
Weighted Matrix Factorization Recommendation Model Incorporating Social Trust


Abstract
1. Introduction
- Before calculating the predicted ratings based on user historical ratings, two filtering layers are added to reduce the impact of noise data on the computation results.
- Nonlinear fusion of similarity and trust relationships: A dynamically changing weight is set to merge the similarity and trust relationships, where the variation of is influenced by user historical ratings and the two filtering layers.
- A new weighted matrix factorization model is proposed: By modifying the loss function of the existing matrix factorization model, this aims to assign different weights to different data during the matrix factorization process.
2. Related Work
3. User-Based Collaborative Filtering and Trust-Based Social Networks
3.1. User-Based Collaborative Filtering
3.2. Trust-Based Social Networks
3.3. Nonlinear Integration of Similarity and Trust Relationships
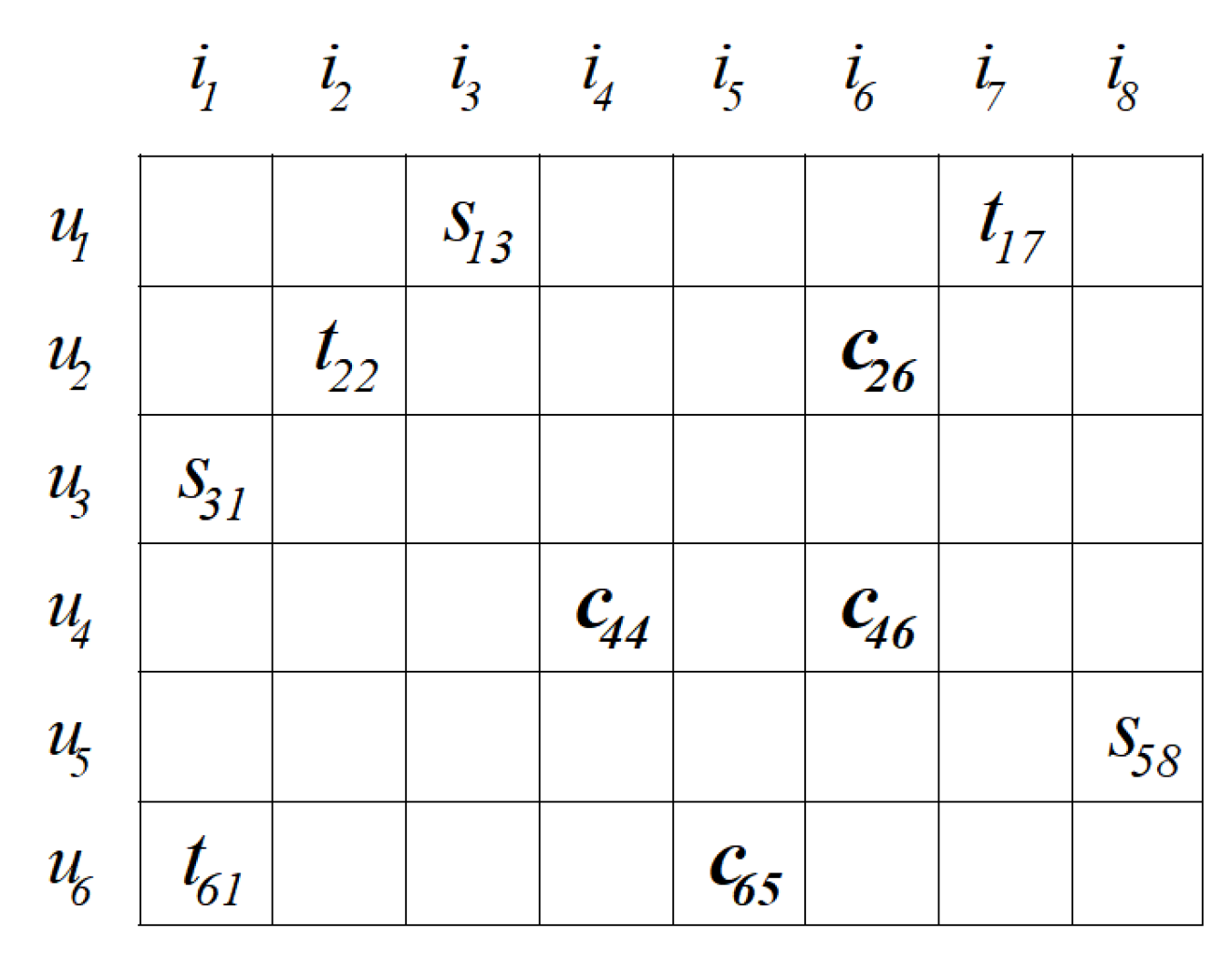
- The first part consists of predicted ratings obtained solely from trust relationships. These ratings have no overlap with those obtained from similarity relationships and are represented in the matrix as .
- The second part includes predicted ratings derived solely from similarity relationships, distinct from those obtained from trust relationships. In the matrix, these ratings are denoted as .
- The third part is derived from the overlapping portion of the two types of predicted ratings, integrated together. This part is represented in the matrix as .
4. Trust-Based Weighted Matrix Factorization
4.1. Bias-SVD Matrix Factorization
4.2. Trust-WMF Recommendation Model
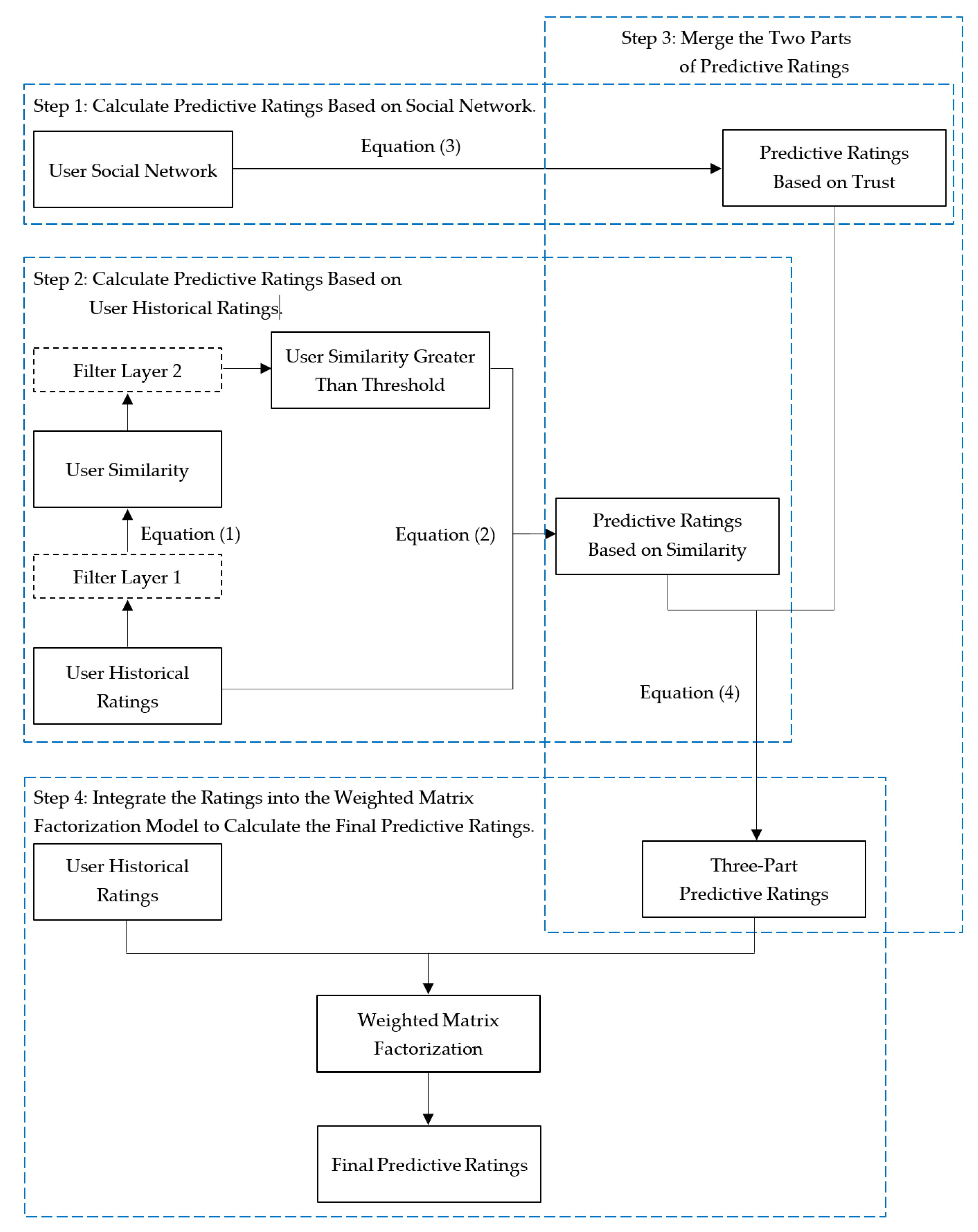
- Utilizing Equation (3), predicted ratings based on the user’s social network are calculated.
- Based on user historical ratings, the predicted ratings are calculated using Equations (1) and (2), and this part includes two filtering layers. The role of Filter Layer 1 is to screen out users with fewer commonly rated items before calculating the similarity between users, ensuring the reliability of the calculated user similarity. Filter Layer 2 aims to filter out pairs of users with low similarity before predicting ratings based on user similarity, further reducing the impact of noise data on predicted ratings.
- Predicted ratings based on trust relationships and similarity relationships calculated in the first two parts are nonlinearly combined using Equation (4).
- After combining the three parts of predicted ratings, they are integrated with user historical ratings, and the improved weighted matrix factorization model within the Trust-WMF recommendation model is used to further capture the latent features and relationships of users and items.
5. Experimental Evaluation
5.1. Experimental Environment and Datasets
5.2. Evaluation Metrics
5.3. Comparison of Model Recommendation Performance
- PMF [25]: Probabilistic Matrix Factorization Model: This model considers the latent factors of users and items under a Gaussian distribution in probabilistic matrix factorization;
- SoRec [11]: It captures the latent features of users and items by jointly decomposing the user-item rating matrix and the user-user social network matrix;
- SoReg [15]: This model uses social information to regularize the user feature vectors;
- SocialMF [14]: It assumes that a user’s preference information largely depends on the preference information of their trusted friends, representing the user feature vector as the weighted average of their trusted friends’ feature vectors;
- TrustMF [12]: This model originates from the genesis of trust relationships, separately modeling trusting and being trusted behaviors;
- NeuMF [19]: This model combines neural networks with matrix factorization, using neural networks to replace the traditional inner product operation;
- DiffNet++ [21]: Based on graph neural networks, model the high-order social influence diffusion in social networks and interest diffusion in interest networks within a unified model;
- GDSRec [23]: Based on graph neural networks, this model considers attitude biases that might exist among different users as vectors and integrates these biases into the process of learning user and item representation vectors.
- Among all models, PMF, which only utilizes user historical ratings, has the lowest accuracy. Meanwhile, the accuracy of SoRec, SoReg, SocialMF, and TrustMF, which integrate user social networks, is higher than PMF. This indicates that incorporating user social networks effectively enhances the accuracy of recommendation models. Distinct from the modeling methods of SoRec, SoReg, and SocialMF, TrustMF considers from the perspective of the generation of trust relationships. It models trust and being trusted behaviors separately, mapping users into trustor feature vectors and trustee feature vectors. This approach enables more effective utilization of the relationships between users in social networks. Although the NeuMF model does not integrate user social networks, its accuracy is still higher than PMF, proving that using neural networks can learn deeper features of users and items, thus improving the accuracy of recommendation models.
- The experimental results of the SoRec, SoReg, SocialMF, TrustMF, DiffNet++, and GDSRec models show that the accuracy of DiffNet++ and GDSRec is significantly higher than the other four models. All six models utilize user historical ratings and social networks, but DiffNet++ and GDSRec are trained based on graph neural network architecture. This suggests that graph neural networks enhance the precision of recommendation models. Unlike DiffNet++, which uses social networks to learn user representations, GDSRec improves model recommendation accuracy by correcting the final prediction scores by learning target users’ preferences by utilizing the preferences of other users related to the target user in the social network.
- Compared to other models, the Trust-WMF model proposed in this paper has a lower MAE and RMSE, indicating that this model can effectively reduce the impact of noise when processing data. Additionally, the improved weighted matrix factorization method effectively controls the weight between different ratings, allowing the model to more accurately reflect user preferences and item characteristics when processing large-scale data.
- The Trust-WMF model demonstrates superior recommendation accuracy on different scales in the Epinions and Ciao datasets compared to other models, indicating good robustness of the model and no bias toward specific datasets.
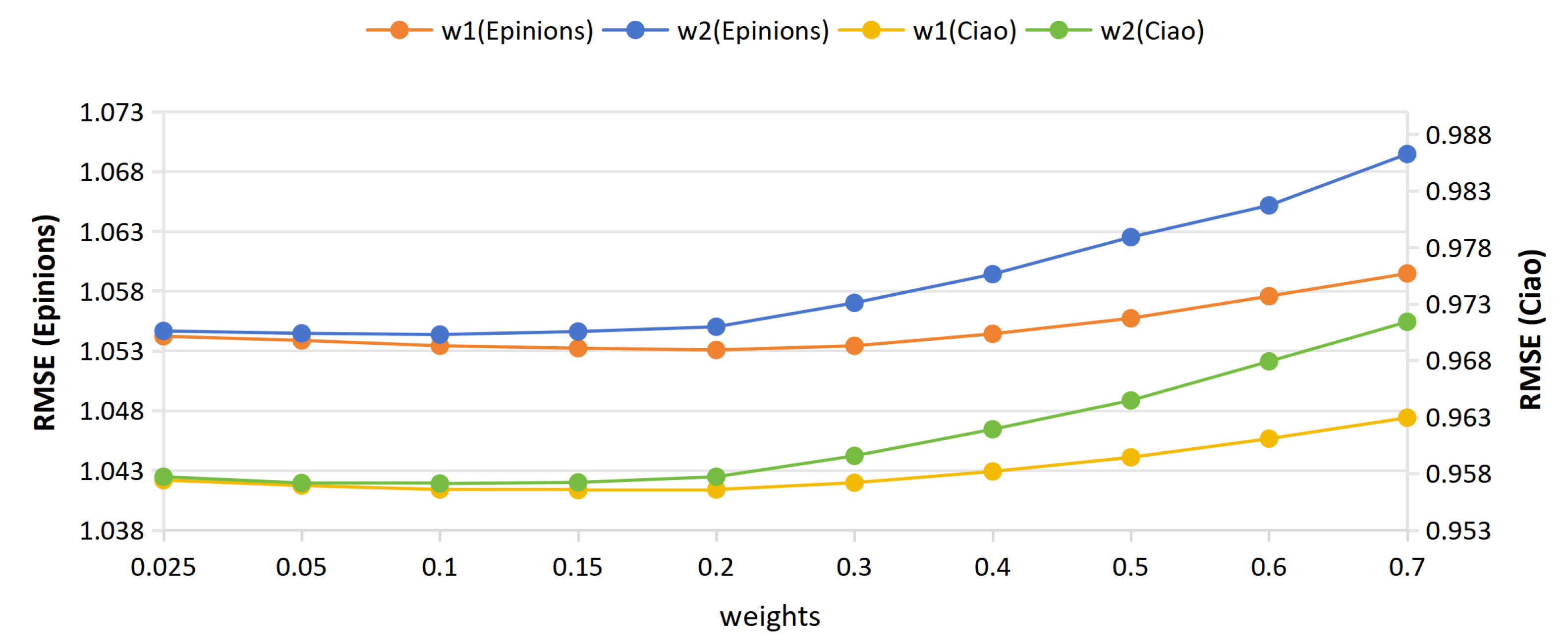
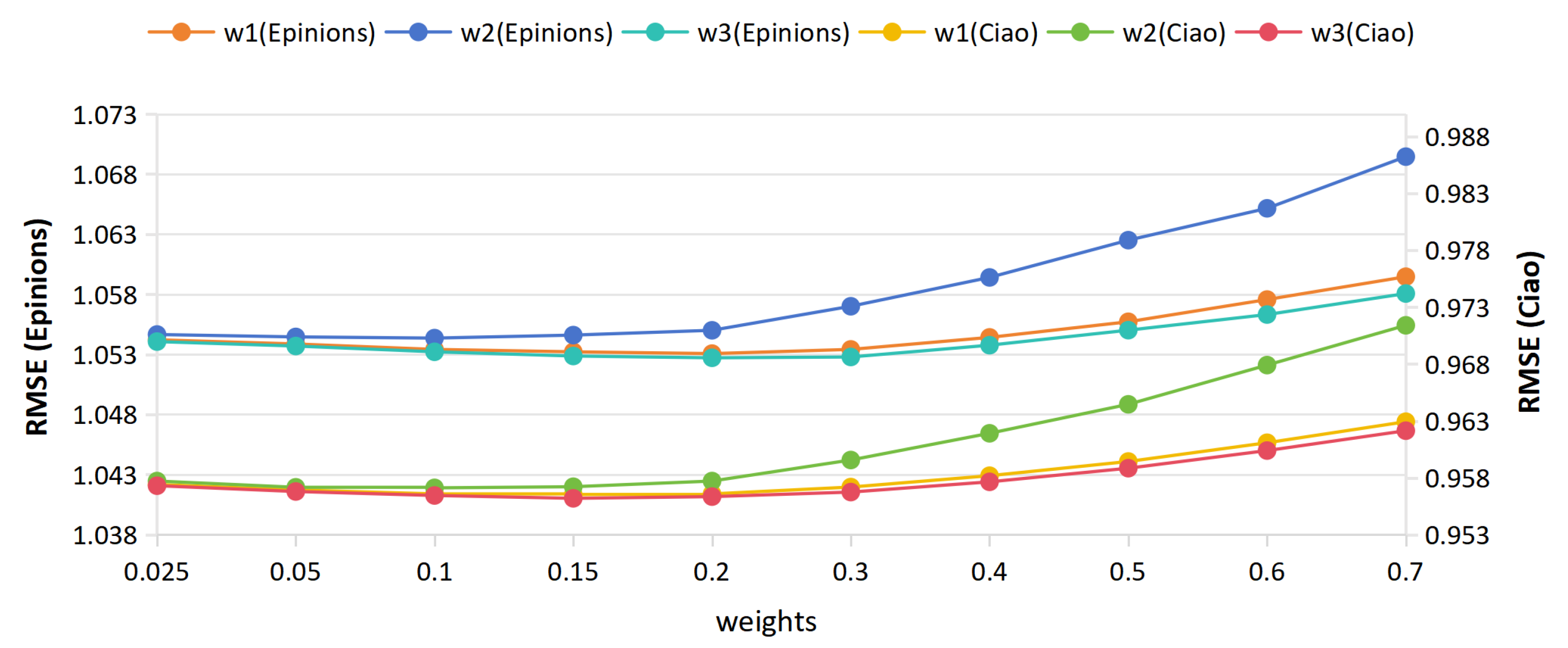
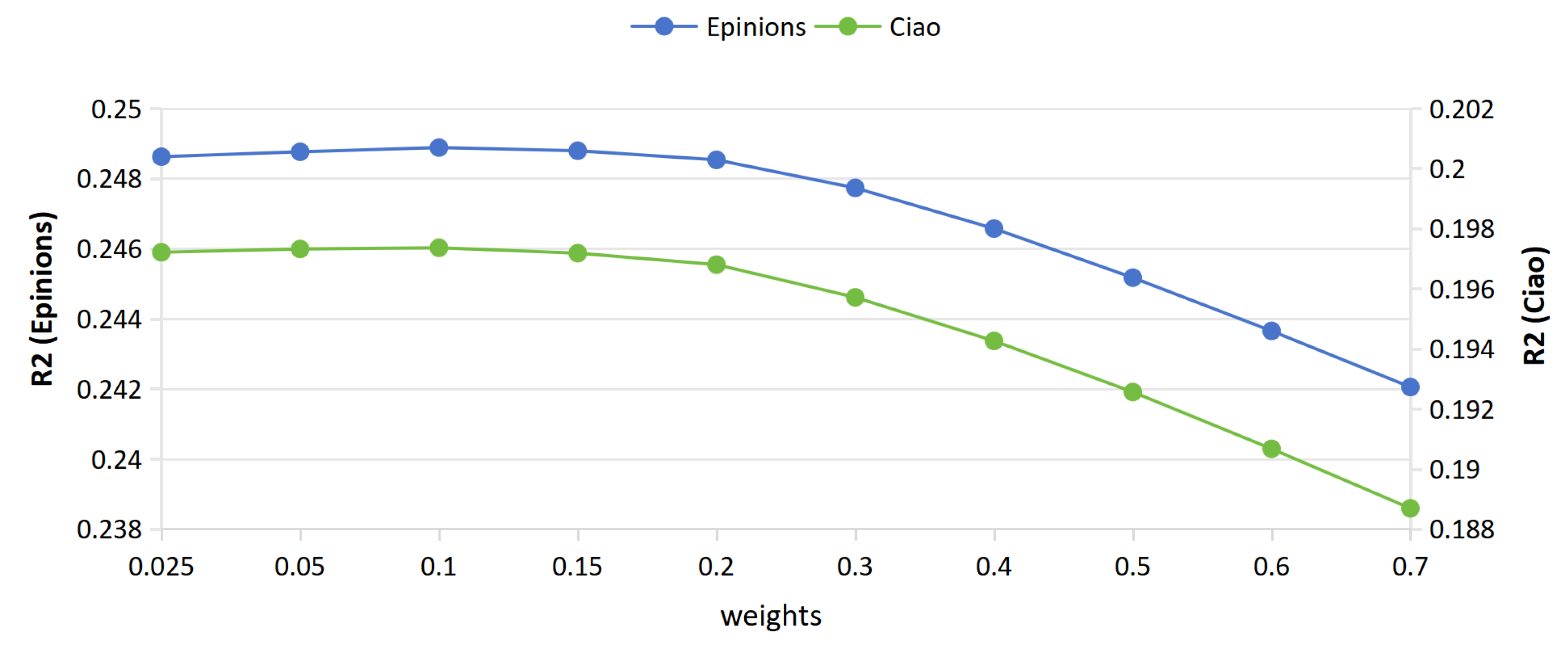
5.4. Impact of Parameters
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schafer, J.B.; Konstan, J.; Riedl, J. Recommender systems in e-commerce. In Proceedings of the 1st ACM Conference on Electronic Commerce, Denver, CO, USA, 3–5 November 1999. [Google Scholar]
- Semeraro, G.; Lops, P.; Basile, P.; de Gemmis, M. Knowledge infusion into content-based recommender systems. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 301–304. [Google Scholar]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. Grouplens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 175–186. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Natarajan, S.; Vairavasundaram, S.; Natarajan, S.; Gandomi, A.H. Resolving data sparsity and cold start problem in collaborative filtering recommender system using linked open data. Expert Syst. Appl. 2020, 149, 113248. [Google Scholar] [CrossRef]
- Massa, P.; Bhattacharjee, B. Using trust in recommender systems: An experimental analysis. In Proceedings of the Trust Management: Second International Conference, iTrust 2004, Oxford, UK, 29 March–1 April 2004; pp. 221–235. [Google Scholar]
- De Meo, P. Trust prediction via matrix factorisation. ACM Trans. Internet Technol. 2019, 19, 1–20. [Google Scholar] [CrossRef]
- Han, L.; Chen, L.; Shi, X. Recommendation Model Based on Probabilistic Matrix Factorization and Rated Item Relevance. Electronics 2022, 11, 4160. [Google Scholar] [CrossRef]
- Fan, W.; Li, Q.; Cheng, M. Deep modeling of social relations for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social collaborative filtering by trust. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1633–1647. [Google Scholar] [CrossRef] [PubMed]
- Ma, H.; King, I.; Lyu, M.R. Learning to recommend with social trust ensemble. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 203–210. [Google Scholar]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Guo, G.; Zhang, J.; Yorke-Smith, N. Trustsvd: Collaborative filtering with both the explicit and implicit influence of user trust and of item ratings. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Hwang, W.-S.; Li, S.; Kim, S.-W.; Lee, K. Data imputation using a trust network for recommendation via matrix factorization. Comput. Sci. Inf. Syst. 2018, 15, 347–368. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Wu, L.; Sun, P.; Fu, Y.; Hong, R.; Wang, X.; Wang, M. A neural influence diffusion model for social recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 235–244. [Google Scholar]
- Wu, L.; Li, J.; Sun, P.; Hong, R.; Ge, Y.; Wang, M. Diffnet++: A neural influence and interest diffusion network for social recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 4753–4766. [Google Scholar] [CrossRef]
- Wan, L.; Xia, F.; Kong, X.; Hsu, C.-H.; Huang, R.; Ma, J. Deep matrix factorization for trust-aware recommendation in social networks. IEEE Trans. Netw. Sci. Eng. 2020, 8, 511–528. [Google Scholar] [CrossRef]
- Chen, J.; Xin, X.; Liang, X.; He, X.; Liu, J. GDSRec: Graph-Based Decentralized Collaborative Filtering for Social Recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 4813–4824. [Google Scholar]
- Claypool, M.; Gokhale, A.; Miranda, T.; Murnikov, P.; Netes, D.; Sartin, M. Combining Content-Based and Collaborative Filters in an Online Newspaper. In Proceedings of the SIGIR’99 Workshop on Recommender Systems: Algorithms and Evaluation, Berkeley, CA, USA, 19 August 1999. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. Adv. Neural Inf. Process. Syst. 2007, 20, 1257–1264. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Users | Items | Ratings | Rating Density | Social Relationships | Social Relationship Density |
|---|---|---|---|---|---|---|
| Epinions | 49,289 | 139,738 | 664,824 | 0.0097% | 487,183 | 0.0201% |
| Ciao | 7375 | 105,114 | 284,086 | 0.0366% | 111,781 | 0.2055% |
| Dataset | Evaluation Metrics | PMF | SoRec | SoReg | Social MF | Trust MF | Neu MF | DiffNet++ | GDSRec | TrustWMF |
|---|---|---|---|---|---|---|---|---|---|---|
| Epinions | MAE | 0.9952 | 0.8961 | 0.9119 | 0.8837 | 0.8410 | 0.9072 | 0.8201 | 0.8047 | 0.8013 |
| RMSE | 1.2128 | 1.1437 | 1.1703 | 1.1328 | 1.1395 | 1.1476 | 1.0635 | 1.0566 | 1.0527 | |
| Ciao | MAE | 0.9021 | 0.8410 | 0.8611 | 0.8270 | 0.7690 | 0.8062 | 0.7398 | 0.7323 | 0.7188 |
| RMSE | 1.1238 | 1.0652 | 1.0848 | 1.0501 | 1.0479 | 1.0617 | 0.9774 | 0.9740 | 0.9562 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sang, S.; Ma, M.; Pang, H. Weighted Matrix Factorization Recommendation Model Incorporating Social Trust. Appl. Sci. 2024, 14, 879. https://doi.org/10.3390/app14020879
Sang S, Ma M, Pang H. Weighted Matrix Factorization Recommendation Model Incorporating Social Trust. Applied Sciences. 2024; 14(2):879. https://doi.org/10.3390/app14020879
Chicago/Turabian StyleSang, Shengwei, Mingyang Ma, and Huanli Pang. 2024. "Weighted Matrix Factorization Recommendation Model Incorporating Social Trust" Applied Sciences 14, no. 2: 879. https://doi.org/10.3390/app14020879
APA StyleSang, S., Ma, M., & Pang, H. (2024). Weighted Matrix Factorization Recommendation Model Incorporating Social Trust. Applied Sciences, 14(2), 879. https://doi.org/10.3390/app14020879