
Fast Coherent Video Style Transfer via Flow Errors Reduction




Abstract
1. Introduction
- 1.
- Novel mask techniques for new initialized images, which are capable of reducing flow errors even for large motions or strong occlusion cases.
- 2.
- Extra constraints like Coherent Losses and Sharpness Losses, which help to obtain a better temporal consistency and retain image quality over long-range frames.
- 3.
- The speed of the gradient-based optimization methods is increased from minutes per frame to less than 2 s per frame.
2. Related Work
2.1. Image Style Transfer
2.2. Video Style Transfer
3. Methods
3.1. Motivation
3.2. Fast Coherent Video Style Transfer
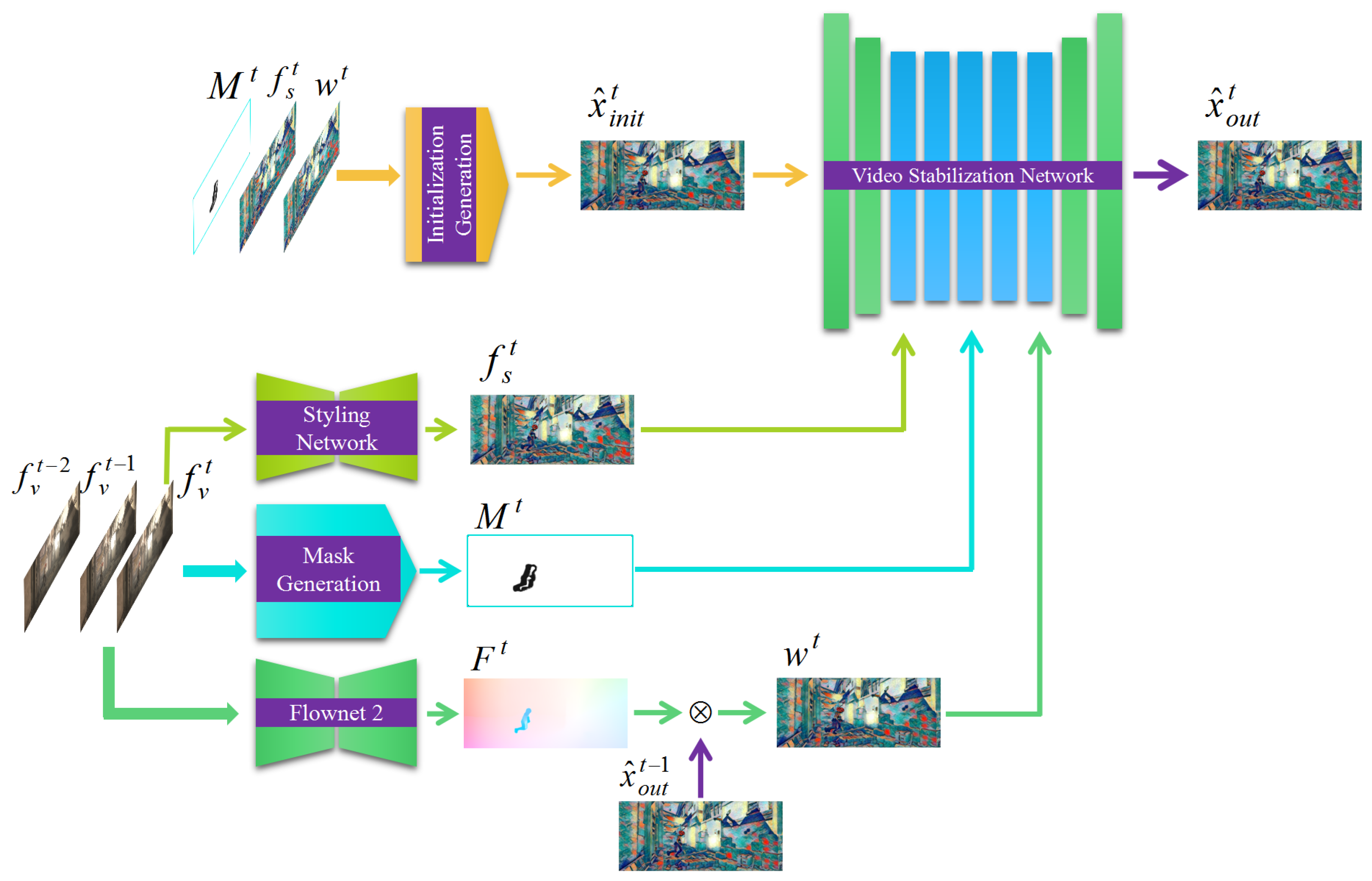
3.2.1. System Outline
3.2.2. Network Architecture Overview
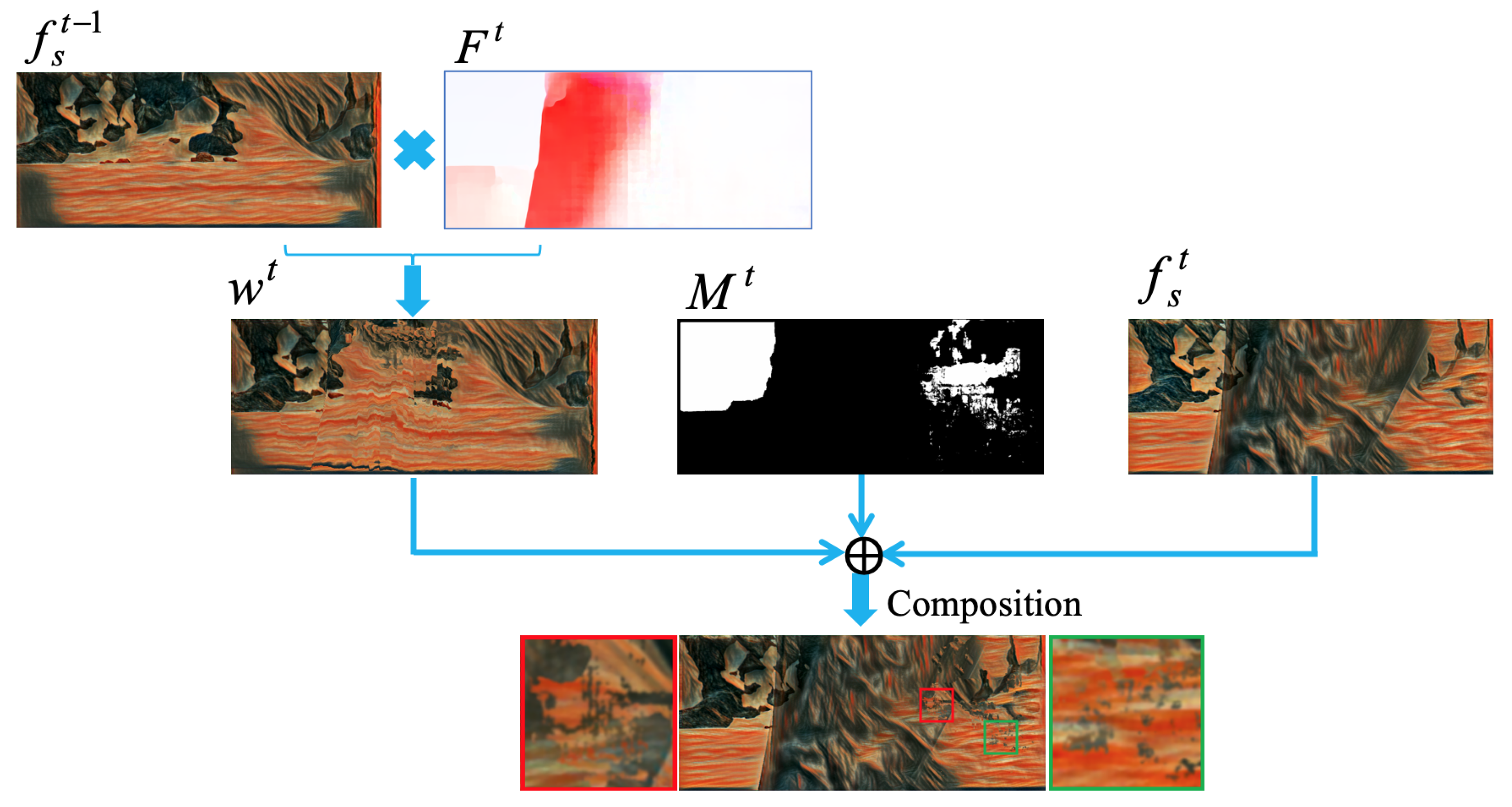
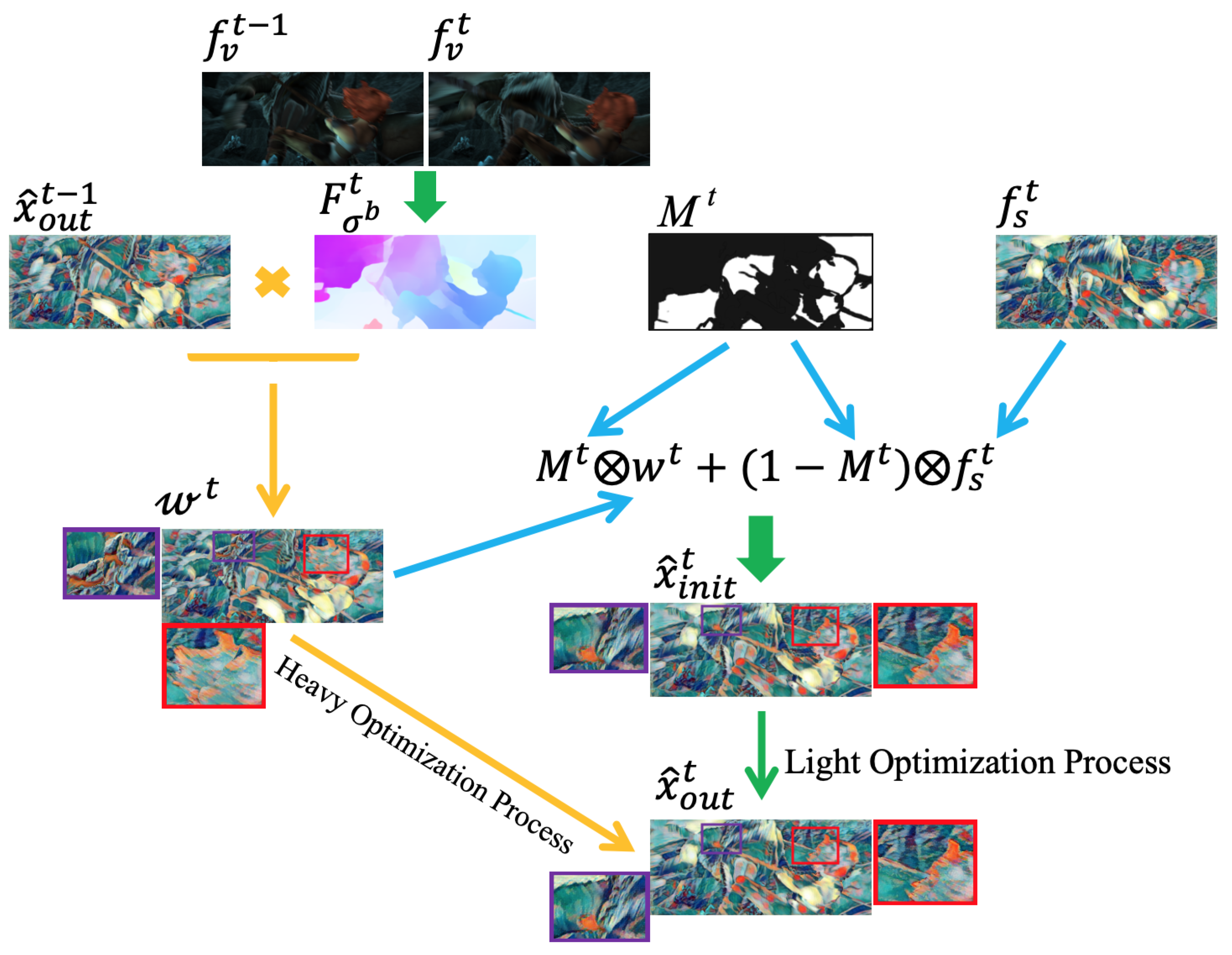
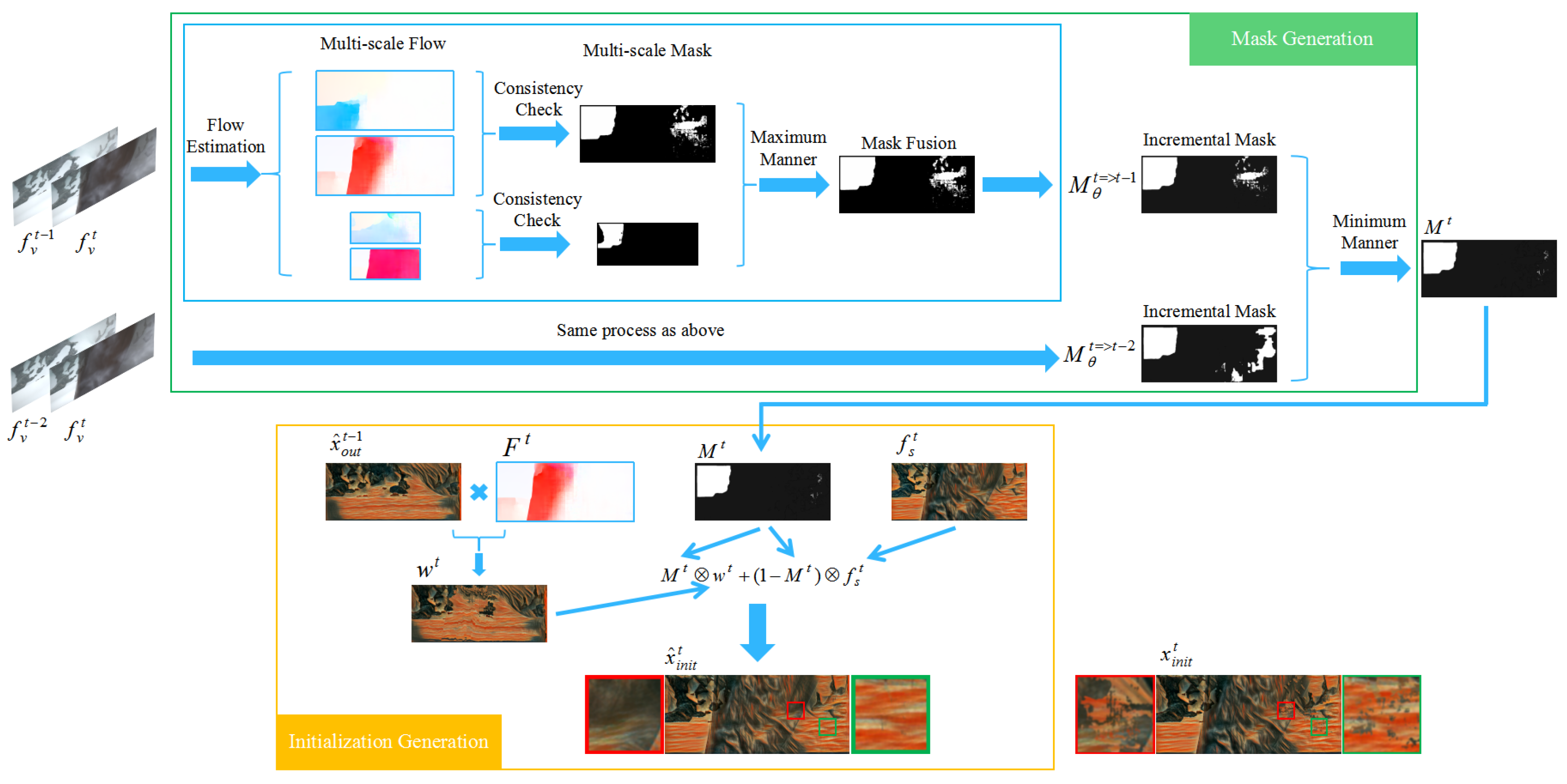
3.3. A New Initialization for Gradient-Based Optimization Network
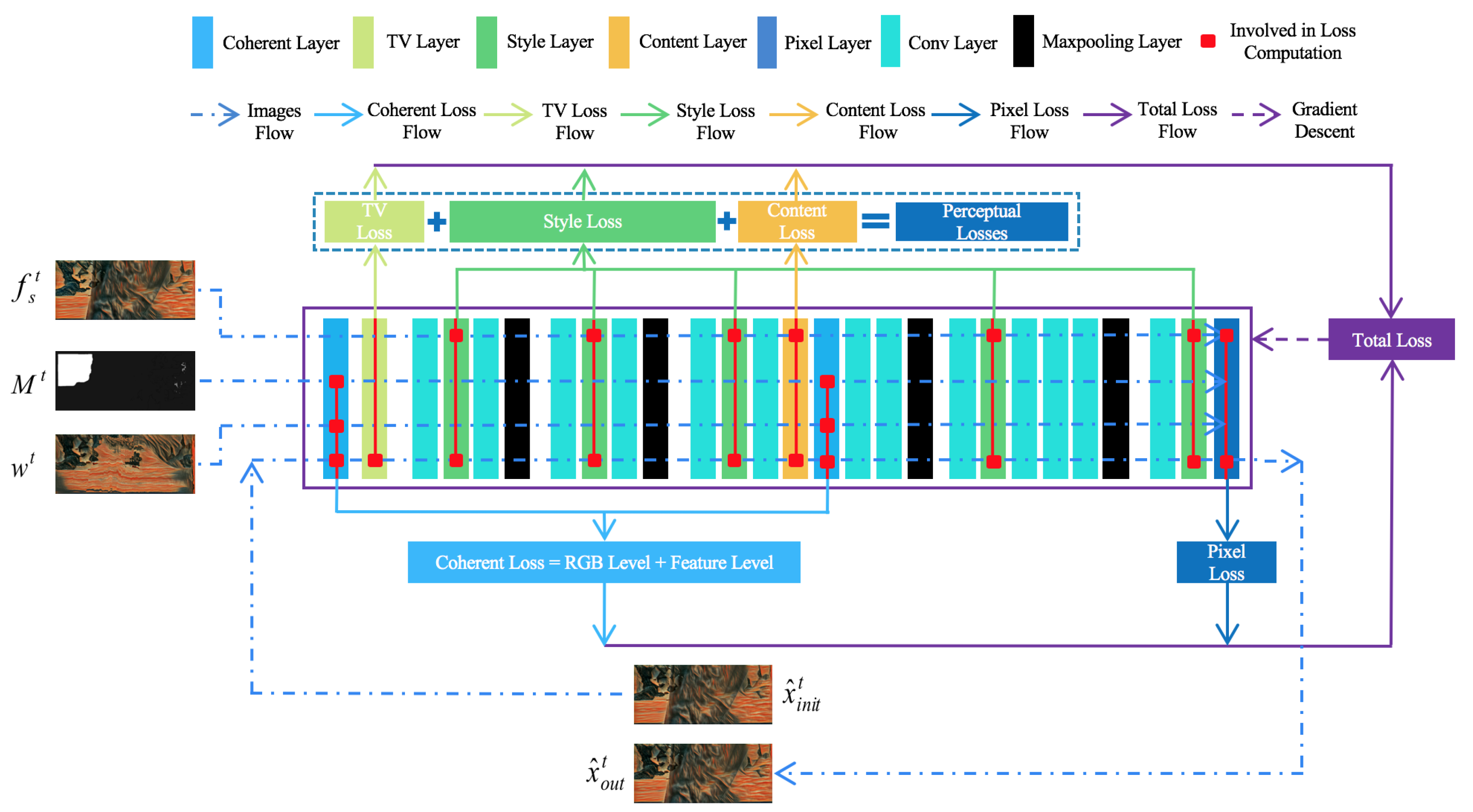
3.4. Loss Functions for Image Sharpness
3.5. Loss Functions for Temporal Consistency
3.5.1. Rgb-Level Coherent Loss
3.5.2. Feature-Level Coherent Loss
4. Implementation Details
5. Experiments
5.1. Qualitative Evaluation
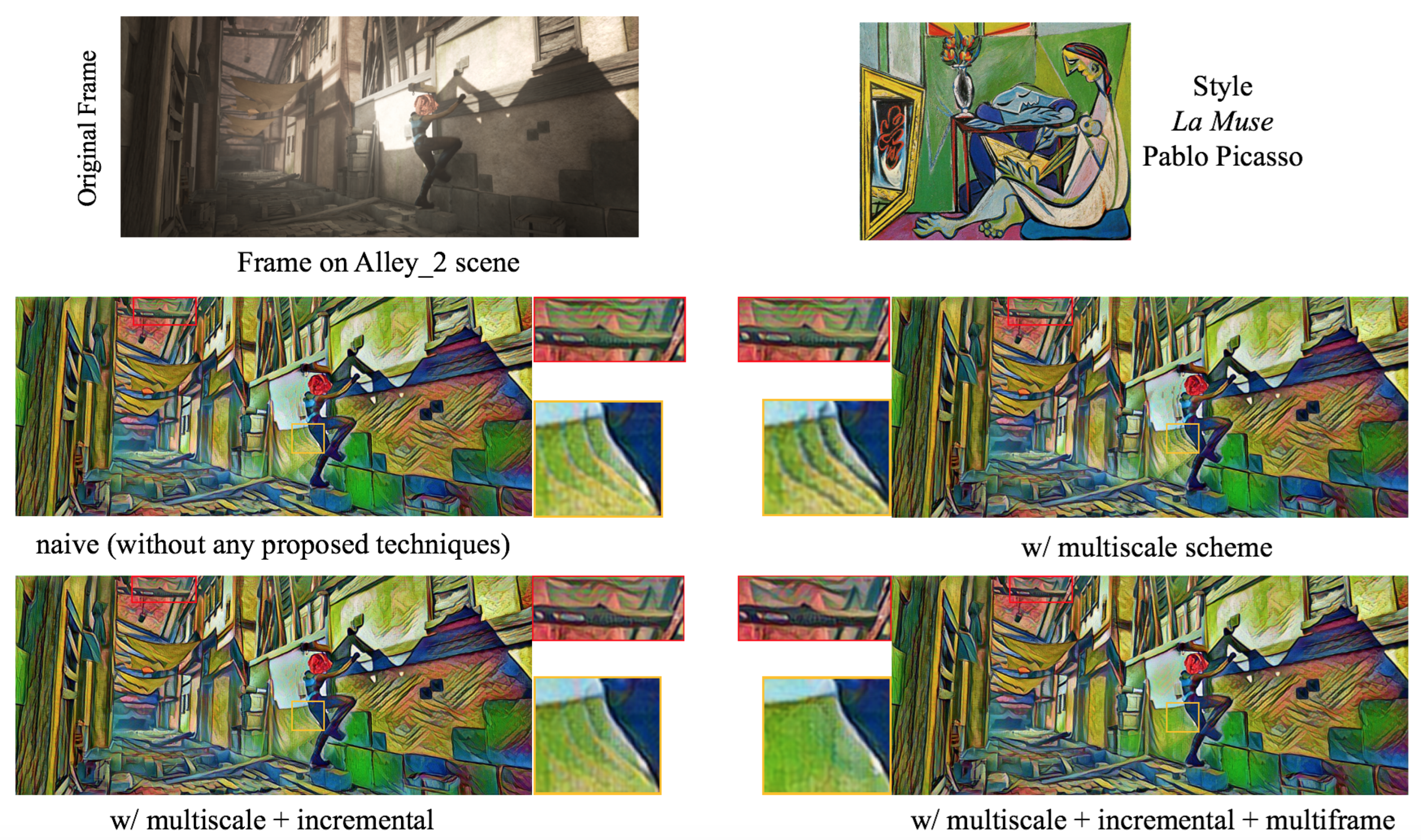
5.1.1. Analysis of Initialization
5.1.2. Analysis of Loss Functions
5.1.3. Comparisons to Methods Found in the Literature
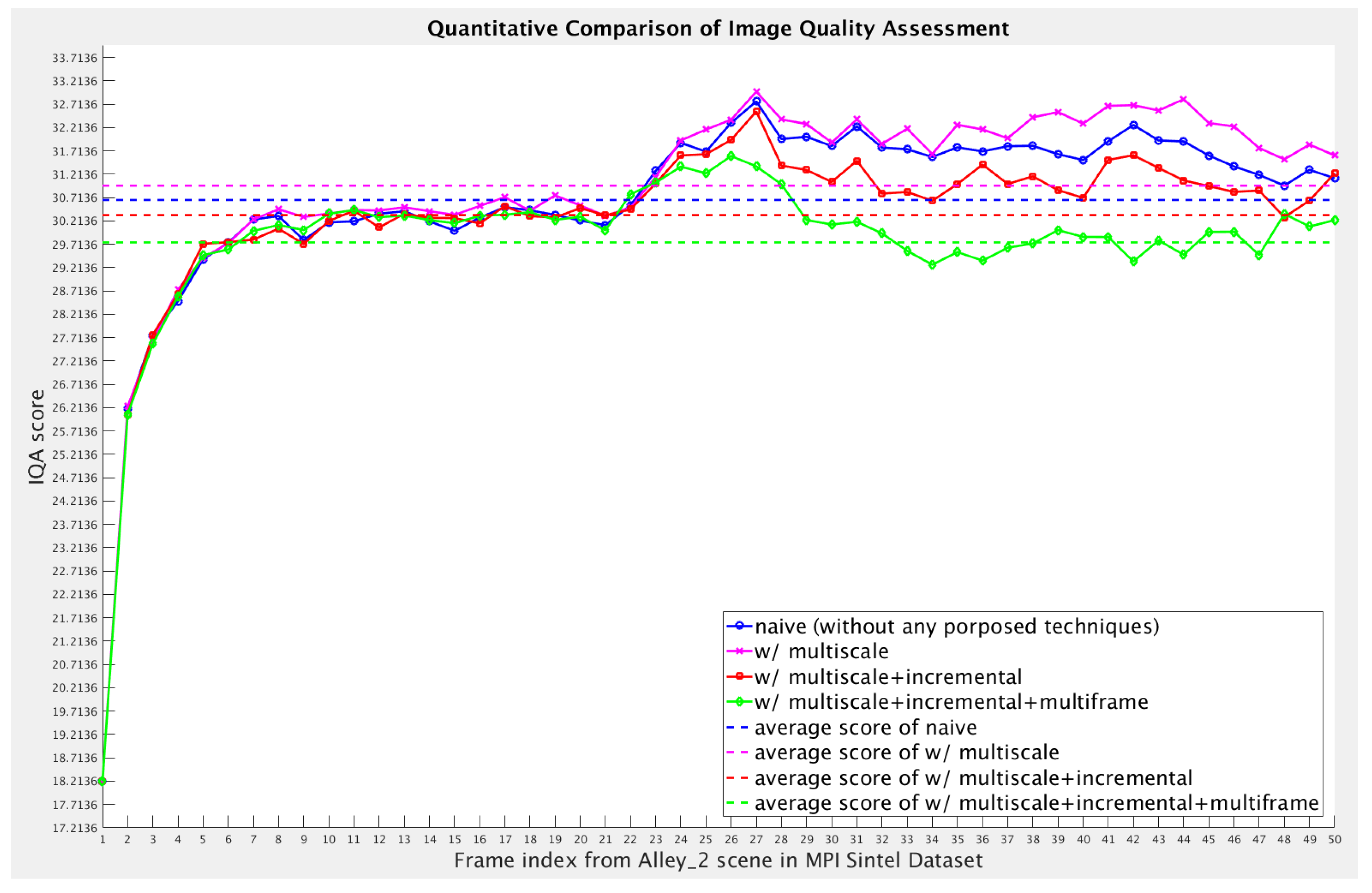
5.2. Quantitative Evaluation
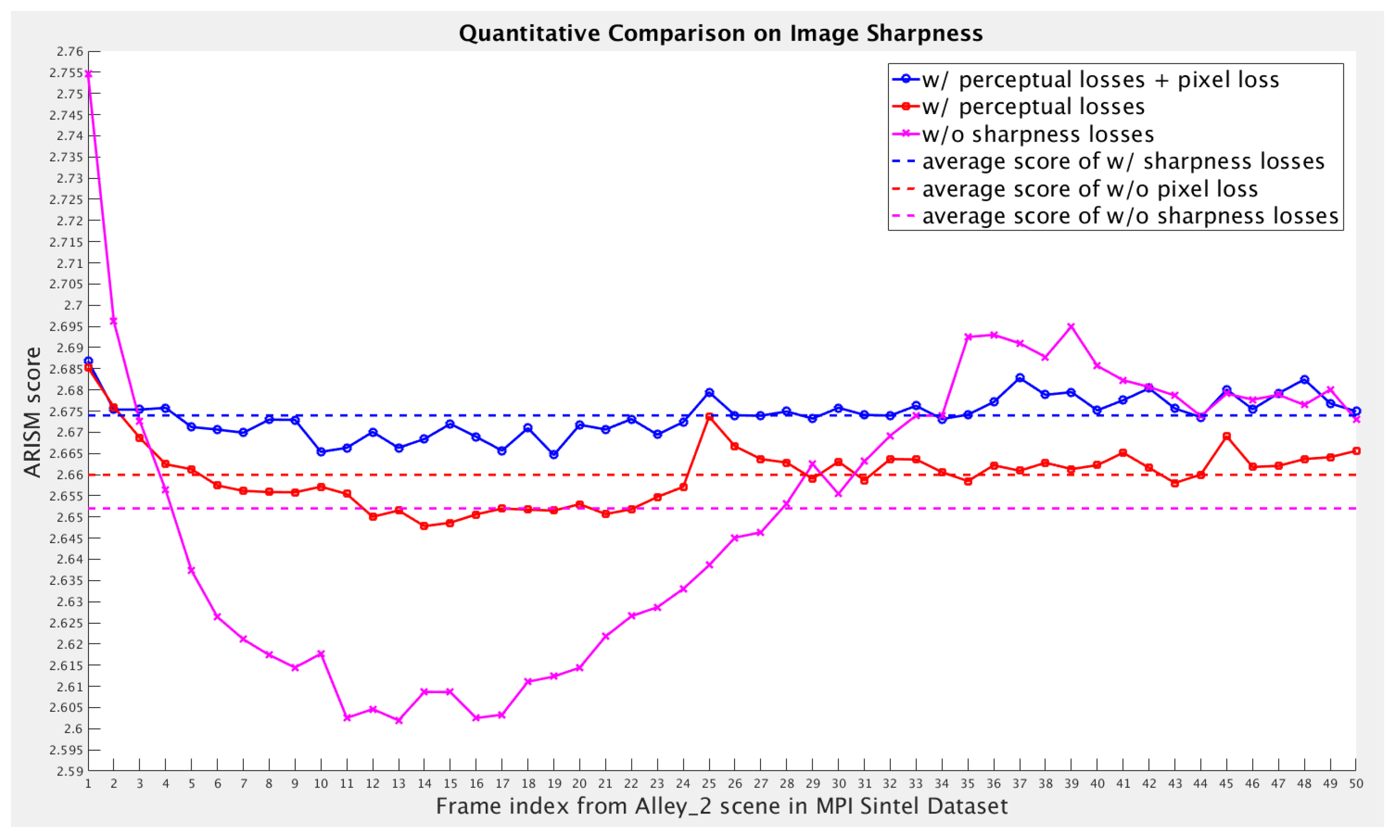
5.2.1. Ablation Study on Loss Functions
5.2.2. Ablation Study on Initialization
5.2.3. Quantitative Evaluation in Literatures
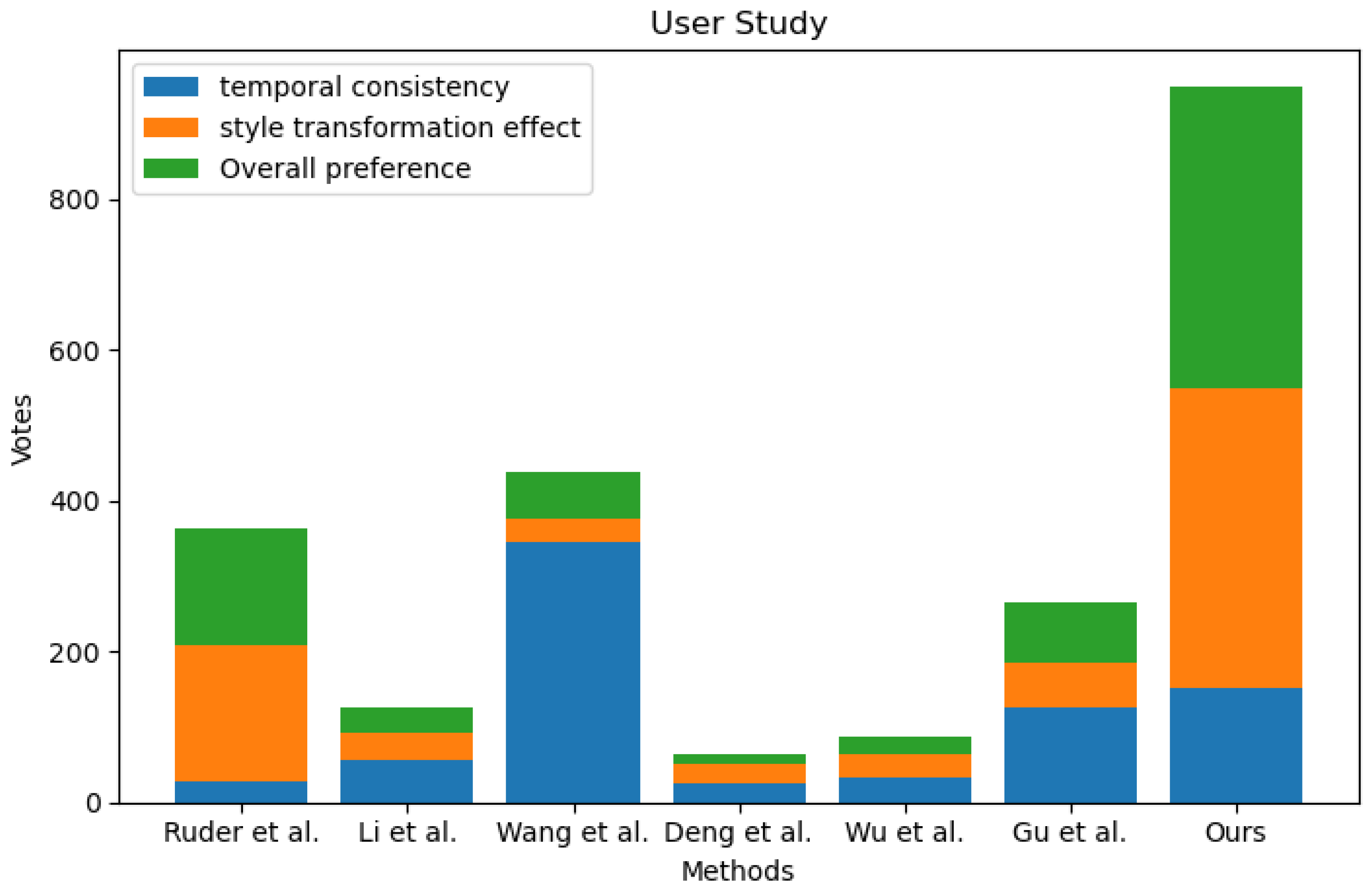
5.2.4. User Study
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Bombay, India, 4–8 January 1998; pp. 839–846. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Winnemöller, H.; Olsen, S.C.; Gooch, B. Real-time video abstraction. Acm Trans. Graph. (TOG) 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Yang, S.; Jiang, L.; Liu, Z.; Loy, C. Vtoonify: Controllable high-resolution portrait video style transfer. ACM Trans. Graph. (TOG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Li, Z.; Wu, X.M.; Chang, S.F. Segmentation using superpixels: A bipartite graph partitioning approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 789–796. [Google Scholar]
- Liu, J.; Yang, W.; Sun, X.; Zeng, W. Photo stylistic brush: Robust style transfer via superpixel-based bipartite graph. IEEE Trans. Multimed. 2018, 20, 1724–1737. [Google Scholar] [CrossRef]
- Lee, H.-Y.; Li, Y.-H.; Lee, T.-H.; Aslam, M.S. Progressively Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. Sensors 2023, 23, 6858. [Google Scholar] [CrossRef] [PubMed]
- Dediu, M.; Vasile, C.E.; Bîră, C. Deep Layer Aggregation Architectures for Photorealistic Universal Style Transfer. Sensors 2023, 23, 4528. [Google Scholar] [CrossRef] [PubMed]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2414–2423. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Diversified texture synthesis with feed-forward networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3920–3928. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Chen, T.Q.; Schmidt, M. Fast patch-based style transfer of arbitrary style. arXiv 2016, arXiv:1612.04337. [Google Scholar]
- Zhang, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Lee, T.; Xu, C. A unified arbitrary style transfer framework via adaptive contrastive learning. ACM Trans. Graph. 2023, 42, 1–16. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, Q.; Li, G.; Xing, W.; Zhao, L.; Sun, J.; Lan, Z.; Luan, J.; Huang, Y.; Lin, H. ArtBank: Artistic Style Transfer with Pre-trained Diffusion Model and Implicit Style Prompt Bank. arXiv 2023, arXiv:2312.06135. [Google Scholar]
- Kwon, J.; Kim, S.; Lin, Y.; Yoo, S.; Cha, J. AesFA: An Aesthetic Feature-Aware Arbitrary Neural Style Transfer. arXiv 2023, arXiv:2312.05928. [Google Scholar]
- Chu, W.T.; Wu, Y.L. Image style classification based on learnt deep correlation features. IEEE Trans. Multimed. 2018, 20, 2491–2502. [Google Scholar] [CrossRef]
- Yang, J.; Chen, L.; Zhang, L.; Sun, X.; She, D.; Lu, S.P.; Cheng, M.M. Historical context-based style classification of painting images via label distribution learning. In Proceedings of the ACM Multimedia Conference on Multimedia Conference, Seoul, Republic of Korea, 22–26 October 2018; pp. 1154–1162. [Google Scholar]
- Hicsonmez, S.; Samet, N.; Sener, F.; Duygulu, P. Draw: Deep networks for recognizing styles of artists who illustrate children’s books. In Proceedings of the ACM on International Conference on Multimedia Retrieval, Sydney, Australia, 6–11 August 2017; pp. 338–346. [Google Scholar]
- Zhou, X.; Liu, Z.; Gong, C.; Liu, W. Improving video saliency detection via localized estimation and spatiotemporal refinement. IEEE Trans. Multimed. 2018, 20, 2993–3007. [Google Scholar] [CrossRef]
- Bak, C.; Kocak, A.; Erdem, E.; Erdem, A. Spatio-temporal saliency networks for dynamic saliency prediction. IEEE Trans. Multimed. 2018, 20, 1688–1698. [Google Scholar] [CrossRef]
- Anderson, A.G.; Berg, C.P.; Mossing, D.P.; Olshausen, B.A. Deepmovie: Using optical flow and deep neural networks to stylize movies. arXiv 2016, arXiv:1605.08153. [Google Scholar]
- Ruder, M.; Dosovitskiy, A.; Brox, T. Artistic style transfer for videos. In Proceedings of the German Conference on Pattern Recognition, Hannover, Germany, 12–15 September 2016; pp. 26–36. [Google Scholar]
- Zhang, H.; Dana, K. Multi-style generative network for real-time transfer. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6924–6932. [Google Scholar]
- Huang, H.; Wang, H.; Luo, W.; Ma, L.; Jiang, W.; Zhu, X.; Li, Z.; Liu, W. Real-time neural style transfer for videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 783–791. [Google Scholar]
- Gupta, A.; Johnson, J.; Alahi, A.; Li, F.F. Characterizing and improving stability in neural style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4067–4076. [Google Scholar]
- Chen, D.; Liao, J.; Yuan, L.; Yu, N.; Hua, G. Coherent online video style transfer. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1105–1114. [Google Scholar]
- Ruder, M.; Dosovitskiy, A.; Brox, T. Artistic style transfer for videos and spherical images. Int. J. Comput. Vis. 2018, 126, 1199–1219. [Google Scholar] [CrossRef]
- Xu, K.; Wen, L.; Li, G.; Qi, H.; Bo, L.; Huang, Q. Learning self-supervised space-time CNN for fast video style transfer. IEEE Trans. Image Process. (TIP) 2021, 30, 2501–2512. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Zhu, T. Structure-guided arbitrary style transfer for artistic image and video. IEEE Trans. Multimed. 2021, 24, 1299–1312. [Google Scholar] [CrossRef]
- Kong, X.; Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Chen, Y.; He, Z.; Xu, C. Exploring the Temporal Consistency of Arbitrary Style Transfer: A Channelwise Perspective; IEEE Transactions on Neural Networks and Learning Systems: Piscataway, NJ, USA, 2023; pp. 1–15. [Google Scholar]
- Huo, J.; Kong, M.; Li, W.; Wu, J.; Lai, Y.; Gao, Y. Towards efficient image and video style transfer via distillation and learnable feature transformation. Comput. Vis. Image Underst. 2024, 241, 103947. [Google Scholar] [CrossRef]
- Li, X.; Liu, S.; Kautz, J.; Yang, M.H. Learning linear transformations for fast image and video style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3809–3817. [Google Scholar]
- Wang, W.J.; Yang, S.; Xu, J.Z.; Liu, J.Y. Consistent Video Style Transfer via Relaxation and Regularization. IEEE Trans. Image Process. (TIP) 2020, 29, 9125–9139. [Google Scholar] [CrossRef]
- Wu, Z.; Zhu, Z.; Du, J.; Bai, X. CCPL: Contrastive coherence preserving loss for versatile style transfer. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 189–206. [Google Scholar]
- Gu, B.H.; Fan, H.; Zhang, L.B. Two Birds, One Stone: A Unified Framework for Joint Learning of Image and Video Style Transfers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 23545–23554. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canad, 7–10 December 2015; pp. 262–270. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Universal style transfer via feature transforms. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 385–395. [Google Scholar]
- Wang, X.; Oxholm, G.; Zhang, D.; Wang, Y.F. Multimodal transfer: A hierarchical deep convolutional neural network for fast artistic style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5239–5247. [Google Scholar]
- Wilmot, P.; Risser, E.; Barnes, C. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv 2017, arXiv:1701.08893. [Google Scholar]
- Shen, F.; Yan, S.; Zeng, G. Meta networks for neural style transfer. arXiv 2017, arXiv:1709.04111. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V.S. Texture networks: Feed-forward synthesis of textures and stylized images. arXiv 2016, arXiv:1603.03417. [Google Scholar]
- Yao, Y.; Ren, J.; Xie, X.; Liu, W.; Liu, Y.J.; Wang, J. Attention-aware multi-stroke style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1467–1475. [Google Scholar]
- Kotovenko, D.; Sanakoyeu, A.; Ma, P.; Lang, S.; Ommer, B. A content transformation block for image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10032–10041. [Google Scholar]
- Kolkin, N.; Salavon, J.; Shakhnarovich, G. Style transfer by relaxed optimal transport and self-similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10051–10060. [Google Scholar]
- Wang, H.; Li, Y.; Wang, Y.; Hu, H.; Yang, M.-H. Collaborative distillation for ultra-resolution universal style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1860–1869. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 12–13 December 2014; pp. 2366–2374. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 2650–2658. [Google Scholar]
- Chen, H.; Wang, Z.; Zhang, H.; Zuo, Z.; Li, A.; Xing, W.; Lu, D. Artistic style transfer with internal-external learning and contrastive learning. Adv. Neural Inf. Process. Syst. 2021, 34, 26561–26573. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Sun, W.; Huang, F.; Xu, C. Arbitrary style transfer via multi-adaptation network. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2719–2727. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 6649–6658. [Google Scholar]
- Luo, X.; Han, Z.; Yang, L.; Zhang, L. Consistent style transfer. arXiv 2022, arXiv:2201.02233. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrary style transfer with style-attentional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5880–5888. [Google Scholar]
- Wu, X.; Hu, Z.; Sheng, L.; Xu, D. Styleformer: Real-time arbitrary style transfer via parametric style composition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 14618–14627. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Pan, X.; Wang, L.; Xu, C. Stytr2: Image style transfer with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 11326–11336. [Google Scholar]
- Bosse, S.; Maniry, D.; Müller, K.R.; Wiegand, T.; Samek, W. Deep neural networks for no-reference and full-reference image quality assessment. IEEE Trans. Image Process. 2017, 27, 206–219. [Google Scholar] [CrossRef] [PubMed]
- Lai, W.S.; Huang, J.B.; Wang, O.; Shechtman, E.; Yumer, E.; Yang, M.H. Learning blind video temporal consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 170–185. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Xu, C. Arbitrary video style transfer via multi-channel correlation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 1210–1217. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. Available online: http://lmb.informatik.uni-freiburg.de//Publications/2017/IMKDB17 (accessed on 20 September 2017).
- Gao, C.; Gu, D.; Zhang, F.; Yu, Y. Reconet: Real-time coherent video style transfer network. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 637–653. [Google Scholar]
- Yang, X.; Zhang, T.; Xu, C. Text2video: An end-to-end learning framework for expressing text with videos. IEEE Trans. Multimed. 2018, 20, 2360–2370. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 611–625. [Google Scholar]
- Weinzaepfel, P.; Revaud, J.; Harchaoui, Z.; Schmid, C. Deepflow: Large displacement optical flow with deep matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 1385–1392. [Google Scholar]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbeláez, P.; Sorkine-Hornung, A.; Van Gool, L. The 2017 davis challenge on video object segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. No-reference image sharpness assessment in autoregressive parameter space. IEEE Trans. Image Process. 2015, 24, 3218–3231. [Google Scholar] [PubMed]
- Vu, P.V.; Chandler, D.M. A fast wavelet-based algorithm for global and local image sharpness estimation. IEEE Signal Process. Lett. 2012, 19, 423–426. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MPI Sintel Dataset + Style | ||||||
|---|---|---|---|---|---|---|---|
| Scene1 | Scene2 | Scene3 | Scene4 | Scene5 | ave | Improvement | |
| Baseline [10] | 10.55 | 7.21 | 6.34 | 12.06 | 6.34 | 8.50 | * |
| RGB-Level only | 2.71 | 3.17 | 2.79 | 5.93 | 2.90 | 3.50 | 58.8% |
| Both Levels | 2.43 | 3.00 | 2.59 | 5.74 | 2.75 | 3.31 | 61.0% |
| Method | MPI Sintel Dataset + Style1 | Davis 2017 Dataset + Style2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | S5 | S1 | S2 | S3 | S4 | S5 | |
| Johnson et al. [10] | 8.15 | 7.91 | 11.96 | 13.06 | 14.50 | 12.73 | 12.63 | 13.01 | 13.62 | 14.11 |
| Ours | 3.13 | 3.56 | 6.82 | 7.88 | 8.25 | 4.08 | 4.42 | 4.85 | 4.92 | 5.13 |
| Huang et al. [13] | 9.16 | 10.11 | 14.51 | 14.32 | 14.44 | 15.50 | 14.52 | 15.43 | 15.77 | 16.28 |
| Ours | 3.46 | 4.39 | 7.66 | 8.28 | 8.38 | 5.00 | 4.99 | 5.86 | 5.90 | 6.14 |
| Method | Stability Errors (↓) | SIFID (↓) | ||||||
|---|---|---|---|---|---|---|---|---|
| Style1 | Style2 | Style3 | Mean | Style1 | Style2 | Style3 | Mean | |
| Ruder et al. [30] | 8.56 | 5.06 | 6.84 | 6.82 | 1.47 | 0.82 | 1.04 | 1.1117 |
| Li et al. [35] | 8.19 | 5.06 | 6.13 | 6.46 | 1.70 | 0.84 | 1.30 | 1.2772 |
| Deng et al. [62] | 9.72 | 5.26 | 6.89 | 7.29 | 2.09 | 1.00 | 1.62 | 1.5695 |
| Wu et al. [37] | 9.52 | 5.74 | 7.49 | 7.58 | 1.95 | 1.17 | 1.57 | 1.5632 |
| Gu et al. [38] | 8.17 | 5.34 | 5.47 | 6.33 | 1.97 | 1.04 | 1.63 | 1.5481 |
| Ours | 7.76 | 4.95 | 6.15 | 6.29 | 1.52 | 0.67 | 0.99 | 1.0615 |
| Wang et al. [36] | 6.68 | 3.57 | 5.75 | 5.34 | 1.94 | 1.76 | 1.40 | 1.7002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Yang, X.; Zhang, J. Fast Coherent Video Style Transfer via Flow Errors Reduction. Appl. Sci. 2024, 14, 2630. https://doi.org/10.3390/app14062630
Wang L, Yang X, Zhang J. Fast Coherent Video Style Transfer via Flow Errors Reduction. Applied Sciences. 2024; 14(6):2630. https://doi.org/10.3390/app14062630
Chicago/Turabian StyleWang, Li, Xiaosong Yang, and Jianjun Zhang. 2024. "Fast Coherent Video Style Transfer via Flow Errors Reduction" Applied Sciences 14, no. 6: 2630. https://doi.org/10.3390/app14062630
APA StyleWang, L., Yang, X., & Zhang, J. (2024). Fast Coherent Video Style Transfer via Flow Errors Reduction. Applied Sciences, 14(6), 2630. https://doi.org/10.3390/app14062630