1. Introduction
Forests, the most extensive and biologically diverse terrestrial ecosystems on Earth, play a crucial role in various essential functions, such as water purification, climate regulation, and maintenance of biodiversity [
1,
2]. Serving as a key pillar of global ecological security, forests are irreplaceable in preserving overall ecological balance and human well-being. With the ongoing evolution of the global climate, the increasing frequency and intensification of forest fires pose escalating challenges to the Earth’s ecosystems and human societies [
3,
4]. These fires not only result in extensive vegetation destruction and habitat loss but also have profound impacts on ecological balance and global climate. In this context, the upgrading of fire monitoring technology becomes an imperative task to enhance the capabilities of early warning, rapid response, and flexible control of forest fires.
The rapid spread of forest fires is attributed to swift air convection and ample oxygen within the forest [
5], leading to the rapid escalation of flames within a short timeframe. In such a scenario, early fire detection becomes particularly urgent. While manual inspection was the earliest method, it was swiftly replaced by sensor-based detection systems, due to expensive manpower costs and inefficiency. Sensor technologies [
6,
7], encompassing smoke sensors, gas sensors, temperature-humidity sensors, etc., exhibit remarkable performance in confined indoor environments. However, they face a series of challenges in large open spaces or extensive areas such as forests, including limited detection distances, high installation costs, and complex communication and power network issues. Moreover, these sensors cannot provide crucial visual information to assist firefighters in rapidly understanding the situation at the fire scene. Although satellite remote sensing can offer clear images [
8], it falls short in achieving real-time detection, especially when affected by weather and cloud cover. In comparison, cameras as sensors possess superior real-time performance, particularly when installed on drones, enabling effective detection in more remote forest areas.
Researchers have proposed a series of highly effective fire detection systems by integrating color characteristics, color-space models, and motion features using various methodologies. Chen, Y. et al. [
9] have successfully created a holistic application for forest fire detection and monitoring. This application harnesses flame chromaticity and the Lab color model, incorporating techniques for enhancing image quality and processing. MAI Mahmoud et al. [
10] utilized background subtraction and a color-segmentation model, employing support vector machines to classify areas as either genuine fires or non-fires. These studies emphasize the holistic application of flame chromaticity, color space, and motion features, providing diverse and refined approaches to forest fire detection. Prema et al. [
11] introduced an effective approach for addressing various fire detection scenarios. This method involves the extraction of texture features, both static and dynamic, from regions identified as potential fire areas, utilizing the YVbCr color model. Additionally, Han et al. [
12] focused on flame extraction, facilitating the precise localization of potential fire locations through the integration of multi-color detection and motion points in RGB, HIS, and YUV color spaces.
Recently, there has been a trend towards combining prevalent algorithms in machine learning or deep learning with remote sensing techniques and fire detection systems [
13]. Mahaveerakannan R. et al. [
14] proposed a Cat Swarm Fractional Calculus Optimization algorithm for deep learning, combining the optimal features of Cat Swarm Optimization with fractional calculus to achieve superior training results. Barmpoutis et al. [
15] utilized the Faster R-CNN architecture for fire detection, proposing an approach that integrates both deep learning networks and multidimensional texture analysis to identify potential fire areas through image analysis. K. Alice et al. [
16] utilized the AFFD-ASODTL model, incorporating Atom Search Optimizer and deep transfer learning for automated forest fire detection, thereby reducing response time and minimizing wildfire destruction. Ji Lin et al. [
17] proposed TCA-YOLO, an efficient and accurate global forest fire detection model based on YOLOv5 and a Transformer encoder. The model includes a coordinated attention mechanism and adaptive spatial feature-fusion technology, reducing manual labeling efforts through semi-supervised learning. TCA-YOLO demonstrates excellent performance across various scenarios. Ghali et al. [
18] proposed an innovative ensemble-learning technique that merges the EfficientNet-B5 and DenseNet-201 models, aiming to detect wildfires in aerial images, achieving superior performance compared to various benchmarks in wildfire classification.
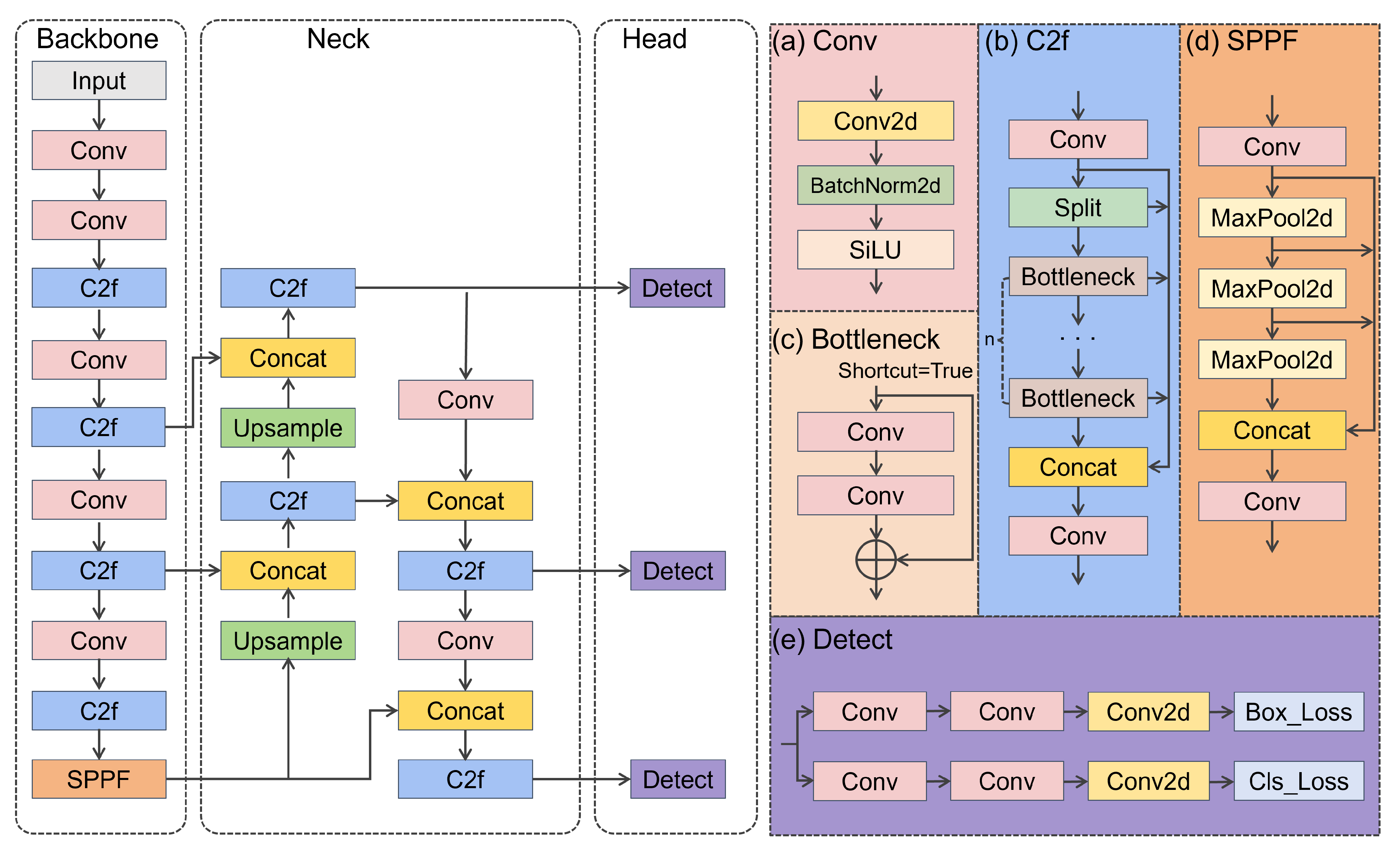
Currently, YOLO has made full-size strides in the subject of object detection. However, when confronted with far-off sensing, particularly in the context of wooded-area fires, the mannequin, as is well known, shows sure limitations. Specifically, detection pursuits in wooded-area fires frequently exist in a diminutive state, imparting a unique challenge, particularly in the early ranges of a fire. In some instances, flames and smoke all through a fire site might also be obscured by way of dense foliage, and their normally small scale makes them hard for the mannequin to seize effortlessly. The intrinsic traits of woodland fires pose significant challenges to the overall detection performance of the YOLOv8 model. Consequently, situations of overlooked detection may additionally arise, whereby the mannequin fails to figure without delay the preliminary symptoms of a fire. This no longer solely influences the timeliness of hearth detection but additionally poses an undertaking to the universal accuracy of the network. Despite YOLOv8 showcasing promise in the subject of object detection, its efficacy in the early and far-off detection of woodland fires needs similar refinement and exploration.
To address these challenges, our study presents an enhanced multiscale forest fire detection approach based on YOLOv8. The key contributions are as follows:
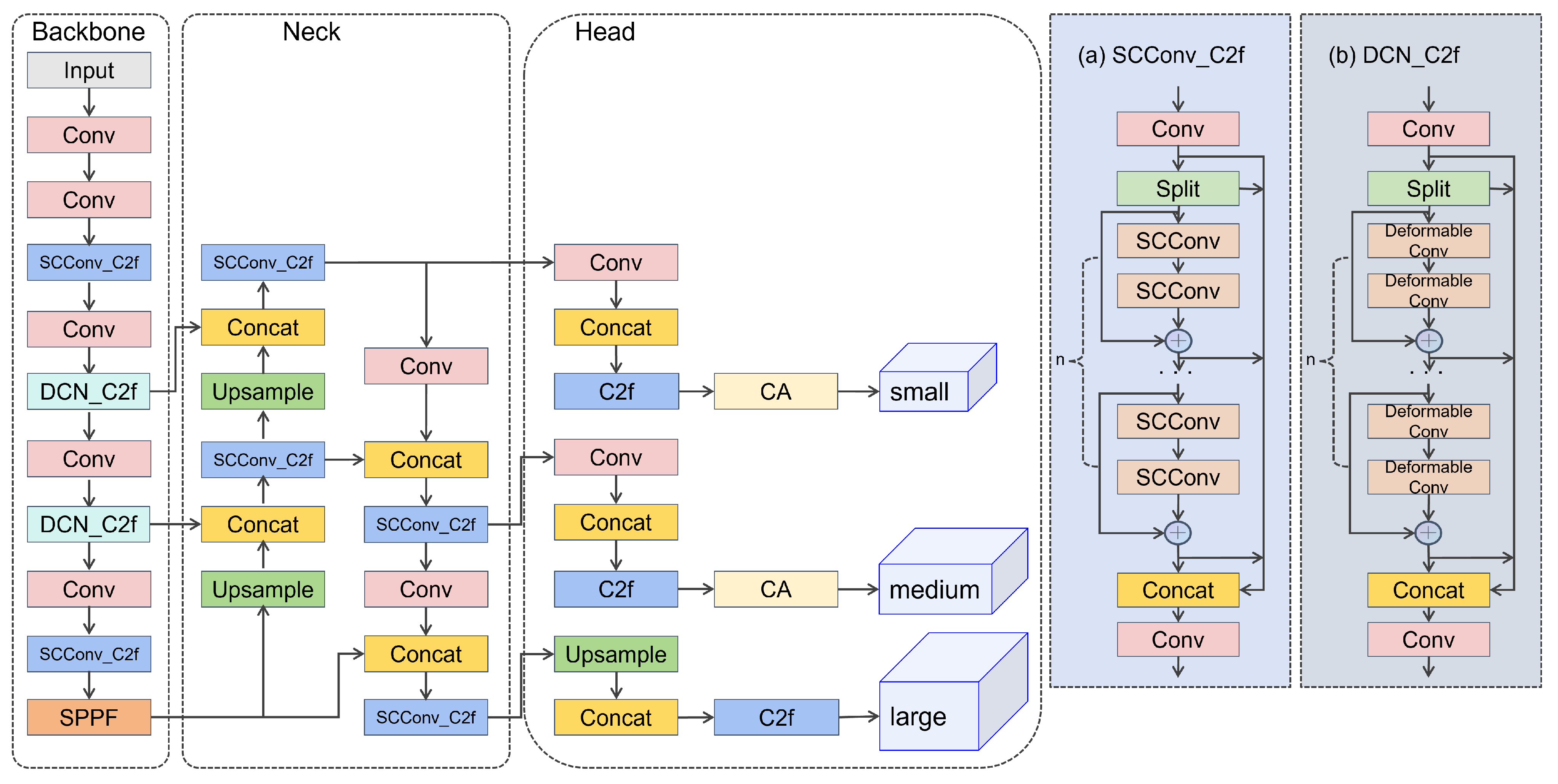
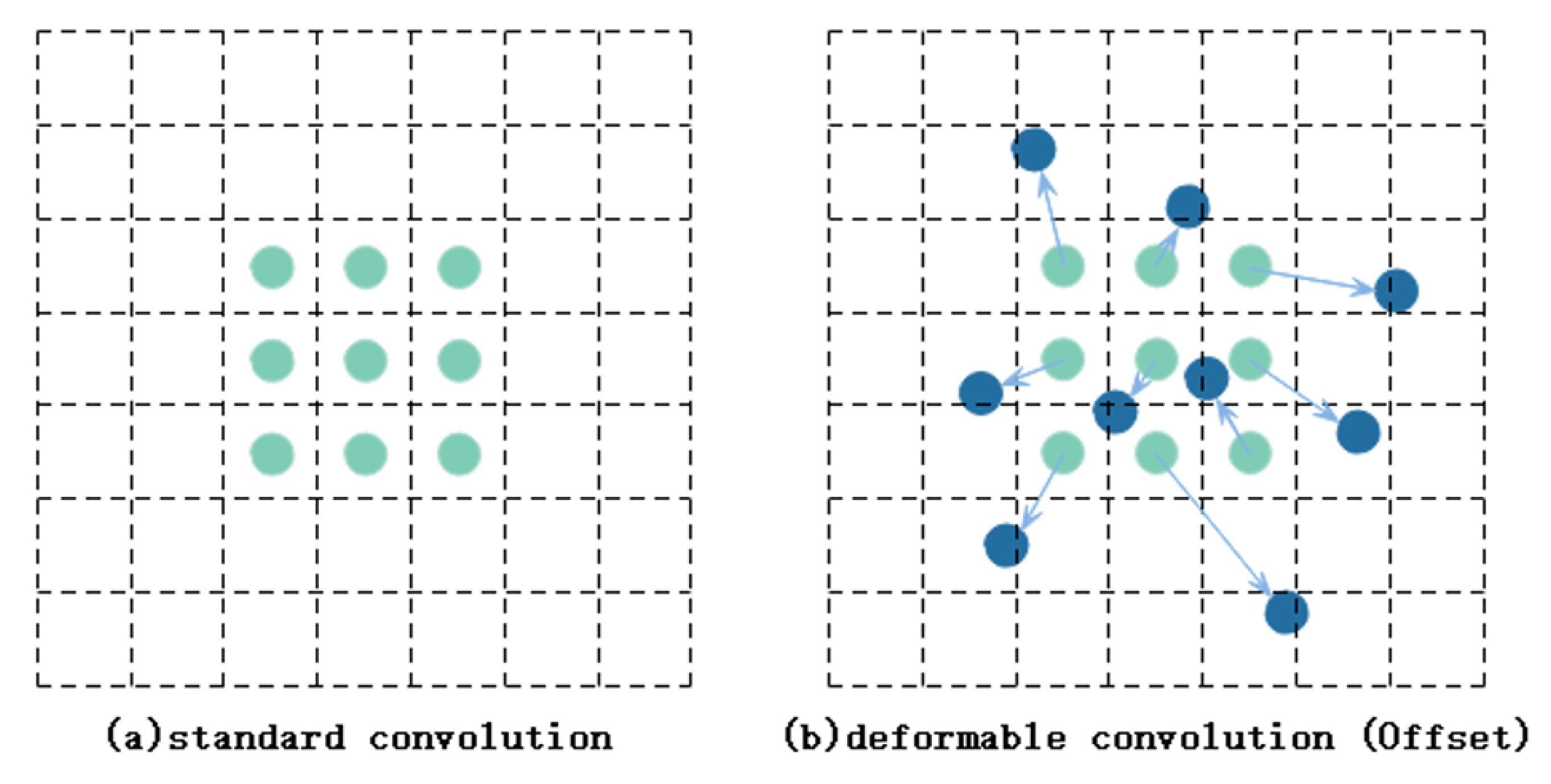
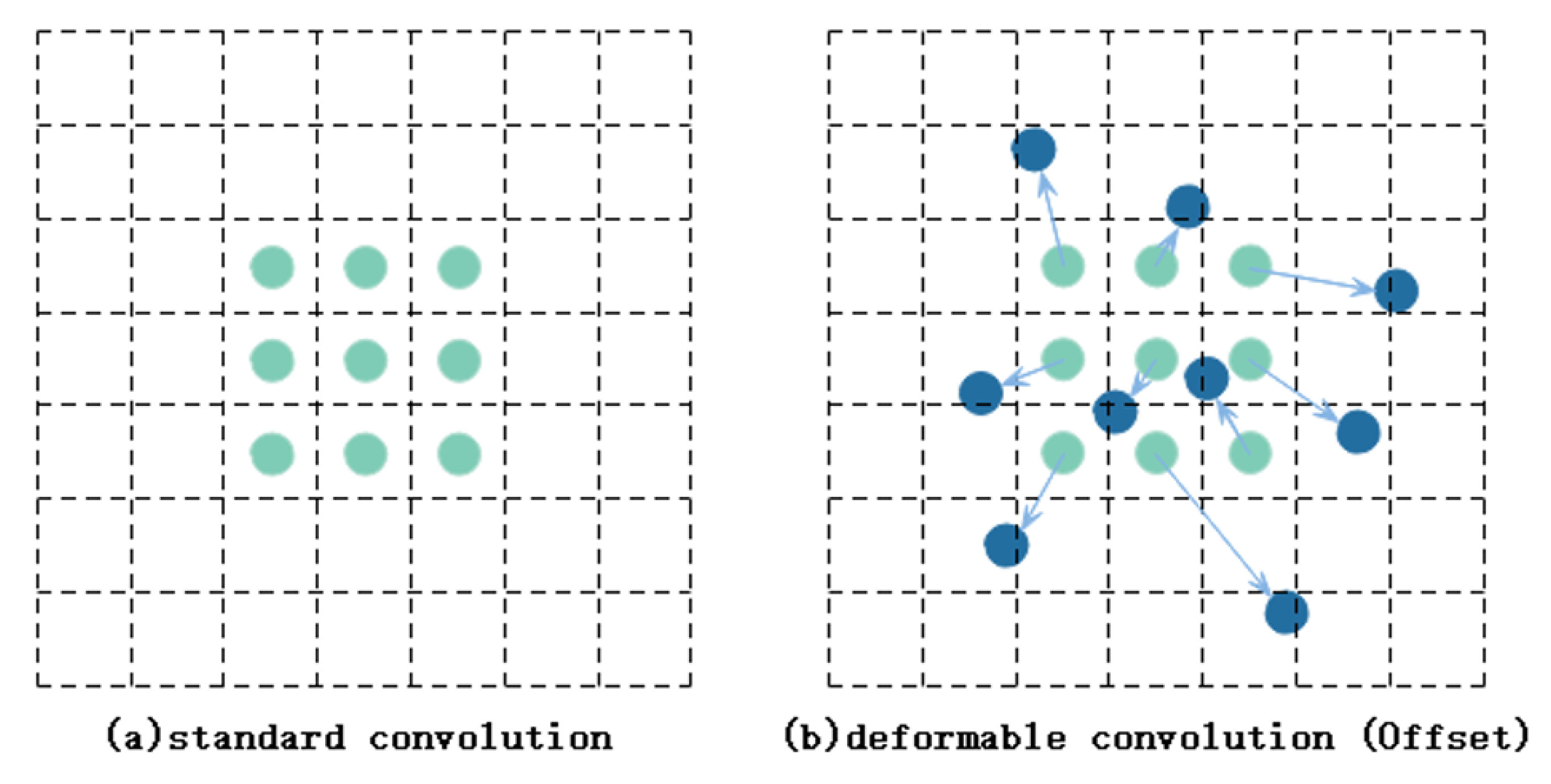
Integration of the Deformable Convolution module [
19] into the C2f network structure introduces the
module. This integration enables adaptive adjustment of the receptive field, enhancing the model’s ability to capture spatial context and object details effectively.
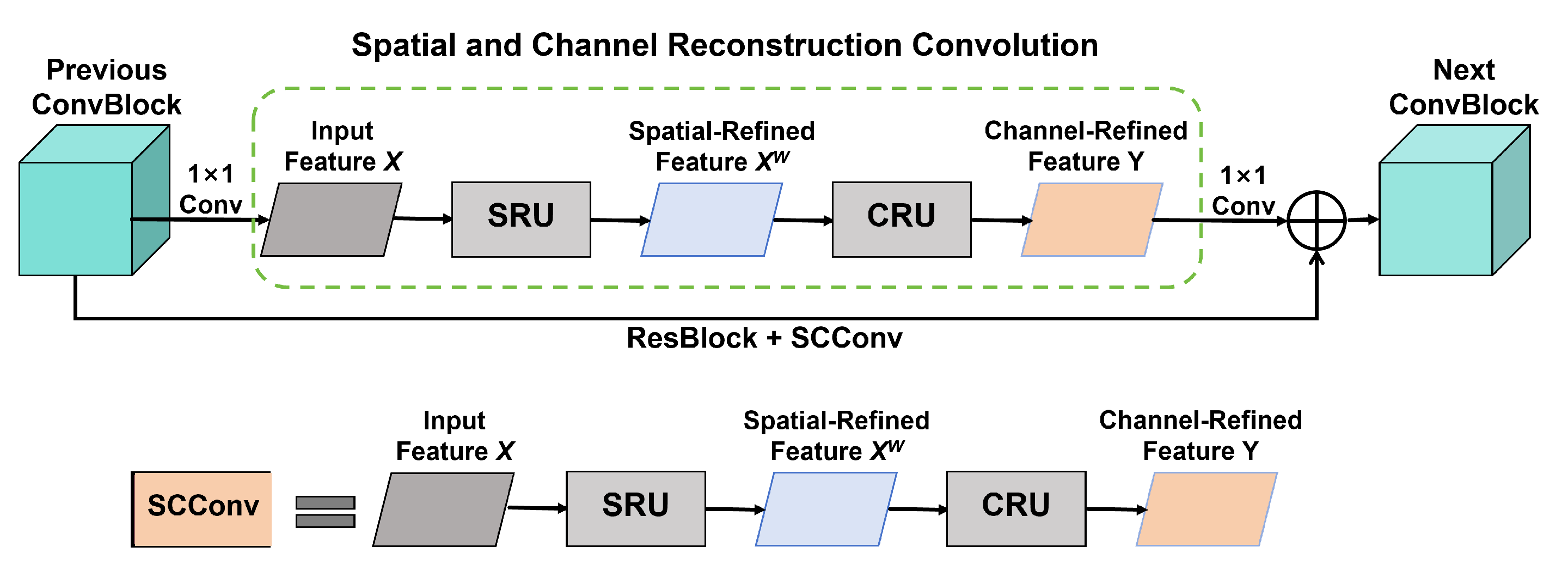
Creation of the
module by integrating the Spatial Channel-wise Convolution module [
20] into the C2f network structure. This aids in optimizing feature representation by capturing channel-wise relationships and semantic information across feature maps.
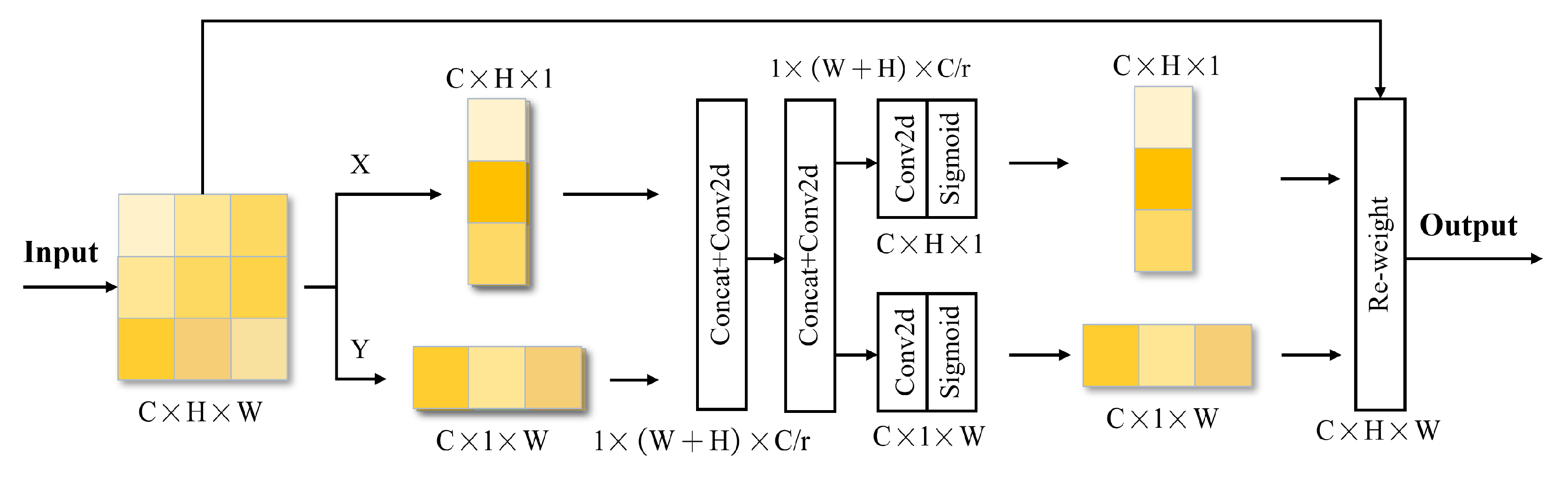
Refinement of the Detect module and introduction of the Coordinate Attention mechanism [
21], which effectively considers and utilizes both inter-channel relationships and positional information.
Integration of WIoU v3 [
22] into the bounding box regression loss, employing a dynamic non-monotonic mechanism to design a more practical gradient allocation strategy. This reduces gradient acquisition for both high- and low-quality samples, enhancing the model’s localization performance and improving its generalization ability.
The remaining Sections of this manuscript comprise the following structure:
Section 2 introduces a specifically tailored dataset for forest fire classification, presenting the methodologies and modules utilized in the conducted experiments. This Section further elucidates the proposed model for forest fire classification detection.
Section 3 furnishes metrics to assess model performance, showcasing experimental results highlighting improvements in each segment.
Section 4 outlines discussions and analyses of the model, along with considerations for future work.
Section 5 provides a comprehensive summary of the entire study.
3. Results
3.1. Training
The experimental hardware and software conditions are detailed in
Table 1.
Table 2 encompasses the parameters of the enhanced woodland-fire-classification detection model, which were initially configured through a preliminary exploration of the default settings of YOLOv8 and subsequently adjusted during the experimental process. Initially, the YOLOv8 model’s learning rate was initialized to 0.01, and the training epochs were adaptively modified depending on the model’s performance on the validation set, with 200 epochs determined as the optimal selection. The dataset for forest fire classification was partitioned into training, validation, and test sets in an 8:1:1 ratio.
3.2. Evaluation Metrics
The main research objective is to classify instances as either positive or negative, where fire and non-fire instances are categorized accordingly. In this context, there are four possible scenarios: True Positive, accurately predicting fires; True Negative, correctly predicting non-fires; False Positive, erroneously identifying non-fires as fires; and False Negative, misclassifying fires as non-fires.
serves as a crucial indicator for assessing the model’s predictive performance, quantified by calculating the ratio of True Positive and True Negative instances to the total expected positive and negative instances. The calculation method is as follows:
, alternatively termed sensitivity or True Positive Rate, assesses the model’s ability to identify positive instances compared to the actual positives. In forest fire detection, a high recall signifies the algorithm’s proficiency in identifying fire occurrences accurately. The calculation method is as follows:
, also known as Positive Predictive Value, measures the ratio of True Positive instances among those labeled as positive. In forest fire detection, high precision suggests that the model can more accurately identify fire instances, reducing the probability of erroneously classifying non-fire instances as fires. The calculation approach is given by:
Assessing the model’s efficacy in forest fire detection necessitates considering Recall and Precision to ensure efficient fire element detection and precise classification simultaneously.
Average Precision (
) emerges as a crucial performance measure, providing a comprehensive evaluation of the Precision–Recall trade-off. The formula for
calculation is as follows:
where the calculation of
involves weighting and averaging the Average Precision values for different classes to obtain
:
where
n represents the total number of categories, and where
is the mean precision value for the
i-th category. In this study, as forest fires belong to a single category,
was employed as the overall performance assessment metric, with an IOU threshold set at 50%, denoted as
.
Frames per Second (FPS) represents the rate at which the model processes images during target detection, providing a measure of the model’s detection speed. The interplay between accuracy and FPS can be assessed by measuring the real-time performance of the model in detection tasks, with FPS and accuracy mutually influencing the model’s feasibility in practical applications.
3.3. Experimental Comparison
This study introduces a bounding box regression loss function, WIoUv3, into the YOLOv8 forest fire detection model. Three alternative bounding box regression loss modules—GIoU, DIoU, and CIoU—are proposed and were compared with WIoU to assess their effectiveness. The objective was to determine the necessity of these enhancement modules and to understand their individual impacts on the performance of the fire detection model. Evaluation of the adequately trained models using the same dataset in our experiments and obtaining corresponding metrics yielded ablation study results as shown in
Table 3. A thorough examination of the ablation study results provides insights into the impact of each enhancement module on model performance, offering valuable data for subsequent optimization and adjustments.
In the first experiment, we combined YOLOv8 with WIOUv3 and further introduced the module. By adjusting the C2f network structure and integrating the concept of Deformable Convolution, the network was adapted to dynamically adjust its receptive field. The experimental results demonstrated a significant improvement in mAP@0.5, increasing from 84.3% to 87.3%. This indicates that the module successfully encouraged the model to more effectively capture target features, especially in handling complex forest fire scenes. The introduction of in the second experiment did not further enhance performance, but such an improvement greatly increased the overall speed of the model.
In the third experiment, the implementation of the CA mechanism aimed to enhance the capture of directional and position-sensitive details regarding the targets. The experimental results demonstrated a notable enhancement in Precision and F1 Score, achieving 90.1% and 86.67%, respectively. Compared to the original model, Precision increased by 8.0%, while the F1 score increased by 4.7%. However, there was a slight decrease in FPS, indicating a slowdown in model processing speed. These findings suggest that CA effectively improves target detection, especially in forest fire scenarios, where directional and position-sensitive attributes are crucial for precise identification.
Despite the significant improvement in performance, the introduction of new modules usually comes with an increase in computational complexity. However, through , the model’s FPS did not significantly decrease, indicating that our model maintains high performance while possessing a certain level of computational efficiency. These results indicate that the proposed improvement modules positively influence forest fire detection performance at different levels, providing a better solution for the practical application of the model.
To comprehensively evaluate the overall performance of the proposed enhanced YOLOv8 model in forest fire detection tasks, this study conducted comparative experiments with other mainstream object detection models, such as YOLOv3, YOLOv5, NAS-FPN, and FSAF. The comparative experimental results are illustrated in
Figure 9. The experimental findings clearly demonstrate the significant superiority of the improved YOLOv8 model in terms of forest fire detection accuracy over other mainstream models, including the widely discussed YOLOv5 and YOLOv7. Additionally, the model’s exceptionally high FPS values highlight its outstanding real-time performance. This overall performance enhancement establishes a solid foundation for the extensive application of the accelerated YOLOv8 model in practical scenarios, particularly in urgent situations requiring efficient and high-precision object detection. It is worth emphasizing that this performance advantage is not limited solely to forest fire detection tasks but also showcases the robust scalability of the model, offering broad possibilities for its application in other object detection tasks.
3.4. Visual Analysis
The evaluation of forest fire target detection outcomes between the enhanced YOLOv8 model and the unmodified YOLOv8 model showed a substantial improvement in the improved model’s detection performance. Specifically, the augmented model demonstrated enhanced capabilities in resisting complex background interference and extracting global information related to forest fire targets. Notably, instances of missed detection and false alarms were significantly reduced, particularly showcasing optimal detection performance for small-scale forest fires. Moreover, the model exhibited commendable detection performance under varying lighting conditions, emphasizing its robustness to changes in illumination and further validating the effectiveness of its individual components. In summary, the proposed model proved to be more suitable for the task compared to the unmodified YOLOv8 model.
To better showcase the feasibility of the model, a selection of images from the test set was utilized for demonstration. The comparative detection results are illustrated in
Figure 10, with the left image representing the unmodified model and the right image displaying our detection model. In scenarios where there was interference resembling forest fire targets, YOLOv8 incorrectly identified such targets as forest fire targets, a shortcoming addressed by the improved YOLOv8.
Examining the detection results in
Figure 11, the YOLOv8 model displayed misfit detection of rectangular box positions for forest fires. Particularly when faced with forest fire targets of varying scales, YOLOv8 exhibited multiple instances of missed detection, leading to suboptimal performance. In contrast, the improved YOLOv8 model aligned more accurately with the actual framework of forest fire targets, eliminating instances of missed detection and improving detection performance for forest fire types.
Promptly identifying initial small-scale forest fires holds paramount importance in forest fire detection. As depicted in
Figure 12, YOLOv8 encountered difficulties in discerning small-scale forest fire targets at a distance. In contrast, the improved YOLOv8 showcased precise detection in the image, attaining a confidence level of 0.92.
As shown in
Figure 13, YOLOv8 encountered difficulties in adequately capturing information about forest fire targets in the image. This challenge led to bounding boxes being restricted to localized areas of the forest fire targets, resulting in inadequate positioning. Conversely, the enhanced YOLOv8 effectively extracted vital details regarding forest fire targets, presenting a more comprehensive perceptual scene.
4. Discussion
The importance of forests to human society cannot be overlooked; hence, the well-timed detection and mitigation of wooded-area fires to minimize their effect on the environment are especially urgent. However, in contrast to other frequent objects, flames showcase a higher morphology and complicated dynamic characteristics. Additionally, the mutual occlusion of timber throughout the whole wooded area makes taking pictures of these points significantly challenging. The current detection that applied sciences go through suffers from a number of deficiencies, making it tough to successfully tackle these issues. Traditional techniques for detecting wooded-area fires require the use of manually created recognizers. These strategies fail to extract the imperative points of flames, resulting in overall subpar detection performance and slow detection speeds.
In deep learning-based detection approaches, the two-stage goal-detection models, such as Faster R-CNN [
34], demand prolonged training periods and detection times, often failing to meet real-time detection requirements. While single-stage goal detection keeps real-time demands, precision barely decreases. SSD [
35] and the YOLO series, exemplified with the aid of the complexity of the SSD debugging system, rely closely on guide expertise. In comparison, the YOLO series, especially YOLOv8, stands out in wooded-area hearth-detection strategies, due to its benefits, such as a compact mannequin size, low deployment costs, and quick detection speed. However, due to massive variants in the scale of woodland fires, obtaining satisfactory cognizance of the consequences remains difficult in the case of multi-scale wooded-area fire-site images. Therefore, wooded-area furnace detection remains a difficult look-up area.
To tackle these challenges, this paper proposes an algorithmic mannequin primarily based on the improved YOLOv8 by adjusting the C2f community shape and integrating it one-by-one with Deformable Convolution and SCConv to shape and . This approach involves augmenting the Channel Attention interest mechanism, modifying backbone network modules, improving the loss function, and employing various techniques. Our experimental results demonstrate that the proposed model exhibits high average precision and rapid frames per second, rendering it applicable to forest fire detection across various types and scales.
The improved YOLOv8 demonstrates high accuracy in forest fire detection; however, there is still room for improvement. Primarily, while fusion modules within the network contribute to enhanced precision, they may inadvertently compromise detection speed. Furthermore, despite comprising 2692 images depicting various scenes and flame types, our research dataset remains relatively small in scale. The operational capabilities and the field of view of the drones may also be limited, especially in complex terrains or harsh weather conditions, such as thick fog or strong winds. This could potentially impact the accuracy and efficiency of fire detection. In our future research endeavors, we will focus on optimizing the model and deploying it on unmanned aerial vehicles equipped with different cameras. Simultaneously, we plan to optimize the dataset to enhance the accuracy of fire detection. Chen et al. [
36] proposed a method utilizing a multi-modal dataset collected by drones, achieving high accuracy in detecting fire and smoke pixels by collecting dual-channel videos containing RGB and thermal images. Furthermore, they provided rich auxiliary data, such as georeferenced point clouds, orthomosaics, and weather information to offer more comprehensive contextual information. This served as inspiration for our work. Mashraqi Aisha M. et al. [
37] emphasized the design of forest fire detection and classification in drone imagery, using the modified deep learning (DIFFDC-MDL) model. Remarkably, they employed the Shuffled Frog Leaping algorithm and simulated the results using a database containing fire and non-fire samples, thereby enhancing the classification accuracy of the DIFFDC-MDL system. In the future, we will explore the use of metaheuristic algorithms to further improve the model.
5. Conclusions
Global forest fires are increasingly frequent, and the challenges associated with their control have risen. Failure to address them promptly results in significant financial losses and safety issues. Flames exhibit a greater diversity and complexity in both morphology and dynamic features compared to other objects, and this is particularly challenging, due to the mutual occlusion of trees in forests. Hence, the identification and recognition of fire types, coupled with corresponding fire suppression measures, hold not only developmental potential but also practical importance.
In this work, an enhanced model for forest fire classification and detection is presented, leveraging the YOLOv8 architecture. By modifying the C2f network structure and integrating Deformable Convolution and SCConv, resulting in and , the model achieves adaptive adjustment of the receptive field. This leads to a reduction in parameters and FLOPs while enhancing feature representation. The incorporation of Coordinate Attention enhances the Detect section, improving the capturing and utilization of features, consequently enhancing fire detection accuracy. WIoU v3 is incorporated into the loss function for bounding box regression, utilizing a dynamic mechanism that is non-monotonic to establish a more rational distribution strategy for gradient gain. Our experimental results showcased the model’s superiority in forest fire performance compared to the YOLOv8 algorithm. Our future research will focus on optimizing the model, particularly in balancing accuracy and detection speed within the fusion module, and deploying the model on drones equipped with different cameras. Additionally, our plans involve expanding the dataset size to enhance fire detection accuracy.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}