Sound serves as an indispensable conduit of information in our daily lives, facilitating human necessary communication, the transmission of factual and emotional content, and the non-verbal expression of emotional and psychological states through phenomena such as crying, laughter, and sighs. It never fails to help humans perceive their environment, identifying the location [
1] and motion state [
2] of objects. In real scenarios, humans can capture the effective information contained in sound signals to a certain extent by combining specific semantics, context, and personal emotion. In Environmental Sound Classification (ESC), the recognition and classification of sound signals remain challenging. Environmental sounds refer to common sounds in daily life, such as animal vocalizations, indoor environment sounds, and outdoor noises. However, in real life, environmental sounds are often disturbed or jammed by background noise. In urban noise environments, elevated levels of background noise have a huge impact on the recognition of environmental sounds. This is evidenced by the diminished clarity at low signal-to-noise ratio (SNR) conditions, the potential masking of the target sound source [
3], and the requirement for extensive annotated datasets [
4]. These factors significantly complicate feature extraction, ultimately leading to recognition errors. Furthermore, obtaining high-quality, accurately annotated audio data presents a significant challenge in real-world scenarios. As a result, this hinders classification tasks [
5]. Therefore, improving the classification accuracy of ESC tasks under noise interference is a challenging research topic and emerges as a pressing research endeavor.
This paper focuses on several key issues in ESC tasks, such as the representation of sound features, the accuracy of classification models, and relevant data augmentation schemes. By addressing these critical challenges, our core research is to focus on developing robust and accurate ESC systems that can operate effectively in noisy environments. The standpoint of our main work stems from addressing urban high-noise environments, meticulously unfolding its central thesis through the adept handling of these intricate challenges. The diverse modules synergize seamlessly, fostering the development of a robust, adaptable, and precise identification system. The innovative Patch-Mix feature fusion strategy and the prowess of contrastive learning, our groundbreaking Contrastive Learning-based Audio Spectrogram Transformer (CL-Transformer) framework, attain remarkable performance in the sound classification method. Our proposed approach is supposed to offer a dependable and precise solution tailored for the real-world situation, thereby enhancing efficacy and accuracy in these demanding environments. A detailed description of the core methods of this paper will be presented in the related work section.
1.1. Related Works
Unlike musical and speech audio signals, urban environmental sounds consist of indoor and outdoor conditions, which contain random and unpredictable background noise. This results in more complex characteristics of environmental sound information, making it a primary issue in the ESC field to extract such features and reduce the impact of noise on model recognition accuracy.
In the existing research on audio signals, traditional feature extraction methods often focus on time domain information, spatial information, frequency domain characteristics, etc. In recent years, feature extraction approaches combining time frequency characteristics with statistical characteristics have played a significant role, such as Mel Spectrogram, Log-Mel Spectrogram, Mel-Frequency Cepstral Coefficients (MFCC), and Gammatone Frequency Cepstral Coefficients (GFCC) [
6]. Due to different extraction methods, these acoustic features have unique application scenarios and advantages [
7]. With the development of deep learning, many researchers have transcended the limitations of relying solely on individual acoustic features [
8], instead adopting feature fusion to integrate multiple acoustic features to harness their collective strengths [
9]. For example, [
10] analyzed various acoustic features and experimentally studied whether different feature fusions affect classification results. Experiments demonstrate that some feature fusions, such as MFCC and Chroma STFT, can enhance classification model accuracy. In [
11], logarithmic operations on Log-Mel spectrograms produced Log2Mel (L2M) and Log3Mel (L3M). The fusion of Log-Mel with L2M and L3M results in new representations, making it easier for these feature sets to capture detailed texture characteristics and abstract features in ESC tasks and, thus, achieves advanced results in recognition methods based on this. In [
12], experiments show that duplicating the Log-Mel spectrogram into three channels as input features yielded higher classification accuracy compared to a single Log-Mel spectrogram. When single features cannot sufficiently represent signals, using multi-feature fusion to jointly represent signals is an effective solution. However, at the current research stage, whether using splicing techniques [
11] or dimensional stacking [
12] to fuse features, it undoubtedly significantly increases the dimensionality of feature vectors. This approach underscores the potential of exploiting feature diversity and redundancy to refine model performance in complex urban environments. Therefore, it is necessary to seek new solutions on this basis.
In order to represent acoustic signals, the proper and clever selection of classification models in ESC tasks goes hand in hand with representing acoustic signals effectively. In [
13], a sub-spectrogram segmentation with score level fusion framework for ESC is proposed, along with a Convolutional Recurrent Neural Network (CRNN) to improve classification accuracy. To tackle challenges such as vanishing gradients, high network loss, and low accuracy, [
14] propose Long Short-Term Memory Neural Networks (LSTM) and Gated Recurrent Unit (GRU) neural networks, constructing a deep recurrent neural network model. However, recognizing environmental sounds in noisy scenarios typically poses a unique challenge due to the sheer diversity and often imbalanced nature of sound data. Some categories of data may be relatively abundant, while others are very scarce. Through transfer learning, pre-trained models on data-rich categories can be transferred to data-scarce categories and, thus, improves overall data utilization. This can significantly reduce the computational resources needed to train models from scratch. Furthermore, the direct training of core models on limited datasets in ESC tasks can easily lead to overfitting. Transfer learning can enhance the recognition effect of the core methods in this paper by leveraging models pre-trained on extensive datasets. This approach not only strengthens the core methods discussed in our manuscript but also addresses overfitting concerns, thereby enhancing the overall recognition effectiveness indeed. More importantly, the application of transfer learning has the potential to improve the performance of ESC models. By pre-training on ESC tasks, the core recognition model can obtain better initial parameters and feature representations. It helps algorithms converge quickly and achieve optimal solutions within the hyperplane, resulting in better performance on the validation set. Therefore, transfer learning is becoming increasingly important in the study of environmental sound classification [
15]. Some conventional computer vision methods are being expanded. Network architectures tailored for image analysis have gradually ventured into ESC applications [
14,
16]. However, current ESC task methods using pre-trained Convolutional Neural Networks (CNNs) often resort to redefining the last layer to address sound classification challenges [
11]. A notable limitation of this approach lies in its inability to capture the intricate long-term dependency relationships in audio signals [
17], and since most of these models are transferred from the image domain, they focus more on the physical meaning and distribution characteristics of images, requiring higher training weights for parts that can effectively reflect abstract feature distribution characteristics and semantic cues. Thus, merely fine-tuning the last output layer and directly applying it to ESC tasks may not yield good results. Consequently, attention mechanisms, as representative optimization strategies, are progressively garnering more and more attentions all over the world. These mechanisms offer a promising avenue to address the limitations of traditional CNN-based approaches, enhancing the model’s capability to exploit critical temporal and contextual information within audio signals in the real-world situation.
As attention mechanisms are introduced into the field of sound classification, some research has improved pre-trained network models by seamlessly integrating attention mechanisms [
7]. In [
3], a ResNet model based on a multi-feature attention mechanism is proposed, which added a Net50_SE attention module to suppress the impact of environmental noise. By redistributing the training weights of the sound signals, this improvement has achieved higher recognition accuracy in noisy environments. Experimental evidence underscores the adaptability of certain attention modules, which can cater to the fine-tuning demands of transfer learning by dynamically adjusting parameter weights. This adaptability empowers the model to interpret increasingly intricate audio signals. Consequently, many previous studies are exploring attention-based solutions [
18], with models based on Transformer concepts demonstrating strong feature learning capabilities [
19]. The Audio Spectrogram Transformer (AST) model is proposed in [
20], and experiments show that AST pre-trained on ImageNet and AudioSet datasets have achieved advanced results in various downstream audio tasks. Using pre-trained models can achieve better generalization on smaller datasets, helping the model obtain better initial parameters and improve training efficiency. However, due to factors such as noise and dataset size, pre-trained models in ESC tasks are also prone to overfitting. Researchers have endeavored to address overfitting through various strategies, including parameter reduction [
21] and data augmentation [
12]. These methods can only partially reduce overfitting and cannot completely eliminate this issue, which significantly constrains the development of urban environmental sound recognition algorithms, especially in high-noise environments where this disadvantage is amplified. Therefore, solving the overfitting of pre-trained models in downstream tasks is also crucial.
At present, the research on urban environment sound recognition tasks in flexible and noisy environments remains untouched. Therefore, transferring network models from the image domain to ESC tasks can effectively improve classification accuracy. However, for ESC tasks with smaller datasets, using pre-trained models through transfer learning can accelerate overfitting, which is detrimental to model training [
6]. As a key technology in ESC tasks, data augmentation emerges as a widely embraced strategy to mitigate these issues. In [
22], a set of offline data augmentation techniques is employed, targeting audio waveforms, performing necessary time-stretching and pitch-shifting. They also incorporate background noise from urban environments to enhance robustness in real-world scenarios. In [
23], time warping based on spectrogram augmentation is utilized, randomly stretching or compressing spectrograms through interpolation techniques. Experiments have shown that data augmentation can alleviate overfitting to some extent. Additionally, some researchers use contrastive learning as a regularization scheme to address overfitting. For instance, [
12] introduce contrastive learning loss into a ResNet-50-based model to solve this problem, achieving good results. Given the current lack of urban environmental sound datasets under noisy conditions, it is essential to use data augmentation techniques and related regularization schemes to assist model training.




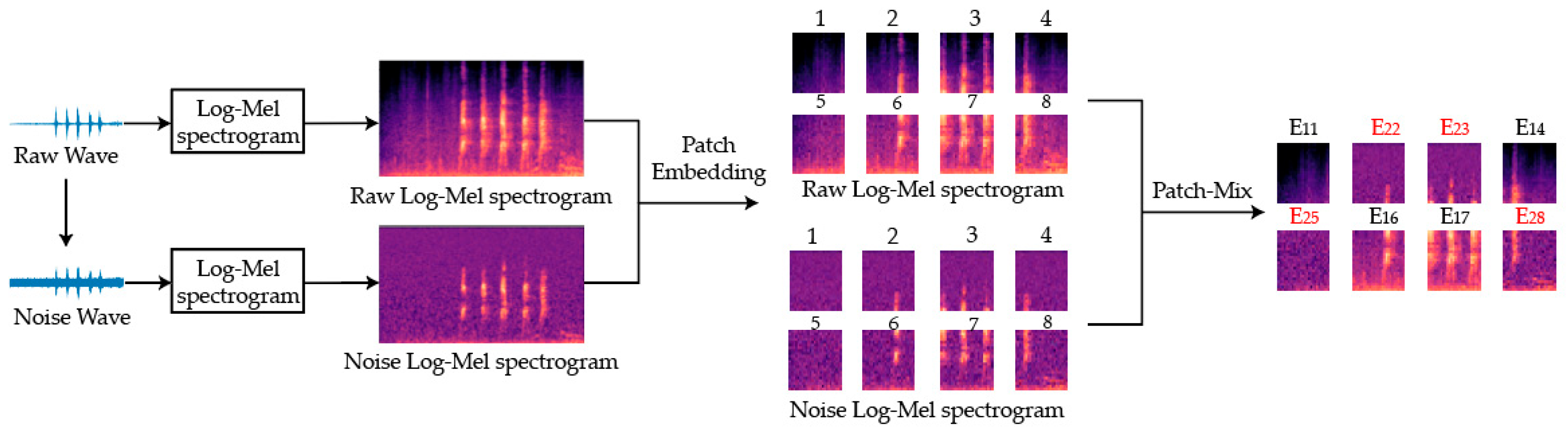
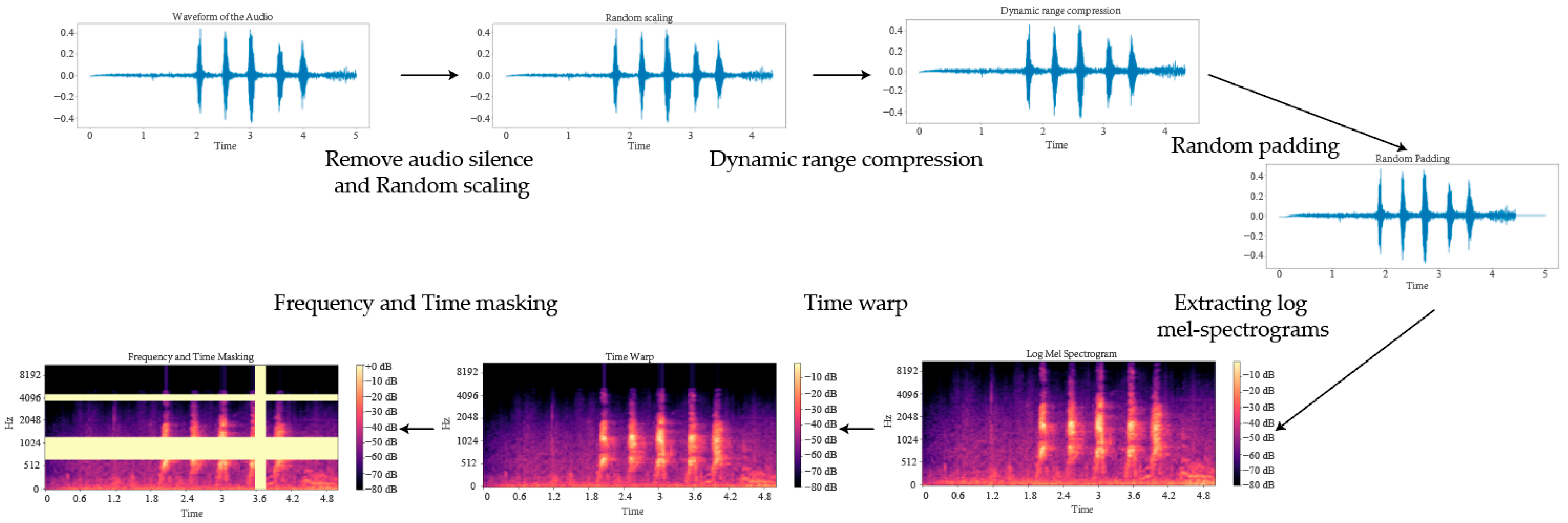
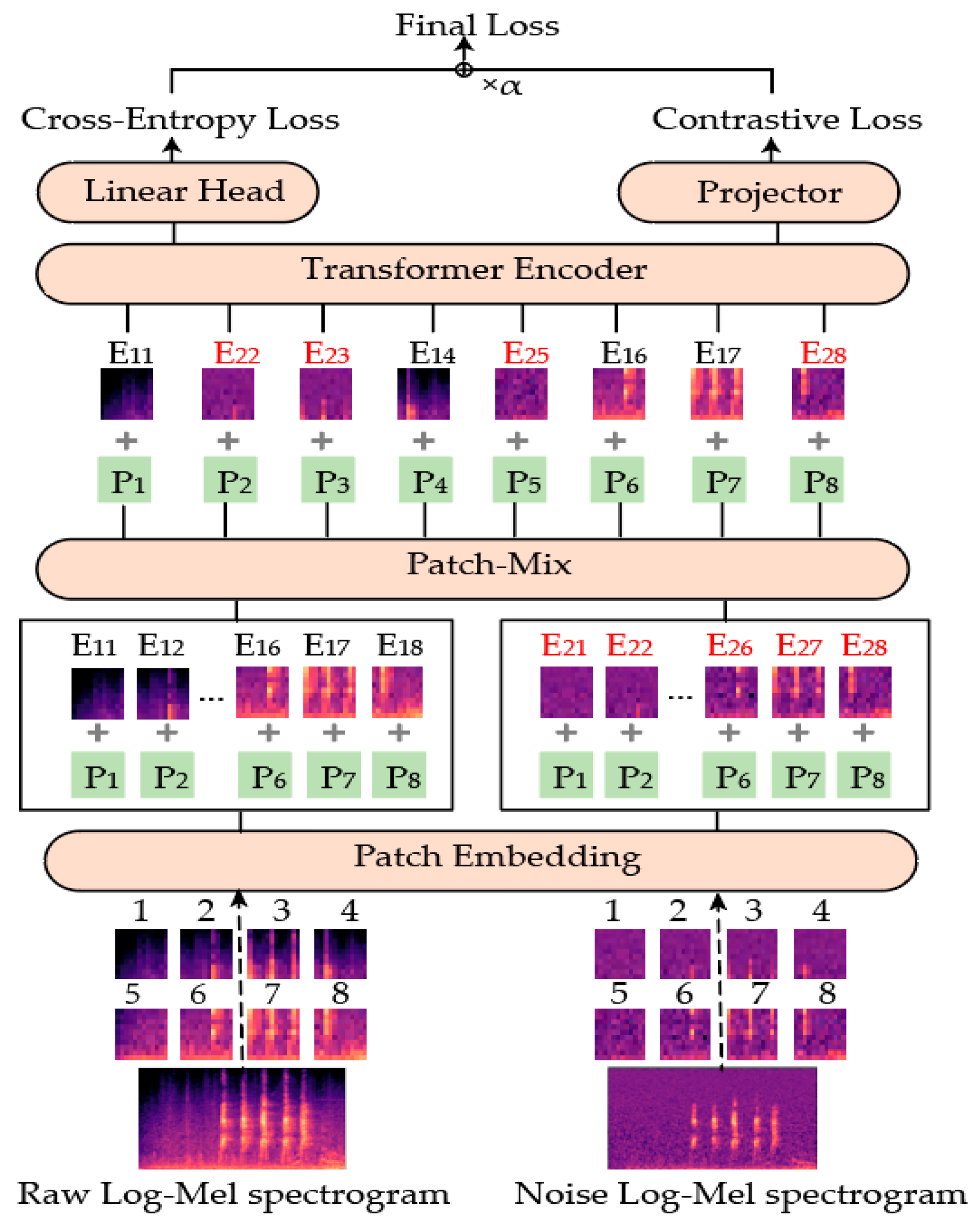
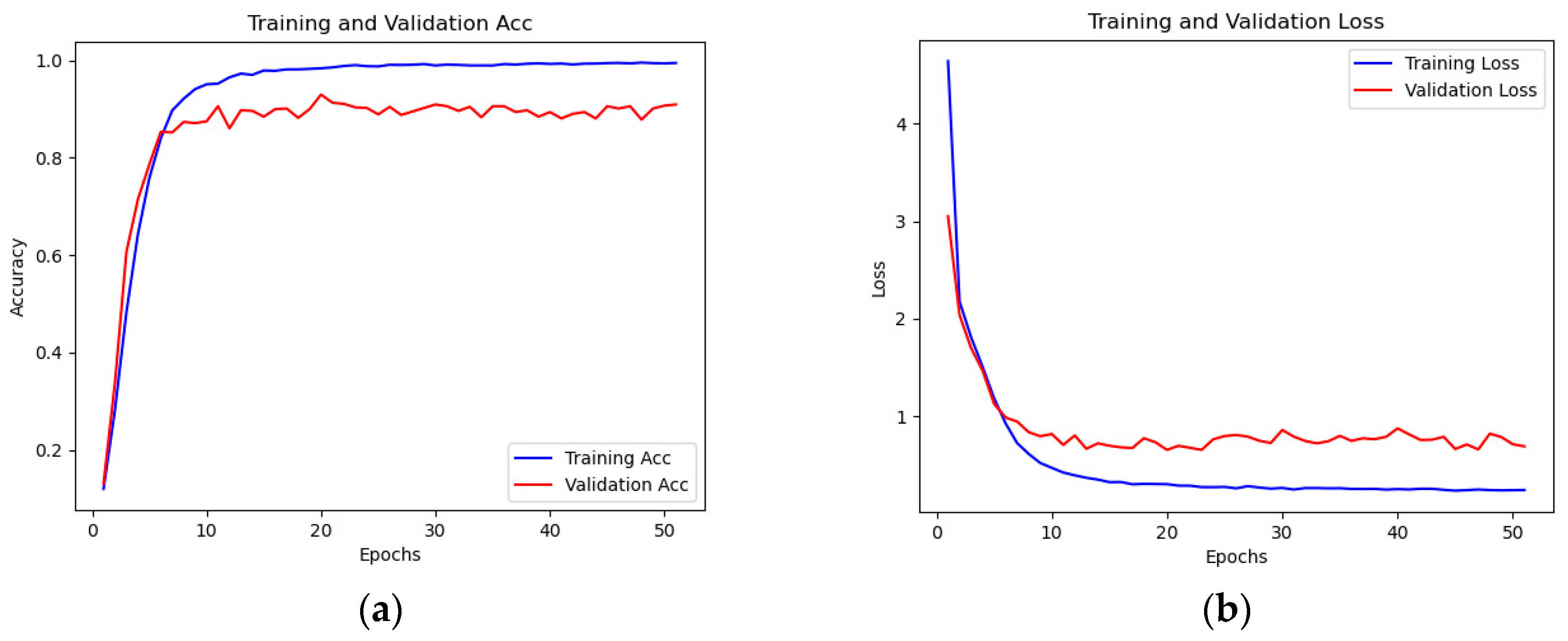
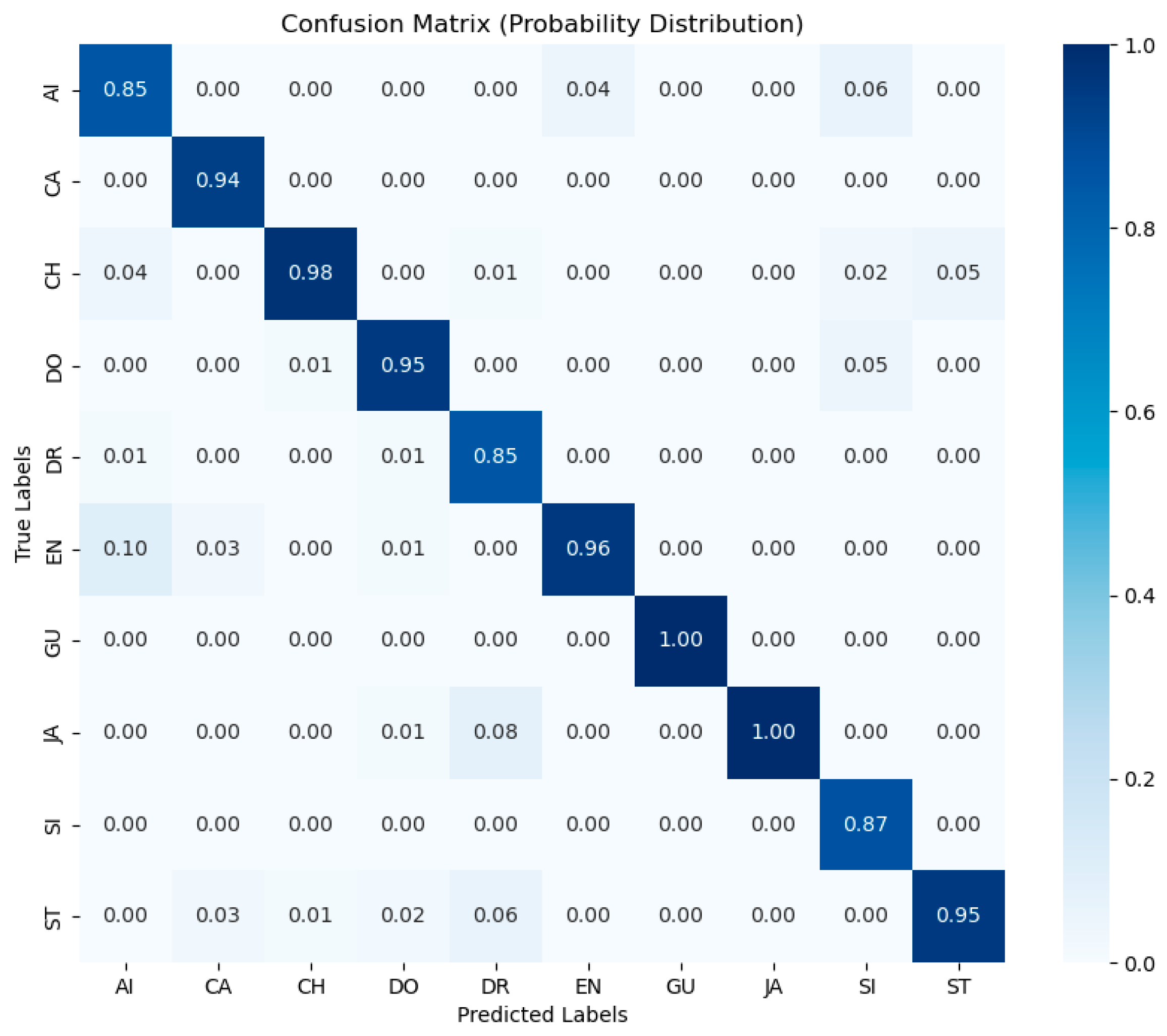
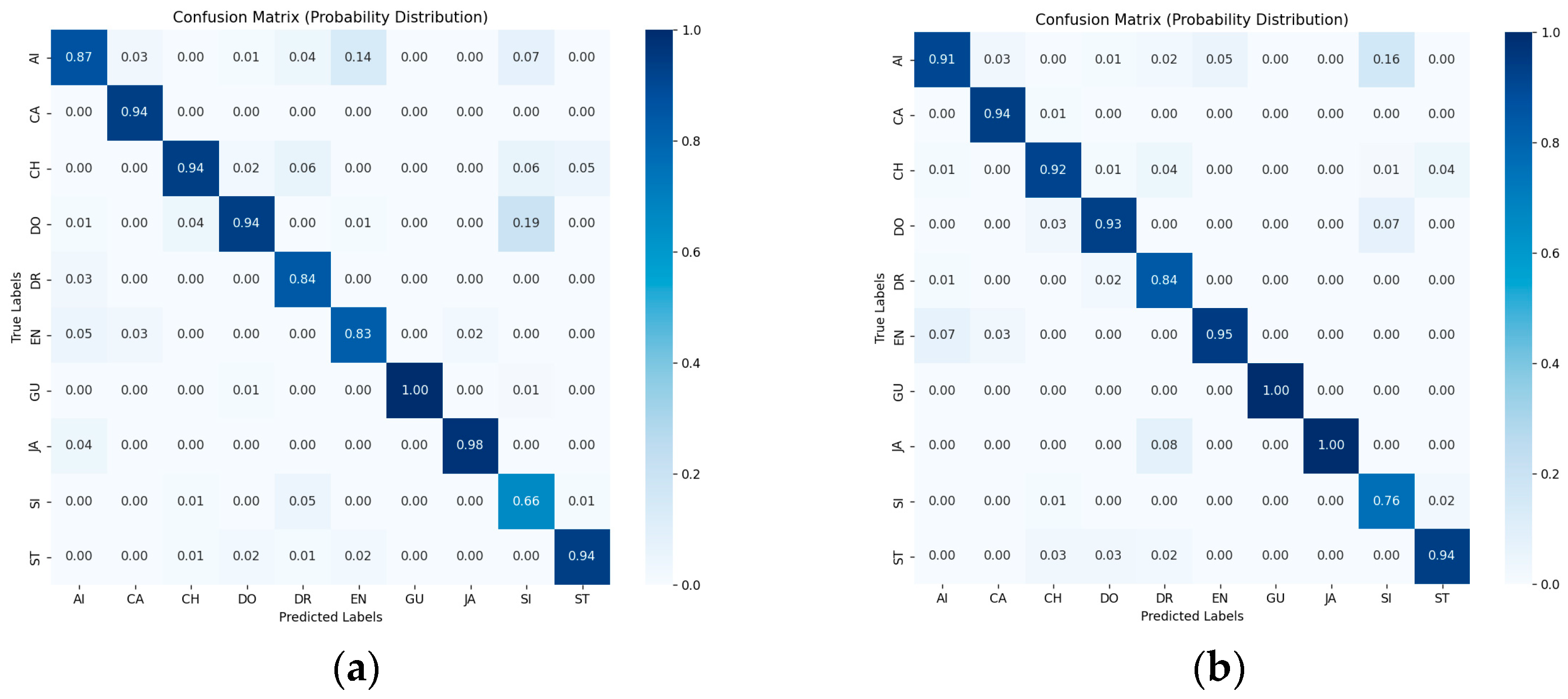

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}