
A Virtual View Acquisition Technique for Complex Scenes of Monocular Images Based on Layered Depth Images

Abstract
1. Introduction
2. Materials and Methods
| Algorithm 1 Virtual view generation algorithm |
| 1. Inputting RGB color image. |
| 2. Generating semantic segmentation image of RGB image and defining semantic segmentation label . 3. Generating depth image of RGB image. 4. Elevating depth image to LDI for multilayer representation. 5. Preprocessing depth image. 6. Sharpening depth image and determining discontinuous pixel segment. 7. Aligning RGB image with depth image. 8. Eliminating spurious response (continuous pixel segment less than 15 pixels) and determining the number of discontinuous layer . 9. Inpainting layered image. 10. for 11. Breaking discontinuous points to generate composite area. The fore ground area, background area and outline of occluded area are determined, and the occluded area is filled by the iterative flood filling algorithm. 12. Inpainting image edge of occluded area. 13. Inpainting of color and depth of occluded area. 14. end for 15. Combining foreground area, background area and occluded area to generate new view angle image. 16. Optimizing virtual view of new view angle image. 17. Determining semantic segmentation label in the new view angle image. The semantic segmentation label is applied to the new view angle image and its depth image. 18. for 19. Optimizing new view angle image. 20. end for 21. Outputting virtual view image. |
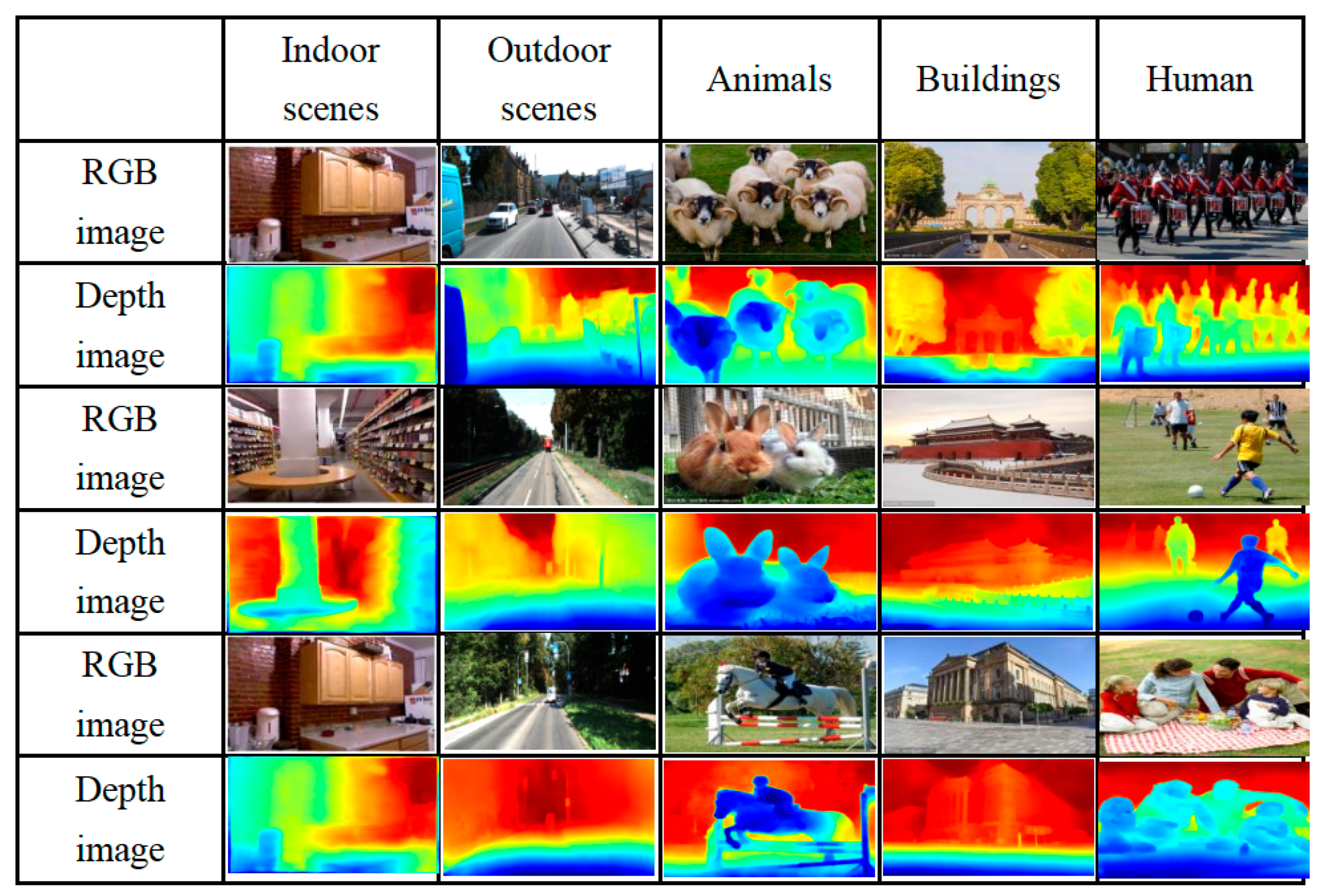
2.1. Depth Estimation
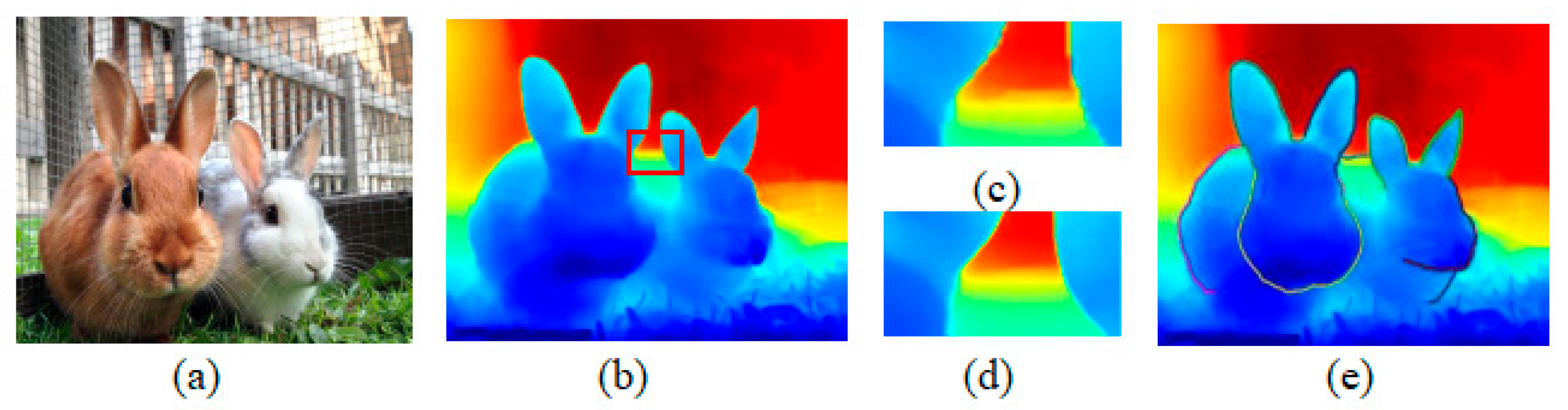
2.2. Generation of Layered Depth Image
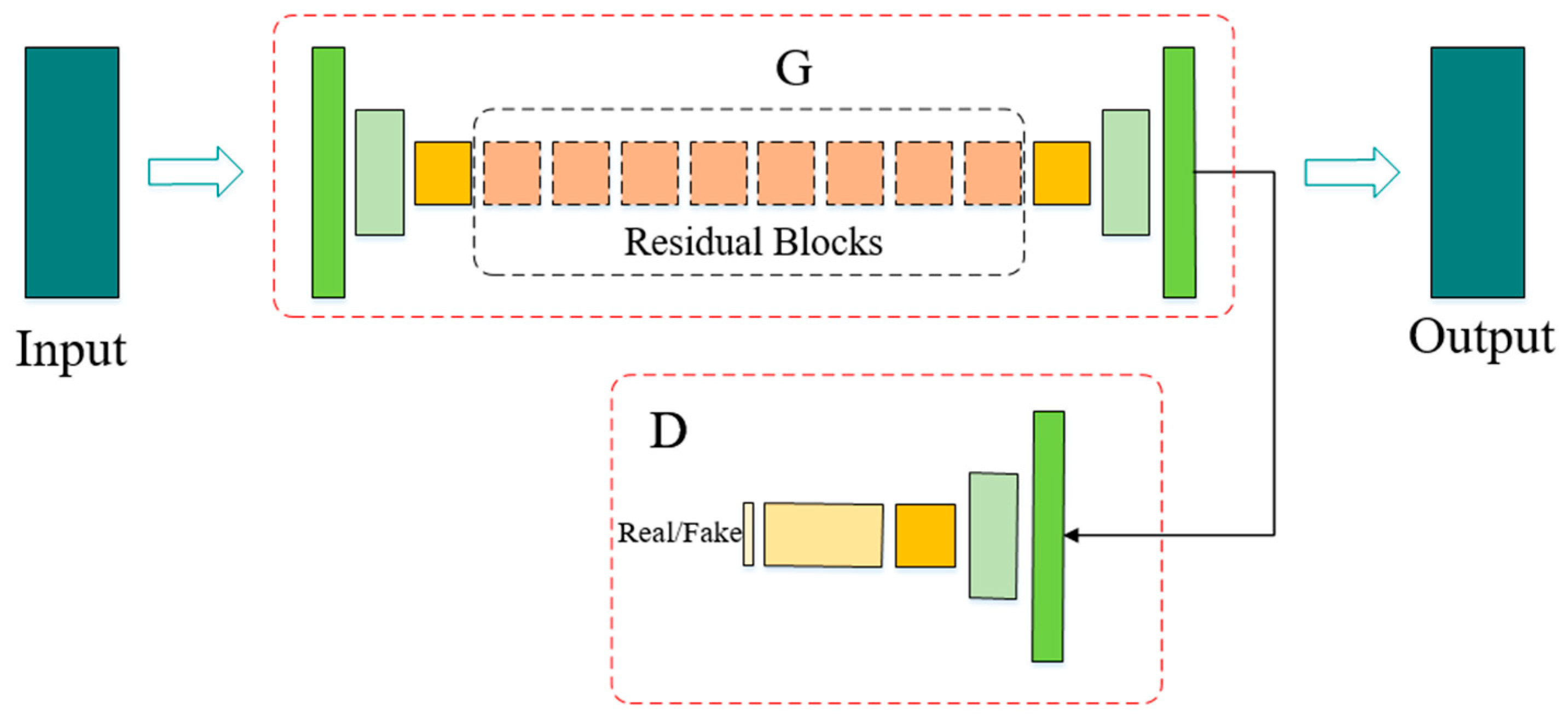
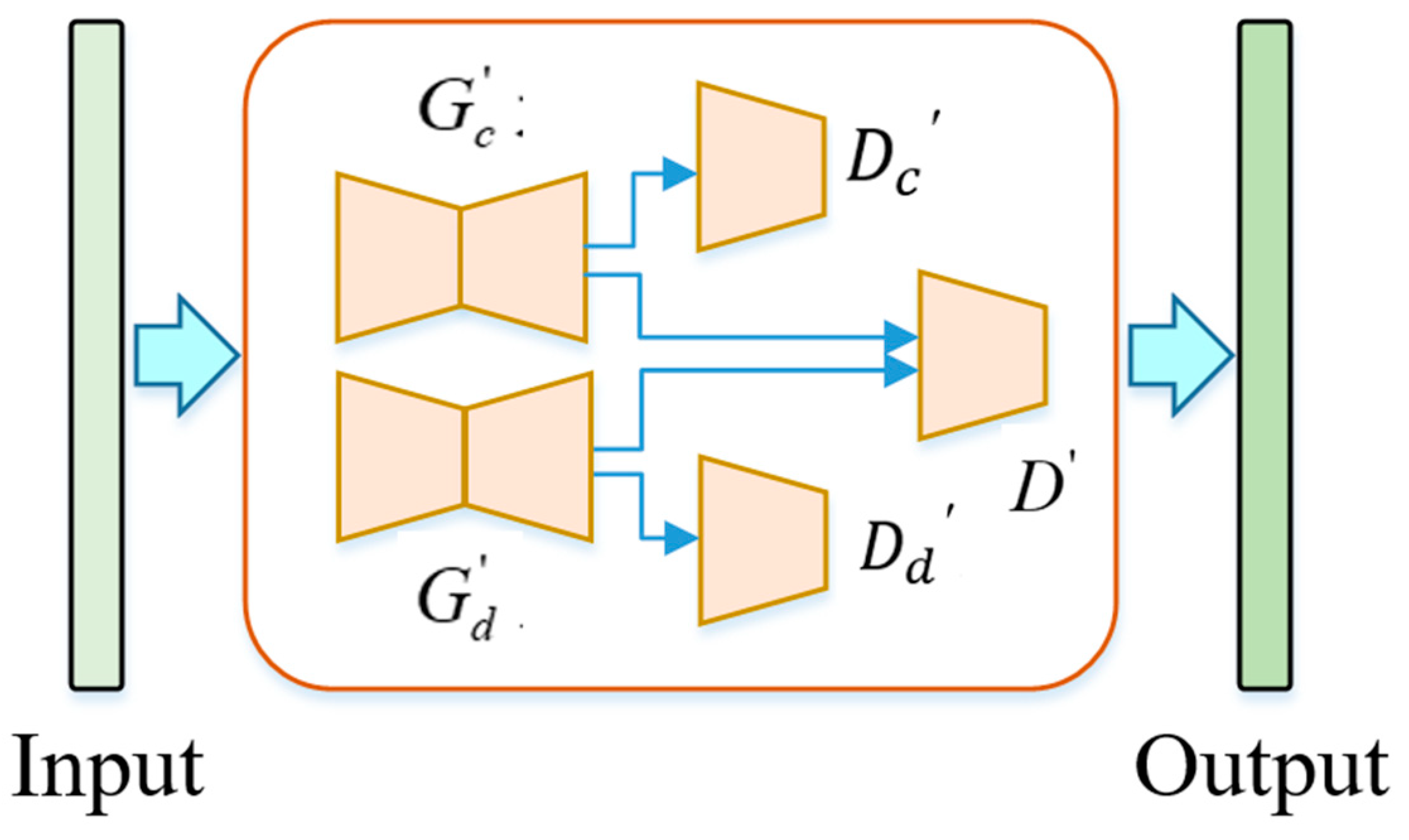
2.3. Layered Depth Image Inpainting
2.4. Virtual View Optimization
3. Results
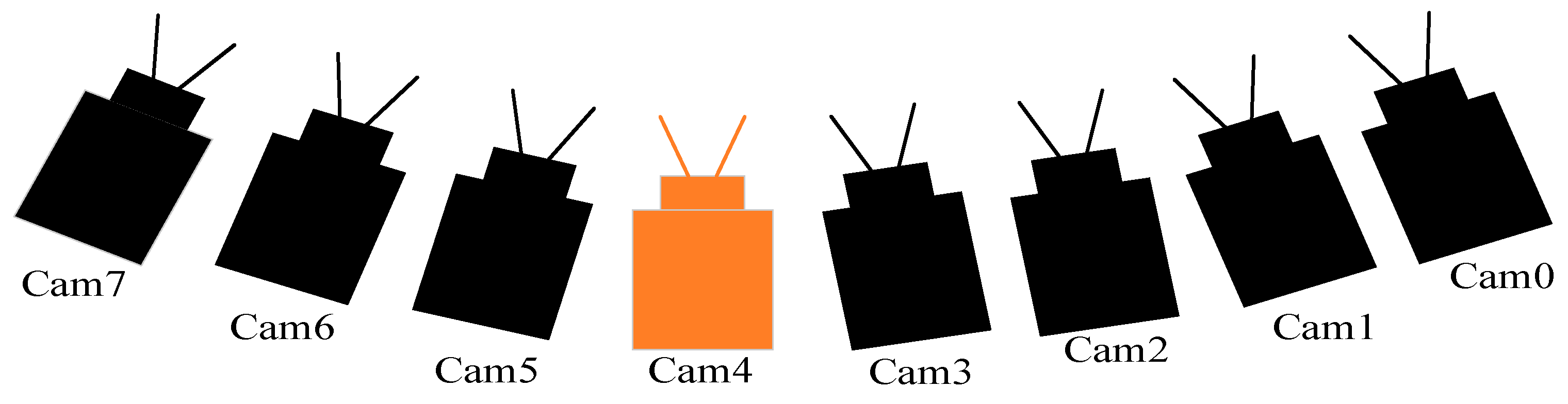
3.1. Training and Dataset
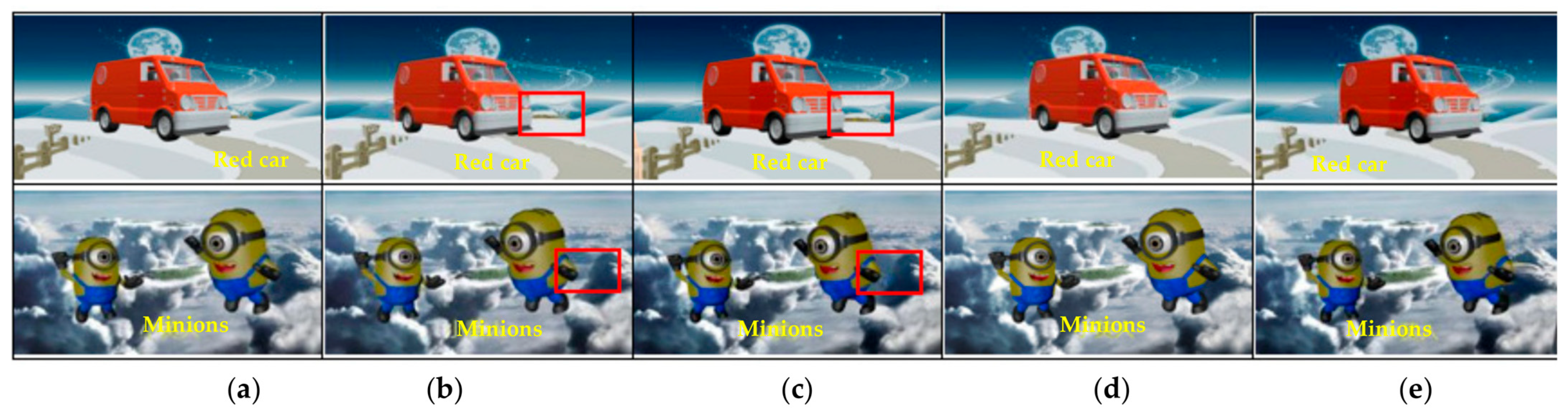
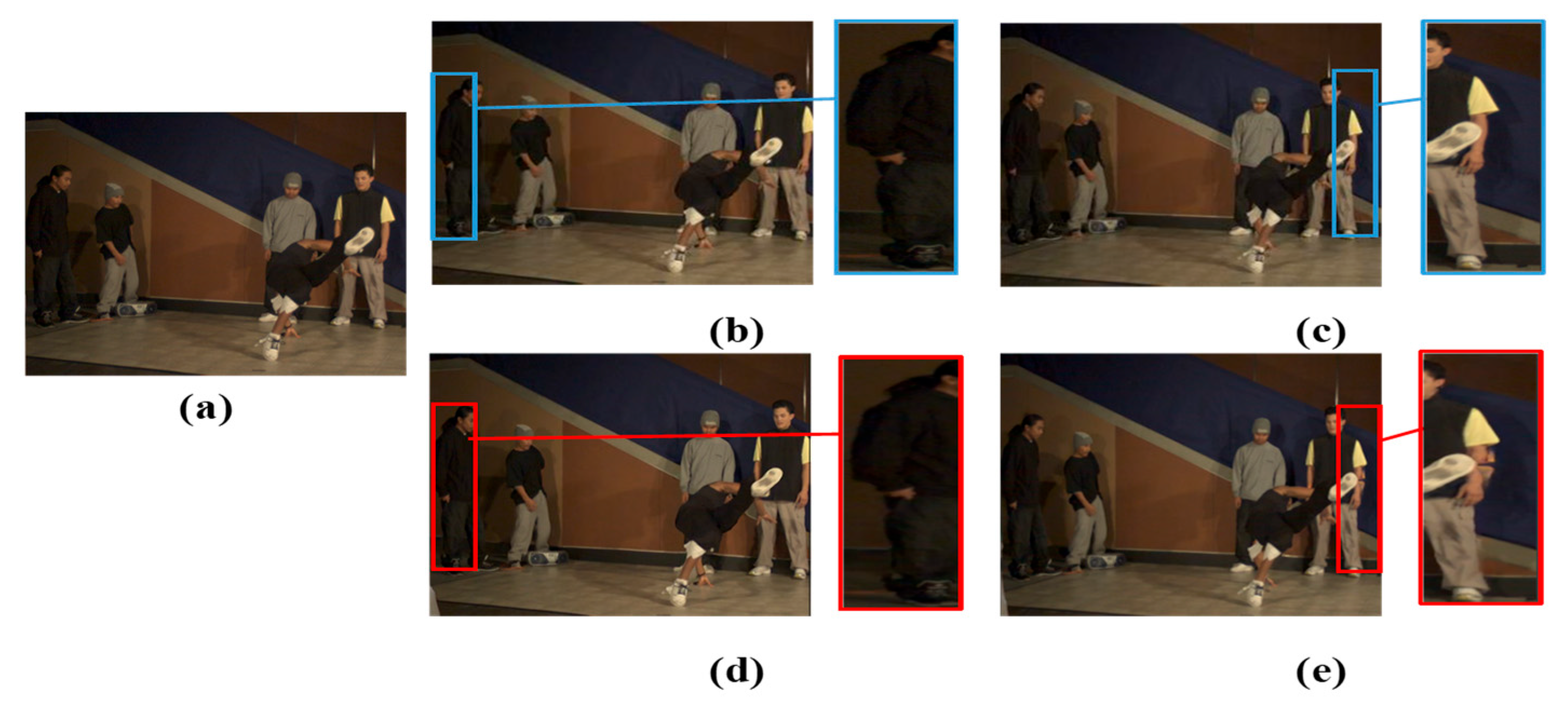
3.2. Comparison of Subjective Quality
3.3. Objective Quality Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, X.; Sang, X.; Xing, S.; Zhao, T.; Chen, D.; Cai, Y.; Yan, B.; Wang, K.; Yuan, J.; Yu, C.; et al. Natural three-dimensional display with smooth motion parallax using active partially pixelated masks. Opt. Commun. 2014, 313, 146–151. [Google Scholar] [CrossRef]
- Debevec, P.; Taylor, C.; Malik, J. Modeling and rendering architecture from photographs: A hybrid geometry and image-based approach. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 11–20. [Google Scholar]
- Gortler, S.; Grzeszczuk, R.; Szeliski, R.; Co-Hen, M. The lumigraph. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 43–54. [Google Scholar]
- Levoy, M.; Hanrahan, P. Light field rendering. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 31–42. [Google Scholar]
- Zhang, Q.; Li, S.; Guo, W.; Chen, J.; Wang, B.; Wang, P.; Huang, J. High quality virtual view synthesis method based on geometrical model. Video Eng. 2016, 40, 22–25. [Google Scholar]
- Cai, L.; Li, X.; Tian, X. Virtual viewpoint image post-processing method using background information. J. Chin. Comput. Syst. 2022, 43, 1178–1184. [Google Scholar]
- Chen, L.; Chen, S.; Ceng, K.; Zhu, W. High image quality virtual viewpoint rendering method and its GPU acceleration. J. Chin. Comput. Syst. 2020, 41, 2212–2218. [Google Scholar]
- Zhou, T.; Tucker, R.; Flynn, J.; Fyffe, G.; Snavely, N. Stereo magnifification: Learning view synthesis using multiplane images. ACM Trans. Graph. 2018, 37, 1–12. [Google Scholar]
- Tucker, R.; Snavely, N. Single-view view synthesis with multiplane images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 548–557. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.; Tatarchenko, M.; Brox, T. Learning to generate chairs, tables and cars with convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 692–705. [Google Scholar] [CrossRef]
- Yang, J.; Reed, S.; Yang, M.; Lee, H. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1099–1107. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Multi-view 3D models from single images with a convolutional network. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 322–337. [Google Scholar]
- Schonberger, J.; Zheng, E.; Frahm, J.; Pollefeys, M. Pixelwise view selection for unstructured multiview stereo. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 501–518. [Google Scholar]
- Zeng, Q.; Chen, W.; Wang, H.; Tu, C.; Cohen-Or, D.; Lischinski, D.; Chen, B. Hallucinating stereoscopy from a single image. In Proceedings of the 36th Annual Conference of the European-Association-for-Computer-Graphics, Zurich, Switzerland, 4–8 May 2015; pp. 1–12. [Google Scholar]
- Liang, H.; Chen, X.; Xu, H.; Ren, S.; Wang, Y.; Cai, H. Virtual view rendering based on depth map preprocessing and image inpainting. J. Comput. Aided Des. Comput. Graph. 2019, 31, 1278–1285. [Google Scholar] [CrossRef]
- Dhamo, H.; Tateno, K.; Laina, I.; Navab, N.; Tombari, F. Peeking behind objects: Layered depth prediction from a single image. Pattern Recognit. Lett. 2019, 125, 333–340. [Google Scholar] [CrossRef]
- Kopf, J.; Matzen, K.; Alsisan, S.; Quigley, O.; Ge, F.; Chong, Y.; Patterson, J.; Frahm, J.; Wu, S.; Yu, M. One shot 3d photography. ACM Trans. Graph. 2020, 39, 1–13. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3827–3837. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D. Unsupervised learning of depth and ego-motion from video. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.; Ortiz-Cayon, R.; Kalantari, N.; Ramamoorthi, R.; Ng, R.; Kar, A. Local light fifield fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Niklaus, S.; Mai, L.; Yang, J.; Liu, F. 3D Ken Burns effect from a single image. ACM Trans. Graph. 2019, 38, 184. [Google Scholar] [CrossRef]
- Penner, E.; Zhang, L. Soft 3D reconstruction for view synthesis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Porter, T.; Duff, T. Compositing digital images. ACM Siggraph Comput. Graph. 1984, 18, 253–259. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Szeliski, R.; Golland, P. Stereo matching with transparency and matting. Int. J. Comput. Vis. 1999, 32, 45–61. [Google Scholar] [CrossRef]
- Roy, A.; Todorovic, S. Monocular depth estimation using neural regression forest. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 5506–5514. [Google Scholar]
- Saxena, A.; Chung, S.; Ng, A. Learning depth from single monocular images. In Proceedings of the 18th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1161–1168. [Google Scholar]
- Liu, B.; Gould, S.; Koller, D. Single image depth estimation from predicted semantic labels. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1253–1260. [Google Scholar]
- Jiao, J.; Cao, Y.; Song, Y.; Lau, R. Look deeper into depth: Monocular depth estimation with semantic booster and attention-driven loss. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 55–71. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.; Savva, M.; Funkhouser, T. Semantic scene completion from a single depth image. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 190–198. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1623–1637. [Google Scholar] [CrossRef]
- Shade, J.; Gortler, S.; He, L.; Szeliski, R. Layered depth images. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 19–24 July 1998; pp. 231–242. [Google Scholar]
- Hedman, P.; Alsisan, S.; Szeliski, R.; Kopf, J. Casual 3D Photography. ACM Trans. Graph. 2017, 36, 1–15. [Google Scholar] [CrossRef]
- Hedman, P.; Kopf, J. Instant 3D Photography. ACM Trans. Graph. 2018, 37, 1–12. [Google Scholar] [CrossRef]
- Tulsiani, S.; Tucker, R.; Snavely, N. Layer-structured 3d scene inference via view synthesis. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 311–327. [Google Scholar]
- Garcia-Mateos, G.; Hernandez-Hernandez, J.; Escarabajal-Henarejos, D.; Jaen-Terrones, S.; Molina-Martinez, J. Study and comparison of color models for automatic image analysis in irrigation management applications. Agric. Water Manag. 2015, 151, 158–166. [Google Scholar] [CrossRef]
- Hernandez-Hernandez, J.; Garcia-Mateos, G.; Gonzalez-Esquiva, J.; Escarabajal-Henarejos, D.; Ruiz-Canales, A.; Molina-Martinez, J. Optimal color space selection method for plant/soil segmentation in agriculture. Comput. Electron. Agric. 2016, 122, 124–132. [Google Scholar] [CrossRef]
- Khot, T.; Agrawal, S.; Tulsiani, S.; Mertz, C.; Lucey, S.; Hebert, M. Learning unsupervised multi-view stereopsis via robust photometric consistency. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3th International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An imageis worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2019. [Google Scholar]
- Ren, J.; Xu, L.; Yan, Q.; Sun, W. Shepard convolutional neural networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 901–909. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1–17. [Google Scholar]
- Xiong, W.; Yu, J.; Lin, Z.; Yang, J.; Lu, X.; Barnes, C.; Luo, J. Foreground-aware image inpainting. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5833–5841. [Google Scholar]
- Ren, Y.; Yu, X.; Zhang, R.; Li, T.; Liu, S.; Li, G. Structureflow: Image inpainting via structure-aware appearance flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 181–190. [Google Scholar]
- Shih, M.; Su, S.; Kopf, J.; Huang, J. 3D photography using context-aware layered depth inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8025–8035. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Liu, G.; Reda, F.; Shih, K.; Wang, T.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 89–105. [Google Scholar]
- Eslami, S.; Rezende, D.; Besse, F.; Viola, F.; Morcos, A.; Garnelo, M.; Ruderman, A.; Rusu, A.; Danihelka, I.; Gregor, K. Neural scene representation and rendering. Science 2018, 360, 1204–1210. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Alahi, A.; Li, F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef]
- Rombach, R.; Esser, P.; Ommer, B. Geometry-free view synthesis: Transformers and no 3D priors. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 14336–14346. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Virtual Viewpoint Images | Method | SSIM | PSNR |
|---|---|---|---|
| Image1 | [58] | 0.8319 | 26.54 |
| Ours | 0.8742 | 30.45 | |
| Image2 | [58] | 0.8517 | 27.10 |
| Ours | 0.8933 | 30.79 | |
| Image3 | [58] | 0.8378 | 26.85 |
| Ours | 0.8825 | 29.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Piao, Y. A Virtual View Acquisition Technique for Complex Scenes of Monocular Images Based on Layered Depth Images. Appl. Sci. 2024, 14, 10557. https://doi.org/10.3390/app142210557
Wang Q, Piao Y. A Virtual View Acquisition Technique for Complex Scenes of Monocular Images Based on Layered Depth Images. Applied Sciences. 2024; 14(22):10557. https://doi.org/10.3390/app142210557
Chicago/Turabian StyleWang, Qi, and Yan Piao. 2024. "A Virtual View Acquisition Technique for Complex Scenes of Monocular Images Based on Layered Depth Images" Applied Sciences 14, no. 22: 10557. https://doi.org/10.3390/app142210557
APA StyleWang, Q., & Piao, Y. (2024). A Virtual View Acquisition Technique for Complex Scenes of Monocular Images Based on Layered Depth Images. Applied Sciences, 14(22), 10557. https://doi.org/10.3390/app142210557