
Bridging Data Distribution Gaps: Test-Time Adaptation for Enhancing Cross-Scenario Pavement Distress Detection



Abstract
1. Introduction
2. Methodology
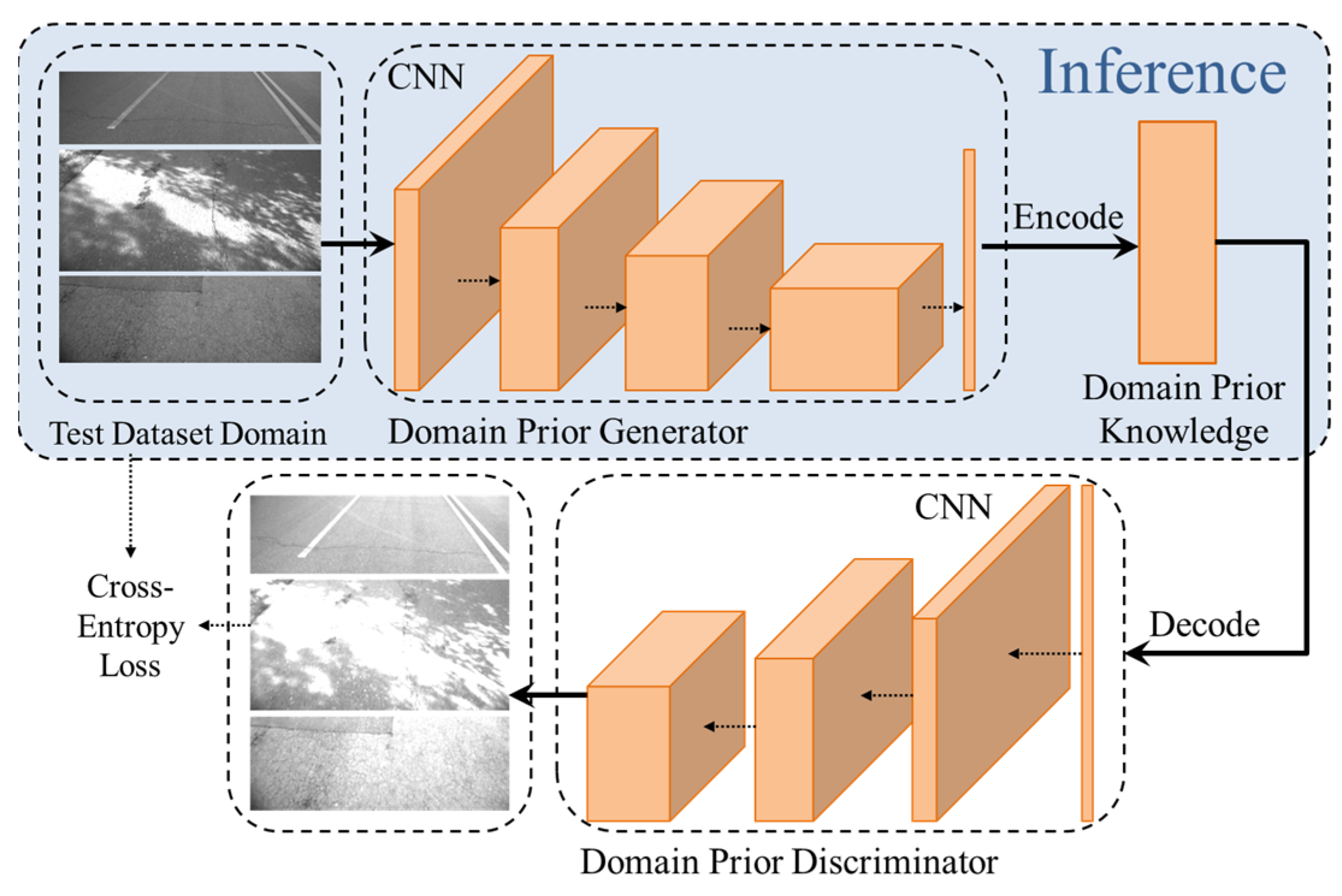
2.1. Domain Prior Knowledge Generator
| Algorithm 1: Training of domain prior knowledge generator | |
| Input: The dataset X composed of data from the source domain and the target domain; Initial Domain Prior Knowledge Generator G; Domain Prior knowledge Discriminator D; Training frequency n; Cross entropy loss function L Output: Trained Domain Prior Knowledge Generator G’, domain prior knowledge ΦX | |
| 1: for epoch in {1, 2,……, n} do 2: for xi in X do 6: loss.backward() 7: G’ = G.optimize() 8: D’ = D.optimize() 9: end 10: end | |
2.2. Viewpoint Transformation
| Algorithm 2: Viewpoint transformation | |
| Input: The Proposal Line Points P, the Input Image X. Output: The Bird’s-eye View Image X’. | |
| 1: for pi in P do 2: li = Hough Transform (pi) 3: L.append (li) 4: for li in L do 5: for lj in L do 6: p = line_intersection (li, lj) 7: P’.append(p) 8: k = KMeans (P’) 9: l1, l2 = Hough Transform (P, k) 10: p1, p2 = line_intersection (l1, x = 0), line_intersection (l2, x = 0) 11: p3, p4 = line_intersection (l1, x = height(X), line_intersection (l2, x = height(X)) 12: X’ = Perspective Transformation (X) | |
2.3. Foreground Focus Module
| Algorithm 3: Foreground focus | |
| Input: The Attention Points P, the Input Image X. Output: The Foreground Focus Image X’. | |
| 1: k = KMeans (P) 2: for i in range(height) do 3: for j in range(width) do 4: wi,j = distance((i, j), k) 5: X’ = X.*w | |
2.4. Adaptive Distribution Normalization
| Algorithm 4: Adaptive distribution normalization | |
| Input: The Distribution Parameters μX, σX, γX, βX, the Input Features X, Distress detection model M. Output: The Adaptive Distribution Normalization Features X’. | |
| 1: 2: O = M(X’) 3: M.optimize() 4: γ.update(), β.update() 5: | |
2.5. Framework Deployment and Application
| Algorithm 5: Whole framework of the test-time adaptation | |
| Input: The pavement distress detection model (trained on the source domain ), a large amount of unlabeled image data (collected on the target domain ), Domain Prior knowledge Generator, Viewpoint Transformation module, Foreground Focus module, Adaptive Distribution Normalization module. Output: The pavement distress detection model ’ (adapted to the target domain ). | |
| 1: , , = Domain Prior knowledge Generator () 2: = Viewpoint Transformation (, ) 3: = Foreground Focus (, ) 4: . Adaptive Distribution Normalization() | |
3. Data Description and Model Evaluation Index
3.1. Data Description
3.2. Model Evaluation Index
4. Results and Analysis
4.1. Validity Experiments
4.2. Ablation Experiments
4.3. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Liu, C.; Shen, Y.; Cao, J.; Yu, S.; Du, Y. RoadID: A Dedicated Deep Convolutional Neural Network for Multipavement Distress Detection. J. Transp. Eng. Part B Pavements 2021, 147, 04021057. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images: Road Damage Detection and Classification. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Coenen, T.B.J.; Golroo, A. A Review on Automated Pavement Distress Detection Methods. Cogent Eng. 2017, 4, 1374822. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks: Deep Learning-Based Crack Damage Detection Using CNNs. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Zakeri, H.; Nejad, F.M.; Fahimifar, A. Image Based Techniques for Crack Detection, Classification and Quantification in Asphalt Pavement: A Review. Arch. Comput. Methods Eng. 2017, 24, 935–977. [Google Scholar] [CrossRef]
- Bai, J.; Li, S.; Zhang, H.; Huang, L.; Wang, P. Robust Target Detection and Tracking Algorithm Based on Roadside Radar and Camera. Sensors 2021, 21, 1116. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement Distress Detection Using Convolutional Neural Networks with Images Captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Gagliardi, V.; Giammorcaro, B.; Bella, F.; Sansonetti, G. Deep Neural Networks for Asphalt Pavement Distress Detection and Condition Assessment. In Proceedings of the Earth Resources and Environmental Remote Sensing/GIS Applications XIV, Amsterdam, The Netherlands, 3–7 September 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12734, pp. 251–262. [Google Scholar]
- Li, Y.; Che, P.; Liu, C.; Wu, D.; Du, Y. Cross-Scene Pavement Distress Detection by a Novel Transfer Learning Framework. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 1398–1415. [Google Scholar] [CrossRef]
- Lin, C.; Tian, D.; Duan, X.; Zhou, J.; Zhao, D.; Cao, D. DA-RDD: Toward Domain Adaptive Road Damage Detection Across Different Countries. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3091–3103. [Google Scholar] [CrossRef]
- Ranjbar, S.; Nejad, F.M.; Zakeri, H. An Image-Based System for Pavement Crack Evaluation Using Transfer Learning and Wavelet Transform. Int. J. Pavement Res. Technol. 2021, 14, 437–449. [Google Scholar] [CrossRef]
- Lei, X.; Liu, C.; Li, L.; Wang, G. Automated Pavement Distress Detection and Deterioration Analysis Using Street View Map. IEEE Access 2020, 8, 76163–76172. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, F.; Liu, W.; Huang, Y. Pavement Distress Detection Using Street View Images Captured via Action Camera. IEEE Trans. Intell. Transp. Syst. 2024, 25, 738–747. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y. Transfer Learning-Based Road Damage Detection for Multiple Countries. arXiv 2020, arXiv:2008.13101. [Google Scholar]
- Peraka, N.S.P.; Biligiri, K.P.; Kalidindi, S.N. Development of a Multi-Distress Detection System for Asphalt Pavements: Transfer Learning-Based Approach. Transp. Res. Rec. 2021, 2675, 538–553. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-Cnn for Object Detection in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3339–3348. [Google Scholar]
- Zhang, Y.; Zhang, L. A Generative Adversarial Network Approach for Removing Motion Blur in the Automatic Detection of Pavement Cracks. Comput. Aided Civ. Eng 2024, 39, 3412–3434. [Google Scholar] [CrossRef]
- Chen, T.; Ren, J. Integrating GAN and Texture Synthesis for Enhanced Road Damage Detection. IEEE Trans. Intell. Transp. Syst. 2024, 25, 12361–12371. [Google Scholar] [CrossRef]
- Ren, R.; Shi, P.; Jia, P.; Xu, X. A Semi-Supervised Learning Approach for Pixel-Level Pavement Anomaly Detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10099–10107. [Google Scholar]
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative Adversarial Network for Road Damage Detection. Comput. Aided Civ. Eng 2021, 36, 47–60. [Google Scholar] [CrossRef]
- Salaudeen, H.; Çelebi, E. Pothole Detection Using Image Enhancement GAN and Object Detection Network. Electronics 2022, 11, 1882. [Google Scholar] [CrossRef]
- Fan, R.; Wang, H.; Bocus, M.J.; Liu, M. We Learn Better Road Pothole Detection: From Attention Aggregation to Adversarial Domain Adaptation. In Computer Vision–ECCV 2020 Workshops; Bartoli, A., Fusiello, A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12538, pp. 285–300. ISBN 978-3-030-66822-8. [Google Scholar]
- Liu, Z.; Pan, S.; Gao, Z.; Chen, N.; Li, F.; Wang, L.; Hou, Y. Automatic Intelligent Recognition of Pavement Distresses with Limited Dataset Using Generative Adversarial Networks. Autom. Constr. 2023, 146, 104674. [Google Scholar] [CrossRef]
- Li, Z.; Shi, S.; Schiele, B.; Dai, D. Test-Time Domain Adaptation for Monocular Depth Estimation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4873–4879. [Google Scholar]
- Segu, M.; Schiele, B.; Yu, F. Darth: Holistic Test-Time Adaptation for Multiple Object Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 9717–9727. [Google Scholar]
- Ahmed, S.M.; Niloy, F.F.; Raychaudhuri, D.S.; Oymak, S.; Roy-Chowdhury, A.K. MeTA: Multi-Source Test Time Adaptation. arXiv 2024, arXiv:2401.02561. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Dosovitskiy, A. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Arya, D.; Maeda, H.; Sekimoto, Y.; Omata, H.; Ghosh, S.K.; Toshniwal, D.; Sharma, M.; Pham, V.V.; Zhong, J.; Al-Hammadi, M. RDD2022-The Multi-National Road Damage Dataset Released through CRDDC’2022. figshare 2022, 10, m9. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wang, J.; Chen, Y.; Yu, H.; Huang, M.; Yang, Q. Easy Transfer Learning by Exploiting Intra-Domain Structures. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1210–1215. [Google Scholar]
- Li, P.; Tuzhilin, A. DDTCDR: Deep Dual Transfer Cross Domain Recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; ACM: Houston, TX, USA, 2020; pp. 331–339. [Google Scholar]
- Liu, B.; Yu, H.; Qi, G. Graftnet: Towards Domain Generalized Stereo Matching with a Broad-Spectrum and Task-Oriented Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13012–13021. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Country | Image Source | Code | Number of Labeled Images | Image Resolution | Viewpoint | Road Type |
|---|---|---|---|---|---|---|---|
| Source domain/Model training | China | Vehicles with HD camera | CHN_C | 65,748 | 1628 × 1236 | Oblique view | Urban road |
| Target domain/Cross-scene transfer performance evaluation | Norway | Vehicles with HD camera | NO_C | 8161 | 3650 × 2044 | Extra-wide view | Expressways and county roads |
| Japan | Vehicles with smartphone | JPN_S | 10,506 | 600 × 600 | Wide view | Urban road and country roads | |
| United States | Google Street View images | US_G | 4805 | 640 × 640 | Wide view | Urban road and highway | |
| China | Motorbikes with camera | CHN_M | 1977 | 512 × 512 | Oblique view | Urban road | |
| China | Drones with camera | CHN_D | 2401 | 512 × 512 | Top-down view | Urban road |
| Dataset | Number of Longitudinal Crack | Number of Transverse Crack | Number of Alligator Crack | Number of Potholes | Number of Images Selected |
|---|---|---|---|---|---|
| CHN_C | 10,463 | 8782 | 6472 | 3247 | 10,000 |
| NO_C | 2147 | 849 | 289 | 271 | 2000 |
| JPN_S | 1275 | 1142 | 1052 | 863 | 2000 |
| US_G | 2753 | 1475 | 357 | 58 | 2000 |
| CHN_M | 2678 | 1096 | 641 | 235 | 1977 |
| CHN_D | 1204 | 943 | 251 | 70 | 2000 |
| YOLO/FasterRCNN | TTA-YOLO/TTA-FasterRCNN | Transfer-YOLO/ Transfer-FasterRCNN | |
|---|---|---|---|
| Train Dataset | Labeled Standard Dataset | Labeled Standard Dataset + Unlabeled Comprehensive Dataset | Labeled Standard Dataset + Labeled Comprehensive Dataset |
| Test Dataset | Comprehensive Test Dataset | ||
| Distress Types | YOLO | FasterRCNN | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision/% | Recall/% | AP/% | F1/% | Precision/% | Recall/% | AP/% | F1/% | |
| Longitudinal Crack | 35.14 | 38.26 | 30.25 | 36.63 | 40.18 | 45.46 | 40.27 | 42.66 |
| Transverse Crack | 32.23 | 37.18 | 30.85 | 34.53 | 42.34 | 45.24 | 40.64 | 45.02 |
| Alligator Crack | 70.28 | 77.23 | 72.43 | 73.59 | 55.78 | 60.28 | 55.98 | 59.27 |
| Pothole | 30.91 | 24.29 | 25.91 | 27.20 | 39.24 | 33.23 | 35.17 | 30.36 |
| Average | 42.14 | 44.24 | 39.86 | 43.16 | 44.39 | 46.05 | 43.02 | 44.51 |
| Distress Types | TTA-YOLO | TTA-FasterRCNN | ||||||
| Precision/% | Recall/% | AP/% | F1/% | Precision/% | Recall/% | AP/% | F1/% | |
| Longitudinal Crack | 66.24 | 59.28 | 57.32 | 62.57 | 67.13 | 58.37 | 64.39 | 62.44 |
| Transverse Crack | 60.18 | 58.46 | 57.80 | 59.31 | 63.74 | 62.31 | 60.42 | 63.02 |
| Alligator Crack | 83.12 | 80.54 | 80.88 | 81.81 | 80.26 | 82.54 | 77.35 | 81.38 |
| Pothole | 71.02 | 51.6 | 44.96 | 59.77 | 73.27 | 65.46 | 54.23 | 69.15 |
| Average | 70.14 | 62.47 | 60.24 | 66.08 | 71.10 | 67.17 | 64.10 | 69.08 |
| Distress Types | Transfer-YOLO | Transfer-FasterRCNN | ||||||
| Precision/% | Recall/% | AP/% | F1/% | Precision/% | Recall/% | AP/% | F1/% | |
| Longitudinal Crack | 70.48 | 63.18 | 60.52 | 66.63 | 71.23 | 59.85 | 65.41 | 65.05 |
| Transverse Crack | 67.36 | 65.24 | 62.84 | 66.28 | 68.52 | 65.42 | 68.50 | 66.93 |
| Alligator Crack | 85.38 | 82.62 | 86.31 | 83.98 | 85.94 | 84.37 | 88.93 | 85.15 |
| Pothole | 78.46 | 54.08 | 45.81 | 64.03 | 79.35 | 75.28 | 51.44 | 77.26 |
| Average | 75.34 | 68.89 | 70.35 | 71.97 | 76.26 | 71.23 | 68.57 | 73.66 |
| Model | Precision/% | Recall/% | mAP/% | F1/% |
|---|---|---|---|---|
| YOLO | 42.14 | 44.24 | 39.86 | 43.16 |
| YOLO + VT | 54.38 | 51.30 | 48.45 | 52.80 |
| YOLO + FF | 50.36 | 50.80 | 45.27 | 50.58 |
| YOLO + AN | 50.29 | 50.84 | 44.26 | 50.56 |
| YOLO + VT + FF | 65.82 | 57.02 | 55.35 | 61.10 |
| YOLO + VT + AN | 66.26 | 53.78 | 49.34 | 59.37 |
| YOLO + FF + AN | 62.27 | 54.85 | 48.30 | 58.32 |
| YOLO + VT + FF + AN | 70.14 | 62.47 | 60.24 | 66.08 |
| Transfer-YOLO | 75.34 | 68.89 | 70.35 | 71.97 |
| FasterRCNN | 44.39 | 46.05 | 43.02 | 45.20 |
| FasterRCNN + VT | 54.61 | 57.47 | 52.27 | 56.00 |
| FasterRCNN + FF | 49.93 | 52.85 | 47.53 | 51.35 |
| FasterRCNN + AN | 50.34 | 51.37 | 47.02 | 50.85 |
| FasterRCNN + VT + FF | 65.86 | 63.29 | 58.68 | 64.55 |
| FasterRCNN + VT + AN | 66.37 | 64.63 | 55.26 | 65.49 |
| FasterRCNN + FF + AN | 63.65 | 60.26 | 54.18 | 61.91 |
| FasterRCNN + VT + FF + AN | 71.10 | 67.17 | 64.10 | 69.08 |
| Transfer-FasterRCNN | 76.26 | 71.23 | 68.57 | 73.66 |
| Model | Precision/% | Recall/% | mAP/% | F1/% | Time/s |
|---|---|---|---|---|---|
| YOLO | 42.14 | 44.24 | 39.86 | 43.16 | 0.0003 |
| FasterRCNN | 44.39 | 46.05 | 43.02 | 45.20 | 0.2500 |
| CycleGAN | 52.16 | 53.34 | 52.17 | 52.74 | 0.0150 |
| EasyTL | 50.56 | 50.19 | 48.27 | 50.37 | 0.0082 |
| DDTCDR | 38.27 | 36.34 | 34.29 | 37.28 | 0.0075 |
| GraftNet | 33.95 | 33.64 | 34.25 | 33.79 | 0.0086 |
| TTA-YOLO | 70.14 | 62.47 | 60.24 | 66.08 | 0.0230 |
| TTA-FasterRCNN | 71.10 | 67.17 | 64.10 | 69.08 | 0.4300 |
| Transfer-YOLO | 75.34 | 68.89 | 70.35 | 71.97 | 0.0003 |
| Transfer-RCNN | 76.26 | 71.23 | 68.57 | 73.66 | 0.2500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; Li, Y.; Du, M.; Li, L.; Wu, D.; Yu, J. Bridging Data Distribution Gaps: Test-Time Adaptation for Enhancing Cross-Scenario Pavement Distress Detection. Appl. Sci. 2024, 14, 11974. https://doi.org/10.3390/app142411974
Hou Y, Li Y, Du M, Li L, Wu D, Yu J. Bridging Data Distribution Gaps: Test-Time Adaptation for Enhancing Cross-Scenario Pavement Distress Detection. Applied Sciences. 2024; 14(24):11974. https://doi.org/10.3390/app142411974
Chicago/Turabian StyleHou, Yushuo, Yishun Li, Mengyun Du, Lunpeng Li, Difei Wu, and Jiang Yu. 2024. "Bridging Data Distribution Gaps: Test-Time Adaptation for Enhancing Cross-Scenario Pavement Distress Detection" Applied Sciences 14, no. 24: 11974. https://doi.org/10.3390/app142411974
APA StyleHou, Y., Li, Y., Du, M., Li, L., Wu, D., & Yu, J. (2024). Bridging Data Distribution Gaps: Test-Time Adaptation for Enhancing Cross-Scenario Pavement Distress Detection. Applied Sciences, 14(24), 11974. https://doi.org/10.3390/app142411974