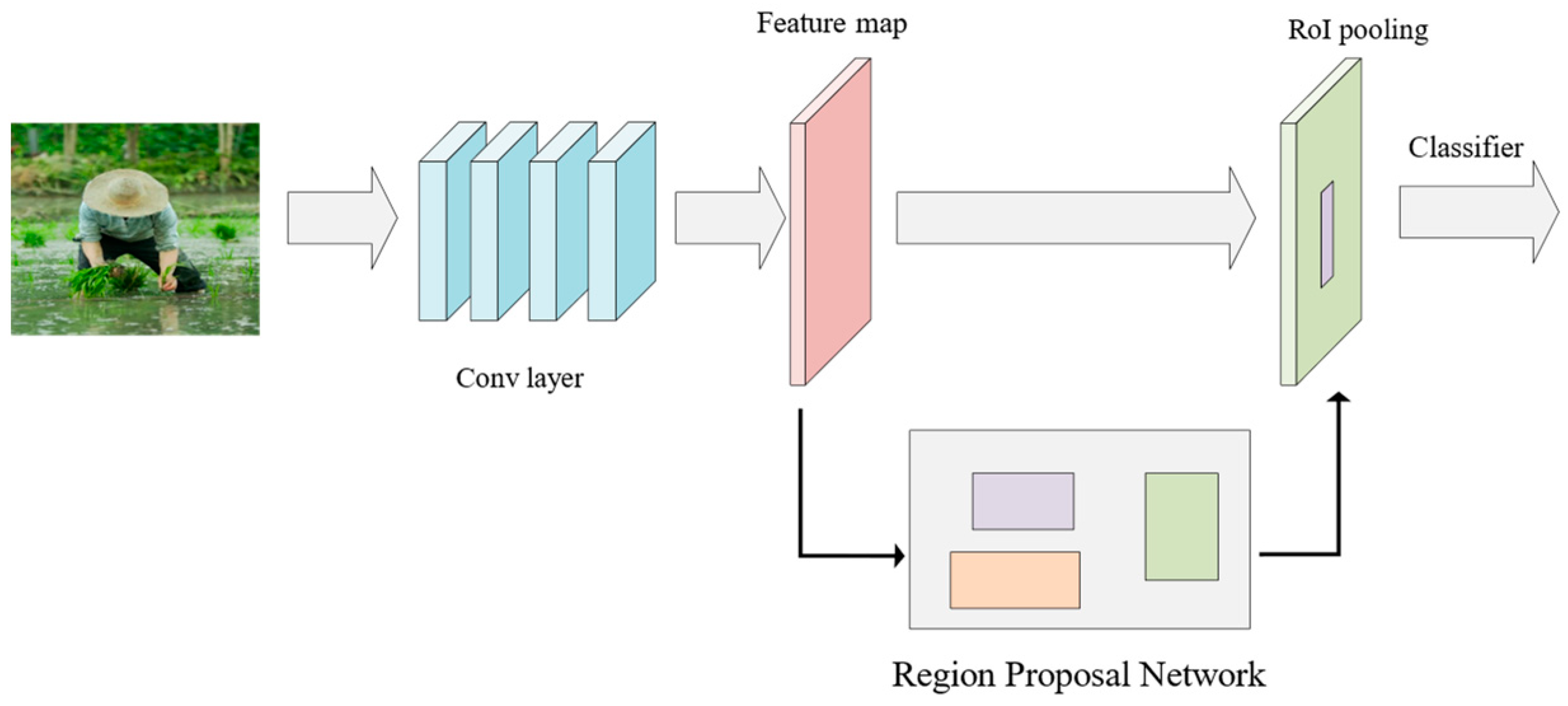
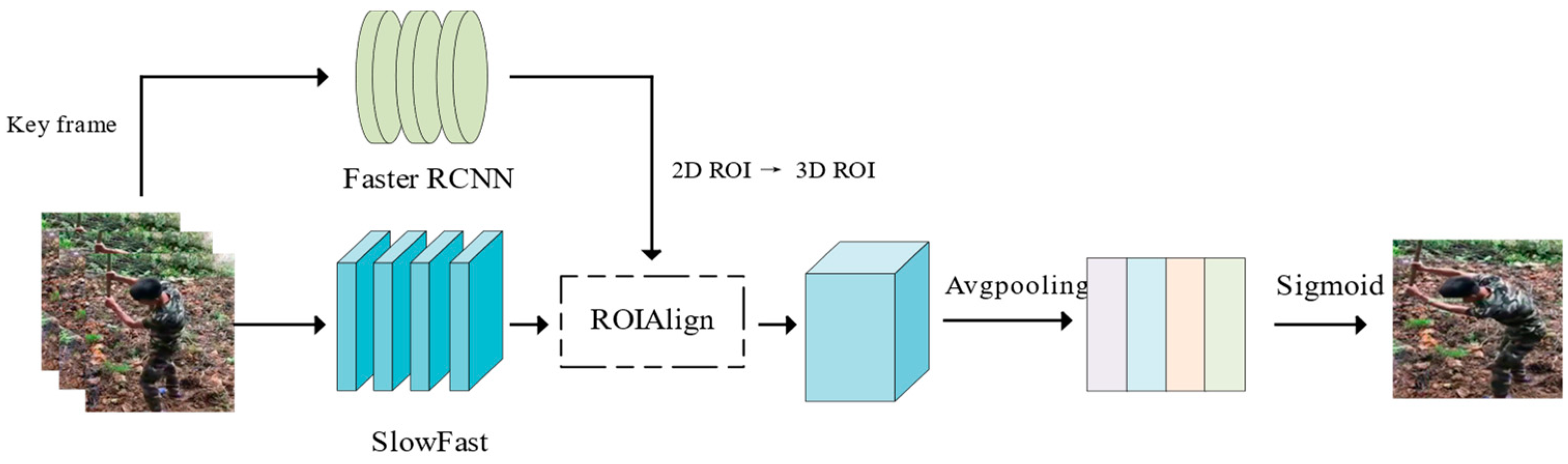
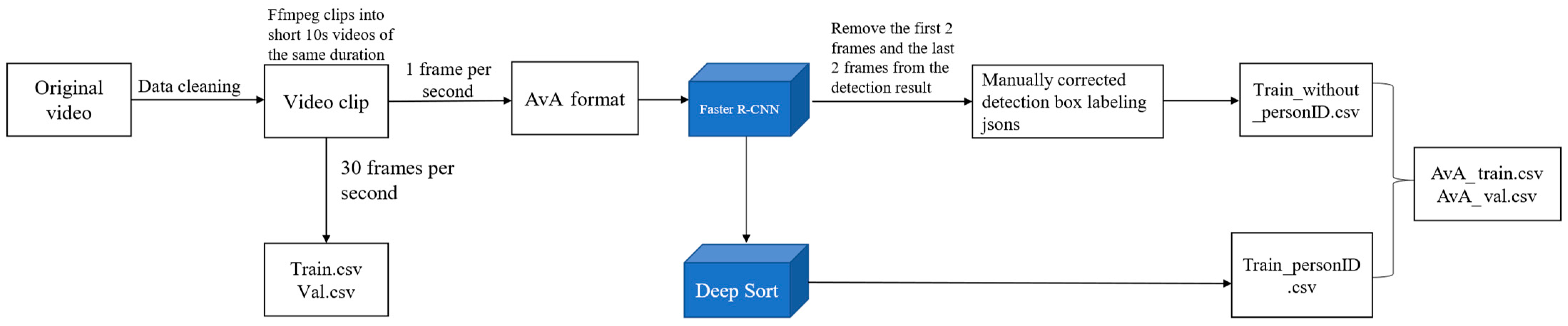
The steps of data processing and labeling are as follows: Step 1: Utilize the ffmpeg command to read the video, segmenting it into short 10 s videos. Subsequently, these videos are renamed based on their behavioral type and stored in the respective folders. Step 2: Construct the FWBD dataset following the AVA dataset format. Crop the video into frames with two requirements. Firstly, employ target detection to annotate key frames with the bounding box of the person in the image. These key frames are extracted at a rate of one frame per second, resulting in 10 images spanning from 0 s to 9 s. Secondly, capture 30 frames per second, equating to 300 images. Step 3: Initially, employ the Faster R-CNN target detection network to frame the target box for the human body’s position in the key frame image. Throughout this process, set the recognition threshold for people by the Faster R-CNN network to 0.5, ensuring comprehensive framing of individuals in the image. Step 4: To comply with the CSV file requirements in the AVA dataset format for character IDs in the images, the outcomes obtained in Step 3 are input into Deep Sort to generate the IDs for characters in the key frames of the images. As the operational principle of Deep Sort [
36] necessitates a minimum of 3 video frames for judgment, the first 2 frames and the last 2 frames are excluded. Only the key frames from the 2nd to the 7th second of each short video are utilized as images that require labeling with behavioral categories, ensuring error-free detection by Deep Sort. Consequently, each short video comprises 6 images necessitating behavioral category labeling. Step 5: After roughly framing the position of the characters using the Faster R-CNN target detection network, the target frames are further manually corrected using the VIA data labeling tool. The reasons for the correction include that the Faster R-CNN did not successfully recognize the characters in the video without framing them and that the target frames of some labor behaviors did not frame the tools used by the characters together. In certain cases, agricultural tools can be considered as an aspect of recognition because they are closely associated with specific labor behaviors. For instance, in agricultural settings, farmers may employ various tools for different farming activities, and the presence and manner of their usage can provide crucial cues for identifying particular labor behaviors. Consequently, the recognition of agricultural tools may be regarded as an aspect of labor behavior recognition that aims to enhance accuracy and comprehensiveness in identifying labor behaviors. For all these reasons, they need to be corrected manually. Following correction, corresponding action categories are labeled with categories. The correspondence of the action categories (label names) is as follows: hoeing (farm), sowing (seed), fertilizing (manure), transplanting (sow), spraying pesticides (spray), weeding (weed), and watering (water). Following this, the final labeled file is generated. The final output comprises four types of files: detection frame annotation files, spatio-temporal behavior annotation files, non-participating frame annotation files, and label annotation files. The semi-automated data annotation and FWBD dataset production process is illustrated in
Figure 4.
The dataset composition is outlined in
Table 2, and it comprises a total of 1445 videos, 8670 key frames, and 9832 labeled frames. Partial images for each behavioral category are illustrated in
Figure 5. This dataset exhibits a broad range of personnel targets, diverse scenarios, and one or more targets engaging in the same type of action within the same video. To create the training and test sets, 80% of the data combinations in each category of the dataset are randomly selected for the training set, while the remaining 20% constitute the test set. This division ensures a relatively even distribution of data in the training and test sets, facilitating a more comprehensive evaluation of the model’s performance.
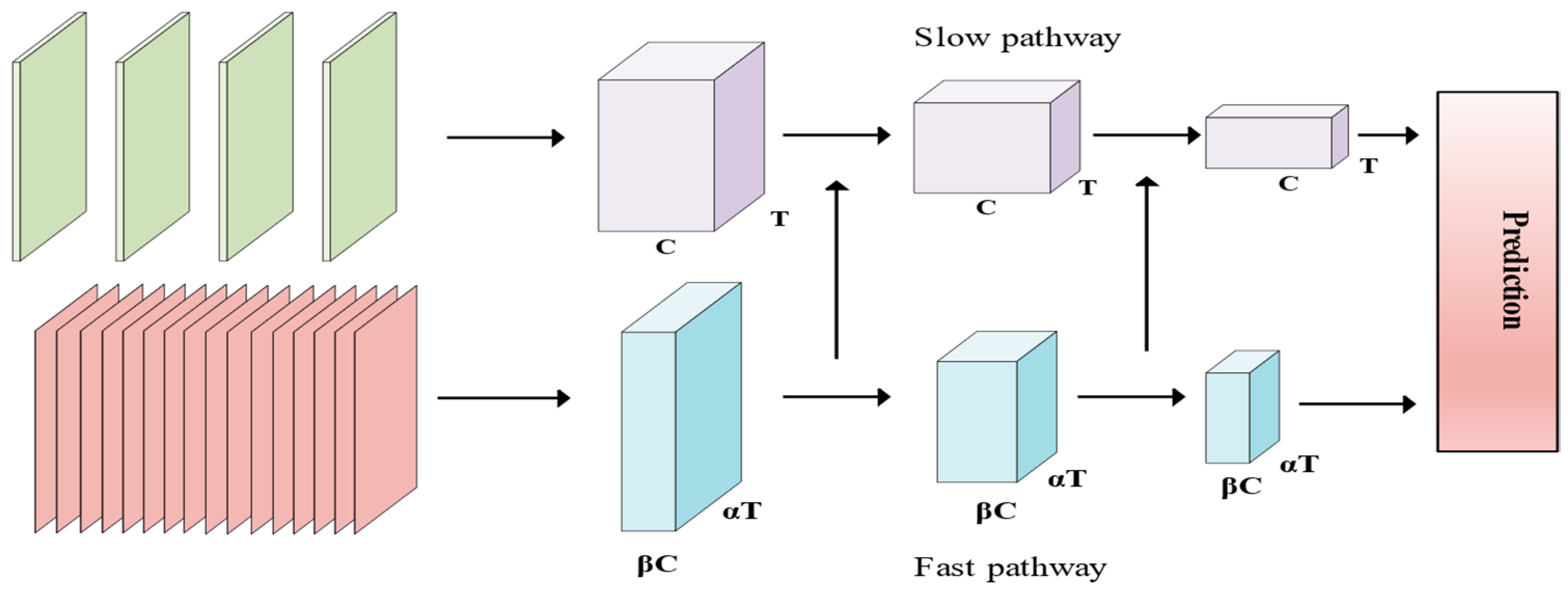
3.2. Improvements to SlowFast Network Structure
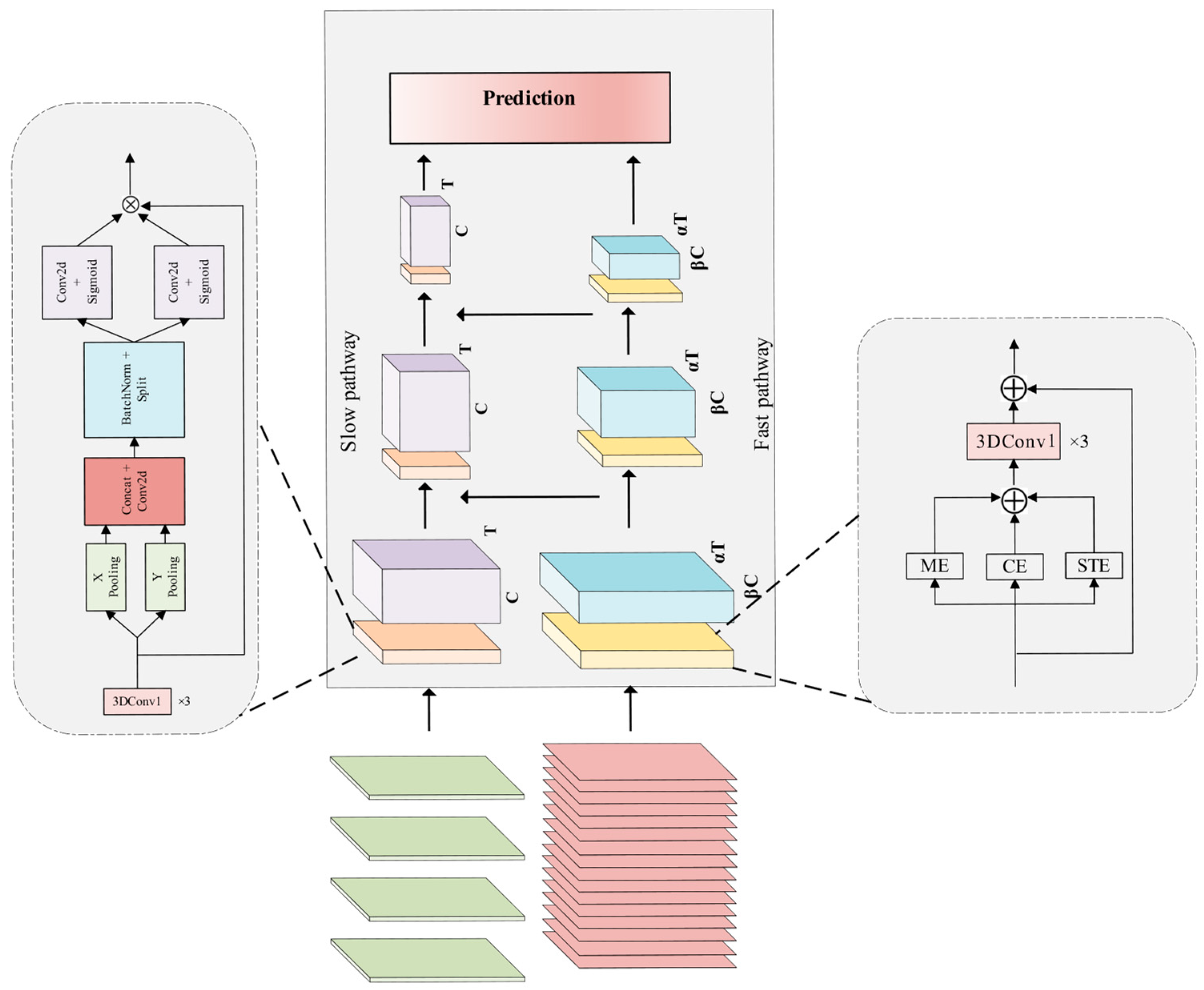
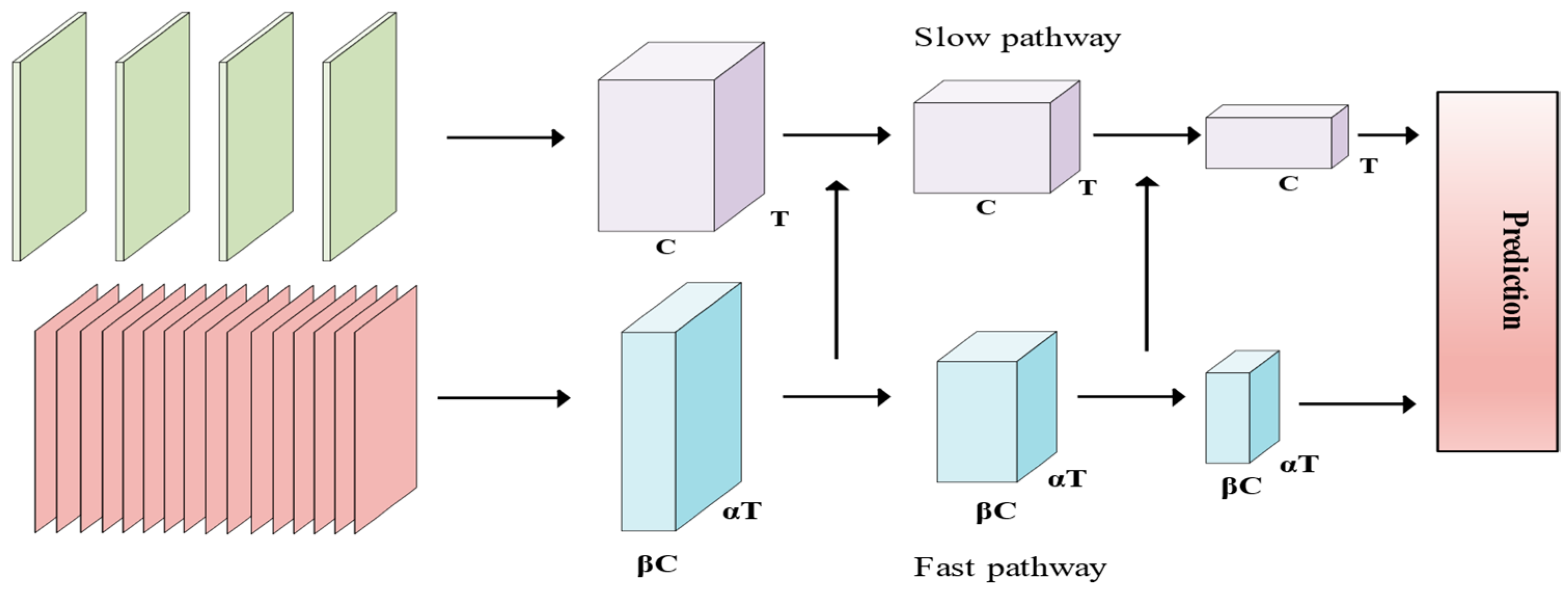
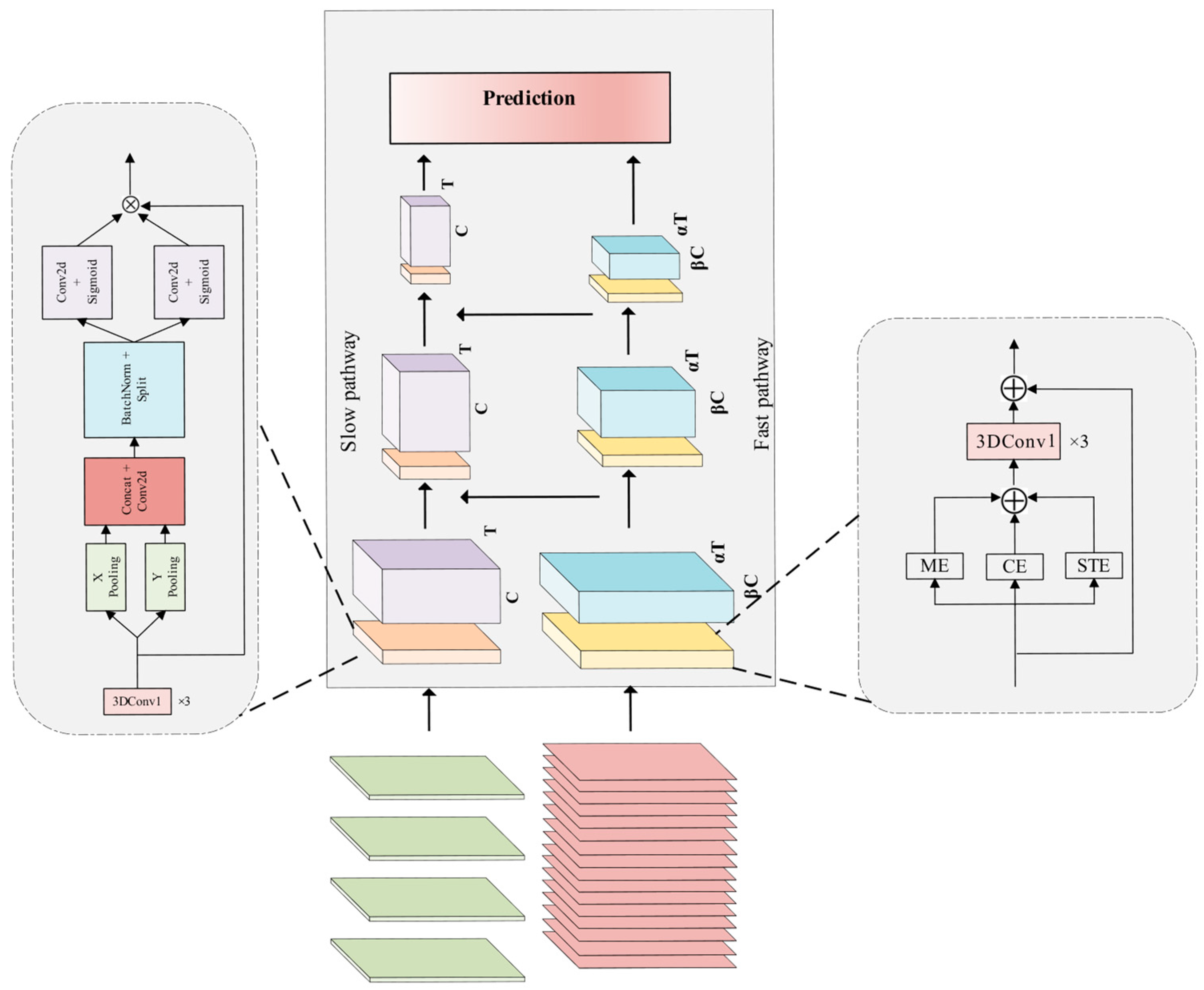
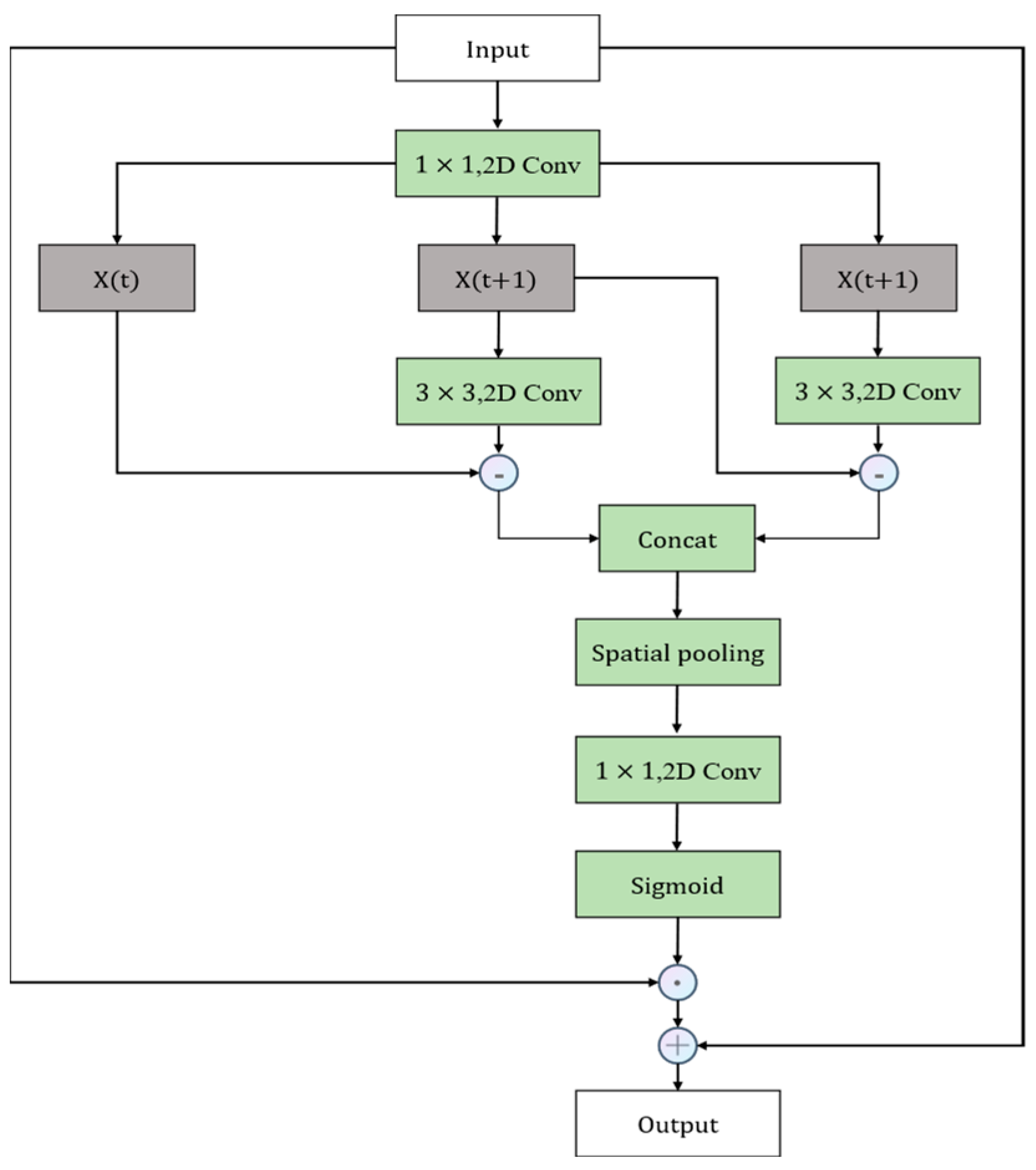
In tasks related to video behavior understanding, human behavior exhibits an array of rich and diverse features, encompassing variations in the same behavior under different execution goals, and the impact of multiple factors such as shooting angle and lighting conditions. While the 3D Convolutional Neural Network (3DCNN) proves effective in spatio-temporal modeling, it faces challenges in capturing the wealth of information embedded in videos and requires the acquisition of more fine-grained features to enhance classification accuracy. To elevate the detection accuracy of the network, this study enhances the SlowFast network in two key aspects. Firstly, for the extraction of spatial features from the video, the CoordAttention (CA) [
37] attention model was incorporated into the slow branch. This enhancement strengthens the network’s capacity, particularly in extracting critical information related to spatial features of behavior, thereby contributing to an overall improvement in performance. Secondly, to augment the network’s proficiency in learning temporal features of behavioral motion, we introduced the action attention module in the fast branch. This module is primarily tasked with extracting such features, and its integration aims to enhance the network’s capability to learn fine-grained features, thereby refining the architecture of the SlowFast network. With these two enhancements, the SlowFast network demonstrates enhanced performance in video behavior-understanding tasks. Specifically, the introduction of the CA (CoordAttention) and ACTION attention modules enables the network to more effectively capture crucial spatial and temporal motion features, thereby improving the comprehension and classification accuracy of intricate behaviors in videos. The enhanced version of SlowFast, denoted as CA-ACTION-SlowFast, is introduced herein, with its network architecture depicted in
Figure 6.
3.2.1. CA Attention Modules
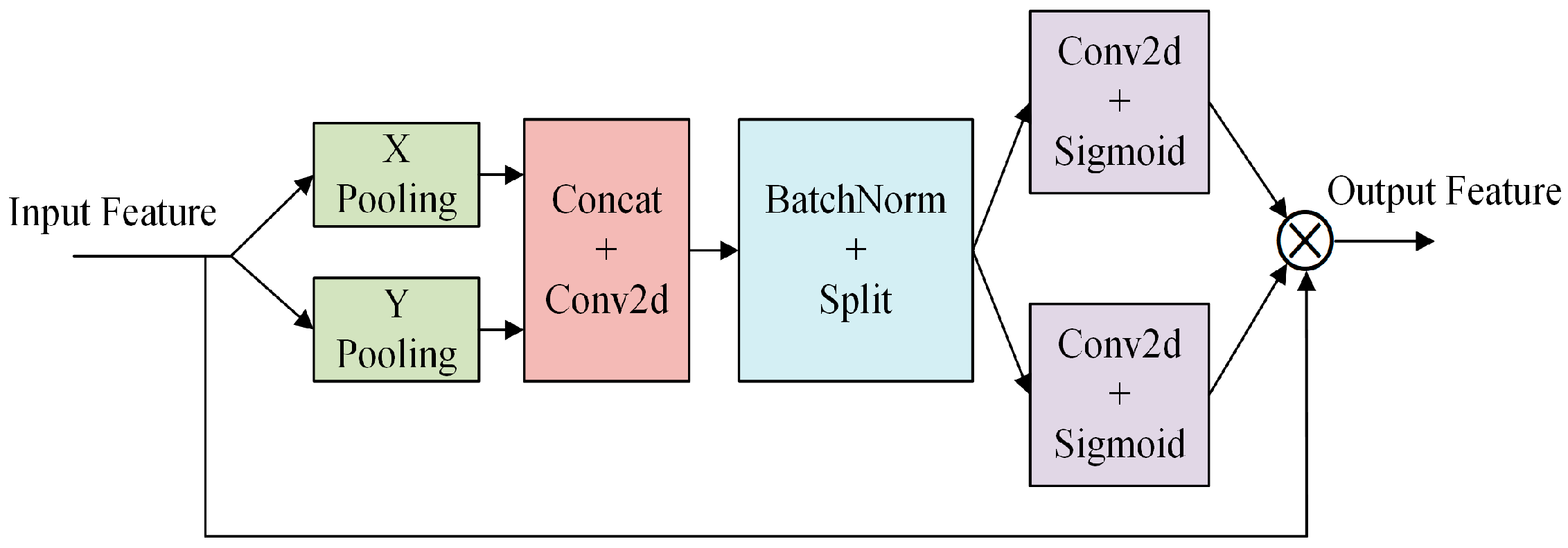
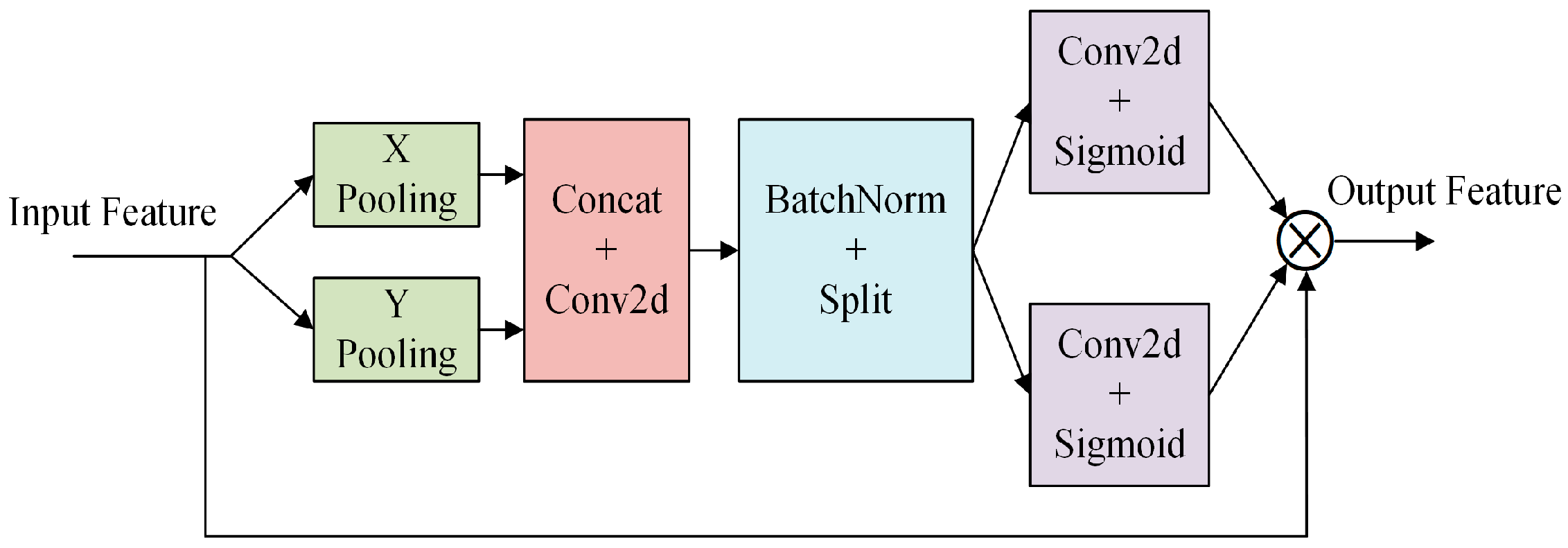
The CA module encodes channel relationships and long-range dependencies through precise location information. It comprises two steps: coordinate information embedding and coordinate attention generation. The specific structure is illustrated in
Figure 7. Examining the network structure diagram of the CA attention module, we observe that the input features undergo two distinct pooling operations to generate spatial dimension features. These features are then inputted into a convolutional layer, and this is followed by processing through Batch Normalization and a Sigmoid activation function to produce the attention graph. This process can be outlined in the following steps:
1. A coordinate information embedding operation is conducted. To enable the attention module to capture spatial long-range dependencies with precise location information, global pooling is decomposed into a pair of one-dimensional feature encoding operations. Spatial information is extracted from the input features through pooling operations, reflecting the statistical information of different locations in the feature map. For input
X, it undergoes pooling (Pooling) using pooling kernels with dimensions (
H, 1) and (1,
W). This process encodes each channel along the horizontal and vertical coordinate directions, resulting in the output of the cth channel with height
h and the output of the cth channel with width
yes, given as follows:
2. The aforementioned two transformations conduct feature aggregation along two spatial directions, yielding a pair of direction-aware attention maps that signify the regions to which SlowFast should “pay attention”. These transformations enable the attention module to capture long-range dependencies along one spatial direction and preserve precise location information along the other, enhancing the network’s ability to accurately localize target regions of interest with deep features. Coordinate attention generation is subsequently performed by concatenating the two feature maps generated by the preceding module and then transforming them into features using a 1 × 1 convolution, Batch Normalization (BatchNorm), and nonlinear activation. The output of this process can be expressed as follows:
The variable
represents an intermediate feature that incorporates both horizontal and vertical spatial information, where
is a constant regulating the channel count, and
denotes batch normalization (BatchNorm). Subsequently,
undergoes a segmentation into two distinct feature maps,
and
, along the spatial dimension. Two 1 × 1 convolutions, denoted as
and
, along with Sigmoid functions are employed for feature transformation. This ensures that the dimensions of the feature maps
and
align with the input
, producing outputs
and
. The output of this process can be expressed as follows:
Here,
signifies the Sigmoid activation function,
and
denote the convolution operation.
3. Feature recalibration: The original feature map undergoes recalibration through the generated attention map. As shown in Equation (6), the original features are weighted based on the generated attention map to accentuate specific regions that demand the model’s focus. Here,
and
represent spatial location coordinates on the feature map, and
signifies the original feature map. The outputs
and
are amalgamated into a weighting matrix for computing the recalibration weights. These weights are then multiplied with the original feature map, yielding
, which signifies the output feature values at position
post the processing by the coordinate attention block. The objective of this step is to optimize the feature representation to align with the attentional requirements of the model by accentuating pivotal regions:
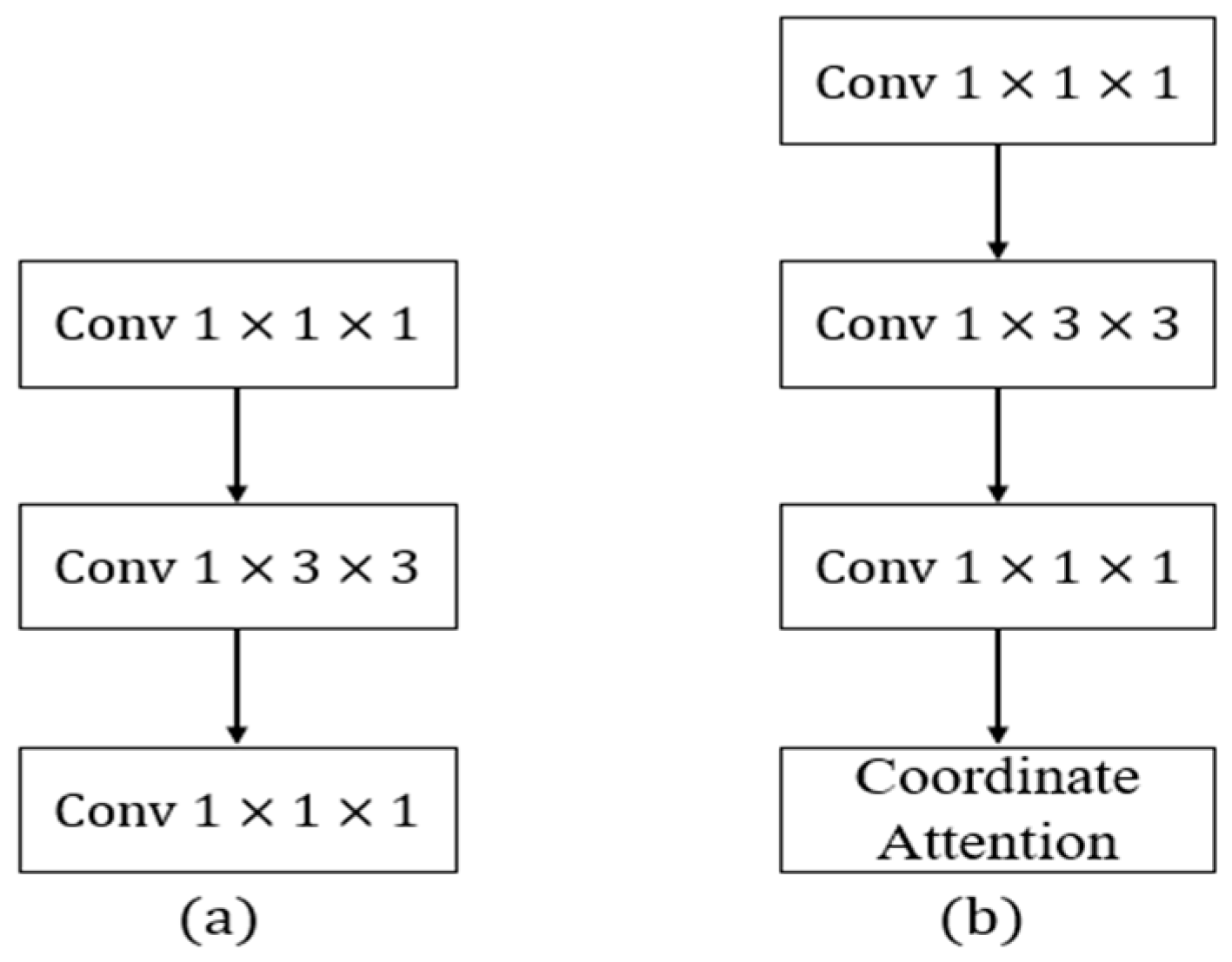
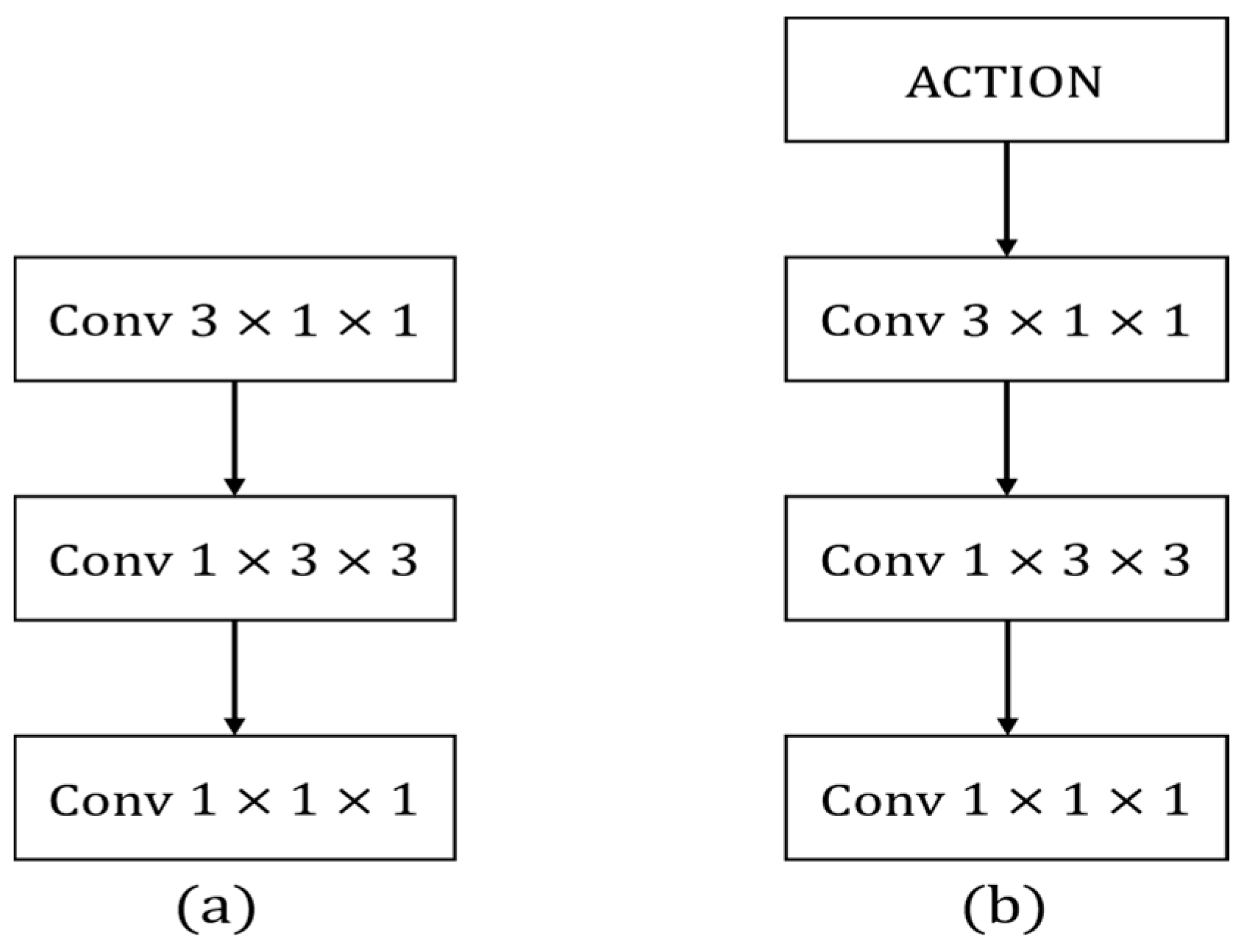
In SlowFast networks, the slow branching network is designed to learn spatial information, with the number of channels set to β times that of the fast branches. The increase in the number of channels implies richer features. However, treating these features equally during the learning process may lead the network to learn features that are not beneficial for behavior classification tasks. To more effectively extract spatial information related to behavior in the video, this paper introduces a CA module, called CA residual block (
Figure 8b), which is introduced in each original residual block (
Figure 8a) of the slow branch.
3.2.2. Action Attention Modules
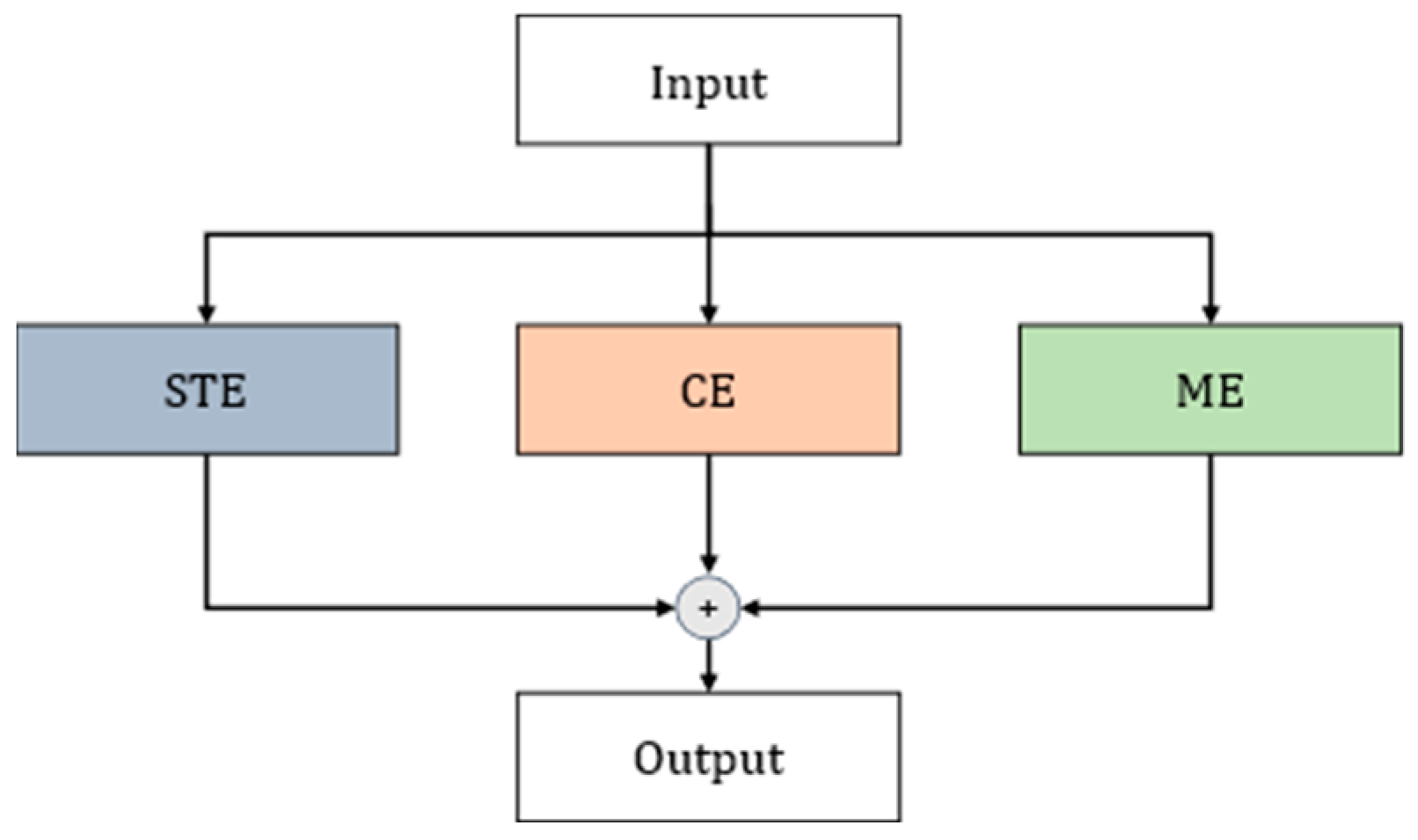
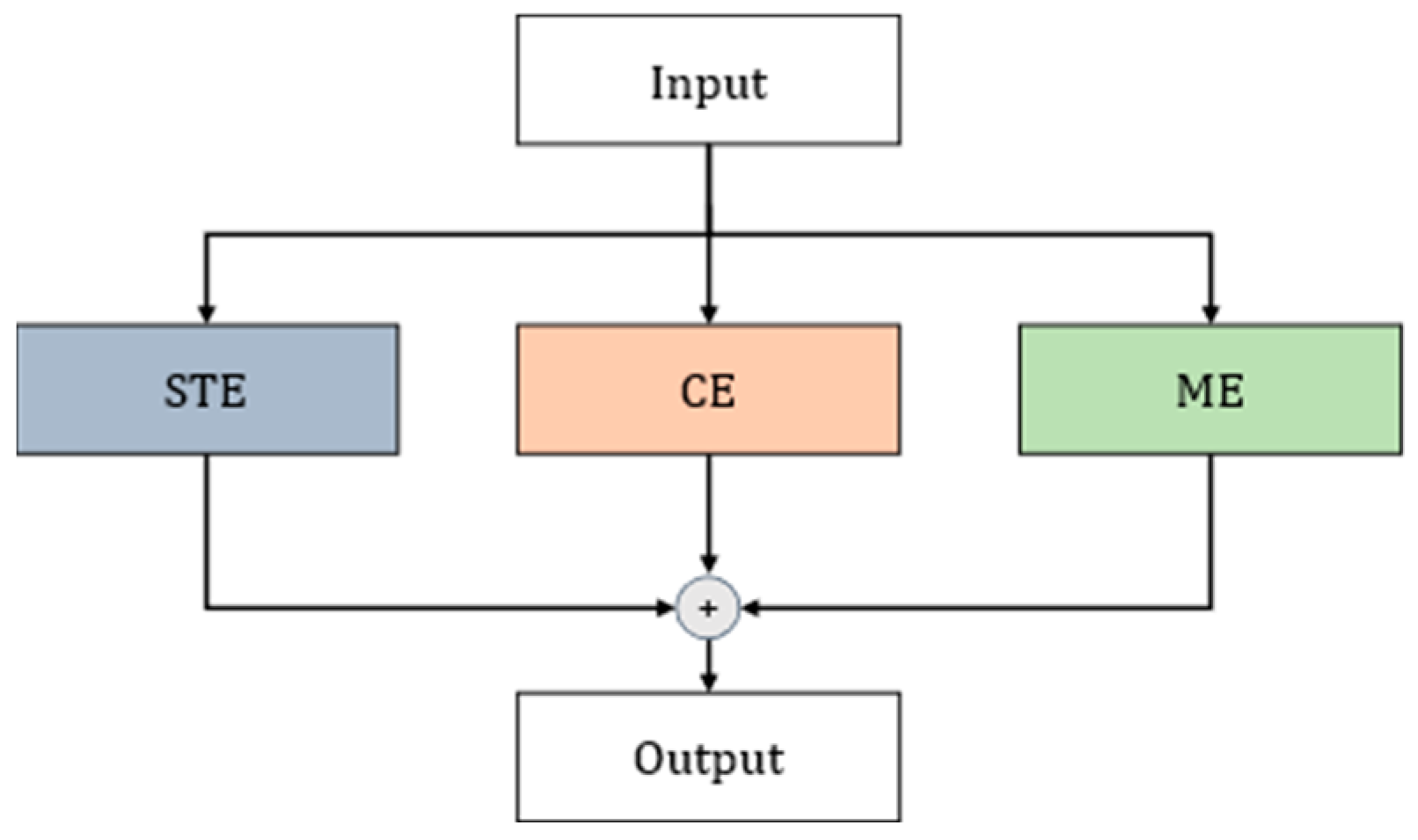
The ACTION [
38] module comprises three complementary attention modules: STE (Spatio-temporal Excitation), CE (Channel Excitation), and ME (Motion Excitation). These consider three crucial aspects of temporal action: (a) spatio-temporal information, i.e., the temporal and spatial relationship of the action; (b) weighting of the temporal information of the action across different channels; and (c) the trajectory of the action between each pair of neighboring frames. Three paths—the spatio-temporal excitation path, channel excitation path, and motion excitation path—are utilized to extract the key spatio-temporal features of the video, the weights of the temporal features of the action across different channels, and the trajectory features of the action’s changes between two adjacent frames. The network structure is illustrated in
Figure 9.
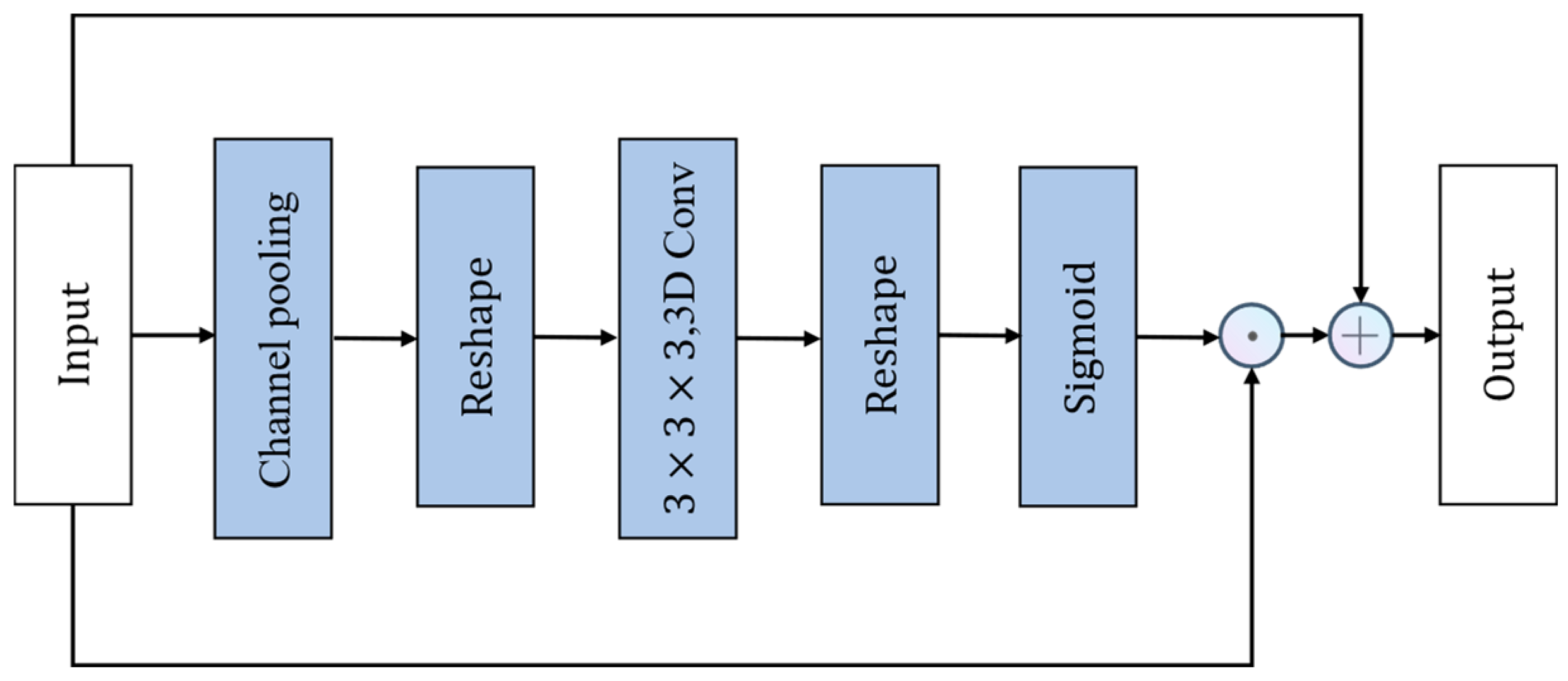
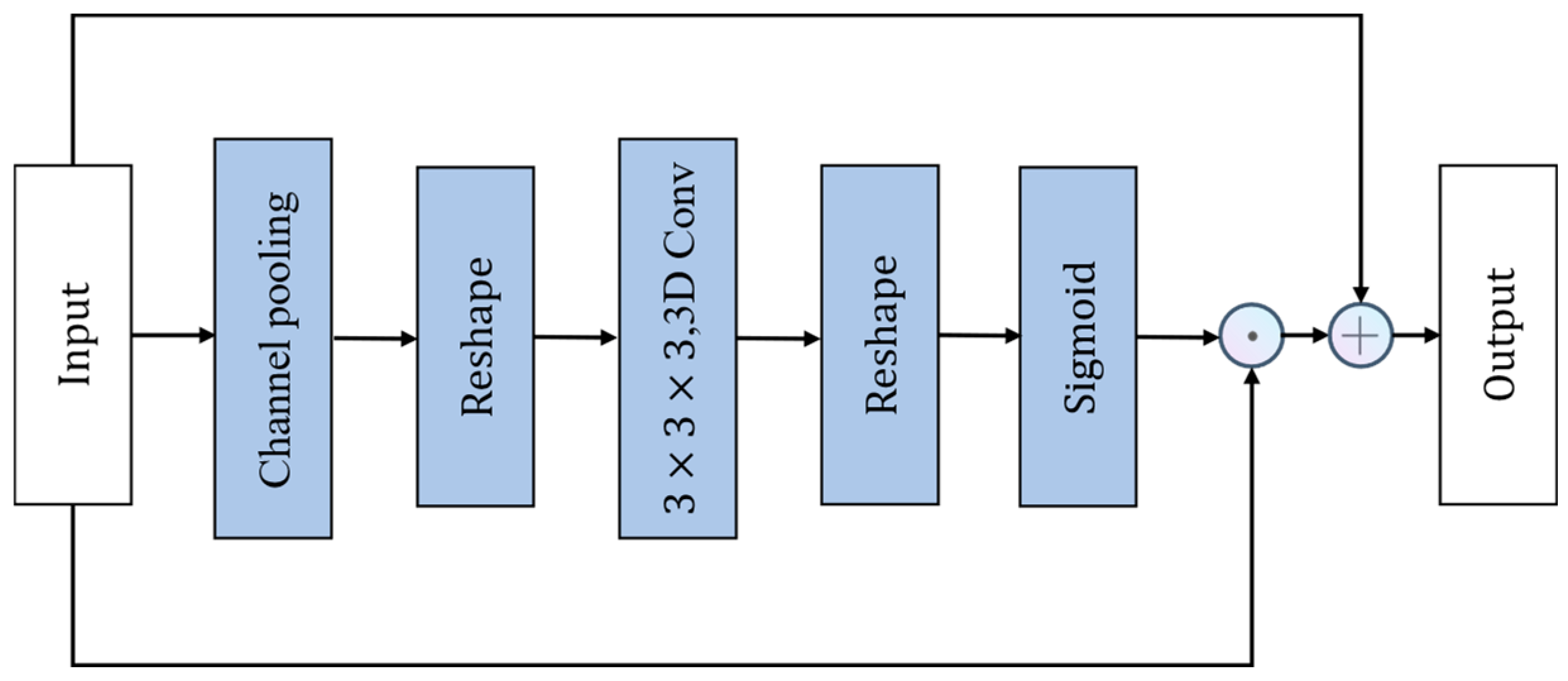
The STE module extracts spatio-temporal features from the video by generating a spatio-temporal mask
, which results in a spatio-temporal attention map. The structure of the STE module is illustrated in
Figure 10.
Traditional spatio-temporal feature extraction typically involves using 3D convolution, but directly employing 3D convolution significantly increases the computational load of the model. Therefore, the Spatio-temporal Excitation (STE) module first performs channel global pooling on the input tensor
obtaining the corresponding channel-wise global spatio-temporal feature map
, Subsequently,
is reshaped into
to make it compatible with 3D convolution operations.
is then convolved with a
kernel
to produce the new spatio-temporal feature map
. The output of this process can be expressed as follows:
Here, N represents the batch size, T denotes the temporal dimension, represents the number of channels, H denotes the height, W denotes the width, and R represents the real domain, indicating that the elements in the feature map belong to the set of real numbers.
Then,
is reshaped to
, and the mask
is obtained through the Sigmoid activation function. The output of
can be expressed as follows:
Finally,
is multiplied element-wise with
and then summed with
to obtain the final output
. The output of
can be expressed as follows:
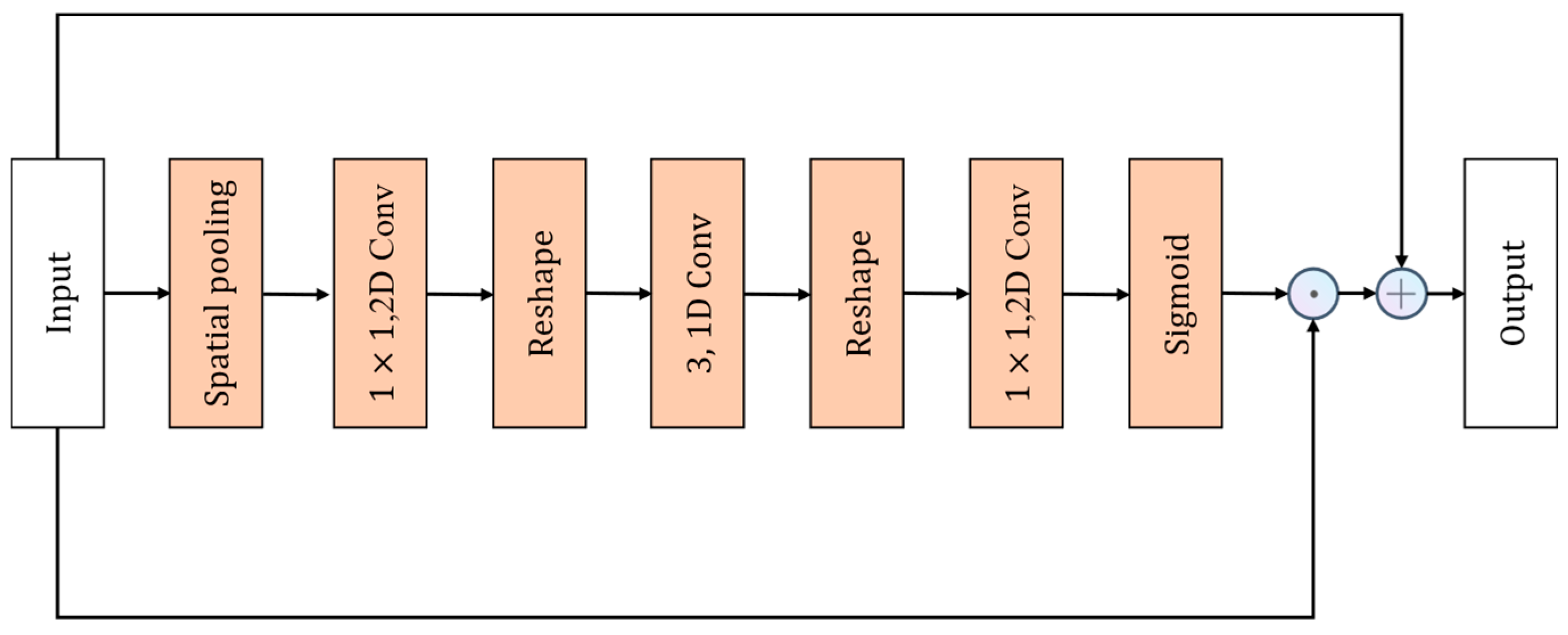
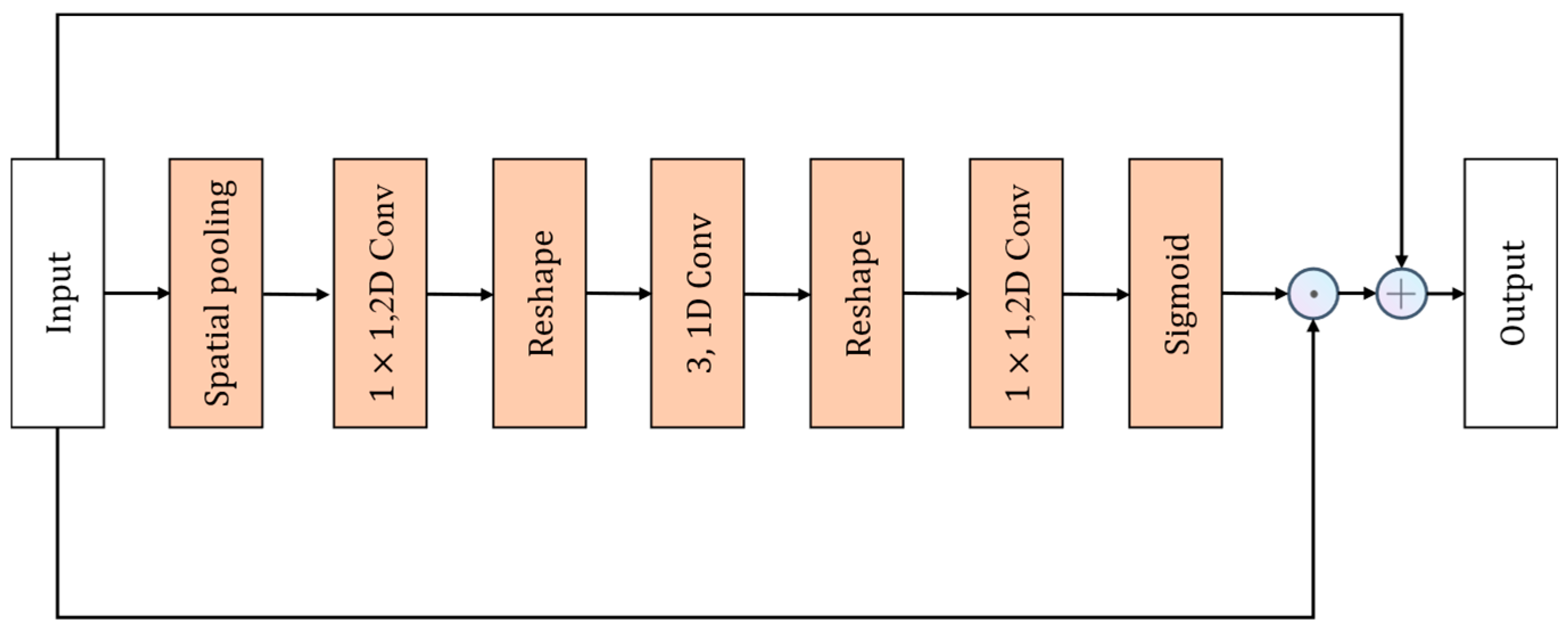
The CE module is an attention module acting on channels, adaptively recalibrating channel feature responses by explicitly modeling the interdependencies among channels in the temporal domain. The design of the CE module is similar to the SE module, with the distinction that, due to the temporal information present in video actions, the CE module inserts a 1 × 1 convolutional layer in the temporal domain between two fully connected (FC) layers. This convolutional layer enhances the temporal interdependence of channels, describing the temporal information of channel features. The network structure diagram of the CE module is shown in
Figure 11.
The CE module first performs spatial average pooling on the input
to obtain the global spatial information tensor of the input features. The global spatial information tensor can be expressed as follows:
The second step involves applying a
convolutional kernel
to
with a channel reduction ratio r to compress the channel count of the feature map
, resulting in a new feature map
:
In the third step,
is reshaped to obtain
, and in the fourth step, a one-dimensional convolutional kernel
with a kernel size of 3 is applied to process
, resulting in a new feature map
:
In the fifth step, the dimension of
is modified to yield a new feature map
. Subsequently, in the sixth step, a final feature map
is derived through additional feature extraction and processing of
using a 2D convolution kernel
with a size of 1:
and the mask
is obtained through the Sigmoid activation function. The output of
can be expressed as follows:
Finally,
is multiplied element-wise with
and then summed with
to obtain the final output
. The output of
can be expressed as follows:
The Motion Excitation (ME) attention module, depicted in
Figure 12, primarily captures the motion information associated with the action’s movement between two adjacent frames. This information is then concatenated as a branch with the two previously mentioned attention modules to form the ACTION module.
The motion excitation (ME) attention module begins with dimension reduction through a 1 × 1 convolution, followed by the computation of adjacent frame features using Equation (16). Here,
represents the motion feature map,
is a
convolutional kernel,
and
represent the features of the current frame and the previous frame, respectively.
Subsequently, motion features are concatenated along the temporal dimension and zero-padded up to the last position. The expression is given as:
where
represents a series of motion feature maps concatenated along the temporal dimension, and t denotes the time dimension. Then,
undergoes spatial average pooling as described in Equation (10), followed by a 1 × 1 convolution, and subsequent unsqueeze dimensionality upscaling, as specified in Equation (13), to obtain a new feature map
, and the mask
is obtained through the Sigmoid activation function. The output of
can be expressed as follows:
Finally,
is multiplied element-wise with
and then summed with
to obtain the final output
. The output of
can be expressed as follows:
The final output
Y of the ACTION module is represented as:
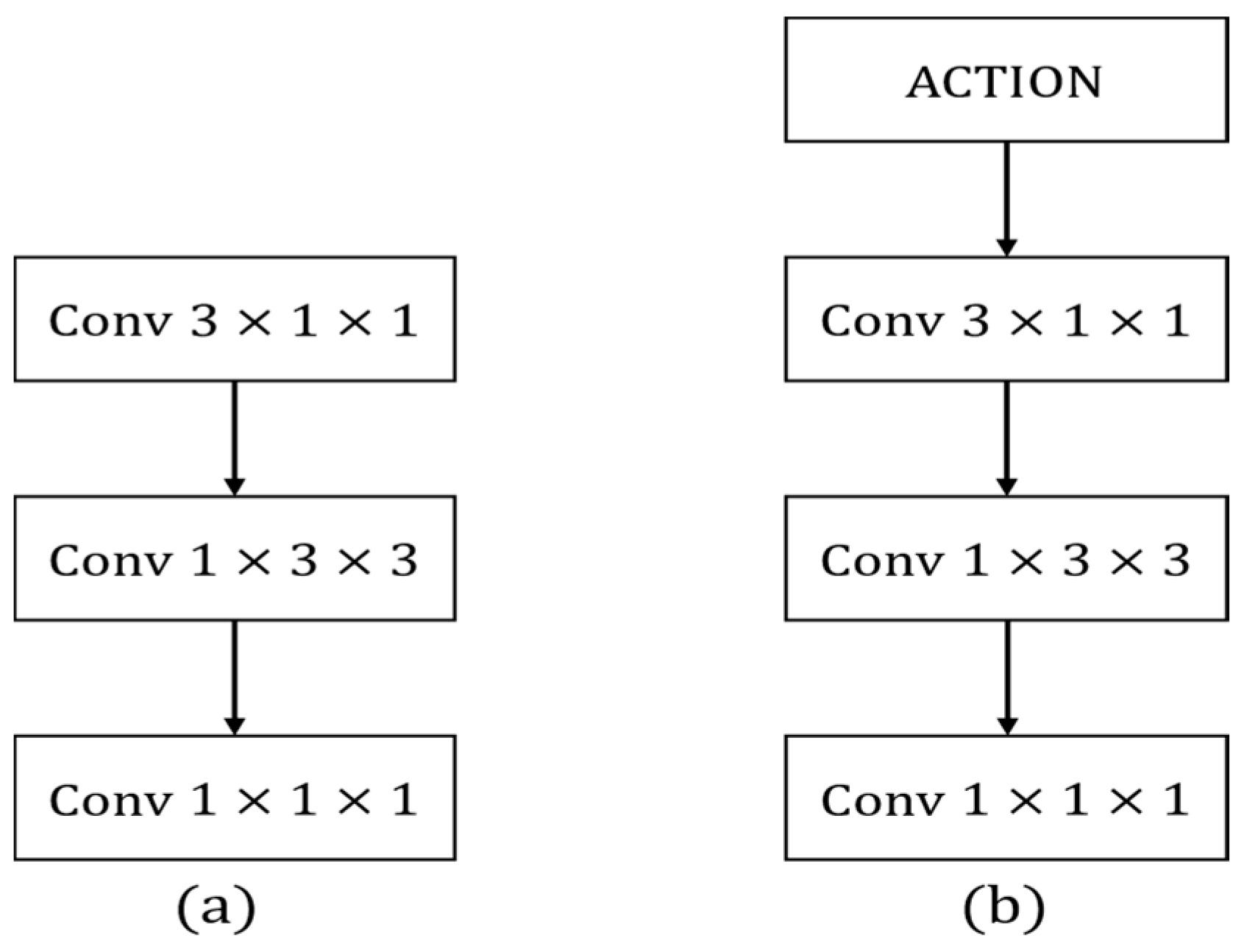
The ACTION attention module models internal features of the network at the feature level, enhancing the representation of diverse information in videos for better action representation. The original fast branch of the SlowFast network extracts spatio-temporal features to represent actions using stacked residual blocks with 3 × 1 × 1 convolution kernels. However, the extensive intra-class diversity necessitates learning more fine-grained spatio-temporal features. By introducing the ACTION module to capture diverse types of activation signals before each original residual block (
Figure 13a) in the fast branch, and subsequently performing convolution, finer-grained features can be obtained. This refinement contributes to improved accuracy in multi-label behavior classification. In this study, an ACTION module is introduced into each original residual block of the fast branch, referred to as the ACTION residual block (
Figure 13b).
3.2.3. Loss Function
This paper employs the Binary Cross-Entropy Loss (BCE Loss). Different categories of physical labor behaviors in the field are not mutually exclusive; instead, they can occur simultaneously. Therefore, normalizing the output using Softmax to probability values between [0, 1] (summing to 1) is not applicable. In the introduced multi-label classification task, the network’s output data are fed into the Sigmoid function to scale the values between [0, 1]. Subsequently, they are treated as multiple binary classification problems. The Sigmoid function—as represented by Formula (21), where y denotes the output probability,
z is the input, and BCE Loss, as per Formula (22)—calculates the loss for each category and obtains the total loss through summation. Here,
t represents the true label values,
w denotes the weight, and
n is the sample count.
5. Conclusions
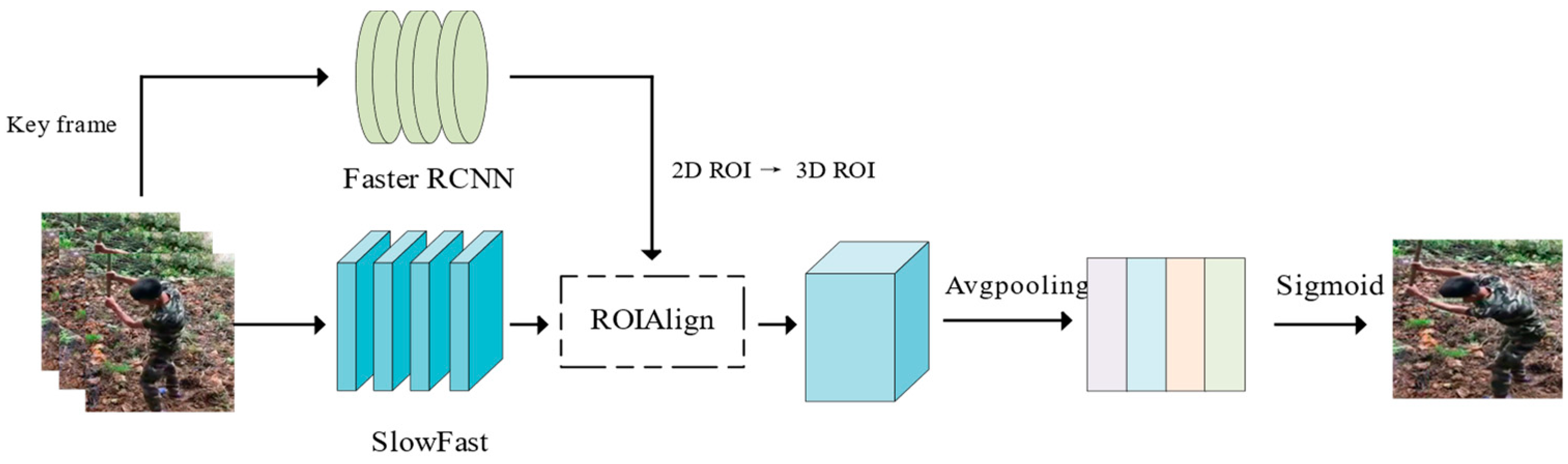
In this study, we employ the Faster-RCNN + SlowFast spatio-temporal action detection algorithm for the purpose of detecting manual labor behavior in agricultural fields. Additionally, we curate a custom dataset named the Field Manual Labor Behavior Dataset (FWBD). The Faster-RCNN model is employed to identify personnel targets within key frame images. Subsequently, the detected targets are input into the SlowFast model’s fast and slow channels based on varying frame counts, facilitating the accomplishment of spatio-temporal action recognition tasks.
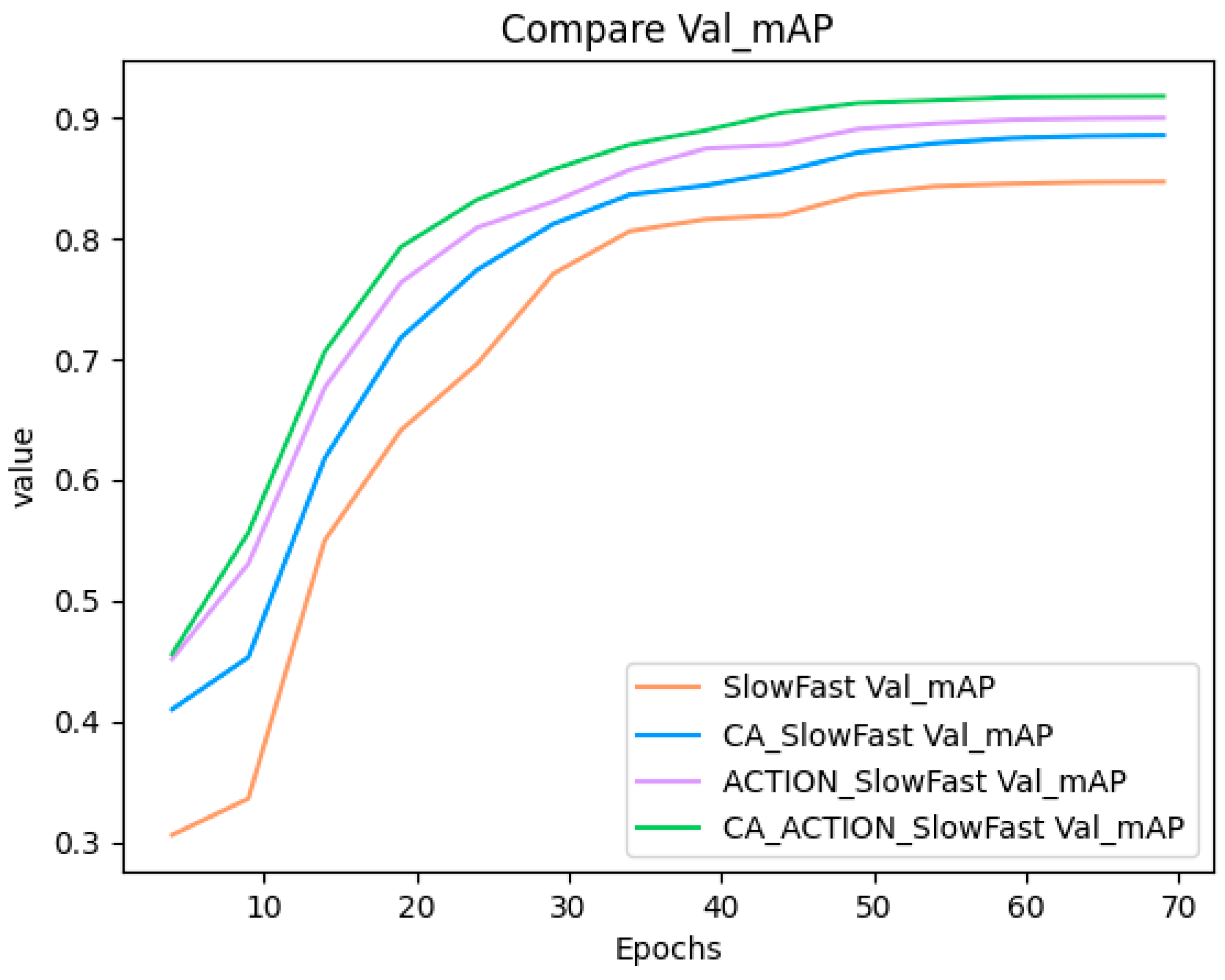
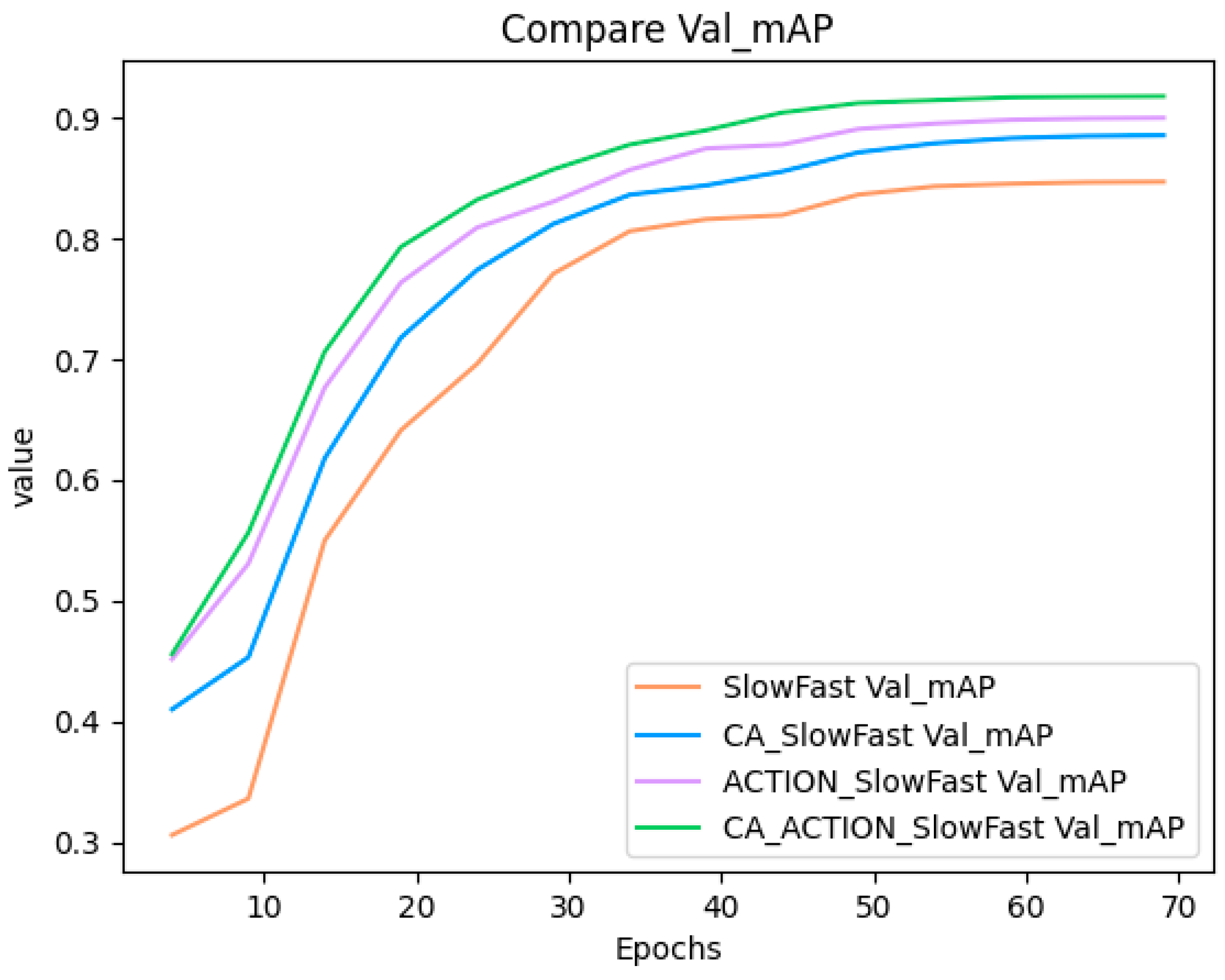
The SlowFast model undergoes innovative enhancement through the incorporation of the CA attention module and ACTION attention module, resulting in improved recognition accuracy compared to the original model. Although the improved model has more parameters, the increase in FLOP compared to the original SlowFast model is not substantial. This indicates that while the CA-ACTION-SlowFast model may have increased the complexity to some extent, it did not significantly increase the computational load during the inference phase. This is beneficial for maintaining the efficiency and utility of the model in practical applications. Furthermore, experimental findings reveal that the CA-ACTION-SlowFast model enhances the mAP by 7.08% in comparison to the original model. The notable performance of the CA-ACTION-SlowFast model underscores the potential for enhancing behavioral detection accuracy through the integration of spatial and dynamic features. Leveraging channel attention and temporal attention proves effective in bolstering the recognition of key features. The substantial improvement emphasizes the significance of the CA and ACTION modules. The model’s capability to prioritize more informative channels proves to be a viable strategy, particularly in real-world scenarios with disturbances. This strategy assists the model in filtering out irrelevant features, allowing it to focus on components critical to the recognition task. Ultimately, the CA-ACTION-SlowFast model offers a viable solution for practical applications, notably in the realm of detecting manual labor behaviors in agricultural settings. The CA and ACTION modules may improve the performance of existing systems by providing more granular contextual information and action recognition capabilities, and can add additional layers and depth to improve overall system understanding and responsiveness. This advancement promotes the digitization and standardization of farm workers, driving traditional agriculture toward further automation and smart farming, which is of significant importance.
Future work will focus on the following aspects. First, integrating the improved network into lightweight monitoring devices. This integration has the potential to effectively capture behavioral events, significantly enhancing the functionality and utility of monitoring devices, and providing valuable information for traceability systems. Second, further exploring the model’s structure and conducting experiments on other publicly available datasets to compare results aim to improve the model’s generalization capability and increase the model’s evaluation metrics to improve its reliability for real-world applications. Eventually, this will enrich the quantity and diversity of datasets. Only large-scale datasets can effectively validate the model’s performance. Additionally, including videos from different weather conditions and different times of day in each category can enhance the model’s robustness against changes in lighting and climate.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}