1. Introduction
In recent years, the field of generative modeling has experienced a substantial surge in development, resulting in the proliferation of numerous generative models. Artificial Intelligence-Generated Content (AIGC) [
1,
2,
3] has garnered significant attention from both the scientific community and society at large. This trend underscores the substantial value of contemporary generative models. Consequently, the protection of intellectual property (IP) rights for these models has emerged as a prominent and pressing concern in the current landscape. To protect the IP of models, both academia and industry have developed a range of model watermarking techniques tailored for the protection of deep models. These models conventionally comprise three fundamental elements: the input, internal structure, and output. Many of these methods [
4,
5,
6,
7,
8,
9,
10] mark the model by altering its internal parameters or structure, thus enabling IP protection of the model. On the other hand, other methods [
11,
12,
13,
14,
15,
16] for verifying model ownership involve creating trigger sets and fine-tuning the model to produce aberrant outputs.
Recently, model watermarking techniques have been extended to protect generative models [
17,
18,
19,
20], which we denote as generative model watermarking. In this paper, we study generative model watermarking [
17,
18,
19,
20] for protecting an image generation network. Specifically, it involves embedding specific watermark information into the images generated by the network. In other words, a watermarked deep neural network is identifiable by the presence of watermarks in all the images it produces. Many of these generative model watermarking frameworks draw upon advanced techniques in image deep steganography [
21,
22]. In this paper, we will focus on the two most popular generative model watermarking techniques [
17,
19]. Wu et al. [
17] introduced a framework that invisibly embeds watermarks into the output of the model by incorporating a watermark loss into the loss functions. The core of this watermarking framework includes a key-controlled watermark extraction network that is co-trained with the protected network. This watermark extraction network is able to extract the watermark from watermarked images. Additionally, any non-marked image or employing an incorrect key for copyright verification prompts the watermark extraction network to output noise, resulting in the failure of copyright authentication. Furthermore, the framework improves its resistance to common pre-processing attacks through adversarial training on manipulated samples. Note that this method utilizes the protected network for watermark embedding, which may potentially impact the quality of images generated by the network. Zhang et al. [
18,
19] proposed a novel watermarking framework designed for image processing networks, specifically aimed at countering surrogate model attacks. Such attacks involve collecting many inputs and outputs from the target model to guide the training of a surrogate model. The objective is to enable the surrogate model to achieve similar capabilities and performance levels as the target model. In this method, an imperceptible watermark is embedded into the model’s output using a watermark embedding network. The watermarked output can then be extracted by the watermark extraction network to retrieve copyright information. In a surrogate model attack scenario, the attacker only has access to their own inputs and the outputs with the embedded watermark. Consequently, the output of their trained surrogate network also contains copyright information, preventing the surrogate model attack. However, it is important to note that this method may not be entirely robust against certain pre-processing attacks since the required consistency could be compromised.
The creation of a generative model of watermarking relies on the watermark embedding network to add a watermark to the output of the protected network for ownership verification. It is crucial to emphasize the watermark embedding network and the watermark addition process, which we will analyze in the following. It is evident that current generative model watermarking techniques [
17,
18,
19] employ deep networks as the watermark embedding network. For instance, Wu et al. [
17] utilize the host network as the watermark embedding network, while Zhang et al. [
18,
19] introduce an additional watermark embedding network. The watermark embedding network often involves numerous up-sampling and down-sampling operations, which may inadvertently introduce high-frequency artifacts into the output image [
23]. Furthermore, the process of adding watermarks to an image is equivalent to introducing high-frequency perturbations, which directly leads to the emergence of high-frequency artifacts within the marked images [
24]. Therefore, we find that all existing generative model watermarking methods encompass the watermark embedding network and watermark addition process as described earlier, inevitably introducing high-frequency artifacts into the images marked by generative model watermarking systems. These high-frequency artifacts undermine the ability of the model watermarking system to maintain invisibility in the frequency domain.
To ensure the effectiveness of watermarking systems, the embedded watermarks must be imperceptible to potential attackers [
20,
25,
26], thus reducing the risk of a successful attack. Conversely, when a watermarking system lacks invisibility, it becomes vulnerable to direct exposure to attackers, making it susceptible to damage and invalidation. Our analysis reveals the presence of high-frequency artifacts within the frequency domain of the images marked by generative model watermarking. Past generative model watermarking assert that their watermarks are invisibly embedded in the image’s spatial domain, making it challenging for an attacker to detect the model watermarking in this spatial view. However, the existence of high-frequency artifacts in the frequency domain of the marked images renders the generative model watermarking conspicuous within the frequency domain, thus making it vulnerable to detection by potential attackers. The lack of invisibility within the frequency domain poses a significant challenge, as it could potentially enable attackers to identify and remove the embedded watermark using specific attacks. This vulnerability may lead to unauthorized watermark removal or fraudulent ownership claims. Hence, we advocate for the consideration of watermark invisibility in both spatial and frequency domains in the context of generative model watermarking. Additionally, we propose an image watermarking to address the existing issues of invisibility associated with generative model watermarks within the frequency domain.
In order to enhance the imperceptibility of generative model watermarking, we introduce a novel image watermarking framework designed to mitigate the high-frequency artifacts. Our approach bypasses traditional watermark embedding networks typically used for image marking, thus effectively addressing the issue of high-frequency artifacts associated with deep networks. We propose a frequency perturbation generation networks responsible for generating frequency perturbations, which can flexibly fine-tune the perturbation range adjustments. These perturbations are subsequently integrated into the frequency domain of the original image to create the marked image. By limiting the size of the watermark perturbation and adding it to the low frequencies of the carrier image (the central region of the frequency domain), we successfully prevent it from affecting the high-frequency regions of the image. Subsequently, we train the watermark extraction network to accurately recover the watermark from the marked image, ensuring high-quality retrieval. Our results conclusively demonstrate the effectiveness of our proposed watermarking framework in embedding the low-frequency perturbation watermark into the image while effectively suppressing high-frequency artifacts. This significantly enhances the frequency-domain imperceptibility and security of the watermarking system. Experimental findings affirm that our method does not compromise the performance of the protected network. It consistently delivers exceptional imperceptibility and robustness. Consequently, our framework exhibits substantial potential as an advanced solution for safeguarding IP rights.
The contributions of this paper are summarized as follows:
Our investigation has revealed the presence of high-frequency artifacts in marked images, emphasizing the limitations of existing watermarking techniques in achieving concealment in the frequency domain. This novel discovery underscores the imperative for further research and refinements in the frequency domain to enhance the concealment capabilities of watermarking.
We propose an image watermarking system with the aim of improving watermark imperceptibility in the frequency domain. Unlike existing methods that use a standard watermark embedding network for marking, our approach involves adding adjustable frequency perturbations to the low-frequency components of the cover image for marking. This strategy minimizes the impact on high-frequency elements of the image, thereby reducing high-frequency artifacts and enhancing the effectiveness of watermark concealment.
A series of experiments validate the efficacy of our proposed method. Across various tasks, such as paint transfer and de-raining, our approach exhibits a notable absence of artifacts, demonstrating its strong concealment characteristics in both the spatial and frequency domains of the image.
The rest of this paper is organized as follows. We introduce preliminaries and the proposed method in
Section 2, followed by the experimental results and analysis in
Section 3. The discussion is provided in
Section 4. Finally, we conclude this work in
Section 5.
2. Preliminaries and Proposed Method
2.1. Detection of High-Frequency Artifacts
High-frequency artifacts manifest as unnatural and inconsistent textures, such as box-like patterns, in the frequency domain. In this section, we show the high-frequency artifacts present in the images that marked by the generative model watermarking, thus revealing the flaws in their covertness. We employed a frequency domain detection method [
23] to detect high-frequency artifacts. Specifically, we used the Type II Discrete Cosine Transform (2D-DCT) to generate a DCT spectrum, which was then represented as a heatmap. Within this heatmap, the size of each data point indicates the coefficient of the respective spatial frequency, with larger values leading to brighter points. Frequency levels gradually increase from left to right and from top to bottom on the heatmap. The upper left section of the heatmap corresponds to lower frequencies, while the lower right section represents higher frequencies. In our experiments, we used two datasets: the Danbooru2019 dataset [
27] and the De-raining dataset [
28], to evaluate the previous generative model watermarking methods [
17,
19].
For the spatial domain, the evaluation results for these datasets are depicted in
Figure 1. In
Figure 1a, randomly selected ground-truth images from the Danbooru2019 dataset are showcased, while in
Figure 1b, carrier images generated by the generative network [
29] are presented.
Figure 1c,d display images marked by [
19] and [
17], respectively. It is evident that the images in
Figure 1a,b exhibit high similarity, indicating that the generative network [
29] effectively accomplishes the image task. Simultaneously, the images in
Figure 1c,d also closely resemble those in
Figure 1a,b, suggesting that the previous generative model watermarking method successfully achieved the watermarking task without compromising the quality of the spatial domain in the original image.
Figure 1e–h demonstrates similar results.
More importantly, our investigation delves into the characteristics and variations of the test images in the frequency domain. Typically, in natural images, low-frequency components depict smoothly varying image intensities and carry the majority of the image information [
30,
31]. Conversely, higher-frequency components approximate image edges, representing abrupt pixel transitions. The DCT heatmap for the various methods is presented at the bottom of
Figure 1. At the bottom of
Figure 1a, the DCT heatmap for the natural image are depicted. In the bottom of
Figure 1b, the DCT heatmap for the generated image are shown, presenting box-like high-frequency artifacts. In the bottom of
Figure 1c,d, the DCT heatmap for the marked images displays even more pronounced high-frequency artifacts. Similar results are observed at the bottom of
Figure 1e–h. Therefore, through the DCT frequency domain analysis, we identify severe high-frequency artifacts in the marked images generated by existing generative model watermarking methods, highlighting a deficiency in frequency domain imperceptibility.
In summary, prior generative model watermarking methods have focused on the invisible embedding of watermarks in the spatial domain of images, making it difficult for potential attackers to discern the model watermarking within this spatial context. However, the identification of high-frequency artifacts in the frequency domain of the marked images renders generative model watermarking conspicuous within this frequency domain, thereby compromising the overall imperceptibility and security of the generative model watermarking system. Consequently, generative model watermarking becomes susceptible to detection by potential attackers. This situation underscores the imperative need for enhancing frequency-based imperceptibility in generative model watermarking.
2.2. Origins of High-Frequency Artifacts
In this section, we investigate the origins of high-frequency artifacts in the current generative model watermarking [
17,
19], building upon insights from previous research. We identify two primary sources of these artifacts: the watermark embedding network and the watermark embedding process. Odena et al. [
32] attributed grid-like anomalies in spatial images to the up-sampling process. Similarly, Frank et al. [
23] explicitly highlighted that incorporating up-sampling within the generative network introduces high-frequency artifacts in the frequency domain. These findings collectively suggest that the use of CNNs for image generation inherently results in structural high-frequency artifacts. Thus, we contend that the prevalent CNN-based watermark embedding networks in generative model watermarking inevitably introduce high-frequency artifacts when generating marked images. Moreover, Zeng et al. [
24] observed that employing image patching triggers in backdoor attacks also leads to the emergence of high-frequency artifacts. Further insights from Zhang et al. [
21] explained that embedding information using deep neural networks essentially adds coded high-frequency information to the carrier image. We posit that the watermark embedding process in generative model watermarking shares similarities with backdoor attacks or DNN-based information embedding. This process requires introducing perturbations to the marked image, leaving a distinguishable trace in the frequency domain due to time–frequency coherence. Without appropriate constraints, watermarking perturbations tend to exhibit high-frequency characteristics, inevitably introducing high-frequency artifacts into the marked image.
In summary, existing model watermarking techniques employ watermark embedding networks that inherently introduce high-frequency artifacts. Additionally, the addition of watermarking perturbations naturally gives rise to high-frequency artifacts. In light of these findings, we propose an image watermarking technology designed to suppress high-frequency artifacts.
2.3. Method Overview
As mentioned previously, existing generative model watermarking techniques [
17,
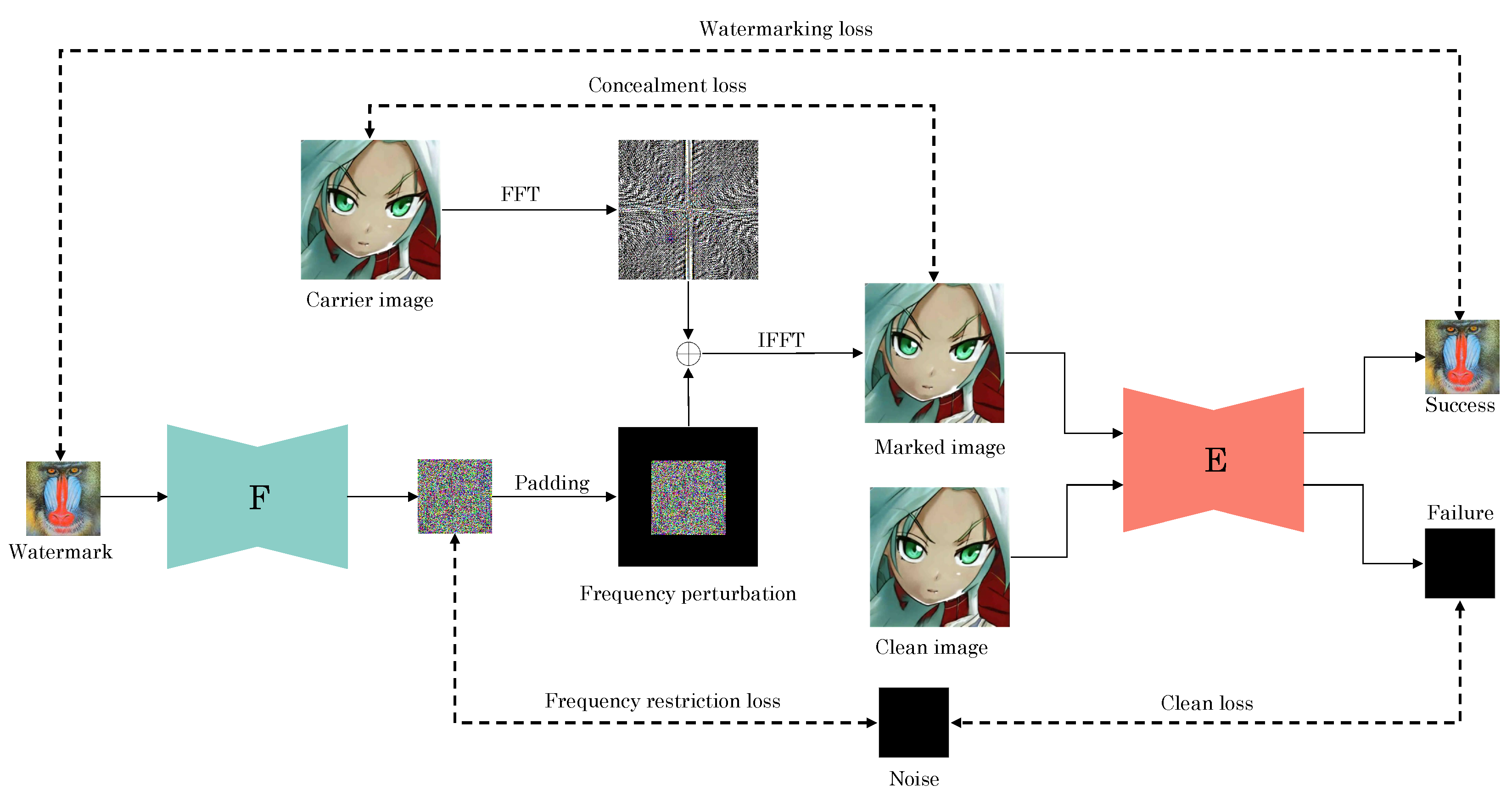
19] suffer from noticeable high-frequency artifacts in the frequency domain, which compromise the overall concealment of the embedded watermark. In response to this challenge, we introduce an innovative image watermarking framework. At its core, this framework revolves around bypassing the watermark embedding network to mitigate the inherent high-frequency artifacts caused by CNNs. We design a frequency perturbation generation network to create frequency perturbations, which are then incorporated into the carrier image to achieve watermarking. Finally, the watermark is extracted from the marked image using a watermark extraction network.
Our proposed framework comprises two primary components: a frequency perturbation generation network
F, and a watermark extraction network
E. As illustrated in
Figure 2, the frequency generation network takes fixed watermarks as input and generates frequency perturbations. Given a
carrier image (i.e., the image generated by the generating network to be protected), we target the central
portion of its frequency domain as the low-frequency component. To insert a frequency perturbation into this low-frequency area, we create a
perturbation and incorporate it into the carrier image’s frequency domain to achieve the watermarking. Importantly, the frequency domain perturbation introduced only affects the
low-frequency region at the center of the carrier image’s frequency domain. Thus, our approach effectively embeds the frequency domain perturbation into the carrier image’s low-frequency component. By controlling the embedding location of the frequency domain perturbation, we selectively modify the carrier image’s low-frequency regions while leaving the high-frequency regions unaltered. This targeted strategy effectively mitigates the high-frequency artifacts commonly associated with the watermark embedding process. Moreover, by bypassing the watermark embedding network, we ensure that the carrier image remains free from the high-frequency artifacts introduced by CNNs. Finally, through joint training, the watermark extraction network is trained to accurately retrieve the watermark from marked images.
2.4. Framework
The proposed framework is shown in
Figure 2. Carrier images are images generated by the protected model. A fixed watermark is input into the frequency perturbation generation network
F, and we expect
F to generate the frequency perturbation
f. As shown in
Figure 2, we constrain the dimensions of
f to
and add it to the low-frequency domain of the carrier image. To match the frequency domain of the carrier image, we apply padding to the frequency perturbation (the filled area is set to 0). To obtain the frequency domain of the carrier image, we employ the Fast Fourier Transform (FFT). We add
f to the frequency domain and subsequently perform an Inverse Fast Fourier Transform (IFFT) to convert it back to the spatial domain, resulting in the marked image. Similarly, our objective is to make the marked image as similar as possible to the carrier image, subject to the constraints of the loss function, while minimizing the impact of the frequency perturbation on the marked image. Lastly, we input the marked images into a watermark extraction network
E, with the expectation that
E learns how to extract watermarks from marked images. To prevent overfitting of the watermark extraction network
E, we provide it with some negative samples from which we aim to extract noise. The above goals will be achieved through joint training of the watermark extraction network and the frequency perturbation generation network.
In our paper, we employ a Unet-like network structure [
33] for the frequency perturbation generation network
F, with the input and output dimensions set to
. For the watermark extraction network
E, we utilize a ResNet-like architecture similar to the one used in paper [
34], with input and output dimensions of
and
. To transform signals from the spatial domain to the frequency domain and vice versa, we employ fundamental signal analysis techniques, namely the FFT for the former and the IFFT for the latter.
2.5. Loss Functions
As an image watermarking framework, the frequency perturbation generation network F is responsible for generating the frequency perturbation f. This perturbation is subsequently added into the frequency domain of the carrier image C, yielding the marked image . And is input into the watermark extraction network E, with the objective of extracting the watermark. It is crucial that, when E receives a clean image, it should generate a noise. To achieve these objectives, our design incorporates four key loss functions: the frequency restriction loss, watermarking loss, clean loss, and concealment loss. These losses play a pivotal role in optimizing the watermarking process and ensuring its effectiveness.
2.5.1. Frequency Restriction Loss
f represents the perturbation generated by the frequency perturbation network
F:
where
represents the output of the frequency perturbation network
F and
indicates the fixed watermark. To minimize the effect of adding the perturbation
f to the carrier image, we aim to minimize the frequency perturbation
f as much as possible. Therefore, we want to optimize:
We will use norm as the distance measure by default, unless otherwise specified.
2.5.2. Watermarking Loss
To watermark the carrier image
C, it is necessary to add the frequency perturbation
f into the frequency domain of
C. Following this, we transform the frequency domain back to the spatial domain, yielding the marked image
. The
is
where
denotes the tunable hyperparameter.
denotes the Fast Fourier Transform and
denotes the Inverse Fast Fourier Transform.
More importantly, To be able to extract a watermark, we use the watermarking loss
where
x denotes the marked images that belong to
.
N denotes the pixel numbers.
represents the watermark recovered from the marked image by the watermark extraction network
E.
2.5.3. Clean Loss
To prevent overfitting of the watermark extraction network, we must introduce a clean loss term:
where
x belongs to the clean carrier images
C and we want the watermark extraction network to extract the noise from the clean image. In this paper,
defaults to zero.
2.5.4. Concealment Loss
To embed the watermark in a spatially invisible way, we have to minimize the visual distance between the carrier image and the marked image, and the concealment loss can be expressed as
Lastly, the frequency domain perturbation generation network and the watermark extraction network will be trained jointly with the total loss as shown below:
3. Experimental Results and Analysis
3.1. Setup
Dataset. To validate the effectiveness of our approach, we conducted evaluations on two distinct tasks: paint transfer [
29] and de-raining [
28]. To protect paint transfer model, we employed the Danbooru2019 dataset [
27] and adopted the training methodology [
29]. Following the training of our paint transfer model, we randomly sampled 4000 images (i.e., carrier images) generated by the network, with 3000 allocated for image watermarking training, 500 for validation, and 500 for testing. To protect de-raining model, we employed the dataset [
28] and followed their training procedure. Following the training of our de-raining model, we randomly selected 2000 images (i.e., carrier images) generated by the network, with 1800 were allocated for image watermarking training, 100 for validation, and 100 for testing.
Parameter Setting. All images were standardized to a size of . We respectively utilized “Baboon” and “MDPI” as watermark images, with a fixed watermark size of . Regarding adjustable parameters, we empirically set , , . We used the Adam optimizer for training with a learning rate of . Our method was implemented on a single TITAN RTX GPU with CuDNN acceleration.
Evaluation Metrics. There are two commonly used metrics to assess the quality of marked images, Peak Signal to Noise Ratio (PSNR) and Structural Similarity (SSIM). Bit Error Rate (BER) is a measure of the quality of binary watermark reconstruction. In addition, to evaluate the performance of watermark extraction, we define a new metric called success rate (SR). Watermark extraction is considered successful if the corresponding PSNR is greater than 25 dB or the corresponding BER is less than
. Finally, the DCT detection results are utilized to measure the frequency-domain invisibility of the image watermarking system. We define the frequency domain invisibility performance (FP), which is expressed by calculating the Learned Perceptual Image Patch Similarity (LPIPS) [
35] between the DCT detection result of the marked image and the DCT detection result of the ground-truth image, with the lower value of the metric being better.
3.2. Qualitative and Quantitative Results
The main objective of this paper is to mitigate the impact of high-frequency artifacts on generative model watermarking, focusing on enhancing imperceptibility and security. It is important to note that strong imperceptibility inherently enhances system security. To achieve this goal, we propose an innovative image watermarking framework that addresses imperceptibility in generative model watermarking within both the spatial and frequency domains. In this section, we will demonstrate the excellent imperceptibility of our proposed framework in both the spatial and frequency domains.
3.2.1. Spatial Invisibility
In this subsection, we assess the performance of our proposed framework by computing the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) between the carrier image and the marked image. Higher PSNR and SSIM values indicate a closer resemblance between the carrier and marked images, indicating that our framework preserves the quality of the carrier image during watermark embedding. Visual representations of the proposed framework are presented in
Figure 3. In the spatial domain, the marked images are nearly indistinguishable from the carrier images, highlighting our framework’s ability to proficiently embed watermarks in the frequency domain without compromising spatial image quality. Our approach achieves commendable visual results, ensuring excellent imperceptibility. Additionally, the extraction of high-quality watermarks from marked images is important for reliable ownership verification. The extracted watermarks from the marked images generated by our framework are also showcased in
Figure 3, both exhibiting favorable visual results.
In further quantitative evaluation, as illustrated in
Table 1 and
Table 2, the quality of both the marked images and the extracted watermarks is assessed. Note that, for the quality of the extracted watermark, we use PSNR and BER (Bit Error Rate) to evaluate it. These metrics demonstrate the high quality of both the marked images (>50 dB) and the extracted watermarks(>40 dB or ≤0.001). And the success rate (SR) of watermark extraction is
. Our image watermarking framework effectively ensures imperceptibility in the spatial domain, upholds carrier image quality, and maintains watermark extraction performance.
3.2.2. Frequence Invisibility
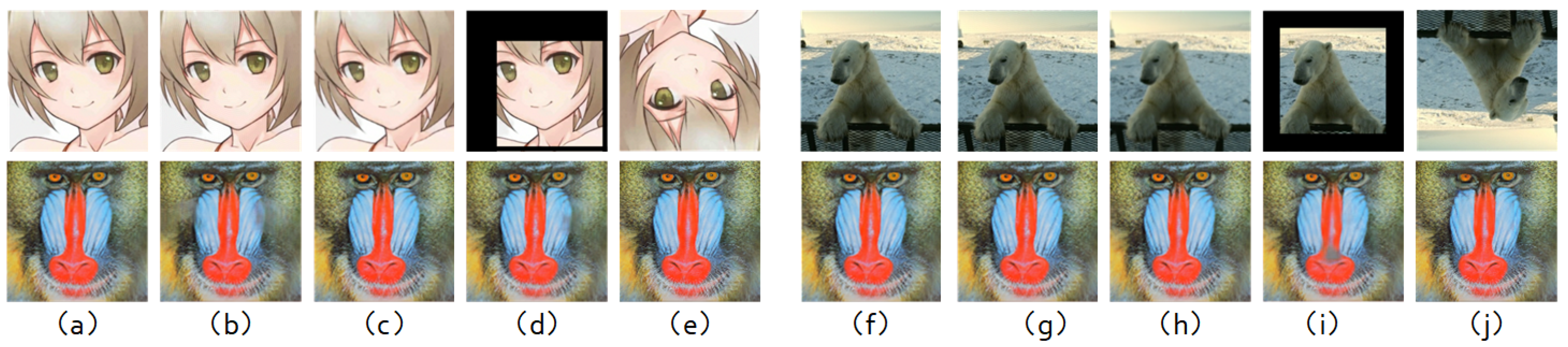
Our primary objective is to achieve imperceptibility of watermarking in the frequency domain by mitigating high-frequency artifacts. To illustrate the good imperceptibility of our novel image watermarking technique in the frequency domain, we examine the DCT heatmaps of the marked images generated by our framework, as displayed in
Figure 4. It is evident that the DCT heatmap results of our framework closely mirror those of natural images at the bottom of
Figure 1a,e, indicating that our proposed framework produces images that are exceptionally natural and devoid of high-frequency artifacts. In contrast, previous model watermarking methods, as depicted in at the bottom of
Figure 1c,d,g,h, exhibit small square high-frequency artifacts, while our method conspicuously eliminates such artifacts.
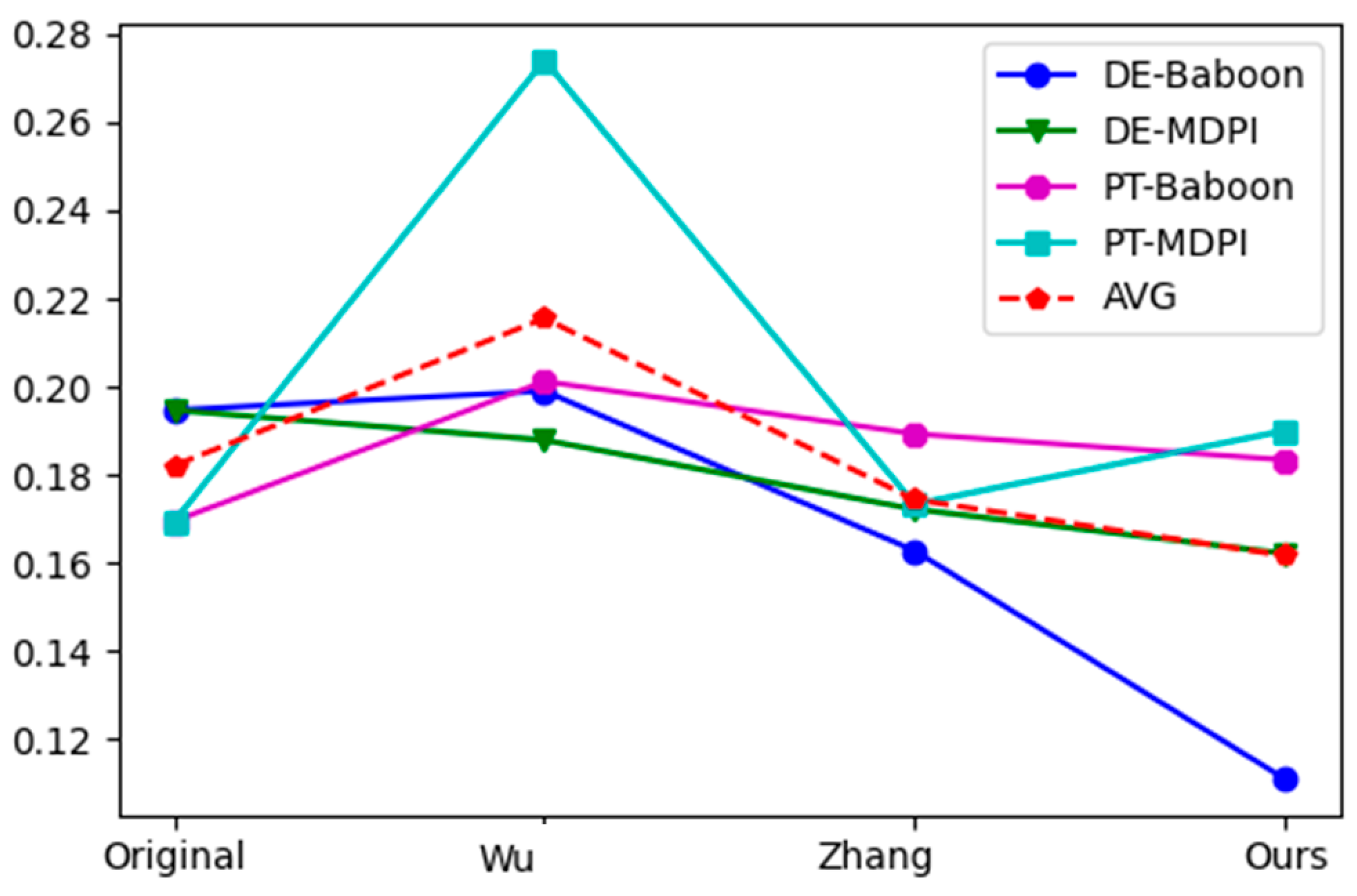
In addition, we evaluate the frequency domain invisibility performance (FP).The results are shown in
Figure 5. Where “Wu” denotes the method [
17] and “Zhang” represents another method [
19]. And “Original” represents the benchmark host network that performs specific image processing tasks such as paint transfer [
29] and de-raining [
28]. We observe good performance across various tasks with our proposed method. For example, in the de-raining task with the “MDPI” watermark, our approach outperforms method [
17] by
, showing a
improvement in average performance compared to method [
17] and a
improvement over method [
19]. These observations reveal that our method produces images with smooth surfaces, avoiding the introduction of high-frequency artifacts, a notable advantage.
This underscores the superior imperceptibility of our proposed framework in the frequency domain. In summary, based on the collective evidence from these experiments, we can assert that our method effectively reduces high-frequency artifacts, preserving the concealment of the embedded watermark in both the frequency and spatial domains, all while upholding the visual quality of the labeled image.
3.3. Robustness
A robust watermarking system must be able to counter attacks encountered in real-world scenarios. In this paper, our focus is on pre-processing attacks, which aim to manipulate the marked image to hinder watermark extraction. To enhance the robustness of our system against these attacks, a common strategy involves including pre-processed images in the training set. Due to limited computational resources, our study focuses on four common attacks: filtering, resizing, cropping, and flipping.
In the filtering attack, an adversary with prior knowledge of the frequency domain may attempt to eliminate the embedded watermark by filtering out high-frequency components from the marked image. To simulate this attack, we filter out high-frequency components from marked images. Specifically, for each channel of a marked image, we calculate the FFT coefficients. We preserve the central region, spanning size , while zeroing out the other coefficients. For the resizing attack, we randomly alter the input images to smaller or larger resolutions within the range and then restore these manipulated images to their original size to extract the watermark. In the cropping attack, we retain only certain pixels within the range , setting the rest to zero to mimic cropping. In the flipping attack, the marked image undergoes a horizontal or vertical inversion. It is important to note that, while our paper tests a limited number of common attacks, there is potential for further exploration, given sufficient computational resources.
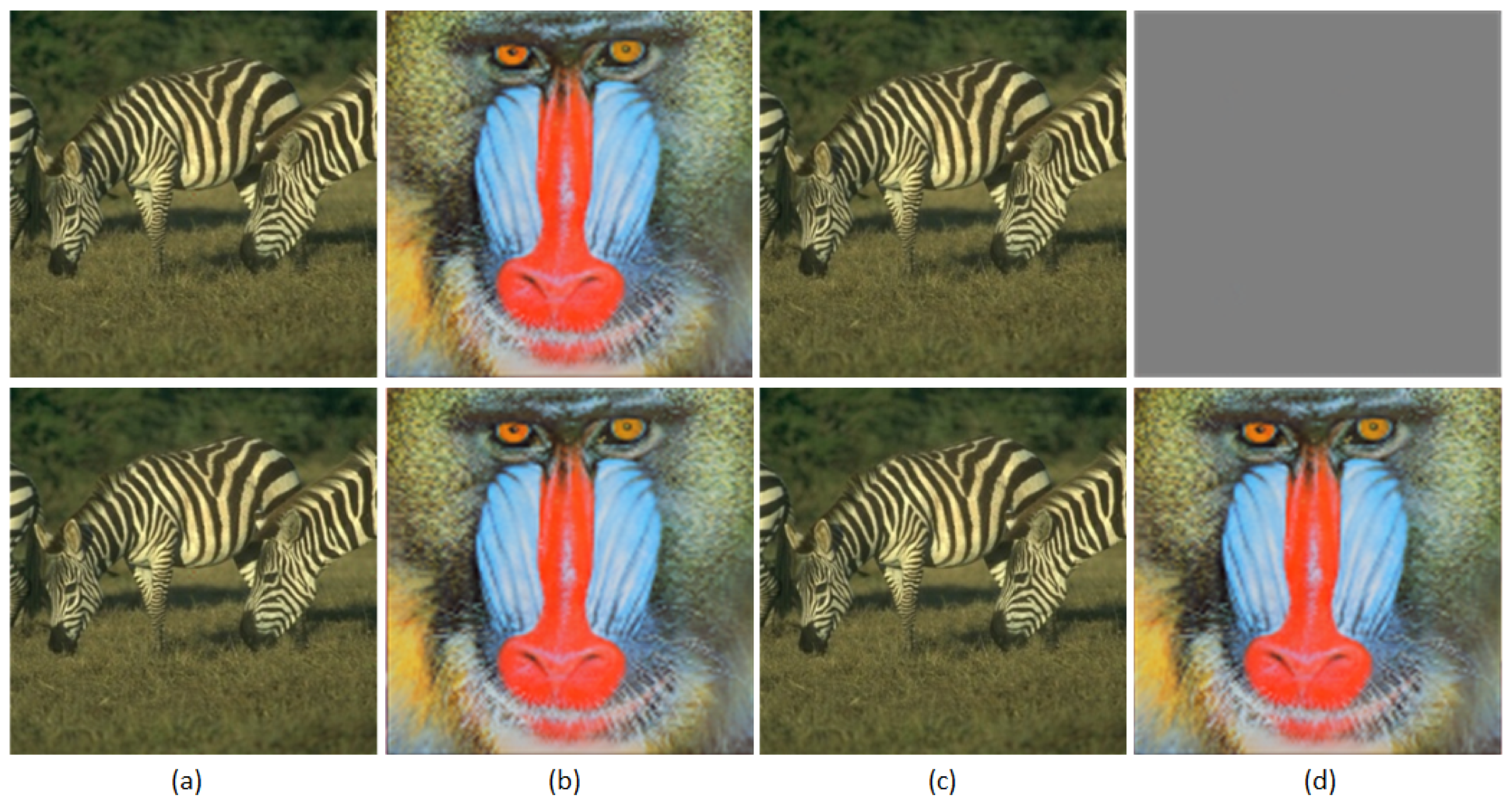
Figure 6 present examples of pre-processed images and the corresponding extracted watermarks. These examples illustrate that the embedded watermark can still be extracted with satisfactory quality despite various pre-processing operations. This underscores the effectiveness of adversarial training in enhancing robustness against pre-processing attacks. Quantitative results in
Table 3,
Table 4 and
Table 5 indicate that, while watermark quality may degrade as attack intensity increases, we generally maintain an acceptable level of quality. These results affirm that our proposed framework effectively withstands pre-processing attacks through the application of adversarial training.
3.4. Comparisons with Previous Model Watermarking Methods
In this section, we present a comparative analysis between our proposed method and prior approaches [
17,
19]. A comprehensive summary of the comparative results is provided in
Table 6, with a focus on resilience against pre-processing attacks and a watermark’s imperceptibility in both spatial and frequency domains. Within
Table 6, “Yes” denotes that the method exhibits robustness against the corresponding attack or achieves imperceptibility in the relevant domain, while “Partially” indicates that some processed images demonstrate good imperceptibility, while others may exhibit noticeable visual artifacts. Our analysis reveals that, in contrast to previous methods, which only partially satisfy these criteria, our proposed method successfully fulfills all the established objectives. This encompasses resistance against pre-processing attacks and ensuring that distortions caused by concealed watermarks remain imperceptible in both spatial and frequency domains.
3.5. Comparisons with Traditional Watermarking Methods
We have proposed an image watermarking technique that considers frequency domain imperceptibility, aimed at protecting the copyright of images generated by generative networks. In this section, we wish to highlight the distinctions between our proposed method and traditional image watermarking techniques, summarized as follows:
Novelty of the research problem: focusing on the high-frequency artifacts problem in generative model watermarking, an image watermarking algorithm that can reduce high-frequency artifacts and improve the effect of copyright protection is proposed.
Innovativeness of the solution: adopting an end-to-end deep learning approach, the watermark is directly embedded and extracted using neural networks to avoid high-frequency artifacts and improve concealment. In contrast, traditional methods require in-depth understanding of various mathematical techniques and careful design of embedding/extraction methods.
Superior Performance: We have compared our method with traditional image watermarking techniques based on DWT-SVD-DCT [
36]. Due to computational constraints, we only compare the case of embedding “MDPI” in the “de-raining” task. As shown in
Table 7, traditional image watermarking techniques tend to be limited in watermark capacity due to the need for carefully designed embedding methods. In contrast, our deep learning-based image watermarking algorithm leverages the capabilities of neural networks to embed a large capacity of watermarks easily. Moreover, our proposed method outperforms in terms of spatial image quality, frequency domain invisibility, and watermark extraction quality.
3.6. Importance of Clean Loss
We have reason to believe that omitting the clean loss from the loss functions could lead to the problem of overfitting in the watermark extraction network, potentially allowing it to erroneously extract watermarks from any image. To empirically investigate this hypothesis, we conducted an experiment where we trained two watermark extraction networks: “
E”, which incorporated the clean loss, and “
”, which excluded the clean loss. Subsequently, we input various clean images into
and observed that it mistakenly retrieved watermarks from these clean images, as illustrated in
Figure 7. In contrast,
E adeptly extracts watermark and noise from watermarked and clean images. Consequently, clean loss prevents the problem of overfitting in the watermark extraction network, making our copyright protection highly effective and practically relevant.
4. Discussion
In the above paper, we have only considered four common pre6processing attacks given the limitation of arithmetic resources. It must be frankly admitted that our proposed framework does not guarantee absolute robustness in the face of a wide variety of real-world attacks. This is because we cannot predict and respond to all potential adversary attack strategies, and there are always attacks that may target weaknesses in our approach. For example, our framework shows some vulnerability against additive noise attacks due to the fact that the addition of noise can cause significant changes in the frequency domain, which in turn destroys the consistency upon which watermark extraction depends. In fact, existing methods also mostly show strong defense only in the face of specific attacks.
However, by reducing the artifacts in the watermarking system, we greatly enhance the covertness of the watermark and effectively hide the existence of the watermark, which not only enhances the imperceptibility of the watermark, but also reduces the possibility of arousing the suspicion of the attacker. In other words, by enhancing the covertness of watermarks, we significantly reduce the risk of watermarks being attacked, thereby enhancing the reliability of deep neural network (DNN) model-based IP protection. It is worth noting that our proposed method is not limited to protecting images generated only by generative models. Instead, it is an image watermarking technique that is applicable to protect any image. We expect that this exploration will inspire more innovative and advanced research in the future.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}