1. Introduction
Traditional centralized machine learning collects all raw data and sends them to a central server for training. However, concerns about data privacy have grown among companies and researchers in the era of big data. Moreover, the implementation of stringent legal regulations, such as the General Data Protection Regulation (GDPR) [
1] in Europe and the California Consumer Privacy Act (CCPA) [
2] in the United States, has underscored the need for new methods of collecting and sharing client data that comply with these laws. In this context, federated learning has emerged as a significant research area, allowing the utilization of diverse data distributed across various devices like smartphones, IoT devices, and wearables while ensuring data privacy.
Federated learning [
3], in contrast to centralized machine learning, does not directly share raw client data with a central server. Instead, it trains models on each edge device and shares only the model’s weights, aggregating them to update a global model. This training approach ensures privacy, as raw data are not shared with the server, and it offers communication cost advantages when dealing with large data sets. However, in real-world scenarios, local data among clients can be highly heterogeneous, exhibiting varying data distributions. This heterogeneity can lower the performance of the global model during server-side aggregation and may introduce a bias towards specific clients.
Therefore, the need for suitable personalization methodologies arises to capture and optimize each client’s unique data characteristics. To address these issues, personalized federated learning (PFL) approaches [
4,
5] are actively being researched. This study utilizes representation learning, which is one of the PFL approaches. Representation learning divides the layers of a deep learning model into base and head components. In representation learning, the base (or feature extractor)part represents common features for all clients and is shared with the server and all clients. The head (or classifier) part represents unique features for specific clients and remains on the local device, not shared with the server. Typically, the head part uses the last fully connected layer (classification layer). In our experimental setup, this work also designates the head part as the last fully connected layer while setting the remaining layers as the base part. Therefore, the need for suitable personalization methodologies arises to capture and optimize each client’s unique data characteristics. To address these issues, personalized federated learning (PFL) approaches [
4,
5] are actively being researched. This study utilizes representation learning, which is one of the PFL approaches. Representation learning divides the layers of a deep learning model into base and head components. In representation learning, the base (or feature extractor) part represents common features for all clients and is shared with the server and all clients. The head (or classifier) part represents unique features for specific clients and remains on the local device, not shared with the server. Typically, the head part uses the last fully connected layer (classification layer). In our experimental setup, this work also designates the head part as the last fully connected layer while setting the remaining layers as the base part.
The proposed algorithm, FedSeq, subdivides the components of the deep learning model in representation learning more densely than just the base and head. The fine-grained layer expansion is carried out sequentially during multiple iterations of local training and aggregation uniquely characterized by FL architecture. Additionally, the layer scheduling approach of FedSeq was inspired by curriculum learning [
6], resulting in the development of both Vanilla and Anti-scheduling. Curriculum learning is a method that, similar to how human learning, gradually progresses from easy examples to more challenging ones. Traditional curriculum learning focuses on determining the difficulty of datasets and utilizes pre-trained expert models on the entire dataset to evaluate the difficulty of each data point. Subsequently, difficulty scores are assigned based on the client’s loss using the pre-trained expert model, and training is conducted either by starting with easy examples and progressing to harder ones or vice versa. In the recently researched federated learning environment, curriculum learning [
7] also necessitates a well-trained expert model.
However, curriculum learning relies on expert models to assess the difficulty of data points. This dependence can result in significantly reduced performance if the expert models are compromised by malicious attacks or poorly trained. Furthermore, the process of assigning difficulty scores and dividing datasets based on difficulty can complicate operations in a federated learning environment, as highlighted by [
7]. In contrast to curriculum learning, our scheduling algorithm does not categorize data based on difficulty levels. Instead, it focuses on decoupling layers according to the principles of representation learning. In typical deep learning models, the initial layers are responsible for extracting low-level features, while the later layers handle the extraction of more complex and abstract features [
8]. Building on this insight, this work has concentrated on more densely separating the base layer in representation learning algorithms and sequentially training it, deviating from the traditional curriculum learning approach.
Hence, our algorithm densely divides the base layer, initially freezing the entire layer set and then progressively unfreezing specific layers for training according to a schedule. There are two scheduling methods: Vanilla scheduling, which starts by unfreezing layers closest to the input and progresses towards the output, and Anti scheduling, which begins by unfreezing layers nearest to the output and works backward. A key advantage of our proposed algorithm is that, during the early rounds, only a portion of the unfrozen base layer is shared with the server rather than the entirety. This approach not only enhances performance but also reduces the communication and computational costs compared to other algorithms.
The remainder of the paper is organized as follows:
Section 2 reviews related work on federated learning and personalization techniques, including representation learning.
Section 3 introduces the proposed algorithms, Vanilla Scheduling and Anti Scheduling, with detailed explanations of the methodology.
Section 4 presents our experimental setup, datasets, and comparative analysis with existing methods.
Section 5 discusses the results of the ablation study, examining the impact of different factors on the performance of the model. Finally,
Section 6 concludes the paper by summarizing the key findings and suggesting potential directions for future research.
The contributions of this paper are as follows:
Our algorithm densely divides the base layer to address the heterogeneity of the client’s data and class distribution, and it proposes two scheduling methods.
The implementation of scheduling reduces the need to communicate all base layers in the early stages of training, thereby cutting down on communication and computational costs.
In scenarios with both data and class heterogeneity, the Anti Scheduling approach outperforms other algorithms in terms of accuracy. In contrast, the Vanilla Scheduling method significantly reduces computational costs compared to other algorithms.
This work visually presents the accuracy for each client and mathematically compares the computational costs of each algorithm.
3. Proposed Algorithm
In this section, this work presents our proposed scheduling algorithms in detail, namely
Vanilla Scheduling and
Anti Scheduling. An overview of the proposed algorithm is shown in
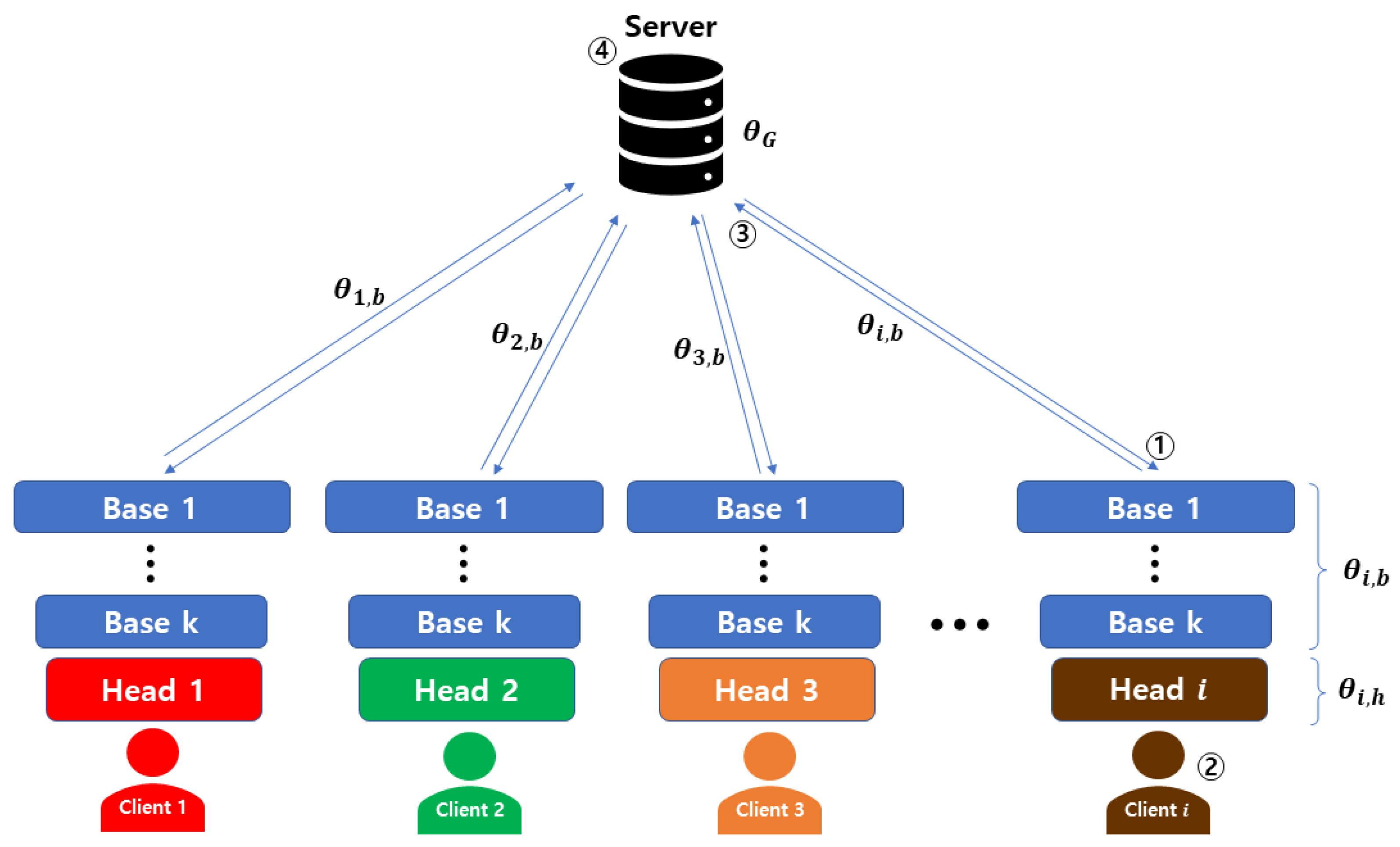
Figure 1. The proposed algorithm executes the following steps: (1) model distribution; (2) local training via sequential layer expansion (Vanilla or Anti Scheduling); (3) update the server with the refined base parameter
; (4) aggregate global model
. Then, steps (1)–(4) are repeated up to the predefined condition. Finally, the server fine tunes with base parameter
and head parameter
. As shown in
Figure 2, Vanilla Scheduling starts by unfreezing the shallowest layers (closest to the input) and progressively moves towards deeper layers. This method allows the model to capture low-level features early in the training process, which is crucial for building a robust foundational understanding before more high-level features are introduced. Conversely, Anti Scheduling begins with the deepest layers (closest to the output) and progressively unfreezes toward the input. This approach prioritizes the learning of high-level features from the outset, which can be beneficial for complex pattern recognition tasks that depend heavily on such features.
As shown in
Figure 2, the structured progression from shallow to deep layers in Vanilla Scheduling, and the reverse in Anti Scheduling, structurally differ from traditional representation learning. In traditional representation learning methods, the base and head of the model are typically trained simultaneously without specific layer prioritization. In our approach, however, each layer’s training is specifically timed and prioritized. This strategic scheduling improves the model’s ability to adapt to the varying complexities of features throughout the training process.
Furthermore, as detailed in
Section 5.2, Vanilla Scheduling can achieve comparable accuracy with significantly lower computational costs in environments characterized by high data and class heterogeneity. In contrast, Anti Scheduling excels in achieving the highest accuracy in scenarios where both data and class heterogeneity are pronounced. They both follow the basic federated learning setup and the representation learning as explained below. The list of symbols used in the paper are shown in
Table 3.
As a basic federated learning setup, this work assumes that each client
possesses data
, where
represents
i-th client out of a total of
N clients and
d represents the input dimension. Each client
i updates its local model parameter
based on its data
and the global model parameter
as
where
is the learning rate,
is the gradient of the loss function
L, and
denotes the number of rounds. The central server updates the global parameter
based on all clients’ local parameter updates as
where
is the number of data points for client
i, and
is the total number of data points.
For representation learning, the model parameters are divided into two components
. Here,
represents the base parameter shared among all clients, and
represents the head parameter of the
i-th client. The model parameters from Equation (
1) are modified as follows:
Excluding FedBABU [
20], previous works stop the gradient of the head parameter during training and during the aggregation phase. The global model is updated using both the base and head parameters. However, FedBABU and our scheduling algorithm perform both training and aggregation using only the base without involving the head. Only after training are a few rounds of fine-tuning included using both the base and head.
The aggregation process, which excludes the use of the head, proceeds as follows:
Our FedSeq algorithm follows the same training setup as FedBABU [
20], wherein the head layer is not trained or aggregated during training; instead, it is fine-tuned for each client after training completion. In FedBABU, the training round sets the learning rate of the head to zero, allowing gradient computation but preventing its application. In contrast, our scheduling algorithm ensures complete decoupling by freezing gradients in both the head and base parts, preventing both computation and application.
3.1. Method 1: Vanilla Scheduling
Vanilla Scheduling is a training method that starts by thoroughly learning the shallowest layers (closest to the input) in the base layer, freezing the rest layers, and then progressively unfreezing them. This enables the model to preferentially learn low-level features and patterns, aiding in better understanding the abstract characteristics and patterns of the data. The training steps of Vanilla Scheduling, which starts with the shallowest layers, can be represented as
where
represent the global rounds where the freeze of each layer is released. Once the first base layer
is sufficiently trained, the freeze on the next base layer
is released for training. This sequential unfreezing and training of base layers up to
defines Vanilla Scheduling. Throughout the training process, the head layer
is initialized and kept frozen, only being utilized in the final fine-tuning stage.
3.2. Method 2: Anti Scheduling
Anti Scheduling is a training approach that initiates in the deepest layers (closest to the output) in the base layer, freezing the remaining layers and progressively unfreezing them for sufficient training. This method allows the model to preferentially grasp high-level and various features. The training steps of Anti Scheduling, starting with the deepest layers, can be given as
Once the deepest base layer is sufficiently trained, the freeze on the preceding layer is released for training. Anti Scheduling is thus defined as the sequential unfreezing and training of base layers starting from and proceeding to the first base layer . The training progresses in the reverse order of Anti Scheduling, and during this process, the head layer remains frozen and is only utilized in the final fine-tuning phase.
Algorithm 1 outlines the training procedure for both Vanilla and Anti Scheduling. In line 2, a subset of clients is randomly selected. Lines 4–8 describe the Vanilla Scheduling mode operation. When the Vanilla mode is selected, if the current global round t is greater than the layers unfreeze round , as specified in line 5, the algorithm unfreezes the k-th base parameter . Then, in line 8, the unfrozen base parameters are used to perform a local update.
Lines 9–13 describe the Anti Scheduling mode operations. In Anti mode, as line 10 indicates, if the current global round
t exceeds the layer unfreeze round
, the algorithm unfreezes the (
)-th base parameter
, which is closer to the head layer. In line 13, the unfrozen base parameters are used for the local update. In lines 15–16, the head is frozen while sending the updated base parameters to the server. In line 18, global aggregation is done after local updates, and fine-tuning is done in lines 20–24, where both base and head parameters are utilized in each client after the global rounds are complete.
| Algorithm 1 FedSeq: Layer Decoupling Algorithm with Vanilla and Anti Scheduling |
Input: Total global rounds T, Total clients N, join ratio r, Learning rate , Total base layers K, Fine-tuning rounds F, Scheduling mode , Layer unfreeze rounds Initialize: Global base parameters and Global Head parameter - 1:
forto T do - 2:
Randomly select clients - 3:
for Each selected client to M do - 4:
if then - 5:
if then - 6:
Unfreeze - 7:
end if - 8:
- 9:
else if then - 10:
if then - 11:
Unfreeze - 12:
end if - 13:
- 14:
end if - 15:
Keep frozen - 16:
Send updated base parameters - 17:
end for - 18:
Aggregate global model - 19:
end for - 20:
forto F do - 21:
Unfreeze all layers for each client - 22:
for each client to N do - 23:
Update all parameters for fine tuning - 24:
- 25:
end for - 26:
end for
|
4. Experiments
In our experimental setup, the total number of clients
N is set to 100, with each round involving a client participation ratio
r of 0.1, indicating that 10 clients participate in each training round. The batch size is configured to 10, and the learning rate is set at 0.005. The datasets used in our experiments include MNIST, which consists of 70,000 grayscale images of handwritten digits (0–9) with a resolution of 28 × 28 pixels; CIFAR-10, containing 60,000 color images of size 32 × 32 pixels across 10 classes, such as airplanes, birds, and cars; CIFAR-100
0, which is similar to CIFAR-10 but includes 60,000 images spanning 100 classes, organized into a hierarchy of 20 superclasses; and Tiny-ImageNet, a dataset consisting of 200 classes with 500 training images and 50 validation images per class, each resized to 64 × 64 pixels. To induce heterogeneity among the data distributed to each client, this work sampled from a Dirichlet distribution with a Dirichlet parameter of 0.1, establishing a highly heterogeneous environment. This approach to data distribution is visualized in
Figure 3, which illustrates the results of sampling the CIFAR-10 dataset among 10 clients. Despite the high heterogeneity induced by the Dirichlet parameter
of 0.1, MNIST, and CIFAR-10 datasets inherently lack significant class heterogeneity. Therefore, our experiments focus on the CIFAR-100 and Tiny-ImageNet datasets because our approach performs well in environments with substantial data and class heterogeneity. The CIFAR-100 dataset contains 100 different classes, and the Tiny-ImageNet dataset contains 200 classes.
In our experiments, the proposed algorithm is compared against six baselines, as detailed in the following references: [
3,
16,
17,
18,
19,
20]. The model used is a CNN model comprising two convolutional layers and two fully connected layers. Here, the last fully connected layer is set as the head, and the remaining three layers are designated as the base. The total number of base layers
K is set to 3, with
at the 0 (initial) round,
at the 100-th global round, and
at the 200-th global round. Additionally, in FedBABU [
20], the learning rate of the head is set to zero during the training rounds, implying that gradients are calculated but not applied. In contrast, our scheduling algorithm achieves complete decoupling by freezing the gradients, thus preventing both computation and application. It will delve into the comparison of computational and communication costs in
Section 5.2.
Table 4 presents a comparison of the accuracies achieved by various federated learning algorithms across multiple datasets, including MNIST, CIFAR-10, CIFAR-100, and Tiny-ImageNet. It encompasses representation learning algorithms such as FedAvg [
3], FedPer [
16], LG-FedAvg [
17], FedRep [
18], FedROD [
19], and FedBABU [
20], as well as our proposed Vanilla and Anti Scheduling algorithms. While FedAvg [
3] serves as the foundational algorithm in federated learning, it is not a personalized federated learning (PFL) method. Unlike PFL approaches, FedAvg updates both the base and head layers of the model uniformly across clients without personalization. In contrast, the other algorithms explored are PFL methods focused on representation learning. For instance, FedPer [
16] retains personalized layers at each client while sharing a global base model. LG-FedAvg [
17] decouples global and local updates to improve personalization. FedRep [
18] separates model representation from the classifier to facilitate client-specific adjustments. FedROD [
19] employs robust optimization to tackle client distribution heterogeneity. A key aspect of both FedBABU and our scheduling algorithms is their approach during the training phases leading up to the final global round, denoted as
T. Characteristically, these algorithms exclusively use the base layers and do not employ the head layer during the training rounds, resulting in relatively lower accuracies prior to the final round. To ensure a fair comparison, the accuracy figures for FedBABU and our scheduling algorithms at
T represent the performance after fine-tuning. Additionally, it is noteworthy that our scheduling algorithms have achieved high accuracy in environments with significant data and class heterogeneity, demonstrating their effectiveness in processing complex and diverse datasets.
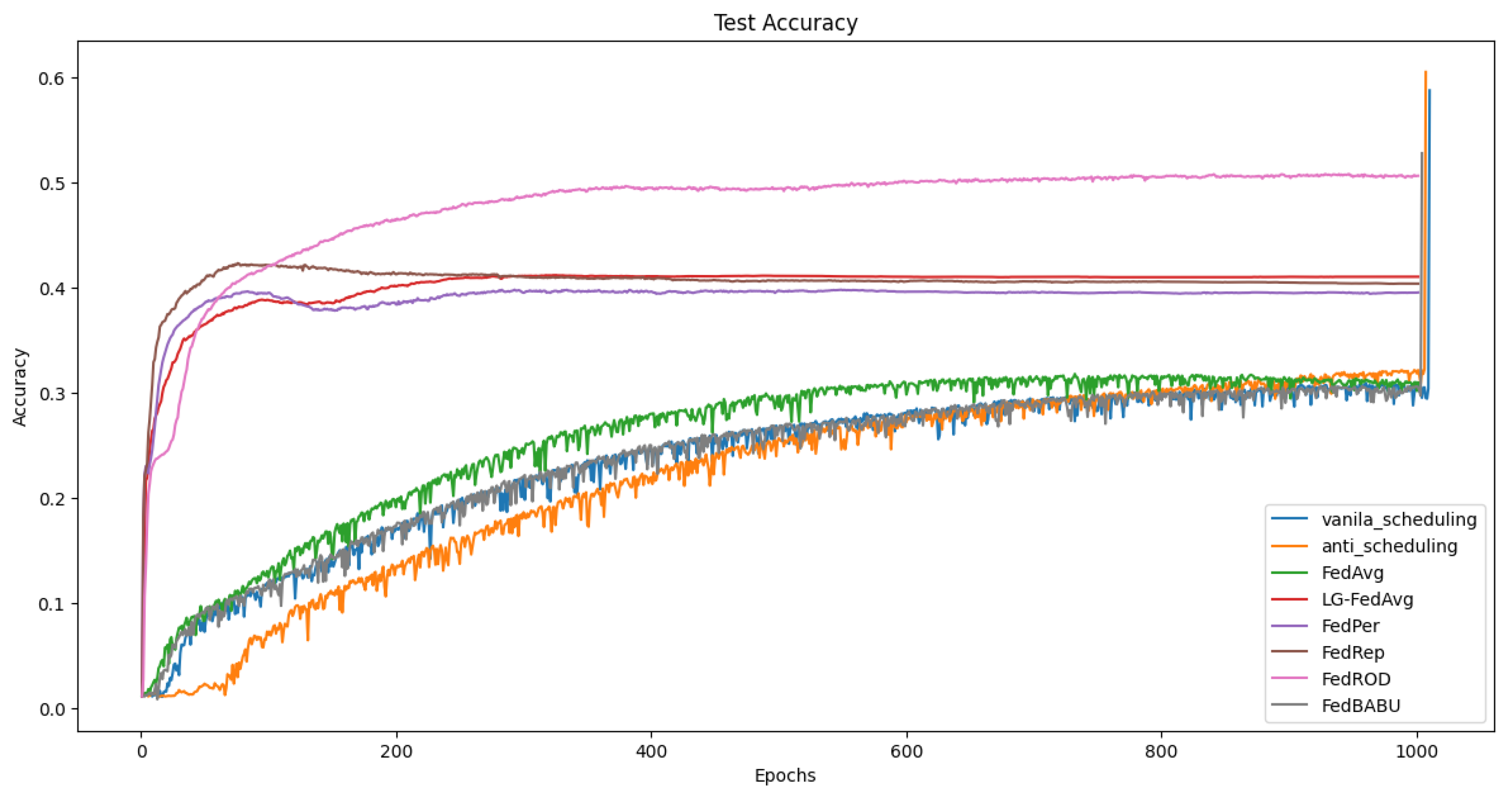
Figure 4 shows the average accuracy of clients on the CIFAR-100 dataset, visualizing the performance of our scheduling algorithms compared to baselines. As can be seen, the earlier round accuracy of our scheduling algorithm is lower than FedAvg and FedBABU, which is attributed to the fact that, in the earlier rounds, not only all base but also head is used, and the training is conducted using only a portion of the unfrozen base layers.
Similarly,
Figure 5 represents the average accuracy of clients on the Tiny-ImageNet dataset. Our scheduling algorithm’s earlier round accuracy is lower than FedAvg and FedBABU, which is consistent with its characteristics. This visualization helps underscore how our scheduling algorithms gradually catch up and potentially surpass other algorithms as the training progresses.
5. Ablation Study
In our ablation study, this work demonstrates the results of varying different parameters. The contents to be covered in the ablation study include:
Comparison of client-specific accuracy
Estimation of computational cost for each algorithm
Effect of layer unfreezing timing on the accuracy
Application of scheduling to the baseline algorithms
5.1. Comparison of Client-Specific Accuracy
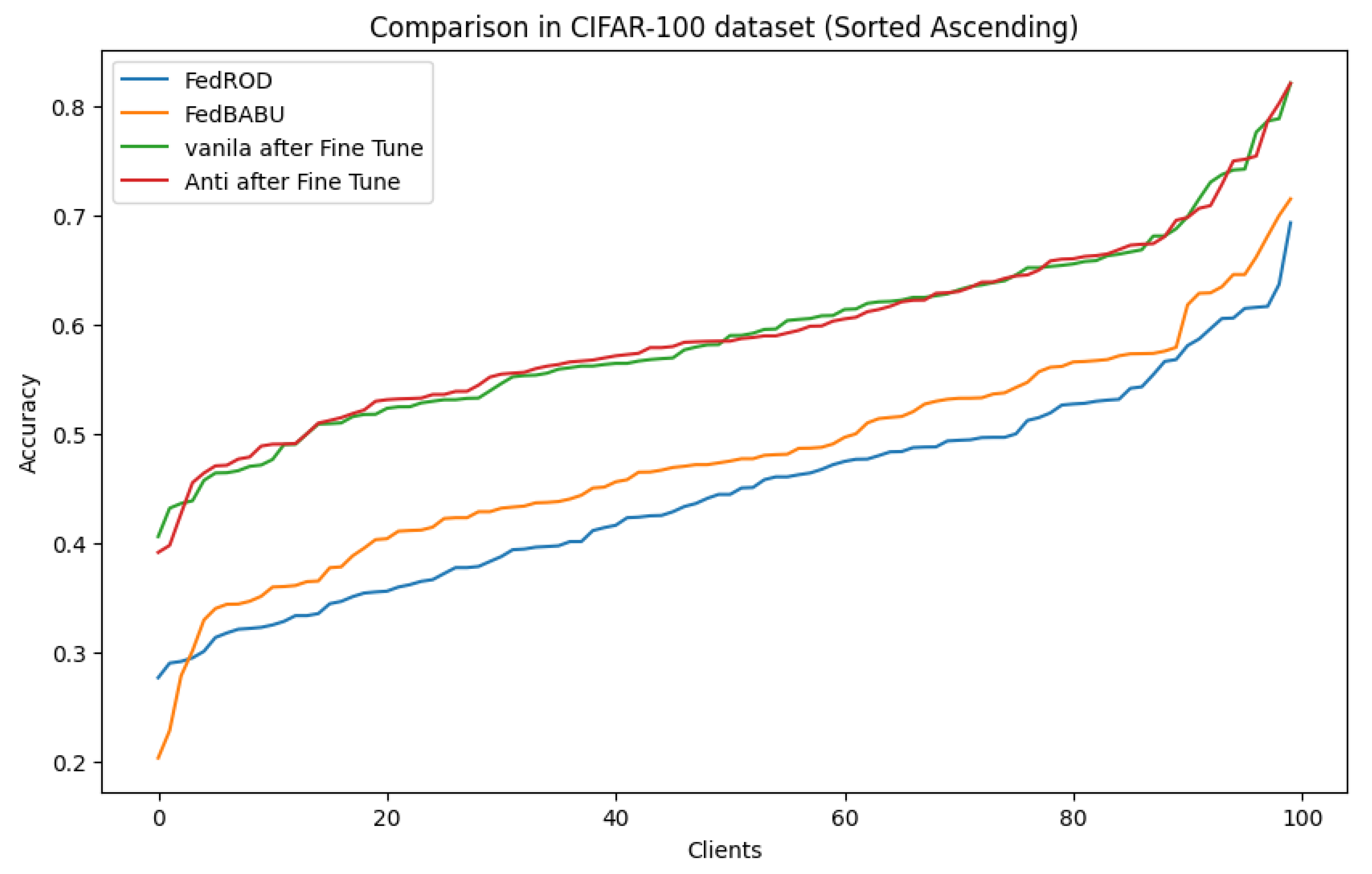
To ensure that accuracy improvements during fine-tuning are not biased or limited to specific clients, This work conducted a comparative analysis of client-specific accuracy between the latest representation learning algorithms and our algorithm. Since the accuracy differences in the MNIST and CIFAR-10 datasets are not significantly pronounced, the comparison was focused on the CIFAR-100 and Tiny-ImageNet datasets. The results demonstrated that the higher average accuracy of our scheduling algorithm was not due to bias towards specific clients but was consistently achieved across all clients.
Figure 6 shows the comparison of client-specific accuracy in the CIFAR-100 dataset. This visualization helps to highlight that our scheduling algorithm achieves consistent accuracy across a spectrum of different clients without favoring any particular group.
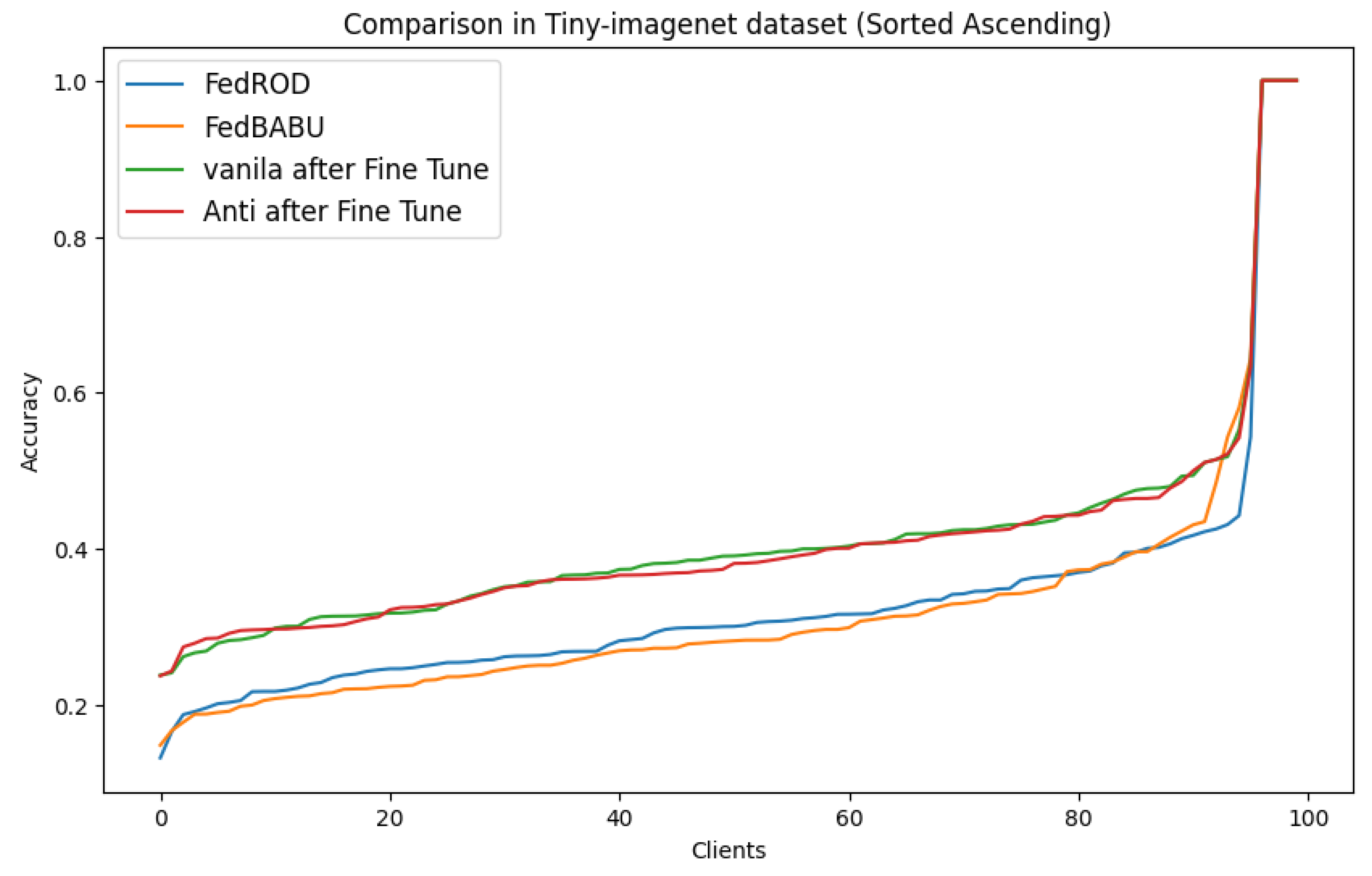
Similarly,
Figure 7 demonstrates the client-specific accuracy in the Tiny-ImageNet dataset. As with CIFAR-100, the visualization confirms that our algorithm manages to maintain high accuracy uniformly across different clients, showcasing its robustness.
5.2. Estimation of Computational Cost for Each Algorithm
In the actual experimental environment, using non-IID data makes it challenging to estimate computational costs. Therefore, this work estimates the computational costs using the number of FLOPs. The number of parameters in each layer is mentioned in
Table 5.
To compare the computational costs of FedAvg, FedBABU, and our scheduling algorithms, this work considers the data processed by each client in an IID (independent and identically distributed) environment. Costs are measured in FLOPs, and for simplicity, all algorithms are assumed to use datasets with an equal pixel count per image. In datasets like MNIST, CIFAR-10, and CIFAR-100, each with a total of 50,000 training data points and 100 clients, each client processes 500 data points. In the setting of our experiments, a batch size of 10 is used, with each client handling 50 batches per epoch.
For FedAvg, as seen in
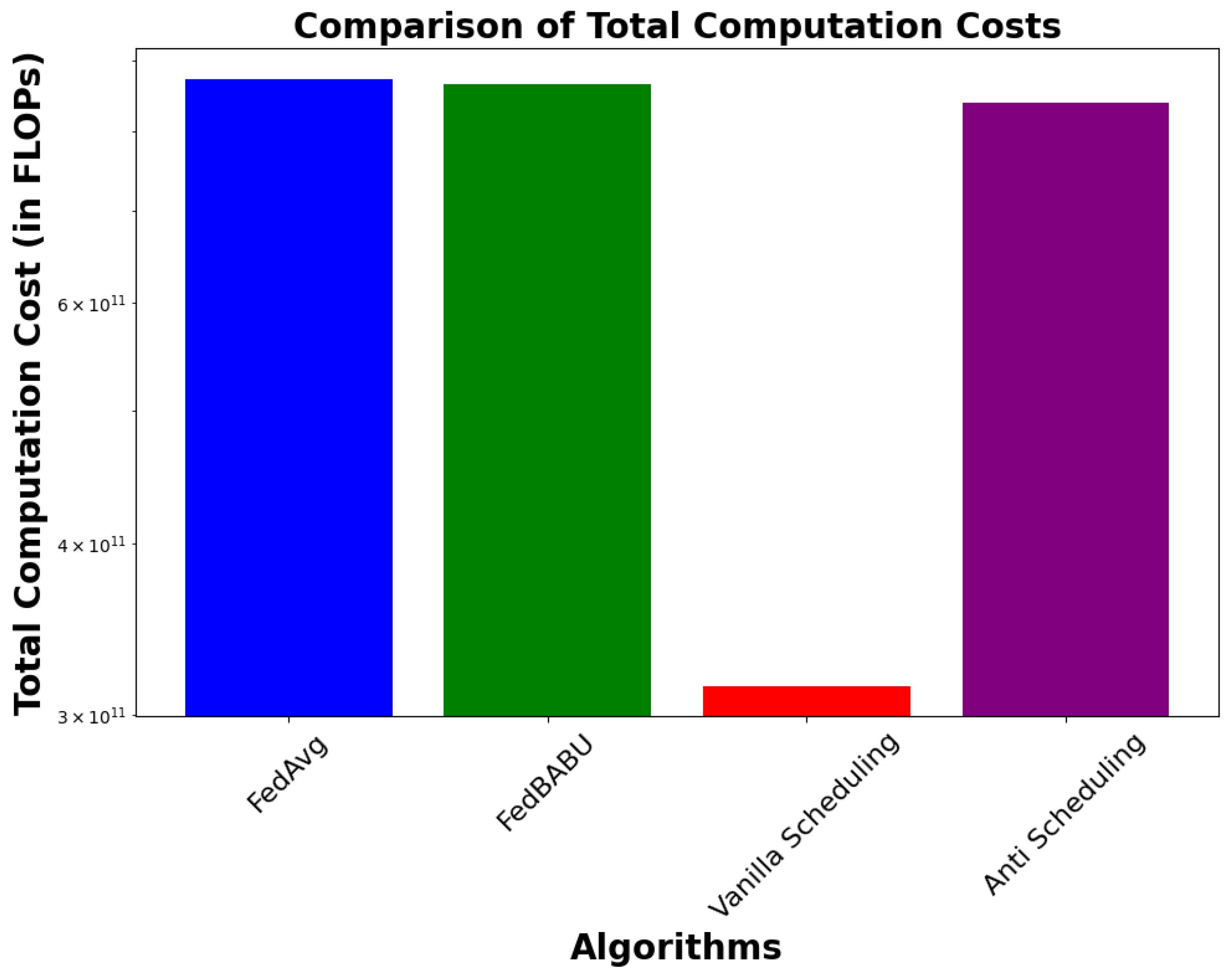
Table 5, the total model parameters are 582,026, and the computational cost per round is 582,026 × 50. Thus, the total computational cost for all clients and all rounds is 873.039 billion FLOPs. In the same environment, the computational cost for FedBABU, considering that the head (fc2) layer parameters are not computed during the training rounds, results in 576,896 learning parameters. Hence, the total computational cost for FedBABU is 865.344 billion FLOPs. Using the same method for our scheduling algorithms, the computed parameters result in 314.912 billion FLOPs for Vanilla Scheduling and 838.880 billion FLOPs for Anti Scheduling, as detailed in
Table 6.
Figure 8 visually compares the computational costs between FedAvg, FedBABU, and our scheduling algorithms. It illustrates how Vanilla Scheduling significantly reduces computational costs in the earlier rounds by updating only the earlier unfreezed layers. This visualization supports the data presented in
Table 6, emphasizing the efficiency of Vanilla Scheduling in managing computational resources.
5.3. Accuracy Differences Due to Changes in Layer Unfreezing Timing
In our two scheduling algorithms, the number of base layers, , is set to 3, leading to parameter unfreezing occurring across three phases. For instance, in Vanilla Scheduling, training proceeds with the unfreezing of the conv1 layer from round to 100. Subsequently, from rounds 100 to 200, both conv1 and conv2 layers are unfrozen for training. Finally, from round 200 to the final global round, all base layers, including conv1, conv2, and fc1, are unfrozen and utilized for training. While the unfreezing points in this paper are arbitrarily set for discussing the effectiveness of layer decoupling, an appropriate scheduling method is required accordingly. Therefore, this work compares the differences in outcomes when unfreezing occurs at rounds 50 and 100 instead of 100 and 200.
In the CIFAR-100 dataset, with the global round
and layer unfreezing round set at
, Vanilla Scheduling achieves an accuracy of 59.52%, while Anti Scheduling achieves 60.06%. However, when the unfreezing round is changed to
, Vanilla Scheduling achieves 58.68%, and Anti Scheduling achieves 59.02% accuracy, slightly lower accuracy. For the Tiny-ImageNet dataset at global round
, with
, Vanilla and Anti Scheduling achieve accuracies of 41.86% and 41.94%, respectively. Changing the unfreezing points to
results in accuracies of 41.23% for Vanilla and 41.63% for Anti Scheduling, which are also slightly lower. The insight gained here is that while the timing of layer unfreezing does not significantly affect accuracy, as seen in
Section 5.2, it has a substantial impact on computational cost. Therefore, setting larger values for
is advantageous where possible.
5.4. Application of Scheduling to Baseline Algorithms
When our scheduling methods were applied to the baseline algorithms, no noticeable improvement was observed in accuracy. This is attributed to the fact that, except for [
20], other algorithms update the head during training rounds, which nullifies the effect of freezing base layers. Furthermore, Vanilla Scheduling achieved a performance similar to the non-scheduled approach, while Anti Scheduling, in particular, resulted in significantly lower accuracy. Therefore, naively applying a dense division of the base layer only for scheduling purposes might inadvertently lead to a negative impact on accuracy. Additionally, if the head layer is utilized for local updates during training, the intended effect of freezing the base layers is effectively nullified.
7. Privacy Considerations and Future Work
While federated learning is designed to enhance privacy by keeping raw data on local devices, recent studies such as ‘Deep Leakage from Gradients [
23]’ and ‘Inverting Gradients [
24]’ have revealed that private information can still be reconstructed from shared model gradients, posing potential privacy risks. Our approach may offer an inherent privacy advantage by limiting the number of base layers actively involved in model updates, thus reducing the amount of sensitive information exposed through gradients. However, to further strengthen privacy protection, future work will explore integrating advanced privacy-preserving techniques, such as differential privacy and secure aggregation, into our framework.
Additionally, Future work will involve visualizing the characteristics of each layer at every global round to track changes as training progresses. This approach is expected to facilitate the introduction of more sophisticated scheduling mechanisms that can reflect the unique data characteristics of clients in heterogeneous environments, thereby enhancing learning efficiency. Dynamic scheduling techniques will also be developed to enable rapid adaptation to new data. Additionally, future work will focus on exploring the trade-off between computational cost and learning accuracy by adjusting the layers involved in training. Furthermore, it will extend to how decoupling techniques can be applied to more complex architectures, such as RNN or Transformer models.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}