
A Deep Reinforcement Learning Floorplanning Algorithm Based on Sequence Pairs †


Abstract
1. Introduction
2. Description of Floorplanning Problem
3. Sequence Pair Representation
3.1. Properties of Sequence Pair
- (1)
- If bi is positioned before bj in Г+, i.e., <....bi....bj....>, and bi is also positioned before bj in Г−, i.e., <....bi....bj....>, it indicates that bi is located on the left side of bj.
- (2)
- If bj is positioned before bi in Г+, i.e., <....bj....bi....>, and bj is also positioned before bi in Г−, i.e., <....bj....bi....>, it indicates that bi is located on the right side of bj.
- (3)
- If bi is positioned before bj in Г+, i.e., <....bi....bj....>, and bj is positioned before bi in Г−, i.e., <....bj....bi....>, it indicates that bi is located above bj.
- (4)
- If bj is positioned before bi in Г+, i.e., <....bj....bi....>, and bi is positioned before bj in Г−, i.e., <....bi....bj....>, it indicates that bi is located below bj.
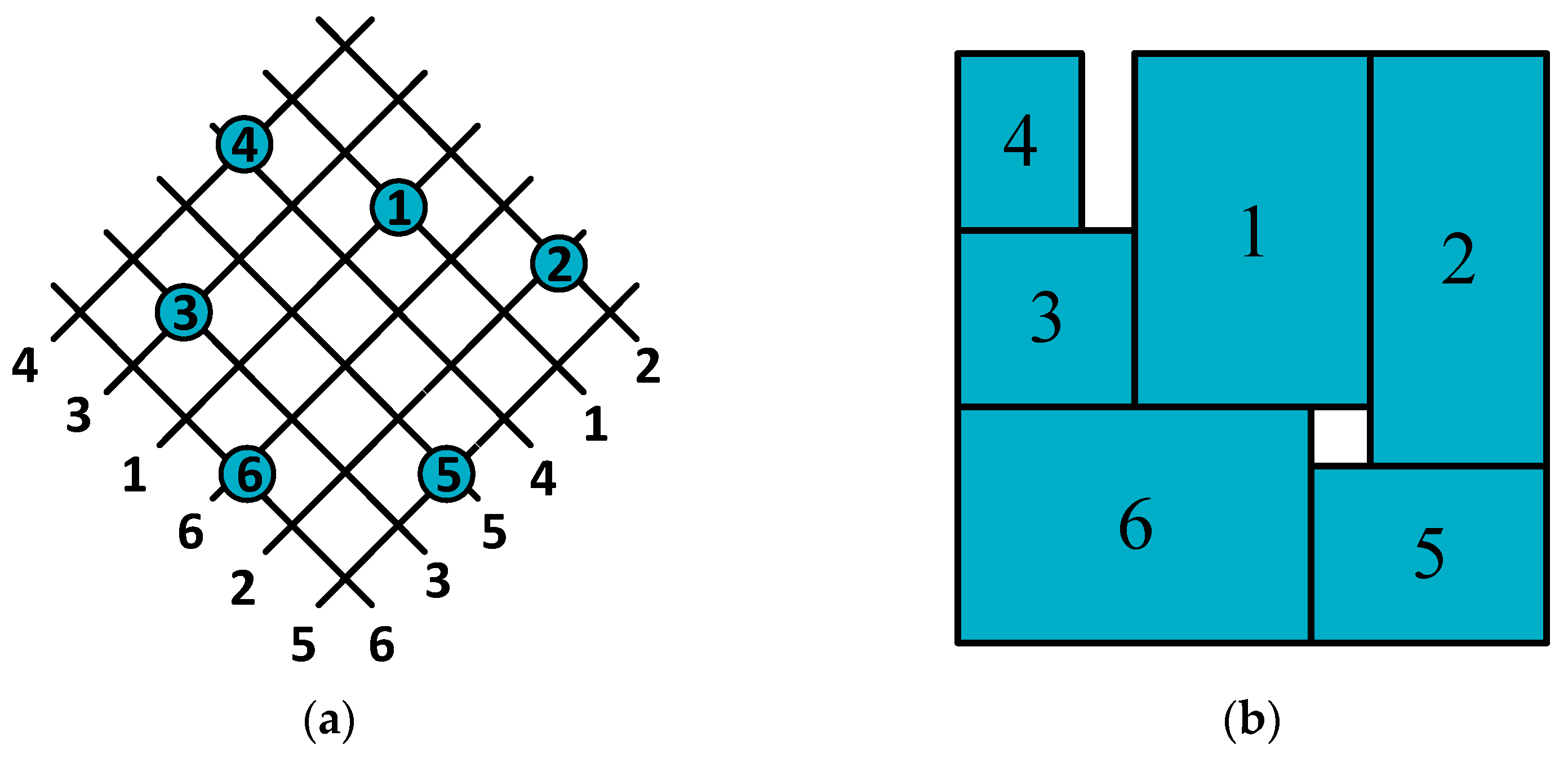
3.2. Sequence Pair Representation Floorplan
- (1)
- For a given module x in the sequence pair (Г+, Г−), we obtain a list of modules that appear before x in Г+ and Г−. These modules are positioned to the left of x in the plane graph. A group of modules that appear after x in Г+ and Г− are positioned to the right of x in the plane graph. A group of modules that appear after x in Г+ and before x in Г− are positioned below x in the plane graph. Finally, a group of modules that appear before x in Г+ and after x in Г− are positioned above x in the plane graph.
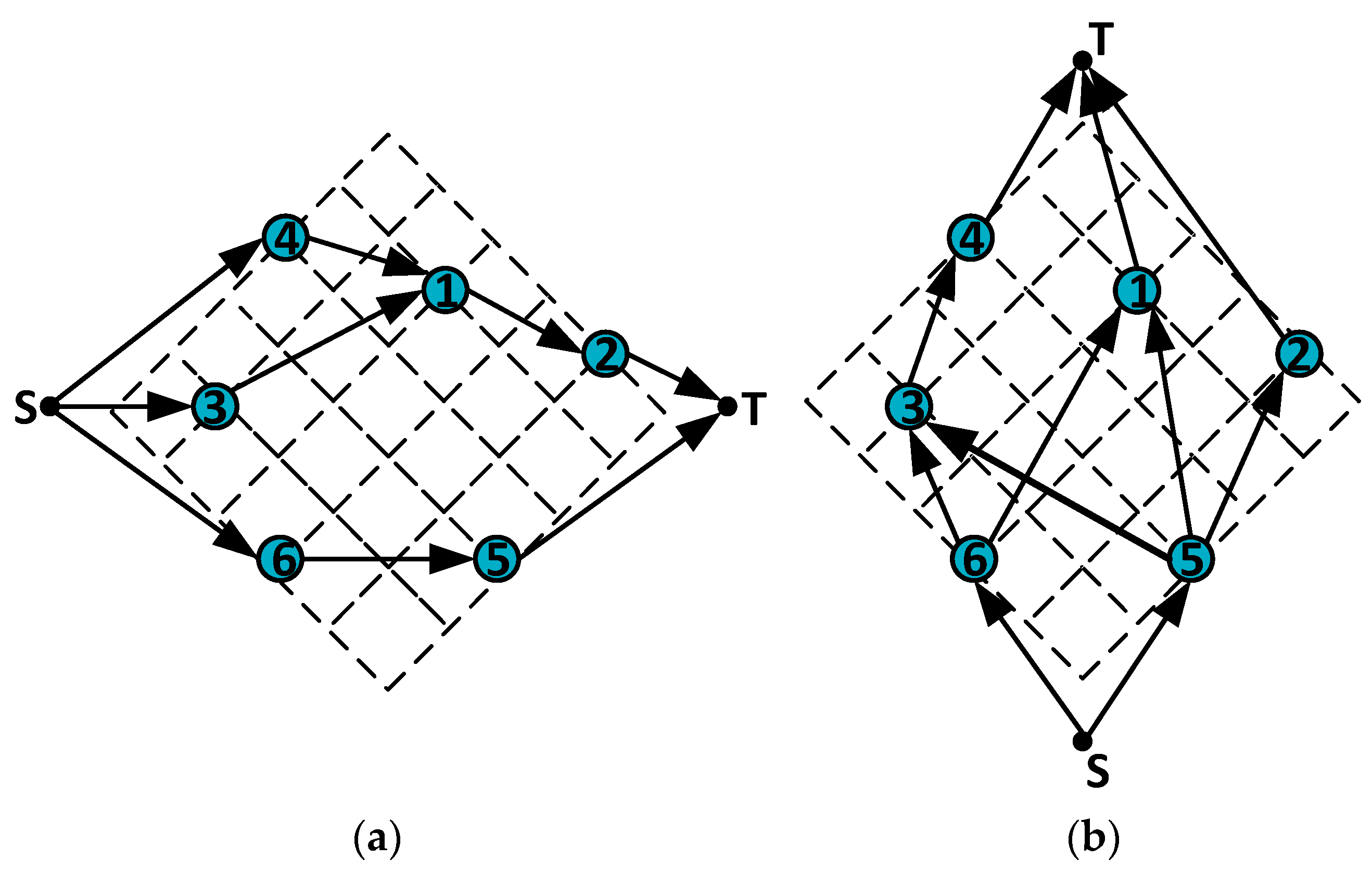
- (2)
- Next, we construct a directed graph for the horizontal constraint graph based on the left and right relationships. A directed edge E (a, b) represents module a being positioned to the left of module b. We add a source node S connected to all nodes in the horizontal constraint graph, and we also add a receiving node T connected to all nodes. The longest path length from the source node S to each node in the horizontal constraint graph represents the x coordinate of the modules in the floorplan.
- (3)
- By computing the longest path length from the source node S to the added receiving node T, we can obtain the width of the floorplan. Similarly, we construct the vertical constraint graph based on the relationships above and below, and calculate the y coordinate of the modules and the height of the plane graph in a similar manner. Figure 2 illustrates the constructed horizontal and vertical constraint graphs for the sequence pair (Г+, Г−) = (<4, 3, 1, 6, 2, 5), (<6, 3, 5, 4, 1, 2>) as an example.
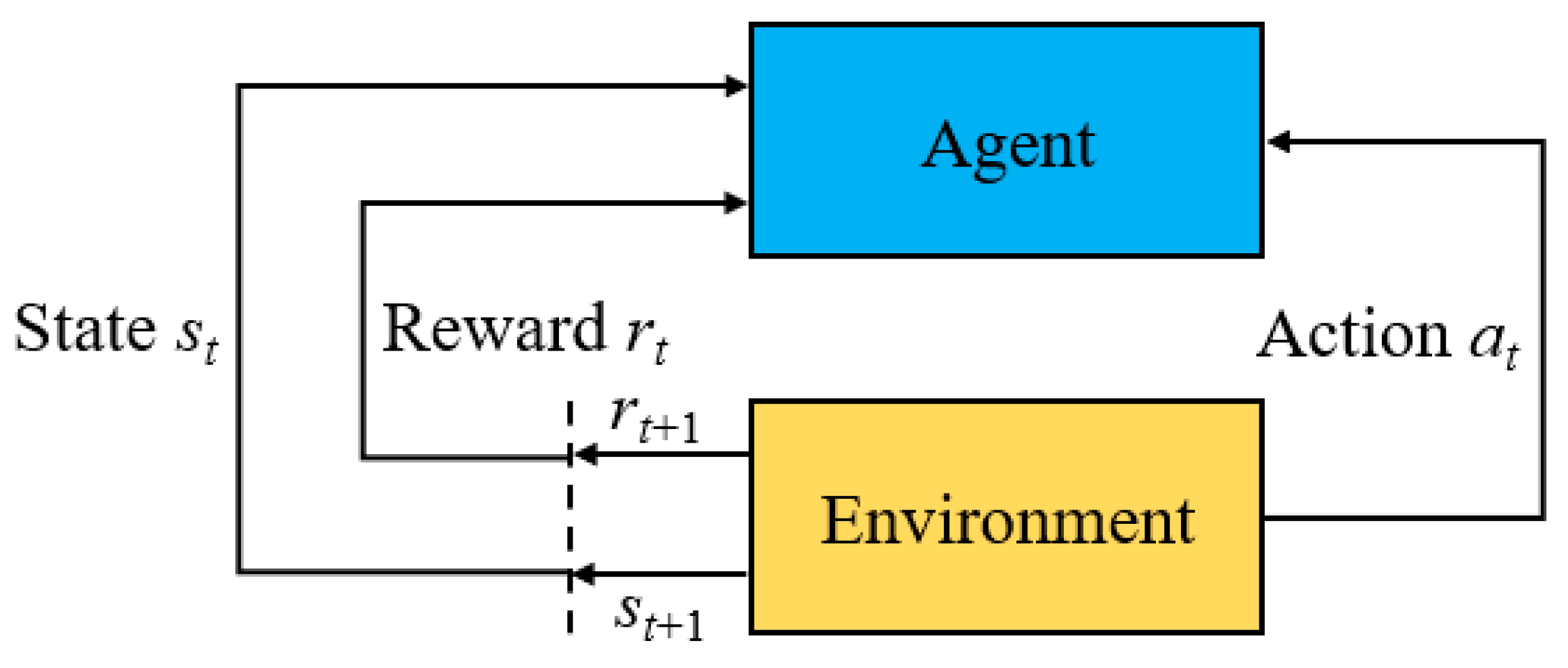
4. Reinforcement Learning
- (1)
- States S: a finite set of environmental states.
- (2)
- Actions A: a finite set of actions taken by the reinforcement learning agent.
- (3)
- State transition model P (s, a, s′): representing the probability of transitioning from state s Є S to the next state, s′ Є S, when action a Є A is taken.
- (4)
- Reward function R (s, a): representing the numerical reward for taking action a Є A in state s Є S. This reward can be positive, negative, or zero.
4.1. The MDP Framework for Solving Floorplanning Problems
- (1)
- State space S: for the floorplanning problem, a state s Є S represents a floorplan solution, including a complete sequence of gates (Г+, Г−), and the orientation of each module.
- (2)
- Action space A: A neighboring solution of a floorplan is generated by predefined perturbations in the action space. The following five perturbations are defined:
- (a)
- Swap any two modules in the Г+ sequence.
- (b)
- Swap any two modules in the Г− sequence.
- (c)
- Swap one module from the Г+ sequence with one module from the Г− sequence.
- (d)
- Randomly move a module to a new position in both Г+ and Г−.
- (e)
- Rotate any module in the sequence pair by 90°.
- (3)
- State transition P: given a state, applying any of the above perturbations will result in the agent transitioning to another state, simplifying the probabilistic setting in the MDP.
- (4)
- Reward R: Allocating rewards for actions taken in a state is crucial in reinforcement learning. In this floorplanning problem, the objective is to minimize the area and wirelength. Thus, the reward is assigned as the reduction in the objective cost. A positive reward is assigned whenever the agent discovers a better solution, while no reward is assigned otherwise. The reward function is defined as follows:
4.2. Deep Reinforcement Learning Algorithm
| Algorithm 1: Deep Reinforcement Learning Algorithm |
| Input: number of episodes, number of steps Output: Policy π 1: Initialize θ (policy network weights) randomly |
| 2: for e in episodes do |
| 3: for s in steps do |
| 4: Perform an action as predicted by the policy network |
| 5: Record s, a, r, s′ |
| 6: Calculate the gradient as per Equation (10) |
| 7: end |
| 8: Update θ as per Equation (9) |
| 9: end |
5. Experimental Results
5.1. Experimental Environment and Test Data
5.2. Experimental Results and Analysis
5.2.1. Experimental Results of MCNC and GSRC Test Sets
5.2.2. Experimental Results of MCNC and GSRC Test Sets with Obstacles
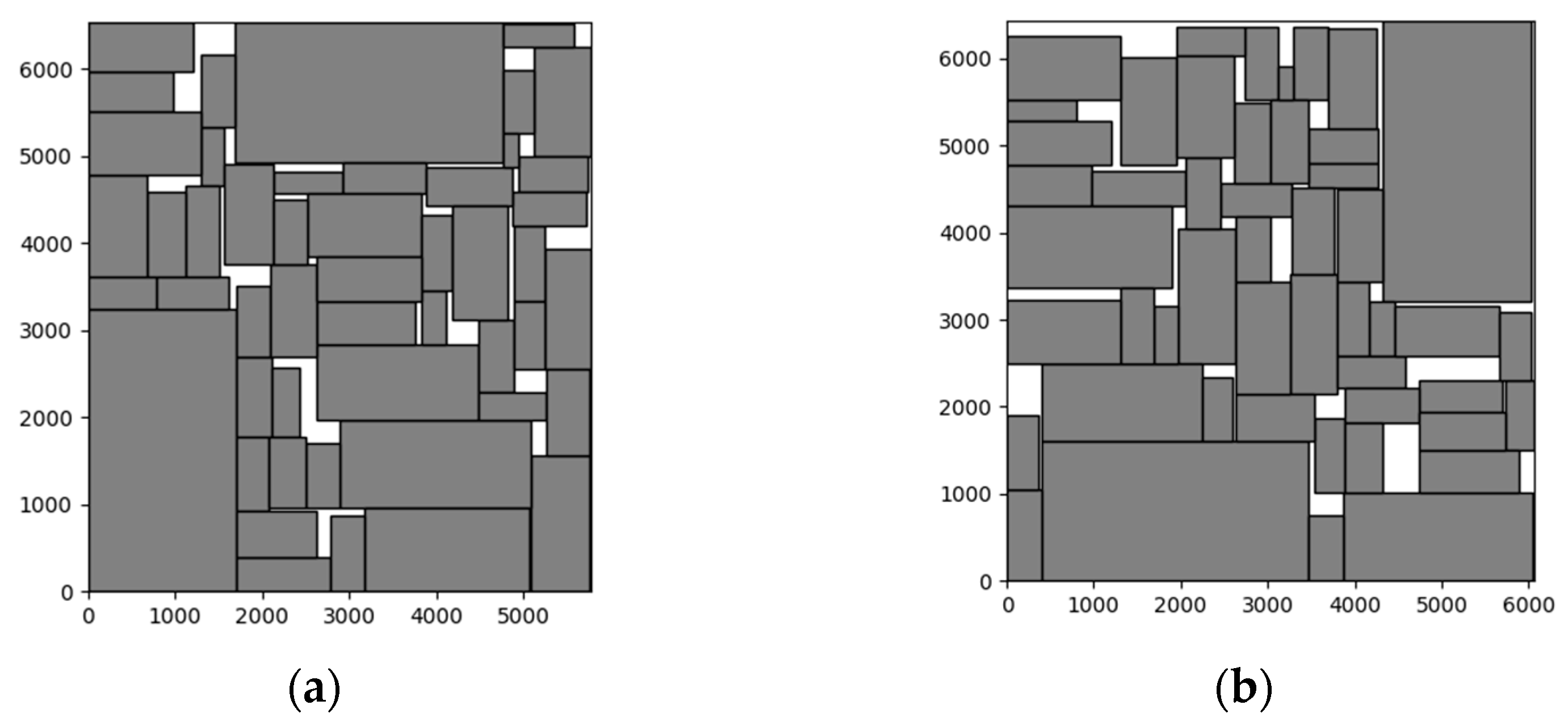
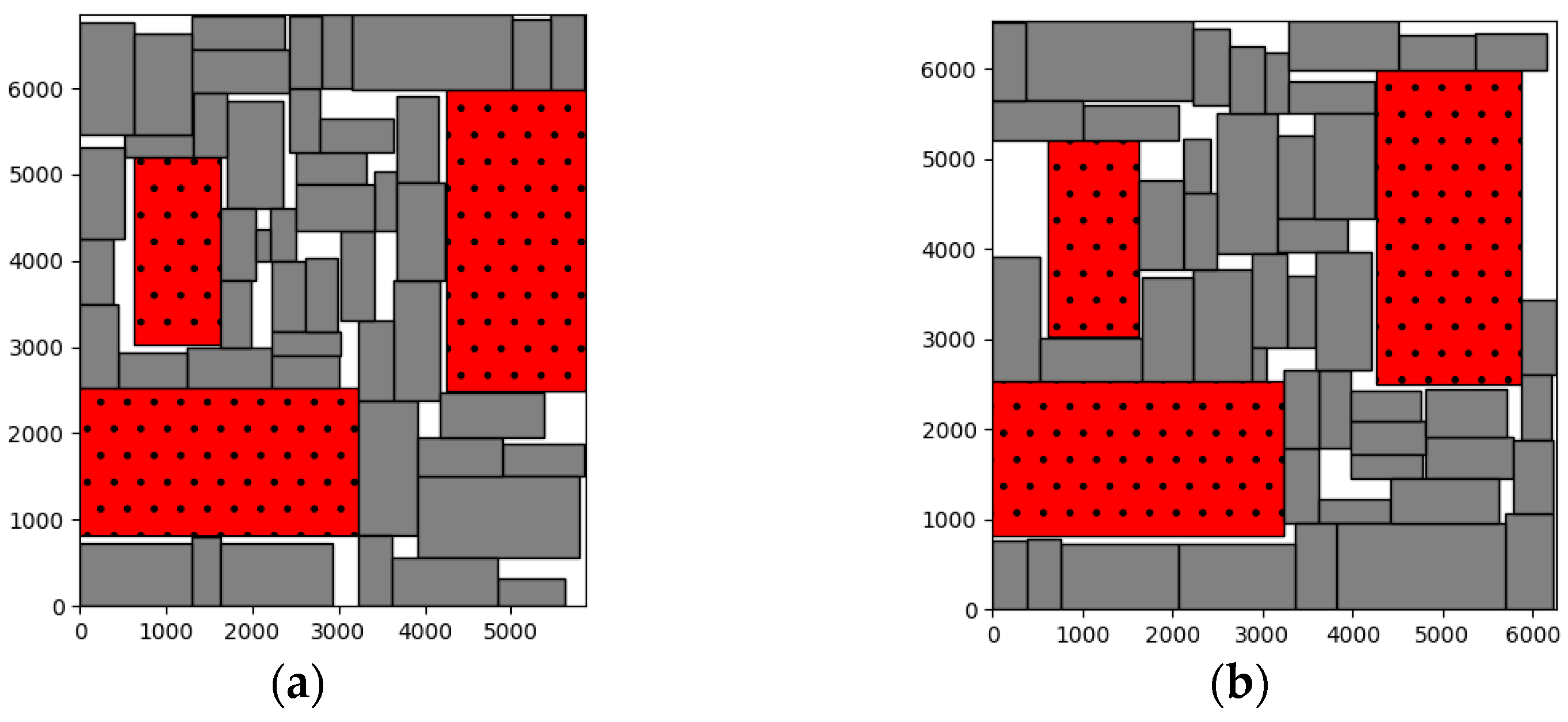
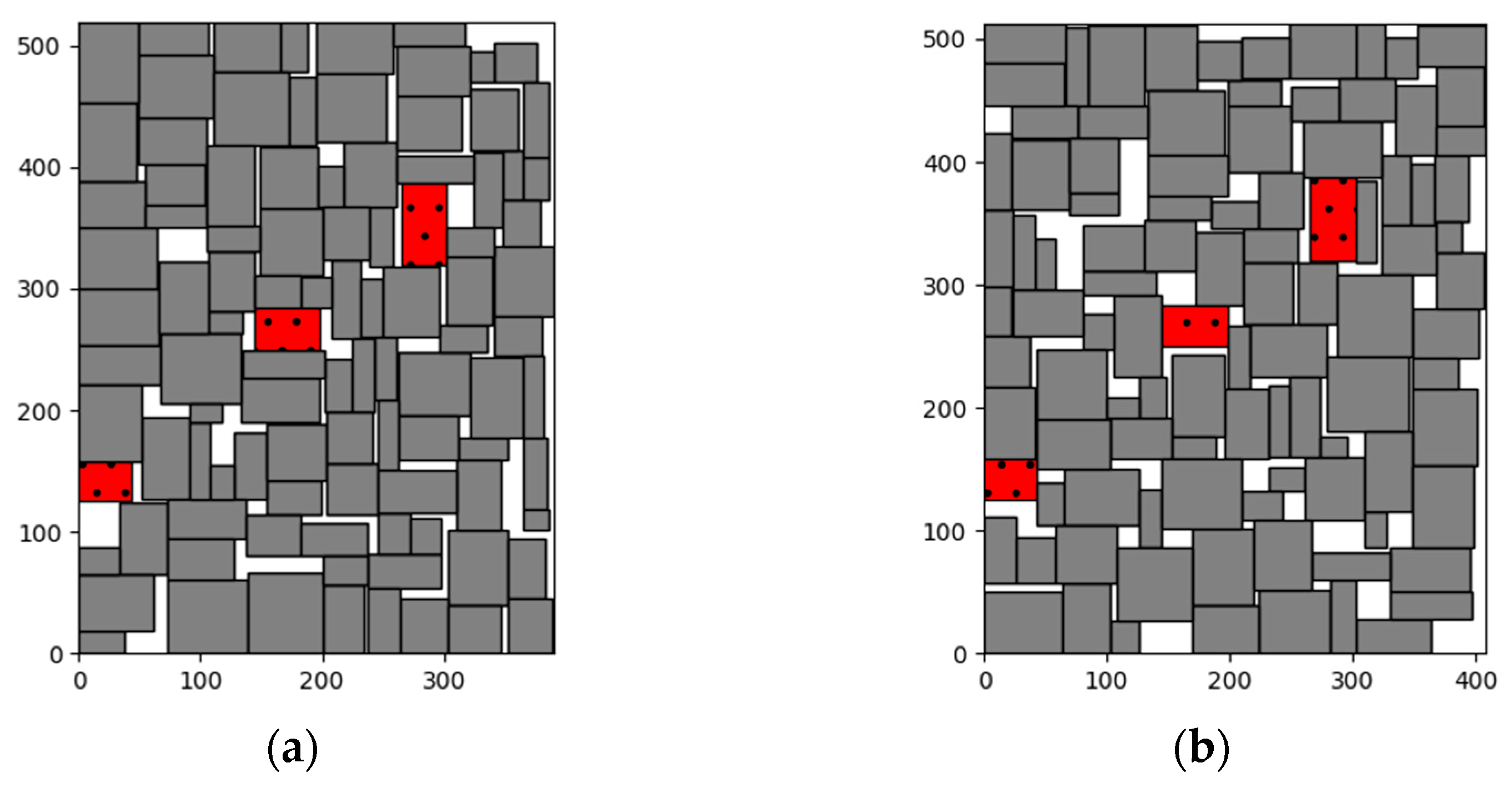
5.3. Floorplan Visualization
5.3.1. Visualization of MCNC and GSRC Circuit Floorplan
5.3.2. Visualization of MCNC and GSRC Circuit Floorplan with Obstacles
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Fleetwood, D.M. Evolution of total ionizing dose effects in MOS devices with Moore’s law scaling. IEEE Trans. Nucl. Sci. 2017, 65, 1465–1481. [Google Scholar] [CrossRef]
- Wang, L.T.; Chang, Y.W.; Cheng, K.T. (Eds.) Electronic Design Automation: Synthesis, Verification, and Test; Morgan Kaufmann: San Francisco, CA, USA, 2009. [Google Scholar]
- Sherwani, N.A. Algorithms for VLSI Physical Design Automation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Adya, S.N.; Chaturvedi, S.; Roy, J.A.; Papa, D.A.; Markov, I.L. Unification of partitioning, placement and floorplanning. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design, ICCAD-2004, San Jose, CA, USA, 7–11 November 2004; pp. 550–557. [Google Scholar]
- Markov, I.L.; Hu, J.; Kim, M.C. Progress and challenges in VLSI placement research. In Proceedings of the International Conference on Computer-Aided Design, San Jose, CA, USA, 5–8 November 2012; pp. 275–282. [Google Scholar]
- Gubbi, K.I.; Beheshti-Shirazi, S.A.; Sheaves, T.; Salehi, S.; Pd, S.M.; Rafatirad, S.; Sasan, A.; Homayoun, H. Survey of machine learning for electronic design automation. In Proceedings of the Great Lakes Symposium on VLSI 2022, Irvine, CA, USA, 6–8 June 2022; pp. 513–518. [Google Scholar]
- Garg, S.; Shukla, N.K. A Study of Floorplanning Challenges and Analysis of macro placement approaches in Physical Aware Synthesis. Int. J. Hybrid Inf. Technol. 2016, 9, 279–290. [Google Scholar] [CrossRef]
- Subbulakshmi, N.; Pradeep, M.; Kumar, P.S.; Kumar, M.V.; Rajeswaran, N. Floorplanning for thermal consideration: Slicing with low power on field programmable gate array. Meas. Sens. 2022, 24, 100491. [Google Scholar]
- Tamarana, P.; Kumari, A.K. Floorplanning for optimizing area using sequence pair and hybrid optimization. Multimed. Tools Appl. 2023, 1–23. [Google Scholar] [CrossRef]
- Nakatake, S.; Fujiyoshi, K.; Murata, H.; Kajitanic, Y. Module packing based on the BSG-structure and IC layout applications. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1998, 17, 519–530. [Google Scholar] [CrossRef]
- Guo, P.N.; Cheng, C.K.; Yoshimura, T. An O-tree representation of non-slicing floorplan and its applications. In Proceedings of the 36th annual ACM/IEEE Design Automation Conference, New Orleans, LA, USA, 21–25 June 1999; pp. 268–273. [Google Scholar]
- Lin, J.M.; Chang, Y.W. TCG-S: Orthogonal coupling of P*-admissible representation with worst case linear-time packing scheme. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2004, 23, 968–980. [Google Scholar] [CrossRef]
- Chang, Y.C.; Chang, Y.W.; Wu, G.M.; Wu, S.-W. B*-trees: A new representation for non-slicing floorplans. In Proceedings of the 37th Annual Design Automation Conference, Los Angeles, CA, USA, 5–9 June 2000; pp. 458–463. [Google Scholar]
- Yu, S.; Du, S. VLSI Floorplanning Algorithm Based on Reinforcement Learning with Obstacles. In Proceedings of the Biologically Inspired Cognitive Architectures 2023—BICA 2023, Ningbo, China, 13–15 October 2023; Springer Nature: Cham, Switzerland, 2023; pp. 1034–1043. [Google Scholar]
- Zou, D.; Wang, G.G.; Sangaiah, A.K.; Kong, X. A memory-based simulated annealing algorithm and a new auxiliary function for the fixed-outline floorplanning with soft blocks. J. Ambient. Intell. Humaniz. Comput. 2017, 15, 1613–1624. [Google Scholar] [CrossRef]
- Liu, J.; Zhong, W.; Jiao, L.; Li, X. Moving block sequence and organizational evolutionary algorithm for general floorplanning with arbitrarily shaped rectilinear blocks. IEEE Trans. Evol. Comput. 2008, 12, 630–646. [Google Scholar] [CrossRef]
- Fischbach, R.; Knechtel, J.; Lienig, J. Utilizing 2D and 3D rectilinear blocks for efficient IP reuse and floorplanning of 3D-integrated systems. In Proceedings of the 2013 ACM International symposium on Physical Design, Stateline, NV, USA, 24–27 March 2013; pp. 11–16. [Google Scholar]
- Fang, Z.; Han, J.; Wang, H. Deep reinforcement learning assisted reticle floorplanning with rectilinear polygon modules for multiple-project wafer. Integration 2023, 91, 144–152. [Google Scholar] [CrossRef]
- Tang, X.; Tian, R.; Wong, D.F. Fast evaluation of sequence pair in block placement by longest common subsequence computation. In Proceedings of the Conference on Design, Automation and Test in Europe, Paris, France, 27–30 March 2000; pp. 106–111. [Google Scholar]
- Tang, X.; Wong, D.F. FAST-SP: A fast algorithm for block placement based on sequence pair. In Proceedings of the 2001 Asia and South Pacific design automation conference, Yokohama, Japan, 2 February 2001; pp. 521–526. [Google Scholar]
- Dayasagar Chowdary, S.; Sudhakar, M.S. Linear programming-based multi-objective floorplanning optimization for system-on-chip. J. Supercomput. 2023, 1–24. [Google Scholar] [CrossRef]
- Tabrizi, A.F.; Behjat, L.; Swartz, W.; Rakai, L. A fast force-directed simulated annealing for 3D IC partitioning. Integration 2016, 55, 202–211. [Google Scholar] [CrossRef]
- Tung-Chieh, C.; Yao-Wen, C. Modern floorplanning based on B*-tree and fast simulated annealing. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2006, 25, 637–650. [Google Scholar] [CrossRef]
- Sadeghi, A.; Lighvan, M.Z.; Prinetto, P. Automatic and simultaneous floorplanning and placement in field-programmable gate arrays with dynamic partial reconfiguration based on genetic algorithm. Can. J. Electr. Comput. Eng. 2020, 43, 224–234. [Google Scholar] [CrossRef]
- Chang, Y.F.; Ting, C.K. Multiple Crossover and Mutation Operators Enabled Genetic Algorithm for Non-slicing VLSI Floorplanning. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Tang, M.; Yao, X. A memetic algorithm for VLSI floorplanning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2007, 37, 62–69. [Google Scholar] [CrossRef]
- Xu, Q.; Chen, S.; Li, B. Combining the ant system algorithm and simulated annealing for 3D/2D fixed-outline floorplanning. Appl. Soft Comput. 2016, 40, 150–160. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Bello, I.; Pham, H.; Le, Q.V.; Norouzi, M.; Bengio, S. Neural combinatorial optimization with reinforcement learning. arXiv 2016, arXiv:1611.09940. [Google Scholar]
- Zhou, C.; Wu, W.; He, H.; Yang, P.; Lyu, F.; Cheng, N.; Shen, X. Deep reinforcement learning for delay-oriented IoT task scheduling in SAGIN. IEEE Trans. Wirel. Commun. 2020, 20, 911–925. [Google Scholar] [CrossRef]
- Nazari, M.; Oroojlooy, A.; Snyder, L.; Takac, M. Reinforcement learning for solving the vehicle routing problem. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Huang, J.; Patwary, M.; Diamos, G. Coloring big graphs with alphagozero. arXiv 2019, arXiv:1902.10162. [Google Scholar]
- Mirhoseini, A.; Goldie, A.; Yazgan, M.; Jiang, J.W.; Songhori, E.; Wang, S.; Lee, Y.-J.; Johnson, E.; Pathak, O.; Nazi, A.; et al. A graph placement methodology for fast chip design. Nature 2021, 594, 207–212. [Google Scholar] [CrossRef]
- He, Z.; Ma, Y.; Zhang, L.; Liao, P.; Wong, N.; Yu, B.; Wong, M.D.F. Learn to floorplan through acquisition of effective local search heuristics. In Proceedings of the 2020 IEEE 38th International Conference on Computer Design (ICCD), Hartford, CT, USA, 18–21 October 2020; pp. 324–331. [Google Scholar]
- Cheng, R.; Yan, J. On joint learning for solving placement and routing in chip design. Adv. Neural Inf. Process. Syst. 2021, 34, 16508–16519. [Google Scholar]
- Agnesina, A.; Chang, K.; Lim, S.K. VLSI placement parameter optimization using deep reinforcement learning. In Proceedings of the 39th International Conference on Computer-Aided Design, Virtual, 2–5 November 2020; pp. 1–9. [Google Scholar]
- Vashisht, D.; Rampal, H.; Liao, H.; Lu, Y.; Shanbhag, D.; Fallon, E.; Kara, L.B. Placement in integrated circuits using cyclic reinforcement learning and simulated annealing. arXiv 2020, arXiv:2011.07577. [Google Scholar]
- Xu, Q.; Geng, H.; Chen, S.; Yuan, B.; Zhuo, C.; Kang, Y.; Wen, X. GoodFloorplan: Graph Convolutional Network and Reinforcement Learning-Based Floorplanning. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 41, 3492–3502. [Google Scholar] [CrossRef]
- Shahookar, K.; Mazumder, P. VLSI cell placement techniques. ACM Comput. Surv. (CSUR) 1991, 23, 143–220. [Google Scholar] [CrossRef]
- Gaon, M.; Brafman, R. Reinforcement learning with non-markovian rewards. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3980–3987. [Google Scholar] [CrossRef]
- Bacchus, F.; Boutilier, C.; Grove, A. Rewarding behaviors. Proc. Natl. Conf. Artif. Intell. 1996, 13, 1160–1167. [Google Scholar]
- Zimmer, L.; Lindauer, M.; Hutter, F. Auto-pytorch: Multi-fidelity metalearning for efficient and robust autodl. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3079–3090. [Google Scholar] [CrossRef]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| discount factor γ | 0.99 |
| learning rate αθ | 3 × 10−4 |
| episode length | 50 |
| number of iterations | 100 |
| number of samples | 64 |
| MCNC | Blocks | I/O Pad | Nets | Area (×106) |
|---|---|---|---|---|
| apte | 9 | 73 | 97 | 46.56 |
| xerox | 10 | 2 | 203 | 19.35 |
| hp | 11 | 309 | 83 | 8.83 |
| ami33 | 33 | 42 | 123 | 1.16 |
| ami49 | 49 | 22 | 408 | 35.45 |
| GSRC | Blocks | I/O Pad | Nets | Area |
|---|---|---|---|---|
| n100 | 100 | 334 | 885 | 179,501 |
| n200 | 200 | 564 | 1585 | 175,696 |
| n300 | 300 | 569 | 1893 | 273,170 |
| MCNC | Area (×106) | DS (%) | Wirelength (×105) | |||||
|---|---|---|---|---|---|---|---|---|
| Ours | SA | Ref. [36] | Ours | SA | Ref. [36] | Ours | SA | |
| apte | 46.94 | 47.65 | 47.08 | 0.81 | 2.29 | 1.10 | 0.45 | 0.51 |
| xerox | 20.40 | 20.91 | 20.42 | 5.15 | 7.46 | 5.24 | 0.49 | 0.55 |
| hp | 9.20 | 9.42 | 9.21 | 4.02 | 6.26 | 4.13 | 0.32 | 0.47 |
| ami33 | 1.22 | 1.27 | 1.24 | 4.92 | 8.66 | 6.45 | 0.61 | 0.75 |
| ami49 | 37.31 | 38.86 | 38.65 | 4.99 | 8.78 | 8.28 | 6.33 | 6.65 |
| Average | 23.01 | 23.62 | 23.32 | 3.98 | 6.68 | 5.04 | 1.64 | 1.79 |
| Normalization | 1.000 | 1.027 | 1.014 | 1.000 | 1.027 | 1.011 | 1.000 | 1.091 |
| GSRC | Area (×105) | DS (%) | Wirelength (×105) | |||||
|---|---|---|---|---|---|---|---|---|
| Ours | SA | Ref. [36] | Ours | SA | Ref. [36] | Ours | SA | |
| n100 | 1.93 | 1.99 | 1.95 | 6.99 | 9.91 | 7.95 | 1.87 | 1.99 |
| n200 | 1.99 | 2.25 | 2.15 | 11.71 | 21.91 | 18.14 | 3.37 | 3.62 |
| n300 | 3.25 | 3.58 | 3.40 | 15.95 | 23.70 | 19.71 | 4.95 | 5.49 |
| Average | 2.39 | 2.61 | 2.50 | 11.55 | 18.51 | 15.27 | 3.40 | 3.70 |
| Normalization | 1.000 | 1.092 | 1.050 | 1.000 | 1.070 | 1.037 | 1.000 | 1.088 |
| MCNC | Area (×106) | Wirelength (×105) | DS (%) | |||
|---|---|---|---|---|---|---|
| Ours | SA | Ours | SA | Ours | SA | |
| apte | 47.82 | 48.73 | 0.52 | 0.61 | 2.63 | 4.45 |
| xerox | 20.75 | 21.59 | 0.57 | 0.68 | 6.75 | 10.38 |
| hp | 9.26 | 9.52 | 0.41 | 0.55 | 4.66 | 7.25 |
| ami33 | 1.27 | 1.32 | 0.68 | 0.81 | 8.66 | 12.12 |
| ami49 | 38.95 | 41.52 | 6.47 | 6.79 | 8.99 | 14.62 |
| Average | 23.46 | 24.51 | 1.73 | 1.89 | 6.34 | 9.76 |
| Normalization | 1.000 | 1.045 | 1.000 | 1.092 | 1.000 | 1.034 |
| GSRC | Area (×105) | Wirelength (×105) | DS (%) | |||
|---|---|---|---|---|---|---|
| Ours | SA | Ours | SA | Ours | SA | |
| n100 | 1.98 | 2.23 | 1.97 | 2.21 | 9.09 | 19.28 |
| n200 | 2.15 | 2.37 | 3.46 | 3.87 | 18.14 | 25.74 |
| n300 | 3.42 | 3.78 | 5.03 | 5.66 | 20.18 | 27.78 |
| Average | 2.52 | 2.79 | 3.49 | 3.91 | 15.80 | 24.27 |
| Normalization | 1.000 | 1.107 | 1.000 | 1.112 | 1.000 | 1.085 |
| normalization | 1.000 | 1.000 | 1.000 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, S.; Du, S.; Yang, C. A Deep Reinforcement Learning Floorplanning Algorithm Based on Sequence Pairs. Appl. Sci. 2024, 14, 2905. https://doi.org/10.3390/app14072905
Yu S, Du S, Yang C. A Deep Reinforcement Learning Floorplanning Algorithm Based on Sequence Pairs. Applied Sciences. 2024; 14(7):2905. https://doi.org/10.3390/app14072905
Chicago/Turabian StyleYu, Shenglu, Shimin Du, and Chang Yang. 2024. "A Deep Reinforcement Learning Floorplanning Algorithm Based on Sequence Pairs" Applied Sciences 14, no. 7: 2905. https://doi.org/10.3390/app14072905
APA StyleYu, S., Du, S., & Yang, C. (2024). A Deep Reinforcement Learning Floorplanning Algorithm Based on Sequence Pairs. Applied Sciences, 14(7), 2905. https://doi.org/10.3390/app14072905