
An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs

Abstract
1. Introduction
- -
- A first ever study that demonstrates that GPT-based large language models can generate safety-critical software code that meets the requirements of the safety-critical industry domain.
- -
- This study compares different approaches and methods for code generation, including overall requirement-based code generation, specific requirement-based code generation, and augmented prompt-based code generation. It proposes a new augmented prompt method called Prompt-FDC, which is suitable for generating safety-critical software code.
- -
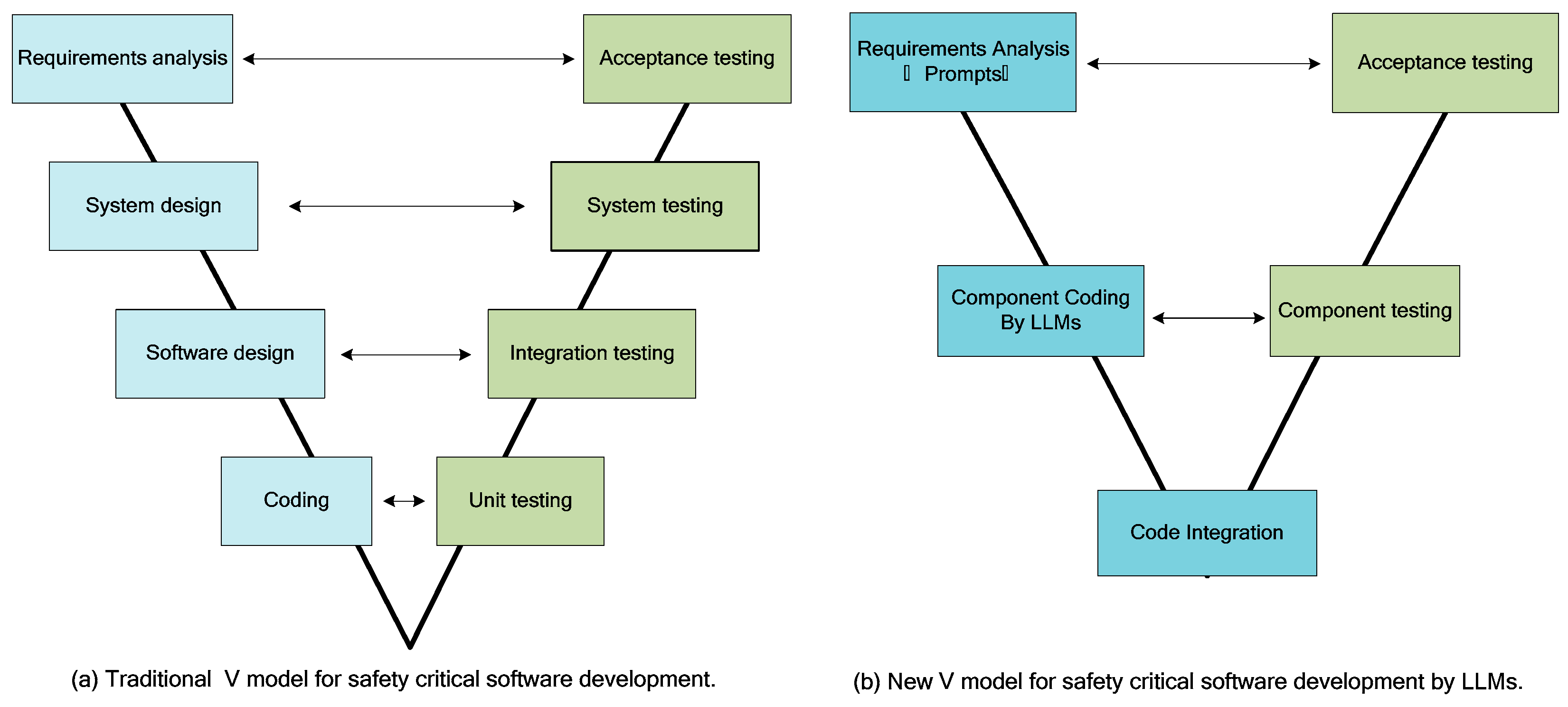
- This research presents a new software development process and lifecycle V model based on LLMs code generation for safety-critical software.
- -
- This study provides two specific examples of safety-critical software from the industrial domain, which can be used by other researchers to explore further code generation methods.
2. Backgrounds and Motivation
2.1. Generative Pre-Training Large Language Models
2.2. Code LLMs
2.3. Prompt Engineering for Code LLMs
2.4. Motivation
3. Methodologies
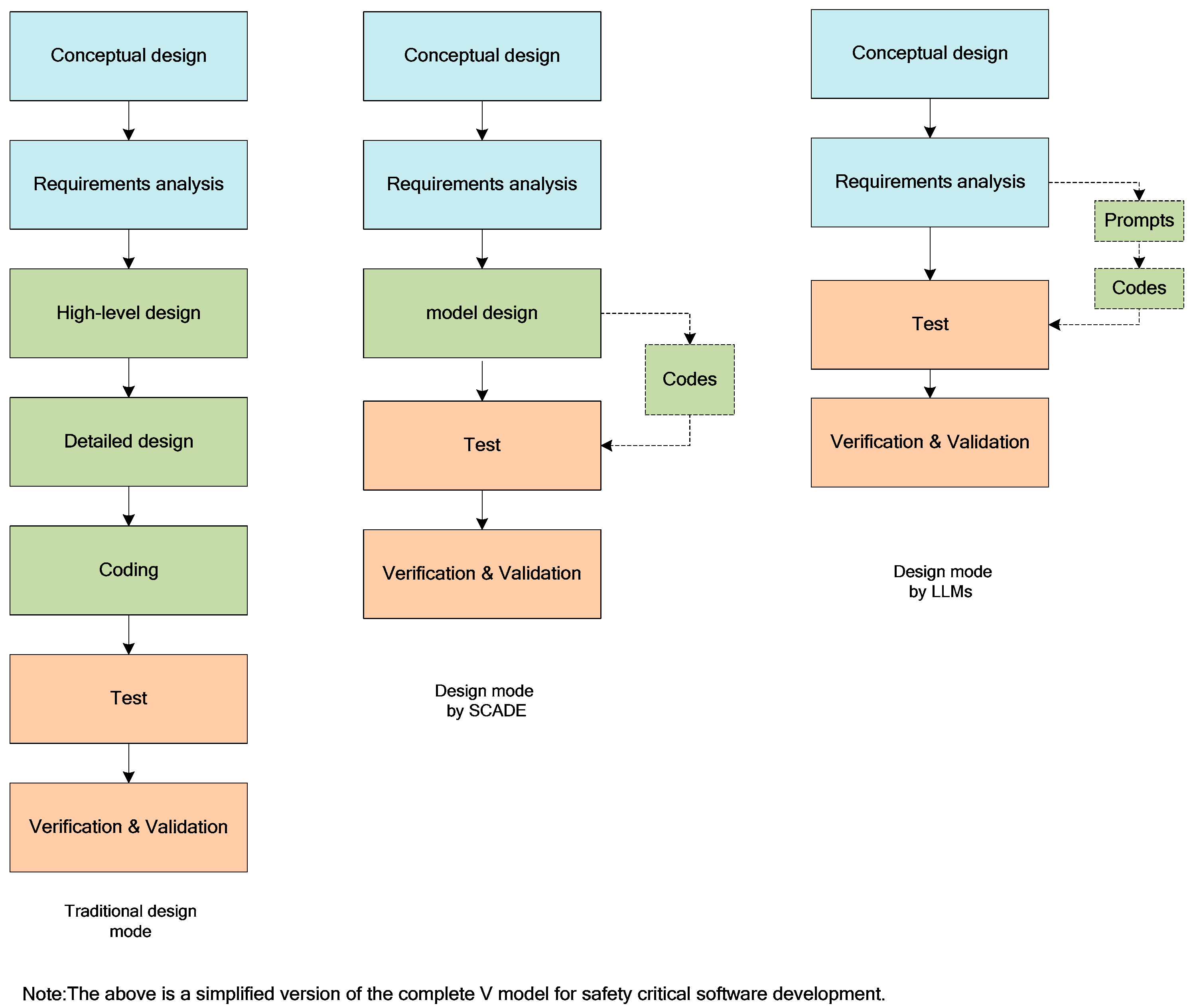
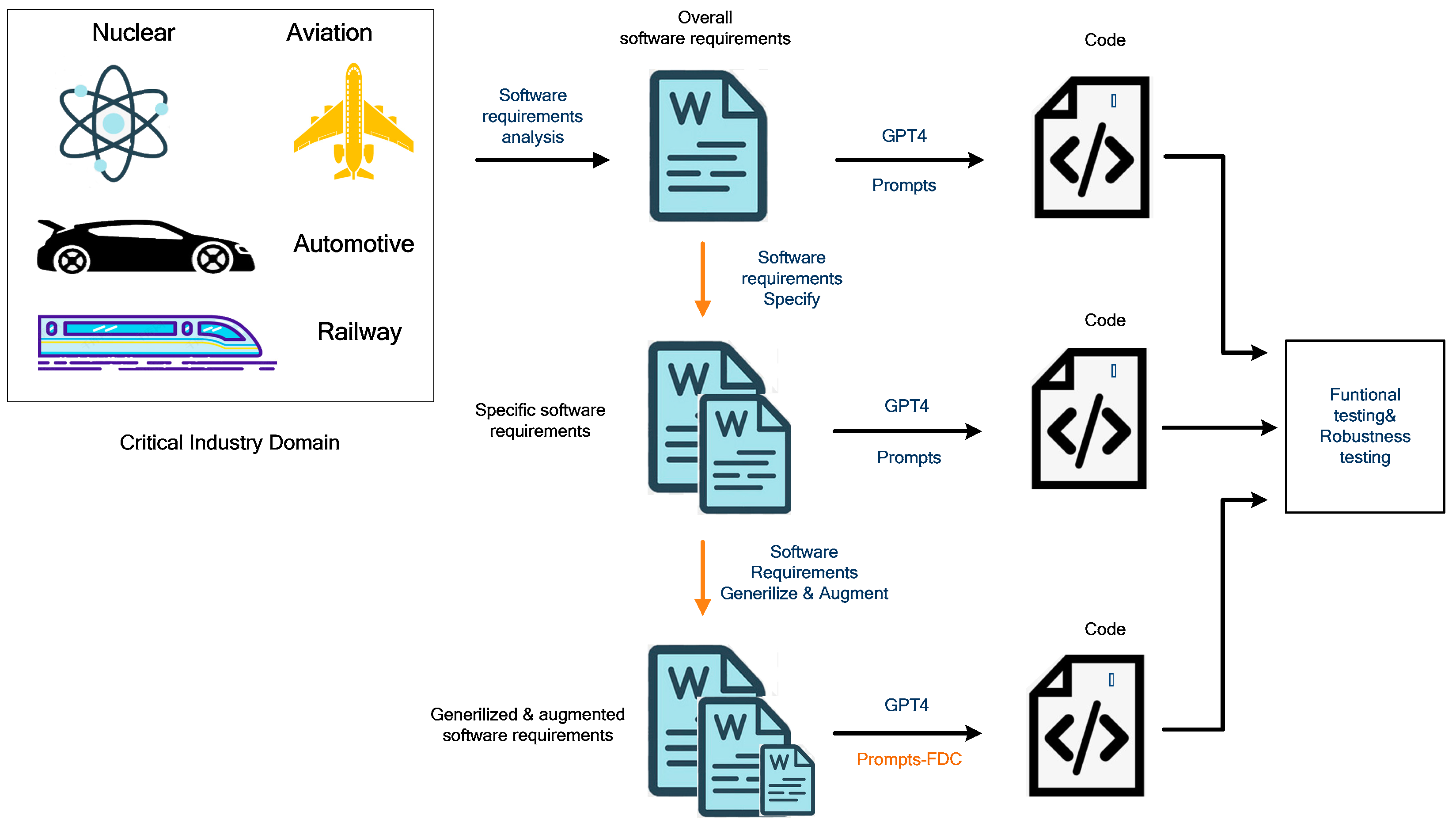
3.1. A New Paradigm for Safety-Critical Software Development
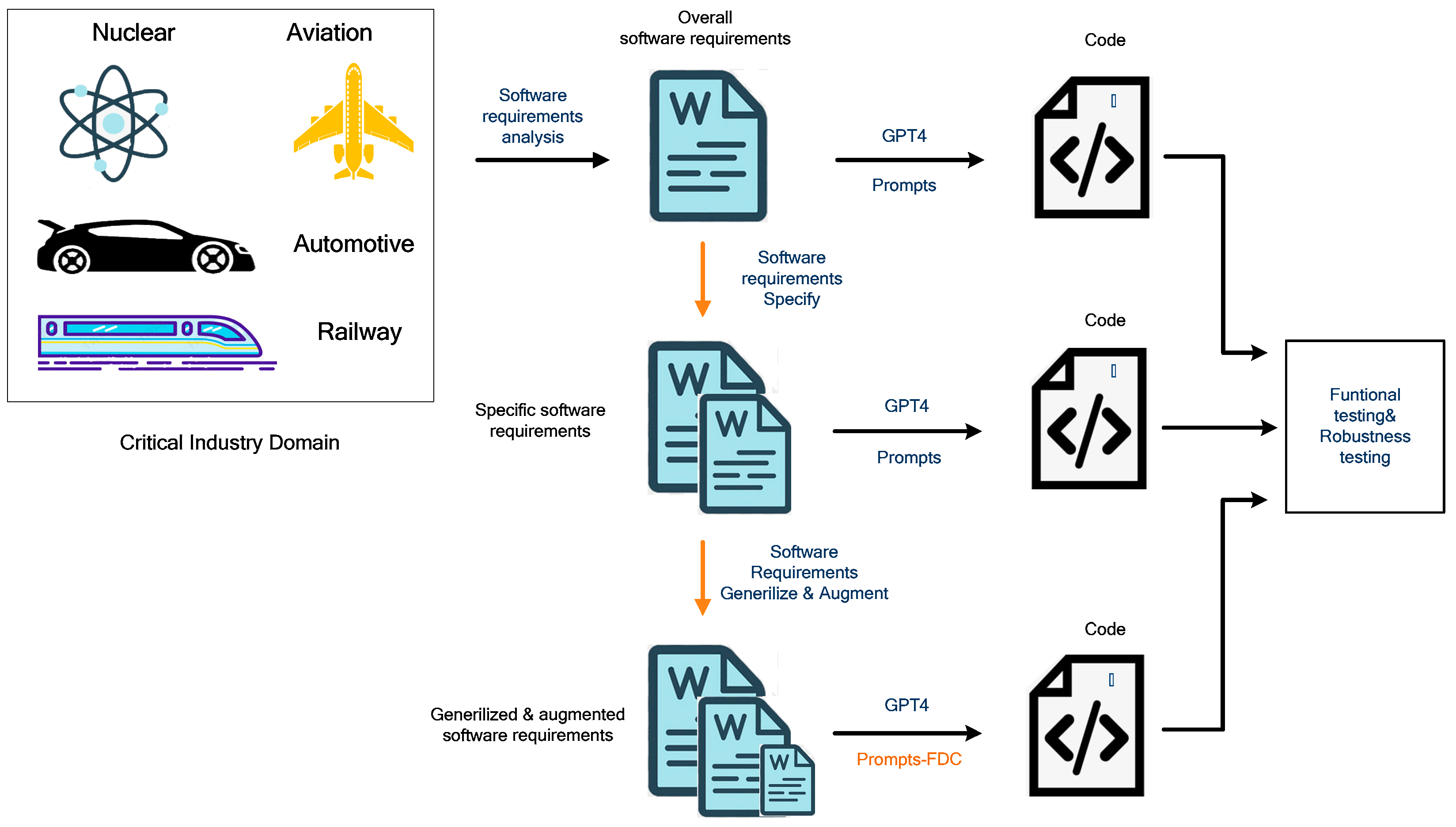
3.2. A New Method of Code Generation for Safety-Critical Software
3.2.1. Software Requirement Analysis of Safety-Critical Software
3.2.2. Code Generation Based on Overall Software Requirements
3.2.3. Code Generation Based on Specific Software Requirements
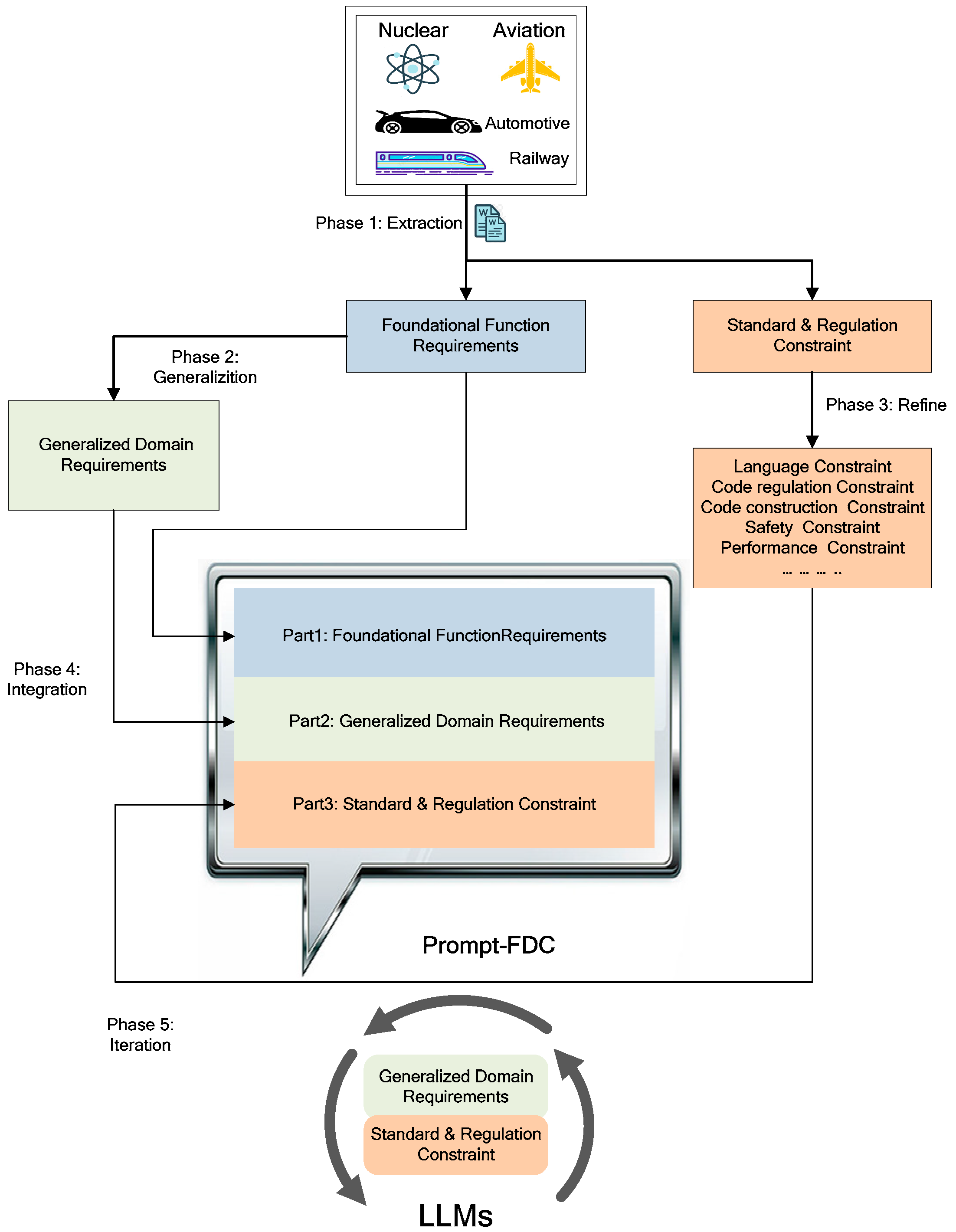
3.2.4. Code Generation Based on Software Requirements through Augmented Prompt
4. Experiments
4.1. Software Requirements Analysis in Nuclear and Automotive Domain
4.1.1. Requirements for Shutdown Algorithm in the Nuclear Energy Domain
4.1.2. Requirements for Cruise Control Functions of Automobiles
4.2. Code Generation Based on Overall Software Requirements
4.2.1. Code Generation Based on the NucRate Algorithm’s Overall Requirements
- (1)
- The requirements of the threshold comparator are not understood, resulting in a missing function.
- (2)
- The function of the RS flip-flop is not fully implemented.
- (3)
- The degradation function of the quality bit in the 4-to-2 voter is still incomplete.
- (4)
- The entire algorithm does not form a top-level function.
- (5)
- The code lacks sufficient comments.
4.2.2. Code Generation Based on the CruiseControl’s Overall Requirements
- (1)
- The control function for cruise speed is not implemented.
- (2)
- The overall requirements do not provide detailed instructions on the control method for the throttle. LLMs have completed this part based on their own understanding, but the function is incomplete.
- (3)
- The entire function has not been encapsulated in a top-level function.
- (4)
- The code lacks sufficient comments.
4.3. Code Generation Based on Specific Requirements
4.3.1. Code Generation Based on NucRate Algorithm’s Specific Requirements
- (1)
- The threshold comparator only implements the upper and lower limit function and does not include hysteresis.
- (2)
- The quality bit function of the 4-to-2 voter is incomplete.
- (3)
- The code has a low comment rate.
4.3.2. Code Generation for CruiseControl’s Specific Requirements
- (1)
- The throttle control implementation is incomplete.
- (2)
- The Pedals pressed detection function and Car driving control function are implemented within the same function, resulting in bad readability.
- (3)
- The car_driving_control function contains unused variables: Kp and Ki.
- (4)
- The input structure in the Main function is not initialized.
- (5)
- The code lacks sufficient comments.
- (6)
- It does not fully comply with industry standards (MISRA).
4.4. Code Generation Based on Software Requirements through Augmented Prompt
4.4.1. Refinement and Generalization of Functional Requirements
4.4.2. Standard Requirements for the Code
4.4.3. Structural Requirements for the Code
4.4.4. Safety and Security Requirements for the Code
4.4.5. Performance Requirements for the Code
5. Results
5.1. RQ1: Can LLMs Generate Software Code That Meets Functional Requirements Directly from the Overall Requirements of Safety-Critical Software?
5.2. RQ2: Can LLMs Generate Software Code That Meets All Functional Requirements, Especially Domain-Specific Feature Requirements, from the Specific Requirements of Safety-Critical Software?
5.3. RQ3: How Can Augmented Prompts Be Provided to Enable LLMs to Generate Code That Meets All Functional Requirements and Complies with Industry Regulations?
6. Discussions
6.1. Code Generation Comparison between LLMs and SCADE
6.2. Prompt Engineering for Code Generation of Safety-Critical Software
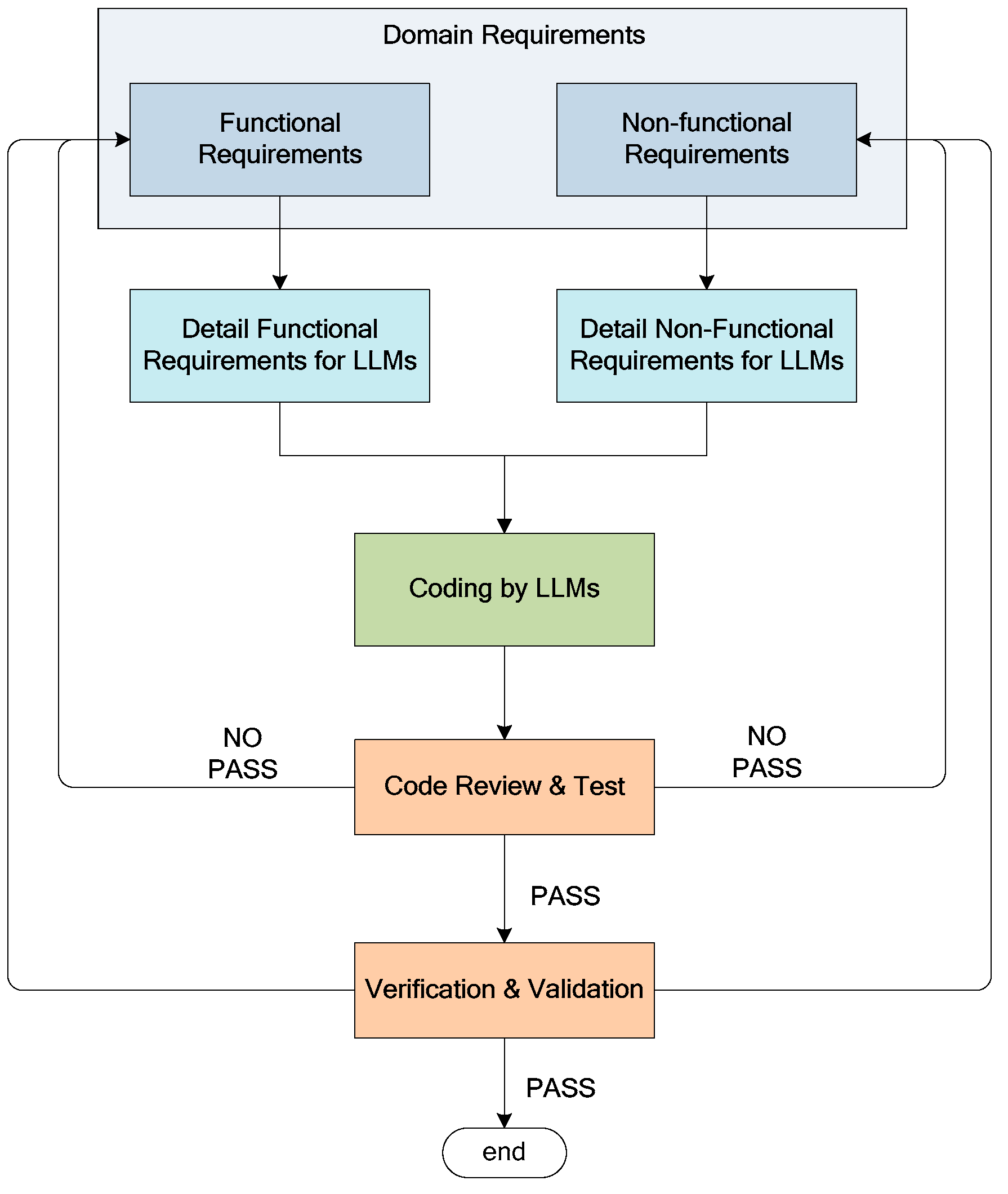
6.3. The Software Development Process Based on LLMs
6.4. The Software V-Model Based on Large Language Models
7. Threats to Validity
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Generated Code for NucRate Algorithm
- (1)
- Generated code based on the NucRate algorithm’s overall requirements is shown in Listing A1:
- Listing A1. Generated code based on NucRate algorithm’s overall requirements.

- (2)
- Generated code based on the NucRate algorithm’s specific requirements is shown in Listing A2:
- Listing A2. Generated code based on NucRate algorithm’s specific requirements.


- (3)
- Generated code based on software requirements through augmented prompt is shown in Listing A3:
- Listing A3. Generated code based on NucRate algorithm’s requirements through augmented prompt.

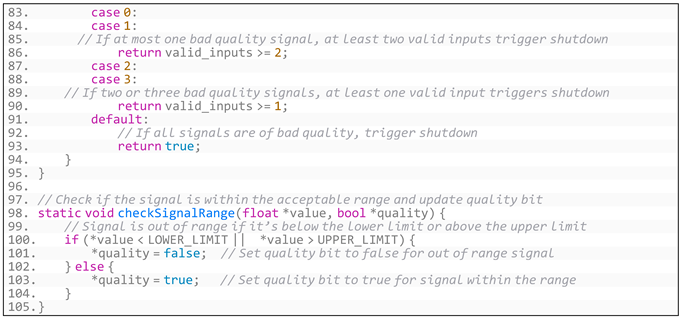
Appendix B. Generated Code for CruiseControl Software
- (1)
- Generated code based on CruiseControl’s overall requirements is shown in Listing A4:
- Listing A4. Generated code based on CruiseControl’s overall requirements.
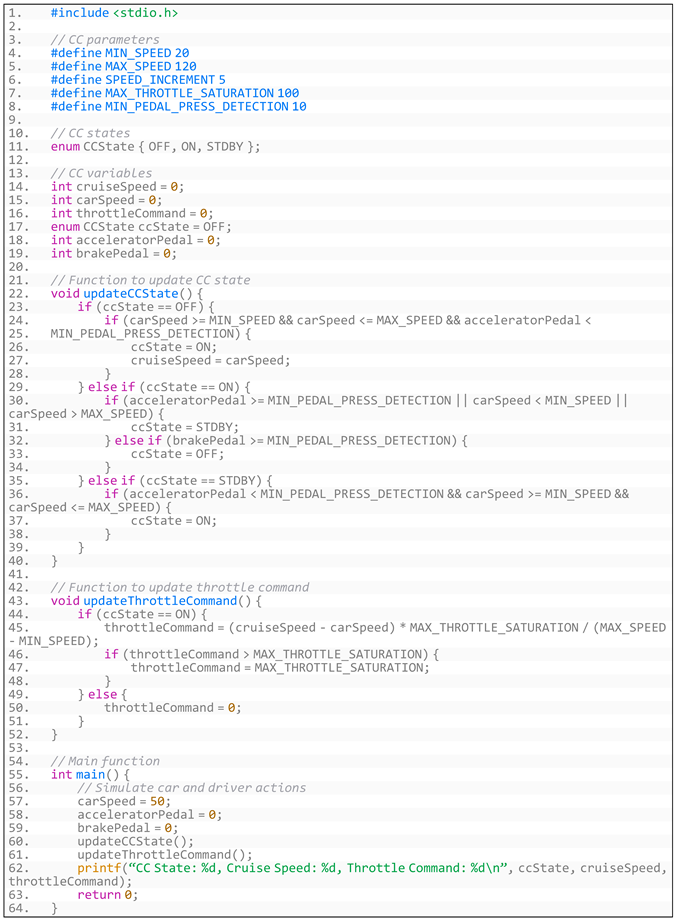
- (2)
- Generated code based on CruiseControl’s specific requirements is shown in Listing A5:
- Listing A5. Generated code based on CruiseControl’s specific requirements.
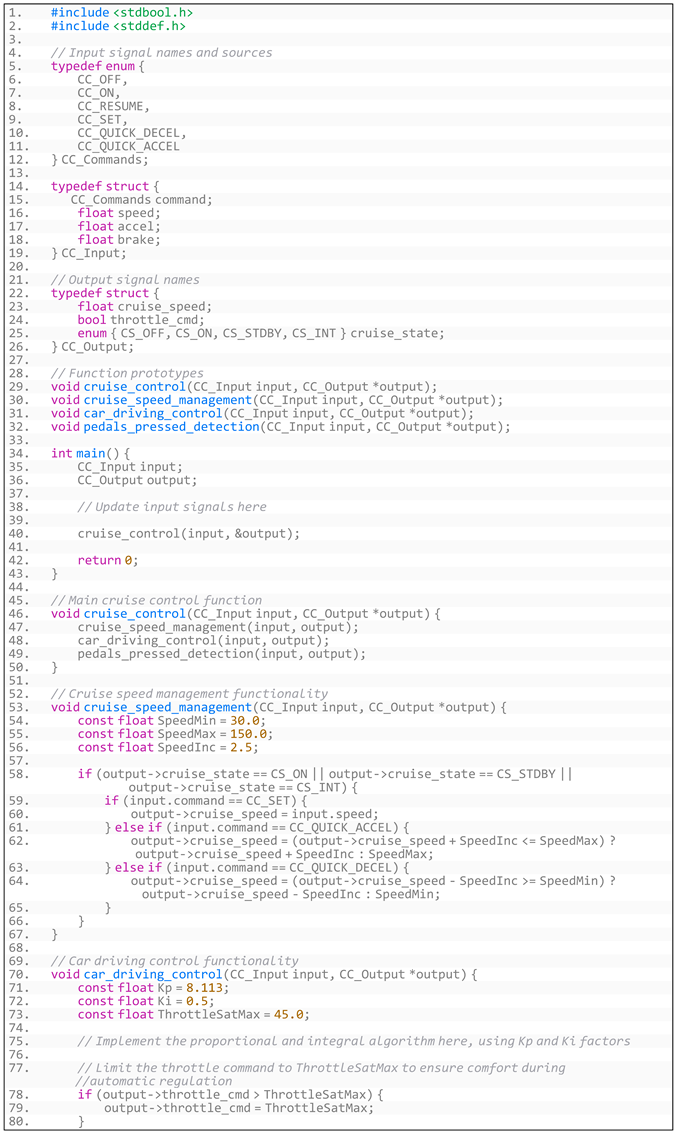

- (3)
- Generated code based on software requirements through augmented prompt is shown in Listing A6:
- Listing A6. Generated code based on CruiseControl’s requirements through augmented prompt.


Appendix C. The Test Code for Robustness Testing
- Listing A7. The test code for robustness testing.
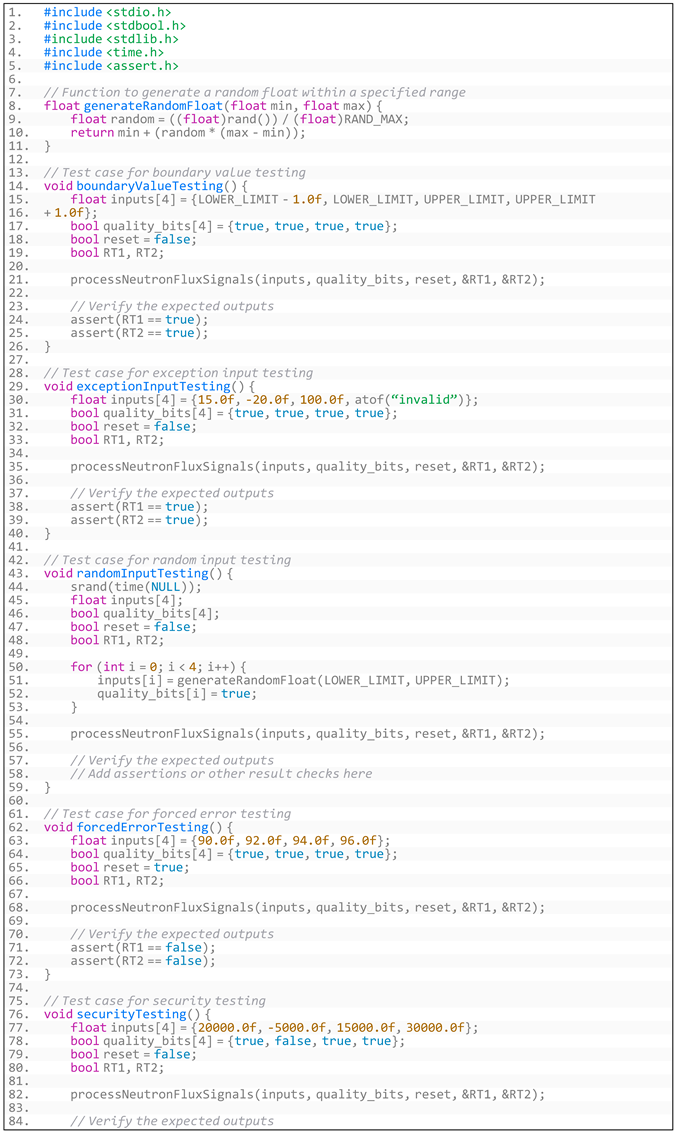

Appendix D. The Standardized XML for Generalized Requirements
- (1)
- The standardized XML template for generalized requirements is shown in Listing A8.
- Listing A8. The standardized XML template for generalized requirements.


- (2)
- The standardized XML generalized requirements of the NucRate algorithm are shown in Listing A9.
- Listing A9. The standardized XML generalized requirements of the NucRate algorithm.



Appendix E. The Detail Procedures for Conducting the Experiments
- Listing A10. The detailed procedures for conducting the experiments.

References
- Leveson, N.G. Engineering a Safer World: Systems Thinking Applied to Safety; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Jolak, R.; Ho-Quang, T.; Chaudron, M.R.V.; Schiffelers, R.R.H. Model-Based Software Engineering: A Multiple-Case Study on Challenges and Development Efforts. In Proceedings of the 21th ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, Association for Computing Machinery. New York, NY, USA, 14–19 October 2018; pp. 213–223. [Google Scholar]
- Colaco, J.-L.; Pagano, B.; Pouzet, M. SCADE 6: A Formal Language for Embedded Critical Software Development (Invited Paper). In Proceedings of the 2017 International Symposium on Theoretical Aspects of Software Engineering (TASE), Sophia Antipolis, France, 13–15 September 2017; pp. 1–11. [Google Scholar]
- Le Sergent, T. SCADE: A Comprehensive Framework for Critical System and Software Engineering. In SDL 2011: Integrating System and Software Modeling; Ober, I., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7083, pp. 2–3. ISBN 978-3-642-25263-1. [Google Scholar]
- Osaiweran, A.; Schuts, M.; Hooman, J. Experiences with Incorporating Formal Techniques into Industrial Practice. Empir. Softw. Eng. 2014, 19, 1169–1194. [Google Scholar] [CrossRef]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of Artificial General Intelligence: Early Experiments with GPT-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; de Pinto, H.P.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Liu, J.; Xia, C.S.; Wang, Y.; Zhang, L. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. arXiv 2023, arXiv:2305.01210. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Retraining of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North, Louis, MI, USA, 14–17 November 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 25 December 2023).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020; pp. 1877–1901. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. J. Mach. Learn. Res. 2022, 23, 5232–5270. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O.; et al. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 25 December 2023).
- Open, A.I.; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. PaLM 2 Technical Report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Anthropic\Claude 2. Available online: https://www.anthropic.com/index/claude-2 (accessed on 24 December 2023).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Lago, A.D.; et al. Competition-Level Code Generation with AlphaCode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef] [PubMed]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Wang, Y.; Le, H.; Gotmare, A.D.; Bui, N.D.Q.; Li, J.; Hoi, S.C.H. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. arXiv 2023, arXiv:2305.07922. [Google Scholar]
- Fried, D.; Aghajanyan, A.; Lin, J.; Wang, S.; Wallace, E.; Shi, F.; Zhong, R.; Yih, W.; Zettlemoyer, L.; Lewis, M. InCoder: A Generative Model for Code Infilling and Synthesis. arXiv 2022, arXiv:2204.05999. [Google Scholar]
- Austin, J.; Odena, A.; Nye, M.; Bosma, M.; Michalewski, H.; Dohan, D.; Jiang, E.; Cai, C.; Terry, M.; Le, Q.; et al. Program Synthesis with Large Language Models. arXiv 2021, arXiv:2108.07732. [Google Scholar]
- Luo, Z.; Xu, C.; Zhao, P.; Sun, Q.; Geng, X.; Hu, W.; Tao, C.; Ma, J.; Lin, Q.; Jiang, D. WizardCoder: Empowering Code Large Language Models with Evol-Instruct. arXiv 2023, arXiv:2306.08568. [Google Scholar]
- Lai, Y.; Li, C.; Wang, Y.; Zhang, T.; Zhong, R.; Zettlemoyer, L.; Yih, S.W.; Fried, D.; Wang, S.; Yu, T. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D.C. A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv 2023, arXiv:2302.11382. [Google Scholar]
- Van Dis, E.A.M.; Bollen, J.; Zuidema, W.; Van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- Jung, J.; Qin, L.; Welleck, S.; Brahman, F.; Bhagavatula, C.; Bras, R.L.; Choi, Y. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations. arXiv 2022, arXiv:2205.11822. [Google Scholar]
- Arora, S.; Narayan, A.; Chen, M.F.; Orr, L.; Guha, N.; Bhatia, K.; Chami, I.; Re, C. Ask Me Anything: A Simple Strategy for Prompting Language Models. arXiv 2022, arXiv:2210.02441. [Google Scholar]
- Zhou, Y.; Muresanu, A.I.; Han, Z.; Paster, K.; Pitis, S.; Chan, H.; Ba, J. Large Language Models Are Human-Level Prompt Engineers. arXiv 2022, arXiv:2211.01910. [Google Scholar]
- Liu, V.; Chilton, L.B. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Koziolek, H.; Gruener, S.; Ashiwal, V. ChatGPT for PLC/DCS Control Logic Generation. arXiv 2023, arXiv:2305.15809. [Google Scholar]
- IEC 61508:2010; Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems. International Electrotechnical Commission: Geneva, Switzerland, 2010.
- IEC 60880:2006; Nuclear Power Plants—Instrumentation and Control Systems Important to Safety—Software Aspects for Computer-Based Systems Performing Category A Functions. International Electrotechnical Commission: Geneva, Switzerland, 2006.
- ISO 26262:2011; Road Vehicles Functional Safety. International Organization for Standardization: Geneva, Switzerland, 2011.
- Robustness Testing: What Is It & How to Deliver Reliable Software Systems with Test Automation. Available online: https://www.parasoftchina.cn/what-is-robustness-testing/ (accessed on 9 January 2024).
- Cppcheck—A Tool for Static C/C++ Code Analysis. Available online: http://cppcheck.net/ (accessed on 24 December 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Prompt Examples | Feature |
|---|---|---|
| Luo et al., 2023 [27] | Prompt1: “Write a Python function to tell me what the date is today”; Prompt2: “List the prime numbers between 20 and 30 with Java”. | function descriptions and code language constraints |
| Austin et al., 2021 [26] | Prompt1: “Write a python function to check if a given number is one less than twice its reverse” | function descriptions and code language constraints |
| Chen et al., 2021 [8] | Prompt1: “Write a function vowels_count which takes a string representing a word as input and returns the number of vowels in the string. Vowels in this case are ‘a’, ‘e’, ‘i’, ‘o’, ‘u’. Here, ‘y’ is also a vowel, but only when it is at the end of the given word. Example: >>> vowels_count(“abcde”) 2 >>> vowels_count(“ACEDY”) 3” | software function descriptions and functional examples |
| Lai et al., 2022 [28] | Prompt1: ”How to convert a numpy array of dtype=object to torch Tensor? array([ array([0.5, 1.0, 2.0], dtype=float16), array([4.0, 6.0, 8.0], dtype=float16) ], dtype=object)” | function descriptions |
| Bubeck et al., 2023 [7] | Prompt1: “Can you write a 3D game in HTML with Javascript, I want: -There are three avatars, each is a sphere. -The player controls its avatar using arrow keys to move. -The enemy avatar is trying to catch the player. -The defender avatar is trying to block the enemy. -There are also random obstacles as cubes spawned randomly at the beginning and moving randomly. The avatars cannot cross those cubes. -The player moves on a 2D plane surrounded by walls that he cannot cross. The wall should cover the boundary of the entire plane. -Add physics to the environment using cannon”. | software function descriptions, code language constraints, detailed step descriptions |
| Koziolek et al., 2023 [36] | Prompt1: Write a self-contained function block in 61131-3 structured text that implements a counter. Prompt2: Write a self-contained function block in IEC 61131-3 structured text to compute the mean and standard deviation for an input array of 100 integers. | function descriptions and code language constraints |
| Robustness Testing | Test Cases | Results |
|---|---|---|
| Boundary Value Testing | Test inputs close to the boundary values or beyond the boundary values for each element in the inputs array. For example, test values near LOWER_LIMIT and UPPER_LIMIT, as well as values below LOWER_LIMIT-1 and above UPPER_LIMIT+1. Test boundary value scenarios for HYSTERESIS_HIGH_THRESHOLD and HYSTERESIS_LOW_THRESHOLD. For example, test values close to these thresholds and values beyond these thresholds. | PASS |
| Exception Input Testing | Test invalid data in the inputs array, such as non-numeric values or strings. Test inputs with formatting errors, such as negative values or values represented in scientific notation. Test inputs that are out of range, such as values below LOWER_LIMIT or above UPPER_LIMIT. | PASS |
| Random Input Testing | Use randomly generated inputs within a reasonable range to test the system’s robustness under different input conditions. | PASS |
| Forced Error Testing | Simulate changes in the reset signal and observe if the system responds correctly and resets the corresponding outputs. | PASS |
| Security Testing | Test malicious data in the inputs and quality_bits arrays, such as extreme values outside the normal range or unexpected data. Simulate errors in the quality_bits array, such as setting quality bits to values that do not match the corresponding inputs, to test the system’s ability to handle exceptional data securely. | PASS |
| Comparison Item | LLMs Code Generation | SCADE Code Generation |
|---|---|---|
| Input | Software Requirements | Software Models |
| Development Time Investment | 1 h | 24 h |
| Code Size | 100+ | 1000+ |
| Learning Curves | Almost no learning curve required | Long-term specialized learning |
| Verification | Comprehensive verification is required | Model correctness implies code correctness; model needs to be verified carefully |
| Domain Compliance | Complies with standards | Complies with standards |
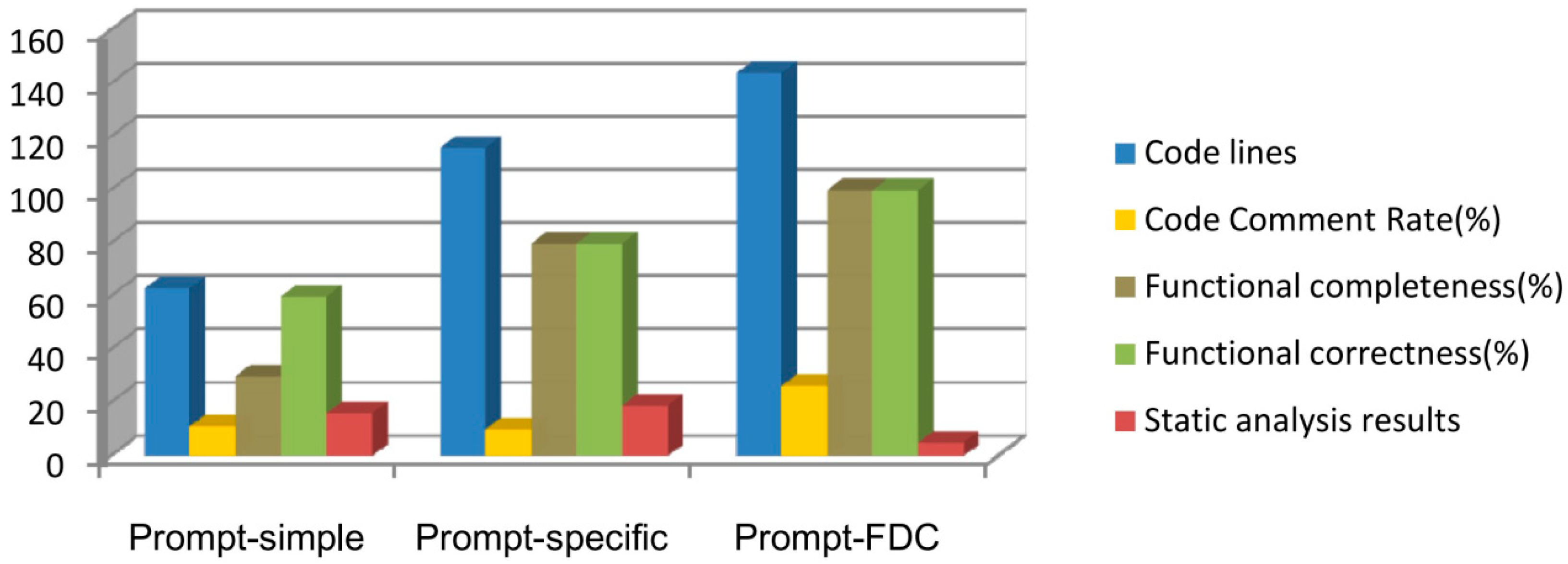
| Comparison Item | Prompt-Simple [27,28] | Prompt-Specific [7] | Prompt-FDC (Proposed in This Paper) |
|---|---|---|---|
| Input | Prompt of overall requirements | Prompt of specific requirements | Prompt of augmented requirements |
| Code size | 63 | 116 | 144 |
| Code comment rate | 11.1% | 10% | 26.3% |
| Completeness of generated code function | 30%, function missing | 80%, domain function missing | 100%, complete function |
| Correctness of generated code function | 60%, partially correct | 80%, partially correct | 100%, completely correct |
| Static analysis results * | Style warnings: 16 | Errors: 4 Style warnings: 15 | Style warnings: 5 |
| Code compliance | Non-compliant | Non-compliant | Compliant with MISRA-C:2004 standard |
| Code readability | Moderate | Moderate | High |
| Code usability | Not directly usable | Not directly usable | Directly usable |
| Prompt | Prompt-Simple | Prompt-Specific | Prompt-FDC | ||
|---|---|---|---|---|---|
| Reference | Luo et al., 2023 [27] | Koziolek et al., 2023 [36] | Chen et al., 2021 [8] | Bubeck et al., 2023 [7] | methodology proposed in this paper |
| Features | Function description, code language constraints | Function description, code language constraints | Function description, function example | Detailed step descriptions, code language constraints | Part1, function description, itemized requirements; Part 2, domain feature generalization part; Part3, domain specification constraint part |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Wang, J.; Lin, T.; Ma, Q.; Fang, Z.; Wu, Y. An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs. Appl. Sci. 2024, 14, 1046. https://doi.org/10.3390/app14031046
Liu M, Wang J, Lin T, Ma Q, Fang Z, Wu Y. An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs. Applied Sciences. 2024; 14(3):1046. https://doi.org/10.3390/app14031046
Chicago/Turabian StyleLiu, Mingxing, Junfeng Wang, Tao Lin, Quan Ma, Zhiyang Fang, and Yanqun Wu. 2024. "An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs" Applied Sciences 14, no. 3: 1046. https://doi.org/10.3390/app14031046
APA StyleLiu, M., Wang, J., Lin, T., Ma, Q., Fang, Z., & Wu, Y. (2024). An Empirical Study of the Code Generation of Safety-Critical Software Using LLMs. Applied Sciences, 14(3), 1046. https://doi.org/10.3390/app14031046