
A Simple Unsupervised Knowledge-Free Domain Adaptation for Speaker Recognition


Abstract
1. Introduction
- (1)
- We introduced a novel speaker recognition adaptation approach called C-LDA. This method is simple (involving a linear transform), unsupervised (utilizing clustering without human labels), and knowledge-free (requiring no knowledge of models and source data). These characteristics make it highly suitable for real-world applications.
- (2)
- It was demonstrated that the C-LDA adaptation is highly effective and even outperforms the more complex front-end and back-end approaches in both multi-domain and single-domain adaptation scenarios. Additionally, the performance of C-LDA is robust against the setting of hyperparameters.
- (3)
- The success of C-LDA further demonstrated our hypothesis that domain mismatch faced by speaker recognition systems based on deep models is primarily attributed to distributional distortion in the embedding space, rather than a decrease in discriminability.
2. Related Work
2.1. Back-End Adaptation
2.2. Front-End Adaptation
2.3. Embedding Adaptation
3. Methodology
3.1. Normalization by Full-Rank LDA
- (1)
- Global shift: Perform centering (mean subtraction) to normalize the data to a zero-mean distribution.
- (2)
- Rotation (first): Rotate the coordinate to align the axes to the principal directions of the within-class covariance.
- (3)
- Scaling: Scale the coordinate axes to unify the within-class variance along each axis, known as whitening.
- (4)
- Rotation (second): Rotate the coordinate again to align the axes to the principal directions of between-class variance (note that since within-class variance has been whitened, the subsequent rotation of the coordinate will not affect the within-class variance).
3.2. AHC Clustering
4. Experiments
4.1. Datasets
4.2. System Configuration
4.3. Main Results
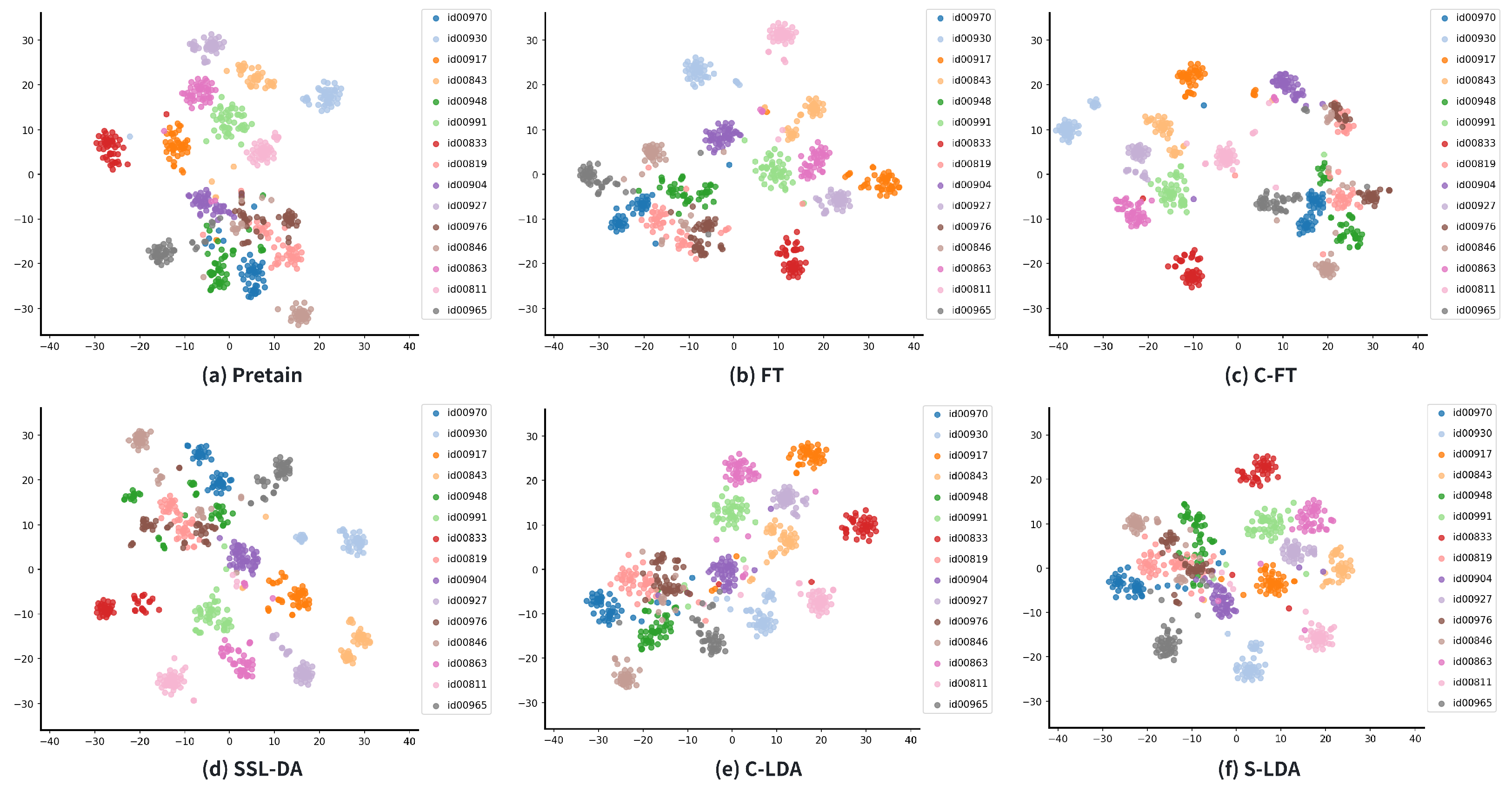
4.3.1. Embedding vs. Front-End
- (1)
- Fine-tuning (FT): The standard front-end adaptation approach, utilizing the development data from CNC1.dev. It uses genuine speaker labels of the speech, requires the knowledge of the source-domain model, and modifies its parameters by back-propagation.
- (2)
- Clustering fine-tuning (C-FT): The same as FT, except that the speaker labels of the adaptation data are pseudo labels from the AHC algorithm (the same as C-LDA). This system is mainly used to test the quality of the pseudo labels.
- (3)
- SSL-DA [43]: Front-end adaptation by (1) self-supervised training with CNC1.dev; (2) distribution alignment between different genres. It does not require speaker labels but needs genre labels.
- (4)
- Clustering LDA (C-LDA): The proposed method of this paper. It does not require any supervision or any knowledge of the front-end model.
- (5)
- Supervised LDA (S-LDA): The same as C-LDA, except that it uses genuine speaker labels. S-LDA presents the upper bound for the capability of C-LDA in compensating for the distributional distortion, by eliminating label errors.
- With all the adaptation methods, the results of the adapted systems are consistently better than that of the pre-trained source-domain model (14.22%). This confirms the impact of domain mismatch and underscores the necessity of domain adaptation techniques.
- FT vs. C-FT (9.50% vs. 11.08%) and S-LDA vs. C-LDA (9.75% vs. 10.66%): It reveals that clustering-based unsupervised learning methods, while not reaching the performance of supervised learning with genuine speaker labels, can still effectively alleviate the domain mismatch problem and achieve performance close to that of the supervised methods. This demonstrated that simple hierarchical clustering can produce high-quality pseudo labels.
- FT vs. S-LDA (9.50% vs. 9.75%): Both of which are supervised, and the difference is that they adapt the embedding network and the embedding space, respectively. It can be observed that the performance of S-LDA is quite close to that of FT. This strongly supports our hypothesis that the domain mismatch issue can largely be attributed to the distributional distortion in the embedding space, and a simple linear mapping can largely eliminate this distortion.
- C-FT vs. C-LDA (11.08% vs. 10.66%): Both of which are unsupervised and rely on pseudo-labels. It can be seen that the embedding adaptation method C-LDA outperforms the front-end adaptation method C-FT. On one hand, it reaffirms that a linear transform such as full-rank LDA can largely eliminate the distributional distortion caused by domain mismatch, even though the LDA is trained with inaccurate speaker labels. On the other hand, more importantly, it indicates that for noisy pseudo-labeled data, compared to fine-tuning the entire front-end network, the simpler embedding adaptation is perhaps more effective. This relative superiority of C-LDA might be attributed to its simple functional form that prevents over-fitting to the errors in the pseudo labels.
- The performance of the SSL-DA approach is relatively weaker (11.54%) compared to other unsupervised methods, though it is still much better than the pre-trained model (14.22%). We guess it is because self-supervised learning is not powerful enough to address the complex multi-domain adaptation problem due to the weak supervision signal from contrastive pairs.
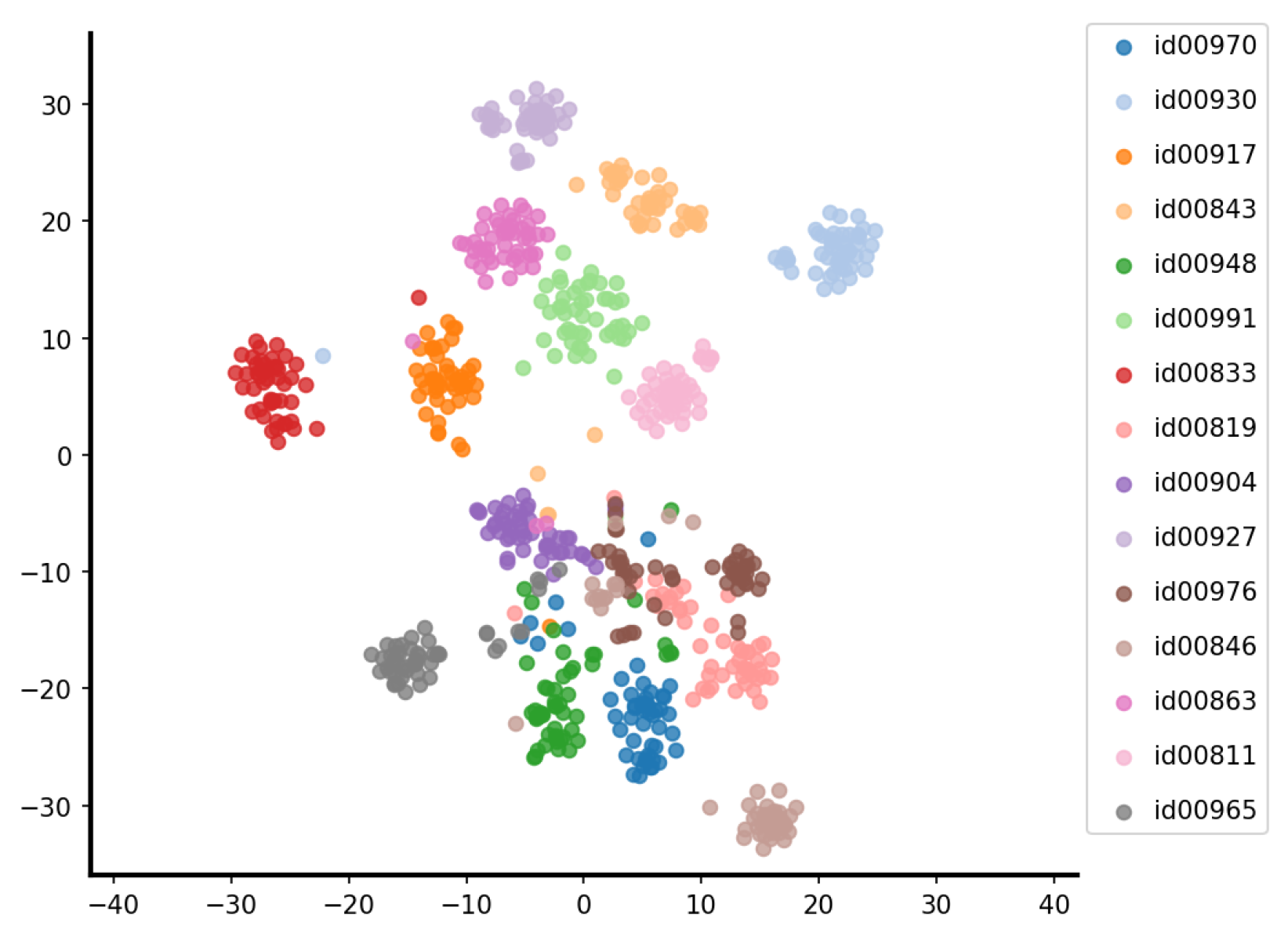
4.3.2. Embedding Visualization
4.3.3. Embedding vs. Back-End
- (1)
- Supervised PLDA (S-PLDA): PLDA re-trained with CNC1.dev, the development data for the target domain, using the genuine speaker labels.
- (2)
- Adaptive PLDA (A-PLDA): An off-the-shelf unsupervised PLDA adaption approach provided by Kaldi [56]. It estimates the change in the between-speaker and within-speaker covariance by the change on the total covariances from the source domain to the target domain. Note that no speaker labels are required.
- (3)
- (4)
- Clustering PLDA (C-PLDA): The same as S-PLDA, except that the speaker labels are pseudo labels produced by clustering. It is the probabilistic version of C-LDA. Note that C-PLDA does not require the parameters of the source-domain PLDA, so it is knowledge-free, just like C-LDA.

{kind=link}
{kind=link}
{kind=link}
| Adaptation/Scoring | Method | Supervision | Knowledge | EER(%) | minDCF |
|---|---|---|---|---|---|
| Label | ( = 0.05) | ||||
| Pretrain | - | - | 14.22 | 0.5137 | |
| Embedding/Cosine | S-LDA | Speaker | - | 9.75 | 0.4047 |
| C-LDA | - | - | 10.66 | 0.4122 | |
| Back-End/PLDA | S-PLDA | Speaker | - | 8.87 | 0.3684 |
| A-PLDA | - | Covariance | 10.86 | 0.4198 | |
| CORAL+ | - | Covariance | 10.54 | 0.4299 | |
| C-PLDA | - | - | 10.11 | 0.3979 |
- All the embedding and back-end adaptation methods outperform the baseline result without any adaptation (14.22%), demonstrating the efficiency of these methods.
- In all the methods, S-PLDA shows the best performance (9.57%). This result is close to the one obtained with front-end fine-tuning (9.50%). It indicates that the PLDA model, if well-trained in the target domain, can effectively solve the domain mismatch problem.
- C-LDA (10.66%) vs. C-PLDA (10.11%) and S-LDA (9.75%) vs. S-PLDA (8.87%): It can be observed that C-PLDA performs better than C-LDA, and S-PLDA outperforms S-LDA. This is expected as PLDA scoring utilizes the between-class information and conducts minimum-risk Bayesian decision [57].
- C-LDA (10.66%) vs. S-LDA (9.75%) and C-PLDA (10.11%) vs. S-PLDA (8.87%): This comparison indicates that using pseudo labels produced by clustering leads to inferior performance compared to using the genuine labels; however, compared to the baseline result, the improvement with the cost-free pseudo labels is highly significant. We also note that the disparity between C-LDA and S-LDA (10.66% vs 9.75%) is smaller compared to that between C-PLDA and S-PLDA (10.11% vs 8.87%). This seems to indicate that LDA relies less on the accuracy of speaker labels compared to PLDA; thus, it is more suitable for unsupervised learning. We hypothesize that this is because LDA does not need an accurate between-class covariance while PLDA does need one.
- C-PLDA (10.11%) vs. A-PLDA (10.86%) vs. CORAL+ (10.54%): All these three methods are unsupervised and are based on PLDA back-end. It shows that C-PLDA performs significantly better than the other two PLDA-based back-end adaptation methods, although it does not require any knowledge of the source-domain PLDA parameters. This further strengthens the evidence that the pseudo labels generated by the clustering algorithm convey reasonable speaker-related information and can be used to train a strong PLDA model. This, in turn, supports the premise that the embeddings extracted by the pre-trained network maintain sufficient discriminant strength in terms of speakers; otherwise, the simple clustering cannot generate such high-quality pseudo labels.
- C-LDA vs. A-PLDA (10.66% vs. 10.86%) vs. CORAL+ (10.54%): In comparison, C-LDA is simpler than the other two PLDA-based domain adaptation methods, both in the adaptation process and scoring process, but obtained similar or even better performance. This suggests that if the distributional distortion can be well alleviated, a simple cosine scoring is sufficient to gain good performance. Considering the simplicity and the good acceptance of cosine scoring, C-LDA is preferable compared to A-PLDA, CORAL+, and even to the more powerful but also more complex C-PLDA. This argument will be further strengthened in the single-domain adaptation experiments presented shortly.
4.4. Further Study
4.4.1. Single-Domain Adaptation
4.4.2. Parameter Sensitivity
4.4.3. Shift, Rotation and Scaling
5. Discussion
- (1)
- If the target-domain speaker vectors extracted by the source-domain model remain highly separable in the embedding space, relatively accurate pseudo-labels can be obtained through simple clustering, which then allows for a reasonably good C-LDA model. Fortunately, modern speaker embedding models trained with max margin loss seem to maintain this cross-domain discrimination.
- (2)
- Full-rank LDA involves only a linear transform, so it is less prone to overfitting issues compared to front-end adaptation methods, especially with potential errors in the pseudo labels.
- (3)
- It does not depend on accurate between-class covariance, making it superior to back-end adaptation methods including C-PLDA, especially when the number of speakers in the adaptation data is limited.
- (4)
- C-LDA is a knowledge-free approach and does not require knowledge of both the front-end and back-end models, providing an important advantage for practical usage compared to most existing methods.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep speaker: An end-to-end neural speaker embedding system. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep neural network embeddings for text-independent speaker verification. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; Volume 2017, pp. 999–1003. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar]
- Zhou, T.; Zhao, Y.; Wu, J. Resnext and res2net structures for speaker verification. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 301–307. [Google Scholar]
- Okabe, K.; Koshinaka, T.; Shinoda, K. Attentive statistics pooling for deep speaker embedding. arXiv 2018, arXiv:1803.10963. [Google Scholar]
- Tang, Y.; Ding, G.; Huang, J.; He, X.; Zhou, B. Deep speaker embedding learning with multi-level pooling for text-independent speaker verification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6116–6120. [Google Scholar]
- Xie, W.; Nagrani, A.; Chung, J.S.; Zisserman, A. Utterance-level aggregation for speaker recognition in the wild. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5791–5795. [Google Scholar]
- Gao, Z.; Song, Y.; McLoughlin, I.; Li, P.; Jiang, Y.; Dai, L.R. Improving Aggregation and Loss Function for Better Embedding Learning in End-to-End Speaker Verification System. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 361–365. [Google Scholar]
- Wang, S.; Rohdin, J.; Plchot, O.; Burget, L.; Yu, K.; Černockỳ, J. Investigation of specaugment for deep speaker embedding learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7139–7143. [Google Scholar]
- Liu, T.; Lee, K.A.; Wang, Q.; Li, H. Disentangling Voice and Content with Self-Supervision for Speaker Recognition. arXiv 2023, arXiv:2310.01128. [Google Scholar]
- Cai, D.; Cai, W.; Li, M. Within-sample variability-invariant loss for robust speaker recognition under noisy environments. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6469–6473. [Google Scholar]
- Zhang, C.; Yu, M.; Weng, C.; Yu, D. Towards robust speaker verification with target speaker enhancement. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6693–6697. [Google Scholar]
- Li, L.; Liu, R.; Kang, J.; Fan, Y.; Cui, H.; Cai, Y.; Vipperla, R.; Zheng, T.F.; Wang, D. CN-Celeb: Multi-genre speaker recognition. Speech Commun. 2022, 137, 77–91. [Google Scholar] [CrossRef]
- Dua, M.; Sadhu, A.; Jindal, A.; Mehta, R. A hybrid noise robust model for multireplay attack detection in automatic speaker verification systems. Biomed. Signal Process. Control 2022, 74, 103517. [Google Scholar] [CrossRef]
- Wang, X.; Li, L.; Wang, D. VAE-based domain adaptation for speaker verification. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 535–539. [Google Scholar]
- Villalba, J.; Chen, N.; Snyder, D.; Garcia-Romero, D.; McCree, A.; Sell, G.; Borgstrom, J.; García-Perera, L.P.; Richardson, F.; Dehak, R.; et al. State-of-the-art speaker recognition with neural network embeddings in NIST SRE18 and speakers in the wild evaluations. Comput. Speech Lang. 2020, 60, 101026. [Google Scholar] [CrossRef]
- Lin, W.; Mak, M.W.; Li, N.; Su, D.; Yu, D. A framework for adapting DNN speaker embedding across languages. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2810–2822. [Google Scholar] [CrossRef]
- Zhang, C.; Ranjan, S.; Hansen, J.H. An Analysis of Transfer Learning for Domain Mismatched Text-independent Speaker Verification. In Proceedings of the Odyssey, Stockholm, Sweden, 26–29 June 2018; pp. 181–186. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Li, J.; Han, J.; Song, H. CDMA: Cross-Domain Distance Metric Adaptation for Speaker Verification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7197–7201. [Google Scholar]
- Mccree, A.; Shum, S.; Reynolds, D.; Garcia-Romero, D. Unsupervised Clustering Approaches for Domain Adaptation in Speaker Recognition Systems. In Proceedings of the Speaker and Language Recognition Workshop (Odyssey 2014), Joensuu, Finland, 16–19 June 2014; pp. 265–272. [Google Scholar]
- Lee, K.A.; Wang, Q.; Koshinaka, T. The CORAL+ algorithm for unsupervised domain adaptation of PLDA. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5821–5825. [Google Scholar]
- Wang, Q.; Okabe, K.; Lee, K.A.; Koshinaka, T. Generalized domain adaptation framework for parametric back-end in speaker recognition. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3936–3947. [Google Scholar] [CrossRef]
- Burget, L.; Plchot, O.; Cumani, S.; Glembek, O.; Matějka, P.; Brümmer, N. Discriminatively trained probabilistic linear discriminant analysis for speaker verification. In Proceedings of the 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4832–4835. [Google Scholar]
- Hu, H.R.; Song, Y.; Liu, Y.; Dai, L.R.; McLoughlin, I.; Liu, L. Domain robust deep embedding learning for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7182–7186. [Google Scholar]
- Li, J.; Liu, W.; Lee, T. EDITnet: A Lightweight Network for Unsupervised Domain Adaptation in Speaker Verification. arXiv 2022, arXiv:2206.07548. [Google Scholar]
- Hu, H.R.; Song, Y.; Dai, L.R.; McLoughlin, I.; Liu, L. Class-aware distribution alignment based unsupervised domain adaptation for speaker verification. In Proceedings of the INTERSPEECH, Songdo, Republic of Korea, 18–22 September 2022. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part III 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Alam, M.J.; Bhattacharya, G.; Kenny, P. Speaker verification in mismatched conditions with frustratingly easy domain adaptation. Odyssey 2018, 25, 176–180. [Google Scholar]
- Lin, W.W.; Mak, M.W.; Li, L.; Chien, J.T. Reducing domain mismatch by maximum mean discrepancy based autoencoders. Odyssey 2018, 23, 162–167. [Google Scholar]
- Izenman, A.J. Linear discriminant analysis. In Modern Multivariate Statistical Techniques: Regression, Classification, and Manifold Learning; Springer: Berlin/Heidelberg, Germany, 2013; pp. 237–280. [Google Scholar]
- Garcia-Romero, D.; McCree, A. Supervised domain adaptation for i-vector based speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4047–4051. [Google Scholar]
- Garcia-Romero, D.; McCree, A.; Shum, S.; Brummer, N.; Vaquero, C. Unsupervised domain adaptation for i-vector speaker recognition. In Proceedings of the Odyssey: The Speaker and Language Recognition Workshop, Joensuu, Finland, 16–19 June 2014; Volume 8. [Google Scholar]
- Li, R.; Zhang, W.; Chen, D. The CORAL++ algorithm for unsupervised domain adaptation of speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7172–7176. [Google Scholar]
- Wang, Q.; Rao, W.; Sun, S.; Xie, L.; Chng, E.S.; Li, H. Unsupervised domain adaptation via domain adversarial training for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4889–4893. [Google Scholar]
- Yin, Y.; Huang, B.; Wu, Y.; Soleymani, M. Speaker-invariant adversarial domain adaptation for emotion recognition. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual Event, The Netherlands, 25–29 October 2020; pp. 481–490. [Google Scholar]
- Wang, Q.; Rao, W.; Guo, P.; Xie, L. Adversarial training for multi-domain speaker recognition. In Proceedings of the 2021 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), Hong Kong, China, 24–27 January 2021; pp. 1–5. [Google Scholar]
- Lin, W.; Mak, M.M.; Li, N.; Su, D.; Yu, D. Multi-level deep neural network adaptation for speaker verification using MMD and consistency regularization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6839–6843. [Google Scholar]
- Zhou, Z.; Chen, J.; Wang, N.; Li, L.; Wang, D. An Investigation of Distribution Alignment in Multi-Genre Speaker Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Chen, Z.; Wang, S.; Qian, Y. Self-supervised learning based domain adaptation for robust speaker verification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 5834–5838. [Google Scholar]
- Mao, H.; Hong, F.; Mak, M.W. Cluster-Guided Unsupervised Domain Adaptation for Deep Speaker Embedding. IEEE Signal Process. Lett. 2023, 30, 643–647. [Google Scholar] [CrossRef]
- Lin, W.; Li, L.; Wang, D. Multi-Domain Adaptation by Self-Supervised Learning for Speaker Verification. arXiv 2023, arXiv:2309.14149. [Google Scholar]
- Cai, Y.; Li, L.; Abel, A.; Zhu, X.; Wang, D. Deep normalization for speaker vectors. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 733–744. [Google Scholar] [CrossRef]
- Li, L.; Wang, D.; Kang, J.; Wang, R.; Wu, J.; Gao, Z.; Chen, X. A principle solution for enroll-test mismatch in speaker recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 443–455. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Dehak, N.; Dehak, R.; Kenny, P.; Brümmer, N.; Ouellet, P.; Dumouchel, P. Support vector machines versus fast scoring in the low-dimensional total variability space for speaker verification. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Misra, A.; Hansen, J.H. Maximum-likelihood linear transformation for unsupervised domain adaptation in speaker verification. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1549–1558. [Google Scholar] [CrossRef]
- Nagrani, A.; Chung, J.S.; Xie, W.; Zisserman, A. Voxceleb: Large-scale speaker verification in the wild. Comput. Speech Lang. 2020, 60, 101027. [Google Scholar] [CrossRef]
- Fan, Y.; Kang, J.; Li, L.; Li, K.; Chen, H.; Cheng, S.; Zhang, P.; Zhou, Z.; Cai, Y.; Wang, D. CN-Celeb: A challenging Chinese speaker recognition dataset. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7604–7608. [Google Scholar]
- Xiang, X.; Wang, S.; Huang, H.; Qian, Y.; Yu, K. Margin matters: Towards more discriminative deep neural network embeddings for speaker recognition. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1652–1656. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011; number CONF. [Google Scholar]
- Wang, D. A simulation study on optimal scores for speaker recognition. EURASIP J. Audio Speech Music. Process. 2020, 2020, 18. [Google Scholar] [CrossRef]

| Datasets | # of Spks | # of Utts | # of Hours | # of Avg Dur |
|---|---|---|---|---|
| CN-Celeb1 | 997 | 126,532 | 271.71 | 7.73 |
| CNC1.dev | 797 | 107,953 | 228.01 | 7.60 |
| CNC1.eval | 200 | 18,579 | 43.71 | 8.47 |
| CNC1.dev.interview | 637 | 53,035 | 120.94 | 8.21 |
| CNC1.dev.entertainment | 351 | 18,443 | 27.40 | 5.35 |
| CNC1.dev.singing | 250 | 10,544 | 23.83 | 8.14 |
| Layer | Kernel Size | Stride | Dilation | Output |
|---|---|---|---|---|
| Input | – | – | – | 80 × 200 |
| Conv1D | 1 × 5 | 1 × 1 | 1 × 1 | 1024 × 200 |
| SE-Res2Block1 | 1 × 3 | 1 × 1 | 1 × 2 | 1024 × 200 |
| SE-Res2Block2 | 1 × 3 | 1 × 1 | 1 × 3 | 1024 × 200 |
| SE-Res2Block3 | 1 × 3 | 1 × 1 | 1 × 4 | 1024 × 200 |
| SE-Res2Block4 | 1 × 1 | 1 × 1 | 1 × 1 | 1536 × 200 |
| Pooling | ASP | 3072 × 1 | ||
| Dense | – | 192 × 1 | ||
| Dense | AAM-Softmax | # of Spks | ||
| Adaptation | Method | Supervision | Knowledge | EER(%) | minDCF |
|---|---|---|---|---|---|
| Label | ( = 0.05) | ||||
| Pretrain | - | - | 14.22 | 0.5137 | |
| Front-End | FT | Speaker | NeuralNet | 9.50 | 0.3991 |
| C-FT | - | NeuralNet | 11.08 | 0.4820 | |
| SSL-DA | Domain | NeuralNet | 11.54 | 0.4551 | |
| Embedding | C-LDA | - | - | 10.66 | 0.4122 |
| S-LDA | Speaker | - | 9.75 | 0.4047 |
| Scoring | Method | Domain | |||
|---|---|---|---|---|---|
| CNC1.dev | CNC1.dev. | CNC1.dev. | CNC1.dev. | ||
| Interview | Entertainment | Singing | |||
| Pretrain | 14.22 | 9.35 | 10.88 | 28.08 | |
| Cosine | SSL-DA | 11.54 | 7.02 | 7.89 | 16.93 |
| C-FT | 11.08 | 7.62 | 8.99 | 21.54 | |
| C-LDA | 10.66 | 6.21 | 7.12 | 18.57 | |
| PLDA | A-PLDA | 10.86 | 6.53 | 7.29 | 18.89 |
| CORAL+ | 10.54 | 6.72 | 7.36 | 19.23 | |
| C-PLDA | 10.11 | 5.35 | 7.18 | 18.89 | |
| Method | EER(%) | minDCF ( = 0.05) |
|---|---|---|
| Pretrain | 14.22 | 0.5137 |
| Global Shift | 11.48 | 0.4351 |
| +Rotation (1st) | 11.48 | 0.4351 |
| ++Scaling | 10.66 | 0.4122 |
| +++Rotation (2nd) | 10.66 | 0.4122 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, W.; Li, L.; Wang, D. A Simple Unsupervised Knowledge-Free Domain Adaptation for Speaker Recognition. Appl. Sci. 2024, 14, 1064. https://doi.org/10.3390/app14031064
Lin W, Li L, Wang D. A Simple Unsupervised Knowledge-Free Domain Adaptation for Speaker Recognition. Applied Sciences. 2024; 14(3):1064. https://doi.org/10.3390/app14031064
Chicago/Turabian StyleLin, Wan, Lantian Li, and Dong Wang. 2024. "A Simple Unsupervised Knowledge-Free Domain Adaptation for Speaker Recognition" Applied Sciences 14, no. 3: 1064. https://doi.org/10.3390/app14031064
APA StyleLin, W., Li, L., & Wang, D. (2024). A Simple Unsupervised Knowledge-Free Domain Adaptation for Speaker Recognition. Applied Sciences, 14(3), 1064. https://doi.org/10.3390/app14031064