
Detecting IoT Anomalies Using Fuzzy Subspace Clustering Algorithms


Abstract
1. Introduction
- Secondly, a couple of well-known fuzzy clustering approaches are proposed to generate soft clusters.
- A comparative analysis is conducted among all of the proposed approaches along with the traditional fuzzy clustering approaches.
2. Problem Statement
2.1. Definition 2.1 [49]
2.2. Definition 2.2 [49]
2.3. Definition 2.3 [49]
2.4. Definition 2.4 [49]
2.5. Property 1 [9,49]
2.6. Definition 2.5 [9,49]
2.7. Remark 1 [9,49]
2.8. Definition 2.6 [9,49]
2.9. Definition 2.7 [9,49]
2.10. Definition 2.8
2.11. Definition 2.9 [9,49]
2.12. Definition 2.10 [9,49]
2.13. Definition 2.11
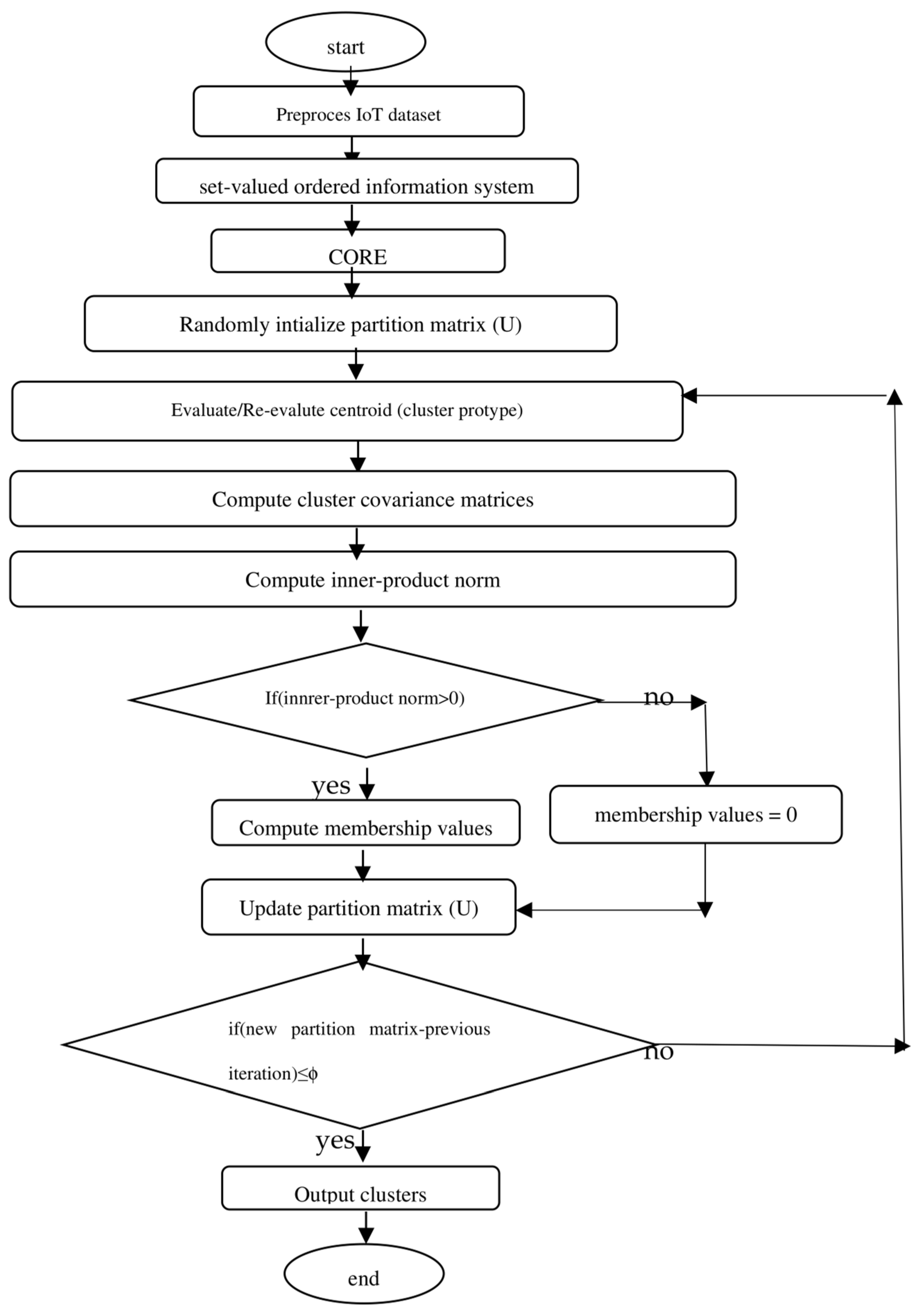
3. Proposed Methods
| Algorithm 1: Nano Topology-based Subspace Generation |
| Input. (U, A): the information system, where the attribute set A is divided into C-conditional attributes and D-decision attributes, consisting of n data instances. Output: Subspace of (U, A) Step 1. Generate a dominance relation on U corresponding to C and X ⊆ U. Step 2. Generate the Nano topology and its basis Step 3. for each x ∈ C, find and Step 4. if () Step 5. then drop x from C, Step 6. else form criterion reduction Step 7. end for Step 8. generate CORE(C) = ∩{criterion reductions} Step 9. Generate subspace of the given information system. |
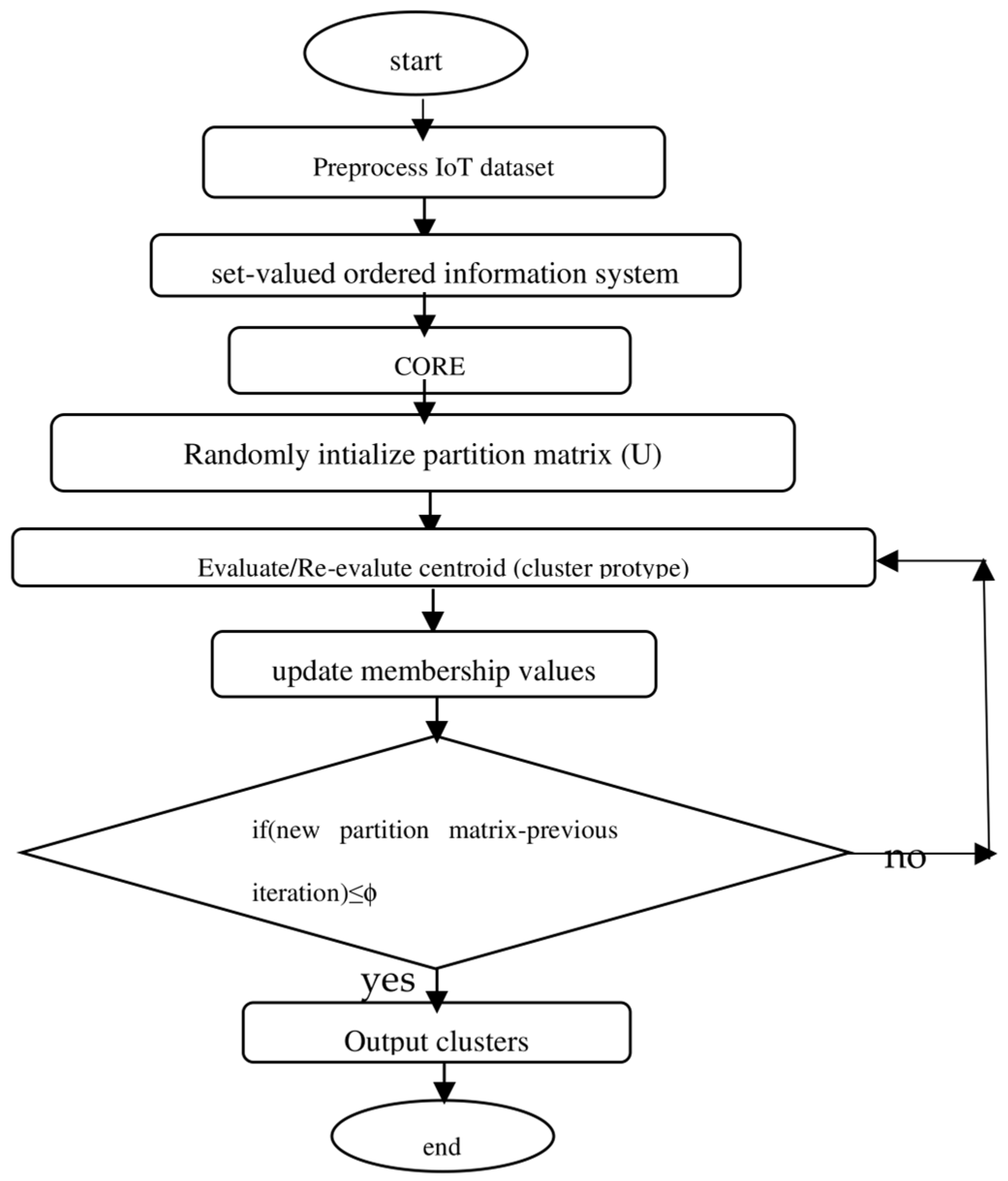
3.1. Fuzzy C-Means (FCM) Algorithm [41]
| Algorithm 2: (FCM) |
| Given dataset X, choose the number of cluster c, (1 < c < N), weighting exponent m > 1, terminating threshold ϕ > 0, and A (norm-inducing matrix). Initialize U = U(0) // U(0) ∈ Ffc for each j = 1, 2,…… step 1 compute cluster mean , i = 1, 2,…, c step 2 compute , i = 1, 2,…, c, k = 1, 2,…, N step 3 for k = 1, 2,…, N // update partition matrix if DikA > 0, for all i = 1, 2,…, c , else = 0 if DikA > 0, with = 1 until ||U(j)-U(j−1)|| < ϕ |
3.2. Definition 2.11 [48]
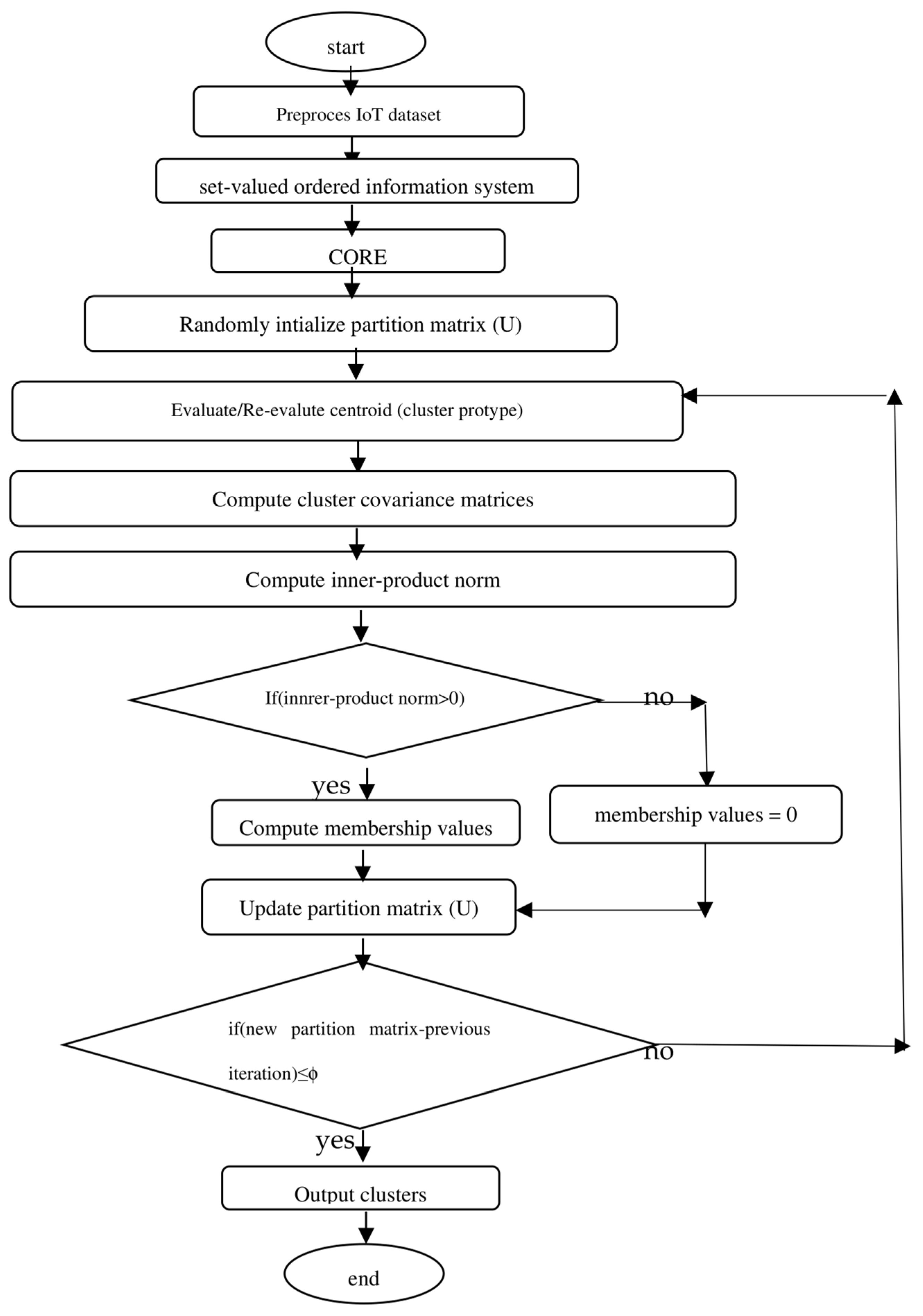
3.3. Gustafson–Kessel (GK) Algorithm [42,47]
| Algorithm 3: (GK) |
| Given dataset X, choose the number of cluster c, (1 < c < N), weighting exponent m > 1, terminating threshold ϕ > 0, and cluster volume M. Initialize U = U(0) // U(0) ∈ Ffc for each j = 1, 2,…… step 1 compute cluster mean , i = 1, 2,…c step 2 compute the cluster covariance matrices , i = 1, 2,…, c step 3 compute (for i = 1, 2,…, c, k = 1, 2,…, N) using Equations (14) and (16) step 4 for k = 1, 2,…, N // update partition matrix if DikA > 0, for all i = 1, 2,…, c , else = 0 if DikA > 0, with = 1 until ||U(j)-U(j−1)|| < ϕ |
3.4. Gath–Geva Algorithm (GG) [43,47]
| Algorithm 4: (GG) |
| Given dataset X, choose the number of cluster c, (1 < c < N), and terminating threshold ϕ > 0. Initialize U = U(0) // U(0) ∈ Ffc step 1 compute cluster mean vi step 2 calculate the distance measure using Equation (18) step 3 calculate Ai step 3 calculate the value of the membership data function using equation (21) and update U, the partition matrix until ||U(j)-U(j−1)|| < ϕ |
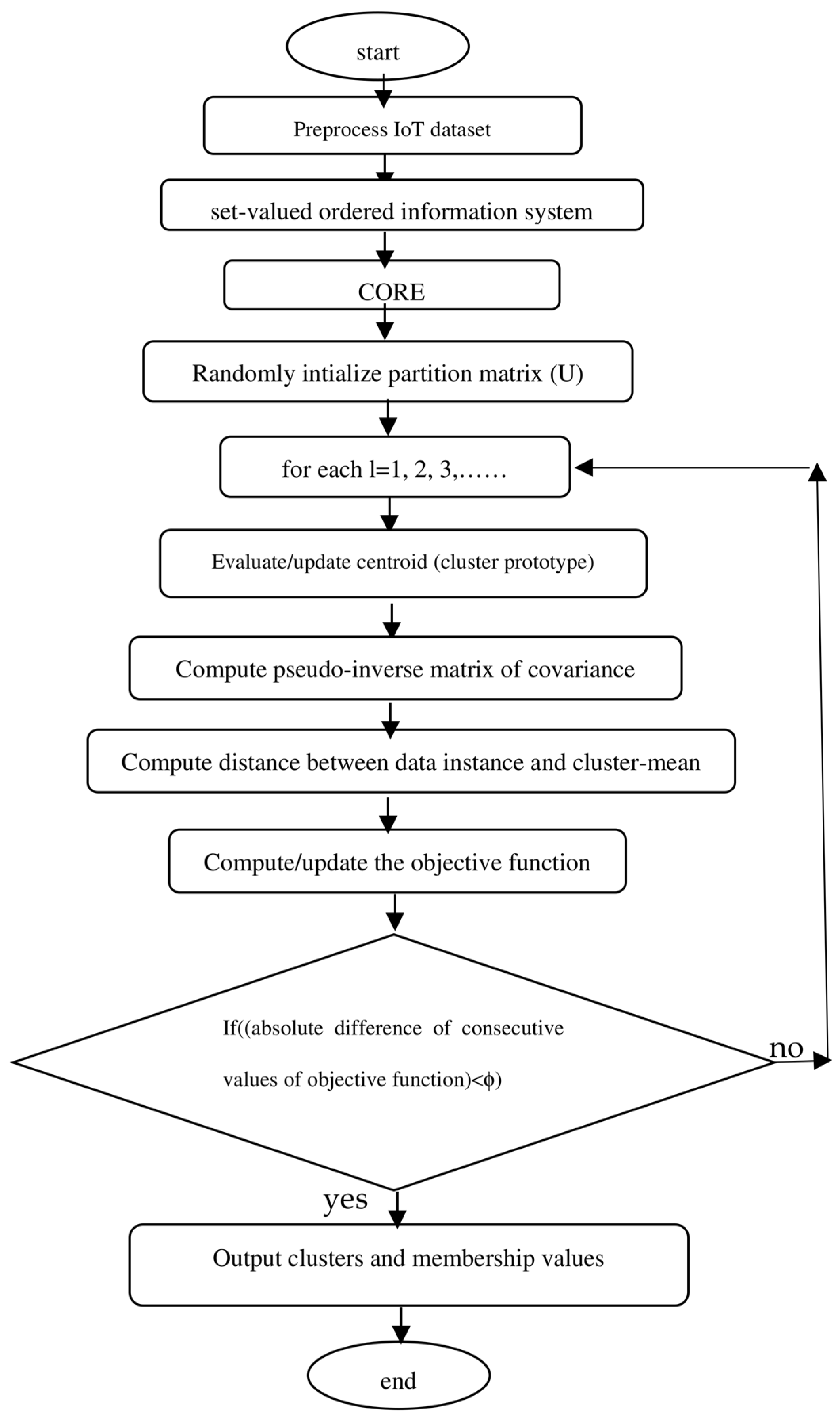
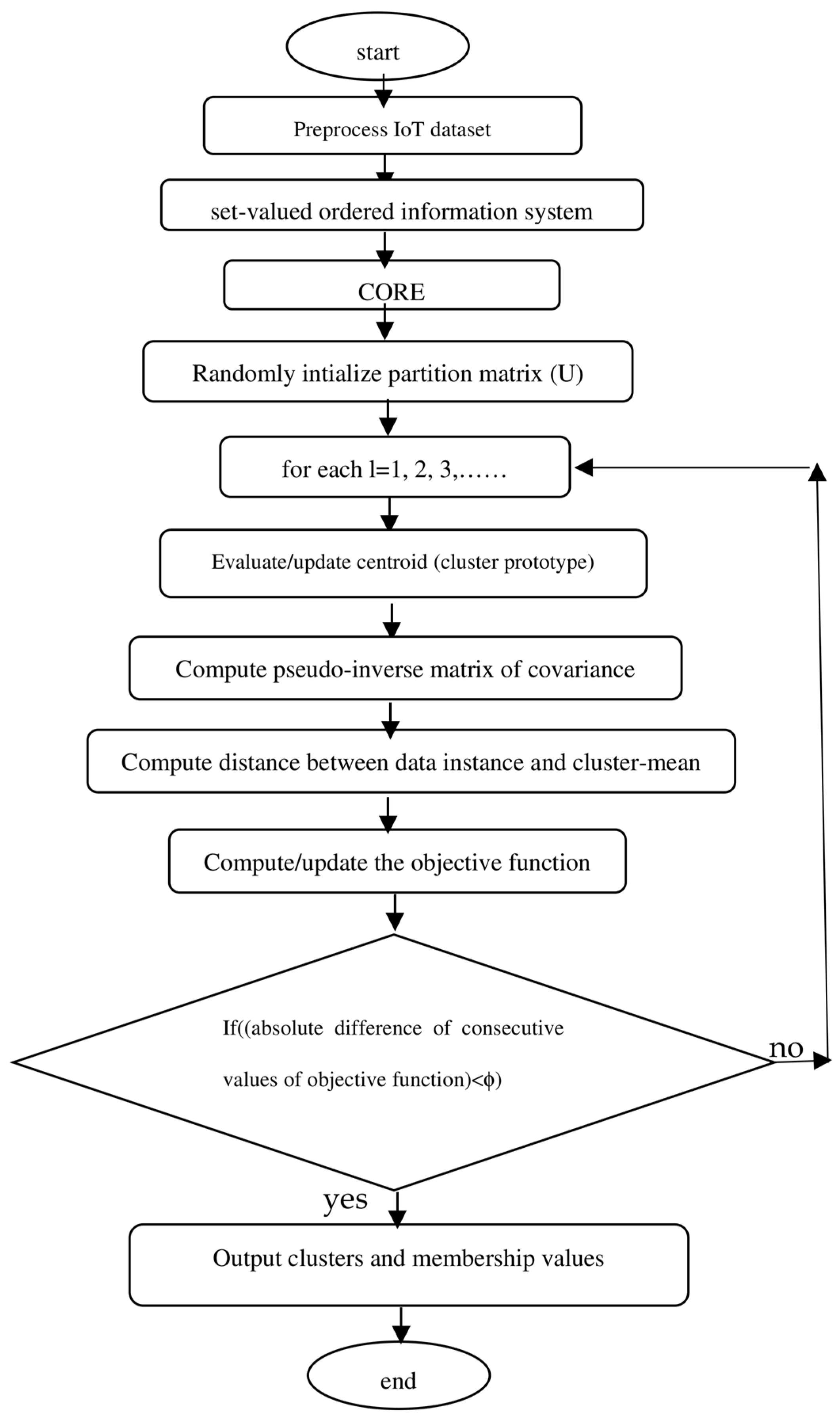
3.5. Mahalanobis Distance-Based Fuzzy C-Means algorithm (M-FCM) [47]
| Algorithm 5: (M-FCM) |
| Given dataset X, choose the number of cluster c, (2 < c < N), weighting exponent m ∈ [0, ∝), iteration stop threshold ϕ > 0. Initialize randomly partition matrix (membership matrix) U subject to the constraint (24), iteration counter l = 1. step 1 Evaluate or update cluster-centroid vi; i = 1, 2,…, c. step 2 Evaluate pseudo-inverse matrix of covariance Step 3 Evaluate using (25) Step 4 Evaluate the value of the objective function (J) using (23) Step 5 Set l = l + 1 to update objective function J Step 6 If the value of the objective function obtained in step 3 satisfies , stop Output cluster set and membership matrix Step 7 Else go to step 1 |
3.6. Common Mahalanobis Distance-Based Fuzzy C-Means algorithm (CM-FCM) [47]
| Algorithm 6: (CM-FCM) |
| Given dataset X, choose the number of cluster c, (2 < c < N), weighting exponent m ∈ [0, ∝), iteration stop threshold ϕ > 0. Initialize randomly partition matrix (membership matrix) U subject to the constraint (27), iteration counter l = 1. step 1 Evaluate or update cluster-centroid vi; i = 1, 2,…, c. step 2 Evaluate pseudo-inverse matrix of covariance Step 3 Evaluate using (28) step 3 Evaluate the value of the objective function (J) using (26) step 4 Set l = l+1 to update objective function J Step 5 If the value of the objective function obtained in step 3 satisfies , stop Output cluster set and membership matrix Step 6 Else go to step 1 |
4. Complexity Analysis
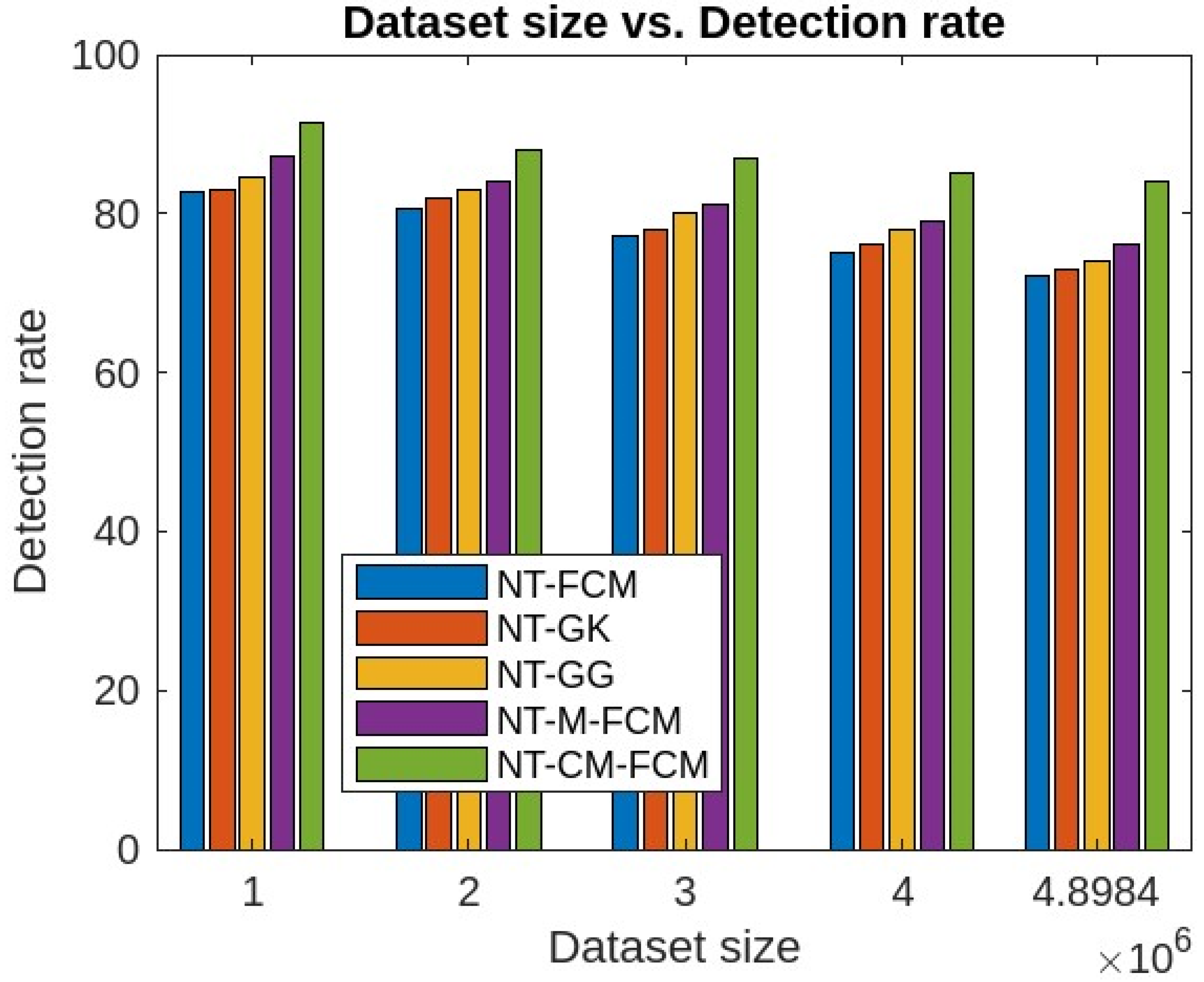
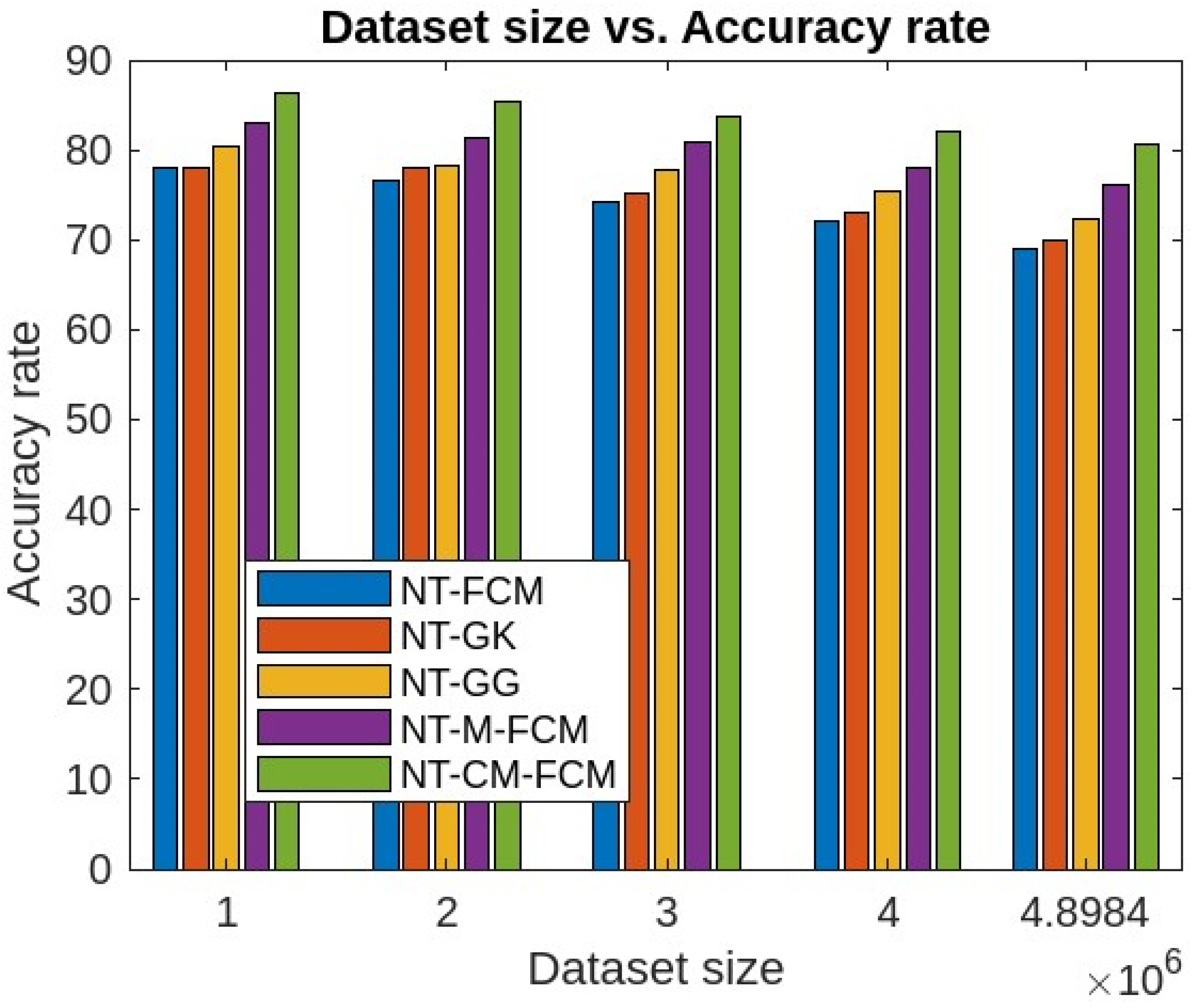
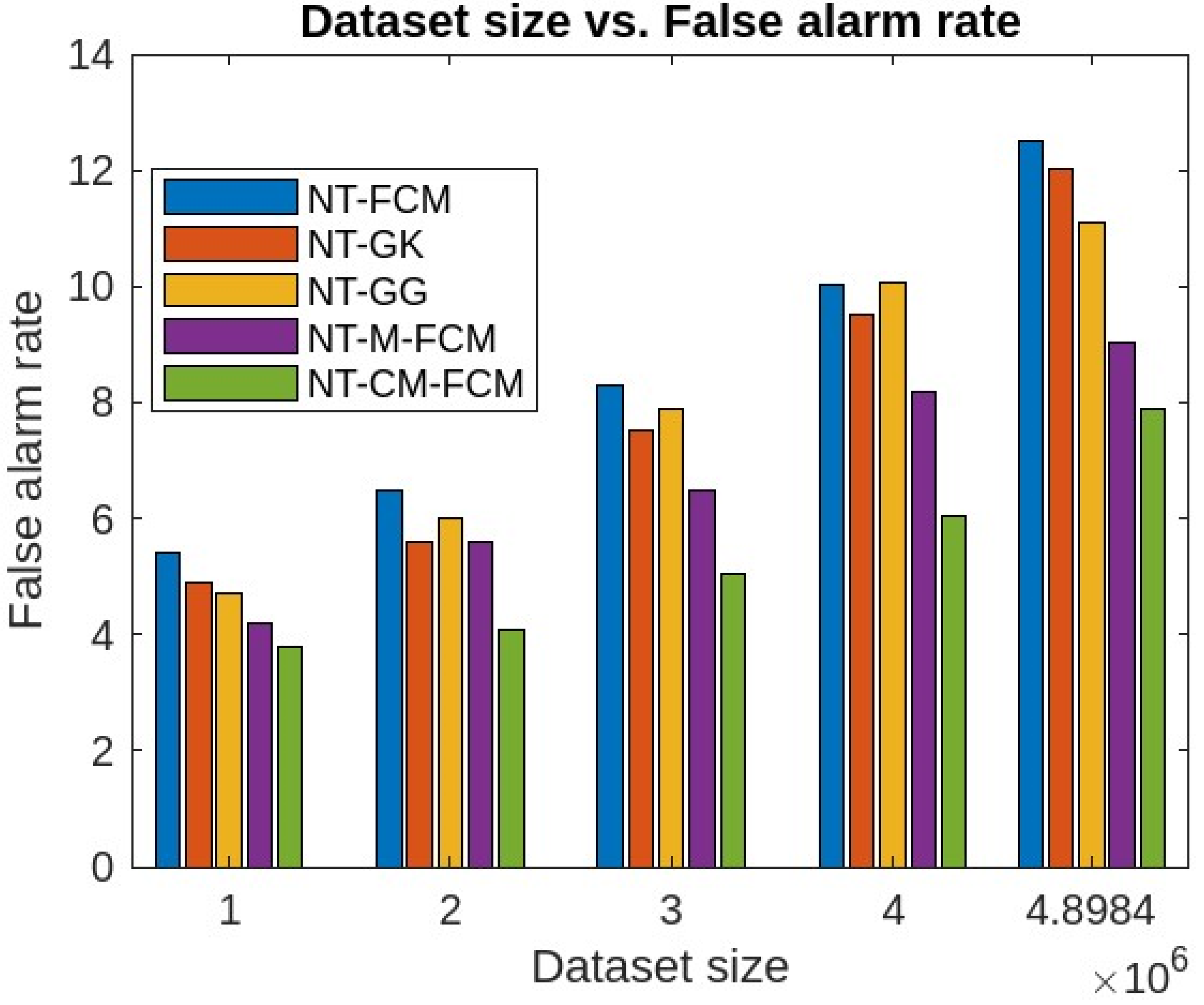
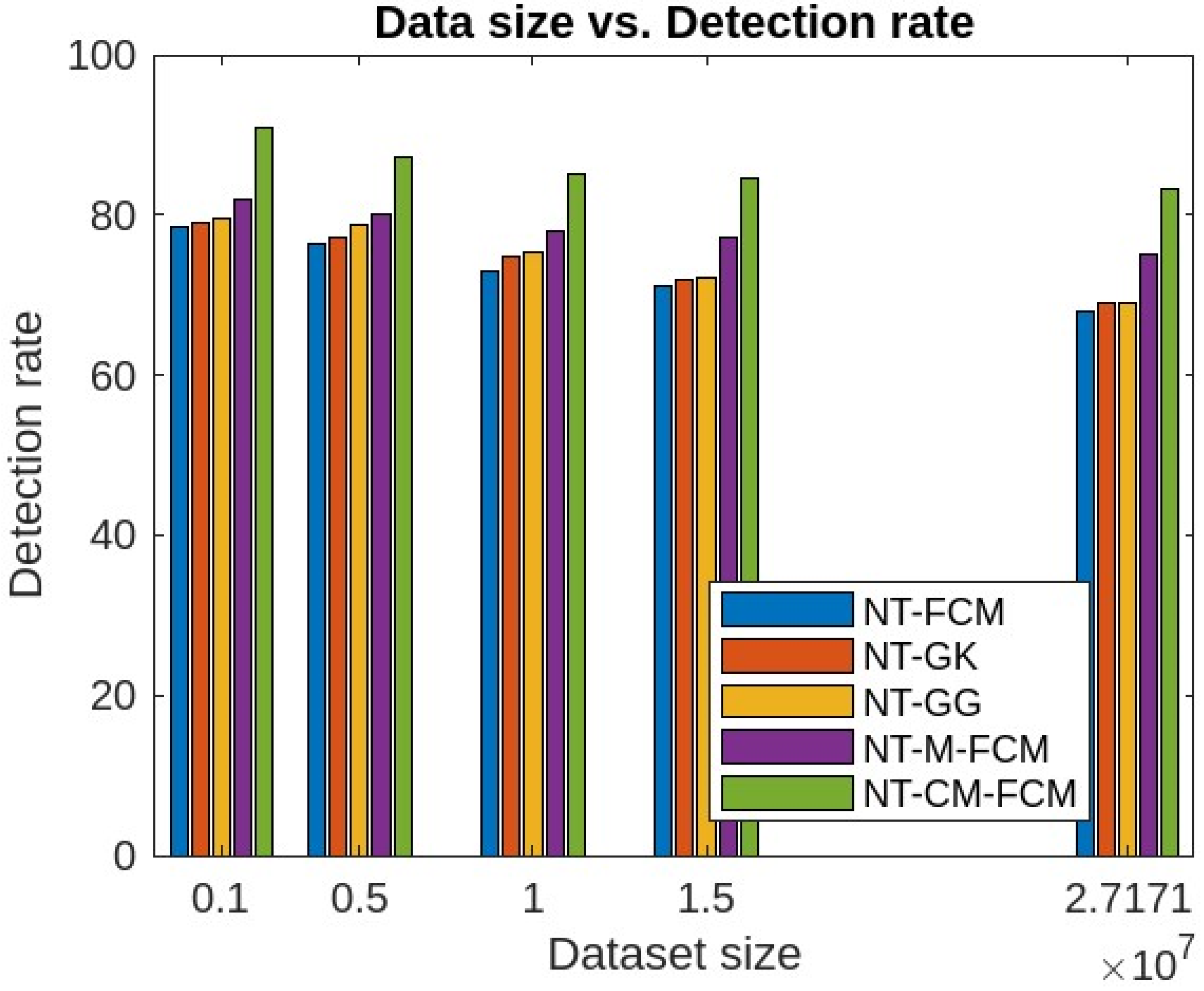
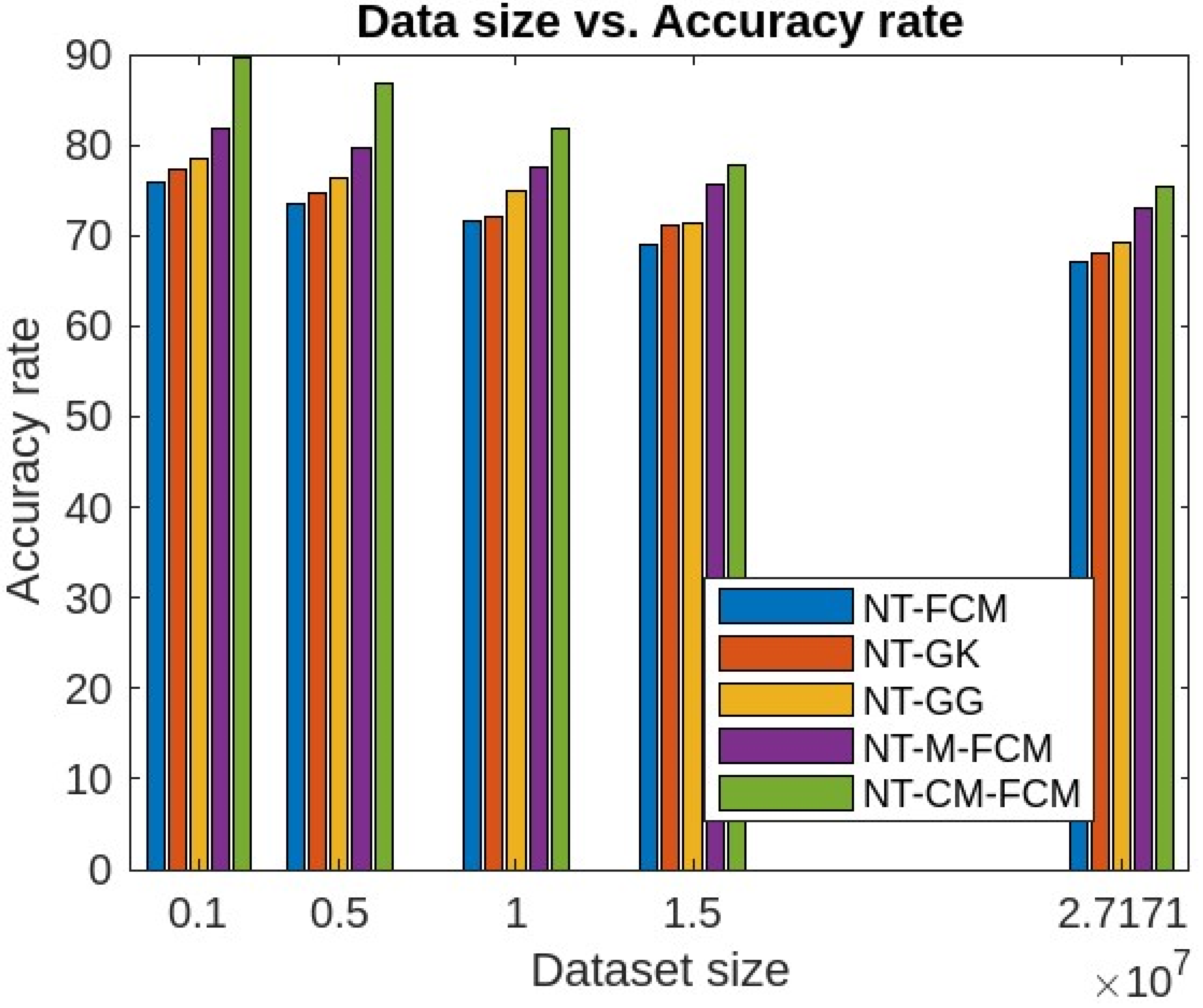
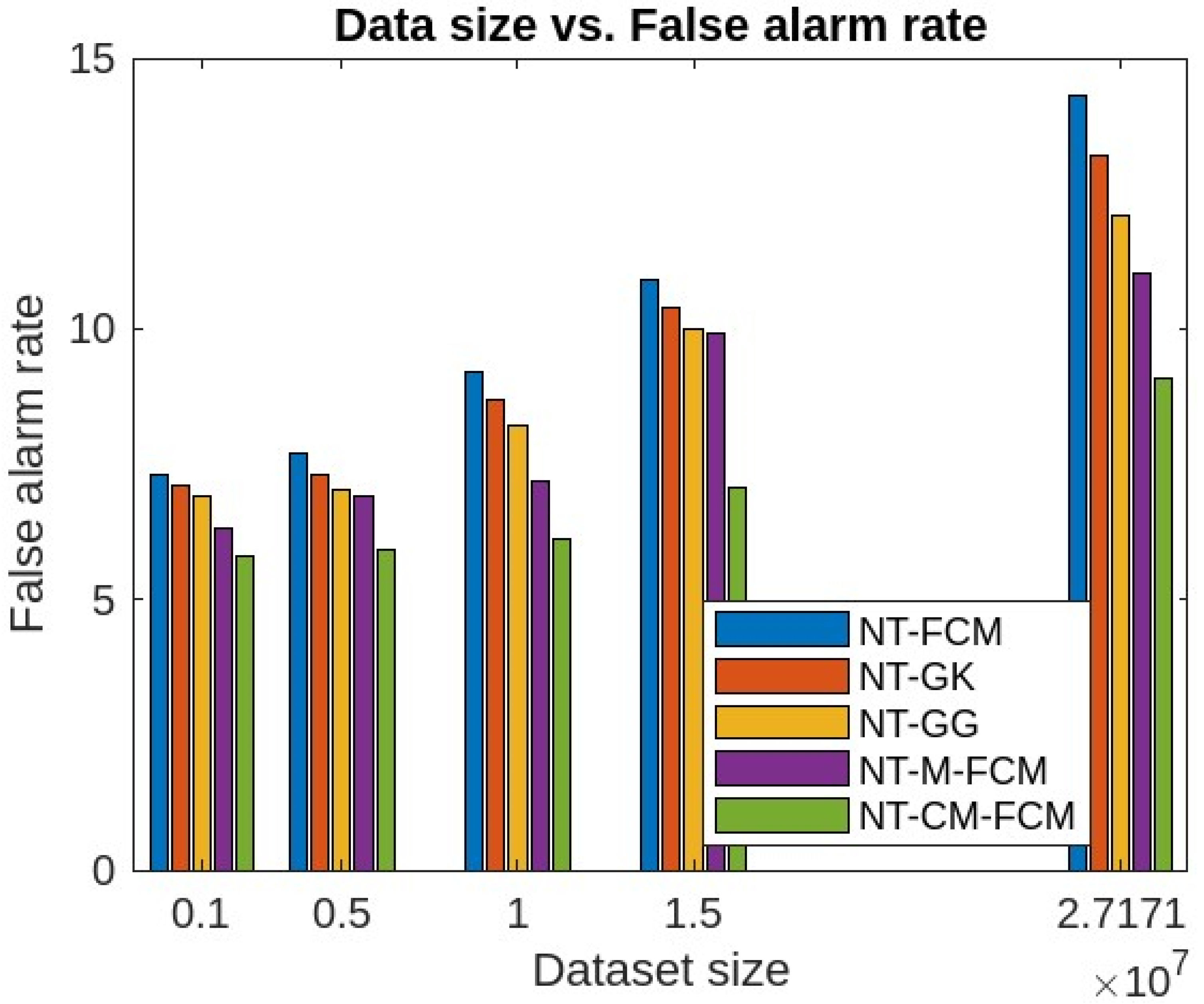
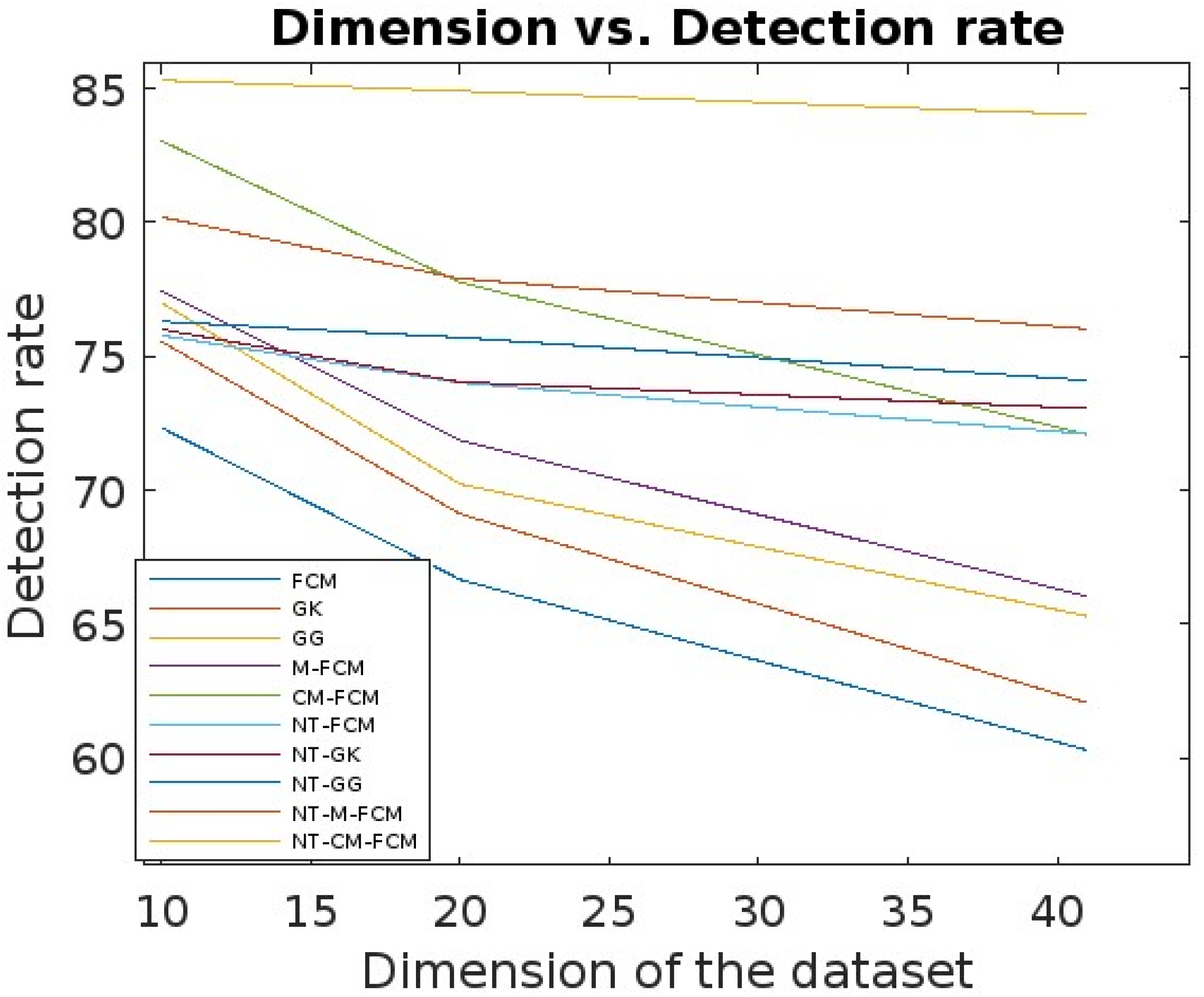
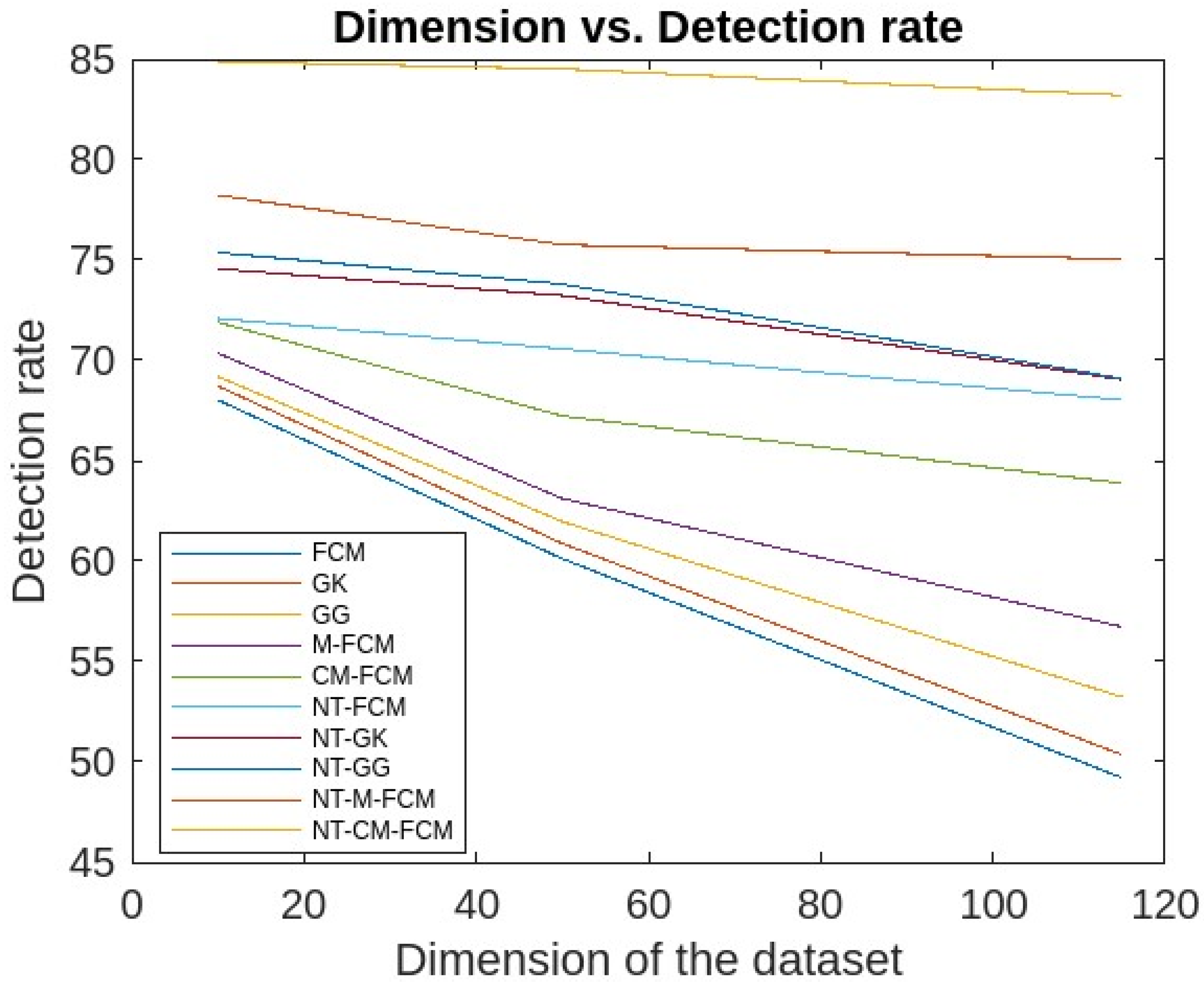
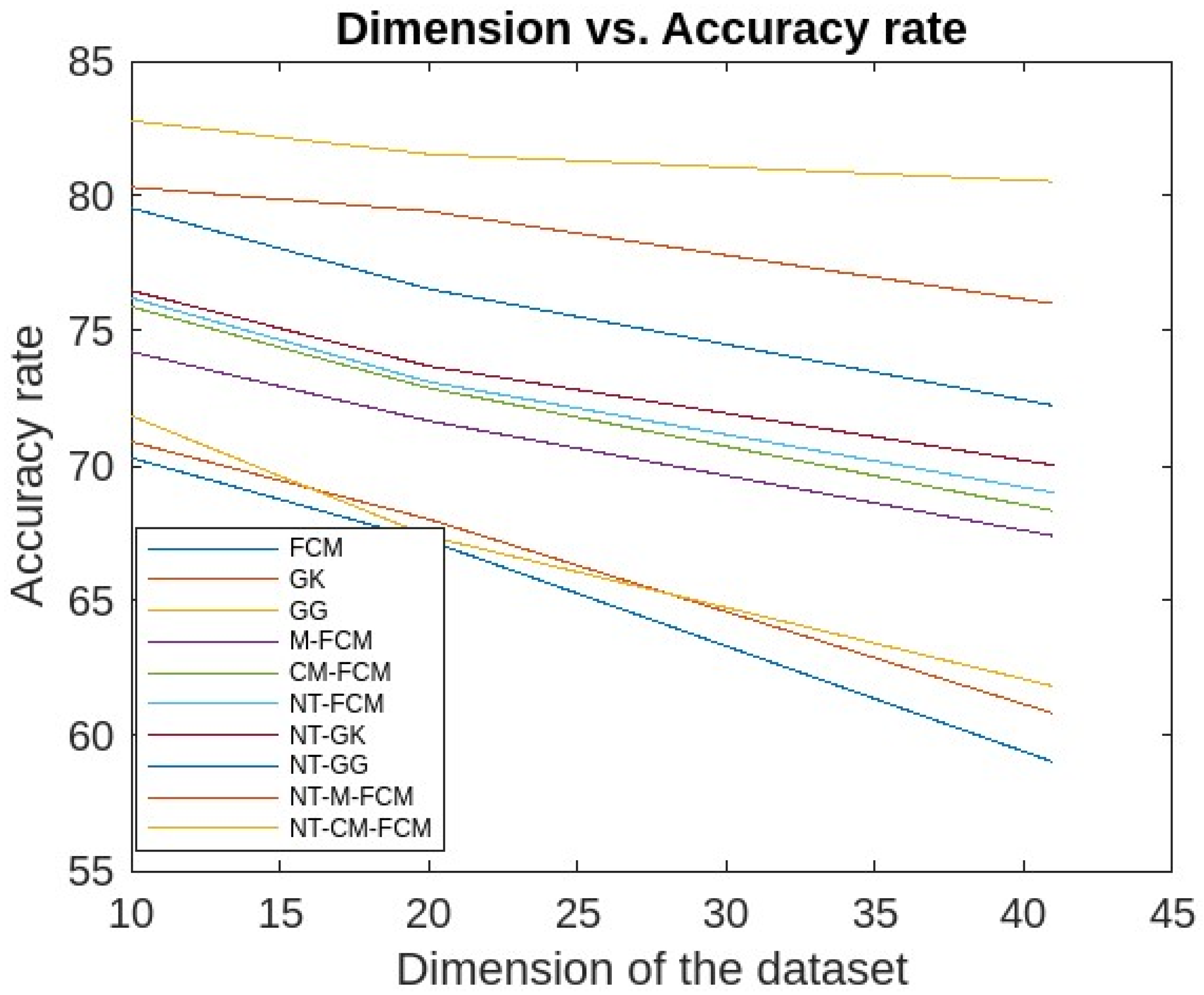
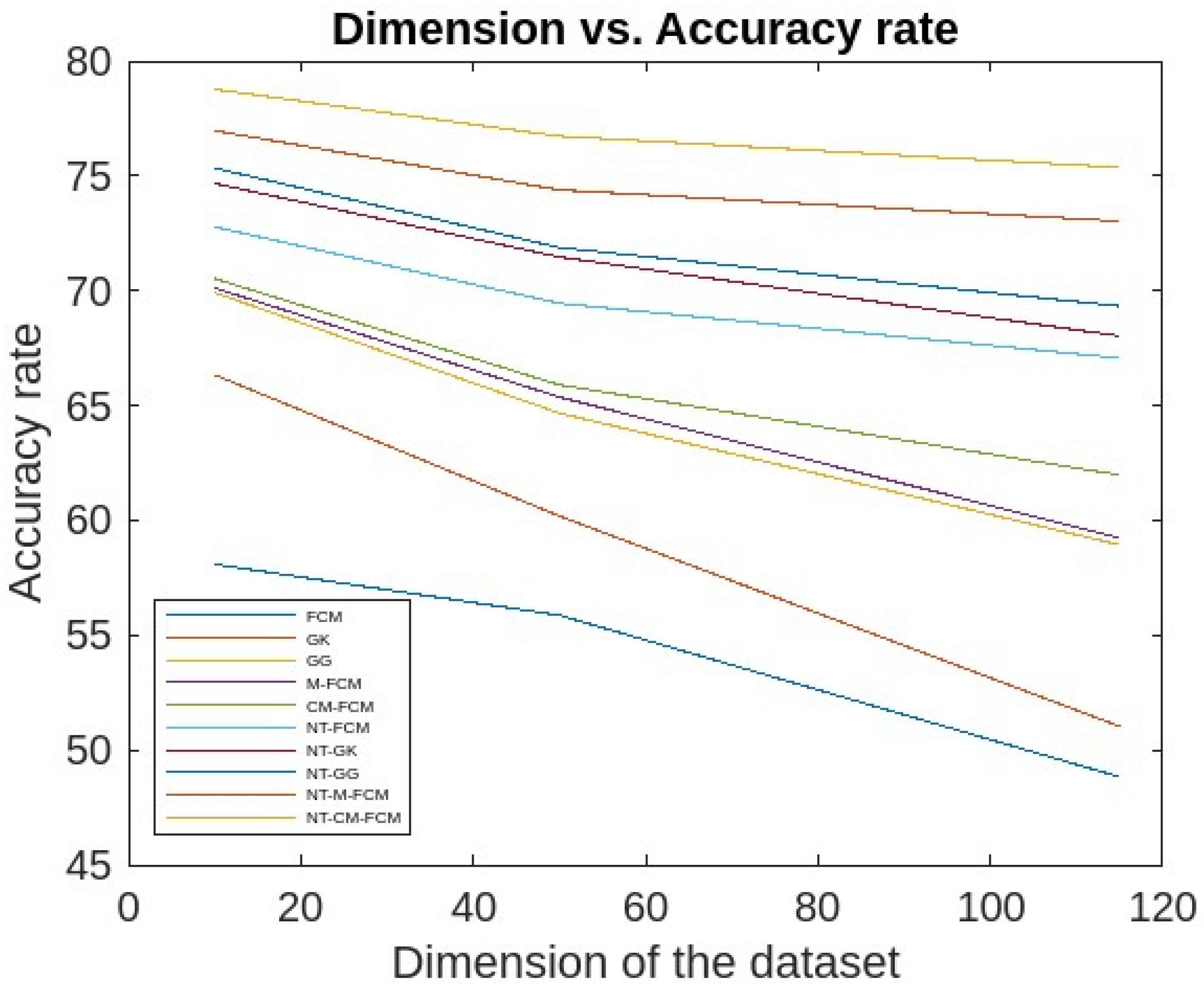
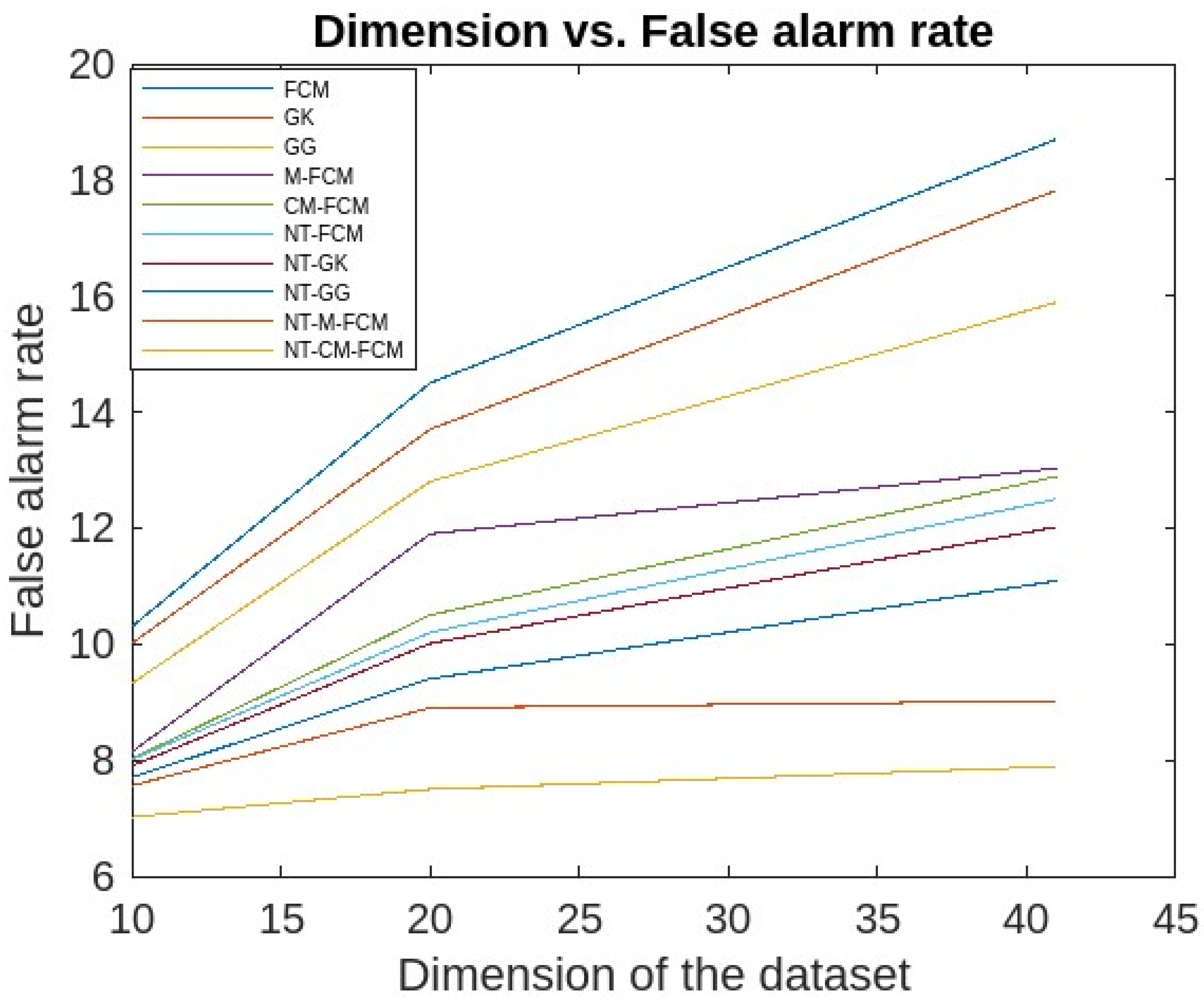
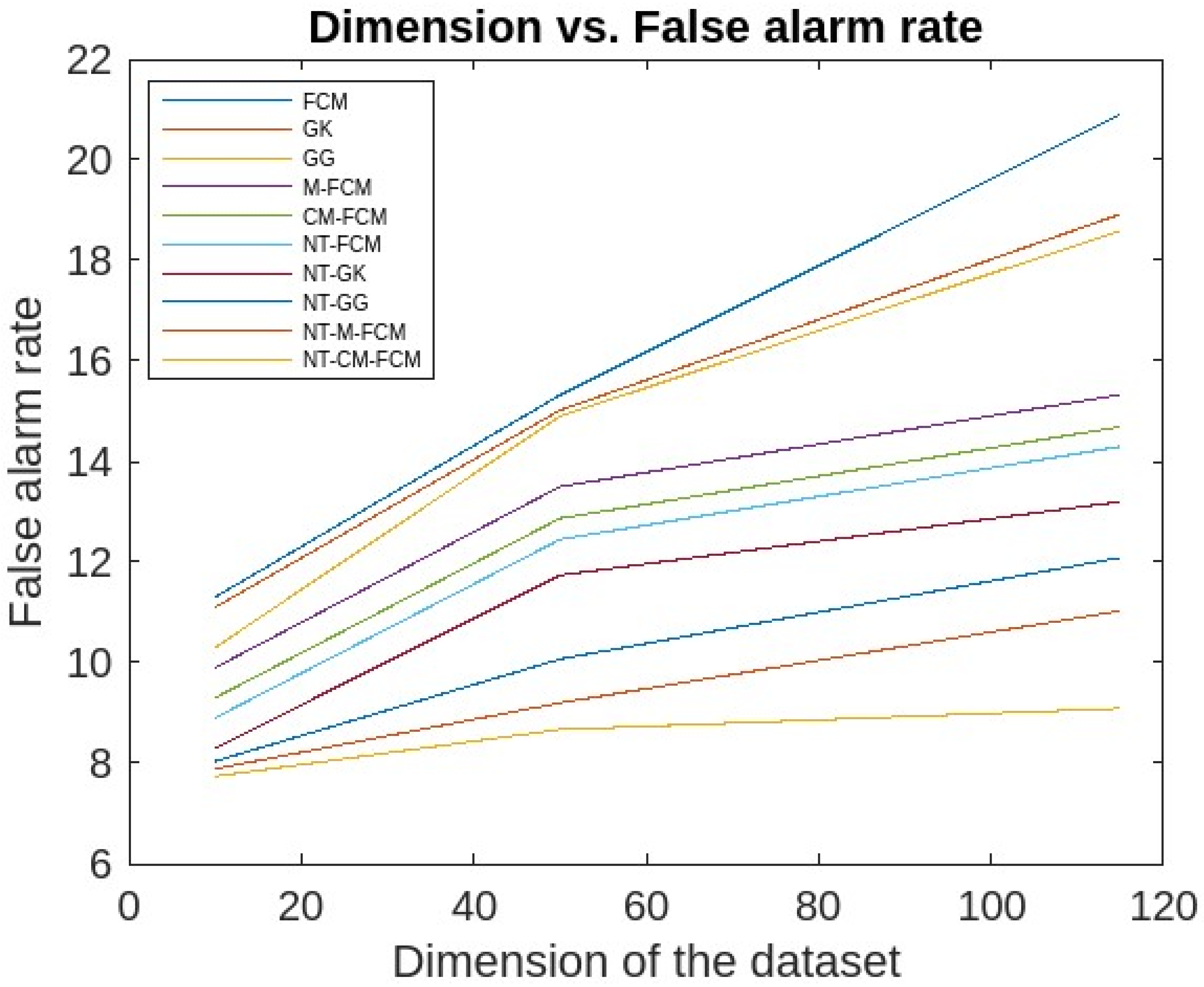
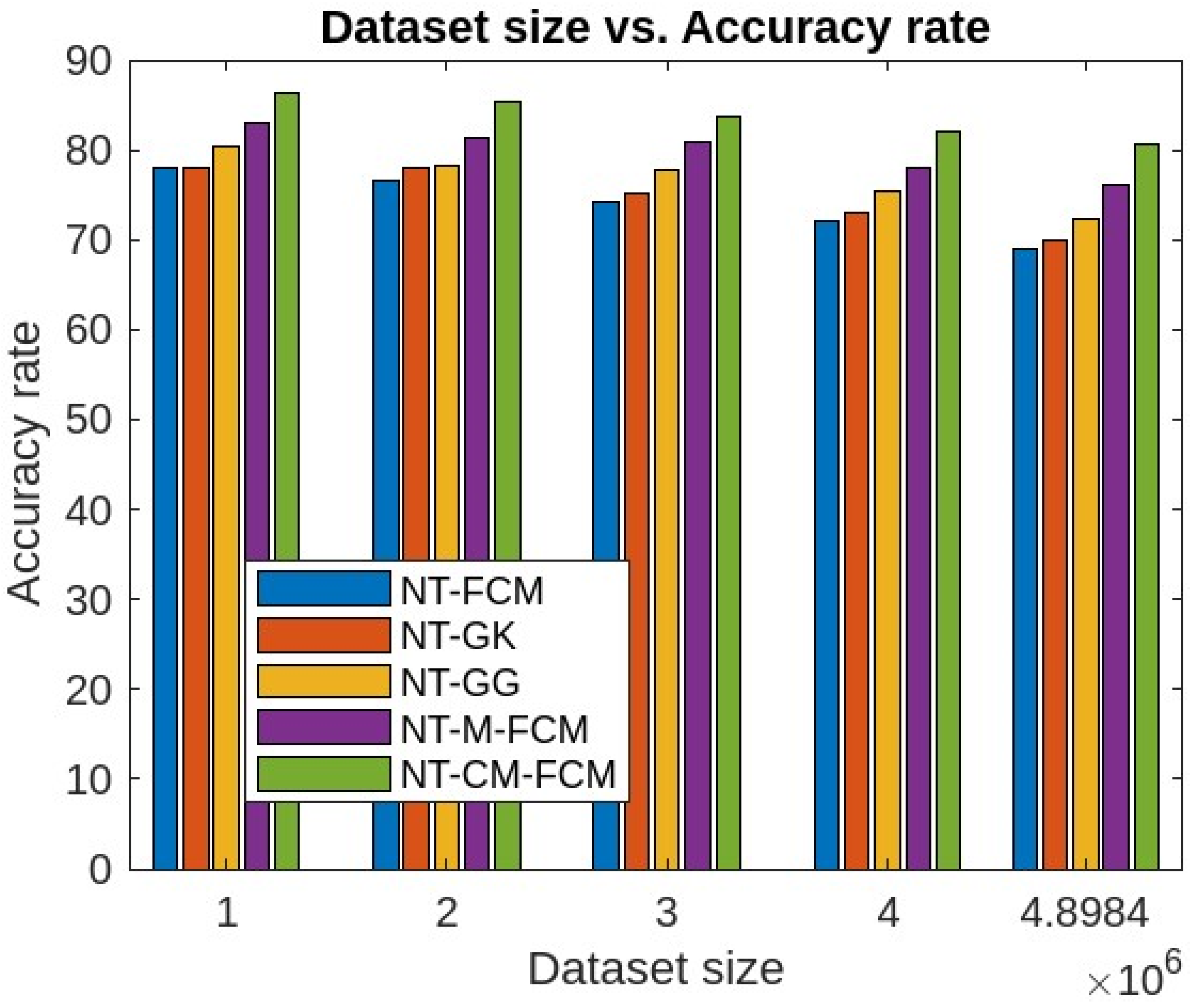
5. Experimental Analysis, Results and Discussions
5.1. Experimental Analysis and Results
5.2. Discussions
6. Conclusions, Limitations, and Lines for Future Works
6.1. Conclusions
6.2. Limitations and Lines for Future Works
- In the future, the time attribute can be addressed separately to find fuzzy clusters along with lifetimes which may provide detailed insights of the IoT system.
- In the future, detecting anomalies from high-dimensional data may be accomplished with an effective supervised approach.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sethi, P.; Sarangi, S. Internet of things: Architectures, protocols, and applications. J. Electr. Comput. Eng. 2017, 2017, 9324035. [Google Scholar] [CrossRef]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recogn. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Hodge, V.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef]
- Hartigan, J.A. Clustering Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 1975. [Google Scholar]
- Aggarwal, C.C.; Philip, S.Y. An effective and efficient algorithm for high-dimensional outlier detection. VLDB J. 2005, 14, 211–221. [Google Scholar] [CrossRef]
- Ramchandran, A.; Sangaiah, A.K. Chapter 11—Unsupervised Anomaly Detection for High Dimensional Data—An Exploratory Analysis, Computational Intelligence for Multimedia Big Data on the Cloud with Engineering Applications. In Intelligent Data-Centric Systems; Academic Press: Cambridge, MA, USA, 2018; pp. 233–251. [Google Scholar]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Mazarbhuiya, F.A. Detecting Anomaly using Neighborhood Rough Set based Classification Approach. ICIC Express Lett. 2023, 17, 73–80. [Google Scholar]
- Thivagar, M.L.; Richard, C. On nano forms of weakly open sets. Int. J. Math. Stat. Invent. 2013, 1, 31–37. [Google Scholar]
- Thivagar, M.L.; Priyalatha, S.P.R. Medical diagnosis in an indiscernibility matrix based on nano topology. Cogent Math. 2017, 4, 1330180. [Google Scholar] [CrossRef]
- Mung, G.; Li, S.; Carle, G. Traffic Anomaly Detection Using k-Means Clustering; Allen Institute for Artificial Intelligence: Seattle, WA, USA, 2007. [Google Scholar]
- Ren, W.; Cao, J.; Wu, X. Application of network intrusion detection based on fuzzy c-means clustering algorithm. In Proceedings of the 3rd International Symposium on Intelligent Information Technology Application, Nanchang, China, 21–22 November 2009; pp. 19–22. [Google Scholar]
- Mazarbhuiya, F.A.; AlZahrani, M.Y.; Georgieva, L. Anomaly detection using agglomerative hierarchical clustering algorithm. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2018. [Google Scholar] [CrossRef]
- Mazarbhuiya, F.A.; AlZahrani, M.Y.; Mahanta, A.K. Detecting Anomaly Using Partitioning Clustering with Merging. ICIC Express Lett. 2020, 14, 951–960. [Google Scholar]
- Retting, L.; Khayati, M.; Cudre-Mauroux, P.; Piorkowski, M. Online anomaly detection over Big Data streams. In Proceedings of the 2015 IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015. [Google Scholar]
- The, H.Y.; Wang, K.I.; Kempa-Liehr, A.W. Expect the unexpected: Un-supervised feature selection for automated sensor anomaly detection. IEEE Sens. J. 2021, 21, 18033–18046. [Google Scholar] [CrossRef]
- Alguliyev, R.; Aliguliyev, R.; Sukhostat, L. Anomaly Detection in Big Data based on Clustering. Stat. Optim. Inf. Comput. 2017, 5, 325–340. [Google Scholar] [CrossRef]
- Hahsler, M.; Piekenbrock, M.; Doran, D. dbscan: Fast Density-based clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef]
- Song, H.; Jiang, Z.; Men, A.; Yang, B. A Hybrid Semi-Supervised Anomaly Detection Model for High Dimensional data. Comput. Intell. Neurosci. 2017, 2017, 8501683. [Google Scholar] [CrossRef] [PubMed]
- Mazarbhuiya, F.A. Detecting IoT Anomaly Using Rough Set and Density Based Subspace Clustering. ICIC Express Lett. 2023, 17, 1395–1403. [Google Scholar] [CrossRef]
- Alghawli, A.S. Complex methods detect anomalies in real time based on time series analysis. Alex. Eng. J. 2022, 61, 549–561. [Google Scholar] [CrossRef]
- Younas, M.Z. Anomaly Detection using Data Mining Techniques: A Review. Int. J. Res. Appl. Sci. Eng. Technol. 2020, 8, 568–574. [Google Scholar] [CrossRef]
- Thudumu, S.; Branch, P.; Jin, J.; Singh, J. A comprehensive survey of anomaly detection techniques for high dimensional big data. J. Big Data 2020, 7, 42. [Google Scholar] [CrossRef]
- Habeeb, R.A.A.; Nasauddin, F.; Gani, A.; Hashem, I.A.T.; Ahmed, E.; Imran, M. Real-time big data processing for anomaly detection: A Survey. Int. J. Inf. Manag. 2019, 45, 289–307. [Google Scholar] [CrossRef]
- Wang, B.; Hua, Q.; Zhang, H.; Tan, X.; Nan, Y.; Chen, R.; Shu, X. Research on anomaly detection and real-time reliability evaluation with the log of cloud platform. Alex. Eng. J. 2022, 61, 7183–7193. [Google Scholar] [CrossRef]
- Halstead, B.; Koh, Y.S.; Riddle, P.; Pechenizkiy, M.; Bifet, A. Combining Diverse Meta-Features to Accurately Identify Recurring Concept Drit in Data Streams. ACM Trans. Knowl. Discov. Data 2023, 17, 1–36. [Google Scholar] [CrossRef]
- Zhao, Z.; Birke, R.; Han, R.; Robu, B.; Bouchenak, S.; Ben Mokhtar, S.; Chen, L.Y. RAD: On-line Anomaly Detection for Highly Unreliable Data. arXiv 2019, arXiv:1911.04383. [Google Scholar]
- Chenaghlou, M.; Moshtaghi, M.; Lekhie, C.; Salahi, M. Online Clustering for Evolving Data Streams with Online Anomaly Detection. Advances in Knowledge Discovery and Data Mining. In Proceedings of the 22nd Pacific-Asia Conference, PAKDD 2018, Melbourne, VIC, Australia, 3–6 June 2018; pp. 508–521. [Google Scholar]
- Firoozjaei, M.D.; Mahmoudyar, N.; Baseri, Y.; Ghorbani, A.A. An evaluation framework for industrial control system cyber incidents. Int. J. Crit. Infrastruct. Prot. 2022, 36, 100487. [Google Scholar] [CrossRef]
- Chen, Q.; Zhou, M.; Cai, Z.; Su, S. Compliance Checking Based Detection of Insider Threat in Industrial Control System of Power Utilities. In Proceedings of the 2022 7th Asia Conference on Power and Electrical Engineering (ACPEE), Hangzhou, China, 15–17 April 2022; pp. 1142–1147. [Google Scholar]
- Zhao, Z.; Mehrotra, K.G.; Mohan, C.K. Online Anomaly Detection Using Random Forest. In Recent Trends and Future Technology in Applied Intelligence; Mouhoub, M., Sadaoui, S., Ait Mohamed, O., Ali, M., Eds.; IEA/AIE 2018; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Izakian, H.; Pedrycz, W. Anomaly detection in time series data using fuzzy c-means clustering. In Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting, Edmonton, AB, Canada, 24–28 June 2013. [Google Scholar]
- Decker, L.; Leite, D.; Giommi, L.; Bonakorsi, D. Real-time anomaly detection in data centers for log-based predictive maintenance using fuzzy-rule based approach. arXiv 2020, arXiv:2004.13527v1. Available online: https://arxiv.org/pdf/2004.13527.pdf (accessed on 15 March 2022).
- Masdari, M.; Khezri, H. Towards fuzzy anomaly detection-based security: A comprehensive review. Fuzzy Optim. Decis. Mak. 2020, 20, 1–49. [Google Scholar] [CrossRef]
- de Campos Souza, P.V.; Guimarães, A.J.; Rezende, T.S.; Silva Araujo, V.J.; Araujo, V.S. Detection of Anomalies in Large-Scale Cyberattacks Using Fuzzy Neural Networks. AI 2020, 1, 92–116. [Google Scholar] [CrossRef]
- Talagala, P.D.; Rob, J. Hyndman, and Kate Smith-Miles, Anomaly Detection in High-Dimensional Data. J. Comput. Graph. Stat. 2021, 30, 360–374. [Google Scholar] [CrossRef]
- Al Samara, M.; Bennis, I.; Abouaissa, A.; Lorenz, P. A Survey of Outlier Detection Techniques in IoT: Review and Classification. J. Sens. Actuator Netw. 2022, 11, 4. [Google Scholar] [CrossRef]
- Yugandhar, A.; Sashirekha, S.K. Dimensional Reduction of Data for Anomaly Detection and Speed Performance using PCA and DBSCAN. Int. J. Eng. Adv. Technol. 2019, 9, 39–41. [Google Scholar]
- Mazarbhuiya, F.A.; Shenify, M. A Mixed Clustering Approach for Real-Time Anomaly Detection. Appl. Sci. 2023, 13, 4151. [Google Scholar] [CrossRef]
- Mazarbhuiya, F.A.; Shenify, M. Real-time Anomaly Detection with Subspace Periodic Clustering Approach. Appl. Sci. 2023, 13, 7382. [Google Scholar] [CrossRef]
- Harish, B.S.; Kumar, S.V.A. Anomaly based Intrusion Detection using Modified Fuzzy Clustering. Int. J. Interact. Multimed. Artif. Intell. 2017, 4, 54–59. [Google Scholar] [CrossRef]
- Gustafson, D.E.; Kessel, W. Fuzzy clustering with a fuzzy covariance matrix. In Proceedings of the IEEE Conference on Decision and Control including the 17th Symposium on Adaptive Processes, San Diego, CA, USA, 10–12 January 1979; pp. 761–766. [Google Scholar] [CrossRef]
- Haldar, N.A.H.; Khan, F.A.; Ali, A.; Abbas, H. Arrhythmia classification using Mahalanobis distance-based improved Fuzzy C-Means clustering for mobile health monitoring systems. Neurocomputing 2017, 220, 221–235. [Google Scholar] [CrossRef]
- Zhao, X.M.; Li, Y.; Zhao, Q.H. Mahalanobis distance based on fuzzy clustering algorithm for image segmentation. Digit. Signal Process. 2015, 43, 8–16. [Google Scholar] [CrossRef]
- Ghorbani, H. Mahalanobis Distance and Its Application for Detecting Multivariate Outliers, Facta Universitatis (NIS). Ser. Math. Inform. 2019, 34, 583–595. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. On the generalized distance in statistics. Proc. Natl. Inst. Sci. 1936, 2, 49–55. [Google Scholar]
- Yih, J.-M.; Lin, Y.-H. Normalized clustering algorithm based on Mahalanobis distance. Int. J. Tech. Res. Appl. 2014, 2, 48–52. [Google Scholar]
- Wang, L.; Wang, J.; Ren, Y.; Xing, Z.; Li, T.; Xia, J. A Shadowed Rough-fuzzy Clustering Algorithm Based on Mahalanobis Distance for Intrusion Detection. In Intelligent Automation & Soft Computing; Tech Science Press: Henderson, NV, USA, 2021; pp. 1–12. [Google Scholar] [CrossRef]
- Qiana, Y.; Dang, C.; Lianga, J.; Tangc, D. Set-valued ordered information systems. Inf. Sci. 2009, 179, 2809–2832. [Google Scholar] [CrossRef]
- KDD Cup’99 Data. Available online: https://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 15 January 2020).
- Kitsune Network Attack Dataset. Available online: https://github.com/ymirsky/Kitsune-py (accessed on 12 December 2021).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
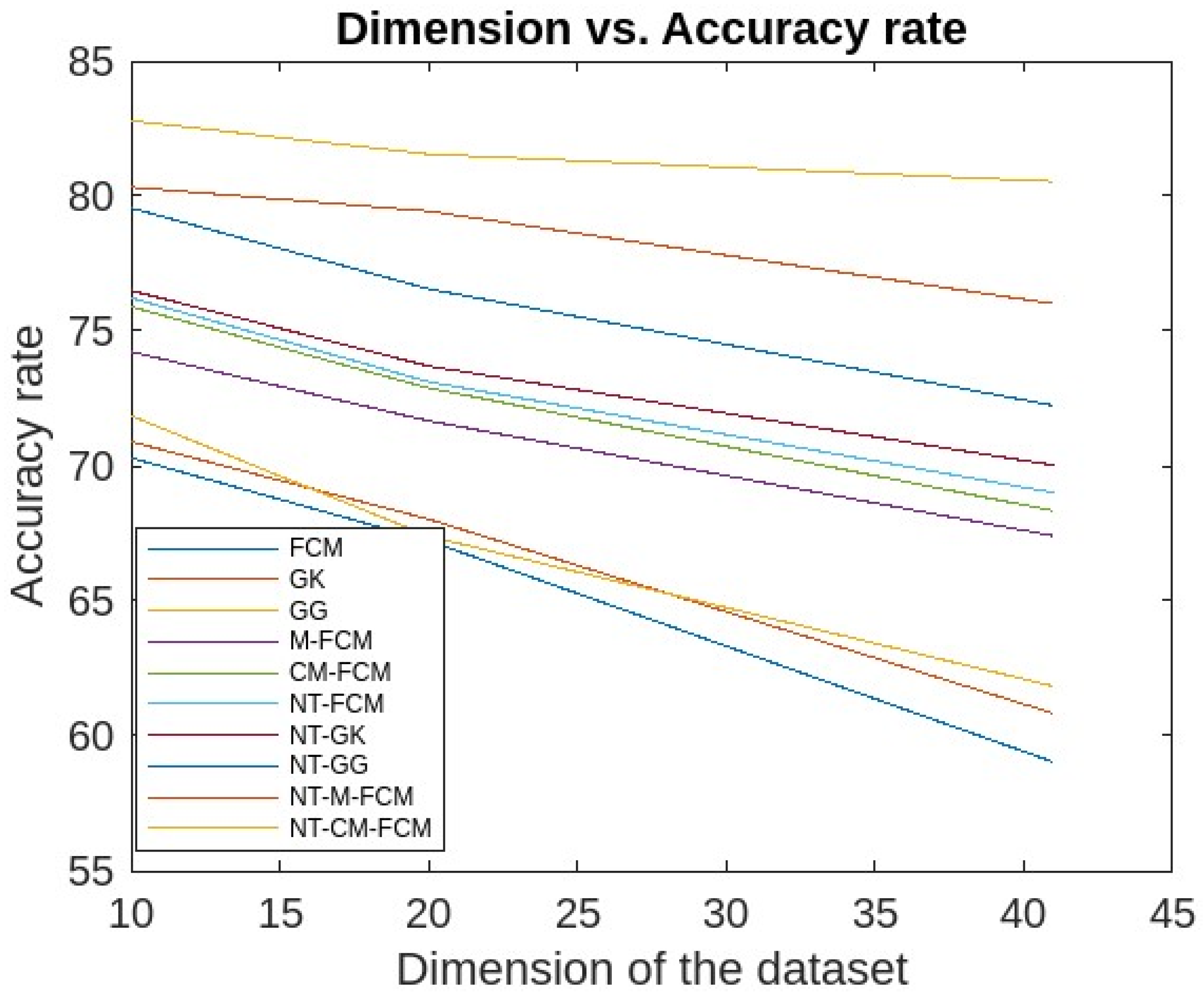
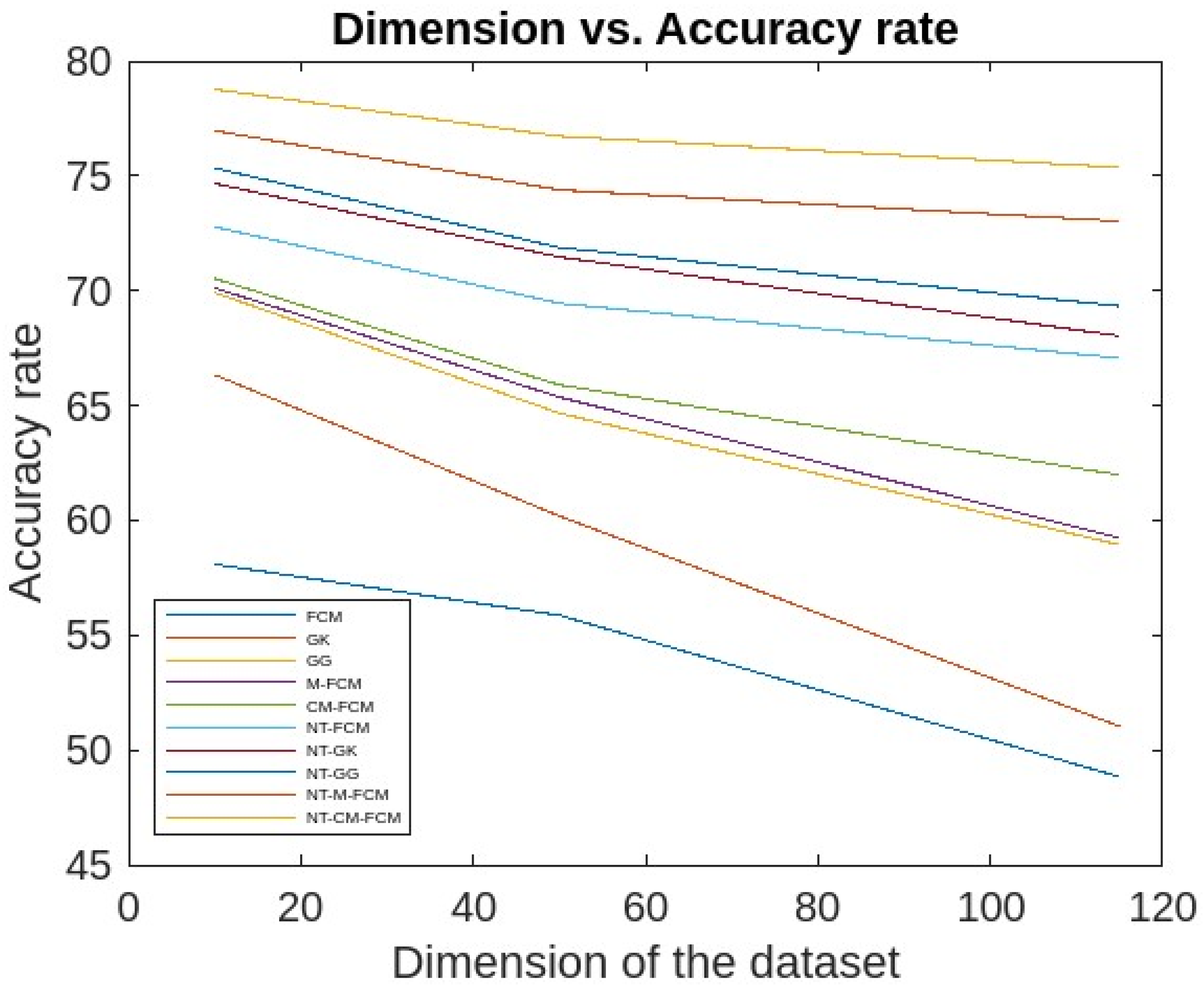
| Dataset | Dataset Characteristics | Attribute Characteristics | No. of Instances | No. of Attributes |
|---|---|---|---|---|
| KDDCup’99 [50] | Synthetic, Multivariate | Numeric, categorical, and temporal | 4,898,431 | 41 |
| Kitsune Network Attack [51] | Real-life, Multivariate, sequential, time-series | Real, temporal | 27,170,754 | 115 |
| Performances of FCM, GK, GG, M-FCM, Using the Two Datasets | ||||||
|---|---|---|---|---|---|---|
| Datasets | FCM | GK | GG | M-FCM | CM-FCM | |
| KDDCup’99 | Detection rate | 60.3 | 62.06 | 65.3 | 66.03 | 72.08 |
| Accuracy rate | 59.03 | 60.83 | 61.84 | 67.41 | 68.34 | |
| False alarm rate | 18.7 | 17.82 | 15.89 | 13.03 | 12.89 | |
| Denial of service | 69.63 | 72.73 | 75.02 | 78.85 | 87.32 | |
| Remote to local | 68.87 | 73.02 | 73.99 | 76.82 | 81.21 | |
| User to root | 42.60 | 50.79 | 52.21 | 54.98 | 61.31 | |
| Probe | 51.47 | 56.35 | 53.98 | 57.88 | 61.13 | |
| Kitsune dataset | Detection rate | 49.21 | 50.36 | 53.23 | 56.73 | 63.88 |
| Accuracy rate | 48.83 | 51.03 | 58.94 | 59.23 | 61.98 | |
| False alarm rate | 20.9 | 18.92 | 18.59 | 15.33 | 14.69 | |
| Denial of service | 67.83 | 71.63 | 73.72 | 80.25 | 84.32 | |
| Remote to local | 66.7 | 71.42 | 71.89 | 73.92 | 80.31 | |
| User to root | 40.90 | 49.29 | 50.91 | 52.77 | 60.91 | |
| Probe | 50.07 | 54.95 | 54.87 | 56.78 | 60.34 | |
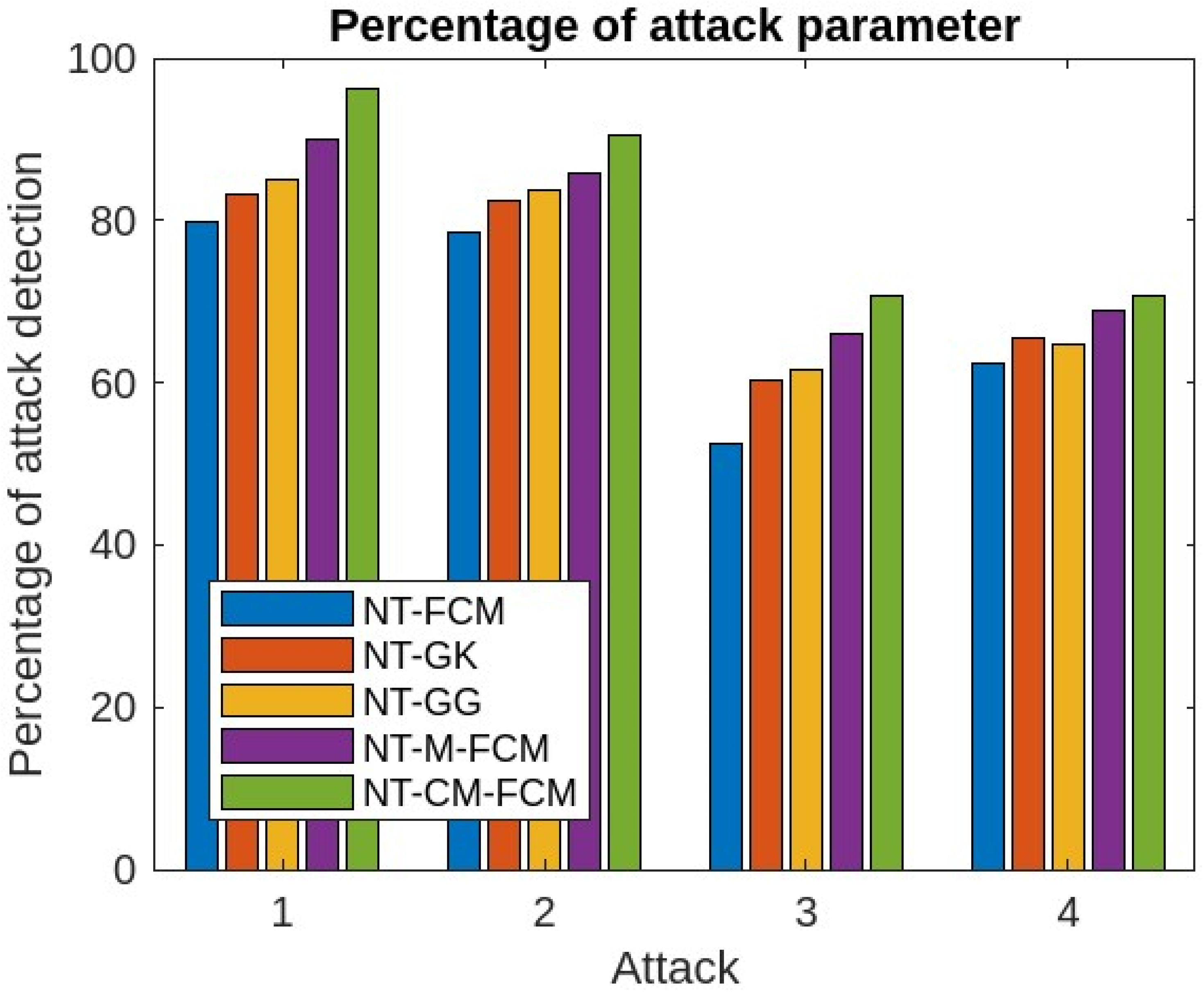
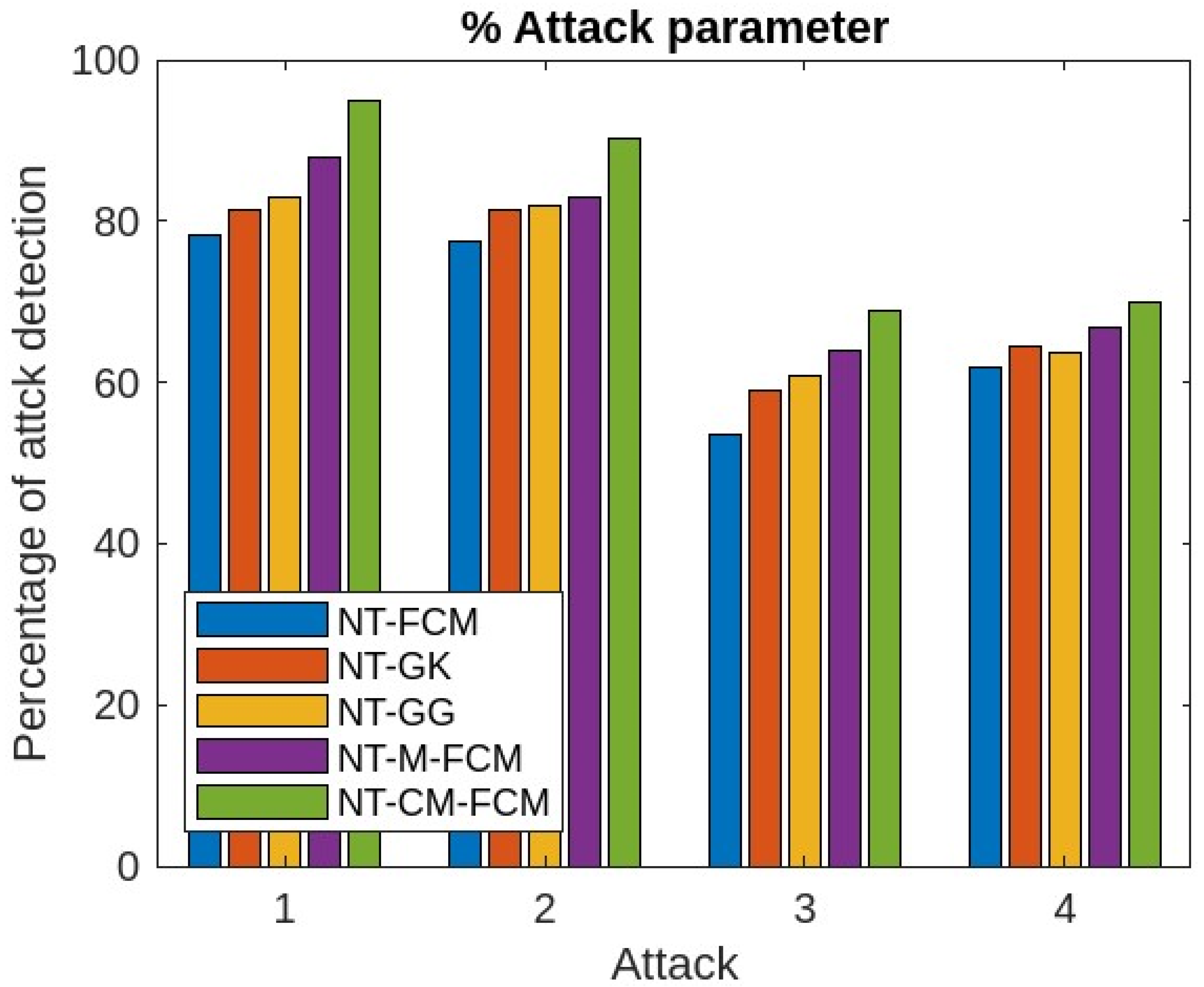
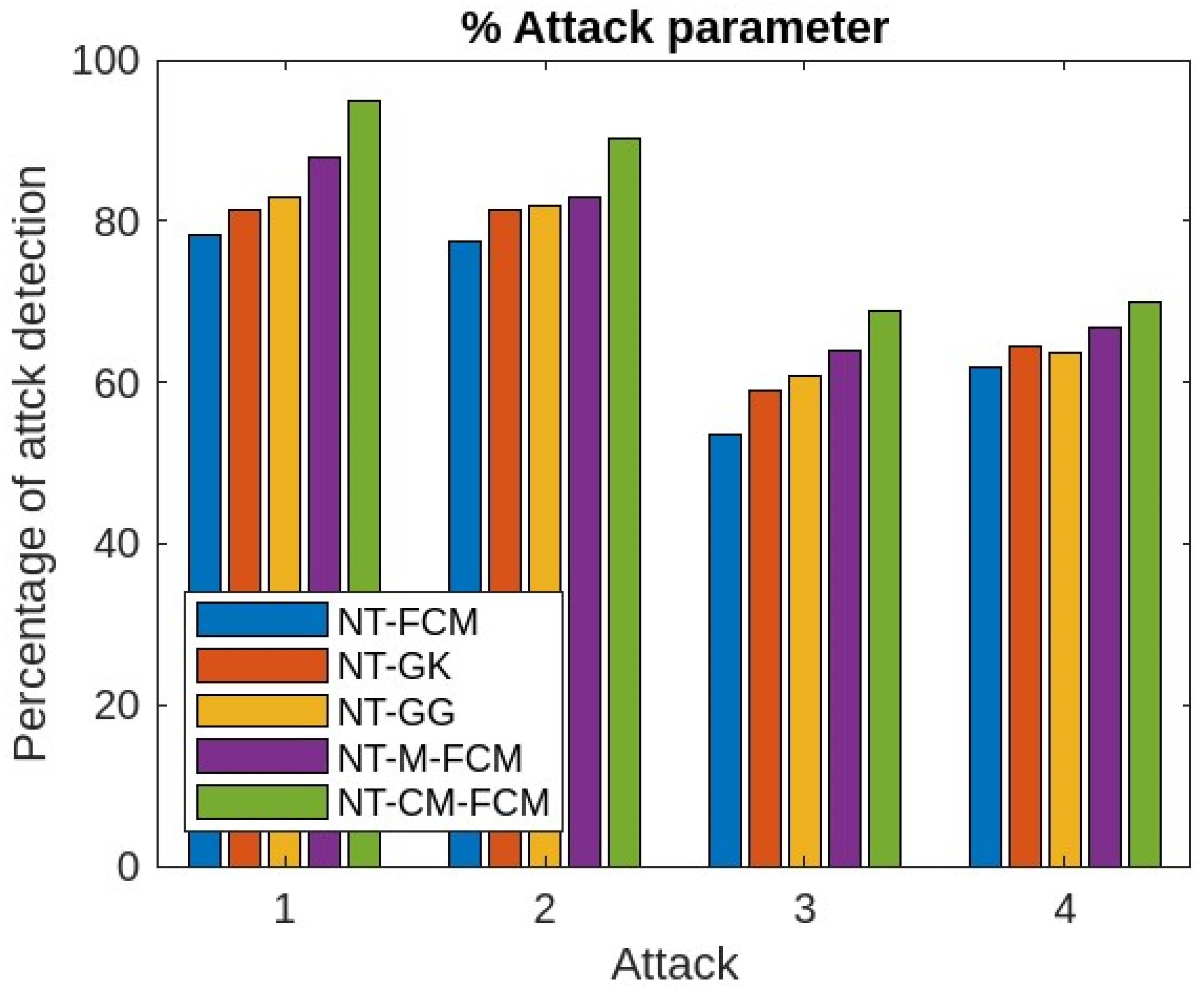
| % of Attack Parameters | ||||||
|---|---|---|---|---|---|---|
| Sl. NO. | Parameters | NT-FCM | NT-GK | NT-GG | NT-M-FCM | NT-CM-FCM |
| 1 | Denial of service | 79.73 | 83.33 | 84.92 | 89.95 | 96.22 |
| 2 | Remote to local | 78.56 | 82.42 | 83.85 | 85.72 | 90.40 |
| 3 | User to root | 52.40 | 60.39 | 61.70 | 65.90 | 70.81 |
| 4 | Probe | 62.37 | 65.45 | 64.65 | 68.81 | 70.73 |
| % of Attack Parameters | ||||||
|---|---|---|---|---|---|---|
| Sl. NO. | Parameters | NT-FCM | NT-GK | NT-GG | NT-M-FCM | NT-CM-FCM |
| 1 | Denial of service | 78.3 | 81.33 | 82.99 | 87.96 | 94.83 |
| 2 | Remote to local | 77.56 | 81.42 | 81.85 | 82.83 | 90.22 |
| 3 | User to root | 53.50 | 58.89 | 60.80 | 63.89 | 68.91 |
| 4 | Probe | 61.79 | 64.53 | 63.75 | 66.91 | 69.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shenify, M.; Mazarbhuiya, F.A.; Wungreiphi, A.S. Detecting IoT Anomalies Using Fuzzy Subspace Clustering Algorithms. Appl. Sci. 2024, 14, 1264. https://doi.org/10.3390/app14031264
Shenify M, Mazarbhuiya FA, Wungreiphi AS. Detecting IoT Anomalies Using Fuzzy Subspace Clustering Algorithms. Applied Sciences. 2024; 14(3):1264. https://doi.org/10.3390/app14031264
Chicago/Turabian StyleShenify, Mohamed, Fokrul Alom Mazarbhuiya, and A. S. Wungreiphi. 2024. "Detecting IoT Anomalies Using Fuzzy Subspace Clustering Algorithms" Applied Sciences 14, no. 3: 1264. https://doi.org/10.3390/app14031264
APA StyleShenify, M., Mazarbhuiya, F. A., & Wungreiphi, A. S. (2024). Detecting IoT Anomalies Using Fuzzy Subspace Clustering Algorithms. Applied Sciences, 14(3), 1264. https://doi.org/10.3390/app14031264