
Research on the Remaining Life Prediction Method of Rolling Bearings Based on Multi-Feature Fusion


Abstract
1. Introduction
- (1)
- Most of the current research focuses on the utilization of single-sensor data, while insufficient attention is paid to the efficient integration and utilization of data from several sensors. Meanwhile, when using parallel networks for feature extraction, the same network structure is often adopted without giving full play to the advantages of multiple networks.
- (2)
- In most of the parallel attention mechanism structure research, each branch of the network utilizes the multi-head self-attention mechanism to adjust the internal connections inside the data. However, using the same feature extraction method to fuse the outputs of each branch network may result in important features being masked while redundant features are retained, ultimately affecting the overall performance of the network.
- (1)
- By fusing information from multiple sensors, more comprehensive, accurate, and reliable information is obtained, and feature extraction by parallel processing TCN, LSTM, and Transformer gives full play to their respective advantages to enhance the efficiency of the prediction model and the precision of the forecast outcomes.
- (2)
- A parallel, multi-scale attention mechanism is designed. By fusing features in both the time and frequency domains, we are able to capture comprehensive and specific contextual information from sequential data while capturing local and global dependencies. A more comprehensive representation of the data can be achieved.
- (3)
- A multi-feature fusion model for predicting the RUL of rolling bearings is proposed, which can enhance valuable information while reducing redundant information, ultimately achieving the effective fusion of multiple features. Better prediction results than the current prediction methods are achieved in the experimental validation.
2. Theoretical Background
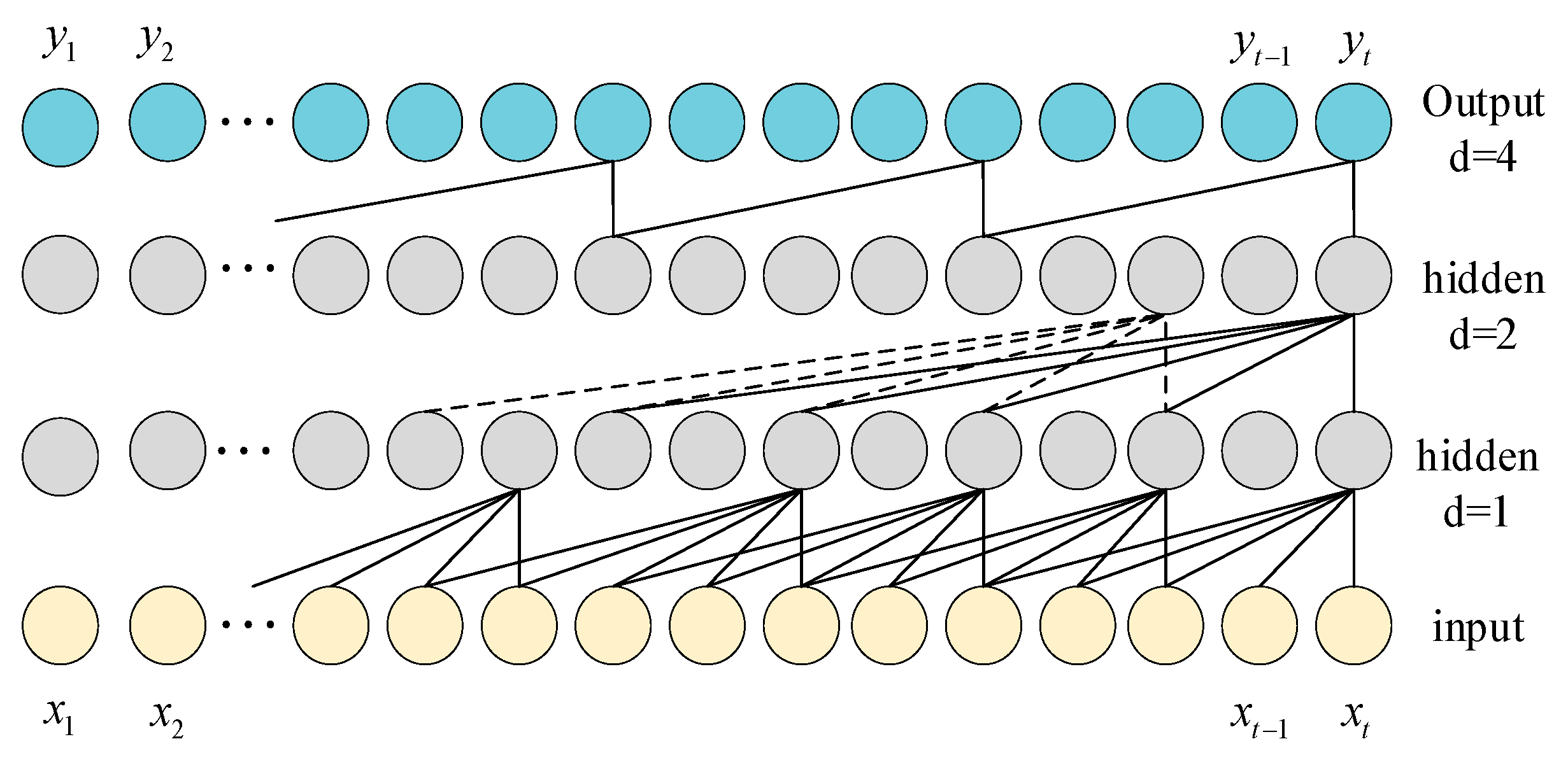
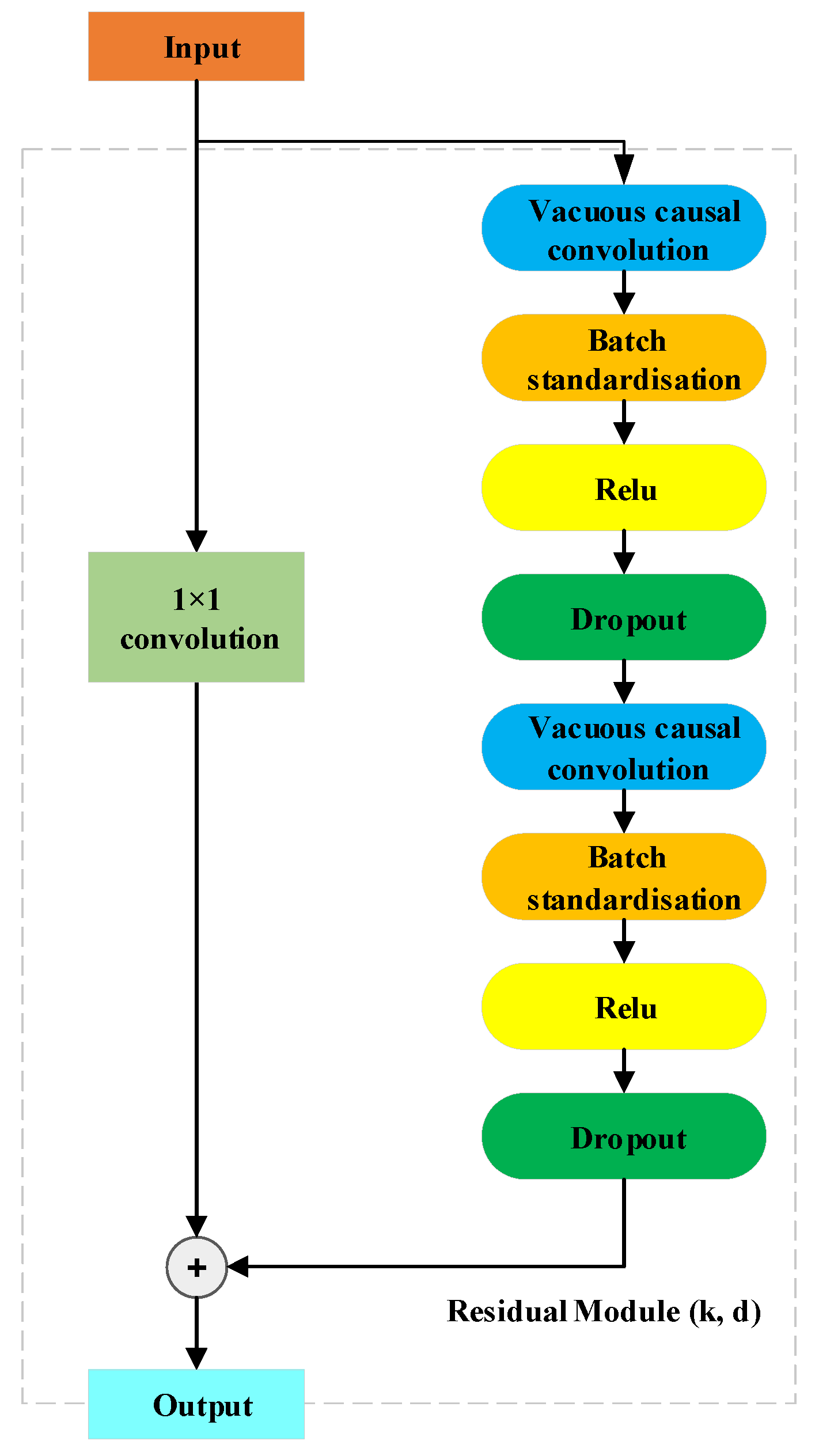
2.1. Temporal Convolutional Network
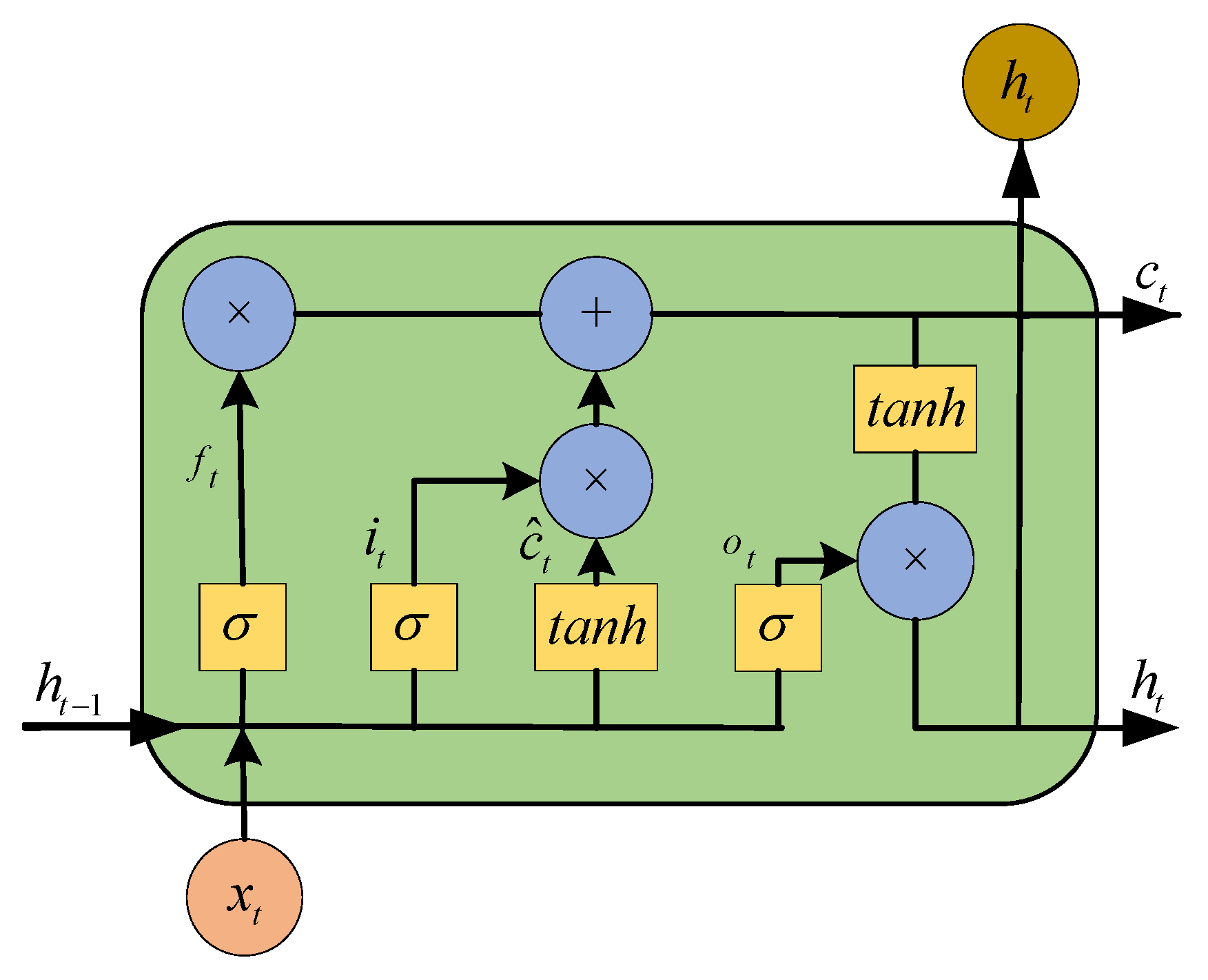
2.2. Long Short-Term Memory
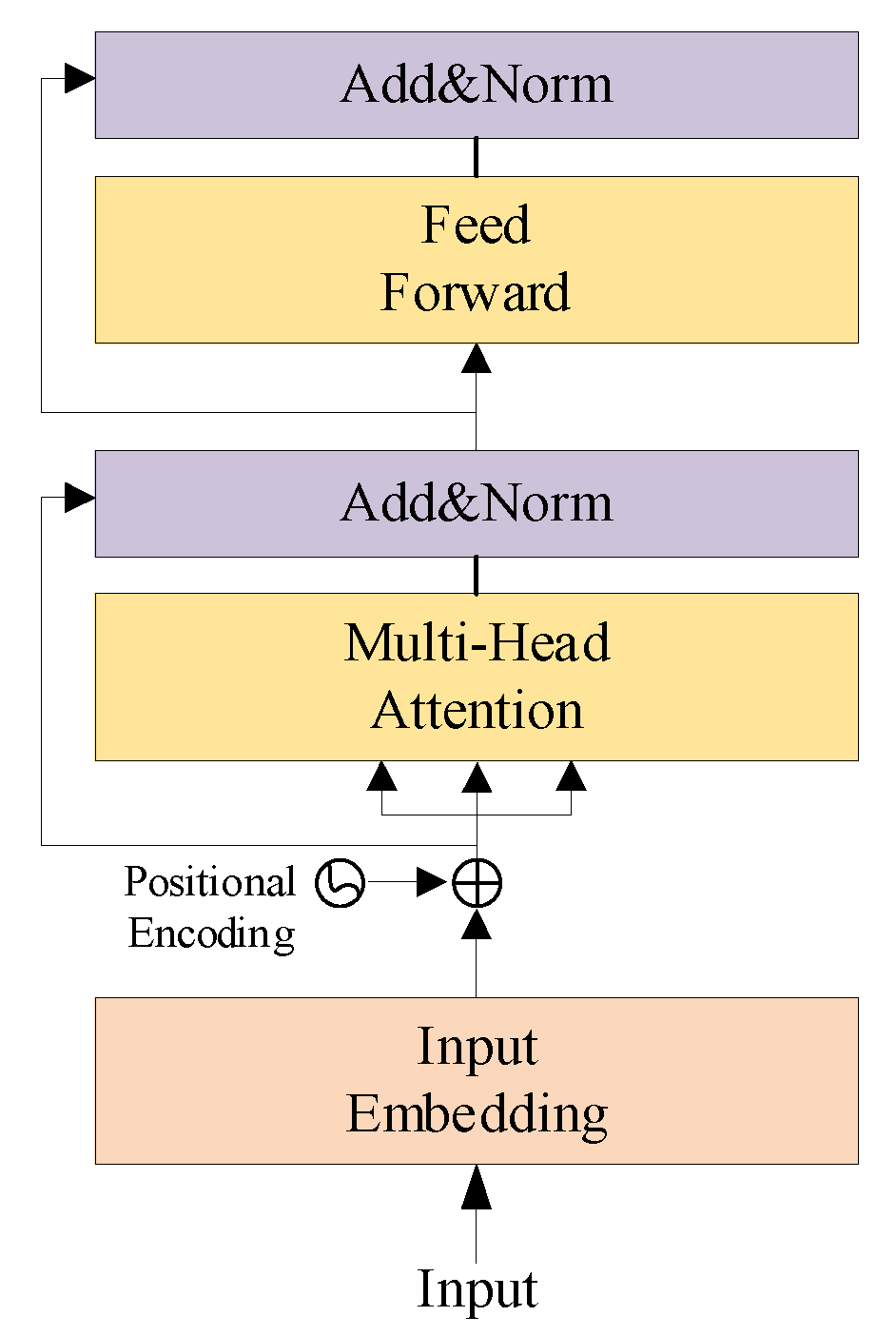
2.3. Enocder of Transformer
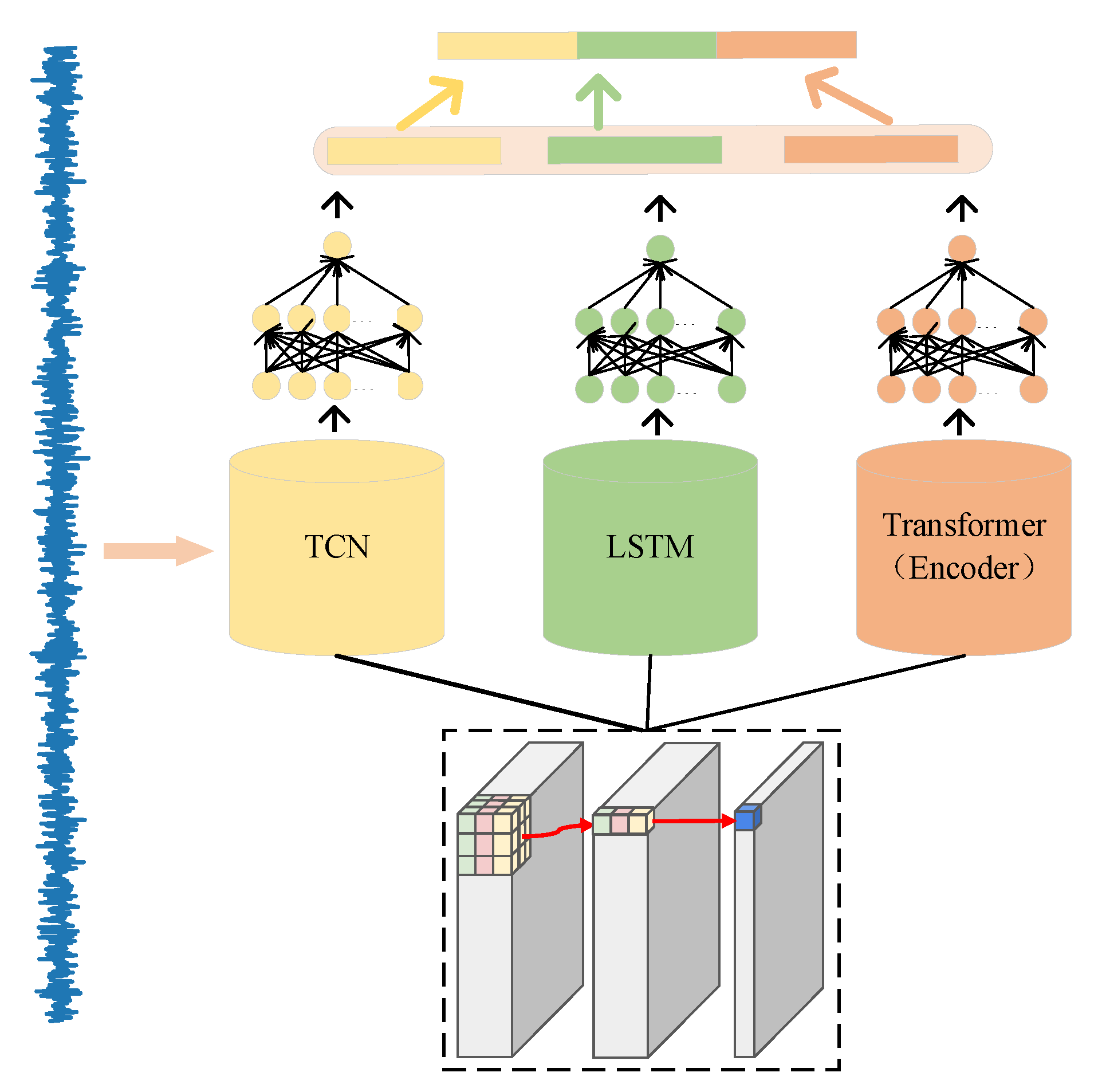
3. Prediction of RUL Based on the Multi-Feature Fusion Method
3.1. Fusion of Multisensor Data
3.2. Parallel TCN-LSTM-Transformer Feature Extractor
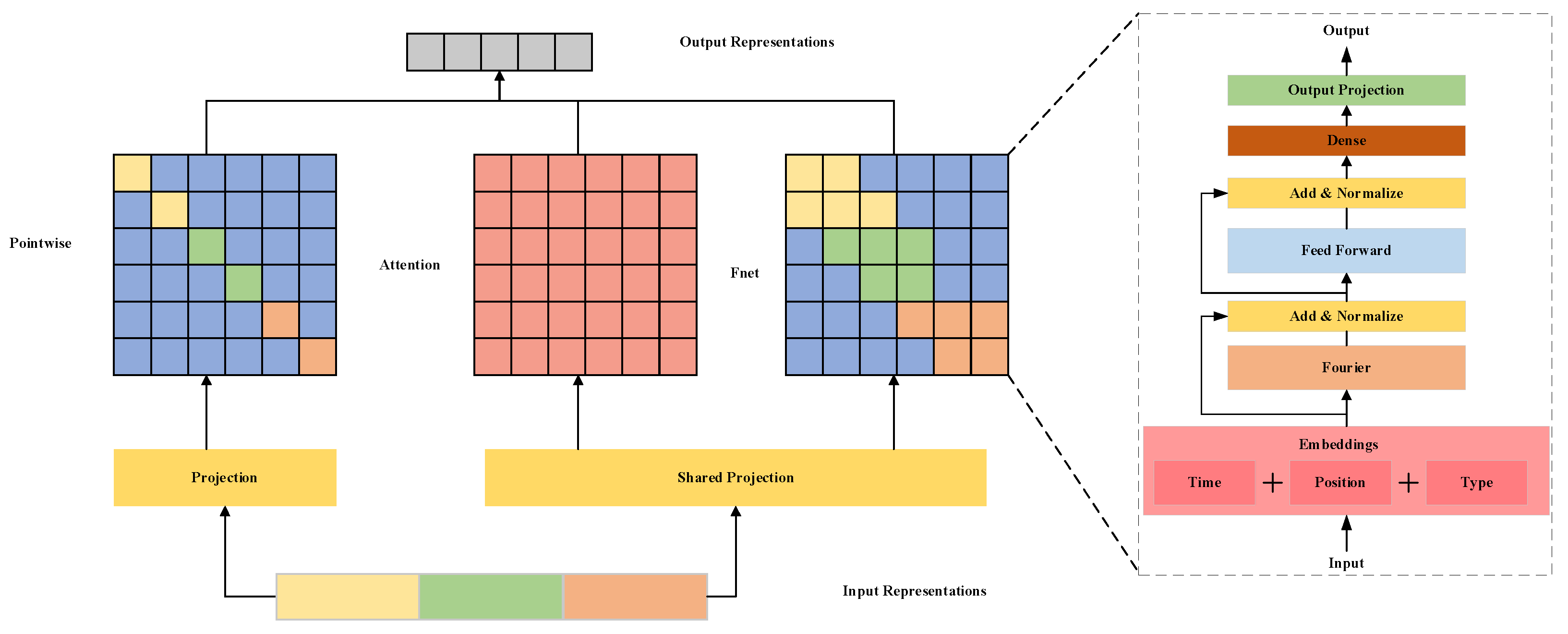
3.3. Parallel Multi-Scale Attention Mechanisms
3.4. RUL Forecast
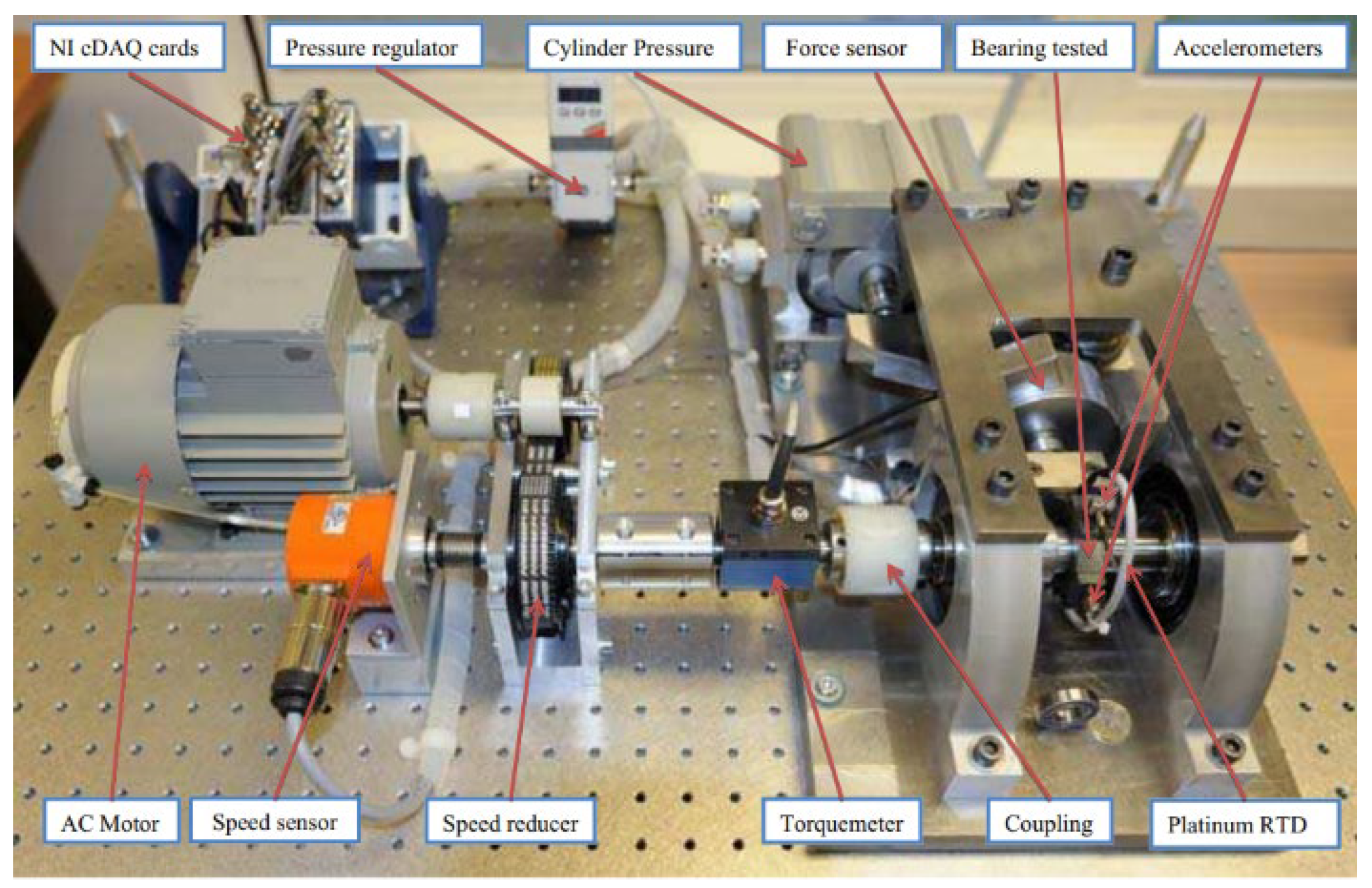
4. Experimental Verification
4.1. Parameter Configuration of Multi-Feature Fusion Networks
4.2. Case Study 1: Predicting the RUL of Bearings Using the PHM 2012 Dataset
4.2.1. Introduction to the Dataset
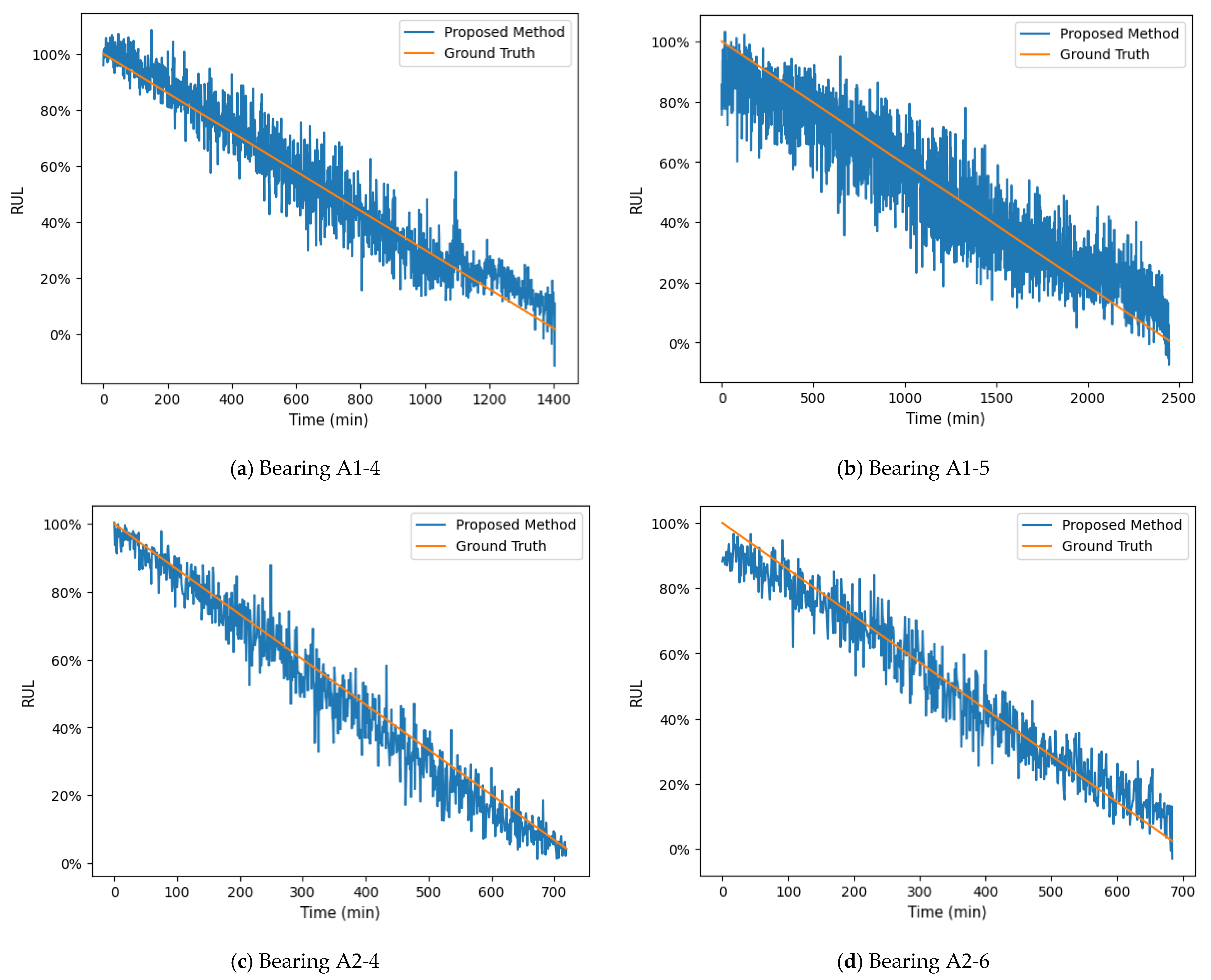
4.2.2. Analysis of Projected Results
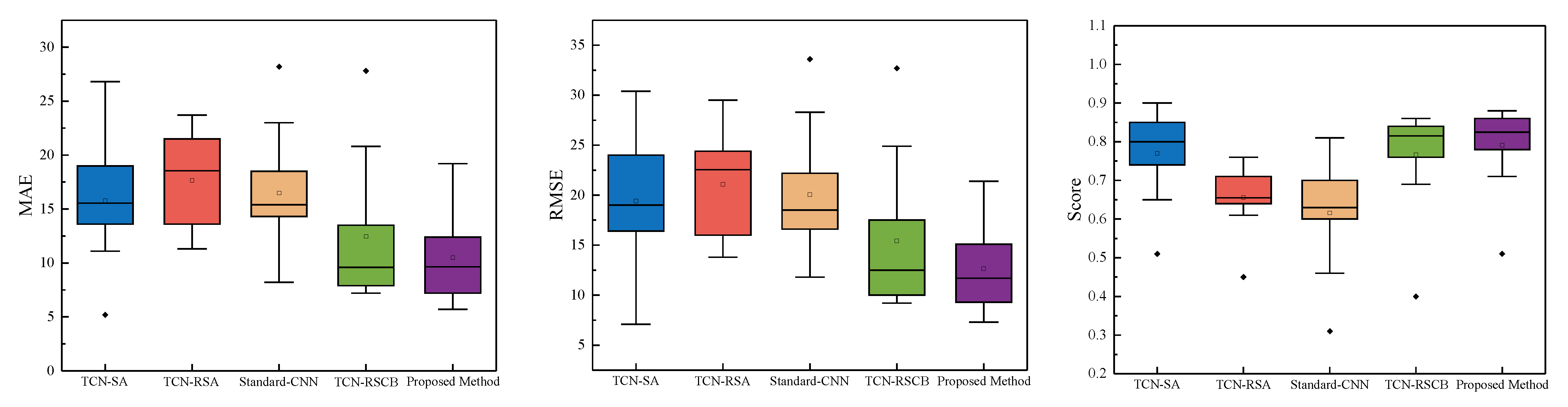
4.2.3. Ablation Experiment
4.3. Case Study 2: Predicting the RUL of Bearings Using the XJTU-SY Dataset
4.3.1. Introduction to the Dataset
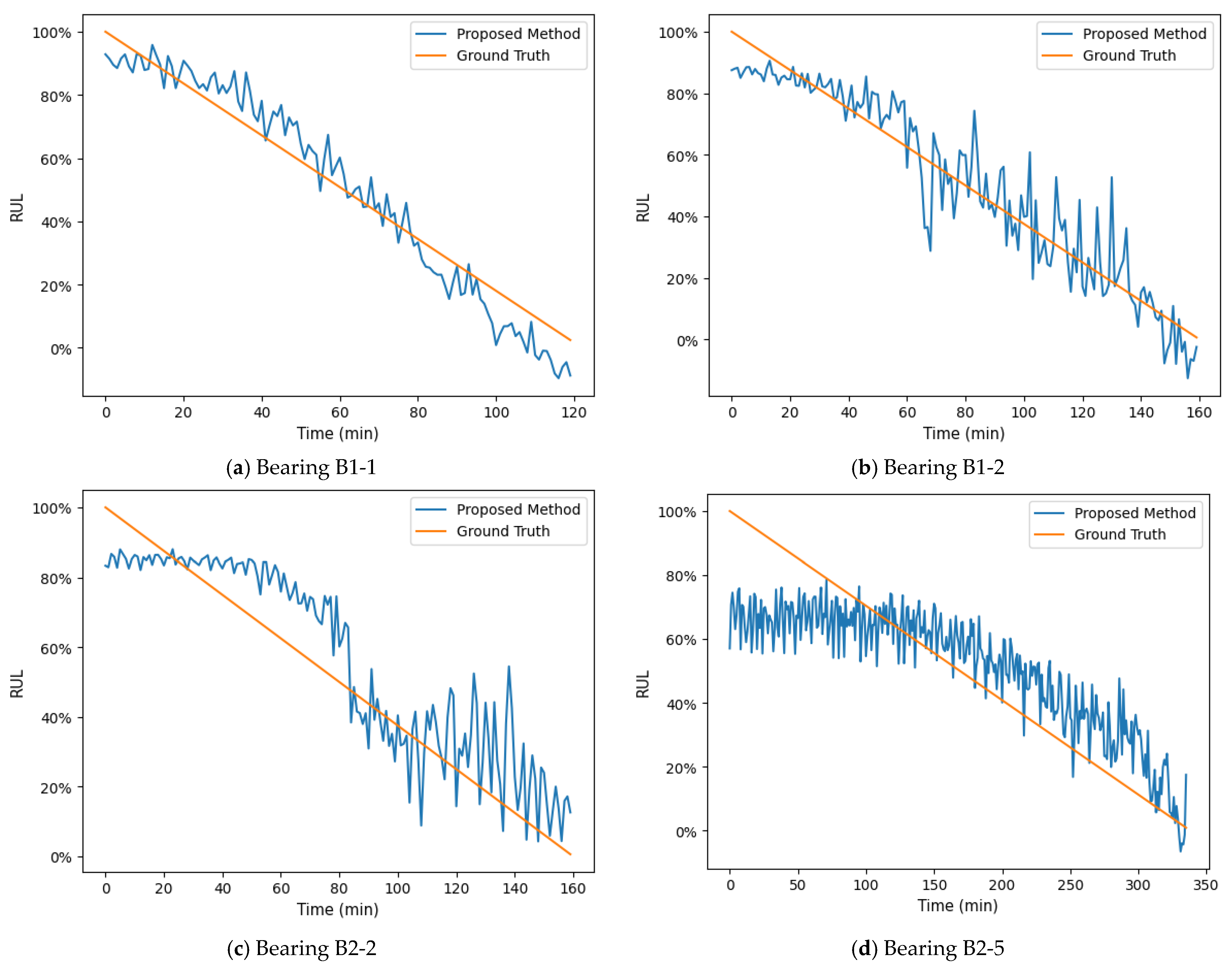
4.3.2. Analysis of Projected Results
4.3.3. Ablation Experiment
5. Conclusions
- (1)
- A method for multi-sensor data fusion has been developed to combine data from many sensors based on their channels. This approach not only provides an effective fusion of multi-sensor data but also compensates for the limitations of standard prediction methods that rely only on data from a single sensor.
- (2)
- To address the issue of incomplete extraction of global feature information throughout the feature extraction procedure, this paper uses TCN, LSTM, and Transformer to construct a parallel multi-branch feature learning network, designs a parallel multi-scale attention mechanism to capture both local and global dependencies, and realizes the adaptive weighted fusion of the output features from three types of feature extractors. The shallow features obtained by the parallel feature extractor are then residually connected with the deeper features through the attention mechanism to improve the utilization efficiency of the before and after feature information so as to learn more comprehensive feature information.
- (3)
- Validation of the validity and generalization ability of the proposed method using the PHM 2012 bearing degradation dataset and the XJTU-SY bearing accelerated life test dataset. The experimental findings demonstrate that the proposed method can precisely forecast the RUL of a variety of bearings. Comparative experiments demonstrate that the proposed method has a reduced prediction error.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Lei, Y.G.; Jia, F.; Kong, D.T.; Ling, J.; Xing, S.B. Opportunities and challenges of mechanical intelligent fault diagnosis under big data. J. Mech. Eng. 2018, 54, 94–104. (In Chinese) [Google Scholar] [CrossRef]
- Fragoso, A.; Martins, R.F.; Soares, A.C. Failure analysis of a ball mill located in a cement’s production line. Eng. Fail. Anal. 2022, 138, 106339. [Google Scholar] [CrossRef]
- Saucedo-Dorantes, J.J.; Arellano-Espitia, F.; Delgado-Prieto, M.; Osornio-Rios, R.A. Diagnosis methodology based on deep feature learning for fault identification in metallic, hybrid and ceramic bearings. Sensors 2021, 21, 5832. [Google Scholar] [CrossRef]
- Shi, H.T.; Hou, M.X.; Wu, Y.H.; Li, B.C. Incipient fault detection of full ceramic ball bearing based on modified observer. Int. J. Control Autom. Syst. 2022, 20, 727–740. [Google Scholar] [CrossRef]
- Zhang, X.C.; Wu, D.; Xia, Z.F.; Li, Y.F.; Wang, J.Q.; Han, E.H. Characteristics and mechanism of surface damage of hybrid ceramic ball bearings for high-precision machine tool. Eng. Fail. Anal. 2022, 142, 106784. [Google Scholar] [CrossRef]
- Si, X.S.; Wang, W.B.; Hu, C.H.; Zhou, D.H. Remaining useful life estimation–A review on the statistical data driven approaches. Eur. J. Oper. Res. 2011, 213, 1–14. [Google Scholar] [CrossRef]
- Singleton, R.K.; Strangas, E.G.; Aviyente, S. Extended Kalman filtering for remaining-useful-life estimation of bearings. IEEE Trans. Ind. Electron. 2014, 62, 1781–1790. [Google Scholar] [CrossRef]
- Chen, C.C.; Vachtsevanos, G.; Orchard, M.E. Machine remaining useful life prediction: An integrated adaptive neuro-fuzzy and high-order particle filtering approach. Mech. Syst. Signal Process. 2012, 28, 597–607. [Google Scholar] [CrossRef]
- Cai, B.P.; Fan, H.Y.; Shao, X.Y.; Liu, Y.H.; Liu, G.J.; Liu, Z.K.; Ji, R.J. Remaining useful life re-prediction methodology based on Wiener process: Subsea Christmas tree system as a case study. Comput. Ind. Eng. 2021, 151, 106983. [Google Scholar] [CrossRef]
- Le Son, K.; Fouladirad, M.; Barros, A. Remaining useful lifetime estimation and noisy gamma deterioration process. Reliab. Eng. Syst. Saf. 2016, 149, 76–87. [Google Scholar] [CrossRef]
- Kundu, P.; Darpe, A.K.; Kulkarni, M.S. Weibull accelerated failure time regression model for remaining useful life prediction of bearing working under multiple operating conditions. Mech. Syst. Signal Proc. 2019, 134, 106302. [Google Scholar] [CrossRef]
- Sun, Q.Q.; Ge, Z.Q. A survey on deep learning for data-driven soft sensors. IEEE Trans. Industr. Inform. 2021, 17, 5853–5866. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern. 2017, 48, 11–20. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.P.; Jia, F.; Lei, Y.G.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Catelani, M.; Ciani, L.; Fantacci, R.; Patrizi, C.; Picano, B. Remaining useful life estimation for prognostics of lithium-ion batteries based on recurrent neural network. IEEE Trans. Instrum. Meas. 2021, 70, 3524611. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Miao, H.H.; Li, B.; Sun, C.; Liu, J. Joint learning of degradation assessment and RUL prediction for aeroengines via dual-task deep LSTM networks. IEEE Trans. Industr. Inform. 2019, 15, 5023–5032. [Google Scholar] [CrossRef]
- Ren, L.; Dong, J.B.; Wang, X.K.; Meng, Z.H.; Zhao, L.; Deen, M.J. A data-driven auto-CNN-LSTM prediction model for lithium-ion battery remaining useful life. IEEE Trans. Industr. Inform. 2020, 17, 3478–3487. [Google Scholar] [CrossRef]
- Bai, S.J.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Wang, Y.W.; Deng, L.; Zheng, L.Y.; Gao, R.X. Temporal convolutional network with soft thresholding and attention mechanism for machinery prognostics. J. Manuf. Syst. 2021, 60, 512–526. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Q.H.; Li, X.; Huang, B.Q. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 32, 1997–2006. [Google Scholar] [CrossRef]
- Egea-Lopez, E.; Martinez-Sala, A.; Vales-Alonso, J.; Garcia-Haro, J.; Malgosa-Sanahuja, J. Wireless communications deployment in industry: A review of issues, options and technologies. Comput. Ind. 2005, 56, 29–53. [Google Scholar] [CrossRef]
- Li, N.P.; Gebraeel, N.; Lei, Y.G.; Fang, X.L.; Cai, X.; Yan, T. Remaining useful life prediction based on a multi-sensor data fusion model. Reliab. Eng. Syst. Saf. 2021, 208, 107249. [Google Scholar] [CrossRef]
- Lee-Thorp, J.; Ainslie, J.; Eckstein, I.; Ontañón, S. Fnet: Mixing tokens with fourier transforms. arXiv 2021, arXiv:2105.03824. [Google Scholar]
- Li, X.; Zhang, W.; Ding, Q. Deep learning-based remaining useful life estimation of bearings using multi-scale feature extraction. Reliab. Eng. Syst. Saf. 2019, 182, 208–218. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management IEEE (ICPHM), Beijing, China, 23–25 May 2012; pp. 23–25. [Google Scholar]
- Cao, Y.D.; Ding, Y.F.; Jia, M.P. A novel temporal convolutional network with residual self-attention mechanism for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- Zhang, Y.Z.; Zhao, X.Q. Remaining useful life prediction of bearings based on temporal convolutional networks with residual separable blocks. J. Braz. Soc. Mech. Sci. 2022, 44, 527. [Google Scholar] [CrossRef]
- Lei, Y.G.; Han, T.Y.; Wang, B.; Li, N.P.; Yan, T.; Yang, J. Interpretation of XJTU-SY rolling bearing accelerated life test dataset. J. Mech. Eng. 2019, 55, 1–6. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layer | Parameters |
|---|---|---|
| Transformer | BatchNorm1d | Num_eatures: 2560 Eps: 1 × 10−5 Momentum: 0.1 affine: True Track running stats: True |
| Transformer Encoder Layer | D_model: 2 Nhead: 2 Dim feedforward: 2048 Dropout: 0.1 Activation: relu Normalize before: False Num layers: 3 | |
| Linear | In features: 5120 Out features: 1 Bias: True | |
| TCN | Temporal Block | N_inputs: 2560 N_outputs: 8 kernel_size: 3 Stride: 1 dilation: 1, 2, 4 dropout: 0.5 |
| Temporal Conv Net | Num_inputs: 2560 Num_channels: 8, 8, 8 Kernel_size: 3 Dropout: 0.2 | |
| LSTM | Nor: 2560 input features: 2 number of hidden states: 3 number of input features: 7680 Hidden Size: 3 Flatten | |
| FNet | Dim: 100 Depth: 3 Mlp_dim: 100 Dropout: 0 | |
| Operating Condition | A1 | A2 | A3 |
|---|---|---|---|
| 1800 r/min 4000 N | 1650 r/min 4200 N | 1500 r/min 5000 N | |
| Bearing | Bearing A1-1 | Bearing A2-1 | Bearing A3-1 |
| Bearing A1-2 | Bearing A2-2 | Bearing A3-2 | |
| Bearing A1-3 | Bearing A2-3 | Bearing A3-3 | |
| Bearing A1-4 | Bearing A2-4 | ||
| Bearing A1-5 | Bearing A2-5 | ||
| Bearing A1-6 | Bearing A2-6 | ||
| Bearing A1-7 | Bearing A2-7 |
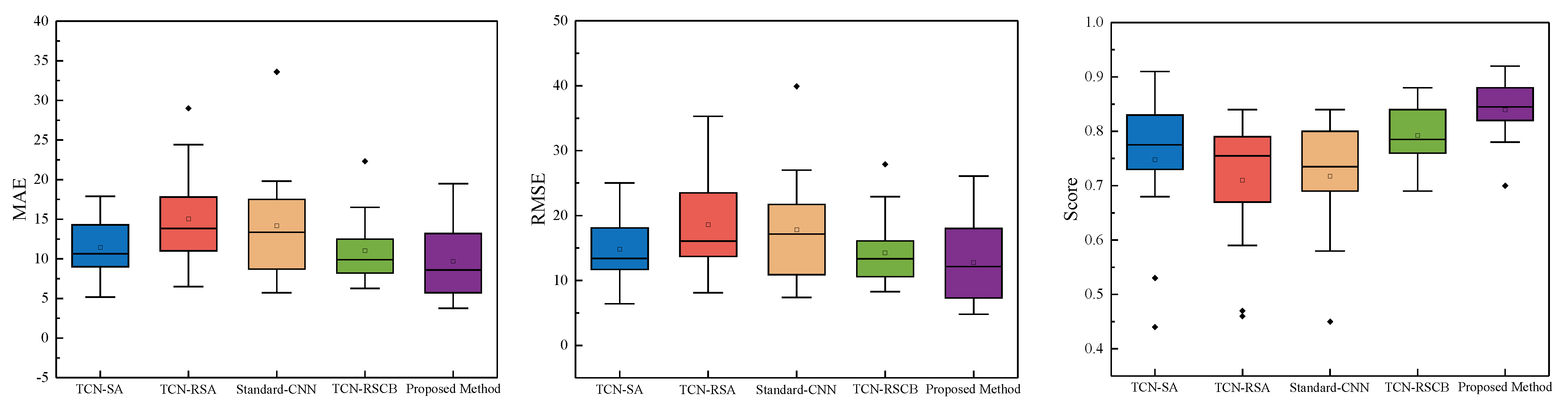
| Test Set | TCN-SA [21] | TCN-RSA [28] | Standard-CNN | TCN-RSCB [29] | Proposed Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | Score | MAE | RMSE | Score | MAE | RMSE | Score | MAE | RMSE | Score | MAE | RMSE | Score | |
| A1-1 | 10.4 | 11.3 | 0.87 | 11.0 | 13.7 | 0.84 | 8.7 | 10.9 | 0.84 | 8.6 | 10.7 | 0.88 | 8.72 | 11.5 | 0.87 |
| A1-2 | 13.0 | 16.9 | 0.80 | 14.0 | 16.3 | 0.79 | 12.1 | 16.1 | 0.58 | 9.6 | 12.8 | 0.71 | 10.9 | 14.7 | 0.85 |
| A1-3 | 9.7 | 11.7 | 0.81 | 11.4 | 14.1 | 0.78 | 15.3 | 18.2 | 0.83 | 11.7 | 14.1 | 0.85 | 6.70 | 8.34 | 0.88 |
| A1-4 | 7.1 | 8.5 | 0.73 | 13.7 | 15.8 | 0.59 | 5.73 | 7.37 | 0.83 | 6.90 | 8.40 | 0.82 | 5.74 | 7.31 | 0.85 |
| A1-5 | 9.11 | 13.0 | 0.83 | 10.9 | 13.2 | 0.80 | 9.51 | 13.0 | 0.74 | 11.5 | 14.2 | 0.76 | 8.45 | 12.8 | 0.84 |
| A1-6 | 8.3 | 11.9 | 0.68 | 8.4 | 11.1 | 0.70 | 12.2 | 15.3 | 0.60 | 8.23 | 10.6 | 0.77 | 14.5 | 18.0 | 0.82 |
| A1-7 | 9.0 | 12.9 | 0.75 | 17.8 | 23.5 | 0.78 | 17.6 | 21.9 | 0.73 | 13.9 | 19.2 | 0.81 | 13.2 | 18.0 | 0.83 |
| A2-1 | 14.3 | 18.1 | 0.74 | 29.0 | 35.3 | 0.73 | 33.6 | 39.9 | 0.69 | 22.3 | 27.9 | 0.74 | 19.5 | 26.1 | 0.78 |
| A2-2 | 14.5 | 18.6 | 0.44 | 17.2 | 21.4 | 0.47 | 17.5 | 21.6 | 0.45 | 10.2 | 13.9 | 0.69 | 11.9 | 16.7 | 0.70 |
| A2-3 | 17.9 | 23.0 | 0.77 | 24.4 | 30.8 | 0.75 | 19.8 | 27.0 | 0.72 | 16.5 | 22.9 | 0.79 | 16.1 | 19.4 | 0.79 |
| A2-4 | 5.18 | 6.42 | 0.91 | 6.5 | 8.1 | 0.82 | 6.05 | 7.58 | 0.80 | 6.27 | 8.28 | 0.88 | 4.94 | 6.30 | 0.92 |
| A2-5 | 13.3 | 16.1 | 0.78 | 15.2 | 18.9 | 0.67 | 17.4 | 21.7 | 0.75 | 12.5 | 16.1 | 0.78 | 3.83 | 4.81 | 0.89 |
| A2-6 | 10.9 | 13.8 | 0.83 | 12.2 | 14.3 | 0.76 | 14.5 | 18.6 | 0.76 | 8.10 | 10.7 | 0.84 | 3.75 | 5.07 | 0.90 |
| A2-7 | 17.5 | 25.0 | 0.53 | 18.6 | 24.1 | 0.46 | 8.61 | 10.4 | 0.72 | 8.20 | 10.0 | 0.77 | 7.38 | 9.23 | 0.83 |
| Average | 11.4 | 14.8 | 0.75 | 15.0 | 18.6 | 0.71 | 14.2 | 17.8 | 0.72 | 11.0 | 14.2 | 0.79 | 10.4 | 13.5 | 0.83 |
| Method 1 | Method 2 | Method 3 | Proposed Method | |
|---|---|---|---|---|
| MAE | 13.4 | 8.71 | 6.32 | 5.74 |
| RMSE | 14.5 | 9.43 | 8.51 | 7.31 |
| Operating Condition | B1 | B2 | B3 |
|---|---|---|---|
| 2100 r/min 12 kN | 2250 r/min 11 kN | 2400 r/min 10 kN | |
| bearing | Bearing B1-1 | Bearing B2-1 | Bearing B3-1 |
| Bearing B1-2 | Bearing B2-2 | Bearing B3-2 | |
| Bearing B1-3 | Bearing B2-3 | Bearing B3-3 | |
| Bearing B1-4 | Bearing B2-4 | Bearing B3-4 | |
| Bearing B1-5 | Bearing B2-5 | Bearing B3-5 |
| Test Set | TCN-SA [21] | TCN-RSA [28] | Standard-CNN | TCN-RSCB [29] | Proposed Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | Score | MAE | RMSE | Score | MAE | RMSE | Score | MAE | RMSE | Score | MAE | RMSE | Score | |
| A1-1 | 5.2 | 7.1 | 0.90 | 21.5 | 25.9 | 0.75 | 14.3 | 16.6 | 0.70 | 12.3 | 14.8 | 0.82 | 5.7 | 7.3 | 0.88 |
| A1-2 | 19.0 | 24.0 | 0.80 | 18.8 | 23.0 | 0.61 | 8.2 | 11.8 | 0.81 | 7.7 | 9.3 | 0.83 | 7.2 | 9.3 | 0.84 |
| A1-3 | 17.0 | 21.7 | 0.65 | 13.6 | 16.0 | 0.65 | 16.1 | 18.9 | 0.61 | 8.4 | 10.0 | 0.69 | 8.2 | 9.7 | 0.71 |
| A1-4 | 26.8 | 30.4 | 0.80 | 11.9 | 14.0 | 0.66 | 18.5 | 22.2 | 0.46 | 7.9 | 10.1 | 0.84 | 7.1 | 8.8 | 0.85 |
| A1-5 | 20.3 | 25.3 | 0.51 | 19.7 | 22.3 | 0.45 | 28.2 | 33.6 | 0.31 | 27.8 | 32.7 | 0.40 | 19.2 | 21.4 | 0.51 |
| A2-1 | 13.6 | 16.4 | 0.80 | 23.7 | 29.5 | 0.65 | 23.0 | 28.3 | 0.64 | 20.8 | 24.9 | 0.76 | 12.4 | 15.1 | 0.81 |
| A2-2 | 14.5 | 18.6 | 0.85 | 11.3 | 13.8 | 0.68 | 14.3 | 16.7 | 0.75 | 8.2 | 10.2 | 0.86 | 8.6 | 10.6 | 0.86 |
| A2-3 | 13.6 | 17.1 | 0.85 | 21.8 | 24.4 | 0.76 | 11.0 | 13.4 | 0.66 | 10.8 | 15.4 | 0.86 | 10.7 | 12.8 | 0.87 |
| A2-4 | 16.6 | 19.4 | 0.74 | 16.0 | 19.0 | 0.64 | 16.5 | 20.8 | 0.60 | 13.5 | 17.5 | 0.79 | 14.4 | 16.6 | 0.80 |
| A2-5 | 11.1 | 14.3 | 0.80 | 18.3 | 22.8 | 0.71 | 14.7 | 18.1 | 0.62 | 7.2 | 9.2 | 0.81 | 11.5 | 14.9 | 0.78 |
| Average | 15.8 | 19.4 | 0.77 | 17.7 | 21.1 | 0.66 | 16.5 | 20.0 | 0.62 | 12.5 | 15.4 | 0.77 | 10.5 | 12.6 | 0.79 |
| Method 1 | Method 2 | Method 3 | Proposed Method | |
|---|---|---|---|---|
| MAE | 16.3 | 11.5 | 9.2 | 7.1 |
| RMSE | 20.5 | 14.9 | 11.1 | 8.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Jiang, D. Research on the Remaining Life Prediction Method of Rolling Bearings Based on Multi-Feature Fusion. Appl. Sci. 2024, 14, 1294. https://doi.org/10.3390/app14031294
Zhang G, Jiang D. Research on the Remaining Life Prediction Method of Rolling Bearings Based on Multi-Feature Fusion. Applied Sciences. 2024; 14(3):1294. https://doi.org/10.3390/app14031294
Chicago/Turabian StyleZhang, Guanwen, and Dongnian Jiang. 2024. "Research on the Remaining Life Prediction Method of Rolling Bearings Based on Multi-Feature Fusion" Applied Sciences 14, no. 3: 1294. https://doi.org/10.3390/app14031294
APA StyleZhang, G., & Jiang, D. (2024). Research on the Remaining Life Prediction Method of Rolling Bearings Based on Multi-Feature Fusion. Applied Sciences, 14(3), 1294. https://doi.org/10.3390/app14031294