An ELECTRA-Based Model for Power Safety Named Entity Recognition


Abstract
1. Introduction
2. Materials and Methods
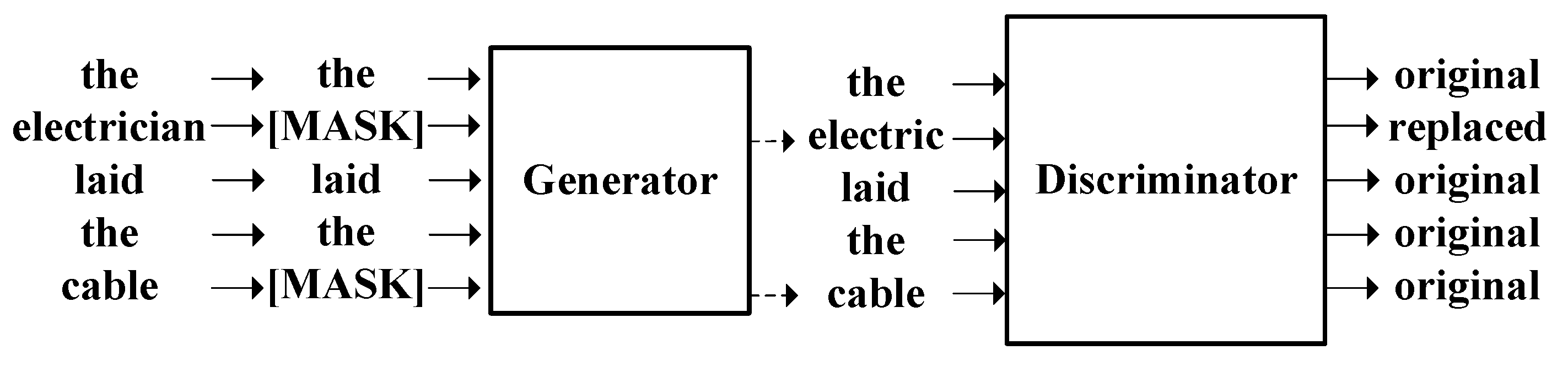
2.1. ELECTRA
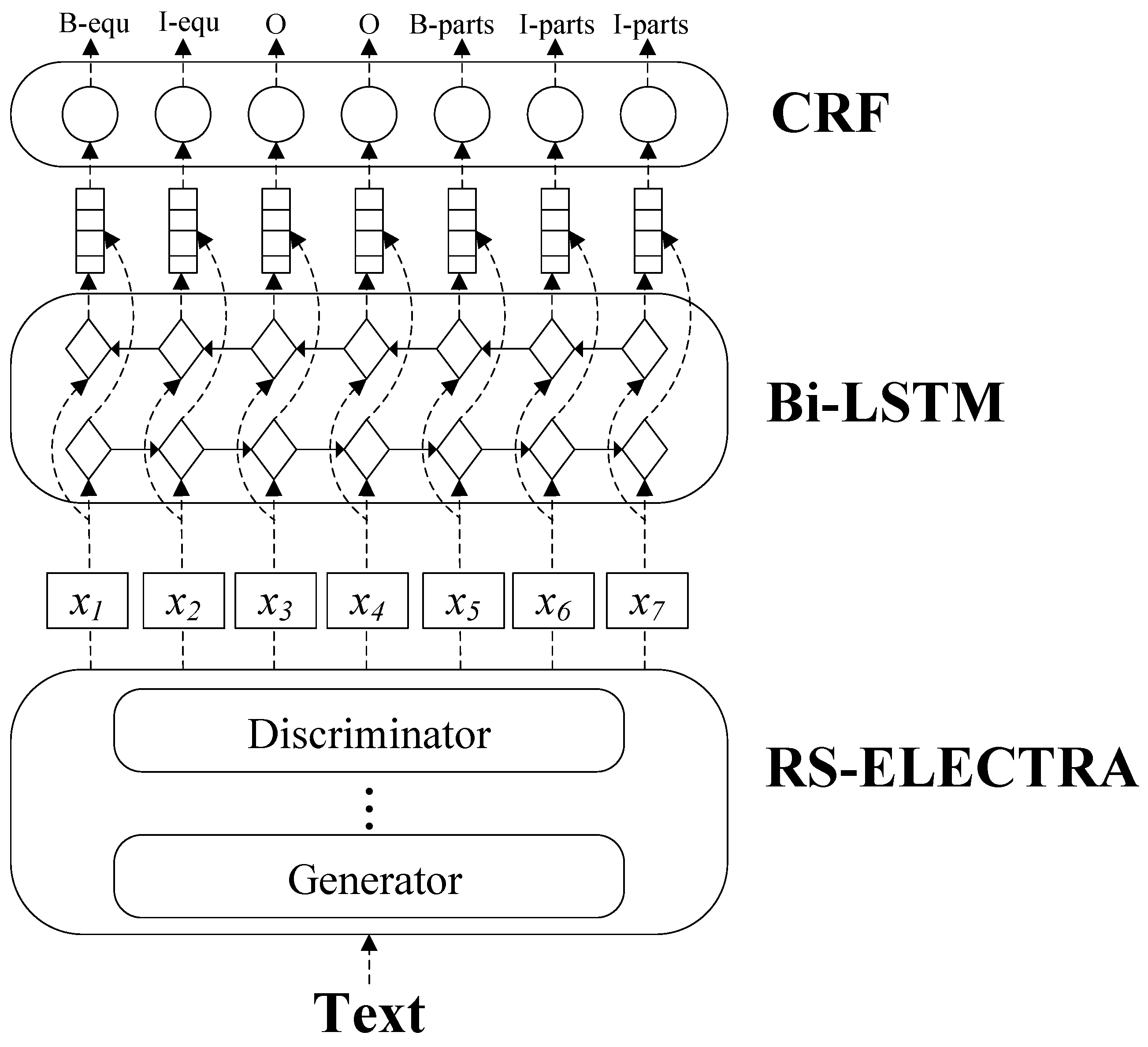
2.2. RS-ELECTRA
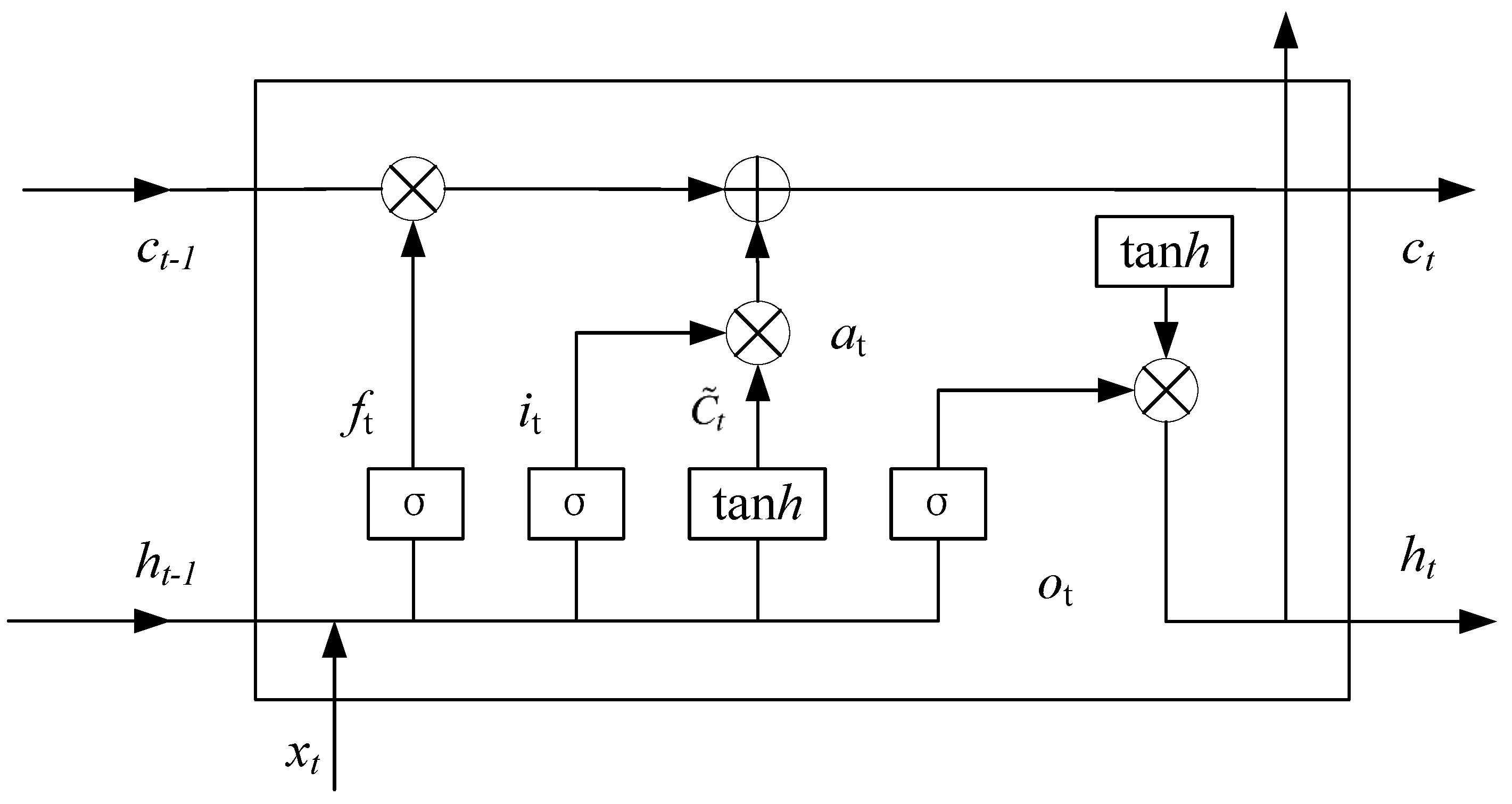
2.3. BiLSTM
2.4. CRF
3. Results
3.1. Dataset
3.2. Evaluation Standard
3.3. Experimental Environment
3.4. Experimental Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Du, N.; Xu, J.; Liu, X.; Song, Y.; Qiu, L.; Zhao, Y.; Sun, M. Application and research of knowledge graph in electric power field. Electr. Power Inf. Commun. Technol. 2020, 18, 60–66. [Google Scholar]
- Sharma, A.; Amrita.; Chakraborty, S.; Kumar, S. Named entity recognition in natural language processing: A systematic review. In Proceedings of the Second Doctoral Symposium on Computational Intelligence: DoSCI 2021; Springer: Singapore, 2022; pp. 817–828. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticæ Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Sutton, C. An Introduction to Conditional Random Fields. Found. Trends Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. ERNIE: Enhanced Representation through Knowledge Integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V. ELECTRA: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Pakhale, K. Comprehensive Overview of Named Entity Recognition: Models, Domain-Specific Applications and Challenges. arXiv 2023, arXiv:2309.14084. [Google Scholar]
- Sun, C.; Tang, M.; Liang, L.; Zou, W. Software Entity Recognition Method Based on BERT Embedding. In Proceedings of the Machine Learning for Cyber Security: Third International Conference, ML4CS 2020, Guangzhou, China, 8–10 October 2020; Chen, X., Yan, H., Yan, Q., Zhang, X., Eds.; Springer: Cham, Switzerland, 2020; pp. 33–47. [Google Scholar] [CrossRef]
- Hu, W.; He, L.; Ma, H.; Wang, K.; Xiao, J. KGNER: Improving Chinese Named Entity Recognition by BERT Infused with the Knowledge Graph. Appl. Sci. 2022, 12, 7702. [Google Scholar] [CrossRef]
- Yang, R.; Gan, Y.; Zhang, C. Chinese Named Entity Recognition Based on BERT and Lightweight Feature Extraction Model. Information 2022, 13, 515. [Google Scholar] [CrossRef]
- He, L.; Zhang, X.; Li, Z.; Xiao, P.; Wei, Z.; Cheng, X.; Qu, S. A Chinese Named Entity Recognition Model of Maintenance Records for Power Primary Equipment Based on Progressive Multitype Feature Fusion. Complexity 2022, 2022, e8114217. [Google Scholar] [CrossRef]
- Chen, Y.; Liang, Z.; Tan, Z.; Lin, D. Named Entity Recognition in Power Marketing Domain Based on Whole Word Masking and Dual Feature Extraction. Appl. Sci. 2023, 13, 9338. [Google Scholar] [CrossRef]
- Meng, F.; Yang, S.; Wang, J.; Xia, L.; Liu, H. Creating Knowledge Graph of Electric Power Equipment Faults Based on BERT–BiLSTM–CRF Model. J. Electr. Eng. Technol. 2022, 17, 2507–2516. [Google Scholar] [CrossRef]
- Fan, X.; Zhang, Q.; Jia, Q.; Lin, J.; Li, C. Research on Named Entity Recognition Method Based on Deep Learning in Electric Power Public Opinion Field. In Proceedings of the 2022 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–25 September 2022; pp. 140–143, ISSN: 2770-7695. [Google Scholar] [CrossRef]
- Yang, A.; Xia, Y. Study of agricultural finance policy information extraction based on ELECTRA-BiLSTM-CRF. Appl. Math. Nonlinear Sci. 2023, 8, 2541–2550. [Google Scholar] [CrossRef]
- Fu, Y.; Bu, F. Research on Named Entity Recognition Based on ELECTRA and Intelligent Face Image Processing. In Proceedings of the 2021 IEEE International Conference on Emergency Science and Information Technology (ICESIT), Chongqing, China, 22–24 November 2021; pp. 781–786. [Google Scholar] [CrossRef]
- Feng, J.; Wang, H.; Peng, L.; Wang, Y.; Song, H.; Guo, H. Chinese Named Entity Recognition Within the Electric Power Domain. In Proceedings of the Emerging Information Security and Applications: 4th International Conference, EISA 2023, Hangzhou, China, 6–7 December 2023; Springer: Singapore, 2024; pp. 133–146, ISSN: 1865-0937. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhang, B.; Sennrich, R. Root Mean Square Layer Normalization. arXiv 2019, arXiv:1910.07467. [Google Scholar]
- Shazeer, N. GLU Variants Improve Transformer. arXiv 2020. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2023. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Eberts, M.; Ulges, A. Span-based Joint Entity and Relation Extraction with Transformer Pre-training. arXiv 2021. [Google Scholar] [CrossRef]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Document Name | Number |
|---|---|
| Compilation of National Power Accidents and Power Safety Incidents | 162,431 |
| Power Safety Work Regulations of the State Grid Corporation—Substation Section | 52,248 |
| Power Safety Work Regulations of the State Grid Corporation—Line Section | 43,881 |
| “Twenty-Five Key Requirements for Preventing Power Generation Accidents”—Case Warning Teaching Material | 110,592 |
| Entity | Description | Example | Number |
|---|---|---|---|
| Equipment | Name of power equipment | Transformer | 7690 |
| Component | Constituent part or accessory of power equipment | Bushing | 6152 |
| Operation | Method or step of operating power equipment | Maintenance | 5384 |
| Status | Working state or attribute of power equipment | Energized | 2692 |
| Condition | Prerequisite or limiting condition for operating power equipment | Pressure | 1538 |
| Result | Consequence or impact of operating power equipment | Short Circuit | 5383 |
| Reason | Cause or inducement of power equipment failure or accident | Overload | 2843 |
| Purpose | Purpose or intention of operating power equipment | Protect | 4229 |
| Other | Entities not belonging to the above types | 110 KV | 8064 |
| Hyperparameter | Hyperparameter Setting |
|---|---|
| learning-rate | 2 |
| optimizer | Adam |
| batch size | 32 |
| epoch | 1000 |
| dropout | 0.1 |
| max seq length | 128 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| BiLSTM-CRF | 0.86 | 0.88 | 0.87 |
| BERT-BiLSTM-CRF | 0.90 | 0.91 | 0.90 |
| RS-ELECTRA-BiLSTM-CRF | 0.92 | 0.93 | 0.93 |
| Entity | BiLSTM-CRF | BERT-BiLSTM-CRF | RS-ELECTRA-BiLSTM-CRF | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | |
| Equipment | 0.89 | 0.83 | 0.87 | 0.94 | 0.89 | 0.92 | 0.96 | 0.97 | 0.96 |
| Component | 0.90 | 0.88 | 0.89 | 0.94 | 0.95 | 0.94 | 0.98 | 0.99 | 0.98 |
| Operation | 0.88 | 0.88 | 0.88 | 0.93 | 0.90 | 0.91 | 0.96 | 0.96 | 0.96 |
| Status | 0.73 | 0.83 | 0.76 | 0.88 | 0.92 | 0.90 | 0.93 | 0.86 | 0.89 |
| Condition | 0.76 | 0.82 | 0.79 | 0.91 | 0.83 | 0.87 | 0.93 | 0.89 | 0.91 |
| Result | 0.86 | 0.71 | 0.78 | 0.87 | 0.85 | 0.86 | 0.87 | 0.94 | 0.90 |
| Reason | 0.79 | 0.77 | 0.78 | 0.86 | 0.90 | 0.88 | 0.92 | 0.86 | 0.88 |
| Purpose | 0.84 | 0.77 | 0.81 | 0.92 | 0.91 | 0.92 | 0.93 | 0.95 | 0.94 |
| Other | 0.83 | 0.84 | 0.83 | 0.92 | 0.90 | 0.91 | 0.92 | 0.92 | 0.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Sun, Z.; Zhou, B. An ELECTRA-Based Model for Power Safety Named Entity Recognition. Appl. Sci. 2024, 14, 9410. https://doi.org/10.3390/app14209410
Liu P, Sun Z, Zhou B. An ELECTRA-Based Model for Power Safety Named Entity Recognition. Applied Sciences. 2024; 14(20):9410. https://doi.org/10.3390/app14209410
Chicago/Turabian StyleLiu, Peng, Zhenfu Sun, and Biao Zhou. 2024. "An ELECTRA-Based Model for Power Safety Named Entity Recognition" Applied Sciences 14, no. 20: 9410. https://doi.org/10.3390/app14209410
APA StyleLiu, P., Sun, Z., & Zhou, B. (2024). An ELECTRA-Based Model for Power Safety Named Entity Recognition. Applied Sciences, 14(20), 9410. https://doi.org/10.3390/app14209410