4.1. Dataset
The data of the experiment come from two parts: a public dataset and self-built data. The data for constructing the knowledge graph come from the dataset crawled by 39 health networks, including 15 items of information encompassing 7 types of entities, about 33,000 entities, and 170,000 entity relations. The entity relationship includes seven categories: diagnostic examination items, departments, diseases, drugs, food, disease sites, and disease symptoms, which are used to construct the knowledge graph of intelligent dialogue.The label distribution is shown in
Table 3.
Named entity recognition uses the CBLUE dataset [
30], including 15,000 pieces of open training set data, 5000 items of verification set data, and 3000 items of test set data. The dataset of medical text naming entities is divided into nine categories, namely disease (dis), clinical manifestation (sym), drug (dru), medical equipment (equ), medical procedure (pro), body (bod), medical laboratory item (ite), microbiology (mic), and department (dep).The label distribution is shown in
Table 4.
Intention recognition uses the CMID Chinese medical intention dataset [
31]; this contains 12,254 medical questions, which can be divided into 4 categories and 36 subcategories. According to the relationship types of knowledge graph constructed in this paper, some of them are selected. These are definition, etiology, prevention, clinical manifestation (disease symptoms), related diseases, treatment methods, departments to which they belong, infectivity, cure rate, drug taboos, laboratory/physical examination programs, treatment time, and others, totaling 8105 items. This is divided into training set, verification set, and test set according to the ratio of 8:1:1.The label distribution is shown in
Table 5.
4.3. Experimental Environment and Parameter Settings
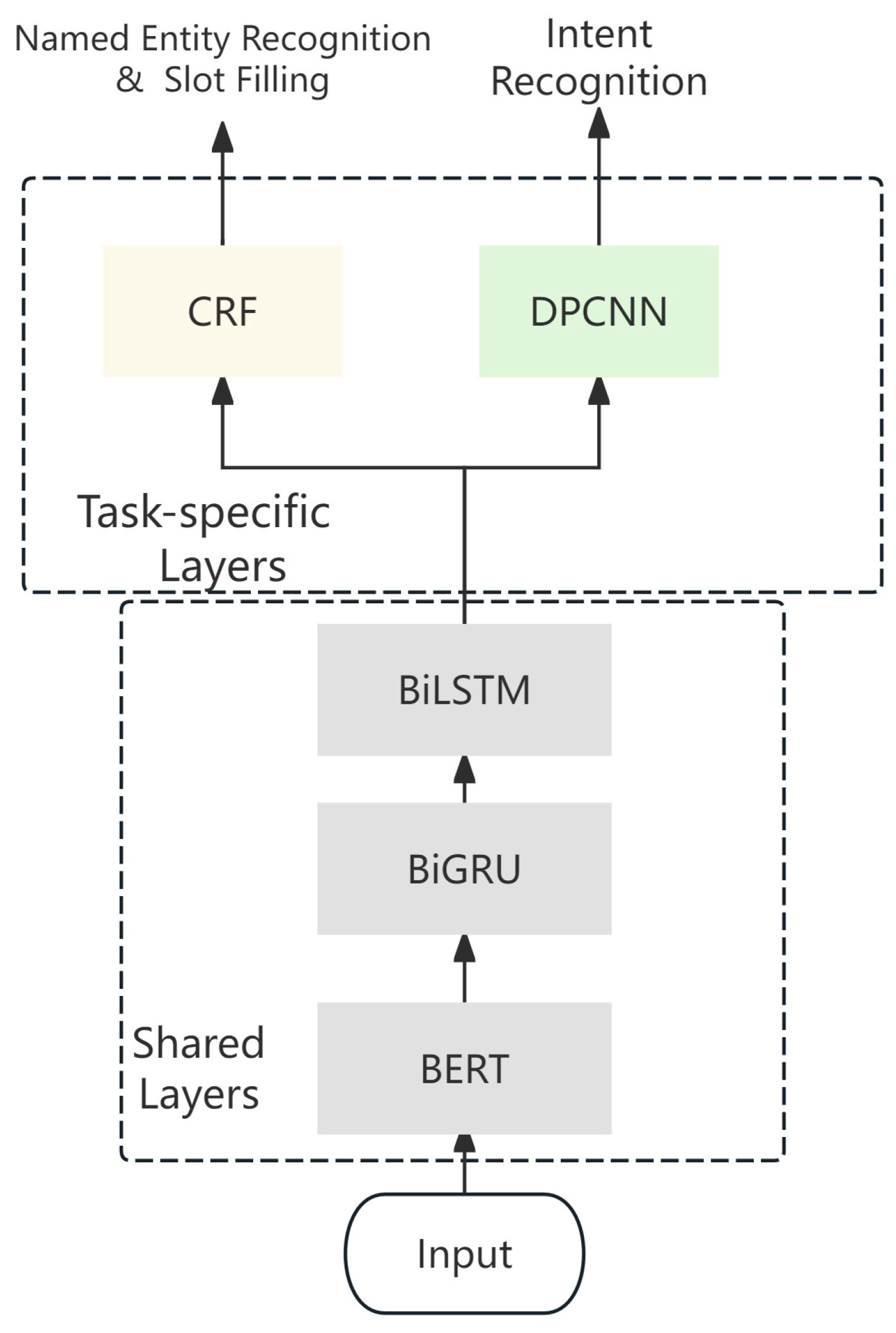
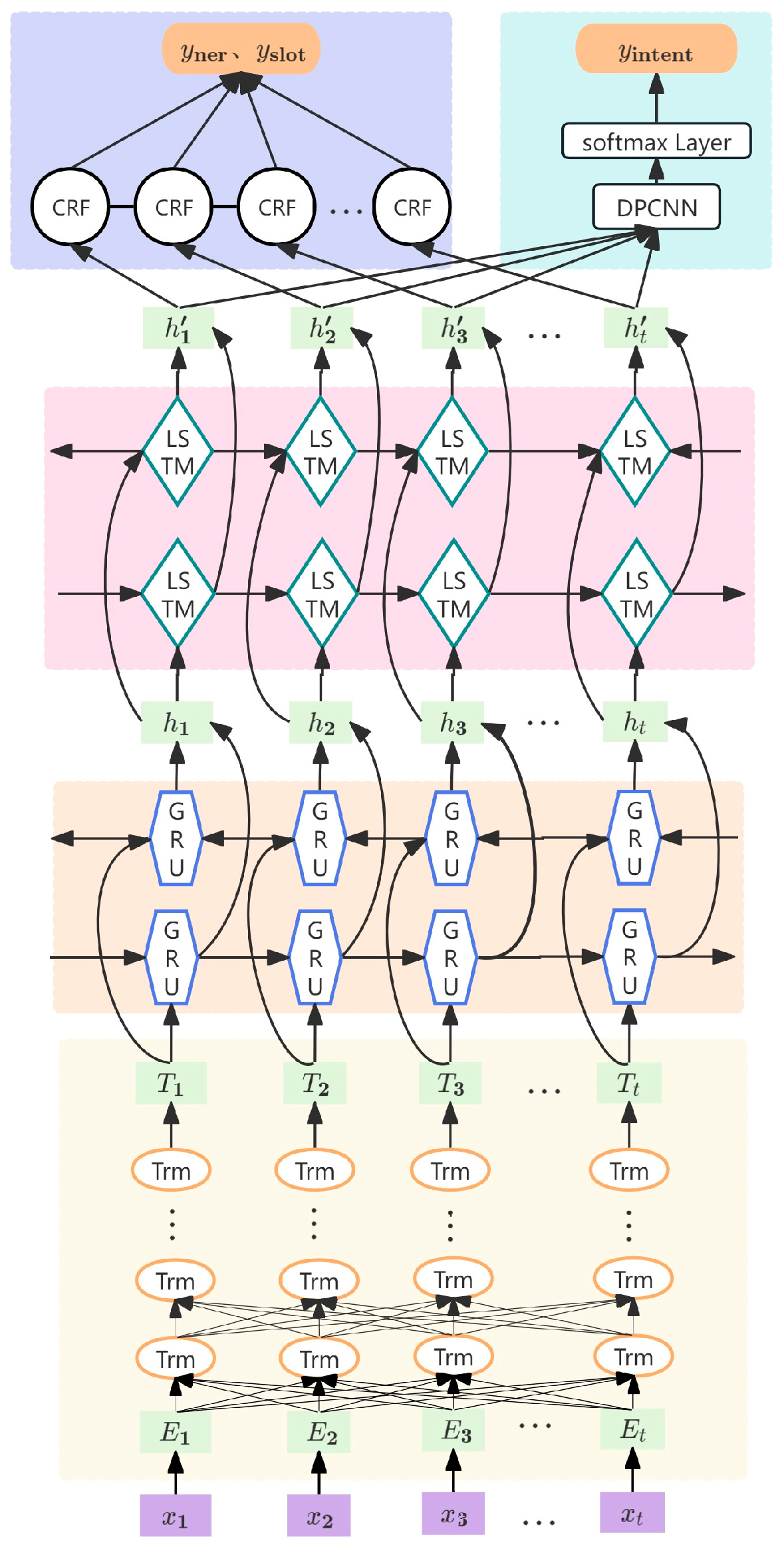
The experiments in this article were based on Python 3.7 and implemented using the Pytorch deep learning framework. The CPU was an Intel CORE i9. The GPU graphics card was a GeForce RTX 3050 and the running memory was 16 GB. The parameters of the multi-task model mainly included the parameters of BERT, BiGRU, and BILSTM. When other parameters were unchanged, the values of variable parameters were changed successively to obtain the optimal parameters of the model. The experiment adopted the Chinese pre-training model “BERT-Base” released by Harbin Engineering University, which contains 12 layers, a hidden layer with 768 dimensions, 12 head models, a total of 110 million parameters, and 128 nodes in the hidden layer. The number of BiGRU layers is 1, the number of BiLSTM layers is 1, the fall rate is set to 0.1 in the entity recognition task, and the fall rate is set to 0.5 in the DPCNN layer. The batch size is set to 32, the global learning rate is , the Adam optimizer is used as the adaptive learning rate optimization algorithm, the convolution kernel of DPCNN is set to 3, and the number of training epochs is set to 20.
In order to verify the validity of the proposed question answering model based on multi-task learning, several models with better performance in intention recognition and named entity recognition are selected for comparison.
4.4. Experimental Results and Analysis
We trained our model using named entity recognition and intent classification training datasets, and tested the performance of named entity recognition and intent classification tasks using F1 values, recall rates, and accuracy rates to evaluate model performance in this study.
The model proposed in this paper was validated in the test set. For the entity recognition task, the accuracy of the model reached 0.8607 in the test set, and for the intention recognition task, the accuracy of the model reached 0.8925.
In order to verify the superiority of the model, the constructed model was compared with BERT, BERTCRF, Bert-BiLSTM and Bert-BiLSTM-CRF models for the entity recognition task, and the results are shown in
Table 6:
As can be seen from
Table 6, the method proposed in this paper has higher accuracy and F1 value, and maintains a high recall rate of 0.8035, while the accuracy reaches 0.8607, which shows its superiority. This shows that the method proposed in this paper can improve the performance of entity recognition. From the comparison, the main conclusions are as follows:
(1) The output of BERT is often the result of word-by-word classification. Adding a CRF layer can optimize the output and make the dependency between tag sequences more reasonable, so as to improve the overall consistency of sequence tagging. Through comparison, it can be found that CRF can effectively capture more relevant information, reduce the missed detection rate, and improve the overall F1 score.
(2) Compared with using BERT or BiLSTM alone, it has the advantage of capturing long-distance dependencies and context information, and is more able to identify complex sequence dependencies. However, compared with simple BERT, the performance improvement of the BERT-BiLSTM model is limited. With the combination of BiLSTM and CRF layers, the model can make use of both the contextual feature extraction ability of BiLSTM and the tag dependency modeling ability of CRF. BiLSTM handles long-distance dependencies and CRF optimizes the dependencies of output tags. The combination of the two makes the model significantly improve in entity recognition tasks. In particular, both precision and recall are improved, which shows that the model has achieved good results in reducing missed detection and false detection.
(3) By adding BiGRU and BiLSTM layers to the output of BERT, the model can make full use of two different cyclic neural network (RNN) structures to process sequence data. BiGRU is relatively simple and can quickly capture short-term dependencies, while BiLSTM is better at capturing long-term dependencies. This dual RNN architecture can effectively balance the capture ability of short-term and long-term dependencies and make the model more robust when dealing with serial data with complex dependencies. This characteristic is particularly evident in the identification of long-distance dependent entities. From the experimental results, this model achieves a good balance between accuracy and recall rate. Compared with other models, this model performs well in capturing the correct entities and covering as many entities as possible. This balance makes the model more practical in real-world application, as it can not only reduce false detection (improve accuracy), but also reduce missed detection (improve recall rate), so as to provide users with more reliable entity recognition results.
For the intention recognition task, we compared the proposed model with CNN, BERT, BiLSTM, TextCNN, and TextRNN, and the results are shown in
Table 7.
As can be seen from
Table 7, the method proposed in this paper shows good results in accuracy rate, recall rate, and F1 value, and the recall rate was maintained at 88% while the accuracy rate reached 89%.
Through comparative experiments, the following can be concluded:
(1) From the introduction of BERT, the CNN and BILSTM models provide relatively low accuracy, and these results show their limitations in capturing contextual information and capturing sequential dependencies. The CNN model mainly extracts local features through convolution operations, which may lose long-distance dependent information. BILSTM is good enough to capture better sequence-dependent information, but its handling of long-distance dependencies may be inadequate. With the introduction of the BERT model, the effect is significantly improved, possibly because the BERT pre-trained model is better able to understand contextual information and capture the bidirectional dependencies of words in a multi-layer bidirectional structure to improve the understanding of the global context of the sentence.
(2) By combining BERT, BiGRU, BiLSTM, and DPCNN, the model can take advantage of the advantages of various frames. BERT provides powerful context understanding, BiGRU and BiLSTM enhance the capture of long- and short-term dependencies, and DPCNN further extracts deep textual features. This multi-layered, hybrid architecture makes the model perform well in intention recognition tasks. In particular, the introduction of DPCNN improves the feature extraction ability of the model, meaning the model can more accurately identify complex intentions.
4.5. Ablation Experiment
In order to test the effect of the proposed method on performance and explore the effect on contextual information and complex text, ablation experiments on the above models were carried out on CBLUE and CMID datasets. The experimental results are shown in
Table 8.
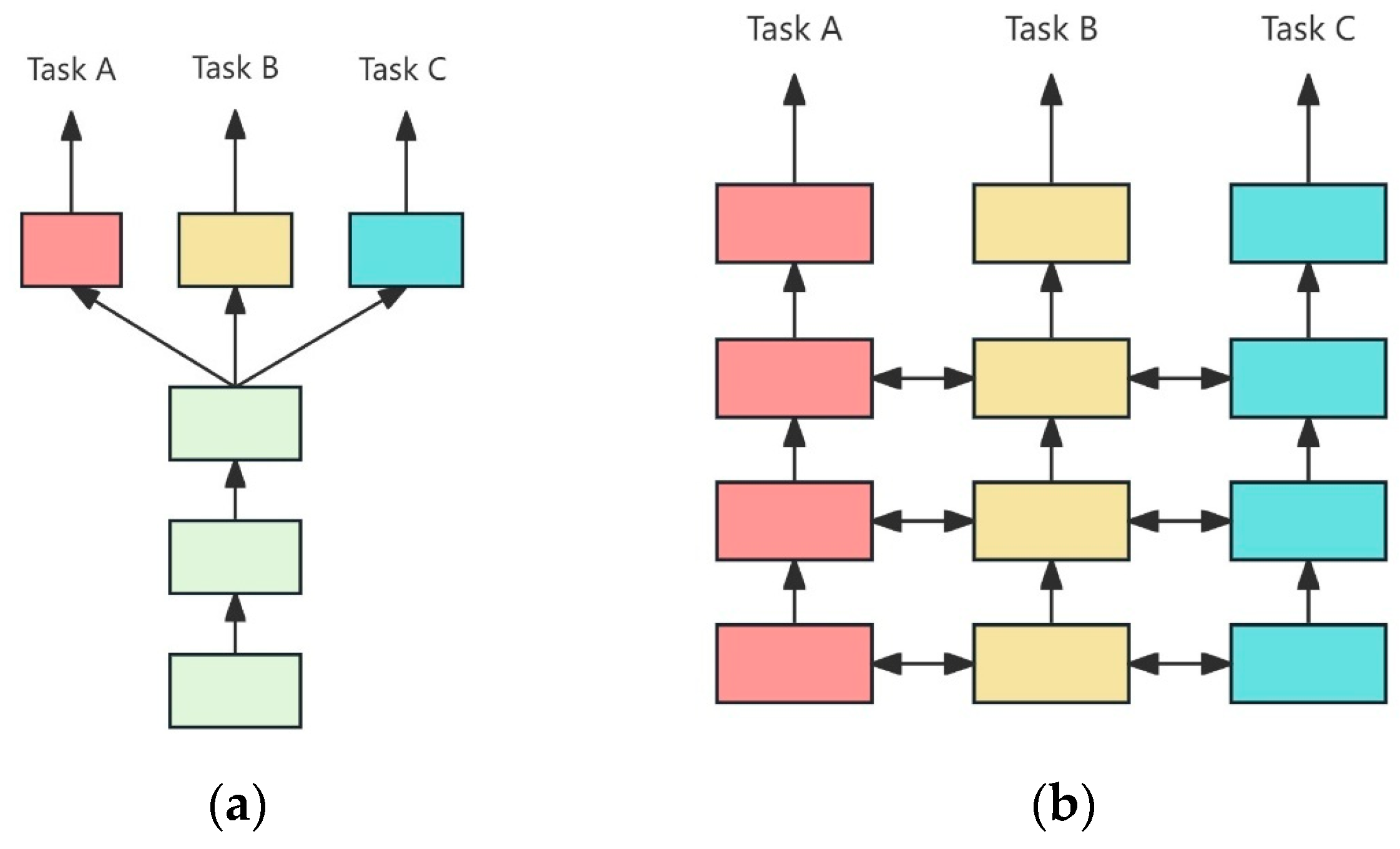
Among them, Modules 1 and 3 are the single task test results of entity recognition and intention recognition, respectively. For entity recognition and intention recognition tasks, F1 values decrease by 1.8% and 1.2%, respectively, compared with the model proposed in this paper, which verifies that multi-task learning can effectively capture the correlation between different tasks. The model’s ability to understand specific tasks is improved. It can be seen from the ablation experiment that in the entity recognition task, the auxiliary task of intention recognition enables the model to better understand the semantic relationship in the context, thus improving the accuracy of entity recognition. In the intention recognition task, the additional features provided by entity recognition enhance the model’s understanding of the user’s input intention, and further improve the accuracy of the intention recognition. Ablation results also show that multi-task learning can make better use of training data, especially in the case of relatively limited data. By training multiple tasks at the same time, the model can more fully learn the common features between different tasks, thereby improving the overall performance. However, it has to be admitted that although multi-task learning has the potential to improve the performance of the model, negative transfer is a potential problem that needs to be paid attention to. Future research should focus on how to effectively alleviate this phenomenon and find ways to optimize task combination and the sharing mechanism to ensure that the impact of negative migration on model performance is reduced while maximizing task synergy.
Modules 2 and 4 are the experimental results of entity recognition and intention recognition after the BiGRU layer is removed from the sharing layer, respectively. For entity recognition and intention recognition tasks, F1 values are reduced by 1% and 3.1%, respectively, but the recall rate of entity recognition tasks is increased by 0.7%, which verifies the ability of two-way information flow with BiGRU. The ability to capture forward and backward context dependencies simultaneously plays an important role in deep secondary feature extraction in the framework of multi-task learning. Through the ablation experiment, we can see that after removing the BiGRU layer, although the recall rate in the entity recognition task is slightly improved, the overall F1 value decreases; in particular, in the intention recognition task, the F1 value decreases significantly by 3.1%. The BiGRU layer can capture the long-term dependency information in the sequence data; in particular, in the intention recognition task, it helps the model to understand the global information of the context more accurately and improve the ability to identify complex intentions. Although the recall rate of entity recognition tasks is improved after removing the BiGRU layer, this can be due to the weakening of the overfitting of some entities by the model, but it also leads to a decrease in the accuracy of some entities, resulting in a decline in F1 values as a whole.
In addition, although complex deep learning models such as BERT, BiGRU, and BiLSTM perform well in processing medical data, their lack of interpretability may pose risks. Especially in the medical field, the transparency of model decision-making is very important to the trust of clinicians and the acceptability of results. Therefore, we need to find a balance between model performance and interpretability. In order to enhance the interpretability of the model, consideration is introduced into the attention mechanism to enable the model to show the input characteristics concerned in the decision-making process. In addition, interpretable techniques such as LIME (locally interpretable model unknowable) and SHAP (Shapley value) can be used to help interpret the prediction results of the model, thereby enhancing doctors’ trust in the AI system.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}