1. Introduction
In the context of the fourth industrial revolution represented by “Industry 4.0”, communication technology and manufacturing technology are deeply integrated, enhancing networking and intelligence industrial of production process [
1]. Thus, it is necessary to establish an interconnected, intelligent and stable industrial wireless network [
2]. Industrial wireless technology, an innovation of this century, has become a hot spot after the field bus. Industrial wireless changes the information transfer of the existing control system. It boasts robust anti-interference capabilities, low power consumption, high reliability, and numerous other technical virtues [
3]. In the future, industrial control technology will necessitate stringent requirements for reliability, low latency, and high-speed performance, further underscoring the significance of these advancements.
The industrial production process involves a large number of industrial tasks and the rapid increase of CPU-bound applications and delay-sensitive applications has added new challenges to the development of industrial wireless networks. Confronted with this deluge of industrial tasks, the conventional cloud computing model encounters limitations in addressing data processing and computational demands. Mobile edge computing (MEC) has emerged to enhance data processing efficiency.
By strategically deploying edge servers at the network’s periphery, the MEC system effectively brings the computing prowess of the cloud center closer to the edge, satisfying the escalating demand for computational augmentation at industrial terminals while fostering proximity between industrial terminals and edge servers. This arrangement curtails transmission time for industrial tasks, mitigating the latency in cloud computing. Nonetheless, when large-scale industrial tasks migrate to these edge servers concurrently, network congestion occurs, escalating task processing time delays and reducing computational throughput. Consequently, computation offloading in industrial wireless networks confronts the following pivotal challenges. Firstly, devising offloading strategies that are prudently calibrated to performance metrics. Secondly, dynamically allocating industrial tasks according to actual demand, ensuring optimal resource utilization. Enhancing resource utilization and optimizing performance metrics like energy consumption, time delay, and computation rate are essential to address these challenges.
When tackling dynamic challenges in the computation offloading strategies, ensuring system stability is very important. The Lyapunov optimization theory, originating from control theory, emerges as a robust approach to validate system stability and has been ingeniously adapted to construct queuing models for dynamic systems. Incorporating queue size into the objective function resolution, it fosters a relatively stable system state, thereby achieving the desired optimization objectives. Solving dynamic problems such as mixed-integer nonlinear programming (MINLP) requires high computation complexity, especially in large networks. The Lyapunov optimization theory excels in dynamically adapting to the ever-changing network conditions at every instant of system evolution, negating the need for manual intervention in adjusting control variables [
4]. It is adaptable to real-time control of dynamically changing systems. Also, it ensures relatively low computation complexity, which is more straightforward than the direct solution of other algorithms [
5]. Therefore, the application of Lyapunov optimization can transform the MINLP problem into continuous deterministic sub-problems while providing theoretical guarantee for the long-term stability of the system.
Traditional model-driven computation offloading and resource allocation strategies rely on exhaustive system information to construct accurate system models. Nevertheless, the inherent dynamism and randomness of industrial wireless networks pose significant challenges in gathering comprehensive system information necessary for accurate modeling [
6]. This becomes particularly problematic in large-scale industrial settings, where a vast amount of intricately coupled system data results in an unwieldy state space, significantly impeding the efficiency of reinforcement learning. To overcome this bottleneck, data-driven deep reinforcement learning (DRL), as an innovative scheme, opens up new avenues for the computation offloading problems. DRL skillfully combines deep learning and reinforcement learning, using deep neural networks (DNN) to directly map from the environment state to the optimal action in order to maximize the long-term reward. This process is done automatically through continuous interaction with the environment. This integration not only alleviates the computational complexity of the problem but also endows the approach with the capability to autonomously learn from past experiences, bypassing the need for manually labeled training data, thus greatly facilitating the feasibility of its real-time online application. This is significant for efficiently generating computation offloading strategies in dynamic environments.
However, existing works have given limited consideration to the long-term network computation rate problem under long-term stability of the system. To this end, this paper proposes an intelligent computation offloading algorithm based on Lyapunov optimization and DRL for the end-edge task offloading problem under long-term stability constraints to maximize the long-term network computation rate. In the case of rapidly changing channel conditions and dynamic task arrivals, our algorithm can maximize the long-term network computation rate and guarantee long-term stability of the system.
The main contributions of this paper are summarized as follows.
Firstly, we construct an edge computing-enhanced industrial wireless network, where each industrial terminal can choose an industrial base station for binary computation offloading. In this scenario, we formulate a network computation rate maximization problem while balancing constraints including offloading time, CPU frequency, energy consumption, transmit power, and data queue stability.
Secondly, to maintain system stability, we define two dynamic queues, which are task queue and virtual energy queue. Based on these two dynamic queues, we minimize the upper bound of the drift-penalty function by using Lyapunov optimization, and transform the long-term MINLP problem into deterministic sub-problems. As the Lyapunov optimization problem is still non-convex, we further solve the problem with DRL.
Thirdly, we employ asynchronous advantage actor-critic (A3C) and propose Lyapunov-guided A3C algorithm named LyA3C for solution. Experiment results show that the LyA3C algorithm can converge stably and effectively improve the long-term network computation rate by comparing it with A2C-based and TD3-based algorithms.
The rest of this paper is organized as follows.
Section 2 discusses related works.
Section 3 describes the system model. Then,
Section 4 presents the proposed LyA3C algorithm. Next,
Section 5 evaluates LyA3C through extensive experiments. Finally,
Section 6 concludes the whole work.
2. Related Work
For industrial tasks, different algorithms were proposed to balance the computation offloading and resource allocation in different scenarios.
Most existing works take delay or energy consumption minimization as the optimization objective. For example, Ref. [
7] employed the double and dueling architectures on the basis of deep Q-network, and proposed the D3QN-based multi-priority computation offloading scheme to minimize overall task delay. Ref. [
8] used Lyapunov optimization to decompose the multi-layer multi-timescale resource allocation problem into three sub-problems, and employed a deep actor-critic algorithm to minimize the total queuing delay of all devices. Ref. [
9] proposed a multi-agent deep reinforcement learning (MADRL)-based scheduling algorithm, which actor-critic (AC) framework with estimation and target networks is designed for policy and value iterations to minimize delay. Similarly, Ref. [
10] proposed multi-agent double actor-critic algorithm to reduce the task processing delay while improving the blockchain transaction throughput. Ref. [
11] designed a joint communication and computation resource allocation mechanism based on Q-learning to minimize the total task delay cost. On the other hand, Ref. [
12] incorporated a data fusion system in the architecture and designed a joint computation offloading and resource allocation scheme to minimize the overall queuing delay of the system. Ref. [
13] designed an algorithm that decomposes the problem into task offloading and channel allocation sub-problems, and proposed a low-complexity heuristic algorithm to solve the sub-problem efficiently for total weighted task processing latency minimization. Ref. [
14] developed a novel online SBS peer offloading framework by leveraging the Lyapunov technique, in order to maximize the long-term system performance while keeping the energy consumption of SBSs below individual long-term constraints. Ref. [
15] aimed to optimize the average energy consumption by using non-orthogonal multiple access (NOMA) technique to improve the spectral efficiency and access, which is solved using successive convex approximation. Ref. [
16] combined NOMA technique and frequency division multiple access and used long short-term memory network to optimize the objective. Ref. [
17] used the air-ground integrated computing networks multi-agent deep deterministic policy gradient algorithm to minimize the average energy consumption by jointly optimizing the computation task allocation and wireless resource allocation.
Furthermore, there are also many works that combined time delay and energy consumption as optimization objectives. For example, Ref. [
18] added a greedy algorithm to multi-intelligence depth determination of policy gradients to minimize the weighted sum of delay and energy consumption. Ref. [
19] established a dual queue model containing data and computation queues, used the proximal policy optimization algorithm to minimize the weighted sum of average time delay and system energy consumption. Ref. [
20] proposed an online joint offloading and resource allocation framework under the long-term MEC energy constraint, aimed at guaranteeing the users’ QoE. Ref. [
21] aimed to minimize the task expected cost, which includes the task execution time delay and energy consumption, and applied the time division multiple access technique to optimize the objective function.
In addition, there are also some works that used other variables as the optimization objectives. For example, Ref. [
22] considered the computation rate and energy consumption in computation offloading, proposed a deep deterministic policy gradient-based multiple continuous variable decision model to make the optimal offloading decision in edge computing. Ref. [
23] proposed a computation offloading algorithm based on deep Q-Learing and used asynchronous federated deep Q-Learing to offload task. Ref. [
24] proposed a multi-agent soft-actor-critic-discrete for task offloading and resurce allocation to maximize throughput while minimizing power consumption on the remote side. Ref. [
25] proposed a low-complexity online computation offloading and trajectory scheduling algorithm to minimize the system energy efficiency by using Lyapunov optimization methods, where the system energy efficiency is defined as the ratio of the system’s total long-term energy consumption. Ref. [
26] took the same variables as the optimization objective and used convex decomposition methods.
3. System Model
3.1. Network Model
In this paper, we propose an end-edge industrial wireless network system with edge computation capability, which consists of an edge layer and an end layer. As depicted in
Figure 1, the industrial wireless network is composed of
M industrial base stations and
N industrial terminals to support industrial production and manufacturing in factories. We define
as the set of
M industrial base stations and
as the set of
N industrial terminals.
In this scenario, the industrial base station is equipped with an edge computing server, which is designed to supply computation resources for multiple industrial terminals. It also facilitates the scheduling of industrial terminals within its service area. The end layer comprises numerous industrial terminals with sensing, computing, communication and control capabilities, each of which generates an indivisible task that necessitates processing. Initially, each industrial terminal endeavors to process the task data using its own resources. However, when the task’s computation requirements, in terms of cycles, are substantial, the industrial terminal may find itself unable to meet the designated deadline due to resource limitations. In such case, the industrial terminal must offload the task to a proximate industrial base station to ensure timely completion.
In t-th time slot, the channel gain between m-th industrial base station and n-th industrial terminal is denoted as , where remains constant during the time slot, but it varies independently from time slot to time slot.
3.2. Task Model
For n-th industrial terminal, its computation task is denoted as . The data arriving at the data queue of n-th industrial terminal is denoted as and it is assumed that , .
When , n-th industrial terminal offloads all task to m-th industrial base station. When , n-th industrial terminal does not offload any task to m-th industrial base station. According to the execution location of the computation task and the size of the offloading data, the offloading decision is binary with two cases: end computing and edge computing.
Correspondingly, each industrial terminal has a task buffer, the queue length of the buffer in
t-th time slot is denoted as
. Thus, the queue length can be updated as
3.3. End Computing Model
When
n-th industrial terminal processes data locally, the local CPU frequency is
is bounded by an upper limit value
, namely
. Thus, the computation size of the offloaded task in
t-th time slot is calculated as
where
is the computation offloading time ratio and
T is the length of a frame. Obviously,
is denoted as the amount of time allocated to the industrial terminal for computation offloading, and there should be
.
Furthermore, the energy consumption in
t-th time slot is calculated as
where
represents the number of computation cycles required to process one bit of data,
represents the computation energy efficiency parameter.
3.4. Edge Computing Model
When n-th industrial terminal decides to offload data on the end layer, we define transmit power as with an upper limit , namely . Note that n-th industrial terminal evaluates the computation resources of each candidate industrial base station, and only chooses one of the multiple industrial base stations for computation offloading at one time.
The energy consumption for computation offloading is calculated as
, where
is the transmit power. At this time, we neglect the delay on edge computing and result downloading. Thus, according to Shannon’s theorem, the computation size of the offloaded task on the end layer is given by
where
W is bandwidth,
is the channel gain between
m-th industrial base station and
n-th industrial terminal, and
denotes the noise power.
In this way, the total computation task by end computing or edge computing is calculated as
, namely
Correspondingly, the network computation rate given by
is calculated as
As the industrial base stations are powered by constant energy, we ignore the computing energy consumption and only consider the offloading energy consumption. Thus, the energy consumption for edge computing is calculated as
. Furthermore, the total energy consumption is calculated as
, namely
where
denotes the computing energy efficiency.
4. End-Edge Computation Offloading Based on Lyapunov-Guided DRL
In this section, we first explicitly formulate the network computation rate maximization problem, then decouple the problem by Lyapunov optimization and finally propose the intelligent computation offloading algorithm based on Lyapunov-guided DRL.
4.1. Problem Formulation
In order to achieve end-edge computation offloading for complex industrial tasks, we formulate the network computation rate maximization problem, assuming that each industrial terminal generates only one indivisible real-time task . The set of tasks is represented as , where each task is denoted as . In detail, , , , .
Then, we formulate the network computation rate maximization problem
as
where
is the weight for
n-th industrial terminal,
is power threshold.
is the computation offloading time ratio constraint, which means the ratio sum of computation offloading time should not exceed one.
is the binary computation offloading decision constraint.
is local CPU frequency constraint, which means there is a maximum value
for the local CPU frequency.
is the transmit power constraint, which means there is a maximum value
for the transmit power.
is the energy consumption constraint used for data offloading, which means there is a maximum value
for the energy consumption.
is the data causality constraint.
is the data queue stability constraint, which means time queue is strongly stable if the average queue length is limited.
is the average energy consumption constraint, which means there is a maximum value
for the average energy consumption.
4.2. Problem Transformation by Lyapunov Optimization
As the problem is a MINLP problem, its direct solution process is complicated, the Lyapunov optimization theory is introduced to model the dynamic queue, and this strategy decomposes the MINLP problem into deterministic sub-problems through the construction of mathematical models under the premise of ensuring the stability of the system.
In order to satisfy the average power consumption constraint
in
, we introduce
N virtual energy queues
for industrial terminals. Let
, the queue length can be updated as
When the virtual energy queue is stabilized, the average energy consumption satisfies .
After establishing dynamic queues, we define
as the total queue backlog, then we employ quadratic Lyapunov function
to represent the stability of the queues.
Correspondingly, the Lyapunov drift function of the total queue backlog is defined as
which demonstrates the improvement from
t-th time slot to (
)-th time slot. That is to say, the Lyapunov drift can reflect the system dynamics between two continuous states. From the perspective of system stability, the smaller the Lyapunov drift, the more stable the system is.
However, the Lyapunov drift still depends on the system information of the next time slot. Thus, we further derive the Lyapunov drift.
According to [
27], for nonnegative real numbers
A,
B,
C, and
D satisfying
, there should be
, so we have
In this way, we can drive the upper bound of the Lyapunov drift function for data queue as
where
.
At the same time, we can have the upper bound of the Lyapunov drift function for virtual energy queue as
where
.
Through the above process, the upper bound of the Lyapunov drift function for total queue backlog is given by
where
.
At the same time, it is obvious that the upper bound of the Lyapunov drift function is no longer decided by the system information of the next time slot. Then, the Lyapunov drift-plus-penalty approach is used to maximize the network computation rate while satisfying queue stability, that is to say minimizing the drift-plus-penalty expression within each time slot, we have
where
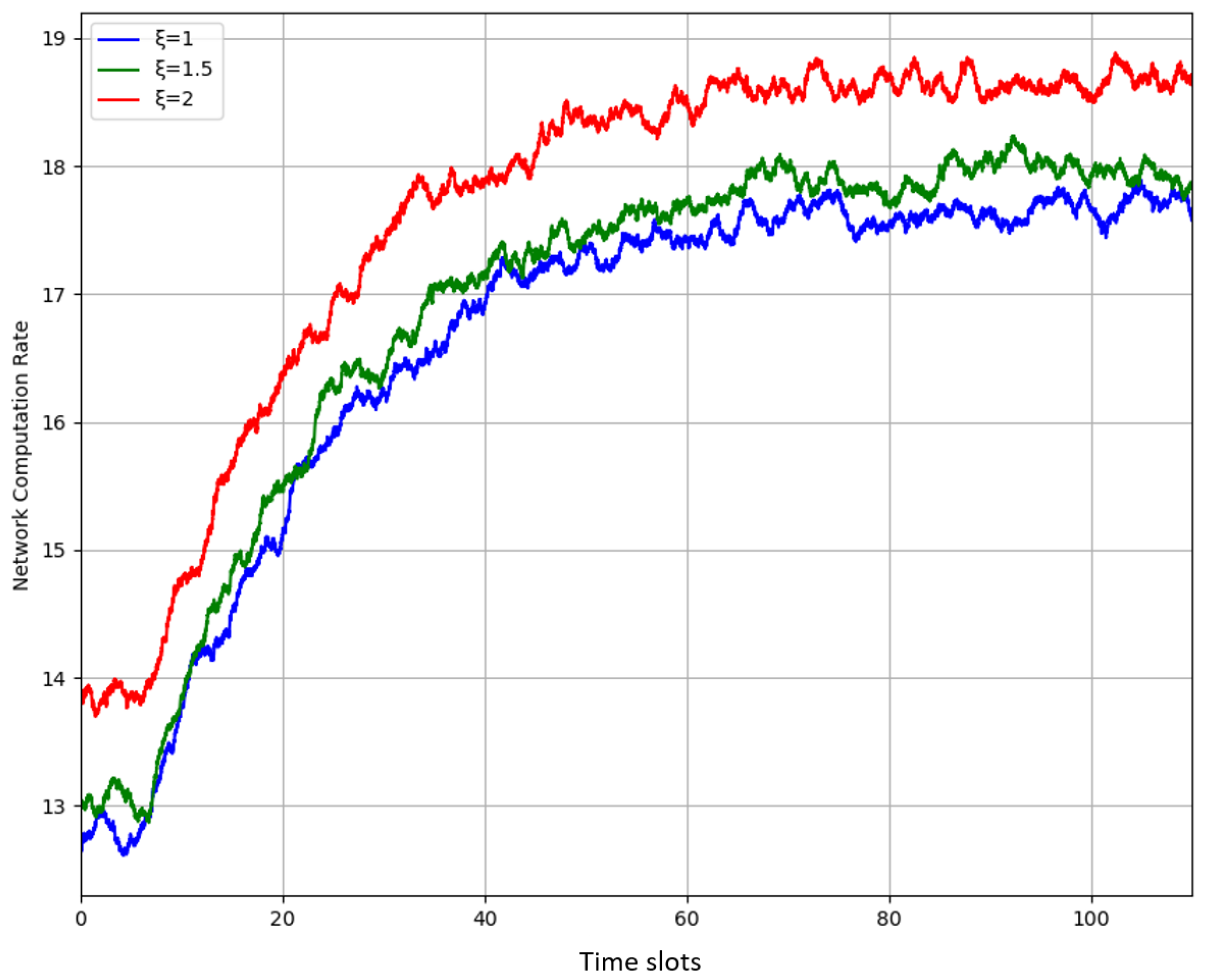
is penalty weight that controls the significance of system data and virtual energy queue backlog.
Then the upper bound of the Lyapunov drift-plus-penalty is given by
By removing the constant terms from observation at the beginning of
t-th time slot, the algorithm decides the actions by maximizing the following
Then the problem
can be decoupled into deterministic sub-problems
, we formulate the problem
as
At this time, has been decoupled into deterministic sub-problems within each time slot, the next step is to apply DRL algorithm to solve in each time slot.
4.3. MDP Modeling
However, the transformed problem is still difficult to solve as the variables are still coupled with each other. Thus, we first transform it into a MDP and then employ DRL to approximate the optimal solution.
For MDP modeling, there are state space, action space and reward space for DRL.
State space: In
t-th time slot, the state
consisting of the channel gain and the system queue is defined as
where
is the channel gain among industrial base stations and industrial terminals,
is the set of data queue length, and
is the set of virtual energy queue length.
Action space: In
t-th time slot, the action
consists of an optimal offloading action, the computation offloading time ratio, the local CPU frequency and the total energy consumption, defined as
where
is the set of optimal offloading action, and
is the set of computation offloading time ratio,
is the set of local CPU frequency,
is the set of energy consumption.
Reward space: The reward
denotes the action reward generated when taking action
in the current state
. According to the objective function, the reward
for
n-th industrial terminal and
m-th industrial base station in
t-th time slot is defined as
Based on this, the sum of incentives received by all industrial terminals is calculated as
Obviously, the larger the reward, the larger the network computation rate of the industrial terminal. Furthermore, the cumulative reward is defined as
where
is the discount factor indicating how the previous reward impacts the current reward.
Through the above process, we model the transformed problem into an MDP. As such, we can maximize the network computation rate by maximizing the long-term accumulative reward while satisfying all constraints, during which an effective policy can be obtained.
4.4. Lyapunov-Guided A3C Algorithm
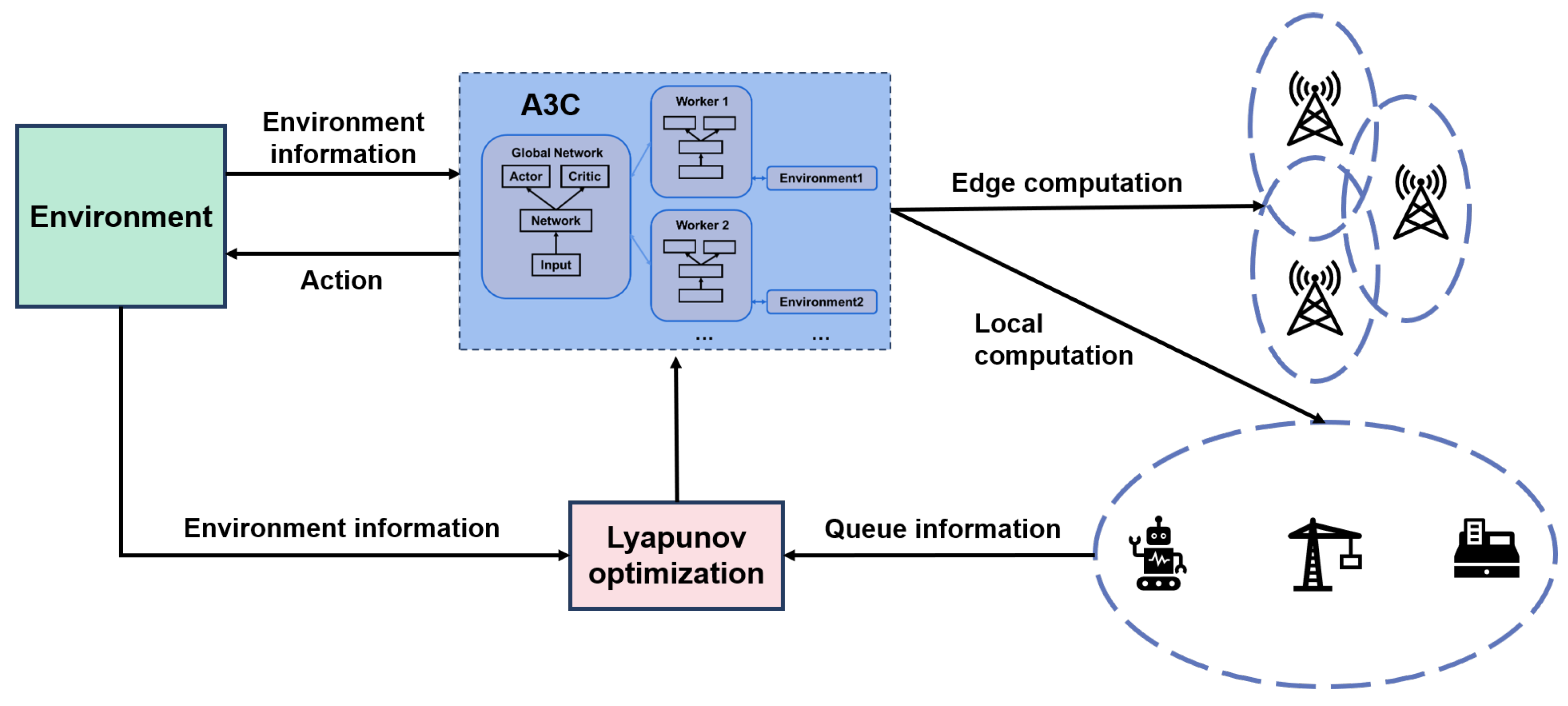
With the formulated MDP model, we further propose the LyA3C algorithm based on the A3C algorithm. The structure of our proposed algorithm is depicted in
Figure 2. There are a global network and several worker agents, where the globe network and the worker agents are set in the same actor-critic structure.
Taking one of the worker agents as an example, it includes two modules: the actor module and the critic module. The two modules accept the state and output the state value as well as the corresponding policy. Specifically,
denotes the policy learned from the current state, where
is the explored offloading policy. The network parameter of actor network is denoted as
. The gradient of the expected cumulative discounted reward is
where
is the advantage function.
is used to measure the dominance of the state
when the agent selects action
and executes the policy
compared to executing an arbitrary action. According to the current strategy, the value of
is obtained from the value
and is calculated as
where
is discount factor.
The parameter
is updated based on
where
is the learning rate of the actor network.
In contrast, the parameter of the critic network
is updated as
where
is the learning rate of the critic network.
Through the above process, each worker agent will send the accumulated updates to the global network, then the global network asynchronously updates and .
To sum up, the overall flowchart of the LyA3C algorithm is shown in
Figure 3.
The algorithm is summarized as Algorithm 1.
| Algorithm 1 The LyA3C Algorithm |
- 1:
Initialize number of industrial terminals N; number of industrial base stations M; Lyapunov drift-plus-penalty parameter V; - 2:
Initialize the A3C network with actor and critic ; - 3:
repeat - 4:
Collect a set of trajectories {, , , }; - 5:
for each time slot to K do - 6:
Actor step sample action ; - 7:
Critic step compute value estimate ; - 8:
Compute advantage function using Equation ( 25); - 9:
Each worker agent update and using Equations (27) and (28); - 10:
Global network update and ; - 11:
end for
|
4.5. Complexity Analysis
The complexity analysis of the proposed LyA3C algorithm is based on the structure of the neural network used for the critic network and actor network. The critic network contains the input layer , the hidden layer and the output layer . The complexity of the critic network is calculated as . Similarly, the actor network also contains the input layer , the hidden layer , and the output layer . The complexity of the actor network is calculated as . For each agent, the overall complexity is the sum of the complexity of the critic network and the actor network: .
6. Conclusions
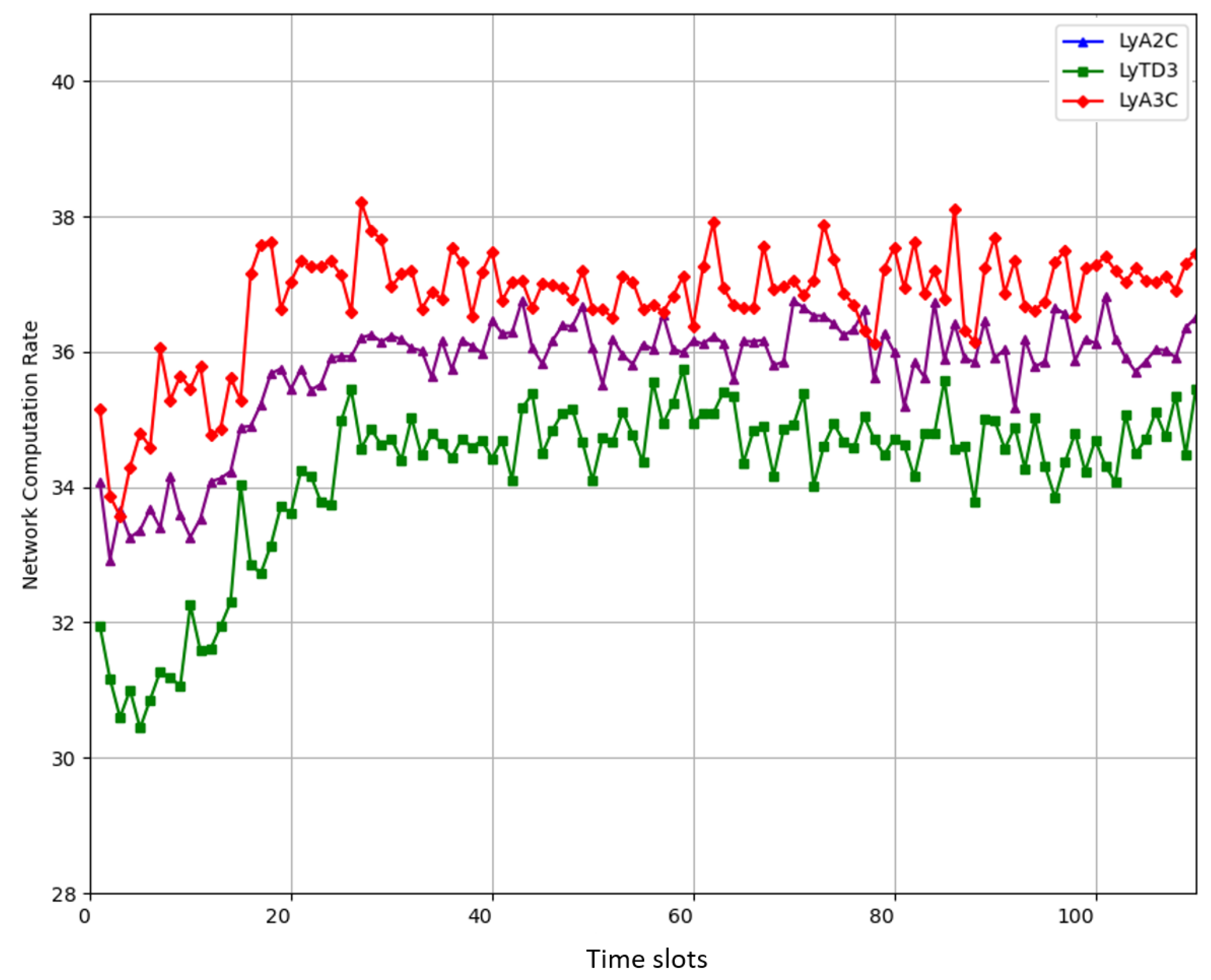
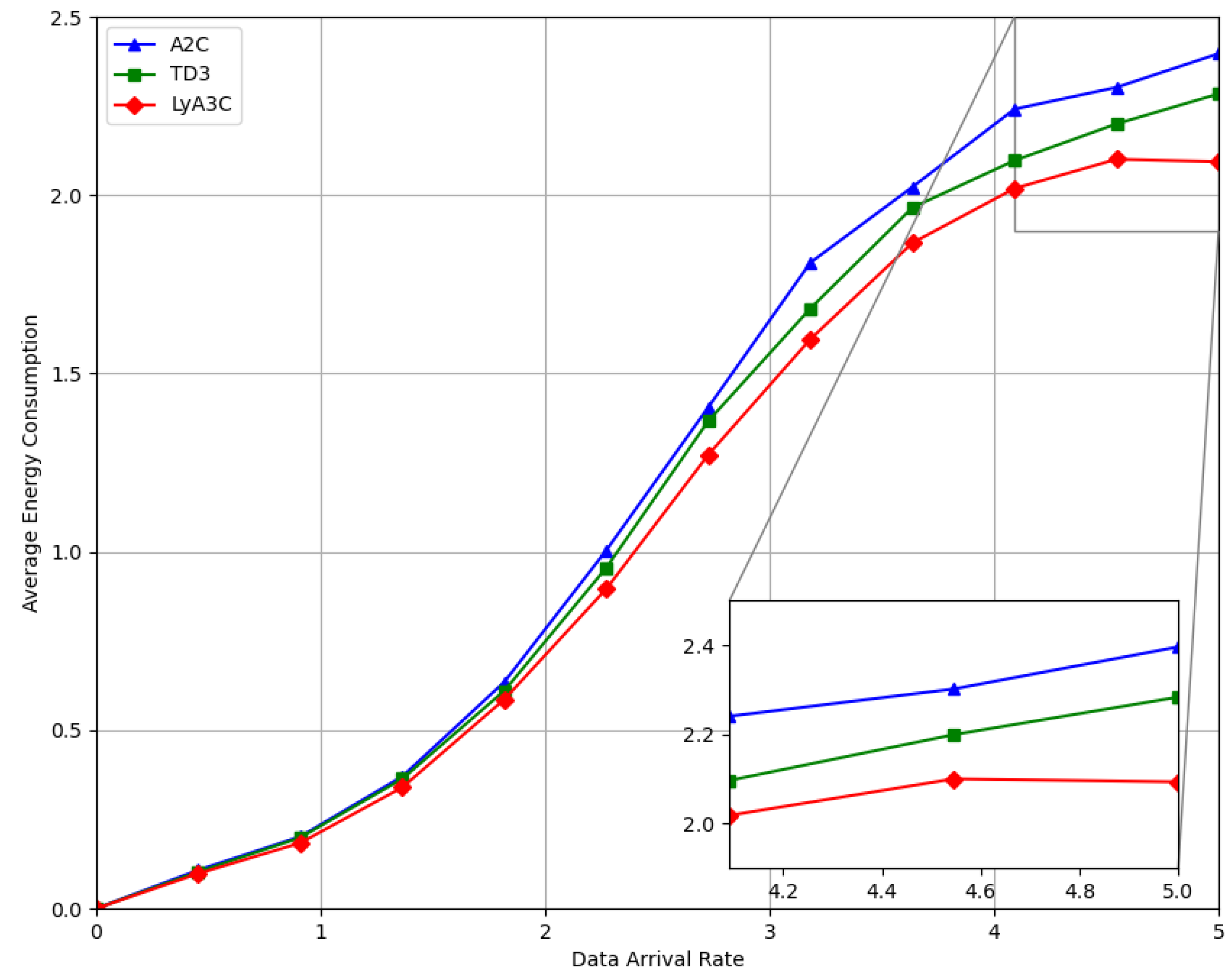
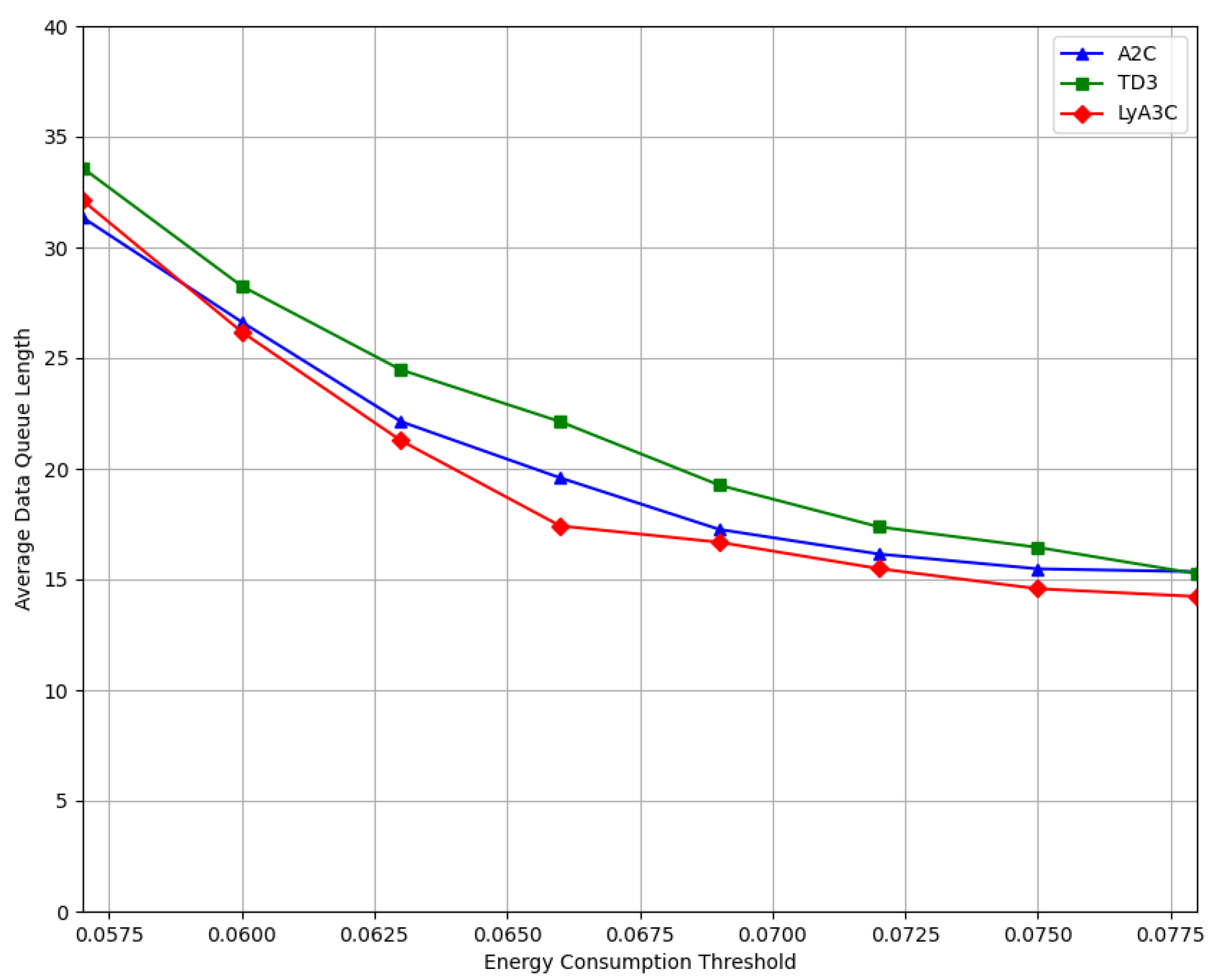
In this paper, we proposed an intelligent computation offloading algorithm based on Lyapunov optimization and DRL. With full consideration of the offloading time, data causality, local CPU frequency, energy consumption, transmit power, and data queue stability, the long-term network computation rate maximization problem was formulated. To solve this problem, we designed the data queue and virtual energy queue backlog, derived the upper bound of the Lyapunov drift based on the Lyapunov optimization theory, and decoupled the complex MINLP problem into deterministic sub-problems. Then, we reformulated the transformed problem into MDP, and approximated the optimal solution using the proposed LyA3C algorithm. Experimental results showed that compared with two benchmark algorithms, including A2C-based and TD3-based algorithms, the proposed LyA3C algorithm could converge stably and effectively improve the long-term network computation rate by 2.8% and 5.7% while satisfying various constraints.
In the future, in addition to the binary offloading adopted in the paper, we will consider dividing the computation task into multiple independent sub-tasks for multi-destination computation offloading. Moreover, different from the fact that all industrial base stations are homogeneous providing the same computation resource, i.e., CPU, we will consider the case that, different industrial base stations provide different kinds of computation resources including CPU, GPU and NPU.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}