1. Introduction
In recent years, deep learning models have shown impressive performance across a wide range of tasks, from image classification to object detection and more. However, they are also known to be vulnerable to adversarial attacks—small perturbations to input data that can cause models to make incorrect predictions. Computer vision tasks, such as object detection or segmentation, are a major target of such attacks [
1]. This vulnerability poses significant risks, especially in security-critical applications such as autonomous driving [
2], surveillance, and healthcare.
Much of the research on adversarial attacks has focused on digital perturbations, where perturbations are applied directly to digital images or signals before being processed by the model. These digital adversarial attacks have been extensively studied, and various strategies have been developed to improve their transferability—the ability of adversarial examples to fool multiple models, even those that were not used during the attack generation. Techniques like ensemble training, input diversity, and feature alignment have all contributed to enhancing the transferability of digital attacks.
However, when it comes to physical adversarial attacks, the problem becomes significantly more complex. Unlike digital attacks, physical attacks must work in real-world scenarios, where the adversarial object or pattern can be seen from different viewing angles, under various lighting conditions, and with potential obstructions [
3]. This introduces additional challenges, such as maintaining robustness to environmental variations, ensuring that perturbations remain effective across different physical conditions, and managing occlusions and distortions that can occur when the adversarial object is captured through a camera.
Despite the growing interest in physical adversarial attacks, there is a noticeable gap in research focused on improving their transferability across multiple models. The current approaches for generating physical adversarial examples often focus on attacking a single model, which limits their effectiveness when deployed against different models in real-world environments. To the best of our knowledge, existing studies have not thoroughly explored methods to enhance the transferability of physical adversarial attacks.
In this work, we aim to address this gap by demonstrating that the transferability of physical adversarial attacks can be significantly improved by training on multiple versions of the YOLO object detection model. Our contributions are threefold: (1) we introduce a multi-model adversarial training approach that enhances the generalization of adversarial textures across diverse object detection models, including one-stage, two-stage, and transformer-based architectures; (2) we demonstrate the effectiveness of our approach through comprehensive experiments, showing a significant improvement in the transferability of adversarial patterns and achieving a 50% reduction in AP@0.5 compared to single-model training; and (3) we provide an in-depth analysis of the factors affecting the transferability of physical adversarial attacks, offering insights into how different variables influence attack success rates.
2. Related Works
2.1. Digital Adversarial Attacks
Research in image classification has yielded a variety of adversarial attack techniques aimed at exploiting neural networks’ weaknesses through carefully designed perturbations [
4,
5]. Gradient-based methods, such as the Fast Gradient Sign Method (FGSM) [
4] and its iterative versions [
6], exploit the gradients of the loss function with respect to the input to craft adversarial examples. To improve invisibility, reference [
7] exploited frequency characteristics by analyzing network sensitivity in the frequency domain and leveraging human visual properties.
Object detection systems typically consist of a backbone network for feature extraction and a head for bounding box regression and classification. This architectural complexity presents additional challenges for adversarial attacks, as perturbations must now affect both the classification and localization components. Early attacks on object detectors focused on white box settings (i.e., for a known detector model), targeting specific parts of the detection pipeline, such as the region proposal network in two-stage detectors like Faster R-CNN [
8]. While these methods exhibited some degree of transferability across different detector architectures, their effectiveness was often limited. To enhance transferability in the digital domain, researchers adapted techniques from classification attacks. Approaches such as attacking intermediate feature representations [
9] and employing input transformations such as scaling and translation [
10] have been proposed to create perturbations that generalize better across models.
Most techniques that improve transferability in digital attacks do not translate directly to physical scenarios. To our knowledge, there is limited research specifically focused on improving the transferability of physical adversarial attacks. One notable exception is the work by Zhang et al. [
11], who enhanced transferability by manipulating model-specific attention patterns. Their method involves smoothing multilayer attention maps and altering attention distributions using a foreground–background separation mask, focusing on localized patterns like the top surface of a vehicle for practical deployment in UAV scenarios. This approach achieves a mean AP@0.5 of approximately 0.4.
Similarly, recent research by Duan et al. [
12] introduced a corruption-assisted framework that employs naturalistic pattern corruptions—such as light spots and shadows—around target objects during training. This strategy pulls the image distribution closer to the decision boundaries of surrogate models. Combined with an MLP-based generator for perturbation mapping, their method improves transferability across both transformer-based and CNN detection models, achieving around 0.7 AP@0.5 for transformers and 0.4 AP@0.5 for CNNs.
In contrast, our approach significantly improves the transferability; our method achieves an AP@0.5 detection score of 0.0972. This score is over 50% lower than textures trained on single models alone and substantially lower than previous methods, highlighting the effectiveness of our approach in improving adversarial transferability across models.
2.2. Physical Adversarial Attacks
Adversarial attacks on object detection systems have evolved significantly, progressing from digital to physical-world scenarios. Early efforts primarily utilized adversarial patches to deceive detectors, such as attaching printed patterns to evade person detection systems [
13,
14]. These methods often focused on simple scenarios and human subjects.
In vehicle-based applications, initial approaches included attaching screens to vehicles that displayed dynamically adjusted adversarial patterns based on the camera’s viewpoint [
15]. A more sophisticated approach explored black box methods that approximated rendering and gradient estimation to generate adversarial patterns without detailed system knowledge [
16]. White box attacks leveraging model parameters also emerged, utilizing techniques like projecting patterns onto 3D models [
17,
18]. However, issues like projection errors on complex surfaces prompted the development of more accurate texture mapping.
The introduction of differentiable renderers allowed for the accurate mapping of textures onto 3D models, enabling the end-to-end optimization of adversarial textures [
19]. Approaches using partial coverage with patches aimed to suppress detection attention maps but were less effective than full-body textures [
20]. Subsequent methods demonstrated that full-coverage adversarial patterns significantly improve robustness and effectiveness [
21,
22].
Recent advancements have focused on generating more natural and customizable adversarial textures. Techniques utilizing diffusion models allow for the creation of diverse and realistic patterns [
23,
24]. While these methods enhance the visual appeal of the adversarial patterns and exhibit some degree of transferability, their attack performance still lags behind the results achieved for the models they were specifically trained on.
3. Materials and Methods
3.1. Use of AI
In preparing this manuscript, we used ChatGPT-4o from OpenAI to enhance the clarity, grammar, and overall readability of the text. Specifically, ChatGPT was used for refining the sentence structure, maintaining consistent language quality, and making the content more accessible to an English-speaking audience. All scientific concepts, analyses, and conclusions are solely the result of the authors’ original work; the AI tool was used exclusively for linguistic refinement and did not contribute to the development of scientific content or data interpretation.
3.2. Problem Statement
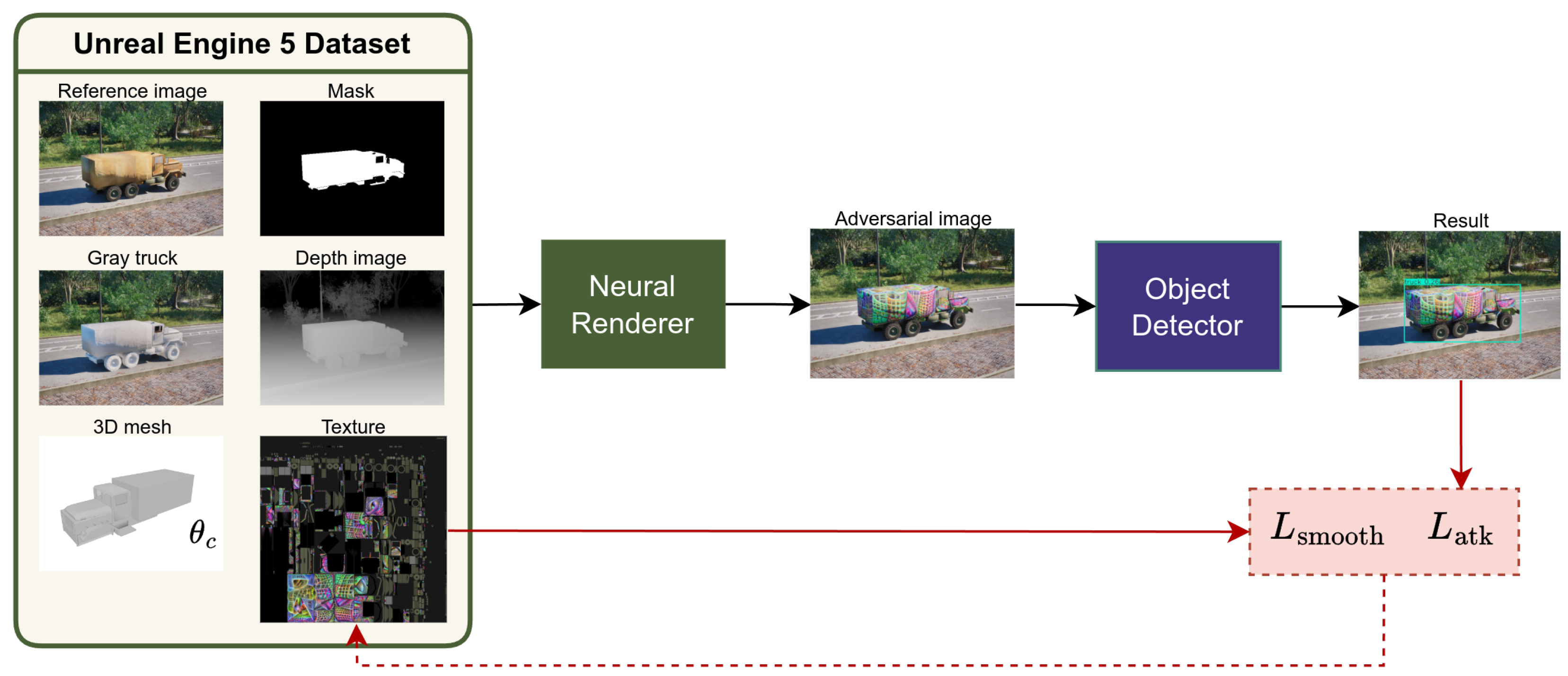
We aimed to generate adversarial textures for a 3D truck model in Unreal Engine 5 (UE5) that minimized the detection confidence in object detection systems. For clarity, first we present the methodology where a single detection model was targeted. Then, the methodology is expanded for the multi-model problem.
3.3. Overview of the TACO Framework
In this work, we employed the Truck Adversarial Camouflage Optimization (TACO) framework to generate adversarial textures for 3D models within a photorealistic rendering environment [
25]. This method enabled the creation of physically realizable adversarial examples. This approach used a dataset obtained from UE5, which included photorealistic reference images of a scene with a truck, depth maps providing distance information, binary masks identifying the truck’s pixels available for texture generation, and camera parameters detailing the camera’s pose and orientation. An additional input image was a render of the truck with a neutral gray texture to capture illumination and lighting conditions.
A neural renderer was utilized to render the truck with adversarial textures in a photorealistic manner. This neural renderer allowed us to generate high-fidelity images of the truck with adversarial patterns while maintaining differentiability in the example generation pipeline.
The core of this method involved optimizing the adversarial texture to minimize the detection confidence scores of the target object detection model for any objects overlapping with the truck. This was achieved by iteratively updating the texture based on the feedback from the detection model, effectively “camouflaging” the truck from being detected. For a more detailed explanation of the framework and the underlying optimization process, the reader is referred to our previous work [
25].
3.4. Problem Setup
The texture optimization is illustrated in
Figure 1. Let
be the dataset, where the elements represent the following for each sample, respectively: a reference photorealistic image, a gray-textured truck image, a depth map, a binary mask, and camera parameters. Our objective was to find the adversarial texture
that minimized the detection confidence scores produced by the detection model
F:
We utilized a neural renderer
R to produce photorealistic images with the adversarial texture. The renderer
R was trained to replicate the rendering process of Unreal Engine 5 (UE5). It employed a differential rendering approach, where the input consisted of the mesh, the adversarial texture
, and the camera parameters
. This setup generated a raw image, which was then refined by a neural network to produce the final photorealistic output, closely resembling images generated by UE5. For a more detailed description, see [
25]. The enhanced image
is generated as
This image was then combined with the background using the binary mask
M to create the final adversarial image
:
3.5. Losses
To minimize the detection confidence, we defined a loss function that combined class confidence, Intersection over Union (IoU), and smoothness terms.
The class confidence term,
, was designed to reduce the confidence scores of bounding boxes overlapping with the truck. For this, we computed the Intersection over Prediction (IoP) between each predicted bounding box
and the ground truth box
:
and selected the set
of boxes where
. The class loss is then
where
is the confidence score for class
c in box
i, and
C is the number of classes.
The IoU term,
, penalizes a high overlap between predicted and ground truth boxes in the set
, defined for boxes where
:
To ensure the adversarial texture was smooth and physically realizable, we utilized the convolutional smooth loss [
25], termed
. For each pixel
in the texture, we calculated a variance:
and the smoothness loss is then
where
W and
H are the texture’s width and height. The total attack loss combines these terms, weighted by factors
and
:
3.6. Multi-Model Optimization Procedure
We extended our single-model optimization framework to a multi-model setting. Let
represent a set of
N object detection models (e.g., YOLOv5, YOLOv8, and YOLOv3). Our goal was to generate an adversarial texture
that minimized the detection confidence across all models in this set. To achieve this, we redefined our total loss
as the mean attack loss across all models. Specifically, the attack loss
for each model
was computed individually and then averaged to produce a unified objective function:
where
represents the attack loss for model
, as defined in Equation (
9) for the single-model setup. This multi-model attack loss formulation encouraged the adversarial texture
to minimize the detection confidence consistently across all models.
3.7. Implementation Details
The neural renderer was configured to produce images at a resolution of
pixels. We set the learning rate to
and used the Adam optimizer with parameters of
and
. The textures were trained on 17,000 images of trucks captured across 17 different locations, and we evaluated the experiments on 8000 images of trucks from 8 unseen positions. All images were taken during the day, though varying illumination at some positions—due to shadows—resulted in changing lighting conditions. At each position, the truck was viewed from multiple angles and distances, ranging from 5 to 35 m. The viewing angles were spread across a half-sphere, with azimuth angles spanning from
to
and elevation angles ranging from
to
. The batch size was set to 6. The weights for the loss terms were set as follows:
for the Intersection over Union (IoU) loss and
for the smoothness loss. These hyperparameters were selected based on extensive experimentation and are consistent with the settings used in our previous work [
25]. The threshold values for the IoP and IoU were
and
, respectively. The optimization process ran for 6 epochs, which was sufficient for convergence in all cases.
4. Experiments
We conducted a series of experiments to evaluate the transferability of adversarial textures across different object detection models and to evaluate the effectiveness of multi-model optimization. Our experiments focused on the Average Precision at an IoU threshold of 0.5 (AP@0.5), which reflects the detection performance of the models on truck images with adversarial textures.
4.1. Evaluated Models
For an extensive assessment of adversarial texture transferability, we evaluated a diverse set of state-of-the-art object detection models. This selection offers a balanced representation of state-of-the-art detection methodologies, encompassing both real-time optimized and accuracy-focused designs.
Table 1 provides a detailed overview of the models evaluated, categorized by their underlying architecture type.
4.2. Baseline Textures Performance
To establish a reference point, we evaluated three standard textures:
Base Texture: A neutral, uniform military green texture.
Naive Texture: A conventional military camouflage pattern.
Random Texture: A texture with random pixel values.
The standard textures (
Figure 2) were applied to the truck model and evaluated on the YOLOv8 model family (
Table 2). In addition to these baseline textures, the figure also include a TACO-optimized camouflage texture, which was trained on the YOLOv8x model. Larger YOLOv8 models exhibited higher detection performance on these baseline textures.
4.3. Transferability Across Model Sizes Within the YOLO Family
We explored how adversarial textures optimized on models of different sizes transferred across the YOLOv8 and YOLOv5 families, which include nano (n), small (s), medium (m), large (l), and extra-large (x) variants. Textures were optimized using individual models and then evaluated across all sizes within the same family and across the other family.
Figure 3 illustrates the AP@0.5 results in a grid map, where each row represents a texture trained on a specific source model, and each column represents the target model on which the texture was evaluated.
From the heatmaps in
Figure 3, we observe a clear trend: textures optimized on smaller models (e.g., YOLOv8n) are more effective at attacking smaller models but their effectiveness decreases as the target model size increases. Conversely, textures optimized on larger models (e.g., YOLOv8x) are more effective against larger models but less so against smaller models. This trend was consistent across both the YOLOv8 and YOLOv5 families and persisted even when textures were evaluated across different model families. This suggests a strong correlation between the size of the source model used for optimization and the target model’s vulnerability to the adversarial texture.
4.4. Effectiveness of Multi-Model Optimization
Building on these insights, we investigated whether optimizing textures using multiple models simultaneously could enhance their transferability across different model sizes. We performed experiments where textures were optimized using combinations of YOLOv8 models of varying sizes and then evaluated across all YOLOv8 variants.
Table 3 presents the AP@0.5 results for each combination.
The results in
Table 3 demonstrate that multi-model optimization significantly improved the adversarial textures’ effectiveness across all models. For instance, a texture optimized on a combination of YOLOv8x, YOLOv8m, and YOLOv8n achieved the lowest average AP@0.5, indicating a more effective attack across different model sizes. This suggests that incorporating models of varying sizes during optimization leads to textures that generalize better and are more robust against a range of target models.
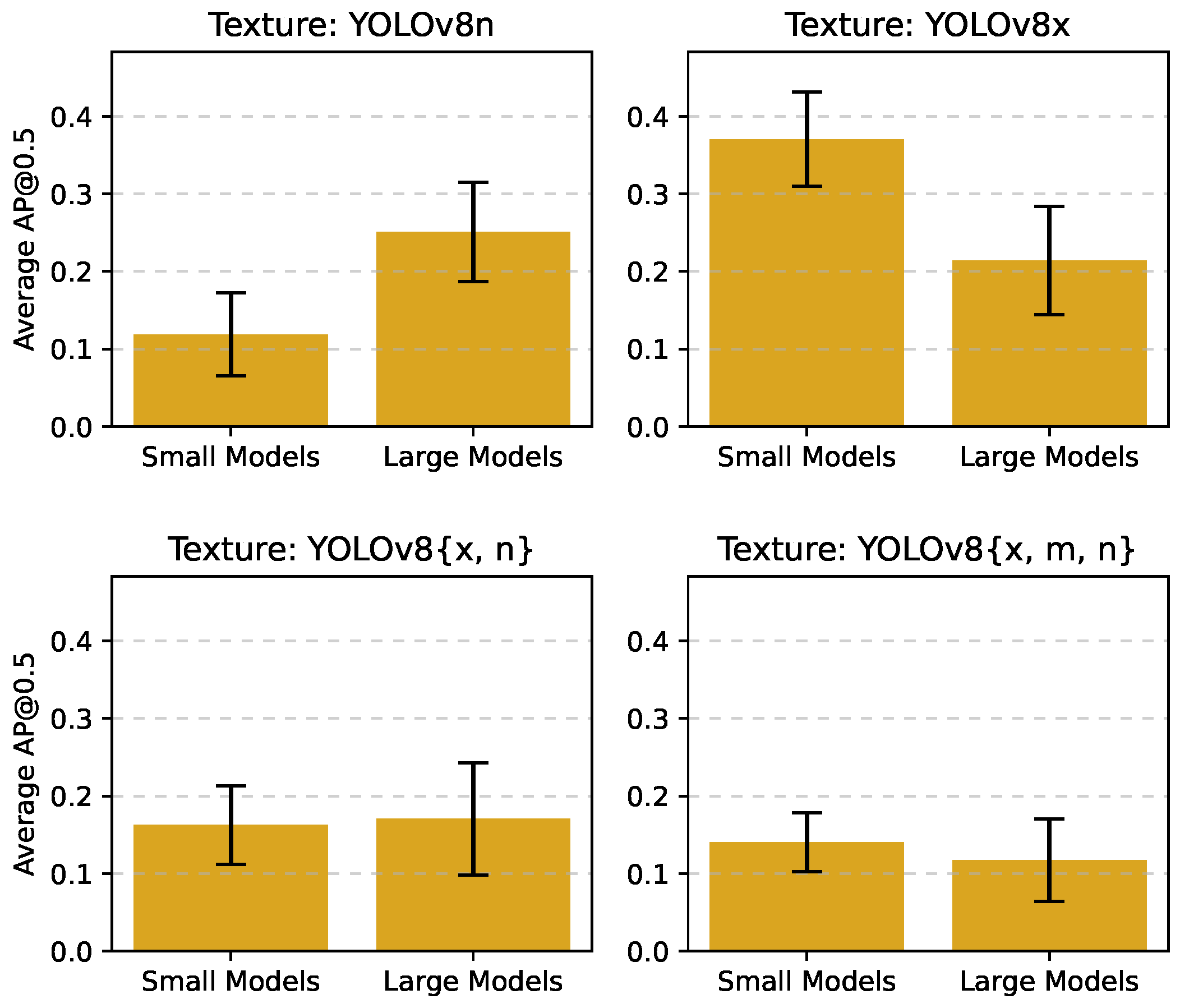
4.5. Generalization to Other Detection Models
To assess whether the observed trends hold for models beyond the YOLO family, we extended our experiments to include other one-stage and transformer-based object detection models. We categorized these models into small and large sizes, similarly to the YOLO models.
Table 4 shows the backbones and parameter counts for each model in this evaluation, where we specifically selected the smallest and largest available model variants.
Table 5 and
Table 6 present the AP@0.5 results for textures trained on different YOLOv8 models when evaluated on these black box models.
The results indicate that the trend observed with YOLO models extends to other detection architectures. Textures optimized on YOLOv8n are more effective against smaller models, while those optimized on YOLOv8x are more effective against larger models. Notably, the texture optimized on the combination YOLOv8x, YOLOv8m, YOLOv8n performs consistently well across both small and large models, achieving lower AP@0.5 scores compared to textures optimized on single models.
To visualize this comparison, we present
Figure 4, which shows the mean AP@0.5 of the textures when evaluated on small versus large models.
4.6. Best Model Combination for Highest Transferability
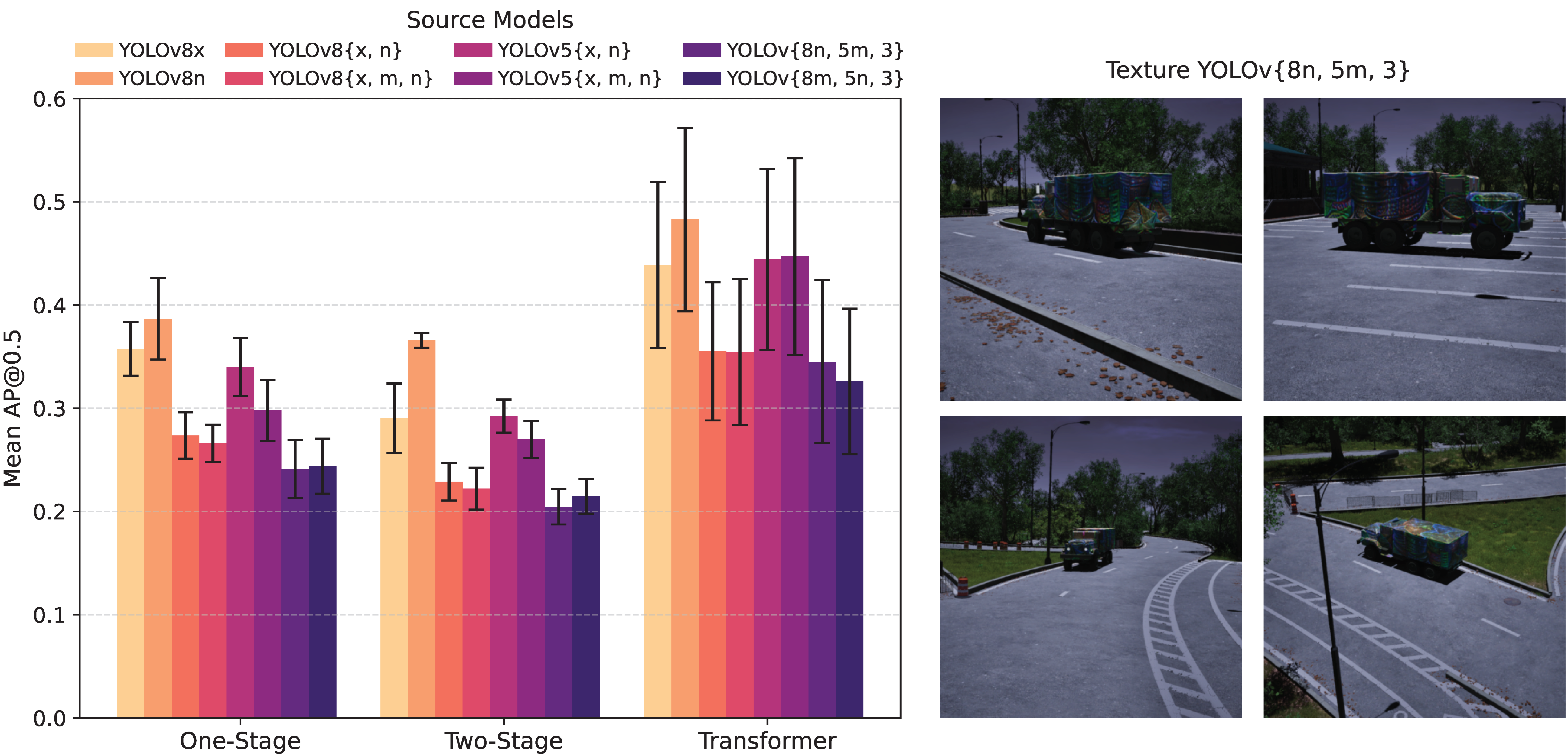
To identify the most effective combination of models for optimizing adversarial textures with high transferability, we experimented with various combinations of YOLOv8, YOLOv5, and YOLOv3 models.
Table 7 presents the AP@0.5 performance of these adversarial textures across a diverse set of object detection architectures, including one-stage, two-stage, and transformer-based models.
Figure 5 presents images of the rendered truck with various textures optimized using different model combinations. The resulting textures demonstrate both recurring structural patterns and a diverse color palette, highlighting the extensive solution space for adversarial textures. This diversity suggests the possibility of a texture sample within this solution space that could be universally effective in deceiving a wide range of object detection models; however, further research is needed to explore and validate this potential.
Figure 6 provides a bar chart summarizing the average AP@0.5 scores for each texture across these model categories. Our findings showed that optimizing adversarial textures on a combination of models from different architectures and sizes yielded the best transferability. Specifically, the texture optimized on the combination of YOLOv8n, YOLOv5m, and YOLOv3 achieved the lowest average AP@0.5 of 0.0972 across all tested models. This is more than 0.11 less than single-model textures (0.1148 less than YOLOv8n and 0.1480 less than YOLOv8x).
In addition to the evaluation under normal lighting conditions, we also tested the performance of the adversarial textures in low-light (night) conditions, as shown in
Figure 7. This figure presents the same evaluation as in
Figure 6, but with images taken at night. As expected, the average AP@0.5 scores were higher under these conditions, likely due to the absence of night images in the training dataset. The results also show that the AP@0.5 scores of different textures do not follow the same trend observed in
Figure 6. Specifically, some textures, such as those optimized on YOLOv8 models, were more robust to low-light conditions than those optimized on YOLOv5 models. Nonetheless, the texture optimized using the combination of YOLOv8n, YOLOv5m, and YOLOv3 continued to perform the best, achieving the lowest average AP@0.5 (0.2636), even in low-light scenarios.
5. Discussion
Our experiments demonstrate that adversarial textures optimized using multiple models exhibit superior transferability across a wide range of object detection architectures. In particular, the combination of YOLOv8n, YOLOv5m, and YOLOv3 in the optimization process produced the most effective adversarial textures, achieving the lowest average AP@0.5 scores.
The performance of this particular model combination can be attributed to the diversity in both the architecture and model size. YOLOv3 represents an earlier generation with a distinct architectural design compared to YOLOv5 and YOLOv8. By including models from different generations and architectural families, the adversarial textures learn to exploit common weaknesses that are not specific to a single model type.
Furthermore, incorporating models of varying sizes—nano (YOLOv8n) and medium (YOLOv5m)—ensures that the textures generalize across different model capacities. Smaller models tend to have limited feature representation capabilities due to fewer parameters, while larger models capture more complex features. Optimizing across this spectrum allows adversarial textures to disrupt both simple and complex feature detectors.
Regarding the generalizability to transformer-based models, our findings indicate that adversarial textures optimized on convolutional neural networks (CNNs) can effectively deceive transformer-based detectors like DINO and RT-DETR. This suggests that despite architectural differences, both CNNs and transformers share underlying mechanisms in feature representation and pattern recognition. Adversarial textures that alter feature extraction in CNNs can also mislead self-attention mechanisms in transformers by introducing deceptive patterns that alter attention weights, leading to incorrect or missed detections. The success against transformer models highlights the adversarial textures’ ability to target fundamental aspects of object detection, such as localization and classification, that are common across architectures.
Our study emphasizes the importance of model diversity in optimizing adversarial attacks. Multi-model optimization leverages the unique characteristics of different architectures and model sizes, resulting in adversarial textures that are not overfitted to a specific model but are instead broadly effective.
However, our study has certain limitations that present opportunities for future research. The multi-model optimization in this work was conducted using only YOLO-based models. Broadening the set of models used during optimization to include transformer-based detectors or other types of CNN architectures could potentially enhance the transferability of adversarial textures even further. By training on a more diverse set of models, adversarial textures might learn to exploit vulnerabilities that are model-agnostic.
Additionally, multi-model optimization comes with increased computational costs due to the need to evaluate and backpropagate through multiple networks simultaneously. This makes the optimization process more resource-intensive and time-consuming. Future work could explore strategies to mitigate this overhead, such as using model distillation, gradient approximation techniques, or selecting a representative subset of models that balance architectural diversity with computational efficiency.
6. Conclusions
In this work, we addressed the challenge of improving the transferability of physical adversarial attacks across diverse object detection models. Utilizing the TACO framework within a multi-model optimization setup, we demonstrated that adversarial textures could be effectively crafted to minimize the detection confidence across a wide array of models, including one-stage, two-stage, and transformer-based architectures.
Our experiments revealed that adversarial textures optimized on individual models tended to be most effective against models of a similar architecture and size but exhibited limited transferability to others. In contrast, textures optimized using combinations of models, especially those varying in architecture and size, significantly improved transferability. Specifically, the texture optimized on a combination of YOLOv8n, YOLOv5m, and YOLOv3 models achieved the lowest average AP@0.5 of 0.0972 across all tested models, which is less than half that of the textures optimized on single models.
These findings underscore the importance of incorporating model diversity during the optimization process to achieve more robust and generalized adversarial examples.
Building on these results, future work could explore the optimization of adversarial textures using combinations of model types from different architectures, such as combining YOLO-based models with transformer-based and two-stage detector models.
Author Contributions
Conceptualization, A.D., T.V.M. and V.R.; methodology, A.D. and T.V.M.; software, A.D. and T.V.M.; resources, V.R.; data curation, A.D. and T.V.M.; writing—original draft preparation, A.D.; writing—review and editing, T.V.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Culture and Innovation of Hungary from the National Research, Development and Innovation Fund, financed under the “Nemzeti Laboratóriumok pályázati program” funding scheme, grant number 2022-2.1.1-NL-2022-00012.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets presented in this study are part of an ongoing research project and are therefore not readily available. For access requests, please contact Adonisz Dimitriu at
dimitriu.adonisz@techtra.hu.
Acknowledgments
In preparing this manuscript, we used ChatGPT-4o from OpenAI to enhance the clarity, grammar, and overall readability of the text. Specifically, ChatGPT version gpt-4o-2024-08-06 was used for refining the sentence structure, maintaining consistent language quality, and making the content more accessible to an English-speaking audience. All scientific concepts, analyses, and conclusions are solely the result of the authors’ original work; the AI tool was used exclusively for linguistic refinement and did not contribute to the development of scientific content or data interpretation. We would also like to acknowledge Eszter Fülöp for her support in developing the figures and offering valuable design advice. Her expertise in visual representation was key to the overall presentation of this work.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Amirkhani, A.; Karimi, M.P.; Banitalebi-Dehkordi, A. A survey on adversarial attacks and defenses for object detection and their applications in autonomous vehicles. Vis. Comput. 2022, 39, 5293–5307. [Google Scholar] [CrossRef]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1625–1634. [Google Scholar] [CrossRef]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Li, C.; Liu, Y.; Zhang, X.; Wu, H. Exploiting Frequency Characteristics for Boosting the Invisibility of Adversarial Attacks. Appl. Sci. 2024, 14, 3315. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Inkawhich, N.; Wen, W.; Li, H.H.; Chen, Y. Feature space perturbations yield more transferable adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7066–7074. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4312–4321. [Google Scholar]
- Zhang, Y.; Gong, Z.; Zhang, Y.; Bin, K.; Li, Y.; Qi, J.; Wen, H.; Zhong, P. Boosting transferability of physical attack against detectors by redistributing separable attention. Pattern Recognit. 2023, 138, 109435. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, Z.; Wen, H.; Hu, X.; Xia, X.; Jiang, H.; Zhong, P. Pattern Corruption-Assisted Physical Attacks Against Object Detection in UAV Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 12931–12944. [Google Scholar] [CrossRef]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Li, H.; Chen, Y. Dpatch: An adversarial patch attack on object detectors. arXiv 2018, arXiv:1806.02299. [Google Scholar]
- Thys, S.; Van Ranst, W.; Goedemé, T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Hoory, S.; Shapira, T.; Shabtai, A.; Elovici, Y. Dynamic adversarial patch for evading object detection models. arXiv 2020, arXiv:2010.13070. [Google Scholar]
- Zhang, Y.; Foroosh, P.H.; Gong, B. Camou: Learning a vehicle camouflage for physical adversarial attack on object detections in the wild. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Suryanto, N.; Kim, Y.; Kang, H.; Larasati, H.T.; Yun, Y.; Le, T.T.H.; Yang, H.; Oh, S.Y.; Kim, H. Dta: Physical camouflage attacks using differentiable transformation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15305–15314. [Google Scholar]
- Suryanto, N.; Kim, Y.; Larasati, H.T.; Kang, H.; Le, T.T.H.; Hong, Y.; Yang, H.; Oh, S.Y.; Kim, H. Active: Towards highly transferable 3d physical camouflage for universal and robust vehicle evasion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4305–4314. [Google Scholar]
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3907–3916. [Google Scholar]
- Wang, J.; Liu, A.; Yin, Z.; Liu, S.; Tang, S.; Liu, X. Dual attention suppression attack: Generate adversarial camouflage in physical world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8565–8574. [Google Scholar]
- Wang, D.; Jiang, T.; Sun, J.; Zhou, W.; Gong, Z.; Zhang, X.; Yao, W.; Chen, X. Fca: Learning a 3d full-coverage vehicle camouflage for multi-view physical adversarial attack. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2414–2422. [Google Scholar]
- Zhou, J.; Lyu, L.; He, D.; Li, Y. RAUCA: A Novel Physical Adversarial Attack on Vehicle Detectors via Robust and Accurate Camouflage Generation. arXiv 2024, arXiv:2402.15853. [Google Scholar]
- Li, Y.; Tan, W.; Zhao, C.; Zhou, S.; Liang, X.; Pan, Q. Flexible Physical Camouflage Generation Based on a Differential Approach. arXiv 2024, arXiv:2402.13575. [Google Scholar]
- Lyu, L.; Zhou, J.; He, D.; Li, Y. CNCA: Toward Customizable and Natural Generation of Adversarial Camouflage for Vehicle Detectors. arXiv 2024, arXiv:2409.17963. [Google Scholar]
- Dimitriu, A.; Michaletzky, T.; Remeli, V. TACO: Adversarial Camouflage Optimization on Trucks to Fool Object Detectors. arXiv 2024, arXiv:2410.21443. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research. pp. 6105–6114. [Google Scholar]
- Li, Y.; Xie, S.; Chen, X.; Dollar, P.; He, K.; Girshick, R. Benchmarking detection transfer learning with vision transformers. arXiv 2021, arXiv:2111.11429. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. In Proceedings of the The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zhang, S.; Wang, X.; Wang, J.; Pang, J.; Lyu, C.; Zhang, W.; Luo, P.; Chen, K. Dense Distinct Query for End-to-End Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7329–7338. [Google Scholar]
Figure 1.
The single-model texture optimization pipeline.
Figure 1.
The single-model texture optimization pipeline.
Figure 2.
The three baseline textures and adversarial TACO camouflage on the truck model.
Figure 2.
The three baseline textures and adversarial TACO camouflage on the truck model.
Figure 3.
Transferability of adversarial textures across YOLOv8 and YOLOv5 model sizes. Each row in the grid represents textures optimized on a specific model variant, while each column shows the AP@0.5 performance on target models.
Figure 3.
Transferability of adversarial textures across YOLOv8 and YOLOv5 model sizes. Each row in the grid represents textures optimized on a specific model variant, while each column shows the AP@0.5 performance on target models.
Figure 4.
Comparison of mean AP@0.5 scores for textures optimized on YOLOv8 model combinations when tested on both small and large object detection models outside the YOLOv8 family.
Figure 4.
Comparison of mean AP@0.5 scores for textures optimized on YOLOv8 model combinations when tested on both small and large object detection models outside the YOLOv8 family.
Figure 5.
Textures and the rendered image of the vehicle optimized by multi-model training.
Figure 5.
Textures and the rendered image of the vehicle optimized by multi-model training.
Figure 6.
Average AP@0.5 performance of adversarial textures across different model types (one-stage, two-stage, and transformer-based detection models).
Figure 6.
Average AP@0.5 performance of adversarial textures across different model types (one-stage, two-stage, and transformer-based detection models).
Figure 7.
Average AP@0.5 performance of adversarial textures across different model types (one-stage, two-stage, and transformer-based detection models) under low-light conditions (nighttime images).
Figure 7.
Average AP@0.5 performance of adversarial textures across different model types (one-stage, two-stage, and transformer-based detection models) under low-light conditions (nighttime images).
Table 1.
Model architecture comparison.
Table 1.
Model architecture comparison.
| Model | Model Type |
|---|
| YOLOX [26] | One-Stage |
| Fully Convolutional One-Stage Object Detector (FCOS) [27] | One-Stage |
| RetinaNet [28] | One-Stage |
| Faster R-CNN (FRCNNv1) [8] | Two-Stage |
| Improved Faster R-CNN (FRCNNv2) [29] | Two-Stage |
| Cascade R-CNN (C-RCNN) [30] | Two-Stage |
| Sparse R-CNN (S-RCNN) [31] | Two-Stage |
| Real-Time Detection Transformer (RTDETR) [32] | Transformer |
| Real-Time Models for Object Detection (RTMDet) [33] | Transformer |
| DETR with Improved Denoising Anchor Boxes (DINO) [34] | Transformer |
| Dense Distinct Query DETR (DDQ) [35] | Transformer |
Table 2.
AP@0.5 performance on three baseline textures.
Table 2.
AP@0.5 performance on three baseline textures.
| Target Models | YOLOv8n | YOLOv8s | YOLOv8m | YOLOv8l | YOLOv8x |
|---|
| base | 0.3934 | 0.5864 | 0.5864 | 0.7768 | 0.8056 |
| naive | 0.3644 | 0.6301 | 0.6202 | 0.7514 | 0.7295 |
| random | 0.3941 | 0.5427 | 0.6077 | 0.7012 | 0.6705 |
Table 3.
Comparison of AP@0.5 for adversarial textures optimized using various combinations of YOLOv8 model variants, with the “Mean AP” column representing the average detection performance over all the target models for each texture.
Table 3.
Comparison of AP@0.5 for adversarial textures optimized using various combinations of YOLOv8 model variants, with the “Mean AP” column representing the average detection performance over all the target models for each texture.
| Target Models | YOLOv8n | YOLOv8s | YOLOv8m | YOLOv8l | YOLOv8x | Mean AP |
|---|
| YOLOv8{x, n} | 0.0252 | 0.0674 | 0.0684 | 0.0585 | 0.0184 | 0.0475 |
| YOLOv8{x, s} | 0.1111 | 0.0277 | 0.0485 | 0.0486 | 0.0172 | 0.0506 |
| YOLOv8{x, m} | 0.1651 | 0.0776 | 0.0192 | 0.0378 | 0.0175 | 0.0634 |
| YOLOv8{x, l} | 0.2047 | 0.1369 | 0.0481 | 0.0182 | 0.0099 | 0.0835 |
| YOLOv8{l, n} | 0.0165 | 0.0474 | 0.0388 | 0.0191 | 0.0576 | 0.0359 |
| YOLOv8{l, s} | 0.0841 | 0.0185 | 0.0286 | 0.0099 | 0.0472 | 0.0377 |
| YOLOv8{l, m} | 0.1059 | 0.0676 | 0.0191 | 0.0191 | 0.0277 | 0.0479 |
| YOLOv8{x, l, m} | 0.1256 | 0.0778 | 0.0193 | 0.0184 | 0.0177 | 0.0518 |
| YOLOv8{x, m, n} | 0.0253 | 0.0467 | 0.0198 | 0.0384 | 0.0182 | 0.0296 |
Table 4.
Model architecture comparison. Small-size and large-size models are separated by the horizontal line.
Table 4.
Model architecture comparison. Small-size and large-size models are separated by the horizontal line.
| Model | Backbone | Params |
|---|
| YOLOv5n | CSPDarknet53 | 1.9 M |
| YOLOv10n | CSPDarknet (optimized) | 2.3 M |
| YOLOX-n | DarkNet53 | 5.1 M |
| RetinaNet-s | ResNet-18-fpn | 21.4 M |
| RTDETR-s | rtdetr_r18vd | 20.2 M |
| YOLOv5x | CSPDarknet53 | 97.2 M |
| YOLOv10x | CSPDarknet (optimized) | 29.5 M |
| YOLOX-x | DarkNet53 | 99.1 M |
| RetinaNet-x | ResNeXt-101-fpn | 95.7 M |
| RTDETR-x | rtdetr_r101vd | 76.6 M |
Table 5.
AP@0.5 performance of textures optimized on various YOLOv8 models, evaluated on small-sized detection models outside the YOLOv8 family.
Table 5.
AP@0.5 performance of textures optimized on various YOLOv8 models, evaluated on small-sized detection models outside the YOLOv8 family.
| Texture Source | YOLOv5n | YOLOv10n | YOLOX-n | RetinaNet-s | RTDETR-s |
|---|
| YOLOv8n | 0.0249 | 0.0387 | 0.1461 | 0.0681 | 0.3162 |
| YOLOv8x | 0.2356 | 0.3062 | 0.5128 | 0.2775 | 0.5209 |
| YOLOv8{x, n} | 0.0668 | 0.0783 | 0.2396 | 0.1059 | 0.3231 |
| YOLOv8{x, m, n} | 0.0755 | 0.0586 | 0.2349 | 0.1041 | 0.2295 |
Table 6.
AP@0.5 performance of textures optimized on different YOLOv8 models, tested on large-sized detection models outside the YOLOv8 family.
Table 6.
AP@0.5 performance of textures optimized on different YOLOv8 models, tested on large-sized detection models outside the YOLOv8 family.
| Texture Source | YOLOv5x | YOLOv10x | YOLOX-x | RetinaNet-l | RT-DETR-x |
|---|
| YOLOv8n | 0.1574 | 0.1975 | 0.2254 | 0.1708 | 0.5032 |
| YOLOv8x | 0.0491 | 0.1482 | 0.1954 | 0.2073 | 0.4705 |
| YOLOv8{x, n} | 0.0393 | 0.0989 | 0.1652 | 0.0997 | 0.4492 |
| YOLOv8{x, m, n} | 0.0293 | 0.0592 | 0.0948 | 0.0781 | 0.3255 |
Table 7.
AP@0.5 performance of textures optimized on different combinations of YOLO models, evaluated across one-stage, two-stage, and transformer-based detection architectures.
Table 7.
AP@0.5 performance of textures optimized on different combinations of YOLO models, evaluated across one-stage, two-stage, and transformer-based detection architectures.
| Texture | One-Stage Models | Two-Stage Models | Transformer Models | Total Mean |
|---|
|
YOLOX
|
YOLOv10l
|
FCOS
|
RetinaNet
|
Mean
|
FRCNNv1
|
FRCNNv2
|
C-RCNN
|
S-RCNN
|
Mean
|
RTDETR
|
RTMDet
|
DINO
|
DDQ
|
Mean
|
|---|
| Base | 0.7528 | 0.7206 | 0.6316 | 0.6374 | 0.6856 | 0.5964 | 0.7769 | 0.5290 | 0.5780 | 0.6201 | 0.8018 | 0.8397 | 0.7458 | 0.7086 | 0.7740 | 0.6932 |
| Green | 0.7089 | 0.6134 | 0.6360 | 0.6517 | 0.6525 | 0.6224 | 0.8376 | 0.5523 | 0.6226 | 0.6587 | 0.8129 | 0.7787 | 0.7002 | 0.6597 | 0.7379 | 0.6830 |
| Random | 0.7188 | 0.5739 | 0.5946 | 0.5905 | 0.6195 | 0.6378 | 0.8201 | 0.5329 | 0.6116 | 0.6506 | 0.7961 | 0.7532 | 0.7188 | 0.6688 | 0.7342 | 0.6681 |
| YOLOv8n | 0.2254 | 0.2265 | 0.1738 | 0.0754 | 0.1753 | 0.0511 | 0.2783 | 0.0612 | 0.1782 | 0.1422 | 0.4521 | 0.4509 | 0.1684 | 0.2027 | 0.3185 | 0.2120 |
| YOLOv8x | 0.1954 | 0.1476 | 0.2410 | 0.1089 | 0.1732 | 0.1498 | 0.3156 | 0.2221 | 0.1610 | 0.2121 | 0.5576 | 0.3919 | 0.2300 | 0.2218 | 0.3503 | 0.2452 |
| YOLOv8{x, n} | 0.1652 | 0.1088 | 0.1361 | 0.0625 | 0.1182 | 0.0561 | 0.1978 | 0.0856 | 0.1436 | 0.1208 | 0.4322 | 0.3031 | 0.1270 | 0.1455 | 0.2520 | 0.1636 |
| YOLOv8{x, m, n} | 0.0948 | 0.0693 | 0.1088 | 0.0412 | 0.0785 | 0.0483 | 0.1502 | 0.0746 | 0.1231 | 0.0991 | 0.3828 | 0.2798 | 0.0871 | 0.0946 | 0.2111 | 0.1296 |
| YOLOv5{x, n} | 0.0860 | 0.0989 | 0.1455 | 0.0688 | 0.0998 | 0.0461 | 0.2027 | 0.0631 | 0.1141 | 0.1065 | 0.2325 | 0.2728 | 0.1049 | 0.1233 | 0.1834 | 0.1299 |
| YOLOv5{x, m, n} | 0.0662 | 0.0990 | 0.1519 | 0.0901 | 0.1018 | 0.0738 | 0.1928 | 0.0844 | 0.1237 | 0.1187 | 0.2470 | 0.2018 | 0.0806 | 0.1222 | 0.1629 | 0.1278 |
| YOLOv{8n, 5mu, 3u} | 0.0576 | 0.0692 | 0.1099 | 0.0576 | 0.0736 | 0.0387 | 0.1278 | 0.0550 | 0.0825 | 0.0760 | 0.2717 | 0.1324 | 0.0802 | 0.0842 | 0.1421 | 0.0972 |
| YOLOv{8m, 5nu, 3u} | 0.0692 | 0.0752 | 0.0853 | 0.0344 | 0.0660 | 0.0386 | 0.1273 | 0.0551 | 0.1018 | 0.0807 | 0.2466 | 0.2033 | 0.0615 | 0.0752 | 0.1467 | 0.0978 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}