



PRC-Light YOLO: An Efficient Lightweight Model for Fabric Defect Detection

Abstract
1. Introduction
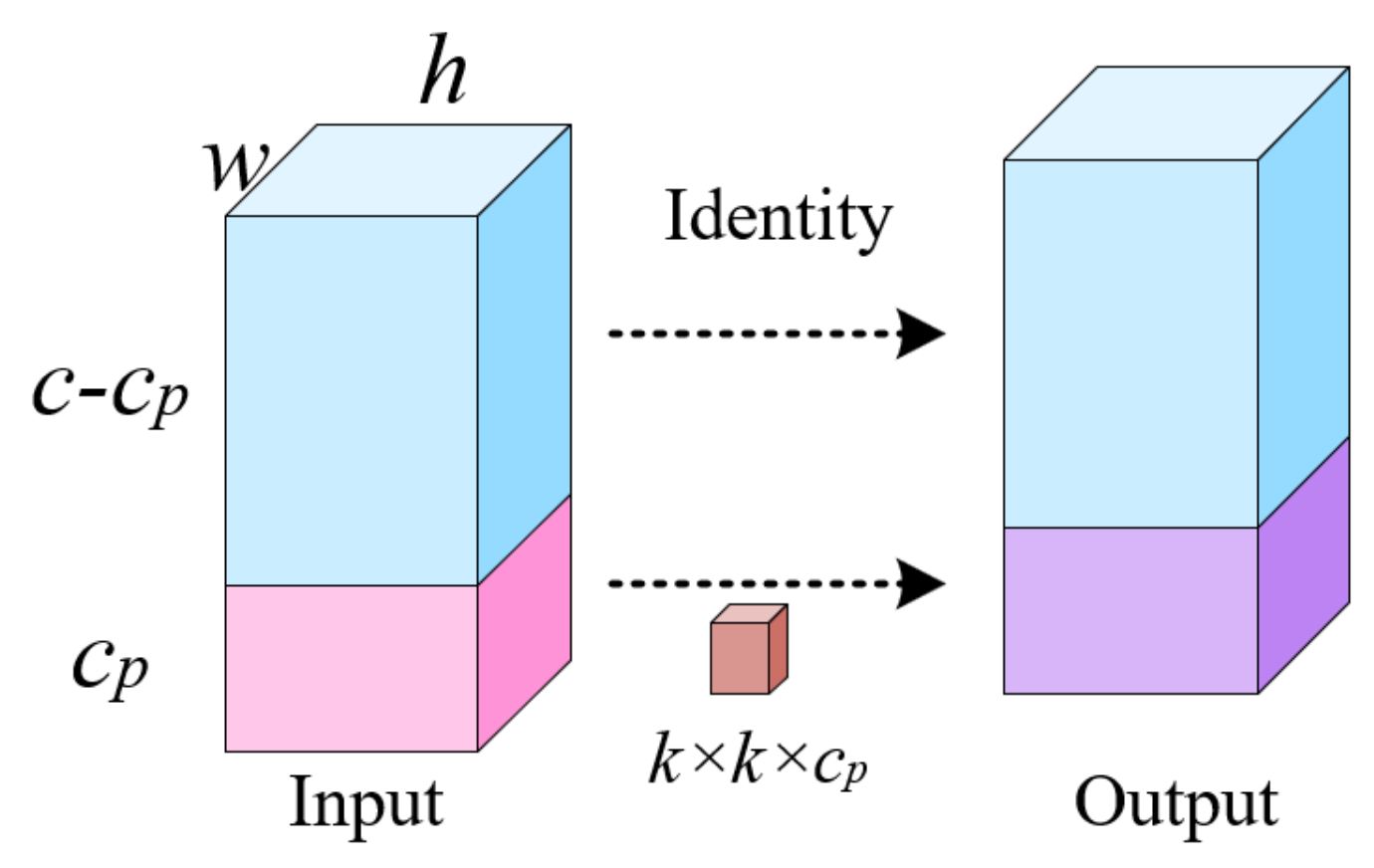
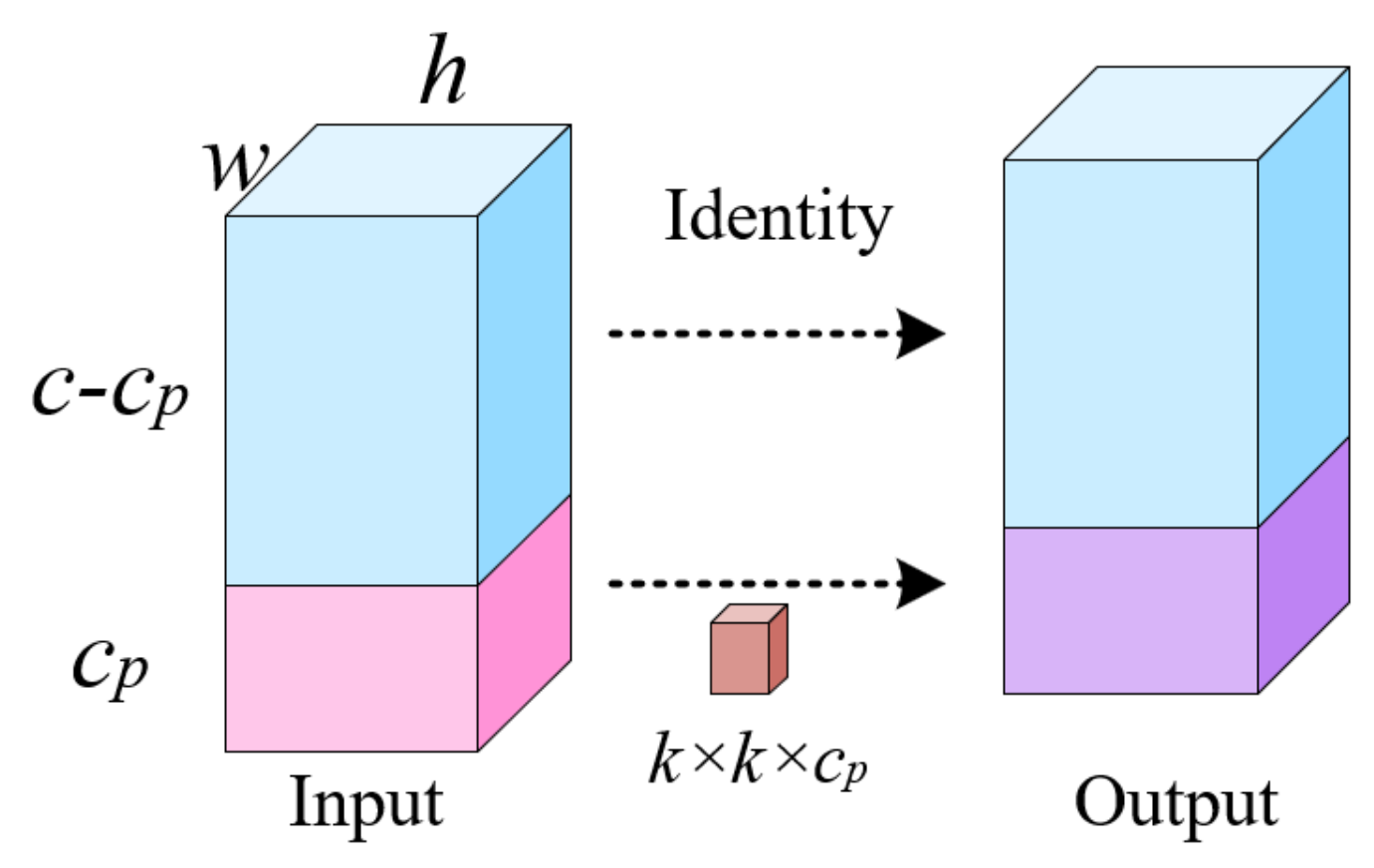
- We propose Partial Convolution (PConv) to replace the Conv of Extended-Efficient Layer Aggregation Networks (E-ELAN) in the Backbone module. This replacement aims to decrease network model calculation and parameters.
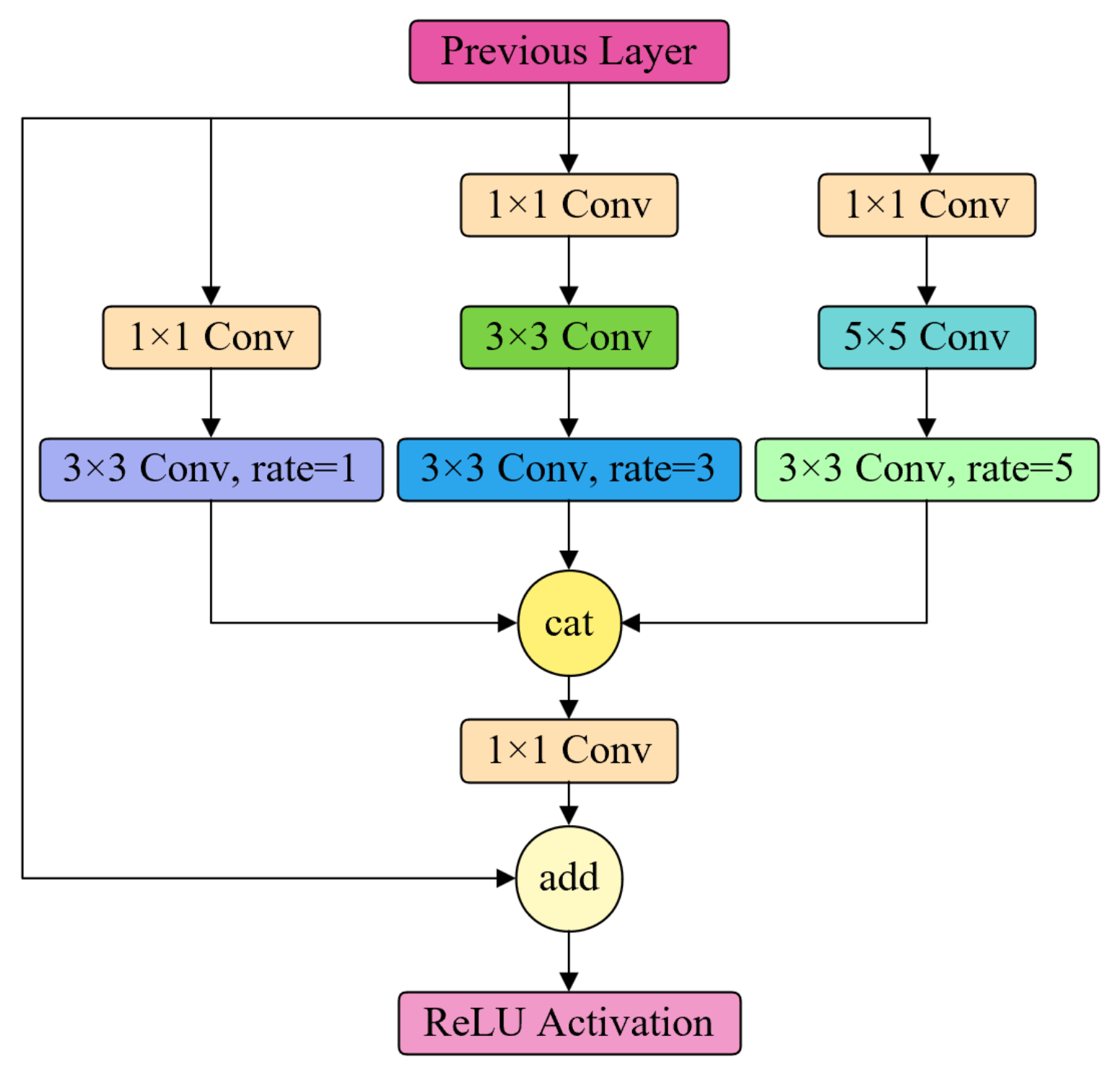
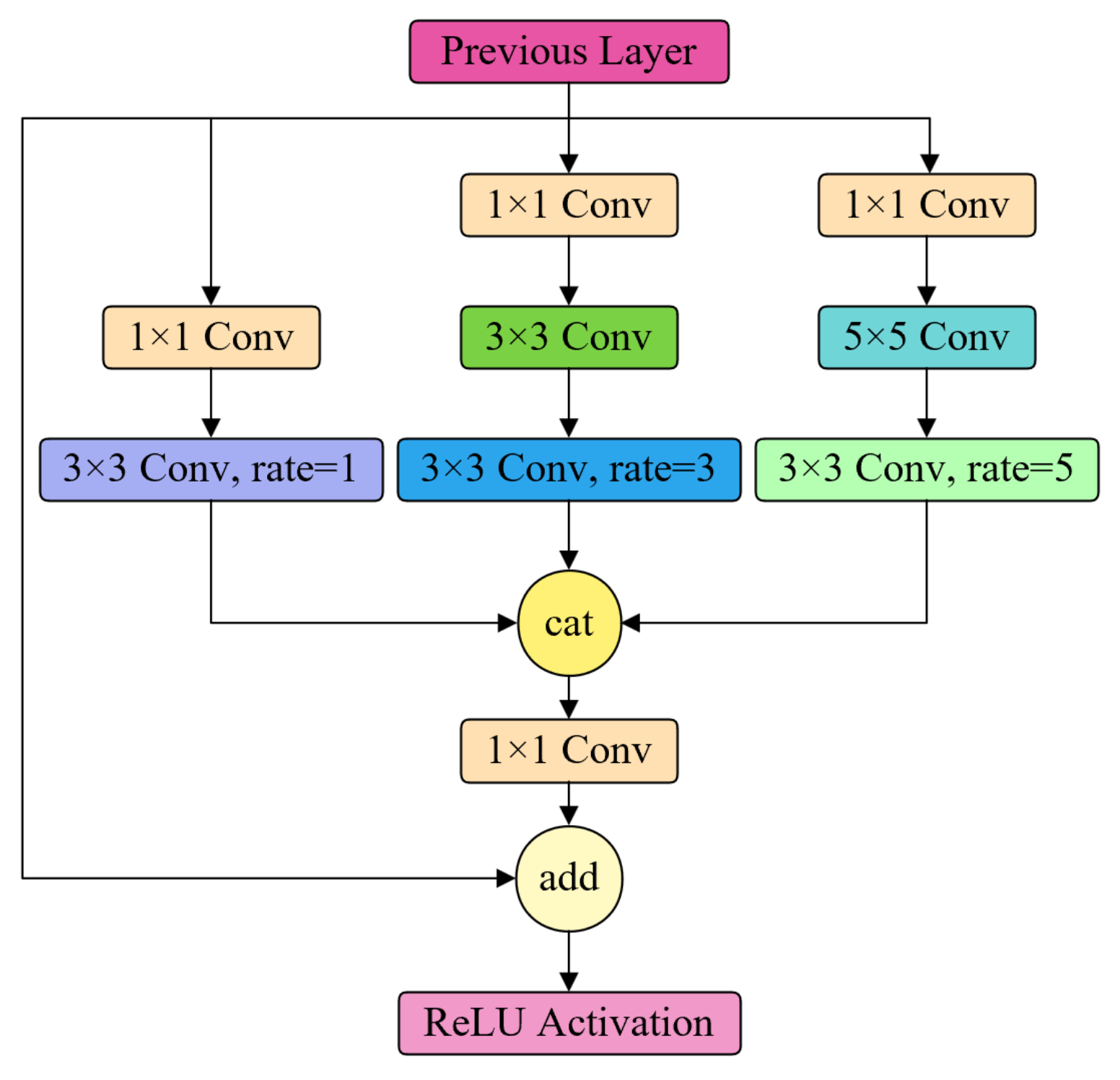
- In the Neck module, we incorporate a Receptive Field Block (RFB) [21] and integrate the Content-Aware ReAssembly of FEatures (CARAFE) lightweight upsampling operator.
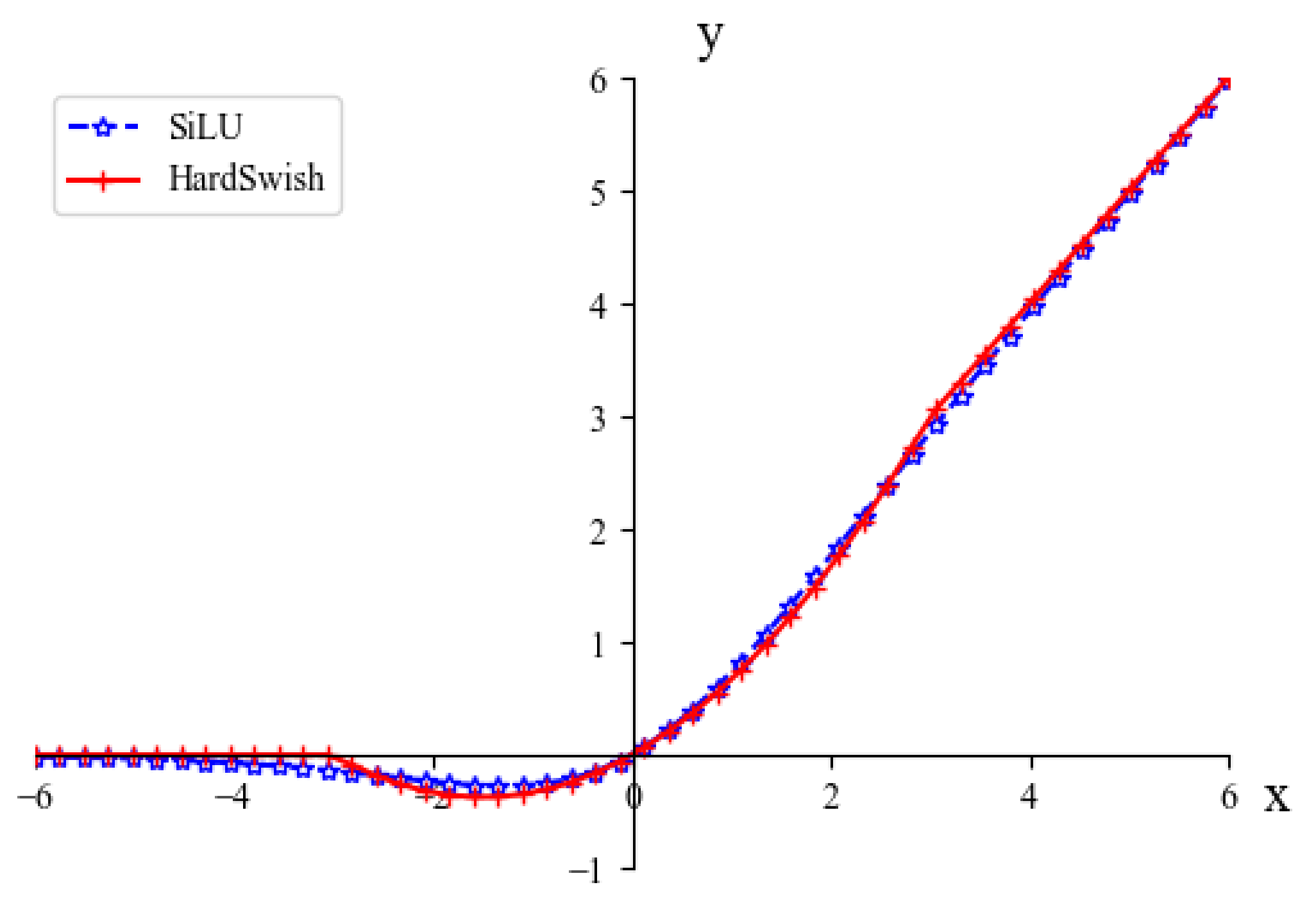
- We utilize the HardSwish activation function to decrease the computational burden and memory access of the network. The Wise-IOU v3 with dynamic non-monotonic focusing mechanism is applied as the bounding box loss function of the model.
- Compared with YOLOv7 and other detection models, the experimental results validate that PRC-Light YOLO has the highest mAP and improves the performance of fabric defect detection.
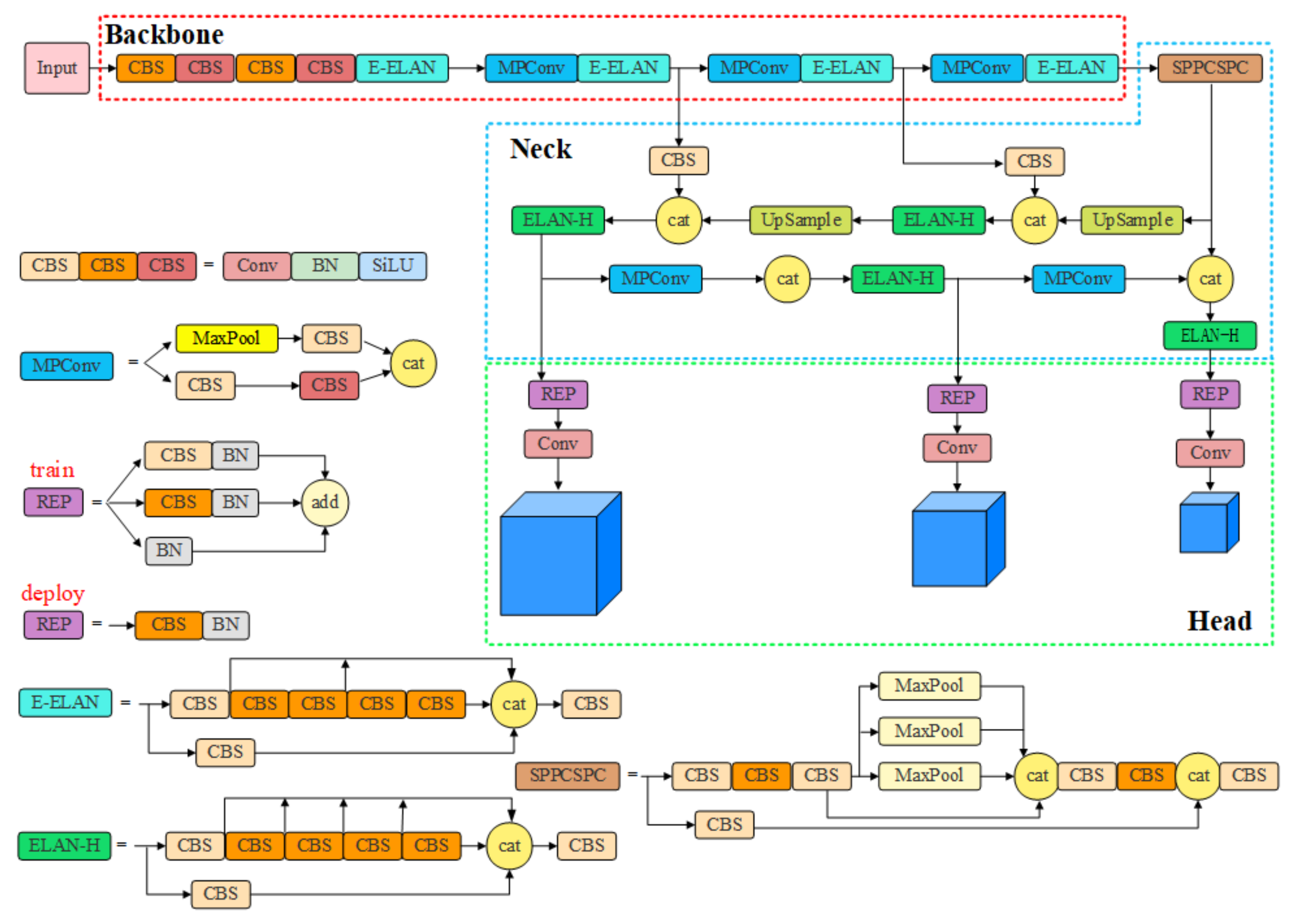
2. YOLOv7 Model Structure
2.1. Backbone
2.2. Neck
2.3. Head
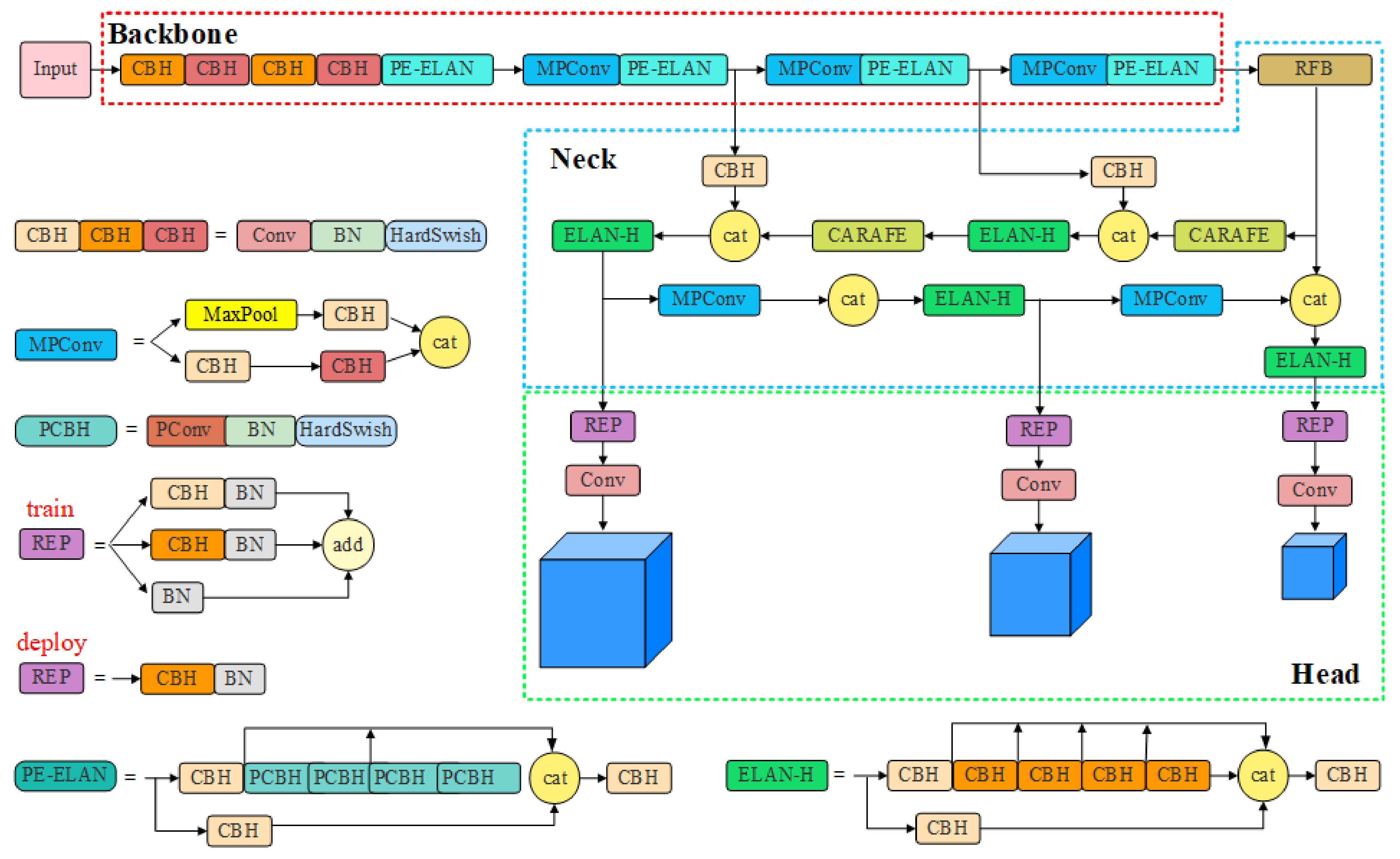
3. Fabric Defect Detection Based on PRC-Light YOLO
3.1. Lightweight Backbone Network
3.2. Improved Feature Fusion Network
3.2.1. RFB Feature Pyramid
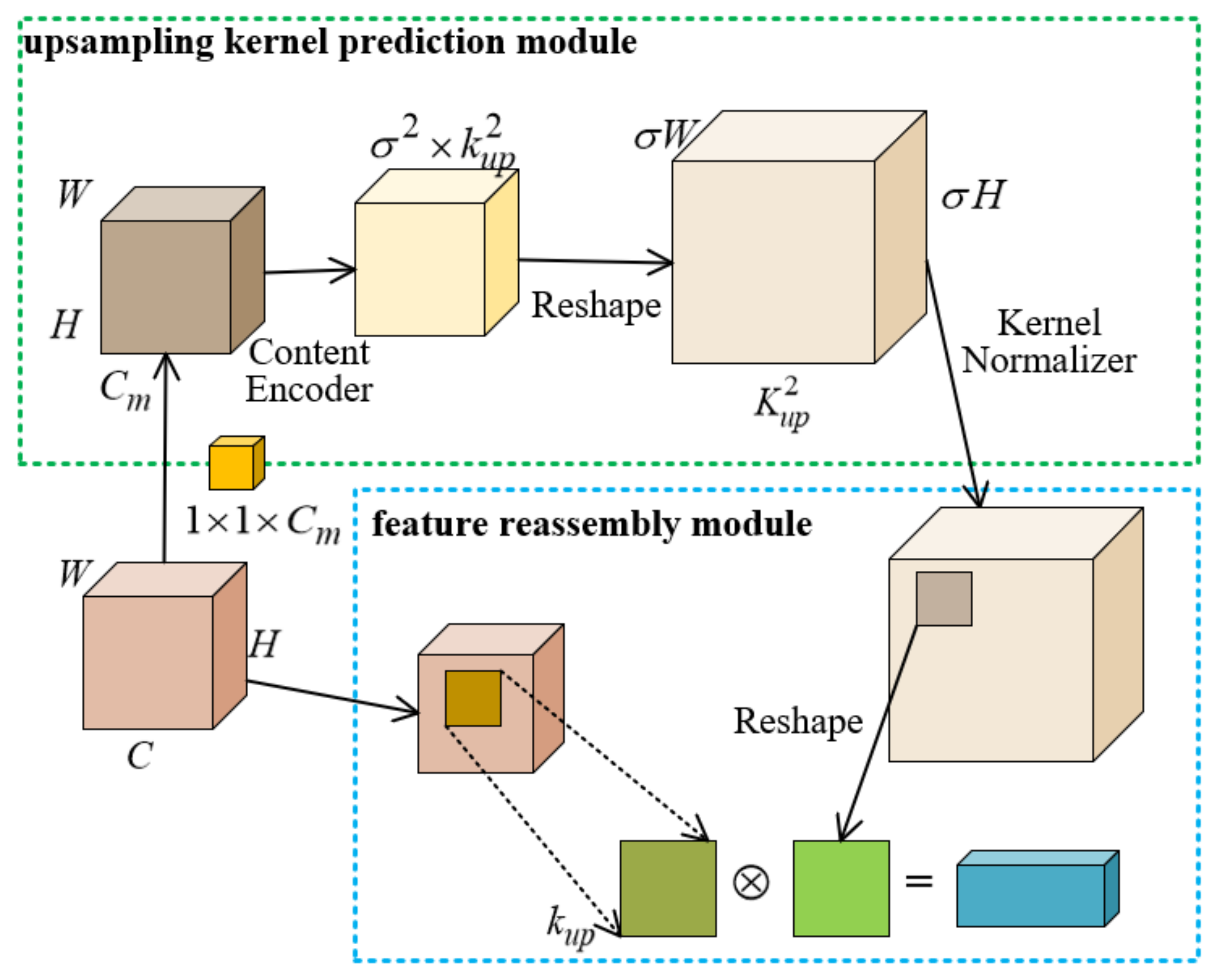
3.2.2. CARAFE Upsampling Operator
3.3. HardSwish Activation Function
3.4. Wise-IOU v3 Bounding Box Loss
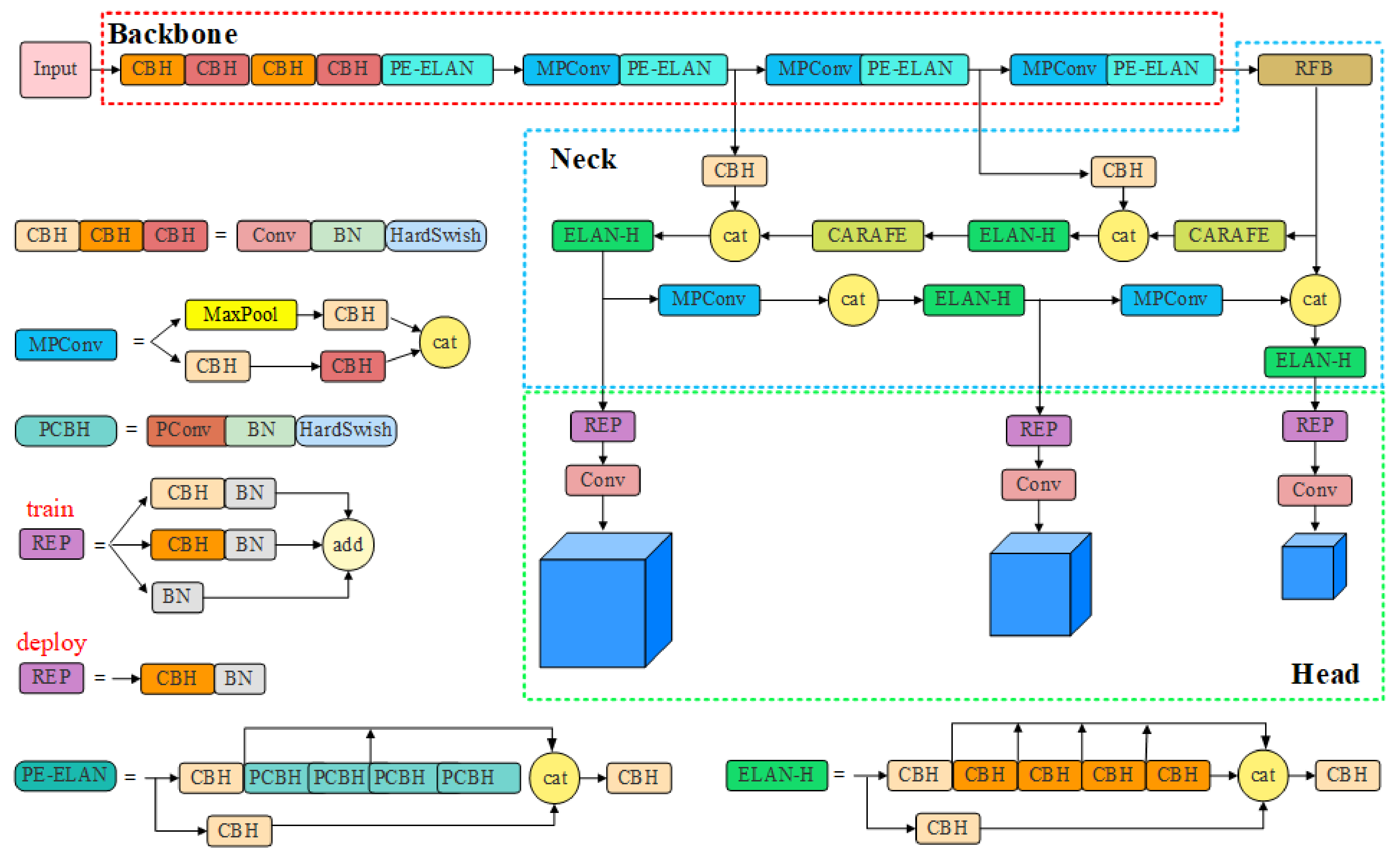
3.5. PRC-Light YOLO Model Structure
4. Experiment
4.1. Fabric Defect Image Dataset
4.2. Experimental Environment and Parameter Configuration
4.3. Evaluation Metrics
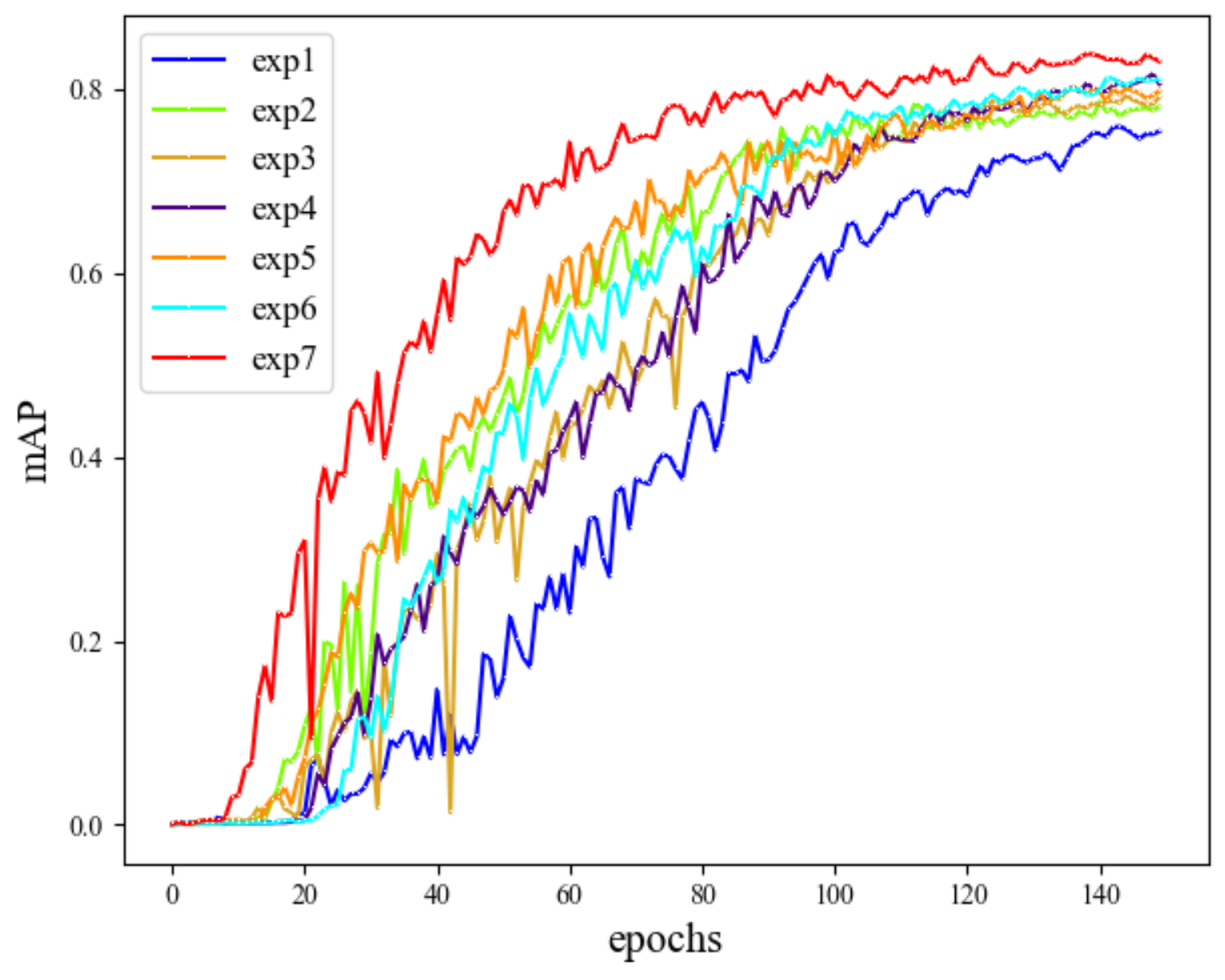
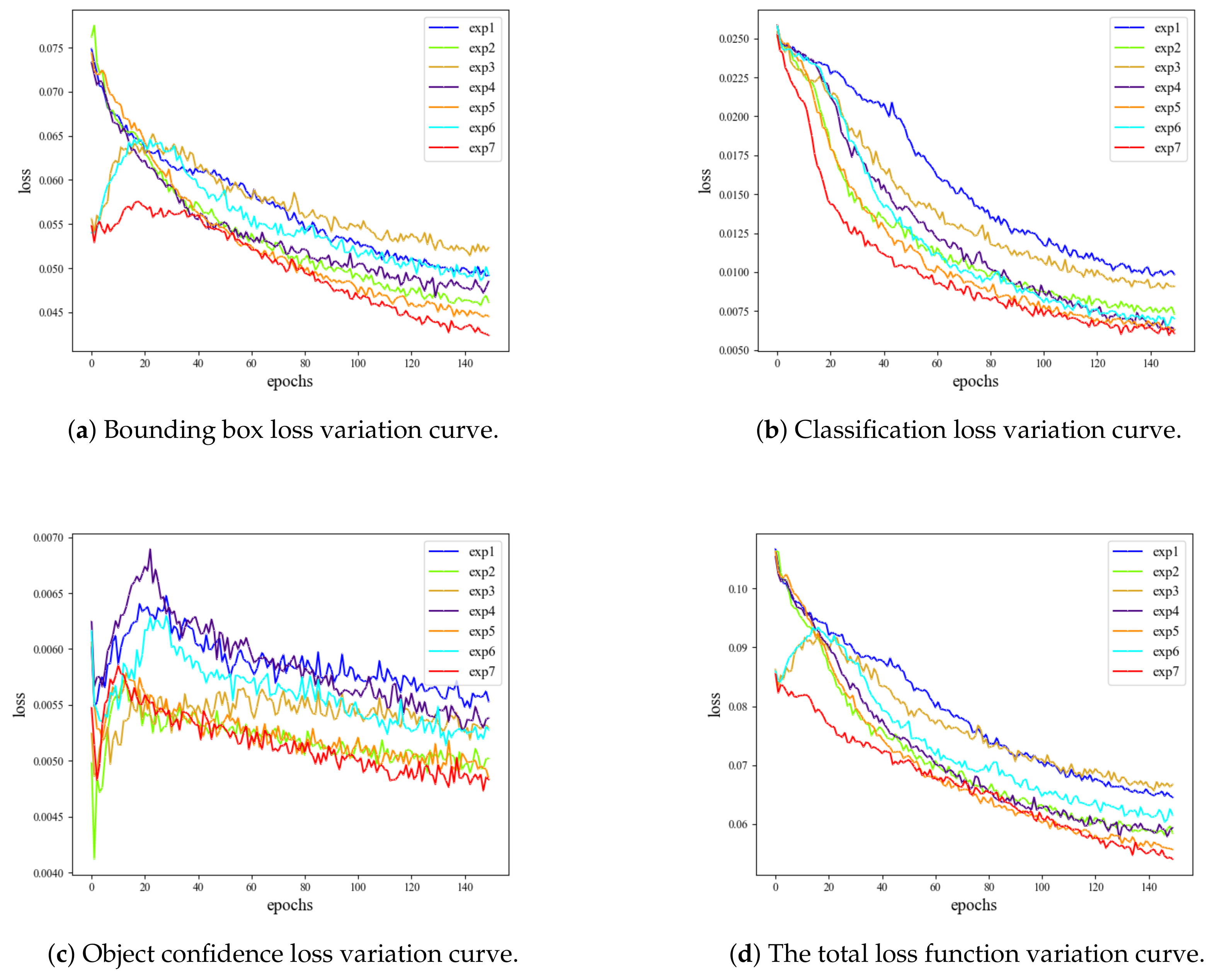
4.4. Ablation Experiment
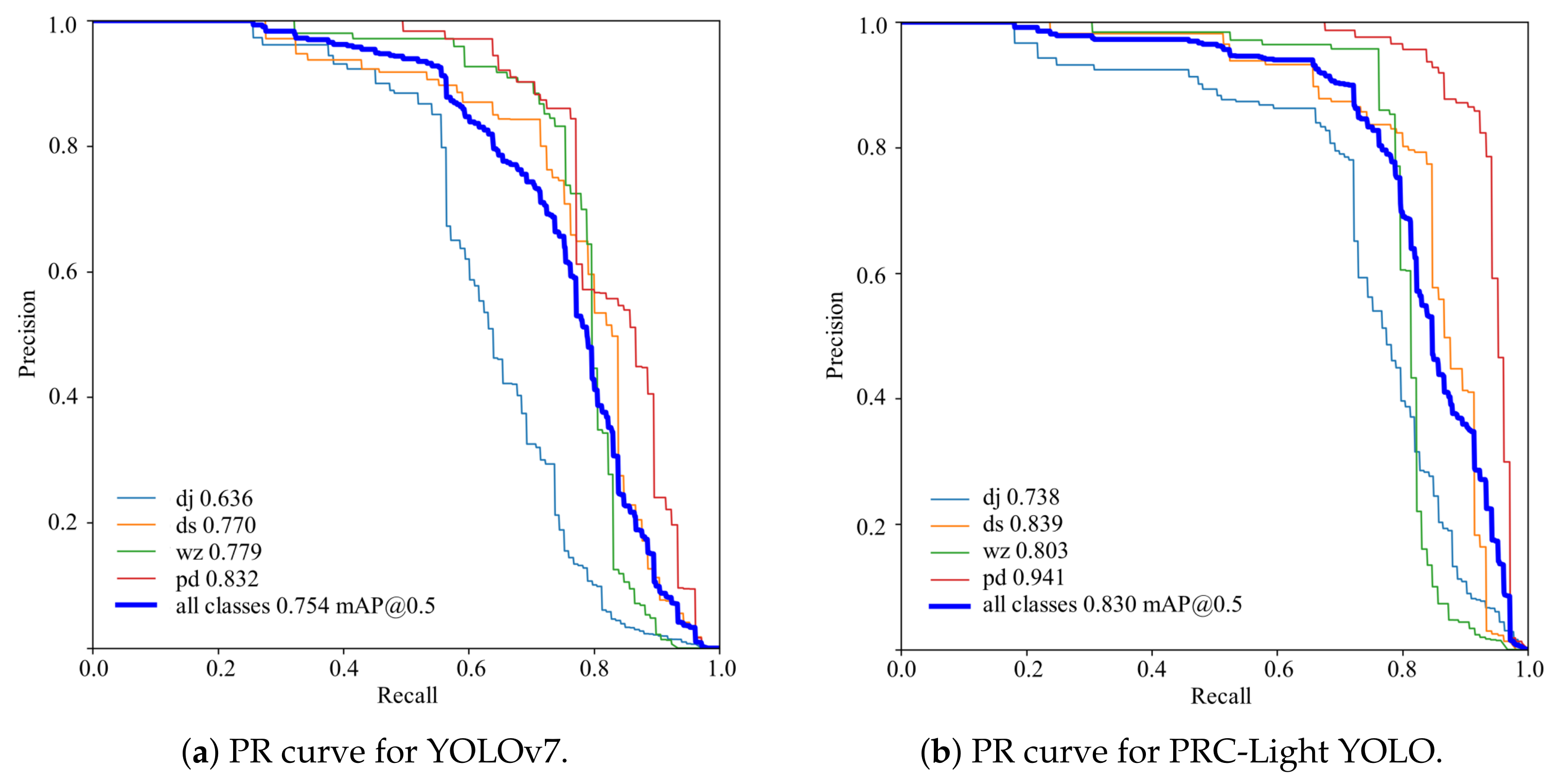
4.5. Comparison of Detection Effect
4.6. Comparison Experiment
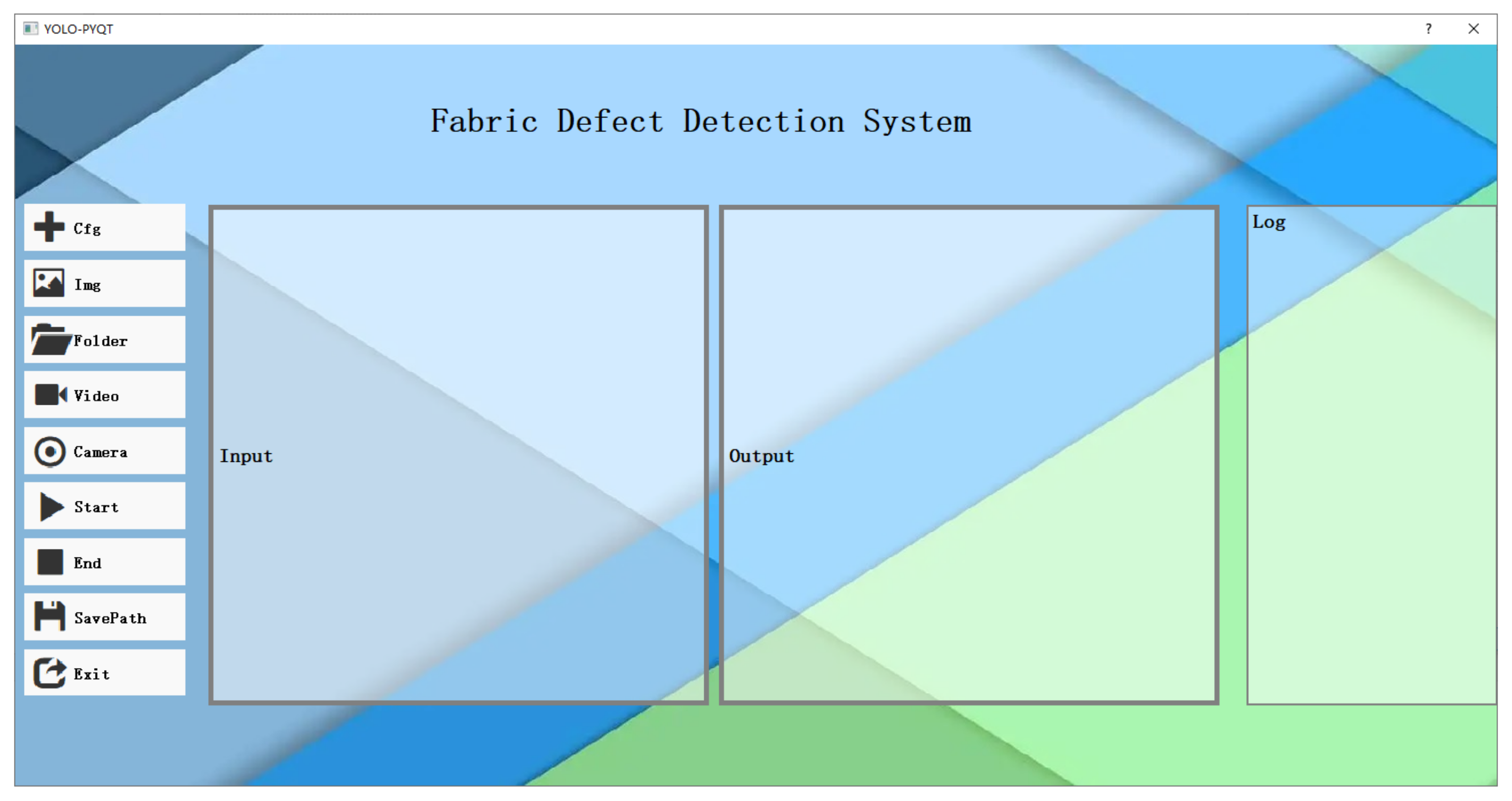
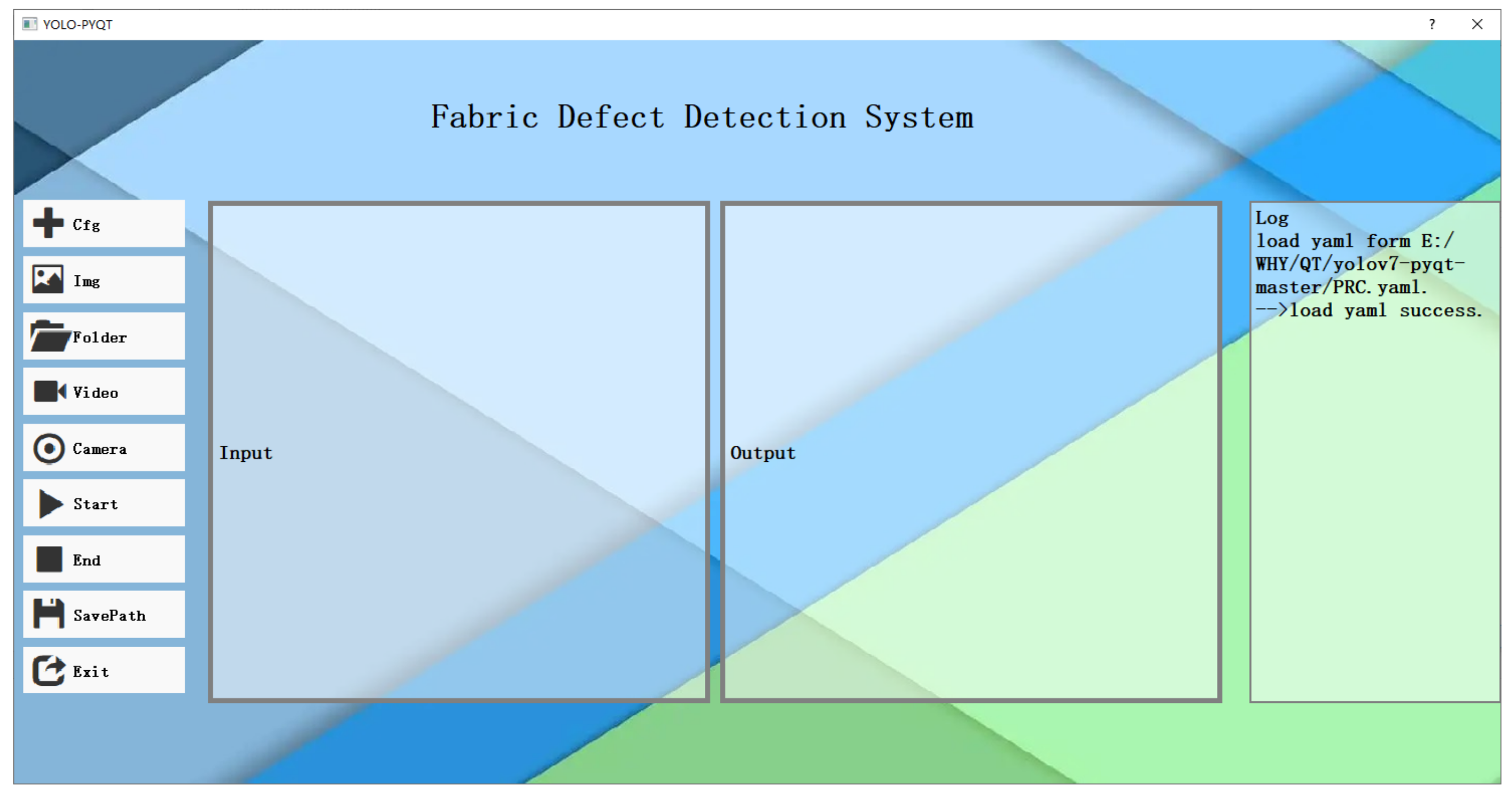
5. Fabric Defect Detection System
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| IOU | Intersection Over Union |
| mAP | mean Average Precision |
| SSD | Solid State Drive |
| R-CNN | Region with CNN |
| ROI | Region of Interest |
| VGG | Visual Geometry Group |
| CARAFE | Content-Aware ReAssembly of FEatures |
| PConv | Partial Convolution |
| E-ELAN | Extended-Efficient Layer Aggregation Networks |
| RFB | Receptive Field Block |
| CBS | Convolution, Batch normalization, SiLU |
| MPConv | Max Pool Convolution |
| PAFPN | Path Aggregation Feature Pyramid Network |
| REP | Re-Parameterization |
| FLOPs | Floating-Point Operations |
| FLOPS | Floating-Point Operations Per Second |
| DWConv | Depthwise Convolution |
| GConv | Group Convolution |
| PWConv | PointWise Convolution |
| MAC | Memory Access Cost |
| ReLU | Rectified Linear |
| GELU | Gaussian Error Linear Unit |
| SiLU | Sigmoid Weighted Liner Unit |
| ObjLoss | Object Confidence Loss |
| ClsLoss | Classification Loss |
| BoxLoss | Bounding Box Loss |
| CIOU | Complete Intersection Over Union |
| PE-ELAN | Partial convolution, Extended-Efficient Layer Aggregation Networks |
| CBH | Convolution, Batch normalization, HardSwish |
| P | Precision |
| R | Recall |
| F1 | F1-score |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| AP | Average Precision |
| GFLOPs | Giga FLoating-Point Operations Per Second |
References
- Zhang, H.; Qiao, G.; Lu, S.; Yao, L.; Chen, X. Attention-based Feature Fusion Generative Adversarial Network for yarn-dyed fabric defect detection. Text. Res. J. 2023, 93, 1178–1195. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Wang, M.; Chen, H. Fabric Defect Detection Algorithm Based on Image Saliency Region and Similarity Location. Electronics 2023, 12, 1392. [Google Scholar] [CrossRef]
- Xiang, J.; Pan, R.; Gao, W. Yarn-dyed fabric defect detection based on an improved autoencoder with Fourier convolution. Text. Res. J. 2023, 93, 1153–1165. [Google Scholar] [CrossRef]
- Wu, J.; Li, P.; Zhang, H.; Su, Z. CARL-YOLOF: A well-efficient model for digital printing fabric defect detection. J. Eng. Fibers Fabr. 2022, 17, 15589250221135087. [Google Scholar] [CrossRef]
- Kanwal, M.; Riaz, M.M.; Ali, S.S.; Ghafoor, A. Saliency-based fabric defect detection via bag-of-words model. Signal Image Video Process. 2023, 17, 1687–1693. [Google Scholar] [CrossRef]
- Kahraman, Y.; Durmuşoğlu, A. Deep learning-based fabric defect detection: A review. Text. Res. J. 2023, 93, 1485–1503. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1916. [Google Scholar] [CrossRef]
- Zhao, J.; Zhou, S.; Zheng, Q.; Mei, S. Fabric defect detection based on transfer learning and improved Faster R-CNN. J. Eng. Fibers Fabr. 2022, 17, 15589250221086647. [Google Scholar]
- Zhang, J.; Jing, J.; Lu, P.; Song, S. Improved MobileNetV2-SSDLite for automatic fabric defect detection system based on cloud-edge computing. Measurement 2022, 201, 111665. [Google Scholar] [CrossRef]
- Zhou, S.; Zhao, J.; Shi, Y.S.; Wang, Y.F.; Mei, S.Q. Research on improving YOLOv5s algorithm for fabric defect detection. Int. J. Cloth. Sci. Technol. 2023, 35, 88–106. [Google Scholar] [CrossRef]
- Wu, Y.; Lou, L.; Wang, J. Cotton fabric defect detection based on K-SVD dictionary learning. J. Nat. Fibers 2022, 19, 10764–10779. [Google Scholar] [CrossRef]
- Lin, G.; Liu, K.; Xia, X.; Yan, R. An efficient and intelligent detection method for fabric defects based on improved YOLOv5. Sensors 2022, 23, 97. [Google Scholar] [CrossRef]
- Guo, Y.; Kang, X.; Li, J.; Yang, Y. Automatic Fabric Defect Detection Method Using AC-YOLOv5. Electronics 2023, 12, 2950. [Google Scholar] [CrossRef]
- Di, L.; Deng, S.; Liang, J.; Liu, H. Context receptive field and adaptive feature fusion for fabric defect detection. Soft Comput. 2023, 27, 13421–13434. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Baranwal, N.; Singh, K.N.; Singh, A.K. YOLO-based ROI selection for joint encryption and compression of medical images with reconstruction through super-resolution network. Future Gener. Comput. Syst. 2024, 150, 1–9. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Zhu, L.; Lee, F.; Cai, J.; Yu, H.; Chen, Q. An improved feature pyramid network for object detection. Neurocomputing 2022, 483, 127–139. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Ding, P.; Qian, H.; Bao, J.; Zhou, Y.; Yan, S. L-YOLOv4: Lightweight YOLOv4 based on modified RFB-s and depthwise separable convolution for multi-target detection in complex scenes. J. Real-Time Image Process. 2023, 20, 71. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Jiang, N.; Wang, L. Quantum image scaling using nearest neighbor interpolation. Quantum Inf. Process. 2015, 14, 1559–1571. [Google Scholar] [CrossRef]
- Manzhos, S.; Ihara, M. Neural network with optimal neuron activation functions based on additive Gaussian process regression. arXiv 2023, arXiv:2301.05567. [Google Scholar] [CrossRef] [PubMed]
- Polyzos, E.; Nikolaou, C.; Polyzos, D.; Van Hemelrijck, D.; Pyl, L. Direct modeling of the elastic properties of single 3D printed composite filaments using X-ray computed tomography images segmented by neural networks. Addit. Manuf. 2023, 76, 103786. [Google Scholar] [CrossRef]
- Siddique, A.; Vai, M.I.; Pun, S.H. A low cost neuromorphic learning engine based on a high performance supervised SNN learning algorithm. Sci. Rep. 2023, 13, 6280. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Sravya, N.; Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. DPPNet: An efficient and robust deep learning network for land cover segmentation from high-resolution satellite images. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 128–139. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Operating System | RAM | Graphics Card | CUDA | Python | Framework |
|---|---|---|---|---|---|---|
| Parameter | Windows X64 | 12G | NVIDIA Quadro P4000 | 11.3 | 3.8 | PyTorch |
| Exp | HardSwish | Wise-IOU v3 | RFB | CARAFE | PConv | Params/M | GFLOPs/G | mAP/% | Inference Time/ms |
|---|---|---|---|---|---|---|---|---|---|
| exp1 | × | × | × | × | × | 37.21 | 105.2 | 75.4 | 35.08 |
| exp2 | ✓ | × | × | × | × | 37.21 | 105.2 | 78.1 | 31.49 |
| exp3 | × | ✓ | × | × | × | 37.21 | 105.2 | 79.1 | 32.08 |
| exp4 | × | × | ✓ | × | × | 33.94 | 102.5 | 80.6 | 33.31 |
| exp5 | × | × | × | ✓ | × | 37.87 | 106.5 | 79.8 | 34.65 |
| exp6 | ✓ | ✓ | ✓ | ✓ | × | 34.6 | 103.8 | 81.1 | 30.62 |
| exp7 | ✓ | ✓ | ✓ | ✓ | ✓ | 30.5 | 83.6 | 83 | 28.46 |
| Models | P | R | F1 | Params/M | GFLOPs/G | mAP/% | Inference Time/ms |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 0.784 | 0.491 | 0.6 | 136.98 | 370.3 | 0.696 | 177.35 |
| SSD | 0.832 | 0.529 | 0.647 | 105.2 | 87.41 | 0.731 | 143.58 |
| EfficientDet | 0.787 | 0.492 | 0.605 | 52.11 | 34.97 | 0.697 | 22.71 |
| CenterNet | 0.838 | 0.547 | 0.662 | 125 | 69.66 | 0.756 | 158.2 |
| YOLOv7 | 0.826 | 0.697 | 0.76 | 37.21 | 105.2 | 0.754 | 32.08 |
| YOLOv8x | 0.754 | 0.754 | 0.754 | 68.23 | 258.5 | 0.784 | 40.39 |
| PRC-Light YOLO | 0.859 | 0.784 | 0.82 | 30.50 | 83.6 | 0.83 | 28.46 |
| Categories | Faster R-CNN | SSD | EfficientDet | CenterNet | YOLOv7 | YOLOv8x | PRC-Light YOLO |
|---|---|---|---|---|---|---|---|
| Warp hanged | 0.738 | 0.756 | 0.731 | 0.802 | 0.636 | 0.732 | 0.738 |
| Yard defects | 0.582 | 0.596 | 0.599 | 0.652 | 0.77 | 0.768 | 0.839 |
| Stain | 0.692 | 0.759 | 0.686 | 0.765 | 0.779 | 0.786 | 0.803 |
| Hotel | 0.773 | 0.814 | 0.773 | 0.804 | 0.832 | 0.850 | 0.941 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Wang, H.; Cao, Z.; Wang, Y.; Tao, L.; Yang, J.; Zhang, K. PRC-Light YOLO: An Efficient Lightweight Model for Fabric Defect Detection. Appl. Sci. 2024, 14, 938. https://doi.org/10.3390/app14020938
Liu B, Wang H, Cao Z, Wang Y, Tao L, Yang J, Zhang K. PRC-Light YOLO: An Efficient Lightweight Model for Fabric Defect Detection. Applied Sciences. 2024; 14(2):938. https://doi.org/10.3390/app14020938
Chicago/Turabian StyleLiu, Baobao, Heying Wang, Zifan Cao, Yu Wang, Lu Tao, Jingjing Yang, and Kaibing Zhang. 2024. "PRC-Light YOLO: An Efficient Lightweight Model for Fabric Defect Detection" Applied Sciences 14, no. 2: 938. https://doi.org/10.3390/app14020938
APA StyleLiu, B., Wang, H., Cao, Z., Wang, Y., Tao, L., Yang, J., & Zhang, K. (2024). PRC-Light YOLO: An Efficient Lightweight Model for Fabric Defect Detection. Applied Sciences, 14(2), 938. https://doi.org/10.3390/app14020938