1. Introduction
The prediction of art auction results is a complex and multifaceted challenge that has gained significant attention in recent years due to the growing importance of data-driven decision-making in the art market. As the art industry becomes increasingly globalized and competitive, auction houses, investors, and collectors seek more reliable methods to forecast the outcomes of auctions, which often involve substantial financial stakes. Accurate predictions of auction results can inform bidding strategies, guide investment decisions, and enhance market transparency [
1], making this area of study highly relevant.
The art market is characterized by its unique and volatile nature, where prices are influenced by a combination of tangible factors, such as the medium, size, and condition of the artwork, as well as intangible elements, including the reputation of the artist, provenance, and current market trends [
2]. These complexities have driven researchers to explore advanced predictive models that can effectively handle the intricacies of tabular data commonly found in auction datasets [
3].
Traditional statistical methods, such as Linear Models, K-Nearest Neighbors (KNN), and Support Vector Machines (SVM) have long been used to model auction outcomes, but they often fall short in capturing non-linear relationships and interactions among variables [
4]. Recent advancements in machine learning have introduced more sophisticated approaches, such as Decision Trees, Random Forests, Gradient Boosting Machines (including XGBoost [
5], CatBoost [
6]), and Neural Networks (such as Multi-Layer Perceptron (MLP) and DeepGBM [
7]), which offer improved predictive accuracy and the ability to handle large, complex datasets. Additionally, modern approaches like VIME [
8], RLN [
9], ModelTree [
10], DeepFM [
11], and SAINT [
12] have been explored for their potential in tackling the nuanced challenges of auction data prediction. However, the art market’s inherent unpredictability and the need for model interpretability present ongoing challenges.
Several publications have explored the application of machine learning in the art market, highlighting both the potential and limitations of current methodologies [
13,
14,
15]. Some studies have focused on the predictive power of specific features [
16], while others have investigated the use of ensemble models to improve accuracy [
17]. Despite these advances, there is still debate over the most effective modelling strategies.
This study aims to provide a comprehensive evaluation of various machine learning architectures for predicting art auction results using tabular data. By systematically comparing traditional models with more advanced techniques, we seek to identify the strengths and weaknesses of each approach. Our analysis includes an exploration of model interpretability, a crucial aspect for stakeholders who need to understand the factors driving predictions. The principal conclusion of this work is that while advanced models generally offer better predictive performance, their complexity necessitates careful consideration of interpretability, especially in a market as nuanced as art.
In summary, this research contributes to the ongoing discourse on the application of machine learning in the art market by offering insights into the most effective prediction architectures and by providing a collected dataset of real-world European online auction results. Our findings are intended to guide auction houses, investors, and market analysts in selecting appropriate models for their specific needs, ultimately improving the precision and transparency of auction result predictions.
3. Results
This section evaluates the performance of the trained models across different datasets, using Symmetric Mean Absolute Percentage Error (sMAPE) as the primary metric for comparison. The sMAPE formula is given by
This metric is particularly well-suited for the art auction prediction problem, as it mitigates the impact of overpredictions, particularly regarding the presented datasets that are skewed towards lower price results. The sections following the presented results explore the underlying factors that contribute to each model’s performance.
3.1. sMAPE Score Analysis Across Datasets
The analysis of sMAPE scores across the different datasets provides valuable insights into the predictive capabilities of the compared machine learning models. sMAPE is particularly useful in this context, as it measures the percentage difference between predicted and actual values, symmetrically penalizing both over- and under-predictions. This makes it especially suitable for art auction price predictions, where both types of errors can have a significant impact.
Table 3 provides a comparative evaluation of the models based on their sMAPE scores across the datasets. In the NoImg dataset, XGBoost demonstrates the best performance, achieving a sMAPE score of 55.11%, with LightGBM following at 57.53%. The LinearModel, however, exhibits significantly inferior performance, with sMAPE over 100% for each dataset, indicating its limitations in handling the complexity of auction data. Similarly, DeepGBM with a sMAPE of 76.92% and VIME with 75.29% struggle to generalize effectively, while other models present moderate performance, ranging from 60.57% for SAINT to 68.50% for ModelTree.
In the Color dataset, RandomForest emerges as the top performer with a sMAPE of 55.95%, outperforming XGBoost, which records 57.50%. Other models result in similar ranges of error, with improvement only for VIME, with almost 10 percentage points of decrease.
In the SVD dataset, XGBoost once again leads with a sMAPE score of 54.83%, followed closely by RandomForest at 56.94%. Contrary to the Color dataset, providing SVD Entropy resulted in the worst noted error for VIME (86.44%) and DeepGBM (87.96%).
For the ColorSVD dataset, RandomForest delivers the best performance, achieving a sMAPE of 55.51%, with CatBoost in second place at 58.25%. VIME (74.09%) and DeepGBM (76.18%) still exhibit higher error rates than other moderately performing models, suggesting that complex neural network-based models are less effective compared to ensemble methods when Colorfulness Score and SVD Entropy enhance the auction data.
The Housing dataset is simpler compared to the auction datasets, as it displays higher linearity between features. In this setting, LightGBM achieves the best performance with a sMAPE of 14.71%, slightly outperforming XGBoost (14.84%). However, DeepGBM performs poorly in this benchmark, with a sMAPE of 35.13%, further demonstrating DeepGBM may not be suitable for this kind of tabular dataset, while this time, VIME is placed among the moderate performers.
Overall, XGBoost and RandomForest consistently exhibit superior performance across the auction-related datasets; however, the prediction errors still exceed the threshold for what would be considered satisfactory results. The LinearModel consistently performs poorly, with sMAPE scores exceeding 100% in most auction datasets, underscoring its unsuitability for these tasks. Models such as DeepGBM and VIME also exhibit subpar performance, particularly in the auction datasets where higher-dimensional transformations (e.g., SVD) are applied. In contrast, for the CaliforniaHousing dataset, more models demonstrate good generalization abilities, with LightGBM and XGBoost achieving the best results.
Tree-based ensemble methods, particularly gradient-boosting techniques like XGBoost and RandomForest, consistently deliver the best performance across various datasets, especially in handling the complexity of auction data with nonlinearity and high-dimensional features. While these models achieve relatively lower sMAPE scores compared to others, indicating their robustness and adaptability to tabular data, the overall prediction errors remain above what would be considered optimal, underscoring the challenge of achieving precise predictions in this domain.
3.2. LiniearModel (Linear Regression)
The LinearModel consistently performed the worst across all auction datasets, with sMAPE scores exceeding 100%. It highlights its inability to capture the complexity of auction price data. Linear regression assumes a linear relationship between the target variable (auction price) and input features, modeled as
However, auction prices are driven by nonlinear interactions between factors such as TECHNIQUE, DIMENSIONS and high-cardinal features, such as ARTIST. The inability to model complex relationships leads to high bias, as the linear model systematically underfits the data. The lack of flexibility in handling nonlinearity and feature interactions, compared to models like XGBoost or RandomForest, results in poorer generalization and high error rates.
3.3. K-Nearest Neighbors
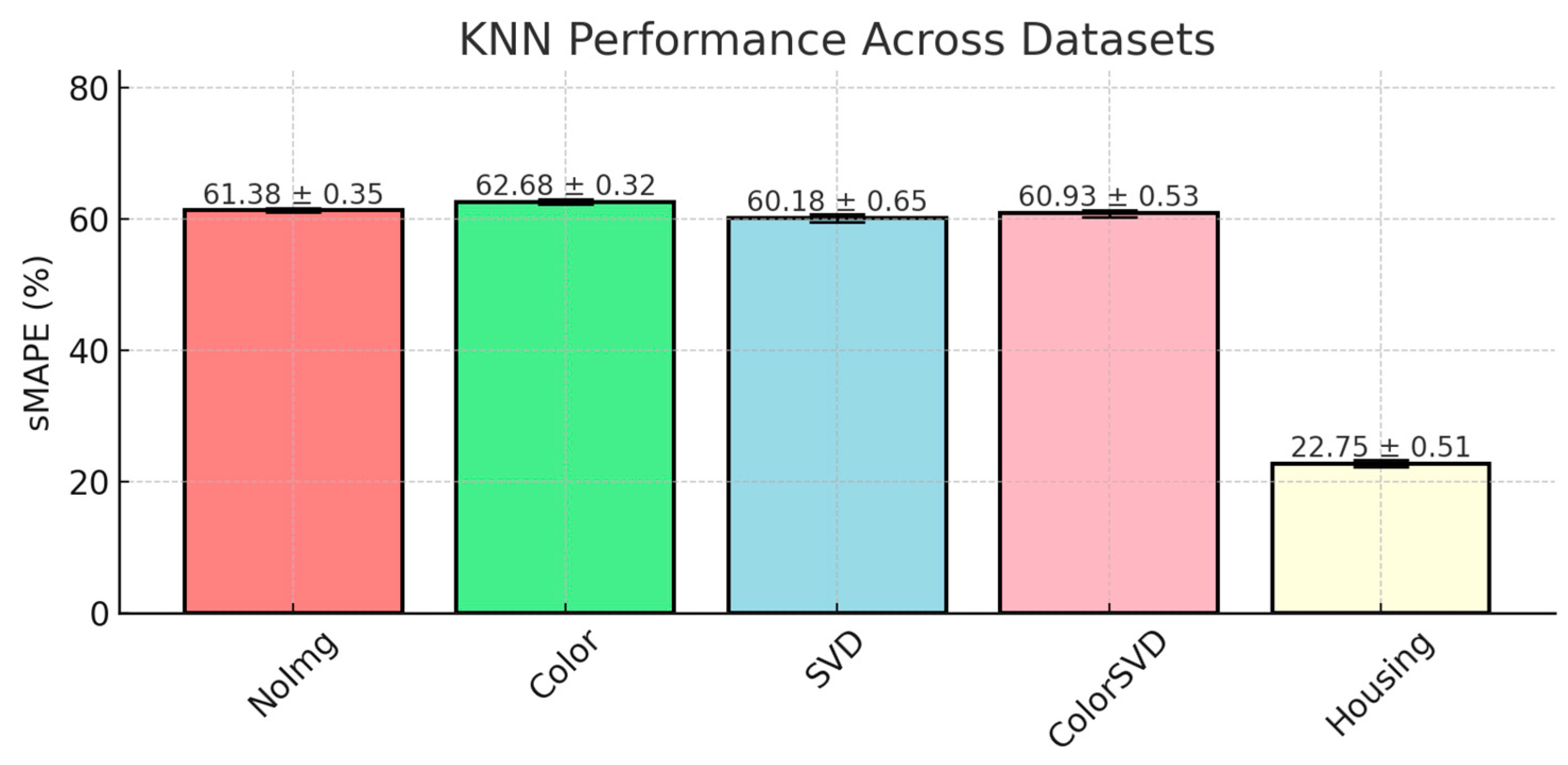
KNN performed significantly better than LinearModel, with its sMAPE scores ranging between 60.38 and 62.68% (presented in
Figure 1), indicating that it struggled with the complexity of the auction datasets.
KNN is a distance-based algorithm that predicts the target variable based on the average of the nearest neighbors’ target values. It is defined as
where
Nk(x) represents the
k nearest neighbors of
x.
We observe that KNN performed relatively consistently across the auction datasets, showing minor improvements when image-derived features were introduced. This indicates that dimensionality alone was not the key factor in KNN’s underperformance compared to Random Forest. Auction datasets, characterized by volatility due to external market factors and the subjective nature of art pricing, often contain outliers, such as unusually high or low auction prices. KNN’s reliance on simple averaging of the nearest neighbors makes it highly sensitive to these outliers, which leads to less accurate predictions.
3.4. DecisionTree
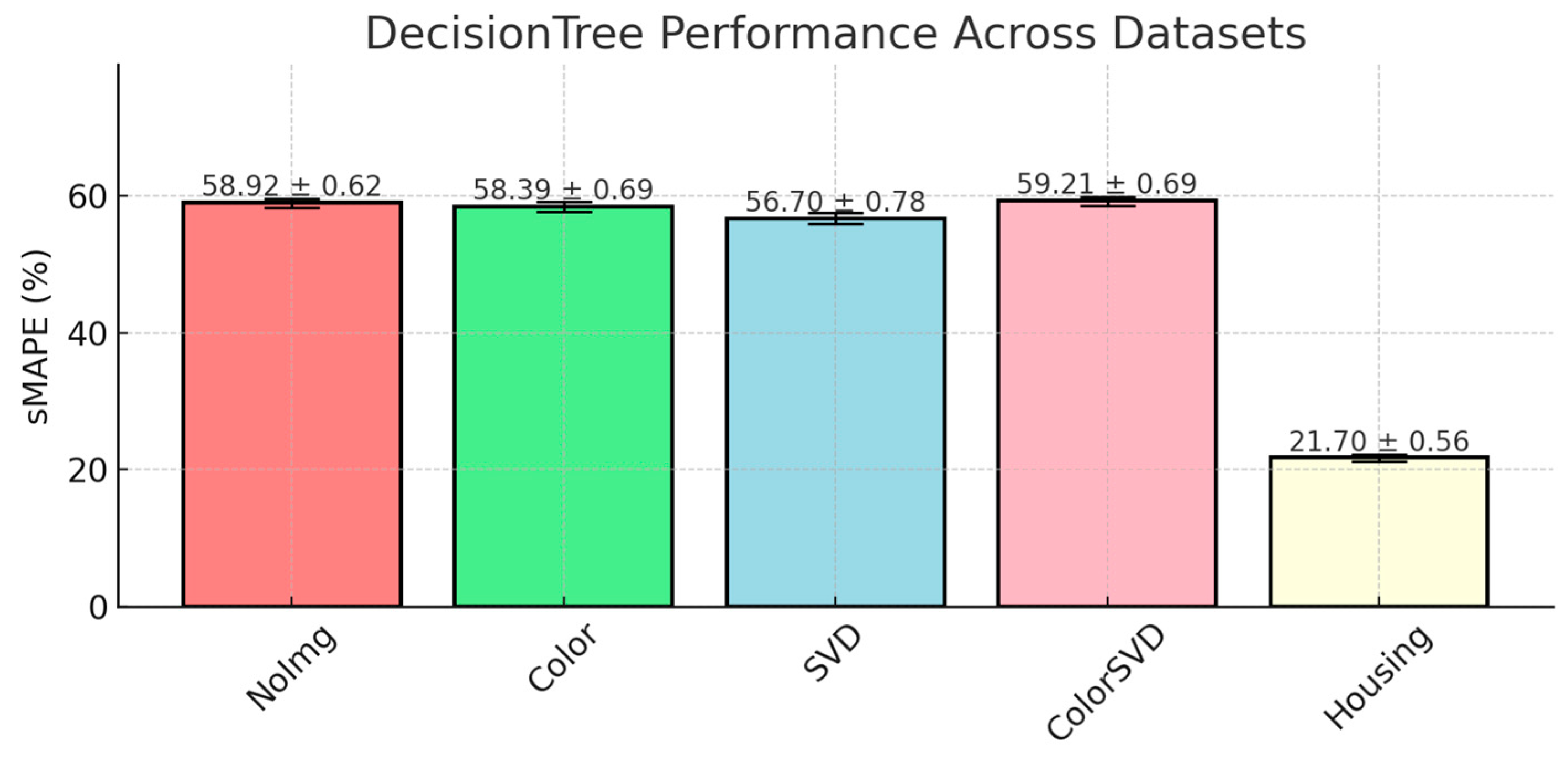
The DecisionTree model demonstrated moderate performance across the auction datasets, with its best result achieved when SVD Entropy was included (56.70% ± 0.78). The comparison is presented in
Figure 2.
The model’s ability to capture nonlinearity is a key factor, but possibly its susceptibility to overfitting in noisy data impacted its performance. DecisionTrees recursively partition the feature space, minimizing the variance (MSE for regression) in the target variable at each node. This characteristic explains its better performance compared to LinearModel and KNN. While DecisionTrees capture nonlinearity, they tend to overfit noisy auction datasets memorizing both signal and noise. In the ColorSVD dataset (59.21%), the model likely overfitted to complex feature combinations, leading to reduced generalization.
3.5. RandomForest
RandomForest is an ensemble learning method that constructs multiple decision trees, each trained on a bootstrapped sample of the dataset. By averaging the predictions across all trees, RandomForest reduces variance, as described by
where
E(
) is the expected value of the
n ensemble model,
is the correlation between trees, and
is the variance of each tree’s prediction.
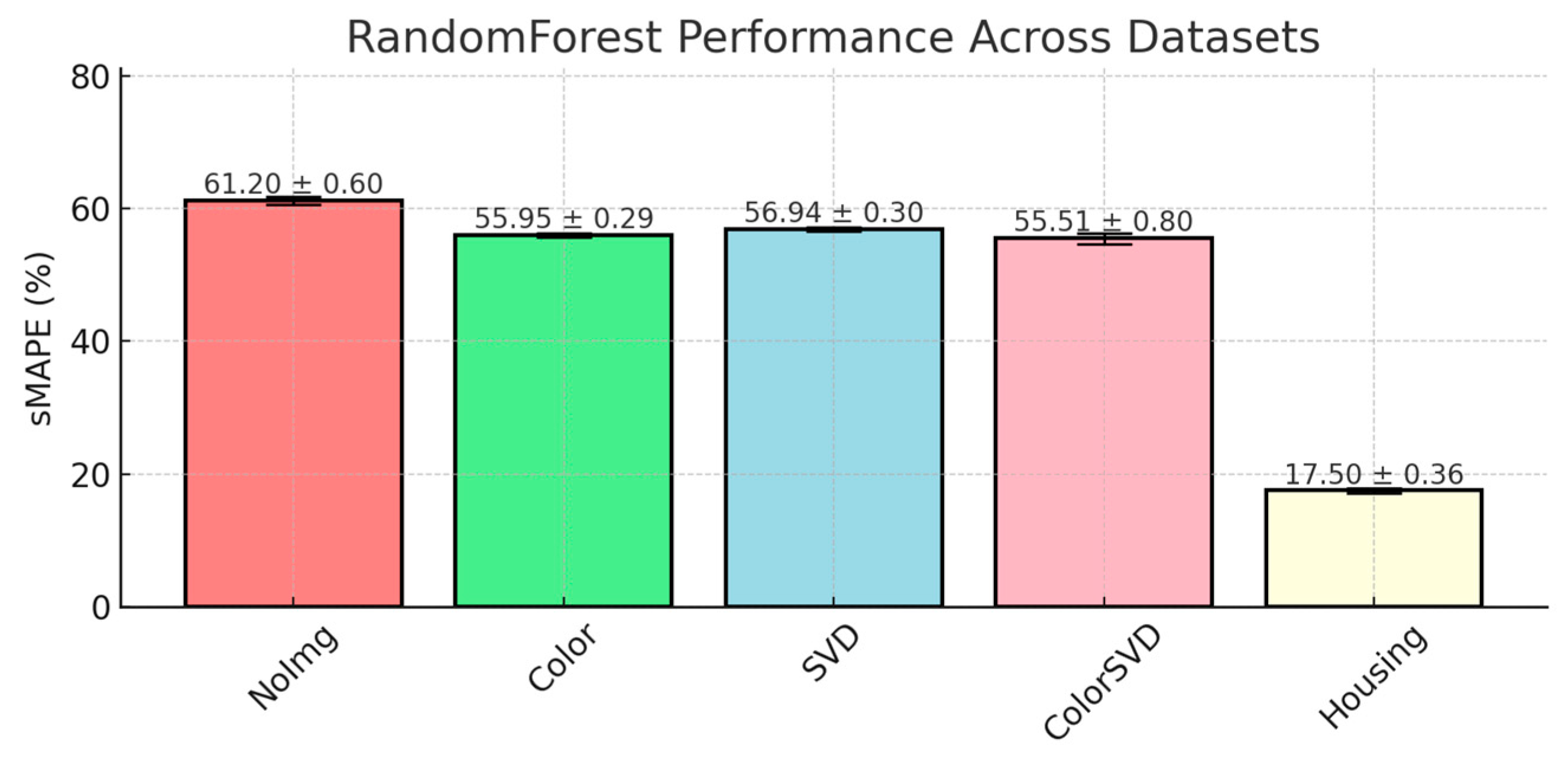
This averaging mitigates overfitting by reducing sensitivity to individual tree errors, leading to more stable predictions. The performance results highlight this advantage, especially in datasets with image-derived features. For instance, as presented in
Figure 3, RandomForest achieved strong results in the Color (55.95% ± 0.29) and ColorSVD (55.51% ± 0.80) datasets, reflecting its robustness in capturing nonlinear interactions. With these datasets, RandomForest maintained better fit and generalization than other models.
3.6. XGBoost
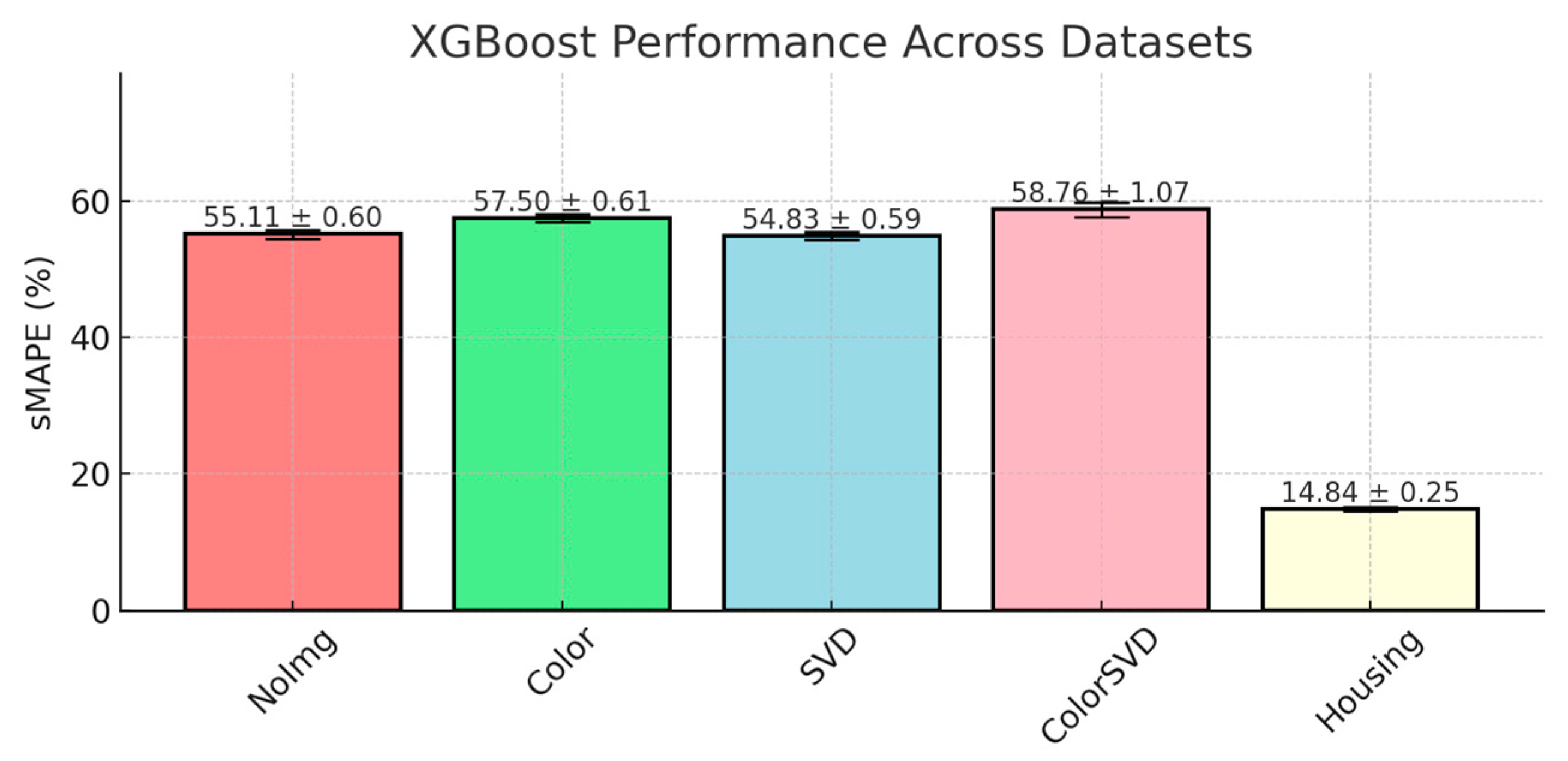
XGBoost outperformed all other models across NoImg and SVD datasets, achieving the lowest sMAPE scores of 55.11% and 54.83% and consistent results in other datasets presented in
Figure 4.
The authors believe it to be due both to its precise optimization and robust regularization capabilities. The core strength of XGBoost comes from its gradient boosting framework, where trees are built sequentially to minimize a regularized objective function. The objective function includes both the gradient (first derivative) and the Hessian (second derivative), allowing for more precise optimization. The function is approximated as follows:
where
represents parameters of the model,
is the gradient,
is the hessian,
is a regularization term.
The second strong point of XGBoost is a solid regularization term that is based on both L1 (Lasso) and L2 (Ridge) techniques that control model complexity. The complete regularization term is described by
where
λ controls the strength of L2 regularization (penalizing large weights), and
α controls the strength of L1 regularization (encouraging sparsity by setting less important weights to zero). In auction datasets, L1 regularization helps focus the model on key features (e.g., ARTIST or TECHNIQUE) by eliminating irrelevant ones, simplifying the model and improving interpretability. L2 regularization, on the other hand, controls the size of the remaining feature weights by penalizing large coefficients. This prevents any single feature from dominating the model and helps reduce overfitting, making the model more stable and robust, especially in noisy auction datasets. Together, L1 and L2 regularization allow XGBoost to balance model complexity and generalization.
3.7. CatBoost
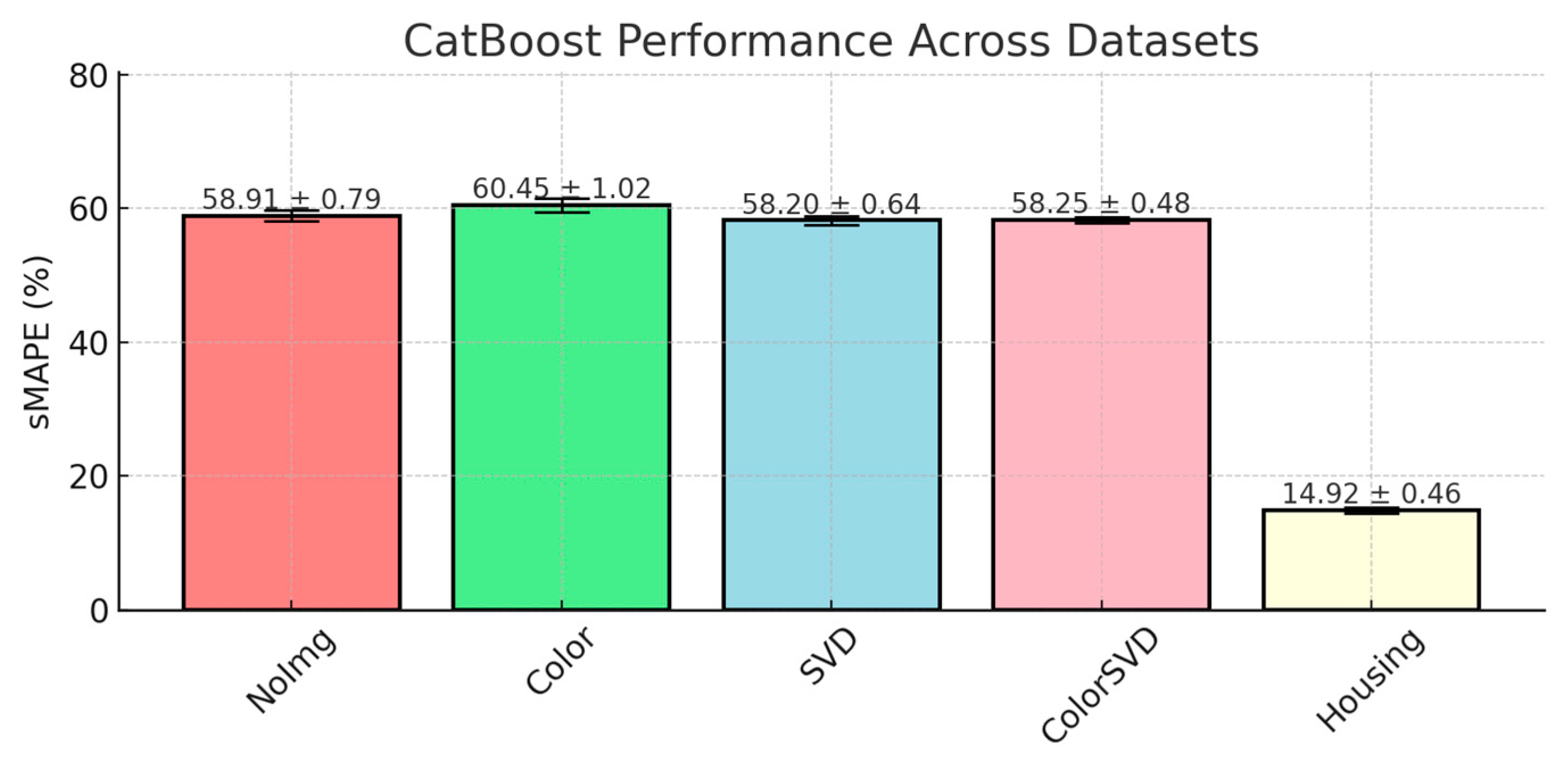
CatBoost demonstrated stable performance across all the auction datasets. The results of this model are presented in
Figure 5.
CatBoost’s key strength lies in its target-based encoding for categorical variables that auction data consist of. Moreover, CatBoost uses ordered boosting, a method that addresses the prediction-shift problem often observed in gradient boosting. In ordered boosting, each tree is trained on a historical view of the data, preventing overfitting and leakage by making sure the model only uses past data for training. This can be useful in auction datasets, where past auction results influence price predictions. In addition, CatBoost incorporates L2 regularization, which helps control the model’s complexity by penalizing large weights, leading to more stable predictions. This is especially important in datasets like auctions, where market volatility can introduce noise. The robust regularization, combined with CatBoost’s ability to efficiently handle categorical data, results in models that generalize well, even with noisy auction prices.
3.8. LightGBM
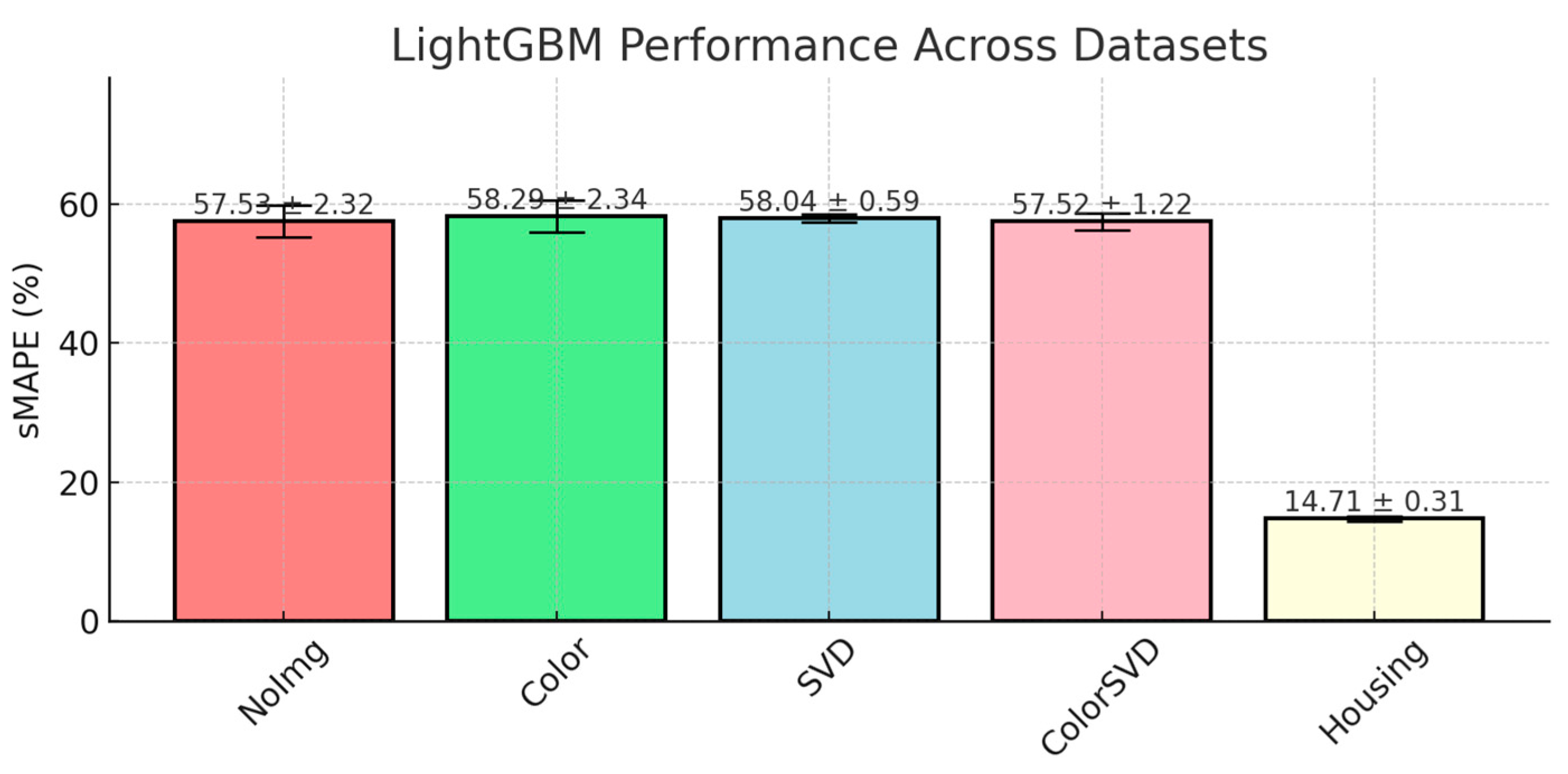
LightGBM performed competitively across the auction datasets, but its sMAPE scores were slightly higher compared to XGBoost, as shown in
Figure 6. The model achieved a sMAPE of 57.52% ± 1.22 in the ColorSVD dataset, and a notable 14.71% ± 0.31 in the CaliforniaHousing dataset, where it performed the best. However, it underperformed compared to XGBoost and RandomForest in more complex auction datasets.
One key difference between LightGBM and XGBoost lies in their regularization strategies. While both models use L2 regularization, XGBoost employs a stronger regularization framework, incorporating both L1 and L2 penalties. This gives XGBoost an edge in controlling model complexity, especially in high-dimensional and noisy datasets like auctions, where feature interactions are nonlinear and difficult to capture. In contrast, LightGBM relies primarily on L2 regularization to prevent overfitting by penalizing large leaf weights. The absence of a strong L1 regularization component means that LightGBM is less effective at enforcing sparsity, which could explain its slightly higher error rates in auction datasets where irrelevant or noisy features might be present. While LightGBM excels in structured data, its regularization framework may not handle noise and complex feature interactions as effectively as XGBoost. The model’s leaf-wise growth strategy, where trees grow asymmetrically based on maximum loss reduction, helps LightGBM capture deep and complex interactions between features like Colorfulness Score and SVD Entropy. This enables the model to handle high-dimensional data efficiently, making it faster and more memory-efficient. However, this extensive tree growth can also lead to overfitting if not adequately controlled, especially in noisy datasets.
3.9. Multi-Layer Perceptron (MLP)
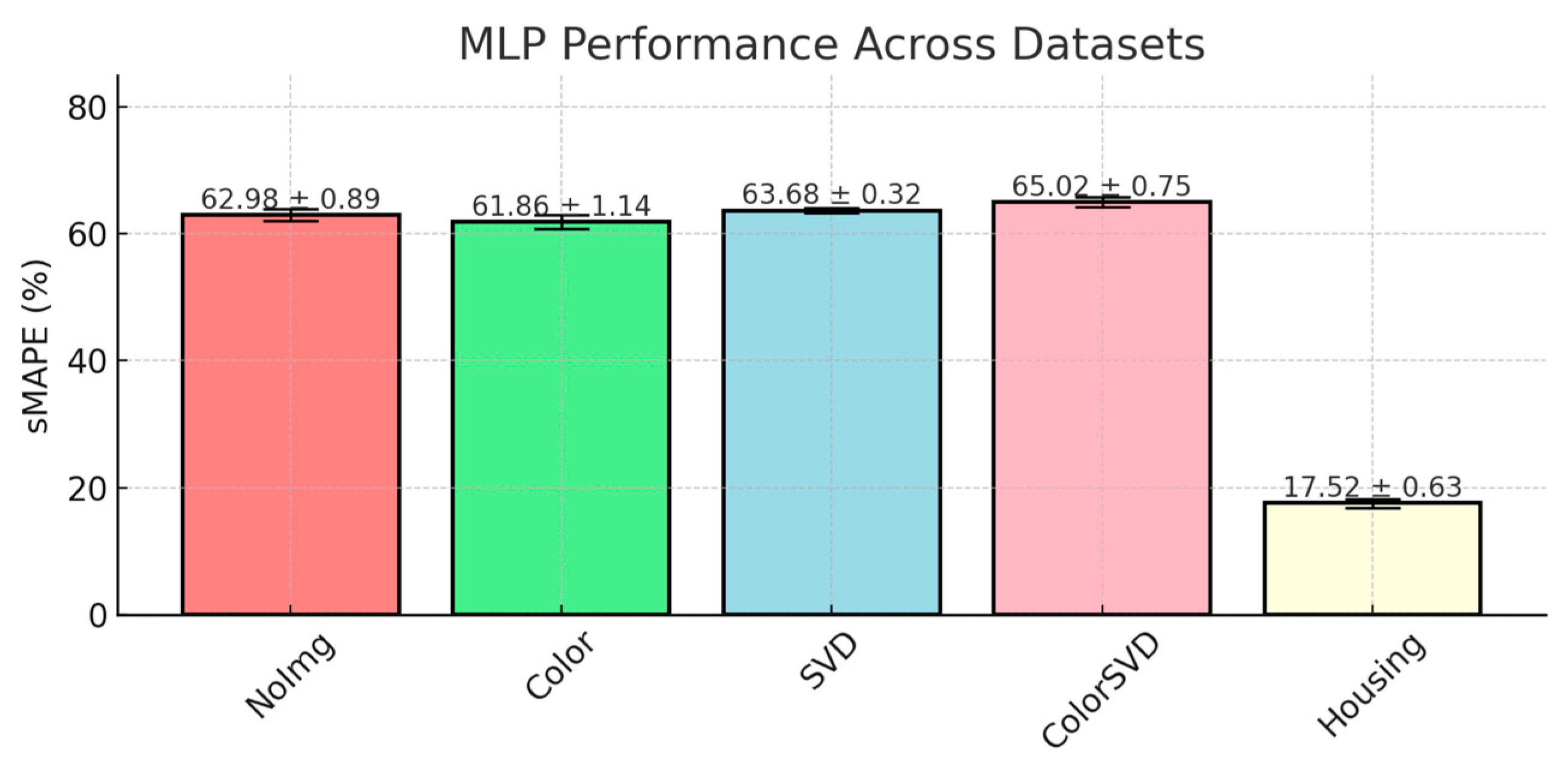
The MLP model showed moderate performance across the auction datasets, with sMAPE scores ranging from 61.86% ± 1.14 in the Color dataset to 65.02% ± 0.75 in the ColorSVD dataset. Despite its theoretical ability to model complex nonlinear relationships, the MLP underperformed compared to tree-based ensemble methods. The model showed a slight improvement when color feature was introduced, but its performance decreased with the addition of SVD features, as illustrated in
Figure 7.
Unlike tree-based models, MLPs lack built-in mechanisms to evaluate feature importance during training, limiting the model’s ability to prioritize the most predictive features. This can dilute the learning process across many irrelevant inputs. Given the relatively small size of the auction datasets (25,408 entries), neural networks like MLP are prone to overfitting, as they tend to learn noise rather than general patterns, resulting in poor performance on unseen auction data. The absence of strong regularization methods (e.g., dropout, weight decay) in the hyperparameters suggests that overfitting was not adequately controlled. As a result, MLPs are more likely to memorize training data rather than generalizing effectively.
3.10. VIME
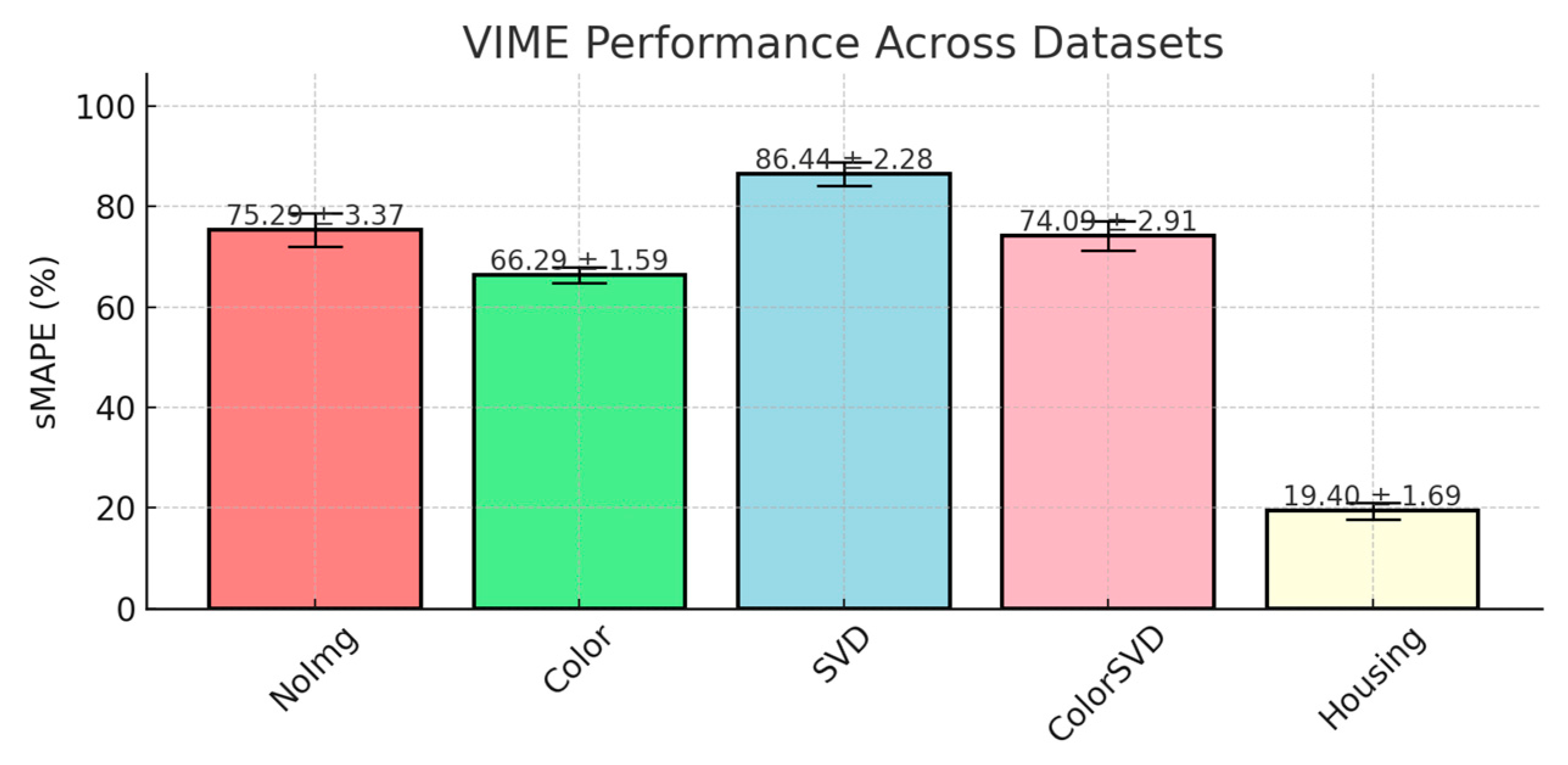
The VIME model exhibited considerable variability in performance across the auction datasets, with sMAPE scores ranging from 66.29% ± 1.59 in the Color dataset to 86.44% ± 2.28 in the SVD dataset. Overall, VIME underperformed compared to models like RandomForest and XGBoost. The results reached by VIME are presented in
Figure 8.
Variational Information Maximizing Embedding (VIME) is a semi-supervised learning model designed specifically for tabular data. It combines supervised and unsupervised learning, leveraging labeled data while making use of additional unlabeled data. VIME’s semi-supervised nature can be an advantage in datasets where labeled data are limited, as the model can extract additional information from the unlabeled portion of the data. In the auction datasets, where labelled data (auction prices) are fully available but noisier due to external factors, the unsupervised component of VIME may have been less effective.
3.11. ModelTree
The ModelTree model exhibited moderate performance across the auction datasets, with sMAPE scores ranging from 66.59% ± 0.66 in the Color dataset to 71.68% ± 3.62 in the SVD dataset.
ModelTree is a hybrid model that combines the strengths of decision trees and linear regression. The model partitions the data recursively, like a traditional decision tree, but instead of making constant predictions at the leaf nodes, it fits a linear regression model to the data in each leaf. This enables the model to blend nonlinear partitioning with localized linear modelling, allowing it to capture both linear and nonlinear patterns in different regions of the feature space. The use of linear regression within each partition provides a localized approximation of the relationship between the features and the target variable (auction prices), offering more flexibility than constant predictions, while still maintaining the tree structure for partitioning.
3.12. DeepGBM
The DeepGBM model performed poorly across all auction datasets, with sMAPE scores ranging from 76.18% ± 4.23 in the ColorSVD dataset to 87.96% ± 10.62 in the SVD dataset, indicating its difficulty in generalizing effectively. The size of the auction datasets could be insufficient for training a model as complex as DeepGBM. The hybrid structure of gradient-boosted decision trees and deep neural networks adds significant complexity, with the neural component likely being too deep for these data. Without strong regularization, the network likely memorized noisy patterns rather than learning generalizable features, leading to poor performance. The model likely failed to generate meaningful low-dimensional representations from these features. Although DeepGBM theoretically has the capacity to capture complex feature interactions through its hybrid approach, its over-complex architecture struggled to fit the highly variable auction data.
3.13. DeepFM
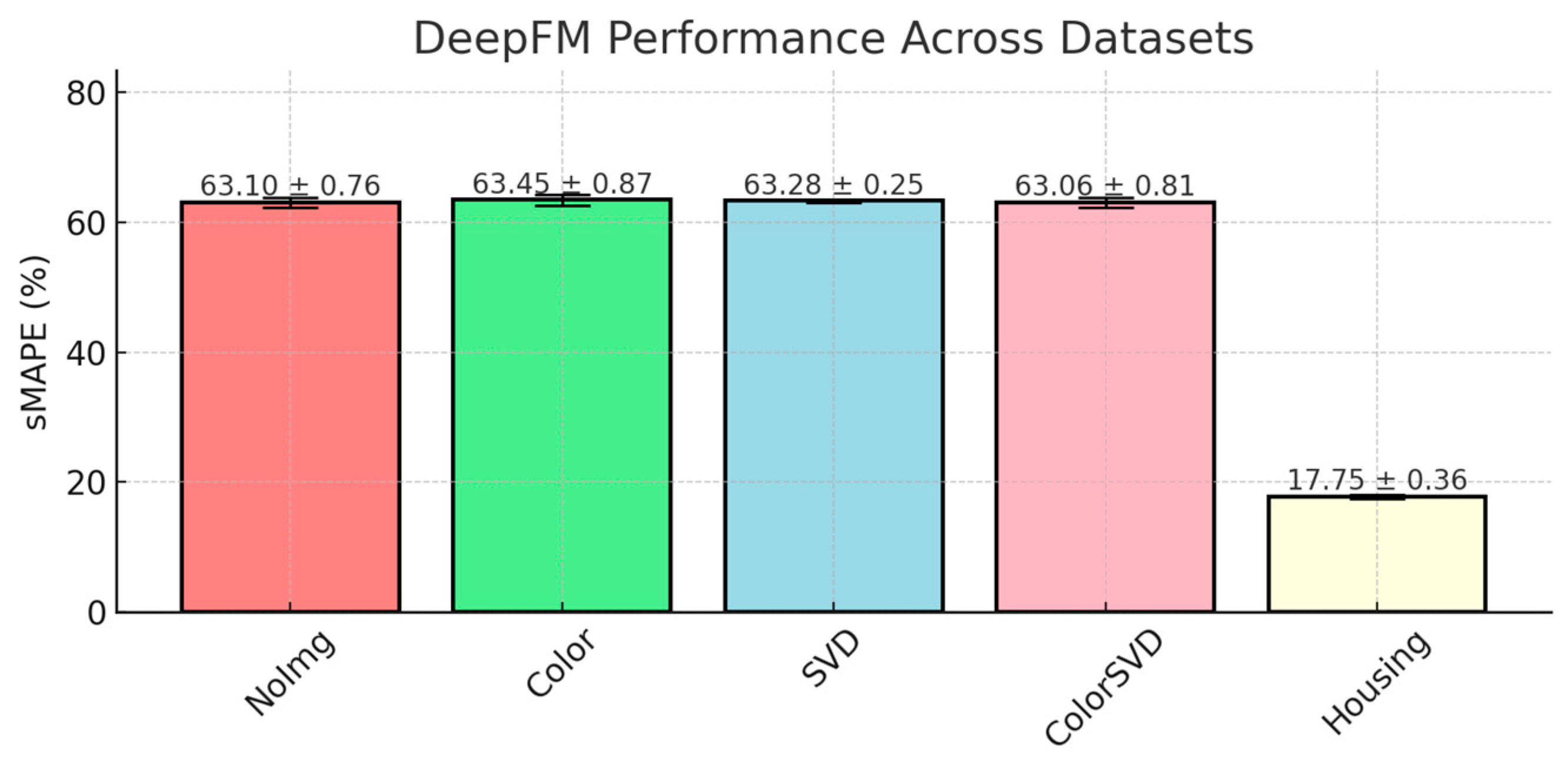
DeepFM is a hybrid model that combines factorization machines with deep neural networks to model both low- and high-order feature interactions. It is designed for tasks where understanding the interactions between categorical and numerical features is critical. Despite its sophisticated structure, DeepFM performed moderately well across the auction datasets, with sMAPE scores ranging from 61.30% ± 0.76 in the NoImg dataset to 63.45% ± 0.87 in the Color dataset, as shown in
Figure 9. The model did not outperform simpler models like RandomForest or XGBoost.
While this architecture theoretically provides a robust way to learn both simple and complex interactions between features, auction datasets present a unique challenge. Many of the feature interactions in auction data (e.g., ARTIST, TECHNIQUE, PRICE) are influenced by external market factors and subjective pricing that cannot easily be captured by standard interaction modeling. This might explain why DeepFM’s additional complexity did not translate into better predictive accuracy compared to tree-based models.
3.14. SAINT
Self-Attention and Intersample Attention Transformer (SAINT) is a relatively new approach that utilizes transformers for tabular data. The model applies two main attention mechanisms: self-attention, which focuses on feature interactions within a single sample, and intersample attention, which focuses on interactions between different samples. Despite its innovative architecture, SAINT delivered only moderate performance across the auction datasets, with sMAPE scores ranging from 60.57% ± 0.95 in the NoImg dataset to 62.41% ± 1.19 in the SVD dataset, as presented in
Figure 10.
The self-attention mechanism in SAINT allows the model to capture relationships between features within a single sample. It operates by computing attention weights that dictate how much each feature should contribute to the prediction. The self-attention mechanism is particularly useful for handling high-dimensional and structured data, as it can model complex dependencies between features that other models (e.g., traditional decision trees) might miss. However, auction datasets contain nonlinear relationships driven by subjective factors like market volatility, which are difficult to model using feature-based dependencies alone. This likely explains why SAINT, despite capturing feature interactions, did not outperform simpler models like XGBoost and RandomForest.
3.15. Feature Importance Plots
In this section, we analyze the feature importance across different datasets to understand the impact of various features on model performance. By examining the importance plots, we aim to identify which features consistently contribute to predictive accuracy and how the inclusion of additional features, such as colorfulness and SVD entropy, influences overall model error. This analysis provides insights into the relative significance of core features versus image-related features in auction datasets.
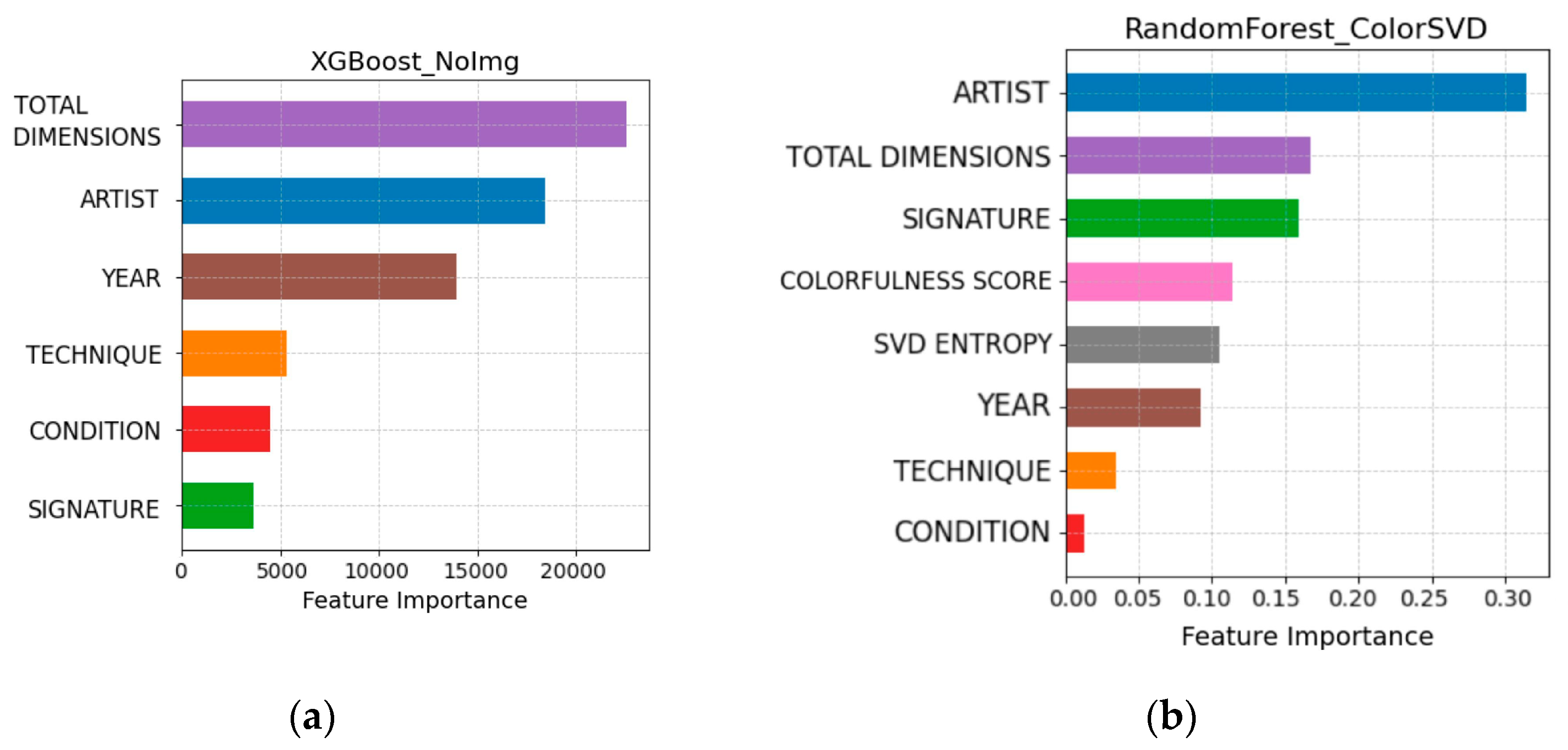
The study highlights that the feature importance plots across different models reveal distinct patterns based on the datasets they are applied to. In
Figure 11b, which represents the feature importance for the ColorSVD dataset using the RandomForest model, ARTIST and TOTAL DIMENSIONS stand out as the most influential features. Additionally, image-related features such as Colorfulness Score and SVD Entropy also contribute significantly to the model’s predictions. However, despite the presence of these image-based features, their inclusion introduces complexity that does not necessarily lead to improved performance. The overall contribution of these features is notable, but the complexity they add may lead to higher error rates with the presented models.
On the other hand,
Figure 11a, which represents the feature importance for the NoImg dataset using the XGBoost model, underscores the prominence of traditional metadata features such as TOTAL DIMENSIONS, ARTIST, and YEAR. These core features are critical to driving model performance, emphasizing their fundamental role in prediction accuracy. Interestingly, the NoImg dataset does not include image-related features, yet the model achieves strong predictive performance based on these traditional features.
This demonstrates the importance of key features, such as ARTIST and TOTAL DIMENSIONS and YEAR, in the initial stages of evaluating artwork value. By identifying which factors most strongly influence auction outcomes, the models provide insights into the early steps of price prediction. With prediction errors remaining at approximately 50%, the study indicates that, although these models introduce a more data-driven framework for artwork evaluation, they still fail to achieve the level of accuracy required to serve as a foundation for artwork evaluation.
3.16. Summary of the Results
In summary, while image-related features in the ColorSVD dataset provide some predictive value, their inclusion does not always result in lower error rates. The analysis indicates that traditional features like TOTAL DIMENSIONS and ARTIST remain consistently powerful across models and datasets. The findings suggest that adding more complex, image-derived features may introduce diminishing returns for the evaluated models, highlighting the need to balance the benefits of added complexity against the risk of reduced model performance.
Across all datasets analyzed, the RandomForest and XGBoost models consistently emerged as top performers, achieving the lowest sMAPE values. This performance highlights ability to generalize well across a relatively small number of features. These models exhibited some level of resilience in scenarios where color features were included or SVD Entropy was added. The sMAPE values, even with relatively tight error bars indicating some stability, may still be insufficient to reliably capture the complex patterns within art auction datasets.
Conclusions can be drawn about the higher performance of models that utilize strong or multiple regularization techniques. XGBoost, for example, effectively combines L1 (Lasso) and L2 (Ridge) regularization, which controls model complexity and prevents overfitting. In contrast, while Random Forest does not use explicit regularization, it incorporates several implicit mechanisms. These include bootstrap sampling, where trees are trained on random data subsets and their predictions averaged to reduce variance, as well as feature subsampling, which prevents any one feature from dominating the model. Additionally, limiting tree depth and setting a minimum number of samples per leaf or split help prevent the trees from becoming too complex and overfitting. Together, these techniques act as implicit regularization, enhancing the model’s generalization.
Conversely, the Linear Model consistently exhibited the highest error across all datasets, underscoring its limitations in handling the complex, non-linear relationships likely present in the auction data. Despite being a simpler model, its poor performance indicates that linear assumptions are insufficient for this type of dataset, which likely includes complex interactions and non-linear dependencies that linear regression cannot capture effectively.
KNN and Decision Trees showed very limited effectiveness, generally ranking in the mid-range of achieved sMAPE scores. The underperformance of these models could be due to the sensitivity of these models to specific characteristics of the data, such as outliers or noisy features. More complex models like Multilayer Perceptron (MLP) and VIME failed to achieve satisfactory results. While these models are theoretically capable of capturing complex, non-linear relationships, they struggled to deliver competitive MSE scores, particularly when compared to the more stable performance of boosting methods like LightGBM and XGBoost. This underperformance could be attributed to the challenges in tuning these deep learning models for specific data applications, which require careful optimization of hyperparameters, architecture, and regularization techniques to prevent overfitting.
In summary, this analysis highlights the critical need for careful model selection that aligns with the intrinsic characteristics of the art auction dataset. While tree ensembles and boosting models like LightGBM, XGBoost, and CatBoost have shown relative strengths when handling complex features, their performance still falls short of what would be considered robust and reliable. Simpler models and compared deep learning approaches consistently underperform, revealing the persistent challenges of matching model complexity to the specific needs of the dataset. Overall, this analysis suggests that without a precise alignment between model capabilities and data characteristics, achieving satisfactory predictive performance remains difficult.
4. Discussion
The results of this study reveal persistent challenges in applying machine learning models to the prediction of art auction results. While tree-based ensemble models, particularly XGBoost and Random Forest, managed to perform better than other approaches, their effectiveness was still limited when dealing with the complexities of tabular data. Although these models demonstrated some predictive power across the auction datasets, their performance fell short of consistently robust results. This outcome contrasts with prior research that highlighted the effectiveness of gradient-boosting techniques in other domains, suggesting that their capabilities may be less reliable when applied to the nuances of art auction data.
While neural network architectures such as MLP, VIME, and DeepGBM theoretically have the capacity to capture complex interactions in high-dimensional data, they consistently underperformed compared to tree-based models. This outcome suggests that the specific characteristics of art auction data, such as the influence of external market factors and subjective elements like artist reputation and artwork provenance, are not effectively captured by these models. Neural networks tend to excel in larger datasets with abundant feature interactions; however, in the context of auction data, where the sample size is relatively small and features like ARTIST or TECHNIQUE dominate, tree-based models outperform due to their strong regularization ability. These results raise questions about the applicability of neural networks in auction price prediction and suggest that simpler, interpretable models may be more effective in this domain.
One key finding of this study is that the inclusion of image-based features, such as Colorfulness and SVD entropy, did not substantially improve model performance. This contrasts with previous research in the price prediction domain, where image features have been shown to enhance predictions. In the art market, however, core metadata features like ARTIST, TOTAL DIMENSIONS, and YEAR were consistently more influential in driving model accuracy. The limited impact of image features in this study may be due to the highly subjective nature of art valuation, where non-visual factors such as provenance, historical significance, and artist reputation often outweigh visual characteristics in determining price.
The implications of these findings raise concerns for stakeholders in the art market, including auction houses, investors, and analysts. Although tree-based models like Random Forest and XGBoost showed some degree of outperformance, their predictive capabilities still fall short of providing consistently accurate and transparent results. This suggests that relying on these models to optimize bidding strategies or guide investment decisions may not be as reliable as hoped. Furthermore, the feature importance analysis indicates that even traditional metadata, such as artist information, artwork dimensions, and auction histories, may not be sufficient to significantly improve predictive outcomes, highlighting the limitations of current data collection and curation practices in the art market.
The underperformance of neural networks, particularly in the context of art auction prediction, may suggest that future research should focus less on deep learning approaches and more on refining tree-based methods. However, there remains potential for exploring hybrid models that integrate the strengths of both approaches, particularly in cases where additional, higher-dimensional data can be incorporated. For example, the integration of social media sentiment, market trends, or economic indicators could provide a richer dataset for prediction, potentially enhancing the performance of more complex models. Another avenue for future research lies in exploring temporal dynamics in auction data, as the timing of auctions and broader economic conditions often play a critical role in determining final prices.
Furthermore, interpretability remains a critical factor in the practical application of predictive models in the art market. While tree-based models offer transparency through feature importance metrics, advanced techniques such as Shapley Additive Explanations (SHAP) or Local Interpretable Model-Agnostic Explanations (LIME) could provide deeper insights into other models’ behavior, deepening the understanding of the reasons behind the predictions. This is especially important in markets like art, where trust and transparency are paramount.
In conclusion, this study underscores the persistent challenges of applying machine learning to art auction prediction. Although tree-based ensemble models demonstrated relatively better performance, their accuracy remains limited, and neural networks encountered even greater difficulties. The findings indicate that simpler models, despite balancing accuracy and interpretability, still fall short of adequately capturing the complexities of auction data, which include non-linear relationships and subjective factors. Future research should explore hybrid models and integrate additional data sources to enhance predictive performance. However, the ongoing issue of high error rates raises significant concerns about the practical utility and long-term viability of these approaches in the art market.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}