
Dynamic Prediction of Shale Gas Drilling Costs Based on Machine Learning


Abstract
1. Introduction
2. Related Work
2.1. Feature Engineering and Selection for Drilling Costs
2.2. Machine Learning and Ensemble Learning for Drilling Cost Prediction
2.3. Dynamic Cost Prediction for Shale Gas Drilling and Development
2.4. Intelligent Drilling Systems and Automation
2.5. Economic Analysis and Cost Optimization in Drilling Operations
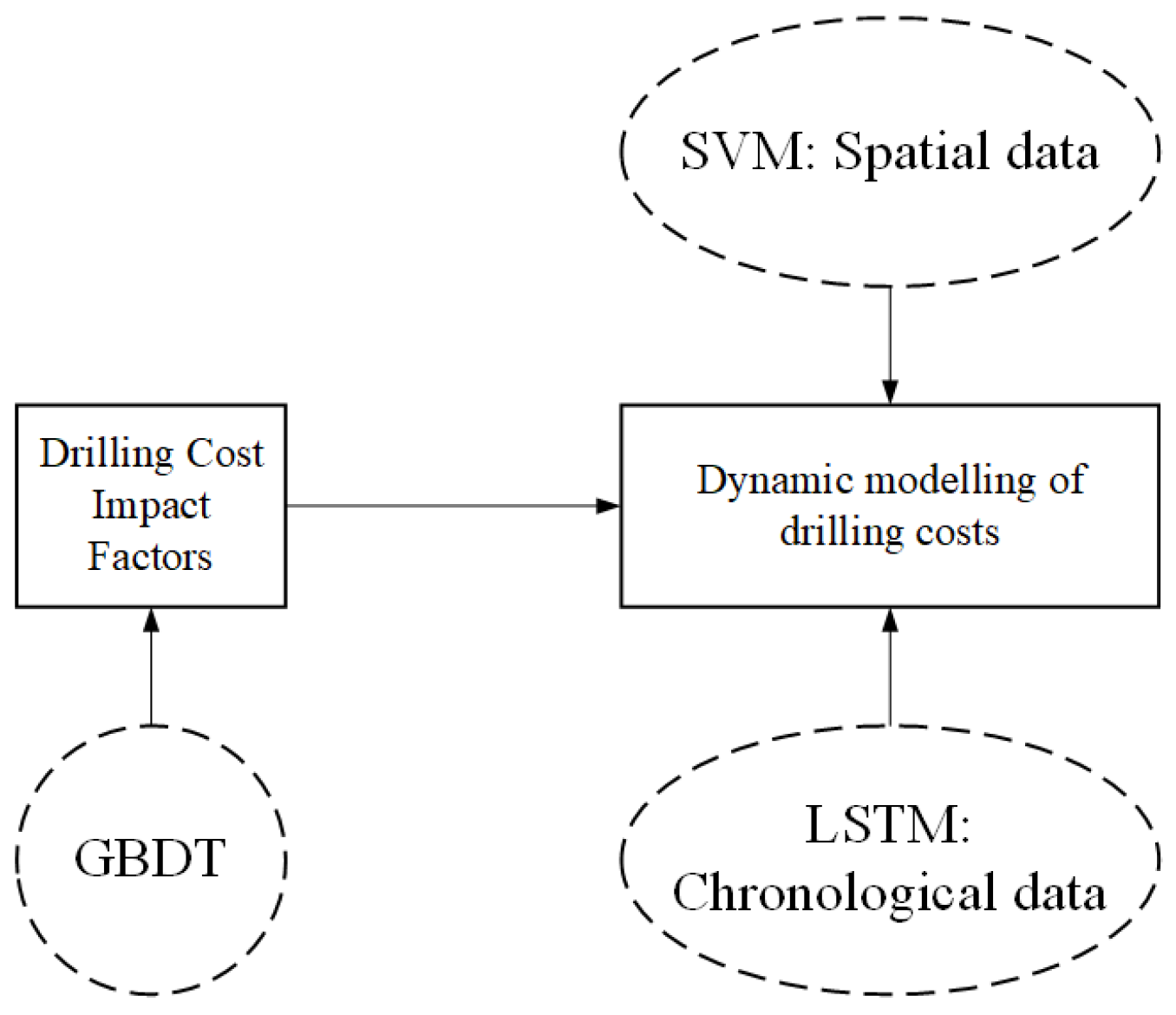
3. Materials and Methods
3.1. Shale Gas Cost Structure Explained
3.2. Model and Proposed Method
- 1.
- GBDT
- 2.
- SVM
- 3.
- LSTM
- 4.
- Stacking Integrated Learning Models
3.3. Optimisation Programme and Valuation Indicators
- Grid search represents a systematic approach to hyperparameter optimisation in machine learning models. The method functions by exhaustively testing predefined combinations of hyperparameters, including those related to learning rate, regularisation strength, and tree depth, through the utilisation of cross-validation for the assessment of model performance. Although grid search is an effective method for identifying optimal hyperparameter combinations and improving model performance through parallel computing, its efficiency is significantly reduced when dealing with large search spaces [50].
- K-fold cross-validation represents a robust methodology for the assessment of machine learning models, whereby the dataset is partitioned into K equal subsets (commonly 5 or 10), with one subset designated as the validation set and the remaining K-1 subsets serving as the training set. This process is repeated K times, with each part serving as the validation set in turn, and the results are averaged to obtain the final performance evaluation. This approach effectively utilises all available data and helps to optimise model hyperparameters while avoiding the limitations of single train-test splits [51].
- Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) are two commonly used error assessment metrics to quantify the deviation between the predicted and actual values of a model [52]. MAE is the average of the sum of the absolute values of the differences between all predicted values and the true values, which measures the average deviation of the predicted values from the true values. The smaller the value of MAE, the smaller the deviation of the model’s predicted results from the true values, indicating better prediction performance. RMSE is the square root of the average of the squares of the prediction errors. It not only focuses on the deviation between the predicted value and the true value, but also amplifies the effect of larger deviations, so RMSE is more sensitive to larger errors.where and are the true and predicted values of the sample, respectively, and n is the total number of samples.
- Decision coefficient. The evaluation measures the strength of the model by calculating the coefficient of determination, where the value is in the range of (0, 1) and, the closer its value is to 1, the better the model is fitted [52].where is the true value, is the average value of the true value, is the predicted value, and is the average value of the predicted value.
4. Experiments and Results
4.1. Data Sources
4.2. Data Processing
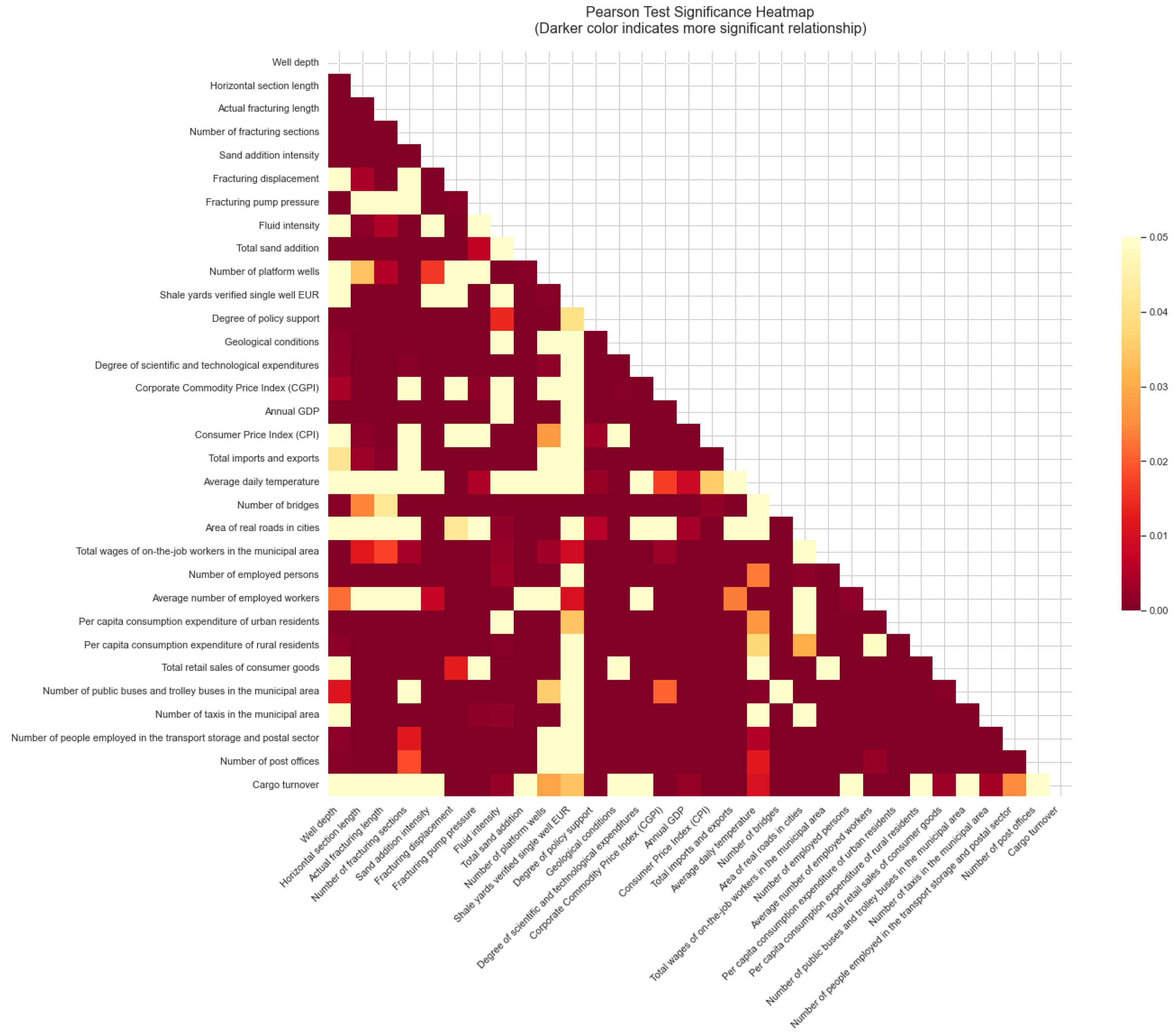
4.3. Pearson Test
- Analysis of factors with very high significance
- 2.
- Analysis of highly significant factors
- 3.
- Analysis of factors influencing moderate significance
4.4. Descriptive Analysis of Data
4.5. Drilling Cost Indicator Construction
4.6. Feature Importance Calculation Based on GBDT Algorithm
4.7. Results
4.8. Analysis of Results
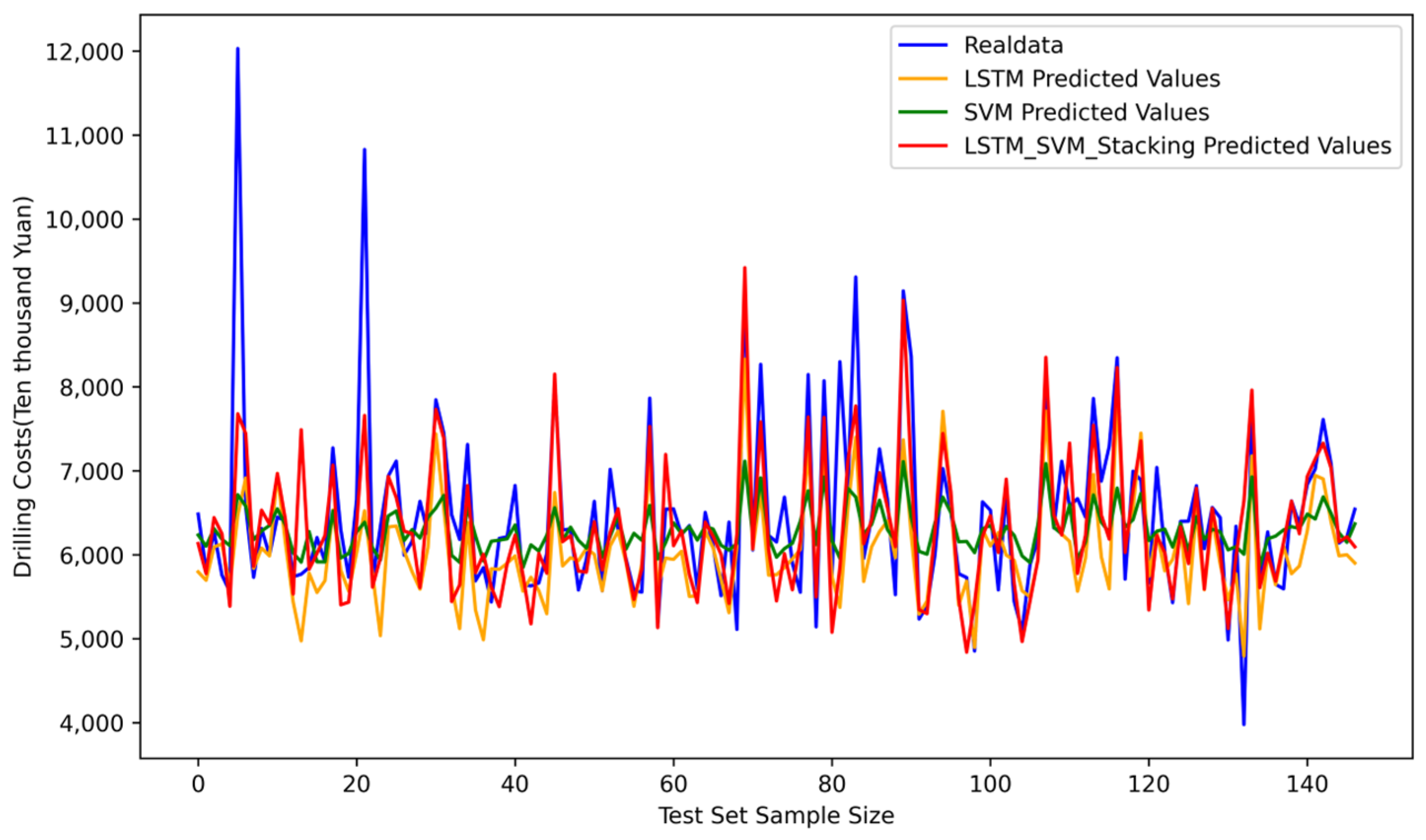
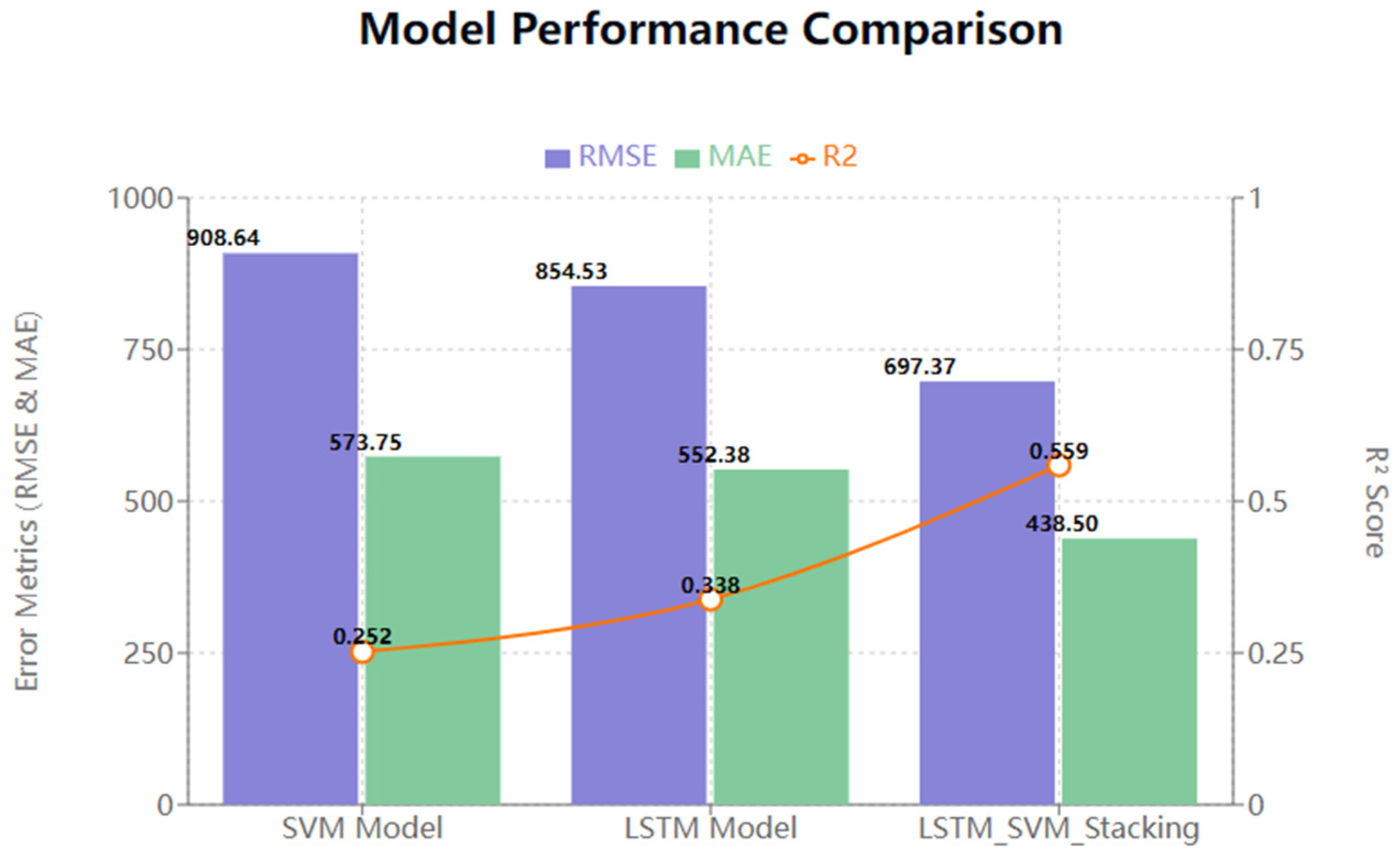
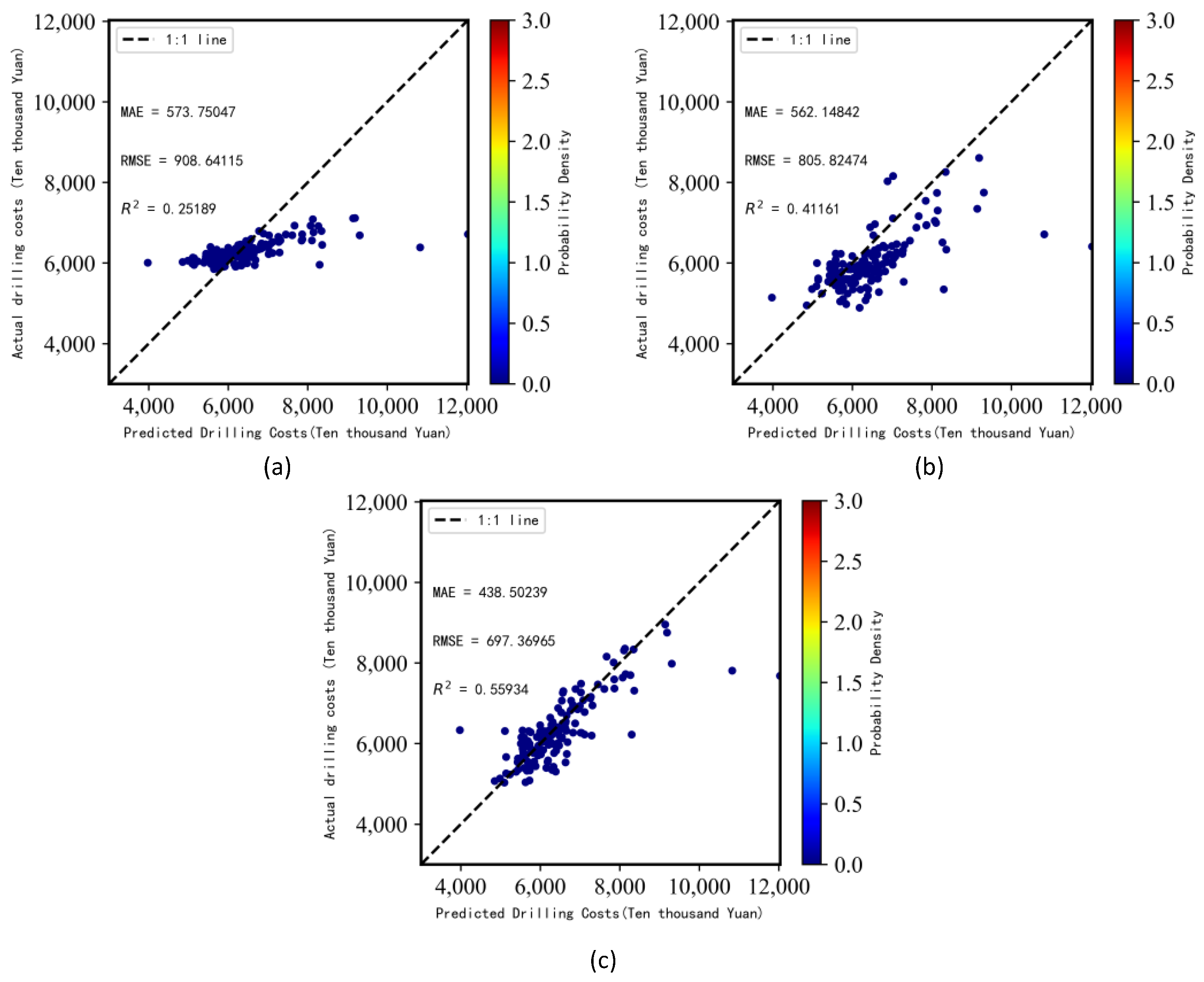
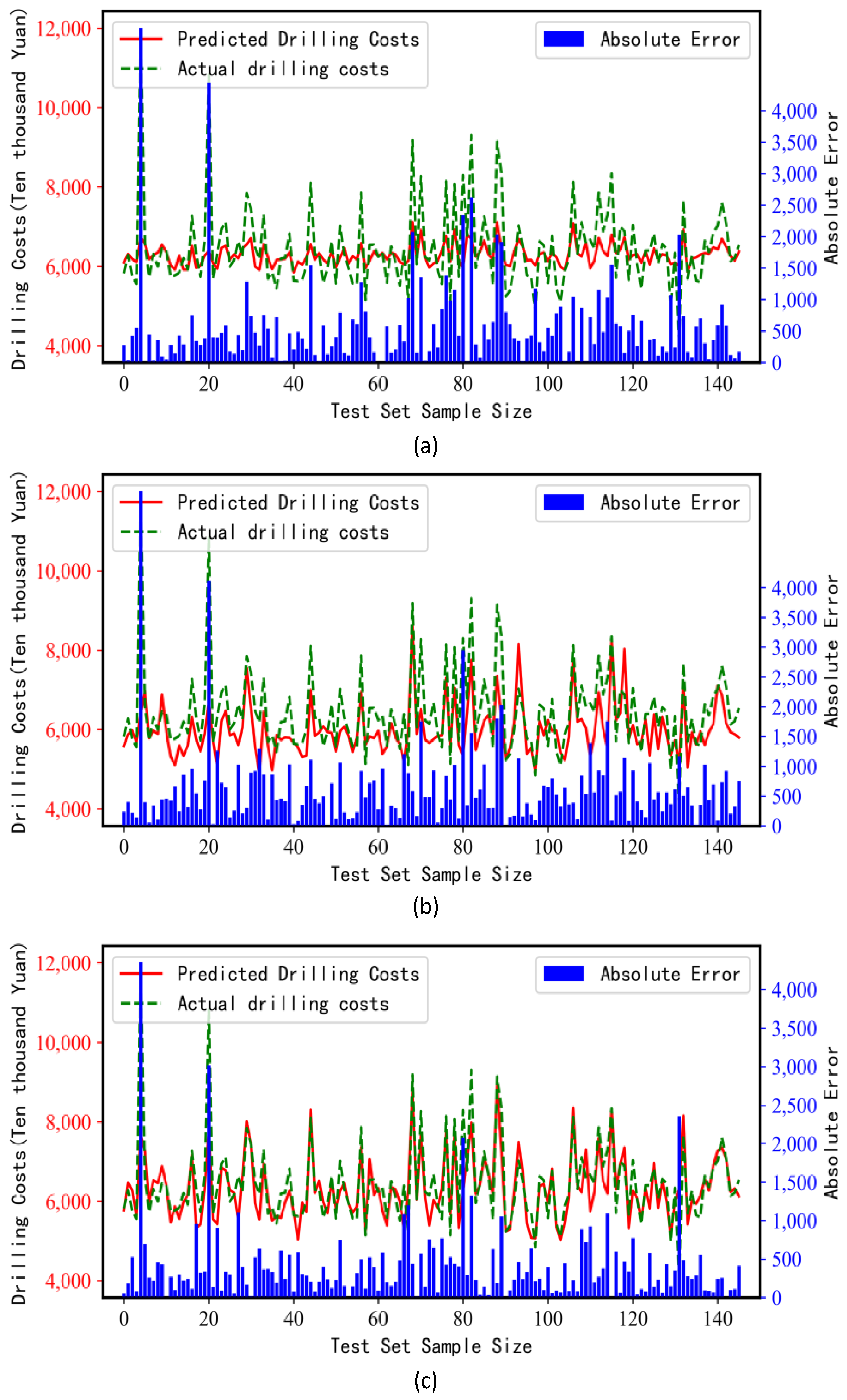
4.8.1. Comparison of Prediction Accuracy
4.8.2. Discussion
- Characteristic Analysis of the Prediction Distribution
- 2.
- Analysis of prediction accuracy:
4.9. Economic Analysis of Investment in Selected Drilling Wells in the Changning Block
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tariq, Z.; Aljawad, M.S.; Hasan, A.; Murtaza, M.; Mohammed, E.; El-Husseiny, A.; Alarifi, S.A.; Mahmoud, M.; Abdulraheem, A. A systematic review of data science and machine learning applications to the oil and gas industry. J. Pet. Explor. Prod. Technol. 2021, 11, 4339–4374. [Google Scholar] [CrossRef]
- Nikolaou, M. Computer-aided process engineering in oil and gas production. Comput. Chem. Eng. 2013, 51, 96–101. [Google Scholar] [CrossRef]
- Gao, J.; You, F. Design and optimization of shale gas energy systems: Overview, research challenges, and future directions. Comput. Chem. Eng. 2017, 106, 699–718. [Google Scholar] [CrossRef]
- Lashari, S.e.Z.; Takbiri-Borujeni, A.; Fathi, E.; Sun, T.; Rahmani, R.; Khazaeli, M. Drilling performance monitoring and optimization: A data-driven approach. J. Pet. Explor. Prod. Technol. 2019, 9, 2747–2756. [Google Scholar] [CrossRef]
- Nautiyal, A.; Mishra, A.K. Machine Learning Application in Enhancing Drilling Performance. Procedia Comput. Sci. 2023, 218, 877–886. [Google Scholar] [CrossRef]
- Goodkey, B.; Carvalho, R.; Davila, A.N.; Hernandez, G.; Corona, M.; Atriby, K.; Herrera, C. Recipe for digital change: A case study approach to drilling automation. In Proceedings of the SPE/IADC Middle East Drilling Technology Conference and Exhibition, Abu Dhabi, United Arab Emirates, 27–29 May 2021. [Google Scholar] [CrossRef]
- Yuan, S.; Han, H.; Wang, H.; Luo, J.; Wang, Q.; Lei, Z.; Xi, C.; Li, J. Research progress and potential of new enhanced oil recovery methods in oilfield development. Pet. Explor. Dev. 2024, 51, 963–980. [Google Scholar] [CrossRef]
- Liu, H.; Ren, Y.; Li, X.; Deng, Y.; Wang, Y.; Cao, Q.; DU, J.; Lin, Z.; Wang, W. Research status and application of artificial intelligence large models in the oil and gas industry. Pet. Explor. Dev. 2024, 51, 1049–1065. [Google Scholar] [CrossRef]
- Hegde, C.; Gray, K. Use of machine learning and data analytics to increase drilling efficiency for nearby wells. J. Nat. Gas Sci. Eng. 2017, 40, 327–335. [Google Scholar] [CrossRef]
- Sajadfar, N.; Ma, Y. A hybrid cost estimation framework based on feature-oriented data mining approach. Adv. Eng. Inform. 2015, 29, 633–647. [Google Scholar] [CrossRef]
- Barbosa, L.F.F.M.; Nascimento, A.; Mathias, M.H.; de Carvalho, J.A., Jr. Machine learning methods applied to drilling rate of penetration prediction and optimization—A review. J. Pet. Sci. Eng. 2019, 183, 106332. [Google Scholar] [CrossRef]
- Ren, J.; Jiang, J.; Zhou, C.; Li, Q.; Xu, Z. Research on adaptive feature optimization and drilling rate prediction based on real-time data. Geoenergy Sci. Eng. 2024, 242, 213247. [Google Scholar] [CrossRef]
- Eskandarian, S.; Bahrami, P.; Kazemi, P. A comprehensive data mining approach to estimate the rate of penetration: Application of neural network, rule based models and feature ranking. J. Pet. Sci. Eng. 2017, 156, 605–615. [Google Scholar] [CrossRef]
- Pan, H.; Cheng, G.; Ding, J. Drilling Cost Prediction Based on Self-adaptive Differential Evolution and Support Vector Regression. In Intelligent Data Engineering and Automated Learning—IDEAL 2013; Yin, H., Tang, K., Gao, Y., Klawonn, F., Lee, M., Weise, T., Li, B., Yao, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 67–75. [Google Scholar] [CrossRef]
- Sircar, A.; Yadav, K.; Rayavarapu, K.; Bist, N.; Oza, H. Application of machine learning and artificial intelligence in oil and gas industry. Pet. Res. 2021, 6, 379–391. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble Learning. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Xu, W.; Zhu, Y.; Wei, Y.; Su, Y.; Xu, Y.; Ji, H.; Liu, D. Prediction Model of Drilling Costs for Ultra-Deep Wells Based on GA-BP Neural Network. Energy Eng. 2023, 120, 1701–1715. [Google Scholar] [CrossRef]
- Liu, N.; Gao, H.; Zhao, Z.; Hu, Y.; Duan, L. A stacked generalization ensemble model for optimization and prediction of the gas well rate of penetration: A case study in Xinjiang. J. Pet. Explor. Prod. Technol. 2022, 12, 1595–1608. [Google Scholar] [CrossRef]
- Yehia, T.; Gasser, M.; Ebaid, H.; Meehan, N.; Okoroafor, E.R. Comparative analysis of machine learning techniques for predicting drilling rate of penetration (ROP) in geothermal wells: A case study of FORGE site. Geothermics 2024, 121, 103028. [Google Scholar] [CrossRef]
- Nautiyal, A.; Mishra, A.K. Drilling efficiency enhancement in oil and gas domain using machine learning. Int. J. Oil Gas Coal Technol. 2023, 32, 121–143. [Google Scholar] [CrossRef]
- Matinkia, M.; Sheykhinasab, A.; Shojaei, S.; Vojdani Tazeh Kand, A.; Elmi, A.; Bajolvand, M.; Mehrad, M. Developing a New Model for Drilling Rate of Penetration Prediction Using Convolutional Neural Network. Arab. J. Sci. Eng. 2022, 47, 11953–11985. [Google Scholar] [CrossRef]
- Tewari, S.; Dwivedi, U.D.; Biswas, S. Intelligent Drilling of Oil and Gas Wells Using Response Surface Methodology and Artificial Bee Colony. Sustainability 2021, 13, 1664. [Google Scholar] [CrossRef]
- Eltrissi, M.; Yousef, O.; El-Banbi, A.; Khalaf, F. Drilling operation optimization using machine learning framework. Geoenergy Sci. Eng. 2023, 228, 211969. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, Y.; Qin, X.; Dou, Z.; Yang, G.; Lv, J.; Hu, Y. Optimization of Drilling Parameters of Target Wells Based on Machine Learning and Data Analysis. Arab. J. Sci. Eng. 2023, 48, 9069–9084. [Google Scholar] [CrossRef]
- Elahifar, B.; Hosseini, E. Automated real-time prediction of geological formation tops during drilling operations: An applied machine learning solution for the Norwegian Continental Shelf. J. Petrol. Explor. Prod. Technol. 2024, 14, 1661–1703. [Google Scholar] [CrossRef]
- Sabah, M.; Talebkeikhah, M.; Wood, D.A.; Khosravanian, R.; Anemangely, M.; Younesi, A. A machine learning approach to predict drilling rate using petrophysical and mud logging data. Earth Sci. Inform. 2019, 12, 319–339. [Google Scholar] [CrossRef]
- Li, G.; Lu, W.; Song, X.; Tian, S.; Zhu, Z. Intelligent Drilling and Completion: A Review. Engineering 2022, 18, 33–48. [Google Scholar] [CrossRef]
- Yang, X.Y.; Cui, M.; Zhang, Y.L.; Jing, L.Z.; Ji, Y.; Shi, X.Y. Optimized Drilling Status Recognition for Oil Drilling Using Artificial Intelligence: Empirical Research and Methodology. In Proceedings of the International Field Exploration and Development Conference 2023; Springer Series in Geomechanics and Geoengineering. Lin, J., Ed.; Springer: Singapore, 2023. [Google Scholar] [CrossRef]
- Bello, O.; Holzmann, J.; Yaqoob, T.; Teodoriu, C. Application of Artificial Intelligence Methods In Drilling System Design And Operations: A Review Of The State Of The Art. J. Artif. Intell. Soft Comput. Res. 2015, 5, 121–139. [Google Scholar] [CrossRef]
- Gan, C.; Cao, W.; Liu, K. To Improve Drilling Efficiency by Multi-objective Optimization of Operational Drilling Parameters in the Complex Geological Drilling Process. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 10238–10243. [Google Scholar] [CrossRef]
- Ozdemir, A.; Güllü, A.; Yaşar, E.; Palabiyik, Y. Drilling Engineering Assessment and Cost Analysis of Oil and Gas Wells Drilled in Onshore of Turkey. Int. J. Earth Sci. Knowl. Appl. 2021, 3, 235–243. [Google Scholar]
- Nwanwe, O.; Teodoriu, C. Matrix selection and comparison for selecting drilling methods and technologies for a wide range of applications. J. Pet. Sci. Eng. 2020, 192, 107289. [Google Scholar] [CrossRef]
- Purba, D.; Adityatama, D.W.; Agustino, V.; Fininda, F.; Alamsyah, D.; Muhammad, F. Geothermal Drilling Cost Optimization in Indonesia: A Discussion of Various Factors. In Proceedings of the 45th Workshop on Geothermal Reservoir Engineering Stanford University (SGP-TR-216), Stanford, CA, USA, 10–12 February 2020. [Google Scholar]
- Mustafa, A.B.; Abbas, A.K.; Alsaba, M.; Alameen, M. Improving drilling performance through optimizing controllable drilling parameters. J. Pet. Explor. Prod. Technol. 2021, 11, 1223–1232. [Google Scholar] [CrossRef]
- Mistré, M.; Crénes, M.; Hafner, M. Shale gas production costs: Historical developments and outlook. Energy Strat. Rev. 2018, 20, 20–25. [Google Scholar] [CrossRef]
- Zou, C.; Dong, D.; Wang, Y.; Li, X.; Huang, J.; Wang, S.; Guan, Q.; Zhang, C.; Wang, H.; Liu, H.; et al. Shale gas in China: Characteristics, challenges and prospects (II). Pet. Explor. Dev. 2016, 43, 182–196. [Google Scholar] [CrossRef]
- Wang, Q.; Li, R. Research status of shale gas: A review. Renew. Sustain. Energy Rev. 2017, 74, 715–720. [Google Scholar] [CrossRef]
- Yuan, J.; Luo, D.; Feng, L. A review of the technical and economic evaluation techniques for shale gas development. Appl. Energy 2015, 148, 49–65. [Google Scholar] [CrossRef]
- Curtis, J.; John, B. Fractured Shale-Gas Systems. AAPG Bull. 2002, 86, 1921–1938. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Alonso-Español, A.; Bravo, E.; Ribeiro-Vidal, H.; Virto, L.; Herrera, D.; Alonso, B.; Sanz, M. The Antimicrobial Activity of Curcumin and Xanthohumol on Bacterial Biofilms Developed over Dental Implant Surfaces. Int. J. Mol. Sci. 2023, 24, 2335. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Wiley-Interscience: New York, NY, USA, 1998. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 1999 Ninth International Conference on Artificial Neural Networks ICANN 99 (Conf. Publ. No. 470), Edinburgh, UK, 7–10 September 1999; Volume 2, pp. 850–855. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef]
- He, J.; Li, K.; Wang, X.; Gao, N.; Mao, X.; Jia, L. A Machine Learning Methodology for Predicting Geothermal Heat Flow in the Bohai Bay Basin, China. Nat. Resour. Res. 2022, 31, 237–260. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Ron, K. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—Volume 2 (IJCAI’95), Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 1137–1143. [Google Scholar]
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?—Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Variable Name | Index | Variable Name | Index | Variable Name | Index | Variable Name |
|---|---|---|---|---|---|---|---|
| 1 | Well number | 10 | Fracturing pump pressure | 19 | Annual GDP | 28 | Per capita consumption expenditure of urban residents |
| 2 | Well type | 11 | Fluid intensity | 20 | Consumer Price Index (CPI) | 29 | Per capita consumption expenditure of rural residents |
| 3 | Commissioning time | 12 | Total sand addition | 21 | Total imports and exports | 30 | Total retail sales of consumer goods |
| 4 | Well depth | 13 | Number of platform wells | 22 | Average daily temperature | 31 | Number of public buses and trolley buses in the municipal area |
| 5 | Horizontal section length | 14 | Shale yards verified single well EUR | 23 | Number of bridges | 32 | Number of taxis in the municipal area |
| 6 | Actual fracturing length | 15 | Degree of policy support | 24 | Area of real roads in cities | 33 | Number of people employed in the transport storage and postal sector |
| 7 | Number of fracturing sections | 16 | Geological conditions | 25 | Total wages of on-the-job workers in the municipal area | 34 | Number of post offices |
| 8 | Sand addition intensity | 17 | Degree of scientific and technological expenditures | 26 | Number of employed persons | 35 | Cargo turnover |
| 9 | Fracturing displacement | 18 | Corporate Commodity Price Index (CGPI) | 27 | Average number of employed workers | 36 | Investment in drilling and completion of wells |
| Index | Variable Name | Pearson Correlation | p-Value (Max) |
|---|---|---|---|
| 1 | Actual fracturing length | 0.091781 | 0.042279 |
| 2 | Annual GDP | 0.119031 | 0.008352 |
| 3 | Area of real roads in cities | −0.097925 | 0.030209 |
| 4 | Average daily temperature | 0.094083 | 0.037349 |
| 5 | Average number of employed workers | 0.102400 | 0.023397 |
| 6 | Cargo turnover | 0.095721 | 0.034148 |
| 7 | Consumer Price Index (CPI) | 0.095045 | 0.035440 |
| 8 | Corporate Commodity Price Index (CGPI) | −0.104520 | 0.020664 |
| 9 | Degree of policy support | −0.125078 | 0.005562 |
| 10 | Degree of scientific and technological expenditures | 0.418286 | 0.000001 |
| 11 | Fluid intensity | −0.110961 | 0.013989 |
| 12 | Fracturing displacement | −0.091786 | 0.042268 |
| 13 | Fracturing pump pressure | 0.122340 | 0.006700 |
| 14 | Geological conditions | 0.159277 | 0.000401 |
| 15 | Horizontal section length | −0.095850 | 0.033905 |
| 16 | Number of bridges | 0.238878 | 0.000001 |
| 17 | Number of employed persons | −0.146708 | 0.001126 |
| 18 | Number of fracturing sections | 0.106456 | 0.018414 |
| 19 | Number of fracturing sections | 0.106456 | 0.018414 |
| 20 | Number of people employed in the transport storage and postal sector | −0.101383 | 0.024816 |
| 21 | Number of platform wells | −0.094622 | 0.036268 |
| 22 | Number of public buses and trolley buses in the municipal area | −0.551319 | 0.000000 |
| 23 | Number of taxis in the municipal area | 0.130173 | 0.003896 |
| 24 | Per capita consumption expenditure of rural residents | 0.605843 | 0.000001 |
| 25 | Per capita consumption expenditure of urban residents | −0.169663 | 0.000161 |
| 26 | Sand addition intensity | −0.108594 | 0.016181 |
| 27 | Shale yards verified single well EUR | −0.092772 | 0.040095 |
| 28 | Total imports and exports | 0.102400 | 0.023397 |
| 29 | Total retail sales of consumer goods | 0.134243 | 0.002906 |
| 30 | Total sand addition | −0.159130 | 0.000406 |
| 31 | Total wages of on-the-job workers in the municipal area | 0.278988 | 0.000001 |
| 32 | Well depth | 0.092305 | 0.041111 |
| Frequency | Percentage | Effective Percentage | Cumulative Percentage | |
|---|---|---|---|---|
| 2015 | 20 | 4.1 | 4.1 | 4.1 |
| 2016 | 24 | 4.9 | 4.9 | 9.0 |
| 2017 | 16 | 3.3 | 3.3 | 12.2 |
| 2018 | 38 | 7.8 | 7.8 | 20.0 |
| 2019 | 100 | 20.4 | 20.4 | 40.4 |
| 2020 | 157 | 32.0 | 32.0 | 72.4 |
| 2021 | 74 | 15.1 | 15.1 | 87.6 |
| 2022 | 61 | 12.4 | 12.4 | 100.0 |
| Total | 490 | 100.0 | 100.0 |
| CGPI Corporate Goods Price Index | Annual GDP (Billion Yuan) | Consumer Price Index CPI | Total Import and Export (Billion Yuan) | Average Daily Temperature (°C) | |
|---|---|---|---|---|---|
| Effective number of cases | 490 | 490 | 490 | 490 | 490 |
| Minimum value | 92.7 | 871.36 | 100.1 | 24.88 | 0.5 |
| Maximum value | 110.1 | 1614.47 | 102.6 | 49.38 | 31 |
| Mean value | 101.13 | 1364.12 | 101.82 | 37.69 | 18.48 |
| Standard Deviation | 4.00 | 190.01 | 0.88 | 6.89 | 8.18 |
| Variant | Mean | Median | Variance | Minimum Value | Maximum Value |
|---|---|---|---|---|---|
| Well depth (metres) | 4875.57 | 4900 | 222,555.88 | 3330 | 6325 |
| Horizontal section length (metres) | 1662.14 | 1500 | 127,824.33 | 850 | 3100 |
| Actual fracturing length (metres) | 1579.62 | 1470 | 147,103.84 | 236 | 3166 |
| Number of fracturing sections (sections) | 25.00 | 24 | 37.73 | 4 | 51 |
| Strength of sand addition (Mg/m) | 2.30 | 2.32 | 0.36 | 0.81 | 4.70 |
| Fracturing displacement (m3/min) | 0.427 | 0.447 | 0.005 | 0.241 | 1.618 |
| Fracturing pump pressure (MPa) | 75.81 | 75.72 | 73.53 | 50.5 | 96.68 |
| Intensity of fluid used (m2/m) | 29.16 | 28.77 | 14.37 | 16.09 | 44.58 |
| Total sand addition (Mg) | 3688.65 | 3369.04 | 2,431,753.95 | 319.48 | 11,813.79 |
| Number of platform wells (ports) | 4.82 | 5 | 2.12 | 1 | 8 |
| Verification of single well EUR by shale yard (109 m3) | 1.14 | 1.12 | 0.15 | 0.19 | 2.42 |
| Investment in drilling and completing wells (106 yuan) | 64.3429 | 62.9134 | 10,597.0741 | 37.4399 | 120.3020 |
| Classification | Variant | Classification | Variant |
|---|---|---|---|
| Basic information | Well number, type of well and time of commissioning | Road conditions | Number of bridges, real urban road area |
| Engineering parameters | Well depth, horizontal section length, actual fracturing length, number of fracturing sections, sand addition intensity, fracturing displacement, fracturing pump pressure, fluid intensity used, total sand addition, number of platform wells, shale yard verification of individual wells EUR | Macroeconomic | Corporate Goods Price Index (CGPI), annual GDP, Consumer Price Index (CPI), total imports and exports |
| Policies | Level of policy support | Labour Force | Total wage bill of workers in employment in the municipal area, number of employed persons |
| Geological conditions | Per capita water resources | Consumption Level | Per capita consumption expenditure of urban residents, per capita consumption expenditure of rural residents and total retail sales of consumer goods |
| Science and Technology Innovation | Degree of expenditure on science and technology | Accessibility | Public Tram Passenger Volume in Municipal Districts and Number of Taxis in Municipal Districts |
| Investment costs | Investment in drilling and completion of wells | Logistics | Transport, storage and postal employment, number of post offices and cargo turnover |
| Temperature | Daily average temperature values | Weather conditions | Daily average temperature value |
| Rank | Factor | Importance Index | Impact Level | Detailed Description |
|---|---|---|---|---|
| 1 | Number of Fracturing Sections | 0.3462 | High Impact | Increasing the number of fracturing sections can enhance shale gas production but leads to higher costs in drilling, fracturing, and equipment. |
| 2 | Well Depth | 0.1806 | High Impact | Greater well depth results in higher exploration and development costs, requiring longer drilling time, larger drilling equipment, and more investment. |
| 3 | Number of Platform Wells | 0.1281 | High Impact | Increasing platform wells improves extraction efficiency and reduces production costs by centralizing multiple wells in one location, saving on drilling and production equipment. |
| 4 | Actual Fracturing Length | 0.0644 | Medium Impact | Longer fracturing lengths can increase shale gas production but require more fracturing materials and fluids, resulting in higher construction costs. |
| 5 | Fracturing Pump Pressure | 0.0589 | Medium Impact | Higher pump pressure can increase well production but results in increased energy consumption and equipment costs. |
| 6 | Sand Intensity | 0.0402 | Medium Impact | Higher sand intensity can improve fracturing results and increase production but increases the amount and cost of sand and fracturing fluid used. |
| 7+ | Other Factors | <0.0400 | Low Impact | Other listed factors have relatively low impact on shale gas costs. While they may have some influence in specific situations, their impact needs to be considered from a comprehensive perspective. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, T.; Liang, Y.; Wang, Z.; Ji, Q. Dynamic Prediction of Shale Gas Drilling Costs Based on Machine Learning. Appl. Sci. 2024, 14, 10984. https://doi.org/10.3390/app142310984
Yang T, Liang Y, Wang Z, Ji Q. Dynamic Prediction of Shale Gas Drilling Costs Based on Machine Learning. Applied Sciences. 2024; 14(23):10984. https://doi.org/10.3390/app142310984
Chicago/Turabian StyleYang, Tianxiang, Yuan Liang, Zhong Wang, and Qingyun Ji. 2024. "Dynamic Prediction of Shale Gas Drilling Costs Based on Machine Learning" Applied Sciences 14, no. 23: 10984. https://doi.org/10.3390/app142310984
APA StyleYang, T., Liang, Y., Wang, Z., & Ji, Q. (2024). Dynamic Prediction of Shale Gas Drilling Costs Based on Machine Learning. Applied Sciences, 14(23), 10984. https://doi.org/10.3390/app142310984