
Improving the Quality of Industrial Robot Control Using an Iterative Learning Method with Online Optimal Learning and Intelligent Online Learning Function Parameters


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
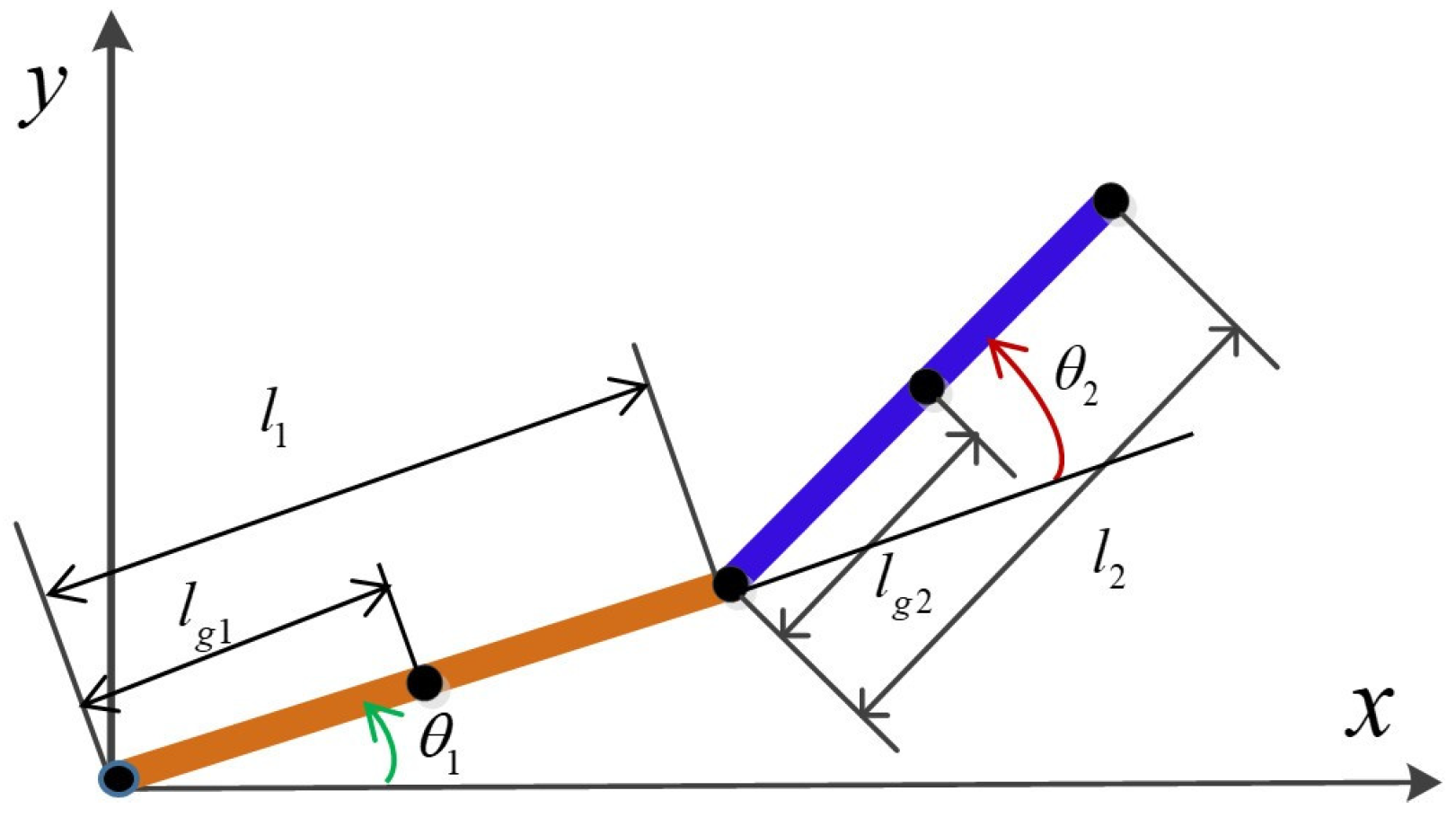
2. Robot Planar Dynamic Model
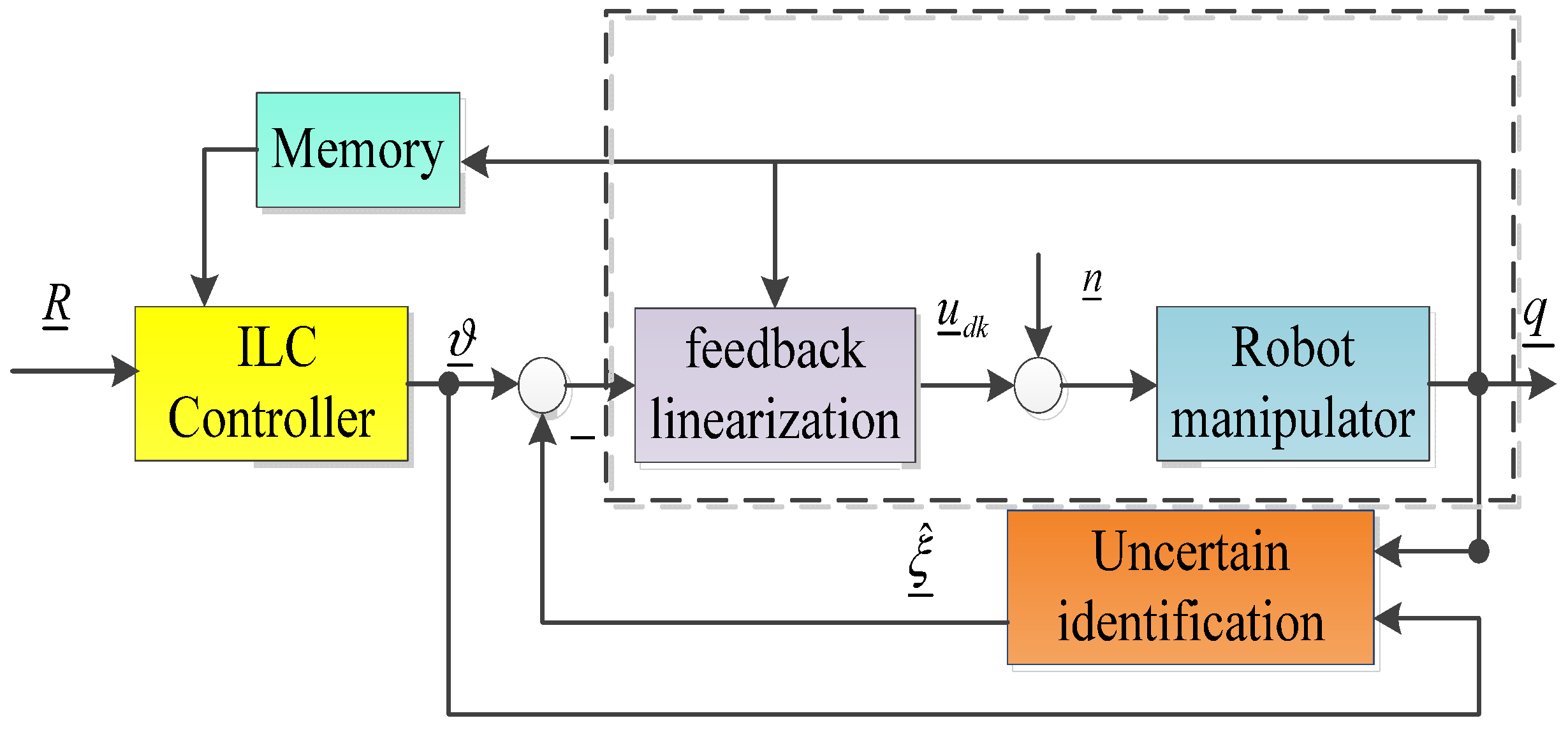
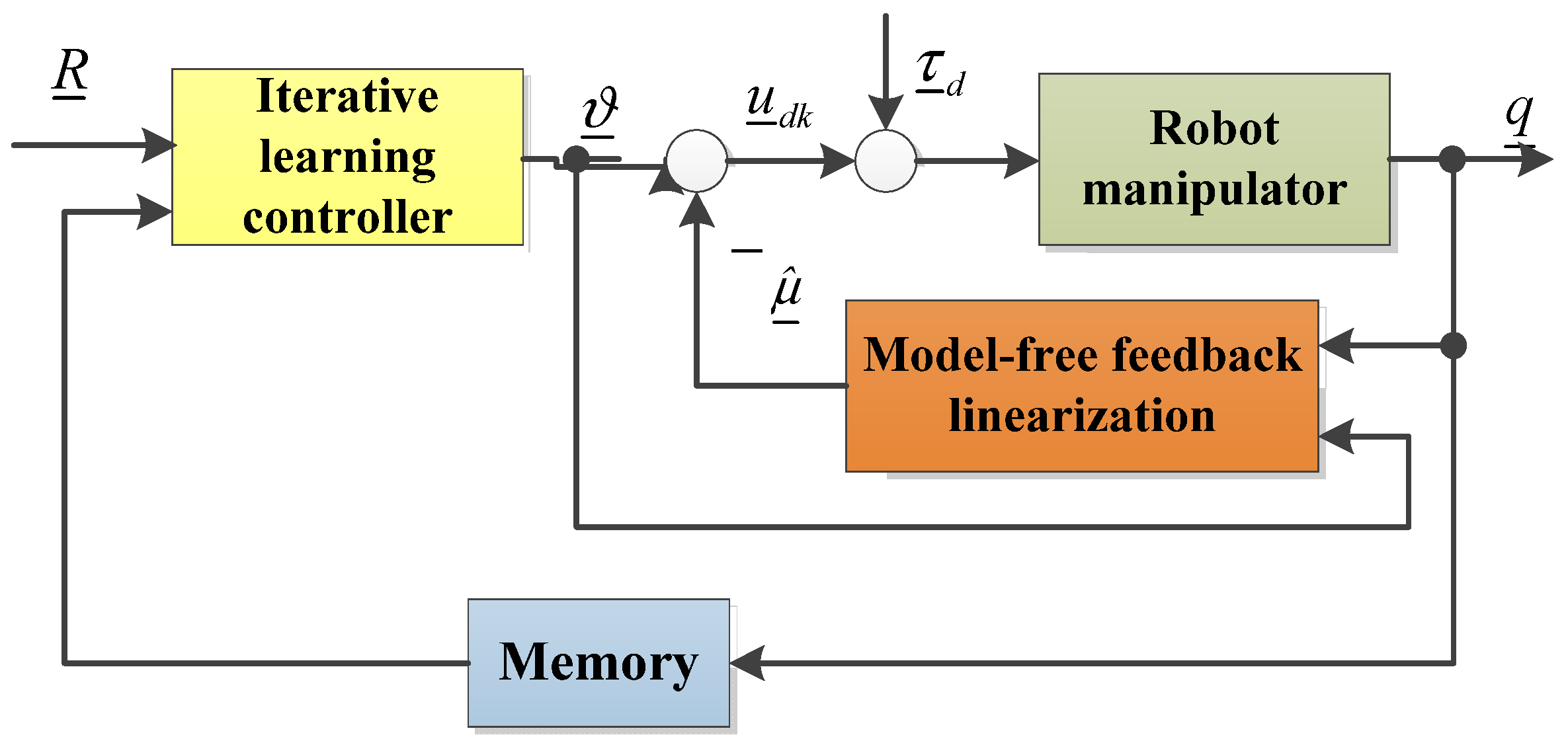
3. Two Structure Diagrams for Robot Control Using the Iterative Learning Method
4. Structure of the First Diagram for Robot Control, the Iterative Learning Method
4.1. Algorithm Content According to the First Control Diagram
| Algorithm 1: The first structure for robot control, the iterative learning method, is with function parameters smart online learning. | |
| 1 | Assign Choose ; Calculate . Choose K; Assign small value . |
| 2 | while continue the control do |
| 3 | for do |
| 4 | Send to into uncertain control (9) and determine . |
| 5 | Calculate . |
| 6 | Establish and calculate . |
| 7 | end for |
| 8 | Set up the sum vector từ , theo (12) |
| 9 | Update vector from its existing value according to (11) that is, calculate the values , for the next try. |
| 10 | Set |
| 11 | end while |
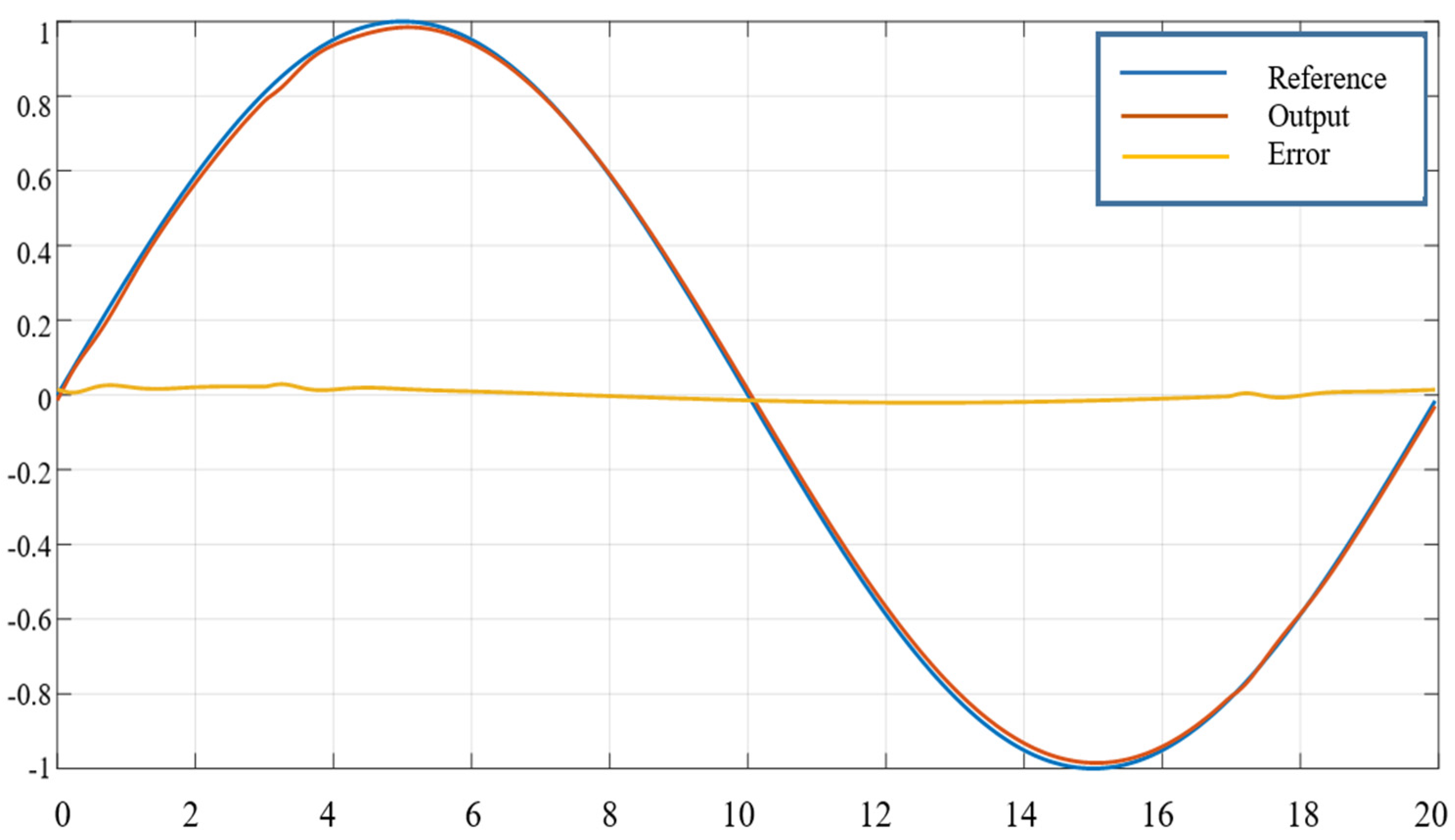
4.2. Applied to Robot Control
5. The Structure of the Second Iterative Learning Controller with Model-Free Determination of Optimal Learning Parameters for an Industrial Robot
5.1. Algorithm Content According to the First Control Diagram
5.2. Model-Free Disturbance Compensation for Internal Loop Control by Feedback Linearization
5.3. Outer Loop Control Is by Iterative Learning Controller Design
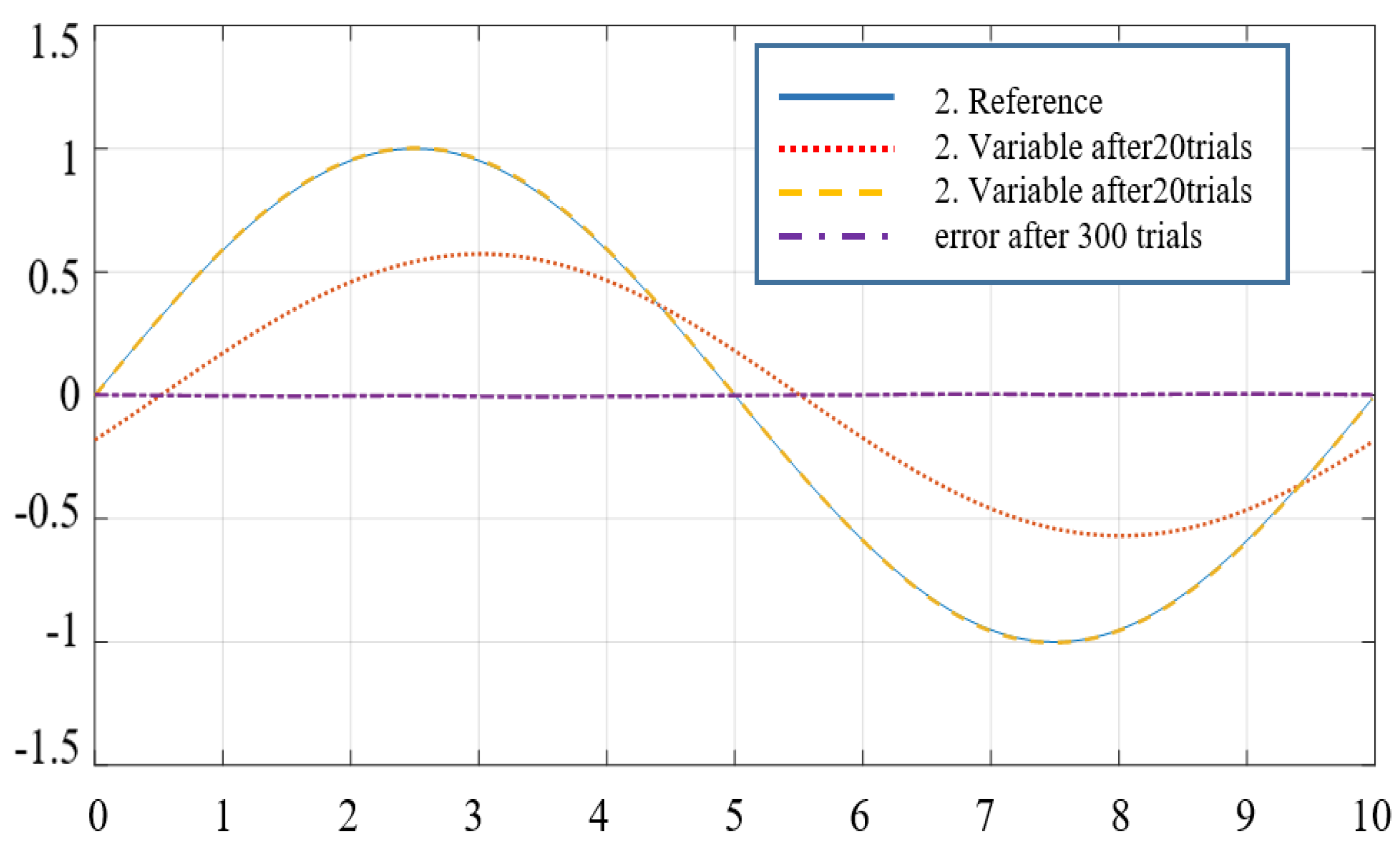
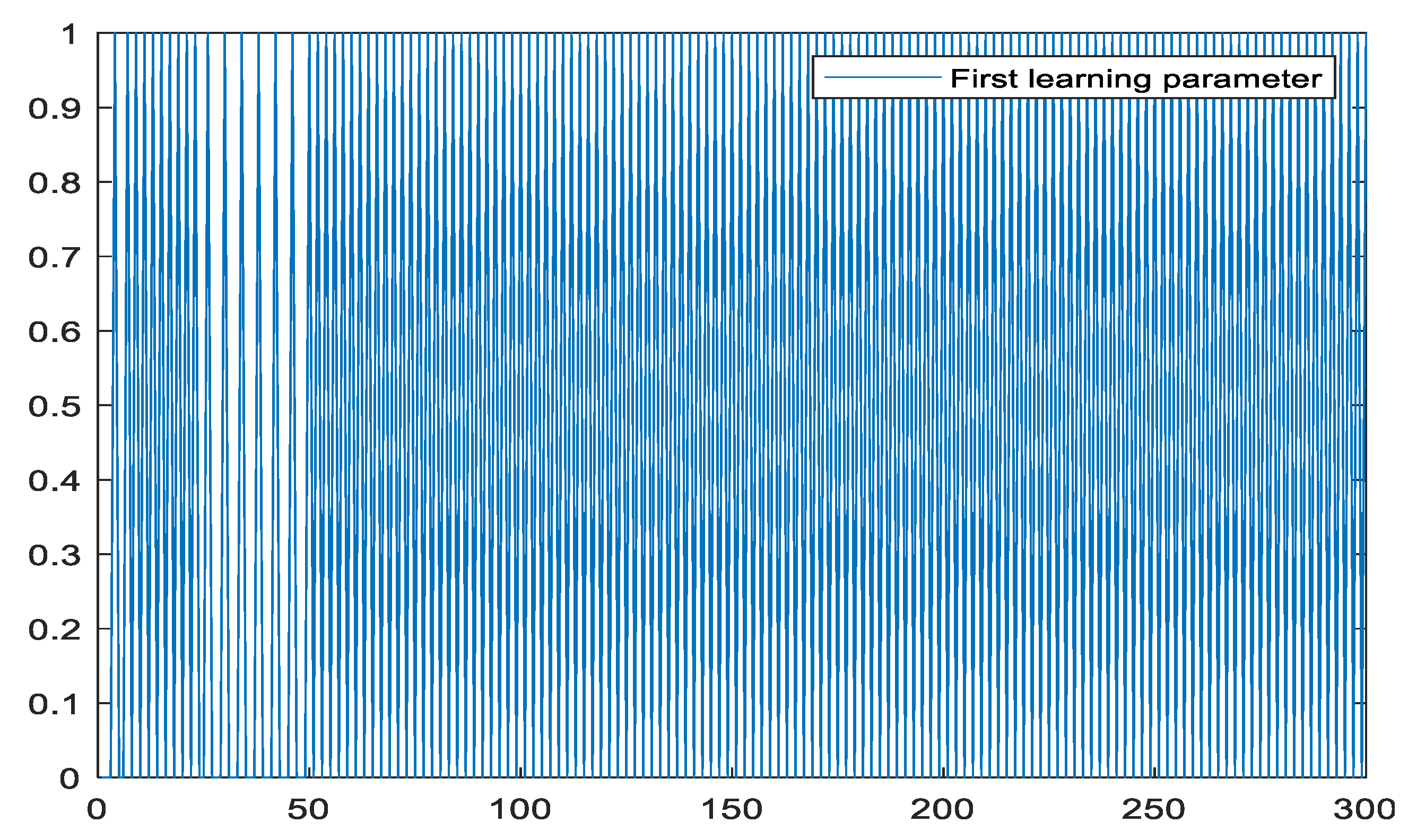
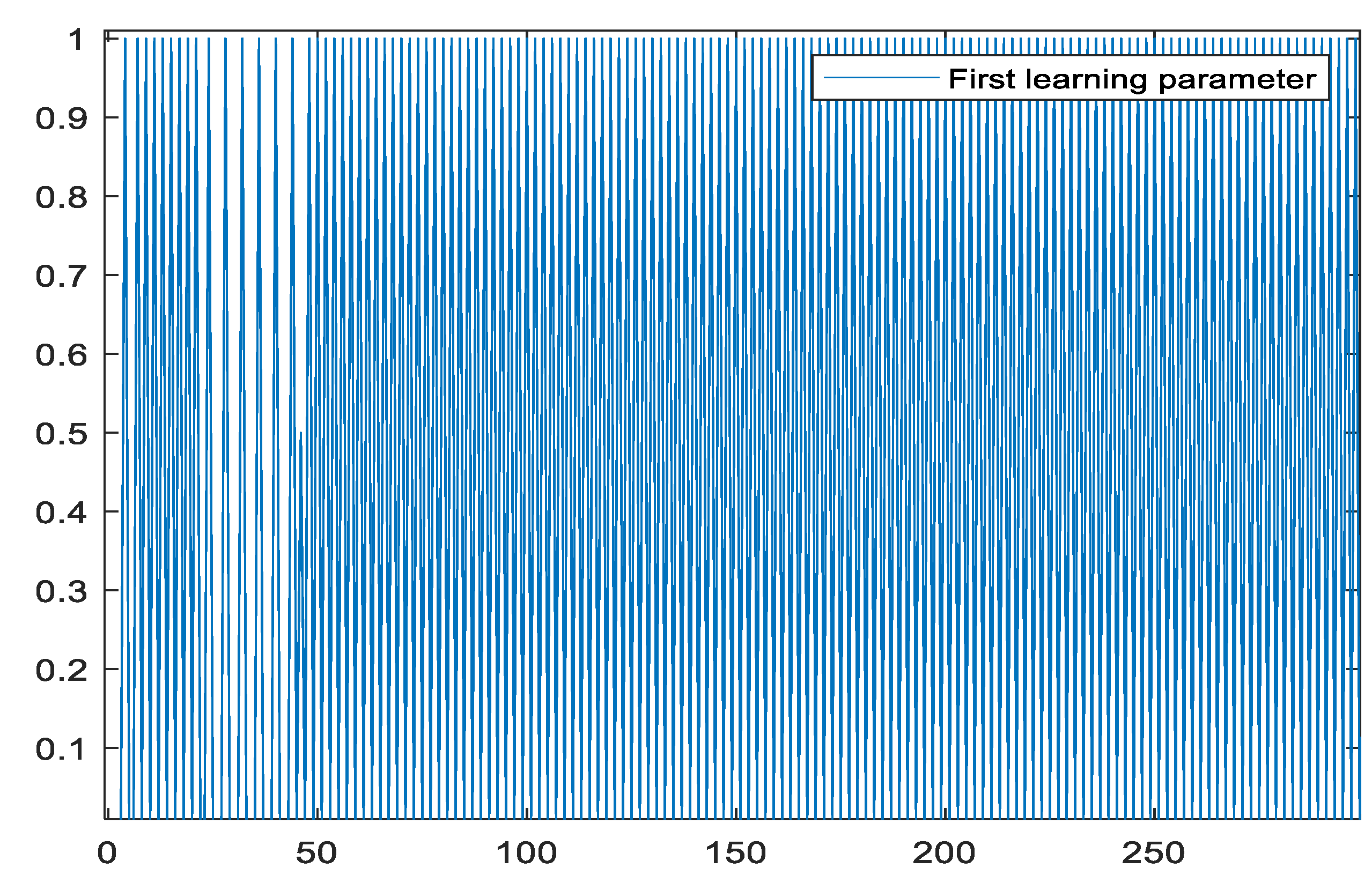
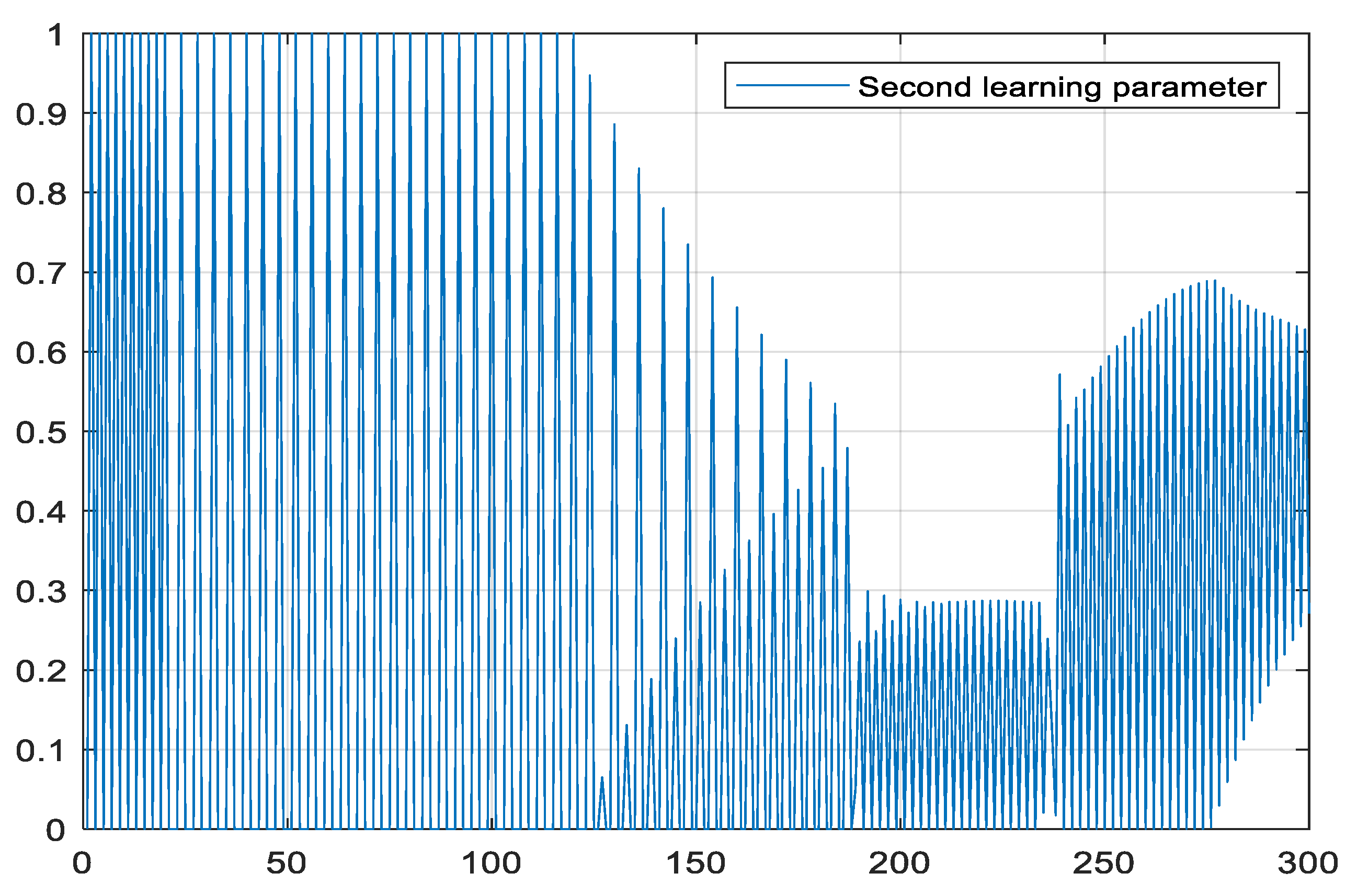
5.4. The Closed-Loop System’s Performance and Control Algorithm
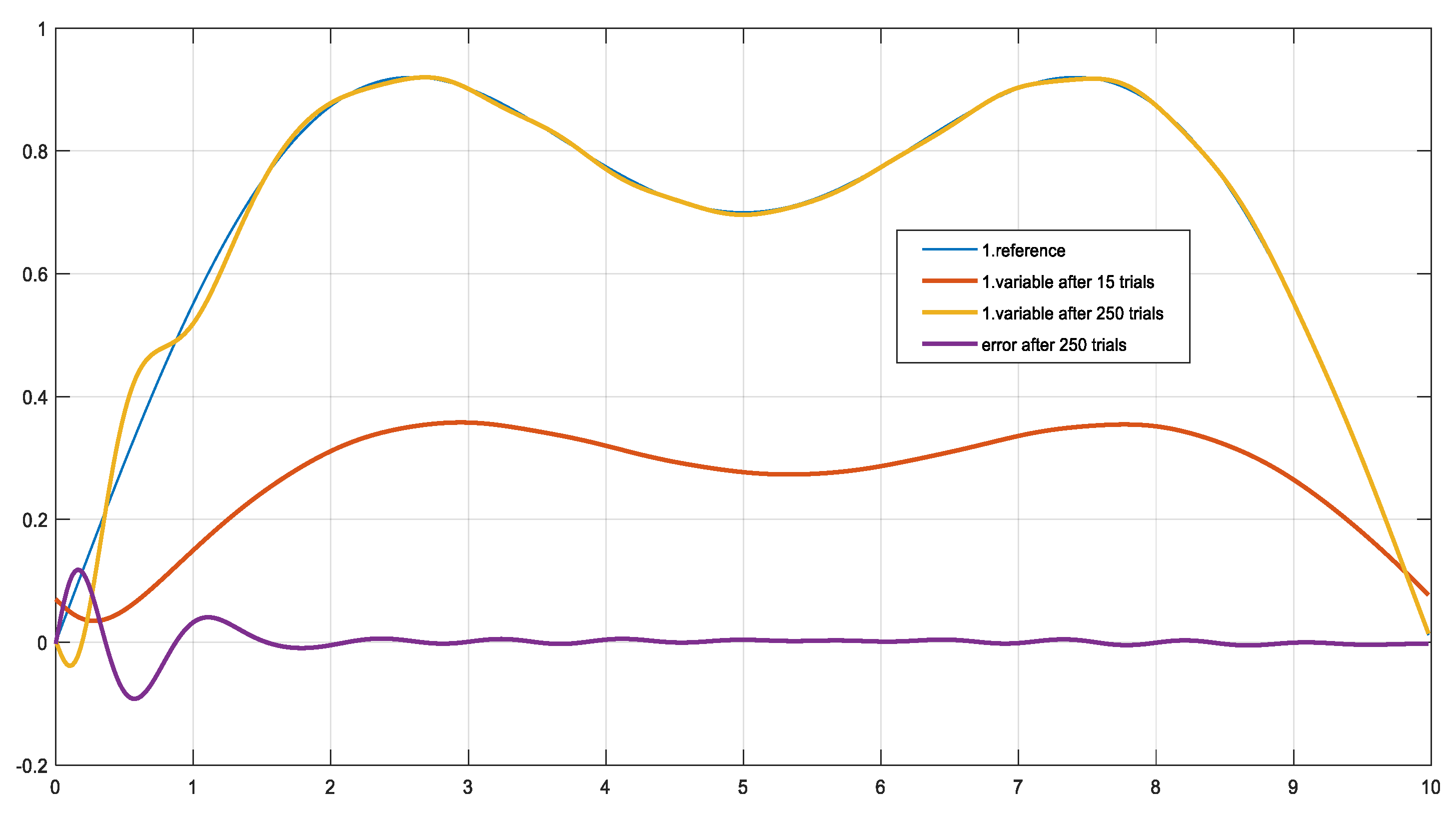
- The validity of Theorem 2 was confirmed by:
| Algorithm 2: The structure of the second iterative learning controller with model-free determination of optimal learning parameters for an industrial robot | |
| 1 | Choose two matrices ,, given in (25) become Hurwitz. Determine given in (25) and given in (28). Choose . Calculate . Determine given in (23) Choose learning and tracking error . Allocate . Choose learning parameter K so that Ф of (28) becomes Schur. |
| 2 | while continue the control do |
| 3 | for do |
| 4 | Send to robot for a while of . |
| measure , . | |
| 5 | calculate . |
| 6 | end for |
| 7 | assemble . |
| 8 | calculate and |
| 9 | end while |
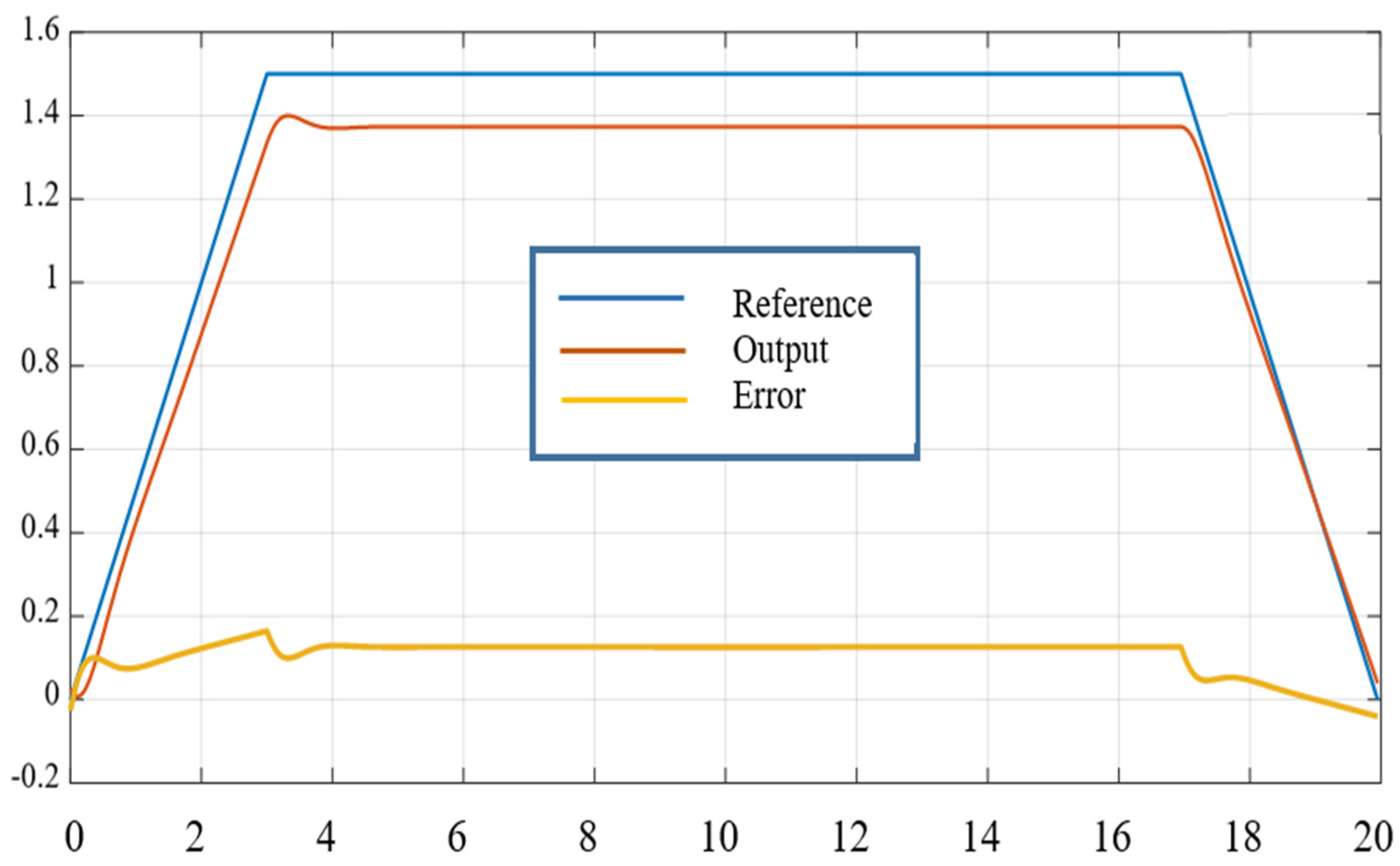
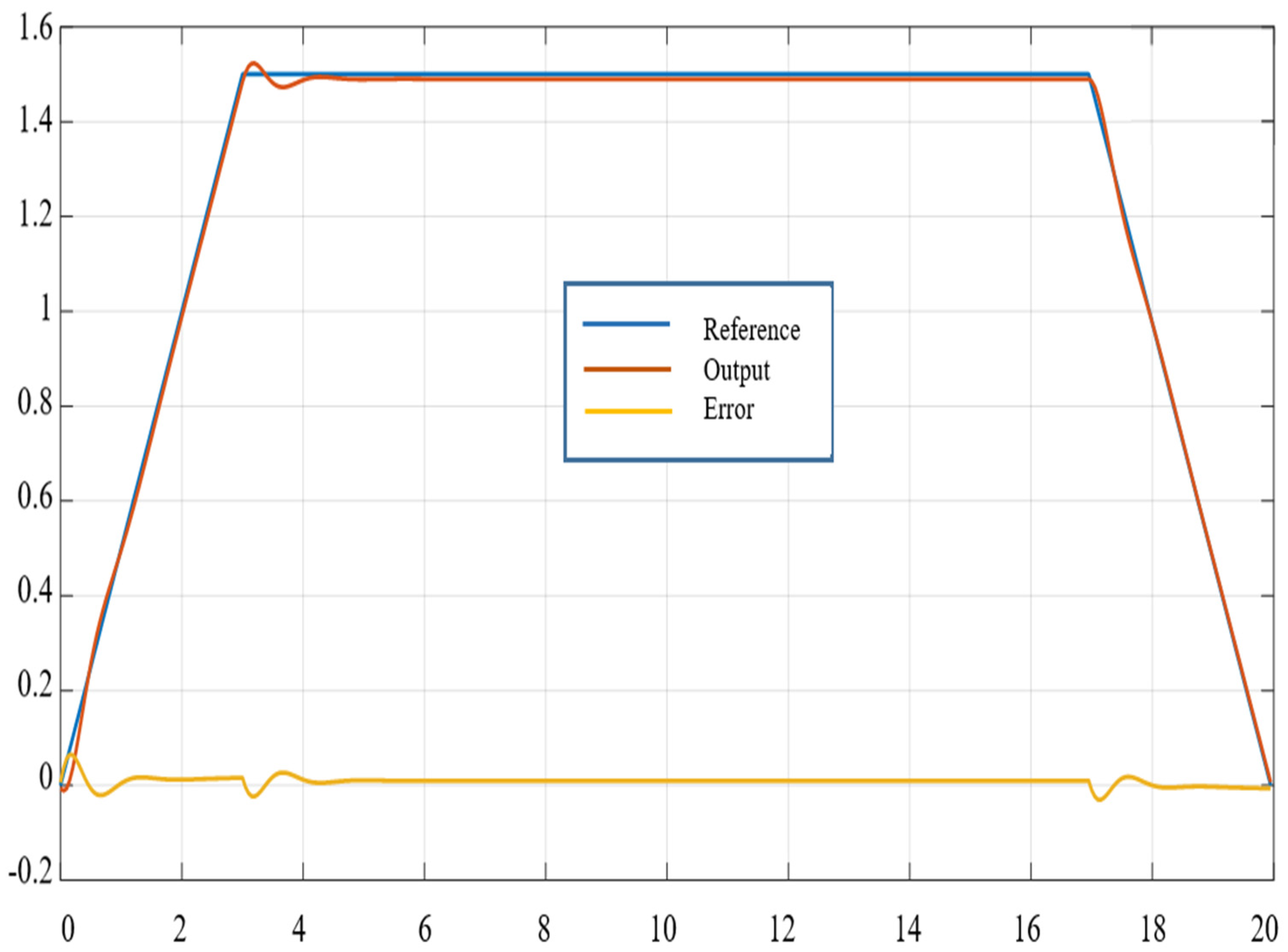
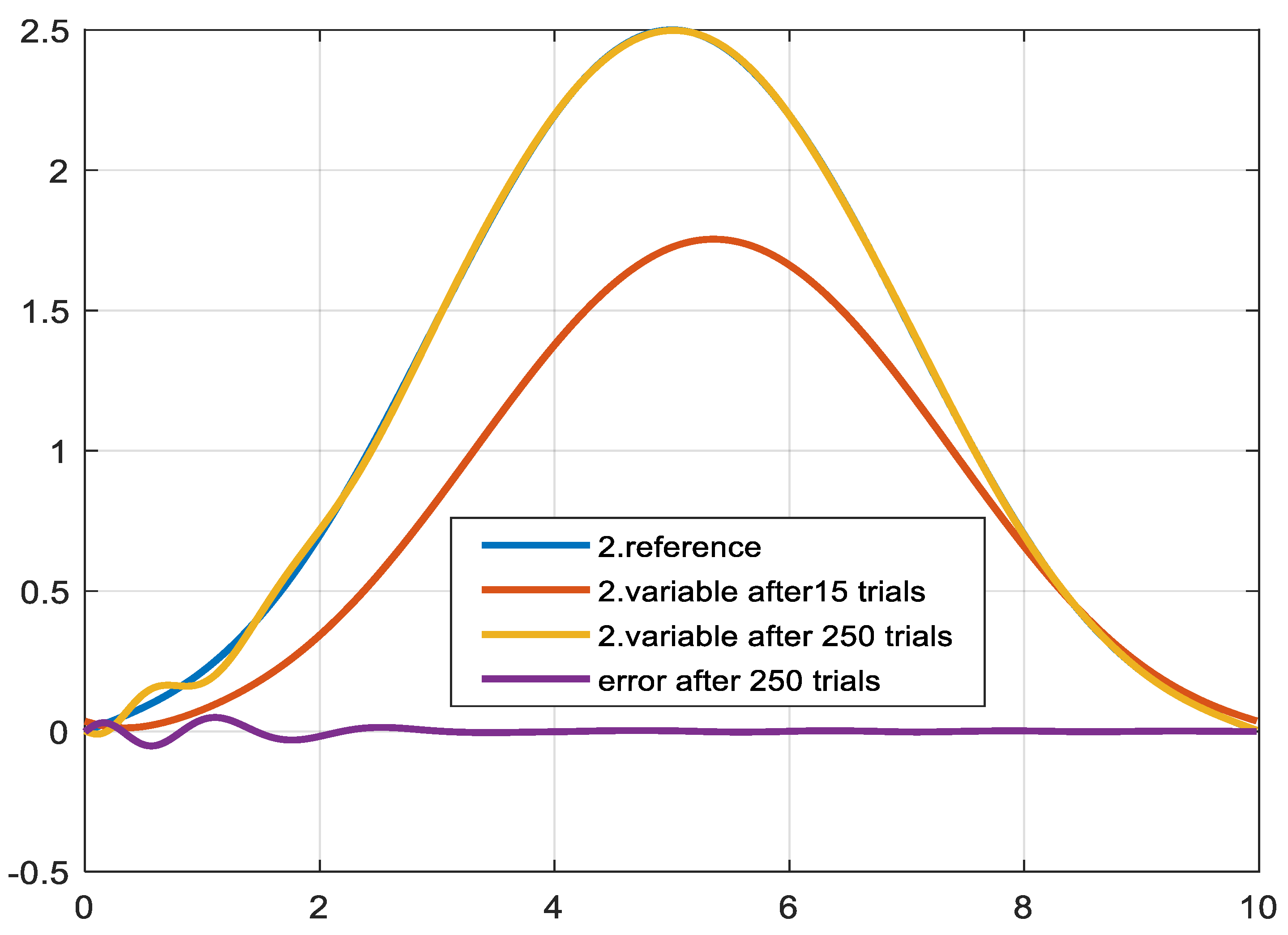
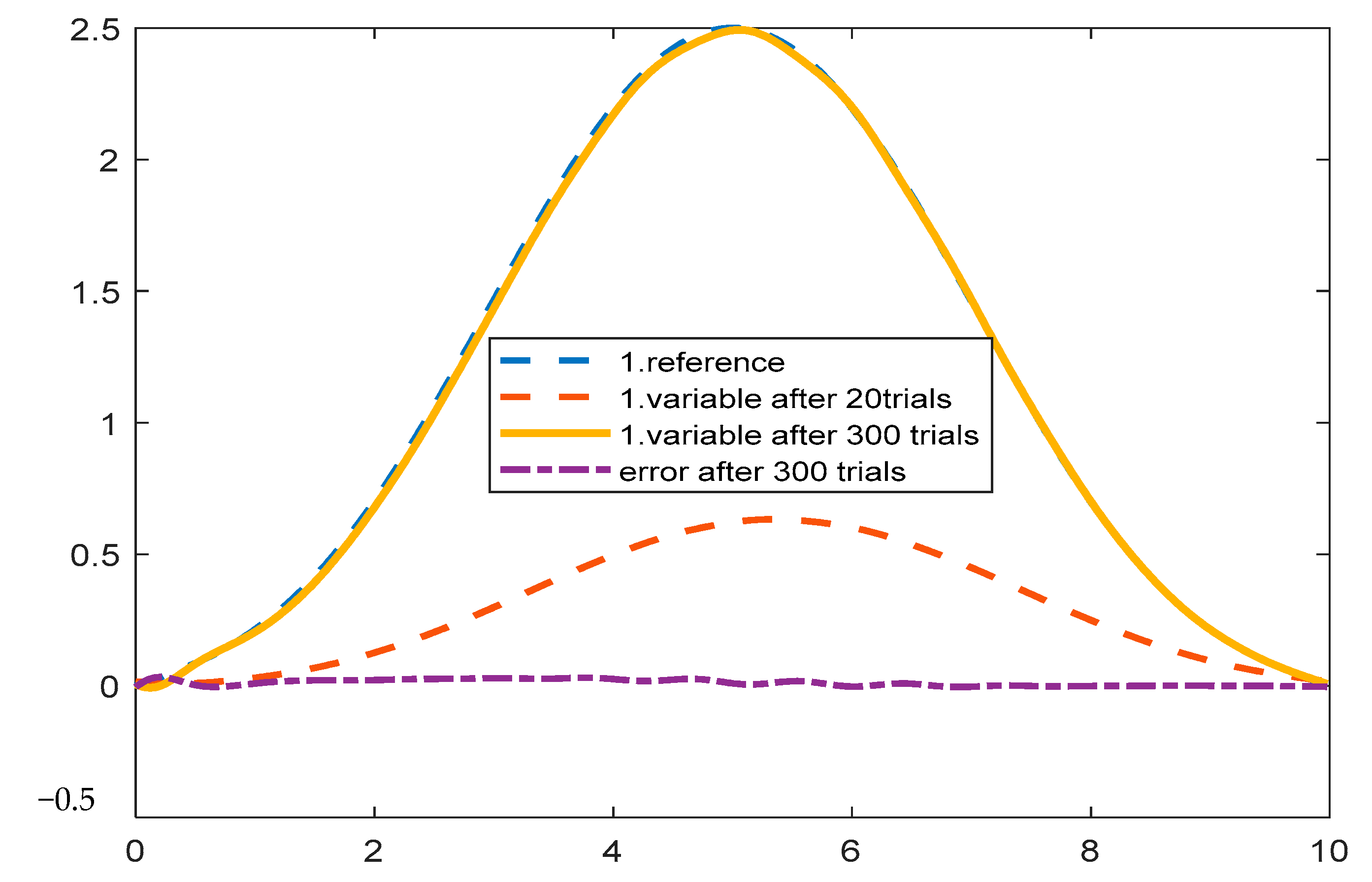
5.5. Applied to Robot Control
6. The Structure of the Second Iterative Learning Controller with Model-Free Determination of Online Learning Parameters for an Industrial Robot
6.1. Control the Inner Loop
6.2. Outer Loop Control Is by Iterative Learning Controller Design
| Algorithm 3: The structure of the second iterative learning controller with model-free determination of online learning parameters for an industrial robot. | |
| 1 | Choose two matrices , , in (6), which become Hurwitz and a sufficiently small constant . Calculate . Determine Choose learning and tracking error . Assign the robot’s initial state and initial output to the outer loop controller (iterative learning controller) |
| 2 | while keeping the controls in place |
| 3 | for do |
| 4 | Forward to robot for a while of . |
| Measure and . | |
| Assess . | |
| 5 | Calculate . |
| 6 | end for |
| 7 | Assemble . |
| 8 | Calculate or |
| and | |
| 9 | end while |
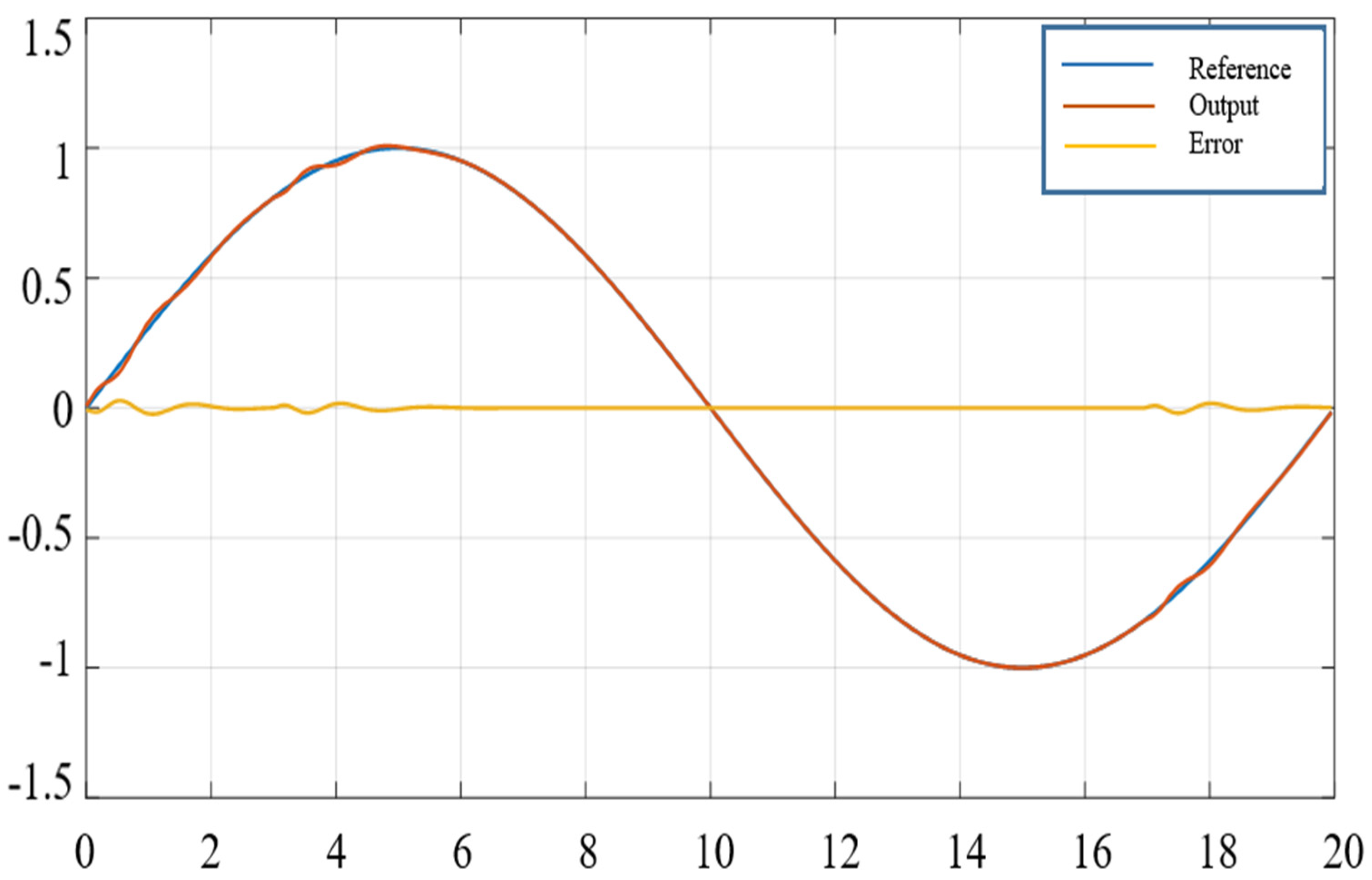
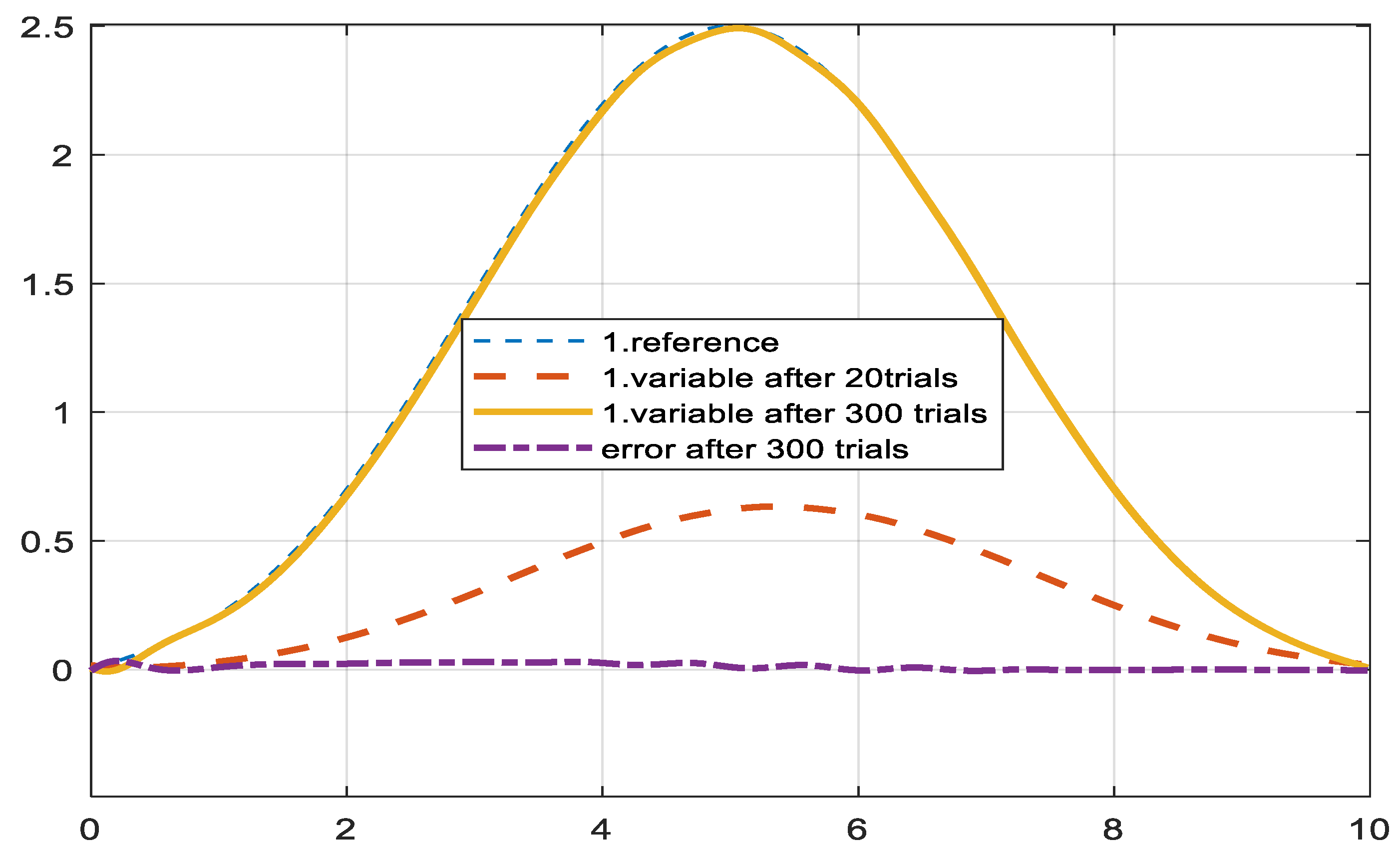
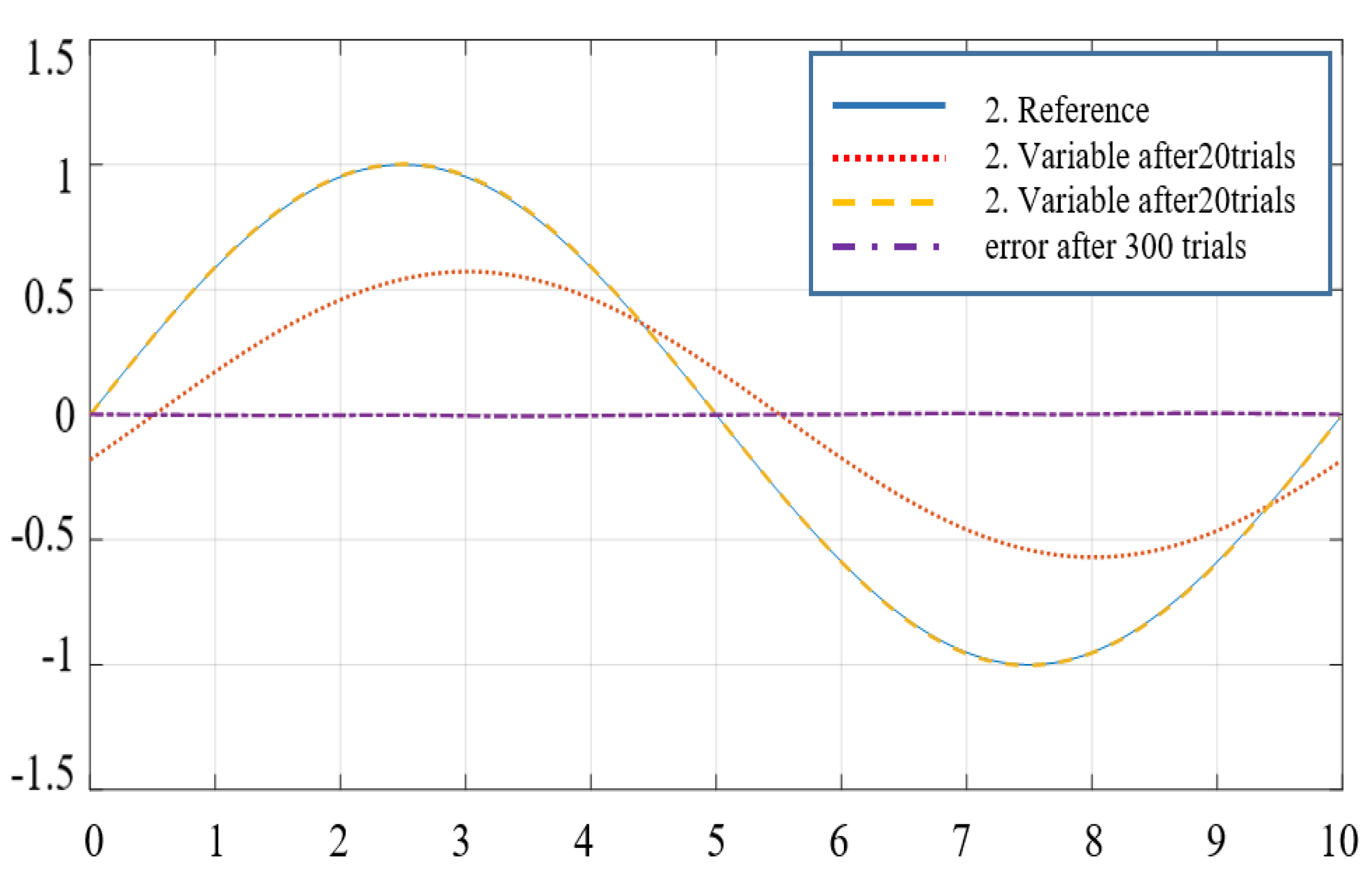
6.3. Applied to Robot Control
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lewis, L.; Dawson, D.M.; Abdallah, C.T. Robot Manipulator Control Theory and Practice; Marcel Dekker: New York, NY, USA, 2004. [Google Scholar]
- Spong, W.; Hutchinson, S.; Vidyasagar, M. Robot Modeling and Control; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Slotine, J.-J.; Li, W. On the Adaptive Control of Robot Manipulators. Int. J. Robot. Res. 1987, 6, 49–59. [Google Scholar] [CrossRef]
- Bascetta, L.; Rocco, P. Revising the Robust-Control Design for Rigid Robot Manipulators. IEEE Trans. Robot. 2010, 26, 180–187. [Google Scholar] [CrossRef]
- Zhao, J.; Jiang, S.; Xie, F.; Wang, X.; Li, Z. Adaptive dynamic sliding mode control for space manipulator with external disturbance. J. Control. Decis. 2019, 6, 236–251. [Google Scholar] [CrossRef]
- Goel, A.; Swarup, A. MIMO uncertain nonlinear system control via adaptive hight-order super twisting sliding mode and its application to robotic manipulator. J. Control Autom. Electr. Syst. 2017, 28, 36–49. [Google Scholar] [CrossRef]
- Gurney, K. An Introduction to Neural Networks; Taylor & Francis: Philadelphia, PA, USA, 2004. [Google Scholar]
- Wang, Y.; Gao, F.; Doyle, F.J., III. Servy on iterative leaning control, repetitive control and run-to-run control. J. Process Control. 2009, 19, 1589–1600. [Google Scholar] [CrossRef]
- Bristow, D.A.; Tharayil, M.; Alleyne, A.G. A Survey of Iterative Learning Control: A learning based method for high-performance tracking control. IEEE Control. Syst. Mag. 2006, 26, 96–114. [Google Scholar]
- Ahn, H.-S.; Chen, Y.; Moore, K.L. Iterative Learning Control: Brief Survey and Categorization. IEEE Trans. Syst. Man Cybern. 2007, 37, 1099–1121. [Google Scholar] [CrossRef]
- Norrloef, M. Iterative Learning Control: Analysis, Design and Experiment. Ph.D. Thesis, No. 653. Linkoepings University, Linköping, Sweden, 2000. [Google Scholar]
- Lee, R.; Sun, L.; Wang, Z.; Tomizuka, M. Adaptive Iterative learning control of robot manipulators for friction compensation. IFAC PapersOnline 2019, 52, 175–180. [Google Scholar] [CrossRef]
- Boiakrif, F.; Boukhetala, D.; Boudjema, F. Velocity observer-based iterative learning control for robot manipulators. Int. J. Syst. Sci. 2013, 44, 214–222. [Google Scholar] [CrossRef]
- Nguyen, P.D.; Nguyen, N.H. An intelligent parameter determination approach in iterative learning control. Eur. J. Control. 2021, 61, 91–100. [Google Scholar] [CrossRef]
- Jeyasenthil, R.; Choi, S.-B. A robust controller for multivariable model matching system utilizing a quantitative feedback theory: Application to magnetic levitation. Appl. Sci. 2019, 9, 1753. [Google Scholar] [CrossRef]
- Nguyen, P.D.; Nguyen, N.H. Adaptive control for nonlinear non-autonomous systems with unknown input disturbance. Int. J. Control. 2022, 95, 3416–3426. [Google Scholar] [CrossRef]
- Tran, K.G.; Nguyen, N.H.; Nguyen, P.D. Observer-based controllers for two-wheeled inverted robots with unknown input disturbance and model uncertainty. J. Control. Sci. Eng. 2020, 2020, 7205737. [Google Scholar] [CrossRef]
- Fortuna, L.; Buscarino, A. Microrobots in Micromachines. Micromachines 2022, 13, 1207. [Google Scholar] [CrossRef] [PubMed]
- Bucolo, M.; Buscarino, A.; Fortuna, L.; Frasca, M. Forward Action to Stabilize multiple Time-Delays MIMO Systems. Int. J. Dyn. Control 2023. [Google Scholar] [CrossRef]
- Bucolo, M.; Buscarino, A.; Famoso, C.; Fortuna, L.; Gagliano, S. Imperfections in Integrated Devices Allow the Emergence of Unexpected Strange Attractors in Electronic Circuits. IEEE Access 2021, 9, 29573–29583. [Google Scholar] [CrossRef]
- Do, D.M.; Hoang, D.; Nguyen, N.H.; Nguyen, P.D. Data-Driven Output Regulation of Uncertain 6 DOF AUV via Lagrange Interpolation. In Proceedings of the 2022 11th International Conference on Control, Automation and Information Sciences, Hanoi, Vietnam, 21–24 November 2022. [Google Scholar]
- Hoang, D.; Do, D.M.; Nguyen, N.H.; Nguyen, P.D. A Model-Free Approach for Output Regulation of uncertain 4 DOF Serial Robot with Disturbance. In Proceedings of the 2022 11th International Conference on Control, Automation and Information Sciences, Hanoi, Vietnam, 21–24 November 2022. [Google Scholar]
- Nguyen, P.D.; Nguyen, N.H. A simple approach to estimate unmatched disturbances for nonlinear nonautonomous systems. Int. J. Robust Nonlinear Control 2022, 32, 9160–9173. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ha, V.T.; Thuong, T.T.; Vinh, V.Q. Improving the Quality of Industrial Robot Control Using an Iterative Learning Method with Online Optimal Learning and Intelligent Online Learning Function Parameters. Appl. Sci. 2024, 14, 1805. https://doi.org/10.3390/app14051805
Ha VT, Thuong TT, Vinh VQ. Improving the Quality of Industrial Robot Control Using an Iterative Learning Method with Online Optimal Learning and Intelligent Online Learning Function Parameters. Applied Sciences. 2024; 14(5):1805. https://doi.org/10.3390/app14051805
Chicago/Turabian StyleHa, Vo Thu, Than Thi Thuong, and Vo Quang Vinh. 2024. "Improving the Quality of Industrial Robot Control Using an Iterative Learning Method with Online Optimal Learning and Intelligent Online Learning Function Parameters" Applied Sciences 14, no. 5: 1805. https://doi.org/10.3390/app14051805
APA StyleHa, V. T., Thuong, T. T., & Vinh, V. Q. (2024). Improving the Quality of Industrial Robot Control Using an Iterative Learning Method with Online Optimal Learning and Intelligent Online Learning Function Parameters. Applied Sciences, 14(5), 1805. https://doi.org/10.3390/app14051805