
Exploring Cutout and Mixup for Robust Human Activity Recognition on Sensor and Skeleton Data †


Abstract
1. Introduction
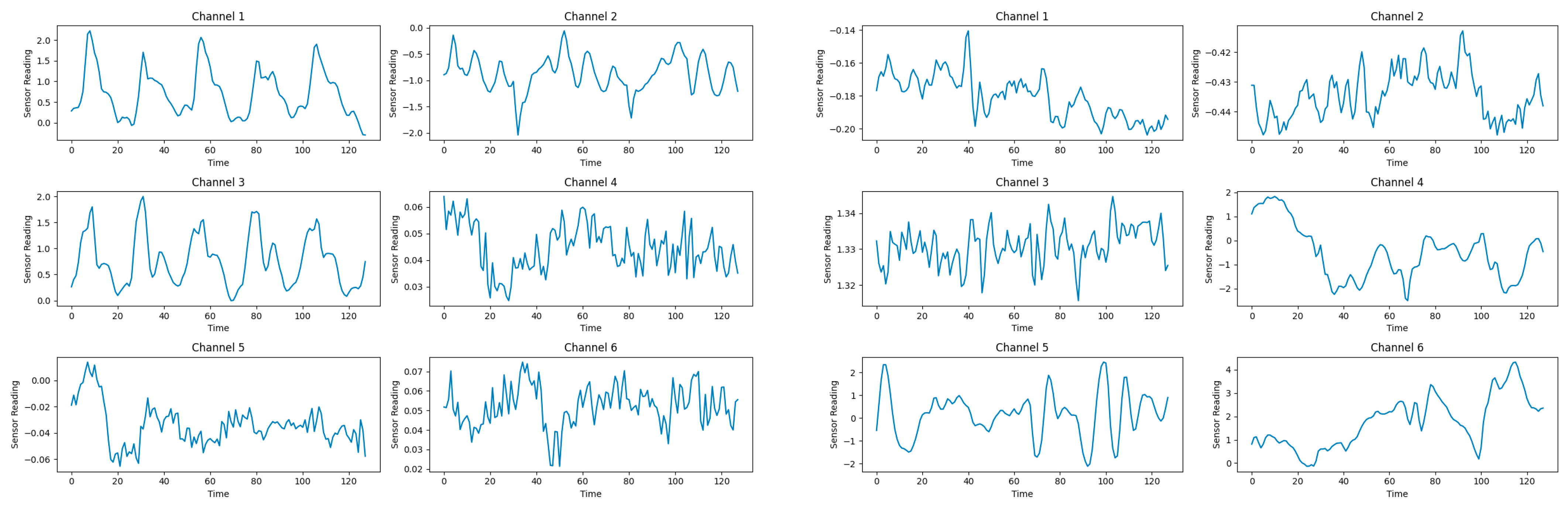
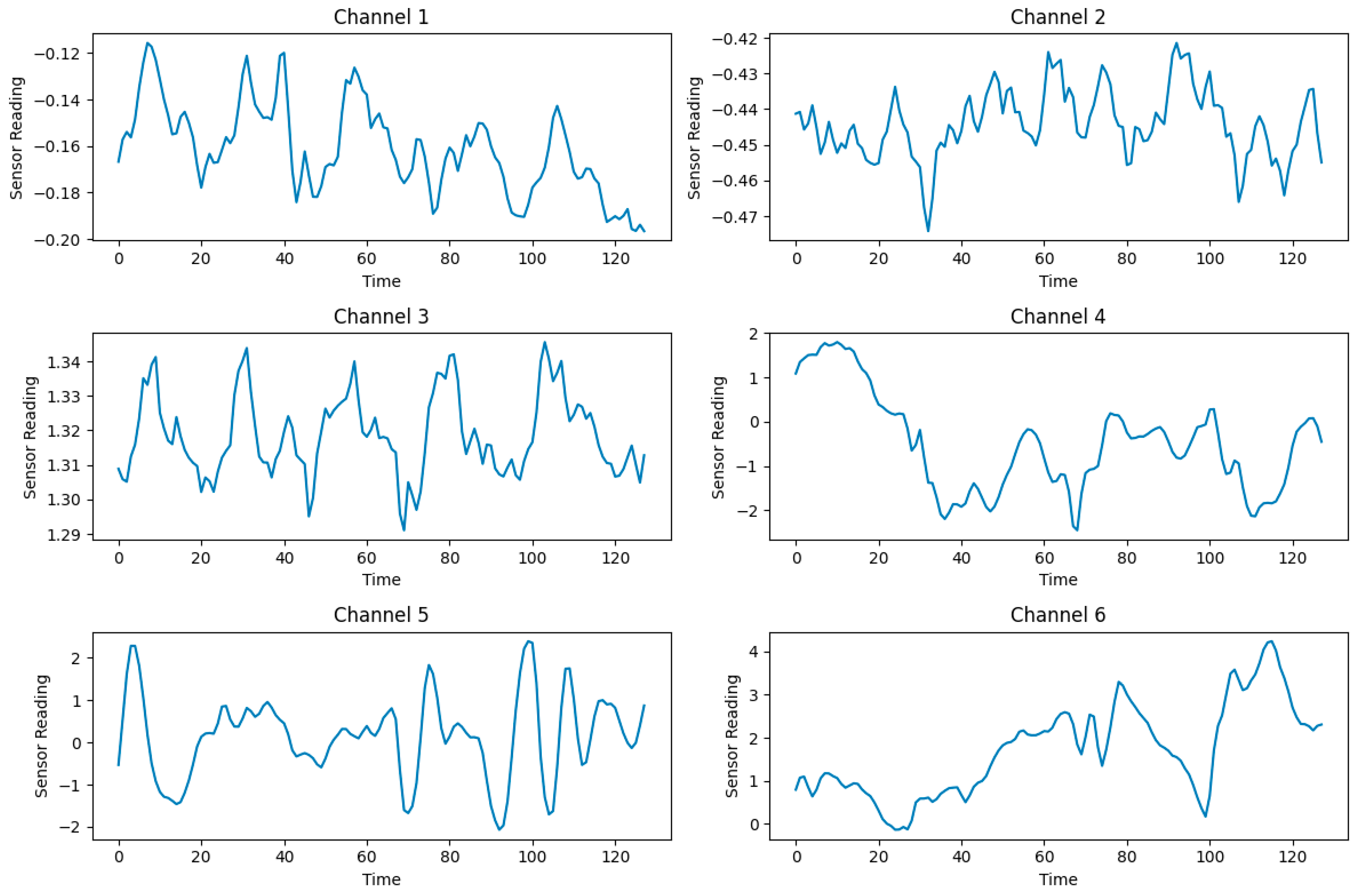
- We introduce and adapt the mixup data augmentation technique for sensor-based time-series data in HAR, improving data diversity and model generalization while preserving the temporal structure.
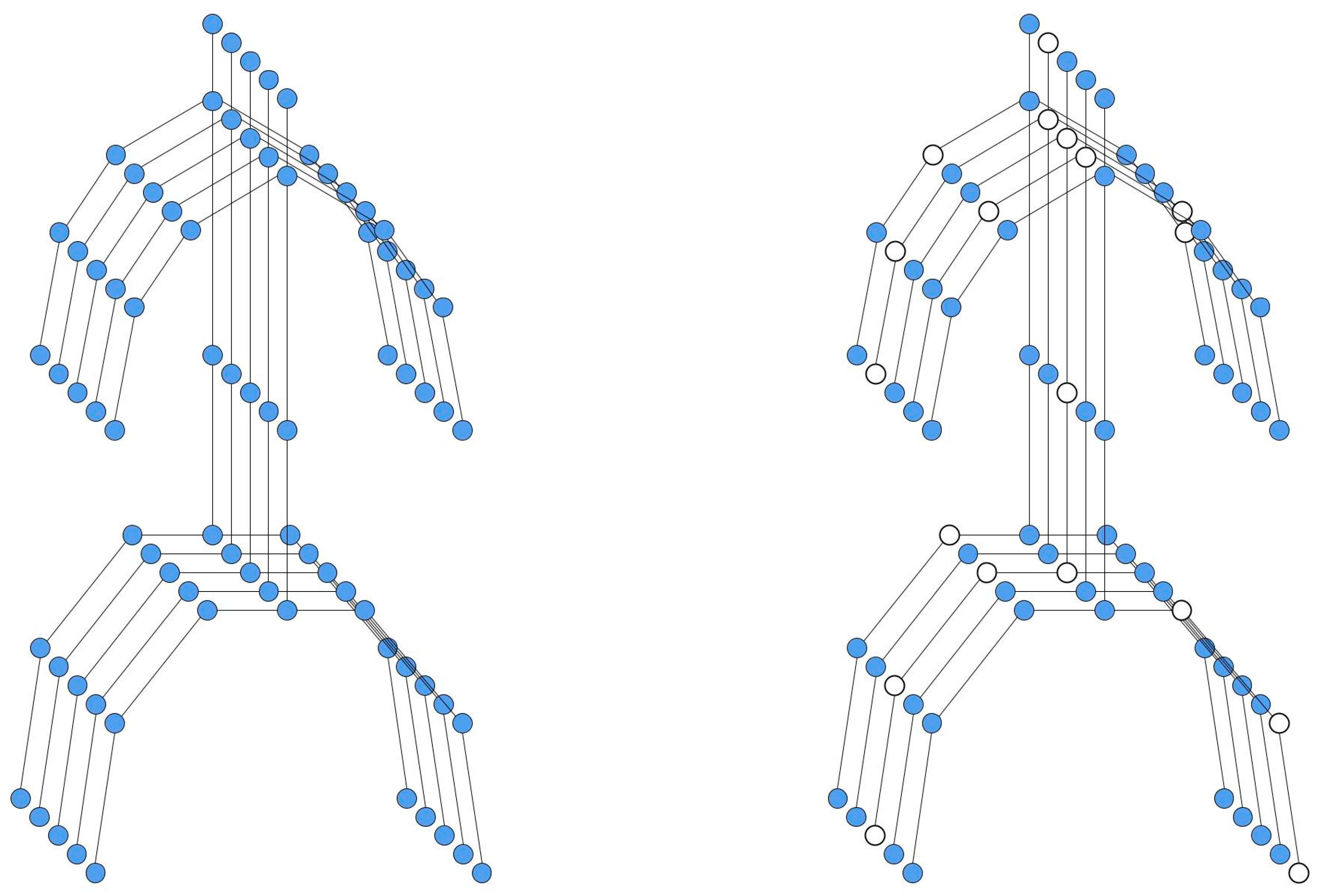
- We extend the cutout data augmentation technique to skeleton-based HAR datasets to simulate partial occlusions and missing data in joint positions, thereby improving model robustness.
- We empirically demonstrate that integrating these techniques with attention-based models and Graph Neural Networks generally improves performance and accuracy across various HAR datasets.
2. Background Literature
3. Methodology
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gupta, S. Deep Learning Based Human Activity Recognition (HAR) Using Wearable Sensor Data. Int. J. Inf. Manag. Data Insights 2021, 1, 100046. [Google Scholar] [CrossRef]
- Kumar, P.; Chauhan, S.; Awasthi, L.K. Human Activity Recognition (HAR) Using Deep Learning: Review, Methodologies, Progress and Future Research Directions. Arch. Comput. Methods Eng. 2024, 31, 179–219. [Google Scholar] [CrossRef]
- Younesi, A.; Ansari, M.; Fazli, M.; Ejlali, A.; Shafique, M.; Henkel, J. A Comprehensive Survey of Convolutions in Deep Learning: Applications, Challenges, and Future Trends. IEEE Access 2024, 12, 41180–41218. [Google Scholar] [CrossRef]
- Bibbò, L.; Vellasco, M.M. Activity Recognition (HAR) in Healthcare. Appl. Sci. 2023, 24, 13009. [Google Scholar] [CrossRef]
- Ohashi, H.; Al-Naser, M.; Ahmed, S.; Akiyama, T.; Sato, T.; Nguyen, P.; Nakamura, K.; Dengel, A. Augmenting Wearable Sensor Data with Physical Constraint for DNN-Based Human-Action Recognition. In Proceedings of the ICML 2017 Times Series Workshop, Sydney, Australia, 6–11 August 2017; pp. 6–17. [Google Scholar]
- Fridriksdottir, E.; Bonomi, A.G. Accelerometer-Based Human Activity Recognition for Patient Monitoring Using a Deep Neural Network. Sensors 2020, 20, 6424. [Google Scholar] [CrossRef]
- Cuperman, R.; Jansen, K.; Ciszewski, M. An End-to-End Deep Learning Pipeline for Football Activity Recognition Based on Wearable Acceleration Sensors. Sensors 2022, 22, 1347. [Google Scholar] [CrossRef]
- Echeverria, J.; Santos, O.C. Toward Modeling Psychomotor Performance in Karate Combats Using Computer Vision Pose Estimation. Sensors 2021, 21, 8378. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Zhan, A.; Wu, C. Fall Detection with CNN-Casual LSTM Network. Information 2021, 12, 403. [Google Scholar] [CrossRef]
- Fan, J.; Bi, S.; Wang, G.; Zhang, L.; Sun, S. Sensor Fusion Basketball Shooting Posture Recognition System Based on CNN. J. Sens. 2021, 2021, 6664776. [Google Scholar] [CrossRef]
- Adel, B.; Badran, A.; Elshami, N.E.; Salah, A.; Fathalla, A.; Bekhit, M. A Survey on Deep Learning Architectures in Human Activities Recognition Application in Sports Science, Healthcare, and Security. In Proceedings of the ICR’22 International Conference on Innovations in Computing Research, Athens, Greece, 29–31 August 2022; Daimi, K., Al Sadoon, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 121–134. [Google Scholar]
- Rashid, N.; Demirel, B.U.; Faruque, M.A.A. AHAR: Adaptive CNN for Energy-Efficient Human Activity Recognition in Low-Power Edge Devices. IEEE Internet Things J. 2022, 9, 13041–13051. [Google Scholar] [CrossRef]
- Das, D.; Nishimura, Y.; Vivek, R.P.; Takeda, N.; Fish, S.T.; Plötz, T.; Chernova, S. Explainable Activity Recognition for Smart Home Systems. ACM Trans. Interact. Intell. Syst. 2023, 13, 1–39. [Google Scholar] [CrossRef]
- Najeh, H.; Lohr, C.; Leduc, B. Real-Time Human Activity Recognition in Smart Home on Embedded Equipment: New Challenges. In Proceedings of the Participative Urban Health and Healthy Aging in the Age of AI: 19th International Conference, ICOST 2022, Paris, France, 27–30 June 2022; Aloulou, H., Abdulrazak, B., de Marassé-Enouf, A., Mokhtari, M., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 125–138. [Google Scholar]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors 2021, 21, 6037. [Google Scholar] [CrossRef] [PubMed]
- Wastupranata, L.M.; Kong, S.G.; Wang, L. Deep Learning for Abnormal Human Behavior Detection in Surveillance Videos—A Survey. Electronics 2024, 13, 2579. [Google Scholar] [CrossRef]
- Maeda, S.; Gu, C.; Yu, J.; Tokai, S.; Gao, S.; Zhang, C. Frequency-Guided Multi-Level Human Action Anomaly Detection with Normalizing Flows. arXiv 2024, arXiv:2404.17381. [Google Scholar]
- Shen, J.; De Lange, M.; Xu, X.O.; Zhou, E.; Tan, R.; Suda, N.; Lazarewicz, M.; Kristensson, P.O.; Karlson, A.; Strasnick, E. Towards Open-World Gesture Recognition. arXiv 2024, arXiv:2401.11144. [Google Scholar]
- Sabbella, S.R.; Kaszuba, S.; Leotta, F.; Serrarens, P.; Nardi, D. Evaluating Gesture Recognition in Virtual Reality. arXiv 2024, arXiv:2401.04545. [Google Scholar]
- Challa, S.K.; Kumar, A.; Semwal, V.B. A Multibranch CNN-BiLSTM Model for Human Activity Recognition Using Wearable Sensor Data. Vis. Comput. 2022, 38, 4095–4109. [Google Scholar] [CrossRef]
- Betancourt, C.; Chen, W.-H.; Kuan, C.-W. Self-Attention Networks for Human Activity Recognition Using Wearable Devices. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 1194–1199. [Google Scholar]
- Ek, S.; Portet, F.; Lalanda, P. Lightweight Transformers for Human Activity Recognition on Mobile Devices. arXiv 2022, arXiv:2209.11750. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A.; Youplao, P.; Yupapin, P. Enhanced Hand-Oriented Activity Recognition Based on Smartwatch Sensor Data Using LSTMs. Symmetry 2020, 12, 1570. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Hybrid Convolution Neural Network with Channel Attention Mechanism for Sensor-Based Human Activity Recognition. Sci. Rep. 2023, 13, 12067. [Google Scholar] [CrossRef]
- Kashyap, S.K.; Mahalle, P.N.; Shinde, G.R. Human Activity Recognition Using 1-Dimensional CNN and Comparison with LSTM. In Sustainable Technology and Advanced Computing in Electrical Engineering; Mahajan, V., Chowdhury, A., Padhy, N.P., Lezama, F., Eds.; Springer Nature: Singapore, 2022; pp. 1017–1030. [Google Scholar]
- Krishna, K.S.; Paneerselvam, S. An Implementation of Hybrid CNN-LSTM Model for Human Activity Recognition. In Proceedings of the Advances in Electrical and Computer Technologies, Tamil Nadu, India, 1–2 October 2021; Sengodan, T., Murugappan, M., Misra, S., Eds.; Springer Nature: Singapore, 2022; pp. 813–825. [Google Scholar]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in Time Series: A Survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- Genet, R.; Inzirillo, H. A Temporal Kolmogorov-Arnold Transformer for Time Series Forecasting. arXiv 2024, arXiv:2406.02486. [Google Scholar]
- Charabi, I.; Abidine, M.B.; Fergani, B. A Novel CNN-SVM Hybrid Model for Human Activity Recognition. In Proceedings of the IoT-Enabled Energy Efficiency Assessment of Renewable Energy Systems and Micro-Grids in Smart Cities, Tipasa, Algeria, 26–28 November 2023; Hatti, M., Ed.; Springer Nature: Cham, Switzerland, 2024; pp. 265–273. [Google Scholar]
- Ghosh, P.; Saini, N.; Davis, L.S.; Shrivastava, A. All About Knowledge Graphs for Actions. arXiv 2020, arXiv:2008.12432. [Google Scholar]
- Hu, L.; Liu, S.; Feng, W. Spatial Temporal Graph Attention Network for Skeleton-Based Action Recognition. arXiv 2022, arXiv:2208.08599. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A New Model for Learning in Graph Domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, 2005, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Ahmad, T.; Jin, L.; Zhang, X.; Lai, S.; Tang, G.; Lin, L. Graph Convolutional Neural Network for Human Action Recognition: A Comprehensive Survey. IEEE Trans. Artif. Intell. 2021, 2, 128–145. [Google Scholar] [CrossRef]
- Wu, W.; Tu, F.; Niu, M.; Yue, Z.; Liu, L.; Wei, S.; Li, X.; Hu, Y.; Yin, S. STAR: An STGCN ARchitecture for Skeleton-Based Human Action Recognition. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 70, 2370–2383. [Google Scholar] [CrossRef]
- Han, H.; Zeng, H.; Kuang, L.; Han, X.; Xue, H. A Human Activity Recognition Method Based on Vision Transformer. Sci. Rep. 2024, 14, 15310. [Google Scholar] [CrossRef]
- Ju, W.; Yi, S.; Wang, Y.; Xiao, Z.; Mao, Z.; Li, H.; Gu, Y.; Qin, Y.; Yin, N.; Wang, S.; et al. A Survey of Graph Neural Networks in Real World: Imbalance, Noise, Privacy and OOD Challenges. arXiv 2024, arXiv:2403.04468. [Google Scholar]
- Arshad, M.H.; Bilal, M.; Gani, A. Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors 2022, 22, 6463. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, C.; Wang, Y.; Wang, P. Detection of Abnormal Behavior in Narrow Scene with Perspective Distortion. Mach. Vis. Appl. 2019, 30, 987–998. [Google Scholar] [CrossRef]
- Kwon, H.; Abowd, G.D.; Plötz, T. Handling Annotation Uncertainty in Human Activity Recognition. In Proceedings of the 2019 ACM International Symposium on Wearable Computers: Association for Computing Machinery, New York, NY, USA, 9 September 2019; pp. 109–117. [Google Scholar]
- Saini, R.; Kumar, P.; Roy, P.P.; Dogra, D.P. A Novel Framework of Continuous Human-Activity Recognition Using Kinect. Neurocomputing 2018, 311, 99–111. [Google Scholar] [CrossRef]
- Alafif, T.; Alzahrani, B.; Cao, Y.; Alotaibi, R.; Barnawi, A.; Chen, M. Generative Adversarial Network Based Abnormal Behavior Detection in Massive Crowd Videos: A Hajj Case Study. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 4077–4088. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, Z.; Soh, Y.C. A Novel Semisupervised Deep Learning Method for Human Activity Recognition. IEEE Trans. Ind. Inform. 2019, 15, 3821–3830. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Ferreira, P.J.S.; Cardoso, J.M.P.; Mendes-Moreira, J. kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning. Computers 2020, 9, 96. [Google Scholar] [CrossRef]
- Mohsen, S.; Elkaseer, A.; Scholz, S.G. Human Activity Recognition Using K-Nearest Neighbor Machine Learning Algorithm. In Proceedings of the Sustainable Design and Manufacturing, Split, Croatia, 15–17 September 2021; Scholz, S.G., Howlett, R.J., Setchi, R., Eds.; Springer: Singapore, 2022; pp. 304–313. [Google Scholar]
- Maswadi, K.; Ghani, N.A.; Hamid, S.; Rasheed, M.B. Human Activity Classification Using Decision Tree and Naïve Bayes Classifiers. Multimed. Tools Appl. 2021, 80, 21709–21726. [Google Scholar] [CrossRef]
- Khan, Z.N.; Ahmad, J. Attention Induced Multi-Head Convolutional Neural Network for Human Activity Recognition. Appl. Soft Comput. 2021, 110, 107671. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. User Identification Based on Human Activity Recognition Using Wearable Sensors: An Experiment Using Deep Learning Models. Electronics 2021, 10, 308. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar] [CrossRef]
- Zheng, Y.; Gao, C.; Chen, L.; Jin, D.; Li, Y. DGCN: Diversified Recommendation with Graph Convolutional Networks. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar]
- Mumuni, A.; Mumuni, F. Data Augmentation: A Comprehensive Survey of Modern Approaches. Array 2022, 16, 100258. [Google Scholar] [CrossRef]
- Lewy, D.; Mańdziuk, J. AttentionMix: Data Augmentation Method That Relies on BERT Attention Mechanism. arXiv 2023, arXiv:2309.11104. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Dirgová Luptáková, I.; Kubovčík, M.; Pospíchal, J. Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef]
- Abbas, S.; Alsubai, S.; Haque, M.I.U.; Sampedro, G.A.; Almadhor, A.; Hejaili, A.A.; Ivanochko, I. Active Machine Learning for Heterogeneity Activity Recognition Through Smartwatch Sensors. IEEE Access 2024, 12, 22595–22607. [Google Scholar] [CrossRef]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Protecting Sensory Data against Sensitive Inferences. In Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems, Porto, Portugal, 23–26 April 2018; pp. 1–6. [Google Scholar]
- Sonawane, M.; Dhayalkar, S.R.; Waje, S.; Markhelkar, S.; Wattamwar, A.; Shrawne, S.C. Human Activity Recognition Using Smartphones. arXiv 2024, arXiv:2404.02869. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H. On-Body Localization of Wearable Devices: An Investigation of Position-Aware Activity Recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. PYSKL: Towards Good Practices for Skeleton Action Recognition. In Proceedings of the MM’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.-Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2684–2701. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
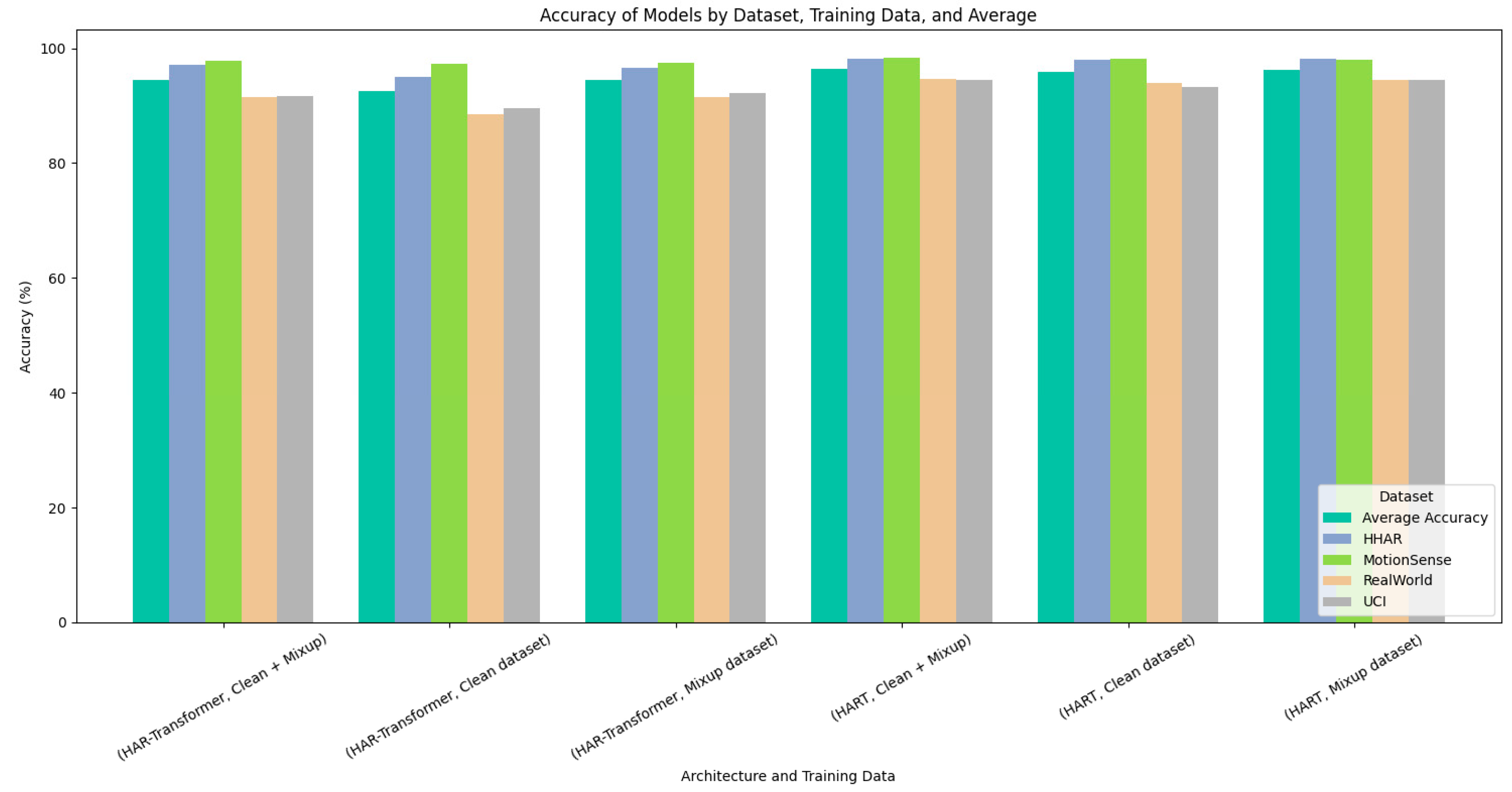
| Architecture | Training Data | HHAR | MotionSense | UCI | RealWorld | Average |
|---|---|---|---|---|---|---|
| HART [22] | Clean dataset | 98.01% | 98.17% | 93.32% | 93.94% | 95.86% |
| Mixup dataset | 98.15% | 97.98% | 94.50% | 94.54% | 96.29% | |
| Clean + Mixup | 98.22% | 98.30% | 94.44% | 94.66% | 96.41% | |
| HAR-Transformer [60] | Clean dataset | 94.99% | 97.33% | 89.62% | 88.57% | 92.63% |
| Mixup dataset | 96.53% | 97.40% | 92.26% | 91.49% | 94.42% | |
| Clean + Mixup | 97.04% | 97.91% | 91.75% | 91.52% | 94.56% |
| Dataset Configuration | NTU RGB + D | NTU RGB + D 120 | ||
|---|---|---|---|---|
| XSubject | XView | XSubject | XView | |
| STGCN [55] | 88.31% | 94.89% | 83.05% | 88.45% |
| STGCN with cutout | 88.50% | 95.48% | 83.25% | 88.30% |
| STGCN++ [65] | 88.02% | 94.93% | 84.35% | 88.64% |
| STGCN++ with cutout | 88.23% | 94.98% | 84.16% | 88.68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dingeto, H.; Kim, J. Exploring Cutout and Mixup for Robust Human Activity Recognition on Sensor and Skeleton Data. Appl. Sci. 2024, 14, 10286. https://doi.org/10.3390/app142210286
Dingeto H, Kim J. Exploring Cutout and Mixup for Robust Human Activity Recognition on Sensor and Skeleton Data. Applied Sciences. 2024; 14(22):10286. https://doi.org/10.3390/app142210286
Chicago/Turabian StyleDingeto, Hiskias, and Juntae Kim. 2024. "Exploring Cutout and Mixup for Robust Human Activity Recognition on Sensor and Skeleton Data" Applied Sciences 14, no. 22: 10286. https://doi.org/10.3390/app142210286
APA StyleDingeto, H., & Kim, J. (2024). Exploring Cutout and Mixup for Robust Human Activity Recognition on Sensor and Skeleton Data. Applied Sciences, 14(22), 10286. https://doi.org/10.3390/app142210286