
Vast Parameter Space Exploration of the Virtual Brain: A Modular Framework for Accelerating the Multi-Scale Simulation of Human Brain Dynamics
 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Mean-Field Model
2.2. Transfer Function
2.3. TVB-AdEx to GPUS
2.4. Output
2.5. MPI
2.6. Analysis Metrics
3. Results
3.1. Functional Connectivity
3.2. Vast Parameter Space Exploration and Analysis
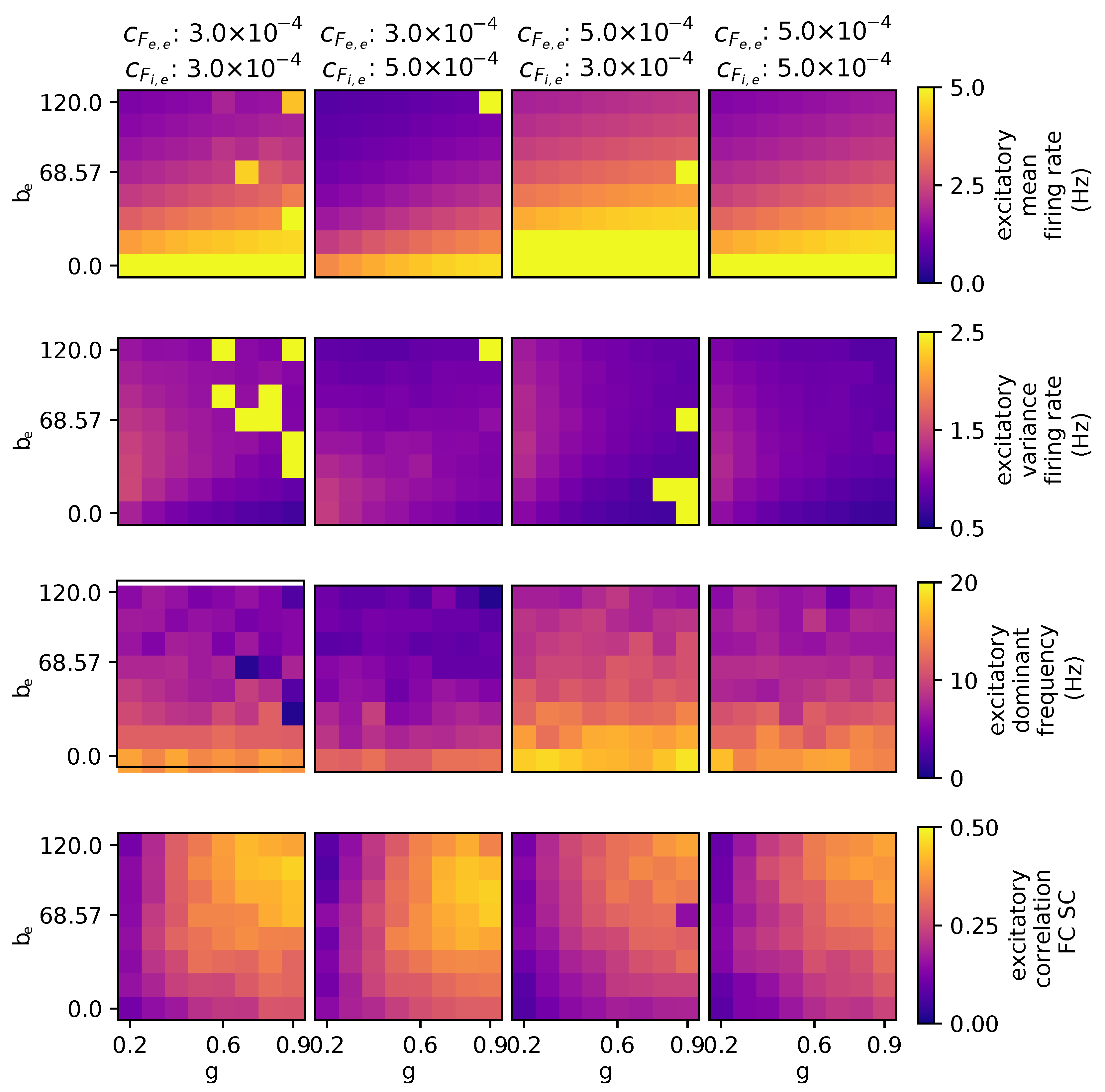
3.2.1. The Effect of Modulating Coupling and Spike-Frequency Adaptation
3.2.2. The Effects of Modulating the Adaptation Time Constant
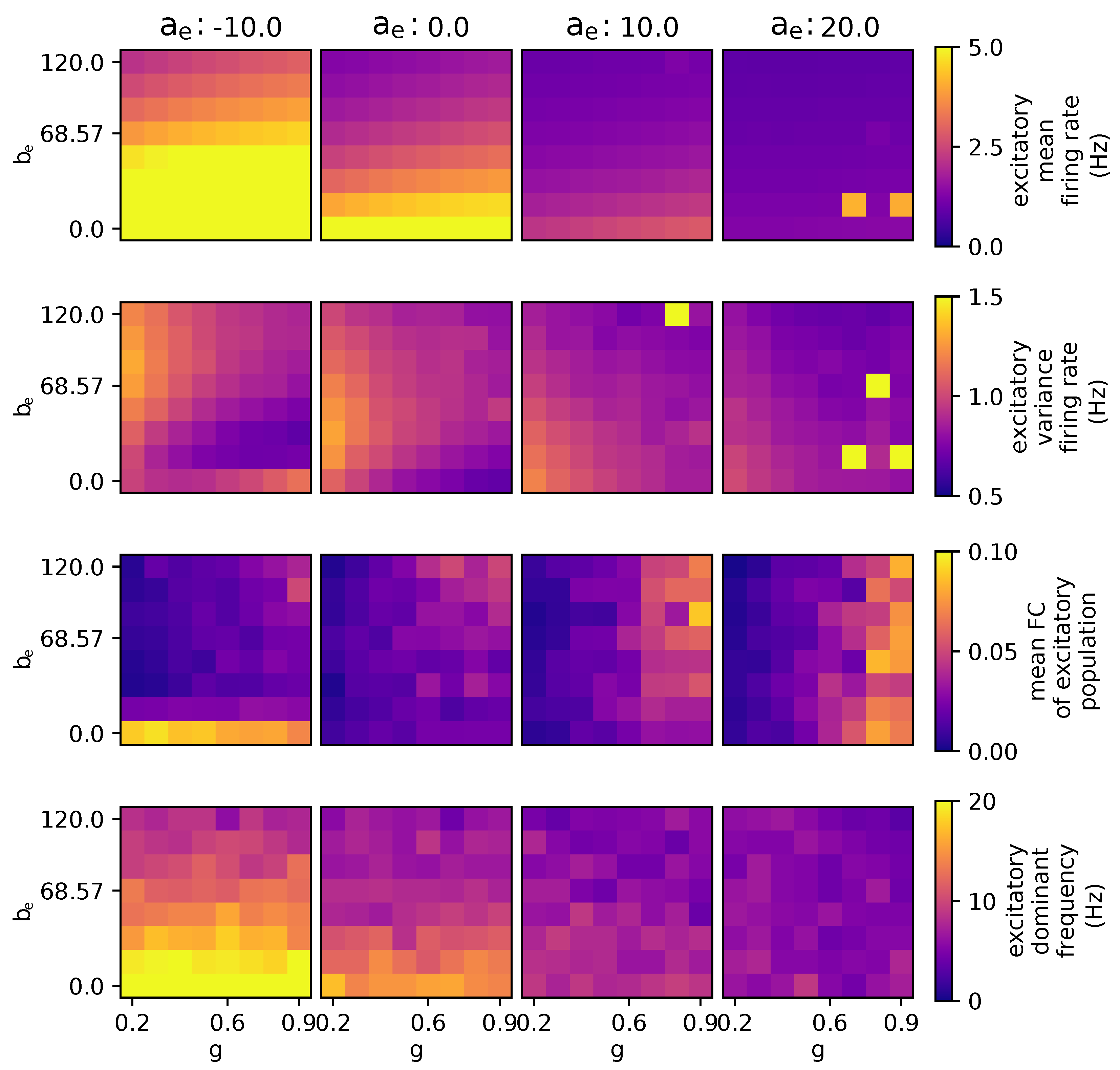
3.2.3. The Effects of Modulating Excitatory Subthreshold Adaption Conductance
3.2.4. The Effects of Stimulating External Excitatory and Inhibitory Populations
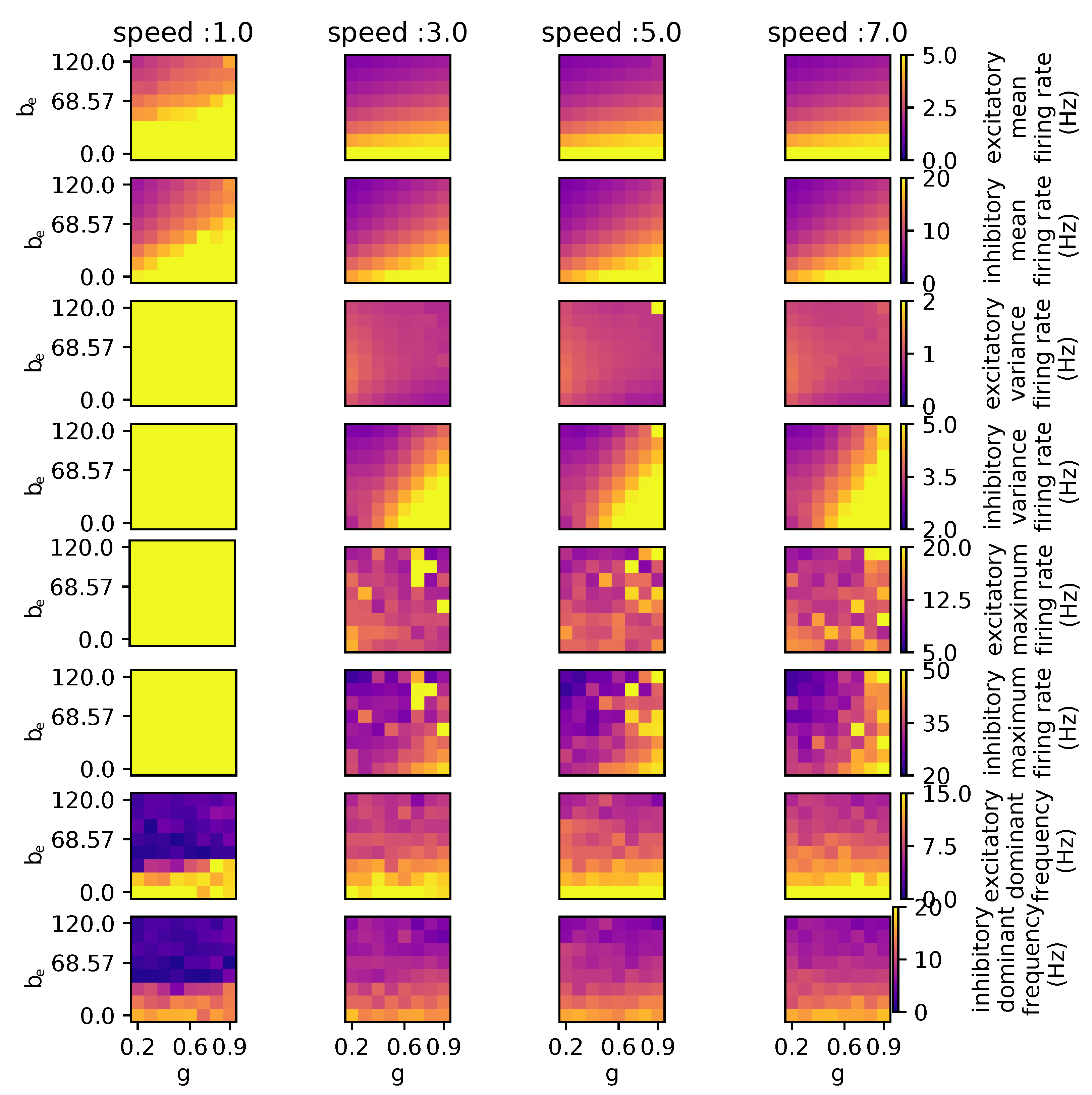
3.2.5. Pathology and the Effect of Modulating the Propagation Speed of Action Potentials through the Connectome
3.3. Performance
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goldman, J.S.; Tort-Colet, N.; Di Volo, M.; Susin, E.; Bouté, J.; Dali, M.; Carlu, M.; Nghiem, T.A.; Górski, T.; Destexhe, A. Bridging single neuron dynamics to global brain states. Front. Syst. Neurosci. 2019, 13, 75. [Google Scholar] [CrossRef]
- Vertes, P.E. Computational Models of Typical and Atypical Brain Network Development. Biol. Psychiatry 2023, 93, 464–470. [Google Scholar] [CrossRef]
- Cabral, J.; Castaldo, F.; Vohryzek, J.; Litvak, V.; Bick, C.; Lambiotte, R.; Friston, K.; Kringelbach, M.L.; Deco, G. Metastable oscillatory modes emerge from synchronization in the brain spacetime connectome. Commun. Phys. 2022, 5, 184. [Google Scholar] [CrossRef]
- Mashour, G.A.; Roelfsema, P.; Changeux, J.-P.; Dehaene, S. Conscious Processing and the Global Neuronal Workspace Hypothesis. Neuron 2020, 105, 776–798. [Google Scholar] [CrossRef] [PubMed]
- Luppi, A.I.; Vohryzek, J.; Kringelbach, M.L.; Mediano, P.A.M.; Craig, M.M.; Adapa, R.; Carhart-Harris, R.L.; Roseman, L.; Peattie, A.R.D.; Manktelow, A.E.; et al. Distributed harmonic patterns of structure-function dependence orchestrate human consciousness. Commun. Biol. 2023, 6, 117. [Google Scholar] [CrossRef] [PubMed]
- Stefanovski, L.; Triebkorn, P.; Spiegler, A.; Diaz-Cortes, M.A.; Solodkin, A.; Jirsa, V.; McIntosh, A.R.; Ritter, P.; Initiative, A.D.N. Linking molecular pathways and large-scale computational modeling to assess candidate disease mechanisms and pharmacodynamics in Alzheimer’s disease. Front. Comput. Neurosci. 2019, 13, 54. [Google Scholar] [CrossRef] [PubMed]
- Shettigar, N.; Yang, C.-L.; Tu, K.-C.; Suh, C.S. On The Biophysical Complexity of Brain Dynamics: An Outlook. Dynamics 2022, 2, 114–148. [Google Scholar] [CrossRef]
- Porta, L.D.; Barbero-Castillo, A.; Sanchez-Sanchez, J.M.; Sanchez-Vives, M.V. M-current modulation of cortical slow oscillations: Network dynamics and computational modeling. PLoS Comput. Biol. 2023, 19, e1011246. [Google Scholar] [CrossRef]
- Goldman, J.S.; Kusch, L.; Aquilue, D.; Yalçınkaya, B.H.; Depannemaecker, D.; Ancourt, K.; Nghiem, T.A.E.; Jirsa, V.; Destexhe, A. A comprehensive neural simulation of slow-wave sleep and highly responsive wakefulness dynamics. Front. Comput. Neurosci. 2023, 16, 1058957. [Google Scholar] [CrossRef] [PubMed]
- Aquilué-Llorens, D.; Goldman, J.S.; Destexhe, A. High-density exploration of activity states in a multi-area brain model. Neuroinformatics 2024, in press. [Google Scholar] [CrossRef] [PubMed]
- Cakan, C.; Jajcay, N.; Obermayer, K. neurolib: A Simulation Framework for Whole-Brain Neural Mass Modeling. Cogn. Comput. 2021, 2, 1132–1152. [Google Scholar] [CrossRef]
- Fasoli, D.; Cattani, A.; Panzeri, S. Transitions between asynchronous and synchronous states: A theory of correlations in small neural circuits. J. Comput. Neurosci. 2018, 44, 25–43. [Google Scholar] [CrossRef]
- Girardi-Schappo, M.; Galera, E.F.; Carvalho, T.T.A.; Brochini, L.; Kamiji, N.L.; Roque, A.C.; Kinouchi, O. A unified theory of E/I synaptic balance, quasicritical neuronal avalanches and asynchronous irregular spiking. J. Phys. Complex. 2021, 2, 045001. [Google Scholar] [CrossRef]
- Sacha, M.; Goldman, J.S.; Kusch, L.; Destexhe, A. Asynchronous and slow-wave oscillatory states in connectome-based models of mouse, monkey and human cerebral cortex. Appl. Sci. 2024, 14, 1063. [Google Scholar] [CrossRef]
- Schirner, M.; McIntosh, A.R.; Jirsa, V.; Deco, G.; Ritter, P. Inferring multi-scale neural mechanisms with brain network modelling. eLife 2018, 7, e28927. [Google Scholar] [CrossRef]
- Hashemi, M.; Vattikonda, A.; Sip, V.; Guye, M.; Bartolomei, F.; Woodman, M.M.; Jirsa, V.K. The Bayesian Virtual Epileptic Patient: A probabilistic framework designed to infer the spatial map of epileptogenicity in a personalized large-scale brain model of epilepsy spread. NeuroImage 2020, 217, 116839. [Google Scholar] [CrossRef] [PubMed]
- Lu, M.; Guo, Z.; Gao, Z.; Cao, Y.; Fu, J. Multiscale Brain Network Models and Their Applications in Neuropsychiatric Diseases. Electronics 2022, 11, 3468. [Google Scholar] [CrossRef]
- Millán, A.P.; van Straaten, E.C.W.; Stam, C.J.; Nissen, I.A.; Idema, S.; Baayen, J.C.; Mieghem, P.V.; Hillebrand, A. The role of epidemic spreading in seizure dynamics and epilepsy surgery. Netw. Neurosci. 2023, 7, 811–843. [Google Scholar] [CrossRef]
- Zerlaut, Y.; Chemla, S.; Chavane, F.; Destexhe, A. Modeling mesoscopic cortical dynamics using a mean-field model of conductance-based networks of adaptive exponential integrate-and-fire neurons. J. Comput. Neurosci. 2018, 44, 45–61. [Google Scholar] [CrossRef]
- Di Volo, M.; Romagnoni, A.; Capone, C.; Destexhe, A. Biologically Realistic Mean-Field Models of Conductance-Based Networks of Spiking Neurons with Adaptation. Neural Comput. 2019, 31, 653–680. [Google Scholar] [CrossRef] [PubMed]
- Sanzleon, P.; Knock, S.A.; Woodman, M.M.; Domide, L.; Mersmann, J.; Mcintosh, A.R.; Jirsa, V. The virtual brain: A simulator of primate brain network dynamics. Front. Neuroinform. 2013, 7, 10. [Google Scholar] [CrossRef]
- Van der Vlag, M.; Woodman, M.; Fousek, J.; Diaz-Pier, S.; Pérez Martín, A.; Jirsa, V.; Morrison, A. RateML: A Code Generation Tool for Brain Network Models. Front. Netw. Physiol. 2022, 2, 826345. [Google Scholar] [CrossRef] [PubMed]
- Schirner, M.; Domide, L.; Perdikis, D.; Triebkorn, P.; Stefanovski, L.; Pai, R.; Popa, P.; Valean, B.; Palmer, J.; Langford, C.; et al. Brain Modelling as a Service: The Virtual Brain on EBRAINS. NeuroImage 2022, 251, 118973. [Google Scholar] [CrossRef]
- Gast, R.; Rose, D.; Salomon, C.; Möller, H.E.; Weiskopf, N.; Knösche, T.R. PyRates—A Python framework for rate-based neural simulations. PLoS ONE 2019, 14, e0225900. [Google Scholar] [CrossRef]
- Brette, R.; Gerstner, W. Adaptive Exponential Integrate-and-Fire Model as an Effective Description of Neuronal Activity. J. Neurophysiol. 2005, 94, 3637–3642. [Google Scholar] [CrossRef] [PubMed]
- El Boustani, S.; Destexhe, A. A Master Equation Formalism for Macroscopic Modeling of Asynchronous Irregular Activity States. Neural Comput. 2009, 21, 46–100. [Google Scholar] [CrossRef]
- Vlag, M.A.v.d.; Smaragdos, G.; Al-Ars, Z.; Strydis, C. Exploring Complex Brain-Simulation Workloads on Multi-GPU Deployments. ACM Trans. Archit. Code Optim. 2019, 16, 1–25. [Google Scholar] [CrossRef]
- Carlu, M.; Chehab, O.; Porta, L.D.; Depannemaecker, D.; Héricé, C.; Jedynak, M.; Ersöz, E.K.; Muratore, P.; Souihel, S.; Capone, C.; et al. A mean-field approach to the dynamics of networks of complex neurons, from nonlinear Integrate-and-Fire to Hodgkin–Huxley models. J. Neurophysiol. 2020, 123, 1042–1051. [Google Scholar] [CrossRef]
- Stephan, K.E.; Weiskopf, N.; Drysdale, P.M.; Robinson, P.A.; Friston, K.J. Comparing hemodynamic models with DCM. NeuroImage 2007, 38, 387–401. [Google Scholar] [CrossRef] [PubMed]
- Silva Pereira, S.; Hindriks, R.; Mühlberg, S.; Maris, E.; Ede, F.; Griffa, A.; Hagmann, P.; Deco, G. Effect of field spread on resting-state MEG functional network analysis: A computational modeling study. Brain Connect. 2017, 7, 541–557. [Google Scholar] [CrossRef] [PubMed]
- Sazonov, A.V.; Ho, C.K.; Bergmans, J.W.; Arends, J.B.; Griep, P.A.; Verbitskiy, E.A.; Cluitmans, P.J.; Boon, P.A. An investigation of the phase locking index for measuring of interdependency of cortical source signals recorded in the EEG. Biol. Cybern. 2009, 100, 129–146. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Melozzi, F.; Bergmann, E.; Harris, J.A.; Kahn, I.; Jirsa, V.; Bernard, C. Individual structural features constrain the mouse functional connectome. Proc. Natl. Acad. Sci. USA 2019, 116, 26961–26969. [Google Scholar] [CrossRef] [PubMed]
- Montbrió, E.; Pazó, D.; Roxin, A. Macroscopic description for networks of spiking neurons. Phys. Rev. X 2015, 5, 021028. [Google Scholar] [CrossRef]
- Kuramoto, Y. International symposium on mathematical problems in theoretical physics. Lect. Notes Phys. 1975, 30, 420. [Google Scholar]
- Wong, K.F.; Wang, X.J. A recurrent network mechanism of time integration in perceptual decisions. J. Neurosci. 2006, 26, 1314–1328. [Google Scholar] [CrossRef]
- Jirsa, V.K.; Stacey, W.C.; Quilichini, P.P.; Ivanov, A.I.; Bernard, C. On the nature of seizure dynamics. Brain 2014, 137, 2210–2230. [Google Scholar] [CrossRef]
- Yegenoglu, A.; Subramoney, A.; Hater, T.; Jimenez-Romero, C.; Klijn, W.; Pérez Martín, A.; van der Vlag, M.; Herty, M.; Morrison, A.; Diaz-Pier, S. Exploring Parameter and Hyper-Parameter Spaces of Neuroscience Models on High Performance Computers With Learning to Learn. Front. Comput. Neurosci. 2022, 16, 885207. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cell Type | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RS-Cell | −48.9 | 5.1 | −25.0 | 1.4 | −0.41 | 10.5 | −36.0 | 7.4 | 1.2 | 40.7 |
| FS-Cell | −51.4 | 0.4 | −8.3 | 0.2 | −0.5 | 1.4 | −14.6 | 4.5 | 2.8 | 15.3 |
| Metric | Description |
|---|---|
| mean_FC | Average FC from Pearson corr. of time-series firing rate |
| mean_PLI | Average PLI between brain regions. |
| mean_UD_duration | Mean duration of UP and DOWN states |
| psd_fmax_ampmax | PSD frequency peaks and amplitude |
| fit_psd_slope | Fits |
| Name | Range | Resolution | Description |
|---|---|---|---|
| g | [0.1, 0.9] | 8 | Coupling strength connectome |
| [0, 100] | 8 | Spike-frequency adaptation [pA] | |
| [, ] | 4 | Scaling weight of noise | |
| [1, 7] | 4 | Connectome speed [m/s] | |
| [250, 750] | 4 | Adaptation time constant exc. neurons [ms] | |
| [−10, 20] | 4 | Subthreshold adaptation conductance [nS] | |
| 2 | External input [Hz] | ||
| 2 | External input [Hz] | ||
| 2 | External input [Hz] | ||
| 2 | External input [Hz] |
| Nodes | Memory (GB) | #TVBs |
|---|---|---|
| 1 | 36,330 | 16,384 |
| 2 | 18,622 | 8192 |
| 4 | 9768 | 4096 |
| 8 | 5336 | 2048 |
| 16 | 3120 | 1024 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van der Vlag, M.; Kusch, L.; Destexhe, A.; Jirsa, V.; Diaz-Pier, S.; Goldman, J.S. Vast Parameter Space Exploration of the Virtual Brain: A Modular Framework for Accelerating the Multi-Scale Simulation of Human Brain Dynamics. Appl. Sci. 2024, 14, 2211. https://doi.org/10.3390/app14052211
van der Vlag M, Kusch L, Destexhe A, Jirsa V, Diaz-Pier S, Goldman JS. Vast Parameter Space Exploration of the Virtual Brain: A Modular Framework for Accelerating the Multi-Scale Simulation of Human Brain Dynamics. Applied Sciences. 2024; 14(5):2211. https://doi.org/10.3390/app14052211
Chicago/Turabian Stylevan der Vlag, Michiel, Lionel Kusch, Alain Destexhe, Viktor Jirsa, Sandra Diaz-Pier, and Jennifer S. Goldman. 2024. "Vast Parameter Space Exploration of the Virtual Brain: A Modular Framework for Accelerating the Multi-Scale Simulation of Human Brain Dynamics" Applied Sciences 14, no. 5: 2211. https://doi.org/10.3390/app14052211
APA Stylevan der Vlag, M., Kusch, L., Destexhe, A., Jirsa, V., Diaz-Pier, S., & Goldman, J. S. (2024). Vast Parameter Space Exploration of the Virtual Brain: A Modular Framework for Accelerating the Multi-Scale Simulation of Human Brain Dynamics. Applied Sciences, 14(5), 2211. https://doi.org/10.3390/app14052211