
Bridging the Appearance Domain Gap in Elderly Posture Recognition with YOLOv9

 , ,
, ,  , and
, and 
Abstract
1. Introduction
- By using Unity for realistic simulations and Roboflow for comprehensive data preparation, a new standard for automated elderly posture recognition is proposed.
- By using synthetic and real videos for YOLOv9 training, the efficiency of elderly posture detection in real life is enhanced, and the need for constant human supervision is reduced.
- The proposed method allows using a combination of a small number of real images with a much larger number of virtual images to train YOLOv9 for human posture detection in real-world images.
2. Literature Review
3. Materials and Methods
3.1. Experimental Design
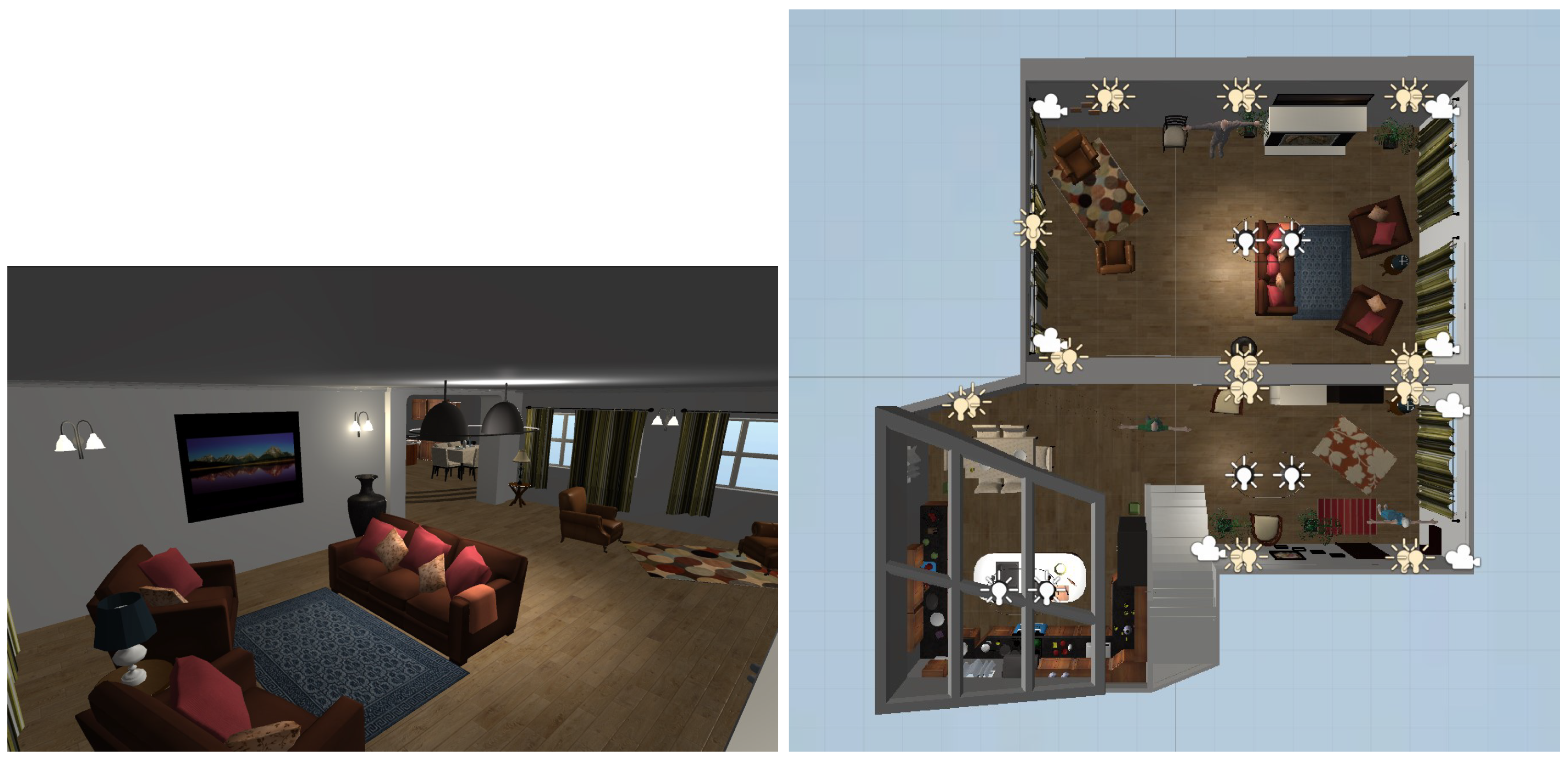
3.2. Virtual and Real Environments
3.3. Methodology
3.3.1. Hyperparameters and Optimisation Process
3.3.2. Data Augmentation
- Data collection and annotation: The images extracted from the videos recorded by the six cameras in the virtual environment (used in the four experiments) and the images from the real-world video (used in the HYBRID–VIRTUAL and HYBRID–REAL experiments) were uploaded to Roboflow. The proportion of real data in the HYBRID dataset was 0.036. Each image was annotated for the three postures.
- Data augmentation: Augmentation techniques, such as rotation, flipping, and scaling, were applied to the dataset to improve model generalisation. The specific augmentation parameters are listed in Table 2.
- Model training: The YOLOv9 model was trained using the annotated and augmented dataset. Training was performed on a machine equipped with CUDA 11.8 to take advantage of GPU acceleration for faster training.
3.4. Performance Evaluation
- Precision: The proportion of true positive detections out of the total number of detections for each posture.
- Accuracy: The overall correctness of the model’s predictions, calculated as the ratio of correctly predicted instances to the total number of instances.
- Recall: The proportion of true positive detections among the actual instances for each posture.
- F1-score: The harmonic mean of precision and recall, providing a balance between the two metrics.
- mAP50: The mean average precision when evaluated at a single intersection over union (IoU) threshold of 0.50. This means that a predicted bounding box is considered a successful detection if it overlaps with the ground truth by at least 50%. This metric provides an indication of the model’s ability to detect objects with a reasonable degree of accuracy.
- mAP50-95: This provides a more comprehensive evaluation by averaging precision across multiple IoU thresholds, ranging from 0.50 to 0.95 in increments of 0.05. This metric is more stringent, as it requires the model to perform well at varying levels of overlap, giving a better assessment of its overall detection performance.
4. Results
4.1. Training Results
4.2. Testing Results for the Virtual Environment
4.2.1. Testing Results for VIRTUAL–VIRTUAL Experiment
4.2.2. Testing Results for HYBRID–VIRTUAL Experiment
4.3. Testing Results for Real Images
4.3.1. Testing Results for VIRTUAL–REAL Experiment
4.3.2. Testing Results for HYBRID–REAL Experiment
4.4. Real-Time Performance Evaluation
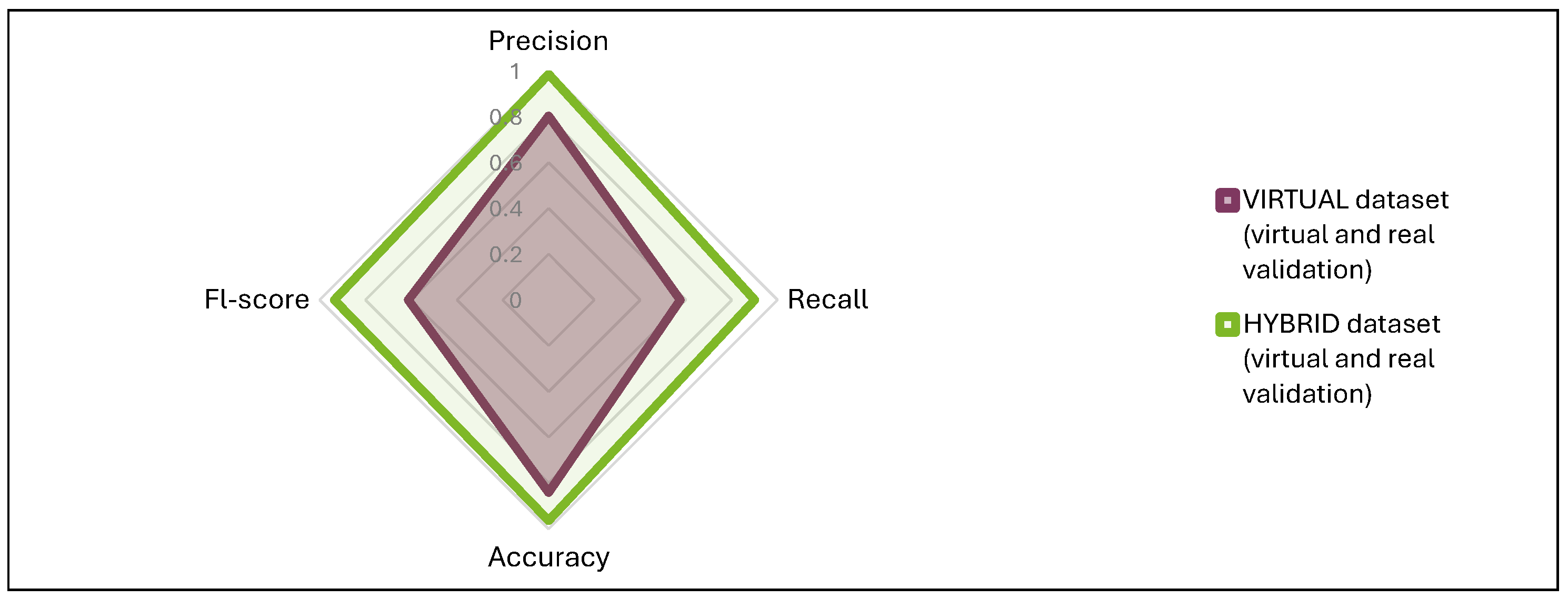
4.5. Testing Results per Dataset
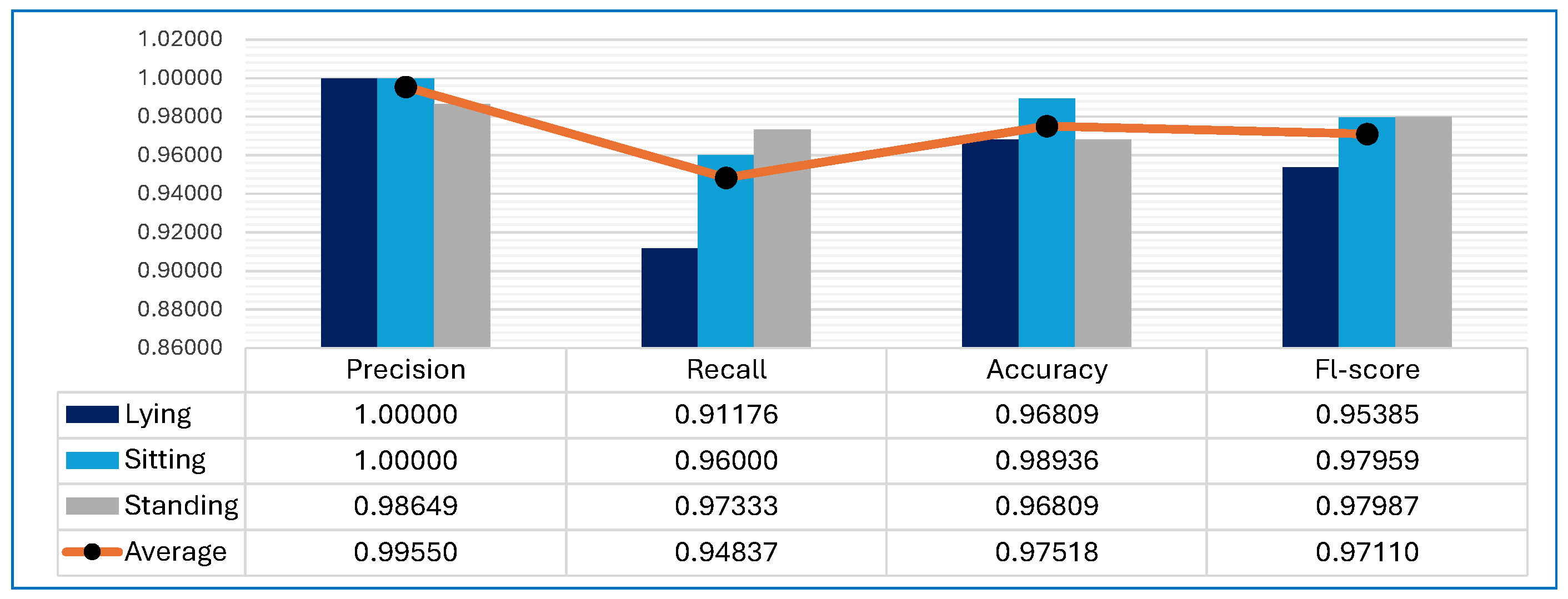
- The hybrid dataset shows a more balanced and generally higher performance across most metrics compared to the virtual dataset. This suggests that adding real images to the virtual dataset can enhance the model’s ability to generalise better, particularly in a real-world validation environment.
- While the virtual dataset performs exceptionally well in a controlled virtual environment, its performance drops significantly when validated in a real-world setting. The hybrid dataset, while slightly lower in virtual settings, maintains more consistent performance across different environments.
5. Discussion
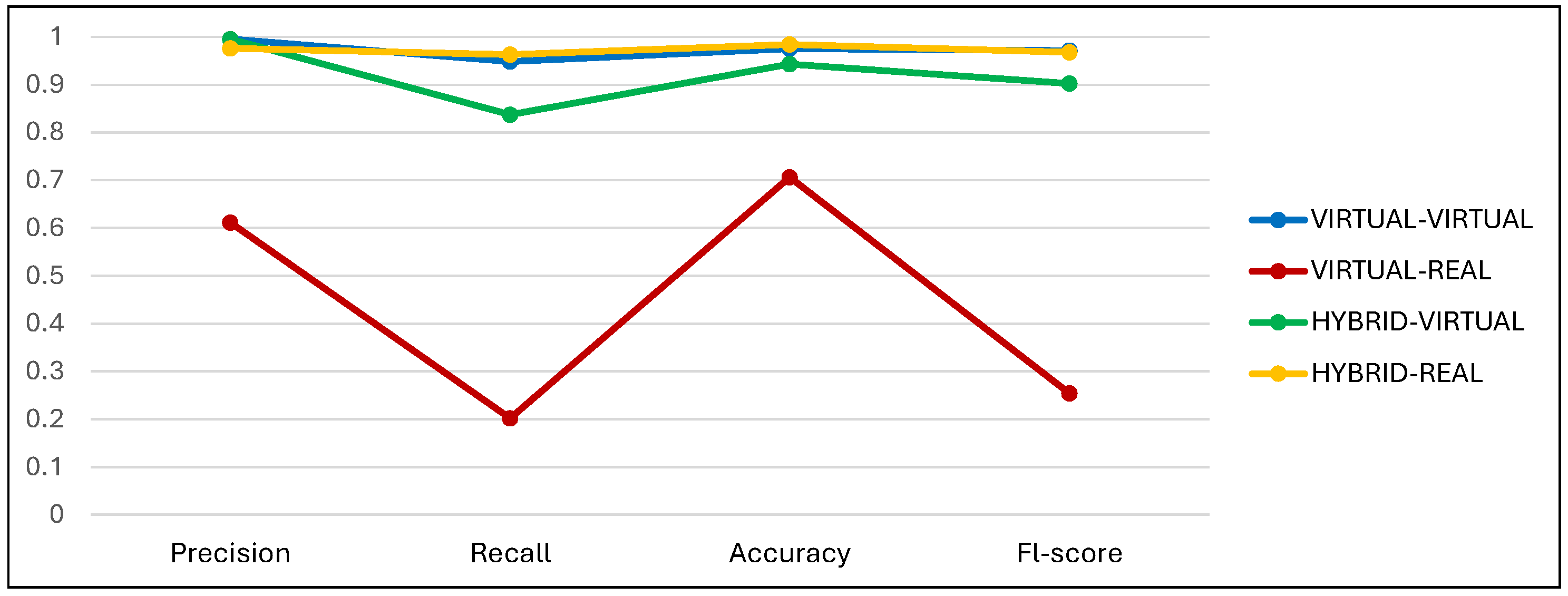
- The performance of the model in recognising postures in the virtual environment using the hybrid dataset showed a slight decrease in all metrics compared to using the virtual dataset. For example, the mean F1-score for the three postures was 0.97 when using the virtual dataset and 0.90 when using the hybrid dataset. This can be attributed to the gap in the appearance domain caused by the difference between the natural and synthetic image formation processes. A real image is the product of an image acquisition process that inherently captures a variety of different natural phenomena, such as motion noise and material properties. On the other hand, a synthetic image is the result of a light transport simulation and rendering [18].
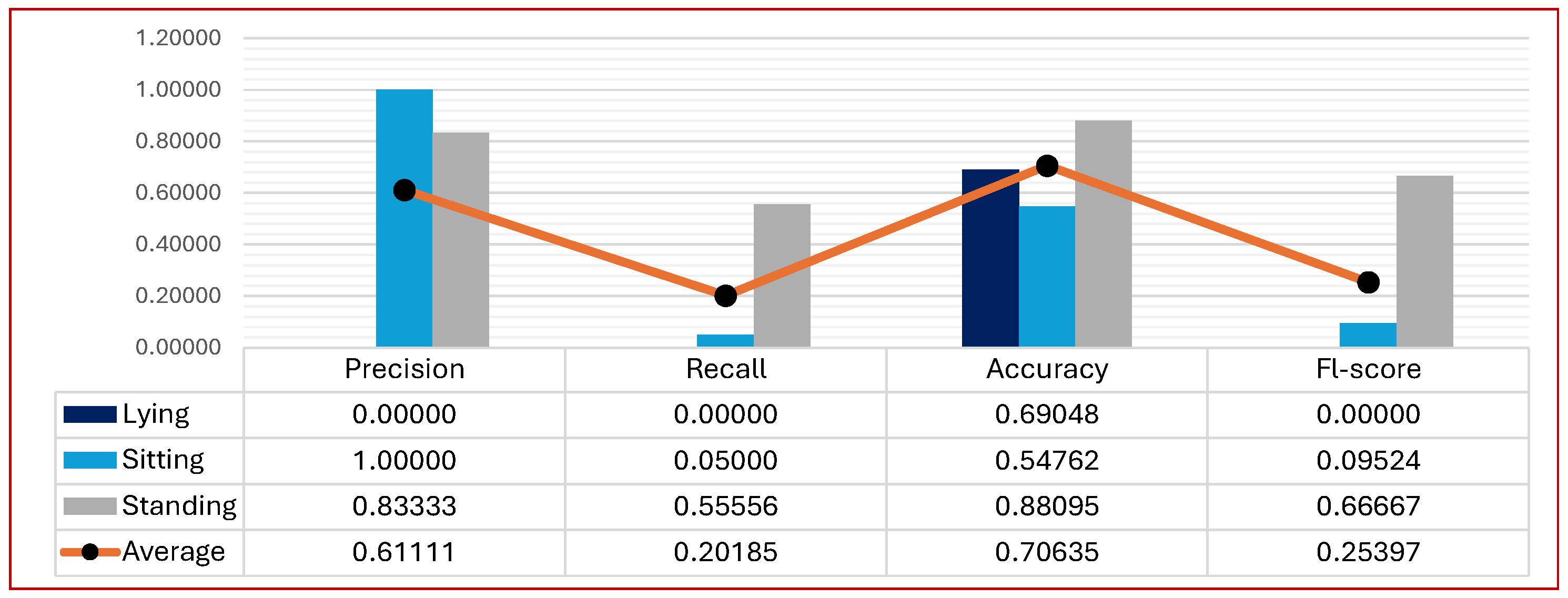
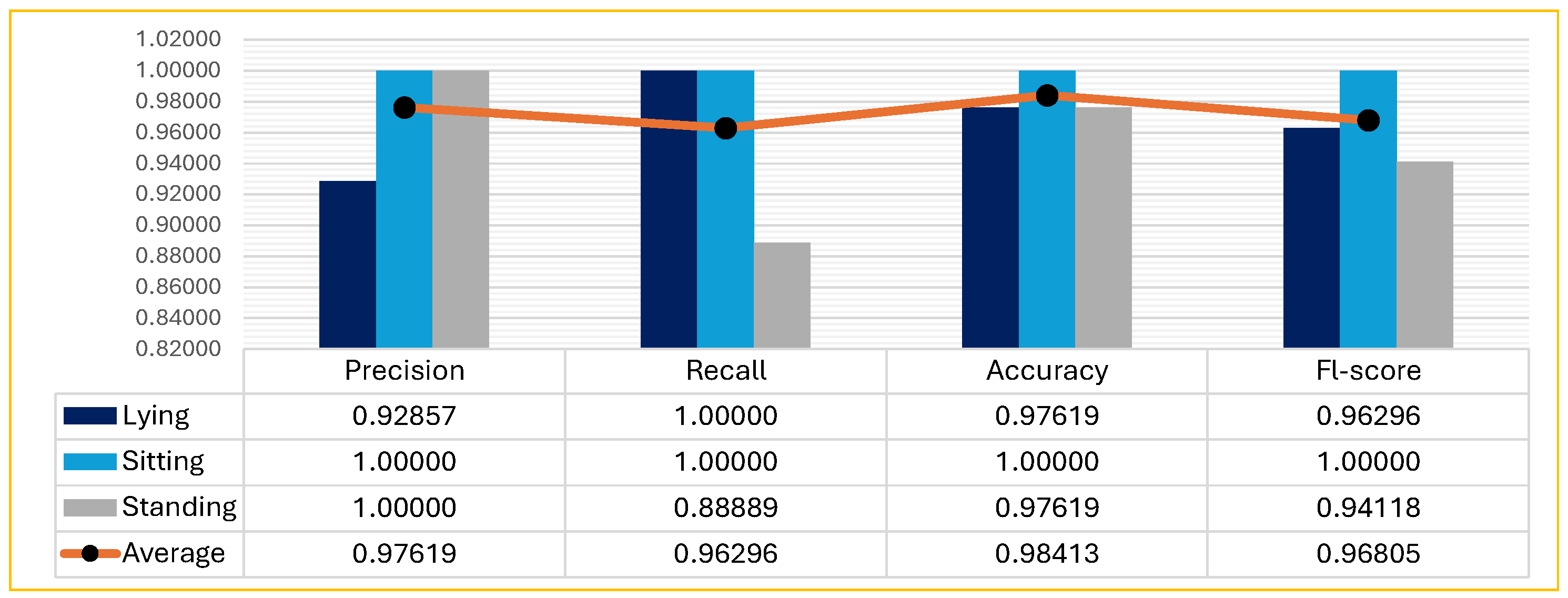
- The real environment recognition results using the hybrid dataset showed impressive improvements in all metrics compared to the virtual dataset. For example, the average F1-score was 0.25 for the VIRTUAL–REAL experiment and 0.97 for the HYBRID–REAL experiment, almost four times higher. Here, on the other hand, the appearance domain gap was largely bridged by including some real (natural) images in the virtual dataset in order to detect postures in the real world.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNN | Deep Neural Network |
| YOLO | You Only Look Once |
References
- Kavitha, A.; Hemalatha, B.; Abishek, K.; Harigokul, R. Fall Detection of Elderly Using YOLO. In Proceedings of the ICT Systems and Sustainability; Tuba, M., Akashe, S., Joshi, A., Eds.; Springer: Singapore, 2023; pp. 113–121. [Google Scholar]
- Raghav, A.; Chaudhary, S. Elderly Patient Fall Detection Using Video Surveillance. In Proceedings of the Computer Vision and Image Processing; Raman, B., Murala, S., Chowdhury, A., Dhall, A., Goyal, P., Eds.; Springer: Cham, Switzerland, 2022; pp. 450–459. [Google Scholar]
- Sokolova, M.V.; Serrano-Cuerda, J.; Castillo, J.C.; Fernández-Caballero, A. A fuzzy model for human fall detection in infrared video. J. Intell. Fuzzy Syst. 2013, 24, 215–228. [Google Scholar] [CrossRef]
- Rojas-Albarracín, G.; Fernández-Caballero, A.; Pereira, A.; López, M.T. Heart Attack Detection Using Body Posture and Facial Expression of Pain. In Proceedings of the Artificial Intelligence for Neuroscience and Emotional Systems; Ferrández Vicente, J.M., Val Calvo, M., Adeli, H., Eds.; Springer: Cham, Switzerland, 2024; pp. 411–420. [Google Scholar]
- Roda-Sanchez, L.; Garrido-Hidalgo, C.; García, A.; Teresa, O.; Fernández-Caballero, A. Comparison of RGB-D and IMU-based gesture recognition for human-robot interaction in remanufacturing. Int. J. Adv. Manuf. Technol. 2023, 124, 3099–3111. [Google Scholar] [CrossRef]
- Wang, Y.; Chi, Z.; Liu, M.; Li, G.; Ding, S. High-Performance Lightweight Fall Detection with an Improved YOLOv5s Algorithm. Machines 2023, 11, 818. [Google Scholar] [CrossRef]
- Bustamante, A.; Belmonte, L.M.; Pereira, A.; González, P.; Fernández-Caballero, A.; Morales, R. Vision-Based Human Posture Detection from a Virtual Home-Care Unmanned Aerial Vehicle. In Proceedings of the Bio-Inspired Systems and Applications: From Robotics to Ambient Intelligence; Ferrández Vicente, J.M., Álvarez-Sánchez, J.R., de la Paz López, F., Adeli, H., Eds.; Springer: Cham, Switzerland, 2022; pp. 482–491. [Google Scholar]
- Ebadi, S.E.; Jhang, Y.C.; Zook, A.; Dhakad, S.; Crespi, A.; Parisi, P.; Borkman, S.; Hogins, J.; Ganguly, S. PeopleSansPeople: A Synthetic Data Generator for Human-Centric Computer Vision. arXiv 2022, arXiv:2112.09290. [Google Scholar]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. Skeleton-based human activity recognition using ConvLSTM and guided feature learning. Soft Comput. 2022, 26, 877–890. [Google Scholar] [CrossRef]
- Usmani, A.; Siddiqui, N.; Islam, S. Skeleton joint trajectories based human activity recognition using deep RNN. Multimed. Tools Appl. 2023, 82, 46845–46869. [Google Scholar] [CrossRef]
- Singh, R.; Khurana, R.; Kushwaha, A. Combining CNN streams of dynamic image and depth data for action recognition. Multimed. Syst. 2020, 26, 313–322. [Google Scholar] [CrossRef]
- Dentamaro, V.; Gattulli, V.; Impedovo, D.; Manca, F. Human activity recognition with smartphone-integrated sensors: A survey. Expert Syst. Appl. 2024, 246, 123143. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Koohpayehzadeh, J.; Ghafour, M.Y.; Ahmed, A.M.; Asghari, P.; Souri, A.; Pourasghari, H.; Rezapour, A. An elderly health monitoring system based on biological and behavioral indicators in internet of things. J. Ambient Intell. Humaniz. Comput. 2023, 14, 5085–5095. [Google Scholar] [CrossRef]
- Piao, X. Design of Health and Elderly Care Intelligent Monitoring System Based on IoT Wireless Sensing and Data Mining. Mob. Netw. Appl. 2024, 29, 153–167. [Google Scholar] [CrossRef]
- Jiang, X.; Hu, Z.; Wang, S.; Zhang, Y. A Survey on Artificial Intelligence in Posture Recognition. Comput. Model. Eng. Sci. 2023, 137, 35–82. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.F.R.; Chen, Y.C.; Tsai, C.Y. Deep Learning-Based Human Body Posture Recognition and Tracking for Unmanned Aerial Vehicles. Processes 2022, 10, 2295. [Google Scholar] [CrossRef]
- Ogundokun, R.O.; Maskeliūnas, R.; Damaševičius, R. Human Posture Detection Using Image Augmentation and Hyperparameter-Optimized Transfer Learning Algorithms. Appl. Sci. 2022, 12, 10156. [Google Scholar] [CrossRef]
- Kviatkovsky, I.; Bhonker, N.; Medioni, G. From Real to Synthetic and Back: Synthesizing Training Data for Multi-Person Scene Understanding. arXiv 2020, arXiv:2006.02110. [Google Scholar]
- Liu, X.; Yoo, C.; Xing, F.; Oh, H.; El Fakhri, G.; Kang, J.W.; Woo, J. Deep unsupervised domain adaptation: A review of recent advances and perspectives. APSIPA Trans. Signal Inf. Process. 2022, 11, e25. [Google Scholar] [CrossRef]
- Himeur, Y.; Al-Maadeed, S.; Kheddar, H.; Al-Maadeed, N.; Abualsaud, K.; Mohamed, A.; Khattab, T. Video surveillance using deep transfer learning and deep domain adaptation: Towards better generalization. Eng. Appl. Artif. Intell. 2023, 119, 105698. [Google Scholar] [CrossRef]
- Singhal, P.; Walambe, R.; Ramanna, S.; Kotecha, K. Domain adaptation: Challenges, methods, datasets, and applications. IEEE Access 2023, 11, 6973–7020. [Google Scholar] [CrossRef]
- Anvari, T.; Park, K.; Kim, G. Upper Body Pose Estimation Using Deep Learning for a Virtual Reality Avatar. Appl. Sci. 2023, 13, 2460. [Google Scholar] [CrossRef]
- Romero, A.; Carvalho, P.; Côrte-Real, L.; Pereira, A. Synthesizing Human Activity for Data Generation. J. Imaging 2023, 9, 204. [Google Scholar] [CrossRef]
- Reddy, A.V.; Shah, K.; Paul, W.; Mocharla, R.; Hoffman, J.; Katyal, K.D.; Manocha, D.; de Melo, C.M.; Chellappa, R. Synthetic-to-Real Domain Adaptation for Action Recognition: A Dataset and Baseline Performances. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; pp. 11374–11381. [Google Scholar] [CrossRef]
- Acharya, D.; Tatli, C.J.; Khoshelham, K. Synthetic-real image domain adaptation for indoor camera pose regression using a 3D model. ISPRS J. Photogramm. Remote Sens. 2023, 202, 405–421. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Zhou, X.; Zheng, L. A Study of Using Synthetic Data for Effective Association Knowledge Learning. Mach. Intell. Res. 2023, 20, 194–206. [Google Scholar] [CrossRef]
- Yue, X.; Zhang, Y.; Zhao, S.; Sangiovanni-Vincentelli, A.; Keutzer, K.; Gong, B. Domain Randomization and Pyramid Consistency: Simulation-to-Real Generalization without Accessing Target Domain Data. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Los Alamitos, CA, USA, 2019; pp. 2100–2110. [Google Scholar] [CrossRef]
- Bustamante, A.; Belmonte, L.M.; Morales, R.; Pereira, A.; Fernández-Caballero, A. Video Processing from a Virtual Unmanned Aerial Vehicle: Comparing Two Approaches to Using OpenCV in Unity. Appl. Sci. 2022, 12, 5958. [Google Scholar] [CrossRef]
- Hennicke, L.; Adriano, C.M.; Giese, H.; Koehler, J.M.; Schott, L. Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data. arXiv 2024, arXiv:2405.03243. [Google Scholar]
- Li, Y.; Dong, X.; Chen, C.; Li, J.; Wen, Y.; Spranger, M.; Lyu, L. Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization. arXiv 2024, arXiv:2403.19866. [Google Scholar]
- Nowruzi, F.E.; Kapoor, P.; Kolhatkar, D.; Hassanat, F.A.; Laganière, R.; Rebut, J. How much real data do we actually need: Analyzing object detection performance using synthetic and real data. arXiv 2019, arXiv:1907.07061. [Google Scholar]
- Ng, P.H.; Mai, A.; Nguyen, H. Building an AI-Powered IoT App for Fall Detection Using Yolov8 Approach. In Proceedings of the Intelligence of Things: Technologies and Applications; Dao, N.N., Thinh, T.N., Nguyen, N.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 65–74. [Google Scholar]
- Lu, K.L.; Chu, E.T.H. An Image-Based Fall Detection System for the Elderly. Appl. Sci. 2018, 8, 1995. [Google Scholar] [CrossRef]
- Hassan, M.M.; Gumaei, A.; Aloi, G.; Fortino, G.; Zhou, M. A Smartphone-Enabled Fall Detection Framework for Elderly People in Connected Home Healthcare. IEEE Netw. 2019, 33, 58–63. [Google Scholar] [CrossRef]
- Alarifi, A.; Alwadain, A. Killer heuristic optimized convolution neural network-based fall detection with wearable IoT sensor devices. Measurement 2021, 167, 108258. [Google Scholar] [CrossRef]
- Tateno, S.; Meng, F.; Qian, R.; Hachiya, Y. Privacy-Preserved Fall Detection Method with Three-Dimensional Convolutional Neural Network Using Low-Resolution Infrared Array Sensor. Sensors 2020, 20, 5957. [Google Scholar] [CrossRef]
- Sadreazami, H.; Bolic, M.; Rajan, S. Contactless Fall Detection Using Time-Frequency Analysis and Convolutional Neural Networks. IEEE Trans. Ind. Inform. 2021, 17, 6842–6851. [Google Scholar] [CrossRef]
- Minvielle, L.; Audiffren, J. NurseNet: Monitoring Elderly Levels of Activity with a Piezoelectric Floor. Sensors 2019, 19, 3851. [Google Scholar] [CrossRef] [PubMed]
- Zerkouk, M.; Chikhaoui, B. Spatio-Temporal Abnormal Behavior Prediction in Elderly Persons Using Deep Learning Models. Sensors 2020, 20, 2359. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Wang, G.; Guo, X. Sensor-based activity recognition of solitary elderly via stigmergy and two-layer framework. Eng. Appl. Artif. Intell. 2020, 95, 103859. [Google Scholar] [CrossRef]
- Chutimawattanakul, P.; Samanpiboon, P. Fall Detection for The Elderly using YOLOv4 and LSTM. In Proceedings of the 2022 19th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Prachuap Khiri Khan, Thailand, 24–27 May 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, T.; Ding, Z.; Li, B. Elderly Fall Detection Based on Improved YOLOv5s Network. IEEE Access 2022, 10, 91273–91282. [Google Scholar] [CrossRef]
- Raza, A.; Yousaf, M.H.; Velastin, S.A. Human Fall Detection using YOLO: A Real-Time and AI-on-the-Edge Perspective. In Proceedings of the 2022 12th International Conference on Pattern Recognition Systems (ICPRS), Saint-Etienne, France, 7–10 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, W. GL-YOLO-Lite: A Novel Lightweight Fallen Person Detection Model. Entropy 2023, 25, 587. [Google Scholar] [CrossRef]
- Li, Y.; Wu, Y.; Chen, X.; Chen, H.; Kong, D.; Tang, H.; Li, S. Beyond Human Detection: A Benchmark for Detecting Common Human Posture. Sensors 2023, 23, 8061. [Google Scholar] [CrossRef]
- Yadav, S.K.; Luthra, A.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling. Knowl.-Based Syst. 2022, 239, 107948. [Google Scholar] [CrossRef]
- Guerra, B.M.V.; Ramat, S.; Beltrami, G.; Schmid, M. Recurrent Network Solutions for Human Posture Recognition Based on Kinect Skeletal Data. Sensors 2023, 23, 5260. [Google Scholar] [CrossRef]
- Shafizadegan, F.; Naghsh-Nilchi, A.; Shabaninia, E. Multimodal vision-based human action recognition using deep learning: A review. Artif. Intell. Rev. 2024, 54, 178. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Resize | True |
| imgsz | 640 |
| epochs | 100 |
| total images | 1433 |
| training images | 1254 |
| validating images | 120 |
| testing images | 59 |
| Parameter | Value |
|---|---|
| Outputs per training example | 3 |
| Hue | Between and |
| Saturation | Between and |
| Brightness | Between and |
| Exposure | Between and |
| Blur | Up to 2.5 pixels |
| Noise | Up to of pixels |
| Metric | Min | Max | Avg |
|---|---|---|---|
| Pre-processing time (ms) | 0.00 | 5.00 | 1.93 |
| Inference time (ms) | 11.5 | 72.58 | 30.45 |
| Post-processing time (ms) | 0.00 | 32.59 | 1.63 |
| CPU usage (%) | 0.30 | 2.20 | 0.77 |
| RAM usage (%) | 13.80 | 14.40 | 14.24 |
| GPU usage (%) | 0.00 | 21.00 | 6.57 |
| GPU memory usage (MB) | 2079.00 | 2585.00 | 2546.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bustamante, A.; Belmonte, L.M.; Morales, R.; Pereira, A.; Fernández-Caballero, A. Bridging the Appearance Domain Gap in Elderly Posture Recognition with YOLOv9. Appl. Sci. 2024, 14, 9695. https://doi.org/10.3390/app14219695
Bustamante A, Belmonte LM, Morales R, Pereira A, Fernández-Caballero A. Bridging the Appearance Domain Gap in Elderly Posture Recognition with YOLOv9. Applied Sciences. 2024; 14(21):9695. https://doi.org/10.3390/app14219695
Chicago/Turabian StyleBustamante, Andrés, Lidia M. Belmonte, Rafael Morales, António Pereira, and Antonio Fernández-Caballero. 2024. "Bridging the Appearance Domain Gap in Elderly Posture Recognition with YOLOv9" Applied Sciences 14, no. 21: 9695. https://doi.org/10.3390/app14219695
APA StyleBustamante, A., Belmonte, L. M., Morales, R., Pereira, A., & Fernández-Caballero, A. (2024). Bridging the Appearance Domain Gap in Elderly Posture Recognition with YOLOv9. Applied Sciences, 14(21), 9695. https://doi.org/10.3390/app14219695