
A Generator for Recursive Zip Files


Abstract
1. Introduction
2. Materials and Methods
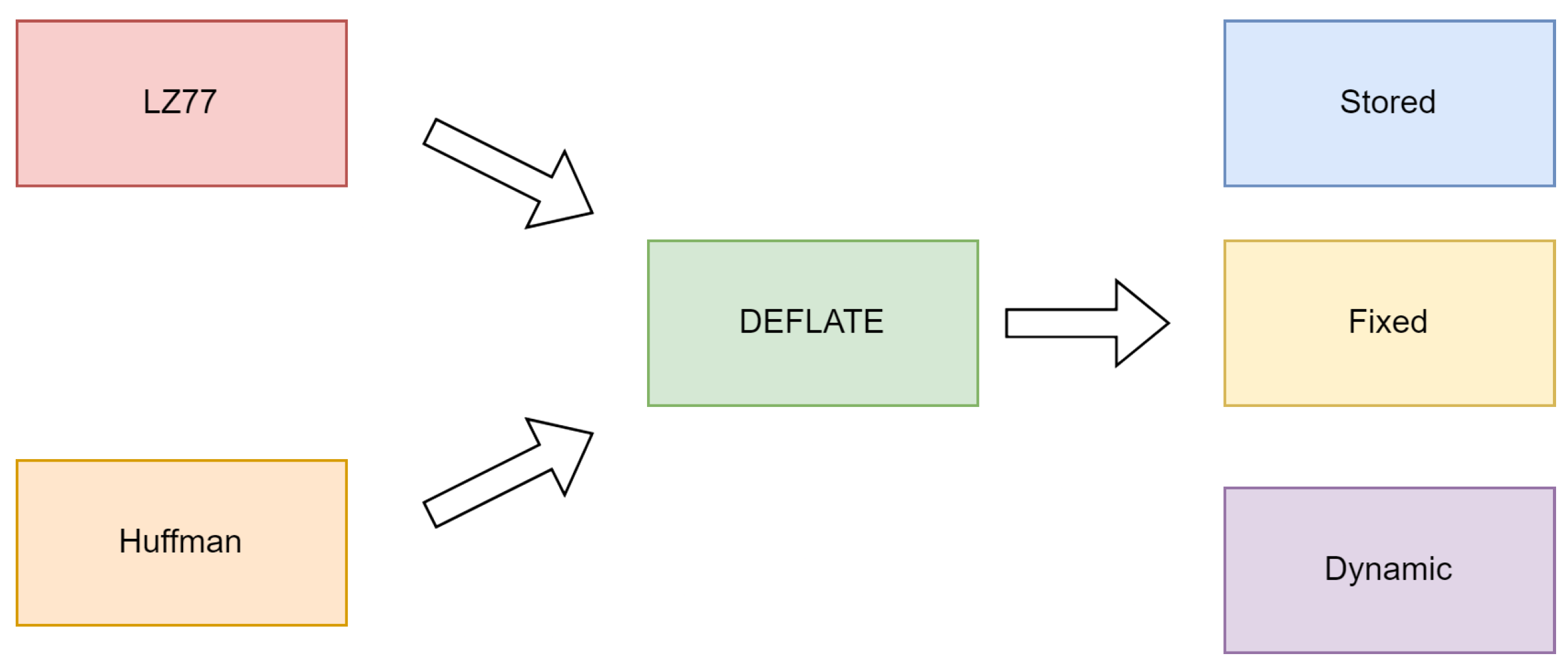
2.1. DEFLATE
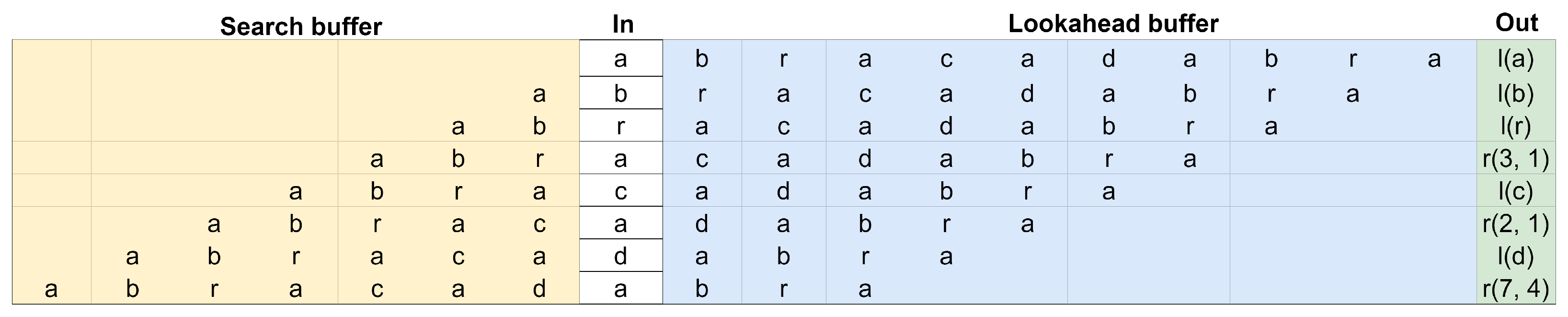
2.1.1. LZ77
- Literal tokens, denoted as , indicate that x is a direct output without modification.
- Repeat tokens, on the other hand, represent recurring sequences. These require two values: y and z. The value y specifies how far back in the output to look (i.e., how many bytes to “backtrack”), while z indicates the length of the sequence to copy from the previous position. Essentially, the repeat token instructs the algorithm to go back y bytes and copy z bytes of data to the current position, which saves space by avoiding redundancy.
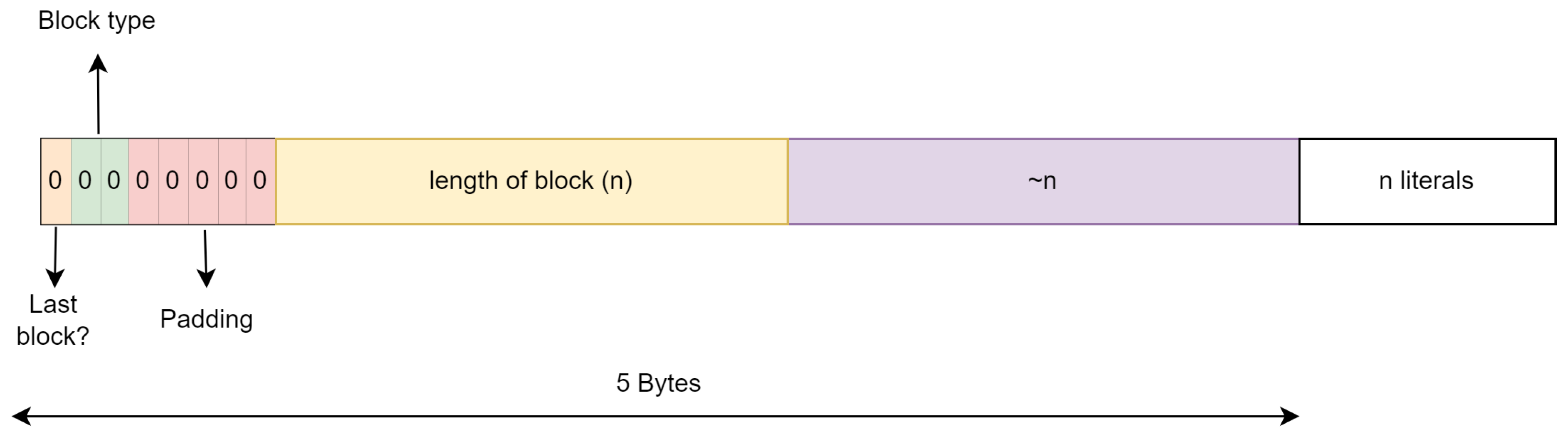
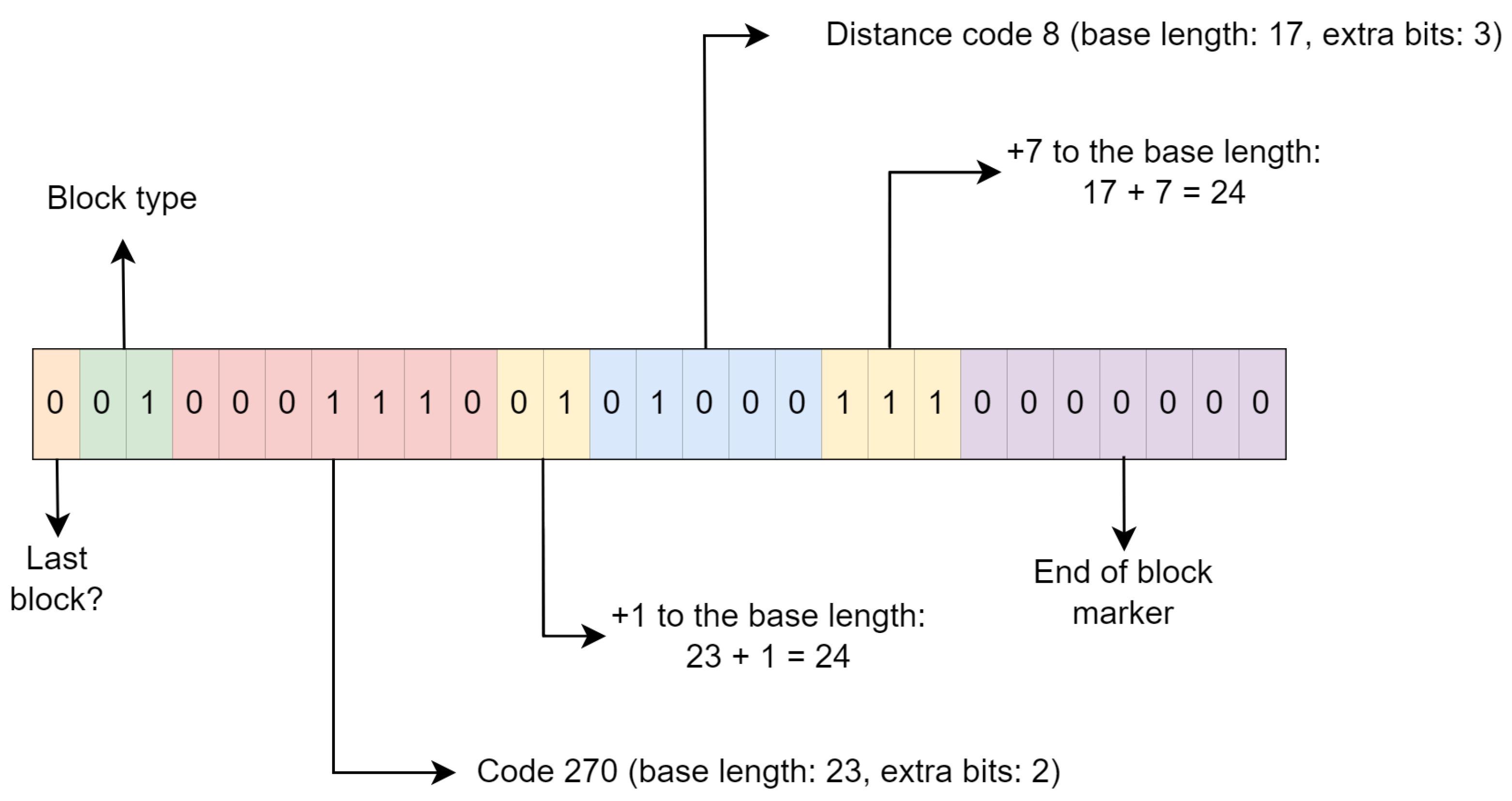
2.1.2. Huffman
- 0 to 255: These codes are assigned to literal tokens.
- 256: This code indicates the end of the fixed Huffman block, signaled by the seven 0 bits previously mentioned.
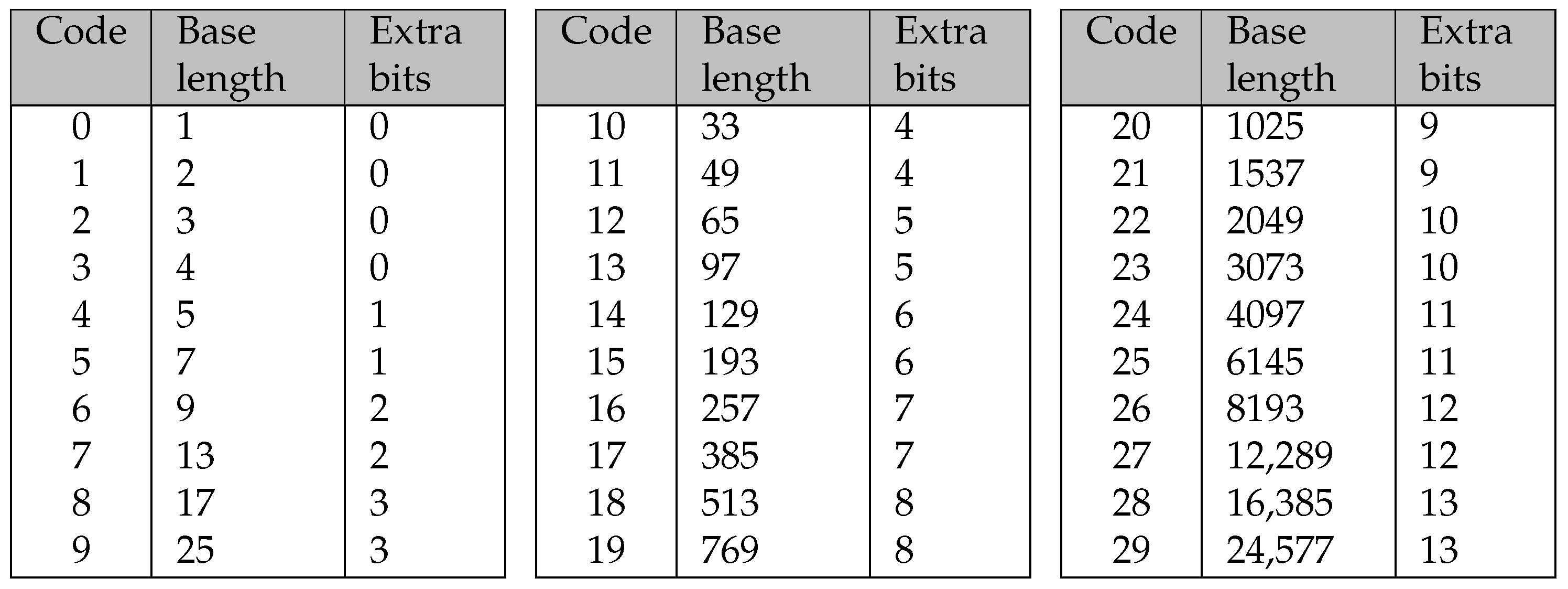
- 257 to 285: These codes represent repeat tokens, specifically the length of the repetition. Additional bits are used depending on the repeat token’s length.
- 286 and 287: Although codes 286 and 287 can be represented within this format, they do not appear in the compressed data. These codes are unused but are part of the overall code design.
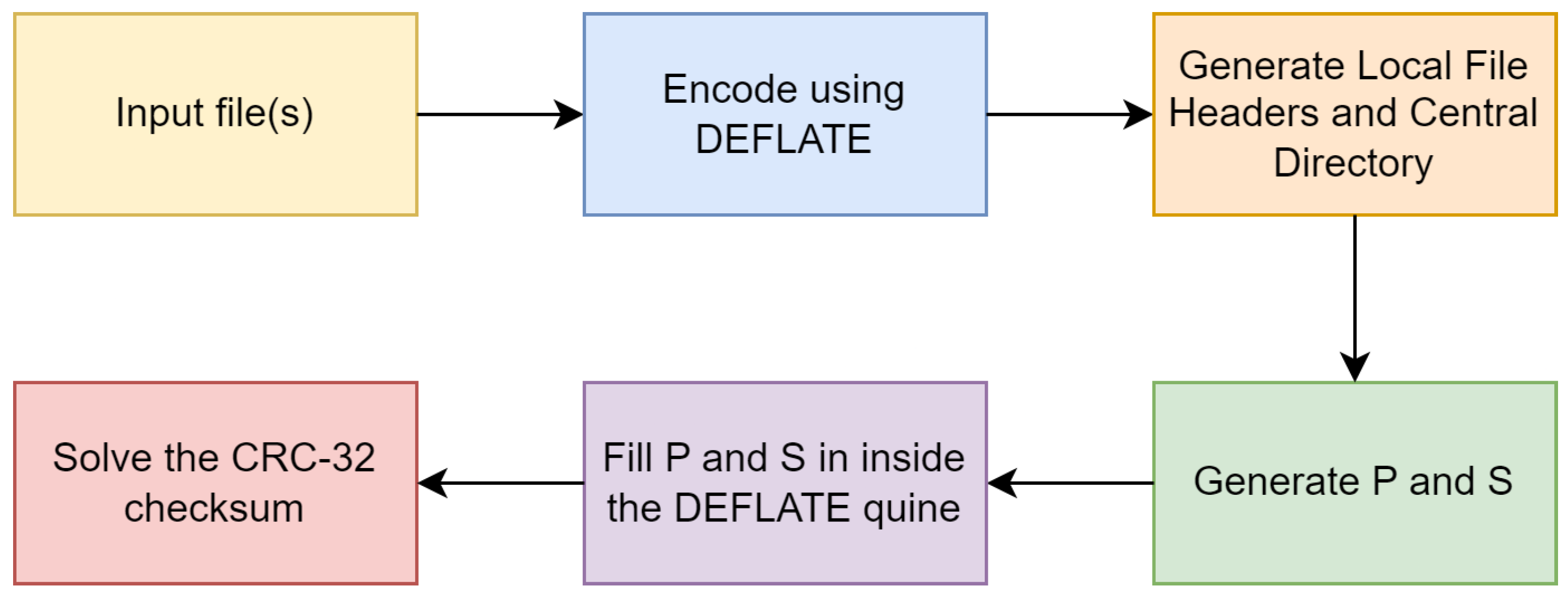
2.2. Limited Zip Quine
Limitations
3. Results
3.1. Beyond the Limitations
Limitations of the Adapted Quine
3.2. Loopy Zip Files
3.2.1. CRC-32
| Listing 1. Reset CRC-32. |
 |
| Listing 2. Calculate CRC-32 checksums. |
 |
3.2.2. Limitations of Loopy Zip Files
3.3. The Generator
4. Discussion
4.1. Advancements
4.2. Applications
4.3. Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CRC | Cyclic Redundancy Check |
| CD | Central Directory |
| CDFH | Central Directory File Header |
| EOCDR | End of Central Directory Record |
Appendix A
Appendix A.1. Local File Header

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0x00 | 0x01 | 0x02 | 0x03 | 0x04 | 0x05 | 0x06 | 0x07 | 0x08 | 0x09 | 0x0A | 0x0B | 0x0C | 0x0D | 0x0E | 0x0F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Signature | Version | Flags | Method | Mod Time | Mod Date | CRC-32 | |||||||||
| CRC-32 | Compressed Size | Uncompressed Size | Name Len. | Extra Len. | Name | ||||||||||
| Name (variable length) | |||||||||||||||
| Extra Fields (variable length) | |||||||||||||||
- Signature: A 4-byte signature that indicates that the file is a Local File Header. This is represented by the bytes ‘0x504b0304’.
- Version: The version of the compression format used for the file. In the implementation of this work, the bytes ‘0x1400’ are used, which correspond to the decimal value 20 (in little endian), representing version 2.0 of the zip format.
- Flags: A series of bits that indicate various properties of the file, such as whether it is encrypted. For the creation of recursive zip files, this is not necessary, and two zero bytes are used.
- Method: The compression method used for the file. The zip format supports various methods, such as store (no compression) or DEFLATE (standard compression for ZIP files). In this work, the standard algorithm used for zip archives is applied, as not every method is suitable for creating a quine. This method is indicated by ‘0x0800’.
- Modification Time: The hour, minute, and second of the last modification to the file. The first 5 bits represent the hour, followed by 6 bits for the minutes, and the last 5 bits for the seconds. According to the specification, the seconds must be divided by two before encoding and multiplied by two during decoding.Example: ‘0x7d1c’ = 0111110100011100
- Hour: (01111)10100011100 = 15
- Minutes: 01111(101000)11100 = 40
- Seconds: 01111101000(11100) = 28 ⇒ 56 s
- Modification Date: The day, month, and year of the last modification to the file. The first 7 bits are used to represent the year, counting from 1980. Therefore, the year 2024 is represented as 44. The next 4 bits are used for the month, and the last 5 bits are for the day.Example: ‘0x5871’ = 0101100001110001
- Year: (0101100)001110001 = 44 ⇒ 2024
- Month: 0101100(0011)10001 = 3
- Day: 01011000011(10001) = 17
- CRC-32: A 4-byte cyclic redundancy check (CRC) value used to verify the integrity of the file [9]. The checksum is calculated before compression. When the file is later decompressed, the checksum can be recalculated. By comparing the two, the integrity of the file can be verified.
- Compressed Size: The size of the compressed file, represented in 4 bytes. This indicates the file’s size after compression by the chosen method.
- Uncompressed Size: The size of the uncompressed file, represented in 4 bytes. This indicates the file’s size before compression. When the file is decompressed, its size should match this value.
- Name Length: The size of the file name in bytes, which corresponds to the number of characters in the file name, including the extension.
- Extra Length: The size of any additional fields appended to the file.
- Name: The actual file name, with a length corresponding to the previously stored value.
- Extra Fields: Any additional fields, with a length corresponding to the previously stored value.
Appendix A.2. Central Directory File Header
| 0x00 | 0x01 | 0x02 | 0x03 | 0x04 | 0x05 | 0x06 | 0x07 | 0x08 | 0x09 | 0x0A | 0x0B | 0x0C | 0x0D | 0x0E | 0x0F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Signature | Version | Min. Version | Flags | Method | Mod Time | Mod Date | |||||||||
| CRC-32 | Compressed Size | Uncompressed Size | Name Len. | Extra Len. | |||||||||||
| Comm. Len. | Disk #1 | Int. Attr. | External Attr. | Local File Header Offset | Name | ||||||||||
| Name (variable length) | |||||||||||||||
| Extra Fields (variable length) | |||||||||||||||
| Comment (variable length) | |||||||||||||||
- Signature: A 4-byte signature indicating that the file is a Central Directory File Header. This is represented by the bytes ‘0x504b0102’.
- Minimum Version: The minimum version of the software required to decompress the zip file. The value of this field usually matches the version specified in the Local File Header.
- Comment Length: The length of the comment added to the compressed file.
- Disk Number: The number of the disk on which the file is located. This field originates from the time when zip files were distributed across multiple physical disks. Larger files could not be stored on a single floppy disk, so the zip specification provided a solution by allowing a zip archive to be split across multiple disks. This disk number indicates on which disk the Local File Header of the encoded file is located.
- Internal Attributes: Internal attributes of the file. These are rarely used and will be represented by four zero bytes.
- External Attributes: External attributes of the file. These are also rarely used and will be represented by four zero bytes.
- Local File Header Offset: The position (offset) of the corresponding Local File Header within the zip archive. This indicates where the Local File Header begins, followed by the compressed data.
- Comment: An optional comment or note for the file, with a length equal to the previously specified value.
Appendix A.3. End of Central Directory Record
| 0x00 | 0x01 | 0x02 | 0x03 | 0x04 | 0x05 | 0x06 | 0x07 | 0x08 | 0x09 | 0x0A | 0x0B | 0x0C | 0x0D | 0x0E | 0x0F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Signature | Disk #1 | Disk # CD | Disk Entries | Total Entries | Central Directory Size | ||||||||||
| Offset of CD | Comm. Len | Zip file comment (variable length) | |||||||||||||
- Signature: A 4-byte signature indicating that the file is an End of Central Directory Record (EOCDR). This is represented by the bytes ’0x504b0506’.
- Disk Number: The number of the disk on which the EOCDR is located.
- Disk Number CD: The number of the disk where the Central Directory File Headers (CDFHs) begin.
- Disk Entries: The number of CDFHs on the disk where the EOCDR is located.
- Total Entries: The total number of CDFHs across all disks.
- Central Directory Size: The size of the Central Directory (CD) in bytes.
- Central Directory Offset: The position where the Central Directory begins. For a zip file spanning multiple disks, this indicates the position on the disk where the Central Directory starts.
- Comment Length: The length of the comment associated with the zip file.
- Zip File Comment: The comment itself, with a length equal to the previously specified value.
References
- Hofstadter, D.R. Gödel, Escher, Bach: An Eternal Golden Braid; Basic Books: New York, NY, USA, 1980. [Google Scholar]
- Cox, R. Zip Files All The Way Down. Available online: https://research.swtch.com/zip (accessed on 1 September 2024).
- Ellingsen, E. Zip Quine. Available online: https://alf.nu/ZipQuine (accessed on 1 September 2024).
- ZIP File Format Specification. Available online: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT (accessed on 1 September 2024).
- Deutsch, L.P. DEFLATE Compressed Data Format Specification version 1.3. Req. Comments 1996, RFC 1951. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Huffman, D.A. A Method for the Construction of Minimum-Redundancy Codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Storer, J.A.; Szymanski, T.G. Data Compression via Textual Substitution. J. ACM 1982, 29, 928–951. [Google Scholar] [CrossRef]
- Peterson, W.W.; Brown, D.T. Cyclic Codes for Error Detection. Proc. IRE 1961, 49, 228–235. [Google Scholar] [CrossRef]
- Quine: Java-C++. Available online: https://web.stanford.edu/class/cs208e/cgi-bin/main.cgi/static/lectures/18-ReflectionsOnTrustingTrust/code/Quine.java (accessed on 1 September 2024).
- Quine: C++-Java. Available online: https://web.stanford.edu/class/cs208e/cgi-bin/main.cgi/static/lectures/18-ReflectionsOnTrustingTrust/code/Quine.cpp (accessed on 1 September 2024).
- Stigge, M.; Plötz, H.; Müller, W.; Redlich, J.-P. Reversing CRC: Theory and Practice. Available online: https://api.semanticscholar.org/CorpusID:17886305 (accessed on 1 September 2024).
- Adler, M. Append calculated CRC to data and recalculate does not yield zero. Electr. Eng. Stack Exch. 2019. Available online: https://electronics.stackexchange.com/questions/450297/append-calculated-crc-to-data-and-recalculate-does-not-yield-zero (accessed on 1 September 2024).
- Canet, M.; Kumar, A.; Lauradoux, C.; Rakotomanga, M.-A.; Safavi-Naini, R. Decompression Quines and Anti-Viruses. In Proceedings of the Seventh ACM Conference on Data and Application Security and Privacy (CODASPY ’17), New York, NY, USA, 22–24 March 2017; pp. 23–34. [Google Scholar] [CrossRef]
- Wani, M.A.; AlZahrani, A.; Bhat, W.A. File System Anti-Forensics—Types, Techniques and Tools. Comput. Fraud. Secur. 2020, 2020, 14–19. [Google Scholar] [CrossRef]
- Maxwell, B.; Thompson, D.R.; Amerson, G.; Johnson, L. Analysis of CRC Methods and Potential Data Integrity Exploits. In Proceedings of the International Conference on Emerging Technologies, Minneapolis, MN, USA, 25–26 August 2003; pp. 25–26. [Google Scholar]



| Local File Header 1 |
| File Data 1 |
| … |
| Local File Header n |
| File Data n |
| Central Directory File Header 1 |
| … |
| Central Directory File Header n |
| End of Central Directory Record |
| Codes | Number of Bits | Binary Representation |
|---|---|---|
| 0–143 | 8 bits | 00110000 to 10111111 |
| 144–255 | 9 bits | 110010000 to 111111111 |
| 256–279 | 7 bits | 0000000 to 0010111 |
| 280–287 | 8 bits | 11000000 to 11000111 |
| Code | Output |
|---|---|
| [P] | |
| Lp+1 [P] Lp+1 | [P] Lp+1 |
| Rp+1 | [P] Lp+1 |
| L1 Rp+1 | Rp+1 |
| L1 L1 | L1 |
| L4 Rp+1 L1 L1 L4 | Rp+1 L1 L1 L4 |
| R4 | Rp+1 L1 L1 L4 |
| L4 R4 L4 R4 L4 | R4 L4 R4 L4 |
| R4 | R4 L4 R4 L4 |
| L4 R4 L0 L0 Ls+1 | R4 L0 L0 Ls+1 |
| R4 | R4 L0 L0 Ls+1 |
| L0 | |
| L0 | |
| Ls+1 Rs+1 [S] | Rs+1 [S] |
| Rs+1 | Rs+1 [S] |
| [S] |
| Local File Header Quine → [P] |
| Encoded LZ77 Quine in DEFLATE |
| Central Directory → [S] |
| Code | Output |
|---|---|
| … | |
| R506 → size = 80 bits | … |
| L10 R506 | R506 |
| L5 L10 | L10 |
| L25 R506 L5 L10 L15 | R506 L5 L10 L25 |
| R25 → size = 32 ≤ 80 bits | R506 L5 L10 L25 |
| L4 R25 | R25 |
| L5 L4 | L4 |
| L19 R25 L5 L4 L19 | R25 L5 L4 L19 |
| R19 → repeat | R25 L5 L4 L19 |
| … | … |
| Code | Output |
|---|---|
| [P] | |
| Lp+5 [P] Lp+5 | [P] Lp+5 |
| Rp+5 → size = x | [P] Lp+5 |
| Lx Rp+5 | Rp+5 |
| L5 Lx | Lx |
| Lx+15 Rp+5 L5 Lx Lx+15 | Rp+5 L5 Lx Lx+15 |
| Rx+15 → until size = 5 bytes | Rp+5 L5 Lx Lx+15 |
| L5 Rx+15 | Rx+15 |
| L5 L5 | L5 |
| L20 Rx+15 L5 L5 L20 | Rx+15 L5 L5 L20 |
| R20 | Rx+15 L5 L5 L20 |
| L20 R20 L20 R20 L20 | R20 L20 R20 L20 |
| R20 | R20 L20 R20 L20 |
| L20 R20 L0 L0 Ls+y+10 | R20 L0 L0 Ls+y+10 |
| R20 | R20 L0 L0 Ls+y+10 |
| L0 | |
| L0 | |
| Ls+y+10 Rs+y+10 L0 L0 [S] | Rs+y+10 L0 L0 [S] |
| Rs+y+10 → size = y | Rs+y+10 L0 L0 [S] |
| L0 | |
| L0 | |
| [S] |
| Local File Header 1 | 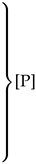 |
| File Data 1 | |
| … | |
| Local File Header n | |
| File Data n | |
| Local File Header Quine | |
| Encoded DEFLATE Quine | |
| Central Directory File Header 1 | 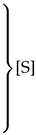 |
| … | |
| Central Directory File Header n | |
| Central Directory File Header Quine | |
| End of Central Directory Record |
| Local File Header 1 | 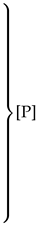 |
| File Data 1 | |
| Local File Header 2 | |
| File Data 2 | |
| … | |
| Local File Header m | |
| File Data m | |
| Local File Header Quine | |
| Encoded DEFLATE Quine | |
| Local File Header m+1 | 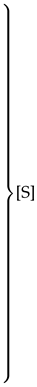 |
| File Data m+1 | |
| … | |
| Local File Header n | |
| File Data n | |
| Central Directory File Header 1 | |
| Central Directory File Header 2 | |
| … | |
| Central Directory File Header m | |
| Central Directory File Header Quine | |
| Central Directory File Header m+1 | |
| … | |
| Central Directory File Header n | |
| End of Central Directory Record |
| Code | Output | |
|---|---|---|
| [P1] | ||
| Lp2+5 [P2] Lp1+5 | [P2] Lp1+5 | |
| Lp1+5 [P1] Lp2+5 | [P1] Lp2+5 | |
| size x | R5 | Lp1+5 |
| Rp1+p2+15,p2+5 | [P2] Lp1+5 | |
| Lx R5 Rp1+p2+15,p2+5 | R5 Rp1+p2+15,p2+5 | |
| … | … |
| Code | Output | |
|---|---|---|
| [P1] | ||
| [S1] | ||
| Lp2+s2+5 [P2] [S2] Lp1+s1+5 | [P2] [S2] Lp1+s1+5 | |
| Lp1+s1+5 [P1] [S1] Lp2+s2+5 | [P1] [S1] Lp2+s2+5 | |
| Rz with size x | R5 | Lp1+s1+5 |
| Rp1+p2+s1+s2+15,p2+s2+5 | [P2] [S2] Lp1+s1+5 | |
| Lx Rz | Rz | |
| L5 Lx | Lx | |
| Lx+15 Rz L5 Lx Lx+15 | Rz L5 Lx Lx+15 | |
| Rx+15 → until size = 5 bytes | Rz L5 Lx Lx+15 | |
| L5 Rx+15 | Rx+15 | |
| L5 L5 | L5 | |
| L20 Rx+15 L5 L5 L20 | Rx+15 L5 L5 L20 | |
| R20 | Rx+15 L5 L5 L20 | |
| L20 R20 L20 R20 L20 | R20 L20 R20 L20 | |
| R20 | R20 L20 R20 L20 | |
| L20 R20 L0 L0 Ly+w+4 | R20 L0 L0 Ly+w+4 | |
| R20 | R20 L0 L0 Ly+w+4 | |
| L0 | ||
| L0 | ||
| Ly+w+4 00 00 00 00 Rw Ry | 00 00 00 00 Rw Ry | |
| size w | Rw | Rw Ry |
| Ry → repeats earlier [S2] | [S2] | |
| [S1] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van Mello, R.; Audenaert, P. A Generator for Recursive Zip Files. Appl. Sci. 2024, 14, 9797. https://doi.org/10.3390/app14219797
Van Mello R, Audenaert P. A Generator for Recursive Zip Files. Applied Sciences. 2024; 14(21):9797. https://doi.org/10.3390/app14219797
Chicago/Turabian StyleVan Mello, Ruben, and Pieter Audenaert. 2024. "A Generator for Recursive Zip Files" Applied Sciences 14, no. 21: 9797. https://doi.org/10.3390/app14219797
APA StyleVan Mello, R., & Audenaert, P. (2024). A Generator for Recursive Zip Files. Applied Sciences, 14(21), 9797. https://doi.org/10.3390/app14219797