1. Introduction
As the development of big data era, the large amount of Web and social media data has grown exponentially. For example, Wikipedia [
1] has more than 5,836,552 articles and more than 27 billion words. The increasing amount of textual data poses a significant challenge to the task of document retrieval, which has led to an urgent need for effective methods in processing large-scale text datasets. As the core sub-task in document retrieval, keyphrase extraction refers to the extraction of a set of meaningful phrases from documents automatically. Keyphrase extraction is a versatile approach and can be applied to a large number of downstream tasks, such as automatic question-answering systems, recommendation systems, sentiment analysis, etc. For example, Lv [
2] proposed the common-sense QA system, which extracted keyphrases from a large number of documents as prior knowledge. Yang [
3] proposed a method that includes both embed keyphrases and user-item preferences, and a closed-end Bayesian method based on keyphrase feedback, which identifies user-item preferences in the interactive recommendation system according to the preferences induced in the natural language space. In addition, keyphrases can be used not only as features for document clustering and classification [
4], but also as topic words for automatic document summarization [
5].
The traditional keyphrase extraction methods can be categorized into supervised and unsupervised. Supervised methods have powerful modeling ability and usually have higher accuracy than unsupervised methods, but also have defects, such as dependence on well-labeled training corpuses, huge training costs by manual labeling, subjectivity problems, and a lack of interpretability. Compared with supervised methods, unsupervised methods have less dependence on labeled training data, and are domain-independent and interpretable. However, the accuracy of existing unsupervised methods is relatively low, which cannot adapt to the growing demand for data processing. Therefore, in recent years, the optimization of unsupervised methods has become a hot issue in the field of information retrieval.
Based on the relevance of documents, the text features by traditional unsupervised keyphrase extraction methods can be roughly classified into two categories: cross-document features and single-document features. The common cross-document features are document embedding, document frequency, etc, which denote the similarity between documents. When documents are related to each other, cross-document features can effectively improve the accuracy of keyphrase extraction. However, when documents are dissimilar and independent of each other, the traditional metrics always lead to the cross-document features degeneration as single-document features, such as the frequency of words, term co-occurrence, etc. Compared with cross-document features, the unsupervised approach, which improves the accuracy by adding effective single-document features, is more general.
Although scholars have come up with a large number of semantic and statistical models, the accuracy is still unsatisfactory. Lau and Baldwin [
6] found that semantic features and statistical features have different effects in different text lengths, for example, the semantic features are more reliable in the context of short-text or medium-text, while statistical features are more robust in long documents (e.g., more than 1000 words). All in all, how to search more short-text features (semantic, statistical, etc.) to improve the accuracy metrics has become a major concern for researchers in the related field.
Inspired by these observations, this paper proposes Y-Rank, an unsupervised keyphrase extraction method for short text in single document scenarios. Y-Rank takes into account both semantic and statistical features, and avoids the problem of phrases that are semantically similar but have sparse co-occurrence in traditional graph construction methods. The main steps of Y-Rank include the following: first, it extracts candidates and various statistical features of the words from a single document and calculates the statistical features. Then, based on the semantic similarity between keyphrases, Y-Rank constructs a graph to obtain semantic features. Finally, the top-ranked keyphrases are acquired by the fusion of the two features. The experimental results show that Y-Rank outperforms nine existing unsupervised methods in terms of phrase quality and ranking quality. The contributions of the paper are summarized as follows:
This paper proposed a single document statistic feature, which can represent the informativeness of candidates more concisely and effectively.
We also put forward a graph-based semantic feature extraction approach for candidates, which can alleviate the problem of information loss by using the node ranking approach.
We propose an unsupervised method called Y-Rank that combines semantic and multiple statistical features, which can effectively improve the evaluation results of keyphrase extraction with low dependency on external resources.
The experimental results on the five benchmark datasets demonstrate that the presented Y-Rank outperforms the existing methods in various metrics. The average improvement is 1.3% (precision), 1.5% (recall), 1.4% (F-Measure), 3.5% (MRR), 4.4% (MAP) and 5.3% (Bpref), respectively, and represents better universality in all five datasets.
2. Related Work
This section introduces the existing keyphrase extraction methods, including both supervised and unsupervised, and finally summarizes the verification and evaluation criteria of keyphrase extraction results.
2.1. Supervised Methods
Supervised methods can be divided into traditional and deep learning methods. Traditional methods treat the keyphrase extraction task as a binary classification tasks; McIlraith and Florescu et al. [
7] follows a Gaussian naive Bayes classifier in model training. Another classic method is deep learning. Yang et al. [
8] offered pre-specified seed keyphrases to guide the model and improve the accuracy by increasing user preferences. The keyphrase extraction task can also be solved by a sequence labeling task. Bekoulis et al. [
9] demonstrated the effectiveness on performance with multiple sequence labeling tasks (e.g., part-of-speech labeling, block, etc) in multi-task learning ways. At present, the mainstream deep learning methods are the deep recurrent neural network(RNN)-based optimization, leveraging an encoder–decoder framework to capture the semantic features of documents.
In order to remove semantic duplication in keyphrases generation, Chen [
10] employed a coverage vector to indicate whether a word of the source document had been summarized, and combined it with previous phrases to eliminate duplications and improve the consistency of the results. Ye and Wang [
11] introduced two unsupervised methods to replace manual labeling. In the first approach, unlabeled documents are annotated with synthetic keyphrases obtained from two extraction methods (TfIdf and TextRank) and then trained by mixing labeled data with synthetic data. The second approach is to follow a multi-task learning framework, combining the keyphrase extraction task with secondary tasks (such as title generation), and the two tasks share the same encoder network but with different decoders. In addition, remote supervision can also supplement costly manual annotation. Wang et al. [
12] proposed that the evaluation results in unlabeled/under-labeled scenarios could be improved by transferring knowledge from resource-rich source domains (cross-domain perspective).
2.2. Unsupervised Methods
Different from supervised methods that rely on manual annotation for modeling, unsupervised methods extract candidates based on some heuristic text features. Existing unsupervised methods can be divided into language models, topic models, semantic models, and statistical models in conformity with the usage features, and can be combined with graph-based methods.
Li et al. [
13] combined basic education characteristics and proposed a term extraction method called DRTE, which integrated Chinese word formation rules and boundary detection by using term definition and term relationship mining. Limited by the word formation rules of different languages, this category of language model has poor transferability.
In the topic models, MultipartitleRank [
14] is a graph-based method that improves the edge weight of the candidates that appear earlier in the document based on TopicRank. This model contains topic features and location features; the former ensures the informativeness of the word, and the latter ensures the popularity of the word. This category of topic models has strong versatility and can be combined with various algorithms for text clustering, but the evaluation results are poor in the scenes with the ambiguous topics (dialogue, commodity evaluation, etc).
In semantic models, EmbedRank [
15] extracts noun phrases as candidates based on POS sequence, and sorts candidates based on the cosine similarity between the candidates embedding and document embedding, which provides a very popular idea for the subsequent cross-document keyphrase extraction tasks.
Combined with graph theory, the semantic model [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25] selected rich sources of semantic features, including semantic features from different knowledge graphs or prior knowledge [
16,
17,
18,
19,
20,
21], and semantic features embedded from different pre-trained word-embedding models [
22,
23,
24,
25]. However, these graph construction methods lack diversity. In traditional graph construction methods, nodes are represented as tokens, and edges are denoted as co-occurrence relations [
22,
23,
24] or the product of co-occurrence relations and semantic similarity [
25], which suffer from the question of information loss [
26]. In other words, if two semantically related nodes in a document have never appeared together within a window size, they will have no edges connected in the corresponding semantic graph. At present, the main stream uses modern embedding methods to convert tokens into word embeddings to calculate semantic similarity based on similarity algorithm (distance, etc). Zhang et al. [
27] reviewed keyphrase extraction based on modern embedding methods, among which Word2Vec [
28] is the most commonly used. Word2Vec learns semantic knowledge from a large corpus of text in an unsupervised manner and is utilized to generate word embeddings. These embeddings can be obtained by aggregating the embeddings of individual tokens that form a given phrase. Word2Vec is widely available, and the corpus for training word embeddings is now readily available. Hence, this paper also takes Word2Vec model in combination.
Statistical models have certain difficulties in extracting keyphrases from a single document, while the graph-based model can only use the information in a single document for keyphrase extraction, but existing ones have poor edge detection effect.
To alleviate these disadvantages, HongseonYeom et al. [
29] effectively combined the graph-based model with the improved C-value method, which realizes the keyphrase extraction of a single document based on unsupervised learning; however, the statistical feature C-value depends on the word frequency feature and the length of the word string, and each document needs to be constructed and ranked by the graph, leading to high algorithm complexity. For the purpose of reducing the algorithm complexity, Rabby et al. [
30] advised a tree-based keyphrase extraction method, which derives a measure called the cohesion index to evaluate the cohesion of the current node relative to the root node and improves the flexibility and personalization of keyphrase extraction by providing a user preference value.
In addition, Won [
31], Zhang [
32] and Campos [
33] have demonstrated the effectiveness of context information in keyphrase extraction. Among them, Won [
31] has achieved excellent results in the field of speech, which is inspired by the repeated keywords used by politicians to guide their speech. The new word-embedding model nominated by Zhang [
32] can achieve the function of generating absent keyphrases by combining captured local context information with other text features. However, these models often degrade in scenarios where local context information is ambiguous or lacking. To ease this problem, Santosh et al. [
34] advocated a new framework to improve keyword extraction by utilizing additional context information, which includes a bidirectional long short-term memory network to capture the hidden semantics in the text, a document-level attention mechanism to contain document-level context information, a gating mechanism to help determine the effect of the fusion of additional and local context information, and a conditional random field to capture the dependency of output labels. Furthermore, Campos [
33] came up with YAKE! with a set of five statistical features and demonstrated the effectiveness of each feature. Compared with other statistical models, YAKE! performs the best keyphrase extraction results in the single medium and short text scenarios, but the score ranking of YAKE! is not dependent on the subject words, and it may produce less representative candidates. To address this problem, Firdausillah [
35] introduced Doc2Vec, which belongs to the cross-document model, and can find similar documents in multiple ones based on the assumption of correlation and then combines Doc2Vec with YAKE! to calculate the similarity of the documents and merge similar ones.
2.3. Phrase Quality Assessment Criteria
A phrase is defined as a sequence of words that appear continuously in a text, forming a complete semantic unit in some context of a given document. Phrase quality is defined as the probability that a word sequence becomes a complete semantic unit, which satisfies the criteria of popularity, consistency, informativeness, and completeness [
36]. High-quality keyphrases [
37] need to meet the above four criteria. To sum up, this paper proposes Y-Rank to solve the shortcomings of traditional approaches that lack balance on both the semantic features and co-occurrence factors, and proposes a single-document-oriented keyphrase extraction method, which combines the semantic feature based on graph-based methods and a variety of statistical features.
3. Motivation
To address the problems of traditional methods, this paper employs an extraction approach that only consider statistical features in extraction results. The definitions are as follows:
Definition 1. Negative low-importance phrases. The phrases have low-importance features, but exhibit high semantic similarity with the top-ranked phrases.
Negative low-importance phrases are filtered out as worthless due to low-importance rank, which still exists in the gold set. To demonstrate this problem, this paper uses YAKE! [
38] to extract keyphrases and select an article from the kp20k dataset for analysis. The gold set of the article is denoted as
Reference, and the length is denoted as
topk. The
topk * 2 candidates with the highest importance are extracted to form a candidates set. In this set, the
topk candidates with the highest importance are marked as
Accept, and the
topk candidates with the lowest importance are marked as
Pass. Then, we traverse the
Pass set and calculate the phrase similarity between keyphrases in the
Reference and
Pass. If a phrase belongs to both the
Reference and
Pass, it is a negative low-importance phrase. The result of the experiment is expressed in
Figure 1, in which the phrases marked with yellow are
negative low-importance phrases, and the phrases in red are top-ranked phrases semantic similar to the yellow ones.
Furthermore, this paper verifies the prevalence of this problem in various datasets, including kp20k, semeval-2010, wikinews-fr-100, termith-eval, and taln-archives. As shown in
Table 1, the proportion of the problem ranges from 5.47% to 40%.
4. Y-Rank Model
4.1. Preliminaries
YAKE! [
38] can identify high-quality keyphrases and meet all the criteria of phrase quality, which includes a five-step approach to extract keyphases through heuristically combining a set of five statistical features into a unique score, as
displayed in (
1).
The statistical analysis of YAKE! focuses specifically on the structure, word frequency, and co-occurrence. A group of five statistical characteristics is as follows:
: The ratio of capitalized or acronyms word frequency to total word frequency.
: The word position. The more forward of a word, the more important it is.
: The frequency of the word in the document.
: The relevance of words to context.
: The frequency of words in different sentences.
and reflect the popularity of the word and point out that the lower the amount of different words that appear simultaneously in the context of a word, the higher the consistency of the word is. The higher the scores reached, the more informative the word is. When the n-gram is generated, setting n = 3 means that the phrase with lengths of 1, 2 and 3 is taken, which can meet the integrity standard of phrase quality.
TextRank [
39]. PageRank [
40] believed that the importance of a page depends on the quantity and quality of other pages linking to it. Later, researchers extended the PageRank algorithm in the NLP field and applied it to document construction, called TextRank. TextRank can be expressed as (
2).
is the in-degree of node that represents the number from other web pages to node . is the out-degree of node , which indicates the number from node to other web pages. is the transition probability and represents the edge weight between node and node . is the damping coefficient, which is usually set to 0.85. Then, TextRank iterates until the TR value of each node reaches stable status.
4.2. Definition
4.2.1. Average Sentence Information ()
Generally speaking, a sentence contains more information when it is longer due to rich modifiers, such as multiple attributes, adverbials, and complements, especially in some content highly condensed scenarios, such as paper abstract, technical conclusion, etc. This paper put forward a new text statistical feature to represent average sentence information, called
, which is defined as the average sentence length that contains given phrases to the average sentence length. The
can be expressed as (
3).
represents the occurrence number of candidate v, represents the average sentence length, and represents the ith sentence length of candidate v in document U. The larger becomes, the higher the quality of phrases it contains. This feature does not rely on cross-document information and can be applied to documents of different lengths in various fields. We experimentally demonstrate the effectiveness of this feature.
4.2.2. Statistical Feature Score
In this section, we extend YAKE! [
38] by new statistical features. Average sentence information is an important feature for high-ranking keyphrases; thus, we heuristically add the statistical feature
by multiplying
. The novel statistical feature score is shown in (
4).
4.2.3. Semantic Feature Score
In this paper, the semantic feature scores of the candidates are performed by a node ranking approach, which constructs a semantic graph and ranks the nodes by semantic correlation between candidates. The semantic similarity of two candidates can be measured by the cosine similarity of their phrase embeddings. Specifically, the embeddings of candidates
and
are represented as
and
respectively, and their semantic similarity is computed by (
5).
Different from the graph construction of TextRank, TopicRank, etc. [
39,
41,
42,
43,
44,
45,
46], this paper chooses candidates as nodes and creates edges based on their semantic similarity between candidates. If the semantic similarity
between
and
is higher than the threshold Semantic, edges are created, and the weight of edges
is assigned
. Otherwise, no edges are created, and
is 0. Particularly, the relationship between two semantically similar nodes is reciprocal, and the edges are bidirectional. The semantic feature score is computed by (
6).
4.2.4. Y-Rank Model
In YAKE!, the keyphrase score is inversely proportional to importance, and the more important the keyphrase ranks, the lower the score is. In contrast, this paper proposes a semantic feature score that is positively proportional to the importance of keyphrases. To facilitate the integration of both semantic and multiple statistical features, this paper modifies the (
4) and (
5); the final score is shown in (
7).
and are the semantic feature scores and statistical feature scores of candidate v, respectively. is the influence factor, which represents the influence of the two scores on the comprehensive score, and b is the bias of the statistical feature scores.
5. Y-Rank Implementation
The Y-Rank implementation is described in
Figure 2, which includes five steps:
Step 1. Y-Rank firstly preprocesses the document, then extracts the candidates and removes duplication, establishes a vocabulary, and records the context information.
Specifically, the method first preprocesses the given document and returns a collection of document sentences (line 2), then extracts noun phrases from the collection as candidates and removes duplicated phrases based on the edit distance algorithm (line 3).
Finally, Y-Rank makes vocabulary construction based on the collection of document sentences and records context information using by a fixed co-occurrence window size (lines 4–10).
Step 2. Y-Rank traverses the vocabulary and records other statistics to calculate statistical feature scores.
Through iterating the vocabulary, the method can extract word statistics and calculate statistical feature scores (lines 12–16). Besides traditional features like
(word frequency),
(word frequency of abbreviations), and
(word frequency of capital letters), Y-Rank expands additional statistics (line 14), including
(sentence length) and
(average sentence length). Based on the aforementioned statistical features, the final scores are calculated according to the (
3) and (
4), as shown in line 15.
Step 3. Calculate and update the statistical feature scores of the candidates.
Y-Rank traverses the set of candidates and calculates and updates the corresponding keyphrase statistical feature score by summing the statistical feature score of non-stop words in the candidates (lines 18–22).
Step 4. Y-Rank constructs a graph based on the semantic similarity between keyphrases, and then obtains the semantic feature scores of candidates based on (
6).
During the construction of the semantic graph, an edge is built when the semantic similarity between nodes is higher than the threshold
(lines 24–29), and the similarity is calculated based on (
5). The semantic feature scores of the candidates can be obtained by performing graph ranking based on (
6) (line 30). Meanwhile, the step can be executed in parallel with step 2.
In contrast to traditional similarity algorithms, such as the edit distance algorithm, which identifies different forms of the same word root to a certain extent (tense, singular and plural, part of speech changes, etc.), it removes duplication (such as ‘Transformation’ and ‘Transformations’). However, the edit distance algorithm is inefficient, especially when it encounters different word roots, and it is difficult to identify when they are semantically similar (e.g., ‘Transformation’ and ‘variant’). Y-Rank follows the word-embedding model [
28] to calculate semantic similarity. Although the pre-training of the word-embedding model relies on a large number of corpora, the Wikipedia (
https://en.wikipedia.org/wiki/Wikipedia:Statistics, accessed on 2 January 2023) website can easily download large general corpora of various languages. In the same way, word-embedding models (such as Word2Vec, Glove, FastText, etc.) are also trivially simple to build and use, which vastly reduces the cost of using word-embedding models.
Step 5. Y-Rank merges the two feature scores and outputs the ranking results in descending order.
Based on (
7), Y-Rank merges statistical and semantic feature scores and outputs the ranked results in descending order (lines 32–35).
The overall flow of the model is illustrated in Algorithm 1.
| Algorithm 1 Y-Rank |
Input: Document , Syntax selector , Co-occurrence window sizes , Distance threshold , Semantic similarity threshold Output: - 1:
# (Step 1) Preprocessing the document - 2:
Initialize by text preprocessing - 3:
Initialize by selecting noun-phrases as candidates based on grammar - 4:
for each in do - 5:
if DistanceSimilarity() > then - 6:
Remove from - 7:
= _vocabulary_building() # build a Vocabulary - 8:
= _contexts_building() # extract context - 9:
end if - 10:
end for - 11:
# (Step 2) Extract the statistical feature (), and calculate the statistical feature score of the word - 12:
for each in do - 13:
Extract traditional word features - 14:
Extract word feature: - 15:
Compute word score - 16:
end for - 17:
# (Step 3) Calculate and update the statistical feature scores of candidates - 18:
for each in do - 19:
Compute candidate’s - 20:
Update - 21:
Compute word score - 22:
end for - 23:
# (Step 4) Construct graphs based on semantic similarity between phrases and rank graphs nodes, which is performed in parallel with Step 2 - 24:
for each in do - 25:
if Word2VecSimilarity() > then - 26:
Add both connected and into - 27:
end if - 28:
end for - 29:
G = build_phrases_graph() - 30:
= textrank(G) - 31:
# (Step 5) fuse statistical and semantic feature-scores into scores, and rank them in descending order - 32:
for each in do - 33:
Fusing and into by ( 7) - 34:
end for - 35:
= sort() by descending score
|
6. Experiments
In this subsection, the basic setup of the experiment, including the dataset, baseline, evaluation metrics, and experimental details, is presented first. Then, it gives and discusses the impact of different strategies on the evaluation results in the ablation experiment, and finally analyzes the experimental results from two aspects of phrase quality and ranking quality.
6.1. Experiment Setup
6.1.1. Datasets
This section evaluates Y-Rank in different models by five widely used scientific publication datasets as the gold sets, all of which are available for download from The HuggingFace (
https://huggingface.co/taln-ls2n, accessed on 2 January 2023). KP20k [
47] is currently the largest dataset in scientific keyword research, and the remaining datasets are SemEval–2010 [
48], wikinews-fr-100 (
https://huggingface.co/datasets/taln-ls2n/wikinews-fr-100, accessed on 2 January 2023), ttermith-eval [
49], and taln-archives [
50]. The details of the datasets are given in
Table 2. Moreover, the dataset is open and contained in the word-embedding training corpus; thus, there is no OOV (Out-Of-Vocabulary) problem. To alleviate the OOV problem of keyphrase extraction in novel datasets, this paper assigns value to the absent words and then retains the missing parts to facilitate the incremental training of the word-embedding model.
6.1.2. Baselines
In the unsupervised case, for the convenience of comparison, this paper mainly compares Y-Rank with the following nine unsupervised methods.
Statistical model
- −
TfIdf [
41] sorted the extracted candidates whose form is a noun phrase in the corpus per word frequency and inverse-document frequency.
- −
KPMiner [
42] introduced a lifting factor for n-gram compound phrases, to mitigate TF-IDF’s preference for 1-g phrases.
- −
YAKE! [
38] extracted a set of five statistical text features from a single document to identify the most relevant keywords in the text.
Graph-based model
- −
TextRank [
39] was a variant of the PageRank algorithm to score phrases.
- −
SingleRank [
43] was an extension of TextRank, which weighted graphs using the number of co-occurrences. Then, the graph-based ranking algorithm was applied to the phrase scoring.
- −
TopicRank [
44] took the topic as a cluster of similar keyphrases, filtered out negative topics in line with the importance of the topic, and selected the most important keyphrase for the topic to represent the core keyword of the document.
- −
TopicalPageRank [
45] was an extension of TopicRank, which established a separate PageRank for each topic, and promoted the words with a high correlation with the corresponding topic.
- −
PositionRank [
46] added the position of each word to PageRank, and then calculated the score and ranking of each keyword.
- −
MultipartiteRank [
14] represented candidates and topics on a graph and used the mutual strengthening relationship between them to improve the ranking of candidates.
6.1.3. Implementation Details
6.1.4. Evaluation Metrics
Based on the literature [
38], this paper evaluates the model from phrase quality and ranking quality, respectively. Here, we take evaluating@K as the metric, which means the top K keyphrase sets with the highest scores. In addition, accurate matching and fuzzy matching are both evaluated using Y-Rank in the ablation experiment. Fuzzy matching is approximate search and pattern matching, which can be used to amplify the evaluation score and verify the validity of Y-Rank.
Phrase Quality (Precision/Recall/F-Measure)
This paper uses P@K, R@K and F@K as measures of top K phrases quality. Specifically, for a phrase list, Precision is defined as the number of true quality phrases divided by the number of predicted quality phrases, and Recall is defined as the number of true quality phrases divided by the total number of quality phrases. Precision and Recall are sometimes contradictory. Here, we use the F-Measure to consider the two indicators, which are the harmonic mean of Precision and Recall.
Ranking Quality (MRR/MAP/Bpref)
The ranking quality measure takes into account the relative order of the extracted phrases. The popular ranking measures in the keyphrase extraction are MRR [
51], MAP [
52] and Bpref [
53]. Mean Reciprocal Rank (MRR) measures the performance of a recommendation system by computing the average of the reciprocal ranks of items in the list of recommended items. Mean Average Precision (MAP) measures the performance of an information retrieval system by computing the average precision scores across all queries. Binary Preference (Bpref) measures the performance of a ranking system by counting the number of times that the system ranks relevant documents higher than non-relevant documents.
6.2. Experimental Results and Analysis
6.2.1. Score Importance Update
Given that the semantic features in (
7) are proportional to the importance of keywords, the statistical features in Yake! [
38] are inversely proportional to the importance. Based on these observations, we evaluate the two strategies to better fuse the comprehensive statistical features of (
4) into (
7). The two strategies are as follows:
The two strategies are evaluated by the set of keyphrases from YAKE!, which were sorted in ascending order by importance, as shown in
Table 4. The experimental input is a document from the wikinews-fr-100 dataset. Here, we pick the wikinews-fr-100 dataset due to its small size, fast reading speed, and the highest probability among provided datasets for negative-low importance phrases. The results are compared by score distribution, as indicated in
Figure 3.
Observing
Figure 3, we can see that Strategy 1 and the original strategy have the opposite trend and similar speed of change, and they are roughly symmetrical concerning the x-axis, while there is no symmetrical relationship between Strategy 2 and the original strategy. In addition, compared with other candidates, the candidates (indexed 45–48) are abnormally small in Strategy 1, and are maximum values in the original strategy and Strategy 2, which indicates that the candidates corresponding to the abnormally large/small scores are worthless. To make all scores integer and extremely low for worthless phrases, this paper adds a bias
b (valued 10), and the final score chooses Strategy 1, as shown in (
7).
Similarly, we evaluated the total wikinews-fr-100 dataset in different metrics, as shown in
Table 5, and
K = 5. In the results of
Table 5, the evaluation result of Strategy 1 wins best, whose scores under each evaluation index can achieve the effect of the original strategy. Therefore, we prefer Strategy 1, which can make the importance of the candidate proportional to its score, and meet the requirements of the experiment.
6.2.2. Statistical Score Importance
This section demonstrates the effectiveness of
by performing ablation experiments of Y-Rank on different heuristic weighting rules, to make it the best optimization of the algorithm. Here, we also choose the wikinews-fr-100 dataset.
is positively correlated with the importance of keyphrases, which demonstrates the information of the word. If the sentence that contains the word is longer, it is more likely to be informative and relevant to the document’s theme. Here, we heuristically expand (
1) by trying different weight combinations, which depends on the modification of numerator and denominator. Furthermore, the division of
by
is also considered to penalize candidates that frequently occur but have many different terms in the context. The total seven strategies, which are classified into three categories and listed as follows.
Only the denominator modification
Only the numerator modification
The experimental results in
Table 6 (with
K = 5) show that adding the statistical feature
to the numerator can improve the evaluation results, suggesting that
has a direct relationship with the score. This implies that
reflects the average information of a word in a document, and when a word frequently appears in a key sentence with a large amount of information, its importance should be higher. Among the different heuristic weighting rules, (
12) wins the best, indicating that
is highly important for the keyphrase extraction task. Furthermore, the statistical feature score obtained by multiplying
can significantly improve both the quality of keyphrases (P/R/F) and the ranking quality (MRR/MAP/Bpref).
6.2.3. Semantic Score Importance
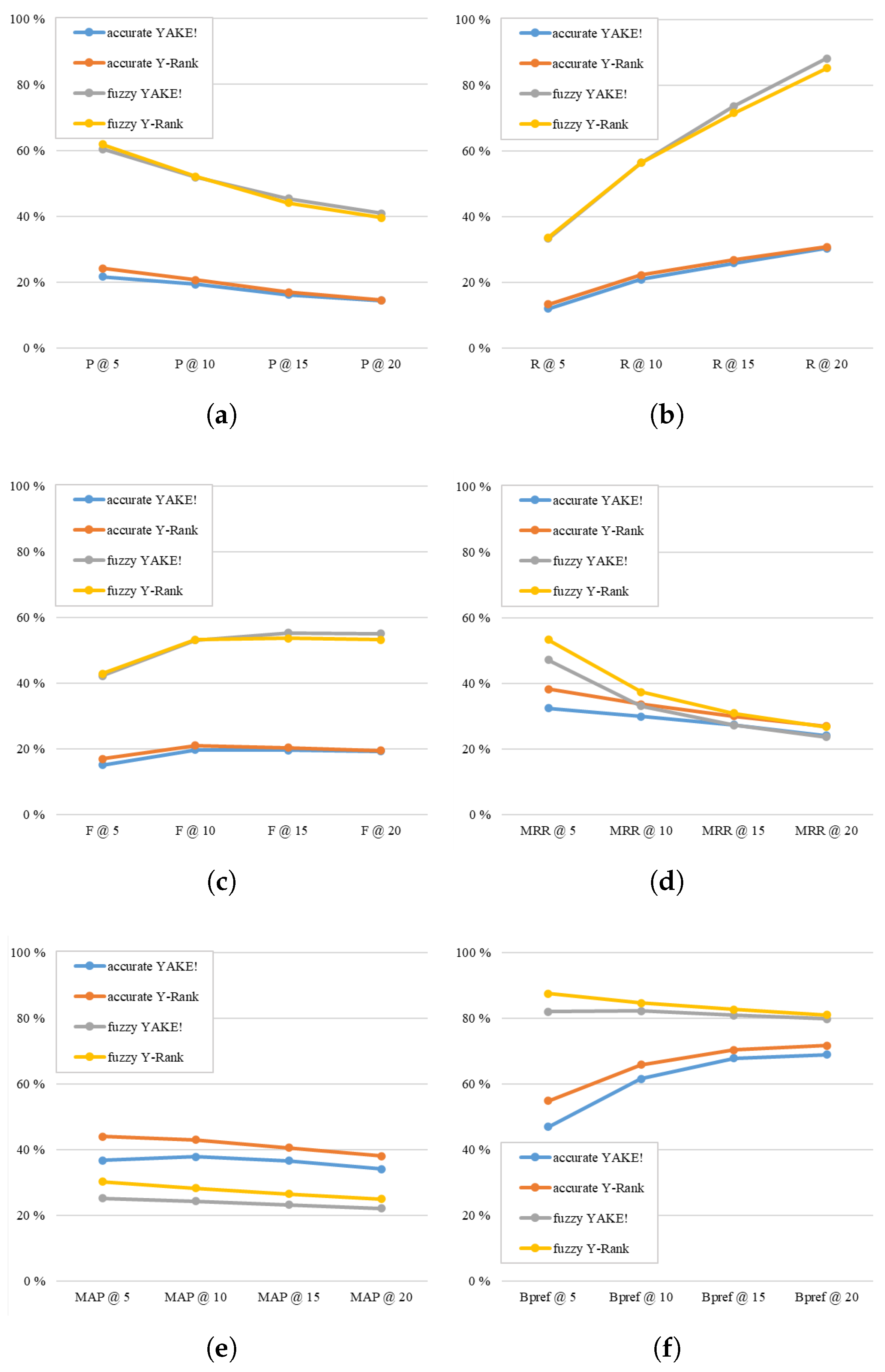
This section carries out ablation experiments on the semantic features of Y-Rank. The experiment also uses the wiki news-fr-100 dataset for ablation experiments, and takes
K = 5, 10, 15, 20, then compares the model scores of semantic features from the perspectives of keyphrase quality (P/R/F) and ranking quality (MRR/MAP/Bpref). The experimental results are explained in
Figure 4.
The experiments show that the semantic feature can effectively improve both the quality of keyphrases (P/R/F,
Figure 4a–c) and ranking (MRR/MAP/Bpref,
Figure 4d–f) in accurate and fuzzy matching. The growth rate of the semantic feature score decreases as
K increases in most cases. When
K = 5, the improvement in the evaluation score wins the highest results, which means that Y-Rank is more suitable for keyphrases extraction with a few numbers (2–3 words).
6.2.4. Fusing Score Importance
The TextRank(TR) [
39] derivations include both biased and unbiased algorithms, depending on whether personalized values are provided. Unbiased TR ranks the importance of nodes by a function of the transition probability matrix and constructs a structure graph. On the basis of unbiased TR, biased TR makes the final convergent answer closer to the given personalized value, which can be regarded as the node attribute, and builds an attribute graph.
Through experiments, the score fusion method in this paper compares two score fusion methods: Biased TR and Unbiased TR, as described in
Table 7. Here, Biased TR refers to the comprehensive score obtained directly based on the biased TextRank. Unbiased TR refers to obtaining semantic feature scores based on unbiased TextRank and then fusing them with statistical feature scores. After experimental verification, the best fusion effect was achieved by using unbiased TR with the impact factor
= 0.25, indicating that semantic features had less influence on the final score than statistical features.
6.2.5. Overall Effectiveness
To evaluate the overall effectiveness of Y-Rank, the model is applied to all five datasets. The evaluation results of Y-Rank are compared with nine advanced unsupervised methods (three statistical models: TfIdf, KPMiner and YAKE!, six graph-based methods: Text-Rank, SingleRank, TopicRank, TopicalPageRank, PositionRank and MultipartiteRank) are compared.
Precision
High accuracy means that the model has a high level of correctness. In compliance with
Figure 5, it can be observed that Y-Rank has better evaluation scores in Precision than the other nine unsupervised methods. Compared with the second-best method, Y-Rank’s evaluation score can be improved by 1.3% on average. Meanwhile, the smaller
K is, the better improvement of Y-Rank is, which proves that Y-Rank is most suitable for the application scenarios of extraction with a few keyphrases.
Figure 5.
Comparison between Y-Rank and other models in Precision. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Figure 5.
Comparison between Y-Rank and other models in Precision. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Recall
A high recall means that the model can find more true keyphrases. As shown in
Figure 6, Y-Rank outperforms the other nine unsupervised methods in recall evaluation. Compared with the second best method, Y-Rank’s evaluation score can be improved by an average of 1.5%. Among them, unsupervised methods based on graph methods generally have lower evaluation scores, especially TextRank, whose recall rate is almost 0% when
K = 5. This indicates that the random walk algorithm has random directionality, which will lower the recall score.
Figure 6.
Comparison between Y-Rank and other models in Recall. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Figure 6.
Comparison between Y-Rank and other models in Recall. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
F-Measure
The F-measure is usually used to comprehensively evaluate the performance of a model. As shown in
Figure 7, compared with the other nine unsupervised methods, Y-Rank has better performance in terms of F-measure. Compared with the second-best method, Y-Rank’s evaluation score can be improved by an average of 1.4%. Obviously, the improvement of Y-Rank is more significant when k is smaller, which further proves that Y-Rank is most suitable for the application scenarios of extraction with a few keyphrases.
Figure 7.
Comparison between Y-Rank and other models in F-Measure. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Figure 7.
Comparison between Y-Rank and other models in F-Measure. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Mean Reciprocal Rank (MRR)
The MRR is the average of Precision, which means more stable ranking recommendation when the score is higher. The evaluation results of MRR are presented in
Figure 8, which demonstrates that Y-Rank outperforms the other nine unsupervised methods and achieves an average improvement of 3.5% in MRR. Compared to other methods, Y-Rank is a mixed method that combines statistical and semantic features. The experiment has demonstrated that Y-Rank can effectively improve the quality of recommendation ranking.
Figure 8.
Comparison between Y-Rank and other models in MRR. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Figure 8.
Comparison between Y-Rank and other models in MRR. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Mean Average Precision (MAP)
MAP is commonly used to evaluate the overall ranking outcomes of a model. As observed from
Figure 9, compared to the other nine unsupervised methods, Y-Rank achieved better evaluation results in terms of MAP. Compared to the second-best method, Y-Rank’s evaluation scores improved by an average of 4.4%. Since the ranking results trend of MAP is similar to MRR, which once again proves that unsupervised methods that comprehensively consider statistical and semantic features can effectively improve the quality of recommendation ranking.
Figure 9.
Comparison between Y-Rank and other models in MAP. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Figure 9.
Comparison between Y-Rank and other models in MAP. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Binary preference (Bpref)
Bpref is commonly used to evaluate the accuracy of the model’s ranking of keyphrases. In keeping with
Figure 10, it can be observed that Y-Rank has better evaluation scores on MRR than the other nine unsupervised methods. Compared with the second-best method, Y-Rank improved the evaluation score by 5.3% on average. The better the Bpref score reaches, the fewer worthless phrases in the predicted value ranking exist, and the higher the ranking quality is.
Figure 10.
Comparison between Y-Rank and other models in Bpref. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
Figure 10.
Comparison between Y-Rank and other models in Bpref. (a) kp20k. (b) wikinews-fr-100. (c) termith-eval. (d) taln-archives.
In summary, Y-Rank expands six statistical features first and then combines semantic features, outperformed all nine other methods, and achieved the best keyphrase quality (P/R/F) and ranking quality (MRR/MAP/Bpref). Moreover, it can stably achieve evaluation scores better than other baselines in different benchmark datasets. In addition, the results also show that the traditional statistical methods (TfIdf, KPMiner, YAKE!) tend to achieve better evaluation scores than graph-based methods in short-text or medium-text scenarios, which demonstrates that statistical features have a greater impact on final scores than semantic features.
7. Conclusions and Future Work
In this paper, we brought forward an unsupervised keyphrase extraction method called Y-Rank, which addresses the issue of limited characteristics and low-quality candidate classification for short text. Y-Rank first extracts noun phrases from the document as candidates. By horizontally introducing novel characteristics of average sentence information, this method optimizes the statistical feature score calculation and traverses the document to collect the statistics. Meanwhile, the method uses word2vec model to capture the semantic similarity between candidates and constructs a semantic graph. Finally, it proposes an importance ranking method combining statistical and semantic feature scores to predict high-quality keyphrases. The experiment results proved that Y-Rank is superior to the existing nine unsupervised methods in terms of keyphrase quality and ranking quality.
At present, the work still has quite a few limitations, including limited Domain-Specific Adaptation, OOV Problems, etc. Due to the limitations of domain-specific corpora, this method may lack the ability for capturing the specific nuances of vocabulary in certain domains. We plan to enhance the generalization ability of word embeddings by specialized corpora or by following a domain-adaptive integration approach. For OOV problems, we may introduce some sub-word tokenization techniques to improve the effectiveness, such as BPE(Byte Pair Encoding),etc. Moreover, we hope to capture more sophisticated term or novel linguistic insights to optimize the statistical feature score. In the future work, we aim to mitigate these identified limitations by enhancing the method’s adaptability, accuracy, and robustness across various document types and domains.
Author Contributions
Conceptualization, Q.L. and Y.J.; Methodology, Y.H.; Software, Q.L. and Y.H.; Validation, Y.H.; Formal analysis, Q.L.; Investigation, Q.L. and S.L.; Resources, Y.J.; Data curation, Y.H.; Writing—original draft, Q.L. and Y.H.; Writing—review & editing, Y.J.; Visualization, Y.H. and S.L.; Supervision, Y.J.; Funding acquisition, Y.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key R&D Program of China (2023YFB2904000, 2023YFB2904004), Jiangsu Key Development Planning Project (BE2023004-2), Natural Science Foundation of Jiangsu Province (Higher Education Institutions) (20KJA520001), The 14th Five-Year Plan project of Equipment Development Department (315107402), Jiangsu Hongxin Information Technology Co., Ltd. Project (JSSGS2301022EGN00), and the Future Network Scientific Research Fund Project (No. FNSRFP-2021-YB-15), NUPTSF (No. NY219132).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare that this study received funding from Jiangsu Hongxin Information Technology Co., Ltd. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
References
- Sun, C.; Hu, L.; Li, S.; Li, T.; Li, H.; Chi, L. A review of unsupervised keyphrase extraction methods using within-collection resources. Symmetry 2020, 12, 1864. [Google Scholar] [CrossRef]
- Lv, S.; Guo, D.; Xu, J.; Tang, D.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Cao, G.; Hu, S. Graph-based reasoning over heterogeneous external knowledge for commonsense question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8449–8456. [Google Scholar]
- Yang, H.; Sanner, S.; Wu, G.; Zhou, J.P. Bayesian Preference Elicitation with Keyphrase-Item Coembeddings for Interactive Recommendation. In Proceedings of the 29th ACM Conference on User Modeling, Utrecht, The Netherlands, 21–25 June 2021; pp. 55–64. [Google Scholar]
- Ezugwu, A.E.; Shukla, A.K.; Agbaje, M.B.; Oyelade, O.N.; José-García, A.; Agushaka, J.O. Automatic clustering algorithms: A systematic review and bibliometric analysis of relevant literature. Neural Comput. Appl. 2021, 33, 6247–6306. [Google Scholar]
- Zhou, C.; Shang, J.; Zhang, J.; Li, Q.; Hu, D. Topic-Attentive Encoder-Decoder with Pre-Trained Language Model for Keyphrase Generation. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 1529–1534. [Google Scholar]
- Lau, J.H.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. In Proceedings of the 1st Workshop on Representation Learning for NLP, Berlin, Germany, 11 August 2016; pp. 78–86. [Google Scholar]
- Florescu, C.; Jin, W. Learning feature representations for keyphrase extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; pp. 1–2. [Google Scholar]
- Yang, M.; Liang, Y.; Zhao, W.; Xu, W.; Zhu, J.; Qu, Q. Task-oriented keyphrase extraction from social media. Multimed. Tools Appl. 2018, 77, 3171–3187. [Google Scholar] [CrossRef]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Adversarial training for multi-context joint entity and relation extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2830–2836. [Google Scholar]
- Chen, J.; Zhang, X.; Wu, Y.; Yan, Z.; Li, Z. Keyphrase generation with correlation constraints. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4057–4066. [Google Scholar]
- Ye, H.; Wang, L. Semi-supervised learning for neural keyphrase generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4142–4153. [Google Scholar]
- Wang, Y.; Liu, Q.; Qin, C.; Xu, T.; Wang, Y.; Chen, E.; Xiong, H. Exploiting topic-based adversarial neural network for cross-domain keyphrase extraction. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 597–606. [Google Scholar]
- Li, L.S.; Xu, B.; Yang, Y.-J. DRTE: A Term Extraction Approach for Elementary Education. J. Chin. Inf. Technol. 2018, 32, 101–109. [Google Scholar]
- Boudin, F. Unsupervised keyphrase extraction with multipartite graphs. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics, New Orleans, LO, USA, 1–6 June 2018; pp. 667–672. [Google Scholar]
- Bennani-Smires, K.; Musat, C.; Hossmann, A.; Baeriswyl, M.; Jaggi, M. Simple unsupervised keyphrase extraction using sentence embeddings. In Proceedings of the 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 31 October–1 November 2018; pp. 221–229. [Google Scholar]
- Shi, W.; Zheng, W.; Yu, J.X.; Cheng, H.; Zou, L. Keyphrase extraction using knowledge graphs. Data Sci. Eng. 2017, 2, 275–288. [Google Scholar] [CrossRef]
- Tosi, M.D.L.; Reis, J.C.D. Keyphrase extraction from single textual documents based on semantically defined background knowledge and co-occurrence graphs. Int. J. Metadata 2021, 15, 121–132. [Google Scholar] [CrossRef]
- Giarelis, N.; Karacapilidis, N. Understanding Horizon 2020 Data: A Knowledge Graph-Based Approach. Appl. Sci. 2021, 11, 11425. [Google Scholar] [CrossRef]
- Zahera, H.M.; Vollmers, D.; Sherif, M.A.; Ngomo, A.C.N. MultPAX: Keyphrase Extraction Using Language Models and Knowledge Graphs. In The Semantic Web—ISWC 2022, Proceedings of the International Semantic Web Conference, Athens, Greece, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 303–318. [Google Scholar]
- Alrehamy, H.; Walker, C. Exploiting extensible background knowledge for clustering-based automatic keyphrase extraction. Soft Comput. 2018, 22, 7041–7057. [Google Scholar]
- Mothe, J.; Rami, R.F.; Rasolomanana, M. Automatic keyphrase extraction using graph-based methods. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 728–730. [Google Scholar]
- Mahata, D.; Kuriakose, J.; Shah, R.; Zimmermann, R. Key2vec: Automatic ranked keyphrase extraction from scientific articles using phrase embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics, Online, 6–11 June 2018; pp. 634–639. [Google Scholar]
- Carpuat, M.; de Marneffe, M.C.; Meza-Ruiz, I. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, Online, 10–15 July 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 1–63. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word embeddings with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Lv, X.; Morshed, S.A.; Zhang, L. Automatic key-phrase extraction to support the understanding of infrastructure disaster resilience. In Proceedings of the International Symposium on Automation and Robotics in Construction, Banff, AB, Canada, 21–24 May 2019; pp. 1276–1281. [Google Scholar]
- Papagiannopoulou, E.; Tsoumakas, G. A review of keyphrase extraction. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, 1339–1398. [Google Scholar]
- Zhang, Y.; Liu, H.; Wang, S.; Ip, W.H.; Fan, W.; Xiao, C. Automatic keyphrase extraction using word embeddings. Soft Comput. 2020, 24, 5593–5608. [Google Scholar] [CrossRef]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef]
- Yeom, H.; Ko, Y.; Seo, J. Unsupervised-learning-based keyphrase extraction from a single document by the effective combination of the graph-based model and the modified C-value method. Comput. Speech Lang. 2019, 58, 304–318. [Google Scholar] [CrossRef]
- Rabby, G.; Azad, S.; Mahmud, M.; Zamli, K.Z.; Rahman, M.M. Teket: A tree-based unsupervised keyphrase extraction technique. Cogn. Comput. 2020, 12, 811–833. [Google Scholar]
- Won, M.; Martins, B.; Raimundo, F. Automatic extraction of relevant keyphrases for the study of issue competition. In Proceedings of the 20th International Conference on Computational Linguistics and Intelligent Text Processing, La Rochelle, France, 7–13 April 2019; pp. 7–13. [Google Scholar]
- Zhang, Y.; Liu, H.; Shi, B.; Li, X.; Wang, S. WEKE: Learning Word Embeddings for Keyphrase Extraction. In Proceedings of the Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, Tianjin, China, 18–20 September 2020; pp. 245–260. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.M.; Nunes, C.; Jatowt, A. A text feature based automatic keyword extraction method for single documents. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; pp. 684–691. [Google Scholar]
- Santosh, T.Y.S.S.; Sanyal, D.K.; Bhowmick, P.K.; Das, P.P. DAKE: Document-level attention for keyphrase extraction. In Proceedings of the European Conference on Information Retrieval, Online, 14–17 April 2020; pp. 392–401. [Google Scholar]
- Firdausillah, F.; Udayanti, E.D. Keyphrase Extraction on Covid-19 Tweets Based on Doc2Vec and YAKE. J. Appl. Intell. Syst. 2021, 6, 23–31. [Google Scholar] [CrossRef]
- Liu, J.; Shang, J.; Wang, C.; Ren, X.; Han, J. Mining Quality Phrases from Massive Text Corpora. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 31 May–4 June 2015; pp. 1729–1744. [Google Scholar]
- Shang, J.; Liu, J.; Jiang, M.; Ren, X.; Voss, C.R.; Han, J. Automated phrase mining from massive text corpora. IEEE Trans. Knowl. Data Eng. 2018, 30, 1825–1837. [Google Scholar] [CrossRef]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 5, 257–289. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Browaeys, R.; Saelens, W.; Saeys, Y. NicheNet: Modeling intercellular communication by linking ligands to target genes. Nat. Methods 2020, 17, 159–162. [Google Scholar] [PubMed]
- Salton, G.; Yu, C.T. On the construction of effective vocabularies for information retrieval. ACM Sigplan Not. 1973, 10, 48–60. [Google Scholar] [CrossRef]
- El-Beltagy, S.R.; Rafea, A. Kp-miner: Participation in semeval-2. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 190–193. [Google Scholar]
- Wan, X.; Xiao, J. CollabRank: Towards a collaborative approach to single-document keyphrase extraction. In Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008), Manchester, UK, 18–22 August 2008; pp. 969–976. [Google Scholar]
- Bougouin, A.; Boudin, F.; Daille, B. Topicrank: Graph-based topic ranking for keyphrase extraction. In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP), Nagoya, Japan, 14–18 October 2013; pp. 543–551. [Google Scholar]
- Sterckx, L.; Demeester, T.; Deleu, J.; Develder, C. Topical word importance for fast keyphrase extraction. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 121–122. [Google Scholar]
- Florescu, C.; Caragea, C. Positionrank: An unsupervised approach to keyphrase extraction from scholarly documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1105–1115. [Google Scholar]
- Meng, R.; Zhao, S.; Han, S.; He, D. Deep Keyphrase Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 582–592. [Google Scholar]
- Kim, S.N.; Medelyan, O.; Kan, M.Y.; Baldwin, T.; Pingar, L.P. Semeval-2010 task 5: Automatic keyphrase extraction from scientific articles. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 21–26. [Google Scholar]
- Bougouin, A.; Barreaux, S.; Romary, L.; Boudin, F.; Daille, B. TermITH-Eval: A French Standard-Based Resource for Keyphrase Extraction Evaluation. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 1924–1927. [Google Scholar]
- Boudin, F. TALN Archives: Une archive numérique francophone des articles de recherche en Traitement Automatique de la Langue. In Proceedings of the Traitement Automatique des Langues Naturelles (TALN), Sables d’Olonne, France, 17–21 June 2013; pp. 507–514. [Google Scholar]
- Voorhees, E.M. The TREC-8 question answering track report. TREC-8 1999, 99, 117–124. [Google Scholar]
- Robertson, S.E.; Spärck, J. Relevance weighting of search terms. J. Am. Soc. Inf. Sci. 1976, 27, 129–146. [Google Scholar] [CrossRef]
- Buckley, C.; Voorhees, E.M. Evaluating evaluation measure stability. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 33–40. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}