
Enhancing Dynagraph Card Classification in Pumping Systems Using Transfer Learning and the Swin Transformer Model

 , , and
, , and
Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
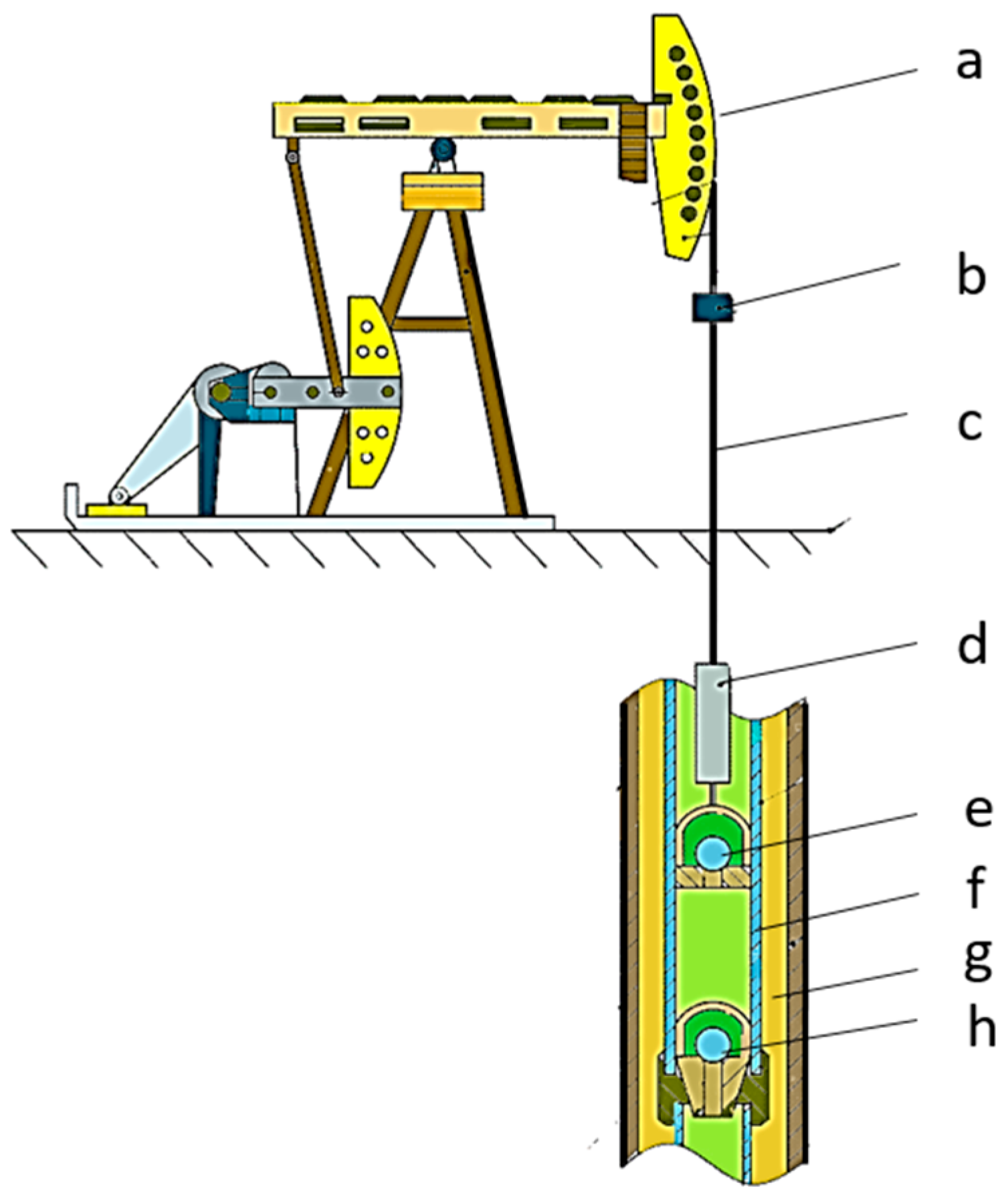
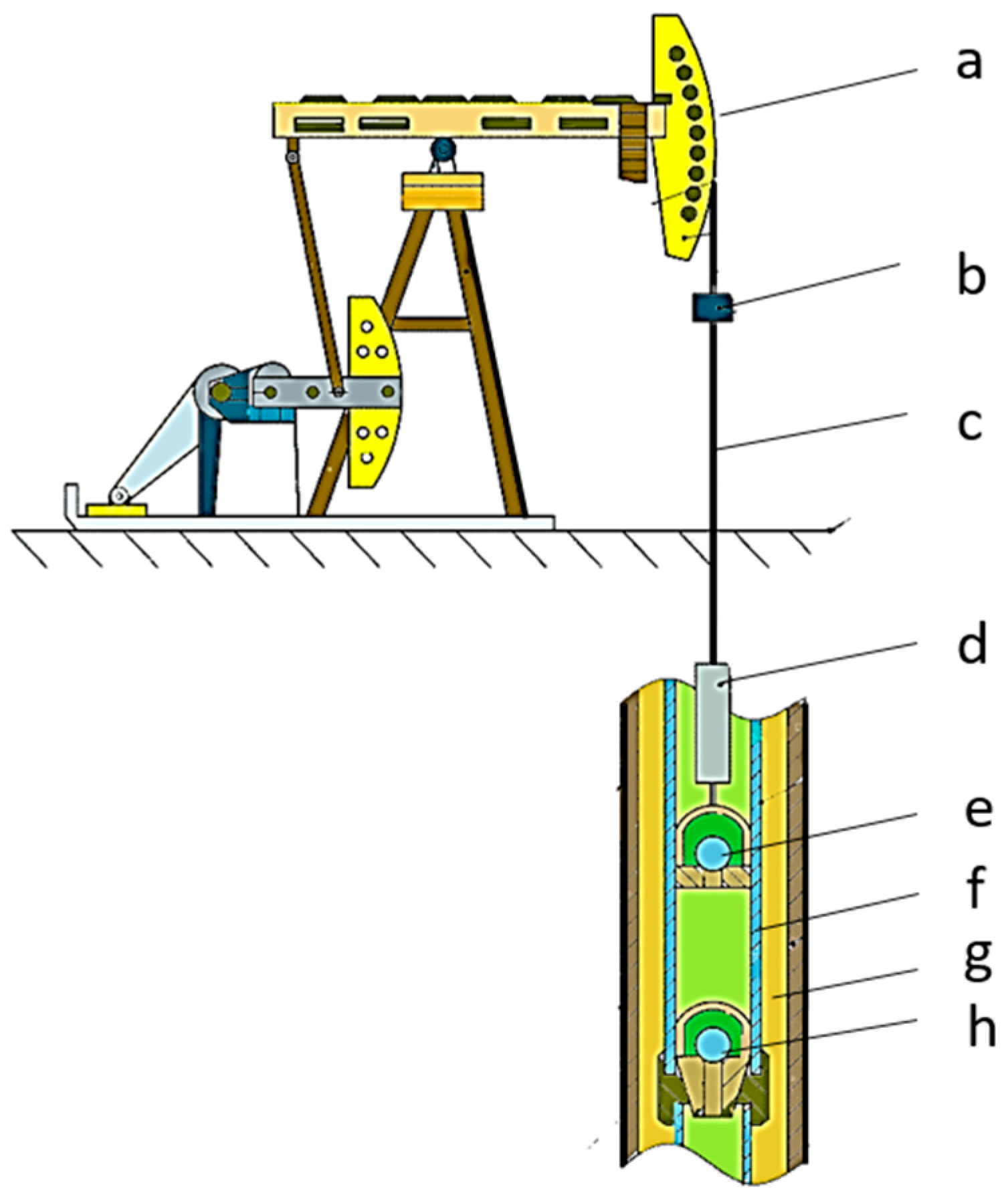
2.1. The Principle of Oil Extraction in a Pumping Unit
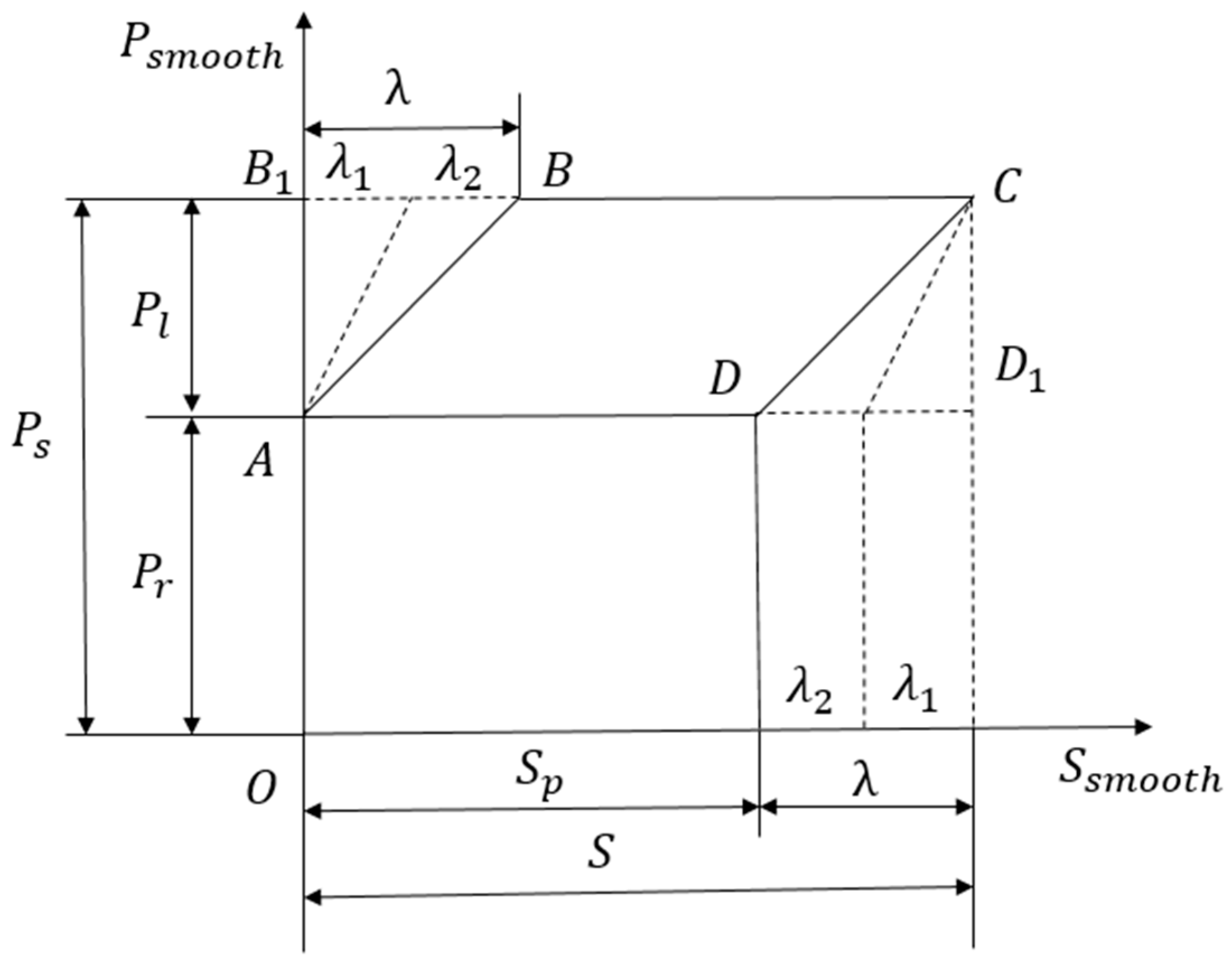
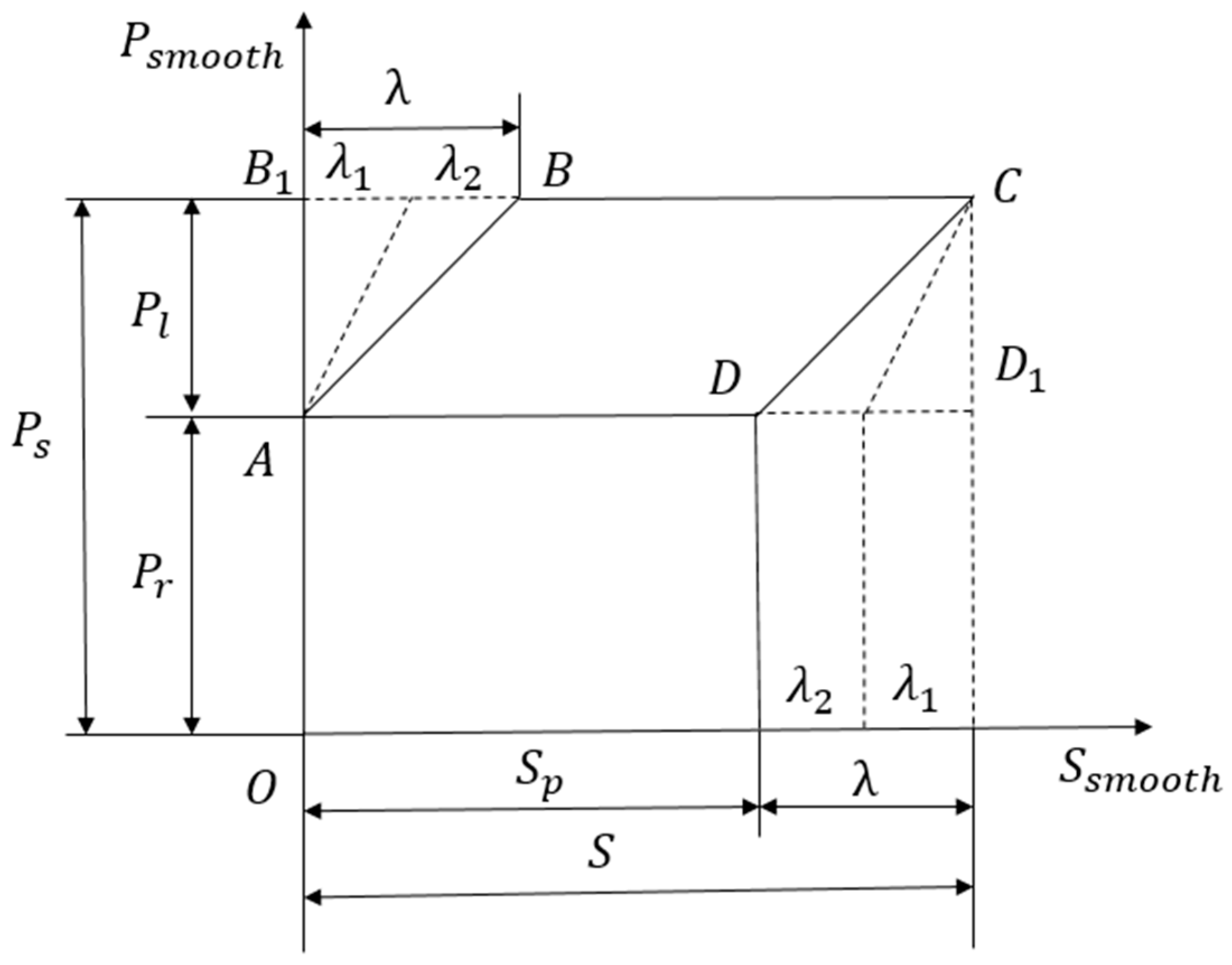
2.2. Theoretical Analysis of the Dynagraph Card
2.3. Analysis of Dynagraph Cards under Different Operating Conditions
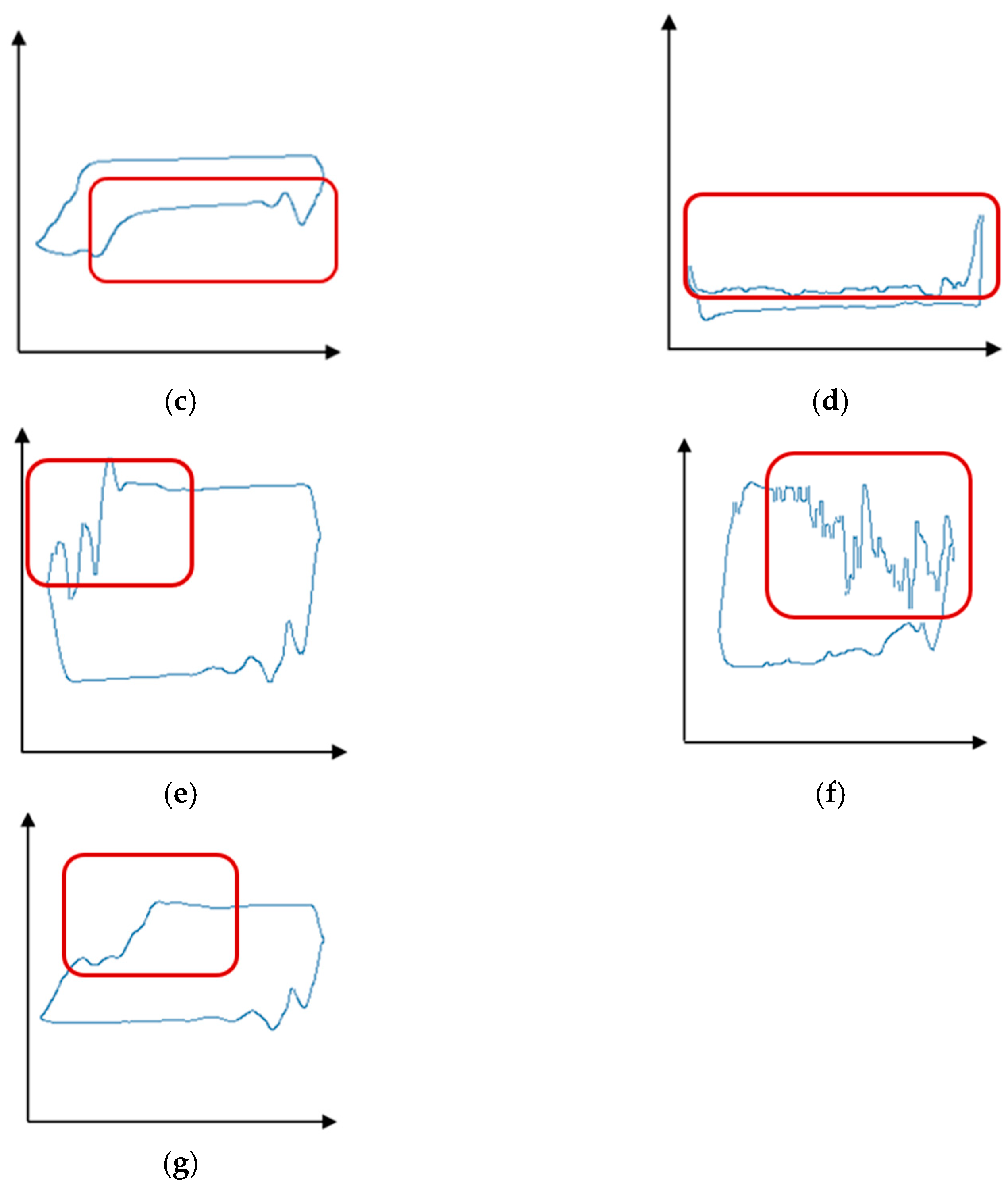
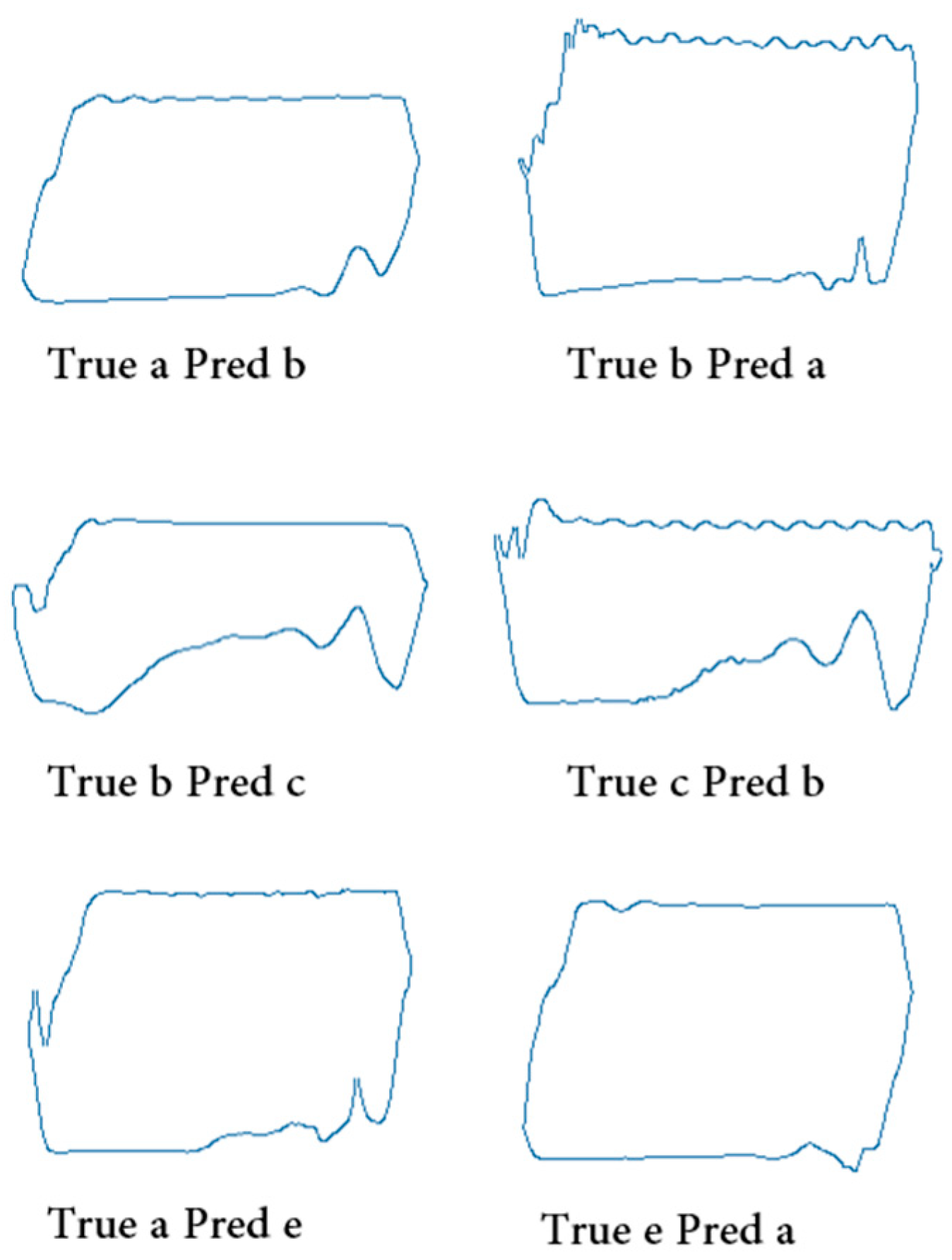
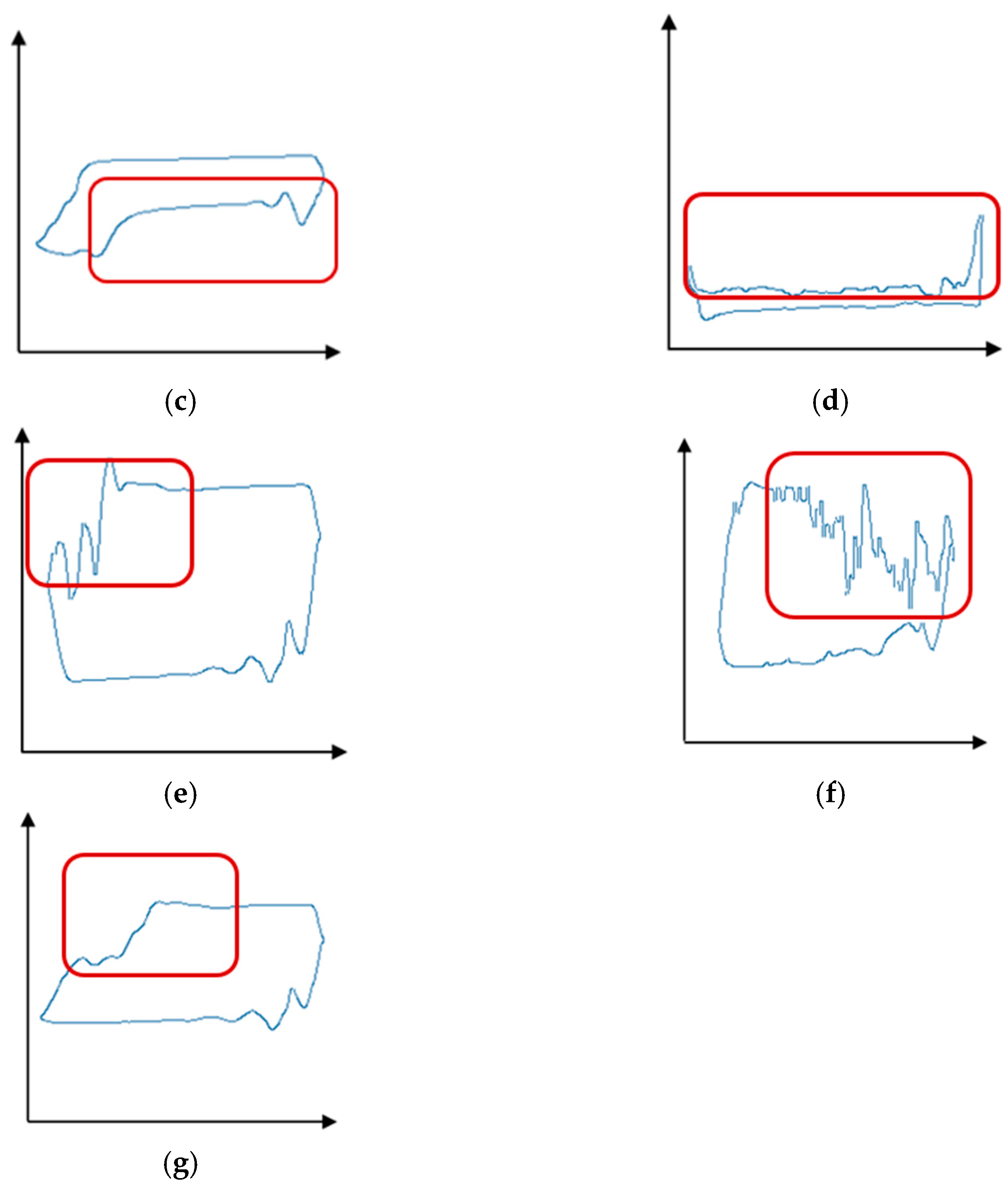
- Normal Pump Operation: The dynagraph card shows a regular pattern without any anomalies, as depicted in Figure 3a.
- Fluid Pound [19]: Fluid pound refers to the impact force generated during the pumping process due to the interaction between the pump barrel and the gas–liquid drive system. Fluid pound is characterized by sudden spikes and steep drops in the dynagraph card. It is often caused by factors such as the excessive downward speed of the pump rod, seal failure between the pump rod and the fluid, and unstable motion of the fluid column (Figure 3b).
- Gas Interference: The presence of gas has a significant impact on pump operation [20]. In the dynagraph card, gas interference is indicated by compression areas during the upstroke and downstroke of the pump, resulting in relatively smooth curve shapes. Gas interference is typically caused by factors such as gas production in the well, gas accumulation between the pump rod and the fluid, and failure of the gas–liquid drive system (Figure 3c).
- Gas Lock [21]: Gas lock refers to the accumulation of gas in the lower section of the pump rod or at the bottom of the well, creating an obstruction that prevents the fluid from entering the pump rod completely and hinders the downward motion of the pump rod. This condition is identifiable on the dynagraph card by an extended compression area during the downward stroke of the pump rod, represented by a relatively flat waveform. Gas lock is often caused by factors such as excessive gas production in the well, declining fluid level, and poor sealing of the pump rod (Figure 3d).
- Delayed Closure of the Traveling Valve [22]: Delayed closure of the traveling valve refers to the phenomenon where the traveling valve in the pump closes with a delay during the upstroke of the pump rod. In the dynagraph card, the delayed closure of the traveling valve results in an increase in the downward speed of the pump rod, leading to an accelerated descent and steeper slope during the downward stage (Figure 3e).
- Pump Barrel Slippage: Pump barrel slippage occurs when the pump barrel becomes dislodged and separates from the pump rod [23]. In the dynagraph card, pump barrel slippage is indicated by a sudden decrease in the slope during the descent stage, resulting in a smoother curve waveform. Pump barrel slippage is typically caused by factors such as poor installation of the pump barrel and wear of the pump barrel (Figure 3f).
- Fluid Pound and Delayed Closure of the Traveling Valve: The occurrence of both fluid pound and delayed closure of the traveling valve has an impact on the normal operation of the pump. Fluid pound can lead to damage to the pump rod and other components, while the delayed closure of the traveling valve can increase the upward speed of the pump rod, resulting in increased friction between the pump rod and the wellbore and affecting the stability of the pump rod’s operation (Figure 3g).
3. Correlation Algorithm
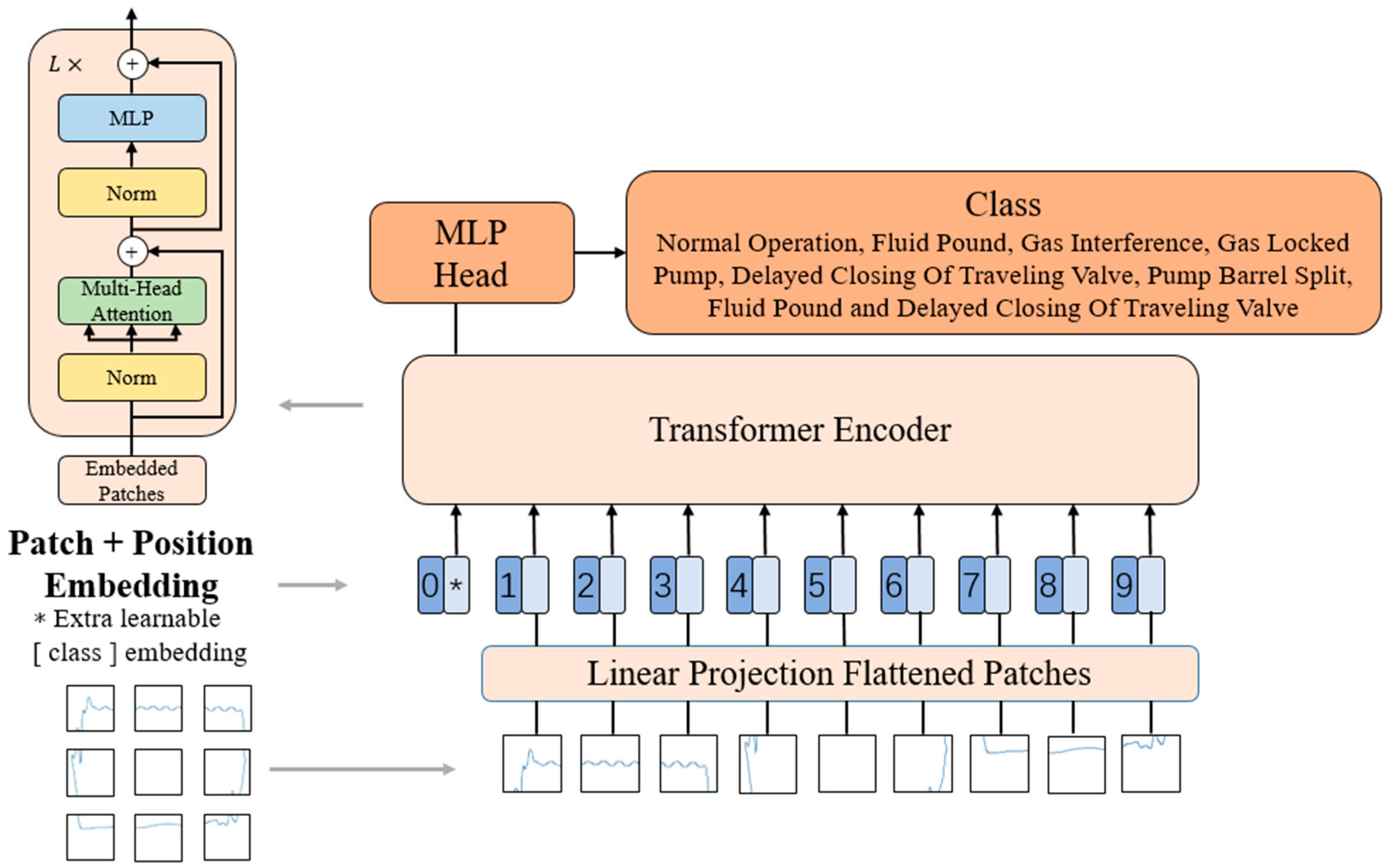
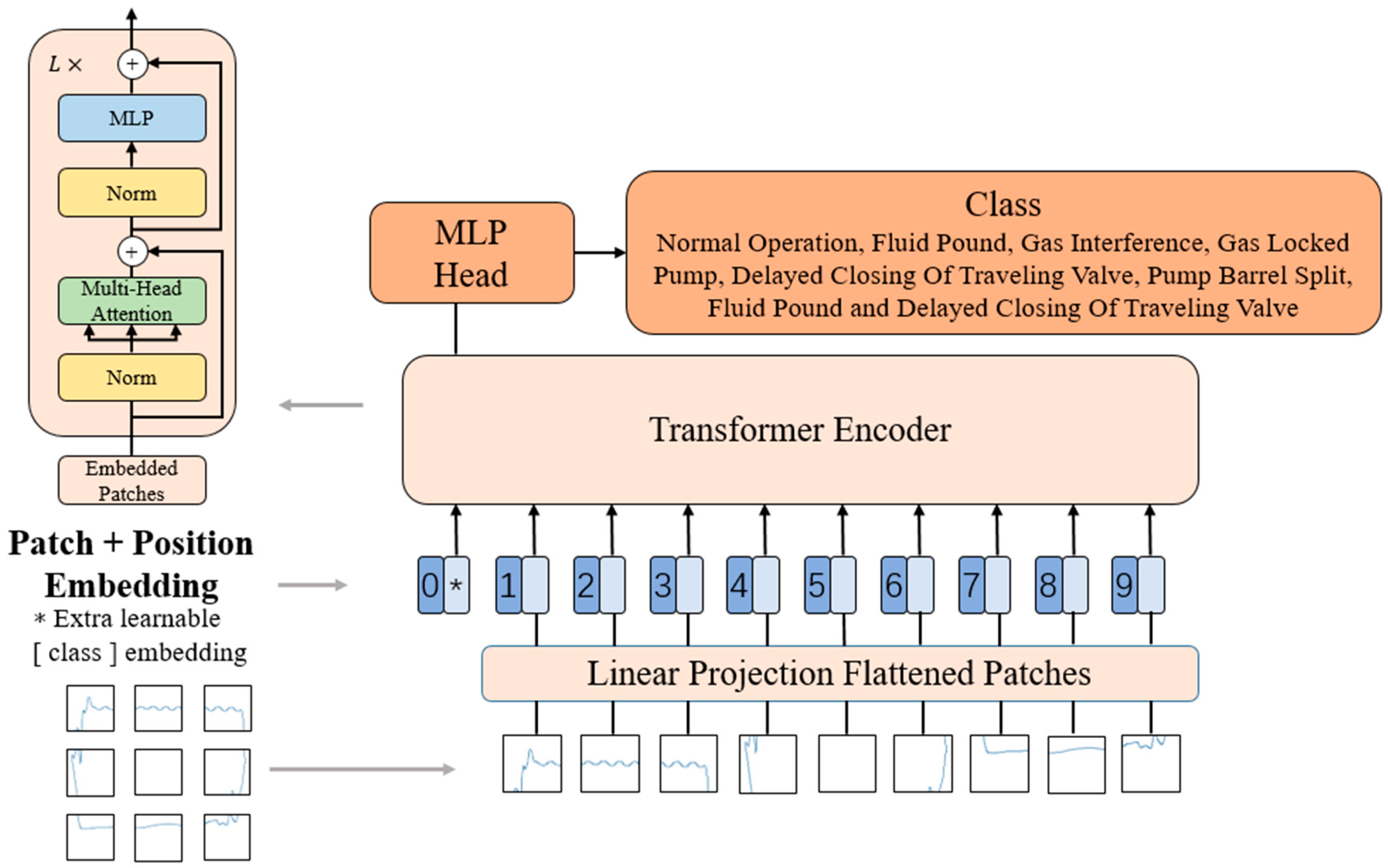
3.1. Vision Transformer
- Patch Embedding: The input image is partitioned into fixed-size patches, with each patch having dimensions of 16 × 16 pixels. Each patch is mapped to a fixed-dimensional vector using a linear projection layer. This way, the image is represented as a sequence where each patch becomes a token with a dimension of 768. An additional special token called CLS is added as the starting marker of the sequence, resulting in a final sequence dimension of 197 × 768.
- Positional Encoding: To capture the positional information of the patches in the image, ViT introduces positional encoding. Positional encoding is a table with the same dimension as the input sequence embedding, where each row represents a position’s vector. By adding the positional encoding to the input sequence embedding, the positional information is fused into the sequence. Thus, the sequence’s dimensions remain 197 × 768.
- Layer Normalization and Multi-Head Attention: ViT employs a multi-head self-attention mechanism to process the sequence. First, the input sequence is mapped to queries (q), keys (k), and values (v). If there is only one attention head, the dimensions of q, k, and v are all 197 × 768. If there are multiple attention heads (e.g., 12 heads with each head having a dimension of 64), the dimensions of q, k, and v are 197 × 64, and there are 12 sets of q, k, and v. These sets of q, k, and v are then concatenated together, resulting in an output dimension of 197 × 768. The output is then layer-normalized, ensuring that each feature dimension has a similar distribution across different positions in the sequence.
- MLP: The sequence is further processed using a multi-layer perceptron (MLP) [30]. The sequence undergoes a linear transformation layer, expanding the dimension to 197 × 3072. Then, an activation function and another linear transformation layer are applied to reduce the dimension back to 197 × 768. This MLP structure introduces non-linear relationships and performs more complex feature transformations.
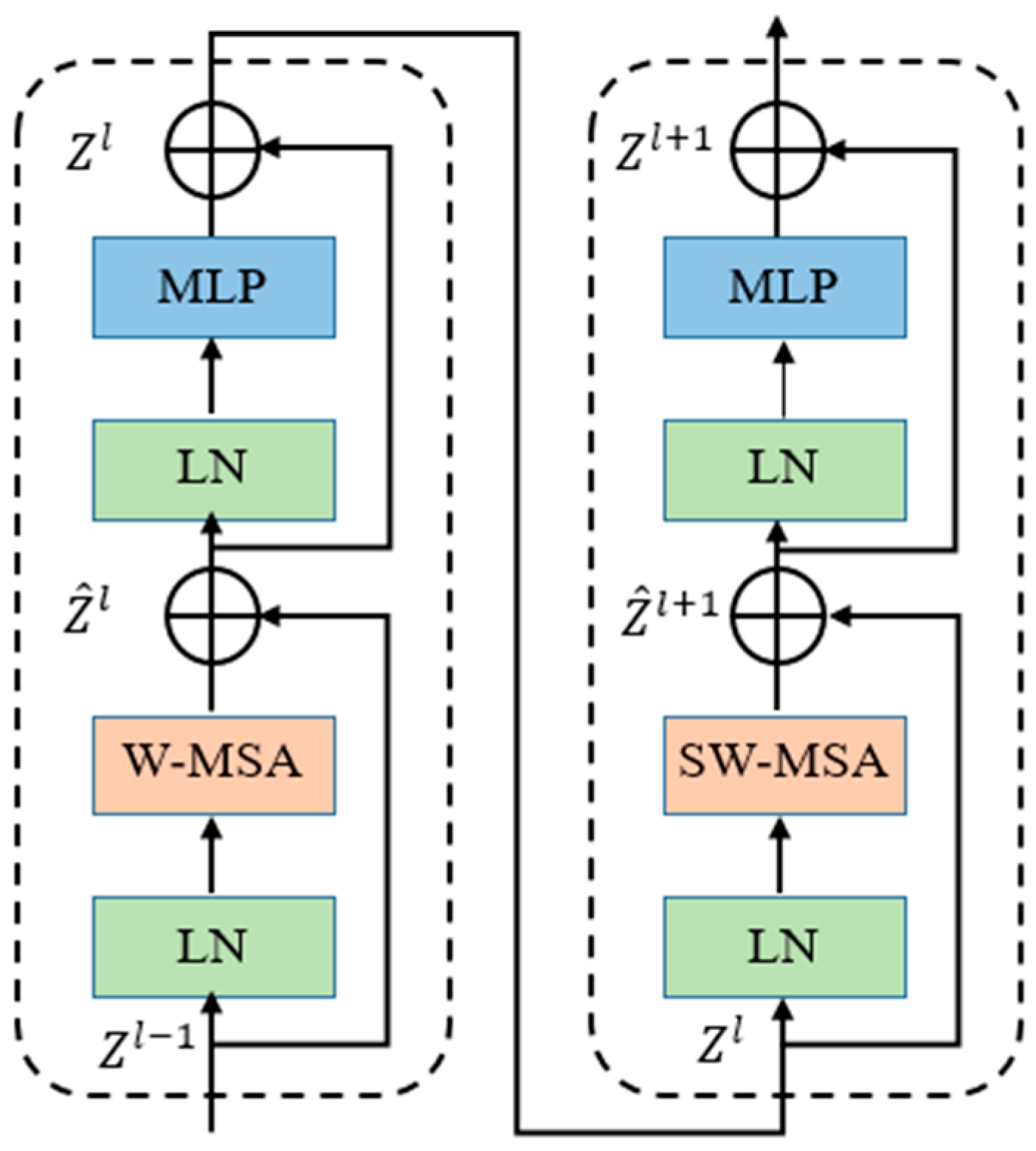
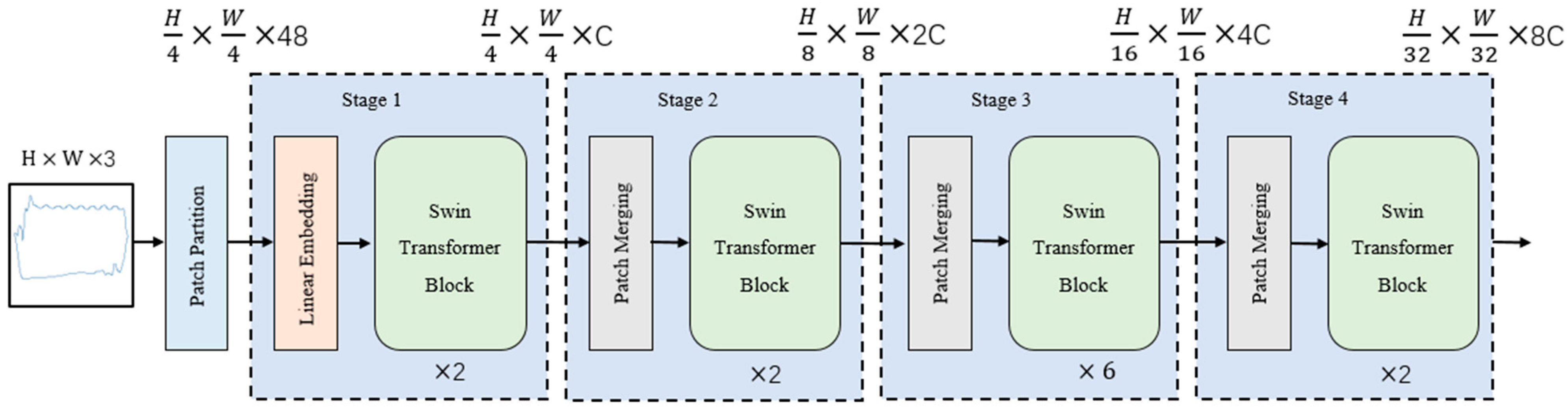
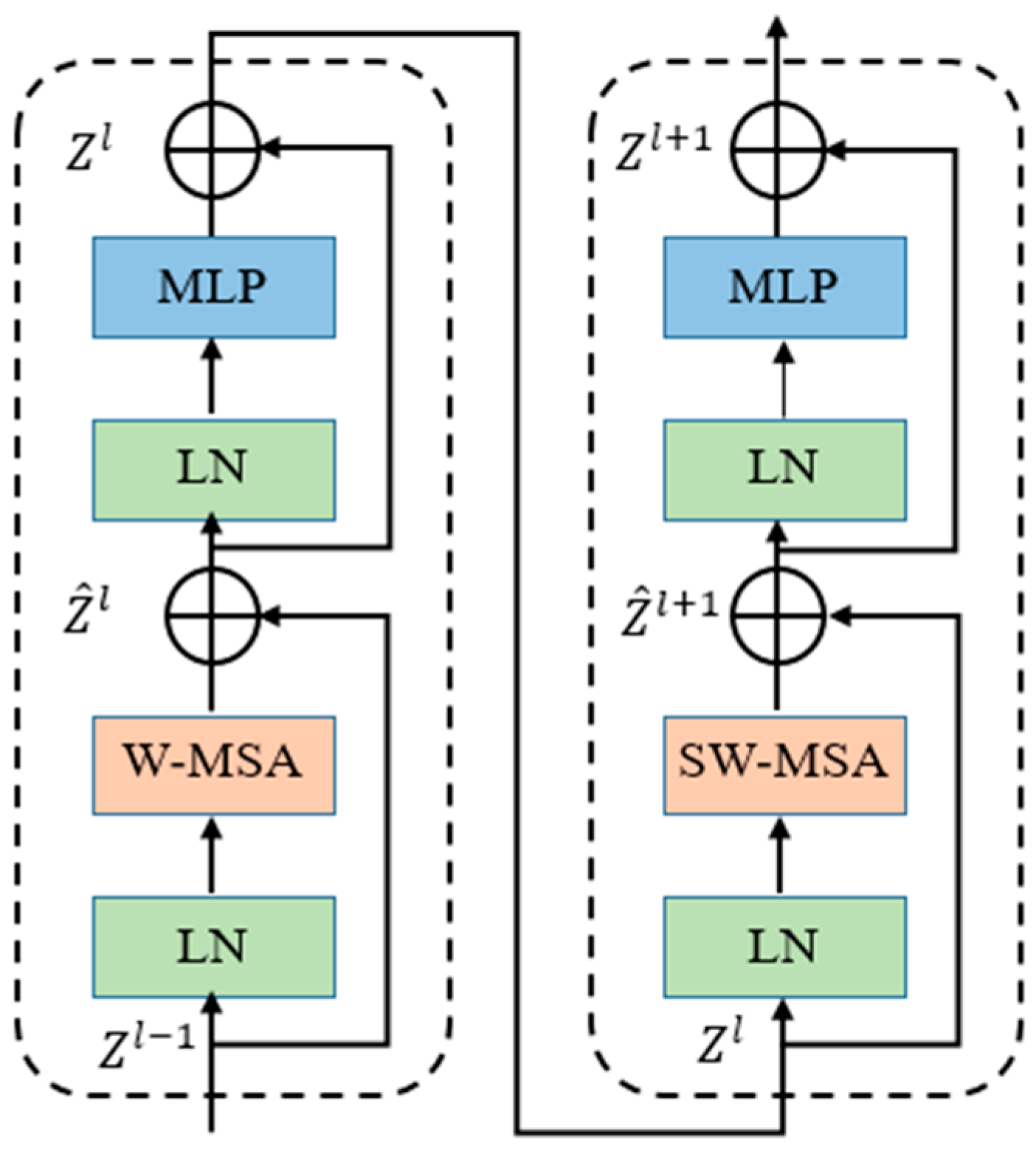
3.2. Swin Transformer
- Image Patch Division and Linear Embedding: The original image is divided into uniform image patches with dimensions of (H/4) × (W/4), where H and W represent the height and width of the input image, respectively. Each image patch’s feature dimension is then converted to C dimensions through linear embedding, where C corresponds to the number of channels in the Swin Transformer module.
- Image Patch Merging and Convolutional Dimension Reduction: Adjacent image patches are merged to form larger image patches. This reduces the number of image patches, and each merged image patch contains more local contextual information. The merged image patches undergo a convolutional network for dimension reduction, reducing the feature dimension to half of its original size. This helps to extract more abstract features.
- Repeat Stage 2: The process of image patch merging and convolutional dimension reduction in Stage 2 is repeated multiple times. With each repetition, the number of image patches is halved, and the feature dimension is also halved, while extracting higher-level feature representations.
- Swin Transformer Module: After Stage 3, the input is passed to the Swin Transformer module for computation. This module is based on the transformer architecture and processes the input using self-attention mechanisms and feed-forward neural network layers. It learns global contextual information and feature relationships to improve the quality of feature representation.
4. Experimental Design and Results
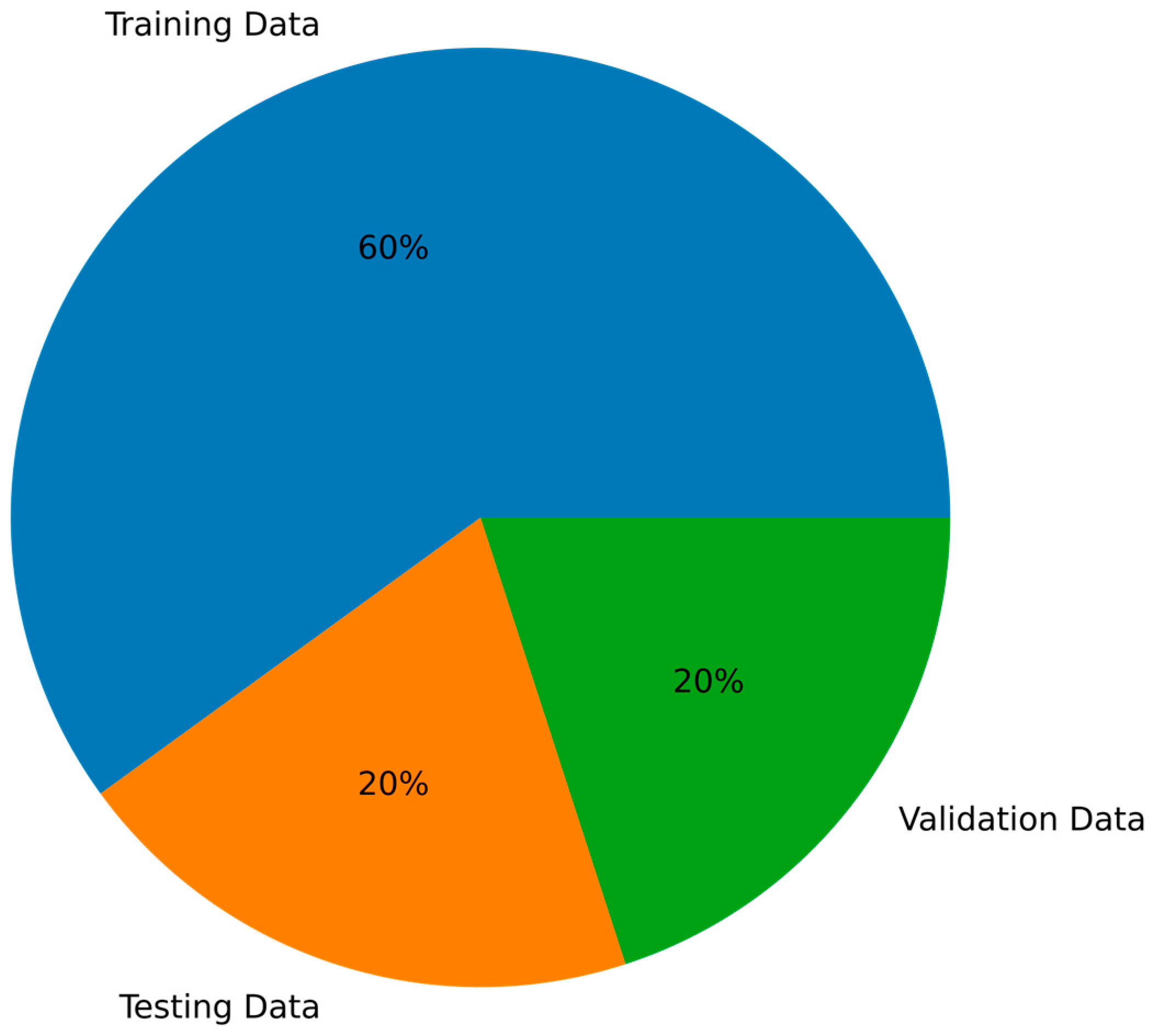
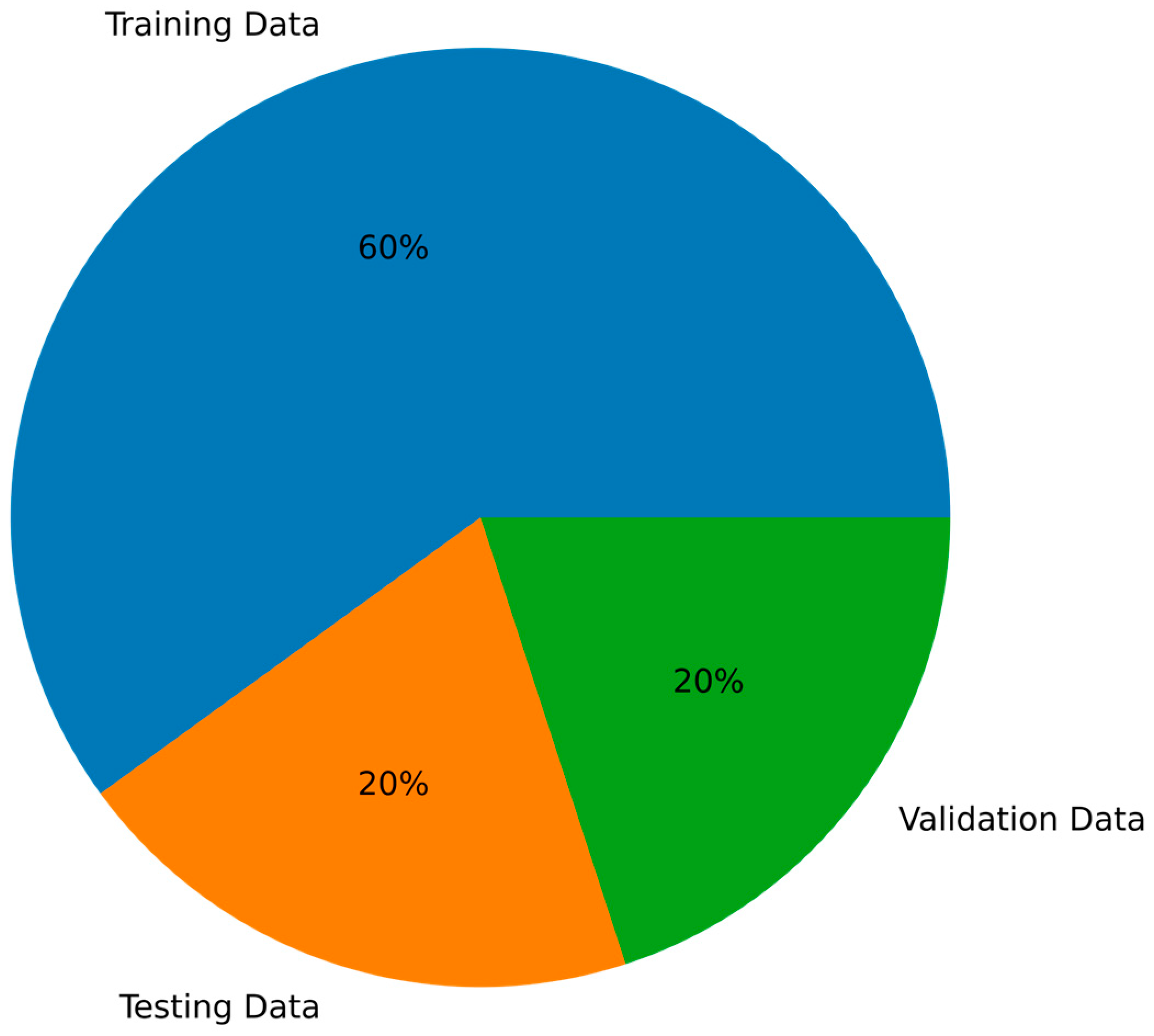
4.1. Dataset
4.2. Experimental Process
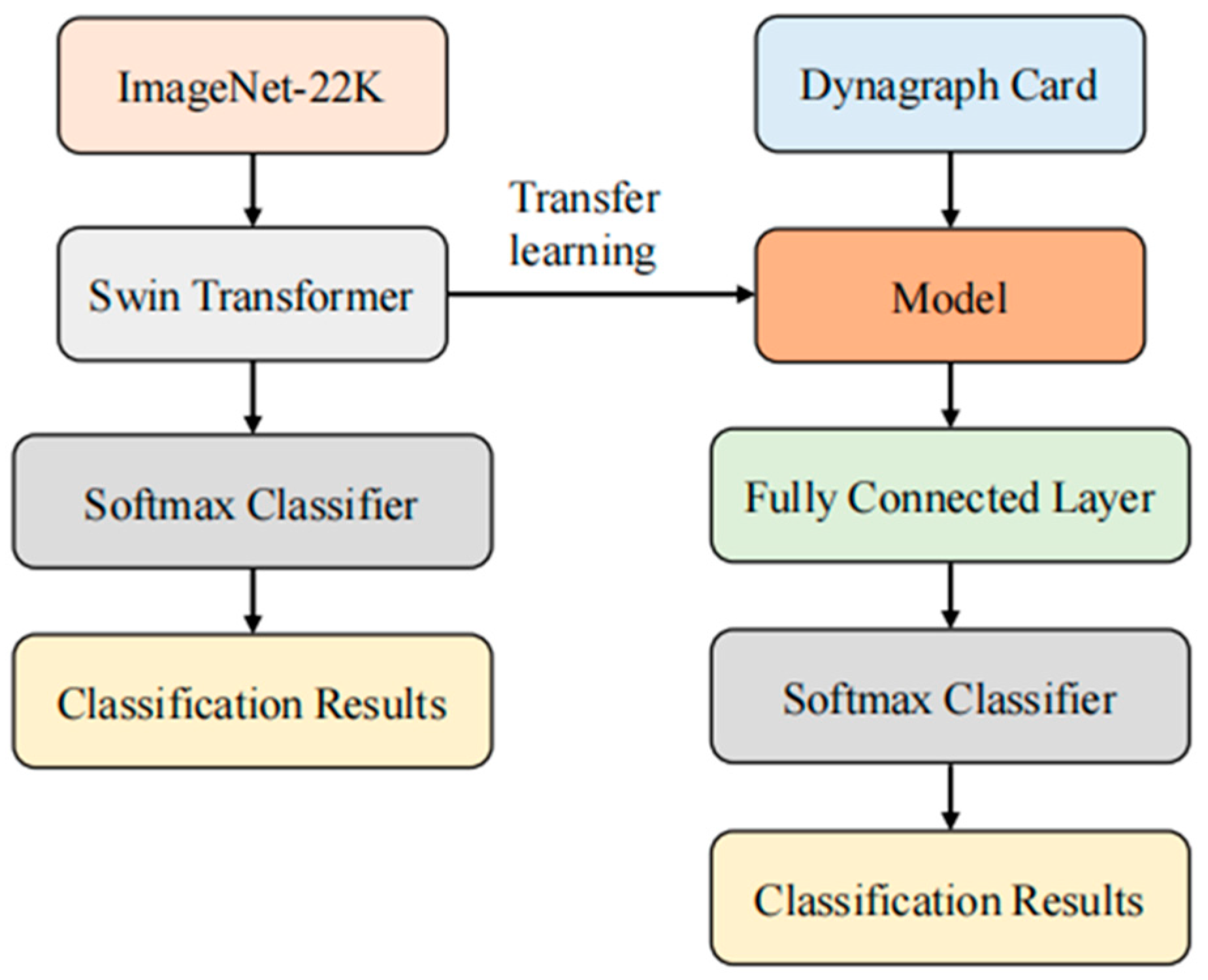
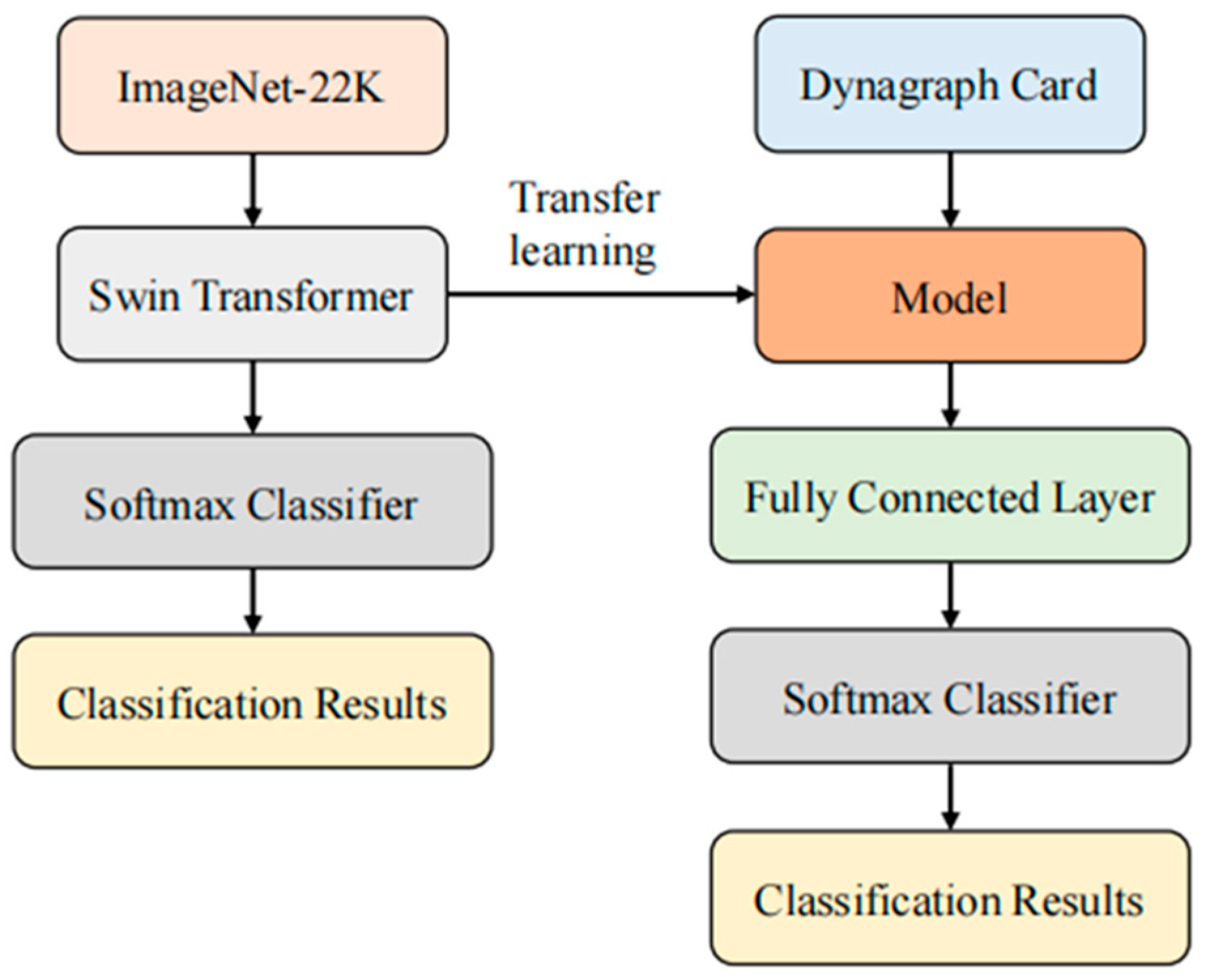
- Pre-Training Stage: First, we loaded a pre-trained Swin Transformer model as the feature extractor. This model consists of multiple layers of transformer structures that effectively handle image data. We used pre-trained weights obtained through self-supervised learning on the ImageNet-22k dataset, which provide high-level semantic feature representations [34]. Next, we added several fully connected layers to map the extracted features to the target classes. These additional layers were initialized with random weights and trained using backpropagation. During this process, we kept the pre-trained feature extractor fixed and only trained the additional layers. This allowed the model to adapt to our specific task and effectively train on limited labeled data [35].
- Training Stage: During the training phase, we used the labeled training dataset of dynagraph cards to train the model. We employed the stochastic gradient descent optimization algorithm and utilized the cross-entropy loss function as the optimization objective for the model. The training dataset was divided into training and test sets, used for monitoring the training progress and model selection [36]. In each training batch, we randomly selected a batch of image samples from the training set and fed them into the model for forward and backward propagation. During the backward propagation process, the model updated its weight parameters based on the gradient information of the loss function. We evaluated the model using the test set, monitoring its accuracy and loss during the training process. We set a total of 10 training epochs, where each epoch corresponds to a complete traversal of the entire training dataset. Throughout the training process, we aimed for the model to learn effective feature representations and exhibit improved accuracy on the test set.
- Testing Stage: In the testing stage, we input the test set images into the model for inference, obtaining classification results and evaluating the model’s performance. The parameters used are consistent with those in the training stage.
- Validation Stage: In the validation stage, we input the validation set images into the model for evaluation, obtaining classification results and evaluating the model’s performance. The parameters used are consistent with those in the training stage.
4.3. Findings and Analysis from the Experiments
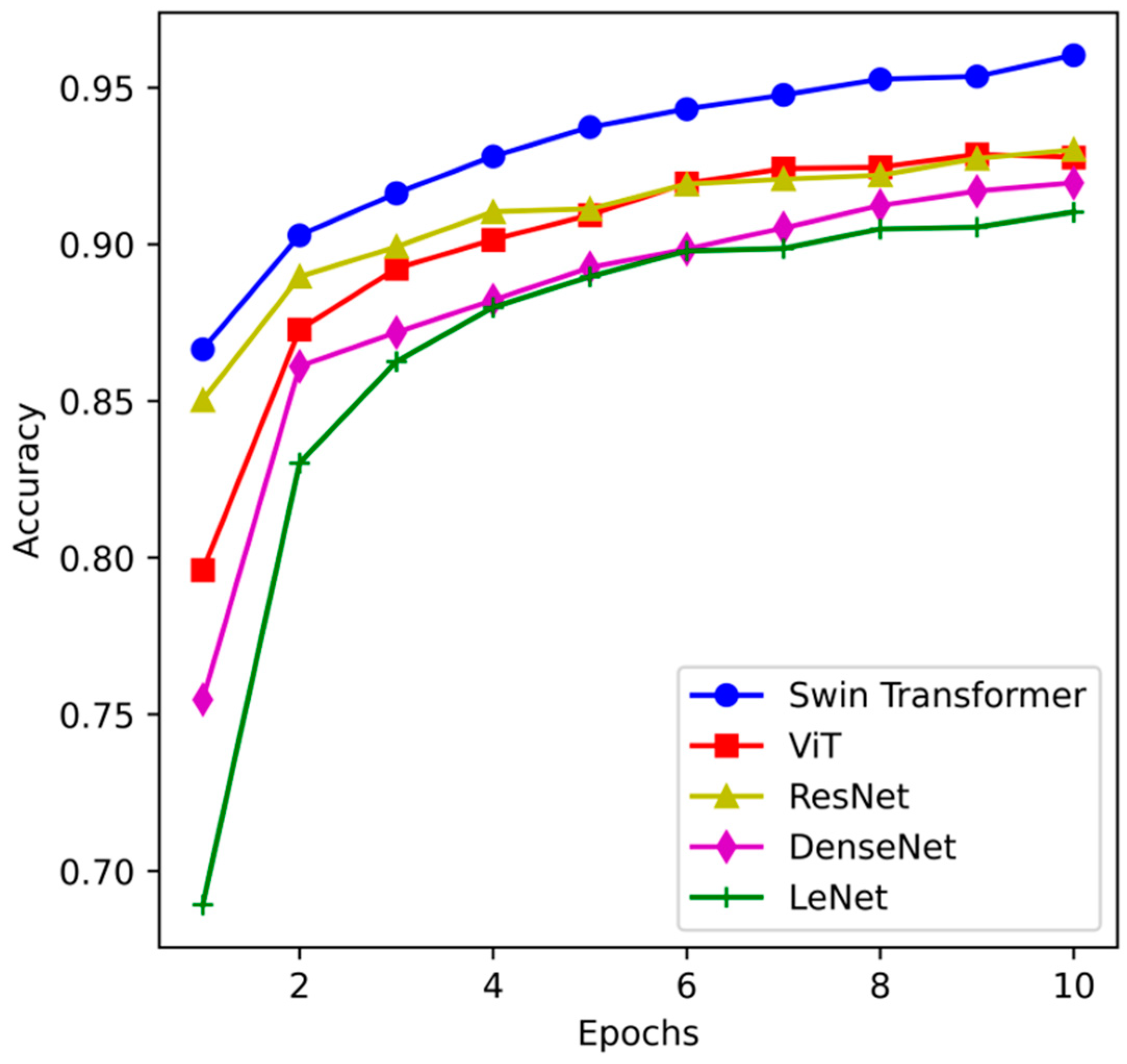
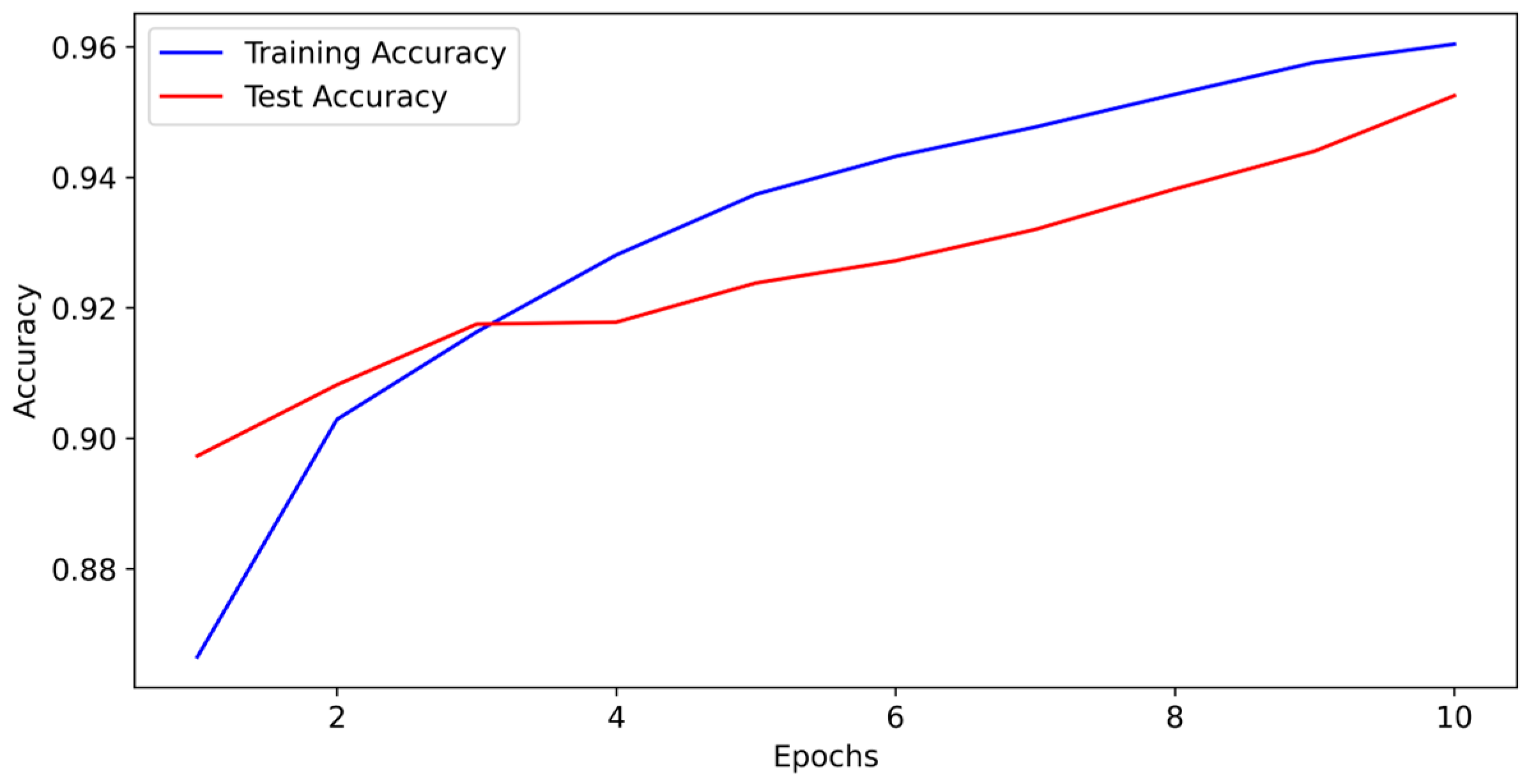
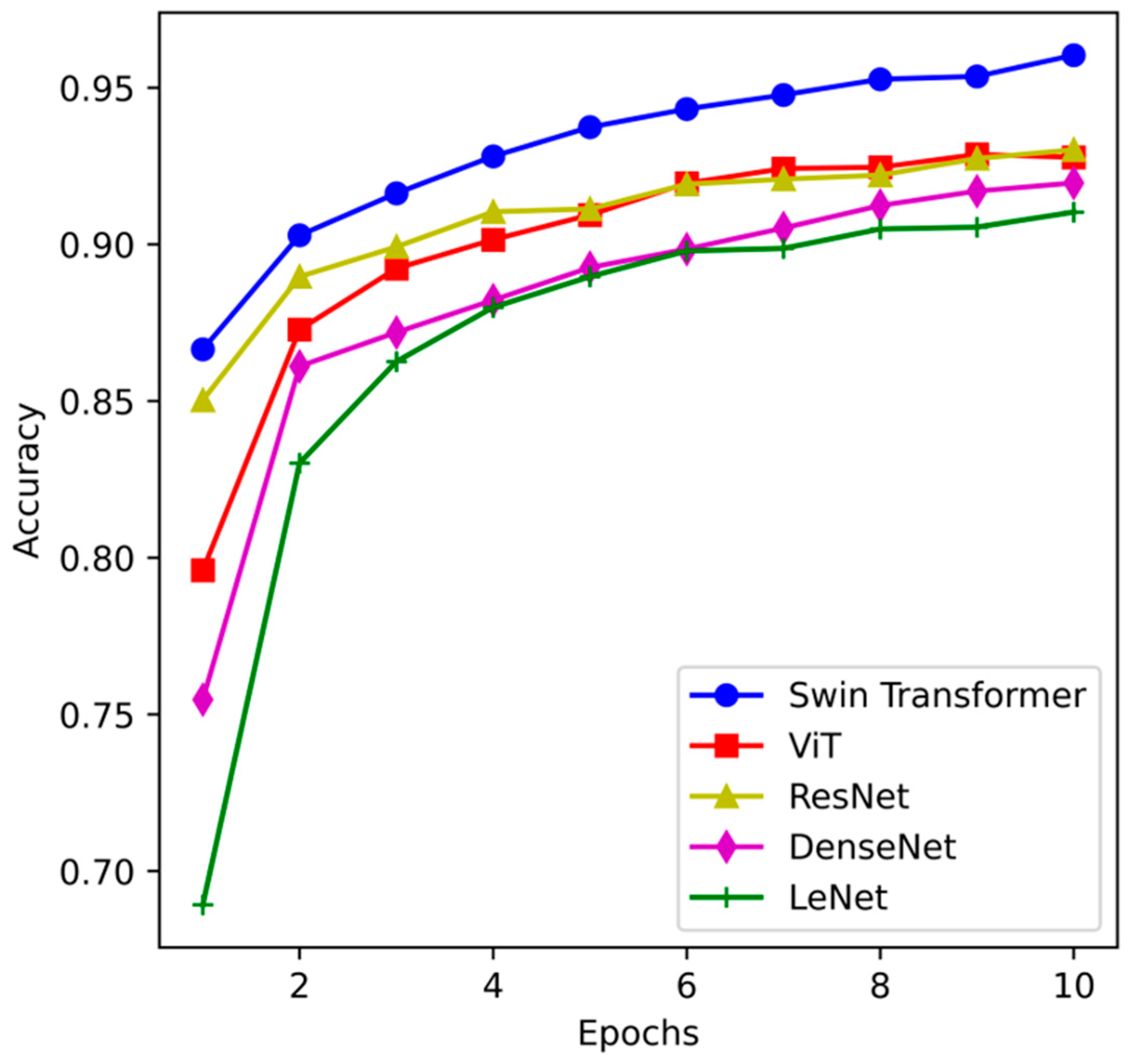
4.3.1. Accuracy
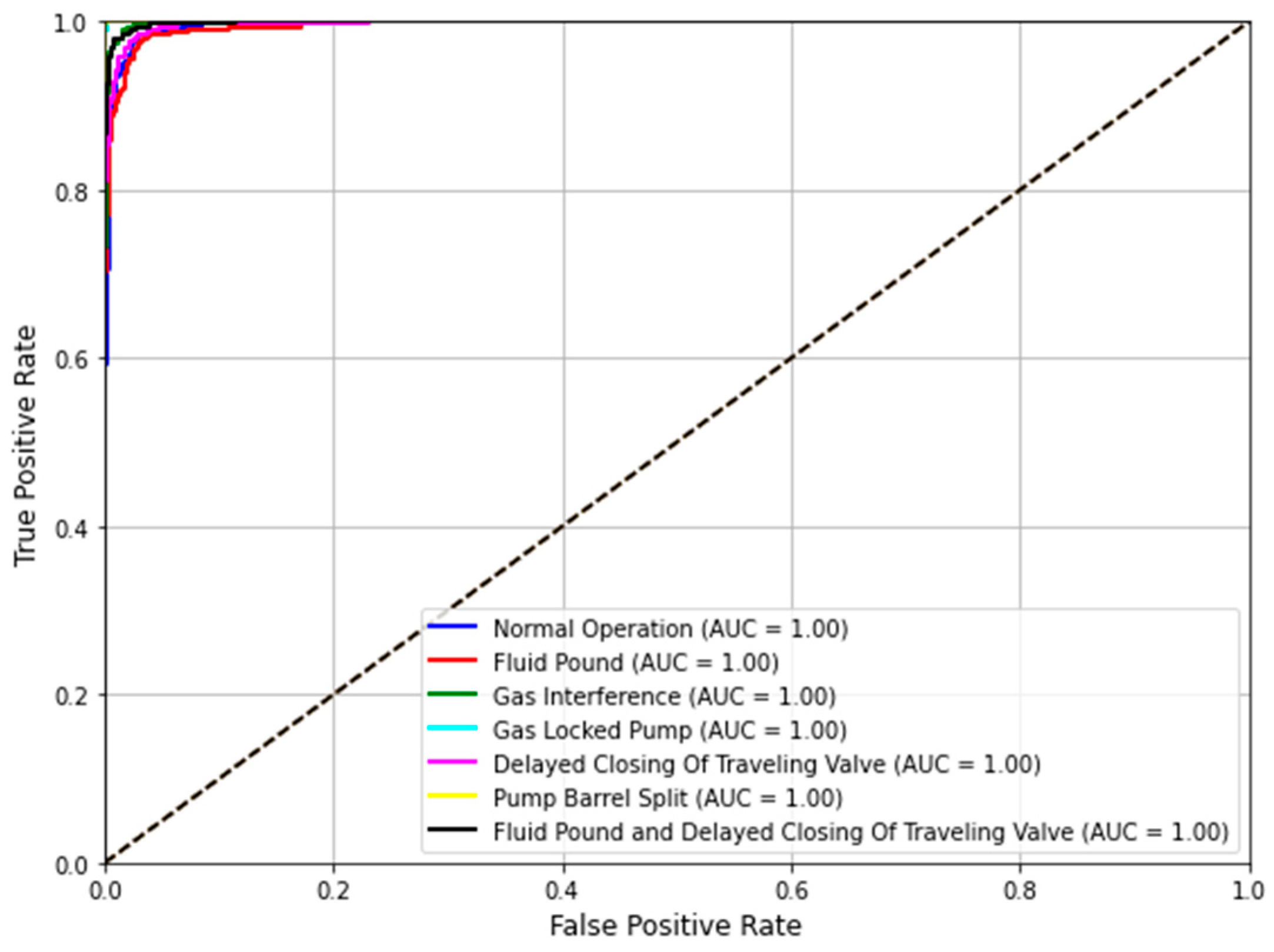
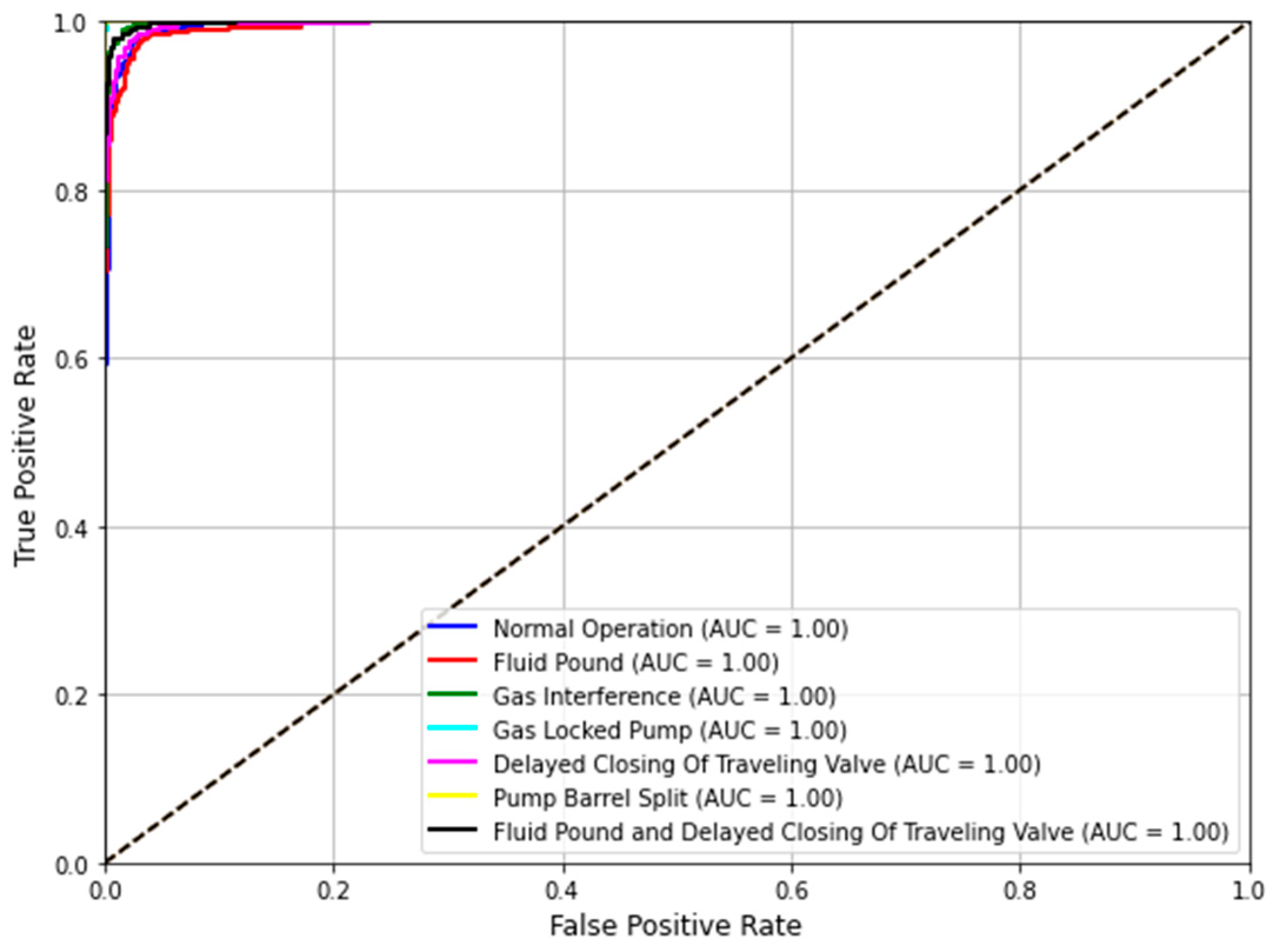
4.3.2. ROC Curve
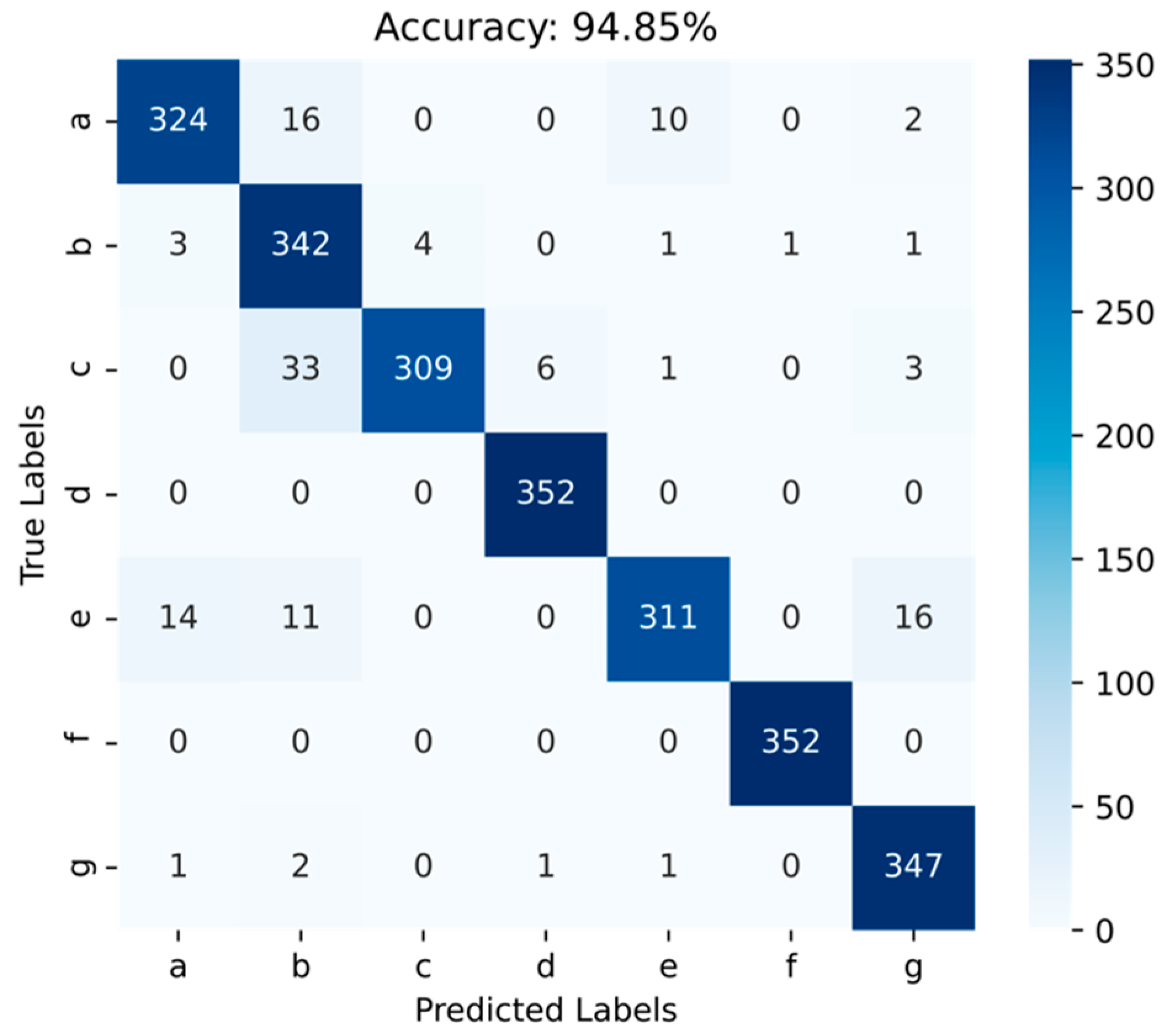
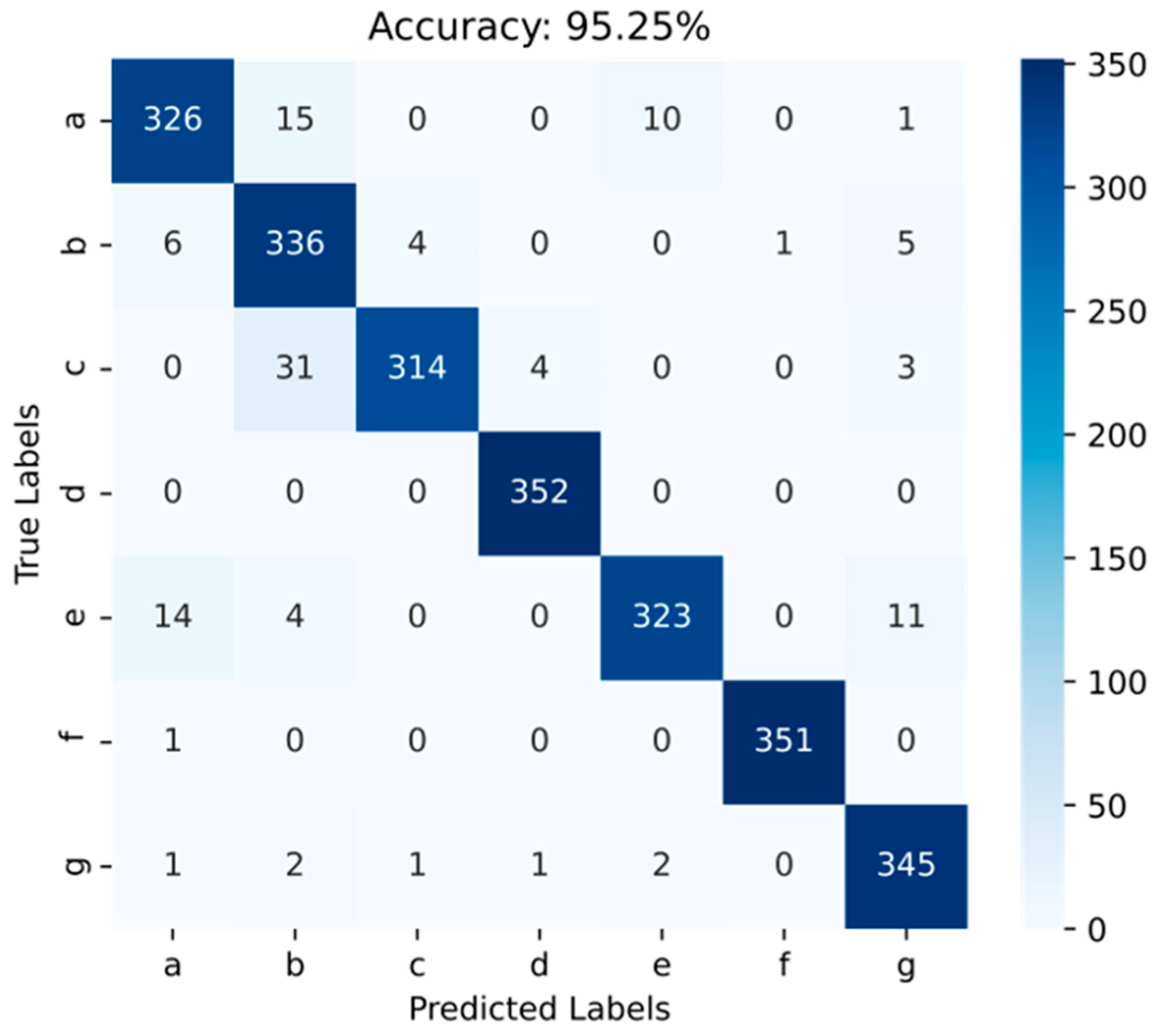
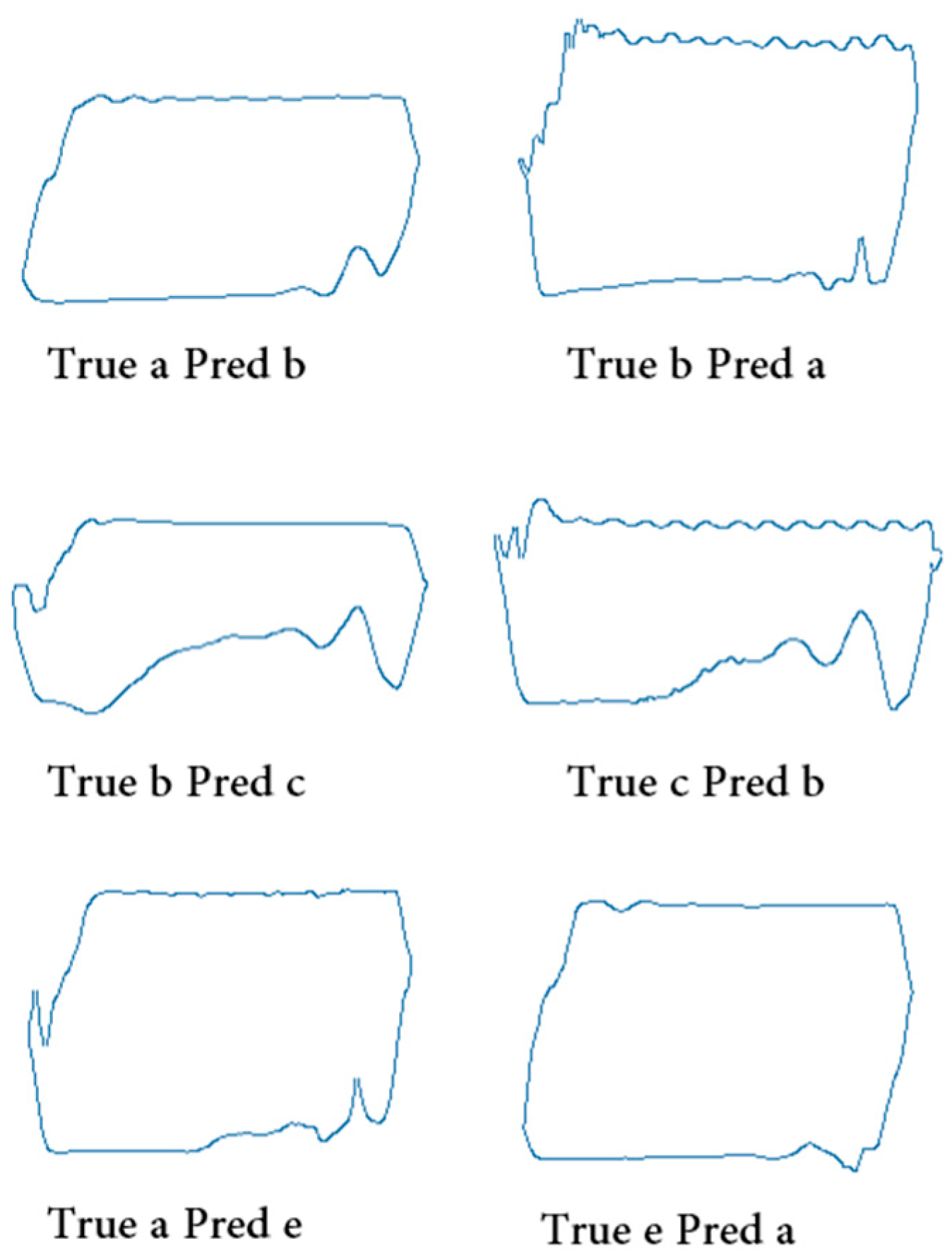
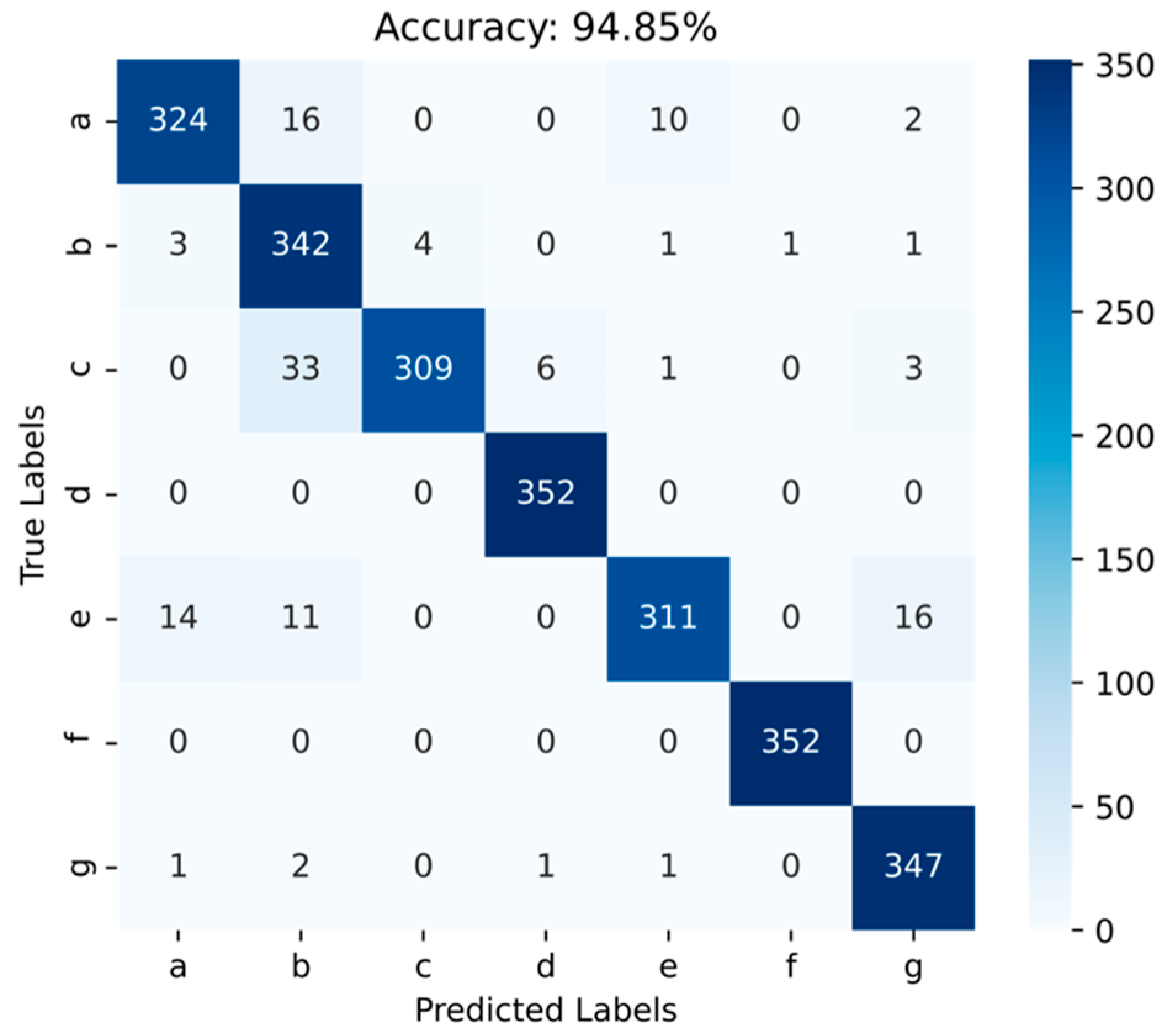
4.3.3. Confusion Matrix
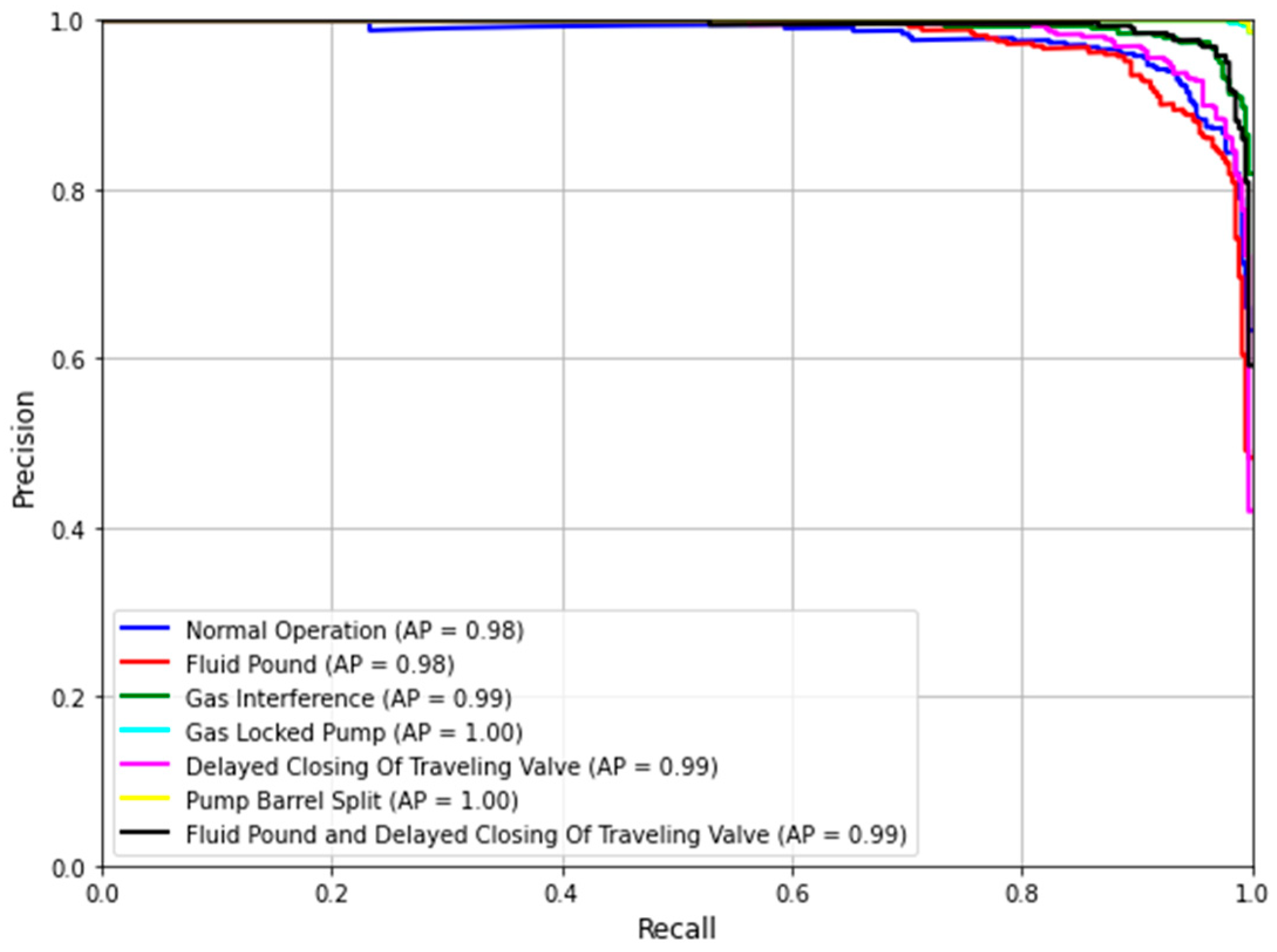
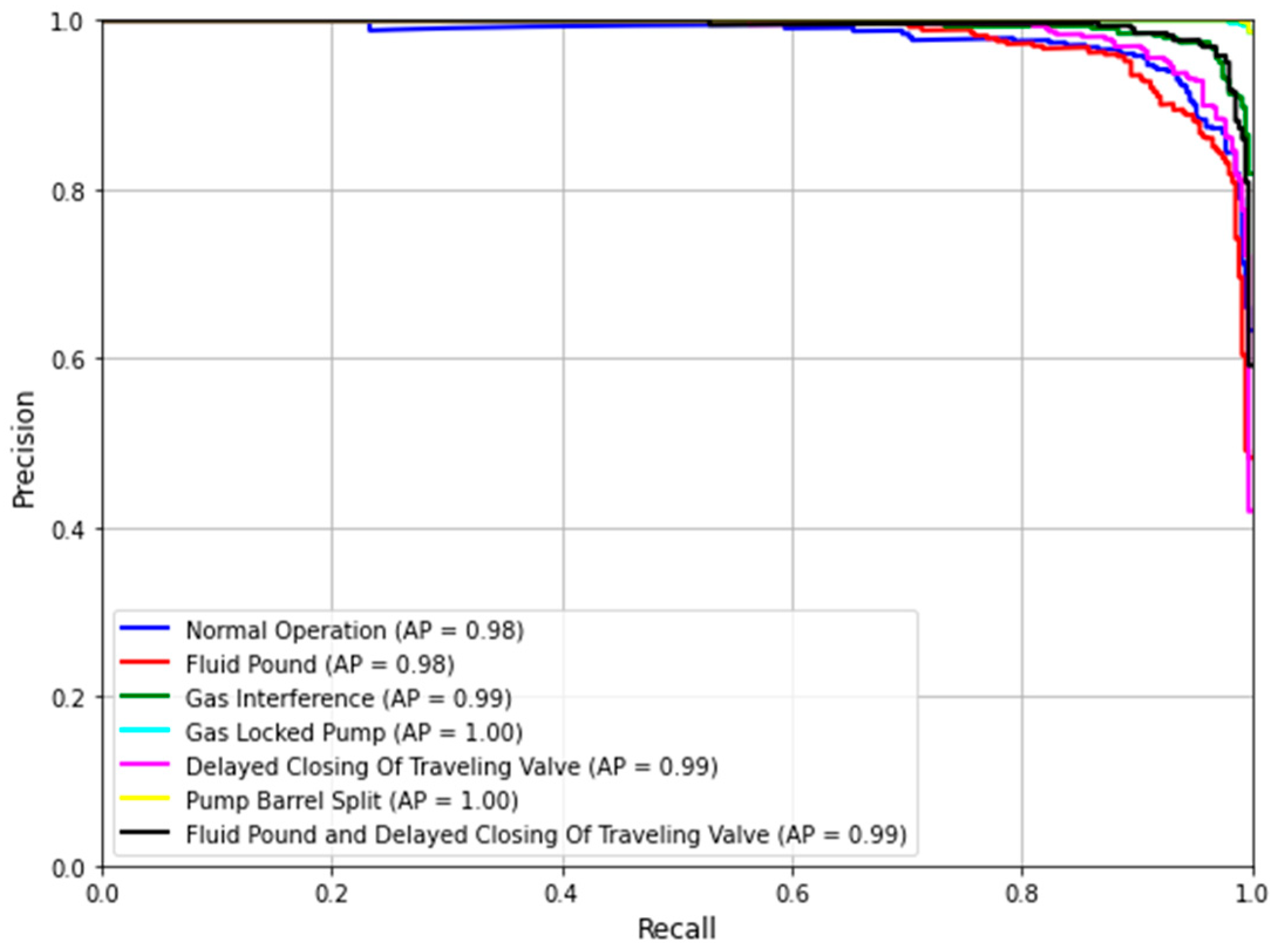
4.3.4. P-R Curve
4.4. Comparative Experimental Analysis
4.4.1. Model Performance Comparison
4.4.2. Model Computational Comparison
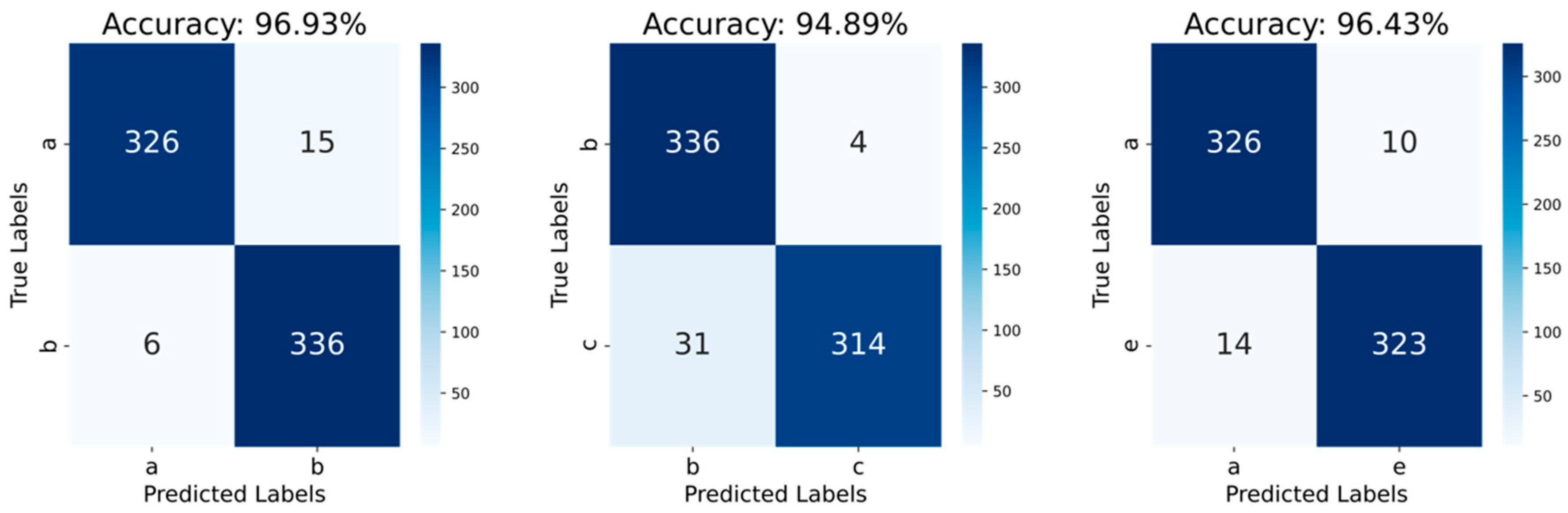
4.5. Model Validation
5. Conclusions
- To address the classification problem of dynagraph cards in the rod pumping system, we have developed a neural network model based on attention mechanisms to achieve the effective identification and classification of Normal Operation, Fluid Pound, Gas Interference, Gas Locked Pump, Delayed Closing of Traveling Valve, Pump Barrel Split, and Fluid Pound and Delayed Closing of Traveling Valve. Compared to previous methods, this approach enables the more efficient and accurate automatic identification of dynagraph cards.
- By utilizing the Swin Transformer model and transfer learning, we introduce a hierarchical window mechanism through the Swin Transformer, which captures local information and details in images more effectively through local window-level attention mechanisms, thus improving the accuracy of condition diagnosis. Transfer learning allows our model to benefit from the pre-trained Swin Transformer model parameters, improving training efficiency and saving time. However, the model to some extent relies on large-scale datasets to achieve better performance.
- Our method demonstrates high accuracy in pumping unit condition diagnosis and holds significant research value for intelligent oilfield development.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Parimontonsakul, M.; Lotongkum, S.; Mularlee, K. A Machine Learning Based Approach to Automate Stratigraphic Correlation through Marker Determination. Improv. Oil Gas Recovery 2023, 7, 1. [Google Scholar]
- Tian, J.; Gao, M.; Li, K.; Zhou, H. Fault Detection of Oil Pump Based on Classify Support Vector Machine. In Proceedings of the 2007 IEEE International Conference on Control and Automation, Guangzhou, China, 30 May–1 June 2007; pp. 549–553. [Google Scholar]
- Li, K.; Gao, X.; Tian, Z.; Qiu, Z. Using the Curve Moment and the PSO-SVM Method to Diagnose Downhole Conditions of a Sucker Rod Pumping Unit. Pet. Sci. 2013, 10, 73–80. [Google Scholar] [CrossRef]
- He, Y.; Liu, Y.; Shao, S.; Zhao, X.; Liu, G.; Kong, X.; Liu, L. Application of CNN-LSTM in Gradual Changing Fault Diagnosis of Rod Pumping System. Math. Probl. Eng. 2019, 2019, 4203821. [Google Scholar] [CrossRef]
- Zhou, X.; Zhao, C.; Liu, X. Application of Cnn Deep Learning to Well Pump Troubleshooting via Power Cards. In Proceedings of the Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, United Arab Emirates, 11–14 November 2019; p. D031S090R004. [Google Scholar]
- Cheng, H.; Yu, H.; Zeng, P.; Osipov, E.; Li, S.; Vyatkin, V. Automatic Recognition of Sucker-Rod Pumping System Working Conditions Using Dynamometer Cards with Transfer Learning and Svm. Sensors 2020, 20, 5659. [Google Scholar] [CrossRef]
- Wibawa, R.; Rosyadi, R.; Nancy, M.; Irfani Hasya Fulki, R. Unlocking the Potential of Unlabeled Data in Building Deep Learning Model for Dynamometer Cards Classification by Using Self-Supervised Learning. In Proceedings of the International Petroleum Technology Conference, Bangkok, Thailand, 1–3 March 2023. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Zhang, K.; Wang, Z.; Yan, X.; Liu, P.; Wang, Q.; Fan, L.; Yao, J.; Yang, Y. Diagnosis of Pumping Machine Working Conditions Based on Transfer Learning and ViT Model. Geoenergy Sci. Eng. 2023, 226, 211729. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Solodkiy, E.M.; Kazantsev, V.P.; Dadenkov, D.A. Improving the Energy Efficiency of the Sucker-Rod Pump via Its Optimal Counterbalancing. In Proceedings of the 2019 International Russian Automation Conference (RusAutoCon), Sochi, Russia, 8–14 September 2019; pp. 1–5. [Google Scholar]
- Xing, M.; Dong, S. A New Simulation Model for a Beam-Pumping System Applied in Energy Saving and Resource-Consumption Reduction. SPE Prod. Oper. 2015, 30, 130–140. [Google Scholar] [CrossRef]
- Ruset, I.C.; Ketel, S.; Hersman, F.W. Optical Pumping System Design for Large Production of Hyperpolarized Xe 129. Phys. Rev. Lett. 2006, 96, 053002. [Google Scholar] [CrossRef] [PubMed]
- Gibbs, S.G. A General Method for Predicting Rod Pumping System Performance. In Proceedings of the SPE Annual Technical Conference and Exhibition? Denver, CO, USA, 2 October 1977; p. SPE-6850-MS. [Google Scholar]
- Xu, P.; Xu, S.; Yin, H. Application of Self-Organizing Competitive Neural Network in Fault Diagnosis of Suck Rod Pumping System. J. Pet. Sci. Eng. 2007, 58, 43–48. [Google Scholar] [CrossRef]
- Gibbs, S.G. Predicting the Behavior of Sucker-Rod Pumping Systems. J. Pet. Technol. 1963, 15, 769–778. [Google Scholar] [CrossRef]
- Feng, Z.-M.; Guo, C.; Zhang, D.; Cui, W.; Tan, C.; Xu, X.; Zhang, Y. Variable Speed Drive Optimization Model and Analysis of Comprehensive Performance of Beam Pumping Unit. J. Pet. Sci. Eng. 2020, 191, 107155. [Google Scholar] [CrossRef]
- Boguslawski, B.; Boujonnier, M.; Bissuel-Beauvais, L.; Saghir, F.; Sharma, R.D. IIoT Edge Analytics: Deploying Machine Learning at the Wellhead to Identify Rod Pump Failure. In Proceedings of the SPE Middle East Artificial Lift Conference and Exhibition, Manama, Bahrain, 28–29 November 2018; p. D021S004R001. [Google Scholar]
- Yavuz, F.; Lea, J.F.; Garg, D.; Oetama, T.; Cox, J.; Nickens, H. Wave Equation Simulation of Fluid Pound and Gas Interference. In Proceedings of the SPE Oklahoma City Oil and Gas Symposium/Production and Operations Symposium, Oklahoma City, OK, USA, 16–19 April 2005; p. SPE-94326-MS. [Google Scholar]
- Allison, A.P.; Leal, C.F.; Boland, M.R. Solving Gas Interference Issues with Sucker Rod Pumps in the Permian Basin. In Proceedings of the SPE Artificial Lift Conference and Exhibition-Americas, The Woodlands, TX, USA, 28–30 August 2018. [Google Scholar] [CrossRef]
- Brauers, H.; Braunger, I.; Jewell, J. Liquefied Natural Gas Expansion Plans in Germany: The Risk of Gas Lock-in under Energy Transitions. Energy Res. Soc. Sci. 2021, 76, 102059. [Google Scholar] [CrossRef]
- Juch, A.H.; Watson, R.J. New Concepts in Sucker-Rod Pump Design. J. Pet. Technol. 1969, 21, 342–354. [Google Scholar] [CrossRef]
- Nickens, H.; Lea, J.F.; Cox, J.C.; Bhagavatula, R.; Garg, D. Downhole Beam Pump Operation: Slippage and Buckling Forces Transmitted to the Rod String. J. Can. Pet. Technol. 2005, 44, 5. [Google Scholar] [CrossRef]
- Chua, L.O.; Roska, T. The CNN Paradigm. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1993, 40, 147–156. [Google Scholar] [CrossRef]
- Kuo, C.-C.J. Understanding Convolutional Neural Networks with a Mathematical Model. J. Vis. Commun. Image Represent. 2016, 41, 406–413. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Zhang, Q.; Zhu, S.-C. Visual Interpretability for Deep Learning: A Survey. Front. Inf. Technol. Electron. Eng. 2018, 19, 27–39. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Abbasi, S.F.; Ahmad, J.; Tahir, A.; Awais, M.; Chen, C.; Irfan, M.; Siddiqa, H.A.; Waqas, A.B.; Long, X.; Yin, B.; et al. EEG-based neonatal sleep-wake classification using multilayer perceptron neural network. IEEE Access 2020, 8, 183025–183034. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Hatamizadeh, A.; Yin, H.; Heinrich, G.; Kautz, J.; Molchanov, P. Global Context Vision Transformers. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 12633–12646. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Bradley, A.P. The Use of the Area under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Rahman, M.M.; Davis, D.N. Addressing the Class Imbalance Problem in Medical Datasets. Int. J. Mach. Learn. Comput. 2013, 3, 224. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing Residual Architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing Efficient Convnet Descriptor Pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Islam, M.R.; Matin, A. Detection of COVID 19 from CT Image by the Novel LeNet-5 CNN Architecture. In Proceedings of the 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; pp. 1–5. [Google Scholar]
- Markovic, D.; Nikolic, B.; Brodersen, R. Analysis and Design of Low-Energy Flip-Flops. In Proceedings of the International Symposium on Low Power Electronics and Design, Huntington Beach, CA, USA, 6–7 August 2001; pp. 52–55. [Google Scholar] [CrossRef]
- Zhan, Z.-H.; Liu, X.-F.; Gong, Y.-J.; Zhang, J.; Chung, H.S.-H.; Li, Y. Cloud Computing Resource Scheduling and a Survey of Its Evolutionary Approaches. ACM Comput. Surv. (CSUR) 2015, 47, 1–33. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Results | |||
|---|---|---|---|
| Positive Example | Negative Example | ||
| Real results | Positive example | TP | FN |
| Negative example | FP | TN | |
| Model | Accuracy | F1 Score | Precision | Recall | ROC AUC | K | |
|---|---|---|---|---|---|---|---|
| Transformer | Swin-T | 0.952 | 0.952 | 0.954 | 0.952 | 0.972 | 0.923 |
| ViT | 0.944 | 0.944 | 0.945 | 0.944 | 0.957 | 0.901 | |
| CNN | ResNet | 0.912 | 0.906 | 0.918 | 0.915 | 0.937 | 0.872 |
| DenseNet | 0.897 | 0.896 | 0.902 | 0.897 | 0.940 | 0.885 | |
| LeNet | 0.890 | 0.887 | 0.898 | 0.884 | 0.918 | 0.862 |
| Model | Param (M) | FLOPs (G) | |
|---|---|---|---|
| Transformer | Swin-T | 0.38 | 8.7 |
| ViT | 0.25 | 743.0 | |
| CNN | ResNet | 24.5 | 3.9 |
| DenseNet | 6.69 | 2.91 | |
| LeNet | 0.06 | 0.005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, G.; Li, W.; Dong, Z.; Wang, C.; Qian, S.; Zhang, T.; Ma, X.; Zou, L.; Lin, K.; Liu, Z. Enhancing Dynagraph Card Classification in Pumping Systems Using Transfer Learning and the Swin Transformer Model. Appl. Sci. 2024, 14, 1657. https://doi.org/10.3390/app14041657
Dong G, Li W, Dong Z, Wang C, Qian S, Zhang T, Ma X, Zou L, Lin K, Liu Z. Enhancing Dynagraph Card Classification in Pumping Systems Using Transfer Learning and the Swin Transformer Model. Applied Sciences. 2024; 14(4):1657. https://doi.org/10.3390/app14041657
Chicago/Turabian StyleDong, Guoqing, Weirong Li, Zhenzhen Dong, Cai Wang, Shihao Qian, Tianyang Zhang, Xueling Ma, Lu Zou, Keze Lin, and Zhaoxia Liu. 2024. "Enhancing Dynagraph Card Classification in Pumping Systems Using Transfer Learning and the Swin Transformer Model" Applied Sciences 14, no. 4: 1657. https://doi.org/10.3390/app14041657
APA StyleDong, G., Li, W., Dong, Z., Wang, C., Qian, S., Zhang, T., Ma, X., Zou, L., Lin, K., & Liu, Z. (2024). Enhancing Dynagraph Card Classification in Pumping Systems Using Transfer Learning and the Swin Transformer Model. Applied Sciences, 14(4), 1657. https://doi.org/10.3390/app14041657