
Modeling Data Sovereignty in Public Cloud—A Comparison of Existing Solutions


Abstract
1. Introduction
2. Literature Review
- (1)
- Legal frameworks and their limitations:The legal dimension of data sovereignty in the public cloud spans various jurisdictions, each with distinct regulatory approaches. Recent studies highlight several challenges:
- −
- International regulations and data transfers:Studies focusing on China [9] illustrate regional complexities by comparing overseas data transfer laws in China, the EU, and the USA. However, these frameworks are limited by jurisdictional constraints, creating challenges for multinational organizations that require seamless data access across borders. The lack of global standardization can result in compliance risks and enforcement difficulties.
- −
- Regional data localization laws:For instance, the EU’s ongoing efforts to govern data through projects aimed at cloud federation and standardization [10] underscore regional attempts to manage sovereignty. Yet, these efforts reveal gaps, as they may inadvertently restrict cross-border data flow, complicating data accessibility in globally distributed environments. Similarly, data localization laws in Russia [11] enforce strict national boundaries but face criticism for impeding economic exchange.
- −
- Historical context of privacy and sovereignty laws:The Data Privacy Matrix (DPM) developed by New Zealand researchers [12] categorizes data privacy laws across major cloud-hosting nations. This resource reflects the inconsistency in data privacy and sovereignty laws globally, which can lead to conflicting legal obligations for cloud service providers and their clients. High-profile events like Edward Snowden’s 2013 revelations about the PRISM program have led to increased scrutiny of US-based cloud providers, raising sovereignty concerns for data stored within the USA.The limitations in these legal frameworks demonstrate the need for cohesive, enforceable international standards that address the complexities of data sovereignty. Existing models are insufficient for managing the nuances of data jurisdiction in cloud environments, particularly as they often lack clear provisions for cross-border data governance.
- (2)
- Governance frameworks and public data management:Research on governance frameworks reveals various national approaches to managing public and government data in the cloud:
- −
- Government cloud strategies and sovereignty:In South Africa, studies explore government cloud migration readiness [13]. Challenges arise when attempting to balance sovereignty with efficiency, as on-premises systems are often outdated but shifting to the cloud risks foreign data control. Other studies [14] analyze the government data strategies of the USA, UK, and Australia, where regulations like the USA PATRIOT Act permit extensive access to data by authorities. This raises significant concerns over data control and sovereignty when using foreign cloud providers.
- −
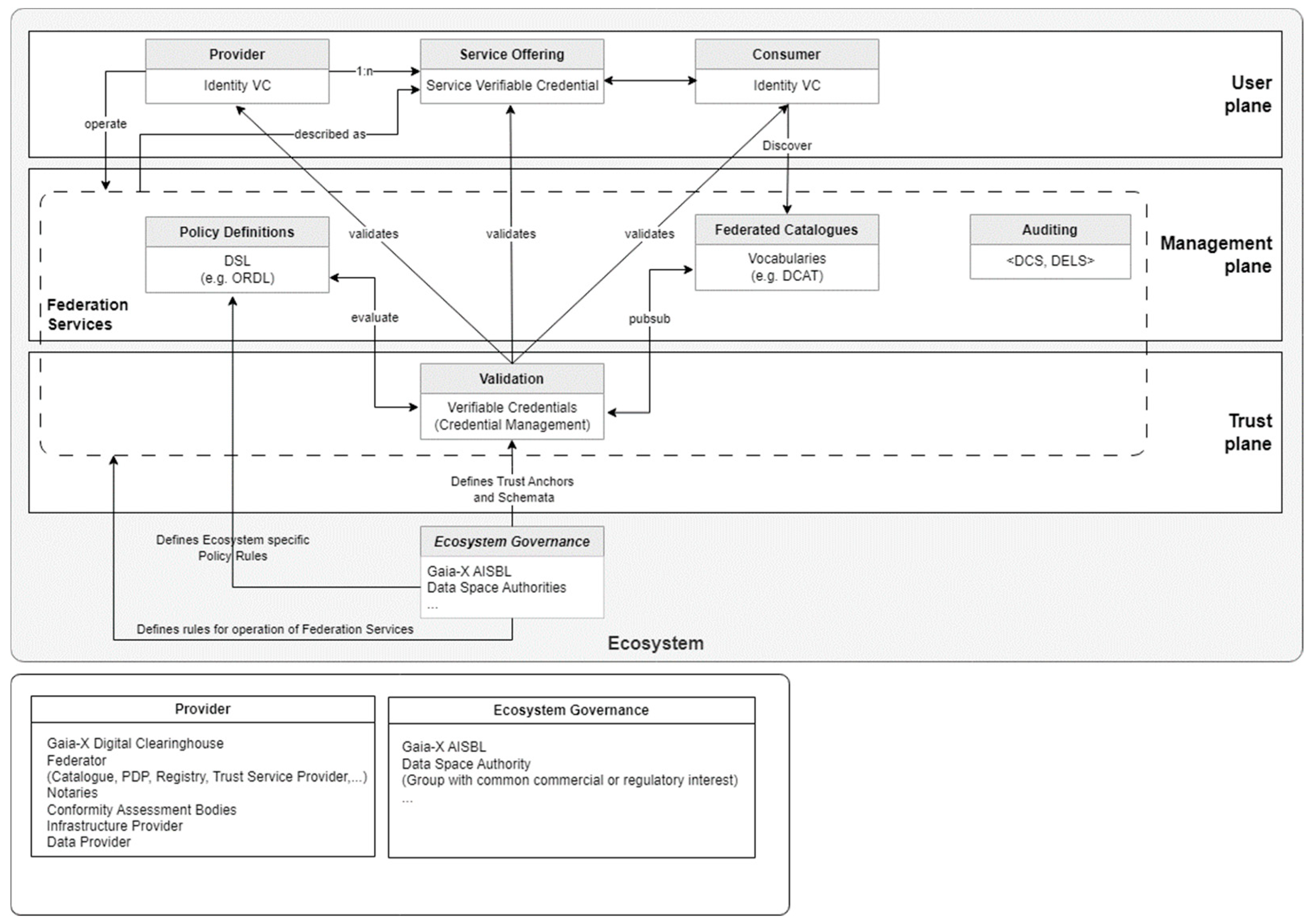
- Cloud sovereignty projects in the EU:European countries, through initiatives like GAIA-X [15], have launched sovereign cloud projects aimed at creating an ecosystem where data can be securely shared. However, these projects face obstacles in balancing openness and control, and the infrastructure is still in early stages, lacking a comprehensive governance model that supports consistent data sovereignty practices across borders.These studies reveal that governance strategies are often reactive, addressing data sovereignty concerns only after challenges emerge. This reactive approach limits the development of proactive, flexible governance models that can adapt to changing cloud environments and multinational data-sharing needs.
- (3)
- Technical Frameworks and Practical Tools for Data Sovereignty:The technical dimension of data sovereignty involves practical solutions to safeguard data in public cloud environments:
- −
- Data encryption and access control solutions:Recent studies introduce proxy re-encryption technologies, such as ID-based proxy re-encryption (IBPRE) [16], designed to streamline data sharing without exposing decrypted information. This technology provides a layer of sovereignty but is constrained by computational requirements and the need for additional key management infrastructure.
- −
- Data partitioning and redundancy:Systems like ARGUS [17], which partition encrypted data across multiple storage providers, add redundancy and security layers to cloud storage. However, while ARGUS enhances security, it does not fully address concerns over the control of data by third-party providers, nor does it provide robust geolocation assurances, which are critical in certain data sovereignty contexts.
- −
- Blockchain-based governance for cloud resources:Platforms like CloudAgora [18] leverage the blockchain to create a distributed marketplace for cloud resources, supporting user control and transparency. However, the reliance on the blockchain brings scalability challenges and may not be practical for environments with high data volumes and rapid access needs.
- −
- Systematization of Knowledge (SoK) in data Sovereignty:The comprehensive SoK article [1] categorizes data sovereignty mechanisms into layers like decentralized identity, access control, and policy-compliant computation, offering a conceptual foundation for Web 3.0 applications. Although promising, the interoperability limitations in Web 3.0 solutions, such as Decentralized Identifier (DID) systems, highlight gaps that limit their immediate application in large-scale public cloud settings.These studies indicate that while technological advancements offer promising solutions, the tools are often experimental, resource intensive, and not yet suited for widespread deployment in public cloud environments. Further research is needed to enhance scalability and efficiency, providing stronger guarantees for data sovereignty in a global context.The reviewed literature underscores significant gaps in existing frameworks for data sovereignty in the cloud. Legal frameworks lack consistent international standards, governance strategies are fragmented and reactive, and technical solutions remain limited in scalability and practicality. Current models are insufficient to address the unique challenges presented by data sovereignty in public cloud environments, where data jurisdiction issues intersect with complex legal, governance, and technical demands.This study focuses on addressing gaps within technical frameworks by proposing an abstract, layered model for data sovereignty in public cloud environments.
3. Materials and Methods
4. Models and Computational Experiments
4.1. Reference Architecture Comparison and Description
- −
- International Data Spaces Association
- −
- Gaia-X
- −
- FIWARE
- −
- IDSA creates international standards for data spaces;
- −
- Gaia-X is focused on data infrastructure for Europe;
- −
- FIWARE creates framework smart solutions.
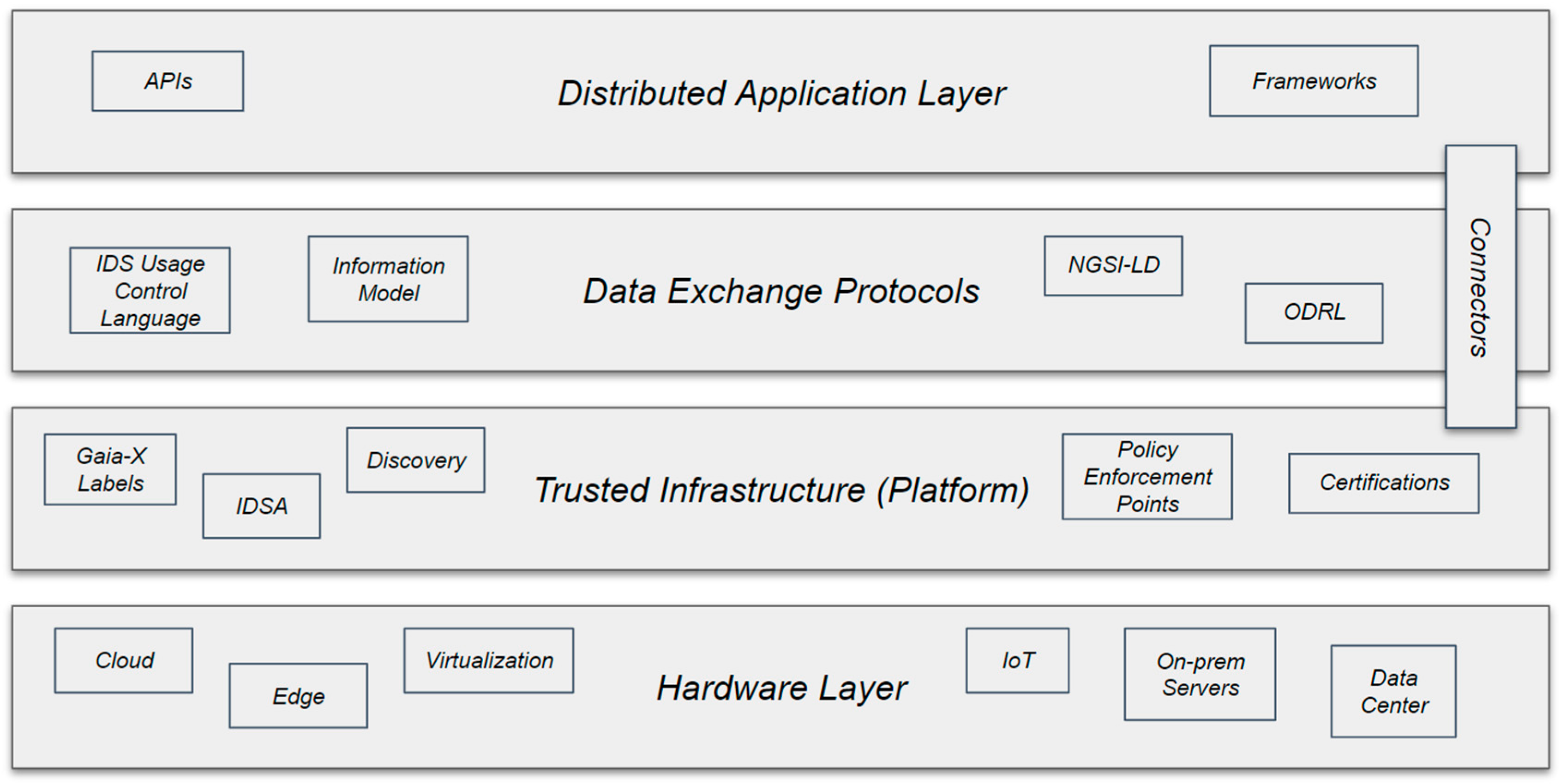
4.1.1. International Data Spaces (IDSA)
4.1.2. Gaia-X
4.1.3. FIWARE
4.2. Data Sovereignty Model
4.3. Experiments
- GET/api/catalogs Get a list of base resources with pagination.
- POST/api/catalogs Create a base resource.
- VM 1
- ○
- Platform: GCP Compute Engine
- ○
- VM size: 2 vCPU, 1 core, 8 GB memory
- ○
- Operating System: Debian GNU/Linux 12 (bookworm)
- ○
- Region: Europe Central 2—Warsaw, Poland
- VM 2
- ○
- Platform: GCP Compute Engine
- ○
- VM size: 2 vCPU, 1 core, 8 GB memory
- ○
- Operating System: Debian GNU/Linux 12 (bookworm)
- ○
- Region: US Central 1—Council Bluffs, Iowa
- VM 3
- ○
- Platform: Azure Virtual Machine
- ○
- VM size: 2 vCPU, 1 core, 8 GB memory
- ○
- Operating System: Debian 11 “Bullseye”—x64 Gen2
- ○
- Region: Europe—Poland Central—Warsaw
5. Discussion
6. Conclusions and Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- import datetimeimport timeimport requestsimport sysimport osimport statistics
- gcp_eu_url = “https://<IP-address>:80/api/catalogs”gcp_us_url = “https://<IP-address>:80/api/catalogs”azure_url = “https://<IP-address>:80/api/catalogs”local_url = “https://<IP-address>:8080/api/catalogs”
- sys.stderr = open(os.devnull, ‘w’)
- basic = requests.auth.HTTPBasicAuth(‘***’, ‘***’)payload = {“title”:”Test-catalog”,”description”:”IDS test catalog”}results = []for i in range(10):x = datetime.datetime.now()
- # GETresponse = requests.get(azure_url, verify=False, auth=basic)
- # POST#response = requests.post(gcp_us_url, verify=False, auth=basic, json = payload)
- y = datetime.datetime.now()elapsed = y-xprint(i, “- response time: “, elapsed.microseconds/ 1000, “[ms]”)results.append(elapsed.microseconds)
- # Print average test time [ms]:print(“Average time: “, statistics.mean(results)/ 1000, “[ms]”)
Appendix B
- Catalogs—Endpoints for operations on catalogs.
- Subscriptions—Endpoints for operations on subscriptions.
- Representations—Endpoints for operations on representations.
- Apps—Endpoints for app handling.
- Daps—Endpoints for operations on daps.
- Artifacts—Endpoints for operations on artifacts.
- _Messaging—Endpoints for invoke sending messages.
- Endpoints—Endpoints for operations on endpoints.
- _Connector—Endpoints for general information.
- Rules—Endpoints for operations on rules.
- Offered Resources—Endpoints for operations on offered resources.
- Brokers—Endpoints for operations on brokers.
- Contracts—Endpoints for operations on contracts (+ agreements).
- _Utils
- App Stores—Endpoints for app store handling.
- _Configurations—Endpoints for operations on configurations.
- Requested Resources—Endpoints for operations on requested resources.
- Data Sources—Endpoints for operations on data sources/sinks.
- Routes—Endpoints for operations on routes.
- Agreements—Endpoints for contract agreement handling.
- Routes (Apache Camel)—Endpoints for dynamically managing Camel routes.
References
- Ernstberger, J.; Lauinger, J.; Elsheimy, F.; Zhou, L.; Steinhorst, S.; Canetti, R.; Miller, A.; Gervais, A.; Song, D. SoK: Data Sovereignty. In Proceedings of the 2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), Delft, The Netherlands, 3–7 July 2023. [Google Scholar]
- Atos Sovereign Cloud Offering. Available online: https://atos.net/en/portfolio/create-the-sovereign-public-foundations-for-the-digital-era (accessed on 25 August 2024).
- International Data Spaces Global. Available online: https://github.com/International-Data-Spaces-Association (accessed on 5 December 2023).
- Hummel, P.; Braun, M.; Augsberg, S. Sovereignty and Data Sharing. ITU J. Future Evol. Technol. 2018, 1–10. [Google Scholar]
- Yaodong, T.; Yang, S. Comparative Study on Data Sovereignty Guarantee Technology. EasyChair Preprint 8965. 2022. Available online: https://easychair.org/publications/preprint/hcFH (accessed on 28 October 2024).
- Merlec, M.M.; Hoh, P. Blockchain-Based Decentralized Storage Systems for Sustainable Data Self-Sovereignty: A Comparative Study. Sustainability 2024, 16, 7671. [Google Scholar] [CrossRef]
- Aruna, M.G.; Hasan, M.K.; Islam, S.; Mohan, K.G.; Sharan, P.; Hassan, R. Cloud to cloud data migration using self sovereign identity for 5G and beyond. Clust. Comput. 2022, 25, 2317–2331. [Google Scholar] [CrossRef] [PubMed]
- Dordevic, D. Data Sovereignty Provision in Cloud-and-Blockchain-Integrated IoT Data Trading. Master’s Thesis, University of Zurich, Zurich, Switzerland, September 2020. [Google Scholar]
- Ziyi, X. International Law Protection of Cross-Border Transmission of Personal Information Based on Cloud Computing and Big Data. Mob. Inf. Syst. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
- Renda, A. Making the digital economy “fit for Europe”. Eur. Law J. 2020, 26, 345–354. [Google Scholar]
- Savelyev, A. Russia’s new personal data localization regulations: A step forward or a self-imposed sanction? Comput. Law Secur. Rev. 2016, 32, 128–145. [Google Scholar] [CrossRef]
- Scoon, C.; Ko, R.K.L. The Data Privacy Matrix Project: Towards a Global Alignment of Data Privacy Laws. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 1998–2005. [Google Scholar] [CrossRef]
- Shibambu, A. Migration of government records from on-premises to cloud computing storage in South Africa. S. Afr. J. Libr. Inf. Sci. 2022, 88, 1–11. [Google Scholar] [CrossRef]
- Irion, K. Government Cloud Computing and National Data Sovereignty. Policy Internet 2012, 4, 40–71. [Google Scholar] [CrossRef]
- Mitchell, A.D.; Samlidis, T. Cloud services and government digital sovereignty in Australia and beyond. J. Law Inf. Technol. 2021, 29, 364–394. [Google Scholar] [CrossRef]
- Kim, W.B.; Seo, D.; Kim, D.; Lee, I.Y. Group Delegated ID-Based Proxy Reencryption for the Enterprise IoT-Cloud Storage Environment. Wirel. Commun. Mob. Comput. 2021, 2021, 7641389. [Google Scholar] [CrossRef]
- Resende, J.S.; Martins, R.; Antunes, L. Enforcing Privacy and Security in Public Cloud Storage. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018. [Google Scholar]
- Bakogiannis, T.; Mytilinis, I.; Doka, K.; Goumas, G. Building Ad-Hoc Clouds with CloudAgora. In Proceedings of the 2019 38th Symposium on Reliable Distributed Systems (SRDS), Lyon, France, 1–4 October 2019. [Google Scholar]
- IDS RAM 4. Available online: https://github.com/International-Data-Spaces-Association/IDS-RAM_4_0 (accessed on 18 June 2024).
- GAIA-X AISBL. Available online: https://gaia-x.eu (accessed on 5 December 2023).
- Gaia-X Architecture Document. Available online: https://gitlab.com/gaia-x/technical-committee/architecture-working-group/architecture-document (accessed on 18 June 2024).
- FIWARE for Smart Cities and Territories. Available online: https://www.fiware.org/wp-content/uploads/Smart-Cities-Brochure-FIWARE.pdf (accessed on 18 June 2024).
- Otto, B.; ten Hompel, M.; Wrobel, S. Designing Data Spaces: The Ecosystem Approach to Competitive Advantage; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Open Digital Rights Language (ODRL). Available online: https://www.w3.org/TR/odrl-model/ (accessed on 25 August 2024).
- NGSI-LD (Next Generation Service Interface with Linked Data). Available online: https://www.etsi.org/deliver/etsi_gs/CIM/001_099/009/01.05.01_60/gs_CIM009v010501p.pdf (accessed on 25 August 2024).
- Dataspace Connector. Available online: https://github.com/International-Data-Spaces-Association/DataspaceConnector (accessed on 19 June 2024).
- Data Connector Report. Available online: https://internationaldataspaces.org/data-connector-report (accessed on 30 October 2024).
- Data Sovereignty Test Results. Available online: https://github.com/OneCloudDesignAuthority/data-sovereignty/tree/development/Experiments/Results (accessed on 19 June 2024).
- Dataspace Connector API Specification. Available online: https://github.com/International-Data-Spaces-Association/DataspaceConnector/blob/main/openapi.yaml (accessed on 22 August 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
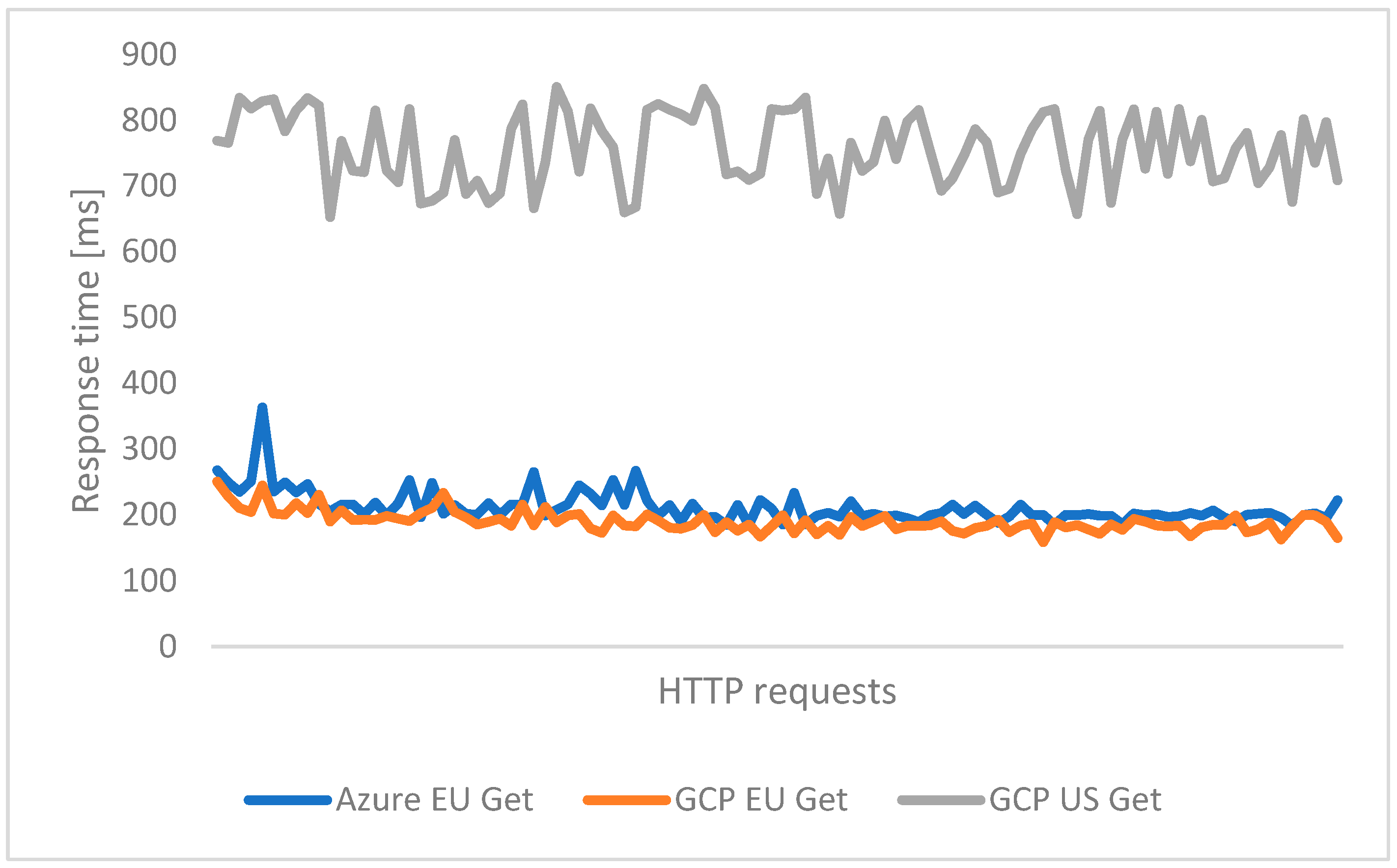
| Environment | GET * | POST * |
|---|---|---|
| Azure EU | 211 [ms] | 187 [ms] |
| Azure EU-local test (public IP) | 105 [ms] | 104 [ms] |
| Azure EU-local test (local IP) | 99 [ms] | 98 [ms] |
| GCP EU | 190 [ms] | 207 [ms] |
| GCP EU-local test (public IP) | 154 [ms] | 134 [ms] |
| GCP EU-local test (local IP) | 133 [ms] | 115 [ms] |
| GCP US | 757 [ms] | 635 [ms] |
| GCP US-local test (public IP) | 125 [ms] | 116 [ms] |
| GCP US-local test (local IP) | 113 [ms] | 103 [ms] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galij, S.; Pawlak, G.; Grzyb, S. Modeling Data Sovereignty in Public Cloud—A Comparison of Existing Solutions. Appl. Sci. 2024, 14, 10803. https://doi.org/10.3390/app142310803
Galij S, Pawlak G, Grzyb S. Modeling Data Sovereignty in Public Cloud—A Comparison of Existing Solutions. Applied Sciences. 2024; 14(23):10803. https://doi.org/10.3390/app142310803
Chicago/Turabian StyleGalij, Stanisław, Grzegorz Pawlak, and Sławomir Grzyb. 2024. "Modeling Data Sovereignty in Public Cloud—A Comparison of Existing Solutions" Applied Sciences 14, no. 23: 10803. https://doi.org/10.3390/app142310803
APA StyleGalij, S., Pawlak, G., & Grzyb, S. (2024). Modeling Data Sovereignty in Public Cloud—A Comparison of Existing Solutions. Applied Sciences, 14(23), 10803. https://doi.org/10.3390/app142310803