
Exploring Synergy of Denoising and Distillation: Novel Method for Efficient Adversarial Defense


Abstract
1. Introduction
- Review current defense strategies against adversarial attacks and classification of defense mechanisms;
- Analysis of the transitivity of adversarial robustness and the definition of considerations required to build an adversarial defense model;
- Conceptualization and design of a defense model based on knowledge distillation and feature denoising for constructing an effective adversarial attack defense measure.
- We propose that the knowledge distillation method for adversarial robustness enhances the effect of denoising, thereby enabling a more efficient response to adversarial attacks.
- We propose that the use of smoothing in distillation can strengthen defense performance under adversarial attacks while maintaining high model accuracy.
- We achieved a notable defense success rate of 72.7%, which represents a significant improvement over the 41.0% success rate of models with only denoising defenses.
2. Related Works
2.1. Adversarial Attack
2.1.1. Exploring Adversarial Attack
2.1.2. Fast Gradient Sign Method
2.2. Obfuscated Gradient
2.2.1. Shattered Gradient
2.2.2. Stochastic Gradient
2.2.3. Vanishing and Exploding Gradients
2.3. Adversarial Defense
2.3.1. Adversarial Training
2.3.2. Defensive Distillation
2.3.3. Feature Denoising
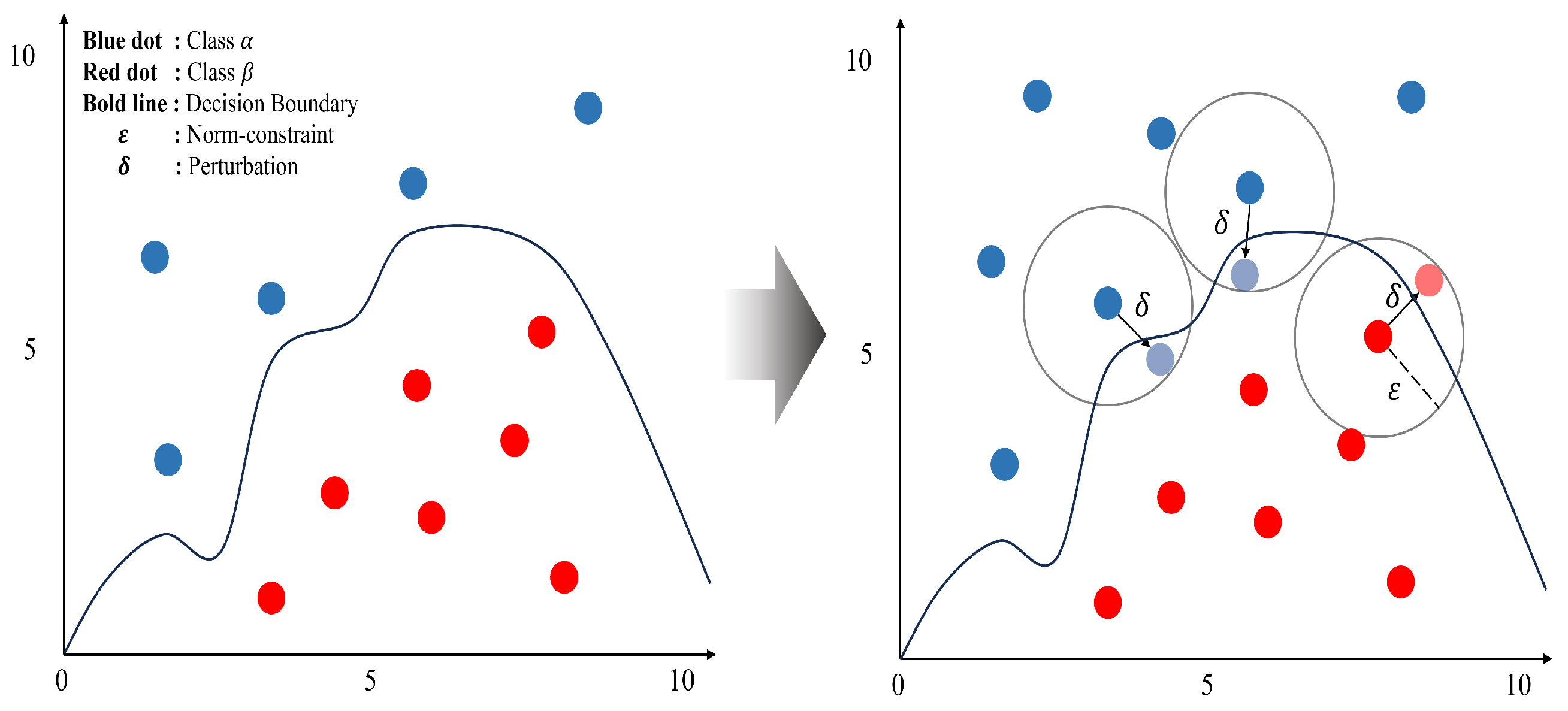
3. Distillation and deNoise Network(DiNo-Net)
3.1. Adversarial Robustness Training
3.1.1. Adversarial Training for Teacher Model
3.1.2. Feature Denoising for Student Model
3.2. Fusion Method Based on Distillation
4. Experiment and Evaluation
4.1. Experimental Environment
4.2. Experimental Result and Evaluation
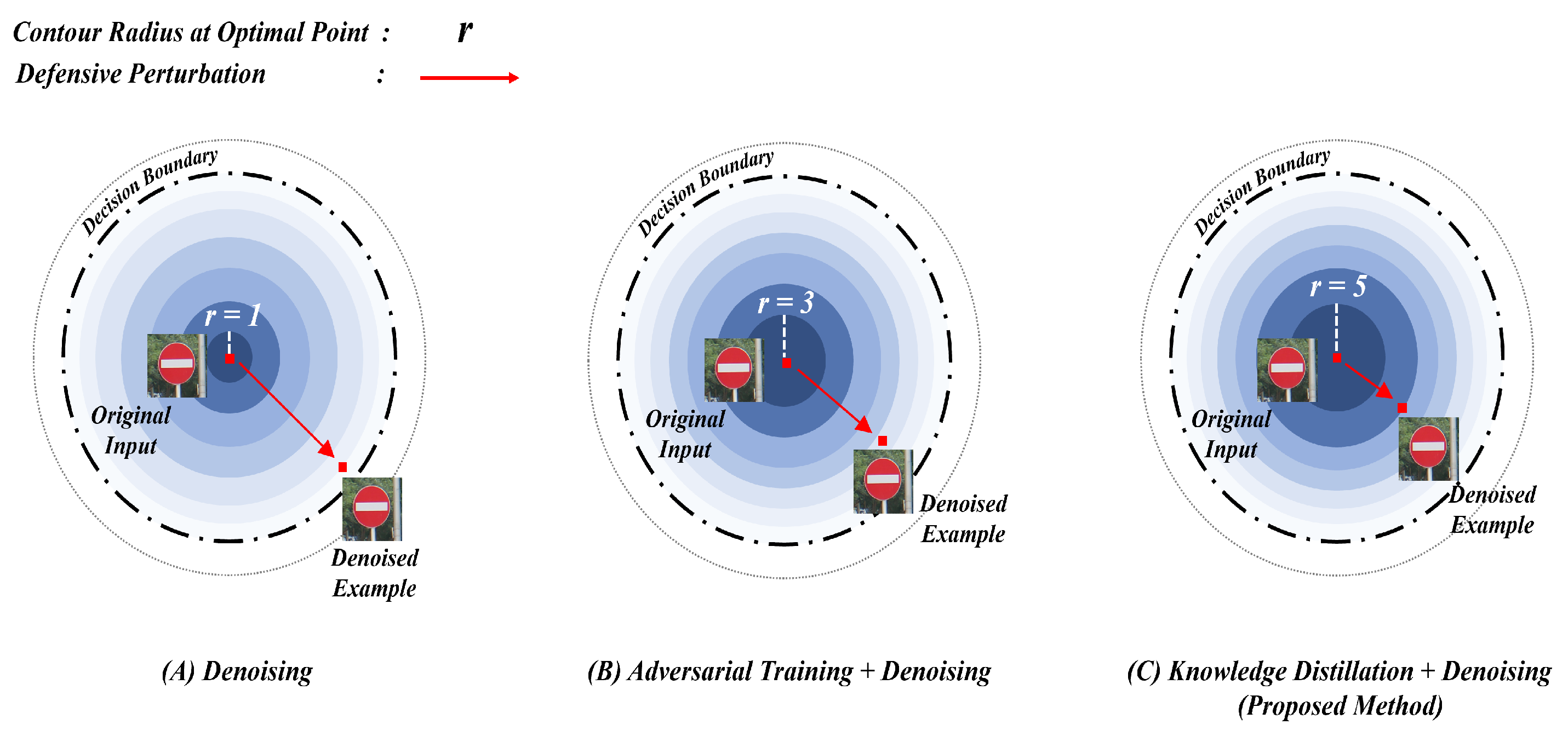
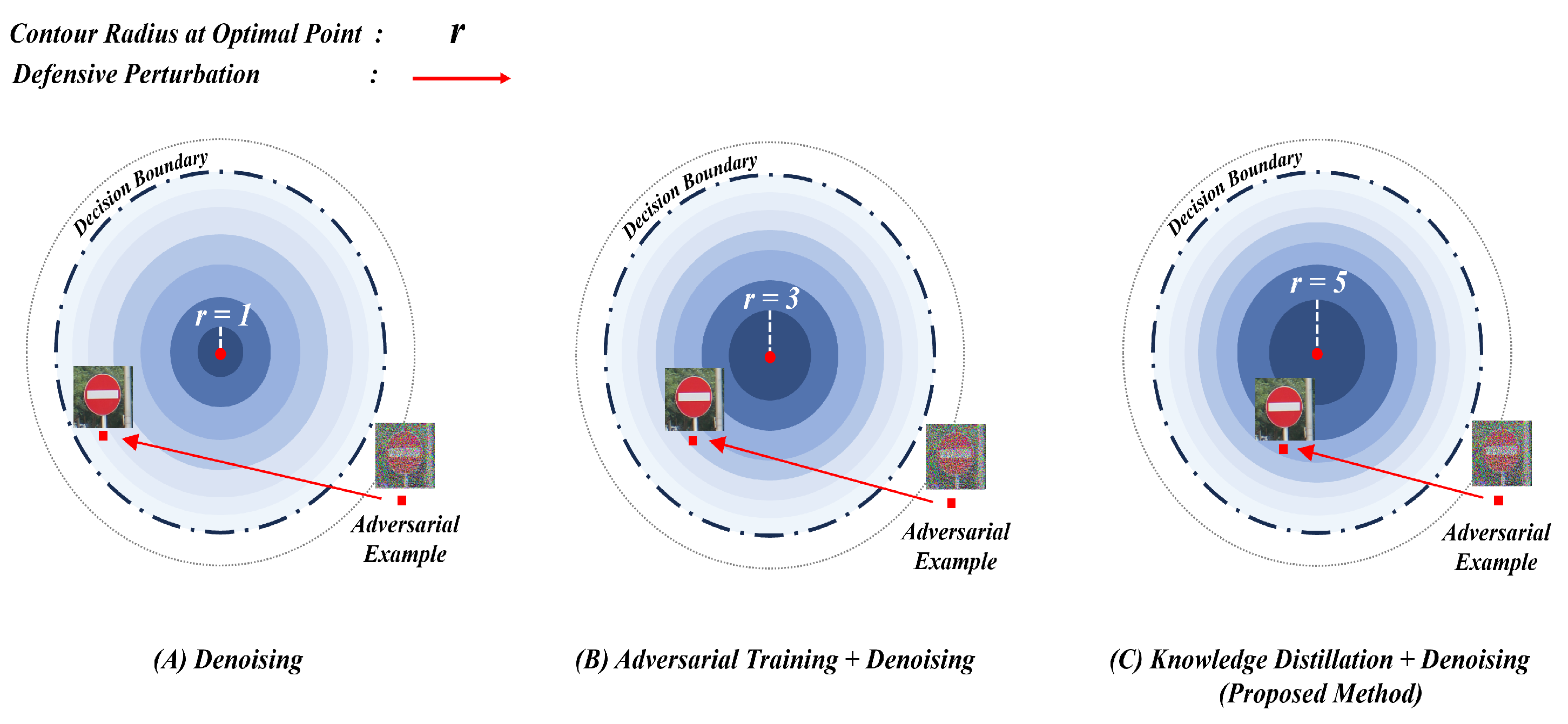
4.2.1. Evaluation of Defensive Performance
4.2.2. Evaluation of Defensive Efficiency
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmad, T.; Zhu, H.; Zhang, D.; Tariq, R.; Bassam, A.; Ullah, F.; AlGhamdi, A.S.; Alshamrani, S.S. Energetics Systems and artificial intelligence: Applications of industry 4.0. Energy Rep. 2022, 8, 334–361. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, Y.; Xing, Y.; Zhao, Y.; Cao, D.; Lv, C. Toward human-centered automated driving: A novel spatiotemporal vision transformer-enabled head tracker. IEEE Veh. Technol. Mag. 2022, 17, 57–64. [Google Scholar] [CrossRef]
- Liu, Y.; Ping, Y.; Zhang, L.; Wang, L.; Xu, X. Scheduling of decentralized robot services in cloud manufacturing with deep reinforcement learning. Robot. Comput.-Integr. Manuf. 2023, 80, 102454. [Google Scholar] [CrossRef]
- Alexander, A.; Jiang, A.; Ferreira, C.; Zurkiya, D. An intelligent future for medical imaging: A market outlook on artificial intelligence for medical imaging. J. Am. Coll. Radiol. 2020, 17, 165–170. [Google Scholar] [CrossRef] [PubMed]
- Park, H.C.; Hong, I.P.; Poudel, S.; Choi, C. Data Augmentation based on Generative Adversarial Networks for Endoscopic Image Classification. IEEE Access 2023. [Google Scholar] [CrossRef]
- Guembe, B.; Azeta, A.; Misra, S.; Osamor, V.C.; Fernandez-Sanz, L.; Pospelova, V. The emerging threat of ai-driven cyber attacks: A review. Appl. Artif. Intell. 2022, 36, 2037254. [Google Scholar] [CrossRef]
- Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of artificial intelligence adversarial attack and defense technologies. Appl. Sci. 2019, 9, 909. [Google Scholar] [CrossRef]
- Girdhar, M.; Hong, J.; Moore, J. Cybersecurity of Autonomous Vehicles: A Systematic Literature Review of Adversarial Attacks and Defense Models. IEEE Open J. Veh. Technol. 2023, 4, 417–437. [Google Scholar] [CrossRef]
- Kaviani, S.; Han, K.J.; Sohn, I. Adversarial attacks and defenses on AI in medical imaging informatics: A survey. Expert Syst. Appl. 2022, 198, 116815. [Google Scholar] [CrossRef]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef]
- Kloukiniotis, A.; Papandreou, A.; Lalos, A.; Kapsalas, P.; Nguyen, D.V.; Moustakas, K. Countering adversarial attacks on autonomous vehicles using denoising techniques: A review. IEEE Open J. Intell. Transp. Syst. 2022, 3, 61–80. [Google Scholar] [CrossRef]
- Yin, H.; Wang, R.; Liu, B.; Yan, J. On adversarial robustness of semantic segmentation models for automated driving. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 867–873. [Google Scholar]
- Memos, V.A.; Psannis, K.E. NFV-based scheme for effective protection against bot attacks in AI-enabled IoT. IEEE Internet Things Mag. 2022, 5, 91–95. [Google Scholar] [CrossRef]
- Carlini, N.; Hayes, J.; Nasr, M.; Jagielski, M.; Sehwag, V.; Tramer, F.; Balle, B.; Ippolito, D.; Wallace, E. Extracting training data from diffusion models. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 5253–5270. [Google Scholar]
- Fritsch, L.; Jaber, A.; Yazidi, A. An Overview of Artificial Intelligence Used in Malware. In Proceedings of the Symposium of the Norwegian AI Society; Springer: Berlin/Heidelberg, Germany, 2022; pp. 41–51. [Google Scholar]
- Mirsky, Y.; Demontis, A.; Kotak, J.; Shankar, R.; Gelei, D.; Yang, L.; Zhang, X.; Pintor, M.; Lee, W.; Elovici, Y.; et al. The threat of offensive ai to organizations. Comput. Secur. 2023, 124, 103006. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Ayub, M.A.; Johnson, W.A.; Talbert, D.A.; Siraj, A. Model evasion attack on intrusion detection systems using adversarial machine learning. In Proceedings of the 2020 54th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 18–20 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Oprea, A.; Singhal, A.; Vassilev, A. Poisoning Attacks Against Machine Learning: Can Machine Learning Be Trustworthy? Computer 2022, 55, 94–99. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; PMLR: Cambridge, MA, USA, 2018; pp. 274–283. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–26 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 39–57. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM Sigsac Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1528–1540. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; PMLR: Cambridge, MA, USA, 2018; pp. 284–293. [Google Scholar]
- Bai, Y.; Wang, Y.; Zeng, Y.; Jiang, Y.; Xia, S.T. Query efficient black-box adversarial attack on deep neural networks. Pattern Recognit. 2023, 133, 109037. [Google Scholar] [CrossRef]
- Williams, P.N.; Li, K. Black-Box Sparse Adversarial Attack via Multi-Objective Optimisation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12291–12301. [Google Scholar]
- Lu, S.; Wang, M.; Wang, D.; Wei, X.; Xiao, S.; Wang, Z.; Han, N.; Wang, L. Black-box attacks against log anomaly detection with adversarial examples. Inf. Sci. 2023, 619, 249–262. [Google Scholar] [CrossRef]
- Bertino, E.; Kantarcioglu, M.; Akcora, C.G.; Samtani, S.; Mittal, S.; Gupta, M. AI for Security and Security for AI. In Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual Event, 26–28 April 2021; pp. 333–334. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 582–597. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; PMLR: Cambridge, MA, USA, 2021; pp. 10347–10357. [Google Scholar]
- Touvron, H.; Cord, M.; Jégou, H. Deit iii: Revenge of the vit. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 516–533. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Chen, L.; Yu, C.; Chen, L. A new knowledge distillation for incremental object detection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Kang, Z.; Zhang, P.; Zhang, X.; Sun, J.; Zheng, N. Instance-conditional knowledge distillation for object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 16468–16480. [Google Scholar]
- Hahn, S.; Choi, H. Self-knowledge distillation in natural language processing. arXiv 2019, arXiv:1908.01851. [Google Scholar]
- Fu, H.; Zhou, S.; Yang, Q.; Tang, J.; Liu, G.; Liu, K.; Li, X. LRC-BERT: Latent-representation contrastive knowledge distillation for natural language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, virtual, 11–15 October 2021; Volume 35, pp. 12830–12838. [Google Scholar]
- Goldblum, M.; Fowl, L.; Feizi, S.; Goldstein, T. Adversarially robust distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3996–4003. [Google Scholar]
- Hong, I.p.; Choi, G.h.; Kim, P.k.; Choi, C. Security Verification Software Platform of Data-efficient Image Transformer Based on Fast Gradient Sign Method. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, Tallinn, Estonia, 26–30 March 2023; pp. 1669–1672. [Google Scholar]
- Hong, I.; Choi, C. Knowledge distillation vulnerability of DeiT through CNN adversarial attack. Neural Comput. Appl. 2023, 1–11. [Google Scholar] [CrossRef]
- Xie, C.; Wu, Y.; Maaten, L.v.d.; Yuille, A.L.; He, K. Feature denoising for improving adversarial robustness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 501–509. [Google Scholar]
- Li, X.; Li, F. Adversarial examples detection in deep networks with convolutional filter statistics. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5764–5772. [Google Scholar]
- Grosse, K.; Manoharan, P.; Papernot, N.; Backes, M.; McDaniel, P. On the (statistical) detection of adversarial examples. arXiv 2017, arXiv:1702.06280. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Wu, B.; Pan, H.; Shen, L.; Gu, J.; Zhao, S.; Li, Z.; Cai, D.; He, X.; Liu, W. Attacking adversarial attacks as a defense. arXiv 2021, arXiv:2106.04938. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 15 October 2024).
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating adversarial examples with adversarial networks. arXiv 2018, arXiv:1801.02610. [Google Scholar]
- Rauber, J.; Zimmermann, R.; Bethge, M.; Brendel, W. Foolbox Native: Fast adversarial attacks to benchmark the robustness of machine learning models in PyTorch, TensorFlow, and JAX. J. Open Source Softw. 2020, 5, 2607. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Defense Model | Attack | F1 Score | Accuracy | Attack Success Rate () | Defense Success Rate () |
|---|---|---|---|---|---|---|
| ResNet18 [52] | - | False | 0.917 (0.010) | 0.918 (0.010) | 66.5 | 33.5 |
| True | 0.254 (0.019) | 0.253 (0.023) | ||||
| DN [45] | False | 0.819 (0.07) | 0.819 (0.007) | 68.3 | 31.7 | |
| True | 0.142 (0.016) | 0.136 (0.017) | ||||
| ADT [20] | False | 0.766 (0.005) | 0.767 (0.004) | 28.2 | 71.8 | |
| True | 0.484 (0.008) | 0.484 (0.004) | ||||
| DN + ADT [48] | False | 0.769 (0.004) | 0.770 (0.004) | 28.0 | 72.0 | |
| True | 0.488 (0.007) | 0.491 (0.006) | ||||
| KD [41] | False | 0.848 (0.004) | 0.848 (0.004) | 28.4 | 71.6 | |
| True | 0.567 (0.009) | 0.564 (0.009) | ||||
| DiNo-Net (Proposed) | KD + DN | False | 0.847 (0.002) | 0.847 (0.002) | 27.3 | 72.7 |
| True | 0.579 (0.004) | 0.575 (0.004) |
| Model | Defense Method | Parameter | Learning Time | Defense Success Rate () |
|---|---|---|---|---|
| ResNet18 [52] | - | 11.17 M | 1:06:22 | 33.5 |
| DN [45] | 11.24 M | 1:11:46 | 31.7 | |
| ADT [20] | 11.17 M | 1:47:13 | 71.8 | |
| DN+ADT [48] | 11.24 M | 1:47:40 | 72.0 | |
| KD [41] | 11.17 M | 1:12:06 | 71.6 | |
| DiNo-Net (Proposed) | KD + DN | 11.24 M | 1:12:33 | 72.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, I.; Lee, S. Exploring Synergy of Denoising and Distillation: Novel Method for Efficient Adversarial Defense. Appl. Sci. 2024, 14, 10872. https://doi.org/10.3390/app142310872
Hong I, Lee S. Exploring Synergy of Denoising and Distillation: Novel Method for Efficient Adversarial Defense. Applied Sciences. 2024; 14(23):10872. https://doi.org/10.3390/app142310872
Chicago/Turabian StyleHong, Inpyo, and Sokjoon Lee. 2024. "Exploring Synergy of Denoising and Distillation: Novel Method for Efficient Adversarial Defense" Applied Sciences 14, no. 23: 10872. https://doi.org/10.3390/app142310872
APA StyleHong, I., & Lee, S. (2024). Exploring Synergy of Denoising and Distillation: Novel Method for Efficient Adversarial Defense. Applied Sciences, 14(23), 10872. https://doi.org/10.3390/app142310872