
Application of Binary Image Quality Assessment Methods to Predict the Quality of Optical Character Recognition Results




Abstract
1. Introduction
2. Proposed Approach and Its Verification
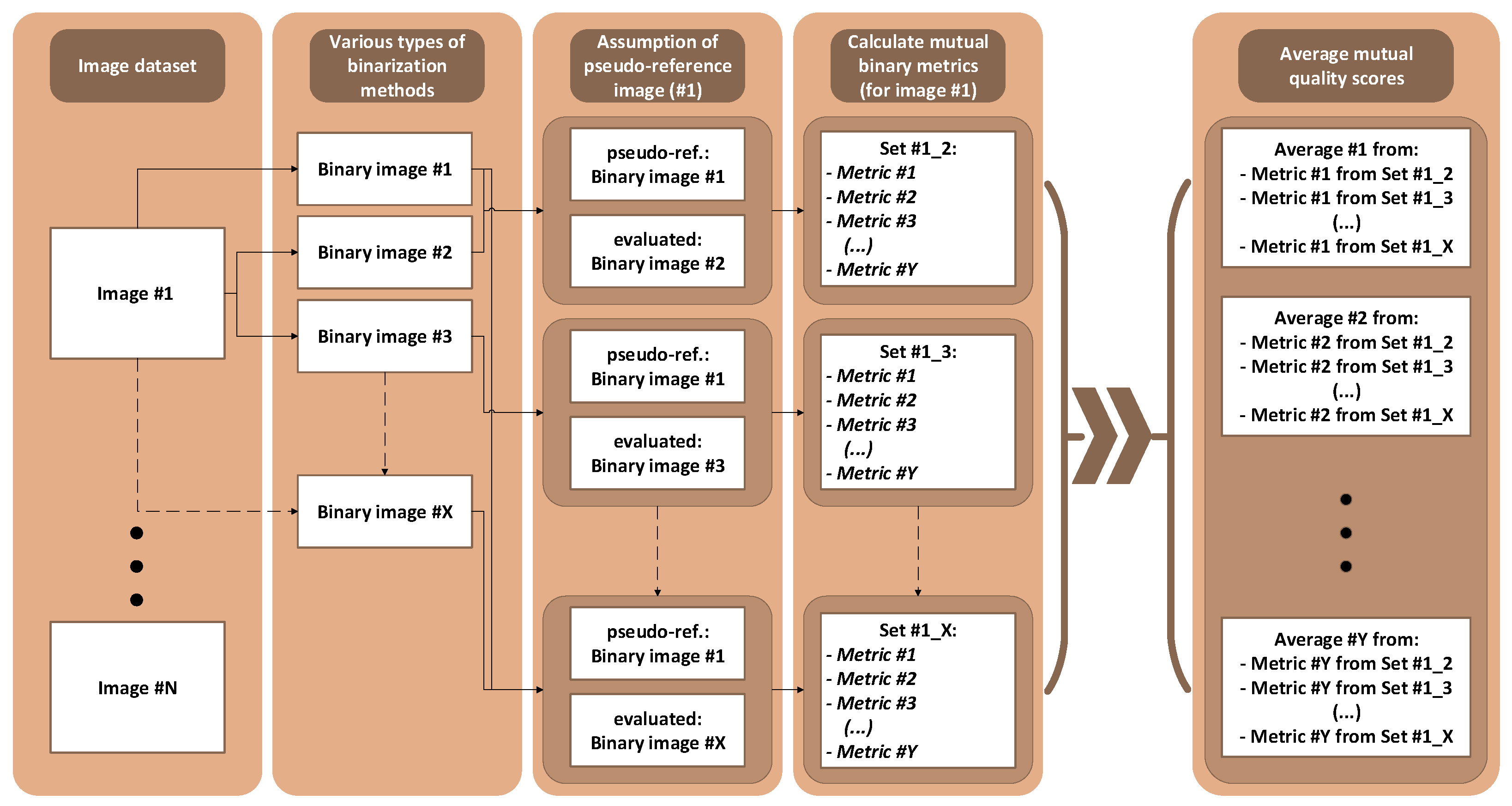
2.1. Mutual Similarity of Binary Images
2.2. Combined Metrics and Discussion of Results
3. Additional Experiments
4. Conclusions and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BCR | Balanced Classification Rate |
| BDPSNR | Border Distance Peak Signal-to-Noise Ratio |
| CISI | Combined Image Similarity Index |
| CM | Combined Metric |
| DRD | Distance Reciprocal Distortion |
| FR | Full Reference (metric) |
| FSIM | Feature Similarity |
| IQA | Image Quality Assessment |
| LD | Levenshtein Distance |
| MPM | Misclassification Penalty Metric |
| MS-SSIM | Multi-Scale Structural Similarity |
| NR | No Reference (metric) |
| OCR | Optical Character Recognition |
| PSNR | Peak Signal-to-Noise Ratio |
| RR | Reduced Reference (metric) |
| R-SVD | Referee Matrix Singular Value Decomposition |
| VIF | Visual Information Fidelity |
| VMAF | Video Multi-Method Assessment Fusion |
References
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Okarma, K.; Lech, P. A method supporting fault-tolerant optical text recognition from video sequences recorded with handheld cameras. Eng. Appl. Artif. Intell. 2023, 123, 106330. [Google Scholar] [CrossRef]
- Ho, J.; Liu, M. Research on Document Image Binarization: A Survey. In Proceedings of the 2024 IEEE 7th International Conference on Electronic Information and Communication Technology (ICEICT), Xi’an, China, 31 July–2 August 2024; pp. 457–462. [Google Scholar] [CrossRef]
- Polyakova, M.V.; Nesteryuk, A.G. Improvement of the color text image binarization method using the minimum-distance classifier. Appl. Asp. Inf. Technol. 2021, 4, 57–70. [Google Scholar] [CrossRef]
- Yang, Z.; Zuo, S.; Zhou, Y.; He, J.; Shi, J. A Review of Document Binarization: Main Techniques, New Challenges, and Trends. Electronics 2024, 13, 1394. [Google Scholar] [CrossRef]
- Kamble, V.; Bhurchandi, K. No-reference image quality assessment algorithms: A survey. Optik 2015, 126, 1090–1097. [Google Scholar] [CrossRef]
- Lu, H.; Kot, A.; Shi, Y. Distance-Reciprocal Distortion Measure for Binary Document Images. IEEE Signal Process. Lett. 2004, 11, 228–231. [Google Scholar] [CrossRef]
- Young, D.; Ferryman, J. PETS Metrics: On-Line Performance Evaluation Service. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 317–324. [Google Scholar] [CrossRef]
- Zhai, Y.; Neuhoff, D.L. Similarity of Scenic Bilevel Images. IEEE Trans. Image Process. 2016, 25, 5063–5076. [Google Scholar] [CrossRef]
- Zhang, F.; Cao, K.; Zhang, J.L. A simple quality evaluation method of binary images based on Border Distance. Optik 2011, 122, 1236–1239. [Google Scholar] [CrossRef]
- Michalak, H.; Okarma, K. Robust Combined Binarization Method of Non-Uniformly Illuminated Document Images for Alphanumerical Character Recognition. Sensors 2020, 20, 2914. [Google Scholar] [CrossRef]
- Bernsen, J. Dynamic Thresholding of Gray Level Image. In Proceedings of the ICPR’86 Proceedings of International Conference on Pattern Recognition, Paris, France, 27–31 October 1986; pp. 1251–1255. [Google Scholar]
- Bradley, D.; Roth, G. Adaptive Thresholding using the Integral Image. J. Graph. Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Feng, M.L.; Tan, Y.P. Contrast adaptive binarization of low quality document images. IEICE Electron. Express 2004, 1, 501–506. [Google Scholar] [CrossRef]
- Khurshid, K.; Siddiqi, I.; Faure, C.; Vincent, N. Comparison of Niblack inspired binarization methods for ancient documents. In Document Recognition and Retrieval XVI; SPIE: Bellingham, WA, USA, 2009; Volume 7247, p. 72470U. [Google Scholar] [CrossRef]
- Niblack, W. An Introduction to Digital Image Processing; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1990. [Google Scholar]
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Wolf, C.; Jolion, J.M. Extraction and recognition of artificial text in multimedia documents. Form. Pattern Anal. Appl. 2004, 6. [Google Scholar] [CrossRef]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. Performance Evaluation Methodology for Historical Document Image Binarization. IEEE Trans. Image Process. 2013, 22, 595–609. [Google Scholar] [CrossRef] [PubMed]
- Okarma, K.; Kopytek, M. A Hybrid Method for Objective Quality Assessment of Binary Images. IEEE Access 2023, 11, 63388–63397. [Google Scholar] [CrossRef]
- Okarma, K. Combined image similarity index. Opt. Rev. 2012, 19, 349–354. [Google Scholar] [CrossRef]
- Rassool, R. VMAF reproducibility: Validating a perceptual practical video quality metric. In Proceedings of the 2017 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Cagliari, Italy, 7–9 June 2017. [Google Scholar] [CrossRef]
- Okarma, K.; Lech, P.; Lukin, V.V. Combined Full-Reference Image Quality Metrics for Objective Assessment of Multiply Distorted Images. Electronics 2021, 10, 2256. [Google Scholar] [CrossRef]
- Lukin, V.V.; Ponomarenko, N.N.; Ieremeiev, O.I.; Egiazarian, K.O.; Astola, J. Combining full-reference image visual quality metrics by neural network. In Human Vision and Electronic Imaging XX; Rogowitz, B.E., Pappas, T.N., de Ridder, H., Eds.; SPIE: Bellingham, WA, USA, 2015; Volume 9394, p. 93940K. [Google Scholar] [CrossRef]
- Gatos, B.; Pratikakis, I.; Perantonis, S. Adaptive degraded document image binarization. Pattern Recognit. 2006, 39, 317–327. [Google Scholar] [CrossRef]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K. An adaptive local binarization method for document images based on a novel thresholding method and dynamic windows. Pattern Recognit. Lett. 2011, 32, 1805–1813. [Google Scholar] [CrossRef]
- Singh, T.R.; Roy, S.; Singh, O.I.; Sinam, T.; Singh, K.M. A New Local Adaptive Thresholding Technique in Binarization. IJCSI Int. J. Comput. Sci. Issues 2011, 8, 271–277. [Google Scholar]
- Su, B.; Lu, S.; Tan, C.L. Robust document image binarization technique for degraded document images. IEEE Trans. Image Process. 2013, 22, 1408–1417. [Google Scholar] [CrossRef] [PubMed]
- Mustafa, W.A.; Abdul Kader, M.M.M. Binarization of Document Image Using Optimum Threshold Modification. J. Phys. Conf. Ser. 2018, 1019, 012022. [Google Scholar] [CrossRef]
- Hadjadj, Z.; Meziane, A.; Cherfa, Y.; Cheriet, M.; Setitra, I. ISauvola: Improved Sauvola’s Algorithm for Document Image Binarization. In Image Analysis and Recognition; Campilho, A., Karray, F., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9730, LNCS; pp. 737–745. [Google Scholar] [CrossRef]
- Nayef, N.; Luqman, M.M.; Prum, S.; Eskenazi, S.; Chazalon, J.; Ogier, J.M. SmartDoc-QA: A dataset for quality assessment of smartphone captured document images - single and multiple distortions. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR). Institute of Electrical and Electronics Engineers (IEEE), Tunis, Tunisia, 23–26 August 2015. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quality Metric | PLCC for Tesseract |
|---|---|
| Precision | 0.5594 |
| Recall/Sensitivity | 0.1003 |
| F-Measure | 0.8460 |
| Pseudo-Precision | 0.5972 |
| Pseudo-Recall | 0.1127 |
| Pseudo-F-Measure | 0.8810 |
| Specificity | 0.2957 |
| Balanced Classification Rate (BCR) | 0.1397 |
| S-F-Measure | 0.2019 |
| Accuracy | 0.2590 |
| Geometric Accuracy | 0.2165 |
| Peak Signal-to-Noise Ratio (PSNR) | 0.2543 |
| Border Distance (chessboard) [10] | 0.2939 |
| Border Distance (city block) [10] | 0.2805 |
| Border Distance (Euclidean) [10] | 0.2932 |
| Distance Reciprocal Distortion (DRD) [7] | 0.3662 |
| Misclassification Penalty Metric (MPM) [8] | 0.1928 |
| Metric | PLCC | |||||||
|---|---|---|---|---|---|---|---|---|
| CM1 | 0.8960 | − | − | − | − | − | ||
| CM2 | 0.9077 | − | − | − | ||||
| CM3 | 0.9085 |
| OCR Engine | Tesseract | EasyOCR | ||
|---|---|---|---|---|
| Quality Metric | Nokia | Samsung | Nokia | Samsung |
| Precision | 0.2275 | 0.2966 | 0.2697 | 0.3151 |
| Recall/Sensitivity | 0.3539 | 0.3286 | 0.4111 | 0.4385 |
| F-Measure | 0.4811 | 0.4569 | 0.5480 | 0.5490 |
| Pseudo-Precision | 0.3571 | 0.1585 | 0.3814 | 0.1935 |
| Pseudo-Recall | 0.2293 | 0.2914 | 0.2719 | 0.3922 |
| Pseudo-F-Measure | 0.4523 | 0.4865 | 0.5170 | 0.5756 |
| Specificity | 0.3402 | 0.4343 | 0.3634 | 0.4932 |
| Balanced Classification Rate (BCR) | 0.3829 | 0.2832 | 0.4476 | 0.3857 |
| S-F-Measure | 0.4272 | 0.3829 | 0.4835 | 0.4832 |
| Accuracy | 0.4789 | 0.3729 | 0.5073 | 0.4021 |
| Geometric Accuracy | 0.4169 | 0.3807 | 0.4737 | 0.4761 |
| Peak Signal-to-Noise Ratio (PSNR) | 0.2336 | 0.3603 | 0.2580 | 0.3559 |
| Border Distance (chessboard) [10] | 0.2129 | 0.3253 | 0.2386 | 0.3191 |
| Border Distance (city-block) [10] | 0.2130 | 0.3273 | 0.2395 | 0.3197 |
| Border Distance (Euclidean) [10] | 0.2134 | 0.3254 | 0.2391 | 0.3190 |
| Distance Reciprocal Distortion (DRD) [7] | 0.4536 | 0.3534 | 0.4878 | 0.3782 |
| Misclassification Penalty Metric (MPM) [8] | 0.0655 | 0.1453 | 0.0748 | 0.1264 |
| OCR Engine | Tesseract | EasyOCR | ||
|---|---|---|---|---|
| Quality Metric | Nokia | Samsung | Nokia | Samsung |
| 0.4839 | 0.5002 | 0.5569 | 0.6002 | |
| 0.4855 | 0.5003 | 0.5669 | 0.5996 | |
| 0.4892 | 0.5005 | 0.5734 | 0.6037 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopytek, M.; Lech, P.; Okarma, K. Application of Binary Image Quality Assessment Methods to Predict the Quality of Optical Character Recognition Results. Appl. Sci. 2024, 14, 10275. https://doi.org/10.3390/app142210275
Kopytek M, Lech P, Okarma K. Application of Binary Image Quality Assessment Methods to Predict the Quality of Optical Character Recognition Results. Applied Sciences. 2024; 14(22):10275. https://doi.org/10.3390/app142210275
Chicago/Turabian StyleKopytek, Mateusz, Piotr Lech, and Krzysztof Okarma. 2024. "Application of Binary Image Quality Assessment Methods to Predict the Quality of Optical Character Recognition Results" Applied Sciences 14, no. 22: 10275. https://doi.org/10.3390/app142210275
APA StyleKopytek, M., Lech, P., & Okarma, K. (2024). Application of Binary Image Quality Assessment Methods to Predict the Quality of Optical Character Recognition Results. Applied Sciences, 14(22), 10275. https://doi.org/10.3390/app142210275