
Multi-Head Transformer Architecture with Higher Dimensional Feature Representation for Massive MIMO CSI Feedback


Abstract
1. Introduction
- Based on the standard Transformer architecture, we propose a two-layer Transformer network for CSI feedback, which is capable of better characterizing the CSI and thus improving the recovery accuracy;
- We adopt higher dimensional feature representation to improve the quality of feedback and increase the number of attention heads to jointly attend to information from different representation subspaces at different positions;
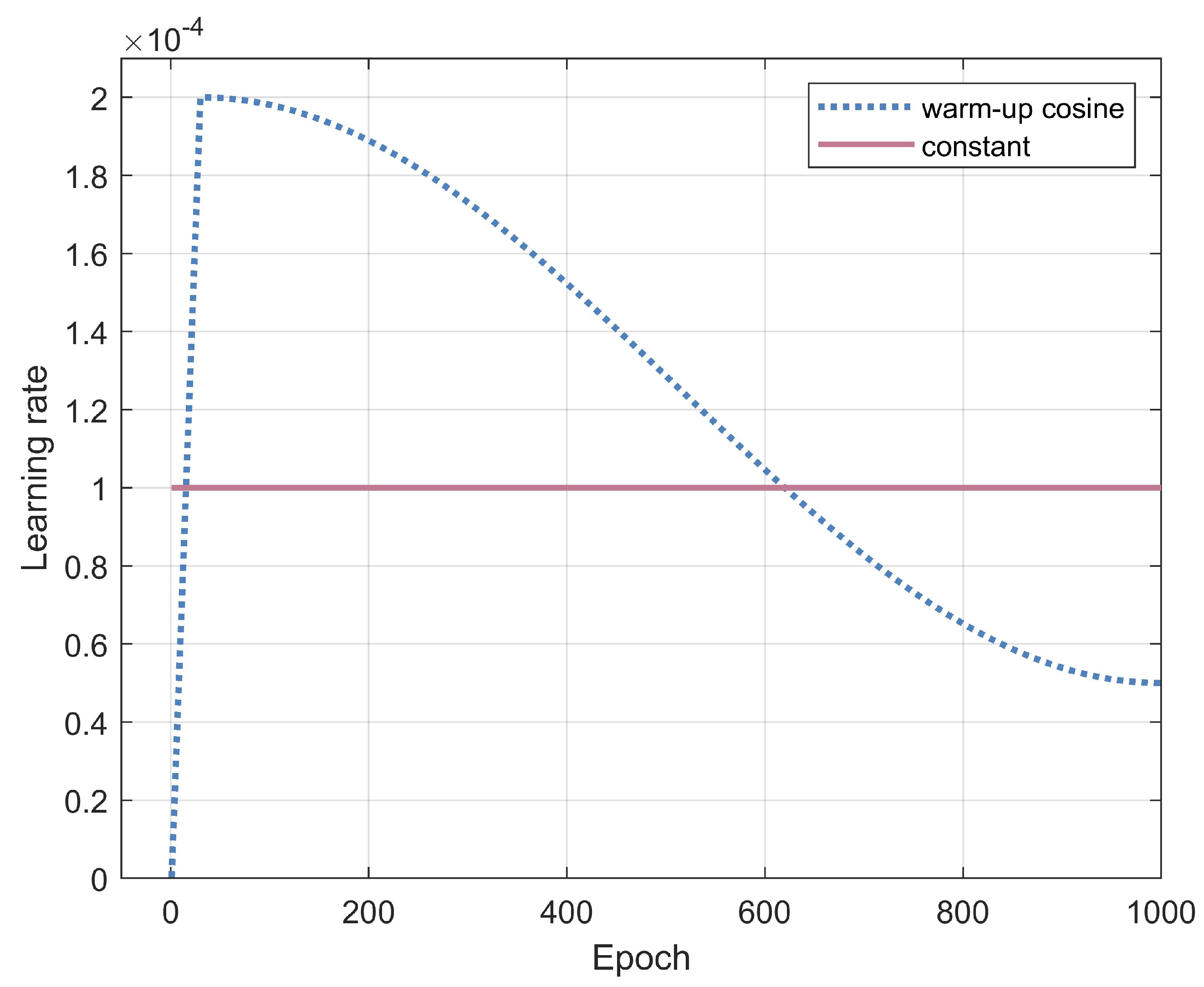
- The warm-up cosine training scheme is introduced for quicker convergence and stronger capability to learn high-resolution CSI features.
2. Related Work
3. System Model
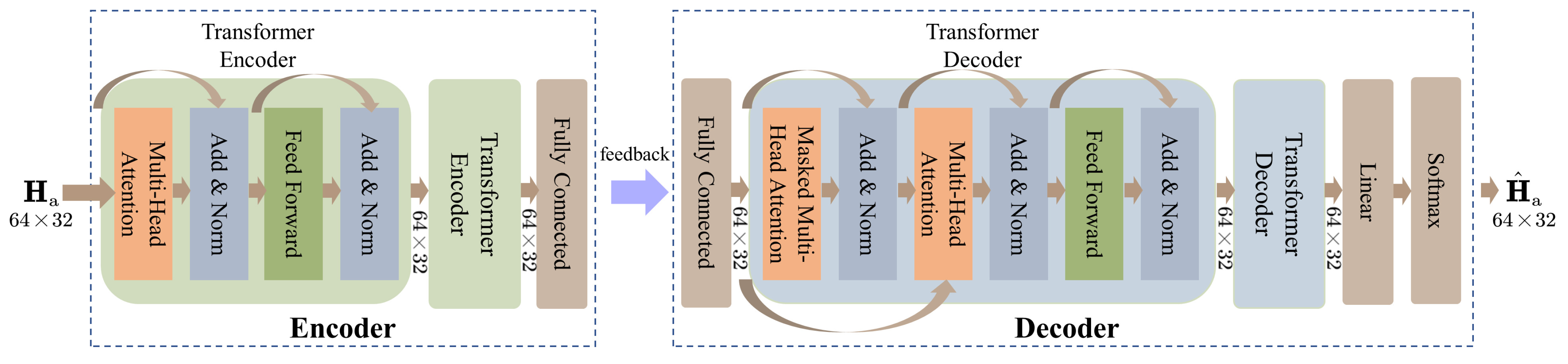
4. Structure of the Network and Training Scheme
4.1. Structure of the Network
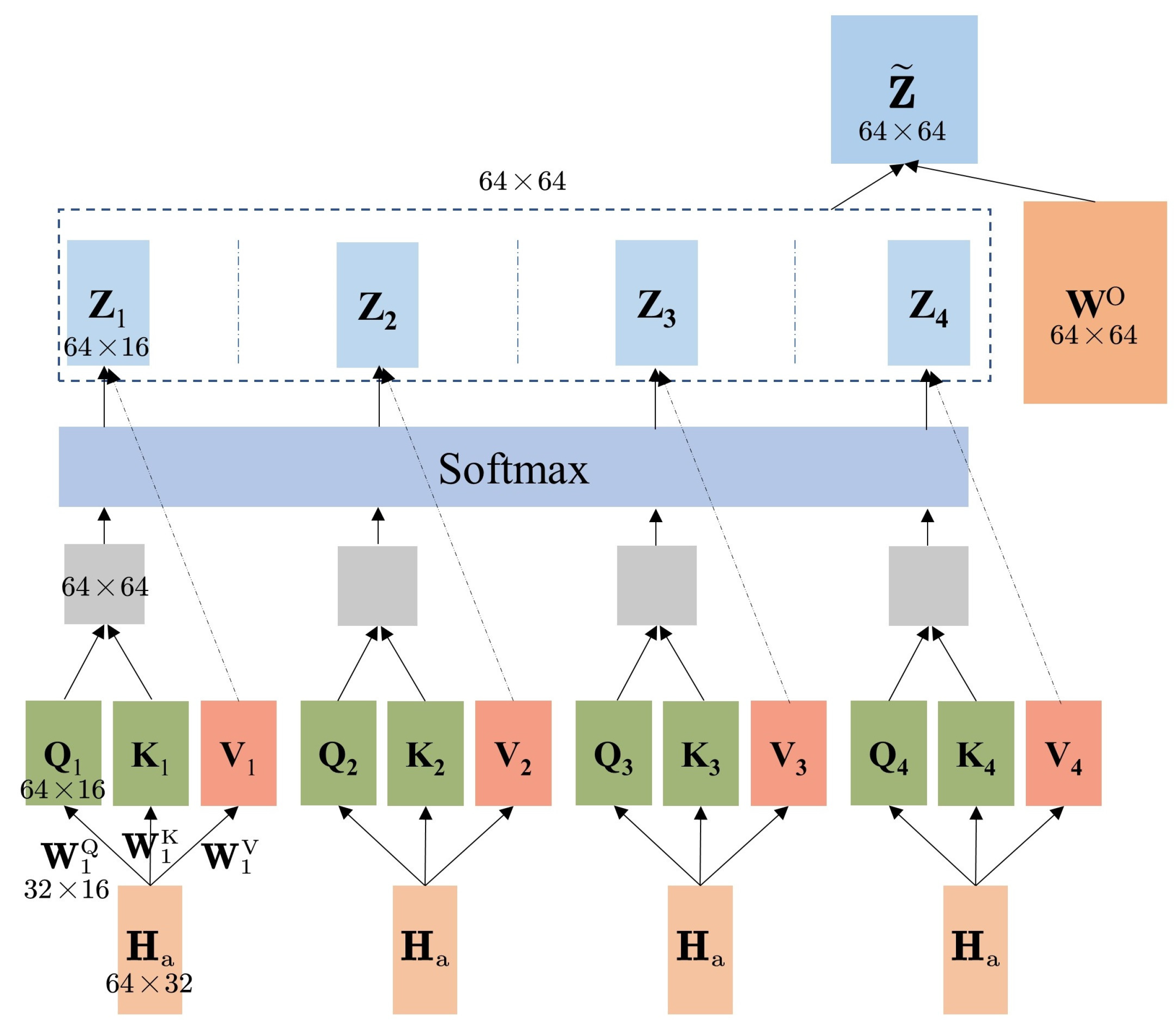
4.2. Multi-Head Attention Layer
4.3. Training Scheme
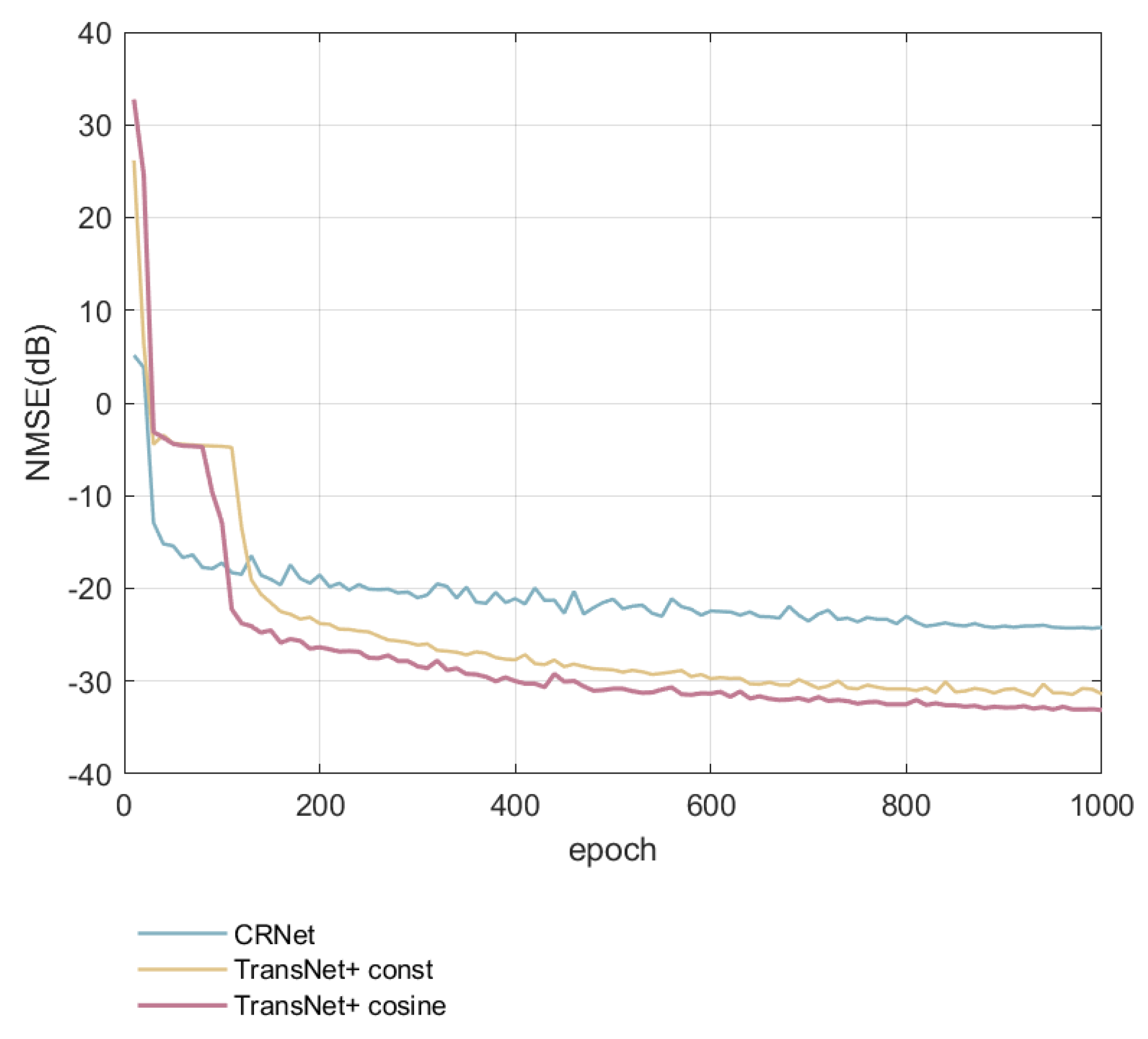
5. Simulation Results and Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, F.; Zeng, J.; Zheng, L.; Zhang, H.; Wang, J. Sensing and Deep CNN-Assisted Semi-Blind Detection for Multi-User Massive MIMO Communications. Remote Sens. 2024, 16, 247. [Google Scholar] [CrossRef]
- Lin, W.-Y.; Chang, T.-H.; Tseng, S.-M. Deep Learning-Based Cross-Layer Power Allocation for Downlink Cell-Free Massive Multiple-Input–Multiple-Output Video Communication Systems. Symmetry 2023, 15, 1968. [Google Scholar] [CrossRef]
- Pan, F.; Zhao, X.; Zhang, B.; Xiang, P.; Hu, M.; Gao, X. CSI Feedback Model Based on Multi-Source Characterization in FDD Systems. Sensors 2023, 23, 8139. [Google Scholar] [CrossRef]
- Liu, Q.; Sun, J.; Wang, P. Uplink Assisted MIMO Channel Feedback Method Based on Deep Learning. Entropy 2023, 25, 1131. [Google Scholar] [CrossRef] [PubMed]
- Riviello, D.G.; Tuninato, R.; Zimaglia, E.; Fantini, R.; Garello, R. Implementation of Deep-Learning-Based CSI Feedback Reporting on 5G NR-Compliant Link-Level Simulator. Sensors 2023, 23, 910. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Zhao, H.; Wang, J.; Chen, W. Deep Learning-Based Joint CSI Feedback and Hybrid Precoding in FDD mmWave Massive MIMO Systems. Entropy 2022, 24, 441. [Google Scholar] [CrossRef] [PubMed]
- Naser, M.A.; Abdul-Hadi, A.M.; Alsabah, M.; Mahmmod, B.M.; Majeed, A.; Abdulhussain, S.H. Downlink Training Sequence Design Based on Waterfilling Solution for Low-Latency FDD Massive MIMO Communications Systems. Electronics 2023, 12, 2494. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, A.; Liu, P. A novel CSI feedback approach for massive MIMO using LSTM-attention CNN. IEEE Access 2020, 8, 7295–7302. [Google Scholar] [CrossRef]
- Manasa, B.M.R.; Pakala, V.; Chinthaginjala, R.; Ayadi, M.; Hamdi, M.; Ksibi, A. A Novel Channel Estimation Framework in MIMO Using Serial Cascaded Multiscale Autoencoder and Attention LSTM with Hybrid Heuristic Algorithm. Sensors 2023, 23, 9154. [Google Scholar] [CrossRef] [PubMed]
- Bi, X.; Li, S.; Yu, C. A novel approach using convolutional transformer for massive MIMO CSI feedback. IEEE Wirel. Commun. Lett. 2022, 11, 1017–1021. [Google Scholar] [CrossRef]
- Cui, Y.; Guo, A.; Song, C. TransNet: Full attention network for CSI feedback in FDD massive MIMO system. IEEE Wirel. Commun. Lett. 2022, 11, 903–907. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, J.; Song, J. Multi-resolution CSI feedback with deep learning in massive MIMO system. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Chen, J.; Mei, M. Numerical Analysis of Low-Cost Recognition of Tunnel Cracks with Compressive Sensing along the Railway. Appl. Sci. 2023, 13, 13007. [Google Scholar] [CrossRef]
- Wen, C.K.; Shih, W.T.; Jin, S. Deep learning for massive MIMO CSI feedback. IEEE Wirel. Commun. Lett. 2018, 7, 748–751. [Google Scholar] [CrossRef]
- Sharma, S.; Yoon, W. Energy Efficient Power Allocation in Massive MIMO Based on Parameterized Deep DQN. Electronics 2023, 12, 4517. [Google Scholar] [CrossRef]
- Zhang, Y.; Luo, Z. A Review of Research on Spectrum Sensing Based on Deep Learning. Electronics 2023, 12, 4514. [Google Scholar] [CrossRef]
- Lu, C.; Xu, W.; Jin, S.; Wang, K. Bit-level optimized neural network for multi-antenna channel quantization. IEEE Wirel. Commun. 2019, 9, 87–90. [Google Scholar] [CrossRef]
- Ji, S.; Li, M. CLNet: Complex input lightweight neural network designed for massive MIMO CSI feedback. IEEE Wirel. Commun. Lett. 2021, 10, 2318–2322. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, J.; Song, J. Binary neural network aided CSI feedback in massive MIMO system. IEEE Wirel. Commun. Lett. 2021, 10, 1305–1308. [Google Scholar] [CrossRef]
- Guo, J.; Wen, C.-K.; Jin, S.; Li, G.Y. Convolutional neural network based multiple-rate compressive sensing for massive MIMO CSI feedback: Design, simulation, and analysis. IEEE Trans. Wirel. Commun. 2020, 19, 2827–2840. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.; Jin, S.; Li, G.Y. Deep learning-based CSI feedback approach for time-varying massive MIMO channels. IEEE Wirel. Commun. Lett. 2019, 8, 416–419. [Google Scholar] [CrossRef]
- Cai, Q.; Dong, C.; Niu, K. Attention model for massive MIMO CSI compression feedback and recovery. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–5. [Google Scholar]
- Song, X.; Wang, J.; Wang, J. SALDR: Joint self-attention learning and dense refine for massive MIMO CSI feedback with multiple compression ratio. IEEE Wirel. Commun. Lett. 2021, 10, 1899–1903. [Google Scholar] [CrossRef]
- Hong, S.; Jo, S.; So, J. Machine learning-based adaptive CSI feedback interval. ICT Express 2022, 8, 544–548. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, L.; Ding, Z. Exploiting bi-directional channel reciprocity in deep learning for low rate massive MIMO CSI feedback. IEEE Wirel. Commun. Lett. 2019, 8, 889–892. [Google Scholar] [CrossRef]
- Wang, J.; Gui, G.; Ohtsuki, T. Compressive sampled CSI feedback method based on deep learning for FDD massive MIMO systems. IEEE Trans. Commun. 2021, 69, 5873–5885. [Google Scholar] [CrossRef]
- Mashhadi, M.B.; Yang, Q.; Gunduz, D. Distributed deep convolutional compression for massive MIMO CSI feedback. IEEE Trans. Wirel. Commun. 2020, 20, 2621–2633. [Google Scholar] [CrossRef]
- Liu, Z.; del Rosario, M.; Ding, Z. A Markovian model-driven deep learning framework for massive MIMO CSI feedback. IEEE Trans.Wirel. Commun. 2022, 21, 1214–1228. [Google Scholar] [CrossRef]
- Guo, J.; Wen, C.K.; Jin, S. CAnet: Uplink-aided downlink channel acquisition in FDD massive MIMO using deep learning. IEEE Trans. Commun. 2021, 70, 199–214. [Google Scholar] [CrossRef]
- Chen, M.; Guo, J.; Wen, C.K. Deep learning-based implicit CSI feedback in massive MIMO. IEEE Trans. Commun. 2021, 70, 935–950. [Google Scholar] [CrossRef]
- Qing, C.; Cai, B.; Yang, Q. Deep learning for CSI feedback based on superimposed coding. IEEE Access 2019, 7, 93723–93733. [Google Scholar] [CrossRef]
- Xu, D.; Huang, Y.; Yang, L. Feedback of downlink channel state information based on superimposed coding. IEEE Commun. Lett. 2007, 11, 240–242. [Google Scholar] [CrossRef]
- Guo, J.; Chen, T.; Jin, S. Deep learning for joint channel estimation and feedback in massive MIMO systems. Digit. Commun. Netw. 2023. [Google Scholar] [CrossRef]
- Jang, J.; Lee, H.; Hwang, S. Deep learning-based limited feedback designs for MIMO systems. IEEE Wirel. Commun. Lett. 2019, 9, 558–561. [Google Scholar] [CrossRef]
- Ye, H.; Gao, F.; Qian, J. Deep learning-based denoise network for CSI feedback in FDD massive MIMO systems. IEEE Commun. Lett. 2020, 24, 1742–1746. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (ICONIP), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Xue, J.; Chen, X.; Chi, Q.; Xiao, W. Online Learning-Based Adaptive Device-Free Localization in Time-Varying Indoor Environment. Appl. Sci 2024, 14, 643. [Google Scholar] [CrossRef]
- Liu, L.; Oestges, C.; Poutanen, J.; Haneda, K.; Vainikainen, P.; Quitin, F. The cost 2100 MIMO channel model. IEEE Wirel. Commun. 2012, 19, 92–99. [Google Scholar] [CrossRef]
- Guo, J.; Wen, C.K.; Jin, S. Overview of deep learning-based CSI feedback in massive MIMO systems. IEEE Trans. Commun. 2022, 70, 8017–8045. [Google Scholar] [CrossRef]
- Hu, Z.; Guo, J.; Liu, G.; Zheng, H.; Xue, J. MRFNet: A deep learning-based CSI feedback approach of massive MIMO systems. IEEE Commun. Lett. 2021, 25, 3310–3314. [Google Scholar] [CrossRef]
- Sun, Y.; Xu, W.; Liang, L.; Wang, N.; Li, G.Y.; You, X. A lightweight deep network for efficient CSI feedback in massive MIMO systems. IEEE Wirel. Commun. Lett. 2021, 10, 1840–1844. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, X.; Liu, Y. Deep learning based CSI compression and quantization with high compression ratios in FDD massive MIMO systems. IEEE Wirel. Commun. Lett. 2021, 10, 2101–2105. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Attention-CsiNet | LSTM-Attention CsiNet | SALDR | CsiFormer | TransNet | TransNet+ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| in | out | FLOPs | in | out | FLOPs | in | out | FLOPs | in | out | FLOPs | in | out | FLOPs | in | out | FLOPs | |
| 1/4 | −20.29 | −10.43 | 24.72 M | −22.00 | −10.20 | ∖ | ∖ | ∖ | ∖ | ∖ | ∖ | ∖ | −32.38 | −14.86 | 35.72 M | −33.12 | −15.80 | 35.65 M |
| 1/8 | ∖ | ∖ | 22.62 M | ∖ | ∖ | ∖ | −21.02 | −9.35 | 141.57 M | ∖ | ∖ | ∖ | −22.91 | −9.99 | 34.70 M | −23.47 | −9.86 | 34.60 M |
| 1/16 | −10.16 | −6.11 | 21.58 M | −11.00 | −5.80 | ∖ | −15.02 | −5.96 | 141.12 M | ∖ | ∖ | ∖ | −15.00 | −7.82 | 34.14 M | −15.70 | −7.88 | 34.08 M |
| 1/32 | −8.58 | −4.57 | 21.05 M | −8.80 | −3.70 | ∖ | −10.65 | −3.79 | 140.87 M | −9.32 | −3.51 | 5.41 M | −10.49 | −4.13 | 33.88 M | −11.98 | −4.87 | 33.82 M |
| 1/64 | −6.32 | −3.27 | 20.79 M | −7.20 | −2.40 | ∖ | −7.80 | −2.37 | 140.74 M | −6.85 | −2.25 | 5.54 M | −6.08 | −2.62 | 33.75 M | −7.99 | −3.07 | 33.69 M |
| FLOPs | |||||
|---|---|---|---|---|---|
| 1/4 | 35.652 M | * | −29.42 | −30.58 | −7.58 |
| 1/8 | 34.603 M | −22.28 | −22.83 | −22.47 | −22.75 |
| 1/16 | 34.079 M | −15.73 | −15.90 | −15.80 | −16.09 |
| 1/32 | 33.817 M | −11.55 | −11.06 | −11.81 | −10.98 |
| 1/64 | 33.686 M | −7.46 | −5.91 | −6.91 | −6.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Guo, A.; Cui, Y. Multi-Head Transformer Architecture with Higher Dimensional Feature Representation for Massive MIMO CSI Feedback. Appl. Sci. 2024, 14, 1356. https://doi.org/10.3390/app14041356
Chen Q, Guo A, Cui Y. Multi-Head Transformer Architecture with Higher Dimensional Feature Representation for Massive MIMO CSI Feedback. Applied Sciences. 2024; 14(4):1356. https://doi.org/10.3390/app14041356
Chicago/Turabian StyleChen, Qing, Aihuang Guo, and Yaodong Cui. 2024. "Multi-Head Transformer Architecture with Higher Dimensional Feature Representation for Massive MIMO CSI Feedback" Applied Sciences 14, no. 4: 1356. https://doi.org/10.3390/app14041356
APA StyleChen, Q., Guo, A., & Cui, Y. (2024). Multi-Head Transformer Architecture with Higher Dimensional Feature Representation for Massive MIMO CSI Feedback. Applied Sciences, 14(4), 1356. https://doi.org/10.3390/app14041356