1. Introduction
In recent years, many researchers have used machine vision and image processing technologies to detect objects in images. By identifying the types of objects and determining their locations within the image, they achieve classification and localization of various targets. However, traditional object detection methods are easily influenced by the detection environment. While they can perform well under specific conditions, in real production environments, factors like lighting and object orientation can affect the accuracy and speed of detection. Moreover, traditional methods rely on manually designed features, requiring extensive prior knowledge and cumbersome procedures. This process is not only complex but also computationally heavy, making it unsuitable for real-time detection. Since metal surface defects are usually detected on production lines to manage defective products, there is a high demand for real-time detection, which traditional object detection algorithms struggle to meet.
With the rapid development of deep learning, object detection technology has made significant progress. Deep learning, by simulating the way the human brain processes information, can automatically learn and extract features from images, enabling efficient object recognition and localization. This approach not only enhances the accuracy and robustness of algorithms but also simplifies the detection process, reducing reliance on prior knowledge. Using deep learning for object detection offers numerous advantages. In the early days, Krizhevsky et al. proposed AlexNet [
1] and achieved remarkable success in the ImageNet (ILSVRC) competition, marking a major milestone for deep learning in computer vision tasks and shifting the focus of object detection towards deep learning techniques. Object detection methods based on deep learning are mainly divided into two branches: two-stage detectors and one-stage detectors. Two-stage detectors first generate candidate object regions through a region proposal network, followed by fine classification and location adjustments of these regions. This approach achieves high accuracy but at the cost of speed. In contrast, one-stage detectors adopt an end-to-end approach, directly predicting object categories and locations across the entire image, offering superior speed, and making them more suitable for real-time object detection.
By integrating deep learning with region proposal techniques, RCNN [
2,
3] emerged as a significant approach. This method converts the object detection task into a region-based classification problem, offering simplicity and scalability. However, due to frequent convolution operations, it suffers from substantial redundant computations, limiting its performance. Girshick et al. further improved RCNN by introducing Fast RCNN [
4], which enhanced detection accuracy and sped up the detection process, though the time-consuming region extraction issue remained unsolved. Building upon this, Ren et al. introduced Faster RCNN [
5], significantly improving model accuracy, but the issue of inconsistent region proposal box sizes in the region proposal network still persists.
Single-stage object detectors directly use deep convolutional neural networks on the raw image to predict the locations and classes of objects, eliminating the need for a region proposal step, which significantly increases detection efficiency. To address the high computational complexity, slow speed, and difficulties in handling different scales and targets associated with traditional object detection methods, Liu et al. introduced the SSD [
6] model, which employs multi-scale features and data augmentation techniques to better adapt to objects of varying sizes, further enhancing the generalization capability of object detection. To continue improving the efficiency of object detection tasks, Redmon et al. proposed YOLO [
7,
8] at CVPR 2016. Subsequently, they introduced Anchor Boxes and additional convolutional layers, resulting in YOLOv2 and YOLO9000 [
9]. YOLOv3 [
10] added context information modules and feature pyramid networks, proposing a new backbone network called Darknet53, which further improved the detection accuracy of multi-scale objects. To further enhance detection efficiency and accuracy, Alexey et al. proposed YOLOv4 [
11] using CSPDarknet53 [
12] and PAN [
13], while Ultralytics introduced YOLOv5 [
14], which operates at an inference speed of 140 FPS, enabling faster and more accurate model deployment. To simplify the model design and training process, Facebook was the first to propose DETR [
15]. The team later combined deformable convolutional networks with Transformer networks to propose RT-DETR [
16]. Addressing the issue of poor model generalization caused by manual setting of positive and negative samples in the YOLO series, Zheng et al. introduced YOLOX [
17]. To meet the needs of industrial applications, Meituan integrated many advanced object detection designs from both industry and academia, resulting in YOLOv6 [
18]. Subsequently, Ultralytics released a model named YOLOv8, which further enhanced the model’s performance and flexibility to meet diverse market demands.
2. Related Works
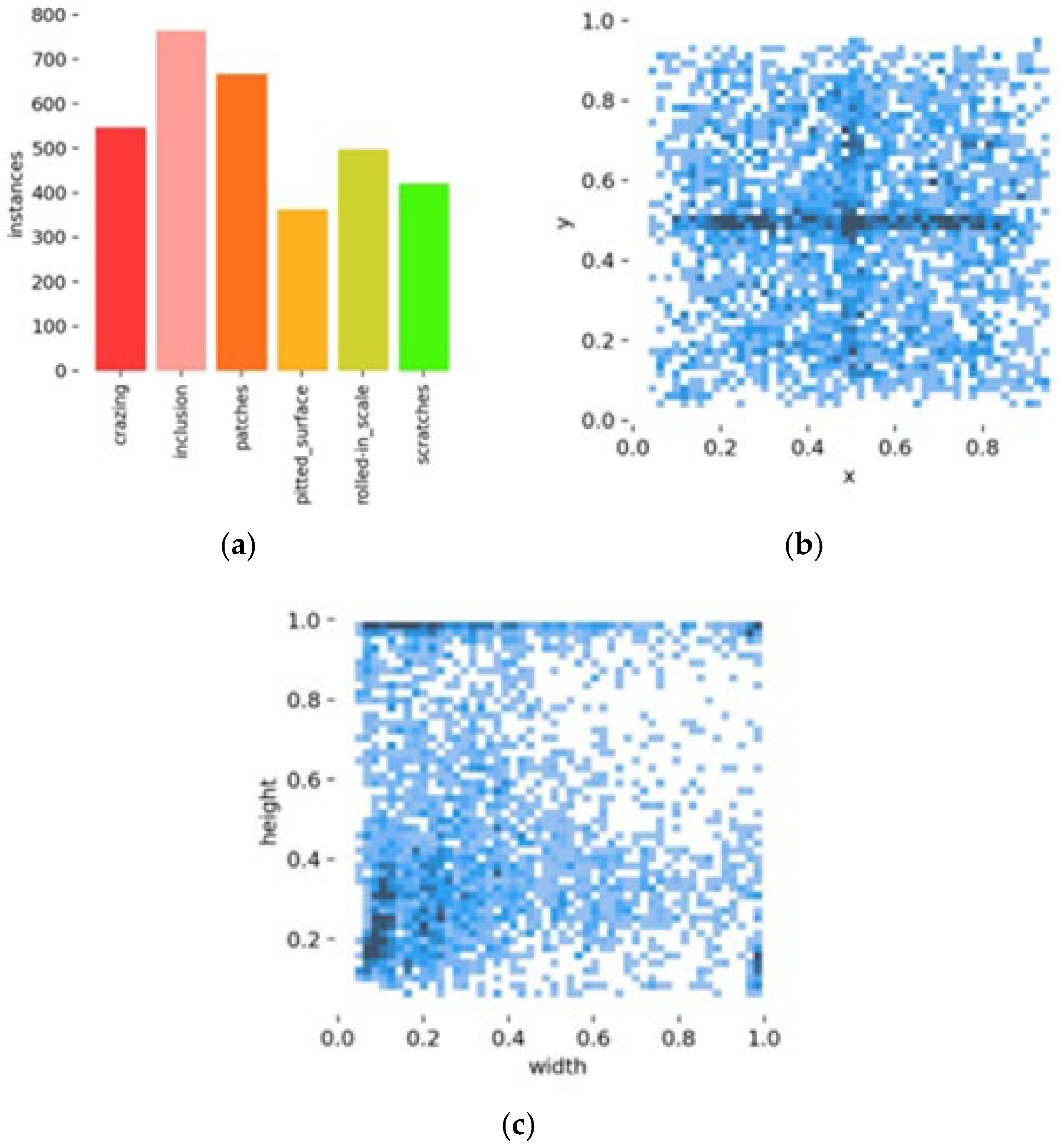
Steel strips play an important role in various fields of industrial production, and their quality is crucial for industrial development. However, due to limitations in production processes and technology, defects such as cracks, inclusions, and spots often appear on the surface of steel. As a result, surface defect detection is particularly important. Currently, steel surface defect detection technology has evolved from traditional manual and machine-vision-based methods to deep learning-based techniques. Traditional manual inspection methods suffer from low accuracy, missed detections, and false positives, while machine-vision-based detection methods typically only extract shallow features of surface defects and are easily influenced by environmental factors, leading to unstable detection performance. Therefore, it is essential to employ deep learning-based object detection algorithms for detecting surface defects in steel strips. In 2022, Guo Zexuan et al. proposed the MSFT-YOLO [
19] algorithm, which introduces the TRANS module based on YOLOv5 and combines a multi-scale feature fusion structure to achieve the integration of features at different scales, enhancing the detector’s ability to dynamically adjust to targets of varying sizes.
In 2023, Zhao Zemin [
20] introduced the Self Notice Ratio (SNR) deep network attention model, combining it with YOLOv6 for surface defect detection in rolled steel. Their method inputs images processed by YOLOv6 into a U-Net convolutional model to confirm the presence of defects and accurately detect their positions. The final output is a binary mask that overlays the original image, achieving the detection goal. However, the detection time is relatively long, requiring further lightweight optimization. Xie et al. [
21] did not directly use a lightweight convolutional network but instead designed the DSConv lightweight convolutional module to optimize the backbone of YOLOv4. Li Fengrun [
22] proposed a novel approach for model lightweighting—a dual-stream network structure—dividing a single path into deep and shallow branches. The optimized YOLOv4 model had a parameter count reduced to 18.4 M, significantly lower than SSD and YOLOv4, successfully achieving model lightweighting. However, the model requires high image resolution, and detection speed may decrease at lower resolutions. Li Shaoxiong [
23] proposed an improved method based on YOLOv5m, significantly enhancing the precision of steel surface defect detection, though the model’s parameter count is relatively large. Wang et al. developed an improved YOLOv5-based algorithm, creating a multi-scale block module [
24] that effectively explores steel surface defects at different resolutions.
By 2024, Ren et al. [
25] optimized YOLOv5 by introducing the ECA mechanism, which focuses on channel information while neglecting spatial information, thus being suboptimal for detection tasks. Their model achieved a mAP of 78.8% in steel surface defect detection, but the accuracy for detecting less visible defects was relatively low. Li et al. [
26], based on the introduction of the spatial attention (SA) mechanism, integrated the CSPCrossLayer module into the YOLOX backbone, establishing cross-layer connections. They also introduced the PSblock convolutional module to replace the CSPLayer structure in the feature fusion network. Experiments on the railway track dataset showed that this algorithm improved detection speed while maintaining accuracy, though the performance for small defect detection in the NEU-DET dataset was suboptimal. Gao Chunyan et al. [
27], to save computational resources, abandoned the FPN optimization of YOLOv7 and proposed a high-precision real-time defect detection algorithm, CDN-YOLOv7. This algorithm introduced the CARAFE lightweight upsampling operator to improve feature fusion ability, though CARAFE is more suited to scenarios requiring high-quality upsampling and devices with limited resources. Fan et al. [
28] designed a new anchor point optimization algorithm, GA-K-Means, based on the K-means algorithm, and proposed the ACD-YOLO model. By using a Genetic Algorithm (GA) to adjust the anchor point boundaries, they reduced dependencies. Although the model achieved 72 FPS in experiments, its detection speed still lagged behind YOLOv7 and YOLOv8, requiring further optimization. To address the problem of aluminum surface defect detection, Kong et al. [
29] introduced the WIoU loss function based on YOLOv8, focusing on anchor boxes of normal quality to reduce harmful gradients generated by extreme samples. By using a convolutional residual module to enhance feature extraction capabilities, the model’s mAP improved by 3.4% compared to the original YOLOv8, reaching 74.9%, although the computational load increased by about 20%. Zhao Baiting [
30] proposed the ECC-YOLO algorithm, which is based on YOLOv7 and incorporates the MPCE module, improving detection accuracy for small steel surface defects. Dai Linhua’s C2f-DD algorithm [
31] expanded the receptive field, effectively enhancing the network’s feature extraction ability. Wang Mengyu [
32] proposed an adaptive weighted downsampling method based on YOLOv8, which combined different downsampled feature maps to improve the model’s focus on defect information.
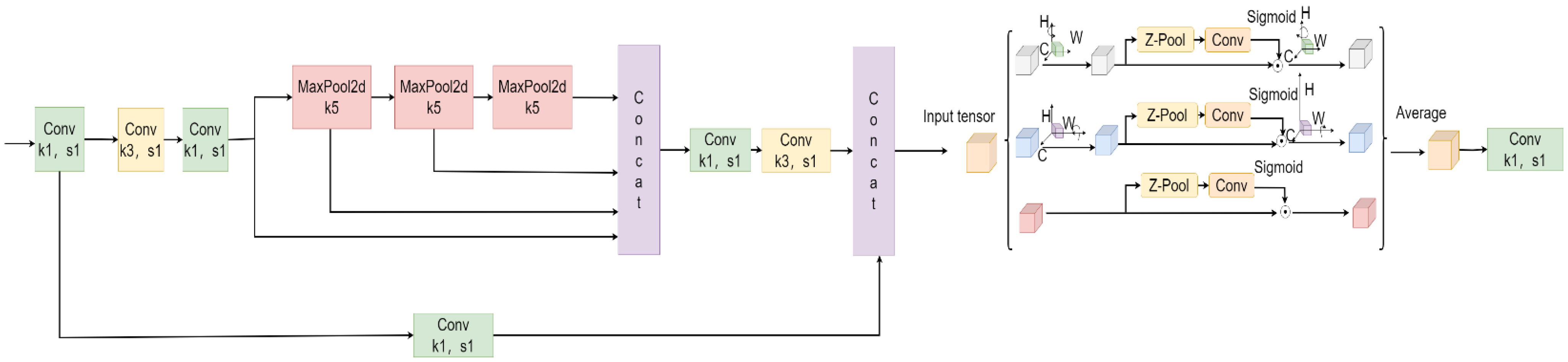
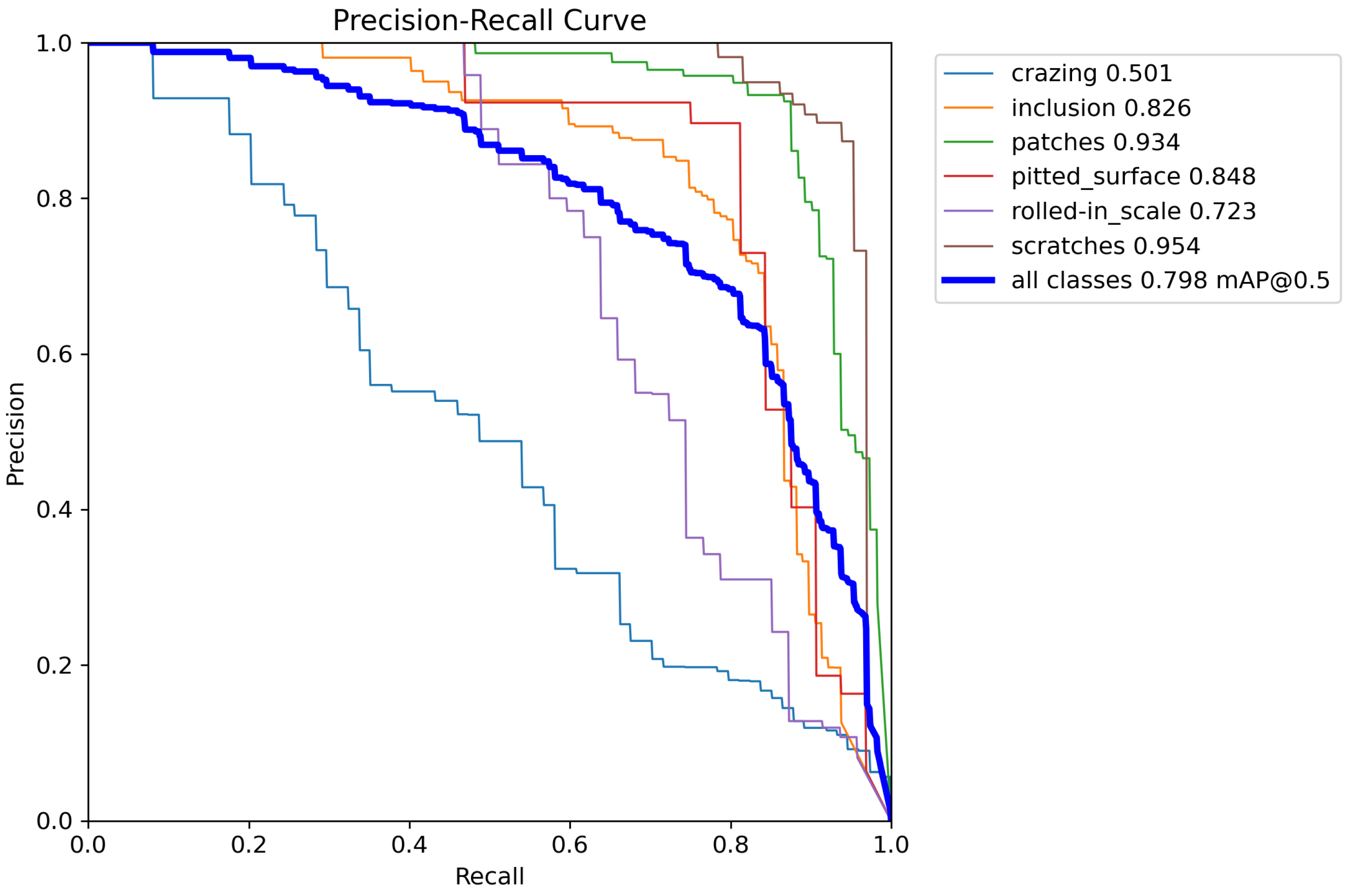
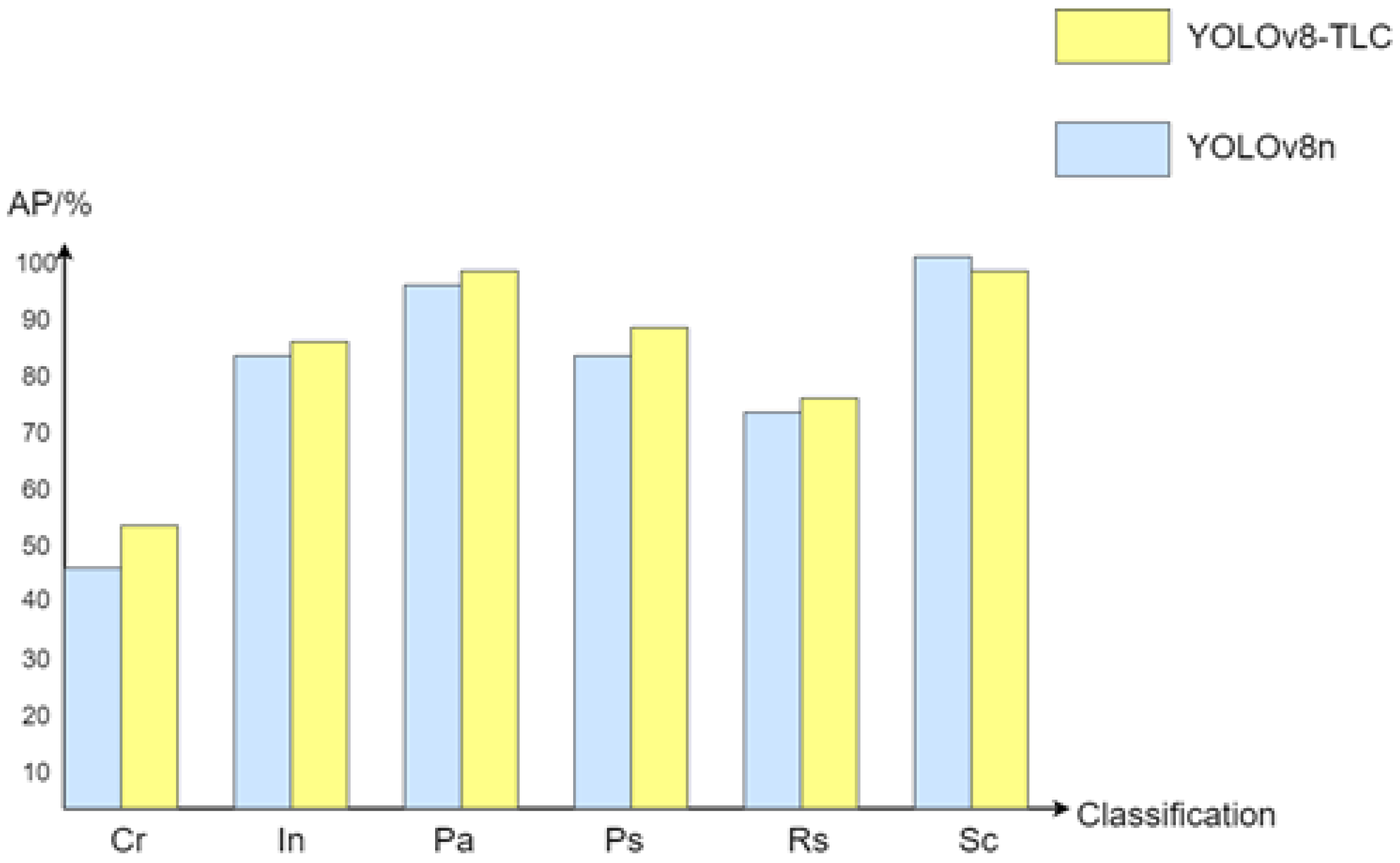
The above examples provide valuable insights for subsequent research, but they generally suffer from insufficient detection accuracy. In response to these shortcomings and the requirements of defect detection, this paper selects YOLOv8n, the model with the smallest weights among the five versions of YOLOv8, as the base model and proposes an improved YOLOv8-TLC (YOLOv8-Triple Space Pyramid module and Large Selective Kernel attention and C2f-DS module) algorithm, which effectively enhances the accuracy of steel surface defect detection.
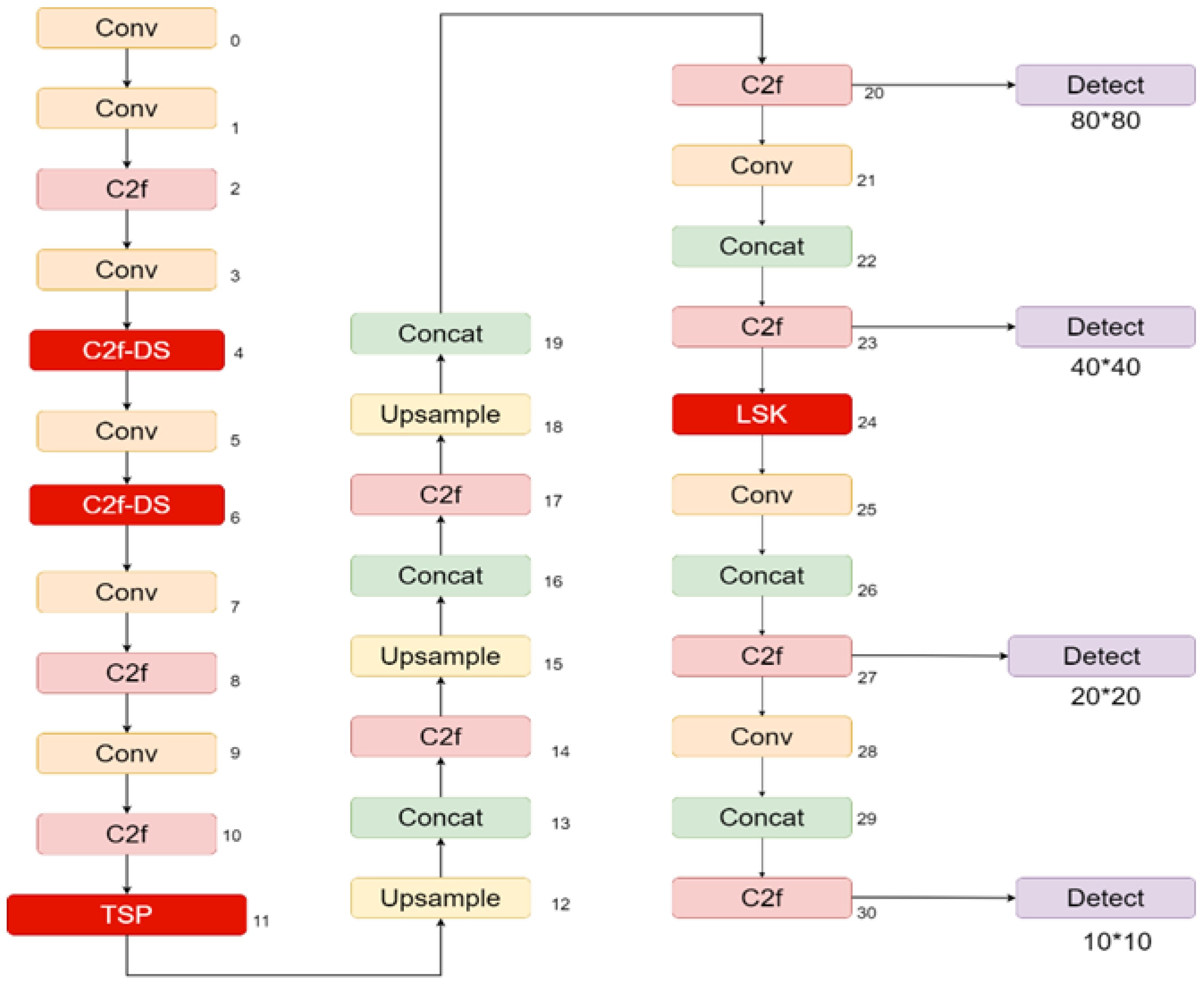
YOLOv8n Algorithm
YOLOv8n consists of three main components: a feature extraction network, a feature fusion network, and a detection head, as shown in
Figure 1. This model is an optimized version of YOLOv5, not only improving detection accuracy but also achieving greater lightweight efficiency. YOLOv8n replaces the C3 module in YOLOv5 with a more lightweight C2f module. Additionally, the detection hea YOLOv8n adopts an Anchor-Free structure and utilizes a decoupled head design that separates classification and regression tasks, enhancing both the model’s accuracy and convergence speed [
33].















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}