Natural Language Processing-Based Deep Learning to Predict the Loss of Consciousness Event Using Emergency Department Text Records

 ,
,  , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Data Collection
2.2. Definition of Outcome Variable
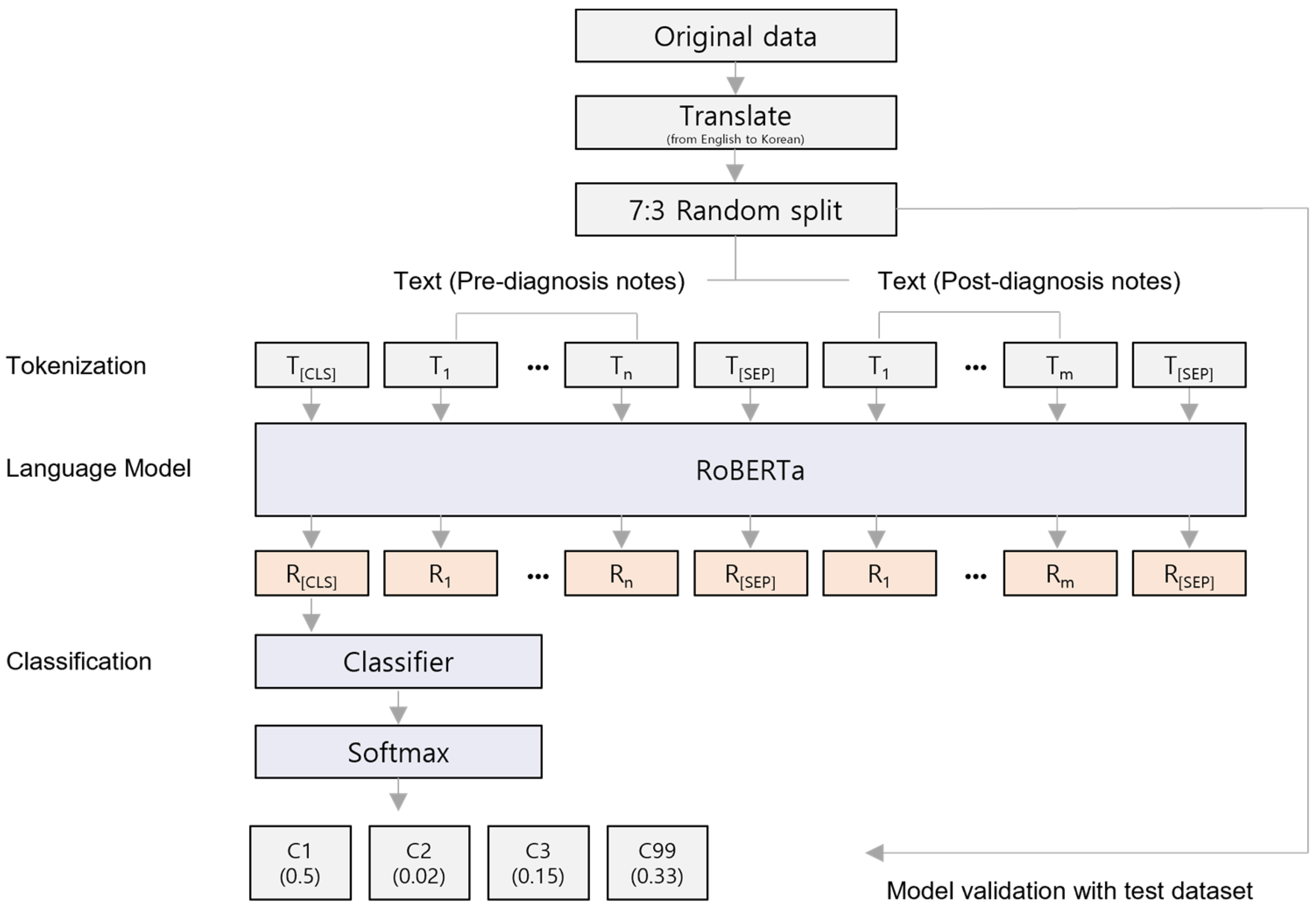
2.3. Data Preparation and Model Development
2.4. Model Performance Evaluation and Feature Interpretation
2.5. Ethics Statement
3. Results
3.1. Analysis of Experimental Dataset
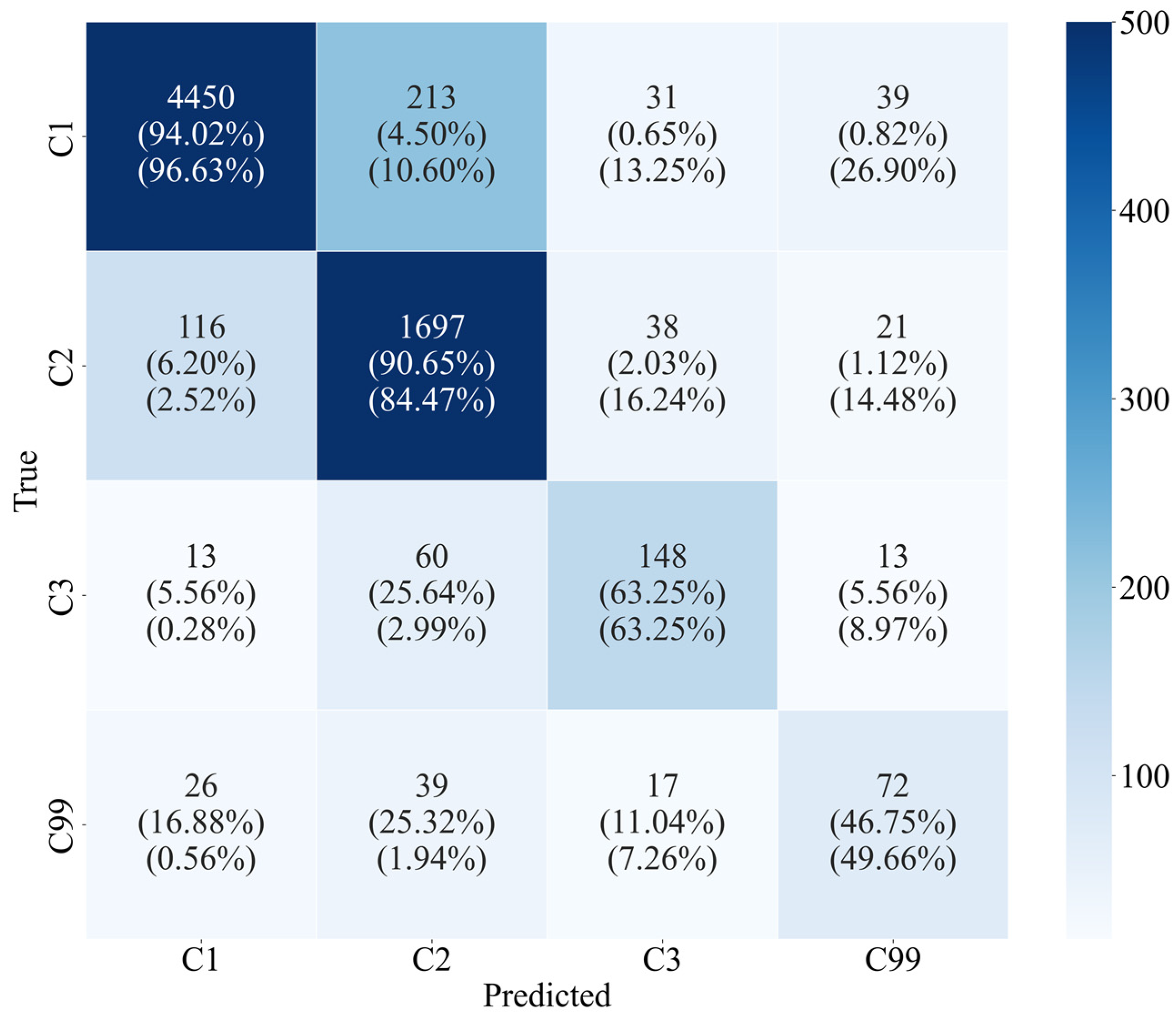
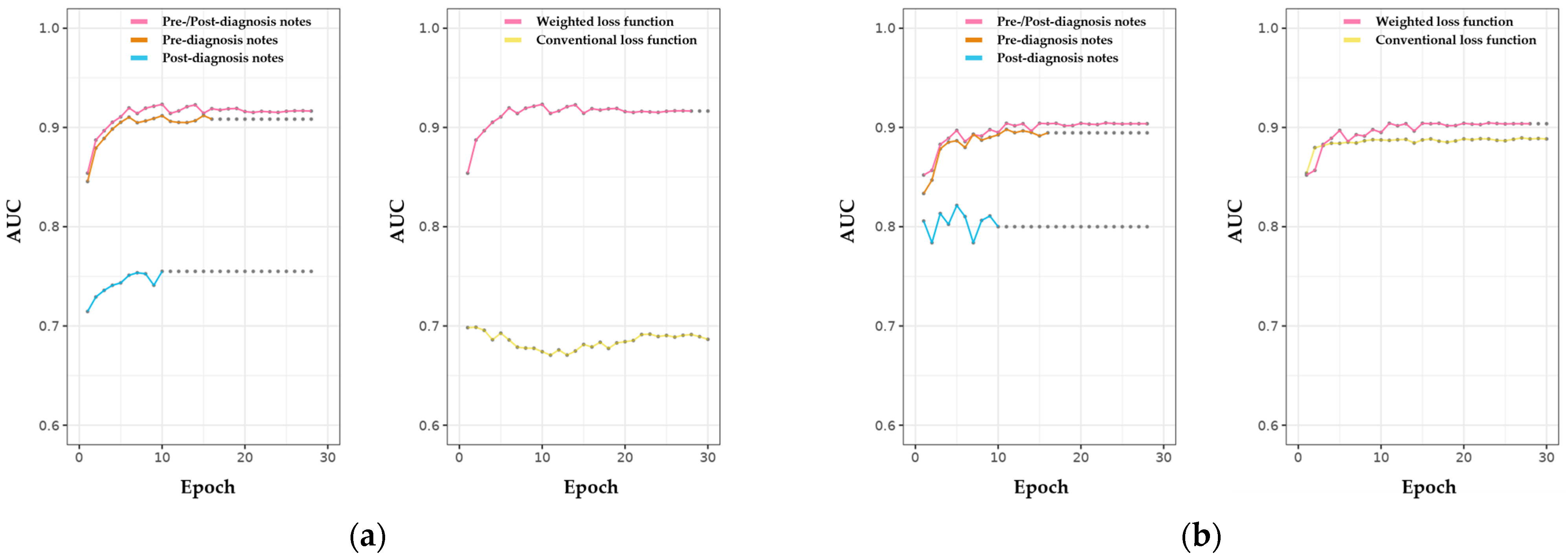
3.2. Classification Results and Model Evaluation
3.3. Quantitative Interpretation of LOC Classification Model
4. Discussion
4.1. Principal Results
4.2. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Polnaszek, B.; Gilmore-Bykovskyi, A.; Hovanes, M.; Roiland, R.; Ferguson, P.; Brown, R.; Kind, A.J. Overcoming the challenges of unstructured data in multisite, electronic medical record-based abstraction. Med. Care 2016, 54, e65–e72. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.S.; Fowles, J.B.; Weiner, J.P. Electronic health records and the reliability and validity of quality measures: A review of the literature. Med. Care Res. Rev. 2010, 67, 503–527. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Lyu, T.; Loiacono, A.; Viramontes, T.M.; Lipori, G.; Guo, Y.; Wu, Y.; Prosperi, M.; George, T.J., Jr.; Harle, C.A. Assessing the practice of data quality evaluation in a national clinical data research network through a systematic scoping review in the era of real-world data. J. Am. Med. Inform. Assoc. 2020, 27, 1999–2010. [Google Scholar] [CrossRef]
- Cho, H.; Yoo, S.; Kim, B.; Jang, S.; Sunwoo, L.; Kim, S.; Lee, D.; Kim, S.; Nam, S.; Chung, J.H. Extracting lung cancer staging descriptors from pathology reports: A generative language model approach. J. Biomed. Inform. 2024, 157, 104720. [Google Scholar] [CrossRef] [PubMed]
- Hossain, E.; Rana, R.; Higgins, N.; Soar, J.; Barua, P.D.; Pisani, A.R.; Turner, K. Natural Language Processing in Electronic Health Records in relation to healthcare decision-making: A systematic review. Comput. Biol. Med. 2023, 155, 106649. [Google Scholar] [CrossRef]
- Tignanelli, C.J.; Silverman, G.M.; Lindemann, E.A.; Trembley, A.L.; Gipson, J.C.; Beilman, G.; Lyng, J.W.; Finzel, R.; McEwan, R.; Knoll, B.C. Natural language processing of prehospital emergency medical services trauma records allows for automated characterization of treatment appropriateness. J. Trauma Acute Care Surg. 2020, 88, 607–614. [Google Scholar] [CrossRef]
- Kulshrestha, S.; Dligach, D.; Joyce, C.; Baker, M.S.; Gonzalez, R.; O’Rourke, A.P.; Glazer, J.M.; Stey, A.; Kruser, J.M.; Churpek, M.M. Prediction of severe chest injury using natural language processing from the electronic health record. Injury 2021, 52, 205–212. [Google Scholar] [CrossRef]
- Edgcomb, J.B.; Zima, B. Machine learning, natural language processing, and the electronic health record: Innovations in mental health services research. Psychiatr. Serv. 2019, 70, 346–349. [Google Scholar] [CrossRef]
- Roy, D.; Peters, M.E.; Everett, A.D.; Leoutsakos, J.-M.S.; Yan, H.; Rao, V.; Bechtold, K.T.; Sair, H.I.; Van Meter, T.; Falk, H. Loss of consciousness and altered mental state as predictors of functional recovery within 6 months following mild traumatic brain injury. J. Neuropsychiatry Clin. Neurosci. 2020, 32, 132–138. [Google Scholar] [CrossRef]
- Waseem, M.; Iyahen, P., Jr.; Anderson, H.B.; Kapoor, K.; Kapoor, R.; Leber, M. Isolated LOC in head trauma associated with significant injury on brain CT scan. Int. J. Emerg. Med. 2017, 10, 30. [Google Scholar] [CrossRef]
- Maas, A.I.; Harrison-Felix, C.L.; Menon, D.; Adelson, P.D.; Balkin, T.; Bullock, R.; Engel, D.C.; Gordon, W.; Langlois-Orman, J.; Lew, H.L.; et al. Standardizing data collection in traumatic brain injury. J. Neurotrauma 2011, 28, 177–187. [Google Scholar] [CrossRef]
- Torres-Silva, E.A.; Rúam, S.; Giraldo-Forero, A.F.; Durango, M.C.; Flórez-Arango, J.F.; Orozco-Duque, A. Classification of Severe Maternal Morbidity from Electronic Health Records Written in Spanish Using Natural Language Processing. Appl. Sci. 2023, 13, 10725. [Google Scholar] [CrossRef]
- Qiu, P.; Wu, C.; Zhang, X.; Lin, W.; Wang, H.; Zhang, Y.; Wang, Y.; Xie, W. Towards building multilingual language model for medicine. Nat. Commun. 2024, 1, 8384. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Delobelle, P.; Winters, T.; Berendt, B. RobBERT: A Dutch RoBERTa-based language model. arXiv 2020, 1, 3255–3265. [Google Scholar]
- Park, S.; Moon, J.; Kim, S.; Cho, W.I.; Han, J.; Park, J.; Song, C.; Kim, J.; Song, Y.; Oh, T. Klue: Korean language understanding evaluation. arXiv 2021, arXiv:2105.09680. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Ho, Y.; Wookey, S. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine Learn-ing in Python. J. Mach. Learn. Res. 2011, 1, 12. [Google Scholar]
- Hand, D.J.; Till, R.J. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- Obuchowski, N.A.; Bullen, J.A. Receiver operating characteristic (ROC) curves: Review of methods with applications in diagnostic medicine. Phys. Med. Biol. 2018, 63, 07TR01. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Chamseddine, E.; Mansouri, N.; Soui, M.; Abed, M. Handling class imbalance in COVID-19 chest X-ray images classification: Using SMOTE and weighted loss. Appl. Soft Comput. 2022, 129, 109588. [Google Scholar] [CrossRef] [PubMed]
- Ling, T.; Jake, L.; Adams, J.; Osinski, K.; Liu, X.; Friedland, D. Interpretable machine learning text classification for clinical computed tomography reports–a case study of temporal bone fracture. Comput. Meth. Programs Biomed. Update 2023, 3, 100104. [Google Scholar] [CrossRef]
- Gholipour, M.; Khajouei, R.; Amiri, P.; Hajesmaeel Gohari, S.; Ahmadian, L. Extracting cancer concepts from clinical notes using natural language processing: A systematic review. BMC Bioinform. 2023, 24, 405. [Google Scholar] [CrossRef]
- Patra, B.G.; Sharma, M.M.; Vekaria, V.; Adekkanattu, P.; Patterson, O.V.; Glicksberg, B.; Lepow, L.A.; Ryu, E.; Biernacka, J.M.; Furmanchuk, A.o. Extracting social determinants of health from electronic health records using natural language processing: A systematic review. J. Am. Med. Inform. Assoc. 2021, 28, 2716–2727. [Google Scholar] [CrossRef]
- Wen, A.; Fu, S.; Moon, S.; El Wazir, M.; Rosenbaum, A.; Kaggal, V.C.; Liu, S.; Sohn, S.; Liu, H.; Fan, J. Desiderata for delivering NLP to accelerate healthcare AI advancement and a Mayo Clinic NLP-as-a-service implementation. NPJ Digit. Med. 2019, 2, 130. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Number | % |
|---|---|---|
| Gender | ||
| Male | 13,371 | 57.4 |
| Female | 9937 | 42.6 |
| Age, years | ||
| 0–19 | 8114 | 34.8 |
| 20–39 | 6497 | 27.9 |
| 40–59 | 5470 | 23.5 |
| 60–79 | 2469 | 10.6 |
| ≥80 | 758 | 3.3 |
| LOC 1 status | ||
| C1 2 | 15,775 | 67.7 |
| C2 3 | 6240 | 26.8 |
| C3 4 | 780 | 3.4 |
| C99 5 | 513 | 2.2 |
| Disposition at emergency department | ||
| Discharge (to home) | 21,038 | 90.3 |
| Admission | 1993 | 8.6 |
| Transfer | 101 | 0.4 |
| Death | 55 | 0.2 |
| NA 6 | 121 | 0.5 |
| Death | ||
| Yes | 119 | 0.5 |
| No | 23,189 | 99.5 |
| Input Data | AUROC | Accuracy | Precision | Recall | F1 | Weighted F1 |
|---|---|---|---|---|---|---|
| Pre-/Post-diagnosis note | 0.916 | 0.910 | 0.735 | 0.737 | 0.735 | 0.911 |
| Pre-diagnosis note | 0.906 | 0.904 | 0.724 | 0.723 | 0.718 | 0.905 |
| Post-diagnosis note | 0.746 | 0.818 | 0.695 | 0.428 | 0.447 | 0.797 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, H.A.; Jeon, I.; Shin, S.-H.; Seo, S.Y.; Lee, J.J.; Kim, C.; Park, J.O. Natural Language Processing-Based Deep Learning to Predict the Loss of Consciousness Event Using Emergency Department Text Records. Appl. Sci. 2024, 14, 11399. https://doi.org/10.3390/app142311399
Park HA, Jeon I, Shin S-H, Seo SY, Lee JJ, Kim C, Park JO. Natural Language Processing-Based Deep Learning to Predict the Loss of Consciousness Event Using Emergency Department Text Records. Applied Sciences. 2024; 14(23):11399. https://doi.org/10.3390/app142311399
Chicago/Turabian StylePark, Hang A., Inyeop Jeon, Seung-Ho Shin, Soo Young Seo, Jae Jun Lee, Chulho Kim, and Ju Ok Park. 2024. "Natural Language Processing-Based Deep Learning to Predict the Loss of Consciousness Event Using Emergency Department Text Records" Applied Sciences 14, no. 23: 11399. https://doi.org/10.3390/app142311399
APA StylePark, H. A., Jeon, I., Shin, S.-H., Seo, S. Y., Lee, J. J., Kim, C., & Park, J. O. (2024). Natural Language Processing-Based Deep Learning to Predict the Loss of Consciousness Event Using Emergency Department Text Records. Applied Sciences, 14(23), 11399. https://doi.org/10.3390/app142311399