1. Introduction
In the digital era, the financial industry is experiencing rapid transformation, with an increasing number of financial services and transactions being conducted online. This shift has made financial data security an increasingly critical concern [
1]. Financial transaction data not only hold significant economic value but also carry personal privacy and corporate secrets, making it crucial to ensure the security and integrity of such data. In order to enhance the guidance for investors interested in financial transactions or for analysts attempting deception, the establishment of a more transparent and trustworthy information system is first required. This can be achieved by ensuring that data and information in financial markets are made publicly available, accurate, and promptly accessible to both investors and analysts. Secondly, regulatory authorities need to intensify their supervision and enforcement efforts in financial markets to deter potential fraudulent activities. Furthermore, investors and analysts should receive high-quality financial education to comprehend the fundamental principles and risks of financial markets, enabling them to better grasp and address market fluctuations. Simultaneously, they also need to acquire the knowledge of identifying potential fraudulent activities and speculative operations to safeguard their investments. Lastly, the development of technological and data analysis tools can assist investors and analysts in making more informed decisions. By employing advanced algorithms and big data analysis techniques, they can gain a better understanding of market trends, identify potential risks, and consequently, formulate investment strategies with greater confidence. Traditional security measures, such as encryption and access control, provide protection to a certain extent, but their effectiveness is often limited in the face of complex cyber-attacks and internal threats [
2]. Moreover, with the rapid development of financial technology, new security challenges continue to emerge, necessitating the development of more advanced and reliable security technologies.
Wu et al. [
3] proposed an enhanced blockchain-based secure sharing (EBSS) scheme for real estate financial certificates that protects shared vouchers and allows for anonymous authentication; however, it is costly. Zhao et al. [
4] designed a new method for secure online data backup to address issues such as data loss. Li et al. [
5] researched a multi-chain model based on financial transactions and its corresponding cross-chain transaction protocol, achieving interoperability between homogeneous or heterogeneous blockchains, though the actual blockchain environment is complex, affecting its application effectiveness. In response, Du et al. [
6] proposed an anti-tampering data query model based on B+ trees and Merkle trees, addressing the issue of single-query blockchain data systems, with experimental results indicating that this method performs best.
Among the emerging technologies, Merkle trees (Merkle Tree) and the Transformer model have attracted widespread attention due to their unique characteristics. Merkle trees, a hash-based data structure, efficiently and securely verify data content and have been successfully applied in various distributed systems and cryptocurrencies. Their main advantage lies in the ability to verify data integrity, enabling the validation of a part of the data without revealing the entire content [
7], which is crucial for protecting the privacy and security of financial data.
On the other hand, the Transformer model, as a revolutionary deep learning architecture, has demonstrated outstanding performance in natural language processing (NLP) and several other domains [
8]. Its main advantage is its capability to process sequential data, particularly in understanding complex, long-distance dependencies [
9]. In the financial sector, this ability can be employed to capture complex patterns in transaction data, thereby improving the accuracy of financial fraud detection and the capability to predict market changes.
Lian et al. [
10] proposed a financial product recommendation network based on the Transformer, showing that it has a faster training speed and better results than RNN. Zhang et al. [
11] used the Transformer for stock trend prediction, proposing a Transformer encoder-based attention network (TeaNet) architecture, addressing the time-dependency issue of financial data. Chen et al. [
12] proposed an MTCformer method combining multi-channel TextCNN and Transformer for Ponzi scheme detection, utilizing the Transformer to extract semantic features, with experimental results showing that MTCformer achieved 97% accuracy, outperforming other methods (although it is time-consuming). Kim Gyeongmin et al. [
13] proposed a Bitcoin trading model—Cryptocurrency BERT Incorporated Trading System (CBITS); research indicates that our model significantly outperforms other trading methods.
However, despite the significant advantages of Merkle trees and the Transformer model, research combining the two in the field of financial security remains relatively limited. This paper proposes an innovative combination—the Merkle-Transformer model—to explore the application potential of these two technologies in secure financial computing. The objective is to enhance the security and efficiency of financial data processing by combining the data verification capability of Merkle trees with the data processing power of the Transformer model.
Karagiannis Ioannis et al. [
14] proposed a method based on blockchain for sharing financial information between financial institutions, but it cannot guarantee the integrity of data during processing; Alegria Alberto Vidal et al. [
15] presented a quantitative analysis method for calculating the risk of cyber-attacks in the data security domain of finance; however, complex environments may affect the performance of this method in practical applications. Ahmed Mohammad Rasheed et al. [
16] proposed a blockchain-based payment system for the Indian financial industry, which can achieve considerable speed, but it has not been tested in real-time, and the performance of the system under different network scenarios cannot be guaranteed.
The design of the Merkle-Transformer model considers multiple aspects of financial data processing. First and foremost, the model ensures the security and integrity of data during processing, which is vital in domains such as financial transactions and stock price prediction. Secondly, by effectively integrating the structure of Merkle trees, the model provides an additional layer of security for financial data. This not only helps prevent data tampering but also makes the data verification process more efficient. Lastly, by combining the advantages of the Transformer model, our model exhibits excellent performance in processing large-scale financial data, especially in capturing complex patterns and long-term dependencies.
In this paper, the design and implementation of the Merkle-Transformer model will be elaborated, including the verifiable computation module based on Merkle trees and the secure verifiable Transformer model. Additionally, a new loss function—the Merkle loss function—specifically designed for the model will be introduced to optimize its performance and enhance security. In the results and discussion section, the application results of the model on financial transaction data (for financial attack detection) and stock price data (for stock price prediction) will be showcased. Through these results, the advantages of the Merkle-Transformer model in terms of performance, security, and cost will be verified, and its application prospects in the domain of secure financial computing will be explored. The methodology presented in this paper is aimed at enhancing fairness and stability in financial markets, while concurrently augmenting the decision-making capabilities and confidence of investors and analysts. This is achieved by devising the model to ensure the aforementioned objectives are met. In conclusion, the Merkle-Transformer model not only provides a new approach to the secure processing of financial data but also holds significant theoretical and practical implications. Through the research presented in this paper, a new perspective and solution for the development of financial technology security is anticipated to contribute.
3. Materials and Method
3.1. Dataset Collection
3.1.1. Financial Transaction Datasets
In the subsection on financial transaction data, it is noted that financial transaction datasets typically consist of a vast array of transaction records, potentially including information such as transaction time, parties involved, amount, and type. These datasets are often employed for financial attack detection to identify anomalous transaction behaviors, such as fraud or money laundering. When selecting datasets, attention is paid to the diversity, authenticity, and completeness of the data. Prominent public financial transaction datasets include the Credit Card Fraud Detection dataset provided by Kaggle [
29]. The reason for utilizing these datasets is that they offer a wealth of real-world cases, assisting in effectively testing and optimizing the performance of the Merkle-Transformer model in financial attack detection. By analyzing real transaction data, more accurate simulation and identification of financial fraud and other abnormal behaviors can be achieved.
3.1.2. Stock Price Datasets
In the subsection on stock price data, stock price datasets, including historical trading data of the stock market such as opening and closing prices, highest and lowest prices, and trading volume, are discussed. These datasets are typically used for training and testing stock price prediction models, to forecast future stock market trends. The stock price data for this study are obtained from various public financial market databases, including Yahoo Finance, Google Finance, and others [
29]. Additionally, professional financial data service providers like Bloomberg and Reuters offer high-quality stock price data. The reason for using these datasets is that they provide detailed market transaction records, reflecting the collective behavior and sentiments of market participants. By analyzing the data, the model can learn complex patterns affecting stock price fluctuations, thereby enhancing prediction accuracy. After acquiring stock price data, data cleaning and preprocessing are conducted to ensure data quality and consistency. Specific to stock price prediction, various technical indicators such as moving averages, Relative Strength Index (RSI), and Bollinger Bands are calculated as input features for the model. Moreover, external factors like macroeconomic indicators and market news, which also influence stock price volatility, are considered.
3.1.3. Generated Datasets
In the subsection on generated datasets, the purpose of generating datasets is to improve the generalization ability and robustness of the model. In the real world, financial data are often imbalanced, particularly in scenarios of financial attack detection where normal transactions far outnumber fraudulent ones. To address this issue, data generation techniques are used to balance the datasets. A primary method employed is the synthetic minority over-sampling technique (SMOTE) [
30]. SMOTE generates new samples by interpolating among minority class samples, thereby balancing class distribution. This method enhances model performance in handling imbalanced data. The basic idea of SMOTE is to find the
k nearest neighbors for each minority class sample and then generate new samples through random interpolation between these samples. Assuming a minority class sample
with its nearest neighbor set
, a new sample
is generated as follows:
Here, is a nearest neighbor of , and is a randomly chosen parameter within [0, 1]. Through these methods, not only high-quality datasets are obtained, but the model’s robustness and generalization ability are also enhanced through data generation techniques. This is crucial for the development and testing of the Merkle-Transformer model.
3.2. Dataset Preprocessing and Augmentation
In the subsection on dataset preprocessing and augmentation, it is outlined that preprocessing and augmenting the dataset are key steps in experimental preparation. This work ensures the quality and diversity of the dataset, crucial for subsequent model training and evaluation. A detailed explanation of data preprocessing and augmentation methods is provided, including annotation methods, preprocessing techniques, and the application and mathematical principles of data augmentation techniques.
3.2.1. Dataset Annotation
In the context of financial data processing, dataset annotation is an important step, particularly in applications such as financial attack detection and stock price prediction. For financial transaction data, the focus is primarily on labeling transactions as normal or anomalous (fraudulent). Stock price data, on the other hand, needs to be labeled according to price trends within a specific time window, such as rising, falling, or stable.
- 1.
Annotation of financial transaction data: Based on historical records and background information of transactions, each transaction is labeled as “normal” or “fraudulent”.
- 2.
Annotation of stock price data: For stock price data, annotation is typically based on historical trends of price changes. For example, if the stock price in a given time window rises beyond a certain threshold, it might be labeled as “rising”; conversely, if the price falls below the threshold, it is labeled as “falling”.
3.2.2. Dataset Preprocessing
Data preprocessing is a key step to ensure data quality and model performance. Initially, data cleaning involves removing or correcting erroneous and inconsistent records in the dataset. This is to ensure the accuracy of model training and evaluation, preventing incorrect data from leading the model to learn incorrect patterns. Following this, normalization or standardization processes involve transforming all features to the same scale for more effective learning and generalization by the model. Common methods include min-max normalization and Z-score standardization. The mathematical expression for Z-score standardization is as follows:
Here, x represents the original feature value, and represent the mean and standard deviations of the feature values, and is the standardized feature value.
Handling missing values is also a crucial aspect of data preprocessing. For missing data, various methods can be employed, such as interpolation, filling with mean values, or simply deleting related records. Finally, feature engineering involves selecting and constructing features according to the needs of the model. In financial data analysis, especially for stock price prediction, calculating moving averages or other technical indicators as input features for the model might be necessary.
3.2.3. Dataset Augmentation
Data augmentation is an important method to enhance model generalization ability, especially in situations with limited data or imbalanced class distribution. Common methods of data augmentation in financial data processing include the following:
- 1.
Synthetic minority over-sampling technique (SMOTE): As previously mentioned, SMOTE is a popular data augmentation method used to address class imbalance issues. It generates new samples by interpolating between minority-class samples.
- 2.
Time series data augmentation: For stock price data, time series-specific data augmentation methods such as time window sliding and time series segmentation can be used to increase the number and diversity of data samples.
- 3.
Feature expansion: In some cases, creating new features by adding noise, transforming, or combining existing features can enhance the diversity of the dataset.
Through the above data preprocessing and augmentation steps, the quality and diversity of the dataset can be ensured, providing a solid foundation for the training and evaluation of the Merkle-Transformer model.
3.3. Merkle-Transformer
3.3.1. Overall
In this paper, we propose an innovative method that combines the advantages of Merkle trees and Transformer models to enhance the security and efficiency of financial computations. The core concept of the Merkle-Transformer model is to ensure the security and integrity of data through Merkle trees while leveraging the efficient computational capability of the Transformer model. This combination not only improves the accuracy of data processing but also ensures that security is not compromised in the pursuit of efficiency.
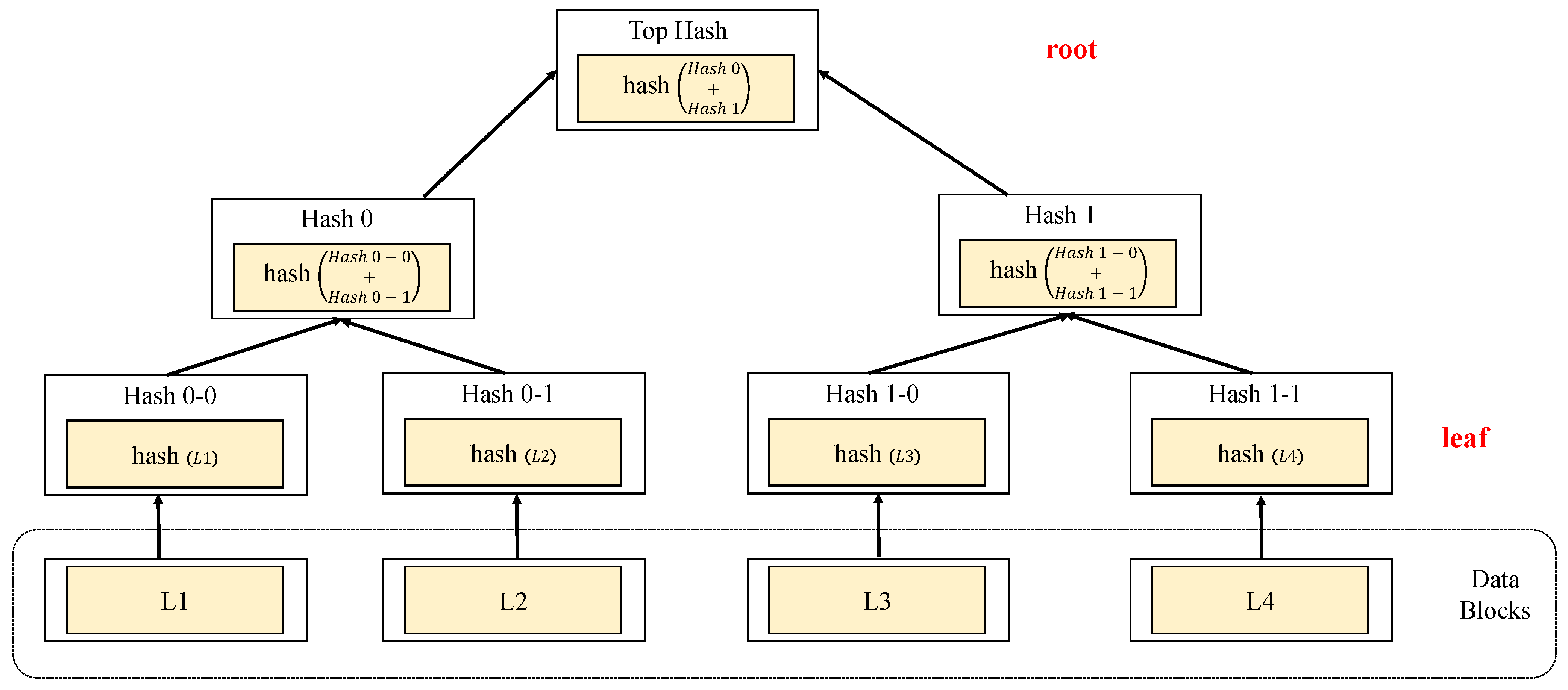
Figure 3 illustrates a schematic of the working principle of the Merkle-Transformer model. The figure elucidates how the outputs of the intermediate layers of a deep learning model are combined with the Merkle tree structure to ensure the security and verifiability of the model’s processing. Each layer (L1 to L8) are first considered as leaf nodes in the Merkle tree. Subsequently, adjacent outputs are paired and combined through a hash function Hash, progressively building the Merkle tree until forming the top hash, representing a unique fingerprint of the entire model’s output.
Specifically, the raw data passes through a series of attention modules, each generating a feature representation (L1 to L8). This paper introduces a shallow convolutional neural network at the model’s entrance for initial feature extraction, and the extracted features are then fed into the Transformer model. These feature representations are further combined through the hash function to form intermediate nodes (Hash 0-0, Hash 0-1, etc.), culminating in the top hash. At the end of the model, after passing through the flattened and dense layers, the output is obtained. Throughout this process, every step of the model’s output is linked to the Merkle tree structure via the hash function, implying that any minor change in output will cause a variation in the root hash, thereby verifying the integrity and unaltered state of data throughout the transmission and processing. This design enables the Merkle-Transformer model not only to process complex financial data but also to ensure security during data processing, as any unauthorized data modification will be detected. This is particularly important for financial data, often involving sensitive information and critical decision-making. Additionally, the Merkle-Transformer model provides a verifiable computation process, allowing every step of the model’s operation to be traceable and verifiable, greatly increasing the transparency and trustworthiness of financial computation models.
In summary, the Merkle-Transformer model integrates deep learning and Merkle trees to provide a secure and efficient new framework for financial computations. This combination effectively utilizes the strengths of both technologies—the powerful data processing ability of deep learning and the unique security advantage of Merkle trees—offering a novel solution for financial data processing and analysis.
3.3.2. Verifiable Computation Module Based on Merkle Tree
The verifiable computation module based on Merkle trees is a core component of the model, playing a vital role in safeguarding data security and integrity throughout the computation process. The design of this module merges the data verification mechanism of Merkle trees with the efficient computation capability of deep learning, aiming to provide a secure and efficient framework for financial data processing. The design details of this module follow the basic principles of Merkle trees, where data blocks are hashed to form a tree-like structure, with each non-leaf node being the hash of the hash values of its child nodes. In our model, this concept is extended to the outputs of the intermediate layers of deep learning models. Specifically, for each intermediate layer of the model, the hash value of its output is calculated, and these hash values are organized in the manner of a Merkle tree.
Considering that each layer in deep learning can be viewed as a data transformation, the outputs of each layer are treated as data blocks. For instance, if the model’s first layer is a two-dimensional convolutional layer with input
x and output
, then the hash value
of
can be calculated. Similarly, the hash value
for the output
of the second layer is computed, and so on. These hash values are then paired and hashed again to form the parent nodes of the Merkle tree, continuing until the root hash is formed. Mathematically, this process can be expressed as follows:
where
is the hash value of the parent node,
and
are the hash values of the child nodes,
H is the hash function, and
denotes concatenation. In practical applications, our deep learning model may include various types of layers, such as convolutional layers (Conv2D), pooling layers, and dense layers. These layers are stacked in sequence to form a network capable of extracting and processing complex features. For example, a typical stacking structure might involve the input passing through two convolutional layers, followed by a pooling layer, several more convolutional layers, and finally, a dense layer to produce the output. The output of each layer is used not only for the input of the next layer but also for constructing the Merkle tree. The output dimensions of each convolutional or dense layer depend on the layer’s configuration and the dimensions of the input. For example, the output dimension of a convolutional layer might be a function of the number of filters, stride, and padding. The advantage of this design is that it combines the efficient computational capability of deep learning models with the data integrity verification mechanism provided by Merkle trees. This combination not only enhances the model’s performance in processing financial data but also increases the security of the data processing. Any unauthorized alteration to the data or model output will be reflected in the root hash of the Merkle tree and can, therefore, be quickly detected. Additionally, due to the structure of the Merkle tree, which makes the verification process highly efficient, only a small portion of nodes need to be verified to ensure the integrity of the entire dataset, significantly reducing computational and storage overhead. In financial computation tasks, this design is particularly important as it not only ensures the reliability and auditability of data processing but also allows for rapid response to potential security threats. Whether in scenarios of financial transaction detection or stock price prediction, ensuring the security and integrity of data is of utmost importance.
3.3.3. MatrixSplit Verification Method
In this subsection, it is explained that while traditional Merkle trees are highly efficient in processing single data streams, a decline in verification efficiency occurs when dealing with matrices or multi-dimensional data using conventional methods. To address this issue, a novel matrix splitting method is introduced and applied within an improved Merkle tree structure.
Figure 4 displays the matrix splitting verification method, a novel approach to data structure processing aimed at enhancing the efficiency of Merkle trees in verifying matrix data. In this method, the matrix initially undergoes processes of consecutive and non-overlapping slicing. Consecutive slicing refers to continuously dividing the original matrix by rows or columns to form multiple smaller submatrices. Non-overlapping slicing involves splitting the original matrix into multiple smaller, non-overlapping submatrix blocks. This slicing approach reduces the amount of data needed to be processed in a single verification while maintaining data integrity. Mathematically, matrix splitting can be expressed as follows:
where
M is the original matrix,
is the resulting submatrix from slicing,
is the splitting function, and
i and
j represent the starting indices of rows and columns for slicing, respectively. During non-overlapping slicing, a specific slicing strategy is used to ensure that each submatrix block can be independently verified, crucial for the parallelization and efficiency of computation. The choice of this slicing strategy depends on the size of the submatrices and the structural characteristics of the original matrix. After slicing, each submatrix block is assigned a unique hash value, then combined using the improved Merkle tree structure. Unlike traditional Merkle trees, the improved Merkle tree allows nodes within the tree to represent submatrix blocks rather than just single data points. For a submatrix block
, its hash value is represented as follows:
where
H is the hash function. In constructing the tree, hash values of adjacent submatrix blocks are combined to compute their parent hash value, continuing until the root hash value of the tree is calculated. The advantage of this design is that when verifying the integrity of matrix data, it is not necessary to verify every element of the entire matrix, but only the hash values of the submatrix blocks and the root hash value. This significantly reduces the computational load in the verification process and enhances the parallelization of verification. In particular, when dealing with large-scale financial data, this method significantly improves verification efficiency.
In the financial computation tasks of this paper, the application of the matrix splitting verification method offers distinct advantages. Since financial data are often multi-dimensional, such as stock price data matrices encompassing time, prices, volumes, and other dimensions, directly applying traditional Merkle trees leads to efficiency issues. By adopting the matrix splitting verification method, the integrity and correctness of data can be verified more quickly, ensuring the reliability and security of the financial computation model. Additionally, this method supports incremental updates and rapid re-computation; when matrix data change, only the hash values of the affected submatrix blocks and their related path need to be recalculated, without processing the entire dataset.
3.3.4. Verifiable Secure Transformer Inference Model
Apart from the verifiable computation module based on the Merkle tree, another core component is the verifiable secure Transformer model. This module aims to efficiently process financial data while providing a mechanism to verify the data processing procedure, ensuring data security and integrity throughout the computation process. The verifiable secure Transformer model, in its design, incorporates the fundamental architecture of the original Transformer model, consisting of multiple self-attention layers and feed-forward networks, with added verifiability. Each layer of the model generates an intermediate output, which is used not only for computing the input of the next layer but also for generating the Merkle tree, facilitating comprehensive data integrity verification.
This self-attention mechanism allows the model to consider the influence of all other inputs while processing each input, thereby capturing long-distance data dependencies. Following the self-attention layer is the feed-forward network, which further processes the output of the self-attention layer. Feed-forward networks typically consist of two linear transformations with an activation function, such as ReLU [
31] or GELU [
32], in between, and are mathematically expressed as follows:
Here, , , and , represent the weights and bias terms of the network layer, respectively. To achieve verifiability, an additional step is added to the output of each layer: the computation of its hash value, which is then integrated as a node in the Merkle tree. This means that at every layer of the model, outputs are produced not only for computation in the subsequent layer but also for validating data integrity. In the financial computation tasks addressed in this paper, the verifiable secure Transformer model offers numerous advantages. Firstly, it improves the efficiency and accuracy of financial data processing, as the Transformer model is capable of effectively handling long sequence dependencies. Secondly, the model enhances the security of data processing, as any unauthorized alteration to the data will be reflected in the root hash value of the Merkle tree and can be rapidly detected. Finally, this design supports the scalability and flexibility of the model, as it allows for the addition of new data processing layers or adjustments to existing ones while maintaining the validity of existing data verifications.
3.3.5. Merkle Loss Function
In this paper, a novel loss function, the Merkle loss function, is introduced. This function is a significant supplement and expansion of traditional loss functions, designed to integrate the data verification mechanism of Merkle trees with the optimization process of deep learning models. The Merkle loss function is conceptualized to consider not only prediction errors at every step of model training but also the integrity and security of data. Traditional loss functions, such as mean squared error (MSE) or cross-entropy, primarily focus on the model’s predictive performance, i.e., the discrepancy between predicted and actual values. The Merkle loss function, however, introduces an additional term that measures the consistency between the model output and the root hash value of the Merkle tree. This new loss function is represented as follows:
where
is the traditional prediction loss term, such as MSE or cross-entropy,
is the loss term related to the root hash value of the Merkle tree, and
is a hyperparameter balancing the importance of the two. The above approach is designed to conform to the general expression of the loss function. In practice, by setting
to a very large number (e.g., 10,000), it allows the model to immediately stop training upon detecting data integrity issues, similar to a penalty term in optimization algorithms.
3.4. Experiment Design
The design of the experiment is a crucial component in demonstrating the effectiveness of the Merkle-Transformer model. The experiment aims to showcase the advantages of our model in processing financial data and verify its capability to ensure data security. To ensure the accuracy and reliability of the experimental results, a standard dataset division strategy is adopted. Specifically, the dataset is divided into training, validation, and test sets. The training set is used for the learning process of the model, the validation set for adjusting model parameters and hyperparameters, and the test set for the final evaluation of model performance. Typically, the dataset is divided into a 70%, 15%, and 15% ratio, although the actual proportions may vary based on the size and characteristics of the dataset. This division ensures the model’s generalization on unseen data and avoids overfitting.
In the experiments, multiple baseline models were selected for comparison, including Transformer [
23], BERT [
33], BERT-wwm [
34], RoBERTa [
35], and SpanBERT [
36]. These models have been widely applied in the field of natural language processing and have demonstrated excellent performance across various tasks. Their selection aims to showcase the performance improvement of the Merkle-Transformer model relative to the current state-of-the-art technologies. The Transformer model, as the pioneer of self-attention mechanisms, serves as the foundation for our comparison. The BERT model, known for its powerful contextual understanding capabilities, has established new benchmarks in multiple NLP tasks. BERT-wwm, RoBERTa, and SpanBERT represent further advancements based on BERT, enhancing model performance through different pre-training strategies and architectural optimizations. The choice of these models as baselines is motivated by their representation of the current level of advancement in natural language processing technology and their exceptional ability to handle sequential data. By comparing the Merkle-Transformer model with these baselines, a fair assessment of our model’s performance can be conducted, especially in the specific domain of financial data processing.
The Adam optimizer [
37] was chosen for optimization. Adam, an adaptive learning rate optimization algorithm, combines the advantages of momentum and RMSprop optimization methods. It adjusts the learning rate for each parameter based on its update history, making it particularly suitable for handling large-scale and complex datasets. Additionally, the Adam optimizer has been proven effective in various deep learning tasks, thus being the preferred choice. Hyperparameter settings are based on an understanding of the problem and preliminary experimental results, including learning rate, batch size, and the number of training epochs. The learning rate starts high and is gradually reduced during training to refine the adjustment of model weights. The batch size depends on the dataset size, model complexity, and hardware resource limitations. The number of training epochs needs to be sufficient to ensure the model can adequately learn patterns in the data but not so numerous as to cause overfitting.
Through such an experimental design, a comprehensive evaluation of the Merkle- Transformer model’s performance in secure financial computation tasks can be conducted, allowing for a fair comparison with current advanced models. By comparing experimental results, it is expected to demonstrate that the Merkle-Transformer not only provides excellent predictive performance in processing financial data but also enhances the security of the data processing process.
3.5. Evaluation Index
In our research, a series of quantitative evaluation metrics were employed to comprehensively assess model performance, reflecting various aspects of model functionality, particularly in prediction accuracy and data integrity protection. Precision is used to measure the proportion of true positives among all samples predicted as positive by the model. High precision directly relates to the credibility of the model in practical applications. The formula for precision is as follows:
where
(true positive) represents the number of samples correctly predicted as positive, and
(false positive) denotes the number of samples incorrectly predicted as positive.
Recall measures the proportion of actual positive samples identified by the model, reflecting the model’s ability to capture important events. Recall is particularly crucial in the field of financial security, as missing any real fraudulent event could lead to significant economic losses. The formula for recall is as follows:
where
(false negative) refers to the number of actual positive samples incorrectly predicted as negative.
Accuracy is an indicator of the overall correctness of the model’s predictions, reflecting the proportion of correctly predicted samples in the total sample set. This metric provides an intuitive overview of model performance and is calculated as follows:
where
(true negative) represents the number of samples correctly predicted as negative.
For regression tasks like stock price prediction, the coefficient of determination
is used to assess the quality of the model’s predictions.
measures the degree of correlation between the model’s predictions and actual values, with values closer to 1, indicating stronger predictive ability. The formula for
is as follows:
where
represents the actual value of the
ith sample,
is the model’s prediction for the
ith sample, and
is the average of all actual values.
These evaluation metrics comprehensively assess the model’s performance from multiple dimensions. Precision and recall are particularly applicable to classification tasks, such as financial fraud detection, assisting in evaluating the model’s ability to identify genuine risk events. Accuracy provides an overall performance evaluation, aiding in understanding the model’s performance across the entire dataset. The coefficient of determination , as a regression task metric, reflects the degree of fit between the model’s predictions and actual outcomes, which is crucial for financial time series analysis like stock price prediction.
4. Results and Discussion
In
Section 4.1, we cover the performance of the model in financial behavior detection and stock price prediction tasks, the verification of its security, the analysis of system overhead, as well as the limitations and prospects of the model. Initially, in the performance analysis section, an in-depth examination of the Merkle-Transformer model’s performance in financial behavior detection tasks is conducted. By comparing it with various baseline models, its precision, recall, and F1 score in identifying fraudulent transactions and money laundering activities are assessed. The experimental results demonstrate that the Merkle-Transformer, considering data integrity and security while processing financial sequential data, exhibits commendable performance in detecting financial fraud, particularly excelling in reducing false positives compared to traditional models.
In
Section 4.2, we discuss the current limitations of the Merkle-Transformer model, such as scalability issues when processing extremely large datasets, and ways to further enhance the model’s security and reduce overhead. Furthermore, future research directions are proposed, including optimizing the model structure, improving security mechanisms, and exploring potential applications in other financial tasks.
4.1. Performance Analysis
The objective of this experiment is to validate and showcase the performance of the Merkle-Transformer model in processing financial data, especially in comparison with current mainstream deep learning models. Through this experiment, the superiority of the Merkle-Transformer in key performance metrics such as precision, recall, accuracy, and F1 score is intended to be demonstrated, thereby proving its potential application in the field of financial security. The results in
Table 1 indicate that the Merkle-Transformer outperforms all other models in all evaluation metrics, followed by RoBERTa, BERT, Transformer, BERT-wwm, and SpanBERT. These results reflect the performance differences of various models in financial behavior detection tasks, where the Merkle-Transformer’s superior performance is attributed to its unique design and algorithms.
Firstly, the Merkle-Transformer model integrates the data integrity verification mechanism of Merkle trees with the efficient data processing capabilities of the Transformer model. The Merkle tree structure provides a mechanism for verifying data integrity, ensuring that data remains unaltered or undamaged during processing, which is especially important in financial data processing. The Transformer model, known for its efficient self-attention mechanism, excels in handling complex sequential data. This combination not only improves the accuracy of data processing but also enhances the robustness of the model when facing challenges unique to financial data. Models like RoBERTa, BERT, and SpanBERT, although performing well in natural language processing tasks, are limited in their performance in financial data processing due to their original design focus. These models primarily concentrate on semantic understanding of text data, not on the specific characteristics of financial data. Additionally, they lack a mechanism for verifying data integrity, an important consideration in financial data processing. The Transformer model, as the originator of the self-attention mechanism, has certain advantages in processing sequential data but its application in the financial domain is limited by its generality. Without customized processing for the specific characteristics of financial data, it may not achieve optimal performance in financial behavior detection tasks. The BERT-wwm model, despite its advantages in processing Chinese text, is limited in this specific task of financial behavior detection due to its understanding of financial-specific contexts.
The superior performance of the Merkle-Transformer model can be attributed to its integration of the data integrity verification mechanism of Merkle trees with the efficient data processing capabilities of the Transformer model. In contrast, models like RoBERTa, BERT, Transformer, and BERT-wwm, despite their exemplary performance in natural language processing, showed slightly inferior results in this specific task of stock price prediction. This is mainly because these models, while capable of processing sequential data, lack customized processing abilities for financial characteristics. For instance, they might be insufficient in capturing complex market trends and subtle financial signals, resulting in lesser predictive performance compared to the Merkle-Transformer, which is specifically designed for financial data. The SpanBERT model performed the worst across all metrics, possibly due to its focus on the span representation of text during pre-training, rather than the time dependencies in sequential data, which may not be optimal for dealing with highly time-sensitive data like stock prices.
4.2. Security and Performance Verification
In this section, the security features of the Merkle-Transformer model and its performance across various hardware platforms are extensively evaluated. Additionally, in combination with the Merkle-Transformer verification method, the impact of various runtime configurations on the model’s performance is further explored. These experiments are designed to not only validate the efficiency and accuracy of the model in performing tasks such as financial behavior detection and stock price prediction but also to ensure the verifiability and security of the model’s operations.
As illustrated in
Table 2, tests across multiple hardware platforms reveal that even on lower-end devices like Raspberry Pi and NVIDIA Jetson Nano, the Merkle-Transformer model maintains stable performance while ensuring integrity verification throughout the computation process. Its performance on the GPU and Apple M1 is particularly noteworthy, indicating the model’s effective utilization of the high-performance computational resources of modern hardware platforms. The data also show that multi-threading execution significantly improves inference throughput while keeping the CPU load at a lower level, crucial for applications requiring deployment in resource-constrained environments.
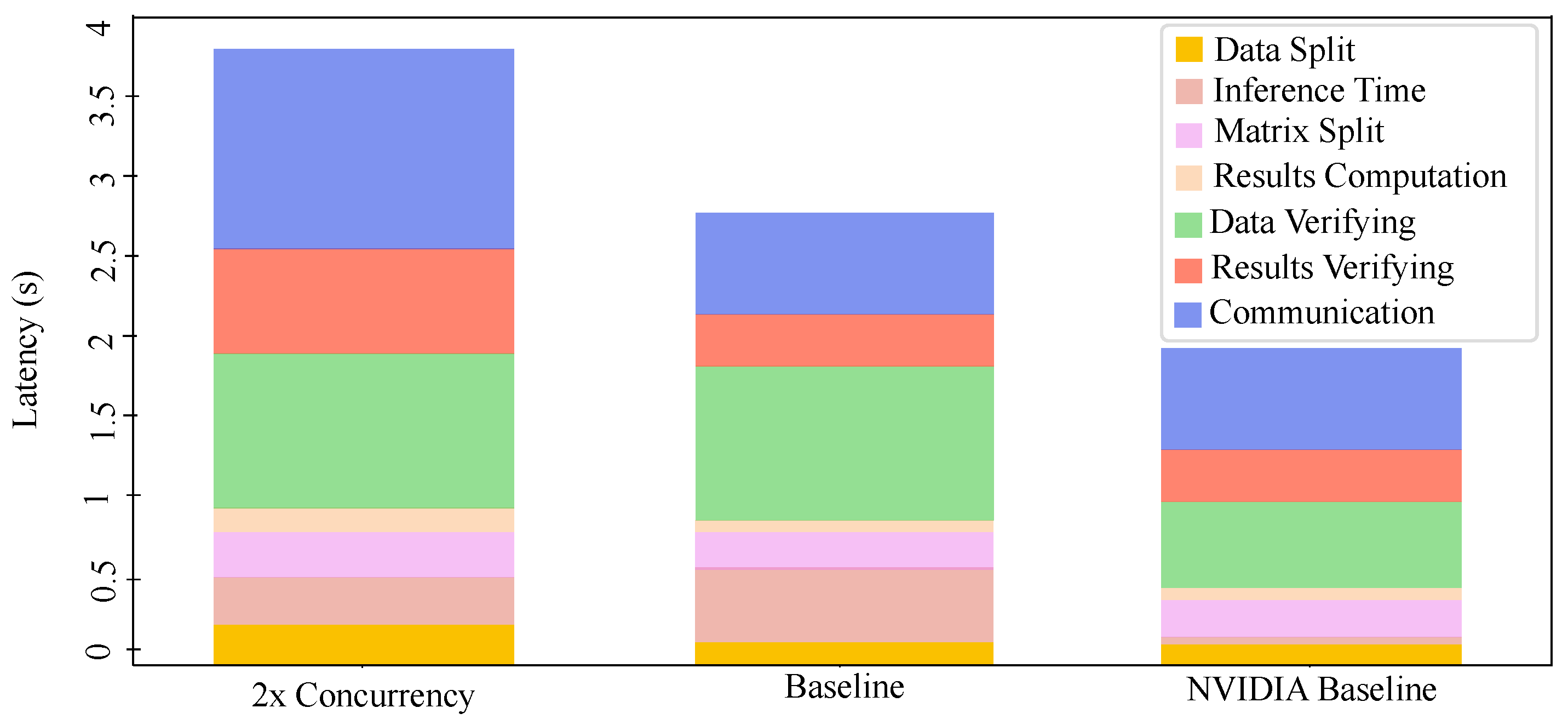
In
Table 3 and
Figure 5, the Merkle-Transformer shows significant advantages over other verification methods like Slalom [
38] in terms of communication and computation overhead, storage requirements, and potential error detection. This result confirms the efficiency of our verification method in ensuring the integrity of machine learning inferences.
Furthermore, the impact of different runtime configurations of MatrixSplit on performance is explored. As indicated in
Table 4, by optimizing communication and computation, latency can be significantly reduced without sacrificing verification stringency. For example, when low partition of the network instead of the entire work, only a slight performance decrease is observed. This flexibility suggests that our model and verification method can be adjusted according to specific application needs to achieve the best balance between security and performance.
4.3. Limitations and Future Works
This section aims to candidly assess the current shortcomings of the model and explore potential future research directions. Firstly, although the Merkle-Transformer has exhibited excellent performance in financial behavior detection and stock price prediction, its effectiveness in processing extremely large datasets has not been thoroughly tested. In practical applications, financial institutions may need to handle enormous volumes of data, posing higher demands on the model’s processing capability and verification efficiency. Therefore, the model’s performance and scalability in handling big data are critical areas for future focus. Secondly, despite the model’s exemplary performance in security verification, new security threats may arise in practical deployment. For instance, adversarial attacks are an active research topic in the field of machine learning, and attackers might develop novel methods to evade the security mechanisms of the Merkle-Transformer. Consequently, continuous research and improvement of the model’s security features to counter evolving threats are necessary. Furthermore, the performance of the Merkle-Transformer is also dependent on hardware platform configurations, as our experiments have shown. While the model maintains good performance across multiple hardware platforms, optimizing the model to reduce computational and storage overheads on resource-constrained devices, such as edge computing scenarios, is another key point for future research. This includes model compression, quantization, and other optimization processes.
Future work should also include testing the generality of the model and verifying the potential application of the Merkle-Transformer in other types of financial tasks, such as credit scoring and market risk management. Additionally, exploring the model’s performance in multi-task learning and cross-domain learning is a promising area, which would further enhance the model’s practicality and flexibility. From a technical research perspective, the mathematical foundation and theoretical framework of the Merkle-Transformer also warrant further exploration. For instance, mathematical optimization of the combination of Merkle trees and Transformers, algorithmic improvements, and mathematical proofs of data integrity verification mechanisms are potential directions for in-depth future research. This would not only help improve the model’s performance but also deepen our understanding of the model’s working mechanism.
Furthermore, implementing Merkle trees in various types of deep neural networks to ensure data integrity and security is a challenging yet highly promising task. Let us first consider the case of convolutional neural networks (CNNs) [
31,
39]. In CNNs, we can compute the hash values of features at each layer, from convolutional layers to pooling layers and then to fully connected layers, to construct corresponding Merkle tree nodes. This helps verify the integrity of features at each layer and detects data tampering or loss when necessary. Another common deep neural network architecture is the residual network (ResNet) [
40]. In ResNet, we can calculate hash values within each residual block and add them to the respective Merkle tree. This ensures the consistency of features within each block while maintaining the smooth flow of information throughout the network. Lastly, for multi-layer perceptrons (MLPs) [
41], we can compute hash values before each hidden layer and the output layer to build corresponding Merkle tree nodes. This aids in verifying the data integrity at each layer, especially when highly trustworthy predictions are needed. By implementing Merkle trees in different types of DNN structures, we can enhance the protection of data integrity by the model. However, it is crucial to carefully balance computational costs and performance overhead to ensure practicality and feasibility.
In summary, while the Merkle-Transformer model has shown significant potential in processing financial data, it also faces many challenges and limitations. We hope that future research will address these limitations, continuously optimizing and refining the model to better serve the needs of the financial industry, and contribute new ideas and frameworks to the research of machine learning in the domain of financial security.
5. Conclusions
In this study, a novel model for financial data processing is presented, which provides a secure and efficient solution for financial data analysis by integrating the data integrity verification mechanism of Merkle trees with the high processing capability of the Transformer model. The research conducted is significant not only for enhancing the accuracy and security of financial data processing but also for propelling development and innovation in the field of fintech.
The performance of the Merkle-Transformer model on tasks such as financial behavior detection and stock price prediction was validated through a series of experiments. It was found that the Merkle-Transformer outperforms other baseline models, including RoBERTa, BERT, Transformer, BERT-wwm, and SpanBERT, across key performance metrics such as precision, recall, accuracy, and the F1 score. Notably, in the task of stock price prediction, the Merkle-Transformer achieved or approached scores above 0.9 across all evaluation metrics, demonstrating its robust predictive power and acute capture of market dynamics. These results affirm the efficacy and superior performance of the Merkle-Transformer in financial applications. Furthermore, we investigated the performance of the Merkle-Transformer, combined with the Merkle-Transformer verification method across various hardware platforms, including experiments on Raspberry Pi, GPU, Apple, and NVIDIA Jetson. The results show that the Merkle-Transformer maintains good performance even on resource-constrained devices while ensuring the integrity and security of the data processing through the Merkle-Transformer method.
The outcomes of this study have profound implications for investors and analysts. On the one hand, novel financial data processing models can enhance data accuracy and security, thereby instilling confidence in investors and enabling them to make more assured investment decisions. On the other hand, the introduction of this model can deter unethical conduct by analysts attempting fraud, thereby upholding the integrity and fairness of financial markets. Firstly, the approach presented in this paper employs the data integrity verification mechanism of Merkle trees to securely validate financial data. Secondly, the method outlined in this paper leverages Transformer models for the swift processing of large volumes of financial data, enabling real-time analysis and decision-making, which is critical for both investors and analysts. Efficient data processing not only accelerates decision-making but also facilitates the timely capture of market dynamics, thereby enhancing the competitive edge of investors and analysts. Furthermore, experimental results in this paper demonstrate that the Merkle-Transformer excels in stock price prediction tasks, with all evaluation metrics reaching or approaching scores of 0.9 or higher, indicating its robust predictive capabilities and keen ability to capture market dynamics. Additionally, this model exhibits broad applicability, running smoothly on both high-end servers and lower-end devices. The core contribution of this article lies in the proposition of a new financial data processing model that not only considers the efficiency of data processing but also introduces a mechanism for data security verification. By incorporating Merkle trees, the accuracy of data processing has been enhanced, and the model’s resistance to data tampering has been strengthened, which is crucial for handling sensitive financial information. Additionally, the model is adaptable to various hardware configurations, ensuring its applicability and stability in different environments. The research and development of the Merkle-Transformer model offer a fresh perspective and methodology for financial data processing. In today’s era where data security is increasingly valued, it is believed that the findings of this study will provide direct technical support and assistance to the financial industry and offer new research directions and foundations for researchers in the field of fintech. Looking ahead, there is an anticipation that the Merkle-Transformer will see wider application in financial data processing scenarios and will continue to be optimized and refined to achieve greater security and efficiency.


 ,
, 

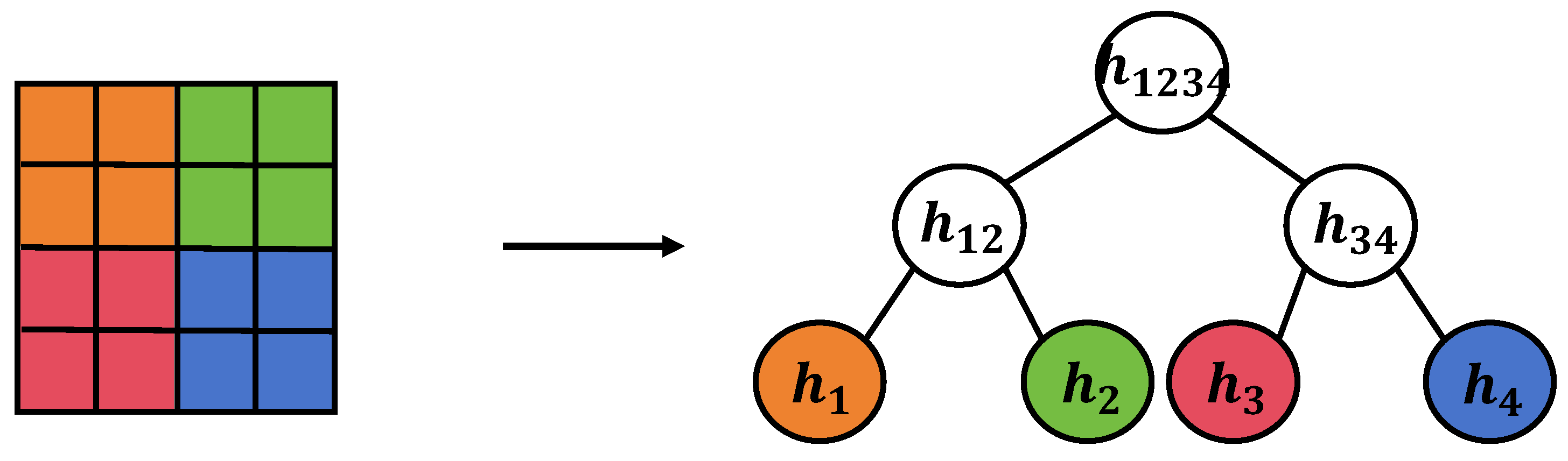

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}